
Abstract
The experiments reported here investigated the format of plural conceptual representations using a picture-matching paradigm. In Experiment 1, participants read sentences that ended with a singular noun phrase (NP), a two-quantified plural NP, or a plural definite description [The parents handed the child the (two) crayon/s] and then saw a picture of one or multiple referents for the NP. Judgement times to confirm that there was overlap between the pictured object(s) and a noun in the sentence showed an interaction between the NP's number and NP–picture match. For singular NPs and two-quantified NPs, participants were reliably faster to respond “yes” to a picture that had the exact number of objects specified by the NP, but for plural definite descriptions, the effect of the number of pictured items was not reliable. Experiment 2 extended this finding to conceptual plurals. Participants read sentences biased toward either a collective (Together the men carried a box—box is interpreted as singular) or distributed (Each of the men carried a box—box is likely interpreted as plural) reading. Experiment 2 showed the same interaction between NP conceptual plurality and NP–picture match as that in Experiment 1. These results suggest that: (a) our default conceptual representations for plural definite descriptions are no more similar to images of small sets of multiple items than to images of singular items; and (b) the difference between singular and plural conceptual representations is unlikely to be simply the presence or absence of a plural feature. The results are consistent with theories in which plurality is unmarked, such that some plural NPs can refer to singular referents [e.g., Sauerland, U., Anderssen, J., & Yatsushiro, J. (2005). The plural is semantically unmarked. In S. Kepser & M. Reis (Eds.), Linguistic evidence (pp. 413–434). Berlin: de Gruyter].
Language comprehension involves constructing syntactic, semantic, and conceptual mental representations from information in the language stream. The current paper focuses on conceptual representations. There has been considerable debate about these representations, focusing on what kinds of information they include and what form they take (e.g., Barsalou, 1999; Johnson-Laird, 1983). This debate has spurred investigation of the representation of many kinds of information; however, notably absent from the debate are discussions about how number information, especially plurality, is conceptually represented. There is evidence that comprehenders represent both morphological and conceptual number (e.g., Berent, Pinker, Tzelgov, Bibi, & Goldfarb, 2005; Humphreys & Bock, 2005; Kaup, Kelter, & Habel, 2002; Patson & Warren, 2010), but how those representations are realized conceptually is not known. For example, it is unclear whether conceptual representations for plurals share properties with images or experiences, or whether they might be amodal abstractions. Furthermore, it is unclear how the issue of highlighting properties of the entire group versus the entities within the group might relate to the format of plural representations. The current paper reports two experiments that begin to explore these issues.
Much of the psycholinguistic work that has focused on plural representations has focused on the referential domain (e.g., Moxey, Sanford, Sturt, & Morrow, 2004; Patson & Ferreira, 2009; Patson & Warren, 2011). Within linguistic theories, referents are usually considered abstract representations of events and entities that can be accessed via anaphors (e.g., Kamp & Reyle, 1993). Language researchers have long argued about what kind of referents and how many referents different kinds of plurals introduce into the referential domain (e.g., Schwarzschild, 1996). As we discuss further below, most plurals, regardless of how specified their numerosity is (e.g., the cats, two cats, etc.), introduce a single referent into the discourse (i.e., a single plural set that can be accessed via the anaphor they; Patson & Ferreira, 2009; Patson & Warren, 2011). Number beyond the gross distinction of singular and plural does not play a large role in referential processing; what does is differentiation, or the ability to distinguish one entity or set from others in the discourse (Patson & Warren, 2011). The question we seek to address in this paper is: Given that number information seems to be only grossly or abstractly represented in the referential domain, does this hold true for the conceptual domain as well? 1
Note that although we refer to separate referential and conceptual representations, the arguments in this paper still hold if there is a single (conceptual) representation, and referential processing is accomplished by routines that are only sensitive to certain features of that representation.
Although, to our knowledge, no one has previously directly investigated the nature of plural conceptual representations, one line of reasoning assumes that they are indeed grossly and abstractly represented, as sets of numerosity greater than (or possibly equal to; see Sauerland, Anderssen, & Yatsushiro, 2005) one with no access to any individuals or subsets within them (i.e., undifferentiated groups). Johnson-Laird (1983) illustrated this with an example like: There were 20,000 fans watching the hockey game at the Joe Louis Arena last night. He argued that sentences like these are perfectly comprehensible, even though it would be impossible to visually, and thus conceptually, represent 20,000 individuals as a collection of singular images. Therefore, he argued, the representations for large plural sets must be abstract in nature.
