
Abstract
With experience, particular objects can predict good or bad outcomes. This alters our perceptual response to them: Reliable predictors of salient outcomes are recognized faster and better than unreliable predictors, regardless of the value (gain, loss) of the outcome they predict. When attentional resources are constrained, learned value associations matter, causing recognition of gain-associated objects to be spared. Here, we ask how learned predictiveness and value change the way we interact with potentially rewarding objects. After associating virtual objects (drinking flutes) with monetary gains or losses, reaching for and grasping corresponding real objects depended on the object's learned value. Action was faster when directed at objects that previously predicted outcomes more rather than less consistently, regardless of value. Conversely, reaches were more direct for gain- than for loss-associated objects, regardless of their predictiveness. Action monitoring thus reveals how value learning components become accessible during action.
As we negotiate and interact with our environment, we learn about the likely outcome of reaching to pick up particular objects (Cisek & Kalaska, 2005; Pessiglione et al., 2007; Pessiglione, Seymour, Flandin, Dolan, & Frith, 2006; Raymond & O'Brien, 2009). Two glasses of beer may be identical in colour, size, and shape, but the cold one rewards effort, whereas the warm one might not. Here we formulate feedback about the outcome of the interaction in terms of monetary value learning, whereby specific stimuli (that is, goals) come to predict value (gain, loss) or probability of a behavioural outcome.
Goal processing involves calculation of physical properties (e.g., size, distance; Milner & Goodale, 2008) but also the properties of goal-irrelevant objects (Howard & Tipper, 1997). Howard and Tipper (1997) showed that when reaching to green-LED buttons in the presence of red-LED buttons (the cues), inhibitory mechanisms alter the curvature of the trajectory of the hand, such that trajectories curve away from cues that are near the hand. More than just the physical presence and position of objects, however, nonphysical properties such as the semantic information associated with the goal also alter motor output (Constable, Kritikos, & Bayliss, 2011; Glover, Rosenbaum, Graham, & Dixon, 2004; Kritikos, Dozo, Painter, & Bayliss, 2012). Specifically, semantic associations related to the object alter spatial parameters of the reach. For example, concurrently articulated words denoting spatial location (Constable et al., 2011) or size (Glover et al., 2004) systematically alter spatial and grasp parameters of goal-directed actions. Moreover, recent evidence indicates that in reach-grasp-and-lift action, spatial positioning of the goal (a mug) is a function of abstract semantic codes such as perceived self- or other-ownership of the goal (Constable et al., 2011). In other words, there is nonphysical information (meaning) accruing to the object, and the cognitive processing of this nonphysical information becomes evident in motor output measures.
The idea that reward (value) and predictiveness associations alter simple button-press responses to targets has gained ground in recent years (O'Brien & Raymond, 2012; Raymond & O'Brien, 2009; Rutherford, O'Brien, & Raymond, 2010). One of the important manipulations of the paradigms implemented in these studies is that the value and predictiveness information is learned over time. This, crucially, is also semantic information that accrues to the target.
We speculate that value learning and predictiveness of outcome modulate goal-directed action parameters, because value is a semantic property accruing to an object. Thus, as in the beer example above, or when picking up a piece of paper that is actually a $100 note compared with a piece of paper that is a shopping list, the effort is rewarded (or not) by the value the object represents. Importantly, value and the probability that it will occur (predictiveness) are learned and consolidated over several occasions. Thereafter, the behavioural responses still occur, at least for a short term, even though the behaviour is no longer rewarded. Here we show that probability (predictiveness) of action outcome, based on experience, modulates motor output even after responses are no longer followed by gains or losses. This is fundamental to our knowledge of psychological processes because value learning drives decision making and choices in life. In an instrumental value learning paradigm (Pessiglione et al., 2006, 2007; Raymond & O'Brien, 2009) one stimulus was associated with high predictiveness and the other with low predictiveness of monetary outcome (winning or losing). Participants selected one from the pair to maximize winnings. These two aspects of outcome prediction, reward value (win/loss) and predictiveness, appear to be coded by distinct neural circuits (Gottfried, O'Doherty, & Dolan, 2003; Knutson, Fong, Adams, Varner, & Hommer, 2001; Montague, Dayan, & Sejnowski, 1996).
