
Abstract
The present experiment examined the use of parafoveally presented first-language (LI) orthographic and phonological codes during reading of second-language (L2) sentences in proficient Russian-English bilinguals. Participants read English sentences containing a Russian preview word that was replaced by the English target word when the participant’s eyes crossed an invisible boundary located before the preview word. The use of English and Russian allowed us to manipulate orthographic and phonological preview effects independently of one another. The Russian preview words overlapped with English target words in (a) orthography (ВЕЛЮР [vʲɪˈlʲʉr]–BERRY), (b) phonology (БЛАНК [blank]–BLOOD), or (c) had no orthographic or phonological overlap (КАЛАЧ [kɐˈlat͡ɕ]–BERRY; ГЖЕЛЬ [ɡʐɛlʲ]–BLOOD). The results of this study showed a clear and strong benefit of the parafoveal preview of Russian words that shared either orthography or phonology with English target words. This study is the first demonstration of cross-script orthographic and phonological parafoveal preview benefit effects. Bilinguals integrate orthographic and phonological information across eye fixations in reading, even when this information comes from different languages.
Keywords
Previous research has shown that preview of a word to the right of a fixation during reading leads to shorter fixation durations on this word, suggesting that parafoveally extracted information is used to start lexical processing even before the word comes into the foveal view of a reader (see Schotter, Angele, & Rayner, 2012, for review). This facilitatory effect is known as the parafoveal preview benefit (Rayner & Pollatsek, 1987). To study this effect, researchers often use a gaze-contingent invisible boundary paradigm (Rayner, 1975). In this paradigm, an invisible boundary is placed to the left of the target word. While the reader’s eyes are to the left of the boundary, the target is replaced with a preview that shares all or many features with the target (related preview) or shares no or very few features with the target (unrelated preview). When the reader’s eyes cross the boundary, the preview is changed automatically to the target word. Readers generally do not notice the change in the display as vision is suppressed during the saccade (Rayner, 1998).
Preview benefit effects (i.e., faster processing of a target when preceded parafoveally by a related than by an unrelated preview) have been consistently demonstrated with previews that are identical to the target (Williams, Perea, Pollatsek, & Rayner, 2006; Yan, Richter, Shu, & Kliegl, 2009), share some orthography with the target (Balota, Pollatsek, & Rayner, 1985; Drieghe, Rayner, & Pollatsek, 2005; Lima & Inhoff, 1985; Pollatsek, Tan, & Rayner, 2000; White, Johnson, Liversedge, & Rayner, 2008; Yan et al., 2009), or overlap with the target in phonology (Ashby & Rayner, 2004; Ashby, Treiman, Kessler, & Rayner, 2006; Miellet & Sparrow, 2004; Pollatsek, Lesch, Morris, & Rayner, 1992; Pollatsek et al., 2000; Rayner, Sereno, Lesch, & Pollatsek, 1995). These numerous studies suggest that readers are able to extract orthographic and phonological information from the parafoveal preview and use it to initiate lexical processing of the target even before the target is fixated.
Most of the studies cited above were conducted in languages where orthography and phonology are intrinsically bound, therefore making it hard to manipulate orthographic and phonological effects independently of one another. For example, based on the observation of the facilitation in the processing of words (e.g., pies) when visually similar nonwords (e.g., picz) were presented as the previews in the par-afovea, Balota et al. (1985) concluded that readers extract orthographic information from the parafovea. In addition to overlap in orthography, however, pies and picz share several phonemes, and, hence, the observed facilitatory effect might be partially driven by phonology. Further, Pollatsek et al. (1992) argued that phonological codes are integrated across fixations based on their finding of shorter first-fixation durations on words (e.g., warn) that were preceded by their homophones (e.g., worn) than by a spelling control (e.g., wire), although gaze durations did not differ. The homophones warn and worn, however, share not only phonology but also orthography, and, therefore, one cannot eliminate the possibility that the observed facilitation might be partially due to greater overlap in letters between the target and the homophone preview than between the target and spelling control preview, or to the combination of shared phonology and shared orthography with the preview. Indeed, in their discussion of the preview benefits in English, Pollatsek et al. (1992) acknowledged that phonological similarity is strongly confounded with orthographic similarity.
