
Abstract
The purpose of this study was to examine the extent to which working memory resources are recruited during statistical learning (SL). Participants were asked to identify novel words in an artificial speech stream where the transitional probabilities between syllables provided the only segmentation cue. Experiments 1 and 2 demonstrated that segmentation performance improved when the speech rate was slowed down, suggesting that SL is supported by some form of active processing or maintenance mechanism that operates more effectively under slower presentation rates. In Experiment 3 we investigated the nature of this mechanism by asking participants to perform a two-back task while listening to the speech stream. Half of the participants performed a two-back rhyme task designed to engage phonological processing, whereas the other half performed a comparable two-back task on un-nameable visual shapes. It was hypothesized that if SL is dependent only upon domain-specific processes (i.e., phonological rehearsal), the rhyme task should impair speech segmentation performance more than the shape task. However, the two loads were equally disruptive to learning, as they both eradicated the benefit provided by the slow rate. These results suggest that SL is supported by working-memory processes that rely on domain-general resources.
Research on language acquisition has shown that novice learners are able to use statistical regularities in the signal to extract new words from a continuous speech stream (Saffran, Aslin, & Newport, 1996). Statistical learning (SL) is considered one of the most rudimentary forms of learning, which appears equally robust in adults and children (Saffran, Newport, Aslin, Tunick, & Barrueco, 1997), and which can occur without intention to learn (Fernandes, Kolinsky, & Ventura, 2010) and without explicit knowledge of what has been learned (Kim, Seitz, Feenstra, & Shams, 2009). As such, it is commonly described as an implicit and automatic learning mechanism, in which passive exposure to the speech stream is sufficient to elicit learning. More recently, however, a number of studies have shown that statistical learning is disrupted when attention is divided (Fernandes et al., 2010; Toro, Sinnett, & Soto-Faraco, 2005) or directed to an irrelevant stream (e.g., Emberson, Conway, & Christiansen, 2011; Turk-Browne, Junge, & Scholl, 2005). This suggests that SL may be resource demanding, but the nature of the resources involved is unknown.
In this study, we investigated whether working memory plays a part in SL and, if so, whether the disruptions mentioned above could be accounted for by a depletion of working memory resources. Working memory is usually described as the system that temporarily holds, maintains, and manipulates information required to perform complex cognitive operations such as comprehension and learning (Baddeley, 1992). Within the working memory framework, it is often assumed that language acquisition is supported by the phonological loop, a domain-specific subcomponent specialized in the maintenance and acquisition of sequenced information (Baddeley & Hitch, 1974; Baddeley, Papagno, & Vallar, 1988; Ellis & Sinclair, 1996; Gathercole & Baddeley, 1990). Indeed, there is considerable evidence showing that phonological memory span predicts the learning trajectory during first- and second-language acquisition, and that both vocabulary learning and the acquisition of grammatical rules are disrupted by tasks that block articulatory rehearsal within the phonological loop (e.g., Ellis & Sinclair, 1996). Given that speech segmentation via SL involves tracking sequential regularities that unfold over time, it is possible that SL, too, is supported by the rehearsal of syllable combinations within the phonological loop. Evidence consistent with this proposal was recently reported by Lopez-Barroso et al. (2011) who demonstrated that speech segmentation is impaired by articulatory suppression (repeatedly uttering “blah” as the speech stream is playing), but not by irrelevant speech (repeatedly hearing “blah” as the speech stream is playing). Since only the former is thought to interfere with phonological rehearsal, this result indicates that rehearsal may play an important role in speech segmentation.
We reasoned that if SL is supported by an active maintenance mechanism (such as phonological rehearsal), then speech segmentation performance should improve when the rate is slow compared to when it is faster. Specifically, given that information held in working memory is subject to decay and interference, a slower presentation rate should improve learning performance because it would allow more time for sequences to be rehearsed before being displaced by incoming information. On the other hand, if working memory does not contribute much to SL, then slowing down the speech rate should have little effect on learning. In fact, it is possible that speeding up rather than slowing down the speech rate would benefit learning, because it would reduce the time between sequence repetitions, allowing less opportunity for memory traces to decay before the statistical regularities are registered (cf. Baddeley & Lewis, 1984). Furthermore, as argued by Emberson et al. (2011), slowing down the speech rate might weaken auditory grouping cues, decreasing the likelihood that participants will form perceptual units between elements in the stream. The effect of speech rate on word segmentation was investigated in Experiments 1 and 2.
