
Abstract
The possible-word constraint (PWC; Norris, McQueen, Cutler, & Butterfield, 1997) has been proposed as a language-universal segmentation principle: Lexical candidates are disfavoured if the resulting segmentation of continuous speech leads to vowelless residues in the input—for example, single consonants. Three word-spotting experiments investigated segmentation in Slovak, a language with single-consonant words and fixed stress. In Experiment 1, Slovak listeners detected real words such as ruka “hand” embedded in prepositional-consonant contexts (e.g., /gruka/) faster than those in nonprepositional-consonant contexts (e.g., /truka/) and slowest in syllable contexts (e.g., /dugruka/). The second experiment controlled for effects of stress. Responses were still fastest in prepositional-consonant contexts, but were now slowest in nonprepositional-consonant contexts. In Experiment 3, the lexical and syllabic status of the contexts was manipulated. Responses were again slowest in nonprepositional-consonant contexts but equally fast in prepositional-consonant, prepositional-vowel, and nonprepositional-vowel contexts. These results suggest that Slovak listeners use fixed stress and the PWC to segment speech, but that single consonants that can be words have a special status in Slovak segmentation. Knowledge about what constitutes a phonologically acceptable word in a given language therefore determines whether vowelless stretches of speech are or are not treated as acceptable parts of the lexical parse.
The English phrase play tennis, when spoken, also contains the unintended words lay, late, and eight, among others. Similarly, the Slovak word kvety “flowers” contains, for example, the embedded words k “to”, v “in”, vety “sentences”, and ty “you”. Users of both languages (and indeed any other language) are faced with the same task when listening to running speech: They have to extract the right words from the speech signal, and not these unintended words, in order to understand the message. Given the continuous nature of the speech signal, how do listeners across languages with differing phonological constraints know where one word ends and another begins?
One proposal that has been made is that listeners have at their disposal a segmentation procedure in which vowelless sequences are disfavoured as parsing units (Norris, McQueen, Cutler, & Butterfield, 1997). In line with this proposal, English listeners find it more difficult to recognize the word apple in fapple than in vuffapple (Norris et al., 1997), because the residue f is vowelless, and hence disfavoured, while the residue vuff contains a vowel. It has been argued that this segmentation principle, called the possible-word constraint (PWC), is language universal, in that it applies in the same way across languages, independently of language-specific constraints on what constitutes a well-formed word.
But Slovak poses an obvious challenge to the PWC. How can Slovak listeners parse the speech stream k vete “to the sentence”, in which the k is a word, but also kvety, in which k is not an intended word? Without doubt, Slovak listeners do not encounter problems in comprehending syntactically well-formed sequences such as k vete. But according to the PWC, the correct parse of this sequence (k & vete) should be disfavoured. So, prima facie, the mere fact that Slovak contains single-consonant words seems to contradict the idea that the PWC is indeed universal. The goal of this study was therefore to investigate how the segmentation of speech works in Slovak.
Previous research has suggested several solutions to how the segmentation problem can be solved across languages (for reviews, see Dahan & Magnuson, 2006; Mattys, 1997; McQueen, 2007). The PWC unifies two popular approaches. The first is that segmentation is modulated by language-specific, signal-driven cues. The second is that segmentation is a by-product of lexical competition. Note that these two approaches are not mutually exclusive. The PWC in fact attempts to explain how signal-based and lexical information can be integrated in the segmentation process.
In support of the first approach, research has shown that the speech signal contains regularly occurring properties such as the aspiration of word-initial plosives or durational cues, which correlate with word boundaries (Lehiste, 1960; Nakatani & Dukes, 1977) and are exploited by listeners (e.g., Dumay, Content, & Frauenfelder, 1999; Gow & Gordon, 1995; Mattys & Melhorn, 2007; Quené, 1987, 1992; Shatzman & McQueen, 2006; Spinelli, McQueen, & Cutler, 2003). But languages differ in how word boundaries are marked by physical cues, and hence the nature of these cues depends on language-specific phonology (Lehiste, 1964). For example, all languages have specific restrictions on sequential probabilities, and listeners can use these cues for word boundary location (Church, 1987; McQueen, 1998; van der Lugt, 2001; Vitevitch & Luce, 1999). A clear demonstration that language-specific sequence restrictions are learned is that listeners apply native-language constraints in the processing of a second language acquired later in life (Weber & Cutler, 2006).
Another language-specific property that listeners rely on is the information provided by rhythmic structure. Cutler and Norris (1988) showed that English listeners exploit the fact that most words are stressed on the first syllable (Cutler & Carter, 1987). Hence, they segment speech more easily at strong syllables (containing a full vowel) than at weak syllables (containing a reduced vowel). In a syllable-timed language such as French, syllables seem to be used for segmentation (e.g., Cutler, Mehler, Norris, & Seguí, 1986; Dumay, Frauenfelder, & Content, 2002; Mehler, Dommergues, Frauenfelder, & Seguí, 1981), while in Japanese, segmentation is based on the mora (Cutler & Otake, 1994; Otake, Hatano, Cutler, & Mehler, 1993). The segmentation procedures based on stress therefore vary depending on the input language's metrical structure (see also Pallier, Sebastián-Gallés, Felguera, Christophe, & Mehler, 1993; Sebastian-Gallés, Dupoux, Seguí, & Mehler, 1992; Vroomen & de Gelder, 1995; and also Cutler, 2005, for a review).
These signal-based cues, however, are probabilistic, and none of them by itself is sufficient to solve the segmentation problem entirely. The second approach to the problem based on lexical competition proposes a more general solution: Words are recognized through the competition of alternative word candidates, and segmentation is a by-product of this process. Through competition, the word-recognition system can settle on an optimal parse of the speech input, even if signal-based cues are not present. The activation and competition of multiple lexical candidates are core mechanisms implemented by most models of spoken-word recognition (e.g., TRACE, McClelland & Elman, 1986; and Shortlist, Norris, 1994; see McQueen, 2005, for a review) and have received a great deal of empirical support (e.g., Allopenna, Magnuson, & Tanenhaus, 1998; Cluff & Luce, 1990; Connine, Blasko, & Titone, 1993; McQueen, Norris, & Cutler, 1994; Norris, McQueen, & Cutler, 1995; Tabossi, Burani, & Scott, 1995; Vitevitch & Luce, 1998, 1999; Vroomen & de Gelder, 1995; Zwitserlood & Schriefers, 1995). In the English phrase play tennis, the words play, lay, late, and any, for example, would compete with each other. The correct segmentation emerges as play and tennis win out over their competitors.
Various sources of information can thus be exploited to solve the segmentation problem. Recent research, however, has emphasized the importance and interaction of these different sources of information (Mattys, 2004; Mattys, White, & Melhorn, 2005). Mattys et al. (2005) proposed a hierarchy of the relative importance of various speech segmentation cues depending on the listening conditions. In a series of English cross-modal fragment priming experiments, for example, Mattys et al. showed that with optimal quality input listeners rely more strongly on lexical knowledge than on sublexical cues such as segmental acoustics and word stress.
The PWC suggests how these multiple information sources are integrated. It unifies the use of signal-based and lexical cues and adds a general viability constraint based on the simple information about whether a vowel is present or absent in the input. The primary support for the PWC comes from studies using the word-spotting paradigm (Cutler & Norris, 1988), in which listeners were asked to respond whenever they found a target word embedded at the beginning or at the end of a nonsense sequence. As introduced earlier, the English word apple was recognized more easily when it was preceded by a nonsense consonant–vowel–consonant (CVC) syllable (e.g., vuffapple) than when it was preceded by a single consonant (e.g., fapple). Neither of these contexts is an existing English word, but only vuff is a possible well-formed word (Norris et al., 1997).
