
Abstract
In spelling-to-dictation tasks, skilled spellers consistently initiate spelling of high-frequency words faster than that of low-frequency words. Tainturier and Rapp's model of spelling shows three possible loci for this frequency effect: spoken word recognition, orthographic retrieval, and response execution of the first letter. Thus far, researchers have attributed the effect solely to orthographic retrieval without considering spoken word recognition or response execution. To investigate word frequency effects at each of these three loci, Experiment 1 involved a delayed spelling-to-dictation task and Experiment 2 involved a delayed/uncertain task. In Experiment 1, no frequency effect was found in the 1200-ms delayed condition, suggesting that response execution is not affected by word frequency. In Experiment 2, no frequency effect was found in the delayed/uncertain task that reflects the orthographic retrieval, whereas a frequency effect was found in the comparison immediate/uncertain task that reflects both spoken word recognition and orthographic retrieval. The results of this two-part study suggest that frequency effects in spoken word recognition play a substantial role in skilled spelling-to-dictation. Discrepancies between these findings and previous research, and the limitations of the present study, are discussed.
Keywords
Word frequency effects have been found in spelling-to-dictation with skilled adults such that participants are quicker to initiate spelling of high-frequency words than that of low-frequency words upon hearing the target stimuli (Bonin, Fayol, & Gombert, 1998; Bonin & Méot, 2002; Bonin, Peereman, & Fayol, 2001; Delattre, Bonin, & Barry, 2006; Kreiner, 1996). Thus far, researchers have attributed these frequency effects to the time taken for orthographic retrieval—that is, the process of retrieving the spelling of a word from the orthographic output lexicon. This conclusion appears to be based on the assumption that spelling-to-dictation involves only writing or, rather, typing (Delattre et al., 2006). However, spelling-to-dictation also involves listening and identifying the spoken target word. In the conventional procedure for spelling-to-dictation, the dependent variable is latency, measured from the onset of the spoken target word until the writing/typing of the word's first letter. Latency is therefore a composite measure of all the processes involved in the time-window before the writing or typing of the first letter (Bock, 1996; Levelt, 2002; Sternberg, 2001), including spoken word recognition, orthographic retrieval, and the response execution for the first letter (see Figure 1).
Based on the dual-route model for spelling of Tainturier and Rapp (2001) adapted by Houghton and Zorzi (2003), three possible loci were proposed: spoken word recognition, orthographic retrieval, and response execution. Dotted arrows show the lexical route, bold arrows the sound–spelling conversion route. A direct input from semantics is also shown. The alignment of the boxes is modified to accommodate for the illustration of the three processes. From “Normal and impaired spelling in a connectionist dual-route architecture”, by G. Houghton and M. Zorzi, 2003, Cognitive Neuropsychology, 20, p. 117. Copyright 2003 by Taylor & Francis. Reprinted with permission.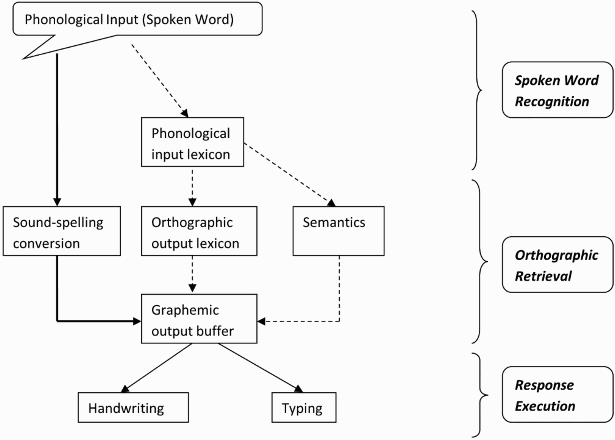
Given that the writing/typing latency reflects not only orthographic retrieval, but also the time taken to recognize the spoken word and to type the first letter, it is possible that the word frequency effects found in the skilled spelling-to-dictation could be located at the spoken word recognition and/or during response execution rather than solely at the orthographic retrieval implied by Bonin, Fayol, and Gombert (1998; see also Bonin, Chalard, Méot, & Fayol, 2002; Bonin, Fayol, & Chalard, 2001), Delattre et al. (2006), and Kreiner (1996). Thus the main aim of the present study was to extend previous research and test whether spoken word recognition during spelling-to-dictation is also sensitive to word frequency effects. Hence, we examined the locus of word frequency effects on latency in skilled spelling-to-dictation at all three loci: spoken word recognition, orthographic retrieval, and response execution of the first letter.
The processing components relevant to these three loci were conceptualized with reference to the dual-route model of spelling (Tainturier & Rapp, 2001; Figure 1). The model explains how the spelling of a spoken target is achieved via lexical and sublexical routes (Bonin, Peereman, et al., 2001; Kreiner, 1996; Tainturier & Rapp, 2001). The operation of these two routes is beyond the scope of the present study but interested readers can refer to Houghton and Zorzi (2003) or Tainturier and Rapp (2001) for further details. Spoken word recognition involves recognizing the phonological input of the spoken target and the subsequent lexical access in the phonological input lexicon. Orthographic retrieval involves the retrieval of the spelling from the orthographic output lexicon via the input from the phonological input lexicon or semantics with possible interaction from sound-to-spelling conversion, followed by the temporary storage of the retrieved spelling in the graphemic output buffer. Response execution of the first letter refers to the initiation of the response—that is, the typing/writing of the first letter.
Although these three loci are well defined in the dual-route model of spelling, there are several gaps in our knowledge with respect to word frequency effects for each locus. First, word frequency effects in spoken word recognition have not been studied in a spelling-to-dictation paradigm yet they have generally been reported in work on auditory lexical decision studies (e.g., Connine, Mullennix, Shernoff, & Yelen, 1990; Goh, Suárez, Yap, & Tan, 2009; Marslen-Wilson, 1990), such that high-frequency words are recognized faster than low-frequency words. According to Dahan and Magnuson (2006), spoken word recognition is a gradual process in which phonological units—that is, word forms—in the phonological input lexicon accumulate their activation in proportion to their match with the incoming phonological input—that is, spoken word (see Figure 1 again). High-frequency words are recognized faster because their resting activation in the phonological input lexicon is higher than that of low-frequency words, so recognition of high-frequency words is easier to achieve (Marslen-Wilson, 1990). Despite the findings for the auditory lexical decision task, word frequency effects on spoken word recognition in a spelling-to-dictation task remain unexplored. It is possible that spoken word recognition in the auditory lexical decision and the spelling-to-dictation differ due to dissimilar task demands: Lexical decision involves recognition and a yes/no response, whereas spelling requires precise sequential production of letters. Nevertheless there remains a gap in our knowledge about frequency effects in spelling to dictation, which warrants a systematic investigation.
Secondly, as mentioned earlier, word frequency effects in spelling-to-dictation were attributed to the orthographic retrieval without taking spoken word recognition or response execution into account. In their hybrid computational model, Houghton and Zorzi (2003) simulated the word frequency effects at the excitatory feedback loop that feeds onto the orthographic output lexicon, which in turn receives feed-forward phonological input. The word's frequency determines the rate at which an orthographic form is activated and selected for spelling production. Although this simulation successfully mimicked the variation of latencies in skilled spelling, Houghton and Zorzi did not specify how the phonological input is achieved from the spoken word recognition, or the mechanisms involved in writing the target spelling out.