Experiment 3 explored the nature of the working memory resources recruited during SL by examining the effect of processing load on speech segmentation performance. Two different types of load were used: One was designed to engage phonological processing (a two-back rhyme task) whereas the other one was purely visual (a two-back shape matching task). It was hypothesized that if SL depends only on domain-specific processes within working memory (i.e., the phonological loop), then the phonological load should cause greater disruption to learning than the nonphonological load. On the other hand, if SL recruits domain-general resources, both load types should be equally disruptive. Importantly, if SL is actively supported by working memory operations, then any detrimental effects of cognitive load should be largest when the contribution of working memory processes is greatest—that is, in the slow speech rate condition.
Experiment 1
Method
Participants
Seventy-two native British English speakers from the University of York participated in the experiment in return for either an honorarium or course credit. All participants had normal or corrected vision and had no known hearing impairment.
Stimuli
For the familiarization phase, two artificial speech streams were created. Each stream was made up of four trisyllabic nonwords taken from Saffran et al. (1996; Stream 1: pabiku, tibudo, daropi, golatu; Stream 2: tudaro, bikuti, budopa, pigola). Although the pool of syllables was identical between the two streams, they differed in how the syllables were assembled into words, which was meant to minimize the phonological and phonotactic idiosyncrasies inherent to each stream. Within each stream, the four words were concatenated in a pseudorandom order, which ensured that there were no immediate word repetitions. Each word was played 125 times, for a total of 500 words for each stream. The transitional probability between the syllables forming a word was 1.00, and the transitional probability between syllables spanning word boundaries was .33. The streams were synthesized using the text-to-speech MBROLA software (Dutoit, Pagel, Pierret, Bataille, & Van der Vrecken, 1996) with an English male diphone database. Synthesis ensured that there were no acoustic segmentation cues within the speech streams (i.e., within- and between-word syllables were equally coarticulated) and that the main cues for inferring word boundaries were the relative between-syllable transitional probabilities within and across words.
Each stream was generated at three speech rates. The fast, normal, and slow rates were 7.45, 4.17, and 2.27 syllables per second, respectively. Accordingly, the total duration of the stream was 3 min 20 s, 6 min, and 10 min 50 s, respectively. The normal rate was comparable to the standard speech rate in SL studies using consonant–vowel syllables. The fast speaking rate corresponds roughly to a slightly faster than average conversational speech rate and the slow speech rate to a slightly slower than average clear-speech or infant-directed speech rate. Note, however, that direct comparisons with natural speech are difficult to make because speech rate is often calculated based on the number of words rather than syllables per unit of time, and, when a count per syllable is provided, syllables are seldom restricted to a simple consonant–vowel structure.
Design and procedure
Participants were randomly assigned to one of the three speech rate conditions (fast vs. normal vs. slow), with 24 participants per condition. Within each rate condition, half of the participants heard Stream 1, and the other half heard Stream 2. All participants completed a familiarization phase, immediately followed by a recognition test. The experiment took place in a sound-attenuated booth, and the speech streams were played over Sony MDR V700 headphones at approximately 70 dB SPL. DMDX display software (Forster & Forster, 2003) was used for presenting stimuli and recording responses.
Familiarization phase
During the familiarization phase, participants were told that they would hear an artificial alien language played over the headphones and that they should try to discover what the words of the language were.