Value and predictiveness learning dissociate in behavioural responses (Raymond & O'Brien, 2009). Raymond and O'Brien (2009) had participants choose between face stimuli in a typical value learning task, such that they became imbued with gain or loss and high or low predictiveness associations. That is, participants could predict the likelihood that they would obtain a reward or incur a loss. After a completion of another object discrimination task, face stimuli were presented briefly and serially in an attention blink task (Raymond, Shapiro, & Arnell, 1992) to constrain attention resources. Participants had to classify the faces as old or new. Constraining attention markedly reduced recognition of loss-associated stimuli but had no effect on recognition of gain-associated stimuli. In contrast, recognition was overall better for stimuli associated with a high versus low predictiveness acquired in the value-learning task, regardless of attention constraints. Thus gain- versus loss-associations enhance attentional competitiveness while the effects of predictiveness seem independent of attention. These findings suggest that different mechanisms may underlie behavioural control resulting from value versus probability learning.
These behavioural modulations are probably underpinned by specific patterns of neural activation. After an object is encountered but before action is initiated, neural activity in the dorsal premotor (Knutson et al., 2001), orbitofrontal (O'Doherty et al., 2004) and prefrontal cortices (Gottfried et al., 2003), and the basal ganglia (O'Doherty et al., 2004) and amygdala (Montague et al., 1996) codes value and probability of potential action outcomes. Midbrain dopamine neurons represent and update the value of reward-predicting stimuli on the basis of experience, providing a learning signal that directs future action (Glimcher, 2011) and encodes prediction errors (Hikosaka, Nakamura, & Nakahara, 2006). Moreover, Cisek and Kalaska (2005) showed in monkeys that dorsal premotor cortex cells coding for action choices can respond to two potential goal locations concurrently. They speculate that this indicates the system weighs costs and benefits of potential actions before a decision is made. The decision may be based on sensory information such as the relative proximity and thus ease of access of the goals (Cisek & Kalaska 2005). We believe it may also be made on the basis of learned information about potential outcomes associated with the target.
We ask whether predictiveness and value learning can be detected distinctly in goal-directed actions no longer followed by gains or losses. We monitored online motor control towards objects associated with different predictiveness–value combinations learned in a value learning task (Raymond & O'Brien, 2009). Pairs of objects (identical physical dimensions but different colours) predicted monetary gains or losses with high or low probability. To isolate the effects of value prediction from those of arousal due to anticipation of the reward itself, we administered the learning paradigm using virtual stimuli on a computer monitor and recorded mouse-click choices. Immediately afterwards, participants selected from pairs of real stimuli corresponding in colour to previously learned ones, this time without reward; here, we recorded participants’ actions with motion capture. We expected that modulations in online motor output would be evident as a function of previously learned (but no longer reinforced) value and predictiveness in the pathway of the hand reaching to the chosen object and in the grasp parameters. Based on previous work (Raymond & O'Brien, 2009), we speculated that there would be alterations in timing parameters for predictiveness of the flutes, such that these parameters should indicate a “speeding up” of movement to highly predictive flutes. Although it is difficult to make predictions about the direction of alteration in trajectory parameters, we postulate that these will be affected, given previous work demonstrating their sensitivity to cognitive processes (Constable et al., 2011; Kritikos et al., 2012).
Method
Participants
Eighteen participants (14 females; mean age 25.72 years, SD = 9.15, range 18–54 years) were tested. All reported right-hand dominance and normal or corrected-to- normal vision. They were informed they would earn financial rewards through the task and that the total reward would be commensurate with their performance, up to a maximum of AUD20. All participants were paid AUD20 at the end of the session, regardless of actual performance.