According to the PWC account, the activation of a word will be reduced if, between this word and any likely word boundary, vowelless sequences such as single consonants are left over. A likely word boundary can be signalled by a pause or by language-specific cues such as stress, allophonic detail, or phonotactic probabilities. Hence, the recognition of a word such as lay in play will be unlikely, because this would leave a single consonant (p) as a residue. In this situation, the word lay is misaligned with the likely word boundary before the first consonant (cued, e.g., by silence if the input word play is utterance initial).
There are two possible interpretations of the Norris et al. (1997) results. One is that the PWC is a language-specific constraint, so the recognition of apple in fapple is difficult because f is not a possible word in English. The other possibility is that the PWC may operate language independently and penalize parses with a vowelless residue irrespective of language-specific constraints. To investigate this issue, Norris, McQueen, Cutler, Butterfield, and Kearns (2001) tested whether English listeners use their knowledge about the well-formedness of English syllables in the segmentation of their native language. A word such as perturb was therefore presented in three contexts: a tense-vowel CV syllable (e.g., dahperturb), a lax-vowel CV syllable (e.g., deperturb), and a single consonant (e.g., sperturb). None of these contexts are existing English words, but only dah could be a word. While there are English words with tense vowels and open codas (e.g., car /ka/ in British English), there are none with a lax vowel without the coda being closed (e.g., deck /dεk/, but not de /dε/). Replicating the results from the Norris et al. (1997) experiments, listeners’ detection of the target word was significantly faster and more accurate in both syllable contexts than in the consonant context. Crucially, word spotting was as efficient with the context dah as with the context de. Norris et al. (2001) concluded that the second interpretation of the PWC was correct: It is a language-universal processing mechanism that penalizes parses with a vowelless residue irrespective of language-specific constraints. This claim stood up to tests in Dutch (McQueen & Cutler, 1998), Cantonese (Yip, 2004), and Japanese (McQueen, Otake, & Cutler, 2001). Especially the latter case provides an ideal test of some aspects of the PWC that were difficult to achieve in English. While there was no perfect match of the segmental length of the context in earlier studies (i.e., one phoneme in single-consonant contexts vs. at least two phonemes in syllabic contexts), the contexts in Japanese always consisted of one phoneme. Yet listeners found it easier to spot a word if the residue contained a vowel than if it contained a consonant.
These examples, however, do not cover the complete range of cross-linguistic variation of what constitutes a well-formed word in a given language. Whereas some Bantu languages such as Sesotho (Doke & Mofokeng, 1957) prohibit one-syllable stand-alone words, other languages such as the Salish language Nuxálk (also known as Bella Coola; Bagemihl, 1991; Nater, 1984) or Berber (Dell & El-Medlaoui, 1985; Ridouane, 2002) allow vowelless sequences to be words. Yet other languages allow words that contain only one consonant, for example Slovak, Czech, and Russian.
On this continuum, the PWC has already been tested on a language in which words must consist of at least two syllables. Cutler, Demuth, and McQueen (2002) showed that the recognition of Sesotho words was as fast in monosyllabic as in bisyllabic contexts, but slower in single-consonant contexts, in line with the universal PWC. But no test has yet been conducted at the other end of the continuum, with languages that allow single-consonant words. The present study thus investigated how segmentation proceeds in the Slovak language. Slovak belongs to the West Slavic language group (together with Czech, Polish, Sorbian, and Kashubian) and is most closely related to Czech. Slovak phonology allows the occurrence of clusters of up to four consonants in onset position (e.g., pstruh “trout”; Rubach, 1993). It also allows words consisting solely of consonants, which, however, always contain at least one sonorant as a syllabic nucleus (e.g., /r/ in the famous tongue twister: strč prst skrz krk “stick the finger down the throat”). In addition, Slovak has four prepositions consisting of single consonants: k “to”, z “from”, s “with”, and v “in”. Each has a voiceless and a voiced positional allophone, and each also has a vocalized form—for example, /k/, /g/ and /ku/; /v/, /f/ and /vƆ/; and so on. The vocalized form occurs when the following word has a similar place of articulation (e.g., zo zeme “from the earth”). Out of one million word tokens in the Slovak National Corpus (Slovenský národný korpus; 2007), 3% are these single-consonant prepositions (vocalized units form an additional 0.4% and are thus considerably less frequent). Prepositions are proclitic, thus combining phonologically with the following word (e.g., v rane /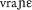 / “in the wound”). However, orthographically they are always separated by a blank from the following noun or adjective (or other word classes) to avoid ambiguity in a phonetically otherwise ambiguous sequence such as /
/ “in the wound”). However, orthographically they are always separated by a blank from the following noun or adjective (or other word classes) to avoid ambiguity in a phonetically otherwise ambiguous sequence such as /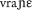 / representing v rane (“in the wound”) or vrane (“crow” + dative inflection).
/ representing v rane (“in the wound”) or vrane (“crow” + dative inflection).
Segmentation of spoken Slovak not only provides an interesting challenge for the PWC, but also, more generally, raises the issue of the relative weight of different processing constraints. On the one hand, the processing system needs to tolerate vowelless sequences for the recognition of, for example, v in /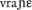 / (v rane, “in the wound”), simply because these sequences occur in spoken Slovak. Indiscriminative acceptance of vowelless sequences, on the other hand, would come with a cost for other input. Allowing the consonant /b/ to be a possible residue would slow down the recognition of words such as brok (“shot”), because more words would be in competition (e.g., rok “year”).
/ (v rane, “in the wound”), simply because these sequences occur in spoken Slovak. Indiscriminative acceptance of vowelless sequences, on the other hand, would come with a cost for other input. Allowing the consonant /b/ to be a possible residue would slow down the recognition of words such as brok (“shot”), because more words would be in competition (e.g., rok “year”).
We see three possibilities how speech segmentation in Slovak could have evolved under these opposing pressures. One option is that the PWC is not operational, such that all words consistent with parts of the speech stream would compete for recognition on an equal footing. That is, the activation of candidate words would be independent of what kind of residues they are associated with (e.g., the word rok, with the residue b given the input brok, would be as strongly activated as in prorok “oracle” and krok “step”). This would certainly make it possible for Slovak listeners to recognize true consonantal prepositions, but would come with the price that segmentations involving parses with single consonants would not be disfavoured.
The second option is that the PWC is, after all, fully operational. In previous PWC experiments, words in single consonant contexts were often still detected. This means that the PWC penalizes recognition of words in vowelless parses but does not prevent word recognition entirely. In Slovak, the penalty imposed on an existing single consonant word could then be overcome if there is lexical and syntactic support for a preposition, as there is in phrases such as /kvεtjε/ (k vete “to the sentence”). It is important to note that the phoneme of a preposition also occurs as an embedded chunk in other morphemes (e.g., kvety “flowers”). The operation of the PWC would thus help listeners to reject vety (“sentences”) in kvety, but the penalization of vete in k vete would make recognition of the prepositional phrase harder.
The third option is that, without recourse to syntactic knowledge, prepositional consonants are given special treatment in the segmentation process. Accordingly, the PWC could operate in Slovak, but single consonants that are words would be treated as acceptable parts of the lexical parse, and this would be independent of the syntactic context they appear in. Under these conditions, the costs and benefits reverse: vete in k vete could now be recognized more easily (i.e., without the use of contextual information) because k would be treated as an acceptable part of the parse. But the sequence kvety would be harder to recognize, because vety would not be penalized by the PWC and would be in competition with kvety.
To investigate these three possibilities, and hence the relative costs and benefits of different processing constraints in spoken-word recognition, we conducted three experiments. We used the word-spotting task. In the first two experiments there were three conditions. Target words were embedded in three preceding contexts: a single prepositional consonant (e.g., /g/, the voiced allophone of the preposition k, “to”), a nonprepositional consonant (e.g., /t/, not a word in Slovak, and neither is /d/) and a syllable (e.g., /dug/, a possible syllable but not a word in Slovak). We did not include a condition that would test whether words are recognized when they are embedded in a well-formed prepositional phrase (e.g., k vete), for two reasons. First, it is obvious that prepositional phrases are easily recognized by Slovak listeners in everyday communication. Such a condition therefore seemed redundant. Second, such a condition would not be directly comparable to the others in the experiment (or indeed to those in previous studies), which all involve nonsense sequences.
