
Abstract
In an eye movement experiment employing the boundary paradigm, we compared parafoveal preview benefit during the reading of Chinese sentences. The target word was a two-character compound that had either a noun–noun or an adjective–noun structure each sharing an identical noun as the second character. The boundary was located between the two characters of the compound word. Prior to the eyes crossing the boundary, the preview of the second character was presented either normally or was replaced by a pseudocharacter. Previously, Juhasz, Inhoff, and Rayner observed that inserting a space into a normally unspaced compound in English significantly disrupted processing and that this disruption was larger for adjective–noun compounds than for noun–noun compounds. This finding supports the hypothesis that, at least in English, for adjective–noun compounds, the noun is more important for lexical identification than the adjective, while for noun–noun compounds, both constituents are similar in importance for lexical identification. Our results indicate a similar division of the importance of compounds in reading in Chinese as the pseudocharacter preview was more disruptive for the adjective–noun compounds than for the noun–noun compounds. These findings also indicate that parafoveal processing can be influenced by the morphosyntactic structure of the currently fixated character.
Introduction
During reading, readers extract information from more than the fixated word. Studies using the boundary paradigm (Rayner, 1975) have shown that when the letters of the word to the right of fixation are left intact, readers have shorter fixation durations on the word when fixating it compared to when the letters are masked prior to fixation (for a review, see Rayner, 2009). This parafoveal preview benefit is typically in the order of 20-40 ms (Hyönä, Bertram, & Pollatsek, 2004; for a review, see Schotter, Angele, & Rayner, 2012). However, research using a within-word boundary paradigm whereby the letters of the second constituent of a compound word are either presented or masked while the first constituent is fixated shows a preview benefit in the order of 100 ms. Hyönä et al. suggested that one of the reasons for this increased preview benefit might be that the second constituent is part of a single linguistic unit (the compound word). This would lead to more processing resources being devoted to processing of the second constituent than is the case for a parafoveal word separated by a space (with the possible exception of a spaced compound such as teddy bear, see Cutter, Drieghe, & Liversedge, 2014). However, some sequentiality of processing whereby the first constituent is prioritized in lexical processing compared with the second constituent seems likely. Drieghe, Pollatsek, Juhasz, and Rayner (2010) compared the preview benefit of correct versus masked letters of the second constituent of a compound word (e.g., bathroom) with a preview manipulation of the corresponding letters within a monomorphemic word of equal length (e.g., fountain, for which parallel processing is assumed across all the letters) and observed a preview effect of 123 ms for the compound and 225 ms for the monomorphemic word. They concluded that parafoveal processing during reading is reduced across a morphological boundary (for similar findings in Chinese, see Cui, Drieghe, et al., 2013). Combined, these studies show differential amounts of parafoveal processing as a function of boundaries in between the fixation point and the parafovea (word boundary, morphological boundary and none such boundary). The topic of this study is the effect of a morphological boundary on parafoveal processing, and more specifically whether this effect depends on the relationship between the constituents of a two-character compound Chinese word (an adjective–noun vs noun–noun compound).
Studies examining the processing of unspaced compound words during reading in alphabetic languages have shown that familiar unspaced compounds are typically decomposed into their constituents (e.g., Hyönä et al., 2004). This is evident from observations that the frequency of the first and second constituent influence the fixation time on a compound. Other experiments (e.g., Juhasz, 2008) have shown that the frequency of the whole compound also influences gaze duration on a word, compatible with the race model proposed by Pollatsek, Hyönä, and Bertram (2000) in which both a morphemic decomposition process and a whole-word look-up take place simultaneously, with the latter being the preference when the compound word is short.
