
Abstract
This study aimed to investigate the role of language in calculation. Two populations were compared, one with a base-10 language, and another (Basque) in which number words are constructed by combining multiples of 20 and units or teens (e.g., “35” is said “twenty and fifteen”). Experiment 1 asked participants to verbally solve additions presented as Arabic digits. Basque participants solved the additions that consisted of a multiple of 20 and a teen (e.g., 20 + 15) faster than controls with identical answers (e.g., 25 + 10). No differences were found in the base-10 language group. Experiment 2 replicated this result even if participants had to type the answer on a numerical keypad, instead of saying it. Hence, the structure of number words in each of the languages influenced the way additions were solved, even if language was not necessary for conducting the task. Finally, in Experiment 3, both language groups performed a numerical comparison task in which no effects of the structure of number words were obtained. Results of the three experiments are discussed in light of current models of numerical cognition.
What are the effects of language on mathematical cognition? Does our language influence the way we calculate? In their paper of 1998, Brysbaert, Fias, and Noël raised this question by rescuing a soft version of the Whorfian hypothesis that had been formulated by Hunt and Agnoli in 1991. Whorf claimed that language shapes the way we think, and determines what we can think about (Whorf, 1956). This idea in its radical conception was soon dismissed by various pieces of evidence (see Gerrig & Banaji, 1994; and Hardin & Banaji, 1993, for a review), although it has been revisited in the domain of numbers, with contrasting results (Butterworth, Reeve, Reynolds, & Lloyd, 2008; Gordon, 2004; Pica, Lemer, Izard, & Dehaene, 2004). In contrast, Brysbaert et al. (1998) sought evidence to support the notion that the language of an individual might cause differences in some thought processes: Evidence in this sense would be sufficient in showing that language is involved in these processes (De Cruz & Pica, 2008).
Testing this “soft” version of the Whorfian hypothesis on mathematical cognition is of particular interest given the different roles that current models (see Figure 1) assign to language (but see also Gallistel & Gelman, 2000, for a view against the dependence of numerical reasoning on language). Thus, McCloskey and colleagues (McCloskey, 1992; McCloskey & Macaruso, 1995) claim that any number we perceive (Arabic digits, number words, dots, etc.) is transcoded into an amodal representation before further processing. Calculation, magnitude comparison, and other numerical tasks are conducted in this representation, which keeps no traces of the original format. Hence, McCloskey et al. deny any possibility that language can affect this central stage of processing.
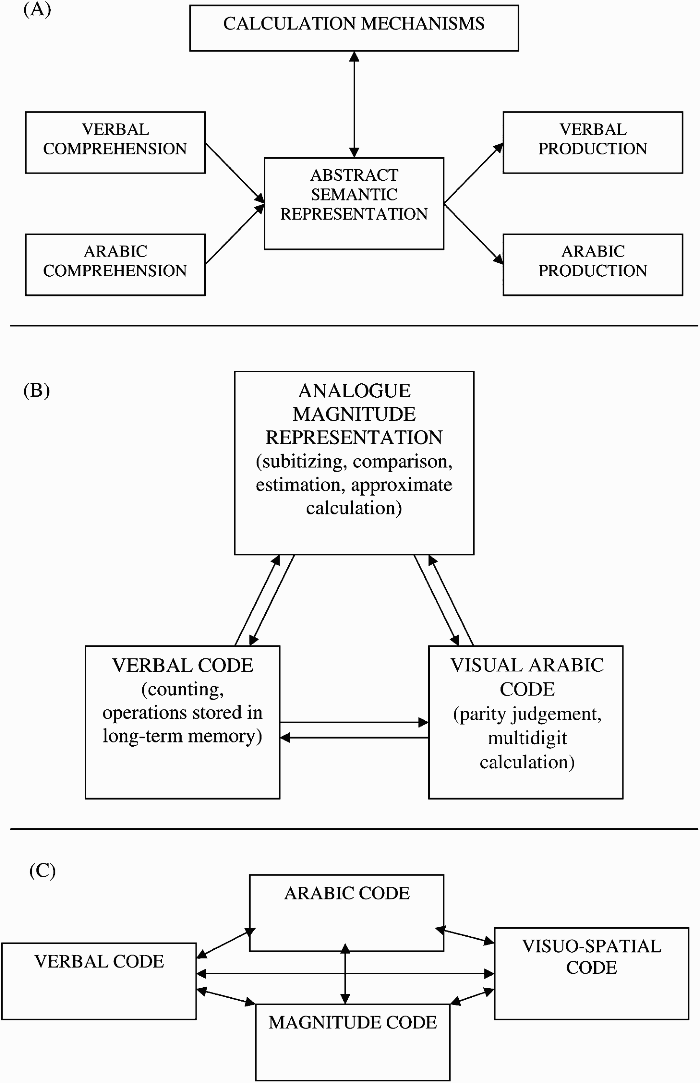
Models on numerical cognition. (A) Abstract-code model by McCloskey (1992). (B) Triple-code model by Dehaene (1992). (C) Multiple encoding hypothesis by Campbell and Clark (1992).
In contrast, the triple code model by Dehaene and colleagues (Dehaene, 1992; Dehaene & Cohen, 1995) proposes three internal representations of numbers: An analogue magnitude system, a visual Arabic sketchpad, and a verbal system. Each system is in charge of certain tasks: The analogue magnitude representation is used for magnitude comparison and approximate calculation, Arabic digits are engaged in parity judgement or multidigit calculation, and, finally, verbal representations are used for counting and retrieving the results of simple one-digit operations stored in long-term memory (e.g., multiplication tables). If numbers are presented in a format different from that of the internal representation in charge of performing a given task, transcoding is required before this task is conducted. For instance, if a multiplication is presented in the form “3 × 2”, it has to be transcoded to a verbal code before its result can be retrieved. Thus, Dehaene et al. predict language effects on both counting and simple calculation, but not on other tasks conducted in the nonverbal representations. Finally, Campbell and colleagues (Campbell, 1994; Campbell & Clark, 1992; Campbell & Epp, 2004) argue that number processing is conducted in multiple codes (e.g., Arabic digits, auditory, written verbal). Their model assumes that repeated experience with a specific task in a particular format increases the excitatory connection upon representations, improving one's performance in that particular task–format combination. Hence, as with Dehaene and collaborators, Campbell et al. also expect that the codes will be, in some way, specialized to do specific tasks. But contrary to Dehaene and colleagues, they also claim that there is a lot of interactivity between internal codes, and language effects can be found in any task. However, they also predict that language effects will be particularly strong when the external format is verbal, since the internal code used for performing a given task may also depend on the input format. 1
Through all the paper the word “format” is used to refer to the external representation of numbers and “code” to talk about their internal representation.
