
Abstract
In a picture–word interference experiment the authors demonstrate that a semantic–categorical relation between a to-be-named target picture and a context picture promotes the phonological activation of the to-be-ignored context picture. No such phonological activation is observed if the objects are semantically unrelated. This finding gives further insight into the mechanisms that modulate the activation flow in the conceptual-lexical system during speech planning. In contrast to recent picture–picture interference studies, the results provide direct evidence that the phonological activation of a context object is dependent on its semantic processing.
Keywords
A crucial question in speech production research concerns the information flow in the conceptual– lexical system during speech planning. One central aspect of this question is whether phonological activation is confined to selected and eventually produced words or whether it extends to other words as well, given that their conceptual representations become activated during speech planning (cf. Dell, 1986; Levelt, 1999; Levelt et al., 1991). Recently, this issue has been addressed by exploring whether to-be-ignored context objects superimposed on a target picture or presented in its close spatial vicinity activate their phonological code. In an influential paper, Morsella and Miozzo (2002) showed that a superimposed context picture (e.g., bell) with a name phonologically related to a to-be-named target picture (e.g., bed) facilitated the naming of the target picture. The effect dissipated if the same materials were used in a language in which no phonological relation between the two objects was present. This observation was taken as support for the notion that phonological activation is not confined to selected words but extends to other words, which are conceptually activated to a sufficient extent, in line with predictions from cascaded models of lexical access in speech production (e.g., Jescheniak & Schriefers, 1998; Peterson & Savoy, 1998). Morsella and Miozzo's finding was replicated in a number of object-naming studies (e.g., Meyer & Damian, 2007; Navarrete & Costa, 2005; Roelofs, 2008), in a colour-naming task in which the name of a coloured object was either phonologically related or unrelated to the colour (Navarrete & Costa, 2005) and is also obtained in the context of a visual search task—that is, a nonspeech task (Meyer, Belke, Telling, & Humphreys, 2007). However, there were also a number of studies that failed to obtain the phonological context picture effect (e.g., Bloem & La Heij, 2003; Bloem, van den Boogaard, & La Heij, 2004; Jescheniak et al., 2009), raising the question of which factors facilitate such an effect.
When having a closer look at the extant data, it appears that phonological context effects in the picture–picture interference task were thus far only found with superimposed target and context pictures—that is, in a situation in which both pictures had to be processed in order to separate the target picture from the context picture (e.g., Meyer & Damian, 2007; Morsella & Miozzo, 2002; Navarrete & Costa, 2005). By contrast, picture–picture interference studies in which target and context pictures were spatially separated (e.g., Jescheniak et al., 2009) failed to obtain effects from phonologically related context pictures. One could thus speculate that phonological context effects from pictures in speech tasks are limited to a small range of rather artificial stimulus conditions with superimposed (and nonoccluding) line drawings, which are hardly ever perceived in everyday life. Indeed, Morsella and Miozzo were reluctant to generalize the phonological context effect they observed in their experimental setting to everyday situations. Thus, the use of spatially separated context and target pictures would be a first step towards exploring more natural stimulus conditions and thus the generality of the phonological context effect.
It is also interesting to note that in all of the mentioned studies, be it with superimposed or nonsuperimposed pictures, the potential phonological activation of otherwise unrelated context pictures has been explored by contrasting the effects from context pictures that bear a phonological relation to the target picture with the effects from completely unrelated pictures. Conversely, some studies have explored the semantic activation of otherwise unrelated context pictures, by contrasting the effects from context pictures that bear a semantic relation to the target picture (e.g., target picture table, context picture chair) with the effects from unrelated pictures (e.g., target picture table, context picture cow). There has as yet been no attempt to explore the phonological activation of a context object as a function of the presence versus absence of a semantic–categorical relation between target object and context object.
