
Abstract
Because the efficacy of behavioral interventions is central to applied psychology, the relative merits of competing approaches to an intervention are important. Many comparative studies examine the differential outcomes of alternative methods of psychotherapy. This paper addresses the issue of impact differences among rival intervention methods by focusing on treatment outcome research that emphasizes the relative (or comparative) efficacy of different psychotherapies. The paper has 4 components. First, it explores the concept of relative efficacy. Second, it reviews the extensive evidence on relative efficacy, which is generally consistent with the null hypothesis. Third, it offers a 3-part explanation of the negative evidence on relative efficacy: (a) a statistical argument about how relative efficacy is bound by a modest upper limit; (b) a research design argument about how relative efficacy studies are confounded by multiple factors, which make it difficult to demonstrate differences in treatment effects; and (c) a theoretical argument about how therapists’ contributions to treatment outcomes depend more on their clinical abilities than the therapy methods they implement. The final section of the paper outlines questions for future research.
Few issues in applied psychology are as important as the efficacy of behavioral interventions, whether clinical, counseling, vocational, educational, social, or organizational (Lipsey & Wilson, 1993). Such innovations require a clearly delineated service model if different individuals are to provide the same service. For each intervention category, the relative merits of competing approaches (or service models) have strong practical and theoretical importance.
To illustrate, in vocational rehabilitation, supported employment models, which emphasize rapid placement in a competitive job followed by on- or off-site training as needed (i.e., place-and-train models), are currently replacing the previous vocational models in mental health treatment, which were either sheltered employment or extensive prevocational preparation and training before placement (i.e., train-and-place models)—for example, the individual placement and support model of supported employment for people with severe mental illness (Drake & Becker, 1996; Drake, Becker, Clark, & Mueser, 1999). The more recent customized employment supports model adapts the individual placement and support model for a substance-abusing treatment population, namely, methadone-maintained clients (Blankertz et al., 2004, 2005). Such supported employment models can be compared with standard services for the relevant client populations.
In education, innovations can, as Cook (2003, p. 114) pointed out, include “school-based management, charter schools, vouchers, more effective teaching practices, higher standards, increased accountability, smaller schools, smaller classes, new technologies, and better trained teachers.” Some of these innovations can be introduced only at the school or the district level; others can also be introduced at the classroom (i.e., teacher) level. These innovations may also be construed as planned organizational changes (i.e., examples of organizational development).
By far the most common type of comparative study, however, examines the differential outcomes of alternative methods of psychotherapy (or counseling). In this article, I address the larger issue of impact differences among rival intervention methods by focusing on treatment outcome research that emphasizes the relative (or comparative) efficacy of different psychotherapies. The article has four components. First, I explore the concept of relative efficacy. Second, I review the extensive evidence on relative efficacy, which is generally consistent with the null hypothesis. Third, I offer a three-part explanation of the negative evidence on relative efficacy: (a) a statistical argument about how relative efficacy is bound by a modest upper limit; (b) a research design argument about how relative efficacy studies are confounded by multiple factors, which make it difficult to demonstrate real differences in treatment effects; and (c) a theoretical argument about how therapists’ contributions to treatment outcomes depend more on their clinical abilities than on the therapy methods they implement. In the final section of the article, I outline questions for future research—especially whether the conclusions regarding the relative efficacy of psychotherapies can be generalized to comparisons of other types of interventions.
Concept of Relative Efficacy
Distinction between Absolute and Relative Efficacy
The investigation of the efficacy of psychotherapy involves two interrelated concepts: the absolute efficacy of psychotherapy and the relative efficacy of different psychotherapies. According to Wampold (2001, p. 34), “Absolute efficacy refers to the effects of a treatment in comparison to no treatment.” In an experiment using random assignment, therefore, the absolute efficacy of a treatment is the expected posttreatment difference between treated participants and no-treatment control participants. Standardized effect sizes provide a useful metric for comparing outcome effects from different studies of the absolute efficacy of psychotherapy. An effect size represents the difference between treatment means relative to within-group variation (Berman, Miller, & Massman, 1985). Thus, the absolute efficacy of psychotherapy refers to the average effect on clients of psychotherapy in comparison to no treatment (Wampold, 2001).
What is the absolute efficacy of psychotherapy? According to Wampold's (2001, p. 70) review of a half century of psychotherapy research, “From the various meta-analyses conducted over the years, the effect size related to the absolute efficacy appears to fall within the range .75 to .85. A reasonable and defensible point estimate for the efficacy of psychotherapy would be .80.” Wampold concluded that “psychotherapy is remarkably efficacious” (p. 71) and that “the documented potency of psychotherapy in clinical trials is remarkably large and robust” (p. 204). I analyze Wampold's optimistic conclusion below.
