
Abstract
1. Introduction
When studying the evolutionary history of a set X of existing species, one can obtain a phylogenetic tree with leaf set X with high confidence by looking at a segment of sequences or a set of genes (Ma et al., 1999; Ma and Zhang, 2011). When looking at different segments of sequences, different phylogenetic trees with leaf set X can be obtained with high confidence, too. To facilitate the comparison of the resulting trees, a number of distance metrics have been proposed in the literature (Buneman, 1971; Robinson and Foulds, 1981; Li et al., 1996; Swofford et al., 1996; Chauve et al., 2017). Among the metrics, the rSPR-distance (Bordewich and Semple, 2005) is an important metric that often helps us discover reticulation events. In particular, it provides a lower bound on the number of reticulation events (Beiko and Hamilton, 2006; Baroni et al., 2015), and it has been regularly used to model reticulate evolution (Maddison, 1997; Nakhleh et al., 2005).
The rSPR distance is usually defined for two phylogenetic trees, T1 and T2. It can be defined as the minimum number of edges that should be deleted from each of T1 and T2 to transform them into topologically identical rooted forests F1 and F2. Roughly speaking, F1 and F2 are topologically identical if they become identical forests after repeatedly contracting an edge (p, c) in each of them such that c is the unique child of p (until no such edge exists). The problem of computing the rSPR distance of two trees is NP-hard (Hein et al., 1996; Bordewich and Semple, 2005). This has motivated researchers to design approximation algorithms for the problem (Schalekamp et al., 2016; Chen et al., 2017) as well as fixed-parameter algorithms for the problem (Whidden et al., 2010; Chen et al., 2015, 2017).
Recently, Chauve et al. (2017) defined two new metrics highly related to the rSPR distance. Basically, to compute the rSPR distance of two phylogenetic trees, we are allowed to delete any edges from the input trees so that the resulting forests become topologically identical, as long as the number of deleted edges is minimized. In contrast, the two new metrics defined by Chauve et al. (2017) require that any edge removed from the input trees must be incident to a leaf. Moreover, the new metrics are defined for any number of phylogenetic trees and also allow that the labels of leaves removed from one input tree are different from those of leaves removed from another input tree. More specifically, given a set of phylogenetic trees, the two new metrics ask us to remove leaves from the input trees so that there is a single tree displaying all the resulting trees, where a tree T displays another tree T′ if and only if T′ is topologically identical to a subtree of T. One of the metrics requires that the total number of leaves removed from the input trees is minimized, whereas the other requires that the maximum number of leaves removed from an input trees is minimized. The problem of computing the former metric is denoted by AST-LR, whereas the latter is denoted by AST-LR-d. Here, AST stands for “agreement subtree” and LR stands for “leaf removal.”
A problem related to AST-LR is the maximum agreement supertree problem (MASP) defined in Jansson et al. (2005). Given a set {T1, …, Tm} of phylogenetic trees not necessarily with the same leaf-label set, MASP asks to compute a maximum set L of leaf-labels in the input trees so that there is a phylogenetic tree with leaf-label set L displaying the trees T1| L , …, Tm| L , where for each i∈{1, …, m}, Ti| L denotes the phylogenetic tree obtained from Ti by deleting those leaves whose labels are not in L. Jansson et al. (2005) show the NP-hardness of MASP and present polynomial-time algorithms for several special cases.
As easily observed in Chauve et al. (2017), the special cases of AST-LR and AST-LR-d where there are only two input trees are basically the maximum agreement subtree problem and hence can be solved in
In this article, we point out that the algorithm in Chauve et al. (2017) for the parameterized version of AST-LR is flawed and we present a new algorithm. The algorithm runs in
Unfortunately, neither Chauve et al.'s algorithm for AST-LR-d nor our new algorithm for AST-LR looks practical. So, we further design integer-linear programming (ILP for short) models for AST-LR and AST-LR-d, and we discuss speedup issues when using popular ILP solvers (say, GUROBI or CPLEX) to solve the models. To evaluate the performance of our ILP models, we implement the algorithm in Chauve et al. (2017) for a much simpler parameterized problem (than the parameterized version of AST-LR), where we are only required to decide whether we can delete a total number of at most q leaves from the input trees so that the resulting trees have no conflicting triplets. Our experimental results show that GUROBI can solve our ILP model for AST-LR within a much shorter time than Chauve et al.'s algorithm solves this much simpler parameterized problem.
