
Abstract
Many older listeners report difficulties in understanding speech in noisy situations. Working memory and other cognitive skills may modulate older listeners’ ability to use context information to alleviate the effects of noise on spoken-word recognition. In the present study, we investigated whether verbal working memory predicts older adults’ ability to immediately use context information in the recognition of words embedded in sentences, presented in different listening conditions. In a phoneme-monitoring task, older adults were asked to detect as fast and as accurately as possible target phonemes in sentences spoken by a target speaker. Target speech was presented without noise, with fluctuating speech-shaped noise, or with competing speech from a single distractor speaker. The gradient measure of contextual probability (derived from a separate offline rating study) affected the speed of recognition. Contextual facilitation was modulated by older listeners’ verbal working memory (measured with a backward digit span task) and age across listening conditions. Working memory and age, as well as hearing loss, were also the most consistent predictors of overall listening performance. Older listeners’ immediate benefit from context in spoken-word recognition thus relates to their ability to keep and update a semantic representation of the sentence content in working memory.
Many older listeners report difficulties in understanding speech, particularly in noisy situations. Noise impacts speech perception as it blends acoustically with speech, thereby making the speech signal less intelligible (Bregman, 1990; Brungart, 2001). In addition to this energetic masking, noise can interfere with speech perception at higher processing levels if the noise itself is linguistically processed. Informational masking in speech perception refers to the additional challenge that is elicited by the linguistic processing of a speech noise masker, on top of its energetic masking of the target speech (Watson, 2005). Listeners can compensate for the effects of masking by using, for example, the semantic context in the target speech stream. Words are recognized more easily when their surrounding words make them more predictable (Kalikow, Stevens, & Elliott, 1977), or if the general topic of the sentence is provided beforehand (Helfer & Freyman, 2008). In the present study, we investigated individual differences among older adults with respect to their immediate use of context information to facilitate spoken-word recognition across different listening conditions.
When listening to speech in noise, separating target speech from noise is complicated by the spectral and temporal overlap between the two signals, thus creating energetic masking (for a review of perceptual segregation, see Bregman, 1990). Whenever the target speech momentarily exceeds the noise in energy, listeners can exploit these “glimpses” to try and understand the speech message (Cooke, 2006). How often target speech glimpses over the noise signal is highly correlated with intelligibility (Cooke, 2006). If the masker itself is speech, then the processing of the target speech is further impacted by the linguistic processing of the competing noise masker (e.g., Brouwer, Van Engen, Calandruccio, & Bradlow, 2012; Garcia Lecumberri & Cooke, 2006; Tun, O'Kane, & Wingfield, 2002; Van Engen & Bradlow, 2007). Brungart and colleagues (Brungart, 2001; Brungart & Simpson, 2002, 2004, 2007) have shown that nonspeech noise with a similar temporal structure and long-term average spectrum as a speech masker does not produce informational masking. Informational masking in speech perception is therefore not due to the acoustic overlap of speech and noise but rather due to the linguistic processing of the speech noise (cf. also Kidd, Mason, Richards, Gallun, & Durlach, 2008; Pollack, 1975). Furthermore, the degree of informational masking is modified by the linguistic content of the masker: Competing multitalker babble containing high-frequency words impairs word recognition more than babble containing low-frequency words (Boulenger, Hoen, Ferragne, Pellegrino, & Meunier, 2010). This suggests that listeners process the words presented in the competing speech stream to a certain extent. Energetic masking thus mainly complicates peripheral processing, and informational masking additionally affects target speech processing at a higher cognitive level (Ezzatian, Li, Pichora-Fuller, & Schneider, 2011; Freyman, Balakrishnan, & Helfer, 2004).
Older adults’ speech understanding suffers more in noisy listening situations than that of younger adults. In addition to age-related hearing loss resulting in elevated audiometric thresholds, age-related declines in temporal and spectral processing (Gordon-Salant, Frisina, Popper, & Fay, 2010) may lead to poorer segregation of the target stream and the noise stream in older than in younger listeners (Huang et al., 2008), making older listeners more vulnerable to the effects of noise. Older adults also seem to suffer more from informational masking than younger adults due to age-related cognitive decline, for example, in attentional control (Tun et al., 2002, but see Schneider, Daneman, Murphy, & Kwong See, 2000). In this study, we examined the factors underlying individual differences in how much an older listener is impacted by energetic and informational masking.
The present study focused on older adults’ ability to use the contextual probability of a word within a sentence for its recognition in different listening conditions. Older and younger listeners have been shown to use contextual information to alleviate the masking effects of noise on the recognition of words (Benichov, Cox, Tun, & Wingfield, 2012). Words in sentences can be recognized more easily when they are more predictable from the preceding or following context (Marslen-Wilson & Tyler, 1980). This effect can be partially explained through associative and semantic priming (e.g., Meyer & Schvaneveldt, 1971) where words recognized earlier in a sentence activate related words, or at least constrain the lexical search space, and hence facilitate the processing of related later occurring words (Altmann & Kamide, 1999; Ferretti, McRae, & Hatherell, 2001; Knoeferle & Crocker, 2007). Context information can reduce the effects of noise masking in speech perception. Listeners tolerate more nonspeech or babble noise when identifying the final word of semantically biasing sentences than when identifying that of neutral sentences (Benichov et al., 2012; Bilger, Nuetzel, Rabinowitz, & Rzeczkowski, 1984; Gordon-Salant & Fitzgibbons, 1997; Kalikow et al., 1977).
