
Abstract
The present study tackles two overlooked aspects of analogical retrieval: (a) whether argumentation activities elicit a spontaneous search for analogical sources, and (b) whether strategic search can relax the superficial bias typically obtained in experimental studies of analogical retrieval. In Experiment 1, participants had to generate arguments for a target situation under three conditions: without indication to use analogies, with indication to use analogies, and with indication to search for sources within domains provided by the experimenters. Results showed that while voluntary search yields analogical retrievals reliably, the argumentation activity seldom elicits spontaneous remindings. A second set of results demonstrated that the superficial bias can be strategically relaxed, leading to a majority of distant retrievals. Experiment 2 replicated this result with the instruction to search within domains different from that of the target, and without providing a list of specific domains. The theoretical and educational implications of these findings are discussed.
Analogical reasoning plays a crucial role in activities as diverse as hypothesis generation, problem solving, instruction, or argumentation (Gentner & Smith, 2013; Holyoak, 2005). Based on the recognition that the elements of two situations are organized by a similar system of relations (Gentner, 1983; Gentner & Markman, 2006; Minervino, Oberholzer, & Trench, 2013), it allows transferring knowledge from a relatively better known situation (the base or source analogue) to a novel situation (the target analogue) in order to improve the comprehension of the latter. A traditional taxonomy (e.g., Gentner, 1989; Holyoak & Thagard, 1995) distinguishes between intradomain analogies (when the compared situations pertain to the same domain) and interdomain analogies (when they belong to different domains). In intradomain analogies, the compared analogues maintain superficial similarity, as the base objects and relations tend to be semantically similar to their counterparts in the target (Gentner, Rattermann, & Forbus, 1993). The present study was carried out to assess the extent to which people can deliberately regulate the number and type of base analogues that are retrieved from long-term memory (LTM).
A large body of empirical studies has demonstrated that people can easily understand analogies even in the absence of superficial similarity (e.g., Gentner et al., 1993; see Holyoak, Novick, & Melz, 1994, for a review). In contrast with the relative ease of finding the right mapping between a source and a target that are simultaneously active in working memory (WM), the process of retrieving interdomain sources from LTM turns out to be rather demanding. A number of studies have shown that intradomain sources are retrieved between two and four times more frequently than interdomain sources (e.g., Gentner et al., 1993; Holyoak & Koh, 1987; Keane, 1987; Trench & Minervino, 2014). These results led researchers to conclude that superficial similarity represents a crucial precondition for analogical retrieval, with explanations ranging from the evolutionary to the computational. In terms of psychological adaptation, this superficial bias is thought to represent no big loss, since surface features tend to correlate with deeper structural features in the natural world (i.e., the “kind world” hypothesis, Gentner, 1989). In the words of Gentner (1989, p. 267): “By and large, if something looks and roars like a tiger, it probably is a tiger.” In terms of psychological plausibility, computational modelers of analogical retrieval agree that the computational cost implicated in carrying out a structural mapping between the target analogue and every potential situation stored in LTM would be prohibitive (Forbus, Gentner, & Law, 1995; Thagard, Holyoak, Nelson, & Gochfeld, 1990).
In line with the above criteria, proponents of the structure mapping theory (Gentner, 1983) developed MAC/FAC (for many are called, few are chosen; Forbus et al., 1995), an algorithm designed to simulate human patterns of analogical retrieval through psychologically realistic computations. MAC/FAC divides retrieval into two phases: MAC, a fast superficial filter, and FAC, a computationally expensive structural matcher. The MAC phase begins by generating content vectors for the target and every situation stored in LTM, with each content vector being generated by assigning a position in an ordered series to all concepts in LTM and counting how many times each concept appears in each of the stored situations. Upon taking the vector products between the content vector of the target and the vector of all situations in LTM, the MAC stage submits the winning base analogues (most of them superficially similar to the target) to the FAC stage. For each base analogue, FAC starts by creating all possible local mappings between elements of the same formal type, with the added restriction that mapped relations must have identical meaning. The program then incrementally coalesces local matches into global mappings that satisfy the constraints of parallel connectivity (if two predicates are mapped, their arguments must also be mapped) and one-to-one mapping (elements in one analogue must map to only one element in the other analogue). Finally, FAC scores the quality of global mappings as a function of their size, their depth, and the semantic similarity of their corresponding objects. This last criterion amplifies the bias of MAC towards base analogues bearing superficial similarity with the target.
