
Abstract
Personalization is a key component of an interactive marketing strategy. Its purpose is to adapt a standardized product or service to an individual customer's needs. The goal is to create profit for the producer and increased value for the consumer. This goal fits nicely into traditional notions of segmentation. Applications of personalization have advanced greatly in conjunction with the Internet, since it provides an environment that is information rich and well suited to interactivity. This article reviews past research on personalization and considers some examples of personalization in practice. We discuss what we believe are key problems and directions for personalization in the future.
Introduction
Personalization is intimately connected with the idea of interactive marketing and refers to the customization of some or all the elements of the marketing mix to an individual level. Personalization is more refined than customization, in that the personalization is automated by the marketer on behalf of the customer, as opposed to customization that a customer requests on her own behalf. For example, a customer ordering specific options for a micro-computer from Dell would be an example of customization, while Dell preloading an individualized software bundle that it expects a particular user would like to purchase is an example of personalization. This distinction is quite important because it puts the burden on the marketer to determine the appropriate degree of customization. As a consequence the marketer must anticipate what the customer wants. Generally this is done by leveraging customer-level information using analytical tools. Hence, personalization is paired closely to the technology and applications for which it is employed.
Our proposed definition of personalization is the adaptation of products and services by the producer for the consumer using information that has been inferred from the consumer's behavior or transactions. A primary enabler of this personalization is technology. Either technology used to create the adaptations, communicate with the consumer, gather consumer information, or used to make inferences about the consumer. Our definition is consistent with recent efforts to define personalization, but given that no commonly accepted definition exists, any definition is not without controversy (Venasen 2007). Perhaps most controversial in our assessment of personalization is whether it should include customizations made at the request of the consumer, which we have called customization. Our reason for taking this narrower focus on personalization is partly philosophical, namely to differentiate it from customization, and also to identify the component that we think has the most potential to be aided by the Internet.
The promise of personalization has always been that it can deliver on the idea of a customer-oriented marketing strategy. Blattberg and Deighton (1991) prominently mention personalization in developing their concept of interactive marketing. They held out the goal that interactive marketing would allow the customer to be provided more pertinent information with less effort. This embodies the idea of what we refer to as personalization. Personalization then is meant to eliminate tedious tasks for the customer, and allow the marketer to better identify the user's needs and goals from past behavior.
It is important to understand that personalization predates the Internet, and as a consequence is broader than this single technology. However, it is clear that the Internet has cultivated much of the interest in personalization and has advanced its practice more than any other technology. Therefore in this paper we intentionally focus on personalization in the context of the Internet, and present our perspectives on current applications of and future directions for personalization. Our primary goal is not to present a systematic survey of personalization, but rather to identify examples of excellence that represent the state of the art for the practice of personalization on the Internet, and then to consider future challenges for personalization.
Our focus on personalization is not meant to slight the importance of other elements of the marketing strategy, but to think about how personalization can improve the functioning of these other elements. We would argue that personalization does not exist alone but as a component within an overall marketing strategy. Additionally, high degrees of personalization are not always beneficial. The explicit costs of personalization may exceed its value. For example, the cost of customizations in manufacturing may be high relative to their value. This would suggest that traditional segmentation strategies are preferable. Alternatively, the implicit costs of personalization to consumers may exceed their value. White et al. (2008) suggests that consumers may respond negatively when messages are personalized but the perceived value of the service is low. Finally, personalization may lessen the social or brand identity of a product which lessens its effectiveness. Calder and Malthouse (2005) provide the example of a personalized pair of jeans that fit perfectly, but lack the peer identification that a standardized pair of jeans may possess, which would again lessen the value of personalization.
Survey of research on personalization
The marketing community's interest in personalization has spawned a wide variety of research. To better organize the work that has been done, in this section we classify this research into several areas: definitions of personalization, conceptual framework for personalization models, methodology for implementing personalization, and the effectiveness of personalization. We leave a discussion of privacy and its related research to the section on new directions for personalization when we discuss future challenges for personalization.
