
Abstract
The literature on repetition processing reveals an intriguing paradox between the particular salience of repetitions, which makes them easy to learn, and a tendency to avoid them when generating sequences. The aim of this experiment was to study the extent to which children can learn to produce these avoided behaviours by means of an artificial grammar paradigm using generation tests with implicit or explicit instructions. The analysis of the control group's performance confirmed the presence of a spontaneous tendency to avoid generating repetitions. A comparison with chance revealed that the children learned to produce repetitions in the explicit test but not in the implicit test. However, a comparison with the control group showed that learning nonetheless occurred in the experimental group with the implicit test. The discussion focused on this antirepetition behavioural bias and how it interacted with the type of information processes elicited by the tests selected for assessing implicit learning effects.
This study investigated the extent to which avoided behaviours can be implicitly induced. Incidental learning to reverse natural behavioural tendencies has been reported by Vinter and Perruchet (2000, 2002) in a graphomotor task in which participants learned to violate a principle described by van Sommers (1984), stipulating that the direction of the movement in the drawing of closed geometrical figures is associated with its starting position. However, this task was atypical and differed from commonly used implicit learning (IL) tasks. In order to generalize these findings, we examined whether nonspontaneous behaviours could be implicitly learned using an artificial grammar learning (AGL) paradigm. In this paradigm (A. S. Reber, 1967), participants are usually required to memorize sequences of elements governed by a finite-state grammar. Then, after being informed of the existence of rules determining the constitution of the sequences, they are invited to judge whether or not new sequences of elements are grammatical (half of them being grammatical, the other half nongrammatical). The AGL paradigm has been criticized, in particular with regard to the potential influence of conscious processes (e.g., Dulany, Carlson, & Dewey, 1984; Shanks & St. John, 1994). One way to limit these conscious influences is to employ, at test, a generation task with implicit instructions 1 that do not explicitly refer to the items seen during training, as in the case of a classification or grammaticality judgement test (Vinter & Perruchet, 1999). The grammatical sequences seen during training should nevertheless unconsciously prime the production of the behaviour required during the test. However, as the test does not constrain behaviour production by referring to training, natural behavioural tendencies are likely to emerge, possibly running counter to the implicit influences exerted during training. Might it still be possible to identify the IL of avoided behaviours in such conditions? In addition, to demonstrate that the use of a test referring explicitly to the training items greatly reduces the risk of bias caused by spontaneous behavioural tendencies, we also used a generation test performed in response to explicit instructions in the present study.
It may be worth preventing, at this stage, any possible confusion arising from the use of the term “implicit” to denote either the modes of information acquisition (learning phase) or the modes of information retrieval (test phase) as distinguished by Perlman and Tzelgov (2006). In our view, implicit learning covers all forms of unintentional or incidental or automatic learning. Learning can be assessed by means of tests that use explicit instructions—that is, instructions that explicitly refer to the material seen during training and which ask participants to judge whether items are grammatical or not: for instance, given that the items seen during training are explicitly designated as grammatical (“intentional retrieval” in Perlman & Tzelgov's terminology). However, using a test with explicit instructions introduces doubts about what is being measured: the genuine consequences of the training phase or the results of conscious recollection of information about the training phase? By contrast, implicit instructions are instructions that do not refer to the training phase at all (“incidental” or “automatic retrieval” for Perlman & Tzelgov).
The apparently avoided behaviour focused on in the present study related to the introduction of repetitions in the generation of sequences of discrete events. Mittenecker (1958) has reported a strong tendency to avoid repetitions when participants were asked to generate random series. A widespread cognitive bias, called gambler's fallacy, is thought to operate here and causes participants to favour alternations over repetitions in sequences (Herzog, 1989; Rabinovitz, Dunlap, Grant, & Campione, 1989; Tversky & Kahneman, 1974). According to Wiegersma (1982), repetition avoidance is probably due to a control mechanism whose purpose is to prevent the phenomenon of perseverance. In the case of spontaneous productions of sequences of colours and tonalities, Frith (1972) reported that only typically developing children systematically used all the available colours and tonalities, in contrast to autistic children who exhibited a strong tendency to introduce repetitions in their sequences. These findings argue in favour of a predisposition, at least in healthy children and adults, to avoid repetitive behaviours when they produce sequences of events.