LISA (learning and inference with schemas and analogies; Hummel & Holyoak, 1997) is the latest computational model developed by proponents of the multiconstraint theory of analogy (Holyoak & Thagard, 1989, 1995). Its architecture encompasses retrieval, mapping, inference, and schema abstraction by a unified set of core processes more neurally plausible than in earlier attempts (e.g., Thagard et al., 1990). LISA's architecture is a system for representing dynamic role–filler bindings in working memory (WM) and encoding them in LTM for later retrieval. When a proposition unit (P) like Peter loves Susan gets activated, it propagates top-down activation to subproposition units (SPs) that represent bindings between each of the case roles of the proposition and its corresponding filler. During the lapse while each SP unit remains active, it transfers top-down activation to two independent structure units representing a case role and its filler (e.g., Peter and lover), which fire in synchrony with each other and out of synchrony with the units of the complementary SP (i.e., Susan and beloved). Case roles and their fillers—which represent the lowest level in the structural hierarchy—in turn activate a collection of semantic units representing their meaning. Therefore, when a proposition such as Peter loves Susan is selected, the semantic primitives of lover (e.g., emotion1, positive1, and strong1) fire in synchrony with the semantic primitives of Peter (e.g., human, male, and adult), while units representing the beloved role (e.g., emotion2, positive2, and strong2) fire in synchrony with units representing Susan (e.g., human, female, and adult). When the semantic primitives of a given role–filler binding in the target fire in WM, predicate, object, and SP units from one or various sources compete in responding to this array as a function of the extent to which their semantic units overlap. Syntactic constraints are enforced by sets of excitatory and inhibitory links. Within a base analogue, units of different hierarchy are linked by symmetric excitatory connections, whereas units of the same level share symmetric inhibitory links. This way, when predicate and object units in a base analogue respond to patterns of activation in WM, they activate SP and P units above them, which inhibit other units of the same type, enforcing the one-to-one mapping constraint. Once a P unit in the target has activated a corresponding P unit the base analogue, the constraint of parallel connectivity is enforced by top-down activation of the structure units below them. As in MAC/FAC, LISA's reliance on semantic similarities between the sources and the target leads to a majority of superficial remindings.
In contrast with the emphasis placed in justifying the appropriateness of the representational and computational assumptions incorporated in each of the above models (e.g., while MAC/FAC uses serial operations on symbolic representations, LISA uses connectionist computations on distributed representations), the presentations of these models are ambiguous as to whether the models are meant to account for voluntary remindings, involuntary remindings, or both. While involuntary remindings are spontaneous responses to the processing of the target without any conscious attempt to retrieve sources from memory, voluntary retrievals are the outcome of a deliberate effort to locate those sources in LTM. Given the importance of this distinction within current memory research (see Mace, 2010, for a review), the first objective of the present study was to assess the extent to which the activity of generating arguments for a target situation elicits a spontaneous search for base analogues in LTM. A second objective of the present study concerns whether the search process involved in deliberate attempts to retrieve analogous situations from LTM is invariably biased towards superficial matches, as in current implementations of the dominant models, or if it can be strategically oriented towards areas of knowledge different from that of the target—a central preoccupation of psychologists and educators (see, e.g., Loewenstein, 2010). Before presenting our study, we briefly review the available evidence bearing on these two questions.
Voluntary versus involuntary retrieval of base analogues
It is a rather common experience to be reminded of analogous situations during activities as diverse as problem solving, hypothesis generation, explanation, or argumentation (Hofstadter & Sander, 2013; Holyoak & Thagard, 1995). However, a sensible question to be asked concerns the extent to which being engaged in the above activities reliably elicits a spontaneous search for base analogues in LTM. Even though no studies on analogical retrieval have yet manipulated whether or not participants are explicitly invited to think of analogous situations during the processing of a target situation, across-studies comparisons within the problem-solving literature suggest that participants’ attempts to find a solution automatically elicit a search for base analogues in LTM. For instance, using roughly comparable materials, Keane (1987) and Holyoak and Koh (1987) assessed the retrieval of a base problem and its solution during a temporally and contextually separated problem-solving activity. Even though the former study (but not the latter) explicitly asked participants to look for analogous problems prior to attempting a solution, both obtained comparable rates of retrieval. This suggests that attempting to solve a problem suffices to trigger a search for analogous situations, and that the explicit intention to remember analogous situations adds little over and above the mere disposition to solve the problem. Other studies of spontaneous analogical retrieval during problem solving (e.g., Chen, Mo, & Honomichl, 2004) point in the same direction. With these antecedents in mind, the specific question that concerns us here is whether this automatic search for analogous situations generalizes to other relevant activities for which analogical reasoning represents a useful heuristic.
A number of studies (e.g., Blanchette & Dunbar, 2000; Trench, Oberholzer, & Minervino, 2009; Trench, Olguín, & Minervino, 2011) have shown that when being asked to generate analogies to convince somebody of performing an action, people profusely retrieve analogous situations from memory. For example, Blanchette and Dunbar (2000) introduced college participants to the zero-deficit strategy for controlling the increase in public debts and asked them to generate analogies that could be used to convince the population about the necessity of supporting (or resisting, depending on the condition) such strategy. They obtained a high number of analogical responses, a result that was interpreted as reflecting the fact that participants were able to retrieve their own sources in the service of an ecologically valid target activity. However, no studies have investigated whether this hint to base persuasive arguments on analogies represents an advantage over a similar condition where participants are not hinted to base their arguments on analogies.