Design
The experiment comprised of two parts: instrumental learning and postlearning reach-to-grasp task. In instrumental learning, participants either gained or lost 20 cents at each choice with a probability of either .8 or .2, with selection probability (how often each value category was selected) and reaction time (how quickly selections were made) as dependent variables. Financial rewards were discontinued for the reach-to-grasp task, and dependent variables were maximum lateral deviation of the hand (x deviation: maximum deviation of the wrist from an imaginary line connecting the wrist marker's start position and the flute's location in the horizontal plane), peak velocity of the finger and thumb opening, and the time during movement that finger and thumb attained maximum opening. Peak grasp (maximum distance, in millimetres, between thumb and index marker), peak velocity of the finger and thumb closing, time to peak velocity (the time, in milliseconds, from movement initiation at which peak velocity is attained), time to peak velocity (the time, in milliseconds, from movement initiation at which peak deceleration is attained), and movement duration were also calculated. Within-subjects factorial designs were implemented for both tasks with value and predictiveness as within-subjects factors.
Apparatus, stimuli, and value assignment
The apparatus and stimuli are presented in Figure 1(a). Target objects in the reach-to-grasp task were 12 painted plastic flutes (height: 16.3 cm, width at rim: 5.5 cm, photographed at head-on angles). Photographs of the flutes were used as instructional stimuli during reach-to-grasp blocks and as stimuli in the instrumental learning block (visual angle of flute height: 23°, width 7°). For each participant, flute pairs were randomly assigned to gain or loss. Flutes within each gain and loss pair were randomly assigned to high or low probability and retained this assignment throughout the experiment. These values were related to monetary outcomes during instrumental learning and were used as categories in reach-to-grasp analyses.
Experimental paradigm. (a) Value learning task: Participants selected one virtual flute to maximize earnings. For gain and loss pairs, one item (randomly left or right) yielded a win or loss of 20 cents, respectively, on .8 of trials when chosen. The other item resulted in the same size outcome on .2 of trials. Outcome and accrued earnings were displayed immediately. Colour–contingency pairings were counterbalanced across participants. The criterion for successful learning was 65% correct or better for all pair types. (b) Reach-to-grasp task: One of two virtual flutes (randomly left or right) moved vertically (depicted here by an arrow), indicating the action target. Participants reached to grasp the corresponding real target flute as quickly as possible (32 trials per pair type). Reflective markers (12 mm) were placed on the thumb and index fingernails and on the distal processes of the radius and ulna of the right hand. A three-camera infrared motion capture system (100 Hz, < 0.3 mm error; standard filtering) recorded spatial positions. (c) Sequence of events during the reach-to-grasp task: The two flutes initially appeared for 1000 ms, then one was displaced for 2000 ms. Finally, white noise was displayed for 3000 ms while participants performed the reach-to-grasp action. Here, the prompt to reach to a low-gain flute is depicted on the left and that to a high-loss flute on the right.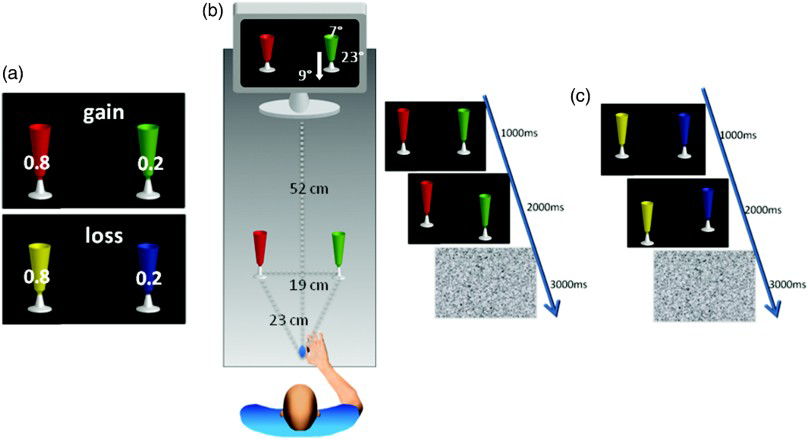
Procedure
Instrumental learning
Participants learned the monetary outcomes associated with flute choice. To ensure genuine reward value encoding, participants were told that winnings would be reimbursed upon the study's completion and that the amount received was contingent on performance. Gains and losses were worth 20 cents, and there were two pairs for each value category. The criterion for successful learning was 65% correct or better for all pair types.