Some previous studies on language effects in number processing have investigated how the properties of the native language of participants affect their acquisition of the numerical system. Thus, for instance, much has been said about the fact that Asian children seem to understand numbers faster and more profoundly than children from Western cultures (Ho & Fuson, 1998; Miller, 1996; Miller & Stigler, 1987; Miura, Kim, Chang, & Okamoto, 1988; Nunes & Bryant, 1996). It has been claimed that the transparency of the number components might make complex numbers in some Asian languages easier to understand. In these languages teens are not irregular words: They are constructed by adding the word for ten and a unit (e.g., “ten two” instead of “twelve”). Likewise, decade words combine a unit and ten (e.g., “two ten” instead of “twenty”). However, other authors have cast doubts on this explanation and have proposed that differences might be due to education, parental involvement, or cultural factors (e.g., Geary, 1996).
In a second set of studies, Seron and Fayol (1994) found differences between French and Belgian francophone children. Belgian French words for seventy and ninety are “septante” and “nonante”, while in France those numbers are “soixante-dix” (sixty-ten) and “quatre-vingt-dix”: four (times) twenty (and) ten. When asked to write some Arabic numbers, Belgian children made fewer errors than French ones, especially for those decades.
Overall, it seems that the structure of number words in the native language has an effect on number processing. But as Brysbaert et al. (1998) argued, those studies were conducted in populations where number processing was not yet a consolidated ability. Does language maintain its impact once numbers have been fully acquired?
In their own study, Brysbaert and colleagues (1998) asked French and Dutch adult participants to report, out loud, the results of additions presented either as Arabic digits or as number words. Dutch speakers invert the order of decades and units in two-digit number words (i.e., 23 is said “three and twenty”), but French speakers do not. The authors studied the solving of two-digit operations such as 20 + 4 (ten + unit) or 21 + 5 (ten–unit + unit). They also manipulated the order of the operands (20 + 4 vs. 4 + 20). If language plays a role in calculation, an interaction should be obtained between language and order of presentation effects. Results confirmed this hypothesis: French participants solved both operations like “20 + 4” and operations like “21 + 5” faster than their counterparts in the other order, both with Arabic digits and with number words. Dutch participants differed according to the kind of operation: Operations like “20 + 4” were performed faster in this order only when presented in the Arabic format. No differences between 20 + 4 and 4 + 20 were obtained for the verbal format. As for the operations consisting of ten–unit + unit (21 + 5), they were answered faster in the inverse order (5 + 21). Thus, results showed that the language of participants had an effect in the order in which they preferred operations to be presented. As the authors argued though, a stronger claim for a Whorfian effect might be made if the differences attributed to language remained even when participants had to answer through a keyboard instead of verbally. In a second experiment where participants had to type their answers, Dutch- and French-speaking participants did not differ in their responses to the ten–unit + unit (21 + 5 vs. 5 + 21) problems. Brysbaert and colleagues concluded that the differences in Experiment 1 were not due to a Whorfian effect but a strategic answer to verbal output requirements. Hence, they concluded against a language influence in the addition stage.
However, some of the differences obtained in the initial experiment remained even when participants did not have to pronounce the answer: While French participants answered 20 + 4 problems in verbal notation faster in the ten + unit order than in the unit + ten one, Dutch speakers did not show an advantage for any of the orders. We agree with Brysbaert et al. (1998) that a much stronger evidence of a Whorfian effect would have been if the two linguistic populations behaved differently with Arabic input and typing response: In that case input and output format would have been the same for the two groups and would have involved no linguistic requirements. Nevertheless, we consider that, even if modest, this small language-specific effect deserves further exploration.
Furthermore, other moderate language effects have been found by Nuerk, Weger, and Willmes (2005), in a number magnitude comparison of two-digit numbers. In a previous study with German participants, Nuerk, Weger, and Willmes (2001) found a unit–decade compatibility effect: Given constant overall distance, participants took longer to decide if decade and unit comparisons led to opposite responses than if both required the same response (e.g., 37_52, where 3 < 5 but 7 > 2, vs. 42_57, for which 4 < 5 and 2 < 7). This was taken as evidence that comparison was not done in a holistic way, since in that case, comparing the first digits (decades) would have been enough to judge the global magnitude of the numbers. Instead, participants seemed to compare tens and units separately. However, German is a unit-first language (i.e., 24 is said “four and twenty”), like Dutch. Nuerk et al. suggested that this property of German might have made the unit number more salient. Thus, the aim of Nuerk et al. (2005) was to investigate the generality of this effect by testing English participants. Both English and German populations showed the unit–decade compatibility effect when items were presented as Arabic digits, but there was no such effect 2 when participants saw the numbers as English or German words. Importantly, these main effects were mediated by language: Further analyses showed that decade distance was a more important predictor in English, while overall distance played a more important role in German, both when the task was performed on number words and, more importantly for our purposes, when performed in Arabic notation. Nuerk et al. (2005) concluded that the lexical representations influenced magnitude comparison even in a nonlinguistic format.
In German, no main effect of compatibility was found, but there was a significant interaction of Compatibility × Unit Distance. In English, no effects of compatibility at all were obtained.
Summarizing, some evidence already exists for language-specific effects in adults’ number processing. However, the evidence is so modest that sometimes it has been dismissed by the very researchers that discovered it. As we said before, indications of language involvement on numerical cognition would be particularly relevant because one of the most debated issues in the field is the role of language. Therefore, finding language-specific effects in one or all of the tasks traditionally labelled as numerical cognition would help us to test the models proposed so far.
The present work aims to find differences in the way speakers of two languages solve the two tasks employed in the previous literature—namely, additions and number magnitude comparison. According to McCloskey and colleagues (McCloskey, 1992; McCloskey & Macaruso, 1995) both of these tasks are conducted in a central amodal semantic representation, and no language effects should be obtained. The model by Dehaene and collaborators (Dehaene, 1992; Dehaene & Cohen, 1995) makes the same prediction regarding number comparison, since according to this model it takes place in an analogue magnitude representation. As for the addition problems, multidigit calculation is said to be performed in the visual Arabic sketchpad: Since our additions involved two 2-digit numbers, we would expect no language effects in this task either. As for Campbell et al. (Campbell, 1994; Campbell & Clark, 1992; Campbell & Epp, 2004), the strong interactivity between codes predicted by their model allows for language effects in any of the tasks, despite the fact that numbers were presented as Arabic digits.