Older adults as a group seem to rely more on contextual information in word processing than younger adults (e.g., Lash, Rogers, Zoller, & Wingfield, 2013; Nittrouer & Boothroyd, 1990; Pichora-Fuller, Schneider, & Daneman, 1995; Sheldon, Pichora-Fuller, & Schneider, 2008). Contextual information can mitigate the negative effects of age and hearing loss on spoken-word recognition (Lash et al., 2013) in tasks where processing time is not limited. Informational masking was reduced in both younger and older adults, for example, when participants were informed about the topic category of the sentence before stimulus presentation (Helfer & Freyman, 2008). Older adults benefited, however, more from meaningful sentence context than younger listeners in identifying speech in multitalker babble noise (Frisina & Frisina, 1997; Pichora-Fuller et al., 1995; Sheldon et al., 2008). Both age groups derived equal context benefit when the masker was broadband noise, which was spectrally shaped to compensate for the individual's hearing loss (Dubno, Ahlstrom, & Horwitz, 2000). This result suggests that age differences in the use of context may differ across listening conditions.
One reason why older adults may rely more on context than younger adults (Lash et al., 2013; Nittrouer & Boothroyd, 1990; Pichora-Fuller et al., 1995; Sommers & Danielson, 1999) could be their greater linguistic expertise, built up over many years of listening to their native language. Verbal ability seems to be preserved with ageing. Older adults can even outperform younger adults on vocabulary tasks (Park et al., 2002; Verhaeghen, 2003). Furthermore, greater verbal expertise in older adults has been evidenced as increased effects of lexical frequency on spoken word recognition, compared to those found for younger adults (Revill & Spieler, 2012).
The apparent greater reliance of older than of younger adults on semantic context could, however, also be a result of the use of nonspeeded listening tasks. The speech-reception threshold tasks (Dubno et al., 2000; Frisina & Frisina, 1997; Pichora-Fuller et al., 1995; Sheldon et al., 2008) used in these studies allowed participants unlimited time to prepare their response. Consequently, older listeners may have had ample time for the semantic processing of the sentence in order to facilitate word recognition. Only the final result of the speech perception process can be evaluated in such nonspeeded tasks, and not the time or effort it took to obtain the result. Recent evidence indeed suggests that older adults’ greater reliance on context may reflect a (postperceptual) bias to respond consistently with the context, rather than their greater skill in using context during word recognition (Rogers, Jacoby, & Sommers, 2012). Preliminary data presented by Aydelott, Leech, and Crinion (2010) suggest that older adults are able to use context information to benefit processing already during spoken-word recognition in clear conditions, but that challenging listening conditions may disproportionately affect older listeners’ ability to make use of semantic context during word recognition, relative to younger listeners. Peelle, Troiani, Wingfield, and Grossman (2010) investigated the connectivity between neural processing regions involved in auditory speech comprehension in younger and older adults. Their age group comparison results suggested that older adults’ limited ability to coordinate activity between processing regions may play a role in older adults’ difficulty with sentence comprehension under difficult listening conditions. This result ties in with the suggestion that age groups differ in how quickly they can benefit from context. The critical question we asked here is whether older adults can process contextual semantic content rapidly enough to facilitate processing as the spoken target sentence is unfolding.
In addition, we asked which factors determine older listeners’ individual differences in the use of context. The use of context by older adults may differ not only across listening conditions, but also across individuals. In addition to hearing ability, cognitive abilities could explain individual differences, especially in more difficult listening conditions. The less intelligible the speech becomes in adverse listening conditions, the greater the need for cognitive resources to filter out irrelevant information and to fill in any missing information by using context information to comprehend the speech content (Francis & Nusbaum, 2009). This is in line with the ease of language understanding (ELU) model by Rönnberg and colleagues (Rönnberg, 2003; Rönnberg, Rudner, Foo, & Lunner, 2008) that assumes that cognitive processes become more important when listening conditions are more challenging, due to hearing loss, background noise, or both. Cognitive processes thus become more relevant if implicit matching of linguistic input to stored representations in long-term memory is not sufficient for lexical access. Listening in difficult conditions has been assumed to contribute to mental effort (Koelewijn, Zekveld, Festen, & Kramer, 2012; McCoy et al., 2005; Piquado, Isaacowitz, & Wingfield, 2010; Rabbitt, 1968; Tun, McCoy, & Wingfield, 2009; Zekveld, Kramer, & Festen, 2010, 2011a). Verbal working memory in particular could play a role in how efficiently contextual probability can be used across listening conditions (but see Otten & van Berkum, 2009). Differences in working memory may also explain why older listeners benefited more than younger adults from context preceding a target word but less so from following context (Wingfield, Alexander, & Cavigelli, 1994). Older adults may have greater difficulty than younger adults in maintaining an unidentified word in working memory for it to be recognized later. Zekveld et al. (2011b) found that adults with better verbal working memory (as indexed by reading span performance) perceived spoken sentences in noise better in a condition with mismatching text cues than did adults with poorer working memory. This correlation between performance and working memory was not found in a condition with matching cues. This suggests that older adults with better verbal working memory were better at inhibiting distraction from irrelevant (written) context. Similarly, in a follow-up study on sentence comprehension cued by matching or mismatching text cues, Zekveld, Rudner, Johnsrude, Heslenfeld, and Rönnberg (2012) showed that better verbal working memory (indexed by reading span) was associated with greater intelligibility benefit from the related text cues, and with less speech-related activation in the left superior temporal gyrus and left inferior frontal gyrus. Zekveld et al. (2012) argue that these results agree with the hypothesis of “neural efficiency” (Neubauer & Fink, 2009) in that those listeners with better working memory are able to use context more efficiently for speech comprehension. We investigated here whether individual differences in working memory affect older listeners’ ability to use context information during the recognition of spoken words. Critically, we also investigated whether age differences among these older adults predict the ability to use context efficiently, beyond working memory differences. If so, this would mean that working memory differences only partially explain age differences in the ability to benefit from context immediately.