Recognition test
The recognition test was an auditory two-alternative forced-choice task composed of 24 pairs. Within each pair, one stimulus was always one of the four trisyllabic words that had been presented during the familiarization phase. The other stimulus was one of three types of trisyllabic foil words. The first type of foil overlapped with the paired word by two syllables. These were formed by concatenating the second and third syllables of the target word with the first syllable of another word. The second type of foil overlapped with the target by one syllable, and these were formed by concatenating the third syllable of the target word with the first two syllables of another word. The third type of foil did not overlap with the target at all and was formed by concatenating syllables from the other three words. By design, some of the first two types of foil were the words of the other streams. The third type of foil was used in the recognition phase of both streams. The order in which the target and the foil were presented within a pair was counterbalanced within participants. The two members of a pair were separated by a 500-ms silent interval. Test stimuli were presented at the same rate as the speech stream that the participant heard during familiarization. Participants were asked to judge which trisyllable was a word of the artificial language using the left or right shift key for the first or second trisyllable of the pair, respectively. The next pair was presented 1 s following the response, or after a 10-s deadline.
Intelligibility testing for speech rates
In order to verify that any differences in the learning outcome associated with the different speech rates could not be attributed to differences in intelligibility, an intelligibility test was conducted for each of the three speech rates. Sixty participants heard the 20 trisyllabic stimuli used in the test phases of the main experiment played one at a time. Twenty participants heard them at each of the three speech rates. Each nonword was played twice, and participants were asked to type what they had heard. Their responses were scored manually by calculating the proportion of consonants and vowels transcribed accurately. To be coded as correct, a response had to be the target phoneme exactly. Small deviations (e.g., voicing, tenseness) were coded as incorrect. Decisions regarding spelling deviations from the original nonword were made with reference to the British Council's Phonemic Chart (British Council, 2010).
Mean transcription accuracy for consonants and vowels at each of the three speech rates
Note: Standard deviations in parentheses.
Results and discussion
One participant was discarded from the analyses because their performance in the recognition task was more than two standard deviations below the mean of the condition to which they were assigned.
The mean accuracy rate in the recognition task averaged across streams and types of foils is shown in Figure 1 for each of the three speech rates. The data were analysed using mixed-effects logistic regression models because these allowed us to consider raw data rather than subject averages, which improves the estimates of source of variance and the accuracy of model comparisons across experiments. Stream rate was the only fixed factor in these analyses, with fast, normal, and slow rates coded −1, 0, and 1, respectively. The random structure included intercepts by participant, by item, and by stream (i.e., Stream 1 vs. Stream 2). Streams were coded as −1 and 1. The effect of stream rate on performance was assessed by using the likelihood ratio test to compare a base model that only included the random structure with a model that included the fixed factor stream rate. Data fit was significantly better when stream rate was added, β = .446, SE = .101, χ2(1) = 16.92, p < .001. Participants in the slow rate condition performed significantly better than those in both the fast, β = .438, SE = .104, χ2(1) = 14.766, p < .001, and the normal rate conditions, β = .417, SE = .198, χ2(1) = 4.11, p = .04. Participants in the normal rate condition performed better than those in the fast rate condition, β = .482, SE = .190, χ2(1) = 6.012, p = .012.
