
Abstract
This study contrasted the role of surfaces and volumetric shape primitives in three-dimensional object recognition. Observers (N = 50) matched subsets of closed contour fragments, surfaces, or volumetric parts to whole novel objects during a whole–part matching task. Three factors were further manipulated: part viewpoint (either same or different between component parts and whole objects), surface occlusion (comparison parts contained either visible surfaces only, or a surface that was fully or partially occluded in the whole object), and target–distractor similarity. Similarity was varied in terms of systematic variation in nonaccidental (NAP) or metric (MP) properties of individual parts. Analysis of sensitivity (d′) showed a whole–part matching advantage for surface-based parts and volumes over closed contour fragments—but no benefit for volumetric parts over surfaces. We also found a performance cost in matching volumetric parts to wholes when the volumes showed surfaces that were occluded in the whole object. The same pattern was found for both same and different viewpoints, and regardless of target–distractor similarity. These findings challenge models in which recognition is mediated by volumetric part-based shape representations. Instead, we argue that the results are consistent with a surface-based model of high-level shape representation for recognition.
The human visual system is remarkably adept at recognizing complex three-dimensional (3D) objects despite the variability in sensory information brought about by changes in viewpoint, scale, translation, and illumination. A fundamental question concerns the organization and structure of the object shape representations mediating recognition (e.g., Attneave, 1954; Biederman, 1987; Cristino, Conlan, Patterson, & Leek, 2012; Cristino, Davitt, Hayward, & Leek, in press; Davitt, Cristino, Wong, & Leek, 2014; Edelman, 1999; Hummel, 2013; Hummel & Biederman, 1992; Hummel & Stankiewicz, 1996; Leek, Cristino, Conlan, Patterson, Rodriguez, & Johnston, 2012; Leek, Reppa, & Arguin, 2005; Leek, Reppa, Rodriguez, & Arguin, 2009; Marr & Nishihara, 1978; Pizlo, 2008; Pizlo, Sawada, Li, Kropatch, & Steinman, 2010; Sawada, Li, & Pizlo, 2011; Ullman, 2006).
Central to current “image- or appearance-based” models is the hypothesis that recognition is accomplished by a hierarchical network of edge-based features from single contours to arrays of vertices forming viewpoint-dependent aspects (e.g., Poggio & Edelman, 1990; Riesenhuber & Poggio, 1999; Ullman, 2006). Other theories have proposed that higher order primitives mediate recognition (e.g., Barr, 1981; Bergevin & Levine, 1993; Biederman, 1987; Biederman & Cooper, 1991; Guzman, 1968; Krivic & Solina, 2004; Marr & Nishihara, 1978; Pentland, 1986; Ullman, Vidal-Naquet, & Sali, 2002; Zerroug & Nevatia, 1999). These have included 2D geons (Biederman, 1987), surfaces (e.g., Faugeras, 1984; Fisher, 1989; Leek et al., 2005; Marr & Nishihara, 1978), and volumetric parts such as 3D geons (Biederman, 1987), generalized cylinders (Brooks, 1981; Marr & Nishihara, 1978) and superquadrics (Barr, 1981; Pentland, 1986).
In this study we focus on the contribution of surface-based shape primitives to object recognition. Several lines of evidence indicate that surfaces are extracted early in visual processing and play a key role in visual perception (e.g., Norman & Todd, 1996; Norman, Todd, Norman, Clayton, & McBridge, 2006; Norman, Todd, & Phillips, 1995). Surfaces contribute to the binding of object shape and other attributes such as colour, texture, and shadow (e.g., Cate & Behrmann; 2010; Chainay & Humphreys, 2001; Fan, Medioni, & Nevatia, 1989; Faugeras, 1984; Fisher, 1989; Leek, Davitt, & Cristino, 2015; Leek et al., 2005, 2009; Marr & Nishihara, 1978). They also influence facilitatory and inhibitory object-based attention (e.g., Leek, Reppa, & Tipper, 2003; Nakayama, He, & Shimojo, 1995; Nakayama & Shimojo, 1992; Reppa & Leek, 2003, 2006; Reppa, Schmidt, & Leek, 2012) and play an important role in the perceptual analysis of shape for the planning and online control of reach-to-grasp movements (e.g., Cristino et al., 2012).
Some of the first evidence that surfaces can act as a high-level shape primitive for recognition was presented by Leek et al. (2005). In a whole–part matching task, observers viewed images of 3D novel objects made of two distinct volumetric parts. On each trial, a whole object was briefly presented, followed by an object part that either matched or mismatched shape information in the whole object. The part stimuli contained contour fragments, a nonvolumetric configuration of spatially adjacent surfaces, or one of the two complete volumetric parts either from the same novel object (match trial) or from a visually similar distractor object (mismatch trial). The main finding was that while whole–part matching for surface and volumetric parts was faster than that for contour fragments, there was no difference in performance between surfaces and volumes. That is, arranging surfaces into volumetric components afforded no matching advantage over nonvolumetric configurations of surfaces. On the basis of this finding, Leek et al. (2005) argued that recognition is mediated not by volumetric structural descriptions, but by surface structural descriptions, whereby the surface shape primitives and their local pairwise spatial configuration is computed from the perceptual input and matched to long-term memory.
