
Abstract
This study examined the effect of unitization and contribution of familiarity in the recognition of word pairs. Compound words were presented as word pairs and were contrasted with noncompound word pairs in an associative recognition task. In Experiments 1 and 2, yes–no recognition hit and false-alarm rates were significantly higher for compound than for noncompound word pairs, with no difference in discrimination in both within- and between-subject comparisons. Experiment 2 also showed that item recognition was reduced for words from compound compared to noncompound word pairs, providing evidence of the unitization of the compound pairs. A two-alternative forced-choice test used in Experiments 3A and 3B provided evidence that the concordant effect for compound word pairs was largely due to familiarity. A discrimination advantage for compound word pairs was also seen in these experiments. Experiment 4A showed that a different pattern of results is seen when repeated noncompound word pairs are compared to compound word pairs. Experiment 4B showed that memory for the individual items of compound word pairs was impaired relative to items in repeated and nonrepeated noncompound word pairs, and Experiment 5 demonstrated that this effect is eliminated when the elements of compound word pairs are not unitized. The concordant pattern seen in yes–no recognition and the discrimination advantage in forced-choice recognition for compound relative to noncompound word pairs is due to greater reliance on familiarity at test when pairs are unitized.
Keywords
In item recognition, participants are presented with items at study and are then subsequently assessed on their ability to discriminate between individual old and new items at test. In contrast, in associative recognition, random pairs of items are typically presented at study, and participants are instructed to form a relation between them. At test, participants discriminate between intact pairs (i.e., old or studied pairs) and rearranged pairs (i.e., new pairs constructed from old items from different study pairs; e.g., Hockley & Consoli, 1999; Humphreys, 1978). Associative recognition is successful when intact pairs are endorsed (i.e., hits), and rearranged pairs are rejected (correct rejections). Memory for the individual items cannot assist associative recognition as both intact and rearranged pairs consist of old items. Thus, successful associative recognition depends only on retrieval of relational information.
Dual-process theory, in its broadest terms, is a generally accepted account of item and associative recognition. This theory holds that recognition decisions are based on two processes: familiarity and recollection (e.g., Jacoby, 1991; see Yonelinas, 2002, for a review). Recollection is a relatively slow process, described as a search for specific details associated with prior presentation of an item. It is a process similar to that involved in a recall task. Familiarity is a relatively fast process and allows a recognition decision to be made even though no specific details of a prior presentation of an item have been retrieved (Wixted, 2007). Thus, participants’ greater use of familiarity in a recognition decision can be ascertained by fast response times, whereas use of recollection has been associated with slower response times (e.g., Yonelinas, 2002; see Hockley, 2008, for a review). Moreover, the pattern of hit and false-alarm rates provide additional evidence for greater use of familiarity than recollection, according to dual-process theory. An increase in hit rate could be due to familiarity or recollection or both, whereas an increase in false-alarm rate reflects a greater use of familiarity than recollection. This interpretation is supported by a study by Greene (1999). In the study, half of the study and test items were familiarized by presenting them in an earlier study phase. Both hit and false-alarm rates were greater for the familiarized items than for the nonfamiliarized items. Greene attributed this concordant pattern of results to the higher familiarity of the previously presented items.
It has been argued that associative recognition relies more on recollection for contextual details, in this case the co-occurrence of each item of the pair, whereas item recognition relies more on familiarity in the absence of retrieval of contextual details (e.g., Tulving, 1985; Yonelinas & Jacoby, 1994). Based on an analysis of receiver operating characteristic (ROC) curves, Yonelinas, Kroll, Dobbins, Lazzara, and Knight (1998) and Rotello and Heit (2000) showed that familiarity contributed more to item recognition of words, and recollection contributed more to associative recognition of word pairs. Curvilinear ROCs were produced by recognition tests of single words, and linear ROCs were produced by associative recognition of word pairs. In addition, using a remember/know procedure, Hockley and Consoli (1999) found that associative recognition judgements were associated with more remember responses and fewer know responses than item recognition judgements. Remember judgements indicate use of recollection at retrieval, whereas know judgements reflect the use of familiarity. Moreover, Hockley and Consoli (1999) found that discrimination between intact and rearranged pairs was at chance for recognition decisions classified as know judgements.
Recently, however, researchers have found that familiarity can support associative recognition when the pairs of items presented at study are unitized (Bastin, Linden, Schankers, Montaldi, & Mayes, 2010; Ford, Verfaellie, & Giovanello, 2010; Giovanello, Keane, & Verfaellie, 2006; Rhodes & Donaldson, 2007; Quamme, Yonelinas, & Norman, 2007; Yonelinas, Kroll, Dobbins, & Solatani, 1999; see Murray & Kensinger, 2013, for a review). Items are considered unitized when the components of the association have been encoded as a coherent whole, so that the well-integrated whole becomes more familiar than its constituents and should then be more familiar than a new recombined association (Bastin et al., 2010; Graf & Schacter, 1989). Thus, unitization would promote similar use of familiarity in associative recognition as in an item recognition task. Unitization has been achieved by instructional manipulation at encoding and by the use of stimuli with preexperimental associations or relations.
Quamme et al. (2007) used an instructional manipulation involving a compound definition to induce unitization at encoding in an associative recognition test. They had young adults study unrelated word pairs using a compound definition. For example, given the unrelated word pair CLOUD–LAWN, participants were to rate the pair on how well the definition “A yard used for sky-gazing” combined the two words into a sensible compound. In the nonunitized condition, participants studied unrelated word pairs presented in a sentence. For example, given the unrelated word pair WATCH–LECTURE, participants were to rate how well the words fit into a sentence “He glanced at the __ as the __ began”. The sentence condition encouraged relational encoding of the pairs. At test, participants were randomly assigned to a standard or a familiarity-only test instruction group. In the familiarity-only procedure, devised by Mayes, Montalidi, and Migo (2007), participants are instructed to respond quickly and base responses only on familiarity. Quamme et al. found from ROC analyses that participants in the standard recognition test instruction group showed no difference between recognition of unitized and nonunitized pairs. However, participants in the familiarity-only test instruction group showed a discrimination advantage for unitized pairs. A discrimination advantage for unitized pairs was also shown by amnesics with lesions restricted to the hippocampus in Quamme et al.'s first experiment, in which only standard test instructions were provided. Quamme et al. concluded that recognition of unitized word pairs relied on familiarity to a greater extent, whereas associative recognition for nonunitized word pairs was based more on recollection.
Another way to examine the effects of unitization on associative recognition is by presenting pairs of items that have preexperimental associations. Greve, van Rossum, and Donaldson (2007) showed there was greater use of familiarity in associative recognition of semantically related than in that of unrelated pairs. The semantically related word pairs were words of the same category (e.g., rabbit–mouse). They found a concordant effect, with an increase in hit rate and false-alarm rate for semantically related compared to unrelated pairs, indicating greater use of familiarity for semantic than unrelated pairs. Discrimination was also higher for semantically related than for unrelated pairs. Further support for greater use of familiarity for recognition of semantically related pairs was shown by a more positive N400 old/new effect for semantically related than for unrelated pairs.
In an event-related potential (ERP) study, Rhodes and Donaldson (2007) examined whether word pairs with a meaningful relationship and considered to be unitized at encoding elicited ERP components typically associated with familiarity-based responding. In the behavioural task, participants were asked to remember word pairs sharing an association (traffic–jam) or a semantic relationship (cereal–bread) in an associative recognition task. The reported examples of the associated pairs suggest that they were largely compound words 1
Compound words have been distinguished in terms of the relationship between the two lexemes. For example, the modifier (the first word) can define a subclass of the general category denoted by the second word or head noun (e.g., darkroom). The two elements together can also denote a particular kind of unexpressed semantic head (e.g., skinhead or paleface, where the semantic head is “person”). A compound word can also express the “sum” or totality of what the two elements denote (e.g., bittersweet). Compound words are also distinguished as to whether the contribution of the meaning of each lexeme to the compound word is based on its original meaning (transparent) or a shifted meaning (opaque). Both members of a compound can be transparent (e.g., blueberry), the head member can be transparent and the other member opaque (e.g., strawberry), the head member can be can be opaque and the other member transparent (e.g., jailbird), and both members can be opaque (e.g., buttercup). The available evidence indicates that the encoding of familiar unspaced compound words is based on the components, but the meaning of a compound word is not constructed from its separate parts (Frisson, Niswander-Klement, & Pollatsek, 2008).
