
Abstract
A large number of features lead to very high-dimensional data. The feature selection method reduces the dimension of data, increases the performance of prediction, and reduces the computation time. Feature selection is the process of selecting the optimal set of input features from a given data set in order to reduce the noise in data and keep the relevant features. The optimal feature subset contains all useful and relevant features and excludes any irrelevant feature that allows machine learning models to understand better and differentiate efficiently the patterns in data sets. In this article, we propose a binary hybrid metaheuristic-based algorithm for selecting the optimal feature subset. Concretely, the brain storm optimization algorithm is hybridized by the firefly algorithm and adopted as a wrapper method for feature selection problems on classification data sets. The proposed algorithm is evaluated on 21 data sets and compared with 11 metaheuristic algorithms. In addition, the proposed method is adopted for the coronavirus disease data set. The obtained experimental results substantiate the robustness of the proposed hybrid algorithm. It efficiently reduces and selects the feature subset and at the same time results in higher classification accuracy than other methods in the literature.
INTRODUCTION
Over the past two decades, the dimensions of data highly increased due to the rapid growth in information science. However, many features in data sets contain redundant and not relevant information for the machine learning models in data mining, and it leads to slow computation and the performance is adversely affected. Thus, an efficient algorithm is required for reducing the high dimension of the data sets by removing features that are not providing useful information to the learning algorithm, and to keep only the features that are significant for interpretation, making the pattern in the data and maintaining the information quality in data (Van Der Maaten et al., 2009).
Feature selection is a preprocessing method in data mining, which reduces the dimensionality of data by removing the noise and irrelevant attributes and results with optimal feature subset. Two key concepts in feature selection are the criteria of evaluation and the strategy of selection. Considering the criteria of evaluation, there are three main types of feature selection approaches: wrapper-based method, filter-based method, and embedded methods. The filter-based methods, such as Gini Index, Information Gain, Relief, and Chi-Square, use statistical measures to assign scores to each feature, and based on the scores, it makes the ranking of the features and chooses a subset.
The wrapper-based method uses machine learning techniques to select the optimal attribute subset. Most commonly, the wrapper-based method is employed in feature selection processes, because this method results in better classification accuracy. The embedded methods are a combination of the filter and wrapper methods, they are composed of taking the advantages of wrapper-based and filter-based methods.
The total possible number of attribute subsets is
In feature selection problems, due to the exponential increase in the number of features, this kind of problem belongs to nonpolynomial-hard (NP-hard) optimization problems, where traditional exact optimization algorithms would fail. However, stochastic approximation algorithms, such as metaheuristic algorithms are very successful in tackling such problems. They provide an optimal or close optimal solution in a reasonable amount of time. In this study, we propose a hybrid metaheuristic-based approach to address the feature selection problem.
Metaheuristic algorithms are very successful in different optimization problems, such as architecture design in convolutional neural networks (Bacanin et al., 2020a,b; Bezdan et al., 2020a), connection weight optimization in artificial neural networks (Milosevic et al., 2021), task scheduling in cloud computing environment (Bacanin et al. 2019a,b; Bezdan et al., 2020b,c), and wireless sensor network lifetime optimization (Bacanin et al., 2019c; Zivkovic et al. 2020a,b).
The two main processes in any metaheuristic algorithms are intensification and diversification, often the algorithm has one of these two processes more enhanced: one of the approaches for making the right balance between these two phases is by hybridizing two or more algorithms. In this study, we hybridize the brain storm optimization (BSO) algorithm (Xue et al., 2012) by the firefly algorithm (FA) (Yang, 2009) to achieve a better trade-off between the exploration and exploitation and apply it for feature selection problem by using a wrapper-based method.
The main motivation behind the research presented within this article is to improve the classification accuracy by further enhancement of the feature selection task. Even the slight improvement of the accuracy on the medical data sets can be significant, because it can increase chances of successful treatment. Consequently, the scientific contributions of these articles are triple fold:
Improvement of the performances of the basic BSO algorithm by hybridizing it with the FA metaheuristics to address the known deficiencies of the original implementation. Utilization of the novel hybridized algorithm as a wrapper method to improve the feature selection process and obtain better classification results on the benchmark data sets. Application of the devised method on a novel coronavirus disease 2019 (COVID-19) data set.
The rest of the article is organized as follows: Section 2 gives an overview of the background and related studies, Section 3 describes the original BSO as well as the hybridized version with FA, Section 4 presents the results of the experiment, and Section 5 concludes and summarizes the article.
BACKGROUND AND RELATED STUDIES
Metaheuristic algorithms have successful applications in many areas. A gaining sharing knowledge (GSK)-based algorithm is introduced and applied for optimizing the electric distribution scheduling in Hassan et al. (2020). In Chen et al. (2020), swarm intelligence algorithm is applied for optimizing unmanned aerial vehicle-aided (UAV-aided) Internet of Things (IoT) data acquisition deployment. A new GSK-based method is utilized in Xiong et al. (2021) for parameter extraction of solar photovoltaic models. An improved binary differential evolution (DE) algorithm is developed and used for assessing candidate locations for solar energy stations in ElQuliti and Mohamed (2016).
Chaotic variant of the Harris hawks optimization metaheuristics, combined with the quasi-reflection-based learning concepts, was utilized to improve the convolutional neural network (CNN) design for medical images classification in Basha et al. (2021). Hybrid approach of artificial intelligence and beetle antennae algorithm was utilized to estimate the number of COVID-19 cases in Zivkovic et al. (2021).
Recently, many feature selection algorithms were proposed. However, according to No-Free-Lunch theorem (Wolpert and Macready, 1997), there is no single algorithm for solving all optimization problems. Metaheuristic algorithms have been employed successfully for feature selection (Agrawal et al., 2021a), however, there is still a need to develop a more robust method. GSK-based optimization algorithm is applied for feature selection in Agrawal et al. (2021b). In Agrawal et al. (2021c), chaotic GSK-based optimization algorithm is utilized for optimizing the number of features. The authors used a binary GSK-based optimization algorithm for feature selection in Agrawal et al. (2021d).
Clustering-based particle swarm optimization (PSO) feature selection was proposed in Zhang et al. (2021) and Song et al. (2021), targeting high-dimension data that contains missing values. The same problem was tackled with coevolutionary particle swarm feature selection in Song et al. (2020). Multiobjective PSO was utilized for feature selection with fuzzy cost in Hu et al. (2020), whereas Xue et al. (2019) used self-adaptive PSO for large scale feature selection in classifying tasks.
As already mentioned in the introduction section, we are proposing a hybrid approach as a wrapper-based method for feature selection. The well-known BSO algorithm is hybridized with the FA. BSO has a wide range of applications in different areas. Cao et al. (2015) proposed BSO with a new step size technique and DE strategy and employed it for artificial neural network training. BSO is employed for the optimization of wireless sensor network dynamic deployment in Chen et al. (2015). Different BSO solution clustering analyses are performed in Cheng et al. (2013). Tuba et al. (2019) uses BSO for classification problems.
PROPOSED METHOD
This section first outlines the motivation of the original BSO algorithm and its mathematical formulation, afterward, the proposed hybridized BSO is described.
Original BSO algorithm
In 2011, Shi (2011) developed a metaheuristic-based BSO algorithm. The algorithm is motivated by the brainstorming process of humans. Brainstorming is a creative way of solving a specific problem by a group of people. In the brainstorming process, several people share their ideas with each other related to the problem that should be solved, where any idea is acceptable and criticism is not allowed. In the end, from all suggested ideas, the best possible solution is selected. Similarly, in the BSO algorithm, initially, random solutions are generated; as in any other swarm intelligence algorithm, each solution is analogous to an idea in the brainstorming process. At every iteration the idea is modified, in other words, the solution's position is updated according to the previous knowledge.
At the beginning of the procedure, N ideas are generated randomly, then the N number of ideas are classified in m cluster by utilizing the K-means algorithm. Then each solution's fitness value is evaluated and the best solution is selected for cluster centroid. Next, the solution's position is updated according to the following formula:
where the d th dimension of selected idea (solution) is denoted by
The value of
where
For more details about the BSO algorithm, you may refer to Shi (2011).
BSO is a high-performing approach in many problems; however, its drawback is the slow convergence speed. At exploration, the algorithm is very good, however, its performance is poor at exploitation. In this study, we propose a hybridized BSO method to speed up the algorithm's convergence and achieve better results, as well as to make a better balance between exploration and exploitation. Algorithm hybridization blends the benefits of various algorithms, which results in the synergistic synthesis of fused algorithms. In some runs of the algorithm, when BSO finds the promising region of the search space early enough, it converges successfully as it has enough time for exploitation.
However, in other runs, when it hits the promising region of the search space later, it does not have enough iterations for the exploitation (i.e., already the weakest spot of the algorithm), and it is not able to converge. For enhancing the exploitation capability, we incorporated the search mechanism of the FA (Yang, 2009), which is famous for its intensification capability. Various studies have shown that the FA exploitation procedure is efficient and can be used in solving a wide variety of optimization problems. By hybridizing the BSO with FA search, the novel algorithm aims to take the best characteristics from both BSO (excellent exploration) and FA (superior exploitation), and to minimize the known deficiencies. The FA search mechanism is mathematically formulated as follows:
where the current solution is denoted by
In the proposed hybrid approach, if the iteration counter t is even, the original BSO updating mechanism is utilized for solution modification, otherwise, if the iteration counter value is odd, the FA search mechanism is utilized for a position update.
Considering the problem for which the proposed method is applied, we adopted it for the binary selection problem. First, the sigmoid function is used to move the solutions’ values between 0 and 1, then the threshold value, which is set to 0.5 in this experiment, will be decided whether to be 0 or 1. If the value is less than the threshold values, its value will 0, otherwise, it will be 1. The binary conversion of the solution value is described in Equation (4).
the ith solution is denoted by xi,
In this way, the solution representation in the feature selection problem is encoded by binary values. The total number of solutions is N and the dimension of the solutions corresponds to the number of features in a given data set. If the solution value is 0, it means that the corresponding feature is removed, in contrast, if its value is 1, the feature is selected for the classification model.
Algorithm 1 describes the pseudocode of the proposed binary BSO algorithm, and we named it binary BSO FA, in short bBSOFA.
This section first provides the experimental setup, the data sets used for evaluating the proposed bBSOFA's performance, and presents the obtained experimental results.
The dimension of solutions consists of equal number of features in a given data set. Initially, the solutions are generated randomly. In this study, mixed initialization methods are utilized where only about half of the features are selected randomly as was used in Xue et al. (2014). At the end of the algorithm's procedure, the Sigmoid function squeezes the solution's value between 0 and 1, afterward based on the threshold value, it will decide whether 0 or 1 will be assigned to the corresponding feature. If the solution's value is less than the threshold, which is set to 0.5, after applying the transfer function, the solution will be 0, otherwise, it will be 1.
The value of 1 indicates utilizing the feature in the evaluation, contrarily. If the value is 0, the feature is removed. The K-NN classifier is utilized for evaluation purposes, and it represents the objective function. The fitness function takes into account the number of features selected as well as the classification error rate, and it is formulated according to the following formula:
where the error rate of the classification is denoted by
The experiment is repeated in 20 runs, 70 is used for the maximum number of iterations. And the population size is set to 8. The control parameters are summarized in Table 1.
Control Parameters
BSO, brain storm optimization; FA, firefly algorithm.
For evaluating the performance of the proposed method, 21 data sets from UCI Machine Learning Repository are used with different dimension, their summary is presented in Table 2.
Data Sets
In addition, the bBSOFA is applied for COVID-19 (https://github.com/Atharva-Peshkar/Covid-19-Patient-Health-Analytics) patient health prediction (Iwendi et al., 2020), where the data set has 15 different attributes, including the patient's location, country, gender, age, and different symptoms.
The results of the experiment are compared with other approaches, as well as with the original FA and the original BSO algorithm. The results of WOA, bWOA-S, bWOA-V, BALO1, BALO2, BALO3, PSO, bGWO, and bDA are taken from Hussien et al. (2020), where the experiments are conducted in the same way as in this study and on the same data sets. In addition, the proposed method is compared with three GSK algorithm variants (Mohamed et al., 2020), namely V-shaped GSK-based algorithm (bGSK-V4) (Agrawal et al., 2021b), chaotic GSK-based optimization algorithm (CBi-GSK1) (Agrawal et al., 2021c), and binary GSK-based optimization (FS-pBGSK) (Agrawal et al., 2021d).
The results of the COVID-19 are compared with HLBDA, BDA, BMVO, and BPSO and their results are taken from Too and Mirjalili (2021). It is worth noting that the authors have implemented all mentioned algorithms and recreated the experiments independently, therefore, confirming the results that were used for comparison. The original parameters’ values for core algorithms were utilized, as given in Table 3. For additional information about the algorithms, please refer to the original publications, where the mentioned metaheuristics were introduced.
Control Parameters’ Settings for Metaheuristics Used in the Comparative Analysis
DA, dragonfly algorithm; GSK, gaining sharing knowledge; GWO, grey wolf algorithm; PSO, particle swarm optimization; WOA, whale optimization algorithm.
The obtained experimental results on the 21 data sets are presented in Tables 4 and 5. Table 4 shows the comparison of the average fitness value of the comparable approaches, whereas Table 5 presents the comparison of the average accuracy of the comparable approaches.
Comparison of the Average Fitness over Different Approaches
Comparison of the Average Accuracy over Different Approaches
The bold values in both of the tables indicate the best result among all comparable methods.
By analyzing the obtained results, we can conclude that the proposed bBSOFA is a robust and high-performing method in feature selection problem solving. In the case of 15 data sets, the best resulted approach is bBSOFA in the case of average fitness value comparison. Moreover, on the classification accuracy comparison, the proposed method has the best average accuracy on 16 data sets out of 21 data sets. In the case of three data sets, Exactly, M-of-N, and Waveform EW, bSOFA, and bBSO have the same value, both methods have the best average fitness value.
Comparing the proposed method with other approaches, its average fitness is for 7% less than bBSO's average fitness, and for 49% less than bFA average fitness, and for 48%–66% less than the other nine comparable methods.
Over all 21 data sets, the average classification accuracy of bBSOFA is 1% higher than the average accuracy of bBSO, and 6% higher than bFA's classification accuracy, and for 10%–22% higher than the other nine comparable methods. The proposed method excels especially on data sets with a high number of features.
To test the performance of the proposed method, Wilcoxon nonparametric procedure is employed to detect significant differences between the proposed bBSOFA and the other 14 comparable methods. Table 6 presents the Wilcoxon statistical test results at significance level
Wilcoxon Signed-Rank Test Nonparametric Statistical Test Results at Significance Level
Friedman Statistical Test Results at Significance Level
Convergence graphs for the average fitness function have been generated over the course of 20 runs and 70 iterations in each run over all 21 data sets, and shown in Figure 1. The algorithms with the best results have been shown in the convergence graphs, including the proposed bBSOFA method, WOA, PSO, BALO3, bDA, bFA, bBSO, and bGSK-V4. As observed in Figure 1, the proposed bBSOFA method exhibits the fastest overall convergence speed, that is most obvious in case of Wine EW, Ionosphere EW, and Congress EW data sets.
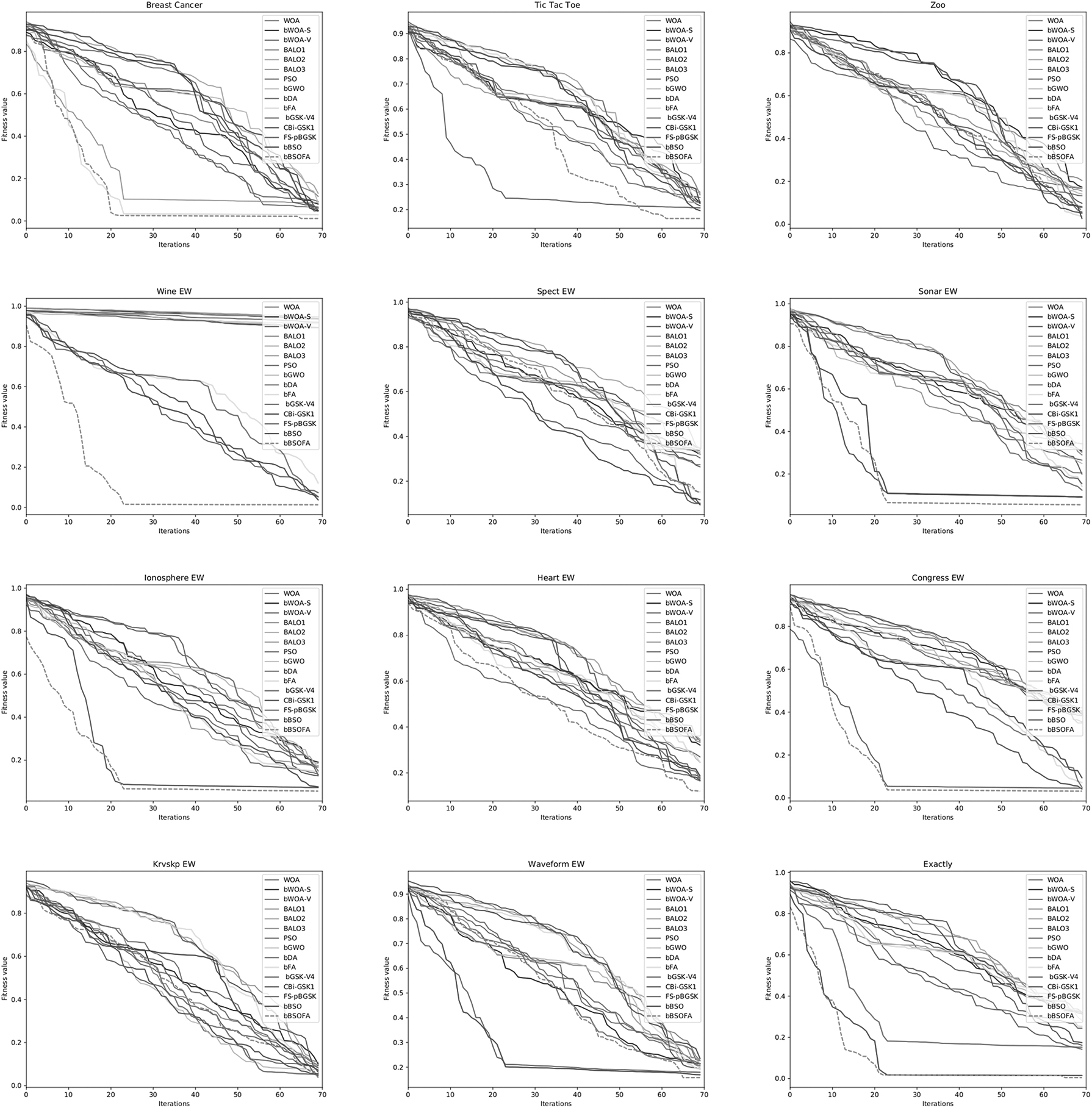
Average fitness convergence speed graphs of the proposed hybrid BSO and other competitor methods over 21 data sets. BSO, brain storm optimization.
The fitness value of the binary FA, BSO, and the proposed approach is shown in Figures 2 and 3. The presented box plot diagrams allow visual comparison of the performances of both basic algorithms and the resulting hybridized method. It can be clearly seen that the basic version of the BSO has a larger dispersion over the runs, meaning that the proposed bBSOFA method is more stable. In addition, in some runs, it is obvious that the basic BSO does not have the exploitation that is powerful enough to converge to the better solutions. The proposed hybrid BSO has a powerful exploitation mechanism and it converges faster to the optimum.
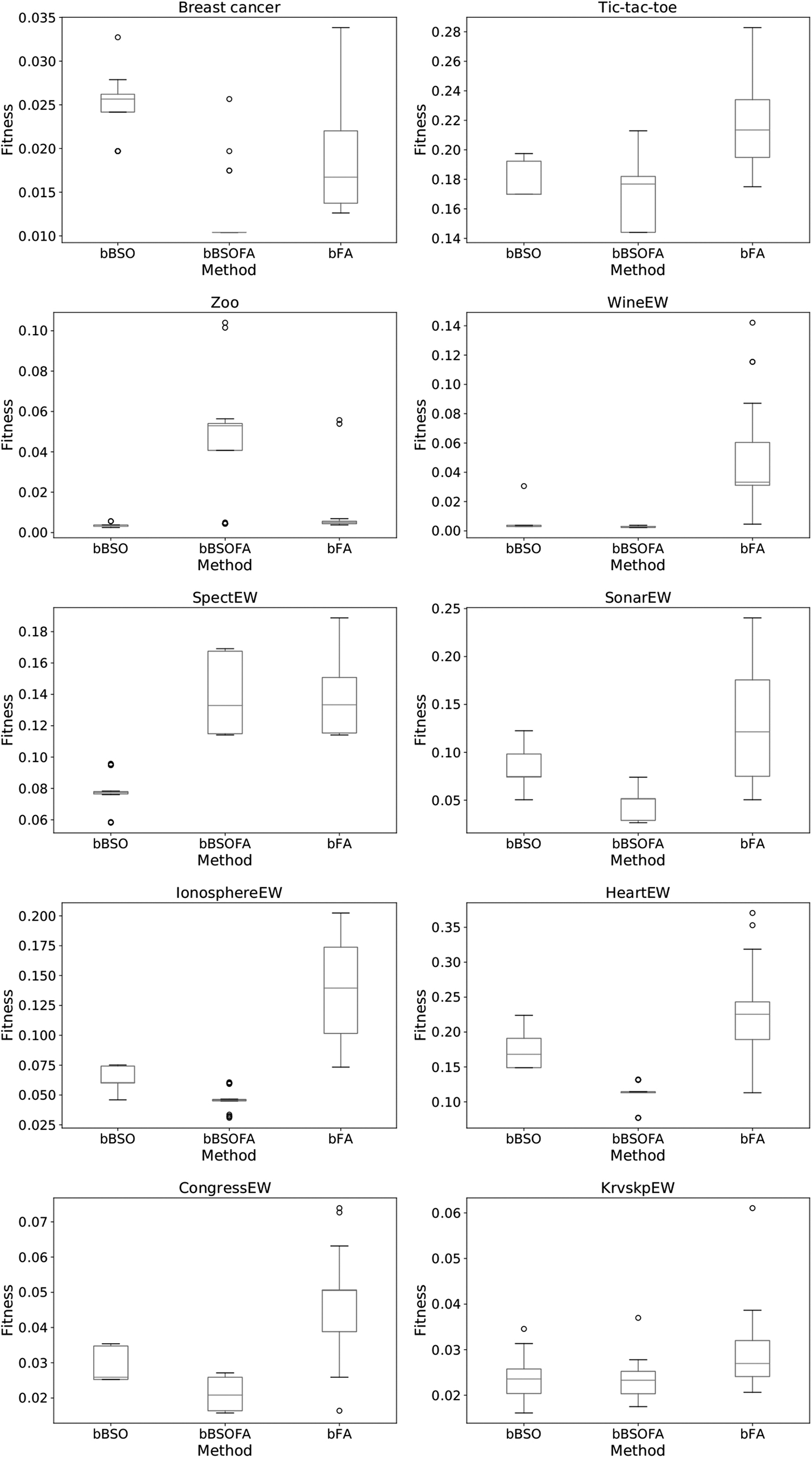
Box plot of the original BSO, original FA, and the proposed hybrid BSO. FA, firefly algorithm.
