
Abstract
This study investigates how bilinguals use sublexical language membership information to speed up their word recognition process in different task situations. Norwegian–English bilinguals performed a Norwegian–English language decision task, a mixed English lexical decision task, or a mixed Norwegian lexical decision task. The mixed lexical decision experiments included words from the nontarget language that required a “no” response. The language specificity of the Bokmål (a Norwegian written norm) and English (non)words was varied by including language-specific letters (“smør”, “hawk”) or bigrams (“dusj”, “veal”). Bilinguals were found to use both types of sublexical markedness to facilitate their decisions, language-specific letters leading to larger effects than language-specific bigrams. A cross-experimental comparison indicates that the use of sublexical language information was strategically dependent on the task at hand and that decisions were based on language membership information derived directly from sublexical (bigram) stimulus characteristics instead of indirectly via their lexical representations. Available models for bilingual word recognition fail to handle the observed marker effects, because all consider language membership as a lexical property only.
Keywords
How do bilinguals realize to which of their languages a word belongs? Surprisingly, this deceptively simple question has hardly received any research attention. Some researchers have proposed models for word retrieval in bilingual reading, listening, or speaking in which lexically orthographic or lexically phonological representations are linked to special “language membership” representations, tags, or indexes that represent the language to which a word belongs (Dijkstra & van Heuven, 1998, 2002; Poulisse & Bongaerts, 1994). In contrast, other researchers have argued that it is not necessary to explicitly represent this information, because it could be derived from the context in which an utterance takes place (French, 1998; Jacquet & French, 2002; Li & Farkas, 2000; Thomas, 1997).
The two types of proposals do not necessarily contradict each other, but could be complementary. Together, sublexical, lexical, and syntactic information sources could codetermine the language membership of a particular word (cf. de Bot, 2004; Dijkstra & Snoeren, 2004). For instance, Dutch–English bilinguals might be aware of the fact that “whisker” is an English word, while their recognition of this English word might also be sensitive to the presence of the “typically” English bigram “wh”. In the present study, we investigated the sensitivity of readers to such sublexical word characteristics or graphotactics that “mark” a particular language with a certain probability in different task situations.
Language-specific properties of the input string may be especially relevant to the word recognition process in bilinguals, because they could be used to discriminate word candidates from target and nontarget language. It seems likely that there are task situations in which bilinguals will exploit sublexical differences in the make-up of the words of their two languages to speed up their responding. In principle, language membership information can become available in two ways, as shown in Figure 1. First, identifying the input word could result in the subsequent retrieval of the language membership information for that word. Second, language membership information could be extracted from the sublexical structure of a word. Whereas the first possibility is commonly recognized in models of bilingual word recognition and language-switching studies, the second option has so far received little attention. Because language membership information derived from the sublexical level (bigrams) is often not completely reliable (consider, for instance, loanwords that by their nature will refer strongly to their language of origin) the use of this source of language information is likely to be context dependent—that is, dependent on task demands and stimulus list composition.

Possible connections between levels of representation in bilingual word recognition. The question mark refers to a link that is not included in current bilingual word recognition studies.
Empirical studies have demonstrated that response patterns in bilingual word recognition may change dramatically depending on task and stimulus list context. For instance, Dijkstra, van Jaarsveld, and ten Brinke (1998) found null effects, facilitation effects, or inhibition effects for interlingual homographs relative to matched control words depending on task and stimulus list context. When Dutch–English participants performed an English lexical decision task, they responded about equally fast to interlingual homographs and purely English matched controls. When purely Dutch words (requiring a “no” response) were added to the stimulus list, reaction times (RTs) became much slower for the interlingual homographs than for the matched controls. Clearly, the additional requirement to retrieve a target word's language membership information (as a consequence of changed list context) led to a slower English lexical decision. Finally, when the task was changed into generalized lexical decision (“say yes to English and/or Dutch words”), a facilitation effect of homographs relative to control items arose. Thus, both stimulus list composition and task demands differentially affected the observed result patterns for the same set of items. As another example from a different domain, Lemhöfer, Koester, and Schreuder (2011) found that Dutch compound words were recognized faster when the bigram at the morpheme boundary did not occur in Dutch morphemes than when it did. Thus, the bigram at the morpheme boundary was able to serve as a cue for the location of the morpheme boundary and affected further processing. This finding again shows that participants are able to use orthographic cues to direct higher level processes.
Such findings raise the question of which information in a stimulus word is used as a “standard” or mandatory component in bilingual word recognition (i.e., as an integral part of the word identification process) and which information is only retrieved or used if this is beneficial to the context-sensitive decision process. For instance, the initial activation of a competitor set of similar word candidates, based on both languages of the bilingual, is usually considered as an inherent and inalienable part of the bilingual word recognition process (these constitute the “intralingual and interlingual neighbourhoods” of the target word; e.g., Beauvillain, 1992; Dijkstra, Grainger, & van Heuven, 1999; Dijkstra et al., 1998; Grainger & Dijkstra, 1992; van Heuven, Dijkstra, & Grainger, 1998). In addition, language-specific sublexical information could be used to speed up bilingual identification processes or decision making. For instance, the orthographic representations for words in the two languages of the bilingual will on average consist of somewhat different bigrams or may even contain language-specific letters. Note that homographs and cognates are exceptional in this respect because their orthographic make-up is shared across two languages. This is one reason we did not include them in our study on the use of language-specific markers.
Language membership information from both the lexical and the sublexical level can potentially facilitate word recognition. As a concrete example, consider a Norwegian–English bilingual who is processing an English word that contains a bigram that is specific to English (e.g., “wh”). Now suppose that the bilingual processes the word “whisker” faster than a matched word without this language-specific marker. In principle, there are two ways to account for such a finding. One option is in terms of a word identification advantage, holding that the marker allows a faster English word identification process, because word candidates from Norwegian can be more quickly excluded than in the case of an otherwise matched language-neutral letter string (the link between the sublexical level and the lexical level in Figure 1). In this case, the language cue facilitates through the lexical level. Alternatively, a language decision advantage might underlie the facilitation effect. Participants would respond faster not because they have a speeded-up word recognition process, but because of the diagnostic evidence for the response provided by the sublexical language membership information. This requires that language membership information is directly derived from sublexical (bigram) characteristics, skipping the lexical level (the link between the sublexical level and the language level in Figure 1).
If a language-specific marker or language cue functions as a word identification cue, its use should not depend on the task situation at hand, because it would be integrated in the task-independent word recognition process itself. However, if the marker functions as a language decision cue, it could be used or not, depending on the diagnosticity of the markers for the response in the particular task. The latter can be the case when the sublexical information reliably indicates language membership.
In the present study, we vary task demands and conditions to examine whether bilinguals use language-biased sublexical stimulus word properties as decision cues or as identification cues. If the word properties are used as decision cues, this implies a direct use of language membership information from the sublexical level. In our study, we consider lexical decision, which (together with word naming) is the most frequently applied task in monolingual and bilingual word recognition studies, and compare it to language decision, a bilingual task that specifically asks for the retrieval of language membership information. Before considering the rationale underlying our experiments in more detail, we discuss the potential effects of language-specific letters and bigrams in two partially overlapping scripts, Norwegian and English.
Effects of language-specific letters in alphabetic scripts: The case of Norwegian and English
Norwegian–English bilinguals are confronted with two scripts that overlap mostly, but differ in a few letters. The Norwegian script variant of Bokmål uses the Roman script, like English, but extends it with the three letters “æ”, “ø”, and “å”, so that the Bokmål alphabet has 29 letters. This implies that Bokmål words could be “marked” as being Bokmål and not English, not only in terms of their constituting bigrams, but also by a unique letter. Similarly, English words can be marked by one of the letters “c”, “q”, “w”, “x”, or “z”, that essentially only occur in Bokmål in the rare loanwords of which the spelling is not adapted.