One of the unique aspects of this research was the use of the Basque language. Basque is a non-Indo-European language spoken in the Basque country (north of Spain and south-west of France) by about 700,000 people. A relevant feature of Basque lies in the structure of number words (see the Appendix). Teens consist of the word ten plus a unit (e.g., twelve is “hama-bi”: ten-two). From twenty on, all two-digit numbers are built by combining twenty, or a multiple of twenty, and a unit or teen. Thus, for instance, 35 is “hogei-ta hama-bost” (twenty-and ten-five), and 56 is “berr-ogei-ta hama-sei” (twice-twenty-and ten-six). Therefore, Basque number words represent a combination of base 10 and base 20. Almost all previous studies have compared number systems with base 10 (although see Iversen, Nuerk, Jäger, & Willmes, 2006, for a research with subbase 5 German Sign Language), and this similarity between languages might have reduced the possibility of finding an effect of language in mental processing. In this case, we decided to compare Basque with a Romance language (Italian/Catalan) with standard base-10 number representation.
Three experiments were conducted. Experiment 1 explored how Italian and Basque speakers solve additions of Arabic digits. Results showed that the oral responses of Basque participants were influenced by the structure of number words in their language. Experiment 2 aimed to replicate this result while discarding the possibility that it was due to output requirements: Hence, participants had to type their responses in Arabic digits. Initial results were replicated, despite the fact that language was not used as either input or output format. Finally, Experiment 3 explored whether language effects extended to a number comparison task.
Experiment 1
This experiment required Basque and Italian speakers to report out loud the result of two-digit additions presented in Arabic format. Additions either reflected the structure of Basque number words (twenty or a multiple of twenty plus a teen) or consisted in a number plus ten. Thus, for instance, participants saw either 20 + 15 or 25 + 10. The right answer to both problems is thirty-five: “trentacinque” in Italian, and “hogeita hamabost” (literally “20 and 15”) in Basque. Our prediction was that if language influences the calculation process even when the operation is presented in Arabic digits, Basque participants might find it easier to respond to the addition that matches the number word structure in their language. Italians, however, should not show advantages for any of the conditions; this would also confirm that both operations have equivalent difficulty.
Method
Participants
A total of 21 Psychology undergraduate students (16 females and 5 males) from the University of Trieste (Italy) and 21 undergraduate Basque Philology students (15 females and 6 males) from the University of the Basque Country in Vitoria-Gasteiz (Spain) volunteered to participate in this experiment. None of them took part in the other experiments reported here. All the Italian participants were Italian monolingual speakers. Since both Spanish and Basque are official languages in the Basque Country, and the use of Spanish, a base-10 language, is widespread, we ensured that Basque was the dominant language for all Basque participants. Basque students answered a language questionnaire: They spoke Basque with at least one of their parents—16 came from monolingual homes, and 5 were Basque–Spanish bilinguals—and had pursued all of their education in Basque. In all cases, counting, operations, and arithmetical facts had been learnt in this language.
Materials and design
A total of 72 additions were used as experimental items. They were assigned to three conditions. A total of 24 consisted of 20 or a multiple of 20 plus a teen (e.g., 20 + 15). We refer to them as the “match” condition, since it matches the structure of number words in Basque. A total of 24 more formed the “control condition” and consisted of additions of a two-digit number plus 10 (e.g., 25 + 10). Finally, we included a “reverse condition” that consisted in the addends of the match condition in the inverse order (e.g., 15 + 20). We created this third condition in order to control for strategic effects in the Basque population. Indeed, some participants could realize that the solution in the match condition could be provided by simply reading the two addends. It is unlikely that participants followed this strategy, given that the match condition accounted for only 11.11% of the trials in the whole experiment, and the first word in the first addend corresponded to the first word in the Basque answer only in 33% of the cases. However, if they had used it, we would not know whether an advantage found in this condition was due to the phonological coincidence between the addends and the solution, or to language effects in the calculation process. By adding this third condition, we could check whether participants benefited from having the elements that make up the solution even if they were not presented in the correct order.
Stimuli in the three conditions were matched in triplets so that for each addition there was a corresponding addition in the other two conditions that had the same result. These 24 answers consisted in numbers from the 30, 50, 70, and 90 decades. Numbers in the decades in between are formed by multiples of 20 plus a unit, instead of a teen. In order to make the three conditions as comparable as possible, we discarded them and had all the operations formed by two 2-digit addends.
A total of 144 additions acted as fillers and served to make the structure of the items variable in order to distract the attention of participants from the match condition. Again, they were distributed in three different conditions, and the answers were the same across the three of them. Additions of Type 1 consisted of a unit plus a ten. Type 2 added a ten–unit number and a unit. Finally, Type 3 consisted of two 2-digit numbers (ten–unit). Hence, for instance, participants had to retrieve “forty-six” in front of, respectively, “6 + 40”, “42 + 4”, and “24 + 22”.
Half of the answers were numbers from the same decades as the experimental items, and the rest belonged to the 20, 40, 60, and 80 decades. We also checked that in the whole experiment there were similar probabilities of the smallest addend appearing in the first and second positions.
All additions were displayed in black on a white background. Characters were presented in Times New Roman 32 (bold). The addition sign appeared centred on the screen, with each addend 25 letter positions away from it.
Three blocks were created. Each block contained additions from the three experimental conditions, but a given answer (see the explanation about the triplets above) had to be provided only once in each of them. Within-block restrictions were: (a) no more than three experimental trials in a row; (b) no more than two trials of the same condition in a row; (c) no consecutive trials in which the answer shared the same decade or unit numbers. Three different lists were created by randomly ordering the blocks.
Procedure
Participants were tested individually in approximately 20-min sessions.
Written instructions asked all the participants to pay attention to the additions that would be presented as Arabic digits and to provide the result through the microphone placed in front of them. Both speed and accuracy in responses were emphasized. Furthermore participants were asked not to produce any sound before their answer or pauses within it. In order to familiarize them with the procedure, a training phase was conducted with six new additions formed by two units or a unit and a teen.
Each trial was structured as follows: A line with the same length as the subsequent addition appeared in the centre of the screen for 500 ms. Thereafter, the addition was shown until the participant provided an answer or for a maximum of 10 seconds. Reaction times were measured by means of a voice key from the onset of the addition and until the beginning of the response. A blank of 1,500 ms preceded the following trial. Superlab was used to display the stimuli and to record the answer times, while the experimenter entered the errors manually.
Results
Three types of response were discarded: (a) numbers that were not the right result of the addition; (b) verbal dysfluencies (stuttering, utterance repairs, nonverbal sounds that triggered the voice key, and pauses during the production); and (c) recording failures. Latencies that were more than two standard deviations from the participant's mean were also removed. The item “55” was discarded because more than a third of the participants incorrectly answered one of the additions in which it appeared as result. Following these criteria, the percentages of discarded responses was 8.59% for the Italian group and 9.38% for the Basque speakers. Table 1 shows the mean reaction times and error rates for each group and each condition.
Mean response times, standard deviations, and error percentages for each condition and language group in Experiment 1
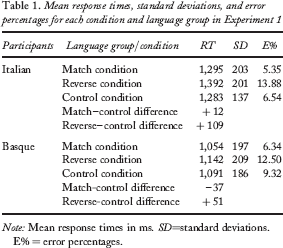
Note: Mean response times in ms. SD = standard deviations. E% = error percentages.