Another line of evidence for word frequency effects in orthographic retrieval comes from works on written picture naming (Bonin, Fayol, & Gombert, 1998; Bonin, Peereman, et al., 2001). After ruling out the possible effects of picture recognition, the data seemed to suggest that the word frequency effects in picture naming are attributable to orthographic retrieval. This interpretation is consistent with Rapp and Dufor's (2011) proposal that the orthographic lexicon (see Figure 1) is a long-term memory store that is sensitive to word frequency. The frequency of a word determines how efficiently an orthographic representation is activated by input, either from the phonological lexicon or from the semantic system. The higher the frequency, the faster an orthographic representation is retrieved. However, one problem with this interpretation is that the orthographic retrieval in the written picture naming and spelling-to-dictation may not be comparable because both the inputs (picture vs. spoken word) and task demands are different. Picture naming requires semantic processing, and the target is more ambiguous than a spoken word—that is, the response depends on the participants’ interpretation (Bock, 1996). By contrast, a spoken word could elicit the target orthographic representation without the semantic processing of the picture (Bonin, Fayol, & Chalard, 2001; Sternberg, 2001). Therefore, although word frequency affects the orthographic retrieval in written picture naming, the same may not be true for the orthographic retrieval in spelling-to-dictation given these task differences.
Finally, Bonin, Fayol, and Gombert (1998; see also Bonin, Fayol, & Chalard, 2001) found that the response execution of the first letter was not affected by word frequency when writing latency was measured in a delayed spelling task. For this task, participants listened to the spoken word but only started writing the spelling out after 1200 ms. The writing latency only measured the response execution of the first letter because the spoken word recognition and the orthographic retrieval had been completed during the delay. However, word frequency effects on response execution are found when other measures have been used—for example, interletter duration (Will, Nottbusch, & Weingarten, 2006), the spelling duration in copywriting (Lambert, Alamargot, Larocque, & Caporossi, 2011), copy-typing (e.g., Gentner, Larochelle, & Grudin, 1988; Inhoff, 1991; Massaro & Lucas, 1984; Will et al., 2006), and spontaneous typing tasks (Cohen Priva, 2010). Arguably, these inconsistencies could have arisen because the latency measures go beyond the execution of the first letter, and they may actually reflect complex serial writing/typing (Gentner et al., 1988; Lambert et al., 2011; Will et al., 2006). For this reason, latency in this study will only be measured up to the execution of the first letter. The onset of latency measurement is described separately in each experiment.
In summary, among the three proposed loci involved in the spelling-to-dictation task, word frequency effects on spoken word recognition have been unambiguously supported by empirical evidence from auditory word recognition paradigm but not from the spelling-to-dictation paradigm, and frequency effects on orthographic retrieval have generally been agreed upon in spelling studies where frequency effects were found in the latencies (e.g., Delattre et al., 2006). On the other hand, the response execution of the first letter appears to be unaffected by word frequency. Thus the aim of the present study was to systematically examine whether the word frequency effects observed in the spelling-to-dictation task are due to the spoken word recognition, orthographic retrieval, or response execution in a spelling paradigm when the dependent variable is the latency measured to the first letter. An immediate spelling-to-dictation task combined with a delayed paradigm (e.g., Bonin, Fayol, & Gombert, 1998) was conducted in Experiment 1 to replicate the word frequency effects in skilled spelling-to-dictation and, more importantly, to replicate the finding that the effects cannot be attributed to the response execution of the first letter. In Experiment 2, participants’ performance in a delayed/uncertain spelling task (Almeida, Knobel, Finkbeiner, & Caramazza, 2007) was compared against its immediate/uncertain version to examine the frequency effects on the other two loci of spelling-to-dictation: spoken word recognition and orthographic retrieval.
Experiment 1
In a delayed spelling task, Bonin, Fayol, and Gombert (1998; see also Bonin, Fayol, & Chalard, 2001) asked participants to listen to a spoken word, but withhold their written response for a variable delay lasting between 1200 ms and 1800 ms until a cue indicated that they should start writing. The latency was measured from the onset of the cue to the writing of the first letter. When the delay is sufficiently long, spoken word recognition and the orthographic retrieval that precedes the written response would have been completed during the delay (see Forster & Chambers, 1973, on delayed word naming). At the same time, the response execution of the first letter is blocked by participants’ strategic control during the delay and is only initiated when the cue is shown (McRae, Jared, & Seidenberg, 1990; Savage, Bradley, & Forster, 1990; Sternberg, Wright, Knoll, & Monsell, 1980). Thus, the delay isolates the response execution of the first letter from the spoken word recognition and orthographic retrieval in the spelling-to-dictation task. The latency only captures response execution of the first letter, and therefore word frequency effects at this locus can be examined exclusively.
This kind of delayed paradigm with a cue has also been used in visual and auditory word naming to investigate the effects of psycholinguistic variables on response execution (Balota & Chumbley, 1985; McRae et al., 1990; Monsell, Doyle, & Haggard, 1989; Savage et al., 1990; Wurm & Seaman, 2008). Importantly, Bonin, Fayol, and Gombert (1998; see also Bonin, Fayol, & Chalard, 2001) found no effect of word frequency in a delayed spelling-to-dictation task and therefore suggested that response execution of the first letter is not affected by word frequency. Although these findings were based on null results for frequency, they are salient because for the same delayed spelling-to-dictation task in their Experiment 4, Bonin, Fayol, and Chalard (2001) found a significant effect of the initial sound-to-spelling consistency. The different findings for frequency and consistency in the same delayed task suggested that the null effect of word frequency was not due to the idiosyncratic task demands in the delayed paradigm.
Taken together, these findings provide convergent validity for the delayed paradigm when examining response execution. Therefore, in Experiment 1, a delayed spelling-to-dictation task was used to examine whether there are word frequency effects on the response execution of the first letter. The aim of Experiment 1 was to replicate Bonin, Fayol, and Gombert's (1998; see also Bonin, Fayol, & Chalard, 2001) findings for French spelling with (tablet) writing but in an English spelling-to-dictation task with keyboard typing. Participants were asked to start typing the spoken word either immediately upon the offset of the word (0-ms delay) or upon three other cued delays (400, 800, 1200 ms) after the offset of the word.
The immediate condition (0 ms) establishes a baseline for comparing with the delayed condition and is similar to the conventional spelling-to-dictation task such that it captures all the processes, and it was included to replicate the word frequency effects observed in studies with French-spellers (cf. Bonin, Fayol, & Chalard, 2001; Bonin, Fayol, & Gombert, 1998; Bonin & Méot, 2002). Also consistent with Bonin, Fayol, and Gombert (1998; see also Bonin, Fayol, & Chalard, 2001), the 1200-ms delayed condition is assumed to be sufficient for the completion of both spoken word recognition and orthographic retrieval. No word frequency effect was expected in this condition because it has been shown that word frequency did not affect response execution of the first letter (Bonin, Fayol, & Chalard, 2001; Bonin, Fayol, & Gombert, 1998). However, if a frequency effect is found, even in this longest delay condition, this would suggest that either frequency influences response execution, or the delay is not long enough for the completion of spoken word recognition and orthographic retrieval, which might be sensitive to word frequency (see McRae et al., 1990; Savage et al., 1990, on response execution in delayed word naming studies). Delay longer than 1200 ms would then be needed in order to differentiate these two interpretations. If frequency genuinely impacts response execution, the effect should also be found in other conditions with delay longer than 1200 ms, such that an asymptote of frequency effect will be achieved. Lastly, the intermediate delayed conditions (400 and 800 ms) were included to prevent any strategic anticipation that could happen when only one delay was used (Balota & Chumbley, 1985). Traces of frequency effects of spoken word recognition or orthographic retrieval should be found in these two conditions because the delays are likely to be too short for the completion of both processes. Therefore, a significant effect of word frequency was predicted in the immediate condition and the intermediate delayed conditions, but not in the 1200-ms delayed condition, resulting in an interaction between word frequency and delayed conditions.
