
Abstract
The temperature control of molten steel is essential to ensure operational stability in a steelmaking plant. The calculation of thermal losses in the steelmaking plant’s operations depends on highly dynamic variables, which motivates the construction of predictive models for the steel temperature. This paper proposed a hybrid ensemble method using multiple linear and random forest regression to predict the end molten steel temperature at the secondary refining required to achieve a target tundish temperature. Combining these two methods makes it possible to account for the linear and non-linear relationships in the data. The implemented models were trained on industrial data, and their performance was assessed using root mean squared error (RMSE) and a custom accuracy metric. The results showed that the proposed hybrid method achieves up to 5% better accuracy compared to linear regression or random forest regression methods alone, thus can enhance molten steel prediction in steelmaking plants.
Introduction
Before the 1960s, the exclusive technique for casting liquid steel into a solid shape was batch casting, which involved pouring the liquid steel into ingots later shaped by stepwise rolling or forging. After the development of continuous casting techniques, it has emerged as the primary method for steel production. According to the World Steel Association, approximately 96% of the total global crude steel production in 2021 was produced through continuous casting [1]. Continuous casting offers several advantages, including enhanced productivity and metal yield, better surface and internal steel quality, reduced energy consumption, and the product being ready for direct rolling.
The basic equipment setup for the continuous casting is illustrated in Figure 1. After secondary treatment, the liquid steel, which has chemical and thermal homogeneity, is transferred to the continuous casting machine through a ladle. The liquid metal is then transferred to the tundish, which distributes the metal into the continuous casting water-cooled moulds, where metal solidification begins. Tundish is the last metallurgical vessel through which molten metal flows before solidifying, and one of the critical process parameters determining the quality of the final steel product is the degree of superheat of the melt in the tundish and in the mould. A diagrammatical overview of the continuous casting process [2].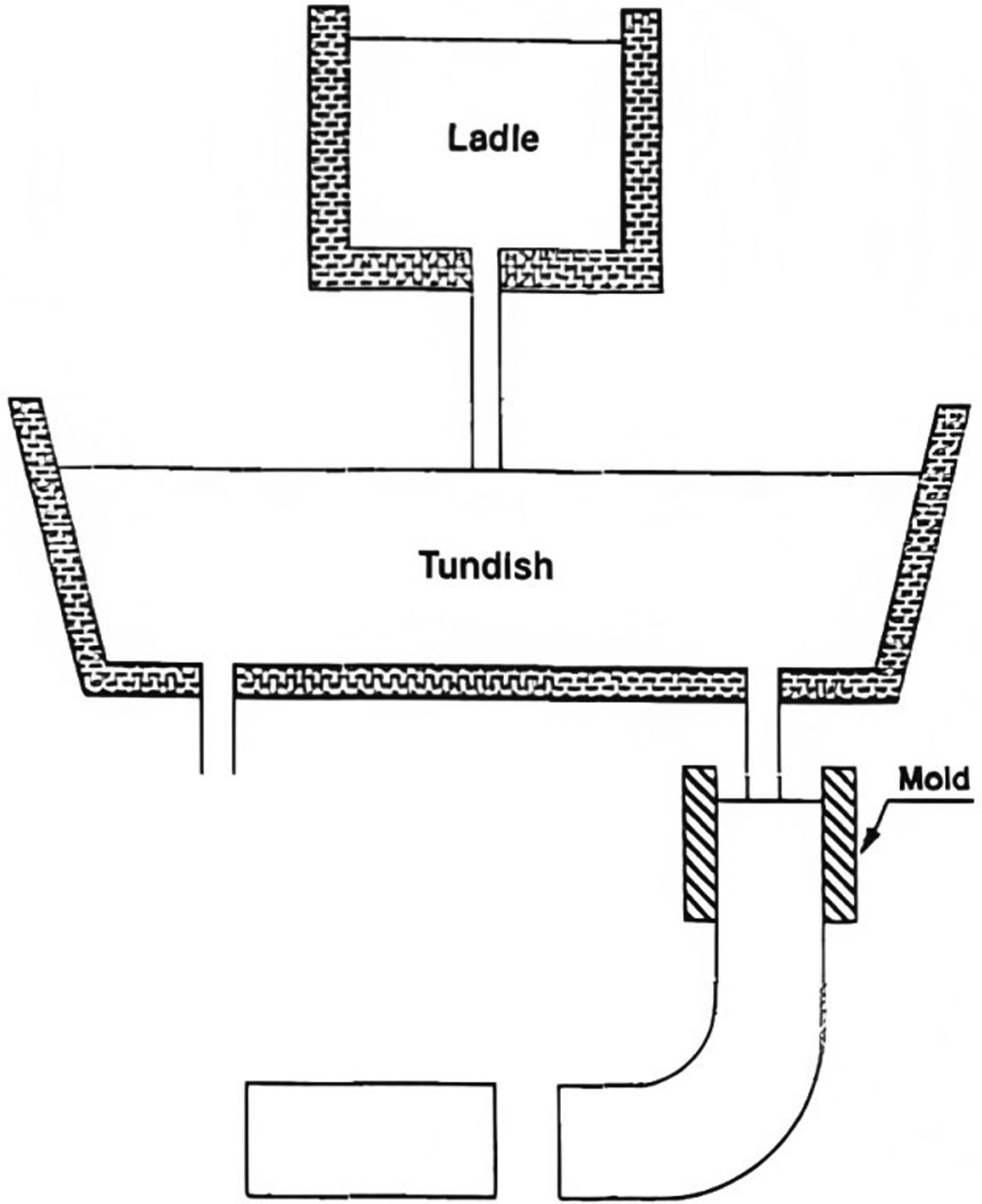
Controlling the temperature of molten steel in a steelmaking plant is essential for obtaining products that meet market specifications. There is a specified suitable temperature range for each step of steelmaking, and deviations from these ranges are associated with failures that affect the product's quality and the plant's productivity.
