
Abstract
A central problem of behavioural studies providing artificial visual stimuli for non-human animals is to determine how subjects perceive and process these stimuli. Especially in the case of videos, it is important to ascertain that animals perceive the actual content of the images and are not just reacting to the motion cues in the presentation. In this study, we set out to investigate how dogs process life-sized videos. We aimed to find out whether dogs perceive the actual content of video images or whether they only react to the videos as a set of dynamic visual elements. For this purpose, dogs were presented with an object search task where a life-sized projected human was hiding a target object. The videos were either normally oriented or displayed upside down, and we analysed dogs’ reactions towards the projector screen after the video presentations, and their performance in the search task. Results indicated that in the case of the normally oriented videos, dogs spontaneously perceived the actual content of the images. However, the ‘Inverted’ videos were first processed as a set of unrelated visual elements, and only after some exposure to these videos did the dogs show signs of perceiving the unusual configuration of the depicted scene. Our most important conclusion was that dogs process the same type of artificial visual stimuli in different ways, depending on the familiarity of the depicted scene, and that the processing mode can change with exposure to unfamiliar stimuli.
Introduction
From the dawn of animal behaviour studies, artificial visual stimuli were an integral part of the scientific toolbox of researchers (e.g., Noble & Clausen, 1936; Tinbergen & Perdeck, 1950). Artificial visual stimuli have the advantage compared to live presentations of being highly controllable and potentially invariable (e.g., Müller, Schmitt, Barber, & Huber, 2015). Images are often-used forms of artificial visual stimuli due to their ease of use (production, manipulation and presentation). Videos have the obvious advantage over static pictures that they can display actions, therefore they are more suitable to present stimuli in experiments about social interactions (e.g., Landmann, Parzefall, & Schlupp, 1999; Macedonia & Stamps, 2010).
A crucial point of using artificial stimuli is whether subjects perceive the correspondence between the image and its depicted natural counterpart (Bovet & Vauclair, 2000). Only after this question has been answered can researchers correctly interpret the results of their experiments (Spetch, 2010). According to Fagot, Thompson, and Parron (2010), animals process images in three different ways: independence mode, confusion mode and equivalence mode. These processing modes represent different models of cognitive connections between the image and the object or scene it depicts. In independence mode, the animal makes no connection between the picture and its content, but processes the picture as a combination of features or patterns independently of what the picture represents. In confusion mode, the animal confuses the image and its referent, thus reacting roughly the same way to an image as to the real object. In equivalence mode, the animal comprehends that the picture is not only an entity in itself but also a representation of the depicted object; this mode of processing is also known as referential understanding (DeLoache, 1991).
There have been an increasing number of studies in the past decade utilising pictures (e.g., Autier-Dérian, Deputte, Chalvet-Monfray, Coulon, & Mounier, 2013; Faragó et al., 2010; Müller et al., 2015; Range, Aust, Steurer, & Huber, 2008; Somppi, Törnqvist, Hänninen, Krause, & Vainio, 2012) and videos (e.g., Harr, Gilber, & Phillips, 2009; Péter, Miklósi, & Pongrácz, 2013; Pongrácz, Miklósi, Dóka, & Csányi, 2003; Téglás, Gergely, Kupán, Miklósi, & Topál, 2012) for testing dogs’ cognitive abilities. The numerous successful applications of images in these studies may suggest that dogs have little difficulty perceiving the content of pictures and videos. However, the crucial question of how dogs process these stimuli has been raised in only one experiment so far (Péter et al., 2013).
Péter et al. (2013) presented dogs with life-sized, pre-recorded videos of a human hiding a target object in one of the three locations. After the video presentation ended, dogs were allowed to search for the hidden object in the containers that were placed identically to the ones seen on the video footage. They could reliably find the object when the video presentation and the hiding locations were in the same room, but could not do so when the video presentation and the hiding locations were staged in different rooms. This finding indicated that dogs were not spontaneously capable of processing the videos in equivalence mode. At the same time, when the dogs had to search in a separate room, there was a connection between the time spent attending to the video demonstration and the probability of choosing the correct location in the subsequent trial. This indicates that some of the subjects could have made a mental connection between the content of the video and its real-life referent.
Based on these results, and the findings of an earlier study where dogs could follow the pointing gesture of a projected life-sized human (Pongrácz et al., 2003), it was concluded that, most likely, dogs processed the videos in confusion mode. In the experiment of Pongrácz et al. (2003), dogs performed with the same accuracy in the two-way choice test whether the pointing cues were given by a projected or a real experimenter. In the case of the study done by Péter et al. (2013), the possibility of processing in independence mode was argued against because dogs showed no sign of learning during the test trials. The logic behind this argument was that if dogs perceived the videos as a set of unrelated low-level visual stimuli, then making the association between these and the target location would have required several trials (as was observed by Milgram et al. (1999)).
Still it remains possible that dogs did solve the tasks both in the studies of Péter et al. (2013) and the Pongrácz et al. (2003) by utilising only local enhancement cues and without perceiving the content of the videos (e.g., by simply going to that location where they previously detected motion). On the other hand, several other studies gave evidence that dogs perceive still pictures according to the content it depicts (e.g., photographs of dogs – Bálint, Faragó, Dóka, & Miklósi, 2013; Faragó et al., 2010; pictures of humans – Adachi, Kuwahata, & Fujita, 2007; Albuquerque et al., 2016; Nagasawa, Murai, Mogi, & Kikusui, 2011). An especially interesting study from this aspect was performed by Müller and colleagues (2015), who showed that dogs can discriminate between human faces showing anger or happiness based on still pictures shown on a touch screen device. With careful control tests, the authors proved that dogs did not only respond to simple discriminatory cues like visible or non-visible teeth on the portraits (which in turn would be equal with processing in independence mode), but the subjects most probably recognized the corresponding emotions from the pictures (which probably means that they responded in confusion mode).
Our aim in this study was to investigate further how dogs process images, and we chose to concentrate on videos that are the most versatile form of artificial visual stimuli. The main question arising from studies using video presentations so far is whether dogs processed them in independence mode (by not connecting the image and the content) or in confusion mode (by recognising the content, for example, there is a human visible on the videos).