Turning to Chinese reading, investigating the processing of two-character compound words is all the more important given their prevalence and unique properties: 42.2% of Chinese words are two characters long and almost all are compounds (Zhu, 2005), and Chinese is unspaced with readers not always agreeing on the locations of word boundaries and therefore also of compound boundaries (for a discussion, see Liu, Li, Lin, & Li, 2013). Note that in Chinese, for two-character compound words, the constituent morphemes are the individual characters. Yan, Tian, Bai, and Rayner (2006) observed effects both of character and word frequency. However, the effect of character frequency was reduced when the word was frequent compared with when it was infrequent, suggesting a whole-word look-up for frequent words whereas an infrequent word needs to be accessed via the characters. A thorough review of boundary studies in reading Chinese is outside of the scope of this report; however, one particularly relevant study is reported by Cui, Yan, et al. (2013), who implemented a preview manipulation of the second character of a compound word. Besides the standard preview effect, the authors also observed that the frequency of the initial character of the compound constrained the identity of the second character (with a low frequency first character being more constraining) and that this constraint modulated the extent to which lexical and semantic properties of the preview influenced the subsequent processing when the second character was fixated. They concluded that in a compound word, parafoveal processing of the next character is influenced by the lexical characteristics of the fixated character.
One of the characteristics of the first constituent that could influence the parafoveal processing of the second constituent is its syntactic category. Juhasz, Inhoff, and Rayner (2005) found that inserting a space into normally unspaced compound words in English significantly disrupted processing. This disruption was more pronounced for adjective–noun compounds (e.g., softball) compared with noun–noun compounds (e.g., cornfield). The interpretation from Juhasz et al. for this finding was that the spatial layout is more important for adjective–noun compounds because presenting adjective–noun compounds in a spaced format impacts the overall interpretation of the compound to a greater extent than for a noun–noun compound. For example, a blue bird can signify any bird that is blue, but a bluebird is a very specific species of bird. However, their finding of increased disruption for inserting a space between an adjective–noun compared to a noun–noun compound would also be compatible with the idea that the meaning of an adjective–noun compound would be determined to a greater extent by the second constituent compared with a noun–noun compound where the division of contributions to the meaning would be distributed more evenly between the two constituents. To be more specific, whereas in a noun–noun compound, the two constituents are syntactically identical, and each contributes to the overall meaning, in an adjective–noun compound, the adjective modifies that noun, and the whole word takes it meaning primarily from the noun, with the adjective modifying that basic meaning. As a result, the insertion of a space would have a more detrimental impact on determining the meaning of the adjective–noun compound. Additionally, some suggestions have been made in the literature that even when the adjective and the noun are two separate words, a comparatively bigger preview benefit is observed on the noun compared with other between-word boundary experiments in which the word preceding the boundary is not an adjective (Juhasz, Pollatsek, Hyönä, Drieghe, & Rayner, 2009). Again, this indicates that an adjective (compared with other syntactic categories) might result in increased parafoveal processing of the subsequent word.
In Chinese, the location of the constituent that is dominant for determining the meaning of the compound is less straightforward than, for instance, in English. Like most Germanic languages, English is right-headed (e.g., Selkirk, 1982) which means that in English, for bimorphemic compounds, the head of a compound – the constituent that determines the semantic category – is usually the second constituent (e.g., the head of the compound noun handbag is bag). In Chinese, due to the ubiquitous prevalence of both right-headed and left-headed compounds, Huang (1998) argued that neither the rightmost nor the leftmost constituent of a compound has a privileged status, claiming Chinese to be an essentially ‘headless’ language. However, in certain circumstances, the location of the head can be predicted, as in a corpus study by Huang (1998) who observed that if the syntactic category of the second character is unknown, a compound with a noun as the first character has a 90% chance of being left-headed versus a 32% chance if the first character is an adjective. In other words, the syntactic category of the first character has a predictive value of the location of the character that is dominant for determining the meaning of the compound, and as such could influence the degree to which the second character is parafoveally processed. Inhoff, Starr, Solomon, and Placke (2008) showed that at least in English, the extent to which the individual constituents contribute to the meaning of a compound has an effect on eye movements. In a norming study, they asked participants to rate whether the meaning of a compound was more closely related to the meaning of the first or the second constituent, and in a subsequent eye movement experiment, they observed more pronounced frequency effects on the constituent that was rated the dominant constituent for determining the meaning of the compound (for a similar finding of the influence of semantic headedness on eye movements during reading in Italian, see Marelli & Luzzatti, 2012).