Giovanello et al. (2006) provide converging evidence for the role of familiarity in the recognition of unitized pairs. They compared associative recognition for the two elements of compound words and unrelated word pairs in a group of amnesic patients and a matched group of middle-aged adults. During the study phase, the experimenter read a sentence aloud that incorporated either the two words of the unrelated pairs or the compound words. For each sentence, participants provided a rating of the likelihood of occurrence of the information conveyed in the sentence. After a 10-minute delay, the test phase began. At test, participants discriminated between studied unrelated word pairs and compound word pairs (e.g., landscape, blackmail, jailbird) and rearranged unrelated word pairs and rearranged compound word pairs (e.g., blackbird). Giovanello et al. found that both hit and false-alarm rates were significantly higher for compound words than for unrelated word pairs for both the control and the amnesic groups. However, only in the amnesic group did discrimination increase for compound words relative to unrelated word pairs; discrimination did not differ for the control group. Giovanello et al. concluded that enhanced familiarity induced by studying compound word pairs led the amnesic group to discriminate more effectively between studied and recombined compounds than between studied and recombined random word pairs. Giovanello et al. also found in a separate experiment that normal participants were more likely to base their associative recognition decisions for compound word pairs on the basis of familiarity as measured by the remember–know response procedure.
In a subsequent study based on Giovanello et al.'s (2006) associative recognition procedure, Ford et al. (2010) used blood-oxygen-level-dependent (BOLD) functional magnetic resonance imaging (fMRI) to identify neural activity during retrieval of unitized and nonunitized pairs. Unlike in Giovanello et al.'s study, participants created a simple sentence including the compound words or the words in the unrelated pair. After completion of the study phase, participants were placed in scanner to provide yes–no judgements to studied and nonstudied word pairs. Ford et al. found that recognition of previously presented compound words was associated with left perirhinal activity (indicating use of familiarity), whereas recognition of unrelated word pairs was associated with activity in left hippocampus (indicating use of recollection). In terms of the behavioural results, however, Ford et al. did not find a significant difference in the hit and false-alarm rates or overall discrimination between compound and unrelated word pairs, although there was a trend toward higher hit and false-alarm rates for compound word pairs. One notable difference between the procedures of Ford et al. and Giovanello et al. (2006) was that participants were young adults (20–25 years) rather than older adults (M = 59 years).
The above studies examining associative recognition for meaningfully related word pairs provide evidence for unitization and the role of familiarity in these decisions. These studies, however, have not provided a consistent pattern of results. Whereas amnesics showed a discrimination advantage for compound word pairs over unrelated word pairs (Giovanello et al., 2006), normal adults typically did not show a difference (Ford et al., 2010; Giovanello et al., 2006; Rhodes & Donaldson, 2007). In contrast, Greve et al. (2007) did find a discrimination advantage for semantically related word pairs. Normal adults demonstrated a concordant increase in both hit and false-alarm rates for compound pairs (Giovanello et al., 2006), only an increase in hit rate (Rhodes & Donaldson, 2007), or no differences (Ford et al., 2010).
It is not clear why findings from previous studies have been inconsistent because differences in procedures make it difficult to isolate the reasons for the various results.
Associative recognition of compound word pairs bears a strong resemblance to the conjunction effect in item recognition. Both tasks involve discriminating between intact and rearranged compound words. In the associative task, the emphasis has been on contrasting recognition for compound versus noncompound word pairs. In the item recognition task, the focus has been on the false-alarm rates for the rearranged lures. In studies examining item recognition of compound words in the conjunction memory paradigm, significantly higher false-alarm rates are found for conjunction lures than for new words. For example, at study the compound words brainwash, hailstorm, and watchtower are presented. During the recognition test, participants would see brainwash (a studied target), brainstorm (a conjunction lure), watchmaker (a feature lure), or stockyard (a new compound word). The proportion of old responses is higher for targets, next highest for conjunction lures, followed by feature lures, and then new stimuli (i.e., old > conjunction > feature > new; Jones & Jacoby, 2001; Reinitz, Lammers, & Cochran, 1992; Reinitz, Verfaellie, & Milberg, 1996). The increase in the false-alarm rate for conjunction lures is referred to as the conjunction effect. Jones and Jacoby (2001) argued that the higher false-alarm rate for conjunction lures than for new words occurs due to the greater familiarity of conjunction lures. It follows that rearranged compound word pairs in an associative recognition test should also be experienced as more familiar.
The purpose of the current study was to examine the contribution of familiarity in the associative recognition of unitized pairs based on preexperimental associations by comparing performance for compound (CW) and noncompound (NCW) or unrelated word pairs. Both types of word pairs were constructed in a counterbalanced manner to equate the familiarity of the individual words in each pair. Based on the findings of Giovanello et al. (2006) and the conjunction effect in item recognition, we predicted that both the false-alarm and the hit rate would be higher for CW than for NCW pairs in yes–no associative recognition (i.e., a concordant effect). The greater false-alarm rate would reflect the preexperimental familiarity of CW pairs. The increased hit rate would reflect familiarity and recollection arising from encoding during the study phase in addition to preexperimental familiarity. Thus, the increase in hit rate should be greater than the increase in false-alarm rate, resulting in a discrimination advantage for CW pairs over NCW pairs.
Seven experiments are reported. Yes–no associative recognition performance for CW and NCW pairs was compared in Experiments 1, 2, and 4A. The basis of the concordant effect found in Experiments 1 and 2 was examined using a two-alternative forced-choice procedure in Experiments 3A and 3B. In Experiment 4A, associative recognition of CW pairs was compared with NCW pairs that were repeated four times at study. Experiment 2 and Experiment 4B were also conducted to demonstrate that item recognition for the individual components is impaired for compound word pairs relative to unrelated word pairs, providing evidence of the unitization of the CW pairs. Finally, Experiment 5 was designed to see whether the difference in item recognition observed in Experiments 2 and 4B could be eliminated when the encoding task emphasized item information rather than associative information.
Experiment 1
Examples of the counterbalanced compound and noncompound sets of word pairs used in each associative recognition experiment
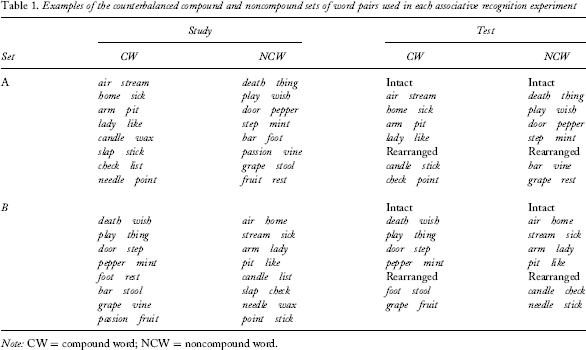
Note: CW = compound word; NCW = noncompound word.
It was predicted that since words within CW pairs (e.g., air stream) are more easily unitized than words in NCW pairs (e.g., passion vine) due to prior learning, familiarity would be used to a greater extent in the recognition of CW pairs. This would be shown in a concordant pattern, where both hit and false-alarm rates would be significantly higher for CW than for NCW pairs. As the encoding of associative information should be much easier for CW pairs, the increase in hit rate should exceed the increase in false-alarm rate, giving rise to a discrimination advantage for CW pairs as well.
Method
Participants
All participants in each experiment were undergraduate students enrolled in a psychology course at Wilfrid Laurier University who participated for course credit. A total of 31 students participated in Experiment 1. One participant's data file was not included in the data analyses because of chance performance in the NCW condition (i.e., their hit rate was less than their false-alarm rate).
Materials and apparatus
The experiment was run on PC compatible laboratory computers equipped with 17″ LCD monitors and SuperLab 2.0 software (Cedrus Corp.) was used to control stimulus presentation and response recording. From a list of 160 compound words provided by Jones (2005), 48 CW pairs and 48 NCW pairs were constructed. To create the NCW pairs, the left word from one CW pair was paired with the right word from another CW pair. This was done to equate the individual words of the compound and NCW pairs. To create a rearranged CW pair, the first member of the parent CW pair was paired with the second member of another CW pair. For example, the rearranged CW pair check–point was made from the parent CW pairs, check–list and needle–point. Two sets (A and B) were constructed to counterbalance the components of the CW and NCW pairs across participants. Examples of the intact and rearranged CW and NCW pairs in Sets A and B are shown in Table 1.
Procedure
At the beginning of the study phase, participants were told they would be presented with a list of word pairs presented one at a time on the screen. They were asked to try to form a relation between the words in each pair by forming either an image or a sentence combining the two words in the pair as this would help them remember the word pair at test. The critical portion of the study list consisted of 48 CW and 48 NCW pairs. In addition, there were two buffer pairs, one CW pair and one NCW pair, at the beginning and end of each study list to minimize primacy and recency effects. The order of the study pairs (excluding buffers) was random, with a different random order for each subject. The two members of the CW and NCW pairs were separated by six blank spaces (e.g., heart beat, death clap). Each word pair appeared in the centre of the screen for 4 s with no interval between successive pairs. After the study phase was completed, for approximately 1 min duration, the experimenter presented the test instructions to the participants. They were informed of the difference between old (intact) and new (rearranged) test pairs and were instructed to press the “/” and “z” keys for old and new judgements, respectively. They were also asked to respond as accurately as possible. Response time was not mentioned. In addition, they were instructed to provide a confidence judgement for old and new responses. That is, after participants entered their old or new response, they made a confidence judgement by pressing 1 for “not sure”, 2 for “sure”, or 3 for “very sure”.