Low steel temperatures can result in nozzle blockages due to early solidification in the tundish and consequent production interruption. Likewise, low superheat values are associated with a lower inclusion flotation efficiency.
On the other hand, temperatures above specification can result in breakouts in continuous casting and affect the structure formed during solidification. Elevated superheat of the melt results in an increase in the proportion of the columnar grain region in the solidified product [3]. The columnar zone is associated with increased segregation, which is the variation in chemical composition, according to position, of various elements dissolved in steel, such as carbon, phosphorus, and sulphur [2]. The columnar zone also correlates to a more extensive formation of midway, centreline, diagonal and longitudinal cracks in the steel product [4]. During the casting, if too much superheat is delivered to the narrow faces, then shell growth may slow down or even reverse locally, likely increasing the incidence of breakouts near the narrow faces [5].
Heat losses throughout the steelmaking process and some important factors [6].
Two predominant approaches are used for building steel temperature prediction models: physical and statistical. The former is based on thermodynamics and energy conservation, and the latter is based on regression models. The quantification of thermal losses through the physical approach involves solving energy balance equations, which require using boundary conditions and properties of complex materials. These equations can rarely be solved analytically. Gupta and Chandra [6] point out that because of the high complexity of steel cooling phenomena, the statistical approach usually achieves better results than the physical one. In addition, Sonoda et al. [7] note that the statistical approach is usually faster and less computationally demanding.
Several studies reporting the prediction of molten steel temperature can be found in the literature. Jormalainen et al. [8] used a physical model to predict the melt temperatures in the ladle and the tundish during continuous casting. Their results reached 95% accuracy within a ±7°C range for steel temperature in the tundish. Tian et al. [9] proposed an incremental learning modelling and updating method to predict molten steel temperature in a 300 tons ladle furnace using an extreme learning machine algorithm. Their results were satisfactory for production, reaching 94% accuracy within a ±5°C range. Wang et al. [10] proposed a prediction model for the final temperature of molten steel in an Ruhrstahl Heraeus vacuum degasser (RH-TOP) refining process for interstitial-free steel production. They used multiple regression models and reported a hitting probability of prediction with a deviation of ±10°C above 95%. He et al. [11] proposed a hybrid physical and statistical model based on the ladle heat status and artificial neural networks for predicting the molten steel temperature target in the ladle furnace to obtain the aimed tundish temperature. They reported an accuracy of 75.38% within a ±5°C range and 88.34% within a ±7°C range for the end ladle furnace temperature in sequence castings.
Many hybrid regression modeling strategies that combine nonparametric and parametric methods have been proposed to derive useful information from complex data. Sousa et al. [12] used a hybrid method to predict ozone concentrations and proposed a methodology based on feedforward artificial neural networks (ANN) using principal components regression (PCR) results as inputs. They reported that the feedforward ANN led to more accurate results than linear models due to the account of non-linearities. AL-Alawi et al. [13] also used a combined PCR and ANN model to predict ozone concentration levels. PCR was used to identify the most appropriate explanatory variables for the regression models, and then ANN was applied to the resulting residuals. They reported a substantial reduction in the measured root mean squared error (RMSE) and mean absolute percentage error (MAPE) in the combined forecast compared to either PCR or ANN forecasts. Adusumilli et al. [14] proposed a hybrid regression model using PCR and random forest regression (RF) for integrating Global Positioning System (GPS) and Inertial Navigation System (INS) data to bridge the GPS signal outages. Their proposed model achieved a 14%–45% improvement in prediction accuracy compared to the RF model alone.