In particular, we focused on individual differences among older adults in the ability to use contextual probability for spoken-word recognition in different listening conditions. Spoken word processing as a function of contextual probability was investigated in a condition without noise (no-noise condition), in a condition with fluctuating speech-shaped noise (nonspeech-noise condition), and in a condition with competing speech from a single distractor speaker (speech-noise condition). In contrast to prior listening studies, we investigated older adults’ ability to process semantic meaning rapidly enough to benefit the recognition of words during sentence processing. So far, studies that have investigated individual differences, rather than age group differences, in the rapid use of contextual probability were only on reading (Federmeier, Kutas, & Schul, 2010; Lee & Federmeier, 2011) and thus did not involve any adverse processing conditions.
In the present study, we asked participants to monitor meaningful spoken sentences of a target speaker for the occurrence of a specific target phoneme. This phoneme-monitoring task is a speeded-response task as processing time is limited (Connine & Titone, 1996). Despite its name, this task reflects lexical processing when meaningful sentences are monitored (Cutler, Mehler, Norris, & Segui, 1987; Cutler & Norris, 1979; Mirman, McClelland, Holt, & Magnuson, 2008). Phoneme monitoring can thus be used to measure the effect of context on the speed of lexical access. The task itself does not interfere with processing the sentences for meaning (Brunner & Pisoni, 1982; Ford et al., 1996; Foss & Blank, 1980). Phonemes are detected earlier in high-frequency words than in low-frequency words (Dupoux & Mehler, 1990; Eimas & Nygaard, 1992) and earlier in semantically biasing sentences than in neutral sentences (Eimas & Nygaard, 1992; Foss & Jenkins, 1973). Target-bearing words varied in our study in their predictability from their preceding sentence context. Contextual probability was manipulated as a continuous variable (see e.g., DeLong, Urbach, & Kutas, 2005) rather than a dichotomous one. Target words in our study had a contextual predictability within the intermediate range.
We examined which characteristics of older listeners relate to the use of context during sentence processing. The main hypothesis investigated was that verbal working memory relates to efficient use of contextual probability by older listeners—that is, those older adults who are better able to keep and update a semantic representation of the sentence content will show more context facilitation of spoken word recognition in a speeded listening task. Possibly, context effects are stronger for those older listeners with more linguistic expertise, as indexed by vocabulary knowledge. We also tested whether there were additional age effects on the ability to immediately use context to facilitate spoken word recognition. Due to age-related decline in other auditory and cognitive abilities, age may affect the degree to which listeners are affected by energetic and informational masking. We also tested specifically whether individual selective attention ability was a potential predictor of the degree to which listeners were affected by noise masking, informational masking in particular. Attentional abilities seem to relate to listening performance in situations with distraction from meaningful speech (Janse, 2012; Tun et al., 2002). Attention has been proposed to involve three attentional networks (Fan, Raz, & Posner, 2003; Posner & Petersen, 1990), carrying out the functions of alerting (defined as achieving and maintaining an alert state), orienting (defined as selection of information from sensory input), and executive control (defined as resolving conflict among responses). The ability to successfully ignore competing speech would be considered as being governed by the listener's executive control ability. We used a flanker task to assess listeners’ executive control ability as the ability to ignore incongruent and irrelevant flanking signals. Results from the flanker task thus allow us to test whether susceptibility to distraction from competing speech relates to general executive control abilities (measured in the visual modality, and not involving language). Hearing sensitivity was also assessed as a standard procedure as hearing sensitivity is known to affect older listeners’ performance in a speech perception study. Hearing sensitivity was therefore viewed as a control variable that was partialled out of age differences within our older adult sample.
Experimental Study
Method
Participants
Sixty-three community-dwelling older adults (22 men) were paid for their participation in the experiment (€8 per hour). All participants were tested at the Max Planck Institute for Psycholinguistics in two 1-hour sessions. Participants completed the phoneme-monitoring study at the beginning of the second session. The background tests were done afterwards and after another main study conducted in the first session (cf. Janse & Adank, 2012). Participants’ mean age was 73.3 years (SD = 5.3; range: 64 to 89 years). This relatively wide age range was needed to investigate the influence of age among older adults. All older adults were native monolingual speakers of Dutch, with no self-reported history of oral or written language impairment or of neurological or psychiatric problems. None of the participants wore hearing aids in daily life. No other criteria were set with respect to participants’ hearing ability. Participants wore, when applicable, their appropriate glasses.
Materials
The sentence materials we used were the audio tracks of a subset of sentences recorded as videos for Jesse and Janse (2012). Sixty sentences contained the target phoneme /p/, and 60 sentences contained the target phoneme /k/. Targets were placed word-initially in these carrier sentences of varying length, such that a target phoneme only occurred once in a sentence. Half of the target-bearing words in each target set were monosyllabic; the other half were bisyllabic with lexical stress on the initial syllable. The four word sets (monosyllabic and bisyllabic /p/ and /k/ words) were matched for lexical frequency (cf. Jesse & Janse, 2012). Sixty foil sentences for each target phoneme set were selected that were similar in complexity and structure to the target sentences, but did not contain the respective target phoneme. Three additional target and foil sentences were created for each target phoneme as practice materials.