In this experiment, we will determine whether the syntactic category of the first character of a two-character compound in Chinese influences the parafoveal processing of the second character. If readers attribute more processing resources to the second character when the syntactic category of the first character more often predicts a right-headed compound (an adjective–noun compound), then an increased preview effect should occur relative to when the syntactic category of the first character more often predicts a left-headed compound (a noun–noun compound).
Method
Participants
A total of 36 undergraduates from Tianjin Normal University participated in the experiment. They were all native speakers of Chinese with normal or corrected-to-normal vision.
Apparatus
Eye movements were collected using a SR Research Eyelink 2000 (1000 Hz) eye-tracker that monitored the position of the right eye. The sentences were presented in simple Song font in black on a white background. Each character was about 2.1 × 2.1 cm2 in size. The viewing distance of the participant to the screen was 60 cm. At this distance, each character subtended approximately 2° of visual angle, ensuring that the preview character was located in the parafovea when the preceding character was fixated.
Materials and design
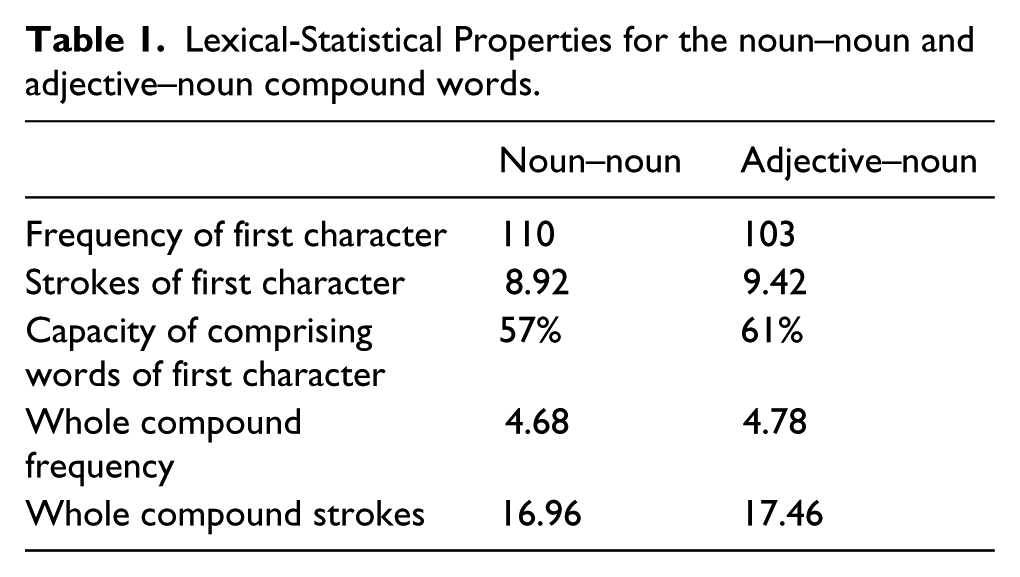
The design was a 2 (Compound Type: noun–noun and adjective–noun compound word) × 2 (Preview: identical and dissimilar preview) within-subject design. A set of 72 pairs of a noun–noun and an adjective–noun two-character compound words was constructed. Both members of the pair contained the same noun as the second character. The pairs were matched on the several lexical statistics (see Table 1): the number of strokes of the first character (t(71) < 1), the number of strokes for the entire compound (t(71) < 1), the capacity of the first character for comprising words (t(71) = 1.62, p = 0.15), character frequency of the first character (t(71) < 1) and the frequency of the whole compound words (t(71) = 1.52, p = 0.13). Word frequency was measured as words per million using the Chinese Daily Word Frequency Dictionary (1998). Character frequency was measured as characters per million (Cai & Brysbaert, 2010). The capacity of comprising words of first character, which is measured using the dictionary of Chinese Character Information (1988), counts the number of compounds which have the character as their first constituent. This measure has also been called the first constituent morphological family size.
Lexical-Statistical Properties for the noun–noun and adjective–noun compound words.