Frisson, Bélanger, and Rayner (2014) attempted to disentangle effects of orthography and phonology on eye fixation measures during reading by using a fast priming technique (Sereno & Rayner, 1992). In fast priming, a target word is first presented as a random letter string. When a reader moves his or her eyes across an invisible boundary located to the left of the target, the random letters are replaced by a prime word for a short duration (e.g., 32 ms or 50 ms) and then quickly by the target word. This technique, therefore, provides information about early foveal processing rather than parafoveal processing. Frisson et al. manipulated primes to examine the effect of orthographic overlap (e.g., bear–gear), phonological overlap (e.g., croak–smoke), and combined orthographic and phonological overlap between primes and targets (e.g., track–crack). The results of this study indicated that the priming effect was the largest when primes and targets shared orthography and phonology. Target processing was also facilitated when targets were preceded by orthographically similar primes. Phonological overlap between primes and targets, on the other hand, had no effect on the speed of processing of targets (there was a priming effect for the 50-ms prime in the single-fixation analysis, but this effect became nonsignificant when data were log transformed to reduce the impact of outliers). These results suggest that orthography is the primary linguistic factor contributing to eye fixation measures, and, hence, previously reported phonological effects, including the parafoveal preview benefit, were probably driven by orthography, which was confounded with phonology in most cases. However, the effects of phonological overlap alone might have been absent in the Frisson et al. study because primes and targets were rhymes and did not share onsets. Nonetheless, the implication of this study is that we need to manipulate the orthographic and phonological similarity of parafoveal previews and targets separately before we can make a strong claim about orthographic influences on the phonological parafoveal preview benefit.
Independent contributions of orthographic and phonological previews on the processing of targets can be examined in Mandarin Chinese, a language where the pronunciation of a character cannot be derived directly from the orthography for about 70% of words (X. Zhou & Marslen-Wilson, 1999). In Mandarin, strong evidence for the presence of the orthographic preview benefit has been provided: Characters preceded by orthographically similar previews were read faster than characters preceded by orthographically dissimilar previews (Pollatsek et al., 2000; Tsai, Lee, Tzeng, Hung, & Yen, 2004). The evidence in favour of the phonological preview benefit in Mandarin, on the other hand, is less conclusive. In some studies, a phonological preview benefit has been observed, although often this benefit was reported only in later measures of eye-movements such as gaze duration (Pollatsek et al., 2000; Tsai et al., 2004). Other studies have failed to identify any phonological preview benefit in Mandarin (Feng, Miller, Shu, & Zhang, 2001; Yan et al., 2009). These results suggest that in Mandarin, phonological preview benefits are weaker than orthographic preview benefit effects.
Considering significant differences in many features of Mandarin and alphabetic languages, it is not clear whether the phonological preview benefit would also be weak or absent in alphabetic languages if the orthographic/phonological similarity confound that characterizes most alphabetic languages was controlled. The goal of the present study, conducted in English, was to examine orthographic and phonological preview benefit effects manipulated independently from each other.
To achieve this goal, we examined the performance of Russian–English bilinguals reading English sentences that had some Russian words presented as parafoveal previews in a gaze-contingent invisible boundary paradigm. This group of bilinguals is of particular research interest as their two languages have different alphabetic writing systems (Cyrillic and Roman) that, nevertheless, share a few letters (e.g., C, P, B). Interestingly, some of the shared letters map onto different phonology (e.g., in Russian, the letter P corresponds to the phoneme [r], and the letter B corresponds to the phoneme [v]). By using Russian preview words and English targets with onset letters that are shared across the two alphabets, but that map onto different phonology in two languages (ВЕЛЮР [vʲɪˈlʲʉr]–BERRY), we managed to examine the orthographic preview benefit when it was not confounded by the phonological similarity of the previews and targets. Further, by using Russian preview words and English targets with onset letters that are different across the two alphabets, but map onto the same phonology in two languages (БЛАНК [blank]–BLOOD), we examined the phonological preview benefit independently of the orthographic similarity of the previews and targets.