In our study, we investigate for the first time the effects of these largely but not completely overlapping scripts on the word recognition process of Norwegian–English bilinguals (for a study on orthographic specificity in Greek and English, see Orfanidou & Sumner, 2005). For example, to Norwegian–English bilinguals the word “høy” should clearly be Bokmål, because the letter “ø” does not occur in the English alphabet. If such information could be used early in bilingual word recognition, the activation of an orthographic neighbour like “hay” during the presentation of “høy” could in principle be avoided or quickly suppressed. Notice that, in contrast to language-specific bigrams such as “sj”, only one letter is involved, which could help a certain “pop out” effect increasing the likelihood of use of this information. Another reason to expect an increased effect size for single letters is that single letters are most likely part of the orthographic encoding whereas bigrams do not necessarily have this status.
Bigram frequency effects in monolingual and bilingual word recognition
Other subtle effects on bilingual word recognition might be exerted by the prominence of certain letter combinations in one language relative to another. A word consists of a number of letters in a particular order, its graphotactics. Some letter sequences are more probable than others, depending on their position in the item. Especially the effects of bigram (letter pair) prominence have been investigated. The mean bigram frequency of a word refers to the average frequency of all bigrams in the word, whereas minimal bigram frequency refers to the frequency of the least frequent bigram in the word. Mean bigram frequency is meant to capture the “orthographic regularity” of a word in the context of its own language (Rice & Robinson, 1975). The role of this variable for the word recognition process has been debated since its first appearance in monolingual word identification studies (Broadbent & Gregory, 1968; Gernsbacher, 1984; McClelland & Johnston, 1977; Rice & Robinson, 1975; Rumelhart & Siple, 1974). All these studies concerned perceptual word identification tasks. Some reported an effect of bigram frequency, primarily for low-frequency words. This effect was inhibitory in nature, which may be a consequence of the difficulty to discriminate “regular” words with high bigram frequency from other words. Westbury and Buchanan (2002) demonstrated that minimal bigram frequency, representing a “simple sublexical marker of how unusual a word is” (p. 68) had an inhibitory effect on lexical decision latencies.
Even when languages share their scripts, and all their letters occur in both languages, some words may be more language-specific than others, because certain of their bigrams are frequent in one language, but not in the other. For instance, the word “sjuk” is more likely to be Bokmål, based on only its orthographic characteristics, than English, because the “sj” combination does not occur, or only rarely, in English words. An exact way to define this language specificity is discussed below in the section on Stimulus Materials. Here we consider several studies that have shown an effect of language specificity on bilingual word recognition.
Grainger and Beauvillain (1987) found that, in a French–English visual lexical decision task, the recognition of words with a language-specific orthographic structure (orthography and pronounceability) took place more quickly than words that were orthographically neutral. No effect of language-specific orthography was found for monolinguals (Beauvillain, 1992).
Thomas and Allport (2000) also found faster responses for items with a language-specific orthography, especially for the second language (L2). However, these studies did not control for orthographic neighbourhood size, a factor that correlates with language specificity. The importance of this matching was shown by Beauvillain (1992), who found that the effect of language-specific orthography disappeared when she controlled for orthographic neighbourhood size. Thomas and Allport concluded that it was not clear whether specific orthography prevented words in the other language from being activated.
Vaid and Frenck-Mestre (2002) found that French–English bilinguals used orthographic cues (language-specific bigrams) to speed up French–English language decision. Orthographically marked words were responded to faster than unmarked words in the second language (L2, English). L2 marked words were responded to faster than native language (L1, French) marked words, a finding that aligns with the increased sensitivity to orthographic cues for L2 found by Thomas and Allport (2000). Vaid and Frenck-Mestre concluded that participants used a perceptual strategy to identify marked words and a lexical strategy for unmarked words. Such a complex strategy was useful, because none of the items were marked for the wrong language; if English-specific orthography was used, the word was always English, and when French-specific orthography was used, the word was always French. In sum, it appears that orthographic language markers can be used to speed up bilingual word recognition.
The present study
The present study examines the mechanisms underlying the effects of language-specific orthography for different bilingual tasks and stimulus list compositions. It is quite likely that language markers result in RT advantages, because participants' responses have been shown to be sensitive to language-specific markers. On the basis of the empirical literature (e.g., Font, 2001; Thomas & Allport, 2000; Vaid & Frenck-Mestre, 2002), for instance, faster language decisions are expected for items that are marked for a specific language in terms of their unique letters or bigrams. The important question is therefore how (rather than if) language markers are used to optimize performance in different tasks. We manipulated the response diagnosticity (cue reliability effect) of the language markers between experiments to test the two accounts discussed above, which explain marker effects in terms of either a word identification advantage or a language decision advantage.
In a series of three Bokmål–English experiments, response diagnosticity was varied by including words with language-specific letters, a language-specific orthography based on bigram frequencies, or a language-neutral orthography. The most important difference between language specificity based on letters and bigrams is that the letters can be learned to be a cue from the stimulus list alone (there are only three Bokmål-specific letters), whereas the recognition of language-specific bigrams depends on knowledge of the bilingual lexicon. In our experiments, words from both languages of the bilinguals were included. We manipulated the task demands by having either both languages as target languages in a language decision task (Experiment 1) or one language as a target language in a mixed lexical decision task in which words of both languages were present (Experiments 2 and 3). In lexical decision, the target language was either L2 (Experiment 2) or L1 (Experiment 3). As a consequence, the opportunities for language-specific marker effects to arise were manipulated across experiments.
The stimuli in all experiments involved three categories of more or less language-specific items. First, an item (word or nonword) was considered to have unique orthography for a language when it contained a letter that does not occur in the bilingual's other language. For example, for Bokmål–English bilinguals the word “smør” is definitely Bokmål, because “ø” does not occur in English words. Second, an item was called marked for a language when it consisted of letters that occur in both languages, but based on the frequencies of its constituent bigrams was nevertheless typical for either Bokmål or English. For example, the English word “whale” contains the bigram “wh”, which is extremely rare in Bokmål. The last category of items consisted of words with a neutral orthography that is very common in both languages, such as “stime” and “mend”. Marked and neutral words were selected using a metric developed specifically for this study that takes the bilingual's full lexicon into account. The metric is described in the section on Stimulus Materials. In all experiments, cross-language neighbourhood size and cross-language Orthographic Levenshtein Distance (OLD20) (Yarkoni, Balota, & Yap, 2008) were controlled. 1
We failed to obtain any effects of within- and between-language neighbourhood density variation in four Norwegian–English experiments. It is possible that our manipulation of stronger markers such as language-specific letters and bigrams underlies this null effect or that the density variation in our study was not large enough to elicit effects. However, a review of neighbourhood density studies by Ferrand (2001, pp. 97–98) shows that null effects are reported in such studies almost as often as inhibition or facilitation effects.
The following predictions were made for each experiment separately and the experiment series as a whole. In the first experiment, the participants performed a Bokmål–English language decision task with Bokmål and English words. In this experiment, Bokmål-specific orthography was always both a reliable identification cue and a reliable decision cue, because words with such orthography always required a Bokmål response and never an English response. The same held for English-specific orthography. Therefore, facilitatory effects (faster language decisions and fewer errors) of language-specific orthography were expected for both languages.