Mean proportion of correct responses in the fast, normal, and slow speech rate conditions under no load (Experiments 1 and 2), and rhyme and shape load (Experiment 3). Error bars represent the standard error of the mean.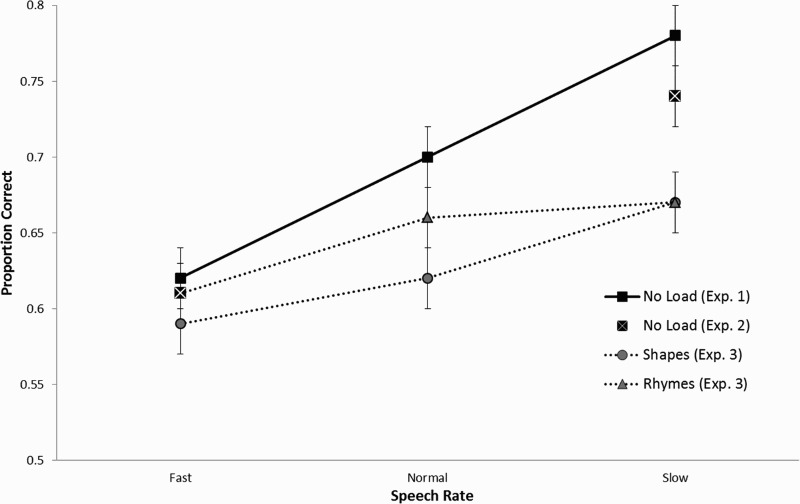
The intercept of each of the three conditions reached significance (all ps < .01), indicating that performance was better than chance (.50) in each of the three rates. However, it should be noted that, as in many SL experiments, significant departure from chance should not be taken as absolute evidence for statistical learning. Indeed, the fact that the streams were made of words of a single length could mean that a form of rhythmic chunking could have partly contributed to learning (see, e.g., Tyler & Cutler, 2009, for an example of an alternative design). Note also that in the test phase, each word was paired with three types of foils. Given that the test was identical in each of the rate conditions, this test design enables us to reliably assess differences in SL performance across conditions, but it is less optimal for establishing the absolute level of SL in any one condition, since the possibility that some learning occurred during the test cannot be ruled out. Thus, we are not necessarily claiming that .50 represents a true reference for statistical learning.
Taken together, the results clearly show that slowing down the speech rate had a beneficial effect on segmentation performance. This finding is consistent with the premise that SL is actively supported by a working-memory maintenance process, such as phonological rehearsal, which operates more effectively when the speech rate is slow. However, because we kept the number of words constant across the three stream rates, speeding up and slowing down the stream led to shorter and longer exposure times, respectively. Thus, the design in Experiment 1 confounded rate and duration. In order to test whether the duration of exposure could account for the rate effect, a second experiment was run in which the duration of exposure was kept constant across stream rates.
Experiment 2
Method
Participants
Thirty-six native British English speakers participated in Experiment 2. These participants were drawn from the same population as those in Experiment 1.
Stimuli
The stimuli consisted of the fast and slow speech streams used in Experiment 1. This time, however, the duration of both stream rates was fixed at 6 minutes, which was the duration of the normal rate condition in Experiment 1. This involved adding repetitions of the artificial words to the fast stream and shortening the slow stream. Care was taken to ensure that each of the four words within a stream was still presented an equal number of times. Equating stream duration meant that participants listening to the fast stream had a greater number of exposures to the novel words than those listening to the slow speech rate. In the fast rate streams, each word was played 224 times, and so there were a total of 896 words in the stream. In the slow rate condition, each word was played 68 times, and there were a total of 272.
Design and procedure
Participants were assigned to one of the two rates (fast vs. slow) randomly, with 18 in each condition. As in Experiment 1, half of the participants in each condition were exposed to Stream 1, and the other half to Stream 2. The familiarization phase and the recognition test were identical to those of Experiment 1.
Results and discussion
One participant was discarded from the analysis because their performance in the recognition task was more than two standard deviations below the mean of the condition to which they were assigned. The mean accuracy rate in the recognition task for each of the two speech rates is shown in Figure 1. As in Experiment 1, the data were analysed using mixed-effects logistic regression models with stream rate as the fixed factor (coded −1 vs. 1, for fast and slow, respectively) and participants, items, and streams as random intercepts. Model comparison showed that participants were significantly more accurate in the slow rate condition than in the fast rate condition, β = −.326, SE = .081, χ2(1) = 13.15, p < .001. The intercept of both rate conditions reached significance (both ps < .01), suggesting above-chance performance.
These data were then compared to those in Experiment 1. Within the fast rate condition, participants who heard the stream for 6 minutes (Experiment 2) performed at the same level as those who heard the stream for only 3.20 minutes (Experiment 1), β = −.046, SE = .092, χ2(1) = 0.25, p = .616. Similarly, within the slow rate condition, participants who heard the stream for 6 minutes (Experiment 2) performed at the same level as those who heard the stream for 10.50 minutes (Experiment 1), β = −.109, SE = .090, χ2(1) = 1.42, p = .23.
