
Abstract

Our understanding of human molecular physiology has been aided by the deciphering of the genetic code and new techniques for measuring the expression of cellular proteins. New developments such as microsequencing are moving genomics and proteomics research forward at high speed; however, many technical barriers still retard rapid progress including access to high-speed computational technology. Information technologies are needed to process, manage, and mine the huge volumes of information being collected through genomic and proteomic research. It is into this arena that IBM Life Sciences Solutions is bringing its capabilities and experience.
Dr. Caroline Kovac, vice president of IBM Life Sciences Solutions, in a recent interview with JALA Managing Editor, Conal Timoney, indicated that she believes the changes currently taking place in the life sciences field will be as revolutionary in their impact on humanity as the Internet or the Industrial Revolution. By way of comparison with other human advances, Dr. Kovac pointed to the fact that human life expectancy increased by 20 years between 1920 and 2000 - due in large part to the development of new drugs and antibiotics. The mapping of the human genome opens the possibility for researchers to develop drugs to meet individual needs, and creates the possibility for them to find the cure for cancer, diabetes, Alzheimer's and heart disease. This accomplishment may even delay the aging process. While it is beyond the scope of this article to assess the impact on society of such changes, clearly every facet of human life has the potential to be altered.
The goal of Kovac's new business unit, launched in August of 2000 with an initial investment of $100 million, is to provide information technology (IT) solutions to companies in the biotechnology, genomics and proteomics arenas. IBM Life Sciences brings together IBM's strengths in supercomputing, research, data management, and other areas to spearhead the development of information technology solutions for biological analysis. IBM intends to provide computational support for projects applying human genome sequence data to the biotechnology, genomics, e-health and pharmaceutical industries. Under Kovac's guidance, the Life Sciences unit has formed a new sales force focused on targeting new and emerging life sciences companies. IBM is not seeking to be a direct player in any one of these areas. Rather, IBM will offer IT support for life sciences companies pushing the envelope with the understanding that the computational demands required to decipher the complexity of biological systems potentially will outweigh the demands required by IBM customers in other industries.
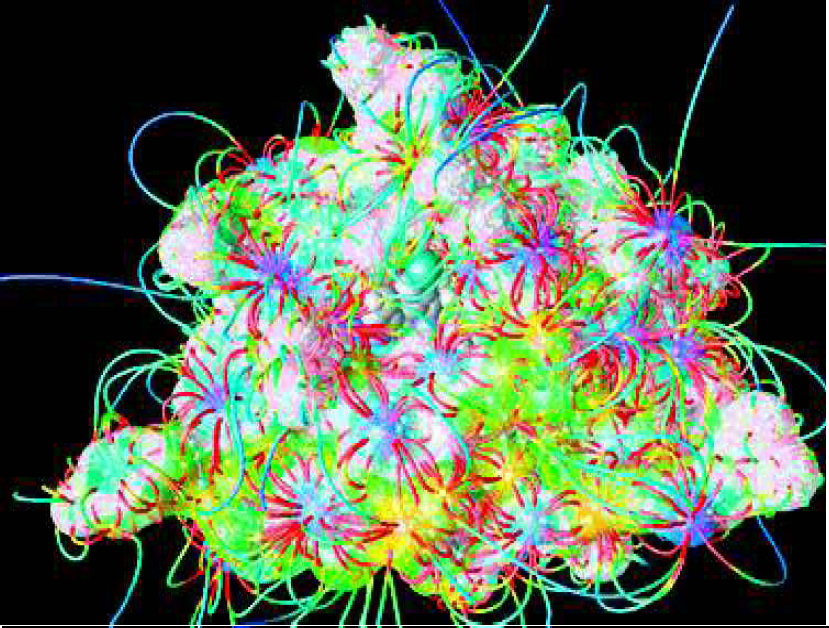
The image shows a portion of the surface of the reverse transcriptase enzyme of the HIV-I virus with a molecular model of an inhibitor drug compound bound to the enzyme's receptor pocket. An inhibitor drug blocks the action of the enzyme, disabling its function and thus crippling the virus. The colors mapped on the surface show extremes in the electrostatic potential of the surface and lines which represent the electrostatic field in the vicinity of the receptor pocket. In order to work, a potential inhibitor must have both the right shape and the right electrostatic characteristics to attach itself to the enzyme to disable it.
