
Abstract
It is still debated whether holistic or piecemeal transformation is applied to carry out mental rotation (MR) as an aspect of visual imagery. It has been recently argued that various mental representations could be flexibly generated to perform MR tasks. To test the hypothesis that imagery ability and types of stimuli interact to affect the format of representation and the choice of strategy in performing MR task, participants, grouped as good or poor imagers, were assessed using four MR tasks, comprising two sets of ‘Standard’ cube figures and two sets of ‘non-Standard’ ones, designed by withdrawing cubes from the Standard ones. Both good and poor imagers performed similarly under the two Standard conditions. Under non-Standard conditions, good imagers performed much faster in non-Standard objects than Standard ones, whereas poor imagers performed much slower in non-Standard objects than Standard ones. These results suggested that (1) individuals did not differ in processing the integrated Standard object, whereas (2) in processing the non-Standard objects, various visual representations and strategies could be applied in MR by diverse individuals: Good imagers were more flexible in generating different visual representations, whereas poor imagers applied different strategies under different task demands.
Introduction
Mental rotation (MR) is an aspect of visual imagery. Typically, in MR tasks, participants are asked to compare a pair of arm-like cube objects rotated in three-dimensional (3D) space relative to one another and to determine whether they are the same objects in different orientations or mirrored ones (Shepard & Metzler, 1971). A series of studies showed that response times (RTs) linearly increase with the angular disparity. This suggests a dynamic imagery process akin to the actual physical rotation, which has been accounted for assuming that MR relies on visual representation. This theoretical stance is known as holistic (Cooper & Shepard, 1973; Metzler & Shepard, 1974). However, that this inference derived merely from the linear increment of the RTs has been challenged (Pylyshyn, 1973, 1981), and the process of piecemeal transformation was proposed instead to account for MR. In contrast to the holistic theory, piecemeal transformation posits an analytical process that transforms the object feature-by-feature or piece-by-piece.
The question of whether holistic or piecemeal transformation underlies MR processing is part of the long-standing ‘imagery debate’ on whether visual experience plays a functional role in cognition (e.g., Kosslyn, Thompson, & Ganis, 2006) or is just an epiphenomenon (Pylyshyn, 1981). Comparing these two theoretical accounts of MR, Cooper (1975) postulated that in processing more complex objects, piecemeal transformation would show a steeper slope in RTs as a function of angular disparity in which the slope is assumed to reflect the MR rate and the intercept reflects the process of stimuli encoding and giving response (Cooper & Shepard, 1973; Just & Carpenter, 1976, 1985). As the complexity of the internal representation increases, more time is needed to replace the features/nodes and the spatial networks among these features/nodes during MR processing in piecemeal transformation. However, in holistic processing, the internal representation is maintained and manipulated as a whole regardless of its complexity. In this context, piecemeal could be distinguished from holistic by predicting an increment of MR rate with the increasing stimulus complexity. Hence, the complexity effect was suggested as an indicator for distinguishing between the two strategies (piecemeal or holistic) proposed to account for MR. To test this complexity effect hypothesis in piecemeal transformation, Cooper and Podgorny (1976) used two-dimensional (2D) polygons as their stimuli with different complexity levels manipulated by the number of vertices (Attneave & Arnoult, 1956). No effect of complexity was observed in this experiment, supporting the idea that a holistic strategy was at play. Some other researchers, however, did observe this complexity effect by replicating Cooper and Podgorny’s (1976) experiment using polygons (Folk & Luce, 1987) or 3D cube figures as stimuli (Bethell-Fox & Shepard, 1988; Yuille & Steiger, 1982), hence supporting the piecemeal transformation hypothesis.
It has been argued that failure to generate the complete image in internal representations leads to the lack of the complexity effect even if piecemeal transformation is at play (e.g., Cooper & Podgorny, 1976; Folk & Luce, 1987). It has been posited that participants have the ability to maintain a simplified representation of the stimuli rather than the whole image in their mind’s eye and rotate this precise representation holistically (Liesefeld & Zimmer, 2013), especially when the stimuli are complex (Yuille & Steiger, 1982). Such precise representations permit a faster MR rate and result in a shallower RT slope (Mumaw, Pellegrino, Kail, & Carter, 1984; Yuille & Steiger, 1982).
The different methods of manipulating stimulus complexity is another possible reason for the inconsistent results gleaned from the literature. Two methods were used to manipulate the stimulus complexity: (1) the number of components of an integrated object, like the number of vertices in polygons (e.g., triangles, polygons with 6, 9 and 12 points; Cooper, 1975; Cooper & Podgorny, 1976; Folk & Luce, 1987), or the number of shaded squares in matrices (Bethell-Fox & Shepard, 1988, p. 2), the number of perceptually distinct pieces, like the figure patterns (1, 2 or 3 pieces) in matrices (Bethell-Fox & Shepard, 1988; Podgorny & Shepard, 1983), or the number of segments in Shepard and Metzler’s (1971) typical cube figures (Yuille & Steiger, 1982). The lack of the effect was mostly observed when complexity was manipulated within one integrated object (e.g., Cooper & Podgorny, 1976; Cooper, 1975); it has been indicated that participants are more likely to operate piecemeal transformation in processing the stimuli consisting of several parts (Bethell-Fox & Shepard, 1988).