Another question that we addressed in the present research was whether, in general, bilinguals whose languages have different scripts benefit from cross-script parafoveal previews. In particular, we examined whether Russian–English bilinguals would integrate orthographic and phonological information across eye fixations in reading, despite the fact that the two languages have different writing systems. Previously, a study examining cross-language preview benefits has been conducted with Spanish–English bilinguals who previewed words of one of their languages that were orthographically and phonologically similar to the words of their second language (e.g., grasa–grass; Altarriba, Kambe, Pollatsek, & Rayner, 2001). Although the researchers did find a facilitatory effect of cross-language preview benefit in this study, it is unclear whether it was, indeed, integration of the codes of two languages or, alternatively, whether the previews were processed as nonwords of the target language of the experiment (see Veldre & Andrews, 2015a; Williams et al., 2006, for evidence that nonwords can act as efficient orthographic and phonological previews) and, hence, whether the observed effect reflected a within-language integration of information across fixations. By employing previews and targets from languages with different orthographic systems, we eliminated the possibility that a preview would be processed in the target language. Thus, the finding of a parafoveal preview benefit in our study would serve as strong evidence for integration of cross-language and cross-script orthographic and phonological information across fixations.
Based on the prior research showing evidence for co-activation of phonology and orthography of two languages in various groups of bilinguals (Ando, Jared, Nakayama, & Hino, 2014; Dimitropoulou, Duñabeitia, & Carreiras, 2011; Haigh & Jared, 2007; Jared & Kroll, 2001; Nakayama, Sears, Hino, & Lupker, 2012; H. Zhou, Chen, Yang, & Dunlap, 2010) including Russian–English bilinguals (Jouravlev & Jared, 2014; Jouravlev, Lupker, & Jared, 2014; Marian & Spivey, 2003; Timmer, Ganushchak, Mitlina, & Schiller, 2014), we expected to observe cross-script orthographic and phonological preview benefits in our study. Alternatively, we considered the possibility that such a benefit would not be observed due to the fact that bilinguals might be not skilled enough in their non-native language (L2) to retrieve information coming from the parafovea. This prediction is based on the observation that parafoveal preview benefits are in general reduced in less skilled readers (Chace, Rayner, & Well, 2005; Henderson, Ferreira, Rayner, & Pollatsek, 1990; Veldre & Andrews, 2015a, 2015b).
Experimental study
Method
Participants
Twenty-five native speakers of Russian (mean age 24 years, range 18–37; 15 female) with normal or corrected-to-normal vision were recruited at the University of Western Ontario and from the local community. They were all born in Russia or Ukraine and moved to Canada on average eight years prior to the study (median 6, range 2–16). The participants reported attending educational institutions in which instruction was provided in English for a mean of 6 years (median 5, range 2–12). As per participants’ self-reports, English was currently their most frequently used language (M = 72% of the day vs. M = 28% for Russian). English was the language of choice in communicating with friends and colleagues (M = 88%), while Russian was mainly used in communication with family members (M = 93%). On a 10-point proficiency scale (1 = none; 10 = very fluent) participants reported native proficiency in Russian (M = 10 for speaking, writing, listening, and reading). The proficiency self-rating in English revealed an average value of 8.89 (SD = 0.85, range 7–10) with slightly more fluency in comprehension (listening: 9.25; reading: 9.33) than in production (speaking: 8.64; writing: 8.75). Participants received $10.
Materials
Sixty English target words were selected and paired with 60 Russian words that overlapped with the targets in orthography (30 items in the orthographic match condition; e.g., ВЕЛЮР [vʲɪˈlʲʉr]–BERRY) or phonology (30 items in the phonological match condition; e.g., БЛАНK [blank]–BLOOD) and with another 60 Russian words that did not overlap with the targets orthographically (30 items in the orthographic mismatch condition; e.g., КАЛАЧ [kɐˈlat͡ɕ]–BERRY) or phonologically (30 items in the phonological mismatch condition; e.g., ГЖЕЛЬ [ɡʐɛlʲ]–BLOOD). The English words, embedded in sentences, were used as critical targets, while the Russian words served as their parafoveal previews.
Orthographic match items shared the first two letters with the corresponding targets, but there was no overlap in phonology. Phonological match items shared the first two or three phonemes with the corresponding targets, but there was minimal overlap in orthography. Ideally, there would be no overlap in orthography, but because English and Russian share the vowels A, E, and O, that ideal is difficult to achieve. Of the 169 letters in the 30 English target words, only 11 (6.5%) appeared in preview words in the same position (all were the vowels A, E, and O), two others appeared in preview words but in a different position, and no target had more than one letter in common with its preview. To make sure that participants did not process Russian preview words as English nonwords, we only selected lexical items that had some letters unique to Cyrillic present in them. None of the selected Russian words were semantically related to English target words. Russian preview words were matched across conditions in their length and word frequency (Lyashevskaya & Sharov, 2009). The characteristics of Russian preview words used in this study are given in Table 1.
