
Abstract
Introduction:
Cannabis is a plant with high potential for use in several sectors of the industry; however, it is also a controversial crop due to its tetrahydrocannabinol (THC) content. Moreover, the plant has a rather unclarified classification. Traditionally, two types of Cannabis have been distinguished, hemp as a source of fiber and low THC content, and marijuana with high THC levels, which is used as a drug. With the increasing use of CBD strains and wide range of commercially used THC strains, it is becoming paramount to be able to develop an easy and reliable method for Cannabis strain differentiation. The use of simple sequence repeat markers, or microsatellites, seems to be an applicable choice.
Materials and Methods:
In this study, 52 strains of Cannabis with variable cannabinoid content were collected from growers from different geographical regions and analyzed using 17 different microsatellite markers. For more precise differentiation, five strains were selected and a higher number of individuals of each were analyzed.
Results:
Fragment analysis and cluster analysis showed that when one to three individual plants per strain were analyzed, the method was able to classify these samples into distinguishable groups with similar gene structure. They also revealed that when a larger sample set was used (10 individual plants per strain), highly specific strain clusters could be fully discriminated.
Conclusion:
Our study involved the highest number of cannabinoid-rich strains up to now and showed that the microsatellite method can be used to reliably differentiate Cannabis strains and show their relationships.
Introduction
Cannabis has been cultivated worldwide and is used as a source of fiber, medicinal substances, and drugs. 1 It is a member of the Cannabaceae family, is diploid, and has nine pairs of autosomes and a pair of gonosomes. It is usually a dioecious plant. 2 Cannabis can be divided into two main groups: hemp, with low tetrahydrocannabinol (THC) content, used mainly for fiber, and marijuana, with higher THC content, which is often used for drugs. 3
Taxonomy of Cannabis has undergone many changes. Historically, the genus Cannabis was divided into two species, Cannabis sativa and Cannabis indica; this was, however, later rejected.4,5 With the description of Cannabis ruderalis, an attempt for the reestablishment of these two species appeared and C. sativa and C. indica were also recognized as subspecies of C. sativa.6,7 Recently, Cannabis is mostly seen as a single highly variable species, despite genetic studies suggesting them as distinct species.8,9 Many varieties of Cannabis have also been named without being registered as cultivars and should be named as Cannabis strains. 10
Numerous variants of Cannabis and its use in multiple fields make methods for its exact differentiation essential. It is important to develop means to analyze Cannabis DNA to identify strains and track sample origin. In the forensic field, marijuana needs to be differentiated from low-THC Cannabis, whereas in hemp used for fiber, identification of variability among its genotypes is essential for the improvement of crops. Many strains of Cannabis are often misidentified and their genome is influenced by their geographic origin. In addition, Cannabis genomic identification is complicated by the fact that the plants are often cultivated by clonal propagation and may show aneuploidy, polyploidy, or multiple gene loci. 11 Development of methods to differentiate Cannabis has increased lately, and one type of them uses the analysis of simple sequence repeats (SSRs).12–16
SSRs, also known as microsatellites, or short tandem repeats, have distinct advantages compared to other methods.17,18 They are codominant, give reproducible results, have high discriminatory power, and can be multiplexed. 19 Microsatellite analysis in Cannabis helps understand its genome, which could lead to the successful cultivation of plants with accurate cannabinoid profiles and also to bring about progress in Cannabis breeding. However, only small-scale SSR markers have been reported in Cannabis.1,3,20 Gilmore and Peakall developed the first 15 variable microsatellite loci in 48 samples of C. sativa, which allow discrimination among individuals and accessions and thus help characterize genetic diversity in cultivated and natural Cannabis populations. 1 Another 11 markers were developed by Alghanim and Almirall. 3 Microsatellites have since been used to identify hemp cultivars or to distinguish forensic marijuana samples.14,21–26
However, few studies have aimed to differentiate between individual strains of Cannabis with high cannabinoid content. In this study, we aimed to differentiate samples belonging to a larger group of strains by using a combination of markers previously used in various studies. Fifty-two different strains of Cannabis, mostly with high cannabinoid content, were analyzed using 17 selected markers to determine whether they could be grouped into similar or identical genetic clusters by the microsatellite method. We also evaluated whether there was any relationship between the clusters and the geographical origin of the strains.
Materials and Methods
Ethics statement
This research did not contain any study involving animal or human participants, nor did it take place in any private or protected area. No specific permission was required for corresponding locations.
Cannabis samples and growth conditions
Samples belonging to 52 Cannabis strains with high CBD and THC contents, as well as one hemp variety, were collected from growers from different geographical regions (Table 1). Each strain was represented by one to three plants with the total of 88 individuals. Five selected strains (Ultimate, Orange Hill Special, Snow Bud, CBD Skunk Haze, and Durban Poison) were used in the cultivation experiment and grown under the same conditions, providing 10 individual plants of each strain to test whether there was an increase in strain identification accuracy.
Analyzed Cannabis Strains, Their Source, Cannabinoid Content, and Type
Cannabinoid content was categorized as follows: low, under 5%; medium, 5–10%; high, 10–15%; and very high, over 15%.
For the uncertain taxonomy of Cannabis, the collected strains were categorized into geographical types, sometimes referred to as species or subspecies, Cannabis sativa and Cannabis indica; when neither type was predominant with at least 70%, the strain was categorized as hybrid.
Momo and CBD US were taken from experiments in Czech Republic and United States (respectively).
CBD, cannabidiol; THC, tetrahydrocannabinol.
All plants were grown from seeds in Cannabis research facilities at Rabbit, Trhový Štěpánov, Czech Republic. Before planting in the growing system, the seeds were left in water for 24 h at 21°C and placed into rockwool seeding rollers for germination. After growing out of the rollers, the plants were moved into AutoPot pots with a volume of 15 L filled with lightly organically fertilized substrate Light-Mix (BioBizz). The organic additives Startrex and Mycotrex (BioTabs), containing PGPR and saprophytic fungi, were added to the substrate. When the seedlings were planted, the main organic fertilizer, with gradual release in the form of tablets, was added. The pots were then filled with a mixture of Orgatrex and Bactrex (BioTabs) dissolved in water, as recommended. Plants were watered automatically, and fertilizers were supplied in quantities and on dates recommended by the fertilizer manufacturer.
SanLight LED modules were used with a total power of 3,150 W to illuminate the plants. Throughout the growth cycle, the plants were exposed to a light regime of 20-h light/4-h dark. The average air temperature reached the level of 26.4°C, the average relative humidity of the air 66.6%, and the CO2 content an average value of 856 ppm.
Isolation of Cannabis DNA
Two leaves were collected from each individual, and all samples were dried on silica gel. For DNA isolation, 20 mg of the prepared plant tissue from each sample was homogenized using TissueLyser II (Qiagen, Hilden, Germany). DNA was isolated from all samples using DNeasy Plant Mini Kit (Qiagen) according to the manufacturer's instructions and dissolved in distilled water. 27 DNA quality and concentration were evaluated using NanoDrop 2000 Spectrophotometer (Thermo Fisher Scientific, Waltham, MA, USA). DNA was diluted to the concentration of 20 ng/μL and subsequently used as a template for PCR reaction.
Selection of microsatellite markers
Primers for amplification of microsatellite markers were selected from previous studies. Only markers with three or more base repetitions were selected because of their high variability among plant varieties. From 22 markers, we further selected 17 markers showing variability among the analyzed plant samples (Table 2).
Primers Selected for the Amplification of Microsatellite Markers (Only Markers Used in Final Reactions Shown)
Used fluorescent dye on forward primers after multiplex optimization is included in the sequence: FAM, blue; PET, red; VIC, green; NED, yellow.
Product size of alleles detected in this study.
Multiplex 4b.
Multiplex 3.
Multiplex 2.
Multiplex 4a.
Multiplex 1.
Optimization of the PCR multiplexes
Primers for the 17 selected microsatellite markers were divided into four multiplexes according to Multiplex Manager v 1.2. 28 After optimization, which included changes in primer combination in multiplexes, annealing temperature, and time of elongation, one of the primers from Multiplex 4 was excluded and used separately in a singleplex reaction. The multiplexes are listed in Table 2.
PCR reaction
The PCR protocol was performed according to Gilmore and Peakall, with changes due to optimization. 1 Multiplexes consisted of 2.5 μL Multiplex PCR Master Mix (Qiagen) per sample, primers as shown in Table 2, 0.5 μL template DNA, and H2O to 5 μL total reaction volume per sample. The reaction comprised a pre-denaturation at 94°C for 15 min, then 35 cycles of 94°C for 30 sec, 53°C or 57°C for 40 sec, and 72°C for 30 sec, and a final elongation step at 72°C for 10 min.
Annealing temperature in multiplex 1 and 2 was 57°C, whereas in multiplex 3 and 4a and singleplex 4b, it was 53°C. The PCR products were subsequently diluted as follows: multiplex 1 product was diluted 10 times, and multiplex 2, 4a, and singleplex 4b products were diluted 5 times. PCR products were separated by agarose gel electrophoresis with 2% agarose to confirm the presence and size range of amplified markers. As a ladder, GeneRuler 100 bp DNA Ladder (Thermo Fisher Scientific) was used, and as loading dye, we used 6×DNA Loading Dye (Thermo Fisher Scientific).
Fragment analysis
Each PCR product (1 μL) was mixed with 12.1 μL of a 120:1 solution of formamide:size standard (GeneScan 500 LIZ; Thermo Fisher Scientific). Multiplex 4a and singleplex 4b were both added to the same mixture. The prepared samples were then centrifuged using Centrifuge 5430 (Eppendorf, Hamburg, Germany) and denatured on Veriti Thermal Cycler (Thermo Fisher Scientific). Denatured PCR products were then prepared for fragment analysis.
Fragment lengths were determined by fragment analysis on ABI 3130 Genetic Analyzer and evaluated using GeneMapper 4.0 (Thermo Fisher Scientific), which visualized alleles as color-coded peaks. Genotyping was performed in 17 markers that showed variability between strains. The lengths of amplicons were rounded to the nearest base pair. In case two different amplicons with the difference of 1 bp were detected, the later detected amplicon was changed to the one detected previously.
Clustering of individual plants
The relatedness of individuals and their division into clusters was performed using Structure software, version 2.3.4, which divided individual plants into clusters according to the likelihood and similarity of results during multiple runs. 29 Each population was characterized by the frequency of alleles in each locus, and the individuals were assigned to one or more populations. The length of the burnin period, representing the number of Markov chain Monte Carlo steps until the results are in balance, was initially set to 10,000, and the number of steps after the burnin period to 50,000 to infer the number of clusters (K). Subsequently, the length of the burnin period was increased to 500,000 and the number of steps after the burnin period to 750,000. The number of iterations for each K was set to 20.
For the determination of optimal K and data visualization, we used MS Excel and Structure Harvester online tool. 30 The distances between individuals were then visualized by principal coordinate analysis (PCA) with Lynch distance using the POLYSAT package in R version 4.2.0.
SPAGeDi1-5d was used to determine the number of alleles, allelic richness, gene diversity, observed heterozygosity, and inbreeding coefficient. 31
Results
Microsatellite markers used in previous studies were adjusted for the analysis of high-cannabinoid strains included in this project. After optimization, 17 markers were selected to determine the genetic diversity of 52 Cannabis strains. Agarose gel electrophoresis revealed the size range of amplified markers (Supplementary Fig. S1). Size of all amplified markers for each strain is listed in Supplementary Tables S1 and S2.
Samples were analyzed using Structure software for every possible number of populations (K=1–88), and the highest value of K was identified by Structure Harvester as the value for which the individual samples were best divided into clusters (Supplementary Fig. S2). This value was identified as K=4 and was set for the subsequent analysis with a greater length of burnin period and number of steps after the burnin period for more accurate results.
The clustering divided alleles into four large groups, and the individual samples belonging to 52 strains were mostly classified into all four to a greater or lesser extent, with one group being predominant (Fig. 1 and Supplementary Table S3). Similar profiles were observed for multiple individuals within the four groups. This was the case for all the individuals belonging to the same strain. Some strains had a distinct profile different from other strains, but similarities in individuals of different strains were also detected, which implied the relatedness of some Cannabis strains.
Clustering of 52 Cannabis strains with one to three individuals per strain using MS Excel. See Table 1 for strain abbreviations.
A larger number of individuals per strain were analyzed to further divide individuals into strain-specific groups. Five strains were selected for this experiment, each represented by 10 individuals. Samples were analyzed using the same method, and the individuals formed five distinct clusters, each corresponding to their strain (Fig. 2 and Supplementary Fig. S3). Only minor similarities were detected between the strains.
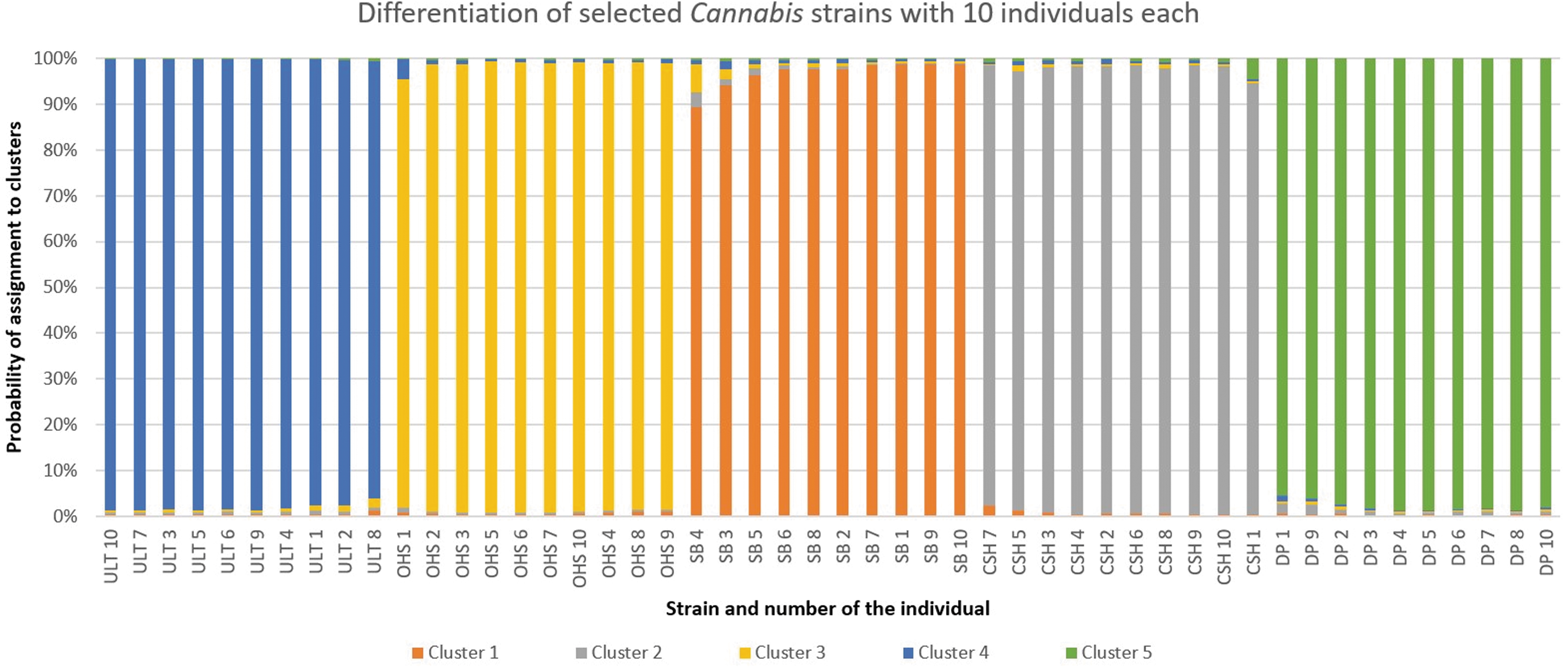
Differentiation of five Cannabis strains with a higher number of individuals per strain using MS Excel. See Table 1 for strain abbreviations.
The distances between five Cannabis strains with 10 individuals each were also visualized using R version 4.2.0, with the POLYSAT package. PCA with Lynch distance was chosen for the visualization for it proved better in distinguishing populations (Fig. 3).
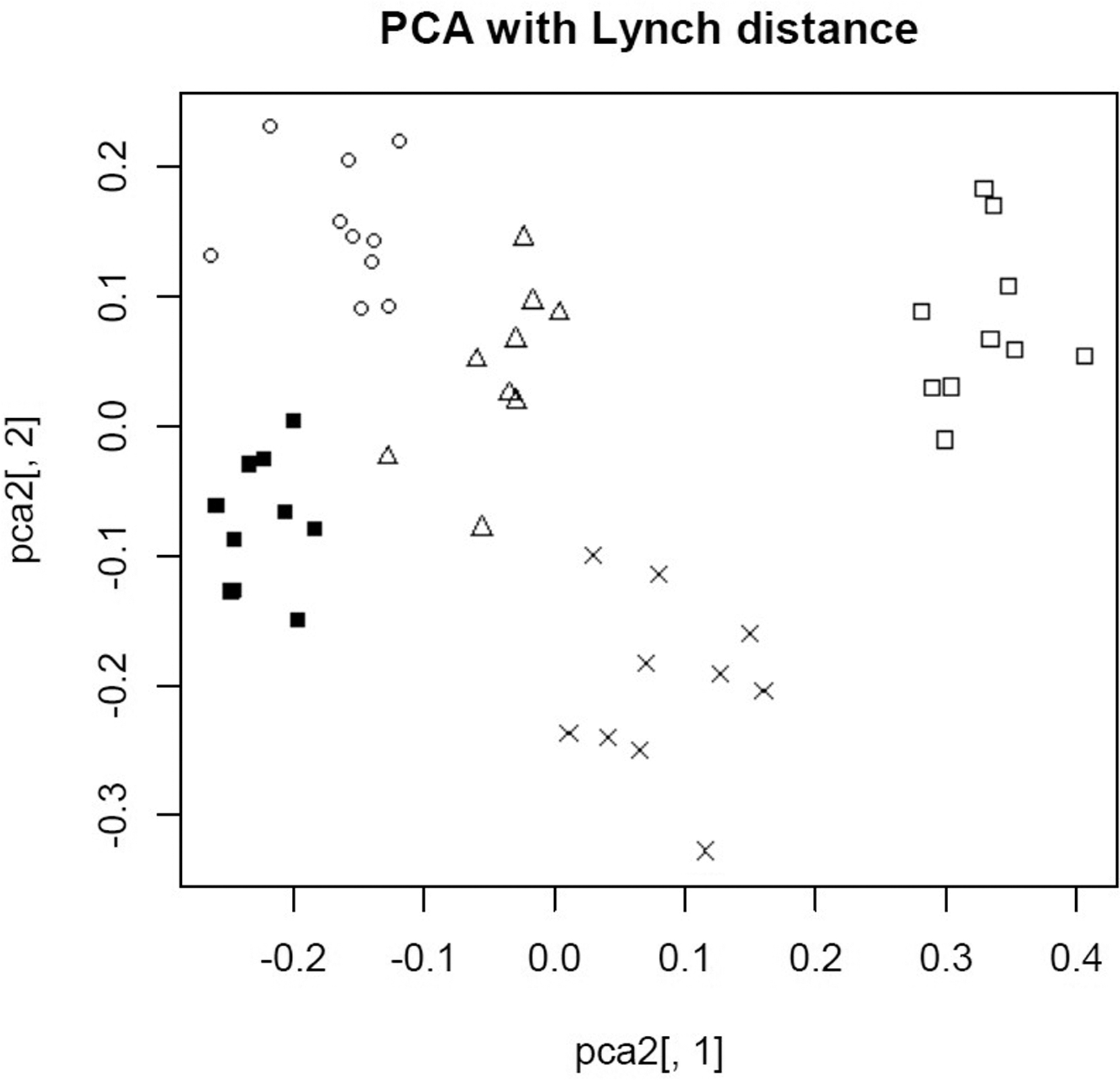
Visualization of genetic distances between individuals by PCA with Lynch distance. Individuals belonging to each strain indicated by symbols: circle, Orange Hill Special; triangle, Snow Bud; square, Durban Poison; fill square, Ultimate; cross, CBD Skunk Haze. PCA, principal coordinate analysis.
The number of alleles and the expected and observed heterozygosity (Table 3) were calculated using SPAGeDi1-5d. The number of alleles ranged from two to eight, the expected heterozygosity ranged from 0.00 to 0.74, and the observed heterozygosity ranged from 0.00 to 1.00. Observed heterozygosity was usually significantly higher than expected. A significant deviation from Hardy–Weinberg equilibrium was found in all populations.
Number of Alleles, Expected and Observed Heterozygosity Determined by SPAGeDi1-5d
Number of alleles (NA), expected heterozygosity (He), and observed heterozygosity (Ho) in tested strains with 10 individuals each and all tested markers.
CSH, CBD Skunk Haze; DP, Durban Poison; OHS, Orange Hill Special; SB, Snow Bud; ULT, Ultimate.
Discussion
For the increasing use of Cannabis plants containing cannabinoids for medical purposes, it is necessary to develop effective methods able to identify Cannabis strains with known cannabinoid content and analyze their relatedness. Our work aimed to distinguish 52 mostly high-cannabinoid strains with 17 microsatellite markers and correctly classified individual samples into four clusters of similar strains. When testing a higher number of individuals per strain, all tested strains were clearly distinguished. Previous studies used microsatellite analysis mostly to individualize samples of hemp and marijuana, differentiate hemp cultivars, and identify the origin of Cannabis samples.11,14,21–26,32–35 Only few studies have aimed to differentiate between individual strains with high cannabinoid content.24,36,37
Schwabe and McGlaughlin developed 10 new microsatellite markers to analyze differences in 122 samples belonging to 30 commercially available C. sativa strains, whereas Soler et al used 6 SSR markers for genotyping 154 individual plants of 20 cultivars, and Dufresnes et al analyzed 24 hemp varieties and 15 marijuana varieties with 13 microsatellite markers.24,36,37 Our work analyzed a higher number of strains using 17 markers. These studies have found similarities in different strains and variability within the same strain, which are likely caused by mislabeling and misidentification, which we did not observe in our study. Dufresnes et al also detected lower diversity within marijuana varieties, and substantially higher genetic distances among them compared to hemp, which is consistent with our results. 24
Although some strains of geographical types sativa, indica, and hybrid clustered together, we did not find any genetic distinction between them, similar to previous studies. 36
Most markers used had a product size in or close to the range documented in previous studies.1,11,14 The exception was marker CAN1347, where the previously documented product had a size of 133 bp, whereas in our strains, the size range was 216–227 bp.
We detected 2 to 13 alleles per locus in all tested samples, with the average of 6.06, and heterozygosity ranging from 0.0 to 1.0 (average=0.47). Heterozygosity was determined for five strains with 10 individuals, as some of the 52 strains did not have enough individuals. Our results were similar to those previously observed, with high polymorphism and heterozygosity. Gilmore and Peakall detected an average of 10 alleles per locus, with the range of 2–28, and mean heterozygosity of 0.68, ranging from 0.28 to 0.94. 1 Soler et al observed very high polymorphism with an average of 17 alleles, with heterozygosity average values of 0.753 and 0.429 for C. sativa var. indica and C. sativa var. sativa, respectively. 37 Borin et al observed comparable heterozygosity among all varieties, which was on average 0.58±0.09, while Dufresnes et al detected heterozygosity of 0.41±0.15.24,33
Observed heterozygosity was usually significantly higher than expected and often reached a value of 1.0. A significant deviation from the Hardy–Weinberg equilibrium was found in all populations. This was likely caused by the high number of alleles for each marker, which led to high genetic variability. The populations were not natural, and some of the strains were polyploid.
In Cannabis, in addition to seed propagation, cloning is also used, which leads to new genetically identical plants.24,38 High clonality leads to greater allele and genotype representation of the largest clones relative to the smaller ones. 39 That explains the deviation from Hardy-Weinberg equilibrium as well as small differences between individuals of the same strain.
Conclusions
Fifty-two Cannabis strains with mostly high cannabinoid content were analyzed using microsatellite markers. While a low number of plants (one to three) were used for analysis, the method was able to divide strains into four distinct clusters with groups of individuals showing more similar profiles, which mostly belonged to the same strain, as well as apparent relationships between strains. When a higher number of individuals per strain (10 plants) were used for the analysis, all individuals were correctly assigned to their particular strain. In this research, for the first time, the method was applied to such a large number of Cannabis strains with high cannabinoid content, and individuals of different strains were clearly distinguished. Our results will help differentiate Cannabis strains of unknown or unsure origin, determine their relatedness to other strains, and unambiguously identify the strain of an unknown sample.
Footnotes
Acknowledgments
We thank Zdeněk Jandejsek and Rabbit, a. s., Trhový Štěpánov, Czech Republic, for providing Cannabis samples.
Authors' Contributions
L.F.: conceptualization (lead); writing – original draft (lead); formal analysis (lead); software (lead); methodology (equal); and review and editing (equal). M.Š.: methodology (equal); writing – review and editing (equal); and software (supporting). A.J.: methodology (equal). J.K.: methodology (equal). M.V.: funding acquisition (lead); conceptualization (supporting); and review and editing (equal).
Author Disclosure Statement
No competing financial interests exist.
Funding Information
This research was funded by the MPO project Biotechnology of hemp cultivation for CBD products (No. FV40103) of the Technology Agency of the Czech Republic.
Abbreviations Used
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.