In this work, a hybrid approach that combines multiple linear and random forest regression to predict molten steel temperature has been proposed and evaluated. The developed models predict the end temperature in the secondary refining that is expected to result in a target tundish temperature. The linear regression method models linear relations in the data, while the random forest method models non-linear relations. The models are combined using the boosting method, an ensemble technique where the models are trained sequentially using the residuals of the previous model’s results. This hybrid strategy increases the accuracy of the molten steel temperature prediction.
Methodology
The methodology employed in this work consists in multiple stages that were carried out iteratively, that is, the results attained in a stage could result in new iterations of previous stages. This methodology is based on the Cross Industry Standard Process for Data Mining (CRISP-DM) [15] and is illustrated in Figure 2. Methodology stages of this work.
In the data collection stage, data from 2500 continuous casting heats were collected from a big steelmaking plant. Automatic online tracking systems generate the production data from each casting heat. Each record contains relevant information about the heat, such as the heat number, casting superheat at five minutes intervals, tundish and ladle’s thermal condition, and the temperatures measured at each stage of steel production.
The data preparation stage consisted of multiple feature engineering and data cleaning techniques, such as removing duplicate, empty, and incorrect data. A data balancing analysis was also performed for all categorical variables, and groups that did not have a representative amount of data compared to the other groups were removed from the data set. The choice of the variables used to fit the models was initially based on the literature and correlation analysis.
After the first model's iterations, these variables were validated with their p-value in the linear regression and the variable’s permutation importance analysis from the random forest model and the proposed model. The p-value for each variable tests the null hypothesis that its coefficient equals zero, which means that the variable does not affect the regression performance. A low p-value, usually less than 0.05, indicates that the null hypothesis can be rejected and that the predictor is likely significant to the model. The permutation feature importance is defined as the decrease in a model score when a single feature value is randomly shuffled [16]. If permuting the values causes a considerable change in the model’s accuracy, the feature is significant for the model.
Most machine learning algorithms can only handle numerical variables, so the data preparation stage also included a categorical variable transformation. The one-hot-encoding transformation was applied for the linear regression model, and the label encoding transformation was used for the random forest regression. Label encoding assigns a unique integer value to every possible value of a categorical variable [17]. On the other hand, one-hot encoding transforms an n-category nominal feature by creating binary indicator variables for the (n−1) feature levels [18]. Each observation indicates the presence (1) or absence (0) of the dichotomous binary variable [19].
Modeling
In the modeling stage, linear and random forest regression algorithms from the Scikit-learn library were initially used. Scikit-learn [20] is a general-purpose machine learning library written in Python. It provides efficient implementations of state-of-the-art algorithms, accessible to non-machine learning experts, and reusable across scientific disciplines and application fields [21].
The model aims to define the secondary refining target end temperature to meet the desired casting superheat. To simplify the use of the model in the industry, the proposed model is backward, which means that the secondary refining end temperature is the dependent variable. Since the steelmaking facility produces different steel classes, the secondary refining end temperature was transformed to secondary refining superheat, and the steel liquidus temperature was subtracted from the secondary refining end temperature before fitting the model.
A hybrid approach was proposed using a linear and random forest regression ensemble to improve the model's performance. A brief explanation of the regression models and the proposed hybrid model methodology is shown in the following paragraphs.
Multiple linear regression (MLR)
The relationship between a dependent variable 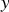
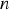
In general, multiple linear regression with n regressor variables is formulated as in (Eq. 1). Where 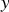
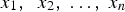
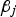

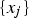
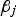
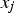
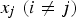
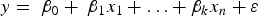
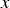
Random forest regression (RF)
The decision tree (DT) is a predictive method in which the predictor space is divided into a set of rectangles, and then a simple model is fitted in each one. A decision tree uses a tree structure to represent several possible paths and an outcome for each path. The process of building a tree is described below [23]: Divide the predictor space into J distinct and non-overlapping regions For every observation that falls into the region
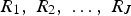
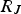
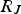
DT can be applied to both regression and classification problems, it is often more interpretable than other models such as neural networks and are flexible enough to handle items with a mixture of real-valued and categorical features [24]. On the other hand, DT suffers from high variance, if the training data is split into two parts at random, and a DT is fitted at both halves, the models result can be very different [23].
Ensemble learning is a combination of simpler base models to build a more robust prediction model, and one technique for reducing the variance of an estimated prediction is bagging, for regression that means fitting the same regression tree many times and then averaging the results [25]. Breiman [16] introduced random forests (RF), combining several randomised decision trees and aggregating their predictions by averaging.