However, a look at studies on naming single pictures suggests that the phonological activation of a context object might be boosted if target object and context object stand in a semantic relation. Studies on single-picture naming provide ample evidence that semantically related concepts become strongly activated during speech planning. That is, when a speaker intends to name a particular object (e.g., bed), semantically similar concepts become coactivated as members of a so-called semantic cohort (including, for example, concepts like wardrobe, stool, table; see Levelt et al., 1991, p. 123), even if they are not present in the visual display. Such semantic coactivation effects have been most reliably observed with semantic-category coordinates. One piece of evidence for the activation of concepts that are semantically related to a to-be-named target object comes from the observation of semantic priming effects in sequential picture naming. If participants are instructed to name two objects in close succession, the naming of the second object is facilitated if it bears a semantic relation to the object that has just been named on the preceding trial (e.g., Huttenlocher & Kubicek, 1983; Sperber, McCauley, Ragain, & Weil, 1979). Such priming effects can also be observed if the first picture is to be named only after having named the second one and if the first picture is presented at or below perceptual threshold such that conscious identification of this picture is made difficult (Carr, McCauley, Sperber, & Parmelee, 1982; McCauley, Parmelee, Sperber, & Carr, 1980; for a comprehensive review, see Glaser, 1992). Another piece of evidence comes from the semantic interference effect in the picture–word interference task, in which a distractor that denotes a semantic-category coordinate to the target (e.g., stool, if bed is the target) reliably interferes with the naming response, when compared to an unrelated distractor (e.g., La Heij, Kuipers, & Starreveld, 2006; Levelt, Roelofs, & Meyer, 1999; Roelofs, 1992; Schriefers, Meyer, & Levelt, 1990; Starreveld & La Heij, 1995).
Together, these data strongly suggest that semantic-category coordinates become coactivated at a semantic level of representation during speech planning. However, the situation for these competitors is different at a phonological level of representation. A number of studies have explored this issue by testing for so-called mediated semantic–phonological priming—that is, they have explored whether lexical retrieval of a picture name (e.g., bed) affects, or is affected by, the processing of a word that is phonologically related to a semantic category coordinate (e.g., stoop, phonologically related to stool). Chronometric behavioural and electrophysiological studies with adult speakers have thus far provided evidence for such priming only in the case of near-synonymous competitors (e.g., couch–sofa; see Jescheniak & Schriefers, 1998; Peterson & Savoy, 1998) and super- or subordinate name alternatives (e.g., carp–fish, see Jescheniak, Hantsch, & Schriefers, 2005), but consistently failed to do so in the case of semantic-category coordinates (Jescheniak, Hahne, & Schriefers, 2003; Levelt et al., 1991; Peterson & Savoy, 1998). However, for the latter type of competitor, some evidence in favour of phonological coactivation comes from speech error analyses, in particular from the observation that semantic word substitution errors tend to be phonologically infiltrated (Dell & Reich, 1981), and from the production pattern in young speakers showing evidence for mediated semantic–phonological priming in elementary-school children (Jescheniak, Hahne, Hoffmann, & Wagner, 2006). The most parsimonious interpretation of these data seems to be that semantic-category competitors are activated to a substantial degree at the semantic level of representation, but that their phonological code is activated only to a detectable extent if the competition between a target and its competitor is extremely strong, as supposedly is the case for near-synonyms, or if the system has as yet not gained adult-like proficiency, or if some other event has temporarily disrupted the speech-planning process as in the case of speech errors.
Given this state of affairs, it seems quite likely that, in situations with double object displays, a context object that bears a semantic-categorical relation to a to-be-named target object is more likely to yield substantial (thus measurable) phonological activation than unrelated context objects, even when the objects are presented side by side rather than superimposed. This prediction rests on the assumption that the concept of a semantically related context picture should receive activation from two sources: On the one hand, in the conceptual-lexical network the activation triggered by the target picture will spread to the concepts of the category coordinates of the target (as just described). On the other hand, the context object can be assumed to accumulate some additional semantic activation due to perceptual processing. Together, these two sources should lead to enhanced semantic–conceptual activation of the semantic-category coordinate, which in turn should then increase the chance that its phonological form will be activated to a substantial degree.