During the test phase, each trial began with a test pair displayed in the centre of the screen in the same format as the study pairs. Test pairs remained on the screen until the participant responded, and response time was measured from the onset of presentation until the response was made. There were 16 intact and 16 rearranged CW pairs and 16 intact and 16 rearranged NCW pairs presented in a different random order for each participant.
Results and discussion
Experiment 1: Mean hit and false-alarm rates, estimates of discrimination, and criterion placement for compound and noncompound word pairs
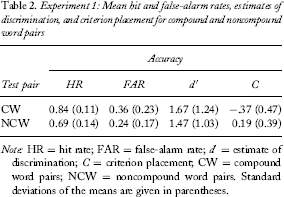
Note: HR = hit rate; FAR = false-alarm rate; d′ = estimate of discrimination; C = criterion placement; CW = compound word pairs; NCW = noncompound word pairs. Standard deviations of the means are given in parentheses.
A 2 (word pair type) × 2 (probe type) repeated measures analysis of variance (ANOVA) was conducted on the proportions of old responses. There was a significant main effect of test probe [F(1, 29) = 133.3, MSE = .049, p < .001, η2 = .821]. The hit rate was significantly higher than the false-alarm rate showing that overall discrimination performance was above chance. There was also a significant main effect of word pair type [F(1, 29) = 56.8, MSE = .010, p < .001, η2 = .662]; the hit and false-alarm rates were both greater for the CW than the NCW pairs, reflecting a concordant effect. The interaction between word pair type and test probe was not significant [F(1, 29) = 0.314, MSE = .015, p = .579, η2 = .011]. Similar analyses of confidence judgements and response times showed that these measures were consistent with the concordant effect observed for hit and false-alarm rates.
2
Statistical analysis showed that mean confidence for hits was higher for CW (M = 2.82, SD = 0.16) than for NCW pairs (M = 2.71, SD = 0.20), and mean confidence for correct rejections was lower for CW (M = 1.98, SD = 0.40) pairs than for NCW (M = 2.09, SD = 0.41) pairs. Response time for hits was faster for CW (M = 1490 ms, SD = 653) than for NCW pairs (M = 1769 ms, SD = 503), whereas response time for correct rejections did not differ for CW (M = 1987 ms, SD = 659) and NCW pairs (M = 979 ms, SD = 506).
To further examine performance between conditions, corrected recognition scores (hit rate minus false-alarm rate) and signal detection theory estimates of discriminability (d′) and response bias (C) were calculated. Analyses of corrected recognition scores and d′ showed the same statistical patterns of results, and only the analyses of d′ are reported. Mean estimates of d′ and C are also shown in Table 2. A 2 (pair type) within-factor ANOVA revealed that there was no significant difference in d′ estimates between CW and NCW pairs [F(1, 29) = 1.13, MSE = 0.569, p = .297, η2 = .038]. The same analysis of estimates of C revealed that there was a significant difference in criterion placement between CW and NCW pairs [F(1, 29) = 40.1, MSE = .121, p < .001, η2 = .580]. Participants adopted a more liberal decision criterion for CW than for NCW pairs.
As several researchers (e.g., Wixted, 2007; Yonelinas, 2002; Yonelinas & Parks, 2007) have suggested that analysis of ROC curves provides a more sensitive measure of recognition discrimination than d′ or corrected recognition scores, ROC curves for CW and NCW pairs were derived from the associative recognition confidence judgements in the manner described by Yonelinas and Parks (2007). That is, ROCs were constructed by plotting hit and false-alarm pairs beginning with the most confidently recognized items [e.g., hits = P(6|old); false alarms = P(6|new)] then repeatedly recalculating the values by including the next most confidently recognized items [e.g., hits = P(6|old) + P(5|old); false alarms = P(6|new) + P(5|new); etc.]. The ROC curves presented in Figure 1 show no difference in discrimination between CW and NCW pairs. In fact, a similar area under the curve was shown for associative recognition of both pair types.
Receiver-operating characteristic (ROC) analysis of averaged performance of all participants in associative recognition of noncompound word (NCW) pairs and compound word (CW) pairs in Experiment 1.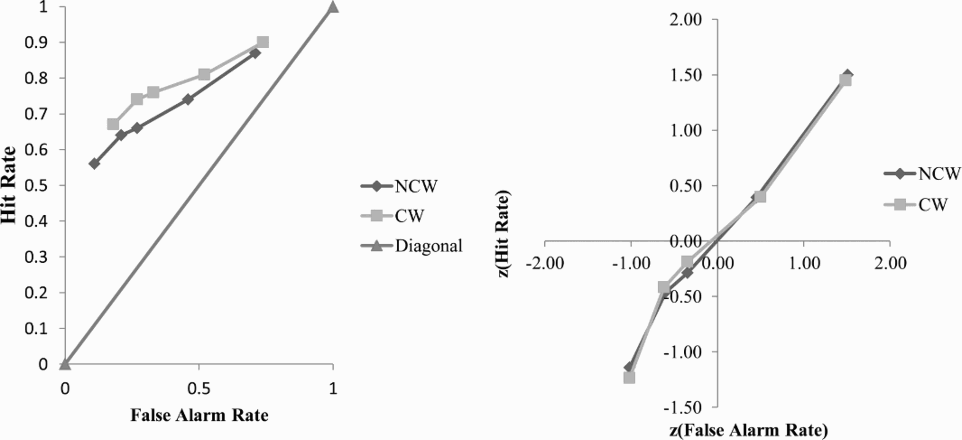
The results of Experiment 1 showed a concordant pattern for hit and false-alarm rates. Hit and false-alarm rates were significantly higher for CW than for NCW pairs without a significant difference in overall discrimination. Although Giovanello et al. (2006) did not find such an effect in their first experiment, they did find a concordant effect for both amnesic and nonamnesic participants in their second experiment. Amnesic patients also showed a discrimination advantage for CW pairs whereas the control participants did not. The results of Experiment 1, therefore, provide a replication of Giovanello et al.'s Experiment 2 results for their nonamnesic participants. Moreover, our ROC analysis follows with Quamme et al.'s (2007) finding of no difference between associative recognition of unitized and nonunitized pairs in the control group.
The concordant effect can be explained by familiarity boosting the proportion of old responses for CW pairs, leading to increased hit rates and decreased correct rejection rates for CW pairs in contrast to NCW pairs. The pattern of confidence judgements and response times were also largely consistent with such a familiarity-based account. Mean confidence was higher for hits and lower for correct rejections for CW than for NCW pairs. Mean response times for hits were faster for CW than for NCW pairs, although there was no difference in response time for correct rejections.
Although the predicted concordant effect was found, there was no difference in the level of accuracy or discrimination between CW and NCW pairs. The absence of a discrimination advantage for CW pairs is somewhat surprising given that the encoding of relational information would be expected to be much easier for CW than for NCW pairs. Any such benefit for hit rate was nullified by the increase in the false-alarm rate. Experiment 2 was designed to replicate this pattern of results in a between-participants comparison of associative recognition for CW and NCW word pairs. A second purpose of Experiment 2 was to provide evidence for the unitization of CW pairs by comparing item recognition for the components of CW and NCW pairs.
Experiment 2
In Experiment 2, participants studied either CW or NCW pairs. They were then tested on both single item and associative yes–no recognition. Pairs of items are considered unitized when the well-integrated whole becomes more familiar than its constituents (Bastin et al., 2010). If the encoding of CW pairs emphasizes the unitized whole, then it follows that the encoding of the individual words of CW pairs would be diminished. In contrast, Hockley and Cristi (1996) showed that the encoding of the individual words of unrelated word pairs is not diminished when participants emphasized the encoding of associative information. It was predicted that single item recognition would be less accurate for the individual words from CW pairs than for words from NCW pairs. That is, there would be an encoding trade-off between the encoding of item and associative information for CW pairs but not for NCW pairs. Such a result would support the view that the CW pairs were encoded as unitized associations.