Dr. James Coffin, worldwide director of Sales for IBM's Life Sciences Solutions, is responsible for managing a worldwide sales force. Dr. Coffin told JALA that IBM's market assessment showed that IT spending in life sciences would expand to more than $40 billion by 2004.

Protein folding, illustrated using the protein Barnase as an example. This figure shows the protein in a completely unfolded (stretched) shape. The “unfolded” figures are hypothetical illustrations, one of the many possible unfolded states. The color in the folded image represent the secondary structures: red is alpha helix, blue is beta sheet. This figure is a schematic drawing, showing the fold as a ribbon on the protein backbone. Displaying all atoms (like in the “beads on a string” image) would prevent us from appreciating the fold.
Due to its long history in business computing, IBM brings significant value to this relatively new market. IBM's customer-focused approach will serve the needs of major pharmaceutical, biotechnology and other life science companies. IBM has formed a life sciences consulting practice comprised of a new breed of consultants with a blend of experience in life sciences, business and IT that work closely with companies to design the most efficient IT solutions. For example, IBM will apply its expertise in data integration and knowledge management to enable biotech customers to mine and do cross-functional queries of their data. At present, IBM's Life Sciences team includes a force of over 100 people and it is training additional professionals to meet the growing demand in the biotech field.
IBM is focusing on IT product development for genomics and the next research frontier, proteomics. New technologies will significantly reduce the amount of time it takes for drug development companies to identify drug candidates and bring them to market. Two main applications for genomic data are predicted. Genomic information may ultimately lead to reliable predictions of an individual's predisposition to certain diseases or other problems, enabling the individual to start taking preventive actions earlier than he or she is presently able. The other use of genomic data will be the development of personalized medicine, whereby a DNA analysis will lead to treatments best suited to an individual's genetic makeup.
The other life science IT challenge, proteomics, involves understanding how proteins interact to achieve cellular function, which is key to disease intervention. Computational methods have been developed that link DNA sequence information to 3D protein structures. However, the theoretical chemistry involved in predicting the 3D conformation of a protein does not provide information about molecular dynamics and protein-protein interactions that might have commercial value.
With the enormous amount of human genome sequence data available, IBM is working to help emerging proteomics companies translate this data into useful knowledge. For example, IBM is the preferred supplier of hardware, software, and services to companies like MDS Proteomics (Toronto, Canada, http://www.mdsproteomics.com) and Structural Bioinformatics, Inc. (San Diego, CA, http://www.strubix.com). The IBM-MDS Proteomics alliance targets one of the most challenging problems in life sciences today: understanding the interactions among proteins that trigger chemical reactions in cells and cause diseases such as cancer, AIDS and depression. To achieve the company's goals, MDS Proteomics is deploying a powerful supercomputing infrastructure — three superclusters of IBM eServer systems running UNIX and the open source operating system Linux. The configuration also includes high-performance data management disk and tape storage systems, which work with MDS Proteomics' fault-tolerant, cluster-based software to accelerate the process of identifying, analyzing and explaining the function of proteins. The supercomputing system processes output from a network of ultra-sensitive mass spectrometers located in North America and Europe. Mass spectrometers are used to identify and microsequence proteins, critical steps in the process of determining protein interactions. A combination of IBM's DB2 Universal Database and Shark disk and Linear Tape Open storage systems will provide a high-speed solution for storing, managing, accessing and retrieving enormous quantities of protein sequence data.