Although referential and conceptual representations do not necessarily have to be similar, differences in the type of referents that different plurals introduce could be reflected in the conceptual representation. As mentioned above, some recent work has focused on the number of referents that different types of plurals introduce into the referential domain (e.g., Patson & Ferreira, 2009; Patson & Warren, 2010, 2011). This work has shown that even for small, easily visualized plural sets like the one invoked by two fans, comprehenders do not represent distinct referents for each of the individuals that make up the plural set (Patson & Ferreira, 2009; Patson & Warren, 2011). Patson and Ferreira (2009) demonstrated this via a garden path paradigm that diagnoses the properties of a noun phrase's (NP's) referential representation. If the subject of a potentially reciprocal verb (e.g., kiss) in a subordinate–main-clause garden path sentence (e.g., While the lovers kissed the baby cried in the crib) is represented as an undifferentiated group, readers interpret the verb transitively (i.e., the lovers kissed the baby), not reciprocally (i.e., the lovers kissed each other). However, if the subject is represented as a complex reference object (e.g., the bride and the groom)—that is, it allows access to sets or entities within the group—readers interpret the verb reciprocally (see also Patson & Warren, 2011, 2013). Patson and Ferreira's data indicated that plural definite descriptions (e.g., the lovers) and numerically quantified plurals (e.g., the two lovers) introduce a single referent (i.e., the plural set), whereas conjoined NPs (e.g., the man and the woman) introduce three referents (one for each individual, and one for the plural set; see also Moxey et al., 2004).
One question that arises with respect to these abstract representations is whether their number is better represented as more than one versus not more than one (+/− plural) or exactly one versus not exactly one (+/− singular; e.g., Sauerland et al., 2005). Previous psycholinguistic work investigating syntactic number agreement has been consistent with the possibility that plurality is marked (e.g., Bock & Miller, 1991; Gillespie & Pearlmutter, 2011; Kreiner, Garrod, & Sturt, 2013; Vigliocco, Hartsuiker, Jarema, & Kolk, 1996; Wagers, Lau, & Phillips, 2009). However, some work in linguistics suggests that +/− singular is more likely. The evidence for this is that plural NPs can be semantically unmarked for number whereas singular NPs must be used to refer to singular, atomic individuals (e.g., Sauerland et al., 2005). For example, consider the following examples from Sauerland et al. (2005):
You're welcome to bring your children. You're welcome to bring your two or more children.
In a situation in which the speaker does not know how many children the addressee has, the plural in (1) is felicitous even if the addressee only has a single child. However, (2) is only felicitous if the addressee has at least two children, and the speaker knows this. This example shows that plural NPs do not always have to refer to sets of multiple individuals—they can also refer to atomic sets (i.e., a single individual). However, these cases in which plurals can refer to singular referents tend to be ones in which the speaker does not know the specific numerosity of the referent. Given that plurals can be used in this way, it might follow that the conceptual representations of these kinds of plural NPs might be less determinate than those of singular NPs because the number of individuals in the set referred to by the plural could be any number greater than or equal to one.
Although the work just reviewed provides us with possible sources of predictions regarding the conceptual representations of plural NPs, it does not directly test the format of those representations. Zwaan, Stanfield, and Yaxley (2002) provided evidence that the conceptual representations of singulars are grounded in experience and may be image-like. They had participants read a sentence and then judge whether a picture represented an object that had been mentioned in the sentence. Critically, participants were faster to say “yes” when the pictured object's shape matched the shape of the object in the sentence. For example, after reading the sentence The ranger saw the eagle in the sky, participants responded “yes” faster to a picture of an eagle with its wings spread than to a picture of an eagle sitting with its wings folded. This effect reversed for the sentence The ranger saw the eagle in its nest. These data and others (e.g., Richter & Zwaan, 2009; Stanfield & Zwaan, 2001) suggest that comprehenders’ conceptual representations of objects include information like shape, orientation, and colour and are probably image-like. The experiments in the current paper use Zwaan et al.'s (2002) picture-matching paradigm to investigate the nature and specificity of comprehenders’ conceptual representation of plurals.
Experiment 1
In Experiment 1, participants read sentences that ended with a singular definite, a plural definite, or a two-quantified plural (see Examples 3a, 3b, and 3c below). Following each experimental sentence, a picture of one or more objects corresponding to the noun in the critical NP appeared. The picture showed a single object, two objects, or a small set of (3–6) objects (see Figure 1). Participants had to indicate whether or not the pictured object(s) had been mentioned in the sentence; practice items and instructions made it clear the judgement was to be based on object identity and not on number.
(3a) The parent handed the child the crayon. (3b) The parent handed the child the crayons. (3c) The parent handed the child the two crayons. Pictures used in Experiment 1, of (a) a single object, (b) a small set of objects, or (c) two objects.

The predictions of an image-matching account motivated by Zwaan and colleagues (e.g., Stanfield & Zwaan, 2001; Zwaan et al., 2002) findings depend on how linguistic number information is represented in the conceptual representation. Given Zwaan and colleagues’ previous results with singulars, it is reasonable to assume that singular NPs are conceptually represented as relatively specified entities. However, if plural number information is conceptually represented as an abstract feature on a set, as it seems to be in the referential domain, predictions for plural definite descriptions will differ depending on whether that feature is + plural or − singular. If it is + plural, and if that + plural feature matches with pictures of sets of numerosity greater than one, then we would predict a main effect of picture match. Participants should be faster to respond “yes” to a picture of a single crayon after reading a singular NP, but faster to respond to a picture of multiple crayons after reading a plural definite description. If, on the other hand, the abstract feature on a plural set is – singular, given that plural definite descriptions can refer to atomic sets (e.g., Sauerland et al., 2005), then we would predict an interaction between NP type and picture match, such that participants should be faster to respond “yes” to a picture of a single crayon after reading a singular NP, but should have similar judgement times for all pictures after reading a plural definite description. The predictions for numerically quantified NPs depend on how explicit number information is represented abstractly. One possibility is that the plural feature might contain numerosity information when it is specified in the NP (e.g., + plural, numerosity 2). Under this account, we would expect participants to be faster to respond “yes” to a picture of exactly two crayons than to a picture of more or fewer than two crayons after reading a two-quantified NP.