The three conditions in Experiments 1 and 2 allowed us to tease apart the three possible accounts. If the PWC is not operational at all in Slovak, spotting the word ruka “hand” should not be easier in the syllable context dugruka than in the prepositional single-consonant context gruka or the nonprepositional single-consonant context truka. If, however, the PWC is operational in Slovak, and recovery is based on syntactic processing, recognition of ruka should be harder in both single-consonant contexts than in the syllable context, irrespective of the lexical status of the single consonant. Given the lack of syntactic support for a parse g + ruka (the noun ruka does not have the correct inflection for the preposition /g/), g is not a viable residue, and the recognition of ruka in gruka should be just as hard as in truka, and both of these sequences should be more difficult than the sequence dugruka. Finally, if the PWC is operational in Slovak but single consonants that are words are accepted without the need for syntactic support, the recognition of ruka should be easy in gruka and in dugruka, but difficult in truka, because there is a lexical item in the residue g, a vowel in the residue dug, and neither of those in the residue t.
Experiment 1
We used the word-spotting task in Experiment 1A to compare detection of the same word in different contexts. Given that we were using naturally produced items, the same target could exhibit acoustic differences over conditions. To control for any influence of this variation, we used a lexical-decision task, presenting targets that had been excised from their contexts. We thus tested whether the words taken from each of the word-spotting contexts were equally recognizable (Experiment 1B).
Method
Participants
A total of 63 native speakers of Slovak, students at the Faculty of Mechatronics (mechanical engineering) and the Department of Political Science at the Alexander Dubček's University in Trenčín, volunteered or received monetary compensation for their participation. A total of 36 students participated in Experiment 1A and 27 in Experiment 1B. They were recruited on the basis of written advertisements or from classes. None of them reported any hearing difficulties.
Materials and Design
A total of 72 Slovak bisyllabic words (nouns and verbs) were selected as targets. All started with a consonant and had no other words embedded in them (with the exception of unavoidable single-vowel or single-consonant words such as a “and” or v “in”, but this applied to all material and all three conditions equally). Each word was embedded in three preceding contexts to yield three nonsense sequences per target. For example, the target word ruka “hand” was embedded in a syllabic context (e.g., /dugruka/), in a single-consonant context that is a preposition in Slovak (e.g., /gruka/), or a single consonant that is not a word in Slovak (e.g., /truka/). The syllabic context (e.g., /dug/) is also not an existing Slovak word, but it could be one, as the Slovak vocabulary contains monosyllabic words with short lax vowels (e.g., zub “tooth”). For the prepositional context, two existing prepositions k “to” and v “in” were chosen (with the allophones /g/ and /f/). Verb targets were embedded only in /g/ contexts, because /f/ is also a verbal prefix (just as s and z), and hence real words would have emerged. It is important to note that all combinations of prepositional consonants and targets always resulted in syntactically illegal nonsense sequences (e.g., /gruke/ “to the hand” is a legal sequence in Slovak, but /gruka/ is not). Further consonants, /p, ∫, t/, which are not possible words in Slovak, were used in the nonprepositional context. The syllable contexts consisted of CVC syllables with short vowels /u, ε, Ɔ, a, I/ as nuclei. The final consonants of the CVC syllables were balanced so as to end equally often either with a prepositional or with a nonprepositional consonant. The consonant clusters that emerged through the combination of consonantal onsets of target words and the added preceding consonantal context (e.g., /tr/ in truka) were all phonotactically legal in Slovak.
The material was controlled for frequency estimates of the lemma and onset consonant clusters, which were taken from the Slovak National Corpus (Slovenský národný korpus, 2007) and logarithmically transformed. The average log lemma frequency per million for the target words was 1.9. The mean log frequency of the onset consonant clusters over all items in the prepositional and the nonprepositional condition was 2.4 each. All experimental items are listed in Appendix A. Further, 133 fillers were constructed so as to match the form of the target-bearing strings. None of the filler words contained existing Slovak content words (again, as previously mentioned, it was unavoidable that single segment words were embedded). Critically, the fillers contained items in which the prepositional and the nonprepositional consonants were followed by nonwords. Hence, listeners could not predict that a sequence starting with a prepositional consonant would contain a target word.
Three experimental lists were then created with all the fillers in each list. Each target appeared in all lists, but in only one preceding context in a given list. Type of context was counterbalanced over lists so that each list had 24 targets in each type of context. For the syllable condition, stimuli were chosen in such a way that half of the syllable contexts per list ended with a prepositional consonant and half with a nonprepositional consonant. The order of stimuli was randomized, but there was a restriction that at least one filler occurred between two target-bearing items. A set of four additional target-bearing items and nine fillers were used for a practice session.
The materials were read by a phonetically trained female native speaker of Slovak who was not aware of the aim of the study. She received instructions to read the material at a normal speech rate. The main stress was always on the first syllable of the whole string. The speaker read the items one by one, separated by a pause, in a clear citation style three times in a row. The recordings were made in a soundproof booth on a Digital Audio Tape (DAT) at 48-kHz sampling rate with 16-bit resolution. They were then redigitized onto a computer and down-sampled to 22.05 kHz. The stimuli were measured, labelled, and spliced into single speech files using the Praat speech editor (Boersma, 2001). All speech files were normalized so that their mean amplitude was approximately equal.
For the lexical-decision task used in Experiment 1B, all target words were carefully excised from their preceding contexts using the Praat speech editor. For example, the target word /ruka/ was removed from its preceding contexts /dug/, /t/, and /g/, respectively. We used visual and auditory criteria to determine the onset of the first segment of the target, cutting at positive zero-crossings. For sequences in which phoneme boundaries could not be easily determined from the spectrogram (such as /fs/), we chose a splicing point based on whether the previous phoneme was still audible in the remaining string. The same procedure was applied to the fillers. The same three lists were used as those in Experiment 1A, but without the preceding contexts.
Procedure
The participants were tested separately in a quiet room. For Experiment 1A, they received written instructions that they would hear nonsense strings over headphones. Their task was on each trial to press a button whenever they spotted a real word embedded at the end of a nonsense string. For Experiment 1B, the written instructions stated that they would hear real Slovak words and nonsense words over headphones. They were asked to press a response button if they thought the presented item was a Slovak word. In both subexperiments, participants were asked to respond both as fast and as accurately as possible and to say aloud the word they found. Both experiments started after the short practice sessions. Participants heard the stimuli one at a time over headphones at a comfortable listening level. Any given participant was presented with only one experimental list.
The presentation of the stimuli, timing, and the response time (RT) measurements were controlled by NESU (Nijmegen Experiment Set-Up). Each trial started with a 500-ms silence, after which the stimulus was presented. The time interval between the onsets of two successive trials was 4,000 ms in Experiment 1A and 3,000 ms in Experiment 1B. The participant's spoken responses were recorded on tape as a control. All responses were monitored during the experiment and checked for correctness a second time using the recordings. Button-press responses accompanied by spoken responses that were not the intended target words were discarded and counted as errors. The RTs in these and the following experiments were recorded from stimulus onset, but prior to the analysis were adjusted so as to measure from word offset by subtracting the total sequence duration.
Results
If an item was missed by more than two thirds of all participants in one of the conditions, it was excluded from the analysis. One item (liga) met this criterion and was eliminated from Experiment 1A. Similarly, if a participant missed more than 50% of all items per condition, his or her data were also excluded. The data of one participant were therefore removed from Experiment 1A. In Experiment 1B, four items (ríša, suma, sebec, and liga) were excluded.