Further evidence that surfaces contribute to recognition was reported by Leek et al. (2009). Observers first memorized a subset of novel objects each consisting of two spatially connected volumetric parts. They then performed a primed recognition memory task in which they had to discriminate between learned and nonlearned objects. Primes consisted of subsets of object surfaces. Some primes contained only surfaces that were visible in the whole (unsegmented) object while other primes contained surfaces that had been occluded in the whole (unsegmented) object. Priming effects were significantly lower for part primes with occluded surfaces, suggesting that visible surface information plays a key role in recognition. Taken together, these findings, and those of Leek et al. (2005), were used to support the hypothesis that object recognition is mediated by surface-based representations of object shape (see also Ashbrook, Fisher, Robertson, & Werghi, 1998; Fan et al., 1989; Faugeras, 1984; Fisher, 1989; Lee & Park, 2002, for implementations of surface-based models in computer vision).
Experimental Study
The aim of the current study was to examine the role of surfaces as shape primitives for object recognition by addressing some important limitations of earlier work and by testing further predictions of the surface representations hypothesis. First, one key issue that was not addressed in previous studies is the extent to which the use of surface primitives in object recognition generalizes across changes in viewpoint. Viewpoint change may be an important factor in determining the kinds of shape representations that are used to support recognition (e.g., Arguin & Leek, 2003; Foster & Gilson, 2002; Harris, Dux, Benito, & Leek, 2008; Leek, 1998a, 1998b; Leek, Atherton, & Thierry, 2007; Leek & Johnston, 2006; Tarr & Bülthoff, 1998; Ullman, 1998). When two stimuli are shown from the same viewpoint, an image-based matching strategy may be sufficient for determining their shape equivalence (e.g., in the extreme via a point-by-point comparison of pixel values). In contrast, judging the shape equivalence of objects across plane or depth rotations is likely to require the computation of more abstract representations of shape—as a purely image-based matching strategy would fail. This is relevant because previous evidence from Leek et al. (2005, 2009) supporting the use of surface-based primitives in recognition comes from studies that did not manipulate viewpoint—a factor that potentially limits the generality of the findings. More specifically, the presentation of stimuli from the same viewpoint in those studies may have resulted in the adoption of an image-based task strategy, potentially obscuring a genuine underlying advantage for volumetric representations. We tested this possibility in the current study by comparing whole–part performance across same and different viewpoints. Different viewpoint here referred to changes in viewpoint in 2D space, not 3D space (not depth rotation), by rotating the object parts clockwise or anticlockwise perpendicular to the viewer.
Second, another issue arising from the earlier studies is whether the critical finding—that is, the equivalence in matching efficiency between surface and volumetric parts—might alternatively be accounted for in terms of a systematic difference in discriminability that masks a genuine underlying advantage for volumetric parts. An important, and theoretically relevant, distinction that defines discriminability is between metric (MP) and nonaccidental (NAP) shape properties. MPs denote feature properties that require precise specification (e.g., aspect ratio, turning angle between contours, and magnitude of curvature). In contrast, NAPs are binary categorical dimensions that distinguish image features (e.g., straight vs. curved, parallel vs. tapered—see Biederman, 1987; Lowe, 2004)—and which, under certain hypotheses, are fundamental to the derivation of higher order part structure (e.g., Biederman, 1987). Other evidence has shown that observers are more efficient at discriminating shape on the basis of changes in NAPs than MPs (e.g., Amir, Biederman, & Hayworth, 2012; Biederman & Bar, 1999; Biederman & Gerhardstein 1993)—consistent with the hypothesis that the rapid computation of NAPs plays an important role in shape perception. Of relevance here is whether the relative efficiency of whole–part matching for volumetric and surface-defined parts could be accounted for in terms of differences in the MP/NAP discriminability of each part type. An underlying advantage in matching volumetric parts over surface-defined parts may be obscured if the surface parts can be matched on the basis of NAPs, but the volumetric parts vary only in MPs. This possibility was not addressed in the earlier studies of Leek et al. (2005, 2009).
Third, we aimed to further examine how surface occlusion/visibility influences object recognition. Consider, for example, the comparison parts for the objects in Figure 1a. Critically, the volumetric parts in the top row contain a surface that is either fully or partially occluded when both parts are combined in the whole object. In contrast, the volumetric parts in the bottom row contain only surfaces that are visible in the corresponding whole object. Surface occlusion/visibility provides a way to test the surface representation hypothesis. If visible surfaces mediate object recognition then we might expect a cost in whole–part matching between segmented volumetric parts that contain an occluded surface relative to volumetric parts that contain only visible surfaces. This is because the additional surface information of the occluded volume would produce a mismatch between the surfaces in the perceptual input and those in the stored object representation (Leek et al., 2009).

The stimulus sets used for (a) participants in the metric properties (MP) mismatch similarity group and (b) participants in the nonaccidental properties (NAP) mismatch similarity group. All the part stimuli are shown for each of the 12 objects, with “occluded” volumetric parts, and corresponding contour and surface parts appearing in the top row and “visible” volumetric parts along with their corresponding contour and surface parts in the bottom row. For each object its mismatch companion appears directly across from it. The NAP/MP column reports the type of difference between the volumes of each object when compared with its paired mismatch object. For instance, in Figure 1a there is an MP difference between the top volume of Object 1 and the top volume of Object 7. Similarly, in Figure 1b there is a NAP difference between the top volume of Object 2 (pyramid) and the lower volume of Object 8 (truncated pyramid). The “Type of difference” column shows the type of MP or NAP differences between the left side and the right side volumes for each object. In some cases where the difference is in terms of NAP, there is more than one difference between the volumes (e.g., in Figure 1b, the volumes differ both in terms of the axis shape and in terms of their ending). CS stands for cross section, and AS stands for aspect ratio. To view this figure in colour, please visit the online version of this Journal.