As in the above studies, the procedure followed by one of the groups of the first experiment reported in the present study consisted in presenting participants with a target situation admitting two alternative lines of action and asking them to provide as many analogies as they could in favour of one of such actions. Based on the results of the above studies, we predicted that the explicit indication to search for analogies in the service of argumentation—that is, a prompt for voluntary retrieval—would lead to the frequent retrieval of source analogues from LTM. In order to determine the extent to which the activity of generating persuasive arguments reliably triggers a spontaneous search for analogous situations, we had another group receive the same target and the same instructions to argue in favour of the intended action, but without any indication to base their arguments on analogous situations.
The superficial bias in analogical retrieval: Can it be strategically relaxed?
As stated above, a wealth of laboratory studies demonstrated that people retrieve mostly superficial matches to the target, and most retrieval algorithms were specially engineered to simulate such pattern of results. More recently, however, a series of naturalistic studies (e.g., Blanchette & Dunbar, 2000, 2001, Christensen & Schunn, 2007; Kretz & Krawczyk, 2014; Richland, Holyoak & Stigler, 2004) have obtained a more balanced proportion of intradomain and interdomain analogies, a result has been interpreted as calling into question the validity of the superficial bias obtained by the experimental tradition. Dunbar (2001) has suggested that the reason behind the divergent results of both traditions—termed “the analogical paradox” by the author—lies in the artificiality of experimental tasks. As these tasks typically fail to highlight the structural features of the base and target analogues during their encoding, participants can only rely on surface features to retrieve the experimental sources from memory. In contrast, when participants are allowed to retrieve their own sources in the service of meaningful tasks like generating analogies for a realistic situation, base and target analogues are processed attending to their structural features. Therefore, retrieval does not need to rely on the existence of shared surface features (Dunbar, 2001; Hofstadter & Sander, 2013).
The second objective of the present study was to assess whether participants who are voluntarily attempting to retrieve analogous cases from LTM can focalize their search on specific domains in the service of interdomain analogizing. In relation to this possibility, some of the computational models of analogical retrieval left open the question of whether the superficial bias typically obtained in behavioural studies could be “tuned” by the analogizer, be it by means of relaxing the weight given to object attributes by the structural component of the system (e.g., the FAC stage of MAC/FAC) or by having the whole retrieval algorithm run on a subset of LTM selected via other general mechanisms of memory, such as spreading activation or indexing (Gentner & Forbus, 1991). Regarding the indexing capabilities of the human memory, Ripoll (1998) obtained evidence for the existence of a synthetic level of representation that specifies the thematic domain to which a problem belongs and demonstrated how these “domain tags” operate during the time-course of analogical retrieval. The procedure consisted in coupling superficially similar and superficially dissimilar target problems with a heading intended to activate a domain tag (e.g., “a learning problem”), which could match (or not match, depending on the condition) the domain tag of the base problem. Using concurrent measures of retrieval, Ripoll (1998) found that the presence of shared surface features facilitated spontaneous retrieval, but only when the domain tags of the problems matched. The present paper seeks to assess whether these domain tags, which allegedly modulate the effectiveness of surface features during spontaneous retrieval, can be strategically exploited during the voluntary search for base analogues in LTM.
To this end, the second and third groups of Experiment 1 received a target situation coupled with an instruction to search for analogous situations that could be used to convince the main character of such episode to pursue a given action (i.e., a voluntary retrieval prompt). However, while participants of the second group were not given any indication to focus search in any particular direction, participants of the third group were provided with domain tags representing domains thematically distant from that of the target and were asked to search for potential situations within such domains. The comparison between the types of analogies provided by these two groups seeks to extend Ripoll's (1998) findings in two ways. On the one hand, they test the psychological reality of domain tags outside the realm of analogical problem solving. Most importantly, though, they explore the extent to which these tags can be strategically exploited by the analogizers to orient the search process in a particular direction.
Experiment 1
Method
Participants and design
One hundred and twenty undergraduate students at University of Comahue volunteered to participate in the experiment (mean age = 21.49 years, SD = 3.42). An even number of participants was randomly assigned to the argumentation condition (GAR), the analogical argumentation condition (GAN), and the analogical argumentation with predefined domains condition (GAN+D).
Materials and procedure
Before advancing to the argumentation task, participants of all groups received an instructional material on argumentation. The material handed to the GAR covered general features of arguments, but did not describe any specific types of arguments (e.g., analogies). The material handed to the GAN and the GAN+D described the use of analogies in persuasion, and illustrated with two examples the distinction between intradomain and interdomain analogies, as well as between analogies based on situations retrieved from memory and analogies based on invented situations. Once the 10 min allotted to reading the instructional material had elapsed, participants of all groups were presented with a short text describing the situation of a family that was accumulating an important debt in the balance of their credit card. All groups had to generate as many arguments as they could to persuade them to cut expenses immediately in order to cancel the debt, on the grounds that otherwise the debt would grow so big that future cuts would need to be even more dramatic. Whereas instructions given to the GAR did not mention the convenience of including analogies to prior cases among their arguments, participants of the GAN and GAN+D were asked to base their arguments on analogies to known situations. The difference between the GAN and the GAN+D was that while participants of the GAN received no instructions concerning the domains of the base analogues to be used in their analogies, participants of the GAN+D were asked to sequentially focus their search within four domains different from economy: health, human relations, housekeeping, and breeding of animals and plants. In order to prevent participants of the GAN and GAN+D from reporting base analogues not originated in retrieval processes, they were encouraged to base their analogies on past episodes that had happened to them or to others, or that were learned from verifiable sources such as newspapers, books, movies, and so on. Participants of the GAR and the GAN were given 20 min to complete the argumentation task. In the case of the GAN+D, participants were allotted 5 min for each of the suggested domains. Once this time had elapsed, participants of all groups were allotted 5 more minutes to report all other arguments (or analogies, depending on the group) that had come to mind during the previous phase but which were not reported for whatever reasons. This question was intended to reveal base analogues that were in fact retrieved but were not reported (cf. Trench et al., 2011), like when a source is rejected for not being persuasive or, in the case of the GAN+D, for not belonging to the specific domain that was requested.