While repetitions are avoided in the production of sequences, several studies have shown that the presence of repetitive elements facilitates sequence learning. In the case of a simple grammar for learning tones, for instance, Endress, Dehaene-Lambertz, and Mehler (2007) reported that in adjacent and nonadjacent repeated conditions (ABB or ABA, where A and B corresponded to high and low tones, respectively), the sequences of tones were learned more easily than in ordinal conditions, involving, for example, low–high–medium or medium–high–low tones. Monaghan and Rowson (2008) directly compared repeated and nonrepeated sequences of tones and confirmed the previous results. In the AGL literature, a number of studies have demonstrated that repetition information is crucial in transfer tasks (Gomez, Gerken, & Schvaneveldt, 2000; Lotz & Kinder, 2006; Tunney & Altmann, 1999). The specific benefits of repetitive structures in sequence learning have also been observed in children (e.g., Marcus, Vijayan, Rao, & Vishton, 1999). Finally, both repetition facilitation and repetition inhibition also proved robust in short-term memory (e.g., Henson, 1998). This literature represents a challenge. Repetitions make sequence learning easier, but the introduction of repetitions into the production of sequences is avoided. Could IL processes be efficient enough to lead individuals to produce what they naturally seek to avoid? This was a key question in the present study.
We decided to investigate this issue in children rather than in adults because children are less likely than adults to use strategies derived from more or less well-formed knowledge about the constitution of random sequences of events. To adapt the AGL paradigm to children, grammatical sequences of successions of colours representing flags of different lengths were presented during a video game involving the participation of teams of animals in a tug of war tournament. According to Perlman and Tzelgov (2006), sequence learning, if successful, would be automatic since it refers to a dimension on which the children did not respond in the task and the processing of which would not be beneficial to them during the training task. The age of 7–8 years was selected in order to ensure that the participants possessed minimal knowledge of the variety of flags that exist around the world, since the test phase involved generating flags following implicit instructions (termed “incidental retrieval” by Perlman & Tzelgov) or explicit instructions (termed “intentional retrieval” by Perlman & Tzelgov). Moreover, young children are exposed to a relatively high level of repetition—for example, in nursery rhymes or simplified speech. We were interested in investigating how this sort of repetition may influence children's cognitive systems.
However, any attempt to identify this type of learning in the context of a generation test with implicit instructions raises a number of methodological questions. A comparison of performance after training with chance levels of exposure in the expectation that participants will perform significantly above chance level would clearly be unsuccessful, as we may assume that chance will not provide a good baseline estimation of a behaviour that is avoided. The use of a control group therefore appeared necessary. Perruchet and Reber (2003) demonstrated the necessity to use trained control groups. We followed this recommendation in the present experiment; however, we also added an untrained control group (UNTRAIN group) for reasons that are explained below.
The colour-based finite-state grammar allowed us to generate grammatical series containing a large number of adjacent (ADJ series) as well as nonadjacent repetitions (non-ADJ series). The children in the trained control group saw series in which the colours were combined randomly (RAND series). Whatever the group, the children performed either an implicit or an explicit generation test after training. Given that the repetitions were encoded during training, the ADJ and non-ADJ experimental groups should produce more correct adjacent and nonadjacent repetitions, respectively, than the trained control group whatever the test. In addition, in conformity with most of the results in the literature, the experimental groups should perform above chance, while the trained and the untrained control groups' performances should equal chance level. Finally, if repetitions are particularly salient, only the experimental groups should produce more grammatical units containing repetitions than grammatical units without repetitions, especially in the explicit test. The reverse should be observed in the trained control group (RAND–TRAIN group) and in particular in the implicit test where repetition avoidance is more likely.
Method
Participants
One hundred and twenty Caucasian first and second graders (62 female and 58 male, 7–8 years of age), participated in the experiment. They were randomly divided into two groups (n = 60 per group), which differed in terms of the instructions given at the time of the test (implicit or explicit generation test). Within these groups, the participants were further divided into three subgroups: two experimental groups (non-ADJ and ADJ groups) and a trained control group (RAND–TRAIN group). An untrained control group (UNTRAIN group) was added. This consisted of 12 children (6 female and 6 male, 7–8 years of age). None of these children was educationally advanced or retarded nor suffered from attentional or intellectual deficits. Their vision was normal or corrected to normal, and they were able to discriminate and name the five colours used in the experiment. Written parental consent was obtained for each child. Table 1 provides the characteristics of the groups.
Characteristics of the groups observed in the experiment
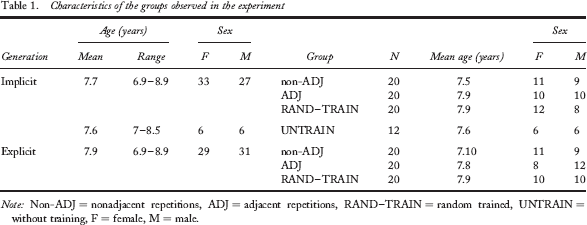
Note: Non-ADJ = nonadjacent repetitions, ADJ = adjacent repetitions, RAND–TRAIN = random trained, UNTRAIN = without training, F = female, M = male.