Experiment 1A: Word spotting
Mean RTs and mean error rates (no response or response other than the intended target) for the three preceding contexts are shown in Figure 1. Responses to target words in the prepositional condition (e.g., /gruka/) were faster and exhibited fewer errors (561 ms, 6% errors) than those in the nonprepositional condition (e.g., /truka/, 668 ms, 8% errors). Responses to words in the syllable context (e.g., /dugruka/) were both slower (744 ms) and less accurate (18% errors) than those in the other two conditions. Analyses of variance (ANOVAs) for both participants (F1) and items (F2) were carried out. There was a significant main effect of context for both the RT analysis, F1(2, 68) = 35.49, MSE = 9,584.5, p < .001; F2(2, 140) = 25.26, MSE = 30,471.3, p < .001; minF′(2, 201) = 14.76, p < .001, and the error analysis, F1(2, 68) = 27.89, MSE = 62.80, p < .001; F2(2, 140) = 22.91, MSE = 174.06, p = .001; minF′(2, 194) = 12.58, p < .001. 1 In this and all subsequent experiments, interpretation of planned pairwise t tests was based on Bonferroni correction. In Experiment 1A, all comparisons were significant, except for those on the error rates in the prepositional and nonprepositional conditions (see Table 1).
We report Greenhouse–Geisser p-values, but the degrees of freedom are uncorrected.
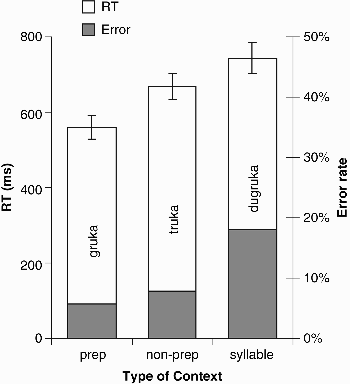
Experiment 1A: Word spotting. Mean reaction times (RTs, measured in ms from word offset) and mean percentage of errors, as a function of type of context (prep = prepositional consonant; non-prep = nonprepositional consonant). Error bars show standard errors.
Experiment 1A: Paired t test comparisons between the three types of context

Note: RT = reaction time.
**p < .01.
To rule out that the main pattern of results could be attributed to the frequency of consonant clusters, a correlation analysis was computed, taking the RTs for items in the prepositional and the nonprepositional condition as the dependent variable and the log frequency of the onset clusters for those items as the independent variable. There was no effect of the frequency that could have explained the difference obtained between those two conditions (R = .01, p = .91).
Experiment 1B: Lexical decision
Figure 2. shows the mean RTs and error rates to target words that were excised from their preceding contexts. Target words were recognized equally fast and yielded a small number of errors in all three conditions (preposition: 364 ms, 3% errors; nonpreposition: 368 ms, 4% errors; and syllable: 376 ms, 5% errors). ANOVAs revealed no main effect of context (i.e., context that had been removed from the target word) for either RTs (all Fs < 1) or errors F1(2, 52) = 1.90, MSE = 16.48, p = .16; F2(2, 134) = 1.78, MSE = 78.37, p = .178.
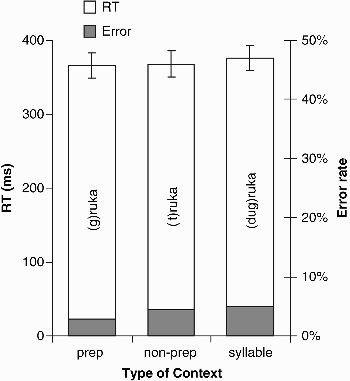
Experiment 1B: Lexical decision. Mean reaction times (RTs, measured in ms from word offset) and mean percentage of errors, as a function of type of context (prep = prepositional consonant; non-prep = nonprepositional consonant) from which words had been spliced out. Error bars show standard errors.
We also conducted an analysis of Experiment 1A based on the Experiment 1B data to check for any acoustic confounds that could have caused the differences in word spotting. To assess the word-spotting results taking the lexical-decision data as a covariate, a by-item linear regression was computed with the mean word-spotting RTs as the dependent variable and the lexical-decision RTs as the independent variable. The same procedure was used in a separate analysis of the error data. There was a significant positive correlation in both the RTs, R = .27, t2(1, 203) = 4.0, p < .001, and the errors, R = .16, t2(1, 203) = 2.28, p = .02. ANOVAs were then run on the residuals of the regressions. The main effect of context for the word-spotting experiment remained significant in the RT analysis, F2(2, 134) = 24.36, MSE = 26,222.2, p < .001, and the error analysis, F2(2, 134) = 22.61, MSE = 178.63, p < .001. The main effect obtained in the word-spotting experiment thus cannot be explained on the basis of acoustic differences of the targets over conditions. A further analysis showed that the exclusion of the same items as those that were excluded from Experiment 1B did not alter the pattern of results in Experiment 1A.
Discussion
The results of Experiment 1A showed that word spotting was not more difficult in single-consonant than in syllable contexts. These results seem to be in line with our first account: that the PWC is not operational in Slovak. But segmentation of a word in the prepositional-consonant context was easier than in the nonprepositional-consonant context. This seems to be in line with our third account and suggests that segmentation is driven by language-specific knowledge; single consonants such as prepositions can be viable residues, and their presence in the lexical parse appears to make target detection even easier. The results of the control experiment (1B) demonstrated that even though target words were produced in natural recording settings, there did not seem to be any acoustic differences among the three versions of each target that caused negative effects on their recognition.
A striking result predicted by none of the accounts outlined in the Introduction, however, is the faster and more accurate word-spotting performance in both types of consonant contexts than in syllable contexts. Syllables can be words in Slovak just as in every language. Hence, according to the PWC, the recognition of words in this context should have been the easiest, or at least easier than in the nonprepositional-consonant condition.
If this result were due to some aspect of the design that we chose, we should have observed similar results in another study using a very similar design (Hanulíková, 2008a, 2008b). In this study with German listeners, the predictions of the PWC were replicated: Spotting a German word such as Rose (“rose”) was faster in syllable contexts (e.g., suckrose) than in single-consonant contexts (e.g., krose and trose), with no significant difference between single consonants (both of which are not possible German words). While German listeners as well as listeners of other languages perform better in syllabic contexts, Slovak listeners appear to be best with single prepositional consonants, not with syllables.
There is, however, another aspect of Slovak that differs from previously studied languages that might explain the poor performance in the syllable condition. Unlike English or German, Slovak has fixed stress on the first syllables of words. Recall that the PWC operates on signal-driven language-specific properties such as stress. The recognition of a word is penalized when only a single consonant appears between that word and any likely word boundary signalled by specific acoustic properties of the speech signal such as phonotactics or stress information. It is hence possible that the metrical structure of Slovak interfered with detection latencies.
Slovak metrical structure alternates between stressed and nonstressed (normally) unreduced syllables (Sabol & Zimmermann, 1994; Zimmermann, 1990). Stress in Slovak is not used for phonological contrasts—that is, it is not used to distinguish one word from another (except rarely and only at the phrasal level: e.g., ZAhla som “I cheated” versus za HLAsom “behind the voice”; stressed syllable in upper case). In addition, the acoustic correlates of fixed-word stress have been previously described as “weak” as compared to free stress languages such as English (e.g., Dogil, 1999a, 1999b; Dube˘da, 2003; Dube˘da & Votrubec, 2005). Not enough is known about how stress information is used in segmentation in languages with fixed initial stress. Because stress in such languages demarcates word boundaries, it is potentially useful for the segmentation of continuous speech (Trubetzkoy, 1939, p. 245). This has been partly demonstrated in Finnish, a language that also exhibits word-initial fixed stress (Suomi, McQueen, & Cutler, 1997; Suomi, Toivanen, & Ylitalo, 2003; Suomi & Ylitalo, 2004; Vroomen, Tuomainen, & de Gelder, 1998). Thus, while stress information might not be helpful for identification of spoken words, it could still be used in segmentation.
