
Abstract
We explored the nature of focal versus nonfocal event-based prospective memory retrieval. In the context of a lexical decision task, people received an intention to respond to a single word (focal) in one condition and to a category label (nonfocal) for the other condition. Participants experienced both conditions, and their order was manipulated. The focal instruction condition was a single word presented multiple times. In Experiment 1, the stimuli in the nonfocal condition were different exemplars from a category, each presented once. In the nonfocal condition retrieval was poorer and reaction times were slower during the ongoing task as compared to the focal condition, replicating prior findings. In Experiment 2, the stimulus in the nonfocal condition was a single category exemplar repeated multiple times. When this single-exemplar nonfocal condition followed in time the single-item focal condition, focal versus nonfocal performance was virtually indistinguishable. These results demonstrate that people can modify their stimulus processing and expectations in event-based prospective memory tasks based on experience with the nature of prospective cues and with the ongoing task.
Since Einstein and McDaniel's (1990) seminal publication, two prominent views have emerged over how people accomplish event-based prospective memory (PM) retrieval. One is that PM retrieval relies on significant attentional resources (Smith, 2003, 2010; Smith & Bayen, 2004), either as people consciously monitor their environment for potential PM cues on a consistent or even intermittent basis (Guynn, 2003), or as they experience reminders about pending intentions (e.g., Kvavilashvili & Fisher, 2007; Marsh, Hicks, & Landau, 1998). PM retrieval is often impaired when executive resources are taxed (e.g., Marsh & Hicks, 1998), and people complete other tasks more poorly or slowly when an intention is active (Marsh, Hicks, Cook, Hansen, & Pallos, 2003; Smith, 2003). In contrast, the multiprocess view (Einstein & McDaniel, 2005; McDaniel & Einstein, 2000) proposes that PM retrieval can occur either via attention-demanding processes or via spontaneous retrieval that does not require attentional monitoring (Einstein et al., 2005; McDaniel, Guynn, Einstein, & Breneiser, 2004).
One manipulation that motivates PM retrieval supported by attentionally demanding versus spontaneous processes is a nonfocal versus focal instruction (Einstein & McDaniel, 2005). Spontaneous retrieval is more likely when the processing required by an ongoing task is highly similar to the processing required of an intention-related cue (i.e., focal). Attentionally demanding processing is more likely when there is little overlap in processing or when the conditions of intention retrieval are ill-specified (i.e., nonfocal). A fairly well-accepted method of operationally defining PM retrieval contexts is to compare an instruction in which a single PM cue is well-learned, well-specified, and focally processed in the context of an ongoing task against conditions in which PM cue processing is more difficult or more ambiguous. For example, Marsh et al. (2003) compared focal conditions in which a single animal word was used as a cue within a lexical decision task (LDT) versus those in which people were told to respond to any animal cue words. The task of word/nonword discrimination motivates focal processing of a single PM cue word. By contrast, responding to animal words for PM retrieval relies on a categorization process to know that the stimulus is consistent with the demands of the intention.
This method of contrasting a single-word cue with a category instruction is common in the PM literature (e.g., Cherry et al., 2001; Einstein, McDaniel, Richardson, Guynn, & Cunfer, 1995; Ellis & Milne, 1996; Loft, Bowden, Ball, & Brewer, 2014; Loft & Humphreys, 2012; Loft & Remington, 2013; Otani et al., 1997; Rummel, 2010). Other nonfocal conditions have been created by instructing people that a syllable is the PM cue, when this syllable might be embedded within any word or nonword stimuli unknown to the participant at the time of instruction (Einstein et al., 2005; McDaniel, LaMontagne, Beck, Scullin, & Braver, 2013). Another variation is giving people a nonfocal intention to respond to words beginning with a certain letter (e.g., Mullet et al., 2013; Scullin et al., 2013; Scullin, McDaniel, Shelton, & Lee, 2010).
One concern with this standard approach is that a single focal item is usually repeated many times for PM retrieval opportunities, whereas in nonfocal conditions many different exemplars are each shown once for the repeated PM opportunities. This creates an experimental confound because full stimulus repetition occurs only for the focal condition. This confound could also possibly hold in cases when the nonfocal condition requires responding to a syllable (e.g., Einstein et al., 2005) or to an initial letter in a word (Scullin et al., 2010). One resolution is to present multiple specific items in the supposed focal conditions by giving people a list of potential PM cues. However, increasing the set of to-be-remembered PM stimuli often produces behaviour consistent with attentional monitoring, such as increased latencies in ongoing task decisions (Cohen, Jaudas, & Gollwitzer, 2008; Marsh et al., 2003).