The position of the target-bearing words within the sentences varied freely. Target words were not highly predictable on the basis of their preceding (or following) context [e.g., “De circusartieste had al jaren een
All sentences were presented in the experiment without a masker (no-noise condition), with a speech masker (speech-noise condition), and with a speech-shaped masker (nonspeech-noise condition). To create the materials for the speech-noise condition, each sentence was assigned to a longer, meaningful masking sentence spoken by a second female native speaker of Dutch. Masking sentences did not contain the respective target phoneme. Each masking sentence was cut off at the end to match the duration of its assigned target speaker sentence. Mean F0 of the target speaker was 224 Hz (SD = 42 Hz), and mean F0 of the distractor speaker was 202 Hz (SD = 31 Hz), thus creating spectral overlap between target and masker speech (mean pitch difference being 1.8 semitones; cf. Assmann & Summerfield, 1990; Brokx & Nooteboom, 1982; Jackson & Moore, 2013). To create energy-matched nonspeech masker versions of each masking sentence for the nonspeech-noise condition, speech-shaped noise was created on the basis of the competing speaker's long-term spectrum. The long-term average spectrum was calculated over a sound file consisting of a concatenation of 10 randomly selected foil sentences of the masking speaker (5 foil sentences meant to go with /p/ target sentences and 5 meant to go with /k/ target sentences), with silences longer than 100 ms removed. The long-term average spectrum was used to spectrally shape a broadband noise file. For each target and foil sentence, the amplitude contour of its masking sentence was computed. Each sentence's amplitude contour was applied to a fragment of the same length taken from the speech-shaped noise file. The resulting energetic maskers hence varied in intensity over time, just as the speech-masker foil sentences they were respectively based on. The target-to-noise ratio was set to +2 dB (average intensity over the sentence) in both masking conditions, similar to the signal-to-noise ratio for the older adults in Jesse and Janse (2012). Target speech and noise were mixed and were presented binaurally.
Three different experimental lists were created to rotate the three target sets through the three noise conditions. Additionally, two versions of each list were created to balance the order in which participants were presented with the /p/ target phoneme block and the /k/ block (/p/ first or /k/ first), yielding six different experimental lists in total.
Procedure
For the phoneme-monitoring task, participants were tested individually in a sound-attenuated booth. Audio was presented binaurally over headphones at a fixed listening level (80 dB SPL). Participants were first familiarized with the voice of the target speaker with a 40-second audio fragment in which the speaker introduced herself as the target speaker and provided some instructions. Participants then received written instructions explaining that on each trial they would hear the target speaker, without noise, embedded in noise, or while hearing a competing speaker. Participants were asked to monitor the speech of the target speaker on every trial for a word beginning with the respective target phoneme [e.g., “p” in plant (“plant”) or “k” in kabel (“cable”)]. The detection of a target phoneme was to be indicated by pressing a button on a button box. Accuracy and speed were to be maximized. If there was no target phoneme within a presented sentence, no response was to be given. Participants first obtained a practice block, presenting one target and one foil practice trial in each of the three listening conditions. Participants then proceeded with two test blocks (one for each target phoneme), each consisting of 120 trials. Presentation of listening condition was mixed within each block. Participants were able to take a short break in between these blocks.
Practice and experimental trials were structurally the same: Each trial began by showing the target phoneme in a white font (Arial, font size 60) for 1000 ms centred on the black computer screen before a sentence was played. Responses were collected up to 1500 ms after sentence offset. The next trial began 500 ms later. Stimuli materials were always played completely, regardless of whether or not a response was given. After another 500 ms, participants proceeded with the next trial. The experiment was controlled by Presentation experimental software (Version 14, Neurobehavioral Systems, www.neurobs.com).
Auditory, cognitive, and linguistic background tests
Hearing acuity
Air-conduction hearing thresholds were assessed with a portable Maico ST 25 audiometer in a sound-attenuating booth. Mean thresholds are given in Figure 1 for octave frequencies from 0.5 to 8 kHz. Given the high-frequency hearing loss associated with ageing, the mean pure-tone average thresholds (PTA) were computed over 1, 2 and 4 kHz (instead of over 0.5, 1 and 2 kHz) for each participant's better ear. Higher PTAs indicate poorer hearing acuity. The overall mean PTA threshold was 25.61 dB HL (SD = 11.11, range = 3.33–48.33 dB HL). Even though none of the participants wore hearing aids, some had clinically significant hearing loss.
Mean thresholds at several octave frequencies (in the better ear). Error bars represent one standard deviation.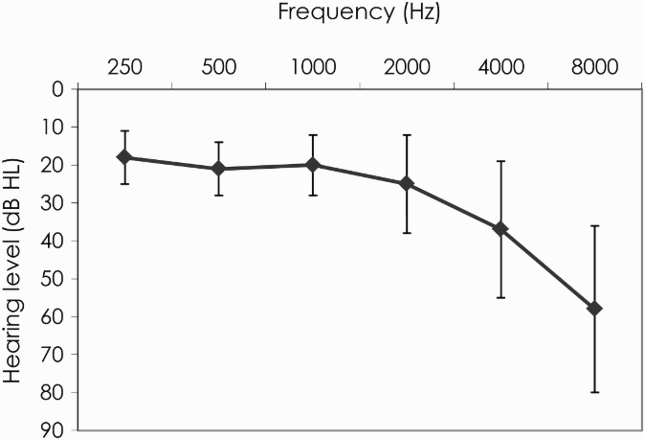
Working memory
A computerized version of the backward digit span task (a subpart of the Wechsler Adult Intelligence Test; Wechsler, 2004) was used to measure individual verbal working memory capacity. The backward version of this task was used to assess the ability to both store and manipulate information in verbal working memory, as the forward version would only reflect passive storage. In this task, a series of digits appeared sequentially in the centre of the computer screen for one second. The interval between consecutive digits was one second. Digits were presented in a large white font (Arial, font size 100) against a black background. After the presentation of a digit sequence (e.g., 3 6 2), participants were prompted to recall the digits in reversed order (e.g., 2 6 3). Participants first practised with 2 three-digit trials, before being tested twice on sequences including two to eight digits (i.e., 14 trials in total). Trials were the same for all participants regardless of their performance. Individual performance on this task was determined as the proportion of correctly recalled digit sequences out of 14 test trials, regardless of digit sequence length. Larger proportions thus indicated better working memory. Mean proportion correct in this task was .36 (SD = .13, range = .14–.86).