Materials
The material consisted of a computer game involving 3-, 4-, and 5-colour flags, as illustrated in Figure 1A. Three types of series of flags were built: two grammatical series generated from the same finite-state grammar, but whose specific items differed (ADJ or non-ADJ series), and a random one (RAND series). All the series included eight flags: two 3-colour flags, three 4-colour flags, and three 5-colour flags. The material used in the test included three templates representing flags of 3, 4, or 5 colours, respectively, and 25 coloured squares (5 blue, 5 green, 5 red, 5 yellow, and 5 turquoise) as illustrated in Figure 1B.
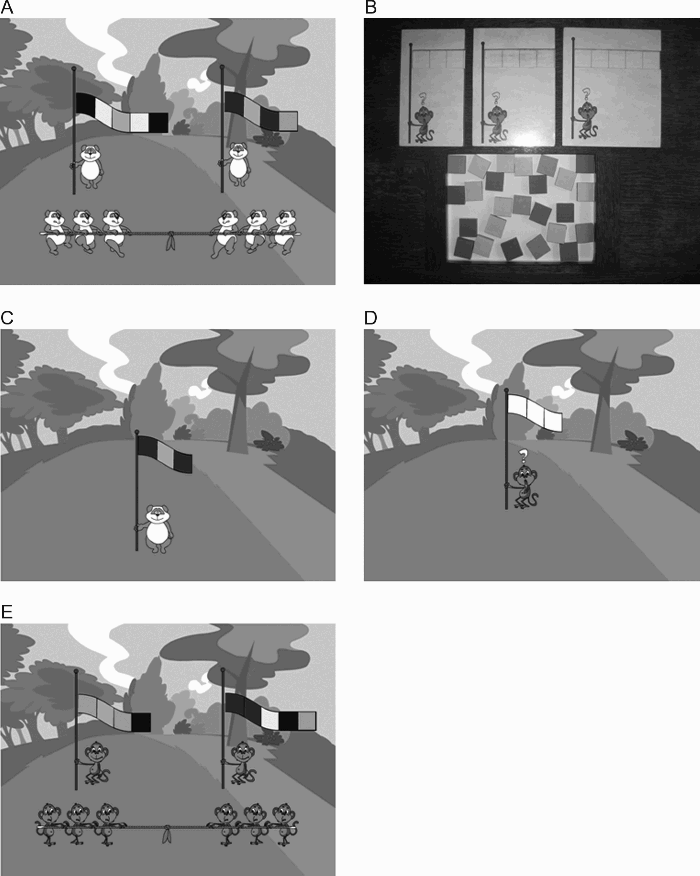
Illustrations of the video game (A. Tug of war tournament; B. Templates and coloured squares; C. Successive presentation of flags; D. Implicit generation phase; E. New flags produced by the children).
Constitution of the grammatical series
The grammatical series were generated using a grammar that combined five colours. An example is shown in Figure 2. The colours were randomly assigned to the positions in the grammar so that 10 different outcomes of both the ADJ and non-ADJ series were generated. Each child within each group was exposed to one of these outcomes.
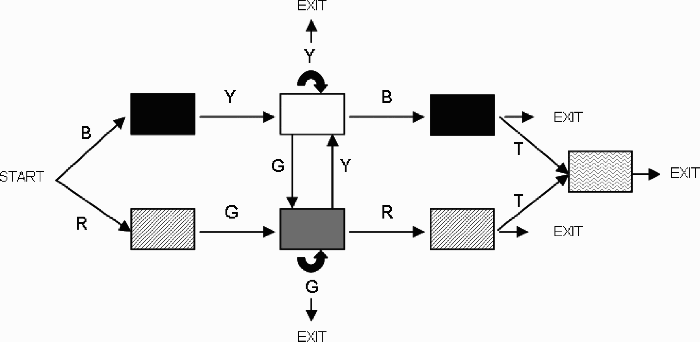
An instantiation of the finite-state grammar used in the experiment (this grammar was used throughout the experiments, but the position of the colours was variable). B = blue, G = green, R = red, Y = yellow, T = turquoise.
This grammar made it possible to generate 10 bigrams, 20 trigrams, and 42 quadrigrams, and it produced nonadjacent repetitions (e.g., BRGB, BYGYB), as well as adjacent repetitions (e.g., BB). The non-ADJ series consisted of 8 nonadjacent repetitions and 2 repetitions, 8 bigrams (without repetitions), 10 trigrams (without nonadjacent repetitions), and 9 quadrigrams. The ADJ series were made up of 8 adjacent repetitions and 1 nonadjacent repetition, 7 bigrams, 10 trigrams, and 8 quadrigrams. The number of nonadjacent repetitions within the non-ADJ series and the number of adjacent repetitions within the ADJ series were identical, while the numbers of adjacent repetitions in the non-ADJ series (2) and of nonadjacent repetitions in the ADJ series (1) were determined by chance. The probability of obtaining an adjacent repetition with 5 colours was calculated as a proportion of the number of flags present in a series (8). We thus obtained 2 adjacent repetitions: (5/25) × 8 = 1.6, rounded to 2. The same method was adopted for the nonadjacent repetitions and led to the inclusion of 1 nonadjacent repetition in the ADJ series.