A different way of resolving the confound is to present a single category exemplar repeatedly in the nonfocal category instruction, allowing more equal footing with the number of presentations of a single item in focal conditions. This change might affect the character of the nonfocal condition. In fact, Einstein et al. (2005) explicitly considered the option of defining a nonfocal syllable condition by having the syllable “tor” repeated in a single item as opposed to embedded in multiple items, but they ultimately decided against it: “The decision to have the nonfocal target occur in four different words was made to prevent participants from associating the syllable with a word, thereby functionally converting the nonfocal target into a focal target” (p. 330). Our study was undertaken partly to establish evidence either for or against this concern.
Theoretically, the basis for a category instruction potentially transforming into a focal condition lies with mechanisms posited to underlie spontaneous retrieval. One mechanism is experiencing a discrepancy in the fluency or quality with which a stimulus is processed (McDaniel et al., 2004). In focal conditions, when a single PM cue is encoded and later processed in the ongoing task, its repetition-induced change in processing fluency may be perceived as different compared to the other stimuli in that task (Whittlesea & Williams, 2001a, 2001b). In a PM context, a likely attribution to the discrepancy is connected back to the formation of an intention to respond differently to that item (McDaniel et al., 2004). Nonfocal conditions in which different exemplars are each presented once as a PM cue would not create such a discrepancy in processing based on mere stimulus repetition. However, if a single category exemplar in a nonfocal condition were shown repeatedly, the second and subsequent presentations of the exemplar should produce a feeling of discrepancy or reminding (Hintzman, 2004, 2010).
Experiments 1 and 2
For the nonfocal conditions, six different animal words were shown once each across trials of the LDT in Experiment 1, whereas a single animal word was shown six times in Experiment 2. The Experiment 1 methodology is typical in prior studies using a category instruction to define a nonfocal condition but represents the stimulus repetition confound. Experiment 2 eliminates this confound by presenting a single item on six occasions in both focal and nonfocal conditions. The Experiment 1 methodology should produce a behavioural profile in which PM cue detection is generally better following the focal instruction, and reaction times (RTs) to the other ongoing task words are generally slower following a nonfocal instruction. This pattern has been interpreted as spontaneous retrieval in focal conditions resulting from a context that preempts the need for conscious monitoring of PM cues, whereas nonfocal conditions require more attentional resources required by processing stimuli as category members. Relatively faster responding in the ongoing task is usually taken as evidence of less monitoring and/or attention devoted to the PM task, relative to the ongoing task (Smith, 2003).
In addition to adopting a given allocation policy at the outset of intention formation (e.g., Lourenco, White, & Maylor, 2013; Marsh, Cook, & Hicks, 2006; Rummel & Meiser, 2013), people can modify strategies or policies after ongoing tasks begin (e.g., Kuhlmann & Rummel, 2014; Loft, Kearney, & Remington, 2008). Experience with repeated cues in the single-exemplar nonfocal condition of Experiment 2 should prompt a change in attention allocation policy, thereby increasing PM cue detection and decreasing lexical decision RTs. Thus, patterns across the two experiments will reveal the extent to which PM accuracy differences and ongoing task RT differences change as attention allocation policies are modified with task and stimulus experience. The focal/nonfocal manipulation was conducted within-subjects so that we could examine how prior expectations and experience with the PM task would impact subsequent performance. Their order was manipulated between subjects. Presenting the focal task first sets up the expectation of a single item being shown within the ongoing task and may have a differential impact on performance in a subsequent nonfocal task.
Method
Participants
Data were collected from Louisiana State University undergraduates who received course credit or extra credit. Ninety-six students participated in Experiment 1, and 99 participated in Experiment 2. Three participants from each experiment were excluded due to extreme RT profiles, as described later, leaving 93 and 96 participants, respectively.
Stimulus Materials
A set of 198 words was selected for the LDT. A comparable set of pronounceable nonwords was created by rearranging syllables or replacing letters from words (e.g., hobby into habby). In each of two LDT phases, 94 words and 100 nonwords were used in a 200-trial task. Ten other words and nonwords were used for a practice LDT phase. Prospective memory cues were the words giraffe, moose, rabbit, sheep, squirrel, tiger, and zebra.