Data analysis
Two judges received instruction on the concept of analogy, as well as on the general distinction between intradomain and interdomain analogies. For the target analogue at stake, they were instructed to regard as “analogical responses” all proposals including the following elements: (a) a problem of increasing magnitude, (b) a delay in the attempts to solve it, and (c) a consequent increase in the cost of solving it. Following a criterion akin to that of Blanchette and Dunbar (2000), judges were instructed to score as intradomain all situations where the problem of increasing magnitude was economic (e.g., a public debt) and to score as interdomain all instances in which the problem of increasing magnitude was not of economic nature (e.g., an illness or a plague). Given that we sought to detect all the situations that were retrieved from LTM in response to the target task, judges were handed all responses produced by the participants, regardless of whether they were reported during the argumentation phase, or during the later requirement to list all other situations that had come to mind during the first task, but were not included among the final proposals. Judges agreed in 82% of the cases regarding the analogical status of proposals, and in 94% of the cases regarding their intra/interdomain nature. Cases of disagreement were resolved by discussion. In order to assess whether the different conditions affected the quality of the analogies, two new judges blind to the objectives of the study were asked to rate the structural similarity between the target situation and the base situation contained in each of the analogical proposals (1 = not analogous, 5 = completely analogous). To this end, judges received an explanation about the concept of structural similarity in terms of the extent to which the central elements of the target analogue have a clear counterpart in the base analogue. This explanation was coupled with five examples corresponding to different degrees of structural similarity. The score used for statistical analyses was the average of the scores provided by the two judges.
Results and discussion
Across conditions, participants proposed a mean of 2.10 responses (SD = 0.94), out of which 44% were rendered analogical by the judges. Further comparisons and statistical analyses were restricted to analogical proposals. Collapsing across conditions, 71.17% of analogical proposals were included in the proper argumentation task, and 28.83% during the later prompt to report other situations that were remembered during the argumentation activity.
Our first empirical question concerned the extent to which the task of generating arguments would elicit the spontaneous retrieval of base analogues from LTM, as evaluated by most studies on problem solving. Taking together intradomain and interdomain proposals, participants of the GAR retrieved a total of 7 base analogues in response to the target situation (M = 0.18, SD = 0.45). This level of analogical retrieval is markedly lower than that of GAN (M = 0.73, SD = 0.60), where participants were explicitly asked to base their arguments on analogies to known situations, t(72.14) = 4.658, p < .01 (see Figure 1). Given the performance exhibited by the GAN, the disappointing number of sources retrieved by participants of the GAR cannot be attributed to a lack of base situations potentially available in LTM for retrieval. Rather, it indicates that the pragmatic of generating arguments for a hypothetical target situation elicits few spontaneous analogical remindings. A likely explanation for the difference between our results and those obtained with problem-solving tasks might lie in the fact that while the types of problems typically used in the problem-solving literature (e.g., the tumour problem, Gick & Holyoak, 1980) do not admit direct methods of solution based on general heuristics like means–ends analysis, our tasks were amenable to direct argumentation. Conversely, it is possible that for target situations for which direct (i.e., nonanalogical) argumentation were less straightforward, the retrieval of base analogues from LTM would be more frequent.
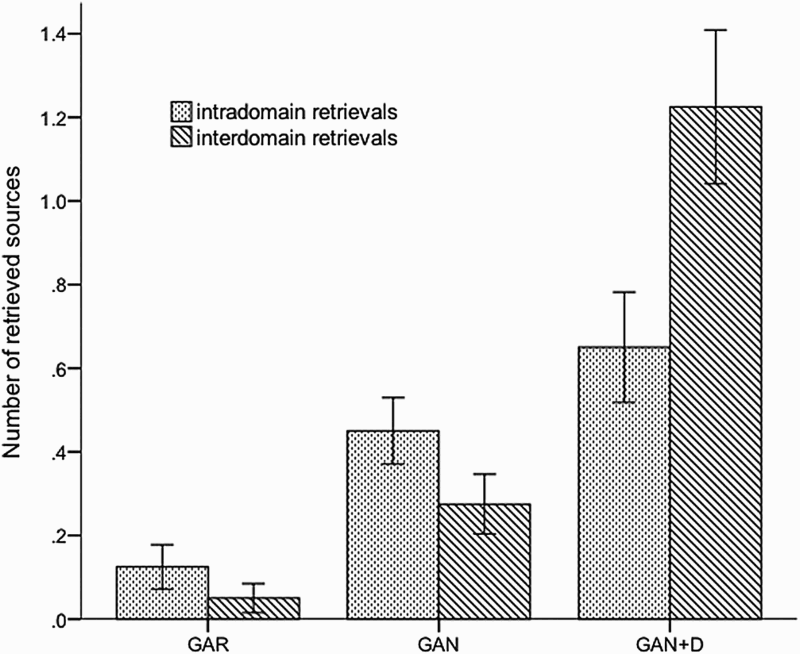
Mean number or retrievals, Experiment 1. GAR = argumentation condition; GAN = analogical argumentation condition; GAN+D = analogical argumentation with predefined domains condition.