Thus, when the speech streams were matched for total duration, participants continued to perform better in the slow rate condition, even though the number of exposures to each word was smaller than in the fast rate condition. These results indicate that the improvement in SL associated with slowing down the speech rate cannot be attributed to the fact that participants heard more repetitions of the stimuli. This reinforces the conclusion that it is processing time (i.e., rate) rather than amount of exposure per se that drives SL performance.
Experiment 3
The finding that processing time constrains SL indicates that the stimuli are likely to undergo some form of active processing or maintenance within working memory. As outlined in the introduction, one possibility is that relevant syllable sequences are rehearsed in the phonological loop, a domain-specific subcomponent of working memory that is thought to have evolved specifically for the purpose of language acquisition (Baddeley, Gathercole, & Papagno, 1998). From this perspective, the slower presentation rate would provide more opportunity for rehearsal, and any secondary task that draws upon phonological resources would mitigate this improvement.
However, an alternative possibility is that SL draws upon domain-general resources within working memory. For example, according to the time-based resource sharing (TBRS) model (Barrouillet, Bernardin, & Camos, 2004; Barrouillet, Bernardin, Portrat, Vergauwe, & Camos, 2007), central attention is required to maintain information in working memory by reactivating or “refreshing” the memory trace. Under this conceptualization, a memory trace stays “active” only as long as it remains under the focus of attention. The trace begins to decay when attention is diverted away from it (by another task, for example), but can be “refreshed” once attention is regained. Like phonological rehearsal, attentional refreshing should operate more effectively when the speech rate is slowed down, because there is more time for information held in working memory to be refreshed before being displaced by incoming information.
If SL recruits domain-general resources within working memory, then any secondary task that engages central processing resources should have a detrimental effect on SL, regardless of whether or not it involves phonological processing. Some evidence consistent with this view has come from studies showing that speech segmentation via SL is significantly reduced (Fernandes et al., 2010) or even eliminated (Toro et al., 2005) when participants’ attention is diverted towards a visual shape-monitoring task during exposure to the speech stream. However, because the visual stimuli used in these studies included nameable images, it is unclear whether the visual task disrupted learning because subvocal naming of the images engaged the phonological loop, or because SL is dependent upon amodal resources that were depleted by the visual task.
These two alternatives were tested in Experiment 3, which examined the effect of processing load on SL. The procedure was the same as that in Experiment 1, but with the addition of cognitive load during the familiarization phase. The cognitive load consisted of a two-back task that was either phonological (rhyme identification) or nonphonological (visual shape matching). Critically, however, the visual stimuli used in this experiment were novel shapes devoid of names or obvious meaning. It was hypothesized that if SL relies upon domain-specific resources, then only the phonological load should disrupt segmentation performance. On the other hand, if SL recruits domain-general resources, then both loads should disrupt learning. Finally, if the two-back task consumes working memory resources required for SL, then any detrimental effects of cognitive load should be largest under the slowest speech rate, where the contribution of working memory processes is presumed to be greatest.
Method
Participants
One hundred and thirty-seven native British English speakers participated in Experiment 3. These participants were drawn from the same population as those in Experiments 1 and 2.
Stimuli
The auditory stimuli in Experiment 3 were those used in Experiment 1. In addition, a phonological and a nonphonological two-back task were created. These consisted of rapid serial visual presentations (RSVP) of stimuli displayed concurrently with the speech stream.
For the two-back phonological rhyming task, the stimuli were written monosyllabic nonwords selected from the ARC Nonword Database (Rastle, Harrington, & Coltheart, 2002). All nonwords conformed to the phonotactic constraints of English. Rhyming nonwords only shared their rhyme (e.g., snief, drief). To encourage phonological processing, the nonwords of some rhyming pairs differed in their spelling (e.g., straise, yace). Foil pairs were also included. These consisted of nonrhyming pairs that shared their nucleus (e.g., swease, feame) or their onset and nucleus (e.g., swease, sweake). The total number of nonwords displayed depended on the duration of the speech streams. The fast rate included 269 nonwords, 42 two-back rhyme-pairs, and 21 foil two-back pairs. The normal rate included 481 nonwords, 78 two-back rhyme-pairs, and 37 foil two-back pairs. The slow rate included 864 nonwords, with 140 two-back rhyme-pairs and 68 foil two-back pairs.