Method
Participants
Fifty-six undergraduates, with English as their first language, took part in the experiment in return for course credit or a small compensation, with data for eight of them replaced. Three achieved an accuracy rate below .85 in the spelling task, which was 2.5 standard deviations lower than the mean accuracy rate, or used backspace to make correction more than 24% of the trials, which was 2.5 standard deviations from the mean number of backspace usage; one participant appeared unable to hear the spelling target clearly 1 ; four other participants did not adhere to the instructions. The final sample consisted of 48 participants (17 males, mean age = 22.19 years, SD = 2.08). None reported a history of speech, language, or hearing disorders, and 44 of them used their right hand for writing.
For example, she spelled “cabin” as “cabinet”, “hammer” as “humble”, “doctrine” as “doctoral”, “acclaim” as “accumulate”, “entice” as “tantalise”, “tulip” as “chili”, “concise” as “consistent”, and so on.
Apparatus
Instructions, presentation of stimuli, and data collection during the spelling task were computerized by using E-Prime Version 1.2 (Schneider, Eschman, & Zuccolotto, 2002). Participants listened to stimuli through Sennheiser HD201 headphones and responded by typing on a Dell keyboard.
Materials
Stimuli
The spelling targets consisted of 172 high-frequency and 172 low-frequency English bisyllabic words. The frequency count was taken from the SUBTLCD count of the SUBTLEXus database (Brysbaert & New, 2009). This frequency count is based on the percentage of the films a word appeared in and is a gauge of contextual diversity (Adelman, Brown, & Quesada, 2006). It has also been shown to have better predictive power in visual word recognition than other frequency counts such as those of Kucera and Francis (1967) and CELEX (Baayen, Piepenbrock, & van Rijn, 1993). The raw value and logarithm of the frequency values of the high-frequency words—for example, because, around—ranged from 4.41 to 94.3, and 2.57 to 3.90, respectively, and that of the low-frequency words—for example, infuse, frugal—from 0.11 to 0.63 and 1.00 to 1.73. Each high-frequency word was yoked with a low-frequency word with the same number of letters and with the same initial letter. The number of letters and syllables of the target words had to be controlled because the latency of writing and typing could be affected by these variables (Bonin & Méot, 2002; Sternberg, Monsell, Knoll, & Wright, 1978; Will et al., 2006). The initial letter of both words in a pair was also matched to ensure that the position of the first keystrokes on the keyboard was the same (Weingarten, Nottbusch, & Will, 2004). It was crucial to match the first keystroke position because the latency is measured until the first keystroke.
In addition to this item-wise pairing, the high-frequency words and low-frequency words were also matched group-wise in terms of sound-to-spelling consistency of the onset and rime of each syllable, number of orthographic and phonological neighbours (Coltheart, Davelaar, Jonasson, & Besner, 1977; Vitevitch & Luce, 1998), orthographic and phonological Levenshtein neighbourhood distance (Suárez, Tan, Yap, & Goh, 2011; Yarkoni, Balota, & Yap, 2008), bigram count, phonological uniqueness point, duration of the spoken target, number of morphemes and phonemes, and imageability 2 (Schock et al., 2012), all ps > .1 according to independent-sample t-tests. The descriptive statistics for the psycholinguistic characteristics of the high-frequency and low-frequency words are shown in Appendix A. Lastly, we did not control for the age of acquisition (AoA) of the stimuli because there are no norms available for our participants. Given that Bonin, Barry, Méot, and Chalard (2004) showed that an age-related variable (frequency trajectory) has no effect on spelling-to-dictation, this omission should not result in a confound.
The imageability rating of 78 words not found in Schock, Cortese, and Khanna (2012) was provided by 32 English speakers not involved in any of the spelling experiments.
Recording of the spelling targets
A linguistically trained female speaker produced all the spelling targets in a sound-attenuated recording booth. The spoken words were recorded with the Computerized Speech Lab (CSL) system and were digitized at a sampling rate of 16 bits per 44.1 kHz with a single channel. The words were saved as individual wav-files, and the overall root-mean-square amplitudes were digitally levelled with Adobe Audition Version 3.
Counterbalancing
The 172 pairs of high-frequency words and low-frequency words were divided into four lists of 43 pairs, with the distribution of the initial letter being the same across the lists. The high-frequency words and low-frequency words were matched for the psycholinguistic variables within each list, ps > .05. The four lists were then counterbalanced across the four delayed conditions, resulting in 24 combinations. Two participants were assigned to each combination at random. The order of presentation of the stimuli was randomized for each participant.
Procedure
Participants were tested individually in sound-attenuated cubicles. They were asked to pay attention to the words and the subsequent tone. They were instructed to use only the index finger of their preferred writing hand to type letters and press buttons to ensure that individual differences in touch-typing ability and manual dexterity were controlled for. In order to manipulate the delay, participants were instructed to press the spacebar without releasing it to initiate each trial, and to release the spacebar and start typing the word once the tone occurred. The pressing of the spacebar was included to ensure that all participants started at the same position on the keyboard and only started typing when the tone occurred. The participants were allowed to use the backspace to make any corrections to their spelling response before pressing the “enter” key to go to the next trial.
Each trial began with a screen asking the participants to press the spacebar. A fixation “+” was presented when the participant pressed the spacebar. After 500 ms, the target word was then presented through the headphones. At the offset of the word, the delayed condition varied. For the 0-ms delay, a tone of 117 ms was presented to cue the participant to start typing at the offset of the word, 3 but the same tone was presented at 400 ms, 800 ms, and 1200 ms after the offset of the word in the respective delayed conditions. The fixation “+” remained on the screen until this tone occurred. After the participants had finished typing and pressed the “enter” key, a blank screen was shown for 500 ms before the screen asking the participants to press the spacebar to initiate the next trial. A warning was shown at the end of a trial if participants released the spacebar before the tone occurred in that trial. Participants completed 40 practice trials prior to the 344 experimental trials and took short breaks every 86 trials.
The immediate condition (0-ms delay), in which participants started typing immediately at the offset of the spoken words differed from the normal spelling-to-dictation in the previous studies (e.g., Bonin et al., 1998; Bonin, Peereman, & Fayol, 2001; Bonin & Meot, 2002) where participants could start writing upon the onset of the spoken words. This modification was important because it ensured that the cue always occurred after the spoken words across all the delayed conditions, thereby reducing any confusion that could have arisen from the different temporal organization of the cue and the spoken word.
Design
Experiment 1 was a 4 (delayed condition: 0 ms, 400 ms, 800 ms, 1200 ms) × 2 (word frequency: high vs. low) within-subject design. There were 43 trials in each condition generated by crossing delayed condition and word frequency.