Selective attention. In a computerized version of the classic flanker task (Eriksen & Eriksen, 1974) participants indicated the direction of a visually presented arrow by pressing the “z” (left) or “/” (right) key on a keyboard. Speed and accuracy had to be maximized. The target (“>” or “<”) was presented in the middle of four other arrows, which either pointed in the same (or congruent) direction as the target (e.g., for target “>”, “> > > > >”), or in a different (i.e., incongruent) direction (“< < > < <”). In a neutral condition, the target was flanked by dashes (“– > –”). All symbols were shown in white in Arial (font size 80) against a black background. Each trial started with a 400-Hz pure-tone beep presented at 50 dB SPL before a fixation cross was shown for 250 ms. A symbol string was then presented for 1500 ms, while responses were collected. Intertrial time was 1000 ms. The two targets (“<”, “>”) were presented 12 times in each of the three flanker conditions. The order of these 72 trials was randomized for each participant. Testing began with one repetition of each of the six stimuli for practice.
Three participants were 33% or less correct in the incongruent condition. Consequently, their mean reaction times (RTs) for this condition were considered to be invalid. The mean accuracy without these three participants was 94% correct (SD = 11). As expected, accuracy was lowest and most variable in the incongruent condition (88%, SD = 20). Accuracy in the congruent and neutral conditions was 97% (SD = 8) and 97% (SD = 8), respectively. Mean response times for correct responses, measured from visual presentation onset, were 768 ms in the incongruent condition (SD = 297), 620 ms in the congruent condition (SD = 201), and 607 ms in the neutral condition (SD = 198). RTs were log-transformed in order to reduce the skew and nonnormality of their distribution (see e.g., Quené & van den Bergh, 2008), as statistical tests assume data distributions to be normal.
A repeated measures analysis of variance (ANOVA) across participants showed a significant effect of condition on log-transformed RTs, after Greenhouse–Geisser correction for violation of the sphericity assumption, F(1.353, 83.897) = 141.957, p < .001, η2 p = .696. Bonferroni-corrected pairwise comparisons (adopting a criterion level of .05/3 = .017) showed that responses in the incongruent condition were significantly slower than those in the neutral (mean difference = −0.228, SE = 0.018, p < .001) and congruent conditions (mean difference = −0.204, SE = 0.016, p < .001), and that the difference in response time between the neutral and congruent conditions was not significant (mean difference = 0.023, SE = 0.009, p = .026). Individual performance on this task was determined by log-transforming a participant's mean RTs in the neutral and incongruent conditions, and then computing the ratio of each participant's log RT in the incongruent condition, divided by the log RT in the neutral condition. Larger ratios indicated poorer selective attention skills. The mean flanker ratio was 1.04 (SD = 0.02, range = 0.99–1.10). This mean ratio was used as individual score for the three participants for whom the mean RT in the incongruent condition could not be computed.
Vocabulary test
A 60-item receptive multiple-choice test was used to assess vocabulary size (Andringa, Olsthoorn, van Beuningen, Schoonen, & Hulstijn, 2012). The test by Andringa et al. (2012) consists of a selection of items from Hazenberg and Hulstijn's (1996) test for second-language speakers of Dutch and new items that make the test suitable for native speakers. Target words were presented on a computer screen (Courier, font size 15) in neutral carrier sentences [e.g., the target word mentaliteit (“mentality”) was presented in the carrier phrase “Wat een vreemde mentaliteit!” (“What a strange mentality!”)]. Participants were asked to choose the best description of the word's meaning out of five alternatives—for example, for “mentality”: (a) table, (b) person, (c) way of thinking, (d) atmosphere, and (e) I really don't know. The last option was always “I really don't know”. Individual scores were defined as the proportion of correct items (out of 60). Higher scores hence indicated better vocabulary knowledge. The mean score was .87 (SD = .09, range = .57–.98).
Predictor intercorrelations
Pearson correlation coefficients indicating intercorrelations between participant characteristics

p < .01.
p < .001.
To avoid collinearity in our predictor measures, we partialled out hearing loss from working memory and age. The highest remaining correlation between working memory (controlled for hearing) and vocabulary no longer exceeded the Bonferroni-corrected threshold (r = .32, p = .011; all other correlations had r values smaller than .20).
Results
Phoneme-monitoring performance in the three listening conditions
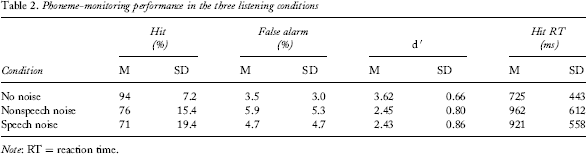
Note: RT = reaction time.
All results were analysed with linear mixed-effect models, including both items and participants as random effects. These offer several advantages over repeated measures ANOVA, as laid out in introductory papers (Baayen, Bates, & Davidson, 2008; Baayen, Tweedie, & Schreuder, 2002; Quené & van den Bergh, 2008). One relevant advantage is that both discrete and categorical predictors can be included in a model (or can be modelled to interact). To deal with the categorical nature of the hit and false-alarm measures, a binomial logit linking function between responses (0 or 1) and predictor variables was included into the hit and false-alarm models (Jaeger, 2008). The no-noise condition was mapped onto the intercept. Target phoneme was contrast-coded (−.5 for /p/ and +.5 for /k/). Regression weights for categorical factors reflect the adjustments to the intercept across conditions. Effects of trial number, contextual probability rating, and position of the target in the sentence (ms from sentence onset) were evaluated as numerical factors. Regression weights of numerical factors indicate adjustments to the slope of the regression line. The best fitting model for each data set was established through systematic stepwise model comparisons using likelihood ratio tests.