A second goal of Experiment 2 was to replicate the concordant effect seen for CW pairs in Experiment 1 in a between-subject comparison. Experiment 2 also provided an additional test of whether or not there is a discrimination difference between CW and NCW pairs in yes–no associative recognition. To further test associative recognition discrimination, distractor pairs consisting of one old and one new item (half-old pairs) were included in addition to rearranged test pairs. Half-old pairs are equivalent to feature lures in the conjunction effect for item recognition. Based on the conjunction effect, it was expected that participants would make fewer false alarms to half-old pairs than to rearranged old pairs because half-old pairs would not be as familiar as rearranged old pairs (cf. Humphreys, 1978).
Method
Participants
A total of 46 students were tested; 22 participants were randomly assigned to the NCW pair condition, and 24 to the CW pair condition. Two participant data files in the NCW and four participant data files in the CW condition were not included in the data analyses because they showed chance performance for item discrimination. Note that excluding more participants from the CW than the NCW condition for chance performance works against the prediction that item recognition will be diminished in the CW condition.
Materials and apparatus
The materials and apparatus were the same as those in Experiment 1; however, an additional 32 compound words were taken from Jones's (2005) list of compound words.
Procedure
The study list consisted of 60 CW or 60 NCW pairs with two buffer pairs at the beginning and end of the list. Study instructions were the same as those in Experiment 1. In the test list, there were 10 intact and 10 rearranged word pairs and 10 studied and 10 new single items. For item recognition, the item was the second member of a word pair. In addition, there were 20 pairs composed of a studied item paired with a new item that was not presented in the study list. The new item was always on the right of the pair. The order of test was random. Each test presentation began with an item or test pair displayed in the centre of the screen and remained on the screen until the participant responded. Associative recognition test instructions were the same as those in Experiment 1; however, for the single words, participants were instructed to press the “/” if the word had been shown at study and to press the “z” otherwise. Participants were also told that if they remembered seeing the word at study, to press the “/” key even if they did not remember the word that was presented with it at study.
Results and discussion
Experiment 2: Mean hit and false-alarm rates for intact, rearranged, and half-old pairs and estimates of discrimination and criterion placement for item recognition and associative recognition of compound and noncompound pairs
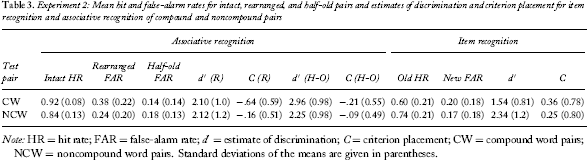
Note: HR = hit rate; FAR = false-alarm rate; d′ = estimate of discrimination; C = criterion placement; CW = compound word pairs; NCW = noncompound word pairs. Standard deviations of the means are given in parentheses.
Associative recognition
A 2 (probe: intact vs. rearranged) × 2 (pair type: CW vs. NCW) ANOVA was conducted on the proportions of old responses. There was a significant main effect of probe [F(1, 38) = 248, MSE = .015, p < .001, η2 = .867]; hits were significantly higher than false alarms. Pair type was also significant [F(1, 38) = 7.27, MSE = .032, p < .05, η2 = .161]; participants made more old responses to CW than to NCW pairs. The interaction between probe and pair types was not significant [F(1, 38) < 1]. The increase in the proportion of old responses for CW compared to NCW pairs was comparable for both hits and false alarms.
A one-way ANOVA for pair type based on d′ confirmed there was no difference in discrimination between CW and NCW pairs [F(1, 38) < 1]. The same comparison of criterion placement indicated that participants adopted a more liberal decision criterion for CW pairs and a more conservative criterion for NCW pairs [F(1, 38) = 7.63, MSE = .302, p = .009].
The results for association recognition replicated the findings of Experiment 1 in a between-participants comparison. Hit rates and false alarms were both higher for CW than NCW pairs, with no difference in overall discrimination.
Pair recognition
To examine recognition performance between intact and half-old test pairs, a 2 (old vs. new tests) × 2 (CW vs. NCW pairs) mixed ANOVA was conducted on the proportions of old responses. There was a significant main effect of probe [F(1, 38) = 705, MSE = .014, p < .001, η2 = .949]; hits were higher than false alarms. Pair type was not significant [F(1, 38) = 0.591, MSE = .009, p = .447, η2 = .015], but there was a significant interaction between probe and pair type [F(1, 38) = 4.69, MSE = .068, p < .05, η2 = .110]. Hit rates were significantly higher for CW than for NCW pairs [t(38) = 0.379, p = .373; t(38) = 2.276, p < .05, respectively] whereas false alarms were similar for CW and NCW pairs.
A between-factor ANOVA comparing d′ for intact and old–new pairs showed that discrimination was greater for CW than for NCW pairs [F(1, 38) = 5.28, MSE = .959, p < .05]. A one-way ANOVA was also conducted for estimates of criterion and showed no significant difference in criterion placement [F(1, 38) = 0.549, MSE = .246, p = .463].
Interestingly, when comparing associative recognition performance based on the discrimination of intact from half-old pairs, a different pattern of results emerged than was seen for discrimination of intact from rearranged papers. As expected, the hit rate was higher for CW than for NCW pairs, but the false-alarm rate was similar for the two types of rearranged pairs, producing a discrimination advantage for CW pairs. The half-old pairs are similar to feature lures in the conjunction effect for item recognition. The familiarity of the half-old pairs is sufficiently reduced to reverse the concordant effect seen for rearranged pairs. Thus, the compound word effect in associative recognition is very similar to the conjunction effect seen in item recognition in that the proportion of old responses is greatest for intact pairs and old compound words, next greatest for rearranged pairs and conjunctions lures, and lowest for new–old pairs and feature lures.
Item recognition
A 2 (old vs. new probe) × 2 (CW vs. NCW pair type) ANOVA was conducted on the proportion of old responses. Hits were significantly greater than false alarms [F(1, 38) = 221, MSE = .022, p < .001, η2 = .853)]. There was no main effect of pair type [F(1, 38) = 1.06, MSE = .056, p = .309, η2 = .027], but the interaction between probe and pair type was significant [F(1, 38) = 6.75, MSE = .022, p < .05, η2 = .151]. The hit rate was higher, and the false-alarm rate was lower in the NCW condition than in the CW pair condition. A one-way ANOVA based on estimates of d′ confirmed that item discrimination was higher in the NCW than in the CW condition [F(1, 38) = 6.05, MSE = 1.07, p < .05]. There was no significant difference in the estimates of criterion placement, F(1, 38) < 1.
The results of Experiment 2 showed, as predicted, that recognition accuracy is greater for single items studied in NCW pairs than for those in CW pairs. The hit rate was higher and the false-alarm rate lower for words studied in NCW than for those in CW pairs. Moreover, discrimination as estimated by d′ was greater for items studied in unrelated word pairs. These results indicate that CW pairs were largely encoded as whole words instead of individual items and support the view that CW pairs are unitized at encoding. In contrast, recognition for the items in NCW pairs is more accurate because the encoding of associative information does not reduce the encoding of item information for unrelated word pairs (cf. Hockley & Cristi, 1996). In other words, there is an encoding trade-off between item and associative information for CW pairs, but not for NCW pairs.
A robust concordant effect was seen in the within- and between-subject comparisons of associative recognition for CW and NCW pairs. Within the framework of signal detection theory, this pattern of results can be explained by assuming that the underlying familiarity distributions representing old and new CW pairs are greater than the distributions representing NCW pairs due to the greater familiarity of the CW pairs. A concordant pattern without a change in discrimination can also occur, however, if participants adopted a more liberal decision criterion for CW pairs and a more conservative criterion for NCW pairs. This would also increase the hit and false-alarm rates for CW pairs without changing discrimination. A two-alternative forced-choice recognition test procedure was used in Experiments 3A and 3B to evaluate the role of response bias in associative recognition for CW and NCW pairs.
Experiments 3A and 3B
The goal of Experiments 3A and 3B was to determine whether response bias contributed to the higher hit and false-alarm rates observed for CW pairs in Experiment 1 using a two-alternative forced-choice recognition task. Major and Hockley (2007) successfully used forced-choice recognition to distinguish between familiarity and response bias accounts of the different forms of the revelation effect. In Experiments 3A and 3B, two types of forced-choice test trials were compared. In the pure pair test conditions, intact CW pairs were tested with rearranged CW pairs, and intact NCW pairs were tested with rearranged NCW pairs. Response bias favouring one pair type cannot play a role in the pure test conditions as both test alternatives are the same type of pair. Therefore, any differences in recognition performance between these two types of tests must be due to differences in familiarity. Response bias, however, could play a role in the mixed pair test conditions where intact pairs of one pair type were tested with rearranged pairs of the other type. In these tests, a response bias to choose the CW test pair would increase the proportion of correct responses when CW pairs were the correct alternative and would decrease performance when NCW pairs were the correct choice. Thus, a comparison of accuracy in the pure and mixed test conditions in Experiment 3A would provide a measure of response bias in associative recognition of CW and NCW pairs.