Definitions
Personalization is often invoked as an important element in an interactive marketing strategy (Blattberg and Deighton 1991). There are numerous versions of interactive marketing offered in the literature including customerization (Wind and Rangaswamy 2001), customer relationship management (Imhoff, Loftis, and Geiger 2001), one-to-one marketing (Allen, Kania, and Yaeckel 2001; Peppers and Rogers 1997), permission marketing (Godin 1999), customer intimacy (Wiersema 1998), real-time marketing (McKenna 1997), McKinsey's continuous relationship management, Gartner Group's technology-enabled marketing, enterprise relationship management, Internet marketing (Hanson 2000; Roberts 2003), database marketing, and e-marketing.
All of these forms of marketing refer to the concept of using technology to help identify and satisfy the customer's needs — which is at the core of any marketing strategy. However, each of these invocations of interactive marketing adopts different definitions for personalization and how it should be used in practice. In Table 1 we provide a list of definitions for personalization compiled by Vankalo (2003). The common element in all these definitions is that personalization is an adaptation of the marketing mix to an individual customer based upon the marketer's information about the customer.
Definitions of personalization.
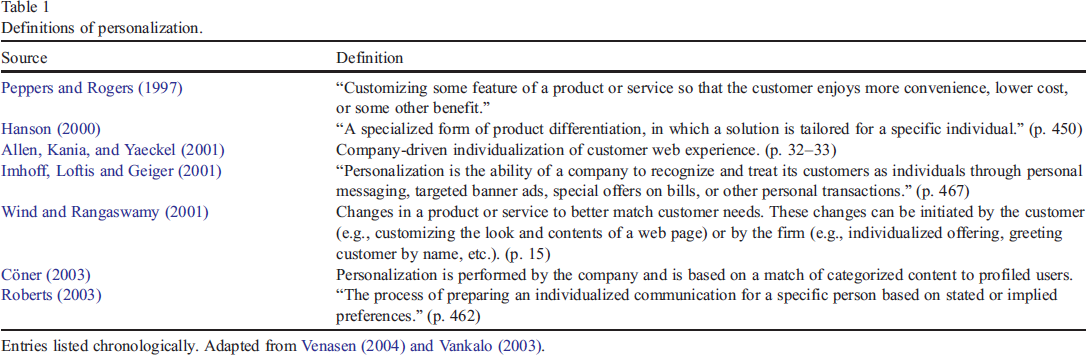
Entries listed chronologically. Adapted from Venasen (2004) and Vankalo (2003).
Conceptual framework for personalization
Given the variety of different interactive marketing strategies, it is not surprising that we lack a unified framework for personalization and customization; however two authors have recently proposed personalization frameworks that attempt to integrate the various viewpoints. Venasen (2007) proposes that personalization is a broad concept that encompasses execution, marketing outputs in the form of products/services, promotion/communication, price and delivery, and the creation of value for both the customer and the marketer (see Figure 2 of Venasen (2007)). Venasen then decomposes each of these concepts further into a series of subtopics to develop a taxonomy which relates the common components of interactive marketing strategies.
A second framework has been proposed by Miceli, Ricotta, and Costabile (2007). They identify four dimensions along which to characterize personalization: value, knowledge, orientation, and relationship quality. Value refers to customer expectations for personalization features. Knowledge pertains to the customer's expertise. Orientation depends upon the consumer's behavior, whether the consumer is utilitarian or hedonic in his/her motivation. Relationship quality refers to the tie that a customer has with the firm and encompasses trust. The authors argue that these dimensions are useful for gauging the value of personalization for a marketer. Both of these frameworks are helpful in reconciling and integrating previous work on personalization, and point to our need to better understand both how, when, and what type of personalization is valued.