The dissimilar previews were pseudocharacters created using True Font software. They closely resembled real characters but were meaningless, as they comprised inappropriate radical combinations (though the number of radicals present in the real character and the pseudocharacter was matched as closely as possible). Furthermore, the pseudocharacter previews did not contain any of the radicals (semantic or phonetic) of the target character.
Sentence frames were created for conditions such that besides the target word itself, the content was the same up until the word after the target word. After this point, differences could occur to guarantee meaningfulness, but these were minimal. The word before the target words was always a two-character verb. The sentences appeared on one line and contained a maximum of 17 characters, and the target word was never the initial or final word. A list of incomplete sentences up to the first character of the target compound was given on a sheet of paper, and 20 students were asked to add the next character, using a Latin square design, such that the participants saw each sentence frame only once with 10 subjects completing each version. The predictability was similar for the noun–noun (M = 42.8%, SD = 0.52) and adjective–noun compound words (M = 46.5%, SD = 0.54), t < 1. A plausibility pretest was also conducted to guarantee the target words fitted well in the sentences. A total of 30 students were asked to rate the target sentences for their plausibility, using a 5-point scale (1 = very plausible, 5 = very implausible). Besides the 72 experimental sentences, we added 30 another sentences which were somewhat implausible. There were no significant differences between the noun–noun (M = 1.26, SD = 0.17) and adjective–noun compound words (M = 1.22, SD = 0.15), t < 1. Finally, 30 participants were provided with one of the two possible sentences and asked to mark with a ‘/’ all of the word boundaries in the sentence. If participants judged the target character pair to be one word, we provided a score of 1; if they judged the target character pair to be two words, we provided a score of 0. No significant differences in segmentation judgments occurred between adjective–noun (74.5%, SD = 0.16) and noun–noun compounds (70.1%, SD = 0.12, ts < 1.79).
We adopted the boundary paradigm (Rayner, 1975). The invisible boundary was placed between the two characters of compound words. As soon as the eyes moved across the invisible boundary, the preview character was replaced by the target character. An example sentence pair is given in Figure 1.

The target words were noun–noun and adjective–noun compound words and are in bold (though they were presented normally during the experiment). The location of the invisible boundary is indicated (|). The preview was either an identity preview (肉, meat) or a dissimilar pseudocharacter, and this was initially displayed in the target location. When the reader’s eyes crossed the invisible boundary, the preview was replaced by the target character (肉, meat). Note that whereas in English, the word fish can refer to both the animal and its meat, in Chinese, the constituent meat is added to fish to refer to the latter.
Procedure
Prior to the experiment, participants were given the instructions for the experiment. Then, a 3-point calibration was performed. The accuracy of the calibration was rechecked before each sentence and another calibration was performed whenever necessary. Participants were told to read sentences for comprehension at their own rate. The items were counterbalanced using a Latin square design such that the participants saw only one version of the compound. After every three sentences, a comprehension question was asked about the preceding sentence. The participants answered the questions by pressing a yes or no key. After the experiment, participants were asked whether they experienced anything unusual during reading. A small number of subjects reported seeing something flicker on the screen on only one or two trials. No participant was able to report exactly what it was that they had seen. The mean comprehension accuracy was 89.6% for the participants who were included in the analysis. In total, participants read 114 sentences: 72 experimental sentences randomly intermingled with 36 fillers sentences, preceded by 6 practice sentences. Including 5 min for the initial calibration of the eye-tracking system, the whole experiment lasted about 30 min.
Results
Three participants were discarded because their comprehension accuracy was below 75%. One additional participant was discarded because more than 25% of the display changes occurred during a fixation. For the 32 participants included in the analyses, trials in which the display change occurred during a fixation on the first character due to drift were excluded. Following Cui, Drieghe et al. (2013), fixations less than 60 ms or greater than 600 ms (a criterion exceeding more than 3 standard deviations from the mean in the current experiment) were also excluded. In total, 10.2% of the data was excluded (including track losses). None of the participants reported noticing more than five display changes, so none were removed for this reason.