In order to further evaluate a familiarity-based account of the concordant effect for CW pairs in the forced-choice procedure, a familiarity-only procedure developed by Quamme et al. (2007) and adapted by Bastin et al. (2010) to the forced-choice test procedure was implemented in Experiment 3B. The familiarity-only procedure facilitates greater use of familiarity than recollection. Quamme et al. found that performance in their unitized pair definition condition was significantly better than that in the nonunitized condition under familiarity-only instructions. In this procedure participants are instructed to make their recognition decisions as quickly as possible based only on degree of familiarity of the association and not the familiarity of the individual words. As Quamme et al. note, the familiarity-only procedure is not expected to eliminate the use of recollection, but reduce the amount of recollection used for each recognition decision. A second purpose of Experiment 3B was to replicate the results of Experiment 3A.
Method
Participants
A total of 28 students participated in Experiment 3A. Two participants’ data files were not included in the data analyses because of chance performance in the NCW pair condition. A total of 31 students participated in Experiment 3B. One participant's data were not included in the analyses because of chance performance for NCW pairs.
Materials and apparatus
For both Experiments 3A and 3B, the apparatus and stimuli were the same as those in Experiment 1 with the exception that Super Lab 4.0 software (Cedrus Corp.) was used to control stimulus presentation and response recording.
Procedure
For Experiment 3A, the study phase was exactly the same as that in Experiment 1. The test pairs were also the same as those in Experiment 1. However, during the test phase two word pairs were presented, and participants were to select which pair had been presented at study. There were four discrimination conditions represented at test in the two-alternative forced choice task. Studied CW pairs were paired with rearranged CW pairs in one condition and with rearranged NCW pairs in another. Similarly, intact NCW pairs were paired with rearranged NCW pairs and with rearranged CW pairs in separate test conditions. For each test presentation, one pair was presented in the top half of the screen and one in the bottom half. A random half of the intact pairs were presented in the top portion of the screen and half in the bottom portion. The order of test presentation was random with a different random order for each participant. Participants pressed the “1” key to choose the top pair and the “2” key for the bottom pair. The test phase was subject paced.
For Experiment 3B, the study and test procedures were identical to those in Experiment 3A, except that participants were instructed to select the test alternative based on the degree of familiarity. Participants were told to press “1” if the top word pair was more familiar or press “2” if the bottom word pair was more familiar. Participants were told to ignore the familiarity of the individual words, but to focus on the association, judging which pair was more familiar. Participants were not told about the difference between intact and rearranged pairs, but were informed about the difference between familiarity and recollection. Familiarity was described as retrieval of gist information compared to recollection as retrieval of specific details. They were asked to respond as soon as they got a feeling of familiarity for a pair without trying to recollect anything about it. To further increase familiarity-based responding, participants were also told to respond as quickly as possible.
Results and discussion
The results of Experiments 3A and 3B are analysed separately.
Experiment 3A
The mean proportion of correct responses, estimates of d′, and mean response times for each test condition, are shown in Table 4. The d′ values for the forced-choice task were computed from the proportion of correct responses corrected for this procedure (Macmillan & Creelman, 1991). 3
According to signal detection theory, the two-alternative forced-choice procedure produces a performance advantage over the yes–no procedure of approximately √2. Thus, it has been proposed to divide the forced-choice d′ score by √2 to compensate for this advantage (Hacker & Ratcliff, 1979; Macmillan & Creelman, 1991).
Experiments 3A and 3B: Mean proportions of correct responses, mean correct response time, and mean d′ estimates for the different combinations of intact and rearranged compound and noncompound test pair alternatives
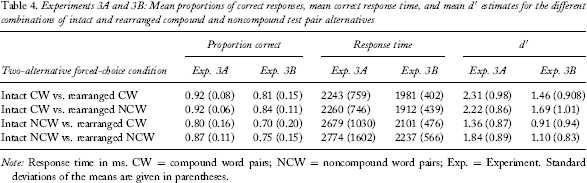
Note: Response time in ms. CW = compound word pairs; NCW = noncompound word pairs; Exp. = Experiment. Standard deviations of the means are given in parentheses.
A 2 (target type) × 2 (distractor type) within-factor ANOVA was conducted on d′ estimates, revealing a significant main effect of target [F(1, 25) = 16.1, MSE = 0.722, p < .001, η2 = .392]. Discrimination was greater for CW than for NCW pairs. There was no significant main effect of distractor [F(1, 25) = 2.01, MSE = 0.484, p = .168, η2 = .075], but the interaction between target and distractor was significant [F(1, 25) = 5.21, MSE = 0.418, p < .05, η2 = .172]. The discrimination advantage for CW pairs was largely unaffected by the nature of the rearranged test pair whereas discrimination of NCW pairs was worse when tested with a CW rearranged pair. Paired t-test showed that discrimination was higher for CW pairs than for NCW pairs in the pure, t(25) = 2.5, p < .05, and the mixed, t(25) = 3.7, p = .001, test conditions.
The results of Experiment 3A demonstrate that the compound word effect in forced-choice recognition is seen as a discrimination advantage favouring the unitized pairs. Proportion correct was significantly greater for CW than for NCW pairs in the pure test conditions where response bias could not play a role. Response bias was seen in the mixed test condition, however, as accuracy was reduced for NCW intact pairs when tested with a rearranged CW pair compared to a NCW lure. Mean response time was also faster for CW than for NCW targets. Thus, it is likely that response bias contributed to the concordant effect seen in Experiment 1, but familiarity was the principal factor.
Experiment 3B
Experiment 4A: Mean hit and false-alarm rates, estimates of discrimination, and criterion placement for compound, noncompound, and repeated NCW word pairs
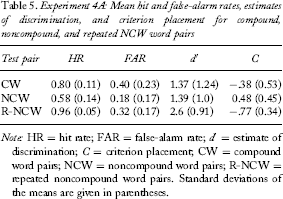
Note: HR = hit rate; FAR = false-alarm rate; d′ = estimate of discrimination; C = criterion placement; CW = compound word pairs; NCW = noncompound word pairs; R-NCW = repeated noncompound word pairs. Standard deviations of the means are given in parentheses.
The same ANOVA conducted on estimates of d′ also revealed that discrimination was higher for CW than for NCW pairs [F(1, 29) = 16, MSE = 0.619, p < .001, η2 = .36]. There was also no significant main effect of distractor [F(1, 29) = 1.97, MSE = 0.660, p = .17, η2 = .063] and no significant interaction [F(1, 29) = .019, MSE = 0.010, p = .892, η2 = .001]. Paired t-tests again showed that discrimination was higher for CW pairs than for NCW pairs for pure test, t(30) = 3.6, p < .001, and mixed test, t(30) = 2.97, p = .006, comparisons.
Participants in Experiment 3B were instructed to respond as quickly as possible based on their feelings of familiarity. Therefore, if participants were able to follow these instructions, mean response times should be faster in Experiment 3B than in Experiment 3A where participants did not receive such instructions. A 2 (Experiment 2 vs. Experiment 3) × 2 (CW vs. NCW target) × 2 (CW vs. NCW distractor) mixed-factor analysis was conducted to compare the correct response times in Experiments 3A and 3B. There was a significant main effect of experiment [F(1, 54) = 5.21, MSE = 1,986,151, p < .001, η2 = .088]. Overall correct response time was faster in Experiment 3B (M = 2058 ms) than in Experiment 3A (M = 2489 ms). This comparison indicates that participants followed instructions introduced in Experiment 3B to respond as quickly as possible. There was also a significant main effect of target [F(1, 54) = 15.7, MSE = 431,553.61, p < .001, η2 = .226]. For both Experiments 3A and 3B, mean response time was faster for CW than for NCW targets. There was no significant main effect of distractor [F(1, 54) = 1.02, MSE = 104,642.6, p = .315, η2 = .019]. The interaction between target and distractor [F(1, 54) = 1.70, MSE = 165,029, p = .198, η2 = .030] and the interaction between target, distractor, and experiment [F(1, 54) = 0.336, MSE = 165,029, p = .564, η2 = .006] were not significant.