In contrast to the concept of absolute efficacy, the concept of relative efficacy refers to the outcome effect sizes obtained when a method of psychotherapy is contrasted with one or more other methods rather than with a no-treatment control group; that is, it concerns differential effects of therapy methods. In short, the difference between studies of absolute efficacy and relative efficacy lies in the choice of the comparison group.
Two Theoretical Paradigms for Treatment Outcome Research
Most psychotherapy outcome research falls within either the specific-factors or the common-factors paradigm. Whereas the common-factors paradigm primarily raises the question of absolute efficacy, the specific-factors paradigm pertains mostly to relative efficacy.
Although support among investigators for each paradigm has waxed and waned over the past 75 years, most research in the past 3 decades has explored the role of specific factors. Wampold (2001, p. xii) described the specific-factors (or medical model) paradigm as follows:
In this model, theoretical explanations for disorders, problems, or complaints are formulated, treatments contain specific ingredients that are theoretically purported to be necessary for change, the therapist focuses on these specific ingredients, and researchers attribute the benefits of psychotherapy to those ingredients.
The alternative to the specific-factors paradigm for outcome research focuses on common (or general) factors. Originally formulated by Rosenzweig (1936) and further elaborated by Frank and Frank (1991), the common-factors approach asserts, according to Glass (2001, p. ix), that “all of the many specific types of psychotherapeutic treatment achieve virtually equal—or insignificantly different—benefits because of a common core of curative processes.”
Wampold (2001, p. xii) elaborated on the commonalities among therapies:
All therapies involve the relationship of a client and therapist, each of whom believes in the efficacy of the treatment. The therapist provides the client with a rationale for the disorder and administers a procedure that is consistent with that rationale. The client discusses the most intimate details of his or her life, confident that the therapeutic relationship will continue. The particular specific ingredients contained in the treatment… are not responsible for the therapeutic benefits.
Accordingly, the list of common factors includes (a) therapist characteristics, (b) client characteristics (e.g., positive initial expectations and treatment motivation), (c) relationship elements (e.g., the therapist–client alliance), (d) an explanation of the client's problems that is persuasive to the client, (e) a rationale for the treatment offered that seems credible to the client and the therapist, (f) treatment structures (e.g., standard procedures and rituals followed in treatment), and (g) a healing environment (Wampold, 2001).
The Evidence on Relative Efficacy
Summary of the Negative Evidence
A plausible implication of the method-based paradigm for evaluating outcomes of psychotherapy is that some methods (and thus some theories) should be better than others—that is, on the basis of an accumulation of evidence, there should be clear-cut evidence of the relative efficacy of different psychotherapies.
Whether and how much the various psychotherapies differ in clinical efficacy has been the focus of thousands of individual comparative studies, hundreds of meta-analyses, and several meta-meta-analyses (Baskin, Tierney, Minami, & Wampold, 2003; Lipsey & Wilson, 1993; Shapiro & Shapiro, 1982; Smith & Glass, 1977; Smith, Glass, & Miller, 1980; Stiles, Shapiro, & Elliott, 1986; Wampold, 2001; Wampold et al., 1997; Wilson & Lipsey, 2001). More important, the relative efficacy conjecture has not been borne out. Indeed, much of the comparative treatment literature has documented the counterintuitive conclusion that despite the vast array of empirical studies, one cannot make a compelling case for differential treatment efficacy (Ahn & Wampold, 2001; Frank & Frank, 1991; Kim, Wampold, & Bolt, 2006; Luborsky, Singer, & Luborsky, 1975; Luborsky et al., 2002; Rosenzweig, 1936; Shapiro & Shapiro, 1982; Wampold, 2001).
Clinical Implications of the Negative Evidence
If, as the preceding summary suggests, different methods of psychotherapy are indistinguishable in their effects, several vexing clinical questions need to be addressed:
Does it make sense to train therapists in particular treatment methods? If not, what should training of therapists consist of aside from building relationship skills and gaining experience (Stein & Lambert, 1995; Wampold, 2001)? What is the value of manualization in treatment research as manuals are intended to promote therapist conformity (or adherence) to methods (Stein & Lambert, 1995; Stiles et al., 1986; Wampold, 2001)? Is it justifiable to designate a certain subclass of therapies as evidence-based (i.e., “empirically supported treatments”; Borkovec & Castonguay, 1998; Chambless & Hollon, 1998; Wampold, 2001)? Are there any grounds for dividing treatment methods into legitimate (i.e., bona fide) versus others (Crits-Cristoph, 1997; Wampold et al., 1997; Wampold, Lichtenberg, & Waehler, 2002)? If more recent therapy techniques are indistinguishable from prior approaches in terms of efficacy, what clinical progress has the field made in the past 75 years? Is there reason to believe that contemporary psychotherapy has greater efficacy than earlier methods? What clinical theories can be cited to delineate change mechanisms that explain the positive outcomes of psychotherapeutic treatment?