Involvement of stress information might explain the slow latencies in the syllable condition of Experiment 1A. In our materials, all strings were produced with the canonical main stress on the first syllable of the string. This means that the target ruka carried the main stress in the bisyllabic string /′gruka/ but not in the trisyllabic string /′dugruka/. This may have disfavoured targets in syllable contexts, because there they lacked main stress cues.
One might wonder, however, why the lexical-decision results (Experiment 1B) did not reflect these possible acoustic differences between targets. A likely reason is that although a trisyllabic string (e.g., /dugruka/) uttered in isolation carries initial stress, the acoustic properties of the subsequent phonological syllabic nuclei also have decreasing prominence. The relative prominence of one syllable as compared to all other syllables in that word determines the perception of stress. This relative degree of perceived stress prominence on the first syllable in a trisyllabic string will be perceptually shifted to the second syllable after the first one is removed, because the second syllable will be more salient than the third one. For example, in the string /dugruka/ the first syllable carries the primary stress, but after its removal, the first syllable in the remaining sequence /ruka/ would be perceived as more salient than the second. This is probably why no effect of stress differences between isolated targets was observed in Experiment 1B. Since fixed stress is not contrastive, listeners seem to be less likely to use stress information in word identification. Note, however, that Slovak listeners are able to detect stress differences in an offline judgement task (Sabol & Zimmerman, 1994). The effect of primary stress on speech segmentation cannot thus be reliably assessed with the lexical-decision task. Instead, to address the role of fixed stress in Slovak and to test whether the unbalanced stress information on targets could have had a negative influence on the detection latencies in the syllable context, we conducted a second word-spotting experiment.
Experiment 2
In this study, we used a cross-splicing technique, but the design was the same as that in Experiment 1A. The target words were spliced in such a way that the stress was kept constant over conditions. If the slow performance in the syllable condition in Experiment 1A were due to the missing main stress on the target as compared to the other conditions, then, when this stress information was not missing, we should expect faster latencies in the syllable condition. Similarly, if the significant difference between the prepositional and the nonprepositional condition is a robust result, we expect a replication of this effect.
Method
Participants
A total of 36 native speakers of Slovak recruited from the Faculty of Mechatronics at the Alexander Dubček's University in Trenčín took part. None of them participated in Experiment 1, and none reported any hearing difficulties.
Materials and Design
The same recordings as those in Experiment 1 were used. All targets were removed from the syllable condition and were replaced by different tokens of the same targets excised from the prepositional or nonprepositional condition as a function of a match with the syllable-final consonant. For example, the target ruka from /dugruka/ was replaced by ruka from /gruka/, and the target recept from /jƆtrεtsεpt/ was replaced by recept from /trεtsεpt/. In order to keep the material comparable and to avoid a bias arising because only part of material was spliced, all bisyllabic items were also manipulated. Thus, a single consonant such as /g/ from /gruka/ was replaced by a /g/ from another recording of the same item. The same procedure was applied to the fillers. All splices were made at positive zero-crossings. The same three experimental lists were used as those in Experiment 1A.
Procedure
The procedure was identical to that in Experiment 1A. No additional lexical-decision study was necessary, because the previous control experiment (1B) indicated no acoustic differences between the versions of each target.
Results and Discussion
Three items were excluded (liga, ríša, lúštit’), because they were missed by more than two thirds of all participants. As can be seen in Figure 3, mean RTs to a target in the prepositional context were faster and more accurate (569 ms, 7% errors) than those in the nonprepositional context (700 ms, 14% errors) and the syllable context (631 ms, 9% errors). In contrast to Experiment 1A, spotting a word in the syllable context was now faster and more accurate than in the nonprepositional context.
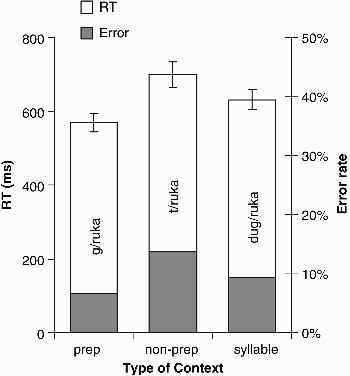
Experiment 2: Word spotting with spliced materials. Mean reaction times (RTs, measured in ms from word offset) and mean percentage of errors, as a function of type of context (prep = prepositional consonant; non-prep = nonprepositional consonant). Error bars show standard errors.
ANOVAs showed a significant main effect for both the RT analysis, F1(2, 70) = 13.04, MSE = 16,095.5, p < .001, F2(2, 136) = 17.11, MSE = 20,617.7, p < .001; minF′(2, 167) = 7.4, p < .001, and the error rate analysis, F1(2, 70) = 10.81, MSE = 46.74, p < .001; F2(2, 136) = 6.40, MSE = 146.03, p = .003; minF′(2, 205) = 4.02, p = .019. Pairwise t tests (see Table 2) revealed that all differences were significant, except for the error rate difference between the preposition and syllable conditions. As in the previous experiment, an additional correlation analysis was conducted to assess the effect of frequency of consonant clusters on the RT data, taking the RTs for items in the prepositional and the nonprepositional condition as the dependent variable and the log frequency of the onset clusters as the independent variable. No effect of cluster frequency was observed that could have explained the difference obtained between those two conditions (R = .025, p = .77). Again, the exclusion of the same items as those that were excluded from Experiment 1B did not alter the results.
Experiment 2: Paired t test comparisons between the three types of context

Note: RT = reaction time.
p ≤ .05.
p < .0167.
p < .01. With Bonferroni correction, the alpha level is p = .0167.
To assess the role of fixed stress in segmentation, a further analysis was conducted that compared the two word-spotting experiments. There was a significant interaction between experiments (taking experiment as a between-subject and a between-item factor), in both the RT analysis, F1(2, 138) = 10.58, MSE = 10,676.8, p < .001; F2(2, 276) = 10.62, MSE = 25,238.1, p < .001; minF′(2, 368) = 5.3, p = .005, and in the error analysis, F1(2, 138) = 20.11, MSE = 54.43, p < .001; F2(2, 276) = 14.51, MSE = 5,594.49, p < .001; minF′(2, 401) = 8.43, p < .001. Independent-sample t tests revealed that spotting a word in the syllable context was faster, t1(69) = 2.28, p = .03; t2(138) = 3.30, p = .001, and more accurate, t1(69) = 3.77, p < .001; t2(138) = 3.27, p = .001, in Experiment 2, where the primary stress information on the target word was provided, than in Experiment 1, where the primary stress was misaligned with the word boundary. There were no differences in latencies for the prepositional and nonprepositional contexts across experiments. Only in the error rate was there a difference: Listeners made more errors in the nonprepositional context in Experiment 2 than in Experiment 1, t1(69) = 3.1, p = .003; t2(138) = 1.40, p = .16.
These results thus clearly replicate one major finding from Experiment 1A: Spotting a word is easier if the residue is a single prepositional consonant than when the residue is a nonprepositional consonant. Experiment 2, however, failed to replicate the other major finding from Experiment 1A: Once stress was matched over conditions, spotting a word in syllable contexts was easier than in nonprepositional contexts and as accurate as in the prepositional contexts. These results are in line with the account of Slovak segmentation in which single consonants are viable parts of the lexical parse if they are themselves words, irrespective of contextual (syntactic) support for their interpretation as prepositions.
Furthermore, the cross-experiment comparison revealed faster and more accurate response latencies to targets in the syllable conditions when primary stress information was provided. This supports the previously unattested assumption that Slovak listeners can exploit fixed-stress information in segmentation.
The findings of Experiment 2 are inconsistent with the first of the three accounts of Slovak segmentation outlined in the introduction. Contrary to that account, the PWC does appear to be operational in Slovak listening (once effects of stress were controlled, spotting words in single-consonant contexts was harder than in syllabic contexts). The data presented so far are also inconsistent with the second account, which proposed that the PWC is fully operational, but that the PWC penalty could be overcome if there were lexical and syntactic support for a prepositional reading of a single consonant. Detection of target words in prepositional-consonant contexts was easiest despite the fact that the input nonsense sequences were syntactically ill-formed. The results are consistent, however, with the third account: The PWC is operational in Slovak, but prepositional consonants are treated specially.