For the two-back nonphonological shape-matching task, the stimuli were 86 line drawings taken from Kroll and Potter (1984). These were all novel and meaningless shapes that could not be associated with existing names in long-term memory. Half of the shapes were rotated 30 degrees to the left, and the other half were rotated 30 degrees to the right. The number of two-back shape repetitions was matched to the number of two-back rhyme pairs. The two-back shape repetitions always involved a change in orientation: If the first shape was rotated to the right, then the repetition was rotated to the left, and vice versa. The total number of images used was also the same as the total number of nonwords used in the phonological two-back task for each of the streams.
Design and procedure
The experiment followed a 2 by 3 between-subjects design with load type (phonological vs. nonphonological) and speech rate (fast vs. normal vs. slow) as independent variables. Participants were randomly assigned to one of the six conditions. As before, within each condition, participants were randomly assigned to Stream 1 or Stream 2. The experimental procedure was the same as that in Experiment 1, except that participants were additionally asked to perform a two-back task while listening to the speech stream.
In both the phonological and nonphonological load conditions, visual stimuli were displayed for 500 ms, with an interstimulus interval of 250 ms. In order to keep the load constant across all conditions, these durations were the same across all three speech stream rates. This particular pace was chosen to differ from each of the three stream rates to avoid synchrony between the onset of visual stimuli and the onset of words or syllables. In the phonological condition, participants were instructed to press the space bar every time they saw a nonword that rhymed with the nonword presented two trials before. Participants were informed that rhyming nonwords might not always share their spelling. In the nonphonological condition, participants were instructed to press the space bar every time they saw a shape that was the same as the shape that appeared two trials before. Participants were informed that the shape might have a different orientation on its second appearance.
Results
Six participants were discarded from the data analysis either because their performance in the recognition task was more than two standard deviations below the mean of the condition to which they were assigned (4 participants) or because their false-alarm rate in the two-back task exceeded 10% (2 participants). Note that the mean false-alarm rate in the two-back task was 2%, and the performance of both excluded participants was more than 4 standard deviations above the mean.
Recognition task
Mean accuracy for the recognition task is shown in Figure 1. The data were analysed using mixed effects logistic regression models with load type and stream rate as fixed factors, and participants, items, and streams as random intercepts. Load type was coded as −1 and 1. The fixed factors, as well as their interactions, were added incrementally, starting from a base model that included only the random terms, and improved fit was assessed using the likelihood ratio test. The analyses showed that load type did not significantly affect learning performance, β = .096, SE = .102, χ2(1) = 0.89, p = .35, but speech rate did, β = .150, SE = .060, χ2(1) = 5.89, p = .015. Participants in the slow condition performed significantly better than those in the fast condition, β = .151, SE = .061, χ2(1) = 5.97, p = .015. However, there was no significant difference between the fast and normal rates, β = .184, SE = .117, χ2(1) = 2.46, p = .12, or between the normal and slow rates, β = .130, SE = .127, χ 2 (1) = 1.03, p = .31. The interaction between load type and stream rate was not significant, β = −.057, SE = .122, χ2(1) = 0.22, p = .64. The intercept of each of the six conditions reached significance (all ps < .05), suggesting above-chance performance.
Given that there was no main effect of load type or interaction with stream rate, a second set of analyses was run in which the data were collapsed across load type. In this analysis, the “cognitive load” data from Experiment 3 were compared to the “no load” data from Experiment 1. These analyses showed a main effect of cognitive load, indicating that SL performance was significantly reduced when participants heard the speech stream under conditions of cognitive load, β = −.153, SE = .049, χ2(1) = 9.61, p < .001. As in the previous analyses, there was also a significant main effect of speech rate, β = −.240, SE = .055, χ2(1) = 17.87, p < .001. Importantly, however, there was a significant interaction between cognitive load and speech rate, β = −.141, SE = .057, χ2(1) = 6.15, p = .013, showing that the main effect of stream rate was weaker in the cognitive load condition, β = −.150, SE = .061, χ2(1) = 15.89, p = .015, than in the no-load condition, β = .446, SE = .101, χ2(1) = 16.92, p < .001.
