
Abstract
To understand the grounding of cognitive mechanisms in perception and action, we used a simple detection task to determine how long it takes to predict an action goal from the perception of grasp postures and whether this prediction is under strategic control. Healthy observers detected visual probes over small or large objects after seeing either a precision grip or a power grip posture. Although the posture was uninformative it induced attention shifts to the grasp-congruent object within 350 ms. When the posture predicted target appearance over the grasp-incongruent object, observers’ initial strategic allocation of attention was overruled by the congruency between grasp and object. These results might help to characterize the human mirror neuron system and reveal how joint attention tunes early perceptual processes toward action prediction.
A recent body of work shows that our communication with others involves the activation of motor systems in the brain. One way to interpret these findings is that communication relies on an internal action simulation process that helps us to understand their intention. In the case of written-language comprehension, for example, this simulation process was documented by congruency effects between the content of a message and the physical response of its recipient (the action–sentence compatibility effect or ACE; Glenberg & Kaschak, 2002; Glenberg et al., 2008 this issue; Zwaan & Taylor, 2006; Taylor & Zwaan, 2008 this issue).
The concept of action simulation and its functional status are currently under debate. As discussed in Wilson and Knoblich's (2005) recent review:
We can distinguish at least three versions of this proposal, in order of increasing strength. The first is that action understanding refers essentially to recognizing or categorizing— understanding various individual acts to be instances of “grasping,” for example. The second is that action understanding involves a teleological component (cf. Gergely & Csibra, 2003) regarding the goals or reasons for which a motor movement is being performed—understanding a grasping hand as being directed at taking a piece of food, for example. The third is that action understanding supports a more full-blown representation of the other's mental state that drives the action—for example, understanding the desire for food that lies behind the action.” (Wilson & Knoblich, 2005, p. 463)
More often than through written language, people communicate verbally and face to face. Importantly, they use a variety of body postures or gestures to support their communicative goals. For the visual perception of such communicative signals, congruency effects between the content of the message and the response of the recipient have also been observed. For example, when we see a person looking or turning to one side, our own attention is also drawn to the same side (e.g., Driver et al., 1999; Ricciardelli et al., 2000). These posture-based congruency effects are often referred to as “joint attention” effects and seem to prepare our bodies for efficient responding in competitive situations. Using standard methods of attention research, joint attention can be measured as facilitated detection of visual targets when comparing detection speed between valid trials (a target appears on the side that was cued by the communicative signal) and invalid trials (where the target appears on the opposite side): Valid trials usually lead to slightly faster detection responses than do invalid trials (Posner, 1978). Moreover, by making the cues more or less predictive of the target location it is possible to show that joint attention is not normally under strategic control. Thus, we cannot help but attend to the same side as the person we observe, even when we know that the target will appear on the opposite side in most trials (Driver et al., 1999, Exp. 3). Similar joint attention effects have been reported for the observation of head and body orientation (e.g., Langton, Watt, & Bruce, 2000). Here we report results from a novel joint attention paradigm that involves grasping postures.
Previous work has already shown that the picture of a hand can be a powerful cue to direct an observer's attention. For example, Craighero, Bello, Fadiga, and Rizzolatti (2002) instructed participants to prepare to grasp a bar, which could be oriented either clockwise or counterclockwise, and to grasp it as fast as possible on presentation of the picture of a hand. Responses were faster when the orientation of the hand picture matched the orientation required for the participant's hand (see also Vogt, Taylor, & Hopkins, 2003). Similarly, simple imitative responses, such as finger lifting, are facilitated when the go signal is a similar hand action (Brass, Bekkering, & Prinz, 2001; Brass, Bekkering, Wohlschläger, & Prinz, 2000). Thus, we expected to also find evidence for joint attention from grasp cues. The present study was approved by the Ethics Review Board of the School of Psychology at the University of Dundee.