Design and Procedure
Each experiment formed a 2 (instruction: focal vs. nonfocal) × 2 (order: focal first vs. focal second) mixed factorial design. Focal versus nonfocal instruction was within subjects, and their order was between subjects. The primary dependent measures were proportion of PM cues detected in each LDT phase and RTs to non-PM words as a measure of relative task interference. Secondary analyses focused on cue-by-cue detection and RTs across blocks of trials within each LDT phase.
Participants were told to complete a word/nonword decision task as quickly and accurately as possible. A 20-trial practice version of the task was followed by focal and nonfocal PM instructions. For focal instructions, participants were told that if they ever encountered a specific word (e.g., moose) during the LDT, they should press the “/” key instead of making the typical word response. For nonfocal instructions, they were told to make the “/” key response if they encountered any animal words. Participants were not informed how often PM cues would appear. The order of these instructions corresponded to the eventual order in which the subsequent LDT phases were presented. Immediately after the research assistant had verified that participants understood the instructions, participants were asked to enter predictions for their PM performance on a percentage scale by typing any value between 0 and 100 on the number keypad, representing the likelihood of remembering to fulfil the intention. Separate predictions were made for the focal and nonfocal conditions. 1
Participants were then reminded which PM instruction was active for the first LDT phase (i.e., either a single specific word or the animal category), and they solved a series of simple mathematical operations (e.g., 18 ÷ 9) for 2 min prior to completing their first LDT phase. PM cues were presented on Trials 40, 73, 101, 134, 167, and 195. In focal conditions, the actual