Methodology for implementation of personalization
Given that a key facet of personalization is adapting to a customer's interests, it is imperative to learn about the customer. Montgomery and Srinivasan (2003) define active and passive forms of learning about consumers, providing a useful dichotomy for understanding the methodology of personalization. Active learning refers to posing direct questions to the customer, while passive learning requires the marketer to make inferences about the customer's interests generally using information from past transactions or clickstream data.
The most obvious example of active learning on the Internet is to pose questions directly to the user. However, customers do not always know the answer and they may not always be truthful. Therefore, conjoint analysis is a popular technique for trying to decompose a customer's preferences into the worth of each attribute. One important application of this technique is in product design, which is quite relevant for personalization since we may want to employ a mass customization framework, but need to understand the value that customers attach to these customizations. Dahan and Hauser (2002) review six web-based methods for actively learning about customers: web-based conjoint design, user design, fast polyhedral adaptive conjoint estimation, virtual concept testing, information pump, and securities of trading of concepts. These approaches demonstrate that virtual design is practical in real-time environment.
Passive learning is more complex because it is necessary to make inferences from actions that may be indirectly related to the personalization that needs to be performed. For example, the marketer may wish to make inferences about price sensitivity from the path taken through a website. Fortunately, there are several major sources of information on the Internet that are available from users from which to passively learn: transaction data, clickstream data, and email.
Transaction data can be used to make inferences about price sensitivity (Smith and Brynjolfsson 2001), and the best predictor of price response is past purchase behavior and not demographics. For example, Rossi, McCulloch, and Allenby (1996) consider how purchase histories can be used to determine personalized couponing policies. They estimate a statistical model known as a multinomial probit model to determine the price sensitivity of a supermarket shopper using information from previous purchases in a single product category, canned tuna. They used the model to determine what value (if any) of coupon to offer a shopper at the checkout stand and the expected profits for different coupons based on various information sets. The blanket coupon drop assumed that all consumers received a coupon for 10¢ off on their next purchase. Using demographic information to choose who received a coupon, they increased expected profits by 10% over a blanket coupon drop. In comparison, by using only data on the last purchase or the entire purchase history, they increased profits by 60% or 90% respectively. Clearly purchase information is more valuable than demographic information in this context. In the full information case, they used information on both previous purchases and demographics and obtained a 260% increase in expected profitability over the blanket coupon drop. Purchase information used properly is an incredible resource. The value of transaction information for personalization is apparent.
Just as we can collect purchase data in physical stores, we can collect purchase data in virtual stores. However, the data set is much richer. In the brick and mortar retail store, we know what the customer purchased and what items and prices were available within the store. But imagine that we also record shopper movements through the store, what items they looked at and considered and those they ignored, how long shoppers considered their decisions, and whether they bought one product and then put a complementary product into their carts. This is exactly the kind of information we can collect in online shopping environments. Generally, we refer to this data as clickstream data. More precisely clickstream data refers to the sequence of pages viewed at a website and the time at which each page was viewed.
Several models for analyzing clickstream data have been proposed in the marketing literature. Montgomery et al. (2004) propose a dynamic multivariate probit model that uses path information to predict where a user is likely to go in the remainder of the session. They discuss an application in which the pages and offers could be adaptively designed to personalize the features based upon a user's implied interests and goals. Sismeiro and Bucklin (2004) develop a sequential probit model, in which movements through the website are decomposed into a series of tasks that must be performed before moving to the next step. For example, after a user completes a product configuration they must then input personal information. They find that users who are likely to purchase can be identified early in their session; suggesting that greater attention to these individuals may increase the profitability of the website. Moe and Fader (2004) develop a model that measures evolving visit behavior across sessions, and find that users that visit more frequently are more likely to purchase, but also that changes in visit frequency over time can also be valuable in predicting conversion.