Two analyses of variance were performed, by participants and by items, taking two variables into account: group (Italian vs. Basque speakers) and type of condition (match, control, reverse). In the participants’ analyses, group was considered a between-subjects variable while type of condition was a within-subject variable. Both were considered within-item variables in the items analyses.
Reaction times showed significant differences between groups, F1(1, 40) = 16.10, MSE = 101,449.10, p < .01; F2(1, 22) = 357.81, MSE = 5,097.36, p < .01, and also between the three conditions, F1(2, 80) = 29.29, MSE = 3,571.73, p < .01; F2(2, 44) = 21.27; MSE = 4,508, p < .01. The interaction between the two variables was marginal by participants and significant by items, F1(2, 80) = 2.79, MSE = 3,571.73, p < .07; F2(2, 44) = 5.88, MSE = 2,213.21, p < .01.
Posterior analyses compared the performance of participants in each condition against the control. The difference between the match and control conditions was not significant either by participants or by items (both Fs < 1). However, there was an interaction between type of condition and group that was marginal by participants and significant by items, F1(1, 40) = 3.14, MSE = 3,956.54, p < .09; F2(1, 22) = 12.70, MSE = 1,396.26, p < .01. Planned comparisons revealed that the match condition differed from the control in the Basque group only: Italian group, t1 < 1, t2(22) = 1.18, p < .30; Basque group, t1(20) = 2.31, p < .04, t2(22) = 2.14, p < .05.
Reverse and control conditions were significantly different, F1(1, 40) = 32.18, MSE = 4,152.28, p < .01; F2(1, 22) = 23.84, MSE = 5,290.70, p < .01. Although this difference was observed in both groups—Italian group, t1(20) = 4.82, p < .01, t2(22) = 5.73, p < .01; Basque group, t1(20) = 3.02, p < .01, t2(22) = 2.50, p < .03—the magnitude of the effect (109 vs. 51 ms, respectively) depended on the language of the participants as revealed by the significant interaction between condition and group, F1(1, 40) = 4.13, MSE = 4,152.28, p < .05; F2(1, 22) = 10.46, MSE = 2,022.43, p < .01.
The analysis of error rates showed a significant effect of condition, F1(2, 80) = 13.39, MSE = 2.58, p < .01; F2(2, 44) = 11.48, MSE = 2.75, p < .01. Neither the main effect of group (both Fs < 1) nor the interaction between group and condition, F1(2, 80) = 1.02, MSE = 2.58, p < .40; F2(2, 44) = 1.44, MSE = 1.67, p < .30, reached significance.
Subsequently, match and control conditions were analysed. None of the comparisons reached significance (all ps > .09). Finally, reverse and control conditions were also contrasted. The difference between the two conditions was significant both by participants and by items, F1(1, 40) = 11.65, MSE = 2.87, p < .01; F2(1, 22) = 8.64, MSE = 3.53, p < .01. This difference was not modulated by the language of the participants, as shown in the lack of interaction between condition and group, F1(1, 40) = 1.83, MSE = 2.87, p < .20; F2(1, 22) = 2.37, MSE = 2.02, p < .20.
Discussion
This experiment tested Italian and Basque participants in three different kinds of addition. For Italians, none of the additions mirrored the structure of their number words. Results showed no significant differences between the match and control conditions either in latencies or in error rates. Hence, we confirmed that the two conditions had an equivalent degree of difficulty, once the linguistic factor was removed from the equation. In contrast, the match additions were easier than the control ones for the Basque group. The match condition replicated the way numbers are constructed in Basque; we claim that having the elements that form the answer as well as the structure that combines them facilitated the answer of the Basque population. Therefore, the language of our participants did influence their responses.
In a second comparison, the reverse condition was more difficult than the control one for both Italian and Basque speakers. Reverse additions were included to have a condition where the lexical elements in the Basque number were present, but Basque participants could not apply the strategy of reading the addition instead of solving it. This way, we wanted to separate the benefits of presenting the participants with the lexical primitives in their answers from an effect of phonological facilitation. However, the reverse condition also differed from the control in that the first addend was always smaller than the second one. It is a fact often reported in the literature that additions where the smallest addends are presented first take longer to be solved than those where the largest number appears first (e.g., Brysbaert et al., 1998). We consider that this might have also been the case in our experiment. The data analyses confirmed that the difference between the two conditions was significantly reduced in the Basque population. We take this to be the sum of two effects: the interference caused by presenting the smaller addend first, and the facilitation due to presenting an operation that contained the lexical primitives (twenty or a multiple of twenty plus a teen) that participants had to retrieve for their answer.
Hence, the data from both the match and the reverse conditions suggest an effect of the structure of the number words in the participants’ native language in the way they perform additions. This is particularly remarkable given that additions were presented as Arabic digits. To put forward real evidence for the Whorfian hypothesis, it is necessary to show that the language-specific effects happen at the central stage of calculation and are not due to peripheral effects at either the input or the output stage. This first experiment controlled for the input processes by presenting the stimuli in a nonlinguistic code. Nevertheless, the answer had to be provided verbally because this combination of input and output formats had given the strongest evidences for language effects in the past (Brysbaert et al., 1998), and we wanted to be sure that our manipulations were able to show a language-specific effect. However, language might have got involved in the calculation process simply because participants had to transcode their answer to number words. Such a possibility is in line with the model of Campbell and Clark (1992; Campbell, 1994), according to whom the code used for performing a given task will depend on aspects such as input/output format. Therefore, a pass through language might not be mandatory each time we have to perform an addition, but might have been induced by the output requirements. To check this point we conducted a second experiment where operations appeared again as Arabic digits, but answers had to be typed. Language was not required at any moment: If we were to find language-specific effects, even in this case, it would serve as strong evidence for the involvement of language in calculation.
Experiment 2
Experiment 2 replicated the previous experiment with the only exception of the modality of response: Instead of providing verbal answers, participants had to type the answer with the numerical keys of the computer keyboard. In this way, both language groups provided exactly the same nonverbal answer. If differences were obtained even in this case, the effect of language in calculation would be strongly supported.
We also changed the language that was compared to Basque. In this case, we used Catalan participants instead of Italians. Catalan, also a Romance language, is spoken in the north-east of Spain and has a base-10 numerical system. We did not expect this change to affect our results. If anything, this change made the two populations more comparable: Both groups had received similar mathematical education, since both populations were trained in the Spanish educational system. Furthermore, they were all bilinguals with Spanish as second language, although they were clearly dominant in the language tested in the experiment.