The results of Experiment 3B replicated the forced-choice discrimination advantage for CW pairs seen in Experiment 3A. The finding of a discrimination advantage for CW compared to NCW pairs in Experiments 3A and 3B contrasts with the finding of no difference in discrimination seen in Experiments 1 and 2. Some researchers have suggested that differences in sensitivity between yes/no and forced choice could arise because of differences in the length of the test list and resulting differences in study–test lag (e.g., Bayley, Wixted, Squire, & Hopkins, 2008). An analysis of shorter versus longer study–test intervals in the test lists of Experiment 1 did not show a decline in discrimination. 4
We thought a more direct approach to examine whether test interference due to study and test delay was responsible for the absence of discrimination in yes–no associative recognition test would be to compare discrimination of CW and NCW pairs in the first half to that in the second half of the test lists of Experiment 1. This analysis, however, showed no difference in the mean estimates of d′. The main effect of test list half was not significant [F(1, 29) = 3.58, MSE = 6.67, p = .069, η2 = .110], but there was a trend for overall discrimination to increase from the first half (1.38) to the second half (1.86) of the test list. There was no significant main effect of pair type [F(1, 29) = 2.50, MSE = 2.46, p = .125, η2 = .079]. Moreover, the interaction between test list half and pair type did not approach significance [F(1, 29) = 0.073, MSE = 0.088, p = .789, η2 = .078].
The results of Experiment 3B are consistent with the view that the recognition advantage for CW pairs was largely due to their increased familiarity. The CW pair advantage is similar in this respect to the advantage of word pairs unitized by compound definitions (Quamme et al., 2007) and the recognition advantage for within-domain associations due to their easier unitization (Bastin et al., 2010). Experiments 4A and 4B were designed to compare yes–no recognition for once-presented CW and NCW pairs with that for familiarized NCW pairs that were repeated four times at study.
Experiments 4A AND 4B
The purpose of Experiments 4A and 4B was to compare the effects of the preexperimental familiarity of unitized associations to study-induced familiarity of repeated NCW pairs. Repeating NCW pairs during the study phase may induce a similar unitization effect to that for CW pairs. Kilb and Naveh-Benjamin (2011) argued that repeating unrelated face–scene pairs prior to the study phase increased their subsequent pair familiarity due to unitization. In their study, they examined whether the associative deficit in older adults would be reduced when they relied more on familiarity in associative recognition.
The age-related associative deficit in older adults is shown by reduced accuracy in yes/no associative recognition for unrelated items in a pair compared to that for young adults. One reason for the age-related associative deficit is older adults’ reduced use of recollection when retrieving associations. As numerous researchers using different methodologies have suggested, there is a reduced use of recollection as people age (e.g., Jennings & Jacoby, 1997; Light, Patterson, Chung, & Healey, 2004). Kilb and Naveh-Benjamin (2011) repeated individual items and item pairs prior to face–scene pairs being presented at study. Older adults showed higher yes–no recognition discrimination for repeated pairs than for pairs consisting of repeated items and concluded that pair familiarity brought about by repeating pairs reduced older adults’ associative memory deficit. Importantly, when comparing the pattern of hits and false alarms for repeated pairs compared to pairs presented once, they found that both young and older showed higher hits but lower false alarms for repeated pairs than for pairs consisting of repeated items.
Experiment 4A was designed to compare yes–no associative recognition performance for once-presented CW and NCW pairs with that for NCW pairs that were shown four times in the study list (repeated noncompound word, R-NCW, pairs). Would associative recognition of R-NCW pairs show a concordant pattern similar to CW pairs or a discrimination advantage as found by Kilb and Naveh-Benjamin (2011)? In Experiment 4B, the study phase was the same as that in Experiment 4A but item recognition for words studied in CW, NCW, and R-NCW pairs was examined. The purpose of Experiment 4B was to replicate the decrease in item recognition for words from CW pairs seen in Experiment 2 and to determine whether item recognition for words from R-NCW pairs shows a similar or opposite pattern of results.
Method
Participants
A total of 32 students participated in Experiment 4A. Two participant data files were not included in the data analyses because of chance performance in the NCW condition. In Experiment 4B, a total of 26 students were tested.
Materials and apparatus
For Experiment 4A, the materials and apparatus were the same as those in previous experiments. However, an additional 96 compound words were taken from the Jones (2005) list and added into the 160 CW list used in previous experiments, in order to create the 36 repeated NCW pairs. Similar to Experiment 1, to create the NCW pairs, a left member from one CW pair was paired with the right member from another CW pair. Two sets (A and B) were constructed to counterbalance the components of the CW and NCW pairs. For Experiment 4B, the materials and apparatus were the same as those in Experiment 4A; however, an additional 72 new single words were taken from components of compound words in Jones's (2005) list.
Procedure
For Experiment 4A, the procedure was the same as that in Experiment 1; however, during the study phase the 36 R-NCW pairs were presented four times in four different study blocks. For each block, 9 CW pairs, 9 NCW pairs, and 36 R-NCW pairs were presented in a random order. The 36 R-NCW pairs were repeated in each block. During the test phase, 12 intact and 12 rearranged pairs of each pair type were presented in a different random order for each participant. For Experiment 4B, the study phase was exactly the same as that in Experiment 4A; however, during the test phase participants made only item recognition judgements. Thirty-six words from each pair type, CW, NCW, and R-NCW, were presented. For half the studied pairs, the item was the first item of the pair, whereas for the other half of the studied pairs, the item was the second item of the pair. In addition, 72 new words were presented. The test list was shown in random order and was subject based.
Results and discussion
For Experiment 4A, the mean proportion of hits and false alarms for CW, NCW, and R-NCW pairs are presented in Table 5. A 3 (word pair type) × 2 (probe type) repeated measures ANOVA was conducted on the proportion of old responses. There was a significant main effect of test probe [F(1, 29) = 311, MSE = .033, p < .001, η2 = .915]. The hit rate was significantly higher than the false-alarm rate, showing that overall discrimination was above chance. There was also a significant main effect of word pair type [F(2, 58) = 74.9, MSE = .016, p < .001, η2 = .721]. Overall old responses were highest for repeated NCW pairs, followed by CW pairs, and then lowest for nonrepeated NCW pairs. There was also a significant interaction between probe and word pair type [F(2, 58) = 18.0, MSE = .016, p < .001, η2 = .384]. Both hits and false alarms were higher for CW and R-NCW pairs than for NCW pairs [t(29) = 6.02, p < .001; t(29) = 4.567, p < .001; t(29) = 6.28, p < .001; t(29) = 11.69, p < .001]. However, hits and false alarms were lowest for nonrepeated NCW pairs.
A 3 (word pair type) one-way ANOVA was conducted on d′ scores. There was a significant main effect of word pair type [F(2, 58) = 26.7, MSE = 0.560, p < .001, η2 = .480]. Paired t-tests showed that discrimination was higher for R-NCW pairs than for NCW and CW pairs [t(29) = 5.52, p < .001; t(29) = −6.31, p = .001, respectively]. As in Experiment 1, discrimination was similar for CW and NCW pairs, t(29) = −0.096, p =. 924. The same analysis revealed a significant effect of criterion placement [F(2, 58) = 86.6, MSE = 0.144, p < .001, η2 = .749]. Participants showed the most liberal criterion for R-NCW pairs and the most conservative criterion for NCW pairs. Criterion placement was more liberal for R-NCW than for CW and NCW pairs [t(29) = −4.3, p < .001; t(29) = −16, p < .001, respectively] and more liberal for CW than for NCW pairs, t(29) = −7.3, p < .001.
The ROC curves presented in Figure 2 show no difference in discrimination between CW and NCW pairs. A similar area under the curve was shown for associative recognition of both pair types. Discrimination was higher for R-NCW pairs than for CW and NCW pairs, as supported by a higher area under the curve for R-NCW pairs than for CW and NCW pairs.
Receiver-operating characteristic (ROC) analysis of averaged performance of all participants in associative recognition of noncompound word (NCW) pairs, repeated noncompound word (R-NCW) pairs, and compound word (CW) pairs in Experiment 4.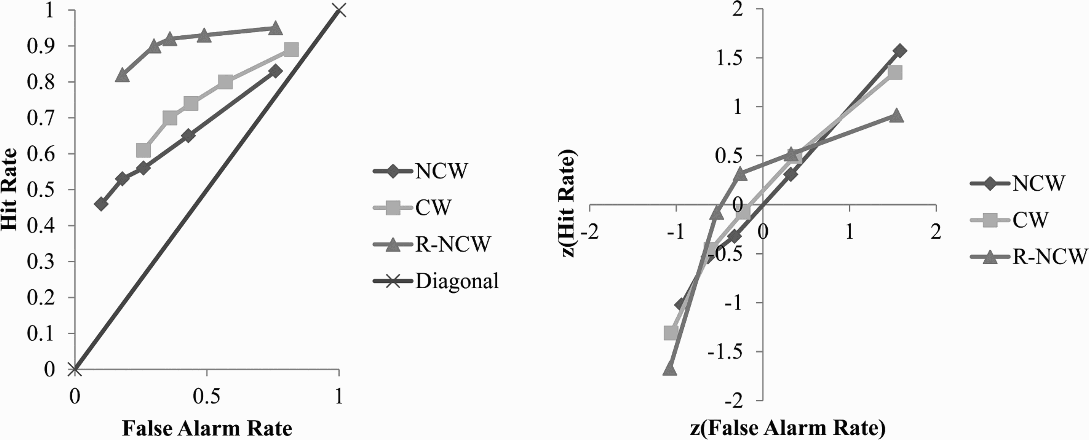
The results of Experiment 4A showed a different pattern of results for R-NCW pairs than for once-presented CW pairs. The hit rate was higher, and the false-alarm rate was lower for R-NCW pairs than for CW pairs (i.e., a mirror pattern; cf. Glanzer & Adams, 1985). Importantly, although a discrimination advantage was seen for R-NCW pairs, there was no difference in discrimination between CW and nonrepeated NCW pairs, replicating the results of Experiments 1 and 2. The discrimination advantage for R-NCW pairs does not appear to be due to unitization. Contrary to Kilb and Naveh-Benjamin's (2011) suggestion that repeating unrelated pairs leads to unitization, the findings of the current experiment do not support such a suggestion. It is more likely that repeated presentation led to a stronger association rather than unitization. Thus, in the framework of dual-process theory, repetition of NCW pairs led to both an increase in recollection and study-induced familiarity. Hits were higher due to the increased contributions of both recollection and familiarity. In contrast, false alarms were lower than CW pairs but higher than nonrepeated NCW pairs, because the increase in recollection could partially offset the increase in study-induced familiarity (i.e., recall-to-reject; Rotello & Heit, 2000).