Mean characteristics of stimuli.
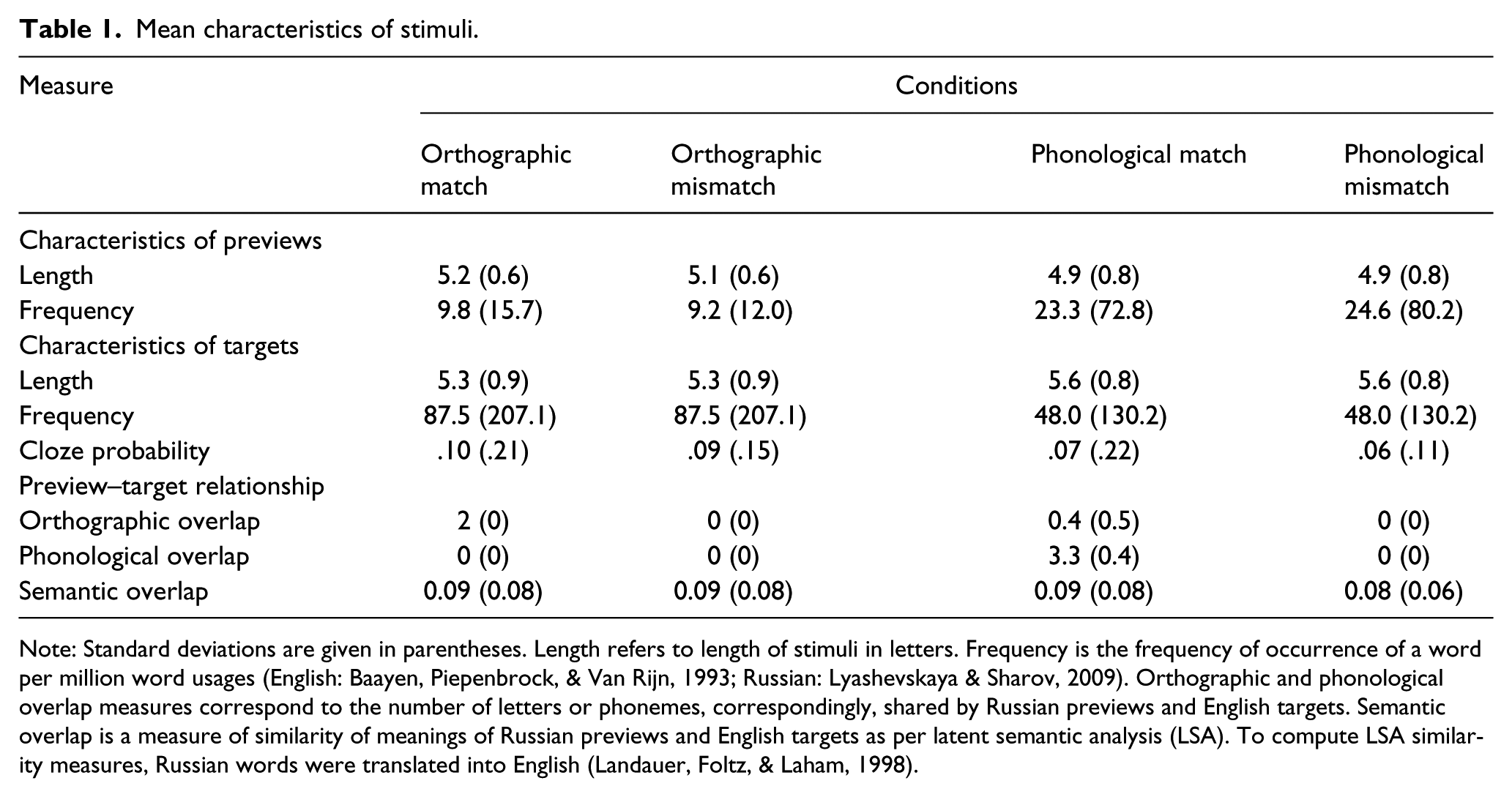
Note: Standard deviations are given in parentheses. Length refers to length of stimuli in letters. Frequency is the frequency of occurrence of a word per million word usages (English: Baayen, Piepenbrock, & Van Rijn, 1993; Russian: Lyashevskaya & Sharov, 2009). Orthographic and phonological overlap measures correspond to the number of letters or phonemes, correspondingly, shared by Russian previews and English targets. Semantic overlap is a measure of similarity of meanings of Russian previews and English targets as per latent semantic analysis (LSA). To compute LSA similarity measures, Russian words were translated into English (Landauer, Foltz, & Laham, 1998).