Method
Participants
A total of 24 Psychology undergraduate students from the University of Barcelona (19 females and 5 males) and 24 undergraduate Basque Philology students (18 females and 6 males) from the University of the Basque Country in Vitoria-Gasteiz took part in this experiment. A total of 22 Basque participants also took part in Experiment 3: Order of presentation of the two experiments was carefully balanced between participants and did not lead to any interaction with the effects reported here (all ps > .25). All the Barcelonian participants were Catalan-dominant speakers: They spoke Catalan at home with at least one of their parents and had completed their education in that language. Basque participants also spoke Basque with at least one of their parents and had completed all their education in Basque. We asked them explicitly about basic mathematics: Counting, operations, and arithmetical facts had been learnt in those languages. For their participation in the study, participants received course credits or economic compensation.
Materials and design
They were the same as those in Experiment 1.
Procedure
Participants were tested individually in sessions lasting approximately 30 minutes. Before the experiment, they answered questions about their linguistic profile to ensure that they met the linguistic requirements we sought (see the participants’ description above). Afterwards, participants were provided with written instructions, either in Catalan or in Basque. They were told that they would see simple additions on the screen. Their task consisted of typing the correct answer on the keyboard.
Each trial had the following structure: First, a fixation point appeared centred on the screen. Participants were asked to press the space-bar when they saw it, triggering the appearance of the addition. Participants were asked to hold the key down until they were sure they knew the answer. They then had to release the space-bar and immediately press the numerical keys corresponding to the two-digit answer. We opted for using this procedure as devised by Brysbaert et al. (1998) because the measure of release time is free from the delays caused by the search of the right numerical key.
The importance of both accuracy and speed was stressed. We also emphasized the importance of not leaving more time than necessary between the release of the space-bar and the pressing of the first number key, nor between the two number keys.
E-prime was used to present the additions and to record the keys pressed by the participants as well as their latencies.
Results
Analyses were conducted on the space-bar release times. Several steps were conducted to prepare the data before analyses. First, we removed all the trials in which participants had pressed a wrong digit key in either the decade or the unit part of the answer. Thereafter, we calculated the mean latency for the second digit for each participant. We cancelled the answers in which the time that elapsed between pressing the first and second digit keys was longer than the mean reaction time plus three standard deviations. We did so to reject cases in which participants had released the space bar before having calculated the whole result.
Finally, analyses focused on the space-bar release times. Latencies that deviated more than two standard deviations from the participant mean were discarded. Following all those steps, the percentage of rejected responses was 11.23% for the Catalan group and 9.90% for the Basque speakers. Table 2 shows the mean reaction times and error rates for each language group and condition.
Mean response times, standard deviations, and error percentages for each condition and language group in Experiment 2
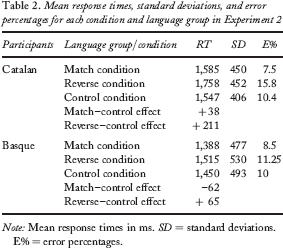
Note: Mean response times in ms. SD = standard deviations. E% = error percentages.
Analyses of variance were conducted with group (Catalan, Basque) as between-participant and within-item variable and condition (match, control, reverse) as within-participant and within-item variable.
Reaction times differed significantly between groups only in the items analysis, F1(1, 46) = 1.81, MSE = 633,428.35, p < .20; F2(1, 23) = 175.55, MSE = 6,366.92, p < .01. As for conditions, they behaved differently in both the participant and the item analyses, F1(2, 92) = 23.78, MSE = 13,995, p < .01; F2(2, 46) = 29.77, MSE = 12,869.42, p < .01. Finally, the interaction between the two variables was also significant, F1(2, 92) = 4.78, MSE = 13,995, p < .02; F2(2, 46) = 8.63, MSE = 11,246.14, p < .01.
Further analyses compared the pairs of conditions relevant to the aim of our research. First, the match and control conditions were compared. No main effect of condition was obtained (both Fs < 1). In contrast the interaction between type of condition and group was significant, F1(1, 46) = 3.86, MSE = 15,475.87, p < .06; F2(1, 23) = 7.84, MSE = 9,928.40, p < .02: Catalan speakers were 38 ms slower in the match than in the control condition, although this difference did not reach significance, t1 < 1, t2(23) = 1.65, p < .20. In contrast, Basque speakers benefited from the similarity between the additions in the match condition and the way they named numbers, and they were 62 ms faster in this condition, t1(23) = 2.46, p < .03, t2(23) = 2.28, p < .04.
Secondly, a comparison of the control and reverse conditions was also conducted. Reverse additions were solved significantly slower than the control ones, F1(1, 46) = 26.57, MSE = 17,162.18, p < .01; F2(1, 23) = 32.40, MSE = 16,354.56, p < .01. However, a significant interaction with the group factor, F1(1,46) = 7.46, MSE = 17,162.18, p < .01; F2(1, 23) = 12.45, MSE = 15,192.73, p < .01, showed that the difference between lexical and control conditions was smaller in the case of Basque speakers (211 against 65 ms): Catalan speakers, t1(23) = 4.42, p < .01, t2(23) = 6.98, p < .01; Basque speakers, t1(23) = 2.68, p < .02, t2(23) = 1.55, p < .20.
Error rates were also analysed. The two groups made a similar number of errors, F1(1, 46) < 1, F2(1, 23) = 1.62, MSE = 2.07, p < .30. In contrast, there were significant differences in the error rates on the three conditions, F1(2, 92) = 10.40, MSE = 2.25, p < .01; F2(2, 46) = 9.04, MSE = 2.59, p < .01. The interaction between these two variables was marginal in the participants’ analysis but did not reach significance in the items’ analysis, F1(2, 92) = 2.96, MSE = 2.25, p < .06; F2(2, 46) = 2.38, MSE = 2.79, p < .20.
As in previous analyses, we did a further comparison of the experimental conditions in theoretically relevant pairs. Match additions elicited significantly fewer errors than the control ones, F1(1, 46) = 5.10, MSE = 1.96, p < .03; F2(1, 23) = 4.82, MSE = 2.07, p < .04. This effect was not modulated by a Group × Condition interaction (both Fs < 1).
Reverse and control conditions were also compared. Participants made significantly more errors in the reverse condition than in the control one, F1(1, 46) = 23.13, MSE = 2.02, p < .01; F2(1, 23) = 4.85, MSE = 2.78, p < .04. The interaction between this variable and the group factor reached significance in the participants analysis, F1(1, 46) = 6.31, MSE = 2.02, p < .02; F2(1, 23) = 2.17, MSE = 2.76, p < .20. Subsequent analyses showed that the two conditions differed only in the Catalan group: Catalans, t1(23) = 2.15, p < .05, t2(23) = 2.39, p < .04; Basques, both ts < 1.