The present study puts this prediction to an experimental test. We used an extension of the picture–word interference task (Oppermann, Jescheniak, & Schriefers, 2008). In this task, participants are presented with displays showing pictures of two objects that appear in close spatial vicinity, one of which is cued by its colour as the to-be-named target object. In addition, participants hear distractor words that are phonologically related or unrelated to the name of the target object, or phonologically related or unrelated to the name of the context object. For the target-related conditions, we expected facilitation effects, in line with the standard findings in the picture–word task. For the context-related conditions, by contrast, one should find an interference effect, if the context object has become phonologically activated. This should be the case because under the given assumption the phonological form of the name of the context object receives convergent activation from two sources—the context picture and the phonologically related distractor. Thus, it should be a strong competitor for the to-be-produced name of the target object. If, by contrast, the phonological form of the context object is not activated, the distractors with a phonological relation to the context object should not cause any specific effect. In this case, distractors that are phonologically related to the context object and unrelated distractors should activate phonological representations that are different from the to-be-produced target, and they should do so to approximately the same degree and thus be equally strong competitors for the target name.
EXPERIMENT
The experiment tested for phonological activation of semantic-categorically related context objects (e.g., sock, if cap is the target) and unrelated context objects (e.g., sock, if grill is the target). To the extent that semantic-categorical relations promote phonological activation of context objects, we expected an interference effect from distractors phonologically related to the nontarget context picture if it bears a semantic-categorical relation to the target. By contrast, no such effect was expected if target and context picture are unrelated (cf. Oppermann et al., 2008).
Method
Participants
A total of 32 native speakers of German, most of them students from the University of Leipzig, took part in the experiment. Participants were paid €6 (approximately $8.50) or received course credit. None of them had any known hearing deficit, and they had normal or corrected-to-normal vision.
Materials
A total of 40 line drawings of simple objects were used as experimental materials. In one condition, these objects were combined to semantic-categorically related pairs (e.g., sock–cap), and in another condition they were recombined to arbitrary pairs (e.g., sock–grill). For the semantic-categorically related pairs, the two objects were drawn from the same superordinate category (e.g., clothing, vegetable, tool, or furniture; see the Appendix for a complete list of the materials). Care was taken that for both types of pairs the directional associative strength between the two objects was minimal. 1 During the familiarization and practice phase with individual objects, black-and-white line drawings were used. In the experimental phase the two objects of a pair were presented in a nonoverlaid manner and in close spatial vicinity, with varying locations for different object pairs and with an imaginary square of about 13 × 13 cm limiting the spatial distribution of the objects. The two objects appeared in different colours, one in green and one in red. For each object a phonologically related distractor was selected. These distractors were bisyllabic nouns sharing the initial consonant or consonant cluster and the adjacent vowel with the object's name. An unrelated control condition was created by reassigning these distractors to different objects. In combining the objects into pairs, care was taken that there was no phonological relatedness of a distractor phonologically related to one object to the name of the other object in a (categorically related or unrelated) pair and that no associative relations held between a phonologically related or unrelated distractor and any of the two objects in the pair. The auditory distractors were spoken by a female native speaker of German. Distractors varied in duration from 483 ms to 908 ms with an average of 651 ms (SD = 101 ms). All auditory materials were digitized at a sampling rate of 48 kHz for presentation during the experiment. An additional set of eight objects arranged in four pairs with corresponding distractors was selected for the construction of practice and warm-up trials.
Associative relatedness was assessed on the basis of the norms by Nelson, McEvoy, and Schreiber (2004a, 2004b). For the semantic-categorically related pairs, it amounted to 0.4% (SD = 1.4%, min = 0.0%, max = 7.7%; for four items, the value was missing). For the arbitrary pairs, all values were equal to 0.0% (four missing values). These values represent the percentage of participants who produced the name of the second object as their first response when the name of the first object was presented as cue. As both objects figured as target and context objects, the association strength from Object 1 to Object 2 and the association strength from Object 2 to Object 1 were pooled in calculating these numbers.
Design
The experimental design included the variables primed element (target vs. context object), distractor relatedness (related vs. unrelated), the blocked variable object relation (semantic-categorically related vs. arbitrary), and sequence of object relation (semantic-categorically related pairs in the first part, followed by arbitrary pairs vs. arbitrary pairs, followed by semantic-categorically related pairs). All variables were tested within participants and within items, except for sequence, which was tested within items but between participants. Thus, there were four crossed variables: the two-level variables primed element, distractor relatedness, object relation, and sequence. Each target was presented under each of eight conditions (resulting from the crossing of primed element, distractor relatedness, and object relation) once, yielding a total of 320 experimental trials per participant.