Constitution of the random series
Ten RAND series outcomes were generated with each colour occurring in initial position at least once. The RAND series were matched to either the non-ADJ series (half of the series) or the ADJ series (the other half). Consequently, the RAND series consisted of 2 adjacent repetitions, 1 nonadjacent repetition, 13 or 12 bigrams, and 15 or 16 trigrams, depending on whether they were paired with the ADJ or non-ADJ series, respectively.
It should be noted that the probability of occurrence of an ADJ or non-ADJ repetition was calculated as a proportion of the number of flags present in a series, rather than the number of bigrams or trigrams. We therefore included an untrained control group (UNTRAIN group) in order to ensure that any potentially low levels of such productions in the trained control group was not due to the underrepresentation of the corresponding repetitions in the RAND series. This precautionary mechanism should make it possible to confirm the genuine spontaneity of repetition avoidance behaviour in the production of sequences.
Procedure
Presentation and training
The experimental session comprised a 20-min phase of exposure to the material, followed by a 5–10-min test phase. The children were comfortably seated in front of a computer and were told that they were going to play a video game. When they were ready, the game started, and they followed prerecorded instructions: “Hello, today the pandas have organized a ‘tug of war’ tournament. Each team of pandas will show you its pretty flag. Press ‘start’ to see the first team's flag.” The colours of the flag appeared one at a time, for 500 ms, from left to right. Then, after an interval of 1 s, the children heard “Now, press ‘start’ to see another team's flag.” The eight flags comprising the series appeared successively one at a time, as shown in Figure 1C. The order in which the flags appeared was random. The instructions then continued: “Now, the tournament is going to start. Press ‘start’ to see the first team's flag” (a flag was displayed, one colour at a time, followed by the sound of a trumpet). “Press ‘start’ to see the second team's flag” (the flag was displayed). “Now, press ‘start’ to start the match.” The first team of pandas faced the second one (see Figure 1A). The two flags remained visible until one of the teams won, and the match ended with an animated sequence lasting a few seconds. This procedure was repeated throughout 16 matches. Thus, the children were exposed to the eight flags of the series five times each (including the initial presentation phase). All the teams won and lost twice, the position (right or left) of the winning team being random. The experimenter made sure that the children maintained their attention during the exposure phase.
Implicit generation test
After training, the prerecorded voice introduced the children to the next part of the game, and a monkey appeared on the screen with a blank flag (Figure 1D). “The following day, it is the monkeys' turn to play ‘tug of war’. Oh, look! The monkey has forgotten to put colours on its flag. You can help him! You know how to make pretty flags, so help the monkey by placing the colours you want on the flag that you have in front of you. Do it now!” The same instructions were repeated for the other five monkeys that appeared with blank flags. In each case, the children were presented with a template consisting of 3, 4, or 5 empty boxes, depending on the length of the flag, together with 25 squares of colours displayed in random order front of them (see Figure 1B). No reference to the flags seen during training was made (implicit instructions). When a flag was completed, the experimenter recorded the production using the numeric keypad and the colours selected by the child appeared on the monkey's flag. A pilot investigation had previously shown that it was better to ask children to build flags using squares of colours rather than by pressing coloured keys on the keypad because, in this latter case, children adopt strategies such as pressing adjacent keys. The coloured squares selected for the flag were put back in the box. The 25 squares were thus available each time a child had to make a flag. The children were asked to produce two flags, of 3, 4, and 5 colours respectively (random order). They then started three matches, pushing the “start” key (Figure 1E).
The children in the untrained control group immediately saw the monkeys that were to take part in the “tug of war” game. The test phase was introduced with the following instructions: “Look, the monkeys have made flags for their teams. Oh look! They forgot to put colours on their flags. Luckily, the colours to make the flags are in this box. You can help them! You know how to make pretty flags, so help the monkey, by placing the colours you want on the flag you have in front of you. Go!” After this, the procedure was identical to that used in the trained groups.
Explicit generation test
The experimenter gave the 25 coloured squares to the children and introduced the task with the following instructions: “A short while ago, you saw the pandas who took part in the tug of war tournament with their flags. I'm going to ask you a question about the pandas' flags, the flags you saw. Look at this box; it contains the colours used by the pandas for their flags. Can you build a whole flag that belonged to the pandas and that you are sure that you saw during the game? Try to remember as best as you can, it is important that you make a flag that you are really sure you've seen.” The instructions made a clear explicit reference to the flags seen during training and thus required an intentional retrieval effort, which was very likely to elicit conscious influences. The children built the requested flag by selecting the coloured squares, and there were no limits to length (one child produced a six-coloured flag; the additional colour was not included in the data). Each child was only asked to produce one flag because of the extent to which the instruction insisted on the participant's degree of confidence in the accuracy of the required response. Pilot studies have shown that many children refuse to build a second flag when exposed to this high level of insistence on the degree of confidence in the response.