There are two possibilities about how the exceptional status of prepositional consonants could influence segmentation in Slovak. The first is that the PWC penalty can be overcome during the lexical competition process. The prepositional consonants are, after all, Slovak words. A lexical parse can be derived for gruka (g + ruka) but not for truka. This account suggests that the PWC operates as a purely phonological constraint, which applies a penalty to words with vowelless residues (just as it does in other languages), but that lexical competition allows for recovery of lexical parses that fully account for Slovak input. This proposal is thus a variant of the syntactic account described earlier: It may be that lexical support for a prepositional consonant is sufficient, even if the resulting sequence of words is ungrammatical. This lexical recovery account makes a clear prediction about word-spotting behaviour. Words should be easier to spot when the input can be fully parsed into words than when it cannot, and this should not depend on the phonological form of the words or on the grammaticality of the whole phrase. That is, a target word should be easier to detect when it follows another word than when it follows a nonword, irrespective of whether the context is consonantal (e.g., g vs. t) or vocalic (e.g., o “about” vs. e, the latter being a nonword in Slovak). This prediction was tested in Experiment 3.
The alternative way in which prepositional consonants could be treated specially in Slovak is that the operation of the PWC itself is modified by language-specific knowledge. Accordingly, the PWC might penalize words leaving residues with single consonants, but only those that are not Slovak words. The facilitating effect of lexical status for consonant residues observed in Experiments 1 and 2 should hence disappear for vowel residues, which are all possible words.
To tease apart these two remaining accounts, a 2 × 2 factorial design was used in which the preceding contexts varied in segment type (vowels vs. consonants) and lexical status (words vs. nonwords). In contrast to the earlier experiments, all contexts were one phoneme long. To create a condition in which the context is a word but contains a vowel, we selected the prepositional vowels o “about” and u “at”, which were the analogues of the prepositional consonants k and v. To provide a vocalic analogue for the nonprepositional consonants (t, š, and p), we selected the vowel e, which has no meaning in Slovak. If the lexical account is correct, we should observe two main effects. First, there should be an effect of lexical status: Target detection should be easier in word than in nonword contexts. Second, we should find an effect of context segment type: Words should be harder to spot in consonant contexts (due to the PWC penalty) than in vowel contexts (no penalty). Importantly, there should be no interaction between the two factors, because, according to the account, the PWC and the lexical parsing process operate independently of each other (the PWC makes no distinction between words and nonwords, and the lexical competition process makes no distinction between vowels and consonants). If, however, the operation of the PWC itself is determined by language-specific knowledge, then we expect an interaction. For vowels, there should be no difference between word and nonword contexts, since all vowels pass the PWC regardless of lexical status. But for consonants, spotting words in prepositional-consonant contexts should again be easier than in nonprepositional-consonant contexts.
Experiment 3
We conducted a word-spotting study (Experiment 3A) and an additional lexical-decision study (Experiment 3B). The lexical-decision control was again necessary because the materials were new, and so there could have been acoustic differences in the target words across conditions.
Method
Participants
A total of 60 native speakers of Slovak recruited from the Philosophical Faculty at the Constantine the Philosopher University in Nitra received a small fee for their participation. A total of 40 of them took part in Experiment 3A and 20 in Experiment 3B. None of them had participated before, and none reported any hearing difficulties.
Materials, design, and procedure
A total of 40 Slovak bisyllabic words were selected as targets. Each word was embedded in four preceding contexts to yield four nonsense sequences per target. For example, the target word ruka “hand” was embedded in two single-consonant contexts (e.g., /gruka/ and /truka/) and two single-vowel contexts (/Ɔruka/ and /εruka/). In each of these sets, one segment was a preposition (e.g., /g/ and /Ɔ/), and one was a nonpreposition (e.g., /t/ and /ε/). In addition to the prepositional consonants from Experiments 1 and 2 (k “to” and v “in”), two vowel prepositions o “about” and u “at” were selected. As nonprepositions we used the single-vowel e, which has no meaning in Slovak, and again the consonants p, š, t. The material was controlled for frequency as described in Experiment 1. All experimental items are listed in Appendix B. Further, 83 fillers were constructed, which matched the form of the target-bearing strings and did not contain existing Slovak content words.
Four experimental lists were created with all the fillers in each list. Each target appeared in all lists, but in only one preceding context in a given list. Type of context was counterbalanced over lists so that each list had 10 targets in each type of context. The order of stimuli was randomized with the only restriction that at least one filler occurred between two target-bearing items. A set of four additional target-bearing items along with six fillers were used for a practice session. Each participant was randomly assigned to one of the four lists.
The materials were read by a female native speaker of Slovak who was not aware of the aim of the study. She received the same instructions as the speaker in Experiment 1, except that the main stress was now always on the target word. The recordings were made and edited as in Experiment 1. For the lexical-decision task used in Experiment 3B, the same method as that described in Experiment 1B was applied. In short, the same four lists as those in Experiment 3A were used, but without the preceding contexts. The procedure was identical to that in Experiment 1.
Results and Discussion
One item from Experiment 3A (liga) and two from Experiment 3B (ryža and suma) were excluded (they were missed by more than two thirds of the participants).
Experiment 3A: Word spotting
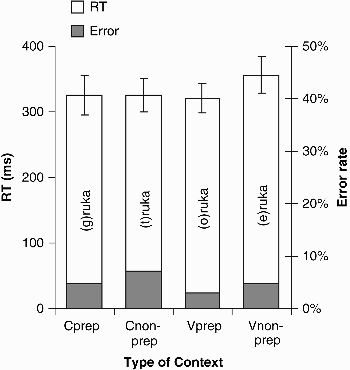
As can be seen in Figure 4, mean RTs to a target in the nonprepositional-consonant context (e.g., /truka/) were slower and less accurate (628 ms, 7% errors) than those in all other contexts: the prepositional-consonant context (e.g., /gruka/; 491 ms, 3% errors), the prepositional-vowel context (e.g., /Ɔruka/; 486 ms, 4% errors), and the nonprepositional-vowel context (e.g., /εruka/; 442 ms, 3% errors). In contrast to Experiment 2, spotting words in syllabic contexts was as fast and as accurate as in prepositional-consonant contexts. Two 2 × 2 factorial ANOVAs were performed for both participants (F1) and items (F2), with two levels for each factor: segment type (vowel and consonant) and lexical status (word and nonword). There was a significant main effect of segment type for RTs, F1(1, 39) = 34.15, MSE = 10,760.3, p < .001; F2(1, 38) = 9.53, MSE = 36,533.4, p = .004; minF′(1, 58) = 7.45, p = .008, but not for errors, F1(1, 39) = 2.47, MSE = 39.26, p = .12; F2(1, 38) = 1.30, MSE = 71.26, p = .26. There was also a significant main effect of lexical status for RTs, F1(1, 39) = 7.36, MSE = 11,612.6, p = .01; F2(1, 38) = 5.19, MSE = 18,756.6, p = .028; minF′ (1, 74) = 3.04, p = .085, but not for errors, F1(1, 39) = 2.07, MSE = 59.11, p = .16; F2(1, 38) = 1.93, MSE = 65.12, p = .17. The main effects were qualified by a significant interaction between the two factors for both RTs, F1(1, 39) = 31.0, MSE = 10,556.6, p < .001; F2(1, 38) = 24.32, MSE = 19,331.8, p < .001; minF′(1, 76) = 13.63, p < .001, and errors, F1(1, 39) = 4.81, MSE = 50.85, p = .034; F2(1, 38) = 3.20, MSE = 80.09, p = .08; minF′(1, 74) = 1.92, p = .17. To investigate the source of this interaction, we tested the effect of consonants and vowels for words and nonwords in separate t tests, correcting for multiple comparisons. In nonword contexts (see Table 3), listeners spotted a target word embedded in a vowel context (e.g., /εruka/) faster and more accurately than one in a consonant context (e.g., /truka/). In contrast to the nonwords, there was no significant difference between words: Vowel and consonant contexts did not differ in either RTs or errors. Moreover, there was a significant difference between the different types of consonants: Word recognition was faster in the prepositional contexts (e.g., gruka) than in the nonprepositional contexts (e.g., truka), as in Experiments 1 and 2. However, for the vowel contexts, word recognition in nonprepositional contexts (e.g., eruka) did not differ from that in prepositional contexts (e.g., oruka).