An alternative approach is to use data mining techniques to extract usage patterns (Mobasher, Cooley, and Srivastava 2000; Mobasher et al. 2001; Nasraoui and Petenes 2003; Pierrakos et al. 2003; Ting, Kimble, and Kudenko 2005). These models hint at the potential for clickstream data in personalization, however we need to also understand that clickstream is underutilized (Sen, Dacin, and Pattichis 2006) and it is likely to take years before its potential is fully leveraged.
Another rich stream of information for learning about customers is email. Ansari and Mela (2003) propose customization (or in our terminology personalization) of email communications with the customer. Specifically, they consider a problem in which the marketer sends targeted messages to customers in order to solicit new business. They estimate the value of different types and different ordering of messages to increase the likelihood of purchase. Their methodology could be employed to create an adaptive web design as well. More generally, one can think of email as a textual database. Great strides have been made over the past ten years in analyzing the textual data that is encoded in user emails. For example, McCallum, Wang, and Corrada-Emmanuel (2007) show how topics can be learned from email text and network links.
Effectiveness of personalization
Another stream of research aims at identifying when personalization is and is not effective. Tam and Ho (2006) develop a model of personalization that posits that effectiveness is moderated by content relevance and self reference. Additionally, Tam and Ho (2005) consider the application of the elaboration likelihood model from the consumer behavior literature and find that a consumer's need for cognition may play a role in the effectiveness of web personalization. More critically Nunes and Kambil (2001) find that many consumers do not like personalization but prefer the control that a user-customizable interface provides. They suggest that users prefer to provide information in a gradual process, and it may be a violation of trust to jump to a highly personalized interface.
The state of the art in personalization on the Internet
In this section we present a series of areas that illustrate how personalization has been applied to the Internet in order to illustrate the state of the art in personalization. Again we remind the reader that these examples are not meant to be exhaustive but are selected to be illustrative of elements of personalization technologies that we see implemented currently. To aid the reader we order our examples along the usual product purchase cycle: search, recommendation, price and promotion, and personalization strategies.
Personalized search
Search engines work by matching keywords or phrases that describe what a user is searching for against an index of web pages. One difficulty with the current approach to search is that it is generally static. Two users who enter the same keyword, such as “travel”, will generally receive the same set of matches, even though these users may differ in their reason for searching, search expertise, age, career, or a variety of other relevant characteristics. The goal of personalization in this context is for sites to adapt the search results based upon the user's previous searches, and potentially their knowledge base and goals. For example, in the search for “travel” above a key potential source of personalization is identifying that one user travels on business frequently to San Francisco while the other does not.
We speculate that it is possible that user profiling can make these types of inferences if a user's history is known (Montgomery 2001). Contextualization is the process through which a user's task is inferred from their behavior, and again path analysis demonstrates that this is possible (Montgomery et al. 2004). The next problem is whether a search engine can use this information to filter or augment search requests. This is precisely what personalized search engines are meant to provide. Google, Yahoo, Ask Jeeves, and A9 all provide personalized search services. Similarly, Minekey follows a hybrid strategy in that it is an applet that exists on the user's computer and makes recommendations of new web sites based upon a user's browsing history.
Personalized recommenders
Collaborative filtering was one of the first examples of personalization technologies widely available on the web. For example, collaborative filtering systems have been employed by Amazon, Barnes & Noble, LibraryThing, and Storycode to recommend books; Blockbuster, Eachmovie, Hollywood Video, Movielens, and Netflix to recommend movies; Audioscrobbler, CDNow, iLike, iTunes, Last.fm, MusicMatch, MSN Music, MyStrands, RealPlayer MusicStore, Rhapsody, and Napster to suggest music; TiVo for television shows; Findory for news items; and StumbleUpon for website recommendations. These sites and others demonstrate the pervasive importance of recommender systems across a variety of different settings.
A recent movement in this area is towards recommenders that operate independently of a retailer and allow users to update their own information. Music provides a nice illustration of the promise of recommender systems and this new approach. The traditional problem in music is that it is extremely expensive to promote new music, and given the small number of songs that terrestrial radio stations play the mass market is a difficult channel through which to introduce new music. Personalization would seem to represent a potential solution by dramatically reducing promotion costs.