Coding of the data
We coded the production of correct adjacent and nonadjacent repetitions. The term “correct” means that the produced units possessed the same colour sequences as those seen during training. They were thus grammatical when produced by the experimental groups or when they corresponded to the sequences seen during training in the case of the trained control group. These frequencies of correct repetitions were calculated as a function of flag length. For example, a correct adjacent repetition scored .50 (1 occurrence out of 2 possible repetitions), .33 (1 out of 3), or .25 (1 out of 4) in a 3-, 4-, or 5-colour flag, respectively. The same procedure was applied to the correct nonadjacent repetitions. We also analysed the production of adjacent and nonadjacent repetitions consisting of colours that differed from those seen in training (incorrect non-ADJ and ADJ repetitions) to check whether the low number of repetitions in the implicit generation test was due to a difficulty in producing them in the appropriate colours. We used the same method for the untrained control group (UNTRAIN group). However, in the absence of training, all productions of adjacent and nonadjacent repetitions were, by definition, “correct”.
In addition, we coded the correct “nonrepetitions” produced in the sequences. Correct nonrepetitions were bigrams consisting of nonrepeated colours (such as BY, RG, …) seen during training. Because of the disparity between the theoretical proportions associated with repetitions and nonrepetitions, we computed the ratio between observed and theoretical frequencies of repetitions or nonrepetitions for each child in order to permit a comparison.
The analyses concluded with comparisons between the observed and theoretical proportions. We employed an analytical approach, which involved computing the precise theoretical probabilities of producing a repetition (ADJ or non-ADJ) in different cases. The children were presented with 25 coloured squares (5 exemplars of 5 colours). Consequently, each draw during the generation test reduced the chance of drawing the same colour at random. We generated the entire set of 3-, 4-, and 5-colour flags that could be produced using the 25 coloured squares in conditions of drawing without replacement (e.g., for 3-colour flags: 25 × 24 × 23 possibilities). On the basis of the generated set, the program then determined the number of ADJ and non-ADJ repetitions for the different flag lengths. A Monte Carlo method provided similar results. Student t tests were used to compare the observed proportions of repetitions with the theoretical values.
Results
Production of correct adjacent and nonadjacent repetitions
The observed and theoretical proportions of correct adjacent and nonadjacent repetitions produced in the experimental groups (the ADJ group for the adjacent repetitions and the non-ADJ group for the nonadjacent repetitions, respectively) and in the RAND–TRAIN group for the explicit and the implicit generation tests are illustrated in Figure 3.
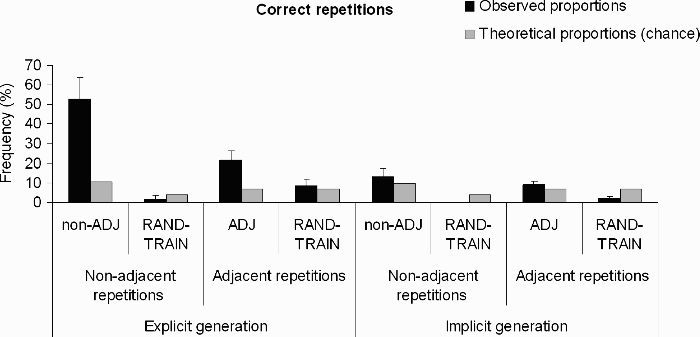
Observed and theoretical frequencies of correct nonadjacent and adjacent repetitions in the experimental groups (non-ADJ and ADJ groups, respectively) and the control (RAND–TRAIN: random trained) group, for the explicit and implicit generation tests. The error bars correspond to one standard error.
Analyses of variance (ANOVAs) were carried out on the production of correct adjacent or nonadjacent repetitions with group (experimental or RAND–TRAIN) and test (explicit or implicit) as between-subjects factors. Group was significant, F(1, 76) = 11.93, p < .01, η2p = .14, and F(1, 76) = 28.24, p < .01, η2p = .27, respectively. The experimental groups introduced significantly more repetitions in their flags than the control group. The test factor also yielded significance, F(1, 76) = 11.11, p < .01, η2p = .13, and F(1, 76) = 11.69, p < .01, η2p = .13, with better performances following explicit than implicit instructions. The group by test interaction failed to yield significance for the adjacent repetitions, F(1, 76) = 1.08, p = .30, η2p = .01, but turned significant for the nonadjacent repetitions, F(1, 76) = 9.87, p < .01, η2p = .11. The production of nonadjacent repetitions did not differ as a function of test in the control group (Scheffé post hoc test, p = .99), while it was much higher following the explicit than following the implicit test in the experimental groups (Scheffé post hoc test, p < .01).