Results
Both accuracy rates and latencies were subjected to participant-wise (F 1) and item-wise (F 2) two-way analysis of variance (ANOVA). An alpha level of .05 was used for all statistical tests. Both word frequency and delayed condition were within-factors in the participant-wise analysis; delayed condition was within-factor, and word frequency was between-factor in the item-wise analysis.
Accuracy rates
Accuracy rates and spelling latencies by participants and by items as a function of word frequency and delayed condition in Experiment 1
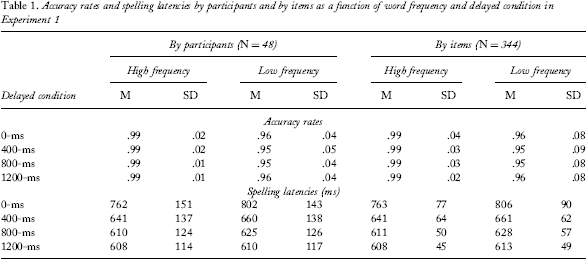
Consistent with previous work (e.g., Bonin, Fayol, & Chalard, 2001; Bonin, Fayol, & Gombert, 1998), participants spelled high-frequency words more accurately than low-frequency words even though the words were matched on all other relevant variables. This frequency effect did not interact with the delay imposed, and no effect of delayed condition was found on the spelling accuracy rate. These findings suggest that any spelling mistakes arise from participants’ inability to recognize the spoken target for low-frequency words and/or inaccurate orthographic knowledge of the low-frequency words (Bonin, Peereman, et al. 2001), rather than any interference from the cue or the time pressure caused by the various delays. Having established that accuracy rates were high, they are not discussed further because they are not relevant to the research questions.
Latencies
The latencies for acceptable trials were measured from the onset of the tone until the first keystroke. Inaccurately spelled trials (2.7%), and accurately spelled trials in which participants corrected the first keystroke (0.4%), released the spacebar before the tone occurred (0.6%), or used more than 3 s or less than 100 ms to type the first letter (0.2%) were excluded. Latencies that were 2.5 standard deviations below or above the individual means for each design cell were also excluded (2.7%). Together these data-cleaning processes resulted in 6.6% of the total number of trials being excluded from the analysis reported here. 4
Another analysis with a more stringent exclusion criterion was also conducted such that trials in which participants used backspace to correct their typing of any letter were also excluded. This stringent criterion was imposed because the latency used to type the first letter of a mistyped response that was corrected might not be a valid indication of how a correct spelling is achieved. This exclusion of corrected trials was also employed by Bonin et al. (1998) who did not allow correction of spelling errors. Nonetheless, the result of this analysis was found to be in the same pattern as the analysis of the less stringent criteria reported here.
The mean latencies by participants and by items are shown in Table 1. The ANOVAs revealed significant main effects of word frequency [F 1(1, 47) = 32.84, MSE = 1023.93; F 2(1, 342) = 22.44, MSE = 6930.80, ps < .001], and delayed condition [F 1(3, 141) = 190.29, MSE = 3255.24; F 2(3, 1026) = 732.20, MSE = 3046.36, ps < .001]. The main effects were qualified by a significant interaction between word frequency and delayed condition [F 1(3, 141) = 9.74, MSE = 643.05; F 2(3, 1026) = 7.02, MSE = 3046.36, ps < .001]. Consistent with the hypothesis, follow-up analysis showed that the spelling of high-frequency words was initiated significantly faster than the spelling of the low-frequency words in the 0-ms delayed condition [t 1(47) = 6.18; t 2(342) = 4.74, ps < .001], 400-ms delayed condition [t 1(47) = 2.63, p = .012; t 2(342) = 2.96, p = .003], and 800-ms delayed condition [t 1(47) = 2.86, p = .006; t 2(342) = 2.94, p = .004], but not in the 1200-ms delayed condition [t 1(47) = 0.70, p = .491; t 2(342) = 1.02, p = .311]. For this follow-up analysis, an alpha level of p = .0125 was used for Bonferroni correction.
Discussion
A normal spelling-to-dictation task, combined with a delayed paradigm, was conducted in Experiment 1 in order to replicate the word frequency effects observed in previous research (e.g., Bonin, Fayol, & Chalard, 2001; Bonin, Fayol, & Gombert, 1998) on skilled spelling-to-dictation. The basic premise was that in the immediate condition (0 ms), the latency for the first letter should reflect spoken word recognition, orthographic retrieval and response execution, whereas in the 1200-ms delayed condition, the latency only reflected the response execution of the first letter.
Consistent with our hypothesis, an interaction between word frequency and delayed condition was found, such that the spelling of high-frequency words was initiated significantly faster than that of low-frequency words in the immediate condition, and in the 400-ms and 800-ms delayed conditions, but no significant difference was found in the 1200-ms delayed condition. These results for English replicate previous findings in French with tablet writing (Bonin, Fayol, & Gombert, 1998; Bonin & Méot, 2002; Bonin, Peereman, et al., 2001) that word frequency affects skilled spelling-to-dictation, and the locus of these observed word frequency effects is not at the response execution of the first letter. Importantly, given that no frequency effect was found in the 1200-ms delayed condition, the other two potentially frequency-sensitive processes—that is, spoken word recognition and orthographic retrieval—should have been completed within 1200 ms.
Experiment 2
Experiment 1 established that word frequency effects in the spelling-to-dictation task are not located at the response execution of the first letter, so a second experiment was designed to test whether they are located at one or both of the remaining two loci: spoken word recognition and orthographic retrieval. In Experiment 2, a delayed/uncertain task, modelled after Almeida et al.'s (2007) picture naming study, was employed to isolate the orthographic retrieval from the preceding spoken word recognition.
Almeida et al.'s (2007) participants were first shown a picture without knowing whether to name it or to categorize it. After a delay of 1000 ms, they were then shown a cue revealing which task to perform, and latency was measured only from the onset of this cue. Almeida et al. assumed that picture recognition was completed during the delay before the onset of the cue and would not be captured by the latency. They also assumed that the participants would not initiate lexical access during the delay because they were not certain about which task to perform before the cue was shown. In addition, to minimize the likelihood of participants preparing for the lexical access prior to the cue during the delay, the number of the categorization trials was triple that of the naming trials. This combination of task uncertainty and the unbalanced task ratio made it likely that, in the naming trials, the lexical access would only be initiated at the onset of the task cue, which was also the onset of the measurement of the response latency.
The spelling-to-dictation paradigm that we employed in Experiment 2 was similar to Almeida et al.'s (2007) task in that it involved a delayed paradigm with biased task uncertainty. This separation of orthographic retrieval from spoken word recognition enabled the measurement of frequency effects on the orthographic retrieval. After hearing the word, participants only knew whether to perform a spelling task or an imageability rating task when a cue was shown 1200 ms after the offset of the spoken word. Again, an unbalanced task ratio between the spelling and imageability rating (1:3) was also introduced to motivate the participants to engage in the imageability rating and thereby minimize the likelihood that they initiated orthographic retrieval during the delay (see Koehler & James, 2009, for probability effects on human behaviour under uncertainty). The latency in the spelling trials, measured from the onset of the task cue until the first keystroke, should therefore capture the task cue decision, orthographic retrieval, and response execution. In this way, orthographic retrieval can be isolated from the preceding spoken word recognition.
