
Abstract
Car networking systems based on 5G-V2X (vehicle-to-everything) have high requirements for reliability and low-latency communication to further improve communication performance. In the V2X scenario, this article establishes an extended model (basic expansion model) suitable for high-speed mobile scenarios based on the sparsity of the channel impulse response. And propose a channel estimation algorithm based on deep learning, the method designed a multilayer convolutional neural network to complete frequency domain interpolation. A two-way control cycle gating unit (bidirectional gated recurrent unit) is designed to predict the state in the time domain. And introduce speed parameters and multipath parameters to accurately train channel data under different moving speed environments. System simulation shows that the proposed algorithm can accurately train the number of channels. Compared with the traditional car networking channel estimation algorithm, the proposed algorithm improves the accuracy of channel estimation and effectively reduces the bit error rate.
Introduction
In recent years, with the rapid development of the Internet of Vehicles, vehicle-to-everything (V2X) communication has become a key technology for in-vehicle services.1,2 V2X mainly includes vehicle-to-infrastructure (V2I), vehicle-to-vehicle (V2V), and vehicle-to-pedestrian (V2P). V2X has become an important part of intelligent transportation system. V2X is an automotive telecommunication device that lets information to be exchanged from an automobile to transportable segments of the road network that may have an effect on the vehicles. The initial aim of V2X technologies is to increase safe driving, power generation, besides congestion effectiveness. In the Internet of Vehicles 5G-V2X scenario, users have extremely high requirements for high reliability and low-latency communication 3 (ultra-reliable and low-latency communication).
Among them, channel estimation, as a key technology in the 5G-V2X communication of the Internet of Vehicles,4–6 is very important in the single-carrier frequency-division multiple access (SC-FDMA) 7 system and directly determines the communication quality. As mentioned previously, the most significant benefit of deep learning techniques is that they attempt to acquire high-level characteristics from information in an improved way. This reduces the requirement for technical knowledge as well as the isolation of strong key features.
The advantages are flexibility, unorganized data support, features synthesis mechanism, cost efficiency, intelligence, unorganized data support, and so on. It directly determines the quality of communication. In the 5G-V2X scenario, the Doppler effect caused by the fast movement of the terminal causes the channel to change rapidly. This causes intercarrier interference. 8 As a result of this, wireless communication synchronization as well as channel estimate become extremely challenging. Therefore, channel estimation9,10 plays a key role in the entire communication system. To ensure the safety of road traffic, it is necessary to improve the accuracy of channel estimation.
The wireless channel in the car networking environment has fast time-varying, non-stationary fading characteristics and has higher real-time and accuracy requirements for channel estimation.11,12 Therefore, most methods use pilot-based channel estimation schemes. Traditional channel estimation algorithms use least square (LS) or linear minimum mean square error (LMMSE) methods to estimate the channel state of the pilot position and then use the linear interpolation method to obtain the channel of the data position state. However, the estimation performance of the LS algorithm is low. The LMMSE algorithm needs to obtain the prior information of the channel, which is not suitable for channel changes in the high-speed mobile environment.
In response to this situation, a basic expansion model (BEM), which is more in line with high-speed mobile scenes, is proposed. 6 Bagheri et al 7 proposed and studied a new discrete Fourier transform extended orthogonal frequency-division multiplexing (DFT-S-OFDM-quadrature index modulation [QIM]) scheme with orthogonal index modulation for practical visible light communication (VLC) systems. It has the ability to enable high-speed data connection while also reducing energy demand and confidentiality. Approaches to standardize include the Visible Light Communications Association (VLCA), as well as IEEE 802.15.7 VLC will supplement current mobile communication in the next years. OFDM-QIM provides greater spectrum utilization than classic OFDM with intensity modulation through conducting sub-band indexing modification on the in-phase and fractional elements of every subcarriers (OFDM-index modulation).
Xu et al 8 proposed pilot-assisted channel estimation with a method based on enhanced atomic norm to promote the low-rank structure of the time-varying narrowband leakage channel. Restore all channel parameters, namely delay, Doppler shift, and channel gain. Check the design options to ensure the only estimation of channel parameters for rectangular, Gaussian, and root raised cosine pulse shapes under noise-free conditions, respectively. Liao et al 9 proposed a fast time-varying channel estimation algorithm based on BEM and uplink sounding reference signal. To pursue higher estimation accuracy, in recent years, researchers have begun to use deep learning methods to estimate the channel. Huang et al 10 proposed a channel estimation scheme based on deep learning, which uses long- and short-term memory (long short-term memory [LSTM]) networks and multilayer perceptron networks to solve the problem of error propagation.
Huang et al 11 modeled the channel response as a two-dimensional image and used the super-resolution algorithm to recover the channel. Akiba et al 12 gave a channel estimation method dependent on deep learning, which employs a fully connected deep neural network (DNN) to jointly complete frequency domain interpolation besides estimation of frequency domain interpolation coefficients and uses LSTM cyclic neural network 13 to jointly complete time domain state prediction as well as estimation of time domain correlation coefficients. The above method does not give too much consideration to the problem of adapting to the moving speed. When the moving speed and multipath conditions change, the distribution of channel data will fluctuate greatly. The performance of the above methods will decrease to varying degrees.
In response to the above problems, the channel estimation accuracy is further improved, thereby improving the communication quality of the 5G-V2X Internet of Vehicles. The 5G-V2X wireless communication scenario model is shown in Figure 1. In this article, the BEM 14 is used as the intelligent channel estimation outline model. Then recommend a new high estimation algorithm for deep learning. The following are the particular components:
5G-V2X wireless communication scenario. V2X, vehicle-to-everything.
This article adopts the BEM of high-speed channel impulse response to build a simulation communication system based on SC-FDMA as the intelligent channel estimation framework for the Internet of Vehicles. The deep learning method is employed to complete the training of the channel estimation model.
Aiming at the problem that the performance of the estimation algorithm is greatly reduced due to the channel change in the high-speed mobile setting, this article introduces the multipath parameter as well as the speed parameter in the neural network. Then, a convolution module comprising multilayer convolution is designed to complete frequency domain interpolation. Gated recurrent unit 15 (GRU) is used to design bidirectional gated recurrent unit (BiGRU) for time domain state prediction. The multipath code vector is applied to the output after multilayer convolution interpolation in the form of weighting, so as to track the change of channel multipath. BiGRU takes the speed vector as the input of the network and tracks the channel changes in different mobile environments through this vector. The program may acquire a priori multipath parameters by offline training, and velocity parameter vectors for different mobile scenarios, and can track channel changes in different mobile environments through these two parameters. So that correct channel data training may be achieved in a variety of mobile contexts, or the suggested algorithm's performance can be verified via modeling.
Related Works
SC-FDMA system transceiver signal processing
The 5G-V2X physical transmission system uses the SC-FDMA-based transmission mode. 16 They will be able to connect with infrastructures, the internet, as well as every other according to V2X technologies. Smart automobiles can benefit from high-speed transmission, continuous networking capabilities, and compared to the results. It has the ability to deliver faster speeds, reduced delay, and more bandwidth than 4G long term evolution networks. It is among the globe's fastest and most accurate technology, which implies faster connections, less latency, and a big change as far as how we lived, collaborate, and perform. The baseband transmission model of the SC-FDMA system is shown in Figure 2. At the transmitting end, user data undergo discrete Fourier transform (DFT) precoding, subcarrier mapping, invert fast Fourier transform (IFFT), and cyclic prefix (CP) precoding. At the same time, the pilot generated by the Zadoff–Chu (ZC) sequence undergoes carrier mapping, IFFT, CP addition, and is transmitted to the space together with the user data.
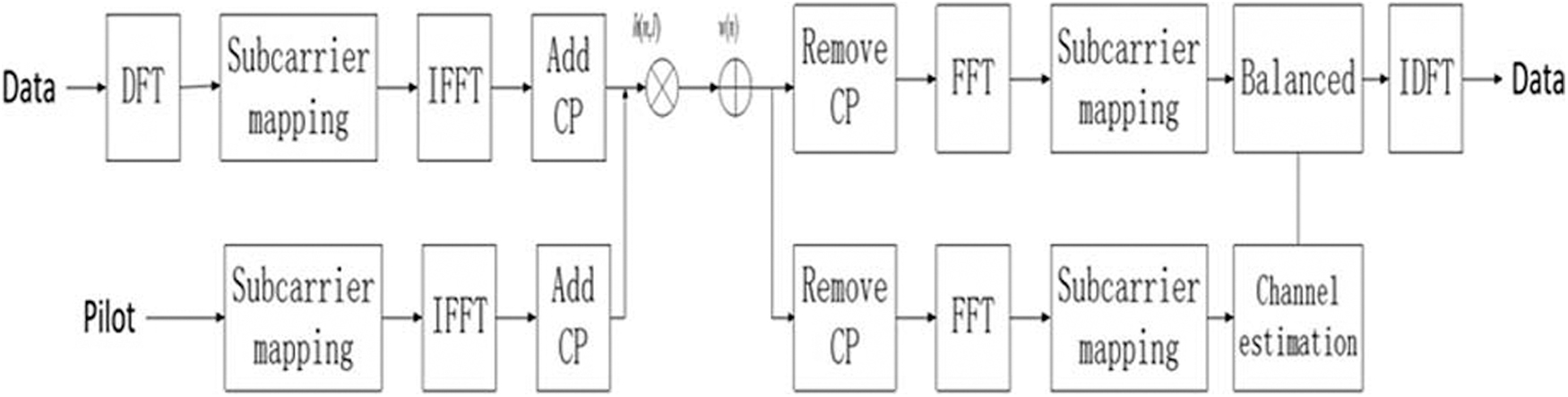
SC-FDMA baseband transmission model. CP, cyclic prefix; DFT, discrete Fourier transform; FFT, fast Fourier transformation; IDFT, inverse discrete Fourier transform; IFFT, invert fast Fourier transform; SC-FDMA, single-carrier frequency-division multiple access.
The inverse discrete Fourier transform (IDFT) method reverses the DFT procedure. It is also known as the reverse Fourier transform. It transforms a frequency domain signal from a space domain waveform. The allocation of data sequencing to different spectral elements produces the DFT signals. The DFT is a complicated measure of the rate that turns a limited succession of equitably observations of a functional into a same length series of equitably observations of the discrete time Fourier transform. The processing procedure of the receiving end is opposite to that of the transmitting end, and finally, the signal is resumed. Since the signal is affected by channel fading and noise, it is necessary to estimate the channel and use frequency domain equalization after fast Fourier transformation (FFT) to compensate for the influence caused by the channel to complete signal detection.
A transmission frame based on SC-FDMA in 5G-V2X contains I transmission symbols, including Id data symbols and Ippilot symbols, and the number of DFT points is M, and the total number of transmission subcarriers is N. Note that the i data symbol after modulation is 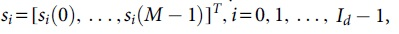 and the transmitted data frequency domain symbol
and the transmitted data frequency domain symbol 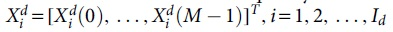 is obtained after M DFT transformation, and the ZC pilot sequence
is obtained after M DFT transformation, and the ZC pilot sequence 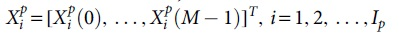 is inserted before the subcarrier mapping. A technique of configuring a hard drive in which the mechanical production removes the information of the disk through truncating them with zeros is known as zero filling.
is inserted before the subcarrier mapping. A technique of configuring a hard drive in which the mechanical production removes the information of the disk through truncating them with zeros is known as zero filling.
The term zero filling comes from the fact that every bit on the disk is substituted by a zero. The information can be retrieved from the storage device after it has been wiped with 0s. Accordingly, to complete the next N IFFT transformation besides moderate the frequency domain symbols to every subcarrier, the current frequency domain symbols need to be zero-filled, and the 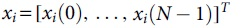 in the time domain. Finally, add CP and perform digital-to-analog conversion as well as send it to the wireless transmission channel. Therefore, the SC-FDMA frequency domain transmission symbol can be expressed as:
in the time domain. Finally, add CP and perform digital-to-analog conversion as well as send it to the wireless transmission channel. Therefore, the SC-FDMA frequency domain transmission symbol can be expressed as:
Among them,
After passing through the wireless channel of the Internet of Vehicles and successfully receiving at the receiving end, it is necessary to perform analog-to-digital conversion and de-CP operation and then perform FFT to obtain the frequency domain received symbol Yi.
Design of the SC-FDMA system based on BEM
In the high-speed mobile environment, the channel has time-varying characteristics, and a DOPPLER FREQUENCY SHIFT owing to excessive motion will lead the frequencies mismatch of the SC-FDMA network subcarriers, which will lead to the destruction of the orthogonality between the SC-FDMA system subcarriers. This variation seriously affects the performance of the system. The conjugate transposition (or Hermitian transposition) of an m-by-n matrix A with complicated elements is the n-by-m matrix formed from A by obtaining the transposed and then the complicated conjugation of every column (the imaginary conjugation of a + ib is a − ib, for real values a or b).
It is commonly abbreviated as AH or A*. Suppose that in the SC-FDMA system model, there are N subcarriers, and one subframe contains I SC-FDMA symbols. Suppose that the i subcarrier symbol on the n SC-FDMA symbol sent is 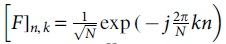 represents the Fourier matrix, and
represents the Fourier matrix, and 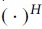 represents the conjugate transpose. The SC-FDMA broadcasting technique can be expressed as
represents the conjugate transpose. The SC-FDMA broadcasting technique can be expressed as
Where 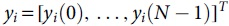 is the time domain symbol vector received on the i-th SC-FDMA symbol; zi is the complex additive white Gaussian noise; hi is the channel impulse response matrix of the i-th SC-FDMA symbol, as demonstrated in the following formula:
is the time domain symbol vector received on the i-th SC-FDMA symbol; zi is the complex additive white Gaussian noise; hi is the channel impulse response matrix of the i-th SC-FDMA symbol, as demonstrated in the following formula:
Among them,
H denotes the frequency domain response matrix of the i symbol, denoted as:
The fast time-varying channel model is modeled as BEM, and the BEM function of the channel is obtained by the following formula:
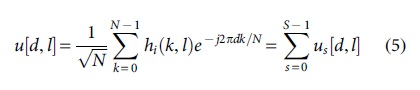
Among them,
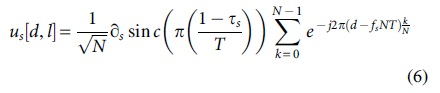
Among them,
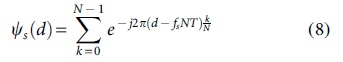
Where
In a general mobile communication system, the normalized Doppler frequency shift is much less than 1, that is,
Based on this feature, it can be reasonably assumed that each subcarrier only affects its adjacent D subcarriers, and then, the channel matrix Hi can be approximated as a band matrix, and the following formula is obtained after sorting:
The above formula retains the diagonal of Hi and the elements between the distance D on both sides of the diagonal, which greatly reduces the complexity of the model.
Methods
This section mainly introduces the channel estimation method using deep learning proposed in this article.
Channel prediction network structure using the deep learning method
The overall channel estimation structure of this article is shown in Figure 3, which is mainly divided into two parts: training and prediction.
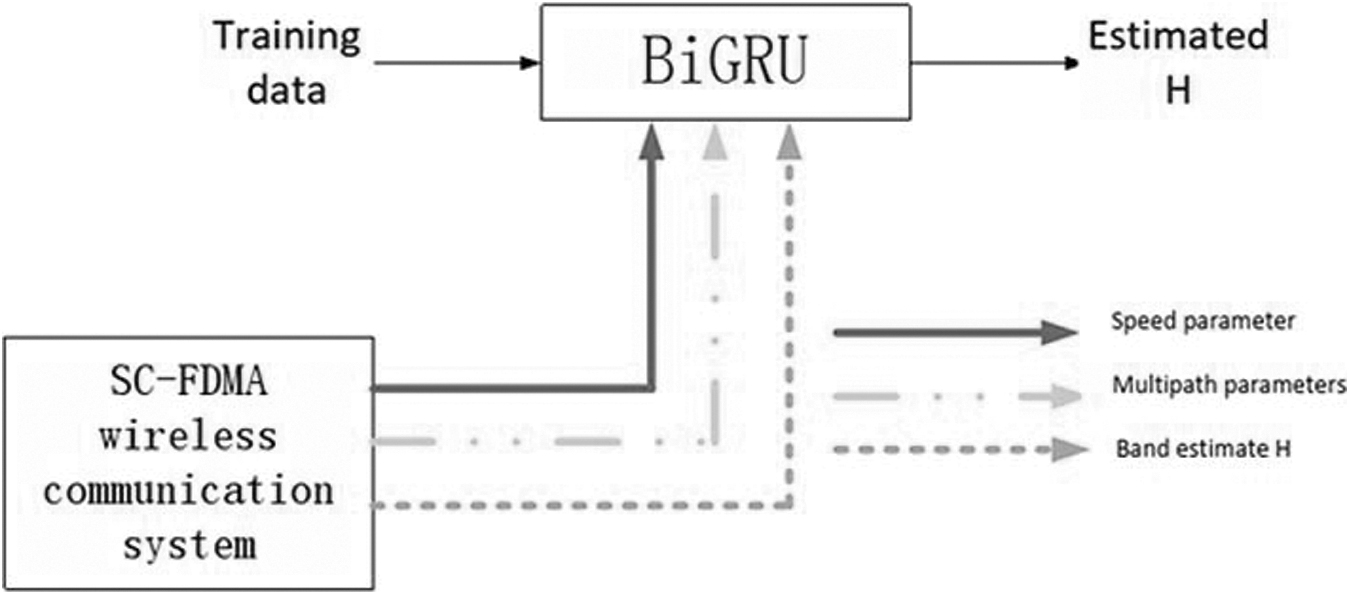
Channel prediction network framework. BiGRU, bidirectional gated recurrent unit.
We train the channel prediction network and get the parameters of the network through training. Through multiple training iterations, the optimal solution of the loss function of the algorithm is solved, so as to learn the change characteristics of the channel. Due to the general hidden layers, neural nets are stronger at data modeling. To create forecasts, statistical models simply utilize transmitter and receiver vertices. The hidden state is also used by the neural network to improve forecasting accuracy. This is because it “learns” in the same manner that humans do. In the prediction stage, through the trained network parameters, the channel prediction network can be used to continue to track and predict the real-time complete live channel estimate with channel modifications.17–19
The technique of detecting association among the understanding of the various values on the left as well as the matrix of arithmetic operations on the right is known as channel estimation. The technique of estimation used in particular might vary based on the execution. The channel estimation network is composed of a multilayer convolutional neural network and a GRU module. In a deep CNN, the convolutional layer processes the original image in several ways. In this system, it refers to the common way of convolutional processing.
The quantity of granules as well as the shape of the particles are by far the most critical characteristics. The multiple levels are 1 × 1, 3 × 3, and 1 × 1 fully connected layers, with the 1 × 1 layer lowering and then raising (preserving) proportions, as well as the 3 × 3 layer acting as a bottleneck with reduced input/output measurements. The specific structure is shown in Figure 4. Among them, multilayer convolution includes 1 × 1 convolution and 3 × 3 convolution. The specific structure is shown in Figure 5.
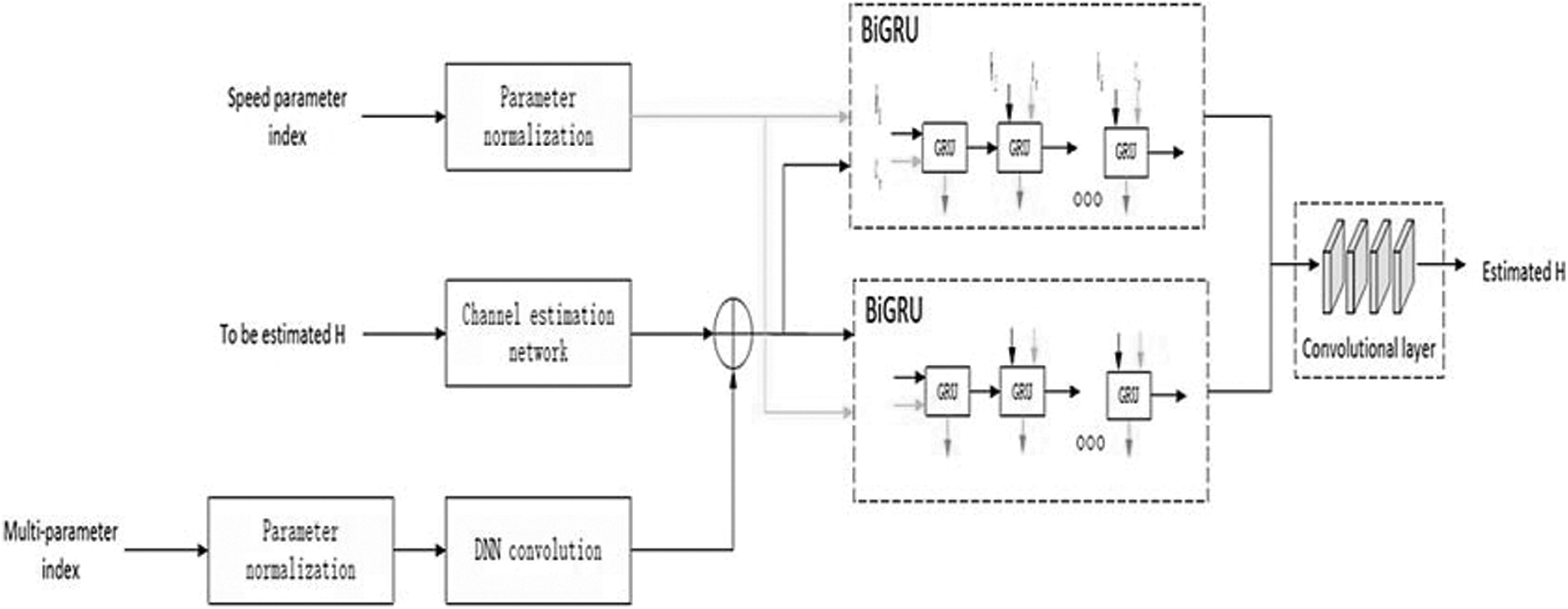
Channel prediction network.
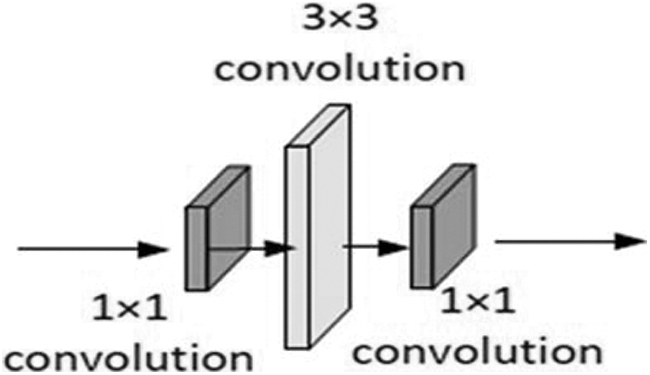
Multilayer convolution structure.
Channel prediction network model
The channel prediction network includes data preprocessing, multivector parameter process, and frequency domain interpolation starts with channel prediction and data dimensionality reduction.
Data preprocessing part
Channel estimation is to evaluate the channel frequency domain response matrix H at the receiving end. In the pilot-based channel estimation technology, the main goal is to forecast the data symbol channel response based on the pilot symbol channel response. By using least squares approach, an investigator will create a line of greatest fit that illustrates the possible link among two or more variables. The linear regression approach explains why the line of greatest fit should be placed among some of the information items under consideration. The input of the channel prediction network model is a subframe size conditional random field matrix, and the channel response at the position of the LS technique is used to initialize the pilot symbol in the matrix. The channel response value at the data symbol position is set to zero. It can be expressed by the following formula:
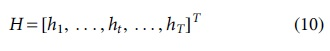
Among them, 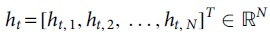 is at the data symbol position
is at the data symbol position
Multiparameter process
To overcome the influence of the mobile environment on channel estimation, we introduce multipath parameters and speed parameters in frequency domain interpolation besides time domain state prediction, respectively. The word interpolation relates to the procedure of transforming a recorded transmitted data (including a sampling speech signals) to one of a greater samples per second (upsampling) utilizing modern multimedia modulation technique in the realm of digital signal analysis (convolution with such a frequency-limited impulsive input for illustration).
Interpolating a succession of time domain sampling is a common (and essential) digital signal processing operation, as well as there are several explanations of time domain extrapolation (a type of template matching) in the research as well as on the internet. These two parameters are used to track changes in multipath conditions and changes in moving speed in a connected car environment. We use the normalization method in deep learning to convert the above two parameters into a vector of the same latitude through a normalization operation. The normalization operation uses a fully connected network, and the output is correspondent toward the weight in the fully connected network. We named the multipath parameter and speed parameter as Nd and Nv, respectively, and the output dimension is
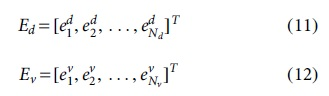
Among them,
Multi-convolution frequency domain interpolation
Compared with other methods 20 using complex DNN for frequency domain interpolation, the interpolation of each SC-FDMA symbol is relatively independent. As a result, the frequency domain interpolation does not make good use of the time domain change characteristics of the channel. Therefore, we use a simple multi-convolution operation for frequency domain interpolation. This module further utilizes the information of the input convolution kernel size on every channel to perform feature extraction and data sorting on the data through two 1 × 1 and one 3 × 3 convolutions. This method can simultaneously utilize the change characteristics of the channel in the time domain and the frequency domain.
Let
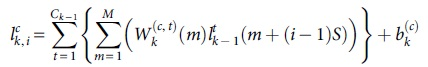
Among them,
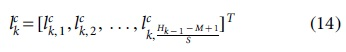
The resultant data of layer k are as follows:
Essentially stated, an activation function can be defined that is applied to an artificial neural network to aid it in learning complicated trends in information. As compared toward a neuron-based paradigm seen in human minds, the training algorithm is responsible for determining whatever is to be discharged toward the next neurons at the conclusion of the process. Each layer of convolutional network is followed by an activation function, so the transformation formula of every layer can be simplified as:
The number of input besides output channels of the channel prediction network is T. Then, the channel response on the n-th subcarrier on the t-th SC-FDMA symbol is as follows:
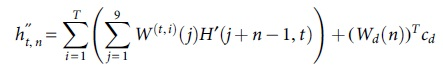
Among them,
Therefore, the frequency domain interpolation method proposed in this article jointly utilizes the time/frequency domain change relationship of the channel, and at the same time tracks the time/frequency domain change of the channel frequency domain response. The frequency domain reaction of the channels at the piloted signal as well as the multipath coding vectors define the channel estimation at every transmission symbolism. The multipath vectors are employed to monitor environmental changes induced through variations in the channel's multipath circumstances. The outcome next to interpolation for every SC-FDMA symbol can be illustrated as:
Among them, t corresponds to the number of output channels in the multi-convolution module.
GRU time domain state prediction
To be able to correct to the mobile environment, we use the GRU network when predicting the time domain state. The network converts various movement velocities into a matrix, which it then feeds into the time domain information system. The network introduces two specific inputs: the speed parameter in the mobile environment as well as the channel information after frequency domain interpolation. We added newly introduced parameters to the loop structure of the original GRU network. The overall structure is shown in Figure 6.
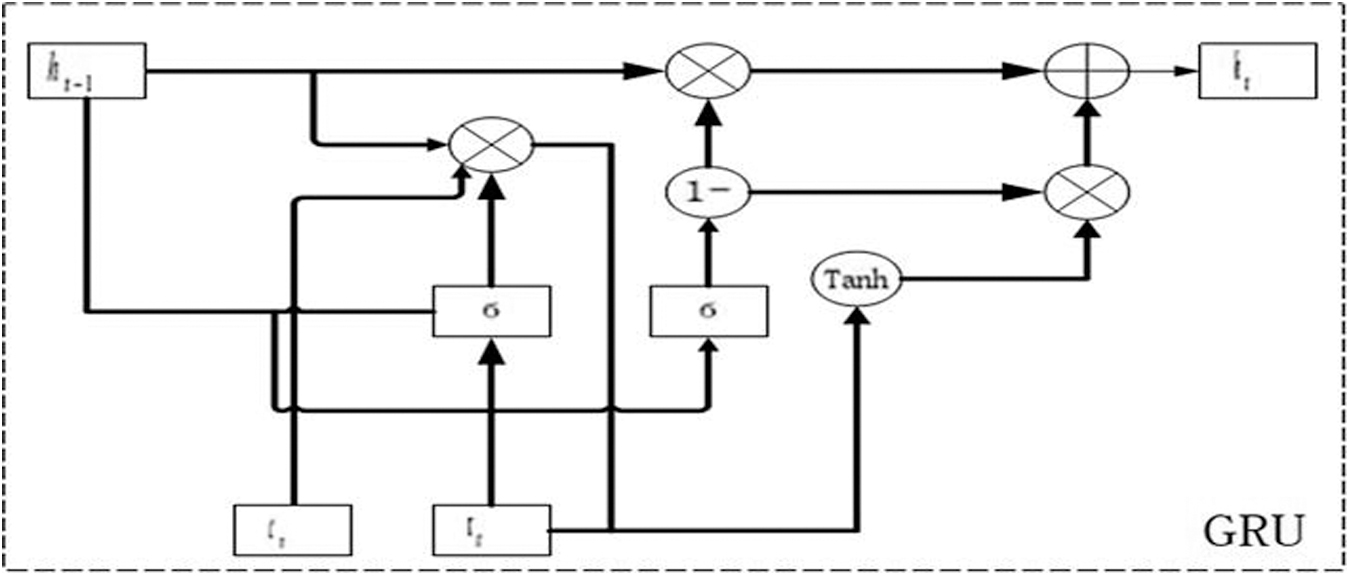
Schematic diagram of GRU network structure. GRU, gated recurrent unit.
The GRU system is mostly made up of GRU divisions. Every gate control device has two gates: an input gateway and an updated gateway. The information intake in every component of the system is controlled by the input nodes and updating gates. From this, we can obtain the time domain state forecasting mathematical transformation formula for the t-th SC-FDMA symbol:
Where it and ut are the input gate and update gate of the gated recurrent unit (GRU), respectively; ct is the memory unit, where σ is the Sigmoid function; is the channel data input at time t; is the state of the previous GRU unit at time
We apply the input gate to the speed parameter part. This is intended to control the flow of only a portion of the information from the speed code into the memory cell in the form of a gate. It is possible that the information in the memory cell will not be completely controlled by the speed code, but rather a fusion of various information. Finally, the memory cell and input are directly controlled through an update gate to attain the final output. Underneath low-speed conditions, in the temporal domain, the network response varies gradually, so the value of ut is small, and then, the last outcome is mainly determined by the input. The sampling frequency of the received signals, however, displays fast time-varying features in this time under high-speed movement situations. The value ut is large, so the final output is determined by the memory unit that contains the influence of the Doppler frequency shift parameter.
We refer to the design of two-way LSTM and adopt a two-way GRU (BiGRU) network.21–23
GRU is a multilayer perceptron that seeks to tackle the overfitting issue. Since both are constructed identically and, in certain situations, achieve comparably outstanding outcomes, GRU might be regarded as a variant of the LSTM. This system is made up of two GRU systems, one that does upward forecasting and the other that does backward forecasting. For the forecast of the present moment, this may make effective utilization of any data during the specific moment. Bidirectional forecasting can prevent experimental error produced by unidirectional predictive model. Every GRU network has T number of GRU units. The results of the two GRUs at time t in the BiGRU network are as follows:
24
Among them,
The final prediction result is that the output at each moment is the concatenation of the two GRU outputs; the final result is dimensionally reduced (DR) to unify the data to the same dimension. The final channel estimation result of the SC-FDMA symbol at time T is as follows:
26
Experimental Results and Analysis
Model training settings
We use the BEM channel model to generate training data. The collection of training samples in offline learning is accomplished by collecting data set from all resource's panels in every frame via simulation environment and then setting the received signal at the information to 0 using particular pilot insertion criteria. The index value of each sample corresponding to speed and multipath is used as training data. The channel estimation network is trained through the training data to obtain the minimized loss function. The parameters of the channel estimation network are as follows: time domain correlation coefficients, frequency domain interpolation coefficients, parameter embedding matrix, as well as dimensionality reduction coefficients. Through training, the parameters in the network can better track changes in the channel.
In required to practice the channel estimation network, assume the transforming equation and therefore entire variables of the whole channel estimation network are 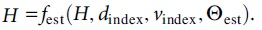 Gradient descent is an optimal scheduling approach for determining a function's local optimal. To use gradient descent to discover a method's single value, we must take measures proportionate toward the negativity of the stored procedure gradients (shift away from the gradients) at the present location. The gradient descent method uses the momentum-driven stochastic gradient descent method. This method can adjust learning parameters through appropriate momentum and can well balance training speed and training results. Our loss function is defined as:
Gradient descent is an optimal scheduling approach for determining a function's local optimal. To use gradient descent to discover a method's single value, we must take measures proportionate toward the negativity of the stored procedure gradients (shift away from the gradients) at the present location. The gradient descent method uses the momentum-driven stochastic gradient descent method. This method can adjust learning parameters through appropriate momentum and can well balance training speed and training results. Our loss function is defined as:
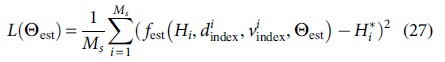
Among them,
The training set, verification set besides test set we use are, respectively, 300,000, 40,000 and 20,000. The various data sets contain the channel data to be evaluated, and then, the index value
Model complexity analysis
First, we compared the complexity of the BEM channel model and the traditional channel model, and the comparison results are shown in Table 1. We mainly compared the number of multiplication operations and time complexity of the algorithm.
Comparison of the Complexity of the Basic Expansion Model Channel and the Traditional Channel Model
BEM, basic expansion model; LMMSE, linear minimum mean square error; LS, least square.
It can be seen from Table 1 that the LS algorithm has the lowest complexity, which is linear order; the LMMSE algorithm has the highest complexity. Since N >> DL, the complexity of the BEM-LS algorithm is much lower than that of the LMMSE algorithm. Compared with the LS algorithm, the complexity of the BEM algorithm is relatively higher, but the higher part is not much, and the result is better than the former. Therefore, the complexity of the BEM algorithm we used is within the tolerable range of research.
Finally, we analyzed the computational complexity of the four traditional channel estimation methods, LS, LMMSE, spectral time average (STA), and constructed data pilots (CDP), the DNN-LSTM algorithm, and the algorithm proposed in this article. This article mainly compares the algorithm to estimate the number of multiplications and computational complexity required for two SC-FDMA symbols. One SCFDM symbol contains pilots, besides the other SC-FDMA symbol adjacent to it does not contain pilots. Table 2 depicts the outcome of analyzed complexity of anomaly techniques.
Comparison of the Complexity of Different Algorithms
CDP, constructed data pilots; STA, spectral time average.
The convergence speeds of LS, STA, and CDP are all in the identical magnitudes, as shown in Table 2. Owing to the necessity to perform transformation function, LMMSE has the greatest overhead of the algorithm. The DNN-LSTM approach has a similar online estimate difficulty toward the spectrum sensing networks in this research, which is fewer than the minimum LMMSE with linear programming method and somewhat greater compared with the LS with linear interpolation technique. The channel estimation network is only the multiplication and addition of some matrices, so its complexity is lower than that of the traditional LMMSE algorithm.
In addition, the neural network can run in parallel, so the calculation time of the algorithm can be reduced. The training parameters are immediately used toward the channel estimation during the live assessment step; hence, the complication is modest. Even though the channel coding networks has the same model complexity as the DNN-LSTM technique, the quantity of arithmetic operations needed indicates that the beamforming system has a lower performance than the DNN-LSTM technique. In general, the complexity of our proposed method is within an acceptable range; it can be better used in complex car networking environments.
Simulation result analysis
In the simulation experiment, the channel model adopts the BEM. A subframe in the transmission system contains 14 transmission symbols, of which the 3rd, 6th, 9th, and 12th symbols are pilot symbols, and the rest of the system parameter settings are shown in Table 3.
Channel Parameter Setting
First, we simulated the effectiveness of the BEM by setting different relative moving speeds of the vehicle terminal (150 km/h for medium speed, and 300 km/h for high speed) and related to the existing LS technique. For comparison, the simulation indicators include the normalized mean square error (NMSE) and bit error rate (BER).
Figure 7 analyzes the NMSE and BER efficiency of the LS technique than the LMMSE algorithm in medium-speed and high-speed environments. It can be seen that in the medium-speed environment, although the LMMSE algorithm considers the influence of noise, since the channel impulse response changes within one symbol in the high-speed mobile environment, neither the LMMSE algorithm nor the LS algorithm can capture the change.
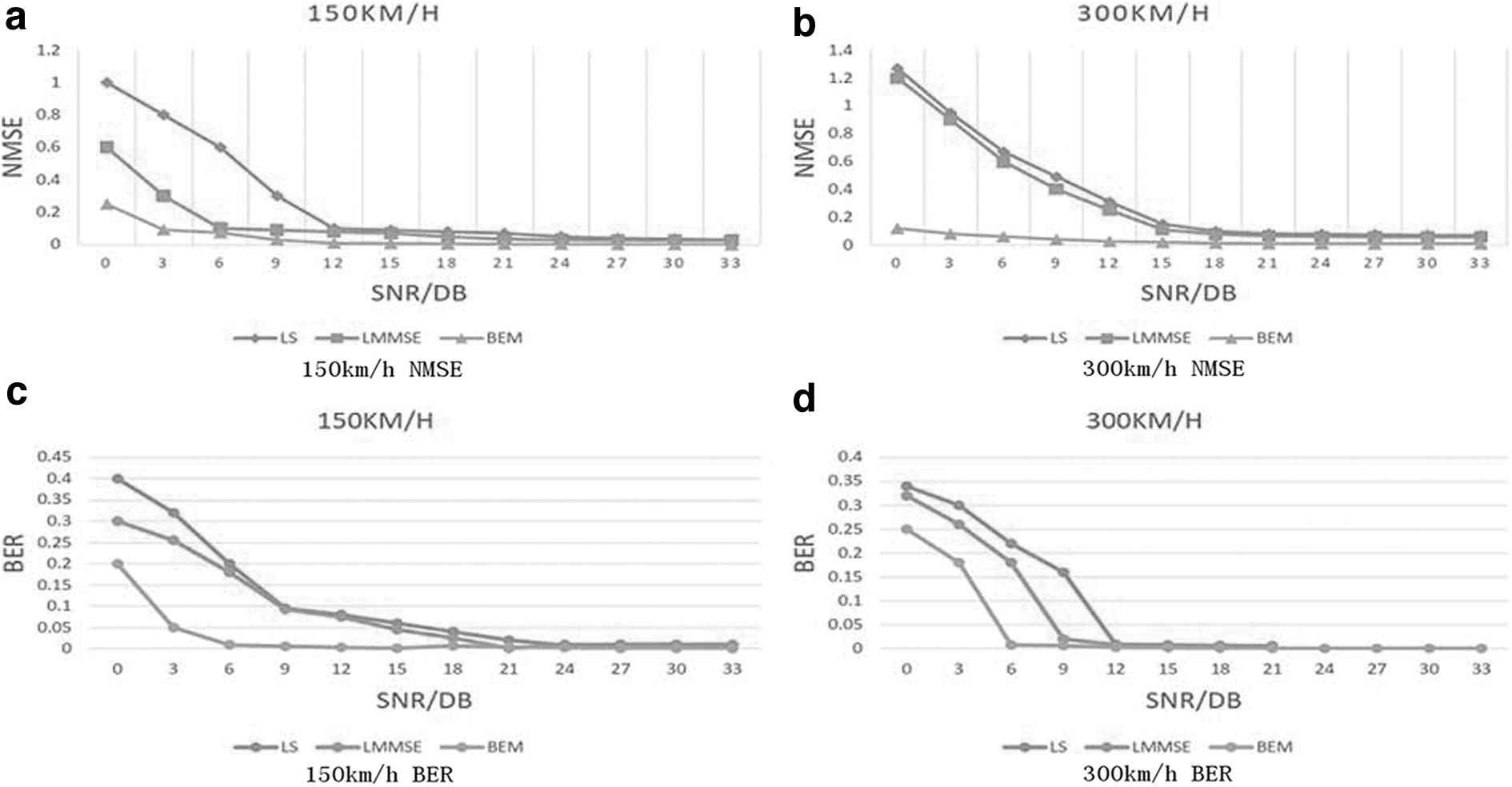
Comparison of the BER and NMSE algorithms for various channel estimation algorithms. BER, bit error rate; NMSE, normalized mean square error; SNR, signal-to-noise ratio.
Therefore, the performance gap between the two has narrowed. The BEM algorithm uses a base extension model to capture changes, so the performance is much better compared with the LS as well as LMMSE methodologies. In a high-speed environment, the advantages of the LMMSE algorithm over the LS algorithm are further reduced, and the LMMSE algorithm has little advantage and high complexity. And BEM can continue to maintain its advantage, still maintaining 5 dB of NMSE gain and 2 dB of BER gain. In summary, we use the BEM algorithm to be more suitable for the high-speed mobile car networking environment.
After that, we compared experiments with different multipath numbers and speeds. Figure 8 shows the NMSE as well as BER accomplishment of several techniques when the multipath number is 9 and the moving speed is 150 km/h. CDP, LS+linear interpolation besides STA algorithms all exhibit poor NMSE efficacy, as shown in the figure. This is because the channel responses at the pilots of these algorithms are all estimated by the LS algorithm, and then, the LS algorithm is incapable of removing noise's impact. This has an effect on the achievement of the information symbols stream responsiveness prediction. LMMSE has good NMSE performance, and the channel estimation network algorithm in this article has the best NMSE performance, which shows that the channel estimation algorithm in this article can not only effectively eradicate the influence of noise at the pilot frequency but also can better monitor the variations of the channel.
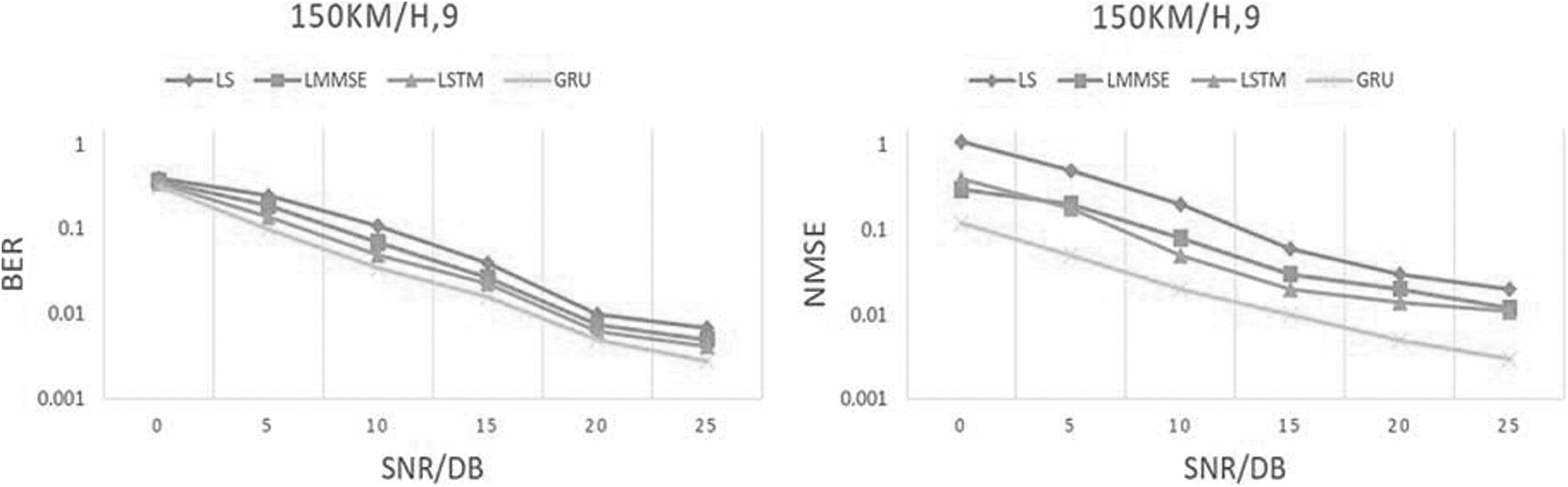
Performance comparison of the BER and NMSE of this algorithm when the number of multipath is 9 and the moving speed is 150 km/h. LMMSE, linear minimum mean square error; LS, least square; LSTM, long-term short memory.
For the DNN-LSTM algorithm, since the training data contain channel data of various environments, it cannot fit the channel data of different environments, so the performance is poor. At the time of the signal-to-noise ratio (SNR) <20, the BER efficiency of the DNN-LSTM technique is equivalent to the LMMSE performance. This shows that the neural network-based solution performs better in terms of noise removal as well as noise resilience. At this time, this article channel estimation method has attained the upper limit of estimation accomplishment. The impact of noise is now limiting the BER effectiveness of this approach.
Figure 9 shows the assessment of the NMSE and BER efficacy of various algorithms with multipath variations at the time of SNR = 25 dB and the moving speed is 150 km/h. The NMSE besides BER efficiency of several methodologies illustrate a downward trend as the moving speed enhances. The NMSE and BER efficiency of the STA, CDP, LS, besides LMMSE algorithms of STA, CDP, LS, and LMMSE decline sharply, representing that the existing technique is less robust to multipath. At this time, the decline trend of the CNN-GRU algorithm is relatively steady, signifying that the proposed method has much robustness.
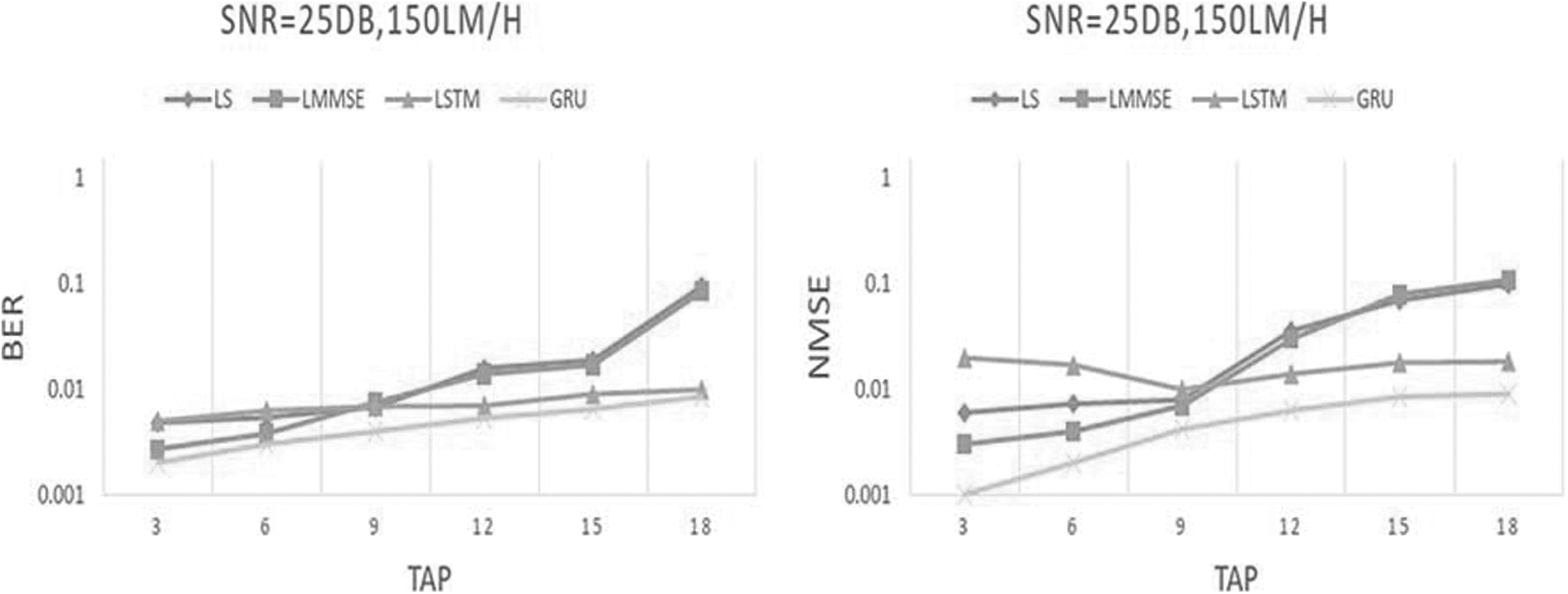
Performance comparison of the BER and NMSE of different algorithms when the moving speed is 150 km/h and SNR = 25 dB.
At this time, the NMSE performance curve of the DNN-LSTM technology fences with the variation of the multipath number, that is, the DNN-LSTM algorithm cannot efficiently monitor the changes in the channel multipath conditions, and the channel estimation algorithm in this article introduces multipath coding. The vector can accurately track the change of each multipath condition, which improves the algorithm's robustness to multipath.
Conclusions
To further enhance the quality of V2I communication in the Internet of Vehicles, this article first established a BEM channel model based on the sparse features of high-speed mobile channels. Dependent on the constructed BEM, a 5G-V2X-based intelligent channel estimation model is designed. Aiming at the problem of insufficient efficiency of existing channel estimation in the Internet of Vehicles environment, a channel estimation network based on deep learning is proposed, which uses multilayer convolution to complete frequency domain interpolation, as well as BiGRU for time domain state prediction, which enhances the accurateness of channel estimation.
To accomplish exact learning, we incorporate movement parameters matrix and multipath variable matrix as additional information to regulate the outcome of the complete spectrum sensing networks. Analysis as well as system simulation illustrate that the intelligent channel estimation model proposed in this article can ensure the accuracy and robustness of channel estimation while reducing complexity.
Footnotes
Authors' Contributions
J.H.: Writing—original draft (lead), data curation, software (lead), editing (equal). C.X.: Conceptualization (lead), methodology (lead), writing—original draft (lead), formal analysis (lead), writing—review and editing (equal). Z.J. and S.X.: Writing—review and editing (equal). T.L.: Conceptualization (supporting), writing—original draft (supporting). N.M.: Conceptualization (supporting). Q.Z.: Writing—original draft (supporting).
Data Sharing Agreement
The data sets used and/or analyzed during the current study are available from the corresponding author on reasonable request.
Author Disclosure Statement
No competing financial interests exist.
Funding Information
This article is a general project of science and technology plan of Beijing Municipal Education Commission (KM202110857002), the key project of Beijing Information Technology College (XY-YN-07-201902), the National Natural Science Foundation of China (Grant No. 62102033, 62171042).