Theoretical Implications of the Negative Evidence
The lack of evidence of relative validity also has significant consequences for psychological theory because most therapy methods are accompanied by a theory. Cumulatively, the many methods invoke a sizable proportion of psychological theory in such areas of psychology as social, cognitive, experimental (e.g., learning theory), and clinical. In general, the efficacy of the therapy is deemed evidence of the validity of its corresponding theory.
Although logically possible, it is unlikely that most or all therapies work equally well for their own specific theoretical reasons. Thus, Glass (2001, p. ix) noted “the implausibility that the great variety of specific ingredients in the multitude of psychotherapeutic approaches would yield indistinguishable outcomes.” The opposite view, namely, that all therapies work for the same reasons (i.e., nonspecific or general factors) is more parsimonious. Although therapies could involve a mix of specific and nonspecific factors, the evidence for specific factors remains sparse (Wampold, 2001).
If only nonspecific factors are involved, the null findings on relative efficacy cast doubt on the theories that predict, and are thought to explain, the efficacy of the treatment methods with which they are affiliated. Is there, therefore, a need to revise theories in both clinical and nonclinical domains of psychology?
In short, although the method-specific theories are not refuted, they lose much of their plausibility. Only a theory addressing nonspecific or general factors could readily account for the data—for example, all therapies work for the same reasons. Such a theory, however, would require a quite different perspective on treatment.
Explaining the Negative Evidence on Relative Efficacy
The failure to establish systematic efficacy differences among psychotherapies doubtless has many causes, three of which are particularly important: (a) a statistical argument about the constraint imposed by absolute efficacy on the upper limit of relative efficacy (i.e., treatment method differences are unlikely to be large), (b) a research design argument about multiple confounds that complicate the detection of relative efficacy (i.e., treatment method differences cannot be easily and accurately detected), and (c) a theoretical argument that treatment method differences may not be important compared with therapist differences (i.e., therapists’ clinical abilities offer an alternative focus to treatment methods in explaining psychotherapy outcomes).
Constraint Imposed by Absolute Efficacy
The extent of relative efficacy is constrained by the true value of the absolute efficacy of psychotherapy because the relative efficacy of pairs of psychotherapies should be considerably smaller than the absolute efficacy of psychotherapy. That is, treatment–treatment comparisons should, and routinely do, produce smaller effects than treatment–no treatment comparisons (Lipsey & Wilson, 1993; Grissom, 1996).
More important, if generally accepted estimates of absolute efficacy are in fact inflated, the constraints on relative efficacy will be greater than existing estimates of absolute efficacy would suggest. Although discussed in the research literature in the 1980s and 1990s, the question of bias in estimates of absolute efficacy no longer receives much scholarly attention. In arriving at his effect size estimate of .8, for example, Wampold (2001) did not review potential psychometric and other biases. Yet such biases exist. Indeed, the constraint placed by absolute efficacy on relative efficacy is probably greater than Wampold's .8 conclusion suggests because, as argued below, synthesized estimates of absolute efficacy have likely been overestimated. In short, the actual value of absolute efficacy that limits relative efficacy may be appreciably lower than an effect size estimate of .8.
To be sure, meta-analyses of absolute efficacy can contain downward biases as well as upward biases, and they can also contain inconsistent (or nonsystematic) biases (Shadish, Cook, & Campbell, 2002), yet the downward and nonsystematic biases pose little threat to absolute efficacy. Standard downward biases in meta-analyses (e.g., unreliability of outcome measures, range restriction of the independent variable, dichotomization of measures, etc.), which in principle can be corrected for by psychometric meta-analytic techniques (Hunter & Schmidt, 1996), are typically either irrelevant to absolute efficacy (i.e., range restriction or dichotomization) or not particularly strong (i.e., unreliability of outcome measures). To illustrate, the outcome measures used in treatment research (e.g., measures of psychological symptoms) usually include standardized multi-item scales with high reliability such as the Beck Depression Inventory (Beck, Ward, Mendelson, Mock, & Erbaugh, 1961). Furthermore, other biases (e.g., nonrandomized designs and methodological deficiencies), which arguably could have been either typically downward or typically upward, have been found to be nonsystematic (Lipsey & Wilson, 1993) and thus act merely as noise (or error) variance rather than as consistent bias.