To address this question, we planned an experiment where similar to the article by Péter et al. (2013), dogs were presented with a two-way object search task, where a life-sized projected human hides the target object. We used three types of video presentations: (1) In the ‘sudden appearance’ condition dogs see a human standing behind one of the two containers hiding the object – therefore attending to simple motion cues would be sufficient to solve the task. This condition resembled in almost every detail to the one used by Péter et al. (2013), with the exception in this study we used only two hiding locations versus three in the earlier article. (2) In the ‘Realistic’ condition, a human is visible entering the room from the side, hiding the target object at one of the two locations and then leaving the room at the other side – we assume that this type of video with ambiguous motion cues would make associating them with the target more demanding, therefore it is unlikely that dogs could successfully perform the search task if they respond only to simple motion cues. Finally, (3) in the ‘Inverted’ condition, dogs see the horizontally inverted (i.e., flipped around the horizontal axis) versions of the ‘Realistic’ videos – an impossible scenario that could be used to determine whether dogs recognised the content of the images.
We collected two main response variables: performance (number of correct first choices) and screen-oriented behaviour (‘SOB’ – sniffing or looking at the screen after the video presentation has ended). The later variable is used instead of looking time (measured during the presentation) that is employed in violation of expectation (Müller, Mayer, Dorrenberg, Huber, & Range, 2011) or preferential looking procedures (West & Young, 2002). We chose to use SOB based on observations made in our previous study (Péter et al., 2013): (1) time spent looking at the presentation was invariably high, most likely because dogs were motivated by the object search task to look at the videos (such a motivation for looking at the presented stimuli is absent in traditional violation of expectation experiments) and (2) we observed dogs on numerous occasions showing SOB, especially in the first few trials, that suggested that this variable could be used to gauge the level of dogs’ specific interest towards the (disappearing) content of the video clip.
Depending on how dogs process the videos, we expect them to show different reactions in the three conditions (Table 1). If dogs process all projected videos in independence mode that would mean that they only perceive them as a combination of visual elements, unrelated to the content of the images. Therefore, we would expect no difference in SOB of dogs between any of the experimental conditions. However, the number of correct choices should be the highest in those conditions (‘sudden appearance’, ‘Realistic’), where the motion cues on the video are easiest to associate with the location of the target object. Additionally, we can expect dogs having a higher rate of correct choices in the later trials compared to the earlier ones, due to dogs learning to associate the motion cues on the video with the location of the hidden target. Another way to show that dogs were attending to motion cues is to test if the path of the human demonstrator in the ‘Realistic’ and ‘Inverted’ conditions influences the dogs’ first choices. If dogs choose the target that is on the side where the demonstrator exits on the screen significantly more often, then it can be argued that they were following simple motion cues, and were not attending to the events depicted in the video.
The distribution of the different variables (rows) predicted by the two opposing hypotheses about dogs’ image processing (columns).
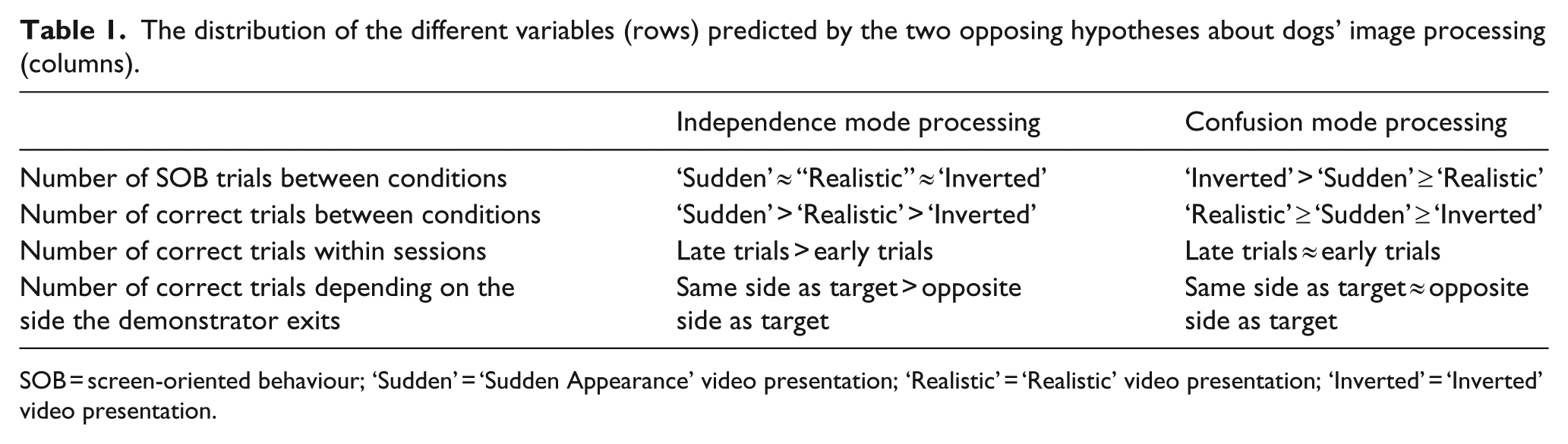
SOB = screen-oriented behaviour; ‘Sudden’ = ‘Sudden Appearance’ video presentation; ‘Realistic’ = ‘Realistic’ video presentation; ‘Inverted’ = ‘Inverted’ video presentation.
In case dogs process the videos in confusion mode, then we expect them to show more SOB in the ‘Inverted’ condition than in the sudden appearance or the realistic conditions. The number of correct choices should be highest in the realistic condition and lowest in the ‘Inverted’ condition, while performance in the sudden appearance conditions might be influenced by the amount of ‘surprise’ (SOB) that dogs would show. We also would not expect dogs to have more correct trials in the beginning or the end of the sessions (in accordance with several other studies, employing repeated trials with two-way choice response upon human or conspecific cueing, for example, Bálint et al., 2015; Hegedüs, Bálint, Miklósi, & Pongrácz, 2013; Pongrácz, Gácsi, Hegedüs, Péter, & Miklósi, 2013), nor would we expect the demonstrator’s path having an effect on dogs’ chance for finding the target.