These issues were investigated using a whole–part matching paradigm. Observers were shown twelve 3D novel objects made from two volumetric components and were later shown a comparison part, requiring a response as to whether they had previously been shown an object that had contained the part. Part stimuli comprised regions of closed contour fragments, complete volumetric parts, or edge-defined surface polygons. Note that the last two types of comparison part contained surfaces of the whole object, while contour parts were closed regions of contour that did not correspond to any object surfaces. The parts were presented from either the same viewpoint as shown in the whole object, or from a different viewpoint. While all surface parts contained only surfaces that were visible in the whole object, some volumetric comparison parts contained an occluded surface (“occluded volumetric parts” shown in the top row of Figures 1a and 1b), while other volumetric parts contained only visible surfaces (“visible volumetric parts” shown in the bottom row of Figures 1a and 1b). This allowed us to examine the effect of surface occlusion on matching performance.
Finally, there were two different types of mismatch trials, manipulated between participants. In the MP participant group, mismatch trials contained wholes and object parts that primarily differed in terms of metric properties. In the NAP participant group, mismatch trials contained whole and object parts that primarily differed in terms of nonaccidental properties. These contrasts are shown in Figures 1a and 1b. This manipulation allowed us to examine whether the relative efficiency of making whole–part judgements for volumetric and surface-defined parts is determined by NAP/MP mismatch discriminability.
Method
Participants
Fifty participants were recruited from Swansea and Bangor Universities, 25 for each of the two participant groups. In the MP mismatch similarity group, participants had a mean age of 22 years (SD = 3.21; 7 males) and took part in the experiment for either course credit or £3 payment. In the NAP mismatch similarity group, participants had a mean age of 21.5 years (SD = 5.13; 3 males) and took part in the experiment for course credit. All participants reported normal or corrected-to-normal vision.
Apparatus and Stimuli
The experiment was run on a Windows XP PC with a 19″ RGB monitor using E-Prime. The stimuli were 12 novel and geometrically regular 3D objects, each of which consisted of two connected volumetric parts: a main base or large component, and a small component. They were rendered in externally lit, three-quarter views using Strata 3D Pro. Each object was scaled to fit within a 6 × 6-cm frame that subtended 6.86° × 6.86° of visual angle from a viewing distance of 50 cm. For each of the 12 objects, closed contour, volumetric, and surface comparison (part) 1
Here and in the remaining text the term “part” is used as a shorter term instead of comparison stimulus. We use the term part in its more general sense to indicate comparison stimuli consisting of image features or combinations of features that may match the primitives that are encoded in mental shape representations of the objects during perception.
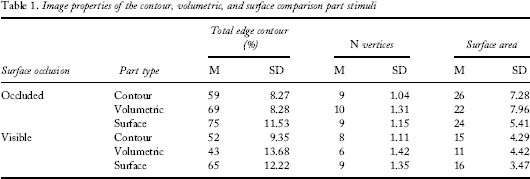
For each volumetric part, two types of surface parts (N = 24) were also created (N = 24). The constraints in the design were that (a) the surface parts did not make up a complete volume; (b) the number of surfaces in the surface part matched exactly the number of surfaces in the corresponding, occluded and visible, volumetric parts; and (c) the surfaces were spatially contiguous. For instance, if a volumetric part comprised of two visible surfaces and one previously occluded surface, the corresponding surface part would have three visible surfaces. Surfaces in both the volumetric and the surface parts were always spatially contiguous.
The contour part stimuli (N = 24) were created by selectively deleting regions of bounding and internal edge contour. The main constraints were that the resulting closed form did not correspond to any single volume or any single object surface and contained edge contour from both volumetric components. Following creation of the closed form, surface information was removed by replacing the yellow colour with white (as the background).
Plane-rotated versions of each part were created by rotating +90° or −90° around the z axis perpendicular to the observer. These were used in the different viewpoint condition (see Design section and Figure 2). Plane rotation ensured that the part rotations preserved across conditions other key surface properties in the stimulus rendering that might support whole–part matching.