In the second experiment, the task was changed into a mixed English lexical decision task. The response diagnosticity of language-specific orthography for English was removed by replacing half of the Bokmål words from the stimulus list used in Experiment 1 with English-derived nonwords. In this situation, English words required a “yes” decision, but English-derived nonwords and Bokmål words required a “no” decision. For Bokmål words, language-specific orthography was still diagnostic for the response, so facilitation is expected there. However, if language-specific orthography indeed was used as a decision cue, the effect for English specific orthography should disappear. Furthermore, if participants would nevertheless attempt to use unique letters or bigrams as a basis for their “yes” decision for English words, this should lead to an increased error rate for nonwords having the marker in question (because the marker has no validity as a decision cue). If it was an effect on word identification, however, the effects from Experiment 1 should remain, as orthography remains a reliable identification cue.
The third experiment was a mixed Bokmål lexical decision task with Bokmål-derived nonwords and English words; thus, the response diagnosticity of the Bokmål orthographic markers was removed. For English, orthography was again informative with respect to the correct response. In this experiment, we expect a facilitatory effect of language markers for English words, but not for Bokmål words (opposite to Experiment 2).
All experiments are first reported and analysed separately. In the General Discussion, we provide an overall analysis comparing the three experiments in terms of the stimulus list composition factor, which was varied across experiments. We also relate any observed language-marker effects to current bilingual word recognition models. As we argue, at present all models are underequipped to handle marker effects without considerable adaptation.
General method
Stimulus materials
To allow between-experiment comparisons, all three experiments used a subset of the same selection of Bokmål and English stimuli. To avoid repetition, stimulus selection is considered in this section. To make choice of stimulus materials possible at all, we first constructed a Bokmål lexical database, which is described in Appendix A. Next, to select items with language-specific orthography in an optimal way, we considered the approaches taken by other authors and then developed our own measure on the basis of statistical considerations. Using the Bokmål database and our definition of sublexical language specificity, we then selected the stimuli for the three experiments. All stimulus materials can be found in Appendix B.
Defining language specificity
Previous studies have used various measures for selecting language-specific stimuli. In their selection of English and French language-specific and neutral words, Grainger and Beauvillain (1987) considered a letter string to be orthographically neutral if it was pronounceable in both languages. A letter string was considered orthographically specific if one or more bigrams or trigrams were orthographic exceptions in the nontarget language.
For a subsequent study, Thomas and Allport (2000) let bilinguals rate a list of words for language specificity and found that the more language-specific a word was judged, the less probable the occurrence was of at least one of the bigrams or trigrams in the other language.
Vaid and Frenck-Mestre (2002) considered a word to be language specific if it contained bigrams that are only frequent in one of the languages. Beauvillain (1992) used average rather than minimal bigram frequencies. All of these studies showed that bigram frequency can be used as a marker of language specificity, and all found significant effects of language specificity on measured reaction times. At the same time, there is no shared systematic method to measure language specificity.
If language specificity is defined as the probability that a word belongs to a particular language on the basis of its orthographic structure, probability theory can be used to construct a more objective measure of language specificity. The probability that an item occurs in a certain language, based on only the frequencies of its constituent bigrams, can be computed by multiplying the (position-specific) probabilities of the individual bigrams in that language, naively assuming independence of these bigrams:
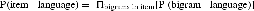
This formula computes the probability of the word in either Bokmål or English, but this does not immediately indicate how language specific the item is. However, using Bayes's theorem, we can reverse language and item and get the probability of a given item belonging to Bokmål (assuming no prior bias for English or Bokmål):
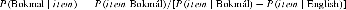
This value is referred to as the Bokmål probability, although it is just as much an indicator of English specificity: A high value (approaching one) indicates that the word is very Bokmål specific; a low value (approaching zero) indicates that the word is very English. A value of .5 means the word is language neutral.
The probability for a specific bigram was computed depending on its position in the word. We calculated separate probabilities for the first bigram position, last bigram position, and bigrams in between. The bigram probabilities were computed from the 3- to 5-letter words in the Bokmål and English lexicon.
What distinguishes this measure from the previously used criteria for language specificity is that it naturally and objectively takes into account the bigram frequencies of all words in the bilingual lexicon at once. It is literally the probability that, given only the sublexical information in bigrams, a guess for Bokmål would be correct. This makes it very suitable for the current purpose.
Stimulus selection
In the experiments, items from four possible language categories were included, depending on the stimulus list composition for the specific experiment: Bokmål words, English words, Bokmål-derived nonwords, and English-derived nonwords. For each language category, items with three levels of language specificity were selected using the Bokmål probability measure described in the previous section.
Letter strings were orthographically unique Bokmål if they contained an “å”, “æ”, or “ø”. Items with English unique orthography contained one of the letters “c”, “q”, “w”, “x”, or “z”. A letter string was considered to be marked for Bokmål if it had a Bokmål probability higher than .85, and marked for English if it had a Bokmål probability lower than .15. Letter strings were language neutral if they had a Bokmål probability around .5. Marked and neutral words did not contain any of the letters that make a word unique.
The Bokmål items were selected from the lexical database we constructed, and English items were taken from the CELEX database (Baayen, Piepenbrock, & Van Rijn, 1993). The Bokmål items did not contain any letter strings that also form a valid word in English, and vice versa. The Bokmål-derived nonwords and English-derived nonwords were created by changing one letter in a Bokmål or an English word, respectively. All created nonwords formed a pronounceable and orthographically legal string in the language from which they were derived. None of the nonwords were orthographic neighbours of a selected Bokmål or English item. Also, care was taken not to include nonwords that were homophonic to valid Bokmål, Nynorsk, or English words. 2
The intimate correlation between orthography and phonology in a relatively shallow orthography like Bokmal precluded including phonotactics as a separate variable in our experiments (the “unique” conditions are “unique” for both orthography and phonology, for instance). The deep orthography of English complicates the examination of phonological factors even further. Future studies should investigate the possible contribution of phonology using dedicated experimental designs.
For each language category and orthographic category, 16 noncognate items were selected as test words for each experimental condition, as well as 4 fillers. Within each language category, the orthographic categories were matched on length, frequency of occurrence per million words (in Bokmål or English, when applicable), and neighbourhood size (in Bokmål and English). Across language categories, items were also matched on length. Orthographic specificity for Bokmål-derived nonwords was determined as if the items were Bokmål words, and orthographic specificity for English-derived nonwords was determined as if the items were English words. After analysis of the results, we also calculated the OLD20 (Yarkoni et al., 2008) of the items in Bokmål and English. The descriptive statistics of the test stimuli can be found in Table 1.
Descriptive statistics of the stimuli selected
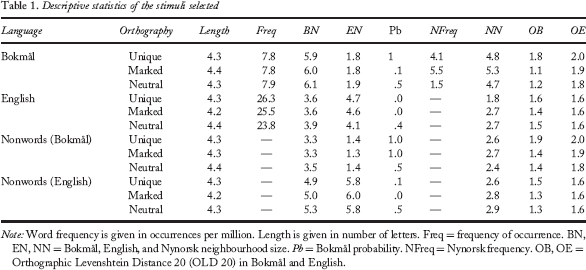
Note: Word frequency is given in occurrences per million. Length is given in number of letters. Freq = frequency of occurrence. BN, EN, NN = Bokmål, English, and Nynorsk neighbourhood size. Pb = Bokmål probability. NFreq = Nynorsk frequency. OB, OE = Orthographic Levenshtein Distance 20 (OLD 20) in Bokmål and English.
To keep the stimulus lists the same length for each experiment, 20 additional filler items were selected per category for Bokmål, English, and Bokmål-derived nonwords. They were never included in the analysis.
After the experimental results had been collected, the Bokmål word “fabel” and the English-derived nonword “shane” were removed from the set of test words because they had an error rate of more than 30%, and “shane” was recognized as an Irish name. This did not significantly disturb the matching of experimental conditions.