Experiment 1
The goal of the first experiment was to establish a joint attention paradigm that uses grasp cues instead of eye, head, or body posture cues. We showed normal observers a hand in front of pairs of objects and presented detection targets on top of the object. Importantly, the object sizes were congruent with different types of grasp. We measured whether attention allocation of our observers was sensitive to the action relation between the hand and the objects. By manipulating the time between the grasp cue and the target onset we measured the time course of their attention allocation.
Method
Participants
In our first experiment 7 males and 11 females (age range 19–35 years) took part. They were naïve with regard to the hypotheses under investigation and gave written informed consent.
Apparatus and materials
The experiment was controlled with E-Prime software (Schneider, Eschman, & Zuccolotti, 2002). Observers sat 45 cm from a 21-inch colour monitor, and their responses were collected on the space bar of the standard keyboard. They saw colour scenes of one small and one larger object in the bottom corners of the screen, together with a right arm with its hand in the centre of the monitor. The object pairs reflect a convenience sample of available large and small objects: can–sharpener (depicted in Figure 1), kiwi–coin, umbrella–barrette, sponge–biro, and cream pot–pencil. All views were from above, with objects about 116 mm apart and about 90 mm in front of the hand. The hand was photographed in three postures: a resting posture (thumb above index, remaining digits flexed), a precision grip (15 mm thumb–index aperture, remaining digits flexed), or a power grip (60 mm thumb–index aperture, remaining digits extended). The target was a yellow star (34 mm diameter). All stimulus scenes were assembled from these picture elements to ensure comparable visual stimulation across conditions.
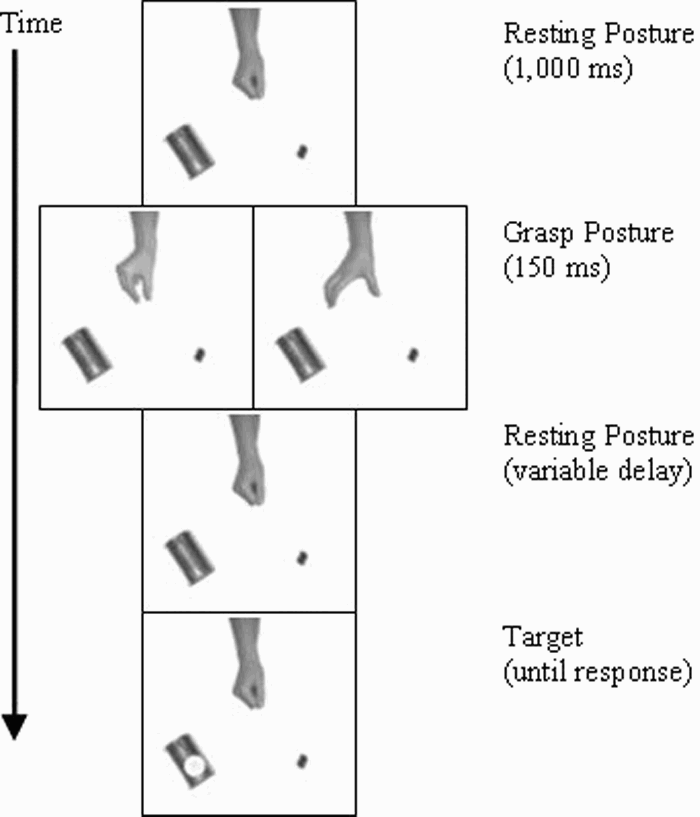
Sample event sequence for Experiment 1, depicting an incongruent trial (left grasp posture panel) and a congruent trial (right grasp posture panel).
Design and procedure
The trial sequence is illustrated in Figure 1. In each trial, the hand was first shown in a resting posture for 1,000 ms, together with the randomly chosen object pair. Next, the hand was shown at the same location in either a precision grip or power grip for 150 ms. We then showed the resting posture for delays of 0, 100, 200, 300, or 450 ms before a target appeared unpredictably and equally often over the left or right object. Observers pressed the space bar of the keyboard with their right hand when they detected the target. We recorded their reaction times (RTs: times from target onset to key response) in milliseconds.