Results of best fitting models for the different dependent variables
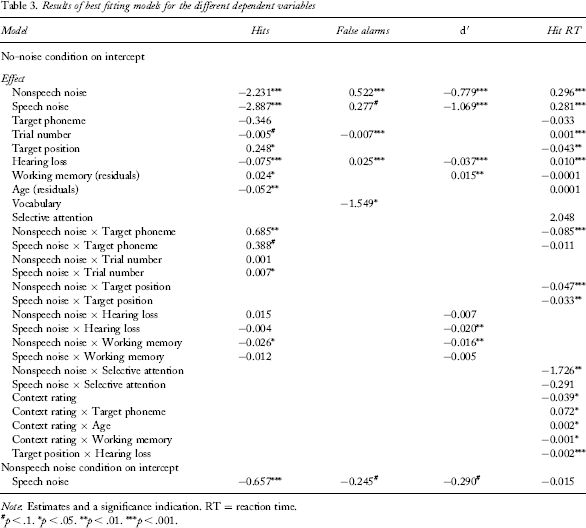
Note: Estimates and a significance indication. RT = reaction time.
p < .1.
p < .05.
p < .01.
p < .001.
Accuracy results
Hits
The best fitting model for hits showed that fewer targets were detected in the nonspeech-noise condition (β = −2.231, SE = 0.237, p < .001) and in the speech-noise condition (β = −2.887, SE = 0.234, p < .001) than in the no-noise condition. Importantly, when the nonspeech-noise condition was mapped onto the intercept, hit rates in the speech-noise condition were lower than those in the nonspeech-noise condition (β = −0.657, SE = 0.151, p < .001). Accuracy was hence affected by energetic and by informational masking. Participants detected targets more reliably the later they occurred in the sentence (β = 0.248, SE = 0.101, p < .05). The effect of probability rating was not included in the best fitting model as its inclusion only marginally improved the model's fit, χ2(1) = 3.485, p = .062.
Participants with poorer hearing detected fewer targets (β = −0.074, SE = 0.012, p < .001), and the older the participant was, the fewer targets were detected (β = −0.052, SE = 0.018, p < .01). Participants with better working memory had higher hit rates (β = 0.024, SE = 0.011, p < .05), but less so in the nonspeech-noise condition (β = −0.026, SE = 0.010, p < .05). There were no other significant interactions between individual participant characteristics and condition or context rating. In summary, hearing loss, age, and working memory predicted hit accuracy. The association between working memory and accuracy was particularly found in the no-noise and the speech-noise conditions.
False alarms
The only random factor included in the false-alarm data analysis was participant, since several foil sentences did not elicit any false alarms. Relative to the no-noise condition, there were more false alarm responses in the nonspeech-noise condition (β = 0.522, SE = 0.136, p < .001). There was no statistical evidence for informational masking. False alarms were hence only affected by energetic and not by informational masking. Participants with more hearing loss gave more false-alarm responses (β = 0.024, SE = 0.007, p < .001). Further, participants with better vocabulary knowledge gave fewer false-alarm responses across all conditions (β = −1.549, SE = 0.780, p < .05). In summary, better hearing and better vocabulary knowledge were associated with lower false-alarm rates.
d′
We also analysed d′s as a measure of detection sensitivity. Higher d′ values indicate greater detection sensitivity, whilst accounting for the fact that (certain) participants may have a bias to respond that the target is present. Given the nature of the d′ statistic, only participant and not item was included as a random variable. Relative to the no-noise condition, d′ was lower in the nonspeech-noise (β = −0.779, SE = 0.156, p < .001) and in the speech-noise condition (β = −1.069, SE = 0.156, p < .001). When the nonspeech-noise condition was mapped onto the intercept, d′s in the two noise conditions did not differ from another (β = −0.025, SE = 0.079, p > .1). Detection sensitivity was thus affected by energetic masking, but not further affected by informational masking.
Participants with poorer hearing had lower d′s (β = −0.037, SE = 0.005, p < .001). This was true in the no-noise condition (mapped on the intercept) and in the nonspeech-noise condition (as the hearing effect was not stronger in the nonspeech than in the no-noise condition: β = −0.007, SE = 0.007, ns), but was even more the case in the speech-noise condition, as indicated by an interaction between hearing loss and the speech-noise condition (β = −0.020, SE = 0.007, p < .01). Further, participants with better working memory had higher d′s, both in the no-noise condition (β = 0.015, SE = 0.005, p < .01) and in the speech-noise condition (as the interaction was not significant: β = −0.005, SE = 0.005, ns). The strength of this relationship between working memory and d′ was decreased, however, in the nonspeech-noise condition (β = −0.016, SE = 0.005, p < .01). In summary, better hearing and better working memory were associated with better detection sensitivity, but the strength of these associations differed across listening conditions.
Hit response time results
Relative to the no-noise condition, response times were slower in the nonspeech-noise condition (β = 0.296, SE = 0.012, p < .001) and in the speech-noise condition (β = 0.281, SE = 0.013, p < .001). When the nonspeech-noise condition was mapped onto the intercept, there was no difference in performance in the two noise conditions (β = −0.015, SE = 0.013, p > .1), indicating a lack of informational masking. Faster responses were given the later the target occurred in the sentence (β = −0.043, SE = 0.016, p < .01). This effect was modified by listening condition, such that it was larger in the nonspeech-noise (β = −0.047, SE = 0.012, p < .001) and speech-noise conditions (β = −0.033, SE = 0.013, p < .01) than in the no-noise condition. Higher contextual probability ratings facilitated response times (β = −0.039, SE = 0.016, p < .05).