An illustration, using Object 1, of the contrasting displays used for the same and different part viewpoint conditions across part types and surface occlusion. The term “occluded” refers to the fact that the volumetric part contains a surface that is occluded (partially or fully) in the whole object. After that, occluded contour and surface parts are simply the corresponding contour and surface parts for that volumetric part. Similarly, the term “visible” refers to the fact that the volumetric part only contains surfaces that are visible in the whole object, and the visible contour and surface parts are the corresponding parts to that volumetric part. See text for more details. To view this figure in colour, please visit the online version of this Journal.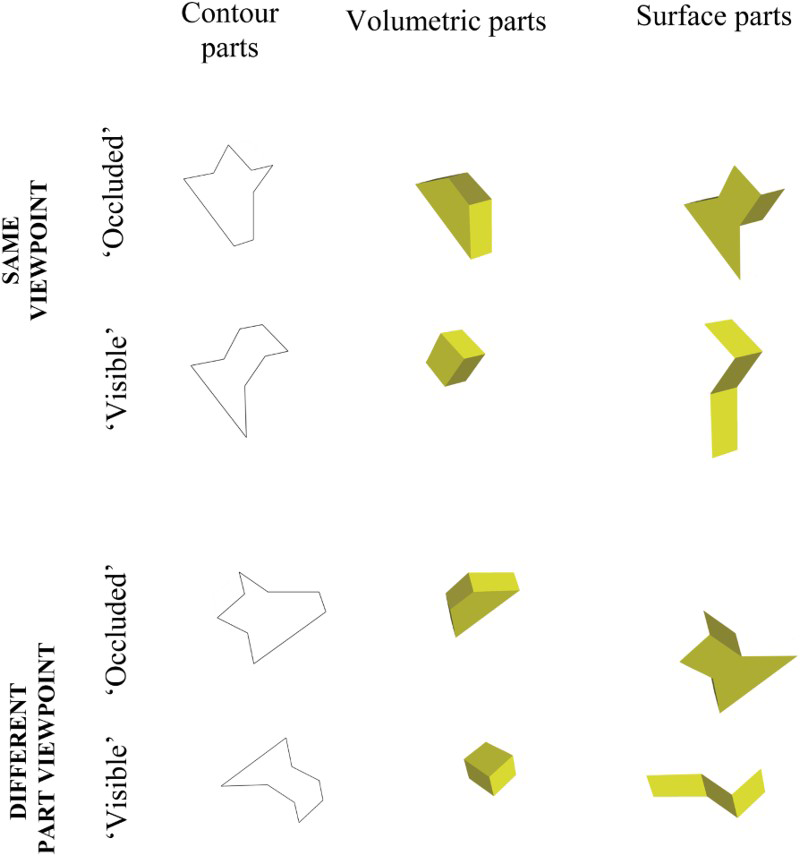
In order to prevent a strategy of simple pixel-by-pixel matching between parts and whole objects in the same viewpoint condition, the whole-object displays were enlarged to 150% the size of the images to be matched. Such moderate size transformations do not influence 3D object recognition (e.g., Fiser & Biederman, 1995; Norman, Swindle, Jennings, Mullins, & Beers, 2009). In addition, comparison part stimuli were centred on the screen so that the image pixels of the whole object and those of the comparison parts did not overlap.
Image properties of the contour, volumetric, and surface comparison part stimuli
Comparisons between each of the three comparison parts along each of three types of low-level feature
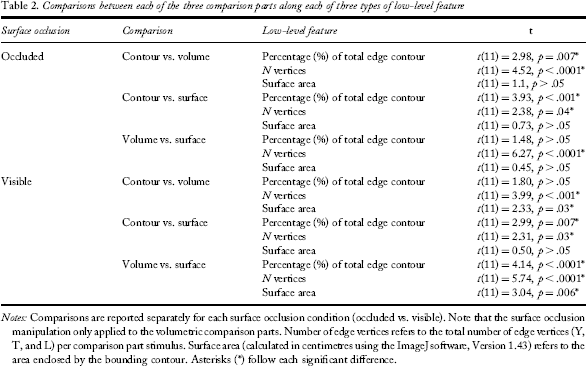
Notes: Comparisons are reported separately for each surface occlusion condition (occluded vs. visible). Note that the surface occlusion manipulation only applied to the volumetric comparison parts. Number of edge vertices refers to the total number of edge vertices (Y, T, and L) per comparison part stimulus. Surface area (calculated in centimetres using the ImageJ software, Version 1.43) refers to the area enclosed by the bounding contour.
Asterisks follow each significant difference.
Design
The experiment was based on a 3 (part type: contour, volume, surface) × 2 (part viewpoint: same vs. different) × 2 (mismatch similarity: NAPs vs. MP) mixed design, with the latter factor manipulated between subjects and the others within subjects. We also included an additional factor of surface occlusion. This relates to whether or not volumetric part stimuli contained a surface that was either wholly or partially occluded in the unsegmented whole object. Thus, for each object, one of the volumetric parts contained an occluded surface—henceforth referred to as “occluded volumetric part”—while the other contained only visible surfaces—henceforth referred to as “visible volumetric part”. For each of these two types of volumetric parts, corresponding contour part stimuli (“occluded contour parts” and “visible contour parts”) and surface part stimuli (“occluded surface parts” and “visible surface parts”) were made matched for contour length and number of surfaces, respectively. The terms “occluded” and “visible” are assigned to the surface and contour conditions for the purpose of comparison with the corresponding volumetric conditions, and neither the surface nor the contour parts contained occluded surface information.
In match trials, the comparison part stimulus comprised a subset of shape information from the whole novel object that was presented in the same trial. In mismatch trials, the comparison part stimulus belonged to a different object, with the nonmatching parts differing from the whole object in terms of MP and NAP contrasts. The ratio of the contrasts was different depending on the mismatch similarity group: In the MP group, the frequency of target objects and mismatch parts differing solely by MPs relative to NAPs was 2:1. In the NAP group, the ratio of MP to NAP differences was 1:2—see Figures 1a and 1b. The reason for using different ratios as opposed to pure sets of MP or NAP mismatch pairs was to avoid the possibility that participants might bias performance by selectively tuning to MP or NAP differences.
Each participant completed 144 match and 144 mismatch trials. There were 24 trials for each of the 12 within-subjects conditions. For each participant, each whole object was presented 24 times, and each part stimulus type was presented four times (twice in the same viewpoint as the whole object and twice in a different viewpoint). Trial order was randomized for each participant.
The measure of performance was d prime (d′), which was chosen because discriminations required in the current study, especially in the MP participant group, hinged on subtle differences, and errors were bound to be high. The d′ scores and the associated response bias (C) were calculated using the hit and false-alarm rate per condition.