Did the performances shown in the experimental groups differ significantly from chance level, in the two tests? Student's t tests were run to compare the observed and theoretical scores, and the Bonferroni correction was used to address the problem of multiple comparisons (the significance level was put at .005).
For the explicit test, the production of correct nonadjacent repetitions in the non-ADJ group (52.5%) and of adjacent repetitions in the ADJ group (21.7%) were significantly higher than chance (6.7% and 10.3%, respectively), t(19) = 3.36, p < .005, and t(19) = 3.72, p < .005. Performances in the RAND group (8.7% and 1.7%) were equal to chance (6.7% and 3.9%), t < 1 and t(19) = –1.35, p = .19. In contrast, for the implicit test, the performance of the experimental groups (9.1% and 13.1%) did not differ from chance (6.7% and 9.3%), t(19) = 1.45, p = .16 and t < 1, while the control group performed significantly below chance (6.7%) for the correct adjacent repetitions (2.1%), t(19) = –5.37, p < .005, and did not produce any nonadjacent repetitions at all. Thus, following explicit instructions in test, the acquired sensitivity of the experimental participants to repetitions led them to produce above-chance numbers of repetitions, whereas the trained control group behaved at chance. Following implicit instructions, the experimental participants performed at chance while the control participants behaved at a below-chance level.
Production of incorrect adjacent and nonadjacent repetitions
The observed and theoretical proportions of incorrect adjacent repetitions (ADJ group, RAND–TRAIN group) and nonadjacent repetitions (non-ADJ group, RAND–TRAIN group) in the explicit and implicit generation tests are presented in Figure 4. The repetitions produced by the untrained control group are also presented in this figure (UNTRAIN).
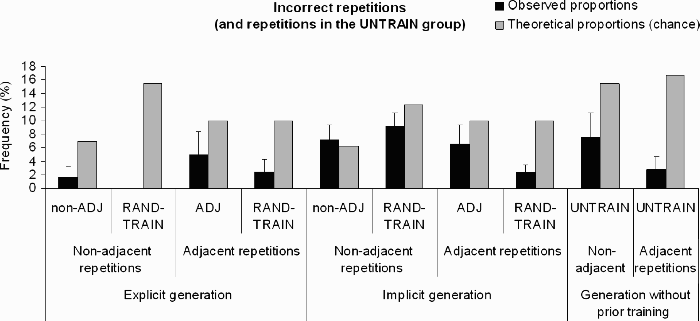
Observed and theoretical frequencies of incorrect nonadjacent and adjacent repetitions in the experimental groups (non-ADJ and ADJ groups, respectively) and the control (RAND–TRAIN: random trained) group, for the explicit and the implicit generation tests, and of adjacent and nonadjacent repetitions in the control group without training (UNTRAIN). The error bars correspond to one standard error.
ANOVAs were run with group (experimental or RAND–TRAIN) and test (explicit or implicit) as between-subjects factors on the production of incorrect adjacent or nonadjacent repetitions. Group failed to yield significance, F(1, 76) = 1.95, p = .17, η2p = .02, and F < 1, respectively. The test factor was not significant for the adjacent repetitions, F < 1, while it turned significant for the nonadjacent repetition units, F(1, 76) = 20.44, p < .01, η2p = .21. Performance was better with the implicit than with the explicit instructions. The group by test interaction was also not significant for either the incorrect adjacent repetitions, F < 1, or the incorrect nonadjacent repetitions, F(1, 76) = 1.30, p = .26, η2p = .02. Clearly, these types of production were not enhanced in the experimental groups, as compared to a trained control group.
It was, however, interesting to investigate to what extent these productions differed from chance level in the different groups and tests. Student's t tests were run to compare the observed and theoretical scores. The same Bonferroni correction was used to determinate the significance level (p = .005).
In the explicit test, the production of incorrect nonadjacent repetitions in the experimental group (1.7%) was significantly below chance level (6.9%), t(19) = –3.23, p < .005, while incorrect adjacent repetitions were produced (5%) at chance level (10%), t(19) = –1.45, p = .16. For both repeated units, the control group (0% and 2.5%, respectively) performed significantly below chance (15.5% and 10%), t(19) = –4.36, p < .005, and t(19) = –30.76, p < .005. In the implicit test, the non-ADJ and ADJ group introduced as many incorrect nonadjacent repetitions (7.2%) or incorrect adjacent repetitions (6.6%) as would predicted on the basis of chance responding (6.2% and 10%, respectively), t < 1 and t(19) = –1.25, p = .23. The comparisons between incorrect nonadjacent repetitions (9.3%) and chance level (12.4%) failed to reach significance in the control group, t(19) = –1.69, p = .11, while the incorrect adjacent repetitions (2.4%) were produced at significantly below chance level (10%), t(19) = –7.65, p < .005. Thus, the experimental group performed at chance level, except in the explicit test for the production of incorrect nonadjacent repetitions where it performed below chance. The control group behaved at a below-chance level, except in the implicit test for the production of incorrect nonadjacent repetitions, which was at chance level.