Methods
Subjects
Dogs (N = 42; 22 females and 20 males) and their owners were recruited on a voluntary basis. The dogs had to be motivated to retrieve a ball. Dogs were older than 1 year (mean age = 3.3 years, range = 1–11 years) and represented various pure and mixed breeds. Prior to the experiment, the owners were given a general explanation of what will happen during the test, what will they be requested to do (and what they should not do), but they were not informed ahead about the exact goal of the study.
Setup
The tests were performed indoors, in an experimental room of the Department of Ethology, Eötvös Loránd University, Budapest (Figure 1). The room used in this study was 3 m wide and 6 m long. In all conditions, two hiding locations were used, each one composed of a blue rectangular plastic panel (30 cm × 30 cm) and a plastic flower pot (diameter = 12 cm) fixed behind the panel. The two hiding locations were 1.5 m from each other and approximately 3 m from the starting position of the dog. We used a small ball as the target object. The projector screen was located behind the hiding locations (2 m wide, 1.8 m tall) and behind the screen were two speakers. The projector was fixed near the ceiling at the other end of the room.
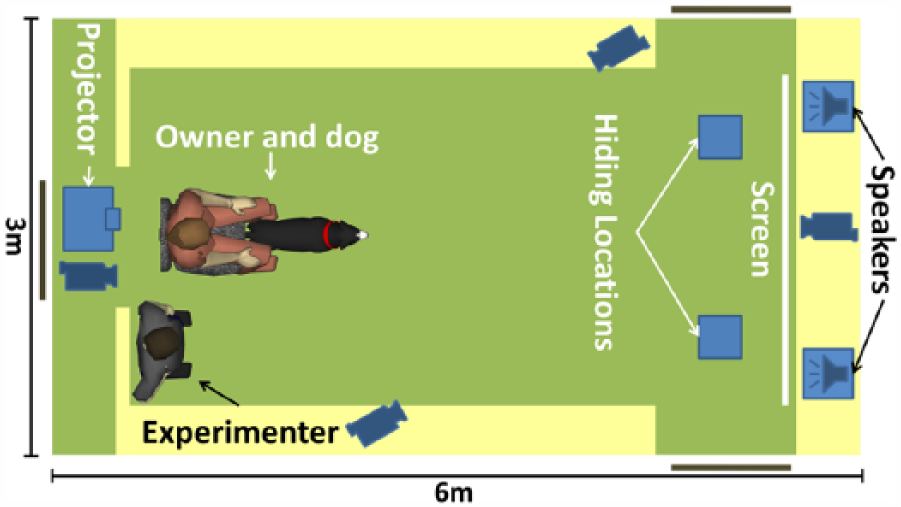
The arrangement of the experimental room. Owner, experimenter and dog are staying at the starting positions in the warm-up trials. The events in the room were recorded by four video cameras. Behind the experimenter there is a curtain, where the experimenter could hide during the test trials.
Procedure
The experiment consisted of three conditions. All subjects participated in each experimental condition; the sequence of conditions was counterbalanced among subjects. The conditions were separated by 5-min long breaks. The procedure of the conditions was identical, except for the projected video demonstration. All conditions comprised 2 warm-up trials and 6 test trials.
Warm-up trials
Each warm-up trial started with the dog, the owner and the experimenter being at the starting position. The experimenter (A.P., the same young man who was visible on the video footages) showed the target object to the dog, went straight to the actual hiding location, stopped behind it facing the dog, called the dog’s attention (‘Look, look, look!’), raised and waved the object, put it into the pot behind the hiding location and finally returned next to the owner. After this, the owner released the dog with one command (‘You can go!’) to search for the target object. The dog was allowed to search until the object was found. Last, the owner called the dog back, praised it and took back the object. We performed two warm-up trials, where the target was placed behind both hiding locations once in a random order.
Test trials
After the warm-up trials, the owner covered entirely the eyes of the dog with his/her both hands, and the experimenter turned off the lights in the room. The windows of the room were covered, therefore the room was semi-dark. The experimenter took the object to the actual hiding location and put the object into the pot behind it, then returned to a location behind the owner where he hid behind a curtain. After returning, the experimenter started the video projection by pressing a button on the wall, and the owner uncovered the eyes of the dog. The pre-recorded video was projected onto the screen behind the hiding locations. On each video, the experimenter was the same person, wearing the same clothes. The resolution of the videos was 720 × 540 with 25 frames per second; the projector was a NEC MT-850, with a resolution of 800 × 600, a refresh rate of 60 Hz, a brightness of 1700 ANSI lumens and a 350:1 contrast ratio; the videos were upsampled to the resolution of the projector during presentation.
One could argue that dogs may use their noses in such experiments to find the target. Besides the fact that after the ball was repeatedly put into each pot they became equally exposed to odour traces from the ball, there is an ample amount of empirical evidence that dogs are less than ready to use their noses in an ordinary task where otherwise visual cues are available. An experiment done by Polgár, Miklósi, and Gácsi (2015) showed that in discrimination tasks where dogs had to identify their owners against strangers, olfactory cues had surprisingly low impact. In the so-called two-way choice setup, where human-given (or, projected human-given) cues were provided, again dogs did not rely noticeably on olfactory cues (e.g., Pongrácz et al., 2003; Szetei, Miklósi, Topál, & Csányi, 2003).
Another factor may affect dogs’ choice in the above described method is the possible influence from the owner (‘Clever Hans effect’). However, as we showed in an earlier study (Hegedüs et al., 2013), even if the owners were asked to bias actively the choice behaviour of their dogs in a two-way choice test, it could not alter the response of the subjects to the experimenter-given cues.
Altogether, although we cannot exclude the possibility that dogs might be sensitive to other cues than the intended experimental treatment was (i.e., the test videos), we should keep in mind that these possible alternative cues (e.g., smell, sound, owner-given information) were present equally in each experimental trials and conditions, therefore the real difference between the conditions came from the different video presentations.