Procedure
Trial procedure is shown in Figure 3. Participants were seated approximately 50 cm from the monitor. Each trial began with the central presentation of a visual prompt “Ready?” until the participant initiated the trial sequence by pressing the space bar. A blank screen was presented for 750 ms before one of the whole object stimuli appeared at screen centre for 1200 ms. Following a blank interstimulus interval of 750 ms, a part stimulus was displayed in the centre of the screen until the participant made a response. Participants were informed that each part would be in the same orientation as the whole object preceding it, or plane-rotated clockwise (for half of the parts) or anticlockwise (for the other half of the parts). The task was to decide as quickly and as accurately as possible whether or not the part stimulus came from the whole object that preceded it. Responses were made by pressing one of two keys (D or K) labelled “Yes” or “No” on a standard keyboard within 3 seconds. If a response was incorrect or timed out participants received feedback in the form of a 500-ms error tone. Half of the participants in each mismatch similarity group made match (Yes) responses with their dominant hand and mismatch (No) responses with their nondominant hand. For the other half, these assignments were reversed. The experiment lasted approximately 35 minutes. D′ scores were calculated using the hit rate per object and condition in the match trials and the false-alarm rate per object and condition in the mismatch trials (Brophy, 1986).
The trial procedure. ISI = interstimulus interval. To view this figure in colour, please visit the online version of this Journal.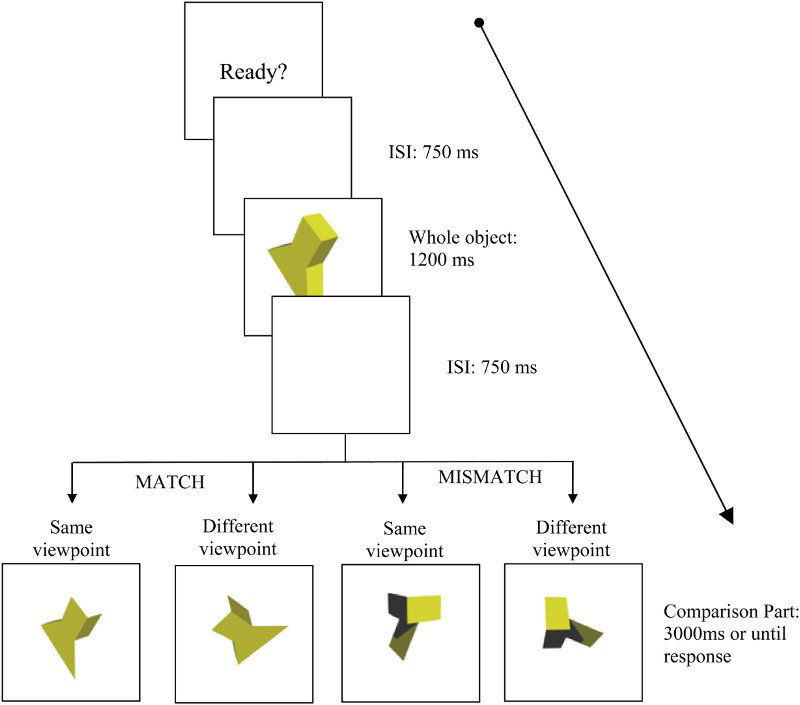
Results
The mean error rate across all conditions was 32% (SD = 15.10%). Mean proportions of hit and false-alarm rates, d′ scores, and their associated response bias measure, C, per condition were calculated per object and are shown in the Appendix. Analyses were carried out on d′ scores.
The goal of the analyses was to examine: (a) whether the pattern of whole–part matching between contour, volumetric, and surface part types is modulated by viewpoint change and (b) surface visibility; and (c) whether matching performance is dependent on mismatch similarity in terms of NAP versus MP whole–part discriminability.
Whole–Part Matching as a Function of Part Type, Viewpoint, and Surface Visibility
A 3 (part type: contour, volume, surface) × 2 (part viewpoint: same vs. different) × 2 (surface occlusion: occluded vs. visible) repeated measures analysis of variance (ANOVA) was used on d′ scores (the same analysis on C scores is reported in Footnote 2). 2
The equivalent analyses on C (response bias) scores revealed the same pattern of results as those on d′. The main effect of part viewpoint on C was significant, F(1, 23) = 64.51, MSE = 11.27, p < .0001, with more conservative response bias when the part appeared in a different viewpoint (M = 0.15, SD = 0.41) than in the same viewpoint (M = −0.25, SD = 0.08) as the whole object. Also significant was the main effect of part type, F(2, 46) = 6.69, MSE = 3.07, p = .003. Contour parts (M = 0.16, SD = 0.36) yielded a more conservative response bias than volumetric parts (M = −0.17, SD = 0.40), t(23) = 5.30, p < .0001, and surface parts (M = −0.14, SD = 0.64), t(23) = 2.81, p < .01, while there was no difference between the latter two, t(23) = 0.24, p > .05. The main effect of surface occlusion was not significant, F(1, 23) = 0.17, MSE = 0.007, p > .05 (occluded parts: M = −0.05, SD = 0.43; visible parts: M = −0.04, SD = 0.44). The Part Type × Surface Occlusion interaction was significant, F(2, 46) = 3.95, MSE = 1.34, p = .03. For occluded parts, there were no differences in C among the three part types (all ps > .05). However, visible contour parts yielded significantly more conservative response bias than both volumetric and surface parts [t(23) = 5.66, p < .0001; t(23) = 2.40, p = .02, respectively], with no difference among the latter two part types, t(23) = 1.36, p > .05. Finally, pairwise comparisons of C scores between occluded versus visible versions for each part type did not reveal any significant differences (all ps > .05).