In a similar vein, to examine the word frequency effects on the spoken word recognition, an immediate/uncertain task was conducted as a comparison condition to the delayed/uncertain task. The manipulation of the immediate/uncertain task was identical to the delayed/uncertain task, except that there was no delay interval during which the spoken word recognition could be completed. The task cue was shown at the offset of the spoken word instead of 1200 ms after. Therefore, the latency measured in the immediate/uncertain task also captured spoken word recognition, in addition to task cue decision, orthographic retrieval, and response execution. By comparing the frequency effects in the immediate/uncertain task with those in the delayed/uncertain task, the frequency effects on the spoken word recognition in the spelling-to-dictation could be examined (see Figure 2).
An illustration showing the manipulation of Experiment 2. Different processes are captured by the latency in the delayed/uncertain task and the immediate/uncertain task. The dashed lines indicate the starting point of the measurement of the latency in each task.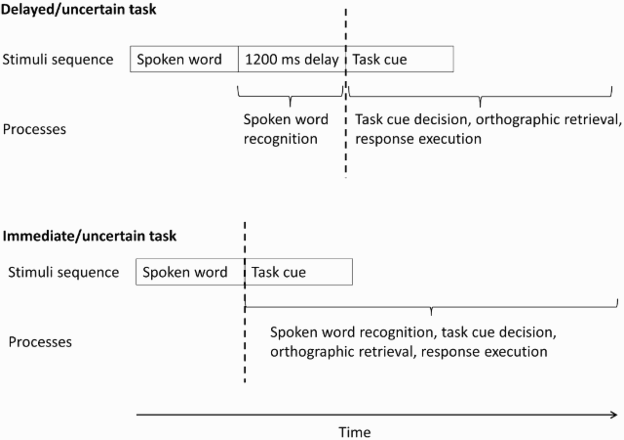
If word frequency effects are located at both spoken word recognition and orthographic retrieval, frequency effects should be found in both tasks, but the effects should be significantly larger in the immediate task than in the delayed task. This is because the immediate task captured spoken word recognition that was not captured by the delayed task, and both tasks captured orthographic retrieval. However, if word frequency effects are located at the spoken word recognition only, frequency effects should only be found in the immediate task but should not be significant in the delayed task. This is because only the immediate task captured spoken word recognition. Lastly, if word frequency effects are located at the orthographic retrieval only, frequency effects of equal size should be found in both tasks. This is because the orthographic retrieval was captured by both tasks.
Method
Participants
Eighty-nine undergraduates, with English as their first language, took part in Experiment 2 in return for course credit or a small compensation. Data from nine participants were excluded: Two responded before the task cue occurred in more than 50% of the trials; the imageability ratings of three participants either were negatively correlated or showed a minimal correlation (r = .2) with published imageability norms (Schock et al., 2012), suggesting limited task compliance; one used backspaces to make correction in the spelling trials for more than 35% of the trials, which was more than 2.5 standard deviations above the mean for backspacing usage; one spelled only 64% of the words correctly; and two used longer than 2.5 standard deviations above the mean latency to initiate the typing of the first letter.
Forty (17 males, 35 right-handers, mean age = 20.78 years, SD = 1.46) were randomly assigned to the delayed/uncertain task, whereas another 40 (11 males, 36 right-handers, mean age = 20.98 years, SD = 2.13) were assigned to the immediate/uncertain task. None of them took part in Experiment 1, and all reported no history of speech, language, or hearing disorders, and the groups were matched on age (p > .60).
Apparatus
The apparatus was the same as that in Experiment 1.
Materials
Stimuli
Eighty-four high-frequency and 84 low-frequency words with accuracy rate of at least .92 in Experiment 1 were selected. The psycholinguistic variables of the high-frequency words and low-frequency words were matched group-wise, all ps > .1, except for the frequency (see Appendix B for details), and the distribution of the beginning letter was also the same across the two groups. Another 176 stimuli used in Experiment 1 were selected as the stimuli for the imageability rating trials (imageability ratings ranging from 1.56 to 6.90, M = 4.19, SD = 1.30; Schock et al., 2012).
Counterbalancing
The lists of high- and low-frequency words were both divided into two sets such that the psycholinguistic variables were matched across the two sets within the frequency group, as well as matched with the other two sets in the other frequency group on all variables except frequency (all ps > .1). The distribution of the beginning letter was also the same across these four sets of words. The four lists were then counterbalanced such that only one set from each frequency group was used as the spelling stimuli for individual participants whereas the other set in each frequency group were used for the imageability rating along with the 176 stimuli. This counterbalancing resulted in four combinations. Ten participants from each participant group were randomly assigned to each combination, and each participant went through 84 spelling trials, half of the stimuli being high frequency and the other half low frequency, and 252 imageability trials. The ratio of the spelling trials to the imageability rating was thus 1:3.
Randomization
The order of the presentation of the imageability trials and spelling trials was pseudorandomized by a computer program such that spelling trials were not consecutive, the number of imageability trials between any two spelling trials was not repeated, and, after the break, at least two imageability trials were presented before a spelling trial.
Procedure
Participants were tested individually in a sound-attenuated cubicle. They were asked to pay attention to the words and the subsequent task cue, which was either a rating scale or a white box on screen. When a rating scale was shown, participants made an imageability rating by pressing 1–7 on the number row of the keyboard. The instructions for the imageability task were based on Cortese and Fugett's (2004) procedure using a Likert scale ranging from 1 (low) to 7 (high). When a white box was shown, participants typed the spoken word they had heard. Participants used only the index finger of their writing hand to do both the typing and the rating. They pressed the spacebar without releasing it to initiate each trial. They only released the spacebar and started typing or pressing the rating number once the task cue occurred. As in Experiment 1, this was to ensure that all participants started at the same point of time and the same position on the keyboard.
Each trial began with a screen asking the participants to press the spacebar. A fixation “+” was presented once the participant had pressed the spacebar. After 500 ms, the target word was then played over the headphones. At the offset of the word, the immediate task and delayed task varied. In the immediate task, at the offset of the words, the colour of the fixation “+” changed from white to yellow, and the task cue was presented. In the delayed task, a delay of 1200 ms, 1300 ms, or 1400 ms occurred before the change of the colour of the fixation “+” and the presentation of the task cue. The fixation “+” remained on the screen during the delay. This variation of the delay duration was employed to prevent the participants from anticipating their response (Balota & Chumbley, 1985; Bonin, Fayol, & Chalard, 2001). There were an equal number of trials with these three delay periods among the high- and low-frequency words within the spelling trials and within the imageability rating trials. The pairing of the delay periods with the spoken target was randomized within each participant.
In both tasks, at the onset of the task cue, participants released the spacebar and responded according to the task cue by using their index finger of their writing hand. Once they had pressed a number in the imageability rating, or the “enter” key in the spelling trial, a blank screen was shown for 500 ms before the next trial began. A warning was shown at the end of a trial if participants released the spacebar before the task cue occurred in that trial.
Before the experiment proper, participants first went through a block of nine trials of imageability ratings and spelling trials. After that, they completed 42 practice trials with a mix of equal numbers of imageability rating and spelling trials. They were then introduced to the experiment proper with 24 filler trials at the beginning with a ratio of spelling trials to imageability rating as 1:3, similar to the ratio of the experimental trials. These fillers were to bias the participants towards imageability ratings before they came across the first experimental spelling trial. The main experiment took 30–40 min to complete.