Across listening conditions, participants with poorer hearing had slower response times (β = 0.010, SE = 0.002, p < .001). Further, the poorer the participants’ hearing, the more their responses were facilitated by the target occurring later in the sentence (β = 0.002, SE = 0.0005, p < .001), such that poorer hearing participants showed larger effects of preceding phonetic context. Participants with poorer selective attention were less affected by nonspeech noise (β = −1.726, SE = 0.620, p < .01), which appears to be an unexpected result at first. When the nonspeech-noise condition was mapped onto the intercept, the results showed that although those participants with poorer selective attention benefited less from the absence of noise (β = 1.726, SE = 0.620, p < .01), they were also impacted more by the presence of competing speech (β = 1.435, SE = 0.683, p < .05). This suggests that adults with poorer selective attention are less affected by energetic masking but more affected by informational masking.
Two individual characteristics related to the size of the contextual probability facilitation on response times: Participants with better working memory benefited more from higher contextual probability (β = −0.001, SE = 0.0005, p < .05). This result is shown in Figure 2, where participants have been grouped on the basis of a median split for working memory ability. Figure 2 illustrates that those participants with better working memory show more contextual facilitation of their responses than those with poorer working memory. In addition to working memory, age interacted with contextual probability, such that the older the participant, the smaller the facilitation by context (β = 0.002, SE = 0.001, p < .05).
Hit response times averaged over listening conditions as a function of contextual probability rating (i.e., how well the target word fit the preceding sentence fragment on a scale from 1 “word does not fit at all” to 7 “perfect fit”) and digit span performance. For illustration purposes, participants have been grouped into High Span and Low Span subgroups, based on a median split on digit span performance.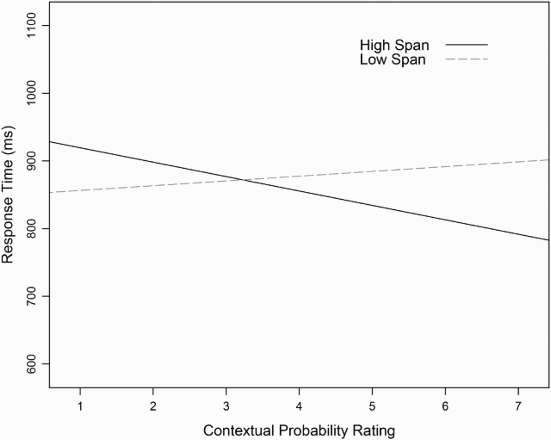
We also evaluated whether these effects were solely driven by those participants with clinically significant hearing loss. To do so, we reevaluated the final model on a subset of 47 participants (out of a total of 63 participants) whose pure-tone average threshold in the better ear was below 35 dB HL, a threshold applied by Dutch health insurance companies as to whether or not to provide a partial reimbursement of a hearing aid. One additional participant was excluded because of a low hit rate (below 50%). The lowest hit rate in the remaining 46 participants was 66% (M = 85%, SD = 8.2, range = 66–98). The results of the subset analysis largely mirrored those of the full participant sample. Importantly, the interactions between contextual probability and working memory (β = −0.001, SE = 0.0005, p < .05) and between contextual probability and age (β = 0.004, SE = 0.001, p < .01) were also found in this subset of participants with relatively normal hearing. Hearing loss thus does not drive our finding that the immediate use of contextual probability is modulated by both working memory and age of the listener.
In summary, hearing loss affected response times across conditions, and those with poorer hearing showed greater facilitatory effects of phonetic context. Those older adults with poorer selective attention were more impacted by speech noise and benefited less from the absence of noise. Both age and working memory related to context facilitation, with more facilitation with younger age and better working memory.
Discussion
In this study, we investigated individual differences in older adults’ ability to efficiently use contextual probability for the recognition of spoken words in sentences presented in different listening conditions. We used phoneme monitoring with meaningful sentences, as performance in this task can then be interpreted as reflecting lexical processing. The time to process the speech materials was limited by requiring participants to maximize response speed and accuracy. Limiting processing time was indeed important as the gradient measure of contextual probability (derived from a separate offline rating study) mainly affected the speed of word recognition in our materials and had only a marginal effect on accuracy. The experimental results showed three main points. First, semantic context facilitation of spoken-word recognition was modulated by verbal working memory and age. Second, hearing loss, working memory, vocabulary knowledge, and age were the most consistent predictors of overall listening performance. Hearing loss also predicted the use of preceding phonetic context in phoneme monitoring. And third, adults with poorer selective attention were less affected by energetic masking, but more affected by informational masking.
The main question was whether verbal working memory and age would independently be associated with the size of the context facilitation effect on spoken-word recognition. There are different components to working memory that can be tested in many ways. Here, we focused on the backward digit span task as it captures the crucial ability to simultaneously store, process, and manipulate verbal information in memory. As predicted, participants who are better at manipulating and updating information in working memory (as indexed by better performance on a backward digit span task) showed larger facilitation of their responses to words with greater contextual probability. This suggests that working memory skills may aid the listener in keeping and updating a semantic representation of the sentence content. Importantly, our results show that verbal working memory is associated with the immediate use of contextual probability for spoken word recognition, as the sentence unfolds. That is, the relationship between working memory and context use for speech comprehension is not limited to situations in which listeners have unlimited processing time (e.g., in Zekveld et al., 2011b, 2012). Our results therefore suggest that contextual probability helps constrain the lexical search space immediately, particularly for those listeners who are better at storing new and updating old information in memory. As a target's contextual probability and position in the sentence were not confounded in our sentence materials, we were also able to show that working memory modulates the immediate use of semantic contextual probability in spoken-word recognition, whereas hearing sensitivity modulates facilitation of word recognition from preceding phonetic context. Even though the monitoring of phonemes in meaningful sentences is interpreted as reflecting lexical processing, participants’ way of listening to speech may have been different from that in normal listening situations as their attention here is explicitly drawn to the occurrence of a specific target phoneme. Future research will have to determine whether our results thus hold for other listening situations. Importantly, however, there are some preliminary indications that our findings on working memory and immediate use of contextual probability may generalize to an experimental method (i.e., eye tracking using a visual world paradigm) with fewer metalinguistic demands, as the latter only requires participants to listen to speech while looking at a computer screen display (Huettig & Janse, 2012).