An alternative hypothesis is that conceptual representations are much more detailed (and possibly more image-like) than referential representations (e.g., Stanfield & Zwaan, 2001), and number information is explicitly represented in the conceptual representation. Under this hypothesis, when the number of entities denoted by a NP is explicitly specified in the NP, then that number of entities is represented conceptually. In singular NPs and numerically quantified NPs, the number of entities is made explicit. Therefore, in our experiment, this would predict that participants will be faster to confirm a picture of a singleton after reading a sentence with a singular NP and a picture of two objects after reading a sentence with a two-quantified plural NP than when the number of the picture and the grammatical number of the NP do not match. However, with plural definite descriptions, the number information is less explicit, as the expression could refer to any number (from one to infinity) of entities (e.g., Sauerland et al., 2005). The predictions for plural definite descriptions in our experiment depend on how this “ambiguity” is resolved conceptually. One possibility is that they could simply be represented as an image of a relatively small set of multiple distinct singulars, like Figure 1(b) and (c). Given that all of the plural pictures used in the experiment had this characteristic, this hypothesis would predict that participants would be faster to say “yes” to both kinds of plural pictures than to a picture of a singleton after reading a sentence with a plural definite description. Alternatively, given the lack of number specification inherent in plural definite descriptions, the conceptual representation might not resolve this vagueness. Consider the previously reviewed evidence suggesting that plural descriptions are by default represented referentially as undifferentiated groups, even when the numerosity is specified (Patson & Ferreira, 2009). It is not clear exactly what an image-like representation of an undifferentiated group would be, but it would probably emphasize properties of the group at the expense of properties of the individuals, and it would have to be underspecified in some critical ways. For example, one critical difficulty in creating an image-like representation for the apples in The farmer picked the apples is that the apples could refer to anything from two apples to a basket, or even tractor, full of apples. Alternatively, the default conceptual representations for plurals may simply be too underspecified to have image-like qualities. Under this hypothesis, we would predict that there would be no difference in picture judgement times after reading a plural NP, because all of the pictures would be similarly good or poor matches to the underspecified representation of the plural definite description.
Method
Participants
Sixty-three native American English speaking undergraduates from the Ohio State University at Marion received partial course credit for participating.
Design and stimuli
The experiment had a 3 × 3 repeated measures within-subjects design. The first factor was the grammatical number of the critical NP (singular definite description versus plural definite description versus two-quantified plural), which was the last word of each sentence. The second factor was the picture type. Participants saw a singular picture, a plural picture with exactly two objects, or a plural picture with more than two but fewer than seven objects.
Sixty-three experimental items were divided into nine lists such that each list contained one condition from each experimental item and seven exemplars of each condition (see Appendix A for a list of the singular items used). Each participant viewed one list. The same set of 63 filler sentences was incorporated into each list. Filler sentences were structured exactly like the experimental sentences. However, in all of the filler items, the picture that followed the sentence was not of an item mentioned in the sentence. Thus, the correct answer for the sentence–picture matching judgement was “no” for all 63 filler items and “yes” for all 63 experimental items. Half of the filler items were followed by pictures of multiple objects, and half by pictures with singleton objects.
It was important to verify that the objects in plural and singular pictures were similarly easy to identify. Twenty-two participants from the Ohio State University at Marion who did not participate in any other aspect of this research participated in a norming task. In the task, participants were shown an object name and were asked to decide whether it was a good label for a picture as quickly and accurately as possible. The numerosity of the NP and the object were always matched. That is, participants always saw a plural NP matched with a plural picture and a singular NP matched with a singular picture. Each participant saw one of two lists containing 63 critical items, approximately half of which were singular and half plural pictures. Each list contained 64 filler items. The fillers were a mixture of singular and plural picture/label combinations. The correct answer for all of the filler items was “no”. Fillers were the same for both lists. The trials were presented using E-Prime v.2 experimental software (Schneider, Eschmann, & Zuccolotto, 2002). Each trial was preceded by a fixation cross at the centre of the screen. The participant pressed the spacebar to begin each trial. The fixation cross was replaced by a word (e.g., crayons). The participants read the word at their own pace and pressed the spacebar when they were ready to see the picture. Participants were asked to decide whether the word was an accurate label for the picture. They pressed the “f” key for “yes” and the “j” key for “no”. The picture disappeared when participants pressed a button.