We decided to present semantic-categorically related and arbitrary pairs in separate blocks (rather than in a random sequence) in order to reduce the chance that the presence of semantic-categorically related pairs triggers more exhaustive processing of the context object in arbitrary pairs as well. The blocked presentation of the two types of pairs should maximize the experiment's sensitivity to potential differences between these pairs. Furthermore, it allows for a direct test of a potential carry-over from semantic-categorically related pairs to arbitrary pairs. If such a carry-over exists, participants starting with the semantic-categorically related pairs should also show a phonological context effect on arbitrary pairs, while for participants starting with arbitrary pairs phonological context effects should be smaller or absent in this condition. In a randomized design, such potential carry-over effects would be much more difficult to capture.
For any given participant, the colour of an object remained constant across the complete experiment. There were two experimental blocks with semantic-categorically related object pairs and two experimental blocks with arbitrary object pairs. The sequence of these two types of blocks was counterbalanced across participants. For each type of block, participants named the objects depicted in one colour in their first experimental block (e.g., name the green one!) and the objects depicted in the other colour in their second experimental block (e.g., name the red one!). The sequence of these two blocks and the assignment of colours to particular objects were also counterbalanced across participants. Within participants green and red objects appeared equally often on the left and the right position of the object configuration. Within each of the four experimental blocks, the sequence of distractor conditions was counterbalanced using a sequentially balanced Latin square procedure (such that, across different lists, each distractor condition appeared equally often at each repetition level of a given item in each block, while controlling for the transition probabilities between distractor conditions). To rule out that the position of the different objects in the left or right part of the display would have an effect, versions of the displays with reversed left and right positions were also generated. Both the original and the reversed version of a display were used equally often, but a given participant received only one version of a given display throughout the experiment. A total of 32 pseudorandomized experimental lists were created according to the following general criteria: (a) repetitions of a target picture were separated by at least eight intervening trials, (b) identical distractors were separated by at least three intervening trials, and (c) no more than three trials with the same distractor condition followed each other.
Apparatus
The visual stimuli were presented on a 19-in. EIZO S1910 TFT screen as black or coloured line drawings (in the familiarization and practice phase versus the experimental phase, respectively) on a light grey background (RGB 244 244 244). Viewing distance was about 60 cm. The presentation of the visual and auditory stimuli and the online collection of the data were controlled by the NESU program (Max-Planck-Institute for Psycholinguistics, Nijmegen, The Netherlands) on a computer with a Pentium processor (Intel Corporation, Santa Clara, CA). Auditory distractors were presented with Sennheiser HD 280 headphones at a comfortable listening volume. Speech onset latencies were measured to the closest millisecond with a Sennheiser ME 64 microphone via a voice-key connected to the computer.
Procedure
Each participant was tested individually in a session lasting about 1 hour. The participant was comfortably seated in a dimly lit room, separated from the experimenter by a partition wall. At the beginning of the experiment, participants were instructed in writing that their task would be to name pictures of simple objects presented along with other objects as fast and accurately as possible. They were then familiarized with the visual materials by viewing all objects presented in isolation in a booklet. Next to each object, the corresponding name was printed. Participants were instructed to use these names only in the course of the experiment.
In a first practice block without distractors, each object was presented once, and participants named it by producing the corresponding noun. Responses other than the expected ones were corrected. In two further practice blocks with eight trials each, the four practice displays depicting two objects each were presented, and the participants were instructed to name one of the elements. Half of the participants were asked to name the object depicted in green colour, and half of the participants were asked to name the object depicted in red colour, depending on which colour they would start with in the main experiment. Auditory distractors were presented only during the second of these practice blocks. Then the first of the four experimental blocks started. Prior to all experimental blocks, a new eight-trial practice block (with distractors) was presented, to acquaint participants with the colour change of the objects across blocks. At the beginning of each experimental block, four warm-up trials containing practice items preceded the experimental trials. There were short breaks between the blocks.