The ability to benefit from semantic context was modulated not only by working memory, but also by age differences among the older adults—namely, above and beyond working memory effects. Increased age within our sample of older adults was associated with smaller context facilitation effects across all listening conditions. However, age-related declines, such as cognitive slowing (Salthouse, 1996) or reduced auditory temporal processing (cf. e.g., Pichora-Fuller, Schneider, MacDonald, Pass, & Brown, 2007; Smith, Pichora-Fuller, Wilson, & MacDonald, 2012) cannot fully account for the present age effects on efficiency of semantic integration, as there was no general age effect on response latencies. Age only modulated the effect of context on response latencies. This result thus rather supports the idea that ageing impairs semantic integration in speech processing, as found for age group comparison studies on N400 effects in reading (Federmeier & Kutas, 2005; Federmeier et al., 2010). This poorer semantic integration may be related to the reduced coherence between activated brain regions in spoken sentence comprehension (Peelle et al., 2010). Some recent evidence suggests that older listeners may also not be able to overcome an initial difficulty in semantic integration with additional (postperceptual) processing (Benichov et al., 2012). Benichov et al. (2012) showed that in a task with unlimited processing time, the age of listeners (ranging from 19 to 89 years) was negatively correlated with spoken word recognition, after hearing sensitivity had been accounted for. This relationship was especially strong for the recognition of words in highly constraining contexts. More research is, however, needed to investigate explicitly the time course of the effects of context on sentence comprehension in younger and older adults. In summary, in the present study, we found associations between immediate context facilitation and working memory and age. These associations held across listening conditions and thus across different degrees of speech processing difficulty.
We also examined the relationship of several other listener characteristics to the performance in this speeded word recognition task. Linguistic expertise, as indexed by vocabulary knowledge, did not modify the efficient use of context among older adults. This suggests that listeners’ knowledge about the words within their native language does not predict their ability to anticipate upcoming words. Possibly, other measures of linguistic expertise may be more relevant. Even though vocabulary knowledge as an index of linguistic expertise did not predict the use of context information in this study, it was an important predictor of overall task performance. Vocabulary knowledge predicted the false detection of phoneme targets. Those listeners with better vocabulary produced fewer false-alarm responses. In addition to vocabulary knowledge, we found that hearing loss and working memory were predictive of hit and false-alarm rates across listening conditions. Hearing loss also predicted listeners’ overall detection sensitivity to the target-bearing words and the impact of competing speech on detection sensitivity. Working memory plays a general role in lexical processing as it modulated performance in the no-noise condition. The finding that working memory relates to listening performance in the speech-noise condition is in line with working memory being the most consistent cognitive predictor across several studies on speech recognition in noise (Akeroyd, 2008). We have currently no explanation as to why working memory was not associated with accuracy in the nonspeech-noise condition.
The only participant characteristic that predicted the degree to which older listeners were affected by masking was selective attention. More specifically, adults with poorer selective attention were affected less by energetic masking, but more by informational masking. The latter result is in line with prior work suggesting that attentional control relates to interference from meaningful competing speech (Janse, 2012; Tun et al., 2002). There has been considerable debate as to whether executive function should be seen as a unitary construct, or whether it is a term covering several distinct cognitive processes, working memory being one of them (cf. e.g., McCabe, Roediger, McDaniel, Balota, & Hambrick, 2010, and references therein). Based on structural equation modelling, McCabe and colleagues (2010) argue that tests of working memory capacity and of executive function share a common underlying executive attention component. Others have also suggested considerable overlap between working memory and attentional abilities (e.g., Baddeley, 1996; Cowan, 1995). Yet other studies have shown that intercorrelations among these cognitive functions may be low (see Miyake, Friedman, Emerson, Witzki, & Howerter, 2000, and references therein), which was also the case for the indices of selective attention and working memory in our participant sample. Selective attention in our study thus predicts, independently of working memory, a listener's susceptibility to masking and is not an index of general task performance.
There are several possible explanations for why we mainly found predictors of general listening performance and only one predictor of masking effects (selective attention). One reason could be that we did not block by listening condition. This might have made the experimental task relatively demanding, as participants may have had to switch back and forth between processing strategies. Another possible account for the fact that we mainly found predictors for general performance could be that our method was sensitive enough to investigate individual differences in the no-noise condition. Most studies on individual differences in speech processing lack a no-noise condition since accuracy in a no-noise condition would be too close to a ceiling level of performance to be able to analyse individual variation. The use of a speeded measure allowed us to investigate individual differences among older adults in this listening condition. Our results illustrate that individual differences are magnified in more difficult conditions, but can already be found in easier listening conditions, if the testing method is sensitive enough.
In conclusion, our results show that older listeners can immediately use contextual probability to facilitate the recognition of spoken words in sentences. The size of this contextual benefit is modulated by the listener's verbal working memory and age. This was found for listening to speech without noise and with noise. Older adults with better working memory also showed generally better speech processing performance, and older adults with better selective attention were less impacted by distraction from competing speech. These results therefore provide evidence that memory underlies efficient speech processing and semantic integration of the spoken message. Importantly, our results also suggest that verbal working memory is not the sole factor, but that other age-related changes matter as well.
Footnotes
Acknowledgements
We thank Antje Meyer for useful feedback on an earlier version of this paper. This work was supported in part by the Netherlands Organization for Scientific Research (NWO) under a Vidi Grant awarded to the first author [grant number 276-75-009].