Our second empirical question dealt with whether the search mechanisms underlying voluntary analogical retrieval are invariably set to favour superficially similar situations. Judges’ analysis of the analogical proposals reported by the GAN showed that 62.07% of the retrieved sources were semantically similar to the target, and 37.93% of the retrieved sources were semantically dissimilar from the target. In contrast with this standard pattern of retrievals, judges’ analysis of the analogies generated by the GAN+D showed that whereas 34.67% of the retrieved sources came from the same domain of the target, 65.33% of the retrieved sources were interdomain, a result that goes against the superficial bias typically obtained in the experimental literature on analogical retrieval, and that aligns well with results from naturalistic studies. This increase in the number of interdomain retrievals thus suggests that participants can strategically favour the retrieval of interdomain sources.
An intriguing question raised by the possibility of shifting search away from the target domain concerns whether the increased number of distant matches comes at the expense of missing a number of intradomain sources that would be retrieved under a non-strategically-oriented search, as a “shift of focus” metaphor might suggest. A comparison between the GAN and the GAN+D in terms of the mean number of superficially similar and superficially dissimilar base analogues showed that whereas the mean number of distant sources generated by the GAN+D (M = 1.23, SD = 1.17) clearly surpassed the mean number of distant sources retrieved by the GAN (M = 0.28, SD = 0.45), t(50.48) = 4.806, p < .001, participants of GAN+D did not retrieve a lesser amount of superficially similar sources than participants of the GAN (M = 0.65, SD = 0.83, vs. M = 0.45, SD = 0.50, respectively), t(64.14) = 1.299, p > .05. Rather than simply shifting the focus towards interdomain retrieval, it seems that participants of the GAN+D are broadening the scope of their search, an operation that boosts access to distant analogues while still retaining baseline levels of intradomain analogizing.
A second relevant question raised by the possibility of shifting search away from the target domain concerns whether the increased number of distant matches was obtained at the expense of relaxing the demands of structural similarity between the target and the sources. Judges’ scores of structural similarity revealed that the quality of the distant analogies reported by participants of the GAN+D did not differ from the quality of the distant analogies reported by the GAN (M = 4.63, SD = 0.29, vs. M = 4.73, SD = 0.41, respectively), U = 100.00, p > .05. This result confirms that the increase in distant retrievals in the GAN+D was originated in a more efficient retrieval of sources and not in a more lenient control of structural similarity.
In view of the observed success of the GAN+D in retrieving distant analogues, an interesting question concerns the extent to which the cognitive system can bootstrap its own resources in the service of interdomain analogizing—that is, whether a reasonable increase in the number of interdomain retrievals can still be obtained without providing participants with a set of promising domains within which to search for useful base analogues. In Experiment 2 we tested this possibility by comparing the analogical argumentation condition (i.e., the former GAN) against a prointerdomain argumentation condition in which participants were asked to come up with interdomain analogies, but without receiving a set of predefined search areas (GANint).
Experiment 2
Method
Participants and design
Eighty students from University of Comahue (mean age = 20.71 years, SD = 2.05) volunteered to participate in the experiment. An equal number of participants were randomly assigned to the GAN and the GANint.
Materials and procedure
The materials and procedure applied to the GAN were identical to those of the GAN of Experiment 1. The materials and procedure employed with the GANint were similar to those of the GAN with the sole difference that participants were asked to base their analogies on episodes pertaining to domains different from that of the target (i.e., economy). Data analysis was identical to that of Experiment 1, with judges’ agreement reaching 85% with regards to the analogical status of proposals and 96% regarding their intra/interdomain nature.
Results and discussion
Across conditions, participants proposed a mean of 1.71 responses (SD = 1.24), out of which 54.74% were rendered analogical by the judges. Collapsing across groups, 76% of analogical proposals were included in the proper argumentation task, and 24% during the later prompt to report other situations that were remembered during the argumentation activity.
The main objective of Experiment 2 was to assess whether a significant increase in interdomain retrieval could still be obtained without providing participants with a set of interdomain search areas to look for analogous situations. Whereas the analogies proposed by the GAN were 62.5% intradomain and 37.5% interdomain, the analogies proposed by the GANint were 39.53% intradomain and 60.47% interdomain. Though not as strong as in Experiment 1, this reversal demonstrates that participants can voluntarily alter the superficial bias classically obtained in experiments of analogical retrieval with the mere intention to search for thematically distant sources in LTM (see Figure 2).