An experimental trial was structured as follows. Pictures were presented for 1,000 ms in the centre of the computer screen. Auditory distractors were presented simultaneously with the onset of the picture (stimulus onset asynchrony [SOA] = 0 ms). Participants named the target element as quickly as possible. Speech onset latencies were measured from the onset of the picture. The total length of a trial was about 4,500 ms.
Results
Observations were coded as erroneous and were discarded from the reaction time analyses whenever any of the following conditions held: (a) A picture had been described with other than the expected name; (b) a nonspeech sound preceded the target utterance, triggering the voice-key; (c) a dysfluency occurred or an utterance was repaired; or (d) a speech onset latency exceeded 2,000 ms. Observations deviating from a participant's and an item's mean by more than two standard deviations were considered as outliers and were also discarded from the reaction time analyses without coding an error. A total of 416 observations (4.1%) were marked as erroneous and 243 observations (2.4%) as outliers. Averaged reaction times were submitted to analyses of variance (ANOVAs). Separate analyses were performed for distractors that were related versus unrelated to the target object and for distractors that were related versus unrelated to the context object. Each of these analyses involved the fixed variables distractor relatedness (phonologically related vs. phonologically unrelated), object relation (semantic-categorically vs. arbitrary), and sequence (semantic-categorically related first vs. arbitrary first). Table 1 displays mean reaction times and error rates broken down by primed element, distractor relatedness, and object relation. These data are collapsed over sequence because descriptive as well as inferential analyses revealed that this factor did not affect the overall pattern of facilitation and interference effects—see analyses below.
Mean reaction times and error rates broken down by object relation, primed element, and distractor relatedness
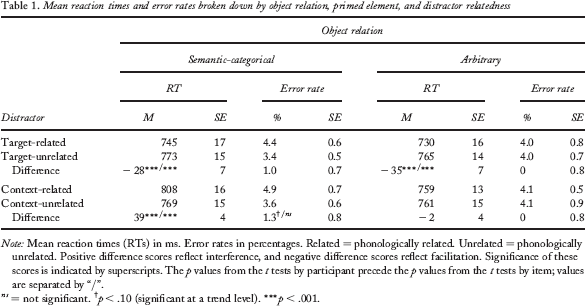
Note: Mean reaction times (RTs) in ms. Error rates in percentages. Related = phonologically related. Unrelated = phonologically unrelated. Positive difference scores reflect interference, and negative difference scores reflect facilitation. Significance of these scores is indicated by superscripts. The p values from the t tests by participant precede the p values from the t tests by item; values are separated by “/”.
= not significant.
p < .10 (significant at a trend level).
p < .001.
Effects from target-related distractors
In the analysis of naming latencies, object relation was significant at a trend level, due to slightly longer naming latencies in the semantic-categorical condition than in the arbitrary condition, F1(1, 30) = 4.00, p = .053, MSE = 1,060.53; F2(1, 39) = 5.24, p < .05, MSE = 1,815.25. Phonologically related distractors facilitated the naming response compared to unrelated distractors, yielding a significant effect of distractor relatedness, F1(1, 30) = 24.64, p < .001, MSE = 1,295.01; F2(1, 39) = 30.16, p < .001, MSE = 2,708.31. Neither the interaction of object relation and distractor relatedness nor the interaction of these variables with sequence were significant, all Fs < 1.02, showing that the facilitation effect was independent of the object relation and was present throughout the experiment (for the group starting with the semantic-categorically related pairs, facilitation effects amounted to −30 ms and −36 ms for semantic-categorically related and arbitrary pairs, respectively. The corresponding facilitation effects for the group starting with arbitrary pairs amounted to −27 ms and −34 ms). There were no significant effects in the analysis of error rates.