However, there are identifiable biases in the meta-analytic literature in the direction of overestimation of absolute efficacy. Although these biases have been analyzed in detail elsewhere (Staines & Cleland, 2007), I briefly describe three of them below.
Partial Sample Bias
Only intent-to-treat analyses of experimental data gain reasonable protection from bias through the use of randomization. If subsets of cases become the basis for analysis (e.g., only those clients who complete a treatment program or only those cases for which there are follow-up data), estimates are biased, usually in favor of treatment effects (Klein, 1998). In short, efficacy for completers should not be confused with absolute efficacy.
Stanton and Shadish (1997, p. 173) observed that “across the field of psychotherapy research as a whole, dropout levels tend to be moderately high—averaging around 50% (Wierzbicki & Pekarik, 1993).” Treatment dropouts include “those assigned to a treatment condition who either failed to participate in that treatment entirely or dropped out before engaging in some minimum number of sessions” (Stanton & Shadish, 1997, p. 177). In assessing absolute efficacy, it is important to include treatment dropouts in the analysis to see the full range of treatment outcomes. Otherwise, when psychotherapy has a high dropout rate and retains only clients with a better prognosis, its efficacy will be appreciably inflated (Stanton & Shadish, 1997).
Researcher Allegiance Bias
As suggested above, the concept of researcher allegiance refers to an investigator's preference for a therapy. In an outcome study comparing two treatments, allegiance concerns a researcher's preference for one treatment over a rival treatment (Luborsky et al., 1999; Wampold, 2001). Researchers regularly report substantially better outcomes for the therapies that they prefer than for those they do not prefer (i.e., an investigator allegiance effect). In a comparison of outcomes between two types of therapies, that is, researchers of opposite allegiances give the advantage in their reports to the therapy they prefer.
To illustrate, Berman et al. (1985) conducted a meta-analysis of 25 studies comparing the efficacy of cognitive therapy and systematic desensitization for treating primarily anxiety disorders and reported the results by researcher allegiance. Studies by proponents of cognitive therapy gave their treatment an average effect size advantage of .27. Studies by proponents of systematic desensitization gave their approach an advantage of .38. Researcher allegiance bias, according to such data, is quite substantial. Although allegiance effects have typically been discussed in the context of comparative treatment research, allegiance might also be expected in treatment-control comparisons (Gaffan, Tsaousis, & Kemp-Wheeler, 1995).
Publication Bias
A further adjustment to the estimated effect size for the absolute efficacy of psychotherapy is needed for the bias favoring positive results in meta-analyses (Grissom, 1996). According to Lipsey and Wilson (1993, p. 1194),
There is good reason to believe that published studies of treatment effectiveness research will tend to show higher effect sizes than unpublished studies (Greenwald, 1975). Authors may be more likely to attempt to publish a study that finds large, statistically significant effects (even though such results can occur solely by chance). Journal editors and reviewers, in turn, are likely to look more favorably on such results when they are submitted for publication. Moreover, there is direct evidence that larger effect sizes do indeed appear more frequently in the published than the unpublished research on the same treatment.
To illustrate, in their meta-analytic study of 30 randomized experiments on behavioral marital therapy (half published and half unpublished doctoral dissertations), Shadish and Baldwin (2005) showed that studies with nonsignificant findings were underrepresented. “Further supporting the possibility of publication bias, the average effect size for published studies was d = .71 and for unpublished studies was d = .47. Although this difference was not statistically significant…it is in the expected direction for publication bias” (p. 8).
Factors that can be Confounded with Treatment Method Effects
Five Confounds
At least five major types of predictors of therapy outcomes may be confounded with treatment method effects in both primary and meta-analytic studies (Howard, Drause, Saunders, & Kopta, 1997). As a result, the detection of true treatment method differences is vulnerable to Type I errors (false positives), Type II errors (false negatives), and bias in estimates of effects. The five types of non–treatment method predictors are researcher allegiance, therapist attributes, client attributes, study method factors (not to be confused with treatment method factors), and social and organizational factors (see Table 1; Wampold et al., 1997).