RF is often a collection of hundreds to thousands of trees, where each tree is grown using a bootstrap sample of the original data. Furthermore, at each node of the tree, a random subset of variables is selected to be candidates to find the best split for the node, which gives the model a second layer of randomisation and allows RF to decorrelate the trees and have low variance [26]. The RF process is described below: Divide the original data in ntree bootstrap subsets. Fit a tree for each bootstrap data set. Aggregate information from the ntree for the new data prediction. Compute an out-of-bag (OOB) error rate, which is calculated using data that is not in the bootstrap node.
Boosting hybrid approach using linear and random forest regression (LRF)
Linear regressions can only handle linear correlations between the variables, and the random forest can handle non-linear relations. The proposed hybrid regression model combines a linear model with a series of random forest models to improve the molten steel prediction accuracy.
The process of training subsequent models using a previous model’s results is called boosting, another ensemble technique. The boosting technique has a slow learning approach, it does not fit a single large random forest to the data, which can lead to overfitting. Instead, it fits small trees to the residuals from the model, and the model is slowly improved in areas where it does not perform well [23].
On the LRF, the linear model, Hybrid approach based on boosting ensemble.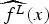
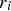

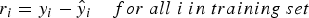
On each iteration, the LRF model is updated with the new random forest regression, Eq. 4. The model’s residual is updated as well, Eq. 5, so the next random forest is fitted on the new training data (X, r). The results of the random forests models are multiplied by a shrinkage parameter 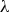

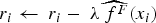
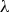
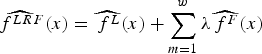
Model performance evaluation
The model was evaluated calculating the root mean squared error (RMSE), given by Eq. 7: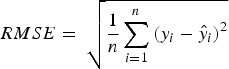
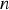

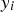
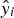
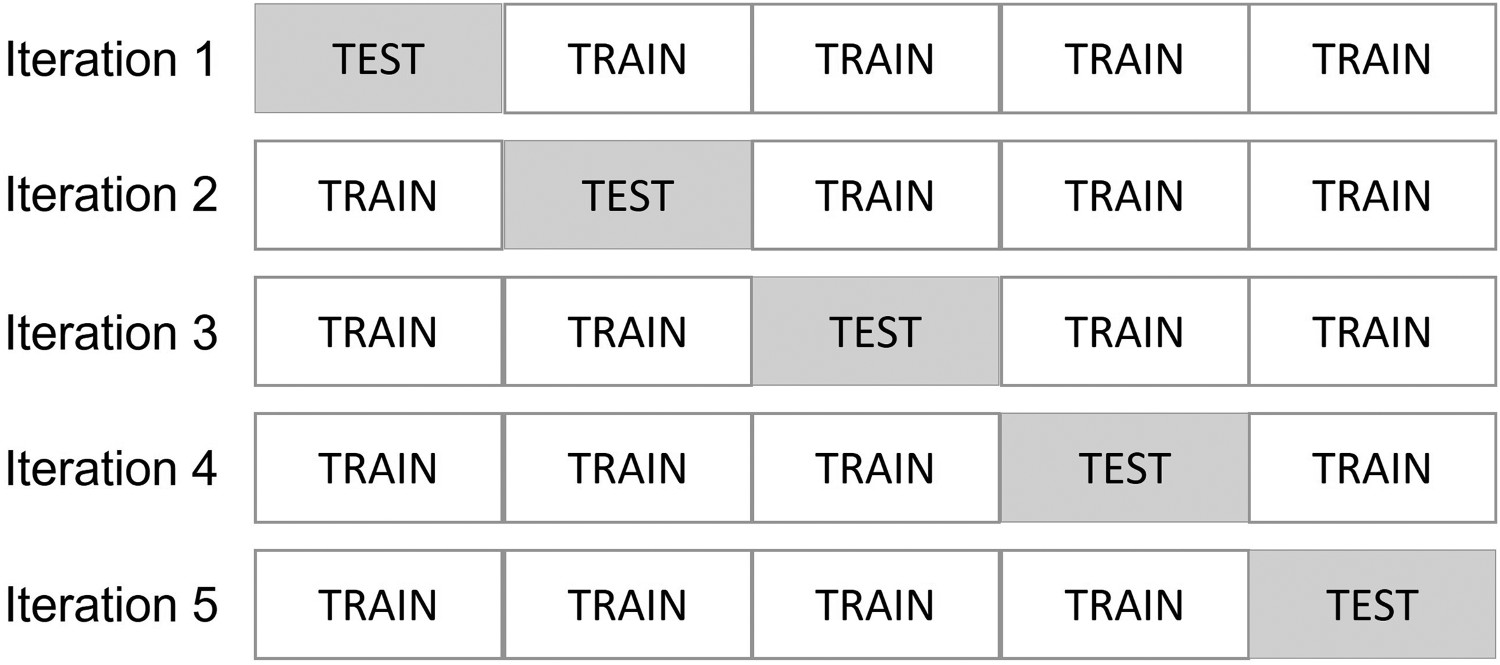
The model was also evaluated using a custom accuracy metric that considers that a prediction is correct if its residual is less than or equal to a fixed threshold. Eq. 8 shows how the accuracy was calculated, where The K-fold cross-validation technique where K = 5.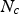
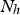
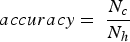
Parameter tuning
Parameter’s description and values used to tune the LRF model.