To analyze the data, linear mixed-effects models were constructed using the lme4 package (Version 1.1-12, Bates, Maechler, Bolker, & Walker, 2015) in R (Version 3.3.1; R Core Team, 2016). Contrasts are reported both for the main effect of Preview and compound structure manipulation. A ‘full’ random structure was implemented specifying subjects and items as random factors including all varying intercepts and slopes of the main effects and their interaction. Fixation time analyses were carried out on log-transformed models to increase normality, and skipping data were analyzed using logistic models. Fixation time measures averaged across participants are presented in Table 2 with significant effects featured in bold; the parameter estimates from the linear models are presented in Table 3, again with significant estimates in bold.
Eye-tracking measures.
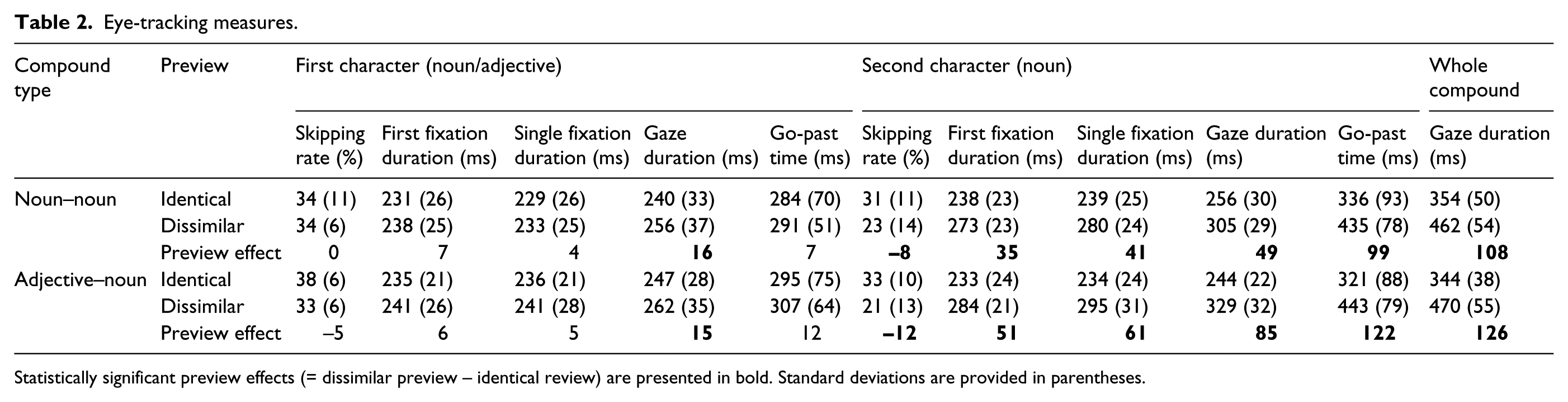
Statistically significant preview effects (= dissimilar preview – identical review) are presented in bold. Standard deviations are provided in parentheses.
Parameter estimates, standard errors and t values or z values from mixed-effects models.