Each flute was presented always with the same partner and an equal number of times on the left and right of the screen. The order of the pairs was randomized within each block. Flute pair randomization and counterbalancing were determined using the Presentation package (Neurobehavioural Systems). At each trial's commencement, a flute pair was presented on the monitor. Participants used their right index and middle fingers to operate the mouse and select the left or right flute. After selection, participants received feedback, either “gain 20c” or “lose 20c”, with a running tally of accrued winnings. There were 600 learning trials—12 (flute pairs) × 50 (trials/flute pair)—in five blocks. In the last (fifth) block, gains and losses were no longer reinforced. Participants were allowed rests between each block.
Postinstrumental learning reach-to-grasp
Gain and loss learning was not reintroduced for this phase. In each trial, one of the 12 flute pairs was placed on the table, one flute to the left and the other to the right of midline [see Figure 1(b)]. These two positions were counterbalanced within the block, such that flutes of each pair were presented on the right or left an equal number of times. The order of the pairs was randomized within each block. Flute pair randomization and counterbalancing were determined using the Presentation package (Neurobehavioural Systems). These locations were counterbalanced across subjects and were reversed in the second block for each flute pair. On a separate monitor, the experimenter was able to see the flute pair of each subsequent trial and thus position on the table the flute pair required for each trial. The trial structure was as follows. Before each trial, the flutes were in their starting positions on the table, placed by the experimenter, and participants had their right hand positioned with their thumb and index finger opposed at the starting position. At the beginning of each trial, two flute images were presented on the participant's monitor for 1000 ms, their positions (left or right of midline) and colours (e.g., green and yellow) corresponding to the relative locations and colours of the real flutes on the table. Next, one flute image was vertically displaced for 2000 ms. This was the cue for participants for movement initiation, upward displacement to move the flute away, and downward to move it towards themselves. Reflective markers (12 mm) were placed on the thumb and index fingernails and on the distal processes of the radius and ulna of the right hand. A three-camera infrared motion capture system (100 Hz, <0.3 mm error; standard filtering) recorded spatial positions of the markers. Participants reached for and grasped the target flute with their right hand, moved it to the indicated location, returned it to its original location, and then returned their hand to the starting position [for locations, see Figure 1(b)]. Finally, a visual white noise mask was presented to eliminate colour afterimages, which might have interfered with the next movement. Intertrial interval was 2000 ms [for trial structure, see Figure 1(c)].
The reach-to-grasp task was administered in two blocks. Both blocks comprised 96 trials: 6 (flute pairs) × 8 (trials/block) × 2 (blocks/flute pair). Within each block, away and toward movement order was randomized to prevent anticipatory movements and motor preprogramming.
Results
Instrumental learning
Preferences for low over high loss and high gain over low gain were evident during the first learning block. The low loss preference remained stable over learning (Cisek & Kalaska, 2005; Raymond & O'Brien, 2009; see Figure 2).