For each target word, two sentences were created in such a way that the target word provided a fit to both sentences semantically and syntactically, but had low contextual predictability (see Figure 1 for an example and the Supplemental Material for the full list of sentences). Target words were never in the sentence-initial or sentence-final position. In prior research, it has been shown that highly predictable words tend to be skipped or fixated for a shorter period of time (Frisson, Rayner, & Pickering, 2005; Rayner, Slattery, Drieghe, & Liversedge, 2011). By using words with low contextual predictability, the likelihood that target words would be fixated was increased. To confirm that target words had low contextual predictability and that the predictability of a word was similar across the two contexts, we ran a cloze probability pilot study. Thirty undergraduate students, who did not participate in the eye-tracking task, were given each sentence frame up until the target word and were asked to write down the word that they thought was most likely to come next. The results of the pilot study showed that the target words were not highly predictable in the given contexts (cloze probability: M = .08, SD = .17) and that cloze probabilities did not differ across conditions, all ts < 1.23, ps >.19.

Example sentence using the boundary paradigm. The target and the preview words, although indicated in boldface, were not presented in boldface in the experiment. The asterisk below each sentence indicates the reader’s fixation location. When the reader’s eyes cross the boundary (indicated as a vertical line in this example —in the actual experiment, this boundary was invisible), the parafoveal preview (i.e., Russian word) changes to the target English word. In the example, a Russian word overlapping with the English target in the orthography serves as the parafoveal preview.
In total, there were 120 critical English sentences (length: M = 10.7 words, SD = 2.02). Critical sentences were mixed with 60 filler English sentences, on which comprehension questions were asked.
Apparatus
Participants’ eye movements were recorded using an SR Research EyeLink 1000 eye-tracker. Viewing was binocular, but fixation location was monitored from the right eye, which was the dominant eye for all of the participants. Stimuli were presented on a 21” CRT monitor with a refresh rate of 150 Hz. Participants were seated 60 cm from the monitor with their head position stabilized by a chin and forehead rest. At this distance 2.7 characters equalled 1° of visual angle.
Procedure
Participants were tested individually. They were instructed to read each sentence silently at a comfortable pace and to press a button on a response box when they finished reading each sentence. The session started with calibration and validation procedures followed by experimental and filler sentences in a random order. Sentences were presented one at a time on the centre row of the monitor in black, uppercase 18-point Courier New font type on a white background. Upper-case characters were used because cross-linguistic orthographic overlap in Russian and English is the greatest for capital letters. The invisible boundary paradigm was used to vary parafoveal preview information for experimental sentences (Rayner, 1986; see Figure 1 for an example). At the beginning of each trial, participants saw a fixation point located on the centre row of the monitor near its left edge. When an experimenter confirmed that the participant had fixated on this point, presentation of a sentence was initiated. In the initially presented experimental sentence, a target English word was replaced by a Russian preview word. As the participant’s eyes crossed an invisible boundary located at the end of the pre-target word, the preview changed to the English target word. Because the change occurred while the participant’s eyes were moving, participants were unlikely to notice any change (Rayner, 1998). 1 The target word remained in the sentence until the end of the trial. For the filler sentences, there was no preview manipulation. The filler sentences were followed by comprehension questions. Participants were instructed to read the comprehension questions and to give a yes/no response by pressing one of two buttons. Participants were recalibrated after every 20 trials or more often if an experimenter noted a drift in eye-movements. None of the participants reported noticing any flickering on the screen. The entire study took about 50 min.
Results
Comprehension scores ranged from 85% to 100%, with the mean accuracy score being 93%. This high comprehension score indicates that the recruited bilingual participants were highly fluent in English. Data from experimental sentences were excluded prior to the analysis if (a) fixation durations on targets were below 80 ms or above 800 ms (2.7% of trials), (b) if a blink occurred immediately before or after a fixation on the target word (2.1% of trials), (c) if the display change completed more than 10 ms into a fixation or was triggered by a saccade that landed to the left of the boundary (6.8%), and (d) if targets were skipped and never fixated on (2.3%).