PM stimulus word was shown six times during the course of the task. Each of the seven specific cue words was used approximately equally across participants. The critical difference between experiments involved the nature of the nonfocal task; recall that participants only knew to respond to animal words as their instruction. In Experiment 1, the nonfocal LDT phase contained the six animal words not used in the focal condition, with each presented once. In Experiment 2, only one of the remaining animal words was presented on each of the six PM cue occasions. Which specific PM cue was presented in these nonfocal blocks was also counterbalanced across participants.
After the first LDT phase, participants had a short break and then a reminder about which PM instruction was active for the next LDT phase. There were more mathematics trials for 2 min to provide a filled interval between the PM instruction reminder and the LDT phase. When this second phase was complete, participants completed a post-experimental questionnaire in which they estimated the number of PM targets and the percentage of PM targets correctly detected in each phase.
Results
For ANOVA models, partial-eta squared (
PM Accuracy
Figure 1, Panel A displays the average proportion of PM cues detected in the various conditions of Experiment 1, replicating the typical outcome that focal PM accuracy is usually better than nonfocal PM accuracy. A 2 (instruction) × 2 (order) mixed factorial ANOVA produced a significant effect of focality, F(1, 91) = 78.45, p < .01, MSE = .04,
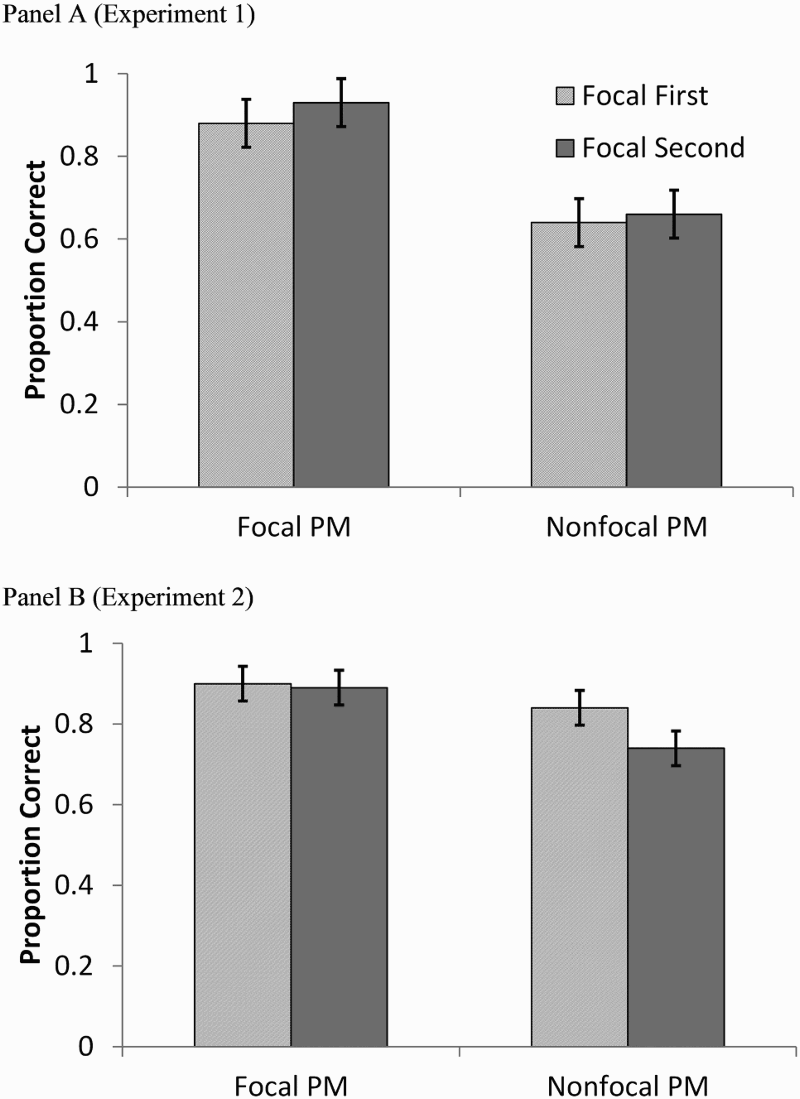
Proportion correct prospective memory accuracy across focal and nonfocal conditions and their order. Experiment 1 data are shown in Panel A and Experiment 2 data in Panel B. Error bars represent 95% within-subject confidence intervals recommended for mixed factorial designs (Masson & Loftus, 2003).