Group means for choice probability (probability of choosing high-loss, high-gain, low-loss, or low-gain flutes) as a function of learning trial number and value: high-loss (red line), low-loss (green line), low-gain (purple line), or high-gain (blue line) flutes across the five blocks of trials in the instrumental value learning task. Note that Block 5 was the extinction block. Preferences for low over high loss and high over low gain were evident during the first learning block. The low loss preference remained stable over learning. The high gain preference increased in magnitude during learning and dropped to a low during extinction. For the gain pair, simple effects of value at Learning Blocks 1, 2, 3, 4, and extinction were significant: F(1, 11) = 42.43, p < .001, 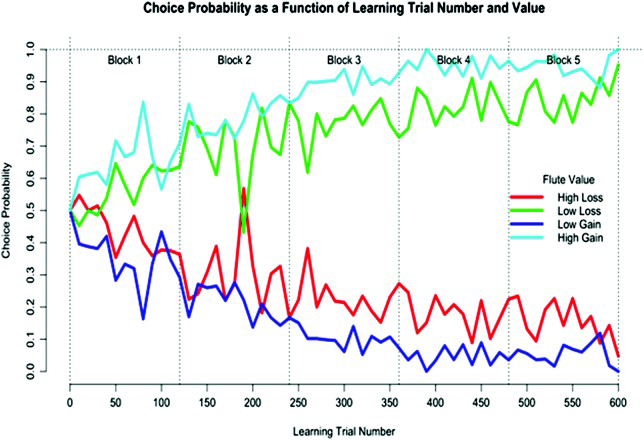
Loss and gain pairs were analysed using separate within-subjects analyses of variance (ANOVAs). For the loss pair, there was a significant main effect of predictiveness, F(1, 11) = 29.96, p < .001,
Postinstrumental learning reach-to-grasp
Despite termination of ongoing reinforcement, value learning modulated movement kinematics in two different ways, consistent with the notion that value and predictiveness associations are dissociable. Actions were more efficient when directed at objects previously associated with gains rather than with losses (a value effect). Specifically, x-deviation was 1.3 mm smaller for reaches directed at gain- than at loss-associated flutes [value main effect F(1, 13) = 9.12, p = .010, For gain- versus loss-associated targets, group mean (a) peak x-deviation was more direct, and grasp opening velocity was faster. (b) Response time (RT) to peak grasp was shorter for targets with high predictiveness. Error bars reflect within-subjects standard error of the mean (SEM).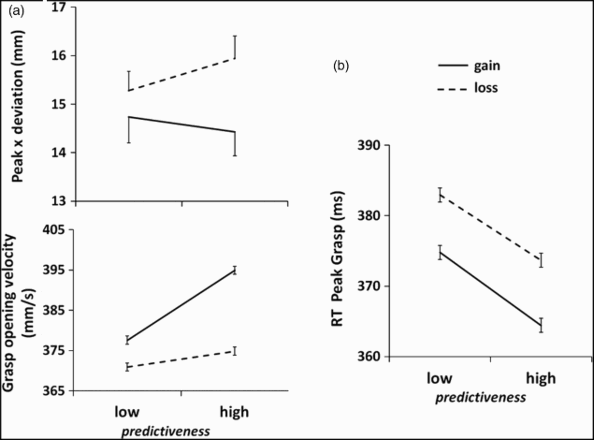
Second, the time between movement onset and the point of maximum finger–thumb separation (RT-peak-grasp) was 10 ms shorter when the action target was associated with high rather than low outcome probability [main effect, F(1, 13) = 9.06, p = .010,
We also calculated two other grasp-based parameters. Main effects and interactions for peak grasp, the greatest separation between thumb and index, during the reach, and grasp closing velocity (the speed with which thumb and index close on the object) were nonsignificant (ps > .05). Moreover, we calculated movement duration (from movement initiation to the point that thumb and index close on the object). Main effects and the interaction were again nonsignificant (ps > .05) 1
Peak grasp value main effect, F(1, 13) = 0.287, p = .601; predictiveness main effect F(1, 13) = 1.252, p = .283; Value × Predictiveness interaction, F(1, 13) = 0.242, p = .631. Grasp closing velocity value main effect, F(1, 13) = 0.745, p = .6404; predictiveness main effect, F(1, 13) = 1.329, p = .576; Value × Predictiveness interaction, F(1, 13) = 2.476, p = .14. Movement duration value main effect, F(1, 13) = 0.188, p = .672; predictiveness main effect, F(1, 13) = 0.578, p = .461; Value × Predictiveness interaction, F(1, 13) = 0.160, p = .696. Time to peak velocity value main effect, F(1, 13) = 0.994, p = .333; predictiveness main effect, F(1, 13) = 0.142, p = .711; Value × Predictiveness interaction, F(1, 13) = 0.961, p =.341. Time to peak deceleration value main effect, F(1, 13) = 0.828, p =.376; predictiveness main effect, F(1, 13) = 0.668, p = .425; Value × Predictiveness interaction, F(1, 13) = 2.012, p = .174.