Since the model has many variables, the number of all the possible parameter combinations is 150.000. Considering a 5-fold cross-validation, the model would be fitted 750.000 times, generating high computational demand. Randomised parameter optimisation was performed to reduce the number of iterations, in which 1.500 random combinations of parameters were generated, and the model was fitted with each of these combinations. The number of parameter values to be tested was reduced based on the best parameters obtained from the randomised parameter optimisation. Subsequently, the complete grid search was performed, and the optimised parameter’s value was selected.
Results and discussion
RMSE and accuracy values of the models.
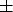
Figure 5(a) illustrates the scatter plot of predicted values versus measured values for the end molten steel temperature at the secondary refining. It shows that 85.3% of the data are found within a range of ±5°C and 94.5% accuracy within a range of ±7°C. Figure 5(b) is the histogram depicting the prediction error for the LFR model. The model's error exhibits a near-normal distribution centred around zero. This analysis indicates that the model is suitable for industrial applications. Prediction error for the LRF regression.
LRF model’s optimal parameters.
A comprehensive analysis was conducted to reveal each variable's importance to the regression models. The variables were evaluated using their p-value and the linear coefficient for the MLR. The permutation importance analysis was employed for the RF and the LRF regressions.
P-value for the model’s variables.
When the input data is normalised, the linear regression coefficient can measure the variable's importance: the larger the coefficient, the more significant the variable is for the regression. Figure 6 shows the linear regression coefficients for each variable used to train the model. Linear regression coefficients for normalised data.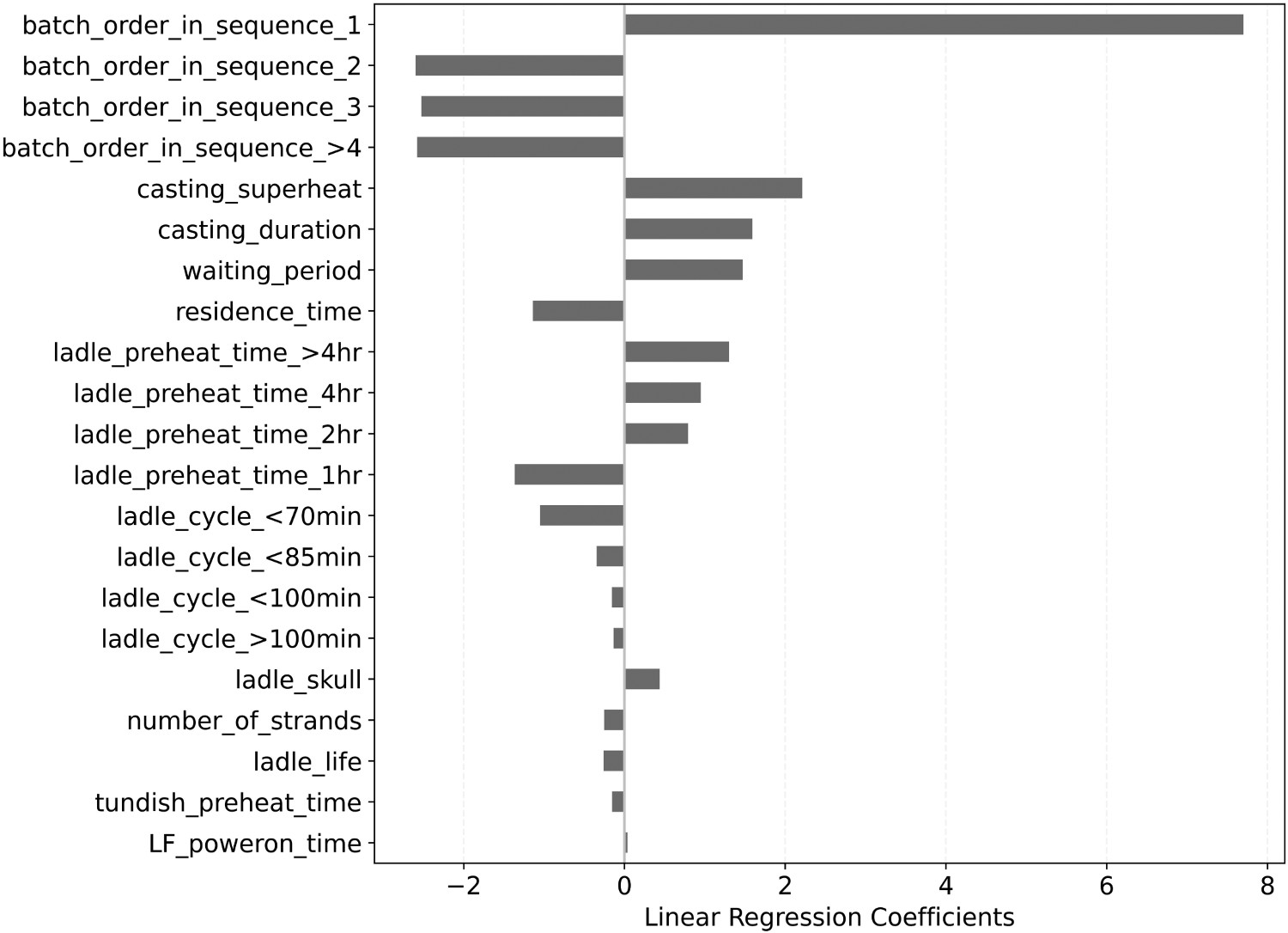
The batch order in the casting sequence was considered a categorical input and divided into four groups: first, second, third, and all subsequent batches after the third. The variable for the first batch in the sequence order has the largest coefficient. This result is expected due to the greater thermal loss of the steel to the tundish refractory walls in the first heat. As the casting continues, tundish walls become progressively hotter, and this thermal loss is reduced. Therefore, there is no significant difference between the coefficients from the second, third, and fourth heats onwards.