Realistic (‘realistic’) condition
The video started with showing the two hiding locations from the perspective of the dog on the starting position. Then a human (the experimenter, P.A.) entered through one of the doors visible on the side while saying ‘Hello!’, walked behind the actual hiding location, turned towards the dog, raised the target object and said ‘Look, look, look!’. Next, the experimenter on the video crouched down, placed the ball to the actual hiding location and stood up displaying his empty hands. Finally, the experimenter continued walking in the same direction as before, left through the door on the opposite side where he entered, and closed the door behind himself (Figure 2). The side on which the experimenter entered was randomly chosen in the first trial and was systematically alternated in the consecutive trials. The video projection (as in each condition) showed a life-size experimenter, and from the dog’s perspective the hiding locations appeared roughly at the same position (although about 40 cm higher) as they were placed in the room in reality.

The key moments of the video demonstration in the realistic condition. The frames are organised in the order of their appearance from left to right, starting in the upper left corner. Dogs were presented alternately with two variants of this video clip, on the other variant the experimenter entered on the left side and left the scene on the right side.
Sudden appearance (‘sudden’) condition
The video was similar to that in the ‘Realistic’ condition; however, the experimenter did not walk across the scene. The video started by showing the experimenter standing right behind the actual hiding location. He stood still for 1 s, greeted the dog saying ‘Hello!’, and waved the ball saying ‘Look, look, look!’. Next, he crouched down, placed the ball to the actual hiding location and stood up displaying his empty hands for 1 s (Figure 3).

The key moments of the video demonstration in the sudden appearance condition. The frames are organised in the order of their appearance from left to right, starting in the upper left corner.
‘Inverted’ condition
In his condition, the video was identical to that in the ‘Realistic’ condition; however, the video was mirrored horizontally so that the whole presentation was displayed upside down (Figure 4). The location where the ball has been hidden on the video sequence was on the same side and (from the perspective of the dog) roughly above the actual location where the real ball has been hidden in the test room. The side on which the experimenter entered was randomly chosen in the first trial and was systematically alternated in the consecutive trials.

The key moments of the video demonstration in the ‘Inverted’ condition. The frames are organised in the order of their appearance from left to right, starting in the upper left corner. Dogs were presented alternately with two variants of this video clip, on the other variant the experimenter entered on the left side and left the scene on the right side.
In case of the ‘Realistic’ and ‘Inverted’ demonstrations, two types of trials can be differentiated based on the relationship between the sides of the experimenter’s entry and the hidden target’s location: (1) trials where the projected human entered the scene on the same side where the (then to be baited) target location was (identical entry) and (2) trials where the human left the scene on the same side where the (already baited) target location was (identical exit).
The experimenter on the videos placed the object to the location on the same side where a real ball was surreptitiously hidden by the real experimenter before the projection was started. After the video was over, the screen changed black and the experimenter turned the lights on. The owner released the dog without a command word and sat silent and motionless. The trial lasted until the dog returned the object to the owner or until 1 min has passed. At the end of the trial, the experimenter started talking to the dog which also served as a signal to the owner that the trial was over. If the dog returned the object to the owner, the dog was praised. If the dog did not find or return the object within 1 min, the owner and the experimenter encouraged the dog to search for or return the object (however, the trial was scored as ‘unsuccessful’). During the six test trials, the object was placed behind each hiding location three times in a semi-random order, so that it was never at the same location in three consecutive trials.
Data collection and analysis
All test sessions were video recorded and the recordings were coded with Solomon Coder beta (© 2012 by András Péter) and data were analysed with IBM® SPSS® Statistics 21. Dogs’ first location choices were coded in each trial: location choice was defined as the first pot the dog looked into. Trials were classified as a ‘correct trial’ if the dog chose the location where the ball was within 1 min. We also coded whether dogs oriented towards the projector screen in the search phase of the trials (after the video demonstration and before the end of the trial). SOB was defined as two behaviours: (1) looking into the direction of the screen while standing still and (2) sniffing at the screen. Trials were classified as an ‘SOB trial’ if the dog showed any of the two above described behaviours in the first 10 s of the trials. The 10-s limit was used to compensate for the variation of trial lengths, while the binary classification of trials was employed to compensate for the individual variability of the duration and frequency of SOB.
For the two variables, inter-rater reliability was determined using the Kappa statistic, based on the data of 25 randomly selected videos (out of 126). Videos were double coded by an independent coder who was naive regarding the aim of the study (correct trials: Kappa = 1.00, p < 0.001, 95% confidence interval [CI] = [1.00, 1.00]; SOB trials: Kappa = 0.84, p < 0.001, 95% CI = [0.74, 0.94]).
We analysed the distribution of our coded variables with a generalised linear mixed model (GLMM) along three factors: (1) condition (cond): what type of video demonstration was used in the session (‘Sudden’, ‘Realistic’, or ‘Inverted’); (2) session sequence (S_seq): whether the session took place as the first, second or third; and (c) trial sequence (T_seq): separating the first three (1−3) and last three (4−6) trials of each session. The condition and session-sequence factors had three states each and were overlapping (depending on the subject, a session could have any demonstration type and any position in the sequence), while the trial sequence had two states and was independent from the other two factors. Because all the data were in binary format, we used a GLMM with a complementary log–log link. The target variable was the sum of the first three and the last three correct or SOB trials of each session. Condition (‘Sudden’, ‘Realistic’, ‘Inverted’), session sequence (first, second and third session) and trial sequence (Trials 1−3 and Trials 4−6) and their interactions (Cond × S_seq, Cond × T_seq, S_seq × T_seq, Cond × S_seq × T_seq) were defined as fixed effects. Subject identifier was used as a random factor. To analyse the pattern of difference between the individual factors, we contrasted the estimated marginal means produced by the model. We only calculated the pairwise contrasts for significant effects or interactions, and used the least significant difference (LSD) method to adjust for multiple comparisons.
The number of correct trials was compared to the chance level. This was performed separately for the first three and the last three trials with binomial test and the obtained p-values were adjusted for multiple comparisons with the Benjamini–Hochberg method (Benjamini & Hochberg, 1995).