To determine whether the sentence contexts were matched for ease of processing just before the target word was encountered, we examined whether there were any differences in early reading times on pre-target words in related and unrelated preview conditions. Indeed, analyses of first-fixation durations on pre-target words revealed no differences between related and unrelated conditions, for either orthographic or phonological previews (all ts < 1.03, all ps > .28).
The following measures of eye-movements and fixations on target words were analysed: single-fixation duration (SFD; the duration of the fixation on the target in which only one first-pass fixation was made); first-fixation duration (FFD; the duration of the first fixation on the target regardless of the number of first-pass fixations on the word); gaze duration (GD; the sum of all successive first-pass fixations on the target); and total viewing duration (TD; the sum of all fixations on the target, including regressions from later in the sentence). The regressions out rate (RO%; the percentage of trials on which a regression out of the target to a word to the left was made) and regression in rate (RI%; the percentage of trials on which a regression into the target from the word to the right was made) were also analysed, but since there were no significant effects in either of these measures, they are not reported. Results are shown in Table 2.
Mean measures of eye fixation durations and eye movements on English targets preceded by Russian parafoveal previews.
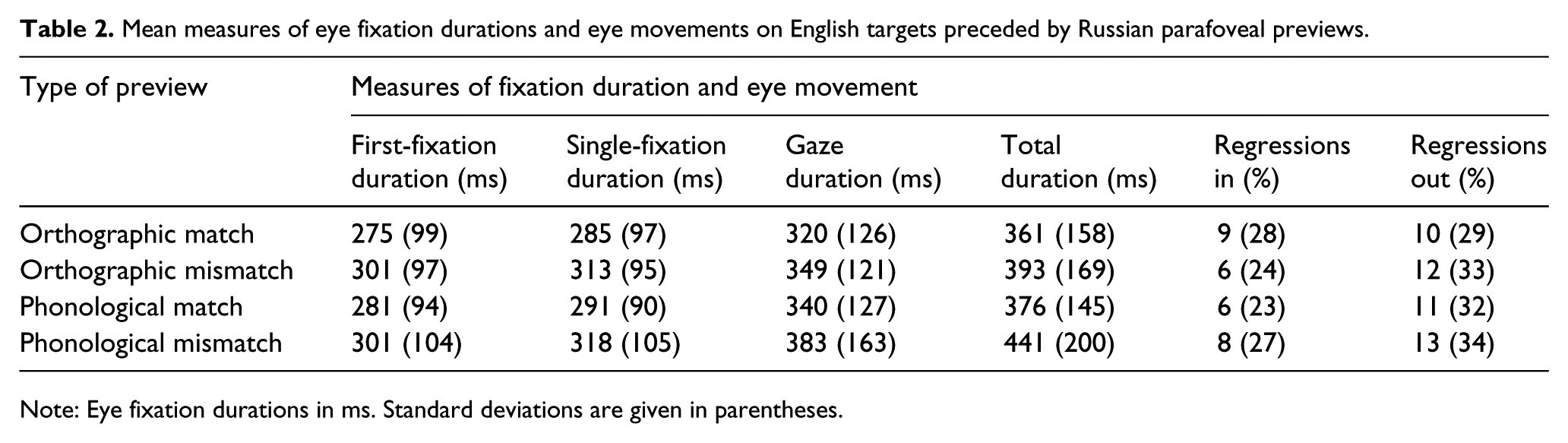
Note: Eye fixation durations in ms. Standard deviations are given in parentheses.
Separate linear mixed-effects models (LMMs; one examining the benefit of cross-language orthographic parafoveal preview and the other exploring the benefit of cross-language phonological parafoveal preview) were fitted to the data from each measure using the lme4 package (Bates, Maechler, Bolker, & Walker, 2014). Each model included random intercepts for subjects and items, and random slopes when possible. 2 The preview–target relationship (related vs. unrelated) variable was entered as a fixed factor. In addition, we entered into the model several factors that might have impacted the processing of previews and targets, including the preview’s frequency, the location of the pre-target fixation in relation to the invisible boundary, and the target’s position in a sentence. The two former variables are believed to be related to the efficiency of parafoveal preview processing (Fitzsimmons & Drieghe, 2011), while the latter one is related to speed of reading in general (Kuperman, Dambacher, Nuthmann, & Kliegl, 2010). Significance values were obtained via Markov Chain Monte Carlo (MCMC) sampling of the posterior parameter distributions (sample size = 10,000).