A complementary between-subjects comparison for Experiment 2 was conducted to examine the focality effect within a given LDT phase to control for the effects of experience with the task in general. Participants who were given the focal instruction first (M = .90) did better than those who were given the category instruction first (M = .74), F(1, 94) = 10.61, MSE = .054, p < .01,
Lexical Decision Performance
LDT performance was generally very good, averaging about 90% correct. For Experiment 1, overall proportion correct differed only by the focality factor, F(1, 91) = 14.22, MSE = .001, p < .001,
Figure 2 displays the median RTs to correct lexical decision word trials. Note that RTs on PM cue trials (e.g., a PM cue on Trial 40) and the subsequent two trials (e.g., Trials 41 and 42) were excluded from these calculations. Individual trial RTs greater than 2.5 standard deviations (SD) from a given subject's mean were excluded, as were trials with RTs less than 300 ms. Data from six participants—three each from each experiment—were excluded because their median RTs were more than 3 SD from relevant condition means. Although median RTs were analysed by participant and by condition, the patterns of results did not change when mean RTs or other various transformations (e.g., a log transformation) were applied to correct for positive skew in RT distributions.
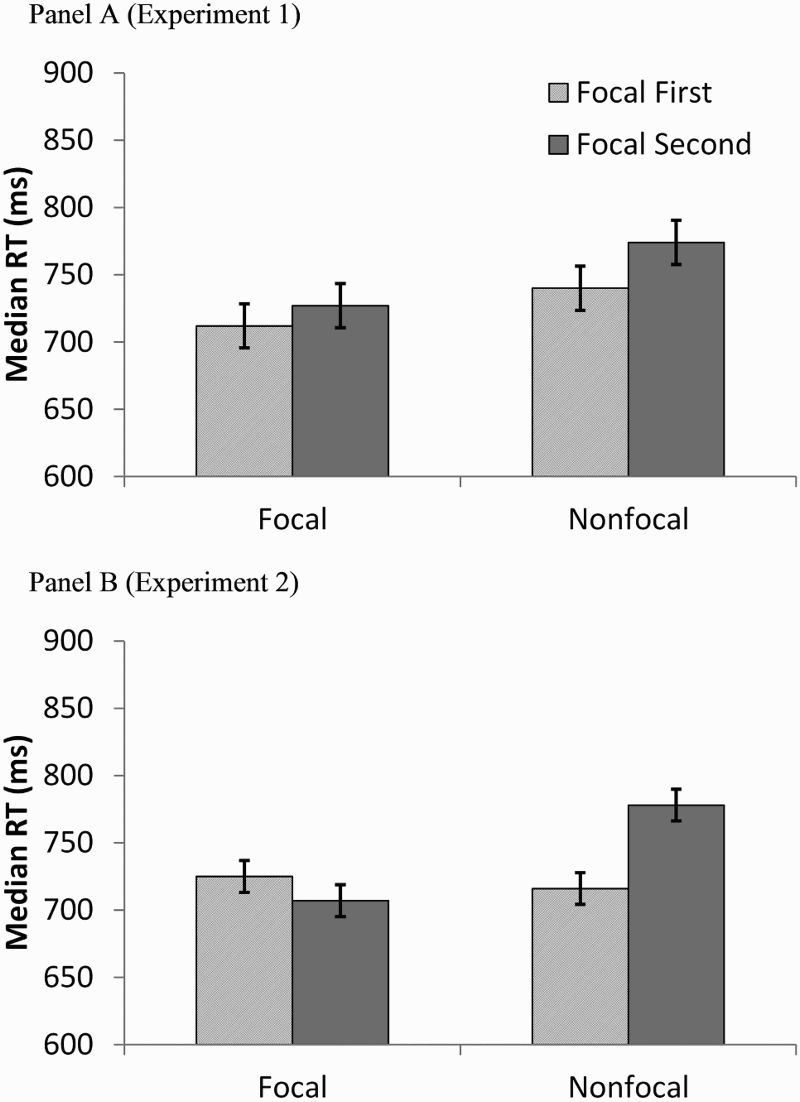
Average median reaction time to non-PM word stimuli in the lexical decision tasks, across focal and nonfocal conditions and their order. Experiment 1 data are shown in Panel A and Experiment 2 data in Panel B. Error bars represent 95% within-subject confidence intervals recommended for mixed factorial designs (Masson & Loftus, 2003).
We found the typical slower RTs for nonfocal conditions in which multiple exemplars were presented (Figure 2, Panel A). The 2 (instruction) × 2 (order) mixed factorial ANOVA again produced a significant effect of instruction with a mean difference of almost 40 ms, F(1, 91) = 22.04, p < .01, MSE = 3090.73,