The Confounding Role of Non-Treatment-Method Factors in Comparative Treatment Research
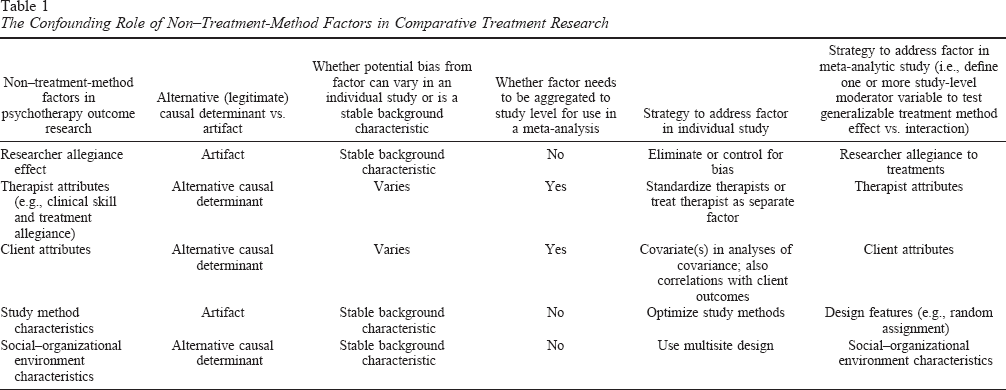
Characteristics of the Confounds
Three of the five factors (i.e., therapist attributes, client attributes, and social and organizational factors) are legitimate alternative determinants of outcomes—that is, inherent in the treatment situation. The remaining two factors (researcher allegiance and study method factors) are superfluous factors (or artifacts). Whether legitimate or superfluous, such factors can act as confounds in relative efficacy analyses because they can bias estimates of treatment method effects. They can also contribute noise (or error variance), thereby reducing power to detect significant treatment method differences. Furthermore, each type can have main effects on outcomes, interactive effects with treatment methods, or both.
In addition to the issue of confounding, legitimate and artifactual predictors have different implications for the validity of the treatment methods–based approach. Legitimate alternative predictors can replace treatment methods as the key determinants of treatment outcomes. Accordingly, relative efficacy will be low to the extent that these factors rather than treatment methods shape treatment outcomes. Artifacts, in contrast, impede the detection of real treatment method effects.
Strategies to Reduce the Confounds
The five types of non–treatment method factors should be measured and controlled in relative efficacy studies, ideally by research design, otherwise by statistical procedures. Wherever possible, unnecessary influences should be eliminated from (or minimized in) the experiment. Statistical controls on alternative determinants of the dependent variable increase statistical power (Shadish et al., 2002). When alternative determinants cannot be measured or controlled, the noise they add reduces statistical power. If unevenly distributed across conditions, they can act as confounds and introduce bias.
Analysis of the Five Confounds
Confounds involving researcher allegiance
Whereas researcher allegiance can produce overestimation of absolute efficacy, it can contribute to underdetection of true treatment method differences (i.e., relative efficacy) in individual studies by introducing noise and confounds (hence bias) and also by reducing power and generalizability. Paradoxically, it often leads to underdetection by producing relative efficacy effects that are not valid—that is, statistical effects that reflect researcher bias rather than treatment method differences. Wampold et al. (1997, p. 404) characterized researcher allegiance as “the primary confound identified in the literature.”
Researcher allegiance effects are always an unnecessary or superfluous source of variance. Their introduction adds variability that increases noise and lowers power. Indeed, researcher allegiance accounts for so much variance in many comparative treatment analyses that detection of possible treatment effects is severely impaired. For example, Luborsky et al. (1999) used difference scores of ratings of allegiance for each pair of therapies being compared in comparative outcome research. Regression analysis showed that the combination of three measures of researcher allegiance (i.e., ratings of allegiance from reprints, colleagues, and investigators) explained 69% of the variance in treatment outcomes.
Confounds involving therapist attributes
Therapist attributes resemble allegiance effects in three respects. In individual studies, they contribute noise that reduces power; they can produce confounds that introduce bias; and they reduce external validity. Unlike allegiance effects, however, therapist characteristics are not extraneous or unnecessary influences. As noted above, they are inherent in the treatment process.
In the ideal experiment, therapists, like clients, would be randomly assigned to conditions to eliminate bias, although not noise. Yet such control via randomization is rarely practical. Assignment of therapists, who are usually present in small numbers, is instead largely ad hoc. As a consequence, therapist effects, like allegiance effects, routinely contribute to error variance. Furthermore, if therapist effectiveness is unevenly distributed across conditions, therapist effects may become confounds that bias treatment method effects. Apparent differences between treatment methods, that is, may simply reflect differences between conditions in average therapist ability. Because therapist ability is difficult to measure independently of outcome effects (unless data are available on past performance), it is a methodological challenge to separate out therapist and method effects, and thus avoid therapist-based confounds (Staines, Cleland, & Blankertz, 2006).