Effects from context-related distractors
In the analysis of naming latencies, object relation was significant, due to longer naming latencies in the semantic-categorical condition than in the arbitrary condition, F1(1, 30) = 18.94, p < .001, MSE = 1,405.79; F2(1, 39) = 14.01, p < .01, MSE = 4,678.35. Phonologically related distractors interfered with the naming response, reflected in a significant effect of distractor relatedness, F1(1, 30) = 44.33, p < .001, MSE = 242.08; F2(1, 39) = 10.29, p < .01, MSE = 2,775.73. Importantly, there was a significant interaction of object relation and distractor relatedness, F1(1, 30) = 48.26, p < .001, MSE = 270.21; F2(1, 39) = 13.32, p < .01, MSE = 2,491.63. Subsequently computed t tests revealed that interference was obtained for the semantic-categorical condition only (39-ms interference), t1(31) = 9.24, p < .001; t2(39) = 4.30, p < .001, with 40-ms interference for the group starting with semantic-categorically related pairs and 37-ms interference for the group starting with arbitrary pairs), but not for the arbitrary condition (2-ms difference in the opposite direction, ts < 1, with effects of −3 ms and 0 ms for the two groups). There was no interaction of object relation, distractor relatedness, and sequence, Fs < 1, providing statistical confirmation that the pattern did not change in the course of the experiment. In the analysis of error rates, there was only an interaction of object relation and sequence, reflecting the fact that the error rates were lower in the second part than in the first part of the experiment. None of the other effects reached significance.
Discussion
Using an extension of the picture–word interference task, the present experiment demonstrates that not-to-be-named context objects substantially activate their phonological code if they bear a semantic-categorical relation to the target object. By contrast, for unrelated context objects no such phonological effects were obtained.
Testing for the phonological activation of a not-to-be-named context object during naming a simultaneously presented target object can be related to studies testing mediated semantic–phonological priming of semantic competitors of a to-be-named target object (e.g., Jescheniak et al., 2006; Jescheniak et al., 2005; Jescheniak & Schriefers, 1998; Levelt et al., 1991; Peterson & Savoy, 1998). The experimental situation is comparable except for the fact that in the latter studies the semantic competitor is not present in the visual display. As described above, in such single-object naming tasks—that is, with only one object being presented—evidence for phonological activation of a category coordinate of the target was only obtained with elementary-school children (Jescheniak et al., 2006), not with adults (Jescheniak et al., 2003; Levelt et al., 1991; Peterson & Savoy, 1998). By contrast, the present results from the semantic-categorically related condition show that such phonological coactivation can also be obtained for adults when both objects are actually present in the visual display. Thus, it seems that only the convergence of (a) activation of a different category member triggered by the visual input and (b) the spread of activation in the conceptual–lexical network from the target concept to the semantically related context object is strong enough to lead to measurable phonological activation of the context object. This view is also corroborated by an additional experiment that we conducted with the present material set testing for mediated semantic–phonological priming in the single-object naming situation. This experiment used the same target objects and distractor conditions (i.e., distractors phonologically related or unrelated to the target or to the context object), but only the target object was presented on a trial. In this situation, no effect from distractors phonologically related to the (nondepicted) semantically related context object was obtained in the first block of the experiment (5-ms difference), ts < 1 for naming latencies and error rates, in line with previous observations from single-object naming paradigms (e.g., Jescheniak et al., 2006; Jescheniak et al., 2003; Levelt et al., 1991; Peterson & Savoy, 1998). This was true even though participants had been familiarized with the full item set (including the semantic competitors that, however, were not presented in the displays during the main experiment) before the experiment started. 2
As in the experiment described in this article, participants named only half of the objects in the first experimental block of that control experiment. Interestingly, a significant 25-ms interference effect, t1(15) = 3.16, p < .01; t2(39) = 2.82, p < .01, for naming latencies, was obtained in the second block of the control experiment, in which participants named the “context objects” of the first part (which, however, were actually not presented in the first part). Thus it appears that in the second experimental block participants had become aware of the mediated relation between a target object and a distractor that is phonologically related to a semantic competitor of the target object. This was probably the case because participants had already named the semantic competitor in the first experimental block.