IBM and MDS Proteomics have founded a new, not-for-profit organization, blueprint WORLDWIDE INC. (http://www.blue-print.org), unveiling the world's most comprehensive public Biomolecular Interaction Network Database (BIND). Through BIND, researchers throughout the world can obtain information on protein interactions that trigger chemical reactions in the body. The development of new medicines will be accelerated by the easy-to-access BIND data. This benefits consumers, increases patient well-being and creates value for research-based companies. BIND, which has support from a consortium of leading international health organizations, builds upon other public biological databases such as NCBI's GenBank, generating a “living” database of all bioinformatics and biomedical data. The BIND database uses IBM technology as its infrastructure for processing, storing and managing biomolecular data.
IBM is also collaborating with Structural Bioinformatics (SBI), whose advanced three-dimensional protein models make it possible for pharmaceutical researchers to design and develop disease-fighting drugs faster and at lower cost. This collaboration will make the content of SBI's extensive databases of protein structural information more readily accessible to researchers worldwide via the Internet. SBI's high-quality protein structures and computational analyses have the capability to significantly speed up the drug development cycle and help get new treatments for many of today's diseases to patients faster. SBI's products are among the first “in silico” approaches to drug discovery, allowing researchers to analyze protein models and predict interactions between proteins and chemicals using information technology, rather than performing time-consuming and costly laboratory experiments.
As SBI's strategic information technology partner, IBM is providing hardware and software, including a high-performance cluster of eServer xSeries servers running Linux. The new system enhances SBI's ability to perform high-resolution protein modeling, including dynamics calculations that track the changing shapes of protein molecules and shed light on the role of individual chemical structures in human disease. SBI is using IBM DB2 Universal Database strategic development platform and IBM WebSphere for its Internet software infrastructure for accessing protein structures on the Web.
IBM has more than a half dozen strategic partnerships to date. NuTec Sciences, Inc. is one such partner. IBM and NuTec Sciences have built the world's largest commercial supercomputer, a system being used to investigate gene-gene interactions in the human body and the role they play in life-threatening diseases.
In order for NuTec Sciences to achieve the unprecedented level of computing power needed to do these analyses, the supercomputing cluster consists of 1,250 IBM eServer p640 devices running IBM's DB2 Universal Database, supported by 2.5 terabytes of memory, 50 terabytes of online disk storage and a high-bandwidth networking infrastructure. State-of-the-art IBM software for Web application serving, information portals and data integration augment the system. The system allows NuTec Sciences to manage, mine and integrate genetic data from a wide variety of sources, and share this information via the Internet with the global life sciences community. The system's massive computational power allows pharmaceutical and biotechnology researchers to study gene combinations behind complex and often fatal diseases like diabetes, heart conditions and strokes, as well as prostate and breast cancers. With a processing capacity of 7 1/2 trillion calculations per second, the supercomputing system ranks among the top 10 of the world's 500 largest supercomputers. This makes it the fastest system installed outside a government agency.
Researchers at the Winship Cancer Institute at Emory University are teaming with NuTec Sciences and IBM to develop GenesysSI, an information system that will enable physicians to tailor cancer treatments based on a patient's specific genetic makeup. The system brings the genomics revolution out of the lab and much closer to patients, giving doctors timely information to support day-to-day treatment decisions of cancer patients. When fully deployed later this year, the system will pinpoint genes and gene combinations that cause cancer in individual patients, as well as highlight genetic risk factors that would suggest the need for early screenings of cancer.
GenesysSI will eliminate much of the guesswork involved in prescribing cancer treatments that today are often ineffective or lead to harmful side effects. Determining the genetic “fingerprint” of a patient's cancer will allow physicians to select the specific treatment that has been proven most effective against similar tumors.