Orthographic preview benefit
Parafoveal preview of Russian words that shared some orthography with English target words was associated with shorter fixation durations on English targets than instances of previews of Russian words that had no orthographic overlap with targets (SFD: β = 24.21, SE = 7.21, t = 3.35, p = .01; FFD: β = 21.92, SE = 6.04, t = 3.62, p = .01; GD: β = 22.95, SE = 9.05, t = 2.54, p = .01; TD: β = 21.27, SE = 10.75, t =1.98, p = .05).
Phonological preview benefit
A clear benefit of the parafoveal preview of Russian words that partially shared phonology with English target words was also found. All fixation duration measures for English target words were significantly shorter when a Russian preview provided matching than when it provided mismatching phonology (SFD: β = 22.30, SE = 9.59, t = 2.33, p = .02; FFD: β = 16.59, SE = 7.83, t = 2.12, p = .03; GD: β = 33.95, SE =15.79, t = 2.15, p = .04; TD: β = 52.37, SE = 18.35, t = 2.85, p = .01).
Some of our preview–target pairs had one letter in common. Furthermore, some of the letters specific to the Russian alphabet that we used in our phonological overlap condition were different from their English counterparts but shared some visual features with English letters (e.g., B–Б, H–И, I–Г). To investigate whether this orthographic similarity influenced the phonological preview benefit, we calculated the overlap in visual features for each pair of English and Russian letters (e.g., visual feature overlap equals 1 for the letters O–O, 0 for the letters Б–O, and .66 for the letters B–Б). Then, for each preview-target pair, we computed a measure of preview–target visual overlap by finding a mean of overlap in visual features for all letters of the preview–target pair. An interaction of this measure with the preview–target relationship was entered into LMMs to examine whether the phonological preview benefit arose because of orthographic overlap. Importantly, the interaction of preview–target visual overlap and preview–target relationship did not reach significance in any of the measures (all |ts| < 0.77, all ps > .43), suggesting that the observed preview benefit was indeed phonological. A significant cross-language phonological preview benefit was still observed in SFD (β = 22.61, SE =11.07, t = 2.04, p = .05), and TD (β = 43.83, SE = 20.67, t = 2.12, p = .05). The effect of phonological parafoveal preview was marginally significant in FFD (β = 20.77, SE =11.80, t = 1.76, p = .08), and non-significant in GD (β = 25.49, SE = 17.01, t = 1.50, p = .14).
Orthographic versus phonological preview benefit
To examine any differences in the magnitudes of orthographic versus phonological preview benefits, we fitted LMMs with an interaction of preview–target relationship and preview type (orthographic vs. phonological) entered as a fixed factor. Additional variables of no interest that were entered into the model as fixed factors were the location of the pre-target fixation, the target’s position in a sentence, and an interaction of the preview type and the preview’s frequency. The latter interaction was introduced to account for the fact that there was a small numeric difference in frequencies of orthographic versus phonological previews. For none of the measures of eye-fixation did the interaction of preview–target relationship and preview type reach significance (all |ts| < 1.78, all ps > .09).
General discussion
The present experiment examined the use of parafoveally presented first-language (L1) orthographic or phonological codes during reading of L2 sentences in proficient Russian–English bilinguals. Russian and English are two alphabetic languages that use different but partially overlapping scripts. Further, some of the shared letters of these two languages map onto different phonology (e.g., in Russian, the letter P corresponds to the phoneme [r]). This feature of the two languages allowed us to manipulate orthographic and phonological codes independently of one another, thus examining orthographic parafoveal preview effects independently of the phonological similarity of the previews and targets (e.g., ВЕЛЮР [vʲɪˈlʲʉr]–BERRY) and phonological parafoveal preview effects independently of the orthographic similarity of the previews and targets (e.g., БЛАНК [blank]–BLOOD).
The results of the present research revealed strong evidence for the presence of independent phonological and orthographic preview benefits in alphabetic languages. Readers had shorter fixations on English target words when the targets were preceded by Russian preview words sharing orthography or phonology with the targets than in instances when targets were preceded by previews having no orthographic and phonological overlap with the targets. These results are consistent with a large body of literature where phonological and orthographic parafoveal preview benefits have been demonstrated (Balota et al., 1985; Drieghe et al., 2005; Pollatsek et al., 1992; Rayner et al., 1995). Our contribution to this line of work is that we established that orthographic codes are integrated across fixations even if previews have no overlap in phonology with the targets and that readers extract phonological information from the parafovea even if previews share no or minimal orthographic overlap with the targets.