As with PM accuracy, in a complementary analysis to control for task experience we compared RTs between PM instruction groups in Experiment 2, separately for each experimental phase. Those with the Phase 1 focal instruction were faster (M = 720.89) than those with a Phase 1 category instruction (M = 773.65), F(1, 94) = 7.88, MSE = 8441.74, p < .01,
Effects of Nonfocal Single-Cue Repetition
In this section we analysed performance across blocks of a given LDT phase. Figure 3 presents the proportion of participants who detected each PM cue in the LDT sequence. The data for Experiment 1 in Panel A demonstrate a consistent advantage for the focal instruction conditions, regardless of instruction order, F(1, 91) = 78.45, p < .01, MSE = .24,
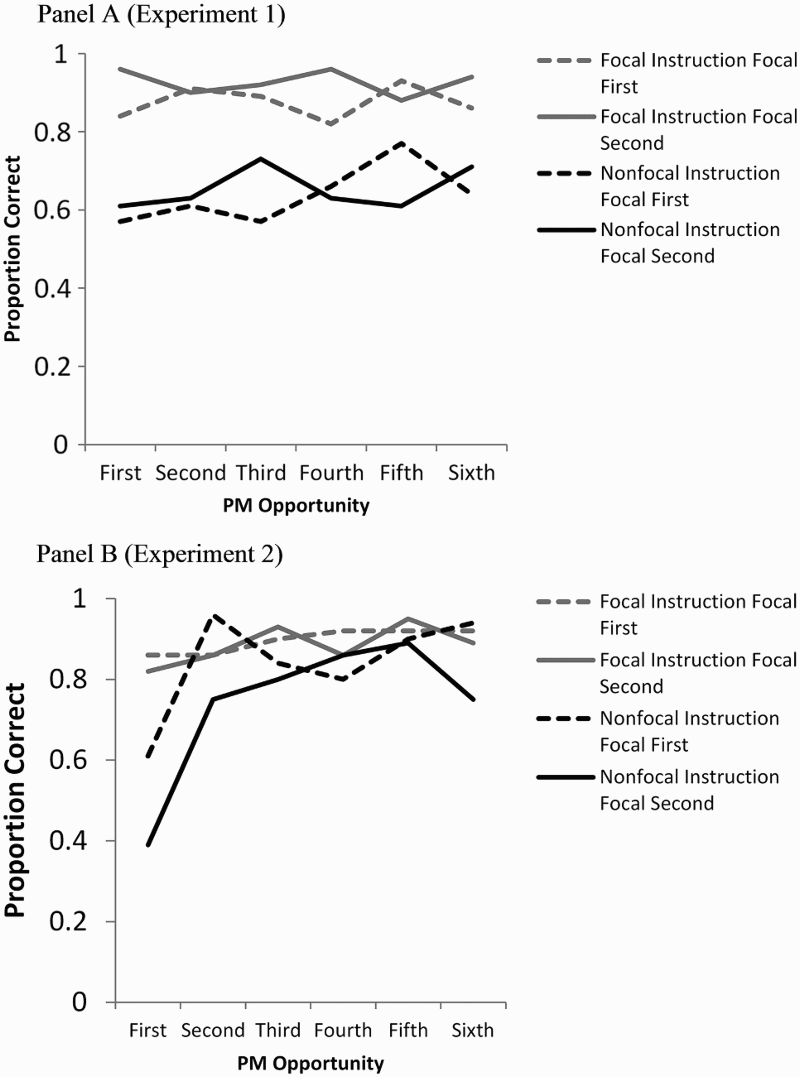
Proportion of participants by instruction and order condition successfully detecting each of the six PM cues. Experiment 1 data are shown in Panel A and Experiment 2 data in Panel B.
For RTs, Block 1 represents the LDT word trials prior to the first PM cue presentation, and the remaining blocks are word trials between successive cue presentations. RT profiles across the LDT sequence provide further evidence that attention allocation policies were adjusted differently across trials in the nonfocal task of Experiment 2, as compared to Experiment 1. For Experiment 1 (Figure 4, Panel A), the only significant effects were the main effect of instruction, F(1, 91) = 21.72, p < .01, MSE = 22,793.56,
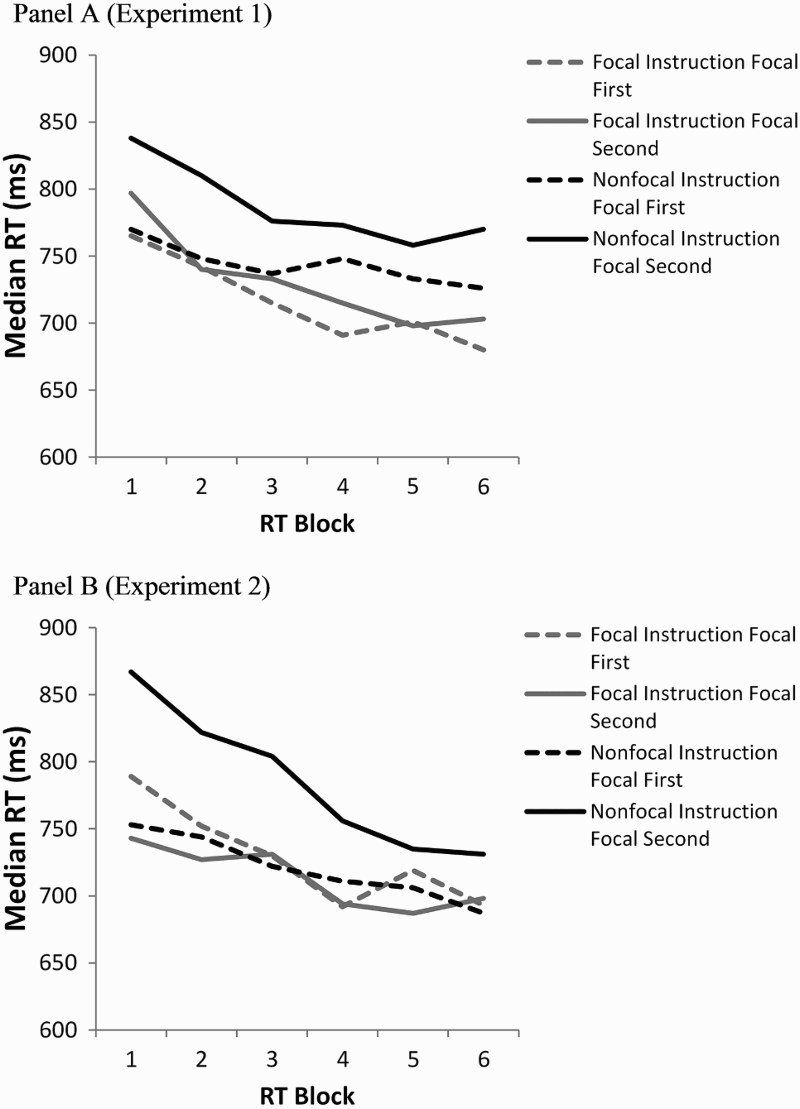
Average median reaction times to non-PM word stimuli over temporal blocks within the lexical decision tasks, across focal and nonfocal conditions and their order. Block 1 is prior to the first PM cue presentation, and subsequent blocks are between successive PM cue presentations. Experiment 1 data are shown in Panel A and Experiment 2 data in Panel B.