Last, we analysed whether the number of correct trials was influenced by the projected human’s path on the video (identical entry vs. identical exit). The trials were only analysed this way in the two conditions (‘Realistic’ and ‘Inverted’) where the demonstrator was actually walking on the video. Correct trials were selected as the target variable; condition (‘Realistic’/‘Inverted’) and demonstrator’s path (identical entry/exit) were entered as fixed factors and interaction in the model; subject identifier was used as a random factor.
Results
First, we analysed the effect of condition, session sequence and trial sequence on the number of correct trials and the number of SOB trials (Table 2). The number of correct trials was significantly influenced by an interaction between condition and trial sequence. The number of SOB trials was significantly influenced by session sequence, trial sequence and an interaction of condition and session sequence.
Results of the two generalised linear mixed models analysing the effects of conditions (Cond), session sequence (S_seq), trial sequence (T_seq) and their interactions on the number of correct trials and the number of SOB trial.
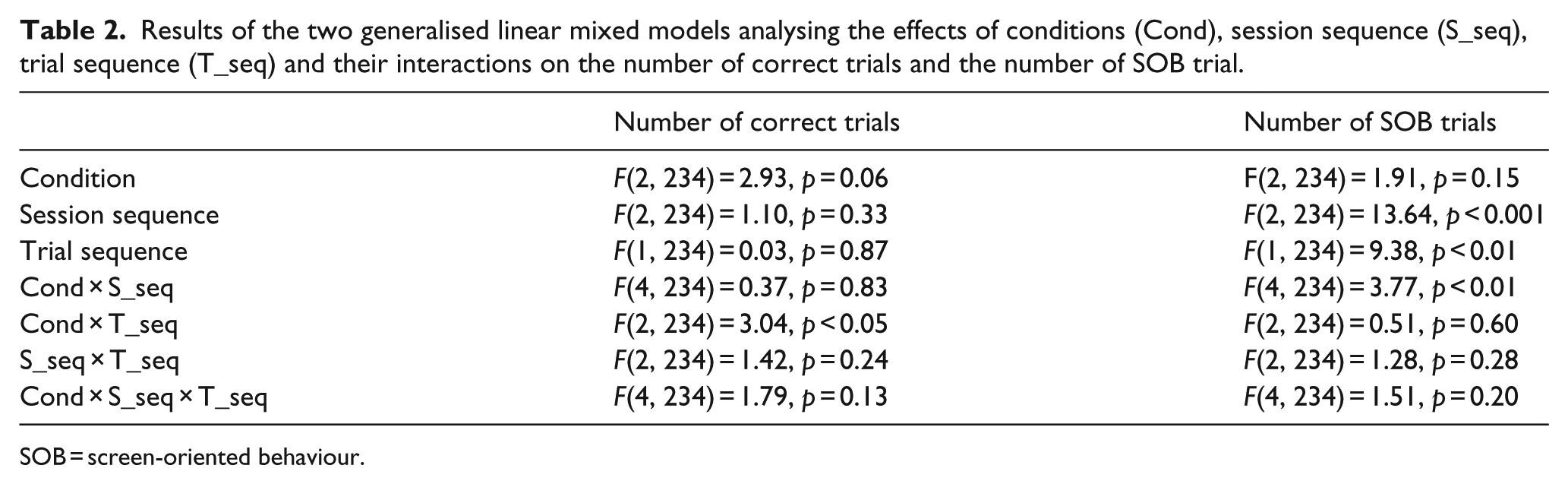
SOB = screen-oriented behaviour.
Next, we calculated the contrasts of the estimated means for all the significant interactions and for the significant effects which were not included in any significant interactions. We started with the condition and trial sequence interaction for the number of correct trials (Table 3). In the ‘Inverted’ condition, dogs performed better in the early trials than in the later ones; however, no such difference was found in any of the other conditions (Figure 5).
Results of the contrasts of estimated means of the interaction condition × trial sequence for the number of correct trials. The condition and trial sequence interaction was analysed with trial sequence selected as the contrast field.

Sud. = ‘Sudden appearance’; Rea. = ‘Realistic’; Inv. = ‘Inverted’.
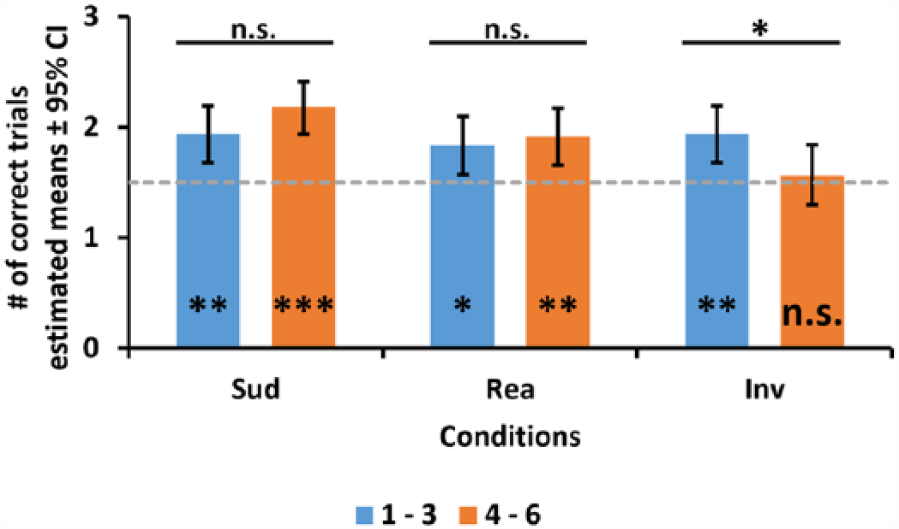
Comparison of the number of correct trials in the experimental conditions between the first three (1–3) and last three (4–6) trials. Solid horizontal lines above the graph mark the results of the pairwise contrasts of estimated means (n.s. = p ≥ 0.05; *p < 0.05). Comparison of the number of correct trials in each condition for the first three and last three trials to that expected by chance (dashed grey line marks the chance level; markings on the bottom of the graph denote the deviation from the level expected by chance; n.s. = p ≥ 0.05; *p < 0.05; **p < 0.01; ***p < 0.001).