In the studies of parafoveal preview benefit in Mandarin Chinese (Feng et al., 2001; Pollatsek et al., 2000; Tsai et al., 2004; Yan et al., 2009), it has been suggested that phonological preview benefits are generally weaker than benefits of the orthographic preview. In our study, orthographic and phonological preview benefits did not differ statistically in any of the eye fixation measures. This finding suggests that in alphabetic languages, readers rapidly compute a phonological code for a word in the parafovea and further use this information in the processing of the word when it enters the fovea. It should be noted that in our study, previews were words in Russian, a language characterized by transparent mapping of orthography to phonology (Jouravlev & Lupker, 2014, 2015). On the other hand, Mandarin Chinese, where only weak evidence for the phonological preview benefit was found, is a language with opaque links between orthography and phonology. Thus, the size of the phonological preview benefit is likely to depend on the speed of the computation of a phonological representation of a parafoveally presented word and, hence, on the degree of the opaqueness of a processing language and the proficiency of a reader in mapping orthography to phonology in this language.
The results of our study also provide some insight on the nature of cross-linguistic parafoveal preview benefits. The orthographic and phonological codes of Russian and English were integrated across fixations, suggesting that both languages were co-activated and impacted reading performance, which is consistent with the prior empirical evidence (e.g., Haigh & Jared, 2007; Nakayama et al., 2012; Jouravlev & Jared, 2014; Jouravlev et al., 2014) and with the architecture of the bilingual interactive activation + model (BIA+; Dijkstra & van Heuven, 2002).
Implications for the BIA+
The BIA+ is a localist connectionist model in which pools of units that represent a word’s spelling and pronunciation are shared across a bilingual’s languages. In a Russian–English version of the model, the pool of sublexical orthographic units would include letters from both the English and Russian alphabets, and, similarly, the pool of sublexical phonological units would include both English and Russian phonemes. Each of these sublexical stores is connected to a corresponding lexical store, which has units that represent whole word orthography or phonology for the words in each of the languages. Units within a lexicon are mutually inhibitory. The lexical stores are connected to one another and to a shared semantic store. The language of a word is captured by a connection from its lexical unit to one of two language units. The language units cannot inhibit lexical representations in the other language.
A Russian word in the parafovea would activate all sublexical orthographic units that are consistent with the word, and these would then send activation to any sublexical phonological units that were consistent with the activated letters. Activation would also flow from sublexical units to the orthographic and phonological lexical units in either language that are consistent with the sublexical representations, and on to corresponding language units and semantic units. As the lexical units for the Russian preview word become active, they would inhibit other lexical units.
When the English target word is fixated upon, the same flow of activation occurs. If the English target word shares letters with the Russian preview word, the units for the shared letters should become activated more quickly and/or more strongly than for new letters. Similarly, if the English target word has phonemes in common with the Russian preview word, the sublexical units for the shared phonemes would become activated more quickly and/or more strongly than for new phonemes. However, lexical representations for the English target word would have to overcome inhibition from the Russian preview word. To account for the facilitatory effects of orthographic and phonological similarity of the Russian preview and English target words that was observed here, this model would have to assume that these effects arise primarily at the sublexical level. The finding of cross-language preview benefits suggests that the English language unit did not inhibit Russian representations, as assumed in the BIA+.
Conclusion and future directions
In this work, we demonstrated the sensitivity of highly proficient bilinguals to L1 orthographic and phonological previews during L2 reading. Questions that need to be addressed in future research is whether the orthographic and phonological preview benefit effects are additive and whether display change awareness has any impact on the strength of cross-language parafoveal preview benefit. Furthermore, because the size of the parafoveal preview benefit has been shown to be influenced by language proficiency (Chace et al., 2005; Henderson et al., 1990; Veldre & Andrews, 2015a), future directions of this work are to examine whether orthographic and phonological parafoveal preview benefits will be observed for less proficient bilinguals, and whether L2 previews during L1 reading are as efficient as L1 previews during L2 reading.
Footnotes
Acknowledgements
We would like to thank Lorin Alarachi for assistance in testing participants and Kiel Christianson, Wouter Duyck, and two anonymous reviewers for their feedback on the manuscript.
Disclosure statement
No potential conflict of interest was reported by the authors.
Funding
This research was supported by a grant from the Natural Sciences and Engineering Research Council of Canada to D. Jared.