In this context, Pandora is a personalized music recommendation system that works by having users select a song or artist that they enjoy listening to. Pandora then makes recommendations, and can adapt these recommendations as users specify approval or disapproval of, or over-exposure to recommended songs. The site works by using 400 different musical attributes defined and rated by the Music Genome Project (e.g., Accordion Playing, Disco Influences, Midwest Rap Roots, etc.). The key to the system is that songs are selected based upon their similarity to the attributes a user enjoys, which stands in contrast to collaborative filtering which makes suggestions based upon your similarity to other user's preferences.
Some of the challenges identified by Wedel et al. (2007) for recommender systems are the large number of choice alternatives, missing data, scale usage heterogeneity, scalability, and that customer choices depend upon the recommendations which introduces endogeneity to the process. One notable example of these challenges is Netflix's recommender system. Netflix has sponsored a prize to the first collaborative filtering system that improves predictions by more than 10% in terms of root mean squared error (RMSE) over Netflix's own Cinematch system. The range of predictions by consumers on the Netflix system is 1 through 5. A 10% improvement in RMSE means that a new recommender system must reduce RMSE from .9525 to .8572. This means that Cinematch can generally predict within a point whether a user will like a movie. On one hand, this is an impressive feat; on the other hand it clearly leaves a good deal of room on a five-point scale to improve recommendations. The promise of recommender systems is clearly demonstrated by the widespread adoption of these tools, but improved techniques must be developed to truly realize their potential.
Personalized price and promotions for airlines
Prices are simple to customize at an individual level, however keeping a consistent marketing strategy is difficult since personalized pricing strategies can degenerate into a confusing, Byzantine system. Perhaps the airline industry is one of the best examples of how a fractured pricing system can lead to confusion amongst consumers. Two examples of personalization in this marketplace are Southwest's Ding service 1 and the Farecast.com website, but each takes a much different approach to the problem.
Southwest's Ding system works by providing customers with special offers that are only available through Ding. Typically consumers report 20–25% reductions in prices over standard fares. Ding works by asking customers to register at Southwest and then download a small applet which is in constant communication with Southwest to receive special, up-to-the-minute offers. The customer specifies markets that they are interested in flying to, but to secure the fare they must act quickly using the Ding applet. This type of system allows Southwest to make unique, personalized offers based upon the customer's history and stated preferences.
An alternative approach is exhibited by Farecast, which serves as an intermediary between the airline and the consumer — effectively offering personalization by filtering another supplier's products. What makes Farecast unique is that it has an extensive database to track previous prices and to make predictions using data mining techniques about what future prices are likely to be available. Farecast then can make personalized recommendations about whether to purchase at the current price or to wait for a (likely) lower fare. Additionally, Farecast can sell guarantees for a specified charge to the consumer (e.g., $9.95) so that if the price drops below what is forecasted then it will reimburse the difference.
Integration of personalization strategies
Perhaps no company has more aggressively pursued personalization technology than Amazon. Amazon's CEO Jeff Bezos stated that “If we want to have 20 million customers, then we want to have 20 million ‘stores’. … Our mission is to be the earth's most customer-centric company” (Ferranti 2000). Amazon provides dozens of forms of personalization features, some of the more notable ones are Your Amazon, Today's Deals, Gifts & Wish Lists, Recommendations by Category, Your Browsing History, Your Lists, and Your Profile. Amazon has made a clear and aggressive foray into personalization, although it is neither the largest nor the most profitable e-retailer. Personalization is not a panacea, but clearly it has demonstrated its promise in the marketplace.
New directions for personalization
Our goal to this point has been to identify the promise of personalization made by research and examine the implementation of personalization in online environments. Our next step is to consider new directions for both research and practice if personalization is to truly deliver on its promise. In this section we consider three problems that we believe must be addressed as personalization advances into the future: privacy, adaptive web design, and computation.