Design
Experiment 2 was a 2 (word frequency: high vs. low) × 2 (delay: immediate vs. delayed) mixed design. Word frequency was a within-subjects factor; delay was a between-subjects factor.
Results
Both accuracy rates and latencies of the spelling-to-dictation trials were subjected to both participant-wise (F 1) and item-wise (F 2) two-way ANOVA. The latency was measured from the onset of the task cue until the first keystroke. In the participant-wise analysis, word frequency was a within-factor, and delay was a between-factor. In the item-wise analysis, delay was a within-factor and word frequency was a between-factor.
Accuracy rates
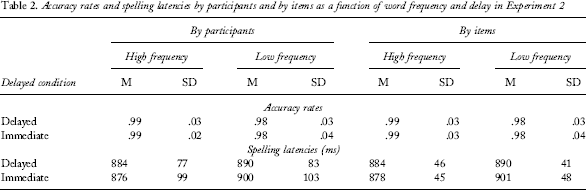
Accuracy rates and spelling latencies by participants and by items as a function of word frequency and delay in Experiment 2
Latencies
Inaccurately spelled trials (1.7%) and accurately spelled trials in which participants corrected the first keystroke (2.4%) or released the spacebar before the task cue occurred (1.2%) or used more than 3 s or fewer than 100 ms to type the first letter (0.1%) were first excluded. After these exclusions, latencies that were 2.5 standard deviations below or above the means of each design cell (1.3%) were excluded. Together, 7.6% of the total trials were thus excluded from the analysis reported here. The result of another analysis, with the more stringent exclusion criteria described in Experiment 1, showed the same pattern as the analysis presented below, so it is not reported here.
The mean latencies by participants and by items are shown in Table 2. The ANOVA revealed a significant main effect of word frequency [F 1(1, 78) = 13.33, MSE = 661.41, p < .001; F 2(1, 166) = 5.91, MSE = 2836.85, p = .016], indicating that the first letter of high-frequency words was spelled more quickly than that of the low-frequency words. There was no main effect of delay [F 1(1, 78) = 0.003, MSE = 15,918.90, p = .955; F 2(1, 166) = 0.45, MSE = 1227.68, p = .505], but the interaction between word frequency and delay was significant [F 1(1, 78) = 4.77, MSE = 661.42, p = .032; F 2(1, 166) = 5.03, MSE = 1227.68, p = .026]. Follow-up analysis showed that the frequency effect was significant in the immediate task [t 1(39) = 4.70, p < .001; t 2(166) = 3.15, p = .002], but not in the delayed task [t 1(39) = 0.94, p = .356; t 2(166) = 0.83, p = .408]. For this follow-up analysis, an alpha level of p = .025 is used for Bonferroni correction.
Discussion
In Experiment 2, a delayed/uncertain task was compared with an immediate/uncertain task to measure possible word frequency effects on orthographic retrieval and spoken word recognition. Latencies in the delayed/uncertain task captured only task cue decision, orthographic retrieval, and response execution, without capturing the spoken word recognition, which would have been completed during the delay. Therefore, the word frequency effects on the orthographic retrieval could be studied in isolation. On the other hand, latencies in the immediate/uncertain task captured spoken word recognition in addition to the processes captured in the delayed/uncertain task because no delay was introduced for the completion of the spoken word recognition. By comparing the frequency effects in these two tasks, the frequency effects on spoken word recognition could also be evaluated.
The results showed an effect of word frequency in the immediate/uncertain task but not in the delayed/uncertain task. This is a clear demonstration that word frequency effects in the spelling-to-dictation task are found for spoken word recognition, consistent with previous findings involving auditory lexical decision paradigms (e.g., Connine et al., 1990; Dahan & Magnuson, 2006; Goh et al., 2009; Jusczyk & Luce, 2002; Marslen-Wilson, 1990). The results of Experiment 2 present a challenge to the widely held assumption that word frequency effects in skilled spelling-to-dictation are attributable solely to orthographic retrieval (e.g., Bonin, Chalard, et al., 2002; Bonin, Fayol, & Chalard, 2001; Bonin, Fayol, & Gombert, 1998; Delattre et al., 2006; Houghton & Zorzi, 2003; Rapp & Dufor, 2011).
Mean spelling latencies (ms) and reaction times (ms) of imageability rating in Experiments 1 and 2
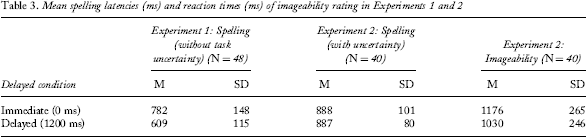
To test the assumption that participants were preparing for the imageability rating rather than orthographic retrieval during the delay in Experiment 2 such that no orthographic retrieval was only initiated after the delay, a two-way mixed ANOVA with task (imageability rating vs. spelling) as a within-subject factor and delay (immediate vs. delayed) as a between-subject factor was conducted. This analysis revealed an interaction, F(1, 78) = 8.18, MSE = 51,480.14, p = .005. Follow-up analysis of the delay effect in the imageability rating revealed a significant difference, F(1, 78) = 6.56, MSE = 65,223.93, p = .012, such that rating was faster in the delayed condition than in the immediate condition. This result suggests that participants did prepare for the imageability during the delay. In contrast, follow-up analysis of the delay effect in the spelling task revealed no difference in latency between the delayed and the immediate condition, F(1, 78) < 0.01, MSE = 7959.45, p = .955, further indicating that participants did not prepare for the spelling during the 1200-ms delay, otherwise they would have been faster in the delayed condition than in the immediate condition, as they were for imageability ratings.
Additionally, to test the assumption that orthographic retrieval is only initiated in the delayed condition of Experiment 2, two independent t-tests were conducted to compare the spelling latency in Experiment 1 with that in Experiment 2 in the immediate condition (0 ms) and the 1200-ms delayed condition, respectively. In the immediate condition, the only difference between Experiment 1 and Experiment 2 was the task uncertainty; thus the latency difference was deduced as the time for the task decision. By subtraction, the latency difference was 106.06 ms on average, and this difference was significant, t(86) = 3.91, p < .001. On the other hand, during the 1200-ms delay, participants were not retrieving the orthographic form in Experiment 2, but were doing so in Experiment 1; thus the latency difference between Experiments 1 and 2 was deduced as the time for the task decision and orthographic retrieval. By subtraction, the latency difference was 278 ms on average, and this difference was significant, t(86) = 13.03, p < .001. A mixed-effect model, with participants and stimuli as random effects, showed that the interaction between the delay (immediate vs. delayed) and experiment (1 vs. 2) was significant, 5 t = 7.68, p < .001, suggesting that the latency difference between Experiments 1 and 2 in the delayed condition is reliably larger than that in the immediate condition. This additional difference should be the time taken for the orthographic retrieval in the delayed condition of Experiment 2. Therefore, the assumption holds up such that participants in the delayed/uncertain condition of Experiment 2 only initiated orthographic retrieval when the task cue was given, and they did not retrieve the spelling during the delay.