All variables (object pair, grasp type, target delay, and target side) were randomized, and each scene appeared equally often in each condition. Each participant completed 6 practice trials and 200 experimental trials. In addition, 10% catch trials (where no target appeared) prevented anticipatory responding. Participants were instructed to respond fast without making catch trial errors and were told that the relationship between grasp size and target location was unpredictable. Catch trial responses were very infrequent, and we accepted RTs > 100 ms and within 2.5 standard deviations of each observer's mean, leaving more than 95% of data for statistical analysis.
Results
RTs from one observer were more than two standard deviations slower than the group mean and were excluded. A 2 (congruency: same vs. different size relationship between grasp and object at target location) × 5 (target delay: 0, 100, 200, 300, 450 ms after cue offset) analysis of variance confirmed a significant congruency effect, F(1, 16) = 8.85, p < .01, a significant delay effect, F(4, 64) = 7.70, p < .01, and a significant interaction, F(4, 64) = 3.49, p = .01. The results are depicted in Figure 2.
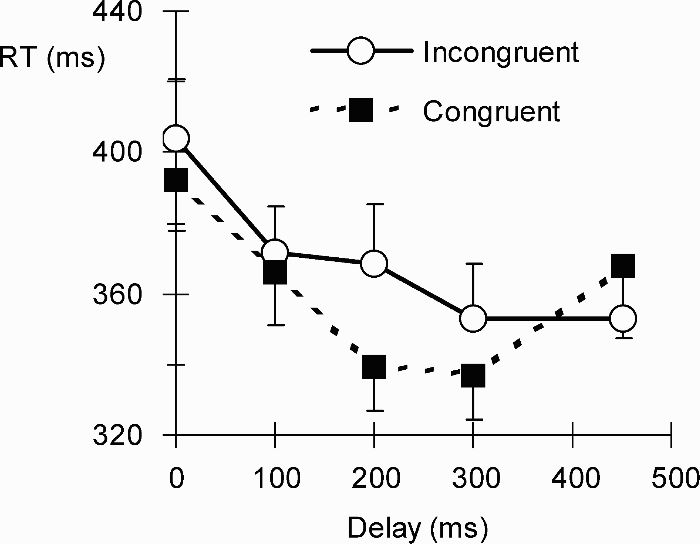
Mean reaction times (RTs, in ms, with 1 SEM) to detect targets in Experiment 1 with unpredictive grasps that were congruent or incongruent with the diameter of the object over which the target appeared.
To determine at which delays the congruency effect was present, post hoc t tests (two-tailed) were conducted. Significant congruency benefits were found after delays of 200 ms, t(16) = 2.52, p < .01, and 300 ms, t(16) = 2.34, p < .05, but not for any of the other delays (p values > .11).
Discussion
The first experiment successfully established a joint attention effect with grasping postures. The results show that after both the 200-ms and the 300-ms delays, observers detected targets faster near the object that would be picked up with the previously shown grasp. Given that the grasp cue itself was visible for 150 ms, it took on average between 250 and 350 ms for the congruency relationship between grasp aperture and object size to influence performance. These results are consistent with the idea of rapid and spontaneous action simulation.
A recent study compared the ability of observed pointing and grasping postures (Fischer & Szymkowiak, 2004) to induce joint attention and reported that only pointing but not grasping led to attention shifts to the potential target of an action. This was interpreted as evidence for action simulation because pointing is a deictic signal that highlights an object of interest whereas grasping that object means that an action toward it has already been performed, and the observer would not have to attend to that location any longer. However, in that study the grasps always occurred near the target locations in valid trials, and this confound may have led to an inhibition of return effect on attention (cf. Fischer, Pratt, & Neggers, 2003). By keeping the grasp cues spatially separated from the target objects we avoided this confound and successfully demonstrated joint attention for grasp cues (see also Nuku, Lindemann, & Bekkering, 2005).