Accuracy rates were high (M = 97%, SD = 0.02%) and did not differ by condition. There was no reliable decision time difference between singular (M = 935.33 ms, SD = 267.56) and plural pictures (M = 928.71 ms, SD = 239.72), t1(21) = 0.22, p = .83; t2(62) = 0.25, p = .80. These data suggest that any differences found between conditions in Experiment 1 are not due to differences inherent in identifying the pictures.
Apparatus
The trials were presented using E-Prime v.2 experimental software (Schneider et al., 2002). A Dell P991 19-inch monitor (800 × 600 pixels; 24 bit) displayed stimuli using a NIVIDIA GeForce3 video graphics card. The screen refresh rate was 100 Hz. Keyboard presses were used to log responses and record reaction time.
Procedure
Participants were tested in groups no larger than six. After providing informed consent, they were given a verbal introduction to the experiment. Computerized instructions guided participants through sample trials, and then they did four practice trials with feedback. Importantly the instructions and practice indicated that participants’ judgements should be based on object identity; they should answer “yes” even if number did not match. For example, one practice sentence ended with the singular noun lion and was followed by a picture of two lions. The correct answer for this item was given as “yes”. Each trial began with a fixation-cross left justified on the computer screen. The cross was then replaced by a sentence. After reading the sentence, participants pressed the space bar, and a picture replaced the sentence. Participants were asked to determine whether or not the picture was mentioned in the sentence. They did so by pressing “Y” for yes and “N” for no on the keyboard. The picture stayed on the screen until participants made their response. Accuracy and response times were recorded.
Results
Comprehension rates for the judgement task were high (98% accurate; SD = 8%) and did not differ reliably by condition. Results for correct trials only were analysed using participants (F1) and items (F2) as random factors. Visual inspection of the data revealed that there were a few extreme outliers, thus data were trimmed at 3.5 standard deviations from the grand mean, resulting in a loss of approximately 5% of trials. The trim did not affect data differentially by condition.
We first analysed the data using a 3 × 3 design. See Figure 2 for means. There was a main effect of NP type, F1(2, 124) = 8.73, MSE = 86,715.36, p = .001; F2(2, 124) = 8.02, MSE = 75,453.49, p = .001. There was also a main effect of picture type, F1(2, 124) = 8.27, MSE = 56,512.96, p = .001; F2(2, 124) = 8.79, MSE = 44,067.08, p < .001. These main effects were qualified by a significant interaction, F1(4, 248) = 7.25, MSE = 76,219.36, p < .001; F2(4, 248) = 7.93, MSE = 58,277.78, p < .001. See Table 1 for post hoc analyses probing this interaction. To account for multiple testing, we used the Bonferroni correction and considered significant only those comparisons for which p < .05/9 (i.e., .0056). The interaction was such that when the NP was a plural definite description, the differences in judgement times for each of the picture types were not reliable. When the NP was a singular description, participants were faster to say “yes” to a picture of one item than to a picture of two items or to a picture of a small set of items. Finally, when the NP was a two-quantified plural, participants were faster to say “yes” to a picture of two items than to a picture of one item or to a picture of a small set of items.
Means (standard errors) for picture judgement times in Experiment 1. Post hoc analyses for Experiment 1 Note: NP = noun phrase. Significance with a Bonferroni correction.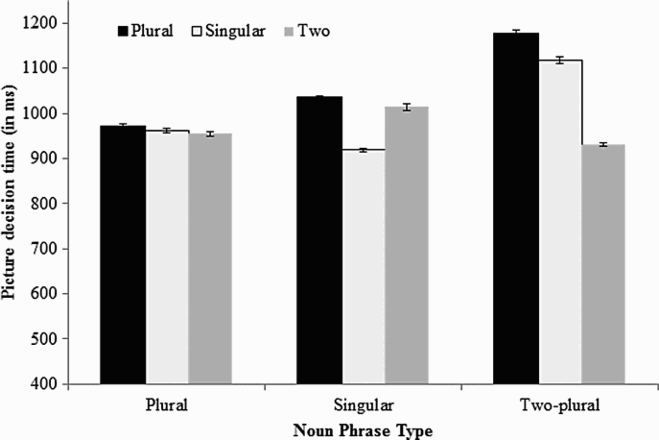
In order to simplify the interpretation of our data, we collapsed picture types across NP types to create two picture categories: match and mismatch. For example, when participants read a plural definite description (e.g., the apples), both the plural picture of apples and the picture of two apples are equally good representations of the NP, because both are plural. Thus, for the plural definite description, we collapsed the two-plural and plural picture categories into a single match category and compared it to the singular picture (i.e., mismatch) condition. For the singular definite descriptions, we collapsed over the same picture types, but refer to that category as the mismatch condition and compared it to the singular picture (i.e., match) condition. Finally, for the quantified plural condition we collapsed over the singular picture and plural picture conditions to create a single mismatch category and compared it to the two-picture (i.e., match) condition. This allowed us to analyse the data as a 2 × 3 design. The first factor was picture type (match, mismatch), and the second factor was NP type (singular definite, plural definite, two-quantified). There was a main effect of picture type, F1(1, 62) = 30.80, MSE = 35,121.01, p < .001; F2(1, 62) = 30.45, MSE = 32,849.11, p < .001, as well as a main effect of NP type, F1(2, 124) = 5.59, MSE = 41,856.66, p = .006; F2(2, 124) = 4.39, MSE = 46,089.14, p = .016. These main effects were qualified by a significant interaction, F1(2, 124) = 8.48, MSE = 47,349.83, p < .001; F2(2, 124) = 12.17, MSE = 26,509.59, p < .001. The interaction showed that differences in picture judgement times between match and mismatch conditions depended on the NP type. When the NP was singular, picture judgement times were faster in the match condition (M = 919 ms) than in the mismatch condition (M = 1025 ms), t1(62) = 3.13, p = .003; t2(62) = 4.17, p < .001. Similarly, when the NP was a two-quantified plural, picture judgement times were also faster in the match condition (M = 930 ms) than in the mismatch condition (M = 1147 ms), t1(62) = 5.38, p < .001; t2(62) = 6.47, p < .001. However, when the NP was a plural definite description, the difference in picture judgement times between the match (M = 963 ms) and mismatch (M = 961 ms) conditions was not reliably different, t1(62) = 0.05, p = .96; t2(62) = 0.49, p = .63.