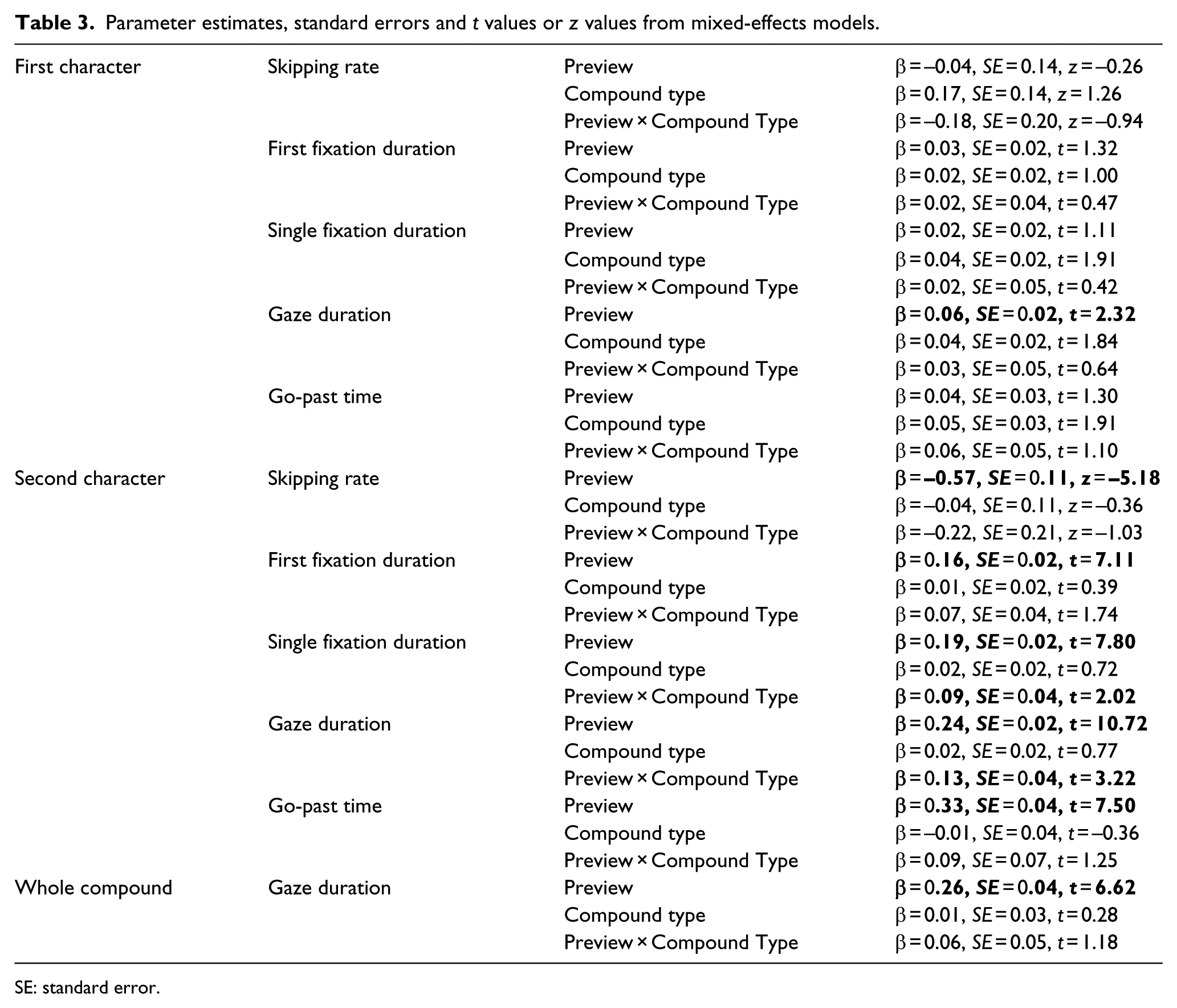
SE: standard error.
Eye fixation measures for the first constituent
No effects of Preview were observed in skipping rates, first fixation duration, single fixation duration or go-past times. However, gaze durations were 16 ms shorter when the second character was presented normally versus when the dissimilar preview was presented. No significant effects of Compound Type were observed but there were marginally significant effects in single fixation duration, gaze duration and go-past times suggesting shorter fixation times when the first character of the compound was a noun compared with an adjective. The interactions between Preview and Compound Type were never close to significant.
Eye fixation measures for the second constituent
Significant effects of preview were observed for skipping rates and all fixation time measures with reduced skipping and longer fixation times when the dissimilar preview was presented compared with when the identical preview was presented. The main effect of Compound Type was never close to significant in any of the measures. However, the interaction between preview and Compound Type was marginally significant in first fixation duration and was significant in single fixation duration (see Figure 2a) and gaze duration (see Figure 2b) but not close to significant in go-past times. As can be seen from Figure 2, the interaction is due to the preview effect being larger for the adjective–noun compounds compared with the noun–noun compounds. It is important to note that a qualitatively identical model was also observed for gaze duration when we restricted the analyses to those instances when the first character was not skipped (66% of valid trials), indicating that the same patterns were observed when restricting our data set to those instances when the visual acuity of the parafoveal preview would be at its best.