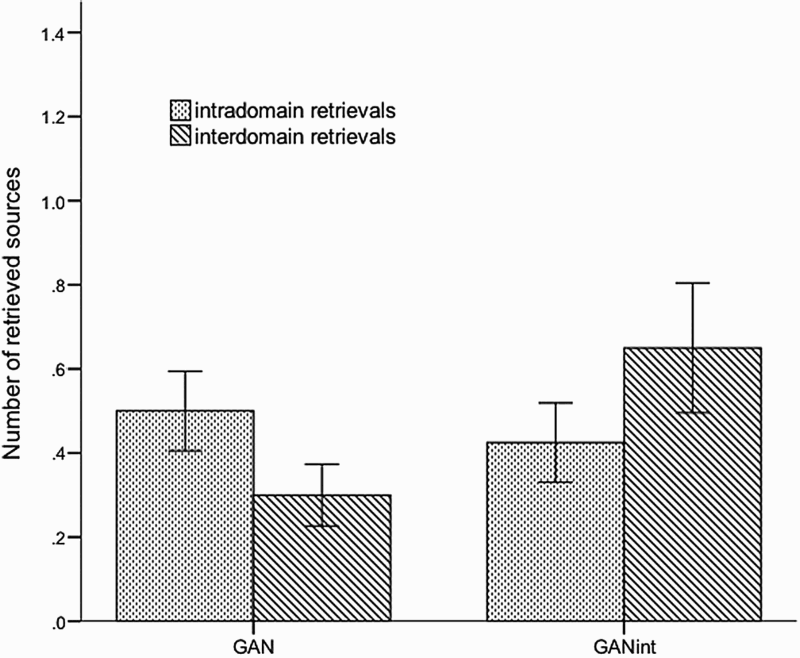
Mean number or retrievals, Experiment 2. GAN = analogical argumentation condition; GANint = prointerdomain argumentation condition.
As in Experiment 1, the augmented proportion of interdomain retrievals in the prointerdomain condition was not obtained at the expense of missing a number of intradomain retrievals. A comparison between the GAN and the GANint in terms of the mean number of close and distant retrievals showed that whereas the GANint clearly surpassed the GAN in the number of interdomain retrievals (M = 0.65, SD = 0.98 vs. M = 0.30, SD = 0.46), t(55.80) = 2.05, p < .05, both groups retrieved similar amounts of intradomain sources (M = 0.43, SD = 0.59 vs. M = 0.50, SD = 0.60, respectively), t(78) = 0.562, p > .05. Once again, it seems that a strategic search for interdomain sources can powerfully boost access to distant analogues, while still retaining baseline levels of intradomain retrieval.
Also as in Experiment 1, the quality of the distant analogies reported by participants of the prointerdomain condition did not differ from the quality of the distant analogies reported by participants of the GAN (M = 4.79, SD = 0.20 vs. M = 4.71, SD = 0.50, respectively), U = 81.00 p > .05, thus confirming that the increase in distant retrievals in the GANint was in fact originated in a more efficient retrieval of sources and not in a looser control of structural similarity.
General Discussion
In order to simulate human patterns of analogical retrieval, extant computational models have specified in great detail a number of assumptions about the types of representations and computations implied in retrieving source analogues from LTM. In contrast to this long-lasting preoccupation, their descriptions are ambiguous as to whether the postulated mechanisms are meant to account for the processes of spontaneous reminding, voluntary retrieval, or both. Albeit unsystematic, the available evidence related to eventual differences between spontaneous and voluntary analogical retrieval comes mainly from studies of problem-solving. As those experiments in which participants were asked to think of analogous problems yielded similar results to experiments where participants had to solve a target problem without being hinted to look for analogous situations, it seems that the mere disposition to find a solution to a problem reliably elicits a search for analogous sources in LTM.
The first experiment of the present study tackled two interrelated issues. The first one was concerned with spontaneous analogical retrieval and had to do with whether the activity of generating persuasive arguments can elicit this kind of remindings reliably, as it seems to be the case with problem-solving activities. To this end, we had two groups of participants come up with arguments that could be used to support a given line of action. While one of the groups did not receive any reference about the use of analogies in their arguments, a second group was asked to base their arguments on analogies to known situations. Results showed that when participants are not explicitly asked to base their arguments on analogies to prior situations, this activity seldom occurs spontaneously. In light of the performance of the group that was explicitly asked to base their arguments on analogies to known situations, the low level of spontaneous retrieval obtained by the group that did not receive this indication cannot be attributed to a lack of available source analogues in LTM. These results have implications for models of analogical retrieval, since they can help specify the activities under which the proposed mechanisms seem to operate. Further studies should determine whether other thoughtful activities like generating hypotheses, explaining concepts to others, or assessing the probability of future events reliably elicit a spontaneous search for base analogues in LTM.