Experiment 4B
Mean hit rates showed item recognition to be highest for R-NCW pairs (M = 0.88, SD = 0.09), next highest for NCW pairs (M = .64, SD = .12), and lowest for CW pairs (M = .59, SD = .13). The mean false-alarm rate was .24 (SD = .07). A one-way ANOVA based on hit rates showed a significant main effect of type of word pair [F(2, 75) = 46.1, MSE = .645, p < .001, η2 = .552]. Two-tailed paired-sample t-tests showed item recognition for R-NCW to be higher than that for NCW and CW pairs [t(25) = −12.9, p < .001; t(25) = −12.8, p < .001, respectively] and item recognition for CW pairs to be lower than that for NCW pairs, t(25) = −3.74, p = .001.
The results of Experiment 4B replicated the item recognition disadvantage for words studied in CW compared to NCW word pairs seen in Experiment 2. In contrast, item recognition was greater for items studied in R-NCW pairs, indicating that repetition of NCW pairs benefited both associative recognition and item recognition of the individual components of NCW pairs. Thus, the results of Experiment 4B provide further evidence that CW pairs are unitized whereas R-NCW pairs are not.
If the encoding of the individual components of CW pairs is diminished due to unitization when associative information is emphasized, it follows that the encoding of item information should improve when item information is emphasized at encoding. Experiment 5 was designed to test this possibility.
Experiment 5
If unitization of CW pairs at encoding is responsible for reduced item recognition of the components of CW compared to NCW pairs seen in Experiments 2 and 4B, then item recognition should not be reduced if the unitization of CW pairs is minimized at encoding. To reduce the unitization of CW pairs in Experiment 5, participants were instructed to encode the items of each word pair as individual items. This was done using Tulving and Osler's (1968) and Winograd, Karchmer, and Russell (1971) cued recognition procedure where the target item is presented in capital letters and the cue word in lower case. Participants in both the CW and NCW pair conditions were told they would be tested on their recognition of the second member of the pair, the capitalized word. Moreover, they were told that their recognition accuracy would be improved if they also studied the first member of the pair.
It was hypothesized that item recognition would be similar for CW and NCW pairs, since the study instructions emphasized the encoding of the individual items rather than the associations. By encoding CW pairs as individual items, participants would be prevented from encoding CW pairs as whole units as they did in the previous experiments, and, as a consequence, item recognition should not suffer. Pair type was manipulated between participants.
Method
Participants
Twenty-two participants studied NCW pairs, and 22 participants studied CW pairs. Two participant data files from each pairs condition were not included in the data analyses because they showed chance performance for item discrimination.
Materials and apparatus
The materials and apparatus were exactly the same as those in Experiment 4A.
Procedure
Participants were randomly assigned to either the CW or the NCW condition. During the study phase, participants were presented with a list of 60 word pairs presented one at a time on the screen. Each word pair appeared in the centre of the screen for 4 s with no interval between pairs. As in the previous experiments, there were six spaces between the words of each pair. The left member of the pair was the cue word in lower case, and the right member of the pair was the target word in upper case. For example, participants in the CW pair condition would see the word pair “night MARE”, whereas those in NCW pair condition would see the word pair “door PEPPER”.
The instructions were adapted from Tulving and Osler (1968). Participants were told:
Your job in this session is to remember as many of the capitalized words as you can. Although you are responsible for remembering the capitalized words, you should also pay close attention to the words with which the capitalized words are paired, because making associations between the two words on each slide may help you to better remember the capitalized words. (p. 596)
The order of the study pairs (excluding buffers) was random, with a different random order for each subject.
After the study phase was completed, for approximately 1 min duration, the experimenter presented the test instructions to the participants. Participants were informed they would be presented with the capitalized words either with a cue word or as a single item. They were instructed to press the “z” if they had not seen the capitalized word at study or press the “/” if they had seen the capitalized word at study. Participants were also told that if they saw the capitalized word with another word, to use the first word in lower-case letters as a cue to help in deciding whether the capitalized word was old or new. They were also instructed to respond as accurately as possible. Response time was not mentioned.
The test list consisted of 10 old items with the same old cue, 10 old items with a different old cue, 20 new items with an old cue, 10 old single items, and 10 new single items. Cues were presented on the right in lower-case letters, and recognition test probes were presented in capital letters to the right of a cue or in the centre of the screen. The order of the tests was random, and the test presentation was subject paced.
Results and discussion
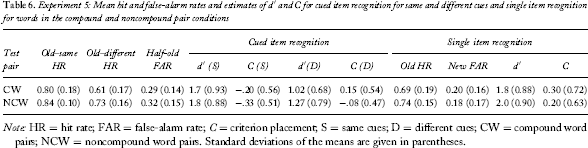
Experiment 5: Mean hit and false-alarm rates and estimates of d′ and C for cued item recognition for same and different cues and single item recognition for words in the compound and noncompound pair conditions
Note: HR = hit rate; FAR = false-alarm rate; C = criterion placement; S = same cues; D = different cues; CW = compound word pairs; NCW = noncompound word pairs. Standard deviations of the means are given in parentheses.
Single item recognition
A 2 (old vs. new probe) × 2 (CW vs. NCW pair type) ANOVA was conducted on the proportion of old responses. Hits were significantly higher than false alarms [F(1, 38) = 361.6, MSE = 5.56, p < .05, η2 = .905]. The main effect of pair type [F(1, 38) = 0.083, MSE = .003, p = .775, η2 = .002] and the interaction between probe and pair type [F(1, 38) = 1.857, MSE = .029, p = .181, η2 = .047] were not significant. A one-way ANOVA based on d′ estimates confirmed that discrimination of words from CW and NCW pairs did not differ reliably [F(1, 38) = 0.559, MSE = .441, p = .459]. There was also no significant difference in criterion placement [F(1, 38) = 0.207, MSE = .095, p = .652].
Cued item recognition
A 2 (cue: same cue vs. different cue) × 2 (pair type: CW vs. NCW) ANOVA conducted on hit rates revealed a significant main effect of cue [F(1, 38) = 22.6, MSE = .028, p < .01, η2 = .373]. Hits were higher in the same cue (.82) than in the different cue condition (.67). The hit rate was also significantly greater for NCW (.78) than for CW (.71) items [F(1, 38) = 4.38, MSE = .120, p = .043, η2 = .103]. The interaction between cue and pair type was not significant [F(1, 38) = 1.37, MSE = .028, p = .250, η2 = .035]. The false-alarm rate was also greater for NCW (.32) than for CW (.29) pairs, but this difference was not reliable, t(38) = −0.646, p = .522.
A 2 (cue) × 2 (pair type) ANOVA based on d′ estimates showed that discrimination was greater in the same cue (1.74) than in the different cue (1.14) condition [F(1, 38) = 15.6, MSE = 0.461, p < .001, η2 = .291]. The main effect of pair type, F(1, 38) < 1, and the interaction between cue and pair type, F(1, 38) < 1, did not approach significance. The same analysis for estimates of criterion showed that criterion placement was lower in the same cue (−.26) than in the different cue (.04) condition [F(1, 38) = 15.6, MSE = .115, p < .001, η2 = .291]. The main effect of pair type [F(1, 38) = 1.59, MSE = .431, p = .215, η2 = .04] and the interaction between cue and pair type, F(1, 38) < 1, were not reliable.