It remains, however, unclear whether the grasp cueing effect is the result of obligatory action simulation, or merely the reflection of a strategic inference. Experiment 2 addressed this question.
Experiment 2
The goal of Experiment 2 was to determine whether attention shifting to grasp-congruent objects was automatic or under strategic control. Although the time course of the effect in Experiment 1 was fairly rapid, it is consistent with the time needed to interpret symbolic cues and then shift attention in the direction indicated by their meaning (cf. Posner, 1978). However, because the visual complexity of the cues contributes to the response times in a detection paradigm, a rapid time course may not be the best diagnostic for whether an attention shift is automatic or requires conscious control. Instead, we manipulated the predictive value of the cues. It is widely accepted that automatic attention shifts are insensitive to the information about target location in a cue, whereas controlled attention shifts usually require a predictive cue (e.g., Yantis & Jonides, 1990). Analogous to the gaze cueing study by Driver et al. (1999), we made the grasp apertures antipredictive. Thus, observers could not rely on the size relationship between grasp cue and object but had to actively reverse this intuitive mapping to optimize their performance.
Method
Participants
A total of 6 males and 15 females (age range 17–51 years) took part. All were unaware of our hypotheses and gave their informed consent.
Apparatus, materials, method, and design
These were identical to those in Experiment 1, with the exception that grasp postures were only 20% predictive of the star's location (e.g., a power grasp was followed in 80% of trials by a target over the small object). Participants were instructed to respond fast without making catch trial errors and were told that the relationship between grasp size and target location was predictable.
Results
The results of Experiment 2 are depicted in Figure 3. There was again a significant congruency effect, F(1, 20) = 3.86, p < .01, a significant delay effect, F(4, 80) = 18.94, p < .001, and a significant interaction, F(4, 80) = 3.01, p < .05. Post hoc t tests revealed significantly faster detection in incongruent trials after 100-ms delays, t(20) = 2.28, p < .05, and significantly faster detection in congruent trials after 300-ms delays, t(20) = 2.13, p < .05, but not for any of the other delays (p values > .56).
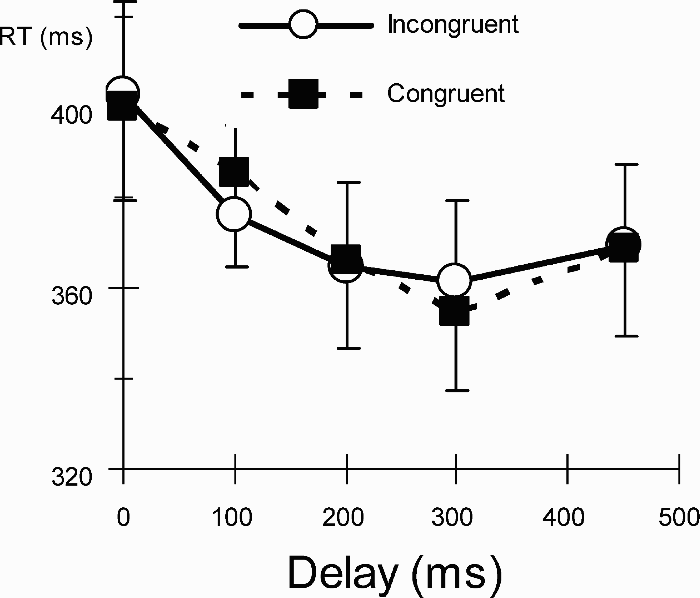
Mean reaction times (RTs, in ms, with 1 SEM) to detect targets in Experiment 2 with predictive grasps.
Discussion
The second experiment replicated the main finding of Experiment 1 that perceived grasp aperture can direct an observer's attention to the potential target of a forthcoming action. In addition to replicating this grasp cueing effect, Experiment 2 also revealed that participants attended to the grasp-incongruent object within 100 ms following grasp cue offset, indicating that they made strategic use of the predictive information in the cue within 250 ms of its appearance. Most surprisingly, however, after the 300-ms delay their attention was at the grasp-congruent object, despite the fact that this was an unlikely target location. This result suggests that an internal action simulation process overrules any temporary grasp–object associations, leading to improved visual sensitivity at the grasp-congruent object within 450 ms. The slightly slower time course compared to Experiment 1 might reflect either the time needed to shift the attention focus from the grasp-incongruent object to the grasp-congruent object, or the resolution of competition between two attentional foci, or individual differences between the two participant groups. In any event, the present result suggests that joint attention from grasp cueing is automatic.