Experiment 1: LANGUAGE DECISION
Method
Participants
Twenty Norwegian late bilinguals (10 women and 10 men, mean age = 26.4 years), all right-handed and with normal or corrected-to-normal vision, participated in the study. The participants had learned and used Bokmål as their primary writing system in primary school and reported to encounter and use almost exclusively Bokmål. All were native speakers of Norwegian and had studied English at school for a minimum of six years. Based on the results of a questionnaire and spoken interactions with the experimenter, all participants were judged to be highly fluent in English. More specifically, they rated their frequency of reading and hearing English at, respectively, 4.1 and 5.9 on a scale of 1 (never) to 7 (a lot). Participants were paid for their participation.
Stimuli and design
In this experiment, the 120 Bokmål (48 test items and 72 filler items) and 120 English stimuli (also 48 test items and 72 filler items) described in the section on Stimulus Materials were presented in a pseudorandom order. This conforms to a 2 × 3 design of language (Bokmål, English) by orthography (unique, marked, neutral). The stimuli were divided into two matched blocks of 120 items, Block A and Block B. Half of the participants first saw Block A and then Block B, and the other half first saw Block B and then Block A. An additional filler item was added at the beginning of each block, so that each block had 120 trial transitions. In this way, each of the 12 experimental conditions occurred as often in a language switch position as in a nonswitch position. One group saw half of the words in a switch condition and the other half in a nonswitch condition. This was reversed for the other group. Furthermore, no more than four items requiring the same response occurred in a row. Within these constraints, the order in a block was randomized separately for each participant.
Procedure
The stimuli were presented on a 17′ Dell 85 Hz CRT Trinitron screen, positioned at 60 cm from the participant, in a lower-case black 18-point Courier font on a white background. Presentation was controlled by an Apple Powerbook, and response times were measured by a button box developed at the Donders Institute for Brain, Cognition, and Behaviour. Before the experiment, participants were informed about their task by an instruction written in Bokmål. All other communication with the experimenter was in English. Participants saw series of words on the screen, one at a time, and were told to decide as quickly and accurately as possible whether each of the presented items was a Bokmål or an English word. They were asked to press one of two buttons with the index finger of their dominant hand if the word was Bokmål and the other button with the index finger of their other hand in case of an English word.
First, the participants saw 22 practice words in a training session. After that, the two blocks of 121 words each were presented with a short break in the middle. Prior to the presentation of each item, a fixation dot appeared on the screen. After 500 ms, the dot disappeared, and the stimulus was presented immediately. It remained on the screen until a response was generated or until a 1,500-ms deadline was reached. The next trial followed 2,000 ms after the previous stimulus had disappeared from the screen. After the two blocks, participants filled out a questionnaire on their experience with the Norwegian dialects and writing systems, their proficiency in English, and their exposure to other languages. The experiment took about 30 min.
Results
The data from two participants were excluded from the analysis. One had a mean response time (1,043 ms) that was more than two standard deviations above the participant mean, the other had an error rate (15.8%) that fell more than two standard deviations above average. Furthermore, erroneous responses (3.7%) and reaction times that fell more than two standard deviations from the participant and item mean (2.1%) were excluded from the analysis.
A 2 × 3 (Language × Orthography) analysis of variance was performed on the mean response times and error rates separately. In the participant (F1) analysis, language and orthography were treated as within-subject factors. In the item (F2) analysis, they were between-subject factors. The minF′ analysis is also reported (Clark, 1973). All significant effects were reliable at p < .05. Confidence intervals (95%) for the differences between the means are reported in the text for all significant effects. All reported means and confidence intervals are based on the participant analysis. No pooled variance was used, because we expect different mechanisms to be used by the participants for responding to the separate orthographic categories. The mean response latencies, standard errors, and error rates are presented separately for each language in Table 2. The analyses of variance are summarized in Table 3.
Mean response latencies, standard error, and error rates of participants in all experiments
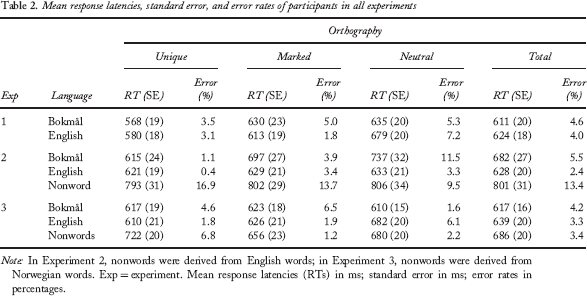
Note: In Experiment 2, nonwords were derived from English words; in Experiment 3, nonwords were derived from Norwegian words. Exp = experiment. Mean response latencies (RTs) in ms; standard error in ms; error rates in percentages.
Summary analysis of variance of language by orthography in all experiments
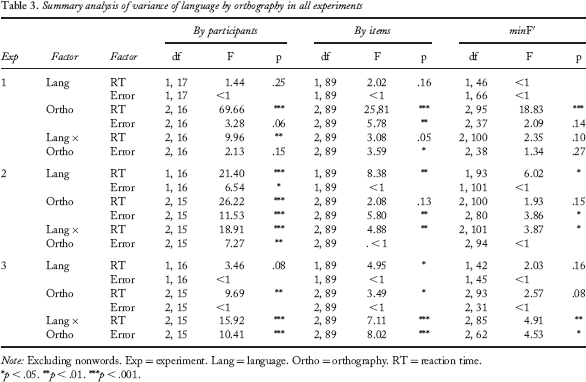
Note: Excluding nonwords. Exp = experiment. Lang = language. Ortho = orthography. RT = reaction time.
p < .05.
p < .01.
p < .001.
No significant differences were found in responses times or errors between Bokmål and English items. However, participants were clearly inclined to use orthographic cues to speed up their responses to words; the main effect of orthography on RTs was significant. Responses to words with a unique orthography were faster than responses to both marked (confidence interval, CI = ±16 ms) and neutral words (CI = ±14 ms). Marked words were also responded to faster than neutral words (CI = ±16 ms). The effect of orthography was not significant for accuracy. Because there was a tendency for the interaction between language and orthography to be significant, responses to each language were analysed separately. The results of this analysis are summarized in Table 4.
Summary analysis of variance of orthography separately for each language in all experiments
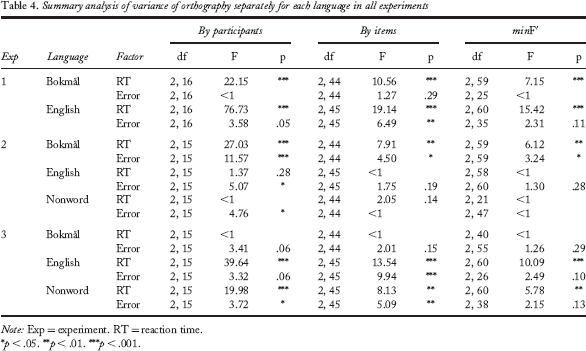
Note: Exp = experiment. RT = reaction time.
p < .05.
p < .01.
p < .001.
Participants were inclined to use orthographic cues to speed up their responses to Bokmål words; the main effect of orthography on RTs was significant. Pairwise comparisons confirmed what is also apparent from the left-hand side of Figure 2—that is, responses to words with a unique orthography were faster than responses to both neutral (CI = ±22 ms) and marked words (CI = ±24 ms). There was no significant latency difference between marked and neutral words. The effect of orthography on accuracy was not significant.

Graphical summary of the mean response latencies (ms) of participants in the three markedness conditions for all experiments. Error rates (%) are given above the reaction time bars of each condition. Experiment 1: Norwegian–English language decision; Experiment 2: English lexical decision; Experiment 3: Norwegian lexical decision. Note the reversal of effects for Bokmål and English words in Experiments 2 and 3.