Simple-effect analyses revealed an effect of load in the slow rate condition, β = −.282, SE = .079, χ2(1) = 11.83, p < .001, a marginal effect of load in the normal rate condition, β = −.157, SE = .079, χ2(1) = 3.86, p = .049, and no effect of load in the fast rate condition, β = −.024, SE = .075, χ2(1) = 0.10, p = .75. These results demonstrate that the performance benefit associated with slowing down the speech rate observed in Experiment 1 is curtailed when participants hear the speech stream under conditions of cognitive load. Moreover, given that there was no main effect of load type, the results of Experiment 3 suggest that SL recruits domain-general resources that are depleted under conditions of cognitive load, regardless of whether or not the load involves a phonological component.
Performance in the two-back tasks
In the next analyses, we considered the possibility that the absence of a difference between the two load types could be related to task difficulty. Specifically, it might be argued that the two-back rhyme task did not cause greater disruption to SL than the two-back shape task because the rhyme task was intrinsically easier than the shape task. In order to explore this possibility, performance in the two-back tasks was examined.
Hit rates, false-alarm rates 1
Incorrect responses to nonrepeating stimuli were considered false alarms. The false-alarm rate was calculated as the total number of false alarms divided by the total number of nonrepeating stimuli.
Proportion of hits, false alarms, and d′ scores in the rhyme and the shape condition across the three speech rates

Note: Standard deviations in parentheses.
General Discussion
This study investigated the extent to which speech segmentation by SL engages working memory processes. First, it was hypothesized that if SL is supported by an active processing or maintenance mechanism, then performance should improve when the speech rate is slowed down. Second, we reasoned that if SL involves working memory resources, then the rate effect should be attenuated when these resources are depleted by a concurrent task. The results of Experiment 1 support our first hypothesis, showing that the slower the speech rate, the better the SL performance. This effect was maintained when the speech streams were matched for total duration (Experiment 2), demonstrating that processing time, rather than amount of exposure per se, determines the effectiveness of SL.
In relation to our second hypothesis, Experiment 3 explored the impact of processing load (a concurrent task) on the rate effect. An additional aim of this experiment was to provide an insight into the nature of the resources involved in SL. It was hypothesized that if SL is supported mainly by domain-specific processes (i.e., rehearsal of relevant syllable combinations in the phonological loop), then learning should be disrupted primarily by tasks that engage phonological processing. It was observed, however, that introducing a concurrent task during the exposure phase disrupted SL regardless of whether the task involved phonological processing or nonlinguistic visual processing. Importantly, in both cases, the level of disruption was largest at the slowest speech rate, where the opportunity for working memory processes to contribute to SL was greatest. These results suggest that SL is supported by domain-general processes within working memory. Although they do not rule out the possibility that phonological rehearsal contributes to SL too, the fact that the learning advantage observed under the slower speech was abolished by the nonphonological load suggests that phonological rehearsal is not the only active mechanism supporting SL under the slower speech rates.
It could be argued that the effect of load was caused by the mere presence of the visual stimuli (shapes or nonwords) rather than by the actual processing of these stimuli. However, this is unlikely because Toro et al. (2005) have already shown that the passive presentation of load stimuli leads to SL performance levels comparable to those of standard no-load studies (between 65% and 70%) and, more importantly, that such performance levels are substantially higher than those when a task on those stimuli is required. Therefore, we can be confident that our pattern of results under CL was due to the tasks required on the visual stimuli rather than to the mere presence of these stimuli.