We also compared the number of correct trials in the three conditions to the level expected by chance (Figure 5). According to this, dogs performed above chance in all conditions, except in the last three trials of the ‘Inverted’ condition (‘Sudden’ 1−3: W = 701, p < 0.01; ‘Sudden’ 4−6: W = 788, p < 0.001; ‘Realistic’ 1−3: W = 639, p < 0.05; ‘Realistic’ 4−6: W = 684, p < 0.01; ‘Inverted’ 1−3: W = 681, p < 0.01; ‘Inverted’ 4−6: W = 496, p = 0.55).
Next, we analysed the significant effects and interactions for the number of SOB trials (Table 4). When contrasting the estimated means of trial sequence, we found significantly more SOB trials in the first three trials than in the last three ones (estimated M ± SD: Trials 1−3: 0.56 ± 0.11, Trials 4−6: 0.30 ± 0.07). When analysing the estimated means for the condition and session sequence interaction we found that in the first session dogs showed significantly more SOB in the realistic than in the ‘Inverted’ condition. However in the third session, the exact opposite was true, with significantly more SOB trials in the ‘Inverted’ condition than in the other two conditions (Figure 6).
Results of the contrasts of estimated means of the effect trial sequence and the interaction condition × session sequence for the number of SOB trials. The condition and session sequence interaction was analysed with condition selected as the contrast field.
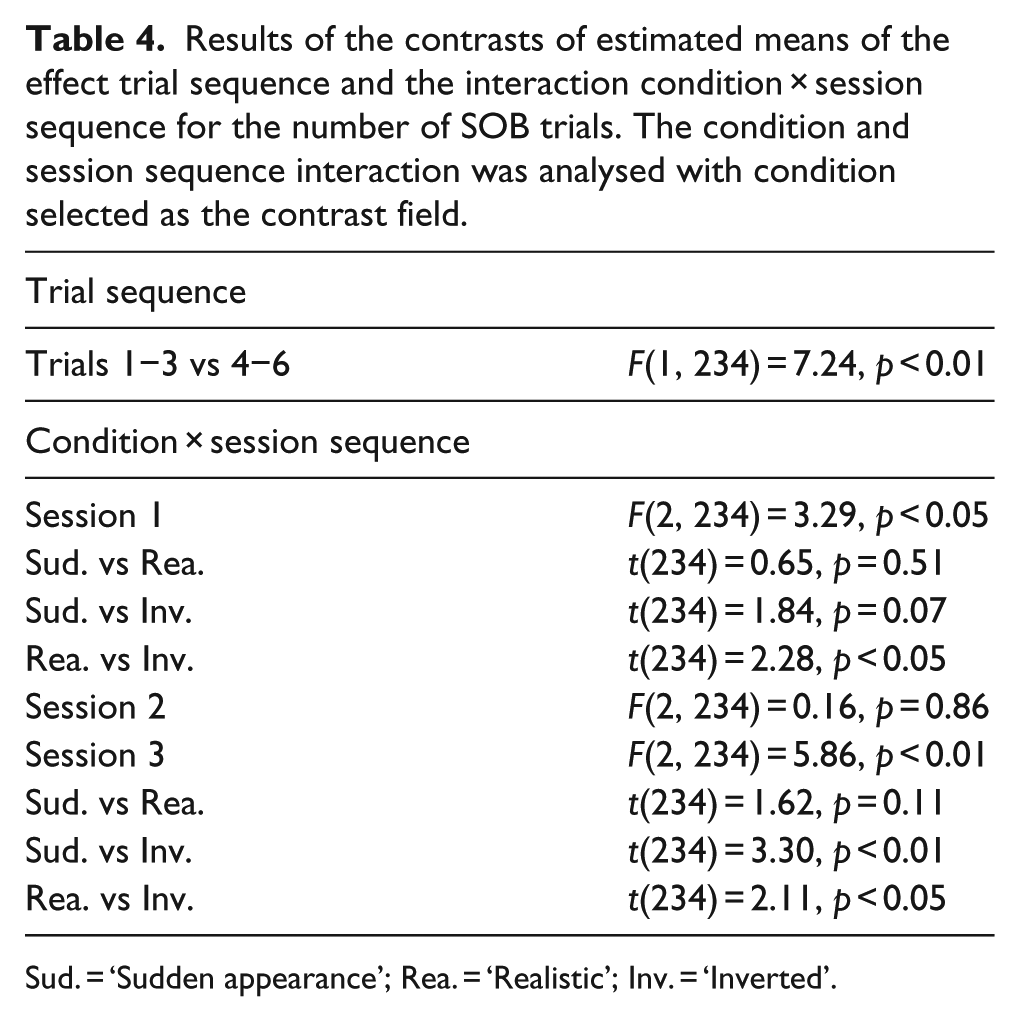
Sud. = ‘Sudden appearance’; Rea. = ‘Realistic’; Inv. = ‘Inverted’.
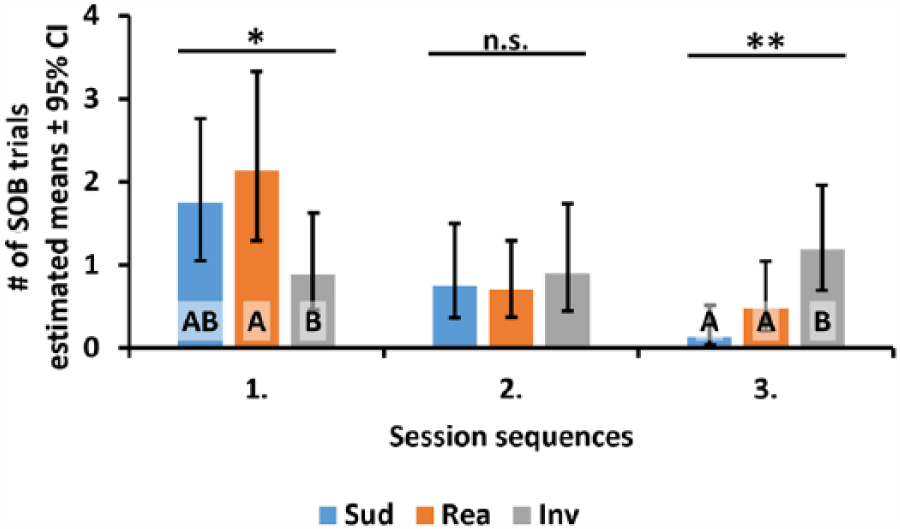
Comparison of the number of SOB trials in the three consecutive sessions between the experimental conditions. Solid horizontal lines above the graph mark the results of the contrasts of estimated means; n.s. = p ≥ 0.05; *p < 0.05; **p < 0.01; capital letters A and B mark the conditions that differ significantly from each other, according to the pairwise contrasts of the estimated means; conditions sharing the same letter(s) do not differ significantly. SOB = screen-oriented behaviour.