Discussion
Experiment 2 tested the generality of the results obtained in Experiment 1. In this experiment a language-specific effect was found when participants solved additions presented as Arabic digits. However, the answer had to be provided orally, and the results could simply reflect a transcoding effect. In order to dismiss this possibility, participants in Experiment 2 had to type their answer in a numerical keypad. Hence, number words were not present either in the input or in the output stages.
Catalan speakers replicated the data obtained in Experiment 1 with speakers of another language and a new form of response: This confirms that the match and control conditions have a comparable level of difficulty for those populations who do not build numbers by combining multiples of twenty and other numbers, like Basque does. We also replicated the advantage of the control condition over the reverse one, in which smaller addends were presented first.
In contrast, we again found a language effect for the Basque group: Having to deal with addends that reflect the structure of number words in their language made Basque participants solve the match additions faster. This advantage also helped them to overcome the difficulty of solving additions with the smallest addend presented first. Thus, we have found evidence that the language of the participants influenced their responses in an addition task. This result cannot be explained by McCloskey et al. (McCloskey, 1992; McCloskey & Macaruso, 1995), who claim that additions take place in an amodal semantic representation. According to these authors, Arabic digits should have been translated to this representation. Afterwards, the addition would be solved, and its result would be transcoded to the format in which response was to be provided (Arabic digits in this case). At no moment did the procedure require access to verbal representations. Hence, the difference between the two populations cannot be explained.
The triple-code model of Dehaene and collaborators (Dehaene, 1992; Dehaene & Cohen, 1995) claims that multidigit calculations take place in an internal representation in a visual Arabic code, and inputs in any other format require transcoding before calculation can take place. Since our participants saw the additions in Arabic digits, the lexical structure of number words should have played no role either in transcoding—which was not necessary—or in the central calculation stage. Following their model, after calculation, the response must be transcoded to the format in which the answer will be provided. In the case of Experiment 1 the answer was given orally. However, since the results in the match and control additions were the same, their model would predict no differences between these two conditions. As for the current experiment, the answer did not involve any linguistic format. Therefore, the triple-code model cannot explain the differences obtained either.
Finally, the model of Campbell and collaborators (Campbell, 1994; Campbell & Clark, 1992) considers that number processing takes place in a complex of representations in different codes, with high interactivity between them. Some of these representations are verbal, and, therefore, their model might give account of the language effects in calculation. However, this model also states that the input format can determine the code in which the operation is calculated; our finding of language effects even when input and output are Arabic digits still provides stronger support for the involvement of lexical representations in calculation. In this sense also, the multiple code model claims that repeated usage of a given format in a task will strengthen the connections between the relevant representations for that task in that format. We do not have statistics on the frequency of use of different formats in calculation. Nevertheless, Campbell (1994) claimed that Arabic digits are a more frequent format for multiple digit calculations than are visual number words; the presence of language-specific effects, even when the input format coincides with the most frequently used (and nonverbal) format shows the relevance of language in calculation.
To sum up, a language effect in addition has been found, and only Campbell's hypothesis of a network of multiple codes can give a forward account of it. However, it is still not clear what has been the role of each of those codes in the addition process. Addition is considered to be a type of operation that can be solved through the direct retrieval of results from long-term memory as well as manipulation of the quantities that numbers refer to. Which of these aspects has been influenced by language? In order to clarify this issue, we conducted a new experiment with a different numerical task—number comparison—which requires a necessary pass through the semantic representation of the quantities conveyed.
Experiment 3
This experiment explored how speakers of different languages perform magnitude comparison on two-digit Arabic numbers. More specifically, their task consisted in deciding which of two numbers was the largest. As in the previous experiment, Basque and Catalan speakers were compared.
Method
Again, the experimental design took advantage of how number words are constructed in Basque. Twenty, forty, sixty, and eighty decades are built up by adding twenty or a multiple of twenty and a unit. Thus, for instance, 42 is “berr-ogei-ta bi” (twice-twenty-and two), and 64 is “hirur-ogei-ta lau” (three-twenty-and four). Decades in between—that is, thirties, fifties, seventies, and nineties—add a teen to the same multiples of twenty. An example might be 52 (“berr-ogei-ta hama-bi”: twice-twenty-and ten-two) or 74 (“hirur-ogei-ta hama-lau”: three-twenty-and ten-four). Hence, the multiple of twenty used in the number word changes every two decades. The first experimental manipulation concerned the presence or absence of this change. Thus, we compared cases such as 42_53 and 52_63. The distance between the numbers in the two pairs is the same, but whereas one implies a change of multiple of twenties (52_63), the other one does not. If digits are transcoded into a semantic representation where number magnitude comparison takes place, as argued by McCloskey, Dehaene, and colleagues (Dehaene, 1992; Dehaene & Cohen, 1995; McCloskey, 1992; McCloskey & Macaruso, 1995), this difference should be irrelevant. However, if digits are transcoded into number words at some point in the comparison process, belonging to different multiples of twenty may speed up the answer of the Basque group, since they would be able to answer simply by comparing the first word of the two numbers. Of course, this manipulation would not make a difference in the case of Catalan speakers.
We also manipulated compatibility (Nuerk et al., 2001; Nuerk, Weger, & Willmes, 2002), an effect that is consistently found in different linguistic groups when numbers are displayed as Arabic digits (Nuerk et al., 2001, 2002, for English and German; Macizo & Herrera, 2008, for Spanish). We expected to find compatibility effects in the Catalan group, but we had no clear predictions for the Basque group; compatibility seems to be mediated by the structure of the number words, with unit-first languages such as German showing stronger influence of the units’ position than languages such as English, with a regular decade–unit order. Basque is also a decade-first language, but the distinction between the words for the decade and unit positions is less clear than in other languages. Take for instance “berrogeita hamabi” (52), which is literally “twice-twenty-and ten-two”. On the one hand, the total value of the decade results from adding the quantity in the first word “berrogei” (forty), plus the tens of the word displayed after the conjunction (“hama” in “hamabi”) (12). This makes the total decade value harder to extract. On the other hand, the second word in the number name comprises both the unit and part of the decade information together. How these two factors affect the relative role of decade and unit in the assessment of the whole number magnitude needs to be explored.
Participants
A total of 24 Psychology undergraduate students (20 females and 4 males) from the University of Barcelona and 24 Basque Philology undergraduate students (17 females and 7 males) from the University of the Basque Country took part in this experiment. A total of 22 Basque students also took part in Experiment 2: Order of presentation of the two experiments was carefully balanced between participants and did not lead to any interaction with the effects reported here (all ps > .25). Both groups had the same linguistic profile as the ones tested in Experiment 2. They received either course credits or economic compensation for their collaboration.