Discussion
In Experiment 1, participants showed a NP–picture match effect for conditions when the NP was singular and two-quantified, but not when the NP was a plural definite description. This pattern suggests that for NPs with an explicitly specified numerosity, comprehenders conceptually represent that number of items, but when numerosity is left underspecified, comprehenders build underspecified or vague conceptual representations. It is also consistent with accounts wherein singularity, but not plurality, is marked. The current data dissociate between the conceptual representations of plural NPs and the referential representations that they establish. Experiment 1's results suggest that comprehenders conceptually represent exactly two entities when they read two-quantified NPs, but we know that two-quantified NPs only introduce a single plural referent (Patson & Ferreira, 2009). Therefore, these separate conceptually represented entities are not instantiated as separate referents until they are assigned differentiating features (Patson & Warren, 2011).
There is a possible alternate account of the data, in which the lack of effect in the plural definite description conditions could be the result of two opposing mechanisms: a speed-up for the plural pictures driven by a plural match effect and a general slowdown in processing for plural pictures. This account is supported by the long processing times for plural pictures across conditions. However, there are two considerations that weigh against this interpretation of the data pattern. First, our norming results indicate that participants took no more time to match a label with our plural pictures than with our singular pictures, making it unlikely that identifying plural pictures was more difficult than identifying singular pictures in this experiment. Second, this account makes predictions about the singular pictures that are not upheld. If there is a hidden mismatch effect in the plural definite description conditions, there should be a mismatch hit for the singular picture with this kind of NP. But no such hit is evident; judgement times for the singular picture are not reliably different across the mismatching plural definite description condition and the matching singular definite description condition, ps > .10, even though they are longer in the mismatching two-quantified NP condition, t1(62) = 3.59, p < .001; t2(62) = 3.04, p = .003. These effects are consistent with our account that the comprehenders’ mental representations for the plural definite description are so underspecified with respect to number that pictures of the object denoted by the noun phrase are judged as equally acceptable regardless of how many objects are present.
Experiment 2
In language, plurality can be explicitly indicated morphosyntactically (i.e., with an –s in English), as it was in Experiment 1, or it can arise from the conceptual representation built for an utterance. Experiment 2 aimed to replicate and extend Experiment 1 by testing the conceptual representations of conceptually induced singulars and plurals. Examples 4a and 4b provide an example of conceptually induced number.
(4a) Each of the men carried a box. (4b) Together the men carried a box.
In (4a), the portioning quantifier each forces a distributed reading of the predicate carried a box, meaning that a box-carrying event is associated with each man. The most natural interpretation of this sentence is one in which box is conceptually plural; each man carries a different box (e.g., Kurtzman & MacDonald, 1993; Patson & Warren, 2010). In contrast, in (4b) the collective quantifier together indicates that there is a single box-carrying event and that it is the combined effort of the men that is moving the box. Therefore, box is both grammatically and conceptually singular in (4b).
Patson and Warren (2010) provided experimental evidence that comprehenders represent nouns in the position of box as plural in sentences like (4a) and as singular in sentences like (4b). They indexed plurality via a number-interference task modified from Berent et al. (2005). Berent et al. found that comprehenders’ judgements about whether one or two words were displayed on a computer screen were slower to a single plural word than to a single singular word, presumably because plurality interfered with a “one” judgement. Patson and Warren had participants read sentences presented in one- and two-word chunks and at a critical word judge the number of words on the computer screen. Judgements were slower on single words like box in sentences like (4a) than in sentences like (4b), suggesting that they are represented as plural in (4a).