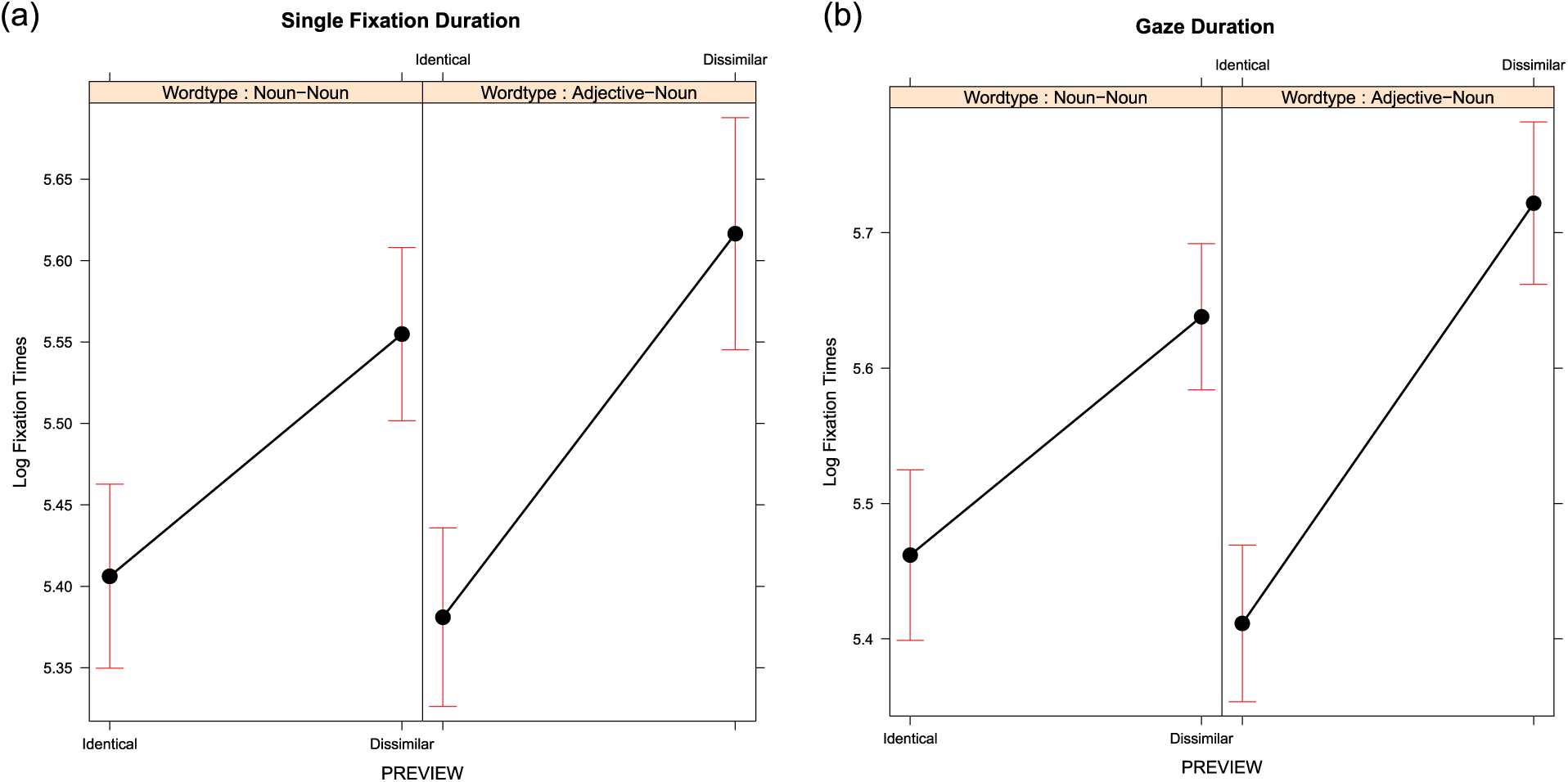
Model estimates for Preview and Compound Type effects for fixation durations on the second constituent: (a) single fixation duration (b) gaze duration.