In addition, the production of nonadjacent repetitions in the UNTRAIN group (7.6%) was significantly lower than chance (15.5%), t(11) = –2.23, p < .05, as was the production of adjacent repetitions (2.8%), t(11) = –7.42, p < .01 (chance: 16.7%). As illustrated by Figures 3 and 4, the percentage of adjacent repetitions was similar in the untrained (2.8%) and trained control groups (4.5% in the implicit test), t(30) = 0.75, p = .46, as were the percentages of nonadjacent repetitions, 7.6% and 9.3%, respectively, t(30) = 0.46, p = .65.
Production of repetitions and nonrepetitions
Figure 5 presented the ratio of the observed to the theoretical proportions of repetitions or nonrepetitions in the explicit and implicit tests for the experimental and control groups, trained and untrained.

Mean ratios of frequencies (observed/theoretical) of repetitions and nonrepetitions in the experimental group (the non-ADJ and the ADJ groups) and the control (RAND–TRAIN: random trained) group, for the explicit and the implicit generation tests. The asterisks indicate a statistically significant comparison, and the hatched line represents chance level (ratio observed/theoretical = 1).
ANOVAs were run with group (2) and test (2) as between-subjects factors. As Figure 5 shows, group and test were significant for repetitions, F(1, 116) = 14.11, p < .01, η2p = .11, and F(1, 116) = 13.13, p < .01, η2p = .10, respectively. The experimental groups outperformed the trained control group, and performance was better in the explicit than in the implicit test. In addition, a just-significant group by test interaction, F(1, 116) = 3.66, p = .05, η2p = .03, revealed that the number of repetitions was greater in the experimental group following the explicit than following the implicit instructions (Scheffé post hoc test, p < .01), while no differences occurred in the control group as a function of test instructions (Scheffé post hoc test, p = .74). By contrast, no group or test main effect, F(1, 116) = 1.69, p = .20, η2p = .01, and F < 1, respectively, or group by test interaction effect, F < 1, was significant for the production of nonrepetitions. The means were close to 1, thus demonstrating that the observed and theoretical proportions of nonrepetitions did not differ, regardless of group and test. Student t tests completed the analysis. As illustrated by Figure 5, the only significant mean difference in the implicit test related to the RAND–TRAIN group in which the production of repetitions (0.32) was significantly less than that of nonrepetitions (1.24), t(19) = –5.54, p < .01. The pattern of results was reversed in the explicit test in which the only significant difference observed occurred in the experimental groups, with repetitions being produced more frequently (4.35) than nonrepetitions (1.42), t(39) = 4.52, p < .01.
Discussion
This experiment investigated whether an IL episode can cause children to produce repetitions in the generation of sequences—that is, a type of behaviour that appears to be quite paradoxical. The current literature shows that subjects avoid introducing repetitions in sequences (e.g., Frith, 1972; Wiegersma, 1982), while the presence of repetitions facilitates sequence learning (e.g., Lotz & Kinder, 2006; Monaghan & Rowson, 2008). The well-established AGL paradigm was used, and the IL effects were assessed by means of a procedure that minimized contamination through conscious influences during testing (Vinter & Perruchet, 1999). These were the reasons behind our choice of a generation test using implicit instructions. While such a test appears to be ideal for controlling conscious influences, it raises certain methodological problems with regard to how to measure the potential impact of incidental exposure to repetitions. We hypothesized that we would be able to resolve this issue by employing trained and untrained control groups and comparing performance in implicit and explicit tests. Our results provoked a number of interesting ideas that are worth discussing in greater detail here.
Assessing repetition learning through comparisons with chance
The children who saw the ADJ and non-ADJ series produced correct adjacent and nonadjacent repetitions, respectively, at above chance level in the explicit generation test, thus revealing IL capacities such as those initially identified by A. S. Reber (1967). These IL effects support the idea, largely documented by Gestaltist authors (e.g., Attneave, 1954), that repetitions are particularly salient and confer a benefit in sequence learning. The analysis contrasting the production of repetitions to that of nonrepetitions in the explicit generation test confirmed that the experimental groups encoded the repetitions during training, presumably to the detriment of the other bigrams.
However, it could be argued that this increased production of repetitions did not reflect an unconscious impact of the exposure to repetitions during training but resulted from conscious processes operating during the explicit test. Indeed, the implicit generation test apparently failed to reveal IL effects, since the production of correct repetitions in the experimental groups did not differ from chance level. The apparently low level of repetitions in the implicit generation test was not due to a difficulty in producing them in the appropriate colours since the experimental groups also produced incorrect repetitions at chance level at test. Because the children who performed the implicit or explicit test received exactly the same training, the performance differences were due to differences in the retrieval processes elicited by the test instructions.