The remainder of this article is organized as follows. Section 2 gives the basic definitions that will be used thereafter. Section 3 is devoted to the parameterized version of AST-LR. Section 4 presents our ILP models for AST-LR and AST-LR-d and evaluates their efficiency experimentally.
2. Preliminaries
Throughout this article, a phylogenetic tree always means a rooted tree whose leaves are distinctly labeled. Unless stated otherwise, a phylogenetic tree is always binary, that is, each nonleaf vertex has exactly two children in the tree.
Let T be a phylogenetic tree. For each vertex v of T, the subtree rooted at v is called a pendant subtree of T. We use X(T) to denote the leaf-label set of T. For each x∈X(T), we use xT to denote the leaf of T labeled x. Moreover, for a subset Y of X(T), we use YT to denote {xT | x∈Y}. If T is clear from the context, we simply write x and Y instead of xT and Y T , respectively. Moreover, for a subset Y of X(T), we use T − Y to denote the phylogenetic tree obtained from T by first removing the leaves in YT and further repeatedly removing an unlabeled leaf or contracting an edge, leaving a unifurcate vertex (i.e., vertex with only one child) until no such leaf or edge exists. We use T| Y to denote T − (X(T)\Y). T displays another phylogenetic tree T′ if X(T′) ⊆ X(T) and T′ = T|X(T′).
A leaf-prune-and-regraft (LPR) operation on T is the operation of replacing T by another phylogenetic tree T′ with X(T) = X(T′) such that T and T′ are different but T − {x} and T′ − {x} are identical, In other words, T′ is obtained from T as follows.
Choose a leaf x and an edge e = (u, v) of T such that v is neither the sibling nor the parent of x in T.
Remove the edge entering x and contract the edge leaving p, where p was the parent of x before the removal.
Replace e by three edges (u, w), (w, v), and (w, x), where w is a new vertex.
We say that T′ is obtained from T by pruning x and regrafting it on e. Intuitively speaking, LPR operations are rSPR operations [defined in Bordewich and Semple (2005)] restricted to leaves.
Let (T1, …, Tm) be a list of phylogenetic trees, where it is unnecessary that X(T1)…=X(Tm). A leaf-disagreement for (T1, …, Tm) is a list L=(Y1, …, Ym) such that each Yi (1 ≤i ≤ m) is a set of leaves in Ti and there is a phylogenetic tree T displaying T1 - Y1 through Tm − Ym. The size of L is

A counterexample to the algorithm for AST-LR in Chauve et al. (2017).
Given a set {T1, …, Tm} of phylogenetic trees with
Let T1 and T2 be two phylogenetic trees with X(T1) = X(T2). A leaf-disagreement (Y1, Y2) for (T1, T2) is one-sided if Y2 =θ. As easily observed in Chauve et al. (2017), the following hold:
For every leaf-disagreement (Y1, Y2) for (T1, T2), (Y1 ∪ Y2, θ) is a one-sided leaf-disagreement for (T1, T2). For every one-sided leaf-disagreement (Y, θ) for (T1, T2) and for every Y1 ⊆ Y, (Y1, Y\Y1) is a leaf-disagreement for (T1, T2).
For simplicity, we use Y to denote a one-sided leaf-disagreement (Y, θ) for (T1, T2). Y is minimal if for every y∈Y, and Y \ {y} is not a one-sided leaf-disagreement for (T1, T2). We use dLR(T1, T2) to denote the minimum size of a one-sided leaf-disagreement Y for (T1, T2). Given T1 and T2, dLR(T1, T2) can be computed in
3. Parameterized Algorithm For AST-LR
A triplet is a phylogenetic tree with exactly three leaves. We use xy|z to denote the triplet t such that X(t) = {x, y, z} and x and y are siblings in t. Two triplets t1 and t2 conflict if t1 = xy|z and t2∈{xz|y, yz|x}. We say that xy|z is a triplet of a phylogenetic tree T if {x, y, z} ⊆ X(T) and T|{x, y, z} = xy|z. For example, in Figure 1, ac|b is a triplet of
3.1. The flaw in Chauve et al.'s algorithm
We first review Chauve et al.'s algorithm for the parameterized version of AST-LR. An instance of the parameterized version consists of an integer q and a set {T1, …, Tm} of phylogenetic trees with X(T1) = ⋯ = X(Tm), and the objective is to decide whether there is a leaf-disagreement L of size at most q for (T1, …, Tm). Chauve et al.'s algorithm for the problem actually solves a more general problem. More specifically, the condition X(T1) = ⋯ = X(Tm) on {T1, …, Tm} is removed. Moreover, in addition to q and {T1, …, Tm}, the input to their algorithm also includes a set F of non-conflicting triplets and the algorithm is supposed to return “yes” if and only if there is a leaf-disagreement L of size at most q for (T1, …, Tm) such that some center tree T witnessing L satisfies that every triplet in F is a triplet of T. The triplets in F are called the fixed triplets. A triplet t∈F conflicts with a tree Ti if Ti has a triplet conflicting with t.