The variable with the second highest coefficient is the casting superheat. The last temperature in secondary refining must increase to increase the casting superheat, so this result is foreseen. The casting duration is the third most influential variable. Considering an approximately constant thermal loss in the tundish, the longer the casting time, the higher the temperature required to maintain the same average casting superheat. The waiting period between secondary refining and casting has the fourth highest coefficient, which is explained by the direct correlation between the waiting period duration and the thermal losses in that stage.
The steel residence time on the ladle and the ladle cycle or pre-heating time are also significant to the model since they represent the ladle's thermal history, which strongly affects steel temperature losses. The residence time has a negative coefficient, which is consistent with the literature, because as the time the ladle stays in contact with molten steel increases, the hotter its refractory walls become, reducing steel thermal losses to the ladle’s walls.
The ladle cycle quantifies the time the ladle stays without steel between heats, and the ladle refractory wall’s heat loss to the environment is larger as the time in this stage increases. Figure 6 shows that the shorter the ladle cycle, the greater its negative coefficient in the regression. This result is expected because the steel heat loss for the ladle is reduced with a shorter ladle cycle, so a smaller secondary refining end temperature is required.
In the plant’s operation practice, the ladle’s pre-heating duration increases with the time the ladle stays without molten steel, which is consistent with the increase in its linear coefficient as the pre-heating time increases since the ladle’s walls become cooler. Ladles that only pre-heat for one hour started their pre-heating process with less than 100 min cycle. This group presented a greater negative coefficient and thus a lower steel temperature loss to the ladle, compared to ladles with less than 70 min cycle. This result may be due to a lower heat loss from the ladle's walls to the environment since the ladle is covered during the pre-heating process and uncovered during waiting periods.
Despite being statistically significant to the MLR, the quantity of skull in the ladle, the ladle life, and the number of strands have a low coefficient in the regression. The tundish pre-heating time and the ladle furnace power on time have the lowest coefficients, which is consistent with their p-value, as they are not statistically relevant to the MLR.