Confounds involving client attributes
To the extent that samples are heterogeneous, client attributes introduce additional variability. Although random assignment of participants reduces the likelihood that client characteristics bias treatment effects, client attributes typically add noise and reduce power. Statistical controls on outcome-related client characteristics can reverse this process and increase power, but such controls are rarely systematic.
Pretreatment client attributes such as treatment motivation, treatment expectations, and problem severity can be important predictors of therapy outcomes (Sloane, Staples, Cristol, Yorkston, & Whipple, 1975; Staines et al., 2003). When the caseloads of individual therapists are examined, considerable variability is observed in client outcomes. Even the best therapists achieve very different results with different patients. Insofar as good therapists succeed with some patients and fail with others, the benefits of psychotherapy are not evenly distributed across clients.
Confounds involving study method factors
For the study of research method factors (e.g., design features), the unit of analysis changes from the individual participant to the research study. Unlike client and therapist attributes, research method factors are restricted to explaining differences among the findings of the comparative treatment studies included in a meta-analysis. That is, research method factors are a major reason why comparative treatment studies produce discrepant findings about relative efficacy. Such discrepancies can also impede efforts at replication.
Using studies as the unit of analysis, Wilson and Lipsey (2001) assessed the effect of research method factors on observed effect sizes relative to that of substantive features of psychological, behavioral, and educational interventions (i.e., primarily psychotherapies). Study methods accounted for nearly as much variability in study outcomes as characteristics of the interventions. Types of research design and operationalization of the dependent variable were the method features associated with the largest proportion of variance.
Confounds involving social and organizational factors
Less well studied in treatment research but nonetheless likely to affect outcomes is the social and organizational environment in which treatment takes place. Included here are both a clinic's organizational climate (Moos, 1974) and the surrounding community environment. Although such environmental factors can affect client outcomes directly (e.g., via the level of stigma associated with attending or being treated at a particular facility), they can also affect them indirectly through their impact on therapist performance (e.g., treatment facilities vary in the training and other support that they give clinical staff).
Relative Importance of Therapist Characteristics and Treatment Methods
Focusing on the Therapist Instead of Methods of Psychotherapy
There is a third (partial) explanation of the paucity of treatment method effects. It involves a shift in emphasis from the methods of therapy to the characteristics (especially skills) of therapists as the key to variability in treatment outcomes. This is also a shift from the specific-factors paradigm to a version of the common-factors paradigm that emphasizes the importance of one general factor (therapists). Whereas the prior discussion of therapist effects concentrated on how they could be confounded with (and otherwise complicate the detection of) treatment-method effects, this analysis focuses on therapists as the factor of interest rather than as a confound.
The consistent evidence of equivalence of outcomes across therapy methods might give the impression that psychotherapy is a bland, undifferentiated process in which what the therapist does matters little. Nothing could be further from the truth. Although therapies may not differ appreciably, therapists can and do. The study of differences among therapists may thus advance knowledge more than the minimal progress registered by studying differences among therapy methods.
Reconceptualizing the Role of the Therapist
According to the treatment methods–based framework, the therapist's job is to deliver the specific method competently, where competence is defined in terms of treatment methods–based factors such as manualization, adherence behavior, and so forth (Wampold, 2001). Relevant differences among therapists thus concern the consistency, efficiency, and fidelity of the delivery of the treatment method. In contrast, the therapist-oriented approach assigns a greater role to therapist skills, which, although not yet fully understood, can vary appreciably, as can the clinical results that therapists obtain.
Although important, the shift in emphasis from therapy methods to therapists is not as large conceptually as it may appear, nor is it a step backward. A method of therapy is not independent of the therapist. It is an abstraction of certain prespecified behaviors of the therapist (i.e., adherence behavior). That is, it is a single variable (e.g., cognitive–behavioral vs. systematic desensitization) used to classify therapists according to their treatment of certain clients. The label refers to a set of behaviors in which a therapist is expected to engage.
Although a treatment methods–based analysis of a therapist's behavior is legitimate, it is not the only way to measure or classify such behavior, and it may not be the best way. As the pervasive evidence of outcome equivalence across methods indicates, other characterizations (or dimensions) of a therapist's behavior may be more relevant to outcomes. The problem with the relative efficacy literature may be that the various competing theories have steered it toward too narrow a view of the therapist's role. In other words, both the treatment methods–based approach and the approach that emphasizes therapist abilities contend that the therapist is critical in determining treatment outcomes. Where they differ is in their account of what makes the therapist important.