Materials and design
A total of 128 pairs of two-digit numbers between 24 and 98 were used as experimental stimuli. Decade numbers were excluded. We manipulated unit–decade compatibility (compatible vs. incompatible) and change in the multiple of twenty (same multiple of twenty vs. different), leading to 32 pairs in each of the four groups. Following Nuerk et al. (2001) several variables were controlled (see Table 3). Problem size and absolute and logarithmic unit distance were matched for all the groups (all Fs < 1). Decade distance was kept constant at 10 because the main purpose of our experiment was to check what happens when passing to the next decade with or without change of multiples of twenty. This constraint caused the absolute and logarithmic overall distance to be equated through the multiple of twenty axis (F < 1) but not on the compatibility contrasts. In the case of compatible trials (e.g., 24_39), the overall distance is obtained by adding the distance of the decades and that of the units (10 + 5 = 15 in the example above). As for incompatible numbers (e.g., 59_74), overall distance is computed by subtracting the unit distance from the decade distance (e.g., 20 – 5 = 15). As it can be derived from the examples, the only way to equate overall distance is by increasing the decade distance in the incompatible pairs (Nuerk et al., 2005). Since our main aim required keeping decade distance constant, overall distance was always significantly larger for the compatible trials: absolute distance, F(1, 31) = 535.85, p < .001; logarithmic overall distance, F(1, 31) = 460.16, p < .001.
Variables controlled in the design of Experiment 3 following the criteria set by Nuerk et al. (2001)
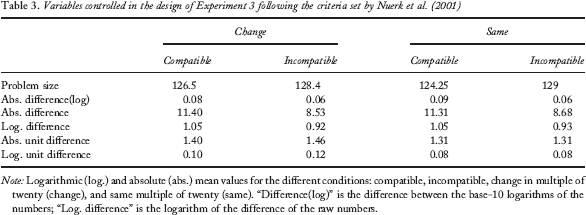
Note: Logarithmic (log.) and absolute (abs.) mean values for the different conditions: compatible, incompatible, change in multiple of twenty (change), and same multiple of twenty (same). “Difference(log)” is the difference between the base-10 logarithms of the numbers; “Log. difference” is the logarithm of the difference of the raw numbers.
A total of 60 extra pairs of numbers were used as fillers; 20 contained numbers from the same decade, while the rest had a decade distance of either 20 or 30. Half led to compatible comparisons, and half were incompatible.
Number pairs were presented simultaneously. 3 They were displayed in a diagonal fashion, with the number above placed on the right. The number of “up” and “down” answers was equated throughout the whole experiment.
Zhou, Chen, Chen, and Dong (2008) showed that finding a compatibility effect might depend on how numbers are displayed: Simultaneous presentation led to compatibility effects, while sequential presentation favoured a holistic comparison. We opted for avoiding sequential displaying because it requires keeping the first number in working memory. If the phonological loop is engaged in this process, language effects might be found. However, we were not interested in representations in short-term memory processing, but on the code of long-term representations. To avoid any confounding in the location of hypothetical language effects, we discarded this type of presentation.
Stimuli were randomized across participants with the following restrictions: (a) no more than two consecutive items in which the words for the numbers of the pair belonged to different “multiple of twenty” decades; (b) no more than three compatible trials in a row; and (c) no more than four consecutive trials requiring the same response (up/down). Half of the participants saw a given pair with the largest number in the upper position, and half saw it placed below.
Procedure
Participants were tested individually in a session lasting approximately 20 minutes. Written instructions asked them to decide which was the largest of the two numbers displayed. Both accuracy and speed were emphasized. The experiment was preceded by six warm-up trials.
Stimuli appeared in black on a white screen. Numbers were displayed in Courier New font and size 32 (bold). Congruently with the stimuli location on the screen, the response keys were also placed diagonally. Participants were asked to use the left index finger for the bottom key and the right index finger for the top key.
Each trial had the following structure: First, an asterisk appeared centred on the screen for 500 ms; immediately after, the two numbers appeared diagonally above and below the position in which the asterisk had been presented—they remained on the screen until the participant answered or for a maximum of 3 seconds. An interval of 300 ms was left between trials. Reaction times were measured from the appearance of the numbers on the screen. E-prime was used to display the stimuli and record the reaction times and answers.
Results
Latencies outside two standard deviations from each participant mean were discarded. None of the items or participants had to be rejected. Responses excluded were 9.50% of the data points for the Catalan group and 7.77% for the Basque speakers. Table 4 shows the mean reaction times and error rates for each group and condition.
Mean response times, standard deviations, and error percentages for each condition in Experiment 3
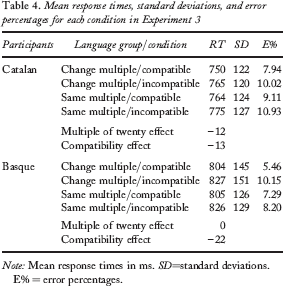
Note: Mean response times in ms. SD = standard deviations. E% = error percentages.
Analyses of variance were conducted for latencies and error rates with group (Catalan, Basque) as a between-participants and a within-items variable and compatibility (compatible, incompatible) and multiple of twenty (change, same) as both within-participant and within-item variables.
Basque participants were slower than Catalans, although this effect reached significance only in the analysis by items, F1(1, 46) = 1.90, MSE = 66,355.95, p < .20; F2(1, 31) = 112.80, MSE = 1,465.12, p < .001.
Latencies from trials in which numbers were part of decades within the same multiple of twenty did not differ from those in which number words were formed with different multiples of twenty, F1(1, 46) = 2.49, MSE = 679.92, p < .15; F2(1, 31) < 1. This absence of significance was common to both populations, as shown by the lack of interaction, F1(1, 46) = 2.40, MSE = 679.92, p < .15; F2(1, 31) = 1.27, MSE = 1,004.12, p < .30.
In contrast, participants were faster with compatible number pairs, F1(1, 46) = 17.55, MSE = 840.65, p < .001; F2(1, 31) = 6.61, MSE = 2,900.36, p < .02. None of the interactions between compatibility and other variables reached significance (all ps > .20).
As for the analysis of errors, Catalan speakers were less accurate than the Basque group, F1(1, 46) = 4.85, MSE = 3.012, p < .04; F2(1, 31) = 4.33, MSE = 2.72, p < .05. Number pairs whose words were formed with the same multiple of twenty did not cause more errors than those in which different multiples of twenty were used (all Fs for main effect and interactions < 1). In contrast, participants made fewer errors in the compatible trials, F1(1, 46) = 10.45, MSE = 2.65, p < .003; F2(1, 31) = 7.53, MSE = 2.91, p < .02. The rest of comparisons were not significant (all ps > .20).
Discussion
This third experiment investigated whether the structure of number words in Basque influences the way its speakers perform magnitude comparison on Arabic digits. Pairs of numbers whose words are formed in Basque by combining the same multiple of twenty and a teen or unit were compared with pairs whose words included different multiples of twenty. If participants translated the Arabic digits to number words prior to comparison, the answer to pairs from the same multiple of twenty might be harder, since participants would have to process the numbers beyond the first word in order to decide between the two of them. In contrast, the discrimination between numbers formed with different multiples of twenty would be much more immediate.