Similar to Bokmål, the effect of orthography on RTs for English words was significant. Orthographically unique words were responded to fastest, followed by marked words. Response times for neutral words were the highest. Pairwise comparisons showed that all these differences were significant (unique–neutral CI = ±17 ms, unique–marked CI = ±16 ms, marked–neutral CI = ±22 ms); hence, the clearer the sublexical language cue, the faster the response. Error rates were not significantly affected by orthographic make-up.
Discussion
Participants in the language decision task were sensitive to the language markers in both Bokmål and English words, as was evident from faster response times for language-specific items than for language-neutral items. These results extend those obtained by Thomas and Allport (2000) and Vaid and Frenck-Mestre (2002) to a new language combination (Bokmål–English) and to new language markers involving unique letters and a Bayesian bigram probability specification. Note that for Bokmål items, no significant difference was observed between marked and neutral orthography, whereas for English items the response times to marked words were significantly situated between response times to unique words and neutral words. Apparently, participants are more sensitive to orthographic cues for their L2 than their L1, a conclusion also reached by Vaid and Frenck-Mestre.
However, these results cannot tell us if the sensitivity to language markers was due to a word identification advantage or a language decision advantage. In this experiment, Bokmål- and English-specific orthographic markers both were diagnostic with respect to the response. Therefore, in the following experiment, the response diagnosticity of English specific orthography was removed by including English-derived nonwords with English-specific orthography that require the same response as Bokmål words. If the facilitation effects are decision based, they should disappear for English, but remain for Bokmål. If the effects are due to the word identification process itself, they should remain for both Bokmål and English.
Experiment 2: ENGLISH LEXICAL DECISION WITH BOKMåL WORDS
Method
Participants
Eighteen Norwegian late bilinguals from the same population as that in Experiment 1 participated in the study (11 women and 7 men, mean age = 29.7 years). They rated their frequency of reading and hearing English at, respectively, 4.5 and 6.6 on a scale of 1 (never) to 7 (a lot).
Stimuli, design, and procedure
In this experiment, the stimulus list was composed of English (48 test items and 72 filler items), Bokmål (48 test items and 12 filler items), and English-derived nonword stimuli (48 test items and 12 filler items), which were presented in a pseudorandom order. This conforms to a 3 × 3 design of language (English, Bokmål, English-derived nonword) by orthography (unique, marked, neutral). The Bokmål words and the nonwords both required a “no” response and were therefore treated as one group in the randomization process. The same procedure was used as that for Experiment 1, except that participants watched the Powerbook screen directly instead of the external CRT. Furthermore, participants were told that they would see letter strings and had to respond with their dominant hand if the string formed an English word and with their other hand if they did not recognize it as an English word.
Results
The data from one participant were excluded from the analysis, because he had an error rate (28.9%) of more than two standard deviations above the participant mean. Additionally, erroneous responses (6.9%) and response times that fell more than two standard deviations from the participant and item mean (1.8%) were excluded from the analysis.
For the Bokmål and English words, a 2 × 3 (Language × Orthography) analysis of variance was performed on the mean response times and error rates separately. The mean response times, standard errors, and error rates are presented separately for each language in Table 2. The analysis of variance is summarized in Table 3.
A significant difference was found in response times between Bokmål and English items. However, the difference in accuracy was not significant. The effect of orthography on response times was only significant in the participant analysis, but the effect of orthography on accuracy was significant. Language-unique words were responded to more accurately than marked (CI = ±2.2%) and neutral words (CI = ±3.9%). Marked words were also responded to more accurately than neutral words (CI = ±24 ms). More importantly, the interaction between language and orthography was significant for response times. Therefore, we decided to analyse each language separately. The results of this analysis are summarized in Table 4.
Orthography significantly influenced response times for Bokmål words. Pairwise comparisons show that responses to words with language-unique orthography were significantly faster than responses to both marked (CI = ±24 ms) and neutral words (CI = ±21 ms). Marked words were also responded to faster than neutral words (CI = ±21 ms). Error rates were also significantly different, where responses to neutral words were less accurate than those to unique (CI = ±4.4%) and marked words (CI = ±4.3%).
The effect of orthography on response times for English words was not significant; the effect on accuracy was only significant in the participant analysis and only for unique words compared to marked (CI = ±2.0%) and neutral words (CI = ±2.6%).
The response times for nonwords were not significantly different for each of the orthographic categories. Accuracy only differed significantly in the participant analysis, where unique items were responded to less accurately than neutral items (CI = ±5.1%).
Discussion
Let us consider the results for Bokmål words, English words, and nonwords in turn. The results for Bokmål words (requiring a “no” response) were similar to those in the previous experiment. Figure 2 reflects that orthographic markers of Bokmål items affected both their response times and error rates. In other words, adding English-derived nonword items to the stimulus list did not lead to a significantly different use of language-specific markers for Bokmål, as confirmed by a between-experiment comparison (Table 5). This is expected by both the word identification advantage and language decision advantage hypotheses.
Between-experiment comparison

Note: Exp = experiment. The facilitation is the absolute time between the means of the fastest and slowest word type.
However, the decision advantage hypothesis is favoured by the absence of effects of language markers for English words. Because there was a marker effect for the exact same set of stimuli in Experiment 1, and orthography remained a reliable identification cue, the identification advantage hypothesis predicted a similar effect in Experiment 2. However, this effect was not obtained, and the difference with Experiment 1 was significant (Table 5). In contrast, the decision advantage hypothesis correctly predicts that, when language markers lose their response diagnosticity, the facilitation effect disappears.
In addition, there was no effect of language-specific orthography for nonwords. This is predicted by the language decision view as well, because orthography was not response diagnostic for nonwords (English words contained the same orthography). It is also indirect evidence against a word identification advantage, because other studies (Lemhöfer & Dijkstra, 2004; Lemhöfer & Radach, 2009) have shown that nonword rejection in lexical decision is affected by language cues (at least under conditions where neighbourhood density was not controlled for). Note that in our study, the nonwords were first and above all included to remove the diagnosticity of English orthography for responses to English words.
Figure 2 shows that responses to nonwords with English-specific characters were relatively inaccurate compared to marked and neutral nonwords. Because nonwords required the same response as Bokmål words, nonwords wrongly judged to be Bokmål were not discernable as errors. Nonwords with neutral orthography are more likely to be mistaken for Bokmål than English-specific nonwords. Thus, a higher proportion of the misjudged neutral nonwords is counted as correct, increasing the measured accuracy compared to English specific nonwords. Therefore, the difference in accuracy for nonwords might be (partially) ascribed to this aspect of the experimental design.
The slightly improved accuracy of responses to English words with unique orthography compared to marked and neutral English words was only significant in the participant analysis. This tendency can be explained by a response bias due to the experimental design. Because there were twice as many unique English words (“yes”) than unique English nonwords (“no”), the speed–accuracy trade-off that participants choose could result in a response bias for “yes” when English unique orthography is detected. Thus, even though it was not a diagnostic property, participants still appeared to detect the presence of English-specific orthography. This suggests that, although it can be used or not, the detection of language-specific orthography cannot be turned off.
The disappearance of the orthographic effect for English words stands in contrast with results by Thomas and Allport (2000, Experiment 1) who found that, in an English–French generalized lexical decision task, marked English words were responded to faster than unmarked English words, even though nonwords were marked for English as well. However, they did not control the orthographic neighbourhood of their stimuli. In experiments by Beauvillain (1992), controlling orthographic neighbourhood made effects of language-specific orthography disappear. This finding indicates that the two variables must not be confounded, and conclusions can only be drawn when both are controlled for.
Due to the difference in stimulus list composition, Experiment 1 was a language decision task, whereas Experiment 2 was a lexical decision task. Experiment 3 involved another lexical decision task, but here language-specific orthography was response diagnostic for English items instead of Bokmål. Therefore, the language decision advantage hypothesis predicts an effect opposite to Experiment 2—that is, a facilitation effect of language-specific orthography for English words and not for Bokmål words. The word identification advantage hypothesis, not expecting an effect by task demands and stimulus list composition, predicts a pattern similar to that in Experiment 2.