As in most experimental studies of analogical retrieval (e.g., Gentner et al., 1993; Trench & Minervino, 2014), the analogies proposed by participants in the above groups were mostly intradomain. Our second concern dealt with whether participants’ deliberate disposition to search for distant sources can in fact relax the superficial bias typically obtained in experimental studies of analogical retrieval and simulated by the dominant computational models (e.g., MAC/FAC, Forbus et al., 1995; or LISA, Hummel & Holyoak, 1997). To this end, a third group of participants was required to generate analogical arguments for the received target situation, but with the additional instruction to search for base analogues pertaining to four thematic domains provided by the experimenters. In contrast with participants not receiving any indication as to the domains on which to base their analogies, those participants that were provided with a series of distant domains to focus their search retrieved mostly interdomain analogies.
In view of these results, in Experiment 2 we further probed the cognitive system's ability to bootstrap its own resources in the service of interdomain analogizing. As in the previous experiment, we had two groups of participants come up with analogies that could be used to support a given line of action. While one of the groups (similar to the GAN of Experiment 1) was not given any indication as to the domains from which to search for potential source analogues, the second group was simply asked to identify base analogues pertaining to domains different from that of the target situation. Albeit less extreme than the results of the GAN+D of the previous experiment, this simpler and less direct instruction still yielded a majority of interdomain remindings, in sharp contrast to the intradomain pattern exhibited by participants not receiving any indication as to the domain of the intended analogies.
In terms of psychological mechanisms, we speculate that the increase in interdomain retrievals obtained by participants of the GAN+D and the GANint might be due, in part, to a process of late analogical abstraction (Gentner, Loewenstein, Thompson, & Forbus, 2009). According to Gentner et al. (2009), the remotion of surface information from the WM probe to be used for retrieval can increase the retrieval of distant analogues by way of reducing the competition exerted by nonanalogical surface matches that would tend to be evoked by virtue of their surface overlap with the original (unabstracted) target. It seems likely that the very task of looking for interdomain analogies promotes a remotion of surface features from the memory cue to be used for retrieval, in favour of more general descriptors (e.g., “a little problem”). However, the fact that the number of interdomain retrievals was higher in the GAN+D of Experiment 1 than in the GANint of Experiment 2 suggests that this process of late analogical abstraction cannot be the sole explanation, since the advantage of abstracting away surface information from the target representation seems to be as useful for searching within a particular domain as for searching for interdomain sources more broadly. In both cases, the inclusion of surface information about the target in the memory probe seems equally inconvenient. In light of the observed differences between these conditions, we conjecture that participants of the GAN+D and the GANint are coping with the strategic retrieval tasks that were assigned to them by using domain tags in order to concentrate search on a partition of LTM, somewhat akin to the “search area effect” obtained by Ripoll (1998) during a traditional problem-solving activity. Prima facie, we envision two ways in which this highlighting of particular regions of LTM can take place: one of them more parallel, and the other one more serial. Consistent with established models like MAC/FAC or LISA, the first possibility would consist in loading the WM probe with concepts pertaining to the particular domain within which search is to be circumscribed (e.g., “sports”) and having massive inexpensive matchers (e.g., the MAC stage of MAC/FAC or the bottom-up responding to the semantic primitives of LISA) run in parallel across the whole of LTM. According to the second possibility, and upon strategically selecting a specific domain within which to focus search, the reasoner sequentially loads WM with specific situations pertaining to such domain (e.g., sports-related problems that the reasoner has experienced) and carries out a full-fledged structural comparison between the target situation and each of the evoked representations until an analogical match is found, or else iterates this process within other domains that she regards as promising. Any of these two processes would operate in a deeper and more systematic way under the conditions of the GAN+D of Experiment 1, in which participants were given a set of domains to focus search, than in the more open-ended interdomain instruction of Experiment 2. Future studies should attempt to determine which of these processes makes a larger contribution to strategic analogical retrieval. In any case, the fact that participants of the prointerdomain conditions of both experiments still retrieved a significant number of intradomain matches suggests that strategic search can be somewhat demanding, leading to recurrent cycles of nonstrategic retrieval attempts.
Albeit never implemented, the developers of MAC/FAC left open the possibility of relaxing its superficial bias either by suspending FAC's computation of object attributes, or by having the system run on a subset of LTM selected via mechanisms of spreading-activation or indexing. Given the strong superficial constraints imposed by the MAC stage, it seems that only by running on a subset of LTM (e.g., on a subset defined by thematic search areas or domains) the program might have a chance of obtaining the pattern of interdomain analogizing elicited during strategic analogical retrieval.