Therapist Heterogeneity as a Prerequisite for Therapist Effects
Crucially, an approach emphasizing the therapist's influence on client outcomes differs structurally from a treatment methods–based paradigm. Given the goal of understanding client outcomes in psychotherapy, the treatment methods–based paradigm is useful only if different treatment methods typically produce different outcomes. By comparison, an investigation of how therapists facilitate client improvement does not imply that any particular sample (or all samples) of therapists will exhibit therapist effects. A sample of equally skilled therapists can all make similar contributions to their clients’ recovery. That is, although therapists’ clinical skills always contribute to client outcomes, if all therapists have equivalent skills, such skills cannot explain any variation in client outcomes.
Therapist effects, in short, play an epistemological role. A sample of therapists with different (or heterogeneous) levels of ability—one that displays therapist effects—is needed to investigate the extent to which therapist skill determines client outcomes and to identify which therapist skills (or other characteristics) contribute to client improvement. Attempts to standardize what therapists do (or to select homogeneous therapists) may defeat the purpose of understanding what therapists can contribute. The magnitude of therapist effects, which will vary across therapist samples, is not a direct test of the validity of a therapist-oriented approach. Instead, the existence of therapist effects is a methodological prerequisite for exploring the therapist-oriented approach effectively. The demonstration of therapist effects, in short, represents the beginning, not the end, of an inquiry into the processes by which therapists facilitate positive client outcomes.
Upper Limit of Therapist Effects
The absolute efficacy of psychotherapy constrains the outcome contributions of therapy-related factors (just as it constrains the magnitude of relative efficacy). If, despite the possibility of inflation, Wampold's (2001) effect size estimate of .8 is accepted as the absolute efficacy of psychotherapy, only 13% of the outcome variance is explained by the difference between treatment and no treatment (Wampold, 2001). That is, various components of the treatment intervention can collectively explain no more than approximately 13% of the outcome variance. Therapist effects, other common-factor effects, treatment method effects, artifacts and biases, and so forth cannot jointly exceed this modest limit. In other words, the impact of intervention components should be judged against a limit of 13% rather than 100%. It is thus reasonable to express the variance explained by a treatment component as a proportion of the 13% accounted for by receiving treatment (i.e., absolute efficacy).
Estimating the Magnitude of Therapist Effects
Estimates of therapist effects based on efficacy studies include (a) two analyses of the Treatment of Depression Collaborative Research Program clinical trial data, using different statistical models: 1.9% in Elkin, Falconnier, Martinovich, and Mahoney (2006) and 8% in Kim et al. (2006); (b) two major collaborative clinical trials: 6% in Project MATCH Research Group (1998, as cited in Wampold, 2001) and 8% in Huppert et al. (2001); and (c) two meta-analyses of clinical trials: 4.2% in Crits-Christoph and Mintz's (1991) synthesis of 10 trials and 8.6% in Crits-Christoph et al.'s (1991) synthesis of 15 studies (representing 27 different treatment methods). These therapist effects in efficacy studies mostly fall in the range from 4% to 8% of the outcome variance, with an average score of approximately 6%. The differences between the estimated values of psychotherapy effects (approximately 13%) and therapist effects (approximately 6%) can be attributed to other general factors (e.g., the therapeutic [or working] alliance), specific factors such as therapy methods (although there is no consistent evidence of this), upward biases in the assessment of absolute efficacy (e.g., investigator allegiance and publication bias), various methodological artifacts (e.g., research methods), and so forth.
Estimating the Magnitude of Effects for Individual Therapist Attributes
Although approximately 6% is the estimate of the outcome variance accounted for by all therapist attributes, multiple studies have provided data on the variance accounted for by specific therapist-related factors.
Allegiance
Therapist allegiance is defined as “the degree to which the therapist delivering the treatment believes that the therapy is efficacious” (Wampold, 2001, p. 159). There is considerable evidence that therapist allegiance is positively and significantly related to client outcomes (Krupnick et al., 1996; Wampold, 2001). Although the positive relationship between therapist allegiance to a treatment method and the study's outcome measures accounts for up to 10% of the variance (Wampold, 2001), therapist allegiance is in all likelihood confounded with investigator allegiance (Truax & Carkhuff, 1967). Without a design-based or statistical control on investigator allegiance, the unique contribution of therapist allegiance remains indeterminate.