Experiment 3: BOKMåL LEXICAL DECISION WITH ENGLISH WORDS
Method
Participants
Twenty Norwegian late bilinguals from the same population as that in Experiment 1 participated in the study (13 women and 7 men, mean age = 26.4 years). They rated their frequency of reading and hearing English at, respectively, 3.5 and 5.5 on a scale of 1 (never) to 7 (a lot).
Stimuli, design, and procedure
In this experiment, the stimulus list was composed of Bokmål words (48 test items and 72 filler items), English words (48 test items and 12 filler items), and Bokmål-derived nonword stimuli (48 test items and 12 filler items), which were presented in a pseudorandom order. This conforms to a 3 × 3 design of language (Bokmål, English, Bokmål-derived nonword) by orthography (unique, marked, neutral). The English words and the nonwords both required a “no” response and were therefore treated as one group in the randomization process. The same procedure was used as that for Experiment 1, except that participants were told that they would see letter strings and had to respond with their dominant hand (in most cases their right hand) if the string formed a Bokmål word and with their other hand if they did not recognize it as a Bokmål word.
Results
The data of three participants were excluded from the analysis. Two of them had an error rate (18.9% and 24.5%) of more than two standard deviations above the participant mean; the other participant's mean response time (835 ms) lay more than two standard deviations above average. Additionally, erroneous responses (6.2%) and response times that fell more than two standard deviations from the participant and item mean (2.4%) were excluded from the analysis.
For the Bokmål and English items, a 2 × 3 (Language × Orthography) analysis of variance was performed on the mean response times and error rates separately. The mean response times, standard errors, and error rates are presented in Table 2. The analysis of variance is summarized in Table 3.
No significant difference was found in responses times or accuracy between Bokmål and English items. There was only a tendency for orthography to have a significant effect on response times. However, the interaction between language and orthography was significant for both response times and accuracy. As for Experiment 2, we therefore decided to analyse each language separately. The results of this analysis are summarized in Table 4.
Orthography did not significantly influence response times or accuracy for Bokmål words. The effect of orthography on response times to English words, on the other hand, was significant. Pairwise comparisons showed that responses to the language-neutral words were significantly slower than responses to unique (CI = ±17 ms) and marked words (CI = ±17 ms). The effect of orthography on accuracy was not significant.
The response times to nonwords showed a significant effect of orthography. Pairwise comparisons show that the nonwords with Bokmål-unique orthography were responded to significantly slower than marked (CI = ±24 ms) and neutral nonwords (CI = ±15 ms). The difference between marked and neutral nonwords was also significant (CI = ±18 ms). Accuracy differed significantly in the participant and item analyses, where responses to unique nonwords were less accurate than marked (CI = ±4.2%) and neutral (CI = ±4.4%) words, but no significant difference was found in the minF′ analysis.
Discussion
The result pattern for Bokmål words (requiring a dominant-hand “yes” response) was different from that in Experiment 2. As is also reflected in Figure 2, orthographic markers of Bokmål items affected neither their response times nor their error rates, even though exactly the same Bokmål stimuli showed facilitation of language markers in Experiments 1 and 2. This difference is significant (Table 5). In other words, adding Bokmål-derived nonwords items to the stimulus list removed the response diagnosticity of Bokmål-specific orthography and eliminated the effects of language markers.
In contrast, for English words the significant effect of orthographic specificity that was found in Experiment 1, but not in Experiment 2, has returned to be significant (Table 5). Language cues were clearly used to facilitate responses, which is expected by the decision advantage hypothesis, because of the response diagnosticity of the English language markers, as in Experiment 1.
These results for both English and Bokmål words are exactly opposite to those in Experiment 2. This corresponds with the opposite response diagnosticity of language cues. Because a word identification advantage should not be influenced by that factor, it cannot explain the current results. The results for both experiments have in common that the words for which language markers are a decision cue (English in Experiment 3) were responded to considerably slower than words for which language markers do not aid the decision (Bokmål in Experiment 3).
The experimental design contained the same biases as those in Experiment 2, but for Bokmål instead of English. Inspection of Figure 2 shows that the nonwords with unique Bokmål orthography were responded to slower and less accurately than marked and neutral words. It would appear therefore that participants are trying to use the presence of a unique letter in the item as a cue that a Bokmål word has been presented, delaying the rejection of nonwords with such a letter. This strategy would be understandable, because there are twice as many Bokmål words than Bokmål-derived nonwords in the experiment. This is further evidence that the detection of language-specific orthography cannot be turned off, but only excluded from the decision process. Remarkably, the English-derived nonwords in Experiment 2 showed no such effect, except for a significant difference in only the participant analysis of the accuracy data. The effect of the bias might be more visible in this experiment, because the frequency of the Bokmål words is much lower than the frequency of the English items. The higher accuracy of marked and neutral nonwords is further explained by the fact that an incorrect identification of a nonword as an English word was not counted as an error, because the required response was the same for nonwords and English words (“no”). Such incorrect identification was much less likely to occur for nonword items with unique Bokmål orthography.
General Discussion
In the present study, Bokmål–English bilinguals performed three experiments varying in their performance demands and stimulus list composition. Two of the most frequently used tasks in monolingual and bilingual word recognition were applied. Experiment 1 used the language decision task, whereas Experiments 2 and 3 involved the lexical decision task. The stimulus lists in the experiments consisted of a selection of Bokmål words, English words, Bokmål-derived nonwords, and English-derived nonwords. For each of these categories, words with three levels of language-marking orthographic characteristics were included. By varying the stimulus list composition, the response diagnosticity of the language markers was manipulated.
The aim was to investigate whether bilinguals use language membership information contained in the orthographic characteristics of words to establish a word identification advantage or a language decision advantage. A decision advantage implies that there is a direct connection between sublexical representations and language membership representations. A word identification advantage for orthographically marked words should be independent of the reliability with which the markers in question indicate the correct response. Using orthographic language-specific markers for a language decision advantage, on the other hand, is only profitable when a language marker reliably indicates the correct response. Therefore, the presence of the advantage should depend on the specific stimulus list composition and task demands.
Table 5 summarizes, for all experiments, the reliability of the language markers and the significance of the facilitation effects found for Bokmål and English items. There is an exact match between marker decision reliability and facilitation. Between-experiment analyses, reported in Table 6, confirm that all differences between presence and absence of facilitation effects were significant for both languages. Because of the dependence of the marker effects on stimulus list composition, the most straightforward explanation of the results is that the participants used the language markers to gain a decision advantage. In other words, language markers were used to give the related response possibly even before the word was completely identified, but only if this was profitable given stimulus list composition and task demands.
Results of between-experiment analyses of variance for the experiment by orthography interaction
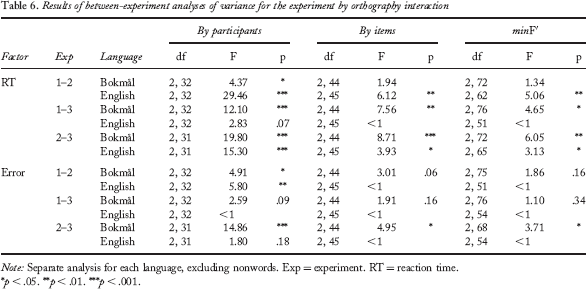
Note: Separate analysis for each language, excluding nonwords. Exp = experiment. RT = reaction time.
p < .05.
p < .01.
p < .001.