Regarding whether the number of correct trials was influenced by the projected human’s path on the video, we found no significant effect of condition, F(1, 500) = 1.93, p = 0.17, but a significant effect of the demonstrator’s path, F(1, 500) = 6.89, p < 0.01, and a significant interaction of the two factors, F(1, 500) = 4.03, p < 0.05. Contrasts of the estimated means for the interaction (Figure 7) revealed that there was no effect of the demonstrator’s path in the ‘Realistic’ condition, F(1, 500) = 0.21, p = 0.65; however, in the ‘Inverted’ condition, dogs chose the correct location more frequently in the identical exit trials, F(1, 500) = 10.58, p < 0.01.
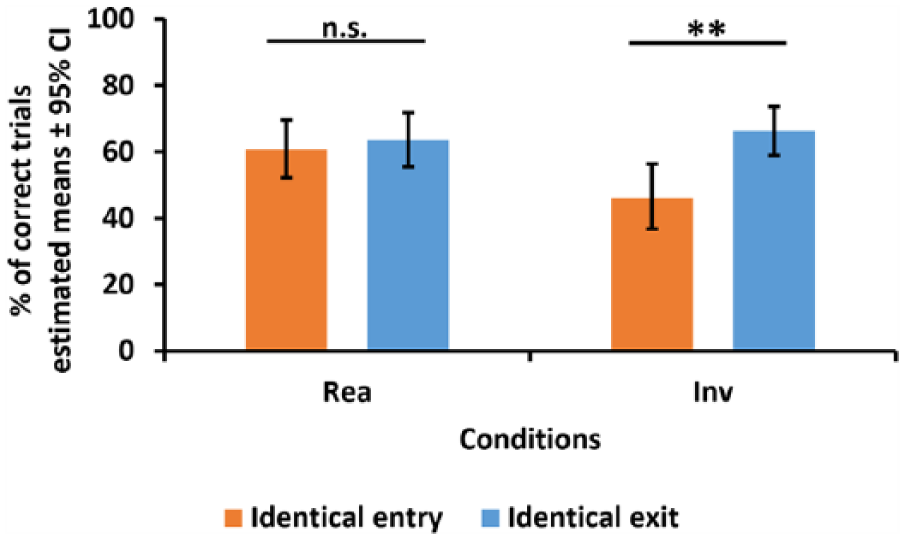
Comparison of the number of correct trials in the ‘Realistic’ (Rea) and ‘Inverted’ (Inv) conditions between trials with identical entry and identical exit. Solid horizontal lines above the graph mark the results of the pairwise contrasts of estimated means; n.s. = p ≥ 0.05; **p < 0.01.
Discussion
Regarding the number of correct trials, we found no significant differences between the conditions that according to our hypotheses (see also in Table 1) are indications of dogs processing the videos in confusion mode instead of independence mode. We also found no indication of the number of correct trials increasing towards the end of the sessions, which points towards a lack of associative learning effect (i.e., operant conditioning) during the trials, and therefore supports the idea that dogs perceived the actual content (i.e., the ongoing hiding of the ball) of the videos (confusion mode processing). However, the results indicated that in the ‘Inverted’ condition, dogs had more correct choices during the early than during the later trials. This kind of decrease of performance does not correspond to any of our initial hypotheses.
Analysis of the number of trials with SOB showed that their frequency drops during the sessions, suggesting that dogs habituated quickly to the videos. However, with a more detail-oriented analysis we found differences in the number of SOB trials between conditions: in the first sessions dogs showed more SOB in the ‘Realistic’ condition than in the ‘Inverted’ condition, while in the third sessions dogs showed more SOB in the ‘Inverted’ condition than in the other two conditions. The finding in the third session, that dogs showed more interest towards the projector screen after seeing an impossible scene, corresponds to the pattern expected in case dogs are processing images in confusion mode. This, together with the opposing trend found in the first sessions, suggests that dogs found the life-like scenes more interesting at the beginning, but then they probably habituated to them faster than to the impossible (‘Inverted’) scenario. In other words, if dogs were presented with one of the ‘possible’ presentations (‘Realistic’, ‘Sudden’) in the first session, their willingness to show SOB declined unless they were presented later with the ‘Inverted’ videos (similarly to the well-known dishabituation effect (e.g., Molnár, Pongrácz, Faragó, Dóka, & Miklósi, 2009). However, if dogs participated in the ‘Inverted’ condition at first, the probability of SOB remained low in the second and third session as well.
The analysis of the relationship between dogs’ correct choices and the demonstrator’s path revealed further details of the results. The interaction between the condition (‘Realistic’ vs ‘Inverted’) and the path (identical entry vs identical exit) showed that dogs chose the correct location with a higher chance only in the ‘Inverted’ condition in those trials where the experimenter left the screen on the side where the target was placed. This suggests that in the ‘Inverted’ condition, dogs relied on simple motion cues to locate the target object (by going to the location where they last detected movement), which in turn indicates that they processed these videos in independence mode. At the same time, this suggests also that dogs processed the videos in confusion mode in the ‘Realistic’ condition.