Finally, for each of the parameters, we separated participants’ reaches when they were placing the flute away from themselves from reaches when they were placing it toward themselves 2
We thank Reviewer 2 for this suggestion.
Discussion
In this study, we asked whether choosing between objects previously associated with high or low predictiveness of gain or loss produced modulations in the online control of goal-directed actions. We expected “speeding up” of timing parameters for highly predictive flutes. Choices were faster to high-gain and low-loss than to low-gain and high-loss virtual objects, replicating previous work (Raymond & O'Brien, 2009). This pattern was maintained when responses were no longer rewarded, indicating that experience and knowledge of likely consequences accrue to objects. When participants reached to grasp the actual objects, action monitoring showed that value prediction influenced distinct components of goal-directed action. Specifically, movements executed toward gain-associated flutes were more efficient than those toward loss-associated flutes, regardless of their predictiveness in two ways: response times and lateral deviation of the trajectory. That is, smaller lateral deviations of the trajectory and faster grasp opening perhaps indicate enhanced processing of highly relevant information (for example, Glover et al., 2004; Howard & Tipper, 1997). In contrast, the target flute's predictiveness distinctly modulated the timing of peak grasp, with high predictiveness associated with earlier peak grasp. An earlier peak grasp also may indicate increased movement efficiency, allowing more time during the movement for grasp “fine-tuning”.
These effects, although small in absolute magnitude, are nevertheless reliable (Constable et al., 2011; Glover et al., 2004; Howard & Tipper, 1997; Kritikos et al., 2012) and demonstrate three important points. First, value learning can transfer to action in contexts different from those in which learning occurred: Learned codes generalized from mouse-clicks to virtual images of flute pairs to reach-and-grasp of a target flute in a pair. Thus value learning can generalize from two-dimensional to three-dimensional stimuli, and from a basic motor system (the fingers) to a more complex one (hand and arm). Moreover, the learned codes continue to exert a subtle and nuanced but significant influence on motor output in this different context, even when outcomes are not forthcoming.
Second, value and predictiveness are distinct and enduring consequences of value learning that have separable influences on the central processes governing motor output beyond response latencies. Lateral (x) deviation of the curvature of the hand's pathway and opening velocity of the grasp varied as a function of value. By contrast, predictiveness, but not value association, modulated timing of grasp during reach. It did not affect the timing of the reach parameters, however (that is, movement duration, and times to peak velocity and deceleration). We speculate that this dissociation indicates the involvement of different cognitive control mechanisms in this task—namely, one sensitive to value learning and the other to predictiveness. As regards lateral deviation and grasp opening velocity, we interpret the pattern of results as indicating a strong preference for, and thus an anticipatory action toward, the stimulus yielding a greater reward. Specifically, the pathway of the hand was straighter, and the grasp opened faster, for highly rewarding flutes. Pathway curvatures have been reported in the presence of irrelevant information (Howard & Tipper, 1997). Thus the straighter trajectory could mean low-rewarding flutes were less salient, attenuating the degree of the curvature. Also, opening grasp velocity is typically higher for larger or less fragile objects and for those located near the hand rather than further distant (Marteniuk, Leavitt, MacKenzie, & Athenes, 1990). Conversely, predictiveness was associated with a temporal measure (Scherbaum, Dshemuchadse, Fischer, & Goschke, 2010): The timing of peak grasp occurred earlier during the reach when outcomes were highly predictable. The earlier grasp opening may indicate faster processing of target features. This would allow proportionally greater time during the movement for precision control over contact with the target, while leaving overall movement duration unaffected. This is consistent with facilitated visual processing when stimuli are highly predictive (Raymond & O'Brien, 2009). As such, we argue that high predictiveness is also associated with increased efficiency of the action. Neither predictiveness nor value altered time to peak deceleration, however, indicating that the latter part of the reach was comparable across all conditions—that is, participants were not adjusting the latter part of their movement.