Privacy
From the outset, a primary criticism leveled at personalization is that it constitutes an invasion of the consumer's privacy. There is a tradeoff between information to implement personalization and the potential violation of privacy that comes with this information. Just as the definition of personalization is diverse, the definition of privacy is equally and perhaps more problematic (Mascarenhas et al. 2003). Adding to this tension is a varied legal framework that sees privacy vary on a continuum between a contractual agreement between consenting parties to a basic human right (Smith 2001). Thus, one crucial issue to address in the future is how can we understand and balance the objectives of businesses and consumers with respect to personalization.
To motivate our discussion consider the idea of a sufficiency in statistics. Sufficiency means that all the information the analyst needs to make inferences about a parameter is contained within a sufficient statistic. For example, if an analyst is interested in making an inference about the mean of a normal population with a known standard deviation, then the analyst would only need to know the mean of the sample. All the information from the sample about making inferences on the unknown population mean is encapsulated in this single parameter. The practical importance of the sufficiency reduction is that it allows one to discard the raw observations. Unfortunately, for some models without closed form solutions the sufficient statistic is the vector of all information. For example, the sufficient information in a multinomial probit model using the method of Rossi, McCulloch, and Allenby (1996) is the vector of all information.
The question for personalization models is whether a sufficient reduction can be made and whether this sufficient statistic can be disguised to protect the anonymity of an individual. From a privacy standpoint sufficiency reductions are helpful because the analyst no longer needs the raw information but can work with a reduced, potentially more anonymized form of data without a loss of information. The added benefit of sufficiency reductions is that they reduce the information that must be stored and transferred. However, the privacy of the sufficient statistic for a personalization model must still be addressed.
Technology may provide one possible solution to insure privacy. Sackmann, Strüker, and Accorsi (2006) propose a combination of controlled disclosure of data, agreement on data collection, transparent processing and usage, and enforcing policy-compliance to insure privacy. For example, the Platform for Privacy Preferences (P3P) is an XML specification that states what kind of data is stored by retailers, how the data is used, how long it will be kept, and how it can be accessed. This provides the user with some input over what information will be shared.
Along with strategic action is a need to understand when is it in the consumer's interest to share this information and at what cost. In this regard, Xu et al. (2007) consider the effects of enabling the user to have some control over the type of information shared. They consider a personalized web search in which the user is given control over how much information is revealed. They found that search results could be significantly improved by only sharing some higher-level user profile information. Smyth and Balfe (2006) have also suggested that similar gains could be made by using social networks to improve search. Although some information about what segment you belong to still must be shared with the search engine.
One solution that would better insure the privacy of the individual is to have the individual perform the computation necessary to make the personalizations. This would require smart agents to act on the user's behalf to collect information and integrate it with their history. However, this requires greater computational resources to be devoted by the consumer and a large feed of information from the producer. Currently, there are no successful commercial systems that reverse this flow of information that have been developed. But this does provide one potential alternative computational model.
Personalization using adaptive web design
The traditional model of web navigation is that an expert creates a site by anticipating what objective a user has. Usually this means that there is a hierarchical structure for the site which allows users to traverse this structure in order to find the information that interests them. Perkowitz and Etzioni (2000) portray these websites as “fossils cast in HTML.” Weld et al. (2003) provide both a survey of progress made in adaptive interfaces at the University of Washington, as well as a summary of the lessons learned. Specifically, they find that users often are unable to specify their goals, and thus it is better to make inferences about their goals based on their observed actions. Additionally, they believe adaptive interfaces must balance the costs of user errors in adaptive environments along with the gains. Also, defaults and automatic responses can help improve adaptive schemes.