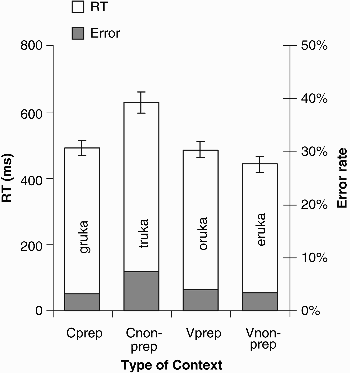
Experiment 3A: Word spotting. Mean reaction times (RTs, measured in ms from word offset) and mean percentage of errors, as a function of type of context (Cprep = prepositional consonant; Cnon-prep = nonprepositional consonant, Vprep = prepositional vowel, Vnon-prep = nonprepositional vowel). Error bars show standard errors.
Experiment 3A: Paired t test comparisons between the four types of context
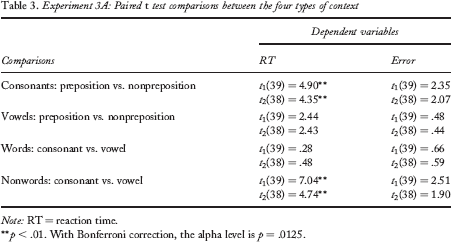
Note: RT = reaction time.
p < .01. With Bonferroni correction, the alpha level is p = .0125.
Experiment 3B: Lexical decision
Figure 5 shows the mean response times and error rates to target words that were excised from their preceding contexts. Target words were recognized equally fast and yielded a relatively small number of errors in all four conditions (prepositional consonant: 325 ms, 5% errors; nonprepositional consonant: 325 ms, 7% errors; prepositional vowel: 321 ms, 3% errors; and nonprepositional vowel: 356 ms, 5% errors). There was a marginally significant main effect of segment type for RTs, F1(1, 23) = 4.48, MSE = 1,051.4, p = .045; F2(1, 37) = 1.41, MSE = 18,317.0, p = .24; minF′(1, 55) = 1.07, p = .31, but not for errors, F1(1, 23) = 1.75, MSE = 59.51, p = .20; F2(1, 37) = 2.25, MSE = 81.40, p = .14. There was no main effect of lexical status either for RTs, F1(1, 23) = 3.99, MSE = 1,773.0, p = .06; F2(1, 37) = 3.36, MSE = 7,202.0, p = .075, or for errors, F1(1, 23) = 1.29, MSE = 77.04, p = .27; F2(1, 37) = 2.47, MSE = 73.89, p = .12. There was also no significant interaction between the two factors for either the RTs, F1(1, 23) = 2.71, MSE = 2,670.2, p = .11; F2(1, 37) = 1.13, MSE = 8,592.1, p = .30, or errors (both Fs < 1).
Experiment 3B: Lexical decision. Mean reaction times (RTs, measured in ms from word offset) and mean percentage of errors, as a function of type of context (Cprep = prepositional consonant; Cnon-prep = nonprepositional consonant, Vprep = prepositional vowel, Vnon-prep = nonprepositional vowel) from which words had been spliced out. Error bars show standard errors.
An additional analysis of Experiment 3A based on the results of Experiment 3B was conducted. As in Experiment 1, the lexical-decision data were taken as a covariate in a by-item analysis of the word-spotting data. A by-item linear regression was computed with the mean word-spotting RTs as the dependent variable and the lexical-decision RTs as the independent variable. The same procedure was applied in a separate analysis of the error data. There was a significant positive correlation in both the RTs (R = .34), t2(1, 147) = 19.31, p < .001, and the errors (R = .18), t2(1, 147) = 4.77, p = .03. Then 2 × 2 ANOVAs were run on the residuals of the regressions. The critical interaction remained significant in both the RT analysis, F2(1, 36) = 29.61, MSE = 19,304.5, p < .001, and the error analysis, F2(1, 36) = 5.59, MSE = 66.31, p = .02. Pairwise t tests (see Table 4) revealed that in nonword contexts, words embedded in vowel contexts (e.g., /εruka/) were recognized faster than those in consonant contexts (e.g., /truka/). For word contexts, there was again no significant difference between vowel and consonant contexts. The difference between the two types of single consonants remained significant. The result for the vowels now also showed a significant result: Responses in nonprepositional-vowel contexts were faster but not more accurate than those in prepositional-vowel contexts. The results obtained in the word-spotting experiment thus cannot be explained on the basis of confounds caused by acoustic differences of the targets over conditions.
Experiment 3B: Paired t test comparisons on residuals between the four types of context

Note: RT = reaction time.
p < .01.
Experiment 3 provides yet another replication of the key finding from Experiments 1A and 2: Consonants that are words have a different status from consonants that are not words. However, once the number of preceding segments was matched, recognition of words in syllabic contexts (both prepositional and nonprepositional vowels) was as fast as that in prepositional-consonant contexts. This result differs from Experiment 2, where the performance in the prepositional context was better than that in the syllable context (but only in the RT analysis).
Critically, Experiment 3 shows that while vowels are viable residues irrespective of their lexical status, consonants that are not existing words are not. The results of Experiment 3 thus contradict the lexical recovery account proposed above. In particular, it was not the case that word spotting was easier in word than in nonword contexts consisting of either vowels or consonants. Furthermore, although there was tendency for there to be a difference between the two vowel conditions (only on residuals in the item analysis and only for RT), this trend was in the opposite direction to that which would be expected if the lexical account were correct (word spotting was faster in nonprepositional-vowel than in prepositional-vowel contexts). The account based on a purely phonological PWC followed by recovery through lexical competition hence can not explain how segmentation proceeds in Slovak. Instead, it appears that the operation of the PWC in Slovak listening is modulated by language-specific knowledge about consonantal words. Consonants appear to be treated by the PWC mechanism itself as viable parts of the lexical parse, but only if they are Slovak words. This seems to apply independently of any contextual (syntactic) or lexical-level support for their interpretation as prepositions. For vowels to be viable, on the other hand, it is not only that the contextual support is not necessary, but they do not even need to be existing words.
General Discussion
This study is the first to address word segmentation in a language that allows single consonants to be words. This feature of Slovak seems to contradict the proposal that the PWC operates in the same way in all languages. According to this universal segmentation constraint, listeners of any language should penalize all lexical parses with vowelless residues. The correct parse of the Slovak phrase k vete (to the sentence), however, contains a vowelless residue k. This raised the question of whether the PWC really is universal.
A priori, there were three possibilities how Slovak listeners could parse a phrase such as k vete. First, the PWC could simply not operate in Slovak, so that the parse k + vete is not penalized despite the vowelless residue k. The second alternative was that the PWC does operate in Slovak, but the penalty for the parse k + vete is overcome by combined lexical and syntactic support. The third alternative was again that the PWC does operate in Slovak, but that recognition of k vete is achieved by giving k a special status in the segmentation process.
The first experiment seemed to suggest that the first account was correct: In contrast to results from other languages, listeners did not find it harder to recognize the word ruka in truka (t being a nonword in Slovak and a vowelless residue) than in the phrase dugruka (though dug is also a nonword, it is not a vowelless residue). Surprisingly, listeners even found it easier to spot ruka in truka than in dugruka. This prompted us to investigate the role of the word-initial fixed stress in Slovak. The target ruka carried the stress in the input truka but not in the input dugruka.