Even when the nonfocal condition was presented first in sequence and participants were the least experienced with the experimental tasks in general, repeating the PM cue increased PM detection and also the rate of RT reduction over the task sequence. Note especially the differential improvement across nonfocal blocks in Experiment 2 (130 ms) versus Experiment 1 (65 ms) in which the nonfocal condition was experienced first (focal second). In Experiment 2 when the nonfocal condition was presented second, its behavioural profile was essentially identical to those of the focal conditions. These data within and across experiments suggest that repeated exposure to a PM cue in a nonfocal instruction improved detection of the cue, modified how people approached the LDT over the sequence (nonfocal first of Experiment 2), and modified how they approached the entire task set from start to finish (nonfocal second of Experiment 2).
General Discussion
When a single animal exemplar was repeated as a PM cue in nonfocal conditions, performance quickly deviated from what is typical of nonfocal conditions in which multiple exemplars were each presented once—PM cue detection improved, and RTs to non-cue word trials in the LDT decreased at a faster rate. Performance improved so much when the single-exemplar nonfocal condition followed the focal instruction condition that it appeared almost indistinguishable in profile. The focality effect was reduced greatly in effect size from η2 = .42 in Experiment 1 to η2 = .03 when the category instruction was experienced in Phase 2 of Experiment 2. 3 Experimentally, presenting the same item repeatedly in nonfocal conditions controls for the confound inherent in stimulus exposure when compared to focal, single-item conditions. Yet controlling this confound also seems to have changed the manner in which people adjusted to task demands, effectively turning a nonfocal task into a focal one. What this outcome means theoretically for hypotheses concerning prospective memory retrieval, especially attention allocation, is discussed next.
Not only do people develop attention allocation policies in preparing for PM cues embedded in ongoing tasks (e.g., Hicks, Marsh, & Cook, 2005; Lourenço et al., 2013; Marsh et al., 2003, 2005, 2006; Rummel & Meiser, 2013), but these policies are flexible and can be modified spontaneously and with experience (e.g., Cohen, Jaudas, Hirschhorn, Sobin, & Gollwitzer, 2012; Knight et al., 2011; Kuhlmann & Rummel, 2014; Loft et al., 2008; Lourenço, Hill, & Maylor, 2015). Two possibilities are most likely to explain the changes in our single-exemplar nonfocal condition. One is that people benefitted environmentally from a discrepancy-plus-search mechanism that is usually ascribed to focal PM retrieval. By this explanation, although a specific PM cue was not provided in the instructions, the fluency of processing repeated PM cues is discrepant from the fluency of processing other words in the lexical decision task, prompting an attribution for the discrepancy (Whittlesea & Williams, 2001a, 2001b). The fact that PM accuracy started at a low point but quickly improved upon the second presentation of the PM cue is consistent with this explanation. However, this hypothesis alone does not seem to obviously account for different RT patterns over time in terms of the non-PM lexical decision word stimuli.
A second, complementary explanation is that people developed a specific expectation to encounter the same item repeatedly after its second or third presentation and adjusted their policies accordingly (e.g., “Now I've seen this word twice, perhaps it will continue to be shown.”). This explanation connotes a more mindful, conscious modification of an attention allocation policy more consistent with the exaggerated RT profile in the nonfocal condition of Experiment 2 when that nonfocal condition was presented first. It could also be that these two explanations of discrepancy-plus-search and explicit expectations are connected. In either case, it would be the discrepancy upon encountering the cue a second time that produces the change in performance. Such a specific change in allocation policy is consistent with evidence that policies are influenced by metacognitive expectations of PM retrieval difficulty (e.g., Kuhlmann & Rummel, 2014; Rummel & Meiser, 2013).