The reason for dogs processing the videos in different modes could be due to the familiarity of the videos’ configuration. The correctly oriented videos of the ‘Realistic’ (and the ‘Sudden’) condition made the scene and the human on the videos easily recognisable; however, dogs may have had difficulties recognising the scene or the presence of a human on the horizontally inverted videos of the ‘Inverted’ condition. Inverted pictures of human faces cause a well-documented deterioration of recognising them in human subjects (Valentine, 1988), which opened up a discussion about whether key features of the face are locally or globally processed. It was assumed that configurational cues (i.e., global processing) are used when the face is shown in a normal position, inversion leads to a qualitative change in processing (i.e., switching to local processing) (Murray, Yong, & Rhodes, 2000). Importantly, it was found later that the difference in how inverted and upright human faces were processed is rather a quantitative one, and can be explained with the different amount of experience of the beholder with one or the other type of display (Sekuler, Gaspar, Gold, & Bennett, 2004). From this aspect, these results show similarity to our study, providing parallel explanation for differences in the processing of ‘Inv’ videos compared to the other two conditions. This notion is also supported by findings about the perception of biological motion on point-light figures. If a point-light figure resembling a walking human is turned upside down, human subjects have more difficulties identifying it, than when it is correctly oriented (Bertenthal & Pinto, 1994; Pavlova & Sokolov, 2000; Sumi, 1984). The same inversion effect has been found when testing domestic chicken with point-light stimuli (Vallortigara & Regolin, 2006), suggesting that this phenomenon is widespread in vertebrate animals. Dogs were tested with inverted pictures earlier; however, in those studies they were presented with upright and inverted portraits of humans and dogs (Racca et al., 2010; Somppi et al., 2016) – a powerful stimulus that includes well-recognisable eyes even when it is turned upside down (Somppi et al., 2016). To our knowledge, however, this is the first study that presented upside-down life-size video sequences paired with a realistic choice task for dogs. Compared to face pictures, a more complex inverted scenario may have provided a harder task to process (at least initially) for the subjects (Sompii et al., 2016).
Assuming that dogs processed the videos in different modes could explain why they showed more SOB in the first and less in the third sessions in the ‘Realistic’ condition than in the ‘Inverted’ condition. When dogs perceived a human in the ‘Realistic’ condition, they showed interest towards the screen at first (they may have tried to figure out where the human went, etc.), but then they quickly habituated to the situation. Contrary to this, the unusual (‘impossible’) scene initially meant only unrelated visual elements in the ‘Inverted’ condition, so dogs showed less SOB. In this condition, it took time until they may start to decipher the presence of an upside-down walking human in the scene, which prevented habituation and elicited more SOB towards the end of the test. Therefore, our results imply that not only did dogs process the videos in different modes depending on the conditions, but that they may switch from independence mode to confusion mode in the ‘Inverted’ condition depending on the amount of exposure to videos. This familiarity-based switching of image-processing modes is similar to findings with pictorially naive humans, who had initial difficulties recognising the content of images (Miller, 1973). It is important to note that based on the results presented here we cannot go deeper than speculating about the possible mechanism behind how (or why) did the dogs switch between modalities of image processing of the ‘Inverted’ condition. We cannot exclude that the effect of ‘exposure’ to the initially unusual stimuli, coupled with the previous experience with the easily recognisable ‘Realistic’ and ‘Sudden’ video sequences, could have influenced image processing in the subjects.
This notion is further supported by the finding that the number of correct trials dropped during the sessions of the ‘Inverted’ condition. This performance drop can be explained if we assume that in the initial trials, dogs processed the videos in independence mode, and located the target object by attending to the motion cues on the video. However, after being exposed multiple times to the videos they switched to confusion mode and the resulting heightened levels of SOB interfered with their search performance. As a summary, we conclude that dogs processed the ‘Inverted’ videos initially in independence mode, while the videos in the later trials of the ‘Inverted’ condition and the normally oriented videos in the ‘Sudden’ and ‘Realistic’ conditions were processed in confusion mode.
An alternative hypothesis could be formulated regarding the interpretation of our findings: namely, it is possible that the higher rate of SOB trials in the ‘Inverted’ condition during the third sessions was not caused by dogs processing the videos in confusion mode. Instead, these dogs reacted to the novelty of the video (perceived as random visual elements) compared to the previously encountered videos containing a human. This interpretation implies that dogs processed the ‘Inverted’ videos always in independence mode and did not switch to confusion mode. However, without assuming that dogs switched processing modes when exposed to the ‘Inverted’ videos, it would not be possible to explain why the number of correct choices dropped during the ‘Inverted’ trials, instead of increasing due to simpler learning mechanisms, as would have been expected in case of purely independence mode processing (Table 1).
The findings of this study showing that dogs process life-sized artificial stimuli in confusion mode supports the already prevalent practice to use images as a replacement for real stimuli (e.g., Faragó et al., 2010; Pongrácz et al., 2003). From a methodological standpoint, our experiment showed that it is possible to measure dogs’ reactions towards an unexpected scene on a video via a novel approach. This method was characterised by the following: (1) providing dogs with a task which motivated them to spontaneously maintain attention towards the videos and (2) measuring dogs’ reactions to unexpected events after the video presentation using a set of behaviours, which we dubbed as ‘screen-oriented behaviours’. The main benefit of this method was that it ensured that dogs paid attention to the presented stimuli without the need of an attention grabber (e.g., Racca et al., 2010), extra reinforcement (e.g., Range et al., 2008) or extensive training (e.g., Somppi et al., 2012); and without a high dropout rate (e.g., Téglás et al., 2012). In this study, we concluded that dogs primarily process life-sized images in confusion mode, which is in line with earlier observations (Fox, 1971). However, the more striking finding was that dogs can process the same type of artificial visual stimulus in different modes, depending on the familiarity of the depicted scene. Furthermore, it is also likely that processing mode can change from independence to confusion mode with repeated exposition to unfamiliar stimuli.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Ethical approval
All procedures involving dogs and dog owners were approved by the Ethical Committee of Eötvös Loránd University (Permission # PEI/001/1492-4/2015), and conducted in accordance with the recommendations of the Hungarian State Health and Medical Service. The owners undertook the test on a voluntary basis and they were informed that they would participate in a scientific study. Dog owners were present at the tests and they were told that they can terminate the experiment at any time when they think their dog is under unwanted stress.
Funding
This research was supported by the Hungarian Scientific Fund (OTKA # K82020).