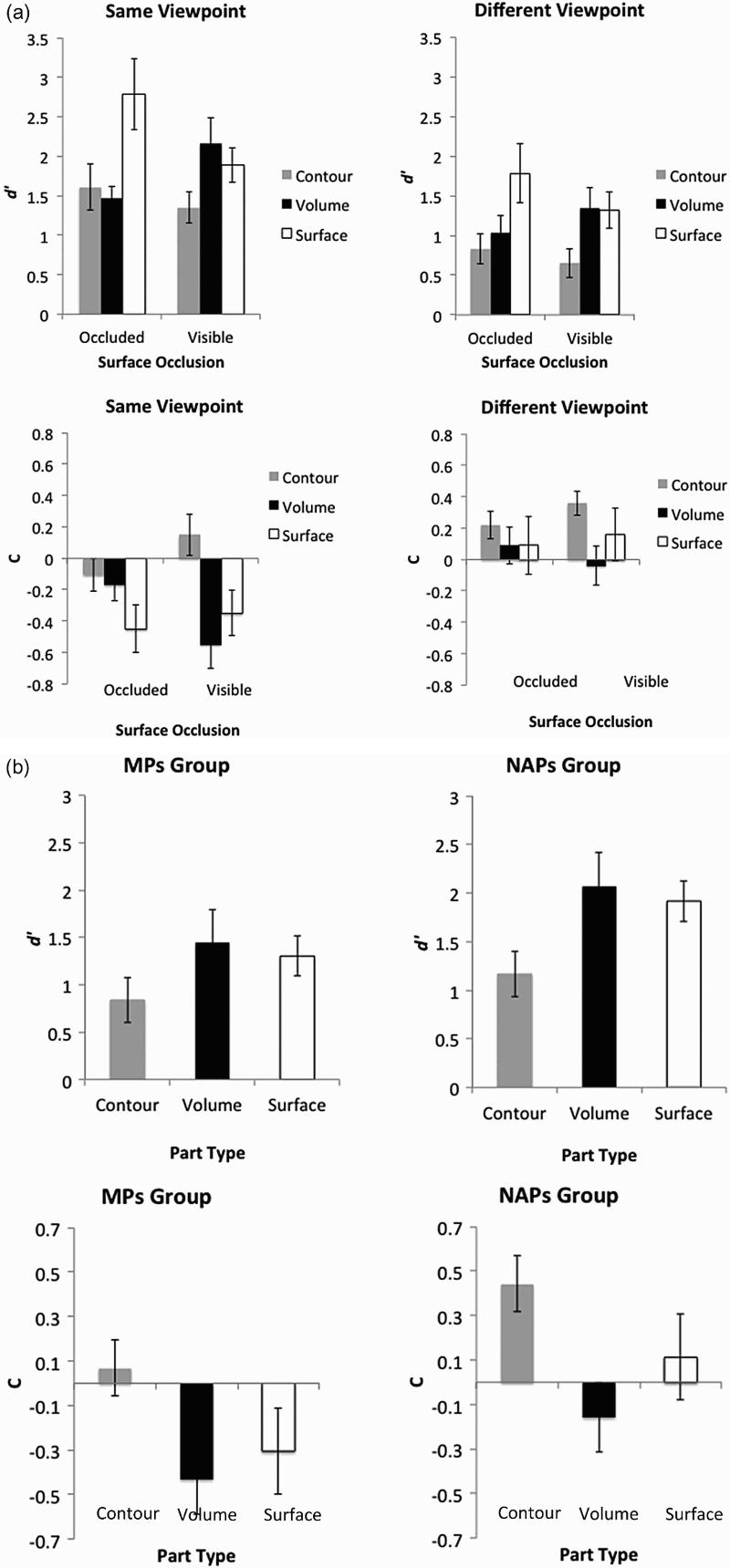
(a) Mean d′ (discriminability) and C (response bias) scores per part viewpoint, part type, and surface occlusion (collapsed across mismatch similarity group). (b) Mean d′ and C scores per mismatch similarity group and per part type for visible contour, volumetric, and surface parts only (see text for details). MP = metric properties; NAP = nonaccidental properties. Error bars indicate standard error of the mean.
There was a significant main effect of part viewpoint, with better performance in same (M = 1.88, SD = 0.79) than in different viewpoint trials (M = 1.24, SD = 0.80); F(1, 23) = 45.74, MSE = 30.47, p < .0001, but part viewpoint did not interact with the other two factors (all ps > .05)—showing that the pattern of whole–part matching across part types was not modulated by viewpoint. There was also a significant main effect of part type, F(2, 46) = 7.51, MSE = 12.79, p = .002, showing that whole–part matching performance was modulated by part type. Contour parts (M = 0.96, SD = 0.66) yielded the lowest d′ scores compared to volumetric parts (M = 1.49, SD = 0.86), t(23) = 3.27, p = .003, and to surface parts (M = 1.95, SD = 1.15), t(23) = 4.11, p < .001. Overall (collapsing across the factor of surface occlusion), surface parts yielded higher d′ than volumetric parts, t(23) = 2.41, p = .02—but only relative to volumes with occluded surfaces (see below). There was no significant main effect of surface occlusion, F(1, 23) = 2.08, MSE = 2.92, p > .05 (occluded: M = 1.67, SD = 0.96; visible: M = 1.46, SD = 0.66), but there was a significant Surface Occlusion × Part Type interaction, F (2, 44) = 4.50, MSE = 4.50, p = .02. To explore this further, post hoc analyses were conducted. These showed that performance with occluded volumetric parts and their corresponding contour parts was equivalent, t(23) = 0.19, p > .05, whereas surface parts yielded significantly higher discriminability (d′) than either contour, t(23) = 2.58, p = .01, or occluded volumetric parts t(23) = 3.00, p = .006. In contrast, visible volumetric parts and their corresponding surface parts yielded higher d′ scores than contour parts [t(23) = 3.07, p < .005; t(23) = 2.45, p < .01, respectively]. The key contrast between performance with occluded (surface) volumetric parts and visible (surface) volumetric parts showed higher d′ scores in the visible (surface) volumetric condition, t(23) = 2.32, p = .03. This suggests that matching performance with segmented volumetric parts is sensitive to surface composition: The presence of previously occluded surface information in the volumetric primes induces a performance cost. 2
Effects of Mismatch Similarity in terms of NAP/MP Discriminability
This analysis examined whether basing mismatch decisions on NAP or MP changes the pattern of matching performance across part types. As part viewpoint did not interact with part type, the data were collapsed across part viewpoint to simplify the analysis. The analyses were restricted to data from the visible volumetric part condition and the corresponding matched contour and surface parts, to ensure that the surface and volumetric parts contained the same number of visible surfaces. The analysis was carried out on d′ scores. Cell means appear in Figure 4b.