One implication of the hypothesized mechanism suggested above is that explicit expectations developed online should lead to poorer performance if the PM cues were changed. If a given cue were presented two or three times to prompt a change in allocation policy, PM performance for a different exemplar might actually drop below levels seen in the standard nonfocal condition. And if a different exemplar was detected, it might even prompt an opposite shift in attention allocation policy. A recent study by Lourenço et al. (2015) is relevant. When people expected to encounter typical animal exemplars in a nonfocal condition but then experienced atypical animals in the ongoing task, task interference on later word trials increased when people were successful at detecting the first atypical PM cue (but not when they were unsuccessful on the first PM cue). In other words, people changed their attention allocation policy in a direction opposite to what we found, presumably due to the uncertainty of what types of animals might be experienced later in the ongoing task and how that matched the expectations built up during the intention formation instructions (see also Nowinski & Dismukes, 2005). This outcome is also consistent with work by Cook, Marsh, and Hicks (2005) showing that an expectation to fulfil a time-based PM task in one context but only getting the opportunity in another context can worsen PM accuracy.
Our characterization of a nonfocal instruction turning into more of a focal one may hold for other nonfocal tasks. On the one hand, in these cases the nonfocal stimulus (e.g., “tor” for a syllable or “c” for the first letter of a word) is embedded in different stimuli to serve as PM cues, which means that the component “stimulus” is actually repeated multiple times, comparable to single-word focal conditions. On the other hand, these stimuli are embedded as components of other stimuli that are typically processed at a higher levels of representation within a task (e.g., lexical decision or category membership). Thus, the same concern exists with these methods because the entire word-level stimulus is not repeated in nonfocal conditions. Repeating the syllable “tor” in multiple words such as tornado, dormitory, and tortoise is likely not the same as repeating the specific stimulus tornado multiple times. The increased spontaneous retrieval coupled with decreased monitoring that occurred in our single-exemplar category instruction conditions would presumably occur in a similar fashion if a particular “tor” word were shown repeatedly.
In conclusion, we have demonstrated in two experiments that a nonfocal, category-cued PM instruction can be turned behaviourally into a focal PM task. These results add to the mounting evidence that attention allocation policies are set during intention formation but are also modified with task experience. Our results also point to the difficulty inherent in controlling obvious confounds between focal and nonfocal conditions, at least when they rely on the difference between presenting a single item repeatedly in focal conditions versus presenting many exemplars from a category in nonfocal conditions. More generally, our study reinforces the notion that factors such as metacognition, expectations of difficulty, and attention allocation are important in understanding the ways in which focal versus nonfocal retrieval are experienced.
Disclosure statement
No potential conflict of interest was reported by the authors.
Footnotes
1
We do not present data on the performance predictions in the main body of the paper because they are not relevant to changes in attention allocation policy over experience with the tasks. However, it is worth noting that predictions for the percentage of PM cues that would be detected averaged 71% in Experiment 1 and 68% in Experiment 2, and that these values were not affected statistically by the nonfocal versus focal instruction condition in either experiment. These data indicate that participants did not appreciate the potential differences in PM retrieval difficulty across these conditions from the instructions alone.
2
An anonymous reviewer argued that this should perhaps be treated as a one-tailed planned comparison because the focality effect is ubiquitous in the literature. Under this assumption, this particular hypothesis test would be declared significant (p = .03). Of course, the important outcome is that the focality effect size was greatly reduced under these circumstances as compared to either the focality effect from Experiment 1 or the focal-second condition of Experiment 2.
3
When PM accuracy was conditional on only the last 5 of the 6 cue presentations, there was no difference between nonfocal (M = 89%) and focal performance (M = 91%), F(1, 94) = 0.24,
Acknowledgements
We wish to thank Benjamin Perrodin, Alexi Petrou, Karyn Warner, and Jessica West for their dedicated help in collecting the data. Portions of these data were presented at the Fourth Annual Conference on Prospective Memory (ICPM 4) in Naples, Italy, May 2014.