The random forest regression’s permutation importance analysis was also performed. Figure 7 shows that most of the chosen variables are likewise relevant to the model. The most significant variables are the batch order in the casting sequence, the casting superheat, the waiting period, and the casting duration, which are also the variables with the highest coefficient in the linear regression model. However, a remarkable difference between the analysis is that some variables that were not statistically relevant for the MLR are meaningful for the RF regression, such as the ladle furnace power on time and the tundish pre-heating time. This indicates the presence of non-linear relationships in the dataset and that the models can potentially complement each other for better performance. RF permutation importance.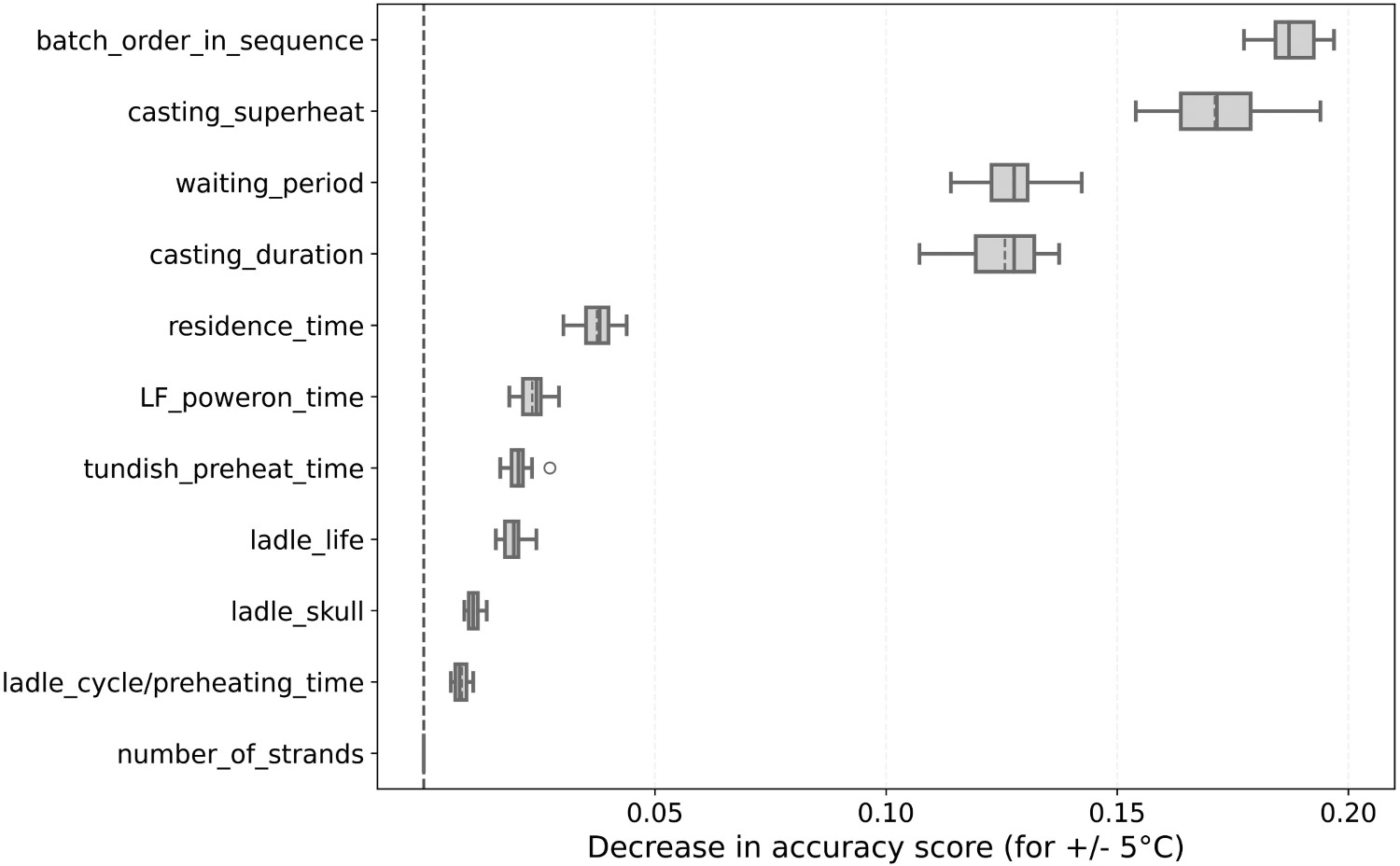
Figure 8 shows the results of the permutation importance analysis for the LRF model. The two most relevant variables for the model are the casting superheat and the order of the batch in the casting sequence, which are also the most relevant variables for both MLR and RF models. Comparing the permutation importance analysis of the RF and the LRF models, some variables that were not relevant for the RF model became more significant for the LRF, such as the ladle cycle and pre-heating time. It is widely acknowledged in the literature that these variables are significant for understanding steel thermal losses in a steelmaking plant. Therefore, the models complement each other for better performance. Permutation importance for the LRF model.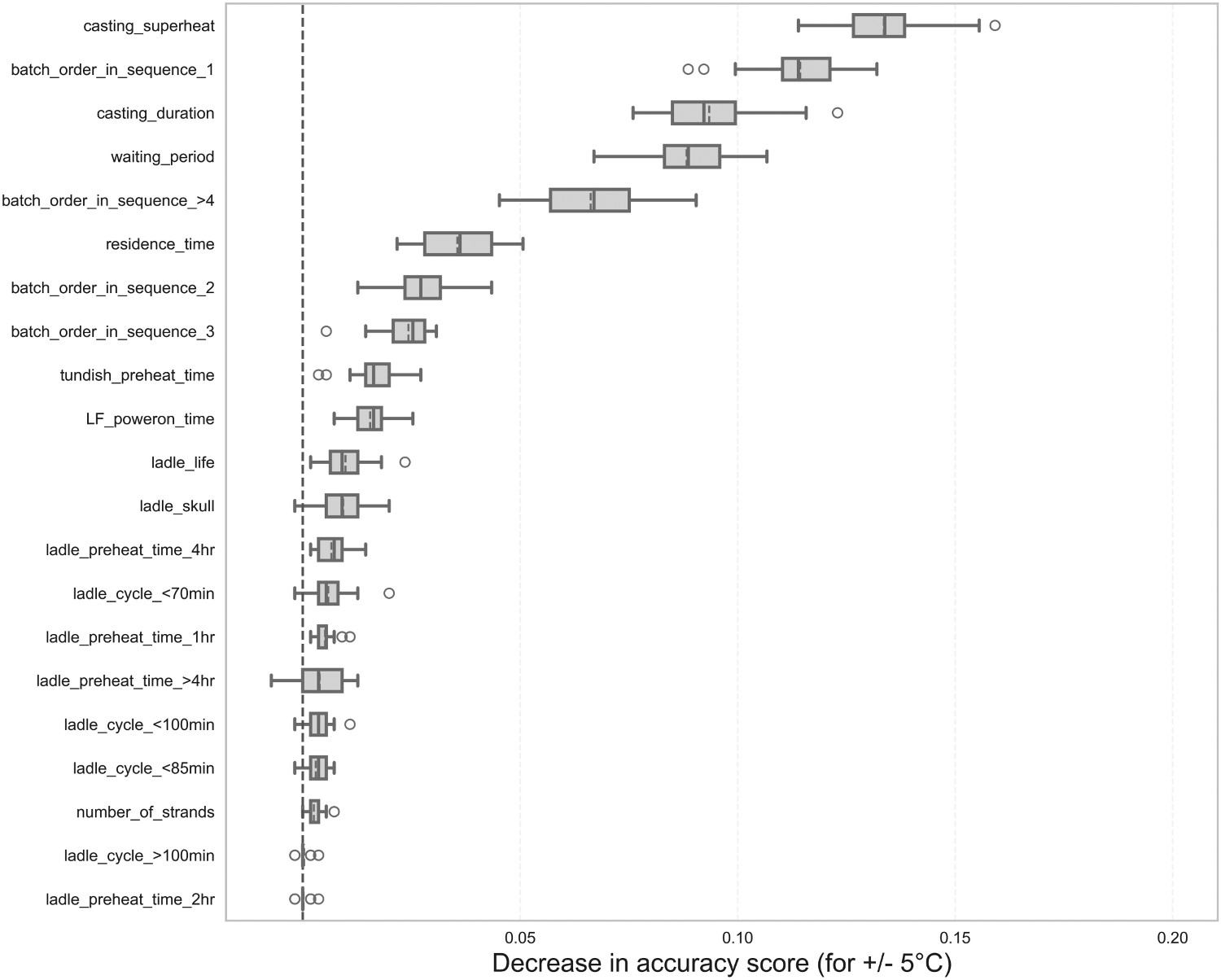
Conclusions