An ANOVA to investigate the interaction between delay and experiment was not possible because the delay was a within-subject factor in Experiment 1 but a between-subject factor in Experiment 2. The degrees of freedom are not reported here because they are debatable, and the statistical packages—that is, lme4 and LanguageR package in R—that we used did not provide the degree of freedom. The package runs a Markov chain Monte Carlo (MCMC) simulation. Interested readers can refer to Baayen, Davidson, and Bates (2008).
Admittedly, the testing of our assumptions is based on comparisons across individuals and experiments. Nonetheless, in the absence of more direct evidence, the results of the present studies indicate that the orthographic retrieval was only initiated upon the task cue in the delayed/uncertain condition in Experiment 2, and the results clearly show no frequency effects for this process.
General Discussion
The aim of this two-part study was to identify the locus of word frequency effects in skilled spelling-to-dictation. Based on Tainturier and Rapp's (2001) dual-route model, three potential loci were identified: spoken word recognition, orthographic retrieval, and response execution. Without taking into account the processes involved in spoken word recognition, previous research in the skilled spelling-to-dictation (e.g., Delattre et al., 2006) suggests that there are word frequency effects at the orthographic retrieval, but not at response execution. Likewise, computational models (e.g., Brown & Loosemore, 1994; Houghton & Zorzi, 2003) only simulate spelling-to-dictation in terms of the connection between phonological representation (the outcome of the spoken word recognition) and orthographic representation, without modelling the other processes involved in the task. Given that spoken word recognition is also engaged in the spelling task, and that latency is a composite measure of all the processes involved (Sternberg, 2001), empirical reports and models that do not take spoken word recognition into account are incomplete. Data from the two experiments reported here addressed this gap in our knowledge and demonstrated that spoken word recognition, instead of orthographic retrieval, was the locus of word frequency effect in the spelling-to-dictation.
The results of Experiment 1 replicated previous findings (e.g., Bonin, Fayol, & Gombert, 1998; Bonin & Méot, 2002; Bonin, Peereman, et al., 2001; Delattre et al., 2006; Kreiner, 1996) and showed that the latency for spelling high-frequency words was faster than that for low-frequency words. Consistent with Bonin and colleagues’ findings (Bonin, Peereman, et al., 2001), there were no frequency effect in the 1200-ms delayed spelling condition, which only measured response execution of the first letter, because both spoken word recognition and orthographic retrieval had been completed during the delay, indicating that the word frequency does not influence response execution of the first letter. In Experiment 2, a delayed/uncertain task was compared with an immediate/uncertain task to separate the effect of word frequency on the orthographic retrieval and spoken word recognition. In the delayed/uncertain task, a 1200-ms delay was introduced for the completion of the spoken word recognition, and a task uncertainty with a bias towards imageability ratings was introduced to minimize initiation of orthographic retrieval during the delay. These manipulations made it possible to isolate the orthographic retrieval from the spoken word recognition, and no effect of word frequency was found. This findings indicate that the orthographic retrieval is not sensitive to word frequency, whereas the frequency effect found in the immediate/uncertain comparison task suggests that spoken word recognition is sensitive to word frequency.
Taken together, Experiments 1 and 2 suggest that spoken word recognition is the locus of word frequency effects in the latency of skilled spelling-to-dictation. According to Marslen-Wilson (1990) on spoken word recognition, high-frequency words will be activated by incoming auditory input faster than low-frequency words because their resting activation in the phonological input lexicon (see Figure 1) is higher. In spelling-to-dictation tasks, this would mean that the latency for the first keystroke in the spelling-to-dictation will be shorter.
Word frequency effect in orthographic retrieval and spoken word recognition
Intriguingly, our results suggested that orthographic retrieval is not sensitive to word frequency when the orthographic output lexicon, which implicated lexical access, is involved in the retrieval process. As mentioned in the introduction (see Figure 1), one pathway for the spelling-to-dictation involves the access of the phonological input lexicon—that is, spoken word recognition—which in turn activates orthographic output lexicon—that is, orthographic retrieval. Houghton and Zorzi (2003) modelled the word frequency effect on the orthographic output lexicon such that the higher the frequency effect, the higher the resting activation of the orthographic form of the word (the spelling), and the faster and the easier it is retrieved. In contrast, they did not model the frequency effect on the phonological input lexicon, which has been shown to be sensitive to word frequency by our result and previous spoken word recognition research.
In our view, in this pathway of spelling-to-dictation, word frequency could affect both phonological input lexicon and orthographic output lexicon because both implicate lexical access (Bonin & Fayol, 2002; Bonin, Fayol, & Gombert, 1998; Dahan & Magnuson, 2006). The lack of frequency effect on the orthographic output lexicon revealed by our results suggested that this frequency effect is not invariable whereas the frequency effect on the phonological input lexicon is obligatory in the spelling-to-dictation task, especially in the highly literate university students. The phonological input lexicon and the orthographic output lexicon among the highly literate university students might be strongly integrated (Dich, 2011) such that the activation of the phonological form of the spoken word would also raise the resting activation of the corresponding orthographic form of the spoken word in the orthographic output lexicon, although retrieval process has not yet been initiated. Thus, in a spelling-to-dictation task, when the spoken word recognition is completed, the resting activation of the orthographic form of the spoken word of both high and low frequency reaches the same level in the orthographic output lexicon. Given the same level of heightened resting activation, the orthographic form of both high- and low-frequency words will be retrieved at a similar rate. This explained the lack of frequency effect in the delayed/uncertain spelling condition of Experiment 2, which measured only orthographic retrieval without spoken word recognition. In contrast, a frequency effect would still be found in the immediate spelling-to-dictation and in the immediate/uncertain spelling condition of Experiment 2 because they also measured the spoken word recognition, which is sensitive to word frequency.
Another intriguing disparity between the current study and past research is that the locus of word frequency effects may be different in written word production tasks with stimuli of different modalities. In the written picture naming task, it is at the orthographic retrieval (Bonin & Fayol, 2002; Bonin, Fayol, & Gombert, 1998), whereas in the spelling-to-dictation, it is at the spoken word recognition, as suggested by our results. This difference could be due to the task-specific processes. In written picture naming, picture recognition instead of the spoken word recognition is engaged at the first stage. It is well established that picture recognition is not influenced by word frequency (Bonin, Fayol, & Gombert, 1998; Stadthagen-Gonzalez, Damian, Perez, Bowers, & Marin, 2009), but spoken word recognition is influenced by word frequency (Connine et al., 1990; Dahan & Magnuson, 2006; Goh et al., 2009; Marslen-Wilson, 1990). More critically, the way to elicit spelling responses differs across the written picture naming and spelling-to-dictation. In written picture naming, a picture is used and could be interpreted by participants to be portraying different alternative words (Bock, 1996). This ambiguity may only be resolved by word frequency, such that the word with the highest frequency would be selected to be written up. Therefore, the orthographic retrieval in the picture naming is sensitive to the word frequency. In contrast, in the spelling-to-dictation task, the spoken word recognition preceding the orthographic retrieval has already provided such a lexical access; thus no word frequency effect is found in the orthographic retrieval.
Caveat: Are spoken word recognition and orthographic retrieval separable?