A note of caution about the above interpretation of our results is in order. The results are different from the pattern of attentional cueing effects that have been reported in the joint attention literature for gaze cueing. Specifically, Driver and colleagues (1999, Exp. 3) found facilitation for targets at gaze-congruent locations after a 300-ms delay between cue and target onset, followed by a (nonsignificant) reversal after a 700-ms delay. Thus, strategic allocation of attention on the basis of probability knowledge required more time than the visually guided attention shift. This pattern of fast automatic attention shifts followed by slower controlled attention shifts also holds in attention research more generally (e.g., Yantis & Jonides, 1990). In contrast with this body of research, our results suggest that the strategic allocation of attention preceded and was later overruled by the automatic attention shifts. If this unusual result replicates in future work, it can be taken as a strong indicator that our grasp-cueing method taps into a distinct set of cognitive processes for joint attention from posture cues.
General Discussion
Our results show that observers rapidly infer the goal object of another person's intended grasping action from the shape of their hand and direct their own attention to it. This finding extends previous work on joint attention with eye gaze, head direction, body orientation, and deictic pointing (e.g., Langton et al., 2000). The present study also expands on the recent work of Riddoch, Humphreys, Edwards, Baker, and Wilson (2003) who showed similar effects of the action relationship between two objects (e.g., cork screw and bottle) on their observers’ attention allocation. That work depicted only nonsocial scenes and measured the percentage of correctly reported objects in the neglected hemifield of neurological patients; it also did not indicate the time course of any possible action simulations. In contrast, our novel results reveal the time course of joint attention from action relations between an agent and an object in normal observers.
With regard to the time course of this simulation, a comparison of the different delays between grasp cue and target onset shows that an observed posture modulated visual sensitivity within 300 ms. This result for grasp cueing is consistent with the time required for gaze cueing of joint attention (Driver et al., 1999) although some have found much faster gaze cueing effects (Hietanen & Leppaenen, 2003). As mentioned above, differences in the absolute time course between cues can be due to a number of visual and procedural factors (see discussion in Driver et al., 1999), and further work using the grasp cueing method will determine the reliability of our estimate. One particularly intriguing possibility is that the critical delay could reflect the nature of the action simulation process itself. Specifically, action simulation might be effector-specific, and arm movements are both slower and computationally more complex than eye movements. While this proposal is speculative, it is in agreement with the pattern of results obtained for motor simulation more generally (e.g., Fischer, 2005; Johnson, 2000): The simpler the to-be-imagined movements, the faster the decisions. Further work with transcranial magnetic stimulation (TMS; e.g., Buccino et al., 2005) or magnetoencephalography (MEG) methodology (e.g., Pulvermüller, 2005) will be helpful in delineating the time course of action simulation (see also Kaschak & Borreggine, 2008 this issue, and Taylor & Zwaan, 2008 this issue).
Action simulation seems to be quite pervasive in social settings—for example, to predict the action potential of others (Fischer, 2005; Frith & Wolpert, 2003). Given the obvious evolutionary benefits of this ability, it is plausible that our brains have evolved dedicated mechanisms to predict what others are about to do, on the basis of eye, head, or body information. Brain areas that are tuned for the visual processing of body parts have been localized, among others, in the superior temporal sulcus and in early visual areas of the human brain (extrastriate body area; Downing, Jihang, Shuman, & Kanwisher, 2001) for the perception of larger body parts. The neural substrate underlying action simulation and the interpretation of action intentions of others more generally has only recently been identified. A key mechanism involved in this ability seems to be the “mirror neuron system” (MNS). It encompasses the rostral part of the inferior parietal lobule and the ventral premotor cortex. Importantly, it includes “mirror neurons” that code action goals regardless of whether we perform or observe a manual action (Blakemore & Decety, 2001; Rizzolatti & Craighero, 2004).