Obviously, to solve the parameterized version for (q, {T1, …, Tm}), it suffices to solve the generalized problem for (q, {T1, …, Tm}, θ). So, consider the call of Chauve et al.'s algorithm on input
Case 1: A triplet t = xy|z∈
Case 2: A triple S = {x, y, z} inconsistent in {
Suppose that the first phase has ended and the input to the current call of the algorithm has become
Counterexample: Suppose we run Chauve et al.'s algorithm on input (
Since {a, d, e} is inconsistent in {
Since de|a in
Since {a, d, j} is inconsistent in {
Since dj|a in
Since {c, d, f} is inconsistent in {
Since cf|d in
After the six steps just cited,
We point out, in passing, that the minimum size of a leaf-disagreement for {
The counterexample just cited shows a concrete instance (q, {T1, …, Tm}, θ) with X(T1) = ⋯ = X(Tm) such that after the first stage,
3.2. Deciding the existence of a center tree
In this subsection, we sketch how to apply Aho et al.'s polynomial-time algorithm (Aho et al., 1981) to deciding whether there is a phylogenetic tree displaying a given set
Recall the well-known fact that each phylogenetic tree T is the unique phylogenetic tree displaying the triplets in tr(T). So, to decide whether there is a phylogenetic tree displaying the trees in
Consider the call of Aho et al.'s algorithm on input
We next detail Aho et al.'s recursive algorithm. In the base case where
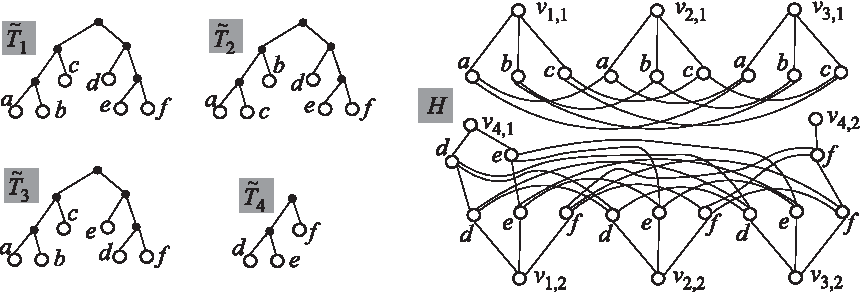
Four trees

Three trees
For convenience, we refer to P as the label-partition for
V1 consists of the leaves (together with their labels) in the trees in
for each
for each
for every two vertices x and y in V1, if x and y have the same label, then E3 contains the edge {x, y}.
For example, H is as shown in Figure 2 if
Let K1, …, Kh be the connected components of H. For each i∈{1, …, h}, let Xi be the set of all
3.3. A new algorithm
In this subsection, we present a new algorithm for the parameterized version of AST-LR. So, consider an instance (q, {T1, …, Tm}) of the problem. Note that X(T1) = ⋯ = X(Tm). For each i∈{1, …, m}, we call Cole et al.'s algorithm (Cole et al., 2000) to compute dLR(Ti, Tj) for each j∈{1, …, m}, and then check whether
Since our algorithm will be recursive, we need to consider a call originated from the root call [i.e., the call on input (q, {T1, …, Tm}) after zero or more subsequent calls]. Let
Let
C1. Each
C2. If i and i′ are different integers in {1, …, ℓ}, then ji ≠ ji′.
C3. The partition P of
For example, if
Consider the auxiliary bipartite graph H = (V1 ∪ V2, E1 ∪ E2 ∪ E3) constructed from
Lemma 3.1.
Let X′ be the set of labels on the vertices in
By the claim just made, H′′ is a tree and hence has |X′| + |V2| − 1 edges. Moreover, each vertex of H′′ not in V2 cannot be a leaf of H′′ because otherwise, we would be able to remove more vertices of
For each i ∈{1, …, ℓ}, let
Lemma 3.2. There is no phylogenetic tree displaying the trees in
By Conditions C1 and C2,
To compute
Try to find an x such that x is a proper leaf descendant of a child of the root of some
If x is found in Step 1, then remove it from
So,
Theorem 3.3. The parameterized version of AST-LR for input (q, {T1, …, Tm}) can be solved in
In Figure 4, we summarize our algorithm for the parameterized version of AST-LR.