A mixed 2 (mismatch similarity: NAP vs. MP) × 3 (part type: contour, volume, surface) ANOVA 3
Two further mixed-model ANOVAs were carried out. One was on d′ scores of occluded volumetric parts only, and the other was on the collapsed d′ means of occluded and visible surface volumes. The Mismatch Similarity × Part Type ANOVA on d′ scores from occluded volumes only showed a significant main effect of mismatch similarity, F(1, 22) = 8.15, MSE = 17.50, p = .01, with higher d′ for the NAP than for the MP group. The main effect of part type was significant, F(2, 44) = 6.66, MSE = 7.52, p < .0001. Volumetric parts were not different from contour parts, t(23) = 0.19, p > .05, while surface parts had higher d′scores than both the contour and the volumetric parts [t(23) = 2.58, p = .02; t(23) = 2.98, p = .007, respectively]. The Mismatch Similarity × Part Type interaction was not significant, F(2, 44) = 2.06, MSE = 1.98, p > .05.
An analyses of C scores revealed the same pattern of results as the one on d′ scores. There was a significant main effect of part type, F(2, 46) = 8.59, MSE = 1.87, p < .001. Pairwise comparisons showed that contour parts (M = 0.26, SD = 0.46) yielded a more conservative response bias than both volumetric (M = −0.29, SD = 0.55) and surface parts (M = −0.10, SD = 0.69) [t(23) = 5.66, p < .0001; t(23) = 2.40, p = .02, respectively], with no difference among the latter two part types, t(23) = 1.36, p > .05. The main effect of mismatch similarity group was significant, F(1, 23) = 4.54, MSE = 2.27, p = .04, but the interaction was not, F(2, 46) = 0.15, MSE = 0.33, p > .05. The NAPs group yielded more conservative response bias (M = 0.13, SE = 0.12) than the MPs group (M = −0.22, SE = 0.12).
Influence of Low-Level Image Features
To examine potential contributions of percentage of edge contour, number of vertices, and surface area, 3 one-way analyses of covariance (ANCOVAs) were carried out with each of these factors as covariates. We collapsed across the variables of part viewpoint and mismatch similarity and combined the part type and surface occlusion factors into a single factor that we called part, with six levels: contour “occluded”, contour “visible”, volumetric “occluded”, volumetric “visible”, surface “occluded”, and surface “visible”. None of the three low-level features contributed significantly to the pattern of d′ (all ps > .05), hence differences in low-level image features did not account for the observed pattern of discriminability among part types. Separate regression analyses were carried out between each image feature and d′ scores. Only percentage of edge contour correlated significantly with d′ scores, (r2 = .73), F(1, 71) = 5.48, p = .02. The correlation between d′ scores and number of vertices was not significant, (r2 = .126), F(1, 71) = 1.1, p > .05, and neither was the correlation between d′ scores and surface area, (r2 = .058), F(1, 71) < 1, p > .05.
General Discussion
The current study used a whole–part matching task to examine the hypothesis that surfaces can act as primitives of shape representations mediating object recognition. Four findings in the current study support this hypothesis. First, where parts contained only surfaces that were visible in the whole object, observers were equally good at matching parts comprising spatially adjacent surfaces to whole objects as they were in matching volumetric parts to whole objects. Second, this pattern of performance was found regardless of whether the part and whole object stimuli were presented at the same or at different viewpoints. Third, these findings cannot be accounted for by systematic differences in the discriminability of volumetric and surface parts in terms of MP or NAP differences. Fourth, there was a significant decrease in matching performance when volumetric parts contained a surface that was wholly or partially occluded in the whole object compared to volumes containing only visible surfaces. This cost arose from the mismatch in surface information derived from the comparison part and the whole object stimuli (due to the presence of a surface in the comparison part that was occluded in the whole object).