In this work, a hybrid statistical approach based on multiple linear and random forest regression to predict the end molten steel temperature at the secondary refining was proposed and evaluated. The proposed hybrid method first applies multiple linear regression to model the linear relationships in the dataset, then applies multiple iterations of random forest regression to improve accuracy by accounting for non-linear relationships. The two regression methods were combined using a boosting ensemble technique, in which the models are fitted sequentially using the previous model's residuals. The performance of the models was evaluated on industrial data using the RMSE metric and the accuracy to a fixed threshold.
The variables included in the models were chosen based on the literature review and validated using the p-value in the linear regression and permutation feature importance analysis for the RF and LRF regressions. The most significant variables were the batch order in the casting sequence, the casting superheat, the waiting period, the casting duration, and the residence time.
The proposed hybrid method outperformed both the linear and random forest regression methods individually. The LRF method achieved 85.3% accuracy within a range of ±5°C and 94.5% accuracy within a range of ±7°C, which is up to 5% better accuracy compared to each method alone. The accuracy of the developed method was found to be suitable for application in the industry to improve the temperature control of molten steel in continuous casting.
Footnotes
Acknowledgements
The authors are grateful to Gerdau Ouro Branco for kindly providing the industrial data for this study. They are also thankful to Redemat, Universidade Federal de Ouro Preto, CNPq and FAPEMIG for all their support.
Disclosure statement
No potential conflict of interest was reported by the authors.