Another collaborative partnership for IBM is with LabBook, Inc. (McLean, VA, http://labbook.com), in which the two companies are working to design a simple, Internet-friendly solution to integrating genomic data from a variety of sources. The partnership brings together LabBook's desktop information retrieval, integration, mining, and visualization software, including Genomic XML Browser, with IBM's back-end data management, data integration and Internet infrastructure software. LabBook aims to optimize its current software tools and develop future tools for IBM platforms and middleware, including DB2 Universal Database, DiscoveryLink data integration software and WebSphere application server. “Open standards are critical to the next phase of genomic research,” said Dr. Caroline Kovac, in a recent press release. “Our work with LabBook will accelerate the adoption of standards in life sciences by defining a simple, Internet-friendly approach for researchers to access and use genomic data from a variety of sources.” LabBook's suite of software tools is built on Bioinformatic Sequence Mark-up Language (BSML), an implementation of the open and widely accepted eXtensible Markup Language (XML) standard. BSML enables data to be more easily represented and exchanged over the Internet in a highly visual and interactive manner.

LCDS System, 9672 G6 Model ZX7 (10 way processor), Memory 32GB.

DASD, Shark 2105-F20 (2.1 terabytes).
IBM's interests in this field are by no means limited to North America. Because the pharmaceutical industry is a multinational one, with many of the big ideas emerging from Europe and Asia, the IBM sales forces are already gearing up for increased activity in these significant markets. Already, IBM and Devgen, a Brussels-based biotechnology company, are partnering to speed genomic sequence analysis of the microscopic Caenorhabditis elegans (C. elegans) worm, which can help in validating target areas for new medical treatments for humans. Devgen is using a cluster of IBM eServer systems running Linux and UNIX to study this transparent worm, better understand gene interactions in humans that trigger chemical reactions in cells and cause diseases, and narrow the search for medical treatments. The IBM/Devgen agreement marks IBM's first such agreement with a company in the European life sciences sector.
One of the most difficult challenges facing the life sciences industry today is how to transform massive quantities of highly complex, constantly changing data from a variety of platforms, data domains, and specialized applications into knowledge. IBM seeks to address this through DiscoveryLink, a solution that creates a single virtual database linking data residing in multiple applications and databases and allowing researchers to access and extract information from many sources, such as public and private databases, using a single query. DiscoveryLink aims to improve research and development cycles and lower drug development costs. The optimization capabilities of DiscoveryLink are unique in that the database is built around middleware from IBM that provides single query access across multiple heterogeneous data sources to applications and end users, while the data remains distributed and undisturbed in its original form. As the amount of data available to pharmaceutical companies becomes unmanageable with current technology, a single “federated database” can provide a solution. Virtual databases are critical to accessing timely data without updating data in a warehouse. The costs associated with maintaining and servicing the warehouse can be avoided.
Perhaps the development that has most caught the public's imagination is “Blue Gene”. In December 1999, IBM announced a $100 million research initiative to build Blue Gene, the world's fastest supercomputer, to tackle fundamental problems in computational biology. The Blue Gene system will be capable of performing more than 1,000,000,000,000,000 operations per second — a petaflop capacity. It will achieve this performance through massive parallelism, with one million processors. The Blue Gene project will use this computer for large-scale bio-molecular simulation to advance our understanding of biologically important processes, in particular our understanding of the mechanisms behind protein folding.
IBM Life Sciences maintains openness among its life sciences partners. As such, IBM makes it clear that it is not a biology company. The intent of IBM Life Sciences is not to discover new treatments, make drugs, or go into content-based businesses like sequencing the genome. Rather, believing that information technology is a critical enabler in life sciences, IBM's IT infrastructure support allows the industry to keep its focus on research and its core businesses. IBM maintains that its depth and breadth of offerings for life sciences are the keys to differentiating among IT providers to life sciences companies. Thus, its strategy is to provide a broad-based infrastructure for new biology.
IBM is clearly playing a key role in developing the IT infrastructure necessary for successful data mining of the human genome and proteome to facilitate advancements in understanding human biology and applying this knowledge to improving health. Ultimately this means more information delivered to doctors through practical IT solutions, so that those doctors can then provide improved individual patient care. Though not the primary goal, a side effect of this will surely be more accurate detection and treatment and therefore lower health-care costs.