It can be noted that an explanation of these results in terms of more efficient retrieval processes involving the activation of intentional processes at test seems counterintuitive in the light of most conceptions of IL (however, see Shanks, 2005). In our opinion, this asymmetry between the implicit and explicit generation tests when performance was compared to chance provides only a partial view of the results. The demonstration that the children spontaneously avoided introducing repetitions in their coloured sequences considerably modified our understanding of the results.
Repetition avoidance in the unconstrained production of sequences
In order to test the antirepetition bias in sequence generation behaviour, the trained control group's performance was compared to estimations of chance-level repetition production. Whereas the trained control group performed at chance level in the explicit test, correct repetitions were produced at significantly below chance level in the implicit test. As might therefore be expected, the production of repetitions in the untrained control group was also significantly below chance. These results testify to the existence of a tendency to produce repetitions only very rarely in the absence of any external influence (trained and untrained control groups) and if intentional information retrieval processes are not elicited (implicit test). Although the present study was not designed to contrast the production of adjacent and nonadjacent repetitions, it is worth noting that the participants tended to avoid adjacent repetitions more than nonadjacent repetitions, perhaps because the latter introduced a measure of variation due to the alternation of colours. Thus, the exposure during infancy and early childhood to an environment presenting a lot of repetitions does not appear influential in terms of the 7–8-year-old child's behaviour.
In our opinion, if there is no intentional effort to perform retrieval during the implicit test then it is possible for spontaneous behaviours—such as the tendency to avoid repetitions in sequence production—to be expressed. When the participants were asked to create their flags, the desire to avoid these repetitive behaviours would have entered into competition with the sensitivity to repetitions implicitly acquired during the exposure phase. Indeed, in response to implicit instructions, we observed a proportion of repetitions identical to that for nonrepetitions in the experimental group while, as pointed out above, the explicit generation test revealed that exposure to grammatical series resulted in an increased production of repetitions. In addition, in the trained control group, the proportion of nonrepetitions was higher than that of repetitions in the implicit test. The explicit/implicit instructions modulated the production of repetitions, but not that of nonrepetitions. Thus, the demonstration of automatic repetition learning in incidental retrieval conditions (implicit test) is based on two parallel findings: on one hand, the fact that both experimental groups produced more repetitions than the trained control group; on the other, the fact that the experimental groups performed at chance level in conditions where the control groups, whether trained or untrained, performed significantly below chance level. It should be noted that according to this line of reasoning, the better learning performance in the explicit test could result as much from a reduced tendency to avoid repetitions in response to the explicit instructions as from the fact that intentional retrieval processes are more efficient than incidental retrieval processes.
Repetition avoidance in sequence generation is an intriguing behaviour. Psycholinguistic studies have suggested that repetitions are also naturally avoided in many human languages. Walter (2007) described three main “antirepetition” biases in language. The first bias seems to be related to production, since repetitions prevent overlapping at the time of pronunciation. The second bias seems to be a perceptual bias and suggests that one of the repeated elements will be ignored. Indeed, the need to consider two consecutive identical elements together could constitute a violation of certain linguistic rules that stipulate that contrasts should define the contours of perceptual units (Coetzee, 2005; Kingston et al., 2006). Finally, the third bias is based on the distinction principle (Richards, 2006), which prohibits units of the same type from being too close together in a single linguistic sequence. Given that linguistic productions constitute the main sequences that are perceived and produced every day by children and adults, it is likely that the absence of repetitions of such sequences influences the production of nonlinguistic sequences such as the colour sequences studied in our experiment.
In conclusion, this experiment showed that nonspontaneous behaviour can be learned implicitly by employing a classical paradigm from the implicit learning research domain. We were able to measure these learning effects in an implicit test when the experiment included both trained and untrained control groups (Dienes & Altmann, 2003; Perruchet & Reber, 2003; R. Reber & Perruchet, 2003). We demonstrated that an implicit procedure was sensitive to the influence of spontaneous behaviours that could constitute behavioural “obstacles” to learning. We therefore needed to control for the influence of these spontaneous behaviours, in this case by using control groups (trained and untrained) rather than by relying on comparisons of observed performance with estimations of chance levels. Spontaneous behaviours of various types can conflict with learning effects in an implicit generation test, and these may vary as a function, for instance, of age, intellectual level, or cognitive deficits. The present study has helped clarify the special case in which an implicit (rather than an explicit) generation test is used in this type of learning context. Further research will be needed to explore how other potential spontaneous behavioural biases may intervene in the course of implicit learning episodes.