The frequency of occurrence of the Bokmål items was much lower than that of the English items. Table 5 shows how this aspect affected the size of the effect in different tasks. Less frequent items with language-neutral orthography take longer to recognize and thus longer to respond to in lexical decision tasks. In language decision, this difference is not influential, because responses can be based on the global activity within a language. Thus, the RT advantage of using an orthography-based response strategy for the relatively low-frequency Bokmål items is much higher in lexical decision (Experiment 2: 122 ms) than in language decision (Experiment 1: 67 ms). For the English items, which were of higher frequency, the effect was even slightly smaller in lexical decision (Experiment 3: 72 ms) than in language decision (Experiment 1: 99 ms).
The absence of an identification advantage in the present study reveals that, apparently, participants do not or cannot restrict their lexical access process to words of the target language only, even when that would lead to faster responses. If this had been the case, the language-specific (i.e., unique and marked) English words in Experiment 2 and the language-specific Bokmål words in Experiment 3 would have been responded to faster and more accurately than language-neutral words. In both experiments, a word's language markers indicated its language membership, but its language-specific orthography did not reliably indicate the correct response. Thus, responses to the items with language-specific orthography would have benefited from an early elimination of all nontarget language word candidates that were activated on the basis of the input letter string. This restriction of the lexical candidate set to one language would have resulted in less competition and faster recognition of language-specific words than of neutral words in all experiments.
Relation to previous research
Focusing on the effects of orthographic markers, the conclusions of our study go beyond those of earlier studies, not only because we used a new type of marker (language-specific letters) and different measures of bigram frequency, but also because we carefully controlled the test items' neighbourhood density characteristics within and across languages. Earlier studies showed that bilinguals were faster to respond when the detection of language-specific orthography was sufficient to determine the correct response (Grainger & Beauvillain, 1987; Thomas & Allport, 2000; Vaid & Frenck-Mestre, 2002), but a clear differentiation based on response ambiguity between L1 and L2 words (in our study, English and Bokmål words in Experiment 2 and 3) was not reported before. As already discussed following Experiment 2, Thomas and Allport (2000) also observed an advantage for language-specific words relative to language-neutral words in a French–English lexical decision task even when the response could not be based on language specificity alone. However, because in their study orthographic neighbourhood density for language-neutral and language-specific words was not matched, it cannot be excluded that this factor was the source of the effect instead. In fact, Beauvillain (1992) found that the effects of language specificity disappeared when orthographic neighbourhood density was controlled for.
The mechanism underlying sublexical language-marker effects
The majority of currently available studies in which language membership information played a role examined the role of this factor at the lexical level. For instance, language decision studies involving cognates (Dijkstra, Miwa, Brummelhuis, Sappelli, & Baayen, 2010) examined how cross-linguistic similarity and item frequency of cognate members affected responding. Because the effect of sublexical item characteristics was not recognized, some puzzling effects were observed with respect to nonword rejection. For instance, Lemhöfer and colleagues (Lemhöfer & Dijkstra, 2004; Lemhöfer & Radach, 2009) found that in L2 lexical decision, nonwords derived from L1 words were rejected at different speeds from those for nonwords derived from L2 words. Their conclusion was therefore that language membership information was quickly available during word recognition. However, this conclusion appeared to be in contrast with lexically oriented literature reviews such as Dijkstra and van Heuven (2002) that concluded that language membership information usually becomes available after word identification. It therefore appeared that, whereas nonword rejection involved language membership information, word recognition would not. However, the present study confirms the nonword results by showing similar results for different types of words. It also resolves the paradox by proposing that there may be both sublexical and lexical sources of language membership information.
The present study leads us to conclude that there are facilitation effects of language-specific orthography that are not caused by faster word recognition, but by a decision mechanism that makes use of language membership information contained in sublexical orthography. There are several ways in which sublexical language information could reach the decision process. First, there could be a more or less direct path from a purely perceptual representation to decision, completely skipping the word identification system. This explanation would not be implausible for the words with language-specific letters, because the letters form unique visual patterns that can be linked to the correct response after only a few stimuli have been seen. However, marked words were selected using a measure based on bigram frequencies. As most of the marked words contain different bigrams, the relevance to the correct response cannot be directly inferred from the stimuli in the experiment. They are only language specific when the organization of the bilinguals' mental lexicon is taken into account. Therefore, if the word identification system was bypassed, no facilitation effects should have been found.
Second, language membership information might be inferred from the activation of words in the bilingual's lexicon. This idea can be likened to the multiple read-out model of Grainger and Jacobs (1996) in which observed global lexical activation is used for responding to nonwords in a lexical decision task. In our study, responses could be based on differences in the aggregated language membership information for Bokmål and English. However, it was already noted before that because neighbourhood density was controlled, the same number of lexical candidates were activated for both language-specific and language-neutral words. Therefore, for differences in aggregated activity to arise, language-specific words must be counted heavier than language-neutral words in its computation. There is little reason to assume this at the level of individual words, because the language to which the words belonged was always known with certainty (there were no cognates or false friends in our study). Furthermore, such a difference in global activation should also result in identification facilitation, which we did not find.
Third, language membership information might be inferred directly from sublexical levels of representation. For example, a Bokmål-specific bigram would contribute more to the Bokmål membership index than to the English membership index, because it occurs in more Bokmål words than English words. In this view, activation at the word level would not directly be influenced by the presence of language-specific orthography, which would be in line with the observed absence of an identification advantage.
The third explanation is the only one that completely fits the results of the present study. It introduces the inference of language membership from sublexical information as an additional notion for bilingual word recognition models. Some models already include a level of language nodes, but these are currently used to represent confirmed language membership information on the basis of word recognition. Clearly, responding to the neutral words in our experiments requires the retrieval of the language membership information of a presented item (Bokmål or English). On the basis of several studies, it has been argued that such information in the visual modality becomes available quickly after word identification, but probably not sooner (Dijkstra, 2005; Dijkstra & Snoeren, 2004; Dijkstra, Timmermans, & Schriefers, 2000). Because this notion of language nodes is based on lexical considerations, an additional type of language node might be required to represent the sublexical language membership information (see de Bot, 2004, for a similar view with respect to bilingual speech production).
The three explanations proposed are independent of whether word identification is language selective or not. However, when assuming language-selective word identification, a fourth explanation of the results could be put forward. In this view, early language information available on the basis of sublexical representations could facilitate responses by suppressing words from the competing language at the lexical level. Because facilitation only occurred in tasks where sublexical language membership information was diagnostic, this proposal would require that the choice to suppress competing words is made early and is dependent on the task demands at hand. However, in our view, the available evidence does not allow us to conclude that such strategies can already be deployed in early stages of word processing. For instance, the finding of task-dependent effects in masked translation priming with primes presented for only 50 ms (Grainger & Frenck-Mestre, 1998) does not necessarily imply that such task effects arise early in target processing (p. 617), and the earlier emergence of cross-script masked priming effects in the electroencephalogram (EEG) relative to same-script conditions (Hoshino, Midgley, Holcomb, & Grainger, 2010) can be ascribed to more efficient processing of the prime stimuli rather than early, task-dependent inhibition of nontarget language items (p. 168).
Yet another interesting position, combining language nonselective and selective views, holds that the bilingual lexicon is increasingly language-specifically organized going from letter input through bigrams to word units. While the letter level would be completely shared by both languages, a partial structural separation might occur at the bigram level, accompanied by an even further (but probably incomplete) separation at the word level. When the bilingual lexicon would be structured like this, language membership could already play a role in prelexical phases of bilingual word recognition. However, it remains to be seen whether such a position can account for all language-nonselective data that have been collected over the last two decades.