One could speculate that the allocation of attention (with semantic-categorically related context objects attracting more attention than arbitrary context objects) might have caused our results. Indeed, there is some recent evidence that attention seems to play a role in explaining phonological context effects from pictures. Malpass and Meyer (2008) presented participants with a colour-cued target object and a context object at two different locations on a computer screen, with the context object and the target object either having phonologically related names or being unrelated. In one experiment, participants had to fixate the target object, and in another experiment they had to fixate the context object, but were instructed to direct visual attention to the target object. Neither experiment provided any evidence for phonological activation of the context object, whereas in another experiment a phonological facilitation effect was found for the same materials, when both objects were presented in the same location. From this pattern of results, the authors concluded that the phonological form of the context object is only activated when it is fully attended. This proposal also fits with the fact that phonological context effects in the picture–picture interference task were thus far only found with superimposed target and context pictures—that is, in a situation in which both objects had to be attended in order to separate the target object from the context object (e.g., Meyer & Damian, 2007; Morsella & Miozzo, 2002; Navarrete & Costa, 2005). By contrast, studies in which target and context object were spatially separated (e.g., Bloem & La Heij, 2003; Jescheniak et al., 2009) failed to obtain effects from phonologically related context pictures. Taken together, these results are incompatible with the view that mere perception of a context object is a sufficient trigger for phonological activation of that object to occur (Morsella & Miozzo, 2002). Rather, the allocation of attention seems to play a role. Whether the allocation of attention to the context object is a (covert or overt) shift of attention to the context object, or whether we are dealing with a parallel distribution of attention across both objects, can not be decided on the basis of the present data (but see Meyer, Ouellet, & Häcker, 2008, for evidence pointing towards a parallel allocation of attention to spatially separated objects).
In the context of the present results, these considerations lead to the question whether the allocation of attention to the context object is more likely if it has a semantic relation to the target object than when it is unrelated. Data from Moores, Laiti, and Chelazzi (2003) provide indirect support to this notion. These authors showed that, in a visual search task, context objects that have a conceptual associative relation with the target object (e.g., monkey–banana) were both recalled more often and recognized more accurately than associatively unrelated context objects. Based on this evidence, Moores et al. proposed “that the activation of object representations in working memory primes associated representations, which either makes them receive more attention in a top-down manner or affords them more rapid and efficient processing, which subsequently attracts attention” (p. 188). One could thus assume that the allocation of attention due to such conceptual associative relations might also promote the phonological activation of context objects. Still, one ought to be cautious drawing this inference prematurely, because Moores et al. investigated associative relations rather than semantic-categorical relations (that were used in the present study), and these different types of relations may have quite different effects (see Hutchison, 2003). A recent study by Belke, Humphreys, Watson, Meyer, and Telling (2008) used semantic-categorical relations in a visual search task in addition to associative relations. In this study, the finding by Moores et al. was replicated for both kinds of relations (Belke et al., p. 1447).
One of our own studies (Oppermann et al., 2008) provides more evidence on the potential role of different types of relations between a target and a context object. Like the present study, it explored the phonological activation of context pictures, but manipulated whether the spatially separated and semantically unrelated target and context objects could be integrated into a conceptually coherent agent–action–patient representation. When the target object and the context object were embedded in a coherent scene (i.e., if they formed a simple agent–action–patient scene like a monk reading a book), there was clear evidence for the phonological activation of the context object during naming of the target object, as indexed by interference from distractors phonologically related to the not-to-be-named context object. However, when the same objects were presented in arbitrary combinations (e.g., a book next to a cat), no evidence for phonological activation of the context object was obtained. There is quite some evidence that recognition of a conceptually coherent scene triggers an automatic process that extracts the gist of the scene (e.g., Biederman, Mezzanotte, & Rabinowitz, 1982; Dobel, Gumnior, Bölte, & Zwitserlood, 2007; Gordon, 2004; Potter, 1975, 1976), such that detailed conceptual analysis extends to context objects as well, and it seems reasonable to assume that phonological activation of that context object is a possible consequence.
Taken the findings by Moores et al. (2003), Belke et al. (2008), Oppermann et al. (2008), and the present experiment together, the studies suggest that the allocation of attention is the underlying process leading to more exhaustive processing of a context object, which, in turn, can lead to the activation of the phonological code of the context object. Furthermore, the allocation of attention to the context object appears to be promoted by different types of semantic, conceptual, thematic, or associative relations.