The algorithm for the parameterized version of AST-LR.

A recursive subroutine called by the algorithm in Figure 4 on input (q, {T1, …, Tm}).
4. Integer-Linear Programming Approach to AST-LR and AST-LR-d
For convenience, we use the notation (j1, …, jk) ⊆ S to denote an ordered subset (j1, …, jk) of a set S. Let
or
The following lemma is well known and will be useful for constructing ILP models for AST-LR and AST-LR-d.
Lemma 4.1. A full set
4.1. Exact integer-linear programming models
We first show an ILP model for AST-LR-d. So, let (d, {T1, …, Tm}) be an instance of the problem. Let
aj,k,l = 0 and bj,k,l = 0 if and only if T|{xj,xk,xl} = xjxk|xl.
aj,k,l = 0 and bj,k,l = 1 if and only if T|{xj,xk,xl} = xjxl|xk.
aj,k,l = 1 and bj,k,l = 0 if and only if T|{xj,xk,xl} = xkxl|xj.
We also introduce an integral variable d whose value is supposed to be an upper bound on the radius of a leaf-disagreement for {T1, …, Tm}. Then, our ILP problem for AST-LR-d is as follows:
Minimize d
Subject to
The constraints can be understood as follows:
The first set of constraints requires that the maximum number of leaves removed from each tree Ti in the output leaf-disagreement is at most d.
The second set of constraints requires that for each (j, k, l) ⊆ {1, …, n}, the output center tree T contains exactly one of the triplets xjxk|xl, xjxl|xk, and xkxl|xj.
The third set of constraints requires that for each (j, k, l) ⊆ {1, …, n}, if Ti contains the triplet xjxk|xl but the output center tree T does not, then at least one of xj, xk, and xl should be removed from Ti.
The fourth set of constraints requires that for each (j, k, l) ⊆ {1, …, n}, if Ti contains the triplet xjxl|xk but the output center tree T does not, then at least one of xj, xk, and xl should be removed from Ti.
The fifth set of constraints requires that for each (j, k, l) ⊆ {1, …, n}, if Ti contains the triplet xkxl|xj but the output center tree T does not, then at least one of xj, xk, and xl should be removed from Ti.
The sixth and the seventh sets of constraints are based on Lemma 4.1. Moreover specifically, the sixth set of constraints requires that at least one of the triplets xjxk|xl, xlxh|xk, xkxh|xj should not appear in the output center tree T, whereas the seventh set of constraints requires that at least one of the triplets xjxk|xl, xlxh|xk, xjxh|xk should not appear in the output center tree T.
To obtain an ILP model for AST-LR, we just simply modify the ILP model cited earlier for AST-LR-d by deleting the first set of constraints and replacing the objective function d with
4.2. Relaxed integer-linear programming models
The ILP models in Section 4.1 are exact in the sense that they solve AST-LR-d and AST-LR exactly. Unfortunately, since the models contain too many constraints, they may take long a time to be solved by an ILP solver (such as Gurobi and Cplex). So, we next propose relaxed ILP models instead; the relaxed model for AST-LR-d (respectively, AST-LR) alone does not solve AST-LR-d (respectively, AST-LR) but will be used to speed up solving the exact model for AST-LR-d (respectively, AST-LR).
As stated earlier, we first present a relaxed ILP model for AST-LR-d and then modify it into a relaxed ILP model for AST-LR. The idea behind our relaxed ILP model for AST-LR-d is to avoid computing the triplets T|{xj,xk,xl} in the output center tree T. Intuitively speaking, the idea is to remove the variables aj,k,l and bj,k,l from the exact models. Without knowing the triplet T|{xj,xk,xl}, we have to resort to removing direct conflicts between the input trees. In other words, for every (j,k,l) ⊆ {1, …, n} and for every
Ti1|{xj,xk,xl} = xjxk|xl, Ti2|{xk,xl,xh} = xlxh|xk, and Ti3|{xj,xk,xh} = xkxh|xj.
Ti1|{xj,xk,xl} = xjxk|xl, Ti2|{xk,xl,xh} = xlxh|xk, and Ti3|{xj,xk,xh} = xjxh|xk
In summary, we have obtained the following relaxed ILP model for AST-LR-d:
Minimize d
Subject to
To obtain a relaxed ILP model for AST-LR, it suffices to modify the relaxed ILP model cited earlier for AST-LR-d by deleting the first set of constraints and replacing the objective function d with
4.3. Using the relaxed models to speed up the exact models
Here, we only explain how to use the relaxed model of AST-LR-d to speed up solving its exact counterpart. Similar discussions apply to the models of AST-LR as well.