Adherence (or compliance)
Therapist adherence refers to therapist compliance with the treatment protocols (e.g., a treatment manual) for a particular method of psychotherapy. If treatment methods do not differ in efficacy in any consistent fashion, however, therapist adherence should not contribute to positive treatment outcomes. Indeed, the available research, which does not include any meta-analyses, has found no consistent relationship between adherence and outcomes (Castonguay, Goldfried, Wiser, Raue, & Hayes, 1996; Feeley, DuRubeis, & Gelfand, 1999; Luborsky, McLellan, Woody, O'Brien, & Auerbach, 1985; Robinson, Berman, & Neimeyer, 1990; Shaw et al., 1999; Tracey, Sherry, & Albright, 1999).
Rogerian therapist conditions
In his account of client-centered therapy, Rogers (1957) contended that to be effective, a therapist needs the “ability to be empathic and congruent and to assume a stance of unconditional positive regard toward the client” (Horvath & Symonds, 1991, p. 139). Correlational research has examined the relationships between the three Rogerian competencies and outcome measures of client change. Empirical evidence (Farber & Lane, 2002) has generated a pattern of broadly positive (but not always significant) correlations between the three concepts and client outcomes. For example, Bohart, Elliott, Greenberg, and Watson (2002, p. 96), who reviewed studies of the relationship between empathy and outcomes, reported that “the single best summary value is the study-level, weighted, unbiased r of .32, a medium effect size.” Such zero-order correlational data, however, include no controls on possible confounds or other factors.
Conceptualizing Therapists’ Clinical Skills and Abilities
The preceding data suggest that measures of clinical skills (i.e., client-centered competencies and other therapist skills) contribute more to therapist effects than do observable clinician attributes (Ahn & Wampold, 2001). What is needed in future research is a systematic approach to assessing therapists’ outcome-related clinical skills. Such an analysis would start with measures of overall intelligence and identify pertinent cognitive skills (e.g., psychological diagnostic skill [i.e., critical thinking and pattern recognition]) that are outcome related (Blatt, Sanislow, Zuroff, & Pilkonis, 1996; Boyatzis & Burruss, 1995). Next would be measurement in other specific skill domains. For example, one plausible candidate for consideration is a therapist's emotional intelligence (Mayer & Salovey, 1997; Salovey & Mayer, 1990), which includes both cognitive and noncognitive skills.
Future Research
Treatment Outcome Research
The negative evidence on relative efficacy raises three questions for future studies in treatment outcome research and two questions about research in other areas of psychology. First, can a systematic assessment of therapists’ various clinical skills and abilities, along with general intelligence, help to explain the variability in therapist performance? Second, can the psychological theories that are used to explain treatment method differences (e.g., social, cognitive, educational, experimental [e.g., learning theory], and clinical) survive the negative evidence on relative efficacy? Third, given that current training for psychotherapists emphasizes proficiency in one or more treatment methods, what alternative focus could be introduced in the training of psychotherapists?
Other Psychological Domains
Of the two questions about extrapolating to other domains, the first concerns whether the negative evidence on treatment method differences is potentially generalizable to other psychosocial interventions that are implemented on a one-to-one basis. For example, is the provider appreciably more important than the method used in determining the outcomes of other forms of psychological treatment (e.g., vocational rehabilitation for the hard-core unemployed or individual counseling for drug abusers) and standard educational interventions (e.g., the role of the teacher in the classroom—especially the relative importance of teacher characteristics and teaching methods—and in human services more broadly)? Furthermore, does such generality also apply to interventions in which a single provider works with a group of clients (e.g., group therapy, family therapy, and substance abuse treatment groups) or a pair of employment specialists work on employment issues with seriously mentally ill clients (based on the individual placement and support model), or a multidisciplinary team of providers provides comprehensive, locally based treatment to people with serious and persistent mental illnesses (e.g., Assertive Community Training; Bond, Drake, Mueser, & Latimer, 2001). In short, wherever psychological interventions involve service providers and methods of intervening, the relative contributions of people and methods need to be determined.
Second, how similar are the sizes of therapist effects in treatment research and provider effects in other human services? To take an educational example, what does the literature on teacher effects on student achievement (e.g., Rockoff, 2004; Rowan, Correnti, & Miller, 2002; Sanders, Wright, & Horn, 1997) indicate about the relative size of teacher effects and therapist effects? Moreover, to what extent do the qualities that distinguish effective from ineffective teachers also separate effective from ineffective therapists? In sum, future research can examine whether the contributions of therapists to psychotherapy are typical (vs. atypical) of the contributions of providers to other human services.