The problem of adaptive design is not unique to personalization. This problem occurs frequently within many online contexts, such as web design, auctions, advertising, search, recommender systems, user navigation support, and tutoring models. Research on adaptive choice in online environments is scattered across many different fields of human computer interaction, machine learning, marketing, and statistics. To continue to move personalization forward we must work on integrating these diverse research streams.
Computational issues
Research into the use of data intensive marketing strategies has been intense over the past decade. For example, researchers have proposed methods for the analysis of clickstream data for adaptive web design (Montgomery et al. 2004), and analyzing consumer choice for shopbot design (Brynjolfson, Smith, and Montgomery 2007; Smith and Brynjolfsson 2001). Much of this progress has been due to Monte Carlo Markov Chain (MCMC) estimation procedures. From a research standpoint these methods have been highly successful, allowing the estimation of previously intractable models. Practically though these simulation techniques can be very time consuming: the estimation of a hierarchical choice model can take hours to complete (Rossi, McCulloch, and Allenby 1996). In practice, Amazon typically requires its system to respond in 2's or less. If the current stream of Bayesian research in marketing is to have an important impact in practice, computational methods that can be implemented in real-time are necessary.
In our assessment the greatest challenge for personalization is the ability to make inferences about consumers using transaction and clickstream data. However, in our discussion of methodology for personalization we find the limitation not in lacking potential statistical algorithms but in the requirement of executing these inferences in real-time decision environments. We believe a promising computational strategy that has been employed by Google, Amazon, Sun, and IBM (as well as a host of others) is to construct grid computing environments (Bryant 2007). This allows companies to harness the power of hundreds of thousands of low-cost personal computers by splitting up the computational tasks so that they can be handled in parallel. Grid computing provides a promising direction for being able to analyze the quantitative models employed in marketing problems. Unfortunately the current simulation techniques used to estimate marketing models are by their nature sequential (e.g., MCMC). Brockwell and Kadane (2005), however, propose a promising method of parallelizing these algorithms. If a general parallelization scheme could be implemented then this would help bridge the gap between academic models that are computationally expensive and the need for fast response in practice.
Conclusions
The promise of personalization is the ability to deliver more relevant products and services to consumers. The current marketplace for most consumer goods with hundreds of products may seem overwhelming; just consider the example of LCD televisions. But if this number is compared with the large degree of heterogeneity between individual preferences and the hundreds of millions of consumers, clearly there are many magnitudes of growth that can occur, potentially there could be more products than consumers in the marketplace. Many managers may cringe at these ideas since traditional product and brand management models are inadequate to support such a system. However interactive marketing strategies can be extremely helpful in this environment. The reward of personalization within an interactive marketing strategy is increased profits for the firm and increased value for the consumer.
Currently the World Wide Web (WWW) is the most popular tool for delivery of personalization systems. However, the WWW is a component of the Internet. In the coming years we are likely to see an increase in mobile devices, embedded computers, smart appliances, and RFID tags and scanners that are networked into the Internet. This ubiquitous computing environment will likely yield richer environments for personalization that are contextually aware (Kenny and Marshall 2000). We see the potential for mobile devices as examples of how the general principal of personalization can be applied, and not pointing out limitations in our current understanding or definition of personalization.
In our assessment there have been substantial gains in delivering personalization in this past decade. Applications of personalized search, recommendations, price and promotions all illustrate that the current business environment is ripe for personalization. We also believe that the statistical methodology for making inferences about customer preferences and goals using transaction and clickstream data has developed to the point where the major hurdle is the computational systems to yield these inferences in real-time from our existing methodologies. Grid computing systems provide a promising direction to this massive inference problem. Another area that we identify for advances in personalization in the coming years is in the area of adaptive web design. This field by its nature is interdisciplinary and includes human computer interaction, machine learning, marketing, and statistics. The challenge in integrating these fields is that they all possess different notions of consumers and how they process information. The technological and strategic impediments to advancing personalization research are substantial. However, these impediments do not appear to provide a barrier to the application of personalization in practice in the near future.