Eye fixation measures for the whole compound
We also examined the gaze duration on the compound as a whole. Gaze durations showed a significant effect of Preview. When the preview was dissimilar, gaze duration on the compound was 117 ms longer than when the preview was identical. No effect of Compound Type was observed and the interaction was not significant.
Discussion
Parafoveal processing of the second character of either an adjective–noun or a noun–noun two-character compound word was examined during Chinese reading. The results were straightforward. Standard preview effects were obtained in that skipping of the second character was increased and fixation durations on the second character were reduced when the preview was identical compared with when the preview was dissimilar. An interaction was observed in terms of the disruption of the dissimilar preview being greater when the first character was an adjective compared with when it was a noun. This effect was not present in the skipping of the second character but first appeared in first fixation duration on the second character (although only marginally significant) and became statistically significant in single fixation and gaze duration but restricted to fixation measures on the second character (no longer present in go-past times which include fixations after a regression originating from the character).
We predicted the presence of increased disruption of the dissimilar preview in an adjective–noun compared with a noun–noun compound based on the predictive value of the syntactic category for the right-headedness versus left-headedness of a compound (with an adjective predicting right-headedness, Huang, 1998) which would lead to increased parafoveal processing of the second character when the first character is an adjective (predicting right-headedness, Huang, 1998) compared with a noun (more often featured in left-headed compounds).
This finding is theoretically important because it demonstrates that parafoveal processing within a compound can be influenced by the lexical characteristics of the first constituent (see also Cui, Yan, et al., 2013, for a similar claim). Chinese has been described as essentially a ‘headless’ language (Huang, 1998), in other words, it does not feature a much higher prevalence of right-headed versus left-headed compounds or vice versa. However, once the syntactic category of the first constituent has been established during reading in Chinese, it does carry a substantial predictive value for the headedness of the compound, and our results indicate that readers use this predictive value. Nevertheless, it is also important to note that this predictive value will still be far from perfect. Also, our norming studies indicated that a word boundary in between the constituents of the compound (i.e., an interpretation in which the first character is a single character word) was not considered unlikely. A word boundary would reduce parafoveal processing regardless of the syntactic category of the fixated character. Combined, our results indicate a dynamic within-word modulation of parafoveal processing highly sensitive to the lexical characteristics of the first character, specifically its syntactic category and the associated predictive value for the headedness of a compound. Moreover, this effect is strong enough to become statistically significant in a reading experiment even though the predictive value of the syntactic category of the first constituent for the headedness of the compound will be far from perfect, and ambiguity regarding word boundaries which itself could have worked against the effect we obtained.
No significant main effects of Compound Type were observed although a marginally significant effect on the first character was present suggesting a small reduction in fixation duration on the noun compared with the adjective. Whether this effect is real is uncertain given that it was not accompanied by any hint of an effect of Compound Type on the second character or the entire compound. Future research may elucidate whether this effect reflects aspects of parafoveal processing. Finally, an effect of Preview on the first character was observed but restricted to slightly longer gaze durations when followed by the dissimilar preview. In other words, only in those instances when the first character received a second fixation did the preview manipulation influence fixation durations on that character. These data are compatible with findings such as Drieghe et al. (2010) who in English observed only a numeric trend towards longer fixation durations prior to the dissimilar preview of a second constituent. We interpret the limited effect as indicative of constituent decomposition whereby the first constituent is prioritized in lexical processing, and as such, fixation durations on the first constituent almost exclusively reflect processing restricted to the fixated constituent.
Summarizing, strong evidence was obtained for parafoveal processing of the second character of a Chinese compound word being influenced by the syntactic category of the first constituent such that increased parafoveal processing occurs when the syntactic category of the compound predicts the second character to be dominant for determining the meaning of the compound.
Footnotes
Declaration of conflicting interest
The author(s) declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: D.D. and S.P.L. were supported by a Leverhulme Trust Research Grant (RPG-2013–205). The L.C. was supported by a grant from the Natural Science Foundation of China (31200765), a grant from the Natural Youth Science Foundation of Shandong (ZR2012CQ034) and a grant from the China Postdoctoral Science Foundation (2015M582125).