The precise manner in which domain-general resources contribute to SL is unclear at this stage, but at least two possibilities can be considered. First, it could be the case that central attention is required to maintain relevant syllable combinations in working memory via a process of attentional refreshing (Barrouillet et al., 2004; Barrouillet et al., 2007). According to clustering models of SL (e.g., Frank, Goldwater, Griffiths, & Tenenbaum, 2010; Perruchet & Vinter, 1998), learners store clusters of syllables that frequently co-occur in the speech stream. Without active “refreshing”, stored sequences may be lost due to decay or interference from subsequent exposure to overlapping syllable sequences, such that the sequence repetitions would not be registered. One of the more prominent clustering models, PARSER (Perruchet & Vinter, 1998), assumes that syllable sequences are passively reactivated by their repeated occurrence within the speech stream. From this perspective, one might predict that slowing down the speech rate would have a detrimental effect on learning because it increases the time-lag between sequence repetitions, allowing more time for decay. In contrast, our finding that a slower speech rate is beneficial to learning is consistent with the idea that learning is supported by an active maintenance mechanism. Attentional refreshing may be more effective when the stimulus presentation rate is slow because there is more time for stored representations to be refreshed before they are displaced by incoming information. However, under conditions of cognitive load, the concurrent task consumes resources required for attentional refreshing such that the performance benefit associated with slowing down the speech rate is mitigated.
A second possibility is that SL recruits domain-general resources to actively update the content of working memory. Assuming that the speech stream is initially segmented randomly (as proposed by clustering models such as PARSER), an active updating mechanism may correct erroneous syllable groupings. For example, at an initial stage, the words “pabiku” and “tibudo” concatenated as “pabikutibudo” could lead to “bikuti” being stored as a potential word candidate. As the stream progresses and listeners repeatedly hear “pabiku”, they may update “bikuti” either by removing it from the memory set entirely and adding “pabiku”, or by performing a partial update in which “ti” is dropped from the end of the sequence, and “pa” is added to the beginning. Updating could also involve integrating syllables initially stored as separate representations (e.g., replacing “pa” and “biku” with the single representation “pabiku”). Since performance in the N-back task is heavily dependent on memory updating, it is possible that this task consumes the executive resources required to actively update representations stored from the speech stream.
At first sight, the idea that working memory actively supports SL might appear to contradict the assumption that SL is an implicit learning mechanism. While the data reported here do not enable us to assess the role of consciousness in SL, there are a few points worth noting. First, Fernandes et al. (2010) reported that SL is disrupted by attentional load independently of whether or not participants are instructed to actively search for words in the speech stream (i.e., with or without “intention” to learn). Along with earlier findings by Pacton and Perruchet (2008), this indicates that even incidental learning is dependent on attentional resources. Second, although some have argued that all working memory operations are conscious (e.g., Baars & Franklin, 2003), recent evidence suggests that some working memory processes (including the active maintenance of ordered information and context relevant updating) can be recruited without conscious awareness or intent (Hassin, Bargh, Engell, & McCulloch, 2009). This suggests that participants may not need to be engaged in active learning for working memory processes to contribute to SL, provided that attention is focused on the speech stream. Finally, it is worth noting that while SL occurs under both intentional and unintentional learning conditions, it is significantly reduced under the latter (Fernandes et al., 2010; Perruchet & Vinter, 1998). In fact, Perruchet and Vinter (1998) noted that under unintentional learning, SL performance drops from 76% to 59%. The latter figure is comparable to that in our study where working memory processes are expected to contribute least (i.e., fast speech rate under cognitive load). Therefore it could be the case that working memory operations support, but are not required for, SL.
In sum, the data presented here are consistent with previous studies showing that divided attention impairs SL (e.g., Fernandes et al., 2010; Toro et al., 2005). They extend these findings by showing that: (a) SL depends upon domain-general resources, and (b) these resources are recruited for a time-dependent process that operates more effectively when the stimulus presentation rate is slowed down. These results are consistent with the hypothesis that SL is supported by active processes within working memory, which might include attentional refreshing or working memory updating. The precise nature of their involvement remains to be further specified.