The research question and the delayed/uncertain task of Experiment 2 were based on the assumption that the spoken word recognition and the orthographic retrieval are separable. This assumption is supported by dissociations in case studies of brain-injured patients who had perfect spoken word recognition but impaired spelling ability, or who had impaired spoken word recognition, but could spell correctly in written picture naming (e.g., Rapp, 2005). Even if this assumption of module separation does not hold so readily for highly literate undergraduates with integrated spoken word recognition and orthographic retrieval (Dich, 2011) or cascading processes, it could still remain the case that frequency effects are not solely located at the orthographic retrieval.
Evidence for some activation of orthographic information during spoken word recognition has come from the findings that spoken words with higher sound-to-spelling consistency are recognized faster than those with low consistency (e.g., Dich, 2011; Ziegler, Petrova, & Ferrand, 2008). Sound-to-spelling consistency is a measure of how often a particular unit of phonology is matched to an orthographic form, so its effect in the spoken word recognition task is generally assumed to be reflecting the role of orthographic representation in spoken word recognition. More crucially, Dich (2011) found that university students who have a higher spelling accuracy rate showed a larger consistency effect in auditory lexical decision. Therefore, it is likely that among literate university students, the orthographic information is activated automatically during the spoken word recognition in the delayed/uncertain task of Experiment 2 despite the strategic blocking of the orthographic retrieval. If this is the case, both the spoken word recognition and orthographic retrieval would have been completed during the delay, rather than being separated. Thus, the latency might actually capture response execution only, with null frequency effects, instead of also capturing orthographic retrieval as assumed. This scenario would render our paradigm invalid for the investigation of word frequency effects on orthographic retrieval.
Set against this, we have shown in the discussion of Experiment 2 that orthographic retrieval was indeed captured by the latency in the delayed/uncertain condition due to the longer latency found. Also, the findings from auditory lexical decision tasks (e.g., Dich, 2011; Ziegler et al., 2008) only suggest that orthographic information is activated during spoken word recognition, but whether this orthographic information is the same as the full orthographic representation—that is, the exact spelling, required for the spelling-to-dictation—remains unclear. Additionally, an event-related potential (ERP) study conducted by Perre, Pattamadilok, Montant, and Ziegler (2009) showed that this orthographic information may actually occur during the early phase, before the lexical access or the frequency effect in the spoken word recognition. Although sublexical information influences the early stage of the spoken word recognition, it might not be sufficient for the orthographic retrieval, which happens after the spoken word recognition. Therefore, it is possible that no orthographic information was activated, or that orthographic information was activated during the delay but did not contribute to the orthographic retrieval that was only initiated after the delay. In either case, the latency in the delay/uncertain condition would genuinely capture the orthographic retrieval, as we assumed.
Admittedly, whether the orthographic retrieval is inseparable from the spoken word recognition remains an empirical question worthy of further investigation. To get around the separability issue between spoken word recognition and orthographic retrieval, and at the same time to further examine the word frequency effects on the two loci in spelling-to-dictation, researchers could consider designing spelling-to-dictation tasks using the process-decomposition approach (Sternberg, 2001). According to Sternberg's (1969, 2001) logic, if word frequency interacts with a factor that is well established to be affecting spoken word recognition only, such as phonological neighbourhood density, then the word frequency effects should be located at the spoken word recognition. The same scenario could apply to orthographic retrieval and orthographic neighbourhood density. However, the close relationship between orthography and phonology in alphabetic languages means that other new variables need to be identified.
Limitations
The present study was aimed at investigating the locus of word frequency effect in the spelling-to-dictation. Given that word frequency generally affects lexical access, and lexical access occurs in phonological input lexicon and orthographic output lexicon, the research question of the present study could be deemed as focusing on the lexical route of the dual-route model (Figure 1), without taking the sublexical route into account. Undeniably, the lexical route could interact with the sublexical route in the spelling process, as shown by Kreiner (1996) and Delattre et al. (2006), and overlooking the sublexical route is a limitation to the present study. Although Delattre et al. (2006) revealed a significant interaction between the word frequency and consistency on the latency of immediate spelling and also on the duration of writing out all the letters of the words, whether this interaction of lexical route and sublexical locates in the spoken word recognition or the orthographic retrieval in the spelling-to-dictation task remained unexplored. Given that the consistency effect has been found in both auditory lexical decision (e.g., Dich, 2011; Ziegler et al., 2008) and spelling-to-dictation (e.g., Bonin, Fayol, & Chalard, 2001), future studies could investigate the locus of consistency and possibly the interaction between consistency and word frequency in the spelling-to-dictation task by using the paradigm of the current study.
Although our results suggested that spoken word recognition in the spelling-to-dictation is affected by word frequency, as it is during auditory lexical decision, it is not clear whether the process of spoken word recognition underlying the two tasks is exactly the same. Comparing word frequency effects within the same participant across the two tasks could throw some light on this question. However, auditory lexical decision and spelling-to-dictation differ in terms of task demands. First, lexical decision does not necessarily require as much precision as the spelling-to-dictation task. Secondly, the response alternatives for the lexical decision are yes and no only, whereas for the spelling tasks, any of the 26 letters could be the response. These complex task differences render the conclusion about processes within and between the tasks ambiguous (Sternberg, 2001) and might not shed light on the locus of word frequency effects in spelling-to-dictation. Given these concerns, and the fact that the word frequency effect in the auditory lexical decision is well established, this comparison was not attempted in the present study. Future researchers could explore the nature of word frequency effects underlying the spoken word recognition in both tasks, now that we have established that locus of word frequency effects in spelling-to-dictation.
Lastly, the current findings could be limited to words that attract a high level of spelling accuracy (>.98 in Experiments 1 and 2). It is possible that word frequency does not impact on the orthographic retrieval of words with such high accuracy levels, but that a frequency effect would be found for orthographic retrieval of words with lower levels of spelling accuracy. However, it is not feasible to investigate this issue in studies where latency for first letter is the main dependable variable for indexing the processes underlying spelling-to-dictation. Using words with low levels of spelling accuracy would reduce the reliability of the data given that only latencies of accurately spelled words would be included in the analysis.
Conclusion
The debate about whether orthographic retrieval and spoken word recognition are separable should not undermine the need to acknowledge the involvement of spoken word recognition in skilled spelling-to-dictation. If it is really the case that the orthographic retrieval is inseparable from spoken word recognition, the present findings still point to the fact that word frequency effects can be located at spoken word recognition as well as orthographic retrieval, in contrast to Bonin, Fayol, and Gombert's (1998; see also Bonin, Chalard et al., 2002; Bonin, Fayol, & Chalard, 2001) argument that the word frequency effects are only located at the orthographic retrieval. On the other hand, if the orthographic retrieval is distinct from spoken word recognition in spelling-to-dictation task, and the design of Experiment 2 is valid, it seems that spoken word recognition is the only locus of word frequency effects in skilled spelling-to-dictation when the dependent variable of interest is latency measured to the first keystroke. We argued that this could be because the spoken word recognition has already lifted the resting activation of the low-frequency words to the similar level as the high-frequency words in the orthographic output lexicon, such that both high- and low-frequency words would be retrieved at a similar rate. In sum, this study has flagged the likelihood that frequency effects are attributable to spoken word recognition in skilled spelling-to-dictation.
Footnotes
Acknowledgements
We thank Melvin Yap and the two anonymous reviewers for their helpful comments on previous versions of this article.
This research was funded by the National University of Singapore's Graduate Research Scholarship awarded to the first author.