Clearly, these options (or assuming no language membership nodes at all) are relevant for current models of bilingual word recognition. For instance, the Bilingual Interactive Activation Plus model (Dijkstra & van Heuven, 2002) includes both a word identification and a task/decision system, but it is not yet equipped to provide a satisfactory account for the present data. It may be possible to include links from sublexical orthography (letters) to language-specific activation aggregators, which are then read out by the task/decision system. A possible extension of the model is shown in Figure 3. However, the model still requires a detailed account of how a decision is reached on the basis of sublexical and lexical language membership information. For example, the details of processing at the sublexical level have not been specified. The processing of letters may take place at an earlier sublexical stage than the processing of bigrams. Furthermore, the experiments were performed using bilinguals with partially overlapping scripts. Whether the results generalize to biscriptal and/or monoscriptal bilinguals depends on how the sublexical level is encoded in each case. This encoding needs to be specified in the model as well.
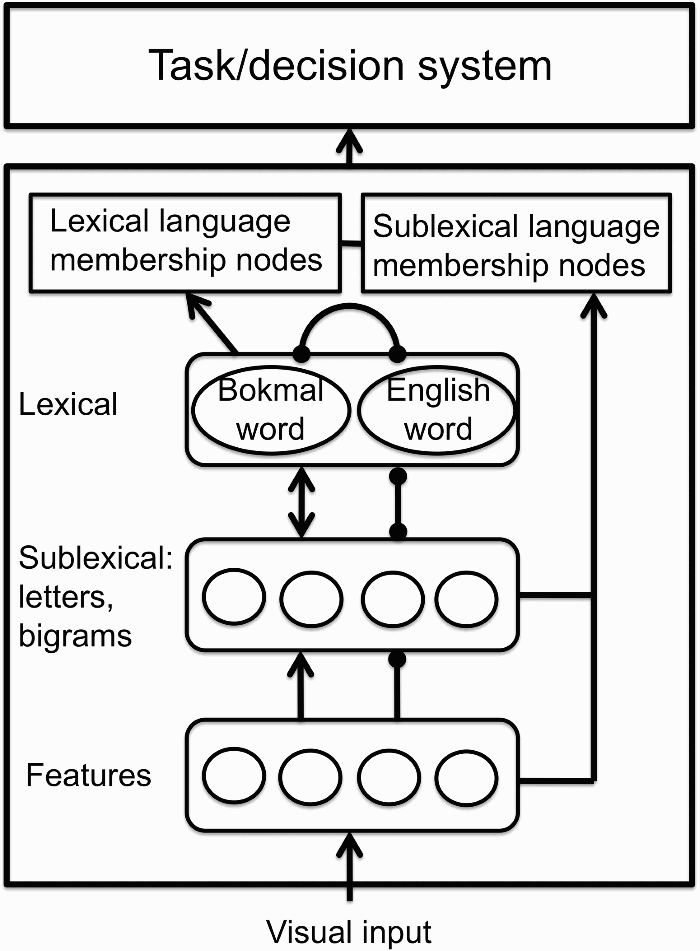
Extension of the Bilingual Interactive Activation Plus (BIA+) model incorporating an additional sublexical link to language membership information.
Bayesian models
So far, we have considered the lexical and language decision processes involving the diagnosticity of sublexical markers from the perspective of activation spreading bilingual word recognition models. However, it must be considered to what extent our results are a reflection of task-specific decision processes rather than of bilingual word recognition itself. Recently, models have been developed that assume participants use all evidence available for decision making (Norris, 2006, 2009; Wagenmakers et al., 2004). In these models, many effects found in lexical decision experiments are explained as strategic effects. The Bayesian Reader model developed by Norris (2006) even claims to make no explicit difference between lexical processing and decision making. Words and experimental items are represented as vectors (created from their constituent letters), and Euclidian distance is used to calculate the distance between vectors. The model assumes that the participants consider the diagnosticity of the evidence provided by previous experimental items for optimal Bayesian decision making. As a consequence, if previously seen nearby items all point towards the same response, participants respond faster. Note that this process is independent of the lexicality of the items involved, because the vector encoding is independent of the contents of the mental lexicon. The predicted effects are therefore not a consequence of lexical processing, but of the availability of (task-specific) evidence. The Bayesian Reader model successfully explains the word frequency effect and various neighbourhood effects and their interaction with word frequency.
To investigate whether the diagnosticity of the evidence provided by previous experimental items is sufficient to explain our experimental results, we used the LD1NN method proposed by Keuleers and Brysbaert (2011). We calculated, for each experiment and orthographic category, what percentage of the experimental items with the closest Levenshtein distance to each item had the same correct response associated as that item. If faster responses correlate with larger diagnosticity, an optimal decision-making strategy can fully explain our experimental results. The results are shown in Table 7.
Percentage of closest experimental items that match in associated response
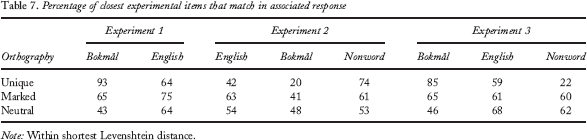
Note: Within shortest Levenshtein distance.
We found that the inherent biases in our experiments calculated this way do not correlate with the response patterns in the experiments. In both Experiments 1 and 3, there is a bias for the correct response for Bokmål unique words (and a smaller one for marked words), but only in Experiment 1 do we find corresponding experimental advantages. Furthermore, in Experiment 2, there is a bias for the wrong response for unique words (and again a smaller one for marked words), but here we do find facilitation for these words. The facilitation we found for English-language-specific words in Experiment 3 is also not supported by the inherent biases. Therefore, when based on a lexically independent encoding, diagnosticity of the available evidence cannot explain our experimental results.
The current series of experiments suggests that language-specific orthography (letters and bigrams) can be used for speeding up responses as long as this language specificity provides diagnostic evidence. The data in Table 7 indicate that bilingual participants can only strategically use information that they are able to detect in relation to their lexicon. A vector space that is independent of the structure of the bilingual mental lexicon provides no way to detect language specificity. To explain the experimental results in such a way, the language-specific items within a language must be positioned closer together than expected based on their Levenshtein distances. That way, they provide no diagnostic evidence when both words and nonwords are included in an experiment. That the structure of the vector space must be influenced by the structure of the mental lexicon has been suggested before. French (1998), for example, showed that in a recurrent neural network, words cluster together based on co-occurrence. If language specificity is encoded in the structure of the vector space, the influence will be task independent and therefore should be attributed to the lexical processing component in a spreading activation framework. This is in line with our earlier conclusion that lexicon-dependent information from the sublexical level may directly activate language membership nodes.
Conclusion
In the present study, language cues only led to improved bilingual performance in lexical decision and language decision tasks when they provided diagnostic evidence for the correct response. This indicates that a language cue functions as a language decision cue and not as a word identification cue. The effect was also shown for language cues based on bigrams, which can only be known to be language specific in previously unseen items when the complete lexicon is taken into account in some way. For bigrams, the diagnosticity of the cues can only be assessed via consultation of the bilingual word recognition system. The required language membership information could be made available directly from the sublexical level in the word recognition system to the task/decision system.
To conclude, the present bilingual word recognition study is innovative and clarifying in several respects. First, after constructing a lexical database for Bokmål (a written norm for Norwegian), we observed language-specific effects for a hitherto unexplored language combination (Bokmål–English) at three (rather than the usual two) levels of language specificity. Second, the language combination Bokmål–English allowed the unique use of items containing characters that only occur in one of the languages (such as “ø” in Bokmål and “w” in English). Third, in contrast to most research on this topic, both within-language and cross-language neighbourhood density were controlled for. Fourth, our study used an objective measure based on the probability of occurrence of bigrams in the two languages to determine language specificity of marked items. Finally, and most importantly, the use of subsets of the same stimulus materials in experiments with systematically varying task demands allowed an in-depth analysis of a hitherto little explored factor in bilingual word recognition: the importance of language-specific sublexical information for making bilingual decisions.