Third, the dissociation is evident because we were able to analyse more than one aspect of the behavioural output. Different aspects of a single goal-directed action unveil distinct facets of value learning. We show that a single metric, such as response time, is insufficient to describe adaptive behaviour fully when value-associated objects are involved. Trajectories of the hand in particular appear sensitive to cognitive processes (Constable et al., 2011; Howard & Tipper, 1997; Kritikos et al., 2012), though there is also similar evidence for modulation of grasp measures (Glover et al., 2004). Here, we show that modulation of motor parameters can also be a result of past experience with the consequences of actions—that is, value learning. More importantly, the value learning associated with the target is detectable over the short term at least.
Another point is that we found no differences in actions moving towards compared with away from the participant. We may have expected to find such differences because research, for example by Markman and Brendl (2005), shows that associated semantics of targets modulate reaches to targets. Participants saw a word referring to self on the screen and either a positive or a negative word positioned in front of or behind this word. They had to make either pulling or pushing actions with a lever to the words. They were faster to initiate responses to positive words by pulling the lever towards them compared with pushing, and the opposite for negative words. Thus, in the current study we might anticipate a difference depending on whether they reached to bring the flute towards or away from themselves. Specifically, they should be faster to initiate to the higher gain/lower loss flutes when these were brought towards themselves. These differences were not apparent in the results of this paradigm. There are at least two reasons for this: The subtle effects attributable to semantics may only be evident if the pulling/pushing action is the initial step, not the second as was the case in this paradigm. Moreover, it may be that for this analysis we had insufficient trials for each pulling/pushing action.
At this stage we can only speculate about the neural mechanisms of the dissociation in motor output. The value learning established in the initial instrumental learning task was probably underpinned by dopaminergic pathways involving the limbic system and basal ganglia (O'Doherty et al., 2004) and more specifically the ventral pallidum (Hikosaka et al., 2006). These areas are involved in response selection, including the programming and online execution of motor output parameters. Furthermore, based on nonhuman primate studies (Cisek & Kalaska, 2005), it is possible that neurons within the premotor cortex held the two possible actions, reaching to either member of the flute pair, in readiness until an internally generated decision was formulated to choose one over the other.
Given that the objects in our task were physically identical, and that the colour coding was counterbalanced between subjects, the only basis for the decision in the instrumental learning task was outcome probability—that is, predictiveness. Crucially, this pattern of performance continued into the fifth (extinction) block. Subsequently, in the subsequent reach-to-grasp task, financial reward was still not available, but value and predictiveness had distinct impact on motor output.
In sum, our findings show that value predictiveness learning is evident in the execution of goal-directed actions. Thus predictions, or learned value about the possible responses, continue to impact behaviour into the future because they facilitate comparisons among behavioural options. Predictions, and hence choices, enable adaptation (Tobler, Fiorillo, & Schultz, 2005) and are important for well-being—for example, choosing exercise over television, or selecting mineral water over wine from the waiter's tray. We speculate that there are different components of outcome prediction resulting in choice of one stimulus over another. More importantly for this paper, we speculate that subtle patterns of motor output can be used to monitor online components of outcome prediction—in this case, value and predictiveness.