Another issue concerns the relation of our findings to recent studies exploring the direct impact of semantic-categorically related context objects on target picture naming in the picture–picture interference paradigm. Evidence from these studies is inconclusive. A number of studies did not find any effect from semantically related context pictures (Damian & Bowers, 2003; Meyer & Damian, 2007; Navarrete & Costa, 2005), one study observed facilitation (Roelofs, 2008), and one study reported interference (Glaser & Glaser, 1989). In still another study, both facilitation and interference effects could be demonstrated, depending on the exposure duration of the context picture (La Heij, Heikoop, Akerboom, & Bloem, 2003). Even more puzzling, however, is the fact that some studies failed to obtain semantic effects from context picture effects while demonstrating phonological effects from context pictures (Meyer & Damian, 2007; Navarrete & Costa, 2005). In view of this seemingly paradoxical situation (as semantic processing is assumed to be a prerequisite for the activation of phonological representations in all models of lexical access in speech production), Navarrete and Costa deduced by inference that a semantic representation must have been activated, but that the semantic activation was obscured by some other counteracting mechanism. In particular the authors speculated whether the semantic null-effect stems from the presence of two opposite effects: (a) a facilitatory effect at the conceptual level, and (b) an interference effect at the lexical level. In contrast to picture–picture interference studies our study allows testing for the activation of the phonological form of a context object as a function of the semantic relation between target and context object. The finding that phonological activation of the context object is only obtained for semantically related pairs but not for arbitrary pairs provides evidence that the phonological activation of the context object requires semantic processing of this object and thus provides support for Navarrete and Costa's assumption of two counteracting mechanisms in their picture–picture study.
The present experiment also allows one to look at the direct effect of a semantic relation between a target and a context object. One way of doing so is to compare semantic-categorically related pairs and arbitrary pairs in those conditions, in which the distractor was either related or unrelated to the target (such that all that varies in this contrast is the type of context picture—semantic-categorically related vs. arbitrary). This contrast revealed slower naming latencies in the semantic-categorical condition (12-ms difference), and this effect was reliable in the analysis by items and just failed to reach the conventional level of significance in the analysis by participants (p = .053), see above. Hence, with respect to the direct impact of the semantic context picture on naming the target object, the present data could be taken as some preliminary evidence in favour of a semantic picture-context effect, albeit that the effect appears to be as subtle and fragile as in previous studies.
A limitation of previous picture–picture studies is that they either used semantically related pairs or phonologically related pairs of target and context pictures. Thus, these studies addressed either the question of semantic activation of context objects or the question of phonological activation of context objects, but they could not address the question of whether the amount of phonological activation of a context object varies as a function of its semantic relation to the target object. 3 By contrast, the present experiments used semantically related or unrelated picture pairs and then probed for the phonological activation of a context object during naming of a target object by means of a distractor word. This allowed us to test for the amount of phonological activation of a context object as a function of the semantic relation it bears to the target object (semantic-categorically related vs. arbitrary). The present data clearly show that the presence or absence of a semantic-categorical relation between the two depicted objects has a clear effect on the amount of phonological activation of the context object. According to these findings there must be a semantics-sensitive mechanism that modulates the information flow in the conceptual-lexical system and that gates the amount of phonological activation (see Roelofs, 2008).
This design feature might also explain why the effects of phonological activation of context objects in some of the above-mentioned studies appear to be rather subtle and weak. According to the present data, these studies tested phonological activation of context objects in a situation in which the chance to observe measurable activation (at least in the experimental paradigm we used) is low, namely for semantically unrelated objects.
In summary, the present study shows that phonological activation of context objects is boosted by a semantic-categorical relation between the target and the context objects. Together with the evidence on the role of thematic relations (Oppermann et al., 2008) and other studies with superimposed context objects (e.g., Morsella & Miozzo, 2002) it appears that the phonological activation of a not-to-be-named context object is promoted when the context object captures sufficient attention, be it due to the existence of established links in the conceptual–lexical network (as in the present study) or a thematic relation it holds to the target (as in Oppermann et al., 2008), or because it appears in the same spatial location as the target.