From single-cell recordings in monkeys we know in some detail under which conditions mirror neurons become active. For example, in monkeys’ MNS about 30% of mirror neurons code both the action goal (e.g., grasping an object) and the means for achieving it (e.g., with a precision grasp); these are called “strictly congruent” mirror neurons. The majority of about 60% of mirror neurons, however, fire also when observed and performed grasp differ. These latter neurons are labelled as “broadly congruent” mirror neurons (Gallese, Fadiga, Fogassi, & Rizzolatti, 1996; Rizzolatti & Craighero, 2004). It is of great theoretical importance to determine whether similar distinctions are present in the human MNS. However, the human MNS cannot normally be investigated with single-cell recordings. Instead, neuropsychological case studies, brain imaging, and behavioural methods are used to characterize the conditions under which we use our own action system to infer the intentions of others. From such studies we know, for example, that the human MNS is more broadly tuned than the monkey MNS: It codes intransitive as well as transitive actions (Fadiga, Fogassi, Pavesi, & Rizzolatti, 1995) and also codes imitative actions (Iacoboni et al., 1999). However, details of the time course and cognitive control over the human MNS are currently lacking. Moreover, in the light of the broader tuning of the human MNS it is at present also unclear whether we possess only broadly congruent or also strictly congruent mirror neurons.
The present results seem to support the view that there is a specialized neuronal circuitry in place for the discrimination of precision and power grasps and the subsequent use of this information to predict the most likely target of a forthcoming action. This action simulation process seemed to occur spontaneously even when it was disadvantageous for the participants of our study, suggesting that the human MNS engages automatically and is not under cognitive control.
However, our study used static images of hand postures that implied different grasping actions. Most studies of the mirror neuron system have been conducted with live experimenters or movie sequences as stimuli. However, a direct behavioural comparison in humans of static and dynamic visual primes (Stürmer, Aschersleben, & Prinz, 2000, Exps. 1 and 2) actually showed stronger visuo-motor priming effects in the static than in the dynamic condition. Moreover, Nishitani and Hari (2002) demonstrated activation of the human MNS from passive viewing of static pictures of lip forms and concluded that “still pictures, only implying motion, activate the human MNS in a well-defined temporal order” (p. 1211). It may well be that the sensitivity to static images is another important difference between the monkey's and the human MNS (see Rizzolatti & Craighero, 2004, p. 176, for further similarities and differences).
Overall, the present behavioural evidence from a novel joint attention paradigm is consistent with the rapid and automatic operation of strictly congruent mirror neurons during action simulation in humans. Similar congruency effects for hand postures have recently been shown by other authors. For example, Borghi et al. (2005) used a visuo-motor priming paradigm where photos of target objects graspable either with a precision grip or with a power grip were preceded by primes consisting of photographs of hands in either grasping posture or in a neutral postures (open hand). The authors found a congruency effect between the prime and the grip required by the object. The present results also converge with those of Bub and Masson (2006) who recently found that the presentation of an object primes the ability to produce a grasping posture that would typically be used to manipulate this object (see also Masson, Bub, & Newton-Taylor, 2008 this issue). While we show here a tight link between grasp postures and associated objects, their results document the reverse association from objects to associated actions. Thus, both the perception and production of grasping postures can trigger complex associative processes. Recent research showed that these associations can extend to the comprehension of concepts and lead to motor resonance (Zwaan & Taylor, 2006; see also Taylor & Zwaan, 2008 this issue) and the production of speech (Gentilucci & Corballis, 2006; see also Gentilucci & Dalla Volta, 2008 this issue). More generally, the present results fit well with the idea that joint attention tunes early perceptual processes toward action prediction.