The present results bear some implications for the debate around the adaptive nature of the mechanisms underlying analogical retrieval. The failure of classic studies like Gick and Holyoak (1980) or Keane (1987) to elicit interdomain retrieval typically elicits a mixture of astonishment and concern. As eloquently expressed by Gentner et al. (1993, p. 567): “How can the human mind, at times so elegant and rigorous, be limited to this primitive retrieval mechanism?” According to an evolutionary account, memory retrieval is an older achievement than the types of relational reasoning afforded by the human prefrontal cortex, and is thus incapable of computing a fully-fledged structural match between the target and every representation in LTM. However, the negative implications of basing retrieval upon surface resemblances might have been overstated, partly as a consequence of regarding surface similarities as being inherently inconsequential. According to the kind world hypothesis (Gentner & Medina, 1998), in the world we live in, the types of surface similarities that people follow are rarely, if ever, causally irrelevant. Taking our own materials as an example, when participants in our GAN inadvertently include target concepts like debt or money in the memory probe that will be used for retrieval, the favoured base analogues are likely to be more similar to the target not only at the level of explicitly represented systems of relations (e.g., two cases where postponing the cancellation of a debt renders its future cancellation more problematic), but also at deeper levels that might not be explicitly represented in the analogizer's memory, or that might not be represented at all (e.g., the fact that in both situations the problem involves a debt implies that in both cases the growing function of the problems is geometric). Under these considerations, many theorists have argued that the way in which we handle mundane situations like those represented by our materials is not severely hindered by a rigid and hard-wired bias towards retrieving semantically related situations, as implemented in computer models like LISA or MAC/FAC. According to this widely shared view, the limitations of a fixed surface bias of the kind implemented in LISA and MAC/FAC would only become apparent within a very narrow category of situations, such as when scientists need to acknowledge that the same abstract principle cuts across disparate situations having non-overlapping surface features.
Contra the assumption of rigidity embraced by most theoretical accounts of analogical reasoning, some authors have contended that the cognitive system can circumvent the superficial constraints of the memory mechanisms to some extent (Loewenstein, 2010). In line with the proposal, the striking contrast between the analogies proposed by our GAN and those proposed by the GAN+D and the GANint suggests that the surface bias of human retrieval mechanisms can be tuned to some extent. On this alternative account, the preference for surface matches could be considered a default, rather than a fixed criterion. Just as in classic theories of problem solving, which recommend resorting to general heuristics only when more specific procedures are not at hand, we suggest that the proficient analogizer begins by including surface information about the target in the WM probe that will be used for retrieval, and opts for removing target-specific information and/or highlighting potential search domains only if more inferentially powerful intradomain sources do not come to mind.
This majority of interdomain retrievals in the prointerdomain conditions of Experiments 1 and 2 also suggests an alternative explanation of the analogical paradox (Dunbar, 2001)—that is, the fact that interdomain retrievals are rare in experimental settings but common in naturalistic activities. By stressing the potential of voluntary retrieval to focus search away from the target domain, the present results suggest that at least a portion of the interdomain analogizing observed in naturalistic settings might originate in people's deliberate intention to seek for interdomain sources under specific circumstances—for example, when the reasoner presumes that base analogues pertaining to domains that are generally familiar to the recipients of the analogy (e.g., soccer) will be better understood.
The present results on voluntary and strategic analogical retrieval also suggest important instructional applications. Until recently, instructional efforts to circumvent the limitations of the memory systems—sometimes called “the problem of inert knowledge” in educational environments— were aimed at promoting an abstract encoding of the base analogues, so as to render them more accessible during later encounters with analogous situations lacking surface similarities. Successful interventions included presenting the base analogue together with its abstract schema (Goldstone & Wilensky, 2008) or with an analogous situation (Catrambone & Holyoak, 1989) and asking participants to compare them. More stripped-down—but still successful—interventions included asking participants to discuss the base analogue with another student (Schwartz, 1995), asking participants to discuss it with themselves (Ahn, Brewer, & Mooney, 1992), removing irrelevant information from the base analogues (Goldstone & Son, 2005), and even replacing domain-specific terms of the base situation with domain-general ones (e.g., replacing “typing” by “writing”, Clement, Mawby, & Giles, 1994). In recent times, the emphasis started to shift from improving the representation of the base analogues during their initial learning to improving the encoding of target situations at retrieval time (i.e., late analogical abstraction). For example, by providing participants with two isomorphic target analogues and asking them to compare such problems prior to attempting their solution, Kurtz and Loewenstein (2007) and Gentner et al. (2009) were able to increase the probabilities of retrieving superficially dissimilar base analogues from memory. As Loewenstein (2010) points out, the appeal of this approach lies in its potential to foster the retrieval of situations that might have been encoded in suboptimal ways. However, a practical limitation of the target-comparison method that hinders its applicability to educational contents acquired during past schooling lies in the fact that learners will need to be provided with a second analogous problem for every new problem they are to solve. The results of the present study suggest some straightforward ways of increasing the accessibility of distant sources at retrieval time, but in ways that are not subject to these applicability limitations. On the one hand, the results arising from our distinction between spontaneous and voluntary analogical retrieval suggest that the mere indication to search for analogous situations increases retrieval probabilities significantly, and without providing participants with any kind of target-specific information. Regarding the distinction between strategic and a nonstrategic forms of voluntary retrieval, our results also suggest some straightforward and portable ways of boosting access to semantically distant sources. Even though participants of our GAN+D were still provided with target-specific information (a set of promising search domains), the GANint of our second experiment retrieved mostly interdomain sources with the sole instruction to search within domains different from that of the target—that is, without receiving target-specific information. We believe that the austerity of these interventions opens up encouraging perspectives for the flexible use of analogy in educational environments.