Taken together, these results provide new evidence that surface-based shape primitives can support object recognition. They also challenge theoretical accounts that recognition is mediated by volumetric part-based representations of shape (e.g., Barr, 1981; Biederman, 1987; Brooks, 1981; Marr & Nishihara, 1978; Pentland, 1986). Previous work by Leek et al. (2005) showed, like the current study, that there is no benefit in matching parts defining volumetric primitives over parts defined by nonvolumetric configurations of spatially adjacent surfaces. This finding is inconsistent with volumetric accounts, which predict a matching advantage for volumetric parts (since those parts, by hypothesis, correspond to shape primitives that are computed during the course of perception). Here, we also showed that this pattern of results is found under conditions of viewpoint change, which in principle favour the computation of volumetric part-based representations to support view generalization. In contrast, we found positive evidence that recognition is sensitive to surfaces. This was shown by the surface occlusion effect. That is, we found a performance cost in whole–part matching for volumetric parts containing a previously occluded surface. This effect cannot be easily explained by hypotheses proposing that volumetric shape primitives mediate recognition. If the objects in the current study were represented in terms of volumes, then volumetric parts should have shown a matching advantage over contour-defined parts, or surfaces, regardless of whether they contained an occluded surface or not, because the occluded surface would be inferred as a result of volumetric completion. On the contrary, the presence of even a single partially occluded surface was detrimental to matching performance, suggesting that visible surface shape contributes information that is necessary for object recognition. These data support those of Leek et al. (2009) who found a reduction in priming when primes contained surfaces that were not visible in the whole object. Here a similar cost in performance was found using a whole–part matching task, providing converging evidence that visible surfaces underlie object recognition.
The current pattern of performance cannot be accounted for in terms of differences in low-level image properties: The pattern of differences in low-level image features did not resemble the observed pattern of discriminability among part types in either viewpoint. The current results can also not be accounted for in terms of global shape similarity between comparison parts and whole objects. For instance, one alternative explanation for the (occasional) good matching performance for surface parts over volumetric parts may be that surface parts looked more similar overall to the whole object than volumetric parts. However, if global shape similarity was driving matching performance there would always be a performance advantage for surface parts, which were the most similar to the whole object because they contained information about spatial configuration of the whole object. This explanation, however, was not supported by the current data. The global similarity between surface parts and whole objects did not always give a performance advantage over volumetric parts. For instance, the “visible volumetric” parts and “visible surface” parts yielded statistically equivalent performance. Additionally, when global shape whole–part overlap was disrupted in the different viewpoint condition, again there was no difference in performance between visible volumetric and visible surface parts. Finally, in the analyses where comparison parts were matched in terms of surface visibility (they only contained visible surfaces), again there was no performance advantage for those parts (surface parts) that were more similar to the whole object than those that were not (volumetric parts). Overall, the pattern of results points to the critical importance of surface visibility in predicting accurate whole–part matching performance.
Another novel finding of the current experiments was that the observed pattern of results was not dependent on part discriminability in terms of NAPs or MPs. This is an important observation because in Leek et al. (2005) mismatch parts all differed from the whole object in terms of metric properties. One concern was that an underlying advantage for matching volumetric parts may have been obscured by a necessity to compute mismatch judgements based solely on metric differences, which favour the use of image-based, rather than parts-based, representations. Here, even with a stimulus environment favouring the computation of volumetric primitives, no volumetric part advantage was observed, again implying that surfaces rather than volumetric primitives underlie performance.
More broadly, the current results support the hypothesis that object recognition is mediated by surface-based descriptions of object shape (Leek et al., 2005). According to this hypothesis, edge-based descriptions of 3D objects are used to define constituent surfaces (see also Fan et al., 1989; Fazl, Grossberg, & Mingolla, 2009; Fisher, 1989; Phillips, Todd, Koenderink, & Kappers, 2003), and the surface-based description is used to access, or index, stored shape representations during recognition. On the original hypothesis outlined by Leek et al. (2005), shape indexing is achieved by approximating surface shape and accessing stored object representations based on pairwise spatial configurations of spatially adjacent surfaces. Thus, recognition is based on local surface configuration and does not require the derivation of global object attributes (e.g., principal axis elongation, symmetry). However, the hypothesis does not assume, or require, that surfaces are computed directly from perceptual input. Neither is it incompatible with other recent demonstrations from computational modelling supporting the use of edge-based (rather than surface-based) reconstructions of 3D object geometry in human vision (e.g., Pizlo, 2008; Pizlo et al., 2010; Sawada et al., 2011). For example, Pizlo and colleagues have elegantly shown how veridical 3D structure can be reliably computed during perception from 2D edge-based descriptions of objects following simplicity constraints (e.g., symmetry, complexity). This is accomplished without inferring object surface structure directly from perceptual input, but instead is based on the recovery of a 3D “wireframe” shape description. Note, however, that the recovery of 3D shape and the recognition of object shape (i.e., matching of a 3D perceptual representation to a stored long-term memory object model) are not the same thing. Sawada et al. (2011) explicitly argue that once the wireframe contour-based 3D model has been computed it may be “wrapped” in surfaces in order that surface-based attributes (e.g., colour, or texture) may be bound to shape to facilitate recognition.
In summary, this study contrasted the role of surfaces and volumetric shape primitives in three-dimensional object recognition. Observers matched subsets of closed contour fragments, surfaces, or volumetric parts to whole novel objects during a whole–part matching task. The results showed a whole–part matching advantage for surface-based parts and volumes over closed contour fragments—but no benefit for volumetric parts over surfaces. We also found a performance cost in matching volumetric parts to wholes when the volumes showed surfaces that were occluded in the whole object. The same pattern was found for both same and different viewpoints, and regardless of target–distractor similarity. These findings challenge models in which recognition is mediated by volumetric part-based shape representations. Instead, we argue that the results are consistent with a surface-based model of shape representation for recognition.
ORCID
Irene Reppa http://orcid.org./0000-0002-2853-2311