The second experiment showed that stress is an important factor in Slovak segmentation. After removing the stress cue by cross-splicing, the results reversed for the syllable and nonprepositional context conditions. That is, while ruka was recognized faster in truka than in dugruka in Experiment 1, it was recognized faster in dugruka than in truka in Experiment 2. After stress was taken into account, it appeared that the PWC was operational in Slovak, at least for nonprepositional consonants. Hence we could dismiss the first account. Furthermore, the target word ruka was recognized better in gruka than in truka in both experiments. This highlights the importance of the lexical status of single consonants: The residue g is an existing word in Slovak but the residue t is not. Importantly, there is no syntactic support for the interpretation of the g as a preposition in gruka, because ruka is not inflected correctly (gruke would be correct). We could thus also dismiss the second account—namely, that Slovak listeners need syntactic support to be able to parse prepositional consonants and thus overcome the PWC penalty applied to these sounds. This led to the conclusion that single consonant residues in Slovak are tolerated, but that the necessary and sufficient condition for this tolerance is that the single consonant is an existing Slovak word. It appeared that the third account, based on the special status of prepositional consonants, was correct.
This conclusion, however, raised the question about how prepositional consonants are treated in Slovak segmentation. One possibility was that their status as words was sufficient to explain why they do not create segmentation problems. On this view, the PWC penalty could apply to all consonants—prepositions and nonprepositions alike—but subsequent lexical competition would allow recovery from this penalty when the input consists of words, even if the resulting lexical parse is ungrammatical (as, e.g., in g + ruka). The special status of prepositional consonants as viable residues in Slovak segmentation would thus simply be that they are words and hence can emerge as winning candidates in the competition process. According to this lexical recovery account, any nonsense sequence consisting of two words should be easier to parse than sequences consisting of a nonword followed by a word.
In the third experiment, therefore, target words were embedded in consonant and vowel contexts that were either words or nonwords. The results showed, contrary to the lexical recovery account, that the lexical status of the context matters for consonants but not for vowels. The word ruka was recognized as fast in a prepositional-vowel context oruka as in a prepositional-consonant context gruka. But ruka was recognized more slowly in the nonprepositional-consonant context truka than in the nonprepositional-vowel context eruka. Moreover, detection times were comparable for the two vowel contexts eruka and oruka. This suggests that prepositional consonants have a status apart in Slovak segmentation because of a language-specific influence on the operation of the PWC itself. Single consonants are only tolerated if they are existing words, else the PWC penalty is applied. But vowels are viable residues irrespective of their lexical status. It is possible that, during language development, the Slovak lexicon educates the PWC that it should not penalize parses containing the single consonants /k, g., f, v, s, z/. Apart from these special cases, however, the PWC appears to operate in the same way as it does in other languages.
Our findings on word segmentation in Slovak, a fixed-stress language with single-consonant words, thus do not invalidate the proposed universal segmentation principle. Just as in languages that do not allow single consonants to be words, the PWC penalizes vowelless parses of Slovak input. However, if a single-consonant word is encountered, it appears that the PWC penalty is not applied. This seems to be independent of the syntactic correctness of the sequence as a whole.
While no previous study tested a language with single consonants in its lexical inventory, other research has also raised the question about whether the PWC tolerates single consonants such as inflectional morphemes (Mauth, 2002) or reduced forms (Cutler, Otake, & McQueen, 2009; Fougeron, 2007; Fougeron, Frauenfelder, & Content, 1999). In many languages, single consonants can be meaningful in certain contexts. For example, this is the case for bound morphemes (resembling closed-class units with respect to their nonproductivity) such as the English inflectional plural marker -s in cars. The resulting question concerns the exact nature of lexical access. Is there decomposition with separate representations for each morpheme or are morphologically complex words accessed by their full-form representations? This question was addressed in a study with Dutch inflectional morphemes -t and -s (Mauth, 2002). Mauth observed no reliable tendency for words to be recognized more quickly in a morphological context than in a nonmorphological context. The present results are thus not in line with Mauth's study. Note, however, that the results were not completely clear-cut and that the status of the single consonants differs across studies. While inflectional morphemes used in Mauth's experiment were bound morphemes, Slovak prepositional consonants are free morphemes and lexical elements. As lexical representations, prepositions need to enter the competition process, while Mauth's study indicates that bound morphemes might not.
Evidence that single consonants can be processed as meaningful units is provided by Cutler et al.'s (2009) study on Japanese vowel devoicing. 2 Cutler et al. tested whether Japanese listeners treat single consonants that result from devoicing contexts as possible residues as compared to impossible devoicing consonants—that is, consonants occurring in contexts where devoicing is not legal. Target recognition succeeded in the context of possible devoicing consonants, but only when those consonants formed parts of potential words in Japanese. Thus, single consonants that may stand for syllables in Japanese can create problems in segmentation for Japanese listeners unless the lexicon provides support for that devoiced vowel.
Vowel devoicing in Japanese occurs, for example, when the high vowels /i/ and /u/ occur between certain voiceless consonants or in an unaccented mora. Thus in sashiko “quilting”, the /i/ of the medial mora can be devoiced but in sashimi “sashimi (raw fish dish)” it cannot.
Similarly, a phoneme monitoring study with native listeners of French (Fougeron et al., 1999; described in Fougeron, 2007) revealed that words aligned with lexically supported consonantal residues are not disfavoured. Detection times of the final phoneme of a target word were faster when that word was preceded by a single consonant representing an underlying syllable and word (e.g., /l/), the definite article le “the”), than when it was preceded by a consonant that cannot be interpreted lexically (e.g., /g/). These results are in line with the present data and strengthen our language-specific parsing account. We therefore propose that the PWC operates universally, but that segmentation is further modulated by language-specific constraints that are determined by the phonological properties of words in a given language. Accordingly, not every single consonant is necessarily an impossible residue.
Additionally, we found evidence that demarcation cues provided by fixed stress in Slovak affect segmentation. If a target was misaligned with the fixed stress in a sequence, it was more difficult to spot than if it was aligned. This effect of stress alignment was observed in the word-spotting task, but not in the lexical-decision task (see Suomi et al., 1997, for a similar result in Finnish). It appears that fixed stress may hence affect word segmentation but not word recognition. Further evidence that initial fixed stress can be used in segmentation comes from a study on Finnish (Vroomen et al., 1998), in which listeners performed better when the first syllable of a word had an elevated F0. However, the principal acoustic correlate of Finnish word stress is segmental lengthening: Stressed syllables are longer (Suomi et al., 2003; Suomi & Ylitalo, 2004). F0 still plays a role in sentence accentuation; the F0 manipulation in Vroomen et al.'s study may hence say more about how intonational structure is used in segmentation than about how word stress is used. By using a natural recording, the phonetic implementation of the fixed stress in our study was probably more realistic. The present results hence provide more certainty that fixed stress is a segmentation cue in a fixed-stress language, in line with what was hypothesized more than half a century ago (Trubetzkoy, 1939, p. 245).
We conclude that single consonants can be possible residues in the segmentation and recognition process if they receive lexical support. In the earlier English example, lay in play will be penalized by the PWC: It is misaligned with a likely word boundary, because p is not a viable residue and can not be an English word. Likewise, in Slovak, lano (“rope”) will be penalized in plano (“bad”), because p is neither a viable residue nor a Slovak word. But vety (“sentences”) in kvety (“flowers”) is not penalized because k is a word in Slovak. It appears that, for the Slovak listener, the processing cost associated with recovering the correct segmentation in situations with spuriously embedded words, such as vety in kvety, is outweighed by the benefits in processing that allow the correct parse to be obtained when the k is actually a preposition, as in k vete. Word segmentation across languages is hence not uniformly constrained such that all lexical parses with vowelless parts are disallowed, and this seems to be the case even though it will tend to make the recognition of some words with spurious embeddings harder.