Recently, individual differences were observed in MR performance. This may be a way to reconcile the two theoretical accounts of MR using the complexity effect to distinguish the two strategies. Different individuals appear to use different strategies to solve the MR tasks (Kirby, Moore, & Schofield, 1988; Paivio, 1971). In particular, high-spatial-ability individuals were faster in encoding the stimuli and in manipulating their visual representations (Mumaw et al., 1984). Low-spatial-ability individuals could not keep a sufficiently stable representation to be operated upon holistically (Just & Carpenter, 1976).
Bethell-Fox and Shepard (1988) maintained that the strategy choice is flexible for individual participants according to stimuli familiarity. In their study, no individual differences were found for novel objects. However, according to the participants’ debriefing, high-spatial-ability individuals swapped their strategy to holistic when the stimuli were well learned after sufficient practice, and their RTs dropped rapidly. On the other hand, low-spatial-ability individuals reported being unable to disengage from piecemeal transformation, and their RTs remained virtually the same before and after practice.
Different MR performances were also observed across individuals under different task demands. Khooshabeh, Hegarty, and Shipley (2013) used integrated and fragmented objects to assess high- and low-spatial-ability individuals. High-spatial-ability individuals adapted to task demand, using holistic strategy in processing integrated objects but applying piecemeal transformation when mentally rotating fragmented objects, thus showing a steeper slope in fragmented stimuli than integrated ones. Low-spatial-ability individuals showed similar performance in fragmented and integrated blocks, suggesting that they used piecemeal transformation for both fragmented and integrated objects.
In addition, the representation of the stimuli as one sub-stage in MR processing has been suggested as fundamental to spatial ability, and the representation ability contributed to the individual differences in MR (Mumaw et al., 1984). Longer RTs and more individual differences were observed in encoding, comparing and rotating unfamiliar objects in Mumaw et al.’s (1984) study. They postulated that high-spatial-ability individuals could maintain a more accurate representation in further mental manipulation so that they performed more accurately and faster in rotating unfamiliar objects, a process in which long-term memory representation is not required.
Differential performances in MR were reported more recently across individuals with different levels of vividness of visual imagery. A good example of the possible use of strategies to address MR is the case of MX, a 65-year-old man who reported the sudden loss of the ability to generate visual images. Although he showed poor vividness in visual imagery, he performed normally on a wide range of mental imagery tasks and other cognitive tasks, except on MR assessed by means of the typical cube stimuli. He was accurate in this task but showed a non-linear pattern in RTs of angular disparity. According to his debrief, he attempted to match individual cubes and angles perceptually before responding, using a strategy different from that of the controls (Zeman et al., 2010). In line with this observation, in the typical MR task (Shepard & Metzler, 1971), different brain areas (for more details, see Logie, Pernet, Buonocore, & Della Sala, 2011) were activated in good and poor imagers, suggesting that they used different ways to manipulate their visual representations to solve the task, although no such group difference was found on either RTs or slopes in behavioural results (Logie et al., 2011).
In accordance with this view, our aim in the present experiment was to investigate the individual differences in imagery tasks. This will add to our understanding of the individual differences observed in memory, reasoning and learning, especially in spatial problem-solving ability (Hegarty & Kozhevnikov, 1999; Wai, Lubinski, & Benbow, 2009). We hypothesised that individuals differing in their imagery abilities may create different formats of visual images under different task demands and utilise these multiple visual representations to generate different strategies for further mental manipulation. Good and poor imagers may not differentiate in processing an integrated object, but would show differences in processing objects consisting of several pieces.
For the purpose of this study, the stimulus complexity level was manipulated in two ways: (1) the cube number in an integrated object and (2) the segment number of the stimuli. Accordingly, good and poor imagers were grouped and assessed with four types of stimuli: two Standard and two non-Standard cube objects. We selected Shepard and Metzler’s (1971) typical objects (Figure 1a) as the basic Standard stimuli, the same types of stimuli used in the studies with MX (Logie et al., 2011; Zeman et al., 2010). The other Standard objects comprised a series of eight-cube stimuli (Figure 1b). In non-Standard objects, one set consisted of two segments (Figure 1c) and the other set three segments (Figure 1d).
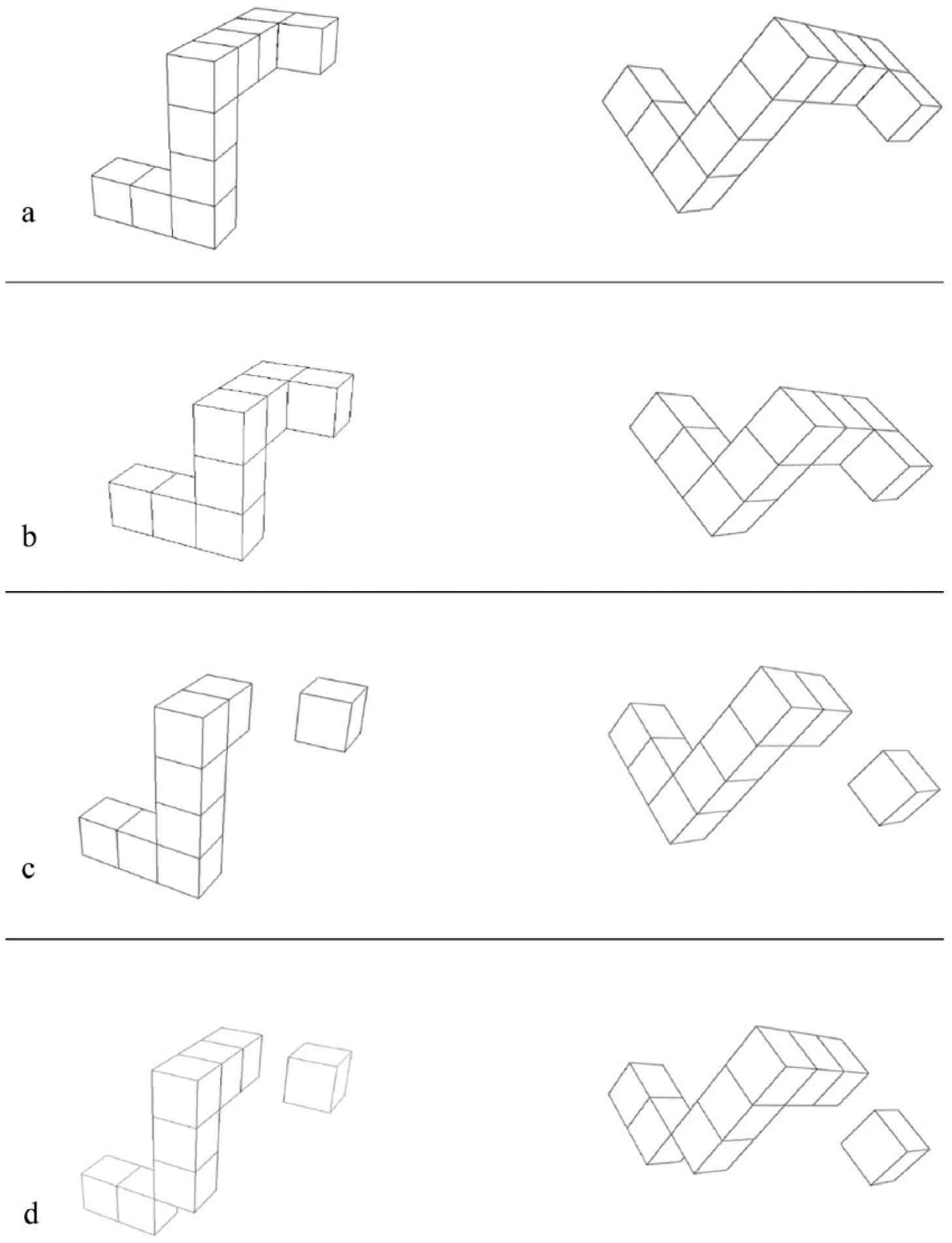
Four types of stimuli used in the present experiment. (a and b) Examples of the two Standard stimuli: (a) typical 10-cube object; (b) 8-cube object. (c and d) Examples of the two non-Standard stimuli designed by withdrawing two cubes from the Standard stimuli: (c) designed by withdrawing two consecutive cubes; (d) designed by withdrawing two non-consecutive cubes.
The effect of cube number was tested to explore the individual differences in processing an integrated object by comparing the two Standard objects (Figure 1a and b). If participants transformed the object cube-by-cube, more time would be needed and a steeper slope should be observed in RTs in the 10-cube object. If instead a holistic strategy is applied, no time difference should be observed between objects and no effect of cube number is predicted. According to the behavioural results reported by Logie et al. (2011), we predicted that no effect of cube number on the slopes would be found in the Standard condition for both good and poor imagers that both of the groups would tend to use holistic strategy. This result will be used as a baseline for further analyses of the effect of segment number.
The effect of segment number was analysed to investigate whether individuals differ in processing objects consisting of several parts by comparing three types of stimuli: eight-cube Standard (Figure 1b) and two-segment and three-segment non-Standard (Figure 1c and d). The eight-cube Standard objects served as control for the effect of cube number compared with the non-Standard objects which also consisted of eight cubes. If participants used piecemeal transformation for the non-Standard objects, they should have slower and less accurate performance with these figures than the Standard ones, assuming that the Standard objects can be rotated holistically. If a precise internal representation of the non-Standard object was generated for MR processing, participants would perform faster and more accurate in these objects than the Standard one in which holistic strategy is assumed to be applied. As good imagers in this article define those who have more vividness, we predicted that they will be more flexible in manipulating their visual representations and would represent more precise images for more complex stimuli and rotate them more efficiently by showing a shallower slope in their RTs. On the other hand, poor imagers might have difficulties in representing the whole non-Standard images and would transform the stimuli piece-by-piece by showing a steeper slope in their RT functions in the non-Standard condition.
Methods
Participants
In total, 34 university students aged 21-36 years (average age = 26.2 years; 16 females) were recruited for this experiment. All participants were right-handed, with no history of neurological disorders and reported having normal or corrected-to-normal vision. Participants were classified as good and poor imagers based on their performance in the Vividness of Visual Imagery Questionnaire (VVIQ-2; Marks, 1999). VVIQ-2 is a standardised questionnaire assessing general visual imagery use and experience (Pearson, Deepros, Wallace-Hadrill, Heyes & Holmes, 2013), the same visual imagery questionnaire used in MX’s series of studies (Logie et al., 2011; Zeman et al., 2010). The VVIQ-2 scores ranged from 76 to 144 out of a possible total of 160 (mean = 110.72, standard deviation [SD] = 17.47) and were normally distributed. Based on the VVIQ-2 performance, nine good imagers (top VVIQ-2 score quartile, mean = 133.11, SD = 6.21, six men and three women, mean age = 24.56 years) and nine poor imagers (bottom VVIQ-2 score quartile, mean = 90, SD = 6.38, six men and three women, mean age = 26.44 years) were selected for further analysis.
Material
The stimuli were arm-like stimuli formed of cubes derived from Shepard and Metzler (1971). Four types of stimuli were used in the present MR task, two Standard and two non-Standard. One set of Standard stimuli (Figure 1a) was exactly the same as the one used in Shepard and Metzler (1971) which consisted of 10 cubes. The other set of Standard stimuli (Figure 2b) consisted of eight cubes. Similar to the ‘fragmented’ stimuli in Khooshabeh et al.’s (2013) experiment, both types of non-Standard stimuli (Figure 1c and d) were devised by withdrawing two cubes from the Standard stimuli (Figure 1a) used in Shepard and Metzler’s (1971) experiment. The difference between these two non-Standard stimuli was the number of segments involved: One set was devised by withdrawing two consecutive cubes from the Standard stimuli (Figure 1c); the other was concocted by removing two non-consecutive cubes (Figure 1d).
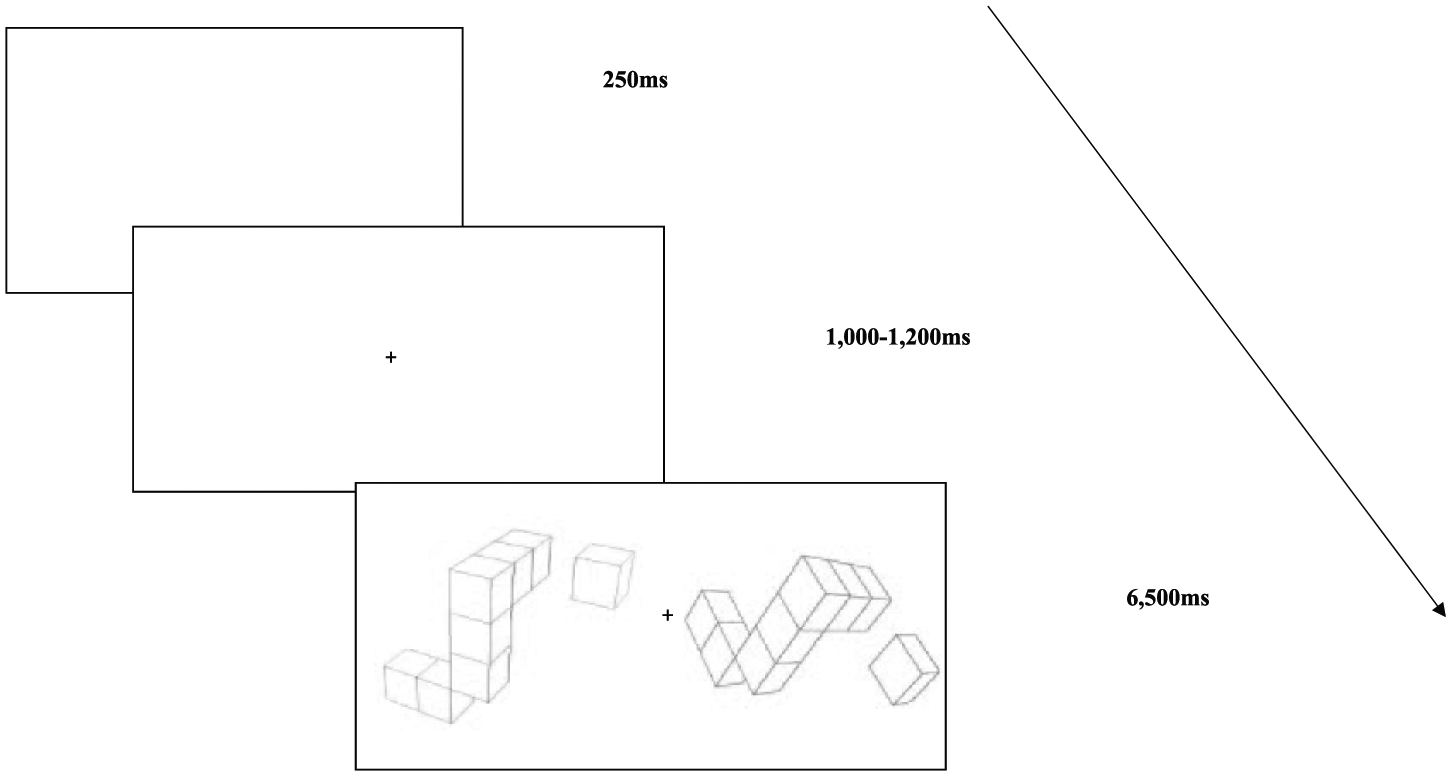
The experiment procedure.
For each type of stimuli, a pair of objects was set as a trial with different angular disparities, between 0° and 180° with 20° increments (10 angular disparities), in which half the stimuli were rotated along with the picture plane and the others rotated in depth (two axes). Within half of the trials, one object was paired with an exactly identical corresponding object with a different orientation, whereas the other half was set with its mirrored figure but still had a different orientation (two identities). There were 160 trials (4 types of stimuli × 10 angular disparities × 2 identities × 2 rotate axis = 160 trials) with 10 repetitions of each stimulus randomly ordered. Accordingly, in total, 1600 trials were included in this four-block experiment with 400 trials in each block.
Procedure
The participants were required to sit in front of a computer with the keyboard all masked except for two buttons marked ‘S’ and ‘D’, indicating ‘same’ and ‘different’, respectively. For half of the participants, the ‘S’ button was set on their right-hand side and the ‘D’ button on their left side. For the other half of the participants, the ‘S’ button was set on their left side and the ‘D’ on their right.
A run-in of 16 trials served as practice allowing participants to familiarise themselves with the task. In both the practice and real experiment sessions (see Figure 2), first a black screen was presented for 250 ms, followed by a fixation cross lasting 1000-1200 ms, and then a pair of 3D cube stimuli were presented for 6500 ms. Participants had to indicate whether these two objects were the same ones (though rotated) or mirror images by pressing the ‘S’ or ‘D’ button. During the whole procedure, the participants were asked to keep their hands on the keyboard. Each experimental block was followed by a debriefing session, in which participants orally reported on the strategy they used in the previous block.
Data analysis
Prior to the analysis, RT data were trimmed for outliers. RTs more than 2 SDs above or below the mean per condition and per subject were excluded (3.7% of the data on average). The results were analysed based on the identical trials only, as is typical in studies of MR. 1 A repeated-measures analyses of variance (ANOVAs) was applied to the corrected RTs as well as accuracy data with one between-subject factor (good or poor imagers) and two within-subject factors: types of stimuli with different complexity levels and 10 rotation angles. When imagery ability was found interacting with types of stimuli or angular disparity, independent t-tests would apply to test group difference (good vs poor imagers). Trend analyses would be applied for testing the effect of angular disparity in each condition followed by Bonferroni-corrected pairwise comparisons, if angular disparity was observed to interact with other factors.
To test the MR rate under different task demands, we fitted a linear line to each participant’s RTs to calculate the slope and intercept of this line. Repeated-measures ANOVA was used for these estimated slope and intercept between two imagery ability groups with different stimulus complexity levels. Independent t-test would apply to test group differences (good vs poor imagers) in each type of stimuli when the interaction of types of stimuli and imagery ability was found. A repeated-measures ANOVA would again be used for good and poor imagers separately, followed by the Bonferroni-corrected pairwise comparisons for testing the complexity effect in each group.
Results
Effect of cube number
Consistent with the previous literature, there was an effect of angular disparity on RTs, F(9, 144) = 56.582, p < 0.001,
Effect of segment number
Response times
Figure 3 details the RTs in all three conditions for both good and poor imagers as a function of angular disparity. As predicted, there was an interaction between imagery ability and types of stimuli, F(2, 32) = 8.378, p = 0.001,
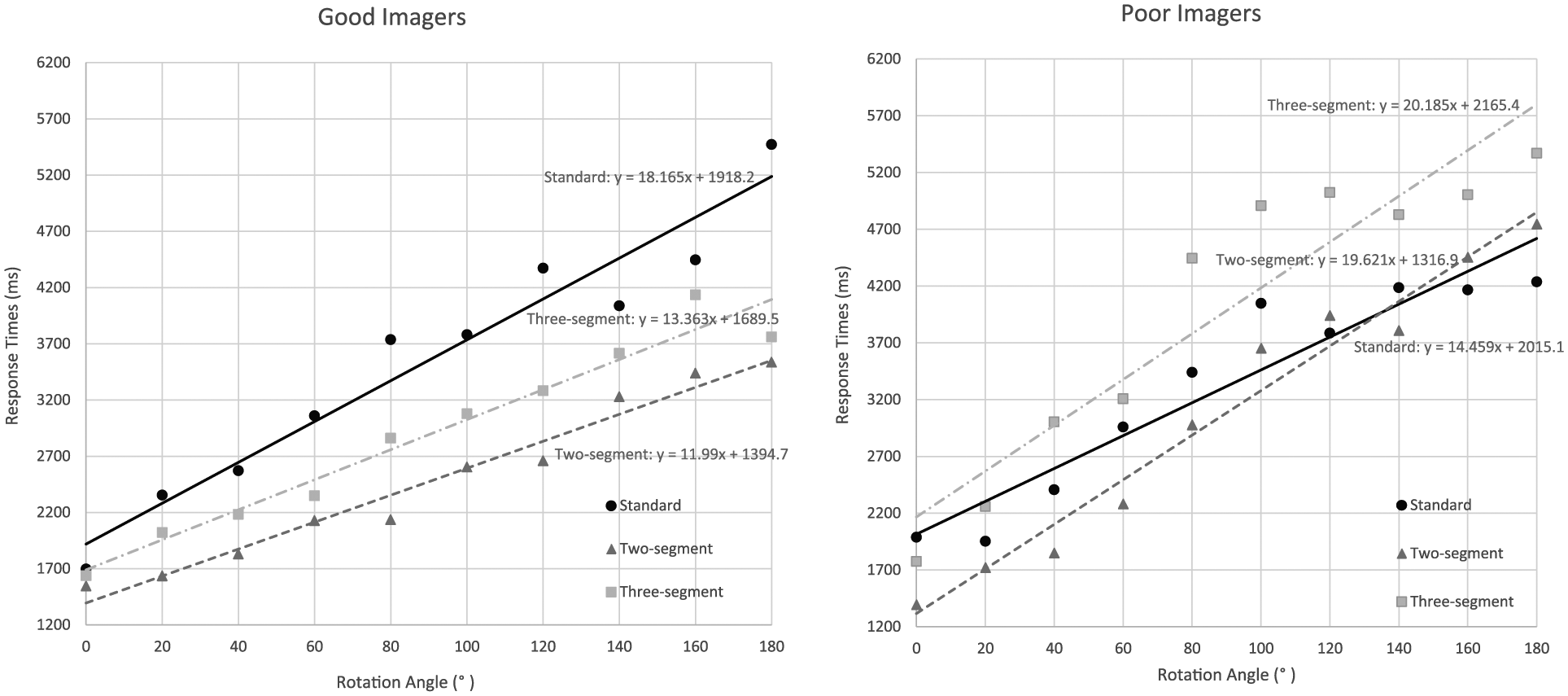
RTs as a function of angular disparity in processing the Standard stimuli as well as the two non-Standard stimuli. (Left) RT functions for good imagers; (right) RT functions for poor imagers.
As revealed by previous studies, a main effect of rotation angle was observed on RTs for all types of stimuli, F(9, 144) = 131.569, p < 0.001,
Accuracy
As depicted in Figure 4, accuracy rate decreased with the angular disparity, F(9, 144) = 43.658, p < 0.001,
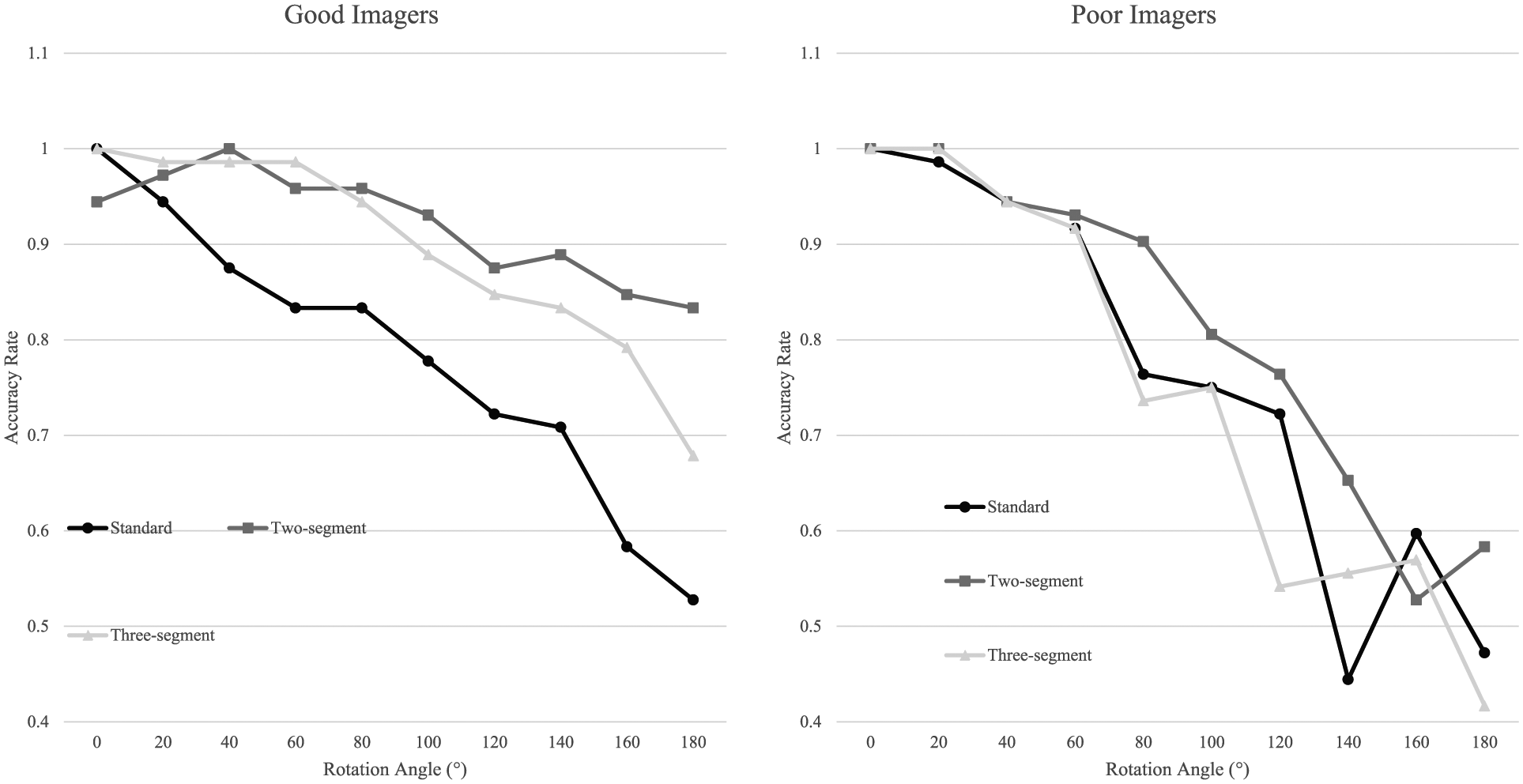
The accuracy rate across the rotation angle from 0° to 180° in processing the Standard stimuli and the two non-Standard stimuli. (Left) Accuracy rate across all the rotation angles for good imagers; (right) accuracy rate for the poor imagers.
A main effect of segment number was also observed on accuracy rate, F(2, 32) = 5.249, p = 0.011,
Slope and intercept
The most direct test of the predictions outlined above is based on estimates of MR rate (reverse of the slope in RTs). Group difference (good and poor imagers) was found on the slope measure, F(1, 16) = 5.273, p = 0.036,
As expected, an interaction between imagery ability and types of stimuli was also found in the slope measure, F(2, 32) = 25.447, p < 0.001,
A repeated-measures ANOVA was applied to the good imagers only, and the main effect of types of stimuli was found on the slope measure of the RTs of angular disparity, F(2, 16) = 15.794, p < 0.001,
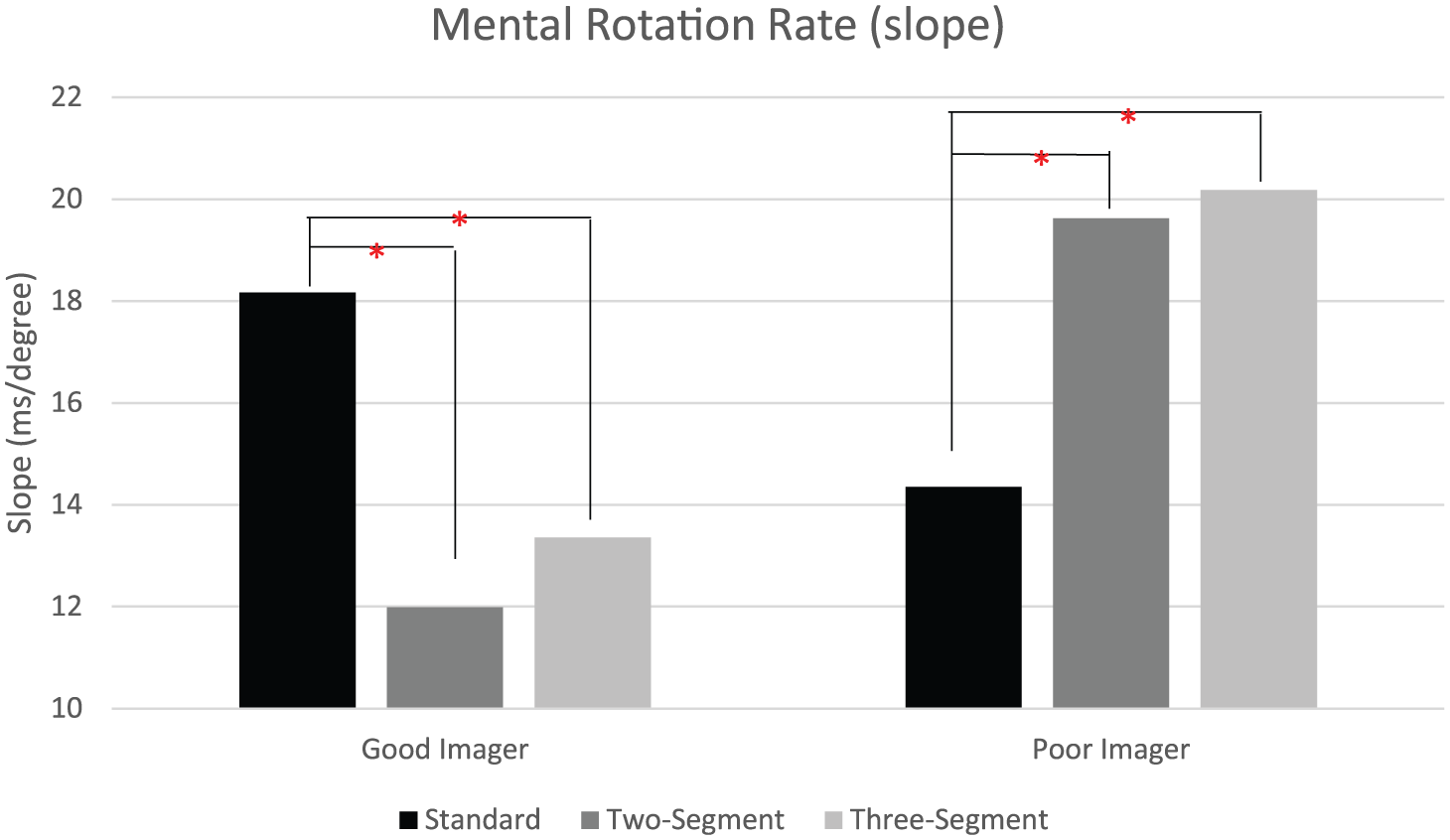
The MR rate (slope) for good imagers (left) and poor imagers (right).
A repeated-measures ANOVA was also applied for poor imagers. As expected, the main effect of types of stimuli was found on slope for poor imagers as well, F(2, 16) = 11.045, p < 0.001,
A main effect of segment number was observed on the intercept measure, F(2, 32) = 9.187, p = 0.001,
Discussion
By manipulating the complexity of the stimuli, we tested and specified individual differences with regard to visual imagery capacities on performing the MR task with one integrated object (Standard condition) and objects consisting of several segments (non-Standard condition). Good and poor imagers, defined according to their vividness of visual representations, performed similarly in the Standard objects and showed no cube number effect on either their RTs or estimated slope measure. However, good and poor imagers differed in processing the multi-part non-Standard objects. Compared with the eight-cube Standard object, good imagers performed faster in non-Standard ones, whereas poor imagers obtained the opposite pattern of performance.
Consistent with Logie et al.’s (2011) behavioural results, in the Standard condition, no effect of cube number was observed on either RTs or slope measure in either the good or the poor imagers. This suggests that the same strategy was adopted by both groups and that they did not transform the Standard objects cube-by-cube.
A different pattern emerged from the analyses of the processing of the multi-part non-Standard objects. Here, the good and poor imagers’ performance differed; various representation formats and various strategies were observed across individuals. Good imagers performed faster in non-Standard objects than in the Standard ones. This finding confirmed Yuille and Steiger’s (1982) precise representation of transformation account which maintains that participants could generate a partial image of the stimuli in their mind’s eye and rotate it to complete the MR task. Alternatively, Liesefeld and Zimmer (2013) postulated that only comparison-relevant information was maintained for further holistic MR processing. Here, we cannot detail the content of the simplified representation but further specify that only good imagers were able to apply this precise transformation in MR tasks.
Poor imagers, on the contrary, showed a steeper slope in RTs in non-Standard objects, suggesting that they used piecemeal transformation to process the fragmented objects. This finding is consistent with the claims that poor imagers have difficulty in rotating the more complex object holistically (Mumaw et al., 1984). Poor imagers might have difficulty encoding the multi-part non-Standard objects as a unit in their mind’s eye. They instead may attempt to encode the non-Standard stimuli as one part attached to another. Given the limitations of our visual system capacity so that only one additional part/information could be maintained attached to another part (Xu & Franconeri, 2015), they might fail to represent the stimuli with multiple parts and have to transform the individual parts separately.
It is notable that poor imagers processed the two-segment and three-segment non-Standard objects at a similar rate. This seems to question the piecemeal transformation account in which more time would be needed for transforming the additional segment in three-segment objects and a steeper slope would be observed in the RT in these objects. One possibility is that poor imagers attempted to use piecemeal transformation for the non-Standard objects but failed under time constraint to transform the additional piece in the three-segment objects for larger angles. This account is supported by their low accuracy and angle-irrelevant RTs in larger rotation angles.
In sum, at odds with the simple dichotomies object/spatial or visualiser/verbaliser (Kozhevnikov, Kosslyn, & Shepard, 2005; Paivio, 1971), the findings from our present experiment support Pearson and Kosslyn’s (2015) recent argument that multiple formats of representation could be created and those representations could be flexibly used in further mental manipulations. We specified the format of representation and strategy selection under different tasks across individuals; we observed that there was no individual difference in processing integrated objects, whereas in processing fragmented objects, multiple formats of representations and multiple strategies could be generated across individuals with different levels of visual imagery ability. Good imagers are more flexible in generating different formats of representation and particularly in processing more complex objects, and they could maintain a precise representation of the stimuli in their mind’s eye for further mental manipulations; poor imagers instead rely more on piecemeal transformation in processing multi-part objects.
Mumaw et al. (1984) speculated that the individual difference in MR across high- and low-spatial-ability individuals is due to their different representational skills. That is to say, good imagers are expected to perform similar to high-spatial-ability individuals in MR; poor imagers would perform similar to low-spatial-ability individuals. However, the present findings in individual differences in MR with regard to their imagery vividness are not fully consistent with those from previous studies considering spatial ability (Khooshabeh et al., 2013). Khooshabeh et al. (2013) posited that in processing the integrated Standard objects, the default strategy of low-spatial-ability individuals is piecemeal transformation, whereas in the present experiment, poor imagers use a holistic approach. Under multi-part non-Standard conditions, Khooshabeh et al. (2013) found that high-spatial-ability individuals would use piecemeal transformation, whereas we found good imagers still use holistic but represent a simplified version of the stimulus. Therefore, we could not support Mumaw et al.’s (1984) speculated correspondence between high/low spatial ability and good/poor representation skills. The representational skill is key to spatial ability, but to better specify in which specific way high- and low-spatial-ability individuals differed in MR tasks, it would be possible in future studies to control for the participants’ ability in working memory as well.
In addition, here we confirmed that it is easier to induce participants to use non-holistic strategies in the non-Standard condition by changing the number of perceptually distinct pieces rather than by merely changing the number of components within an integrated Standard object (see also Bethell-Fox & Shepard, 1988; Podgorny & Shepard, 1983). Therefore, it is possible that the holistic strategy was at play in some studies (e.g., Cooper, 1975; Cooper & Podgorny, 1976) in which the complexity of stimuli was manipulated within one integrated object. Moreover, the present results show that individual differences should be considered in future studies on the role of stimulus complexity in MR even if complexity is manipulated by changing the number of perceptually distinct pieces.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship and/or publication of this article.