The results of Experiment 5 show that when the encoding of the single words of each study pair was emphasized, discrimination was similar for targets from CW and NCW pairs in tests of both single item and cued item recognition. Not surprisingly, in cued item recognition discrimination was also greater when the same study cue was presented at test rather than a different study cue. These results stand in contrast to the results of Experiments 2 and 4B where item recognition was worse for words from CW than for those from NCW pairs. Thus, when participants are encouraged to encode CW pairs as individual units, item recognition is similar to that of NCW pairs. Essentially, when unitization is prevented (or substantially reduced), item information for CW pairs is similar to that for NCW pairs. Conversely, when unitization is encouraged at encoding, item information is reduced for words in CW compared to NCW pairs. Thus, unitization of CW pairs represents a gestalt where the whole is greater than the sum of the parts.
General Discussion
The goal of the current study was to examine how unitization of intraitem associations affects associative recognition. Compound words, known from studies of the conjunction effect in item recognition to be falsely recognized due to their familiarity, were used in both yes–no and forced-choice tests of associative recognition.
In tests of yes–no associative recognition, a concordant effect was found; hit and false-alarm rates were significantly greater for CW pairs than for NCW pairs with no overall difference in discrimination. These results replicate Giovanello et al.'s (2006) Experiment 2 findings for their nonamnesic control group. However, the lack of a discrimination advantage for CW pairs contrasts with Greve et al.'s (2007) finding of both a concordant effect and a discrimination advantage for semantically related pairs.
The pair recognition results of Experiment 2 also showed that the false-alarm rate was less for half-old (i.e., feature lures) than for rearranged (i.e., conjunction lures) pairs. Together, the results of Experiments 1 and 2 provide an associative recognition analogue of the compound word effect seen in item recognition. In both the item and associative recognition versions of the compound word effect, there is a higher false-alarm rate for conjunction lures than for feature lures (cf. Jones & Jacoby, 2001; Reinitz et al., 1996).
Jones and Jacoby's (2001) familiarity-based explanation of the conjunction memory effect seen in item recognition is also consistent with the concordant effect for CW pairs in associative recognition. Both intact and rearranged CW pairs would have a greater degree of familiarity than NCW pairs because of their preexperimental history. In addition, unitization of the CW pairs would provide a basis for participants to use familiarity to make their associative recognition decisions in the same way as they can use familiarity in making recognition judgements for individual words. This interpretation of the CW pair effect is similar to Greene's (1999) account of the familiarity effect in item recognition. Greene found that both hit and false-alarm rates were greater for the familiarized items than for the nonfamiliarized items.
Experiments 3A and 3B provide further evidence in support of a familiarity-based account of associative recognition for CW pairs. The results of Experiment 3A demonstrated a recognition advantage for CWs in a two-alternative forced-choice recognition test, indicating that the concordant effect seen in yes–no recognition is more likely due to familiarity rather than simply a response bias, although response bias could also contribute to the concordant effect. In contrast to the overall results of Experiments 1 and 2, however, the compound word effect found in Experiment 3A was seen as a discrimination advantage; CW pairs were more accurately recognized than NCW pairs. This discrimination advantage was also accompanied by faster correct response times for CW pairs. Interestingly, the nature of the distractor test pair had no effect on the recognition of CW pairs, whereas rearranged CW pair distractors reduced recognition performance for NCW pair targets. The results of Experiment 3B, using a familiarity-based recognition procedure developed by Quamme et al. (2007), replicated the general pattern of accuracy and response time advantages for CW pairs seen in Experiment 3A and provided further support for a familiarity interpretation of the compound word effect in associative recognition.
The finding of a discrimination advantage for CW pairs in the forced-choice tests of Experiments 3A and 3B but not in the yes–no tests of Experiments 1, 2, and 4A was unexpected. The difference in discrimination with test format, however, can be explained by the role of familiarity in each task. A number of researchers have argued that familiarity makes a greater contribution to recognition in the forced-choice than in the yes–no test procedure (e.g., Aggleton & Shaw, 1996; Bastin & Van der Linden, 2003; Clark, Hori, & Callan, 1992; Parkin, Yeomans, & Bindschaedler, 1994; Patterson & Hertzog, 2010). One way to test whether familiarity-based responses contribute more to forced-choice than yes–no associative recognition is to test older adults’ associative recognition in both test formats. Since a number of researchers have suggested that older adults have impaired use of recollection, but intact familiarity (Bastin & Van der Linden, 2003; Jennings & Jacoby, 1997; Patterson & Hertzog, 2010), older adults should show higher associative recognition performance in the forced-choice than in the yes/no test. Bastin and Van der Linden (2003) examined whether the contribution of familiarity to recognition decisions varied by type of test format for both young and older adults. They had both young and older adults study photographs of faces followed by a yes/no or forced-choice recognition test for target and distractor faces. After making their recognition decision, participants also made remember–know judgement to indicate whether their recognition decision was based on recollection or familiarity in the absence of recollection. The researchers found that both young and older adults relied more on familiarity (know responses) in the forced-choice task than in the yes–no task. They also found that the older participants relied more on familiarity than recollection and performed better in the forced-choice task, whereas younger participants showed the opposite pattern.
The findings from Experiments 3A and 3B can also be explained in terms of the greater contribution of familiarity-based decisions in the forced-choice procedure. A discrimination advantage was shown for CW pairs in the forced-choice tests but not in yes/no tests because familiarity contributed to a greater extent to the discrimination advantage for unitized pairs in the forced-choice tests.
In Experiment 4A, the effects of unitization of CW pairs were compared to strengthened associations brought about by repeating NCW pairs. There was a replication of the CW concordant effect as shown by higher hits and higher false-alarm rates for CW pairs than for once-presented NCW pairs with no difference in discrimination. Interestingly, the hit rate was higher, and the false-alarm rate was lower for R-NCW pairs than for CW pairs, and discrimination was highest for R-NCW than for both CW and NCW pairs. The fact that presenting NCW pairs four times during the study phase led to a different pattern of results from that for associative recognition of CW pairs suggests that unitization cannot be brought about by mere repetition of unrelated pairs during the study phase.
In the framework of dual-process theory, repeating NCW would lead to higher familiarity and recollection. Hits were highest for repeated NCW pairs because both familiarity and recollection contributed to the correct old responses. False alarms were lower for repeated NCW pairs than for CW pairs because the increase in recollection would serve to help oppose the increase in familiarity of the rearranged pairs. Experiments 2 and 4B were designed to test the prediction that the encoding of CW pairs that emphasizes the unitized whole results in an encoding deficit for the individual components of these pairs. Hockley and Cristi (1996) demonstrated that the encoding of item information does not suffer when the encoding of associative information between unrelated words is emphasized. The results of Experiments 2 and 4B showed that, while there was no difference in associative discriminability between CW and NCW pairs, single item recognition was lower for words studied in CW than for those in NCW pairs. That is, there was an encoding trade-off between item and associative information for the CW pairs. Experiment 4B also showed that single item recognition was highest for words from repeated NCW pairs, providing further evidence that repetition at study does not produce unitization. The results of Experiments 2 and 4B provide strong empirical support for the assumption that participants encode CW pairs as unitized constructions and that the unitized whole is greater than the sum of its parts.
Finally, in Experiment 5, a cued item recognition procedure was implemented to determine whether the recognition deficit for the components of CW pairs could be eliminated when the encoding task emphasized the individual items rather than their association. Discrimination performance was similar in both tests of single and cued item recognition for items from CW and NCW same pair conditions. This finding contrasts with the results of Experiments 2 and 4B where single item recognition was significantly worse for items from CW than for those from NCW pairs. Thus, the unitized encoding of CW pairs, and the encoding trade-off between item and associative information for CW pairs, is not obligatory. Rather, it depends on the nature of the information emphasized by the encoding task.
In summary, the results of the current study provide a demonstration of familiarity-based associative recognition decisions for unitized pairs. The results of the present experiments support the idea that the compound word effect is due to familiarity arising from unitization. The associative recognition analogue of the compound word effect seen in item recognition is a concordant effect in yes–no recognition and a discrimination advantage for CW pairs in forced-choice recognition. The comparison of associative recognition of CW with R-NCW pairs shows that strong associations arising through repetition are not the same as unitized pairs. Finally, the results also demonstrate that item recognition can be a reliable test of unitization. For unitization to have occurred, item recognition should be significantly lower for the components of unitized than nonunitized pairs.
Footnotes
Acknowledgements
Portions of this work were presented at the 52nd Annual Meeting of the Psychonomics Society, November 2012, Minneapolis, Minnesota, USA.
This research was supported by a Discovery Grant from the National Science and Engineering Research Council of Canada awarded to W. E. Hockley.