Results showed no difference between these two conditions in any of the groups. We concluded that the language of our participants did not affect the way they compared the magnitude of numbers. Lack of language effects in this task is predicted both by McCloskey and colleagues (McCloskey, 1992; McCloskey & Macaruso, 1995) and by Dehaene and collaborators (Dehaene, 1992; Dehaene & Cohen, 1995). Both of them consider that number comparison takes place in a semantic representation of numbers, which is in an abstract code in the case of McCloskey et al. and has the form of a mental number line in which quantities are represented analogically for Dehaene et al. Regarding the proposal by Campbell et al. (Campbell, 1994; Campbell & Clark, 1992), it becomes clear from our results that the involvement of language in this task is much less relevant than in the solution of additions.
Our experiment also replicated the compatibility effect found previously: Participants answered faster when they had to compare numbers in which both the decade and unit digits led to the same decision than when each comparison went in a different direction. This effect is taken as evidence that two-digit numbers are decomposed in their decades and units, and comparison takes place for each digit separately. However, we must be cautious in concluding that our experiment provides evidence in this sense. Due to the restrictions imposed on the material by our main goal, we were unable to perfectly match the number pairs in all conditions. Thus, problem size, unit distance, and decade distance were matched for both their absolute and their logarithmic values, but overall distance was slightly, but significantly, larger for compatible trials (11.35 vs. 8.60). It is a well-known fact that the larger the distance between two numbers, the easier it is comparing the quantities they refer to. Hence, the effect we found might have been due to the distance difference instead of compatibility. To rule out this possibility, we conducted a stepwise regression analysis on the mean reaction time obtained for all the items. Both compatibility and overall distance were initially considered as possible predictors, but only compatibility managed to enter into the equation, significantly predicting reaction times (β = .20, p = .021). Therefore we can conclude that compatibility, and not distance, was responsible for the differences obtained.
General Discussion
This work aimed to investigate whether the language of our participants influenced the way they solved two tasks dealing with numbers.
Experiments 1 and 2 required solving additions of two 2-digit numbers presented in Arabic format. Basque participants found it easier to solve the additions that reflected the structure of number words in Basque, while the control population showed no effects of this manipulation. These results are at odds with the weak linguistic effects obtained by Brysbaert et al. (1998) in a similar task. What could be causing these contrasting results? One important factor might be the feature in which the two languages explored in their and our experiments differ. Brysbaert et al. (1998) compared a language where two-digit number words are unit-first, with a language where the decade word precedes the unit. In contrast, our experiments compared a base-10 language (Italian/Catalan) with Basque, which builds numbers by combining base 10 and mainly base 20. Thus, the feature we manipulated is plausibly “deeper” than that of Brysbaert et al.; in fact, one might wonder whether even the semantic representation of quantity by Basque speakers differs from that of base-10 language speakers. The model proposed by McCloskey and colleagues (McCloskey, 1992; McCloskey & Macaruso, 1995), for instance, claims that the semantic representation takes the form of the basic quantities of numbers and the powers of ten associated to them. Is it the case for Basque speakers as well? Though McCloskey's “base-10-centrism” probably does not reflect the diversity of the ways in which languages convey numbers, we would discard the fact that the language-specific effect we have found lies at the semantic level, because of the lack of effects obtained in Experiment 3. Current models of mathematical cognition consider the fact that number comparison taps into the semantic representation of numbers, because it involves judging the quantities the numbers refer to. When Basque speakers performed a number comparison, though, their performance did not differ from that of Catalan speakers.
Hence, whatever causes Basque and Catalan speakers to answer differently to the additions of Experiments 1 and 2 is not located at the semantic level. Additions are a peculiar operation, thought to lie somewhere “in between” multiplications on one side and subtractions and divisions on the other. Indeed, one-digit multiplications are considered the archetype of operation that we do not calculate each time, but retrieve directly from long-term memory. In contrast, one-digit subtractions and divisions are thought to be solved by manipulating the quantities involved at a semantic level. In additions, both direct retrieval and online calculation seem to play a role, with factors such as individual ability or problem size playing a role in which of the two options is chosen. The results in Experiment 3 suggest that the semantic representation of quantities is not affected by language specificities. It can be hypothesized then, that the advantage found in additions that reproduce the structure of numbers in Basque is due to their storage in long-term memory. In this sense, we claimed that the triple-code model by Dehaene and colleagues (Dehaene, 1992; Dehaene & Cohen, 1995) could not explain the results we had obtained. However, their model could still account for our data if our experimental additions were viewed as a type of “arithmetical fact”. The triple-code model makes a distinction between operations that are calculated every time (multidigit) and are solved in the Arabic code, and arithmetical facts, memorized through extensive practice and stored in long-term memory in a verbal code. Arithmetical facts usually comprise one-digit operations and in particular the multiplication tables and additions with small (≤5) numbers. Nevertheless, adult Basque speakers have had lifelong practice in transcoding from Arabic digits to their language. This, in the case of the interval of numbers used in our experiments, is nothing else than transforming an addition into its result, or vice versa—for example, when writing “hogeita hamabost” (20 + 15) in Arabics or reading 35 out loud. Hence, it could be the case that Basque speakers are particularly good at additions dealing with twenties or multiples of twenties because they have memorized them, turning them into a type of arithmetical fact. Given that retrieval of arithmetical facts is faster and more efficient than calculation by other procedures, this might explain the language-specific effects obtained in our study.
The multiple-encoding view by Campbell and collaborators (Campbell, 1994; Campbell & Clark, 1992) could also explain our results, because of the links that exist between representations of the same numbers in different codes.
In contrast, a strongly modular model such as that of McCloskey et al. (McCloskey, 1992; McCloskey & Macaruso, 1995), without asemantic connections between different codes, where operations take place in an amodal semantic code, cannot provide an explanation for the results described here.
To summarize, three experiments have been presented where language-specific effects in numerical calculation were investigated. Experiments 1 and 2 showed differences in the way in which speakers of Basque and Romance (Italian, Catalan) languages solved a set of additions. Experiment 3 discarded the possibility that this effect was caused by a different semantic representation of numbers in the two language groups. Since addition can also be solved through direct arithmetical fact retrieval, we argued that the complex transcoding rules between Arabic and number words in Basque might have developed the abilities of this population to deal with additions that replicate the structure of number words in their language.
As we predicted initially, the study of a population with a distinct representation of number words allowed us to detect language-driven differences, which in other circumstances might have remained hidden. Moreover, having used two tasks in which the different internal representations of numbers play diverse roles allowed us to formulate precise hypotheses on which processes language might have influenced.