To test whether the findings from Experiment 1 would extend to conceptually induced plurals, we changed our manipulation of NP plurality from being indicated by morphology to being determined by the presence of a distributed versus collective predicate. If comprehenders represent conceptual plurals indistinctly, as Experiment 1 suggests they do for plural definite descriptions, then an interaction like the one in Experiment 1 should be observed. Specifically, participants should be faster to respond “yes” to a picture of a single box than a picture of multiple boxes after reading a collective predicate like (4b), but similarly fast to respond “yes” to either a single or a plural picture of a box after they have read a distributed predicate like (4a).
Method
Participants
Forty-eight native American English speaking undergraduates from the University of Pittsburgh received partial course credit for participating. None had participated in the norming studies or Experiment 1.
Design and stimuli
A 2 (sentence type: distributed versus collective) × 2 (NP–picture match: match versus mismatch) repeated measures within-subjects design was used.
An example of one of the 36 stimulus sentence pairs is given in (4) above (see Appendix B for the full set). In the distributed condition, (4a), the portioning quantifier each forced a distributive interpretation of the predicate and made the critical noun (box) conceptually plural. In the collective condition, (4b), the collective quantifier together forced a collective interpretation of the predicate and made the critical noun conceptually singular. In the match conditions, the distributed sentence was paired with a plural picture (Figure 3b), and the collective sentence was paired with a singular picture (Figure 3a). The pairings were opposite in the mismatch conditions.
Examples of singular (a) and plural (b) pictures used in Experiment 2.
Because a new set of pictures was used in Experiment 2, it was important to verify that pictures of multiple objects and pictures of single objects were similarly easy to identify. Twenty participants from the Ohio State University at Marion, who did not participate in any other aspect of this research, performed the same picture–label matching task as that done for Experiment 1. Accuracy rates were high (99% for both picture types). The small decision time difference between singular (M = 820.40 ms, SD = 188.82) and plural pictures (M = 848.06 ms, SD = 189.19) was not reliable, ps > .1.
The 36 experimental items were divided into four lists such that each list contained one condition from each experimental item and nine exemplars of each condition. Each participant viewed one list. The same set of 36 filler sentences was incorporated into each list. Filler sentences were structured exactly like the experimental sentences. However, in all of the filler items, the picture that followed the sentence was not of an item mentioned in the sentence. Thus, the correct answer for the sentence–picture matching judgement was “no” for all 36 filler items and “yes” for all 36 experimental items. Half of the filler items were followed by pictures of multiple objects, and half by pictures with singleton objects.
Apparatus and procedure
The same apparatus and procedure as those used in Experiment 1 were used in Experiment 2.
Results
Like in Experiment 1, comprehension rates were high. Participants provided correct responses to the pictures on 95% (SD = 4%) of trials. Two items were dropped from analyses due to experimenter error (i.e., during the experimental trials, the picture was stretched and positioned on the screen such that the object could not be identified). Data were again trimmed at 3.5 standard deviations above the grand mean, resulting in a loss of approximately 5% of trials. The trimming did not affect data differentially by condition. See Figure 4 for means. There were no main effects of either sentence type or NP–picture match, all ps > .05. However, there was a significant interaction between sentence type and NP–picture match; F1(1, 47) = 6.11, MSE = 53,888.56, p = .017; F2(1, 33) = 9.33, MSE = 18,743.56, p = .004. After reading sentences with distributing quantifiers (i.e., conceptually plural NPs), reaction times did not reliably differ for pictures of one versus multiple objects (match = 1241 ms, mismatch = 1199 ms), ps > .1. However, after reading sentences with collective quantifiers (i.e., conceptually singular NPs), judgements were faster to pictures of a single object (match condition, 1180 ms) than to pictures of multiple objects (mismatch condition, 1303 ms), t1(47) = 2.40, p = .021; t2(33) = 3.49, p = .001.
Means (standard errors) of picture judgement times in Experiment 2.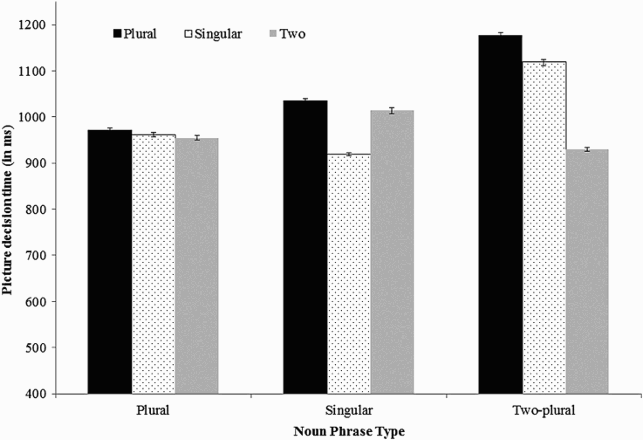
It is important to note that response times to plural pictures were longer than those to singular pictures in both the experimental and the norming tasks (although this was not true in Experiment 1). This may have contributed to the interactive effect observed and could simply indicate that plural pictures take longer to process. In fact, a linear regression indicated that norming judgement times predicted picture judgement times in Experiment 2. The initial model resulted in an R2 = .006, F(1, 1483) = 9.69, p = .002. The standardized regression coefficient for norming judgement time was β = 0.14, t = 3.11, p = .002. In order to determine whether our pattern of data simply reflects difficulty in processing plural pictures, we conducted a repeated measures analysis of variance (ANOVA) on the standardized residual times generated by regressing norming judgement times from experimental judgement times. The analysis over these residuals showed the same interaction as the raw data, F1(1, 47) = 15.11, MSE = 0.12, p < .001; F2(1, 33) = 9.70, MSE = 0.08, p = .004. Again, there was no difference in experimental judgement times when the NP was conceptually plural (each condition), t1(47) = 1.54, p = .13; t2(33) = 0.64, p = .52, but when the NP was conceptually singular (together condition) participants were faster to respond to singular pictures than they were to plural pictures, t1(47) = 4.06, p < .001; t2(33) = 3.62, p = .001. This suggests that the interaction in the experimental task was most likely due to differences in matching pictures to conceptual representations rather than to differences in the difficulty of picture processing.
Discussion
Experiment 2 replicated and extended Experiment 1's interaction between plurality and NP–picture match. Like in Experiment 1, participants showed a NP–picture match effect after reading sentences with conceptually singular NPs, but no match effect after sentences with conceptually plural NPs. Experiment 2's results extended Experiment 1's, because they showed that conceptually induced plurality leads to conceptual representations with similar properties to those of morphosyntactically indicated plurality.
Ramifications of the entire set of findings are addressed in the General Discussion, but Experiment 2 has specific implications for work on quantifier scope. When a sentence has multiple quantifiers, the scope of those quantifiers is ambiguous. For example, the sentence in (5) has two quantifiers: each and a.
(5) Each of the boys carried a piano up the stairs.
One of the quantifiers must take wide scope while the other must take narrow scope. Under any interpretation, this sentence means that there are multiple piano-carrying events, one for each boy that makes up the group “the boys”. If each takes wide scope there is a piano for each boy. The most common interpretation of this reading is that multiple pianos are involved (Kurtzman & MacDonald, 1993). However, it is also possible that each could take wide scope but the pianos associated with the boys all happen to be the same piano. If a takes wide scope there is a single piano that each boy has moved (i.e., the conceptual representation would be the same as that for the reading in which each takes wide scope but all the pianos happen to be the same one). The fact that morphologically singular NPs within distributed predicates in Experiment 2 behaved similarly to morphologically plural NPs in Experiment 1 and differently from singular NPs in both experiments strongly suggests that comprehenders treated the NPs in distributed predicates as plural. In order for this to be the case, they must have assigned wide scope to the distributing quantifiers in these simple sentences. This assignment of scope converges with considerable previous evidence (e.g., Kaup et al., 2002; Kurtzman & MacDonald, 1993; Patson & Warren, 2010), but conflicts with some recent eye-movement evidence demonstrating a lack of scope assignment in relatively complex sentences (Filik, Paterson, & Liversedge, 2004; Paterson, Filik, & Liversedge, 2008). These conflicting findings could indicate that readers assign scope in simple, but not complex, sentences, or they could have arisen from properties of the different methods used to probe comprehenders’ representations.
An alternative explanation of the findings of no difference in judgement times to singular and plural pictures following distributed predicates could be that there are potentially both singular and plural aspects to the conceptual representations of such predicates. For example, a natural reading of Each of the men carried a box is that there are multiple man-carrying-box events, within each of which there is a single box, but across which there are multiple boxes. If singular and plural pictures both match aspects of these representations, it would account for the lack of difference following distributed predicates. However, the fact that a similar pattern and the same lack of difference were found after morphologically marked plurals in Experiment 1 weighs against this account.
General Discussion
Regardless of whether the number of the critical NP in the sentence was indicated morphologically (Experiment 1) or generated conceptually (Experiment 2), after reading a sentence that specified an object's numerosity (e.g., singular NP, two-quantified NP), participants were faster to confirm a picture that contained the same number of that object than a picture of a different number of those objects. However, if the sentence introduced a plural with an underspecified numerosity, participants were similarly fast to respond “yes” to a picture regardless of how many of these objects it contained. These results begin to constrain our understanding of the form of conceptual representations for singular and plural NPs.
Both experiments found that singular NPs better matched a picture of a single exemplar than a picture of multiple exemplars. In a way this seems counterintuitive, because the pictures of multiple exemplars necessarily included images of singletons. However, this finding is consistent with Zwaan and colleagues’ (e.g., Stanfield & Zwaan, 2001; Zwaan et al., 2002) findings of slower processing when a situated NP's secondary characteristics, in this case number, do not match the displayed picture. The fact that neither experiment found a match effect for plural NPs with underspecified numerosities (plural definite descriptions) indicates that a picture of a few singular exemplars matches our conceptual representations for plurals no better than a picture of a single exemplar. This suggests that if our conceptual representations for plurals with underspecified numerosities have image-like qualities, those qualities are not simply those of a small group of exemplars. Additionally, the interaction present in both experiments suggests that our conceptual representations for NPs do not simply have an abstract feature +/− plural, indicating the presence of more than one object, which is matched against the plurality of the pictures. Instead, our findings are consistent with semantic accounts in which singular marking is considered strong and plural marking weak, meaning that singulars require atomic reference (i.e., they must refer to a single, nondivisible entity, like an apple) whereas plurals with underspecified numerosities allow both atomic and sum reference (i.e., a group of atomic entities, like some apples; e.g., Krifka, 1989; Sauerland et al., 2005). Such accounts would predict our results: a mismatch when a singular NP was matched with a plural referent, but no mismatch when plural definite descriptions were matched with either singular or plural referents.
The notion that, semantically, singularity rather than plurality is marked (Sauerland et al., 2005) seems inconsistent with psycholinguistic work on agreement suggesting that, syntactically, plurality rather than singularity is marked (e.g., Bock & Miller, 1991; Gillespie & Pearlmutter, 2011; Kreiner et al., 2013; Vigliocco et al., 1996; Wagers et al., 2009). One of the main findings from this body of psycholinguistic work shows that the processing of singular subject–verb agreement can be disrupted by intervening plural NPs. For example, sentence producers often incorrectly use the plural form of a verb following a complex NP subject such as: The key to the cabinets. The following verb should agree with the head of the NP (key) and be singular, but the grammatical plural marking on the intervening noun (cabinets) seems to interfere and impede singular agreement processing. Importantly, singular NPs do not cause the same disruption in the processing of plural agreement. This has been taken to mean that plurality is grammatically marked whereas singularity is not. Importantly, conceptual plural information has also been shown to disrupt singular syntactic agreement processing (e.g., Humphreys & Bock, 2005; Vigliocco, Butterworth, & Garrett, 1996; Vigliocco, Butterworth, & Semenza, 1995; Vigliocco et al., 1996). For example, Humphreys and Bock (2005) showed that agreement for collective NPs (e.g., gang, group; these NPs are marked as singular in American English) can be influenced by the conceptual representation of the head NP. For example, people were more likely to produce a plural verb after reading a NP that was conceptually distributed (e.g., The gang on the motorcycles) than after reading a NP that was conceptually grouped (e.g., The gang near the motorcycles). These results, taken together with our results, highlight an important distinction between syntactic and semantic processing, as well as the fact that they seem to influence each other. These findings are consistent with the possibility that there may be different kinds of number features, an idea that has been discussed in the theoretical linguistic literature (Sauerland & Elbourne, 2002).
The current results also suggest an interesting distinction between conceptual representations and referential representations. Previous experimental work suggests that quantifying plural NPs with an exact numerosity specifies their numerosity but does not introduce that number of referents (Kamp & Reyle, 1993; Patson & Ferreira, 2009; Patson & Warren, 2011). However, the current findings suggest that comprehenders do conceptually represent exactly two apples after reading the NP two apples. However, we only tested NPs quantified by two. It is likely that NPs quantified with larger numerosities are represented more like plural definite descriptions (e.g., Johnson-Laird, 1983). This would be consistent with work showing that larger number representations are more approximate than smaller number representations (e.g., Dehaene, 1997; Kaufman, Lord, Reese, & Volkmann, 1949; Pietroski, Lidz, Hunter, & Halberda, 2009). Future work will investigate the limits of these types of numerically specified representations.
The current results do more to constrain the potential default form of conceptual representations for plurals with underspecified numerosities than to characterize that form. Although the image-like conceptual representations that Zwaan and colleagues (e.g., Stanfield & Zwaan, 2001; Zwaan et al., 2002) have been gathering evidence for do not preclude underspecification or indeterminacy, the current findings suggest that these image-like representations may not hold for aspects of language that are as underspecified as newly introduced plural definite descriptions. Plural groups have all the indeterminacy that singulars do (e.g., for the apple: shape, colour, size, orientation, whether it's cooked or raw, etc.) but they additionally have indeterminacy about amount. Given that amount can vary between one (cf., Sauerland et al., 2005) and an infinite number, and that the most salient properties of one apple are probably very different from the most salient properties of 4000 apples, specific image-like representations like the ones tested in the current experiments are not likely to fit newly introduced definite descriptions very well. However, the conceptual representation of the plural referent probably depends strongly on context and the reader (e.g., Giora, 2002). If context strongly constrains a newly introduced plural to a small set with particular features, it could be the case that images of plurals with those features match plural NP conceptual representations better than singular images. Future work will investigate this possibility.
Footnotes
Acknowledgements
Financial support from the University of Pittsburgh Honors College and advice from Michael Walsh Dickey, William Horton, Natasha Tokowicz, and Mandy Simons are gratefully acknowledged. We would also like to thank Chelsea Mafrica, Michele Miklos, Amanda Ward, Emily Harbolt, Sam Ludwig, and Hannah Russell for assistance collecting data. We would like to thank members of the Pitt/CMU semantics/pragmatics/sentence processing group and the audiences at Psychonomics 2011 and CUNY 2012 for helpful comments.