By experiments, we have found that the relaxed model for AST-LR-d can be solved much faster than its exact counterpart by Gurobi or Cplex. Of course, an optimal solution s* of the relaxed model may not lead to a correct leaf-disagreement. In more details, even though s* tells us which leaves should be removed from each input tree Ti, there may not exist a center tree displaying all the resulting trees after the removals. Nevertheless, instead of solving the exact model directly, we can first solve the relaxed model to obtain s* and then proceed to solving the exact model with the help of s*. The crucial points are as follows:
The value of d in s* is a lower bound on the optimal objective value of the exact ILP model. We can incorporate this bound into the exact model when solving it with an ILP solver. The bound can help the solver prune a lot of unnecessary branches of the search tree.
The values of yi, j's in s* can be used as a starting partial-solution when solving the exact model by an ILP solver. By experiments, we have found that the partial start can often be extended to a feasible (and hence optimal) solution of the corresponding exact model by the solver. As the result, the solver can often solve the exact model within almost the same time as the relaxed model.
As will be seen in Section 4.4, using the relaxed model as cited earlier leads to significant speedup of solving the exact model.
4.4. Experimental results
To evaluate our ILP models empirically, we run our program on a Ubuntu (x64) desktop PC with i7-4790K CPU and 31.4 GiB RAM and another CentOS (x64) desktop PC with E5-2687W(v4) CPU and 252.2 GiB RAM. We used two machines instead of a single machine in our experiments just for the sake of finishing the experiments sooner. To solve our ILP models, we use Gurobi as the solver.
Our (exact or relaxed) models have many constraints and, hence, it often takes time for Gurobi to get started. Note that most of the constraints are for excluding inconsistent quadruples. In our experiments, we use these constraints as lazy constraints when using Gurobi to solve the models. In greater detail, Gurobi will remove these constraints at the beginning, but will add an initially removed constraint back later if the constraint is found to be violated by the incumbent integral solution. In this way, Gurobi can start up much faster. Moreover, by experiments, we have found that a set of trees without inconsistent triples often have no inconsistent quadruples. Thus, we can often expect that very few initially removed constraints are added back and, in turn, Gurobi can finish within a much shorter time.
To test the performance of our models, we generate simulated datasets as follows. First, for each n∈{15, 25}, we use a program due to Beiko and Hamilton (2006) to generate a set
Our experimental results for AST-LR-d and AST-LR are summarized in Tables 1 and 2, respectively. From the tables, one can see that compared with solving the exact model directly, it is much faster to first solve the relaxed model and then use its output to solve the exact model. Moreover, in case both of the methods fail to find optimal solutions within the time limit, the latter method finds better approximate solutions.
Experimental Results for AST-LR-d
Column #leaf indicates the number of leaves in a single input tree, #nni indicates the number of nearest-neighbor interchange moves used to obtain a single input tree from a simulated center tree, Time indicates the average time in seconds, #fail indicates the number of instances for which Gurobi fails to find an optimal solution within the time limit (1 hour), #inst indicates the number of instances, Exact-only indicates solving the exact model only with a 1-hour time limit, Rlx+Exact indicates solving the relaxed model first with a 40-minute time limit and then using its output to solve the exact model with a 20-minute time limit, and Both-fail indicates both Exact-only and Rlx+Exact fail to find an optimal solution within the time limit.
Experimental Results for AST-LR
The columns mean the same as in Table 1.
To evaluate the performance of our ILP models, we have also implemented Chauve et al.'s algorithm (Chauve et al., 2017) for a much simpler parameterized problem (than the parameterized version of AST-LR), where we are only required to decide whether we can delete a total number of at most q leaves from the input trees so that the resulting trees have no conflicting triplets. By experiments, we have found out that the implemented algorithm always takes much longer time than Gurobi solves our ILP models for AST-LR. Because of this clear superiority of our ILP models, we omit our experimental results on the implemented algorithm.
Footnotes
Author Disclosure Statement
The authors declare they have no competing financial interests.
Funding Information
Z.-Z.C. was supported in part by the Grant-in-Aid for Scientific Research of the Ministry of Education, Science, Sports and Culture of Japan, under Grant No. 18K11183. L.W. was supported by a GRF grant from Hong Kong SAR government Project No. [CityU 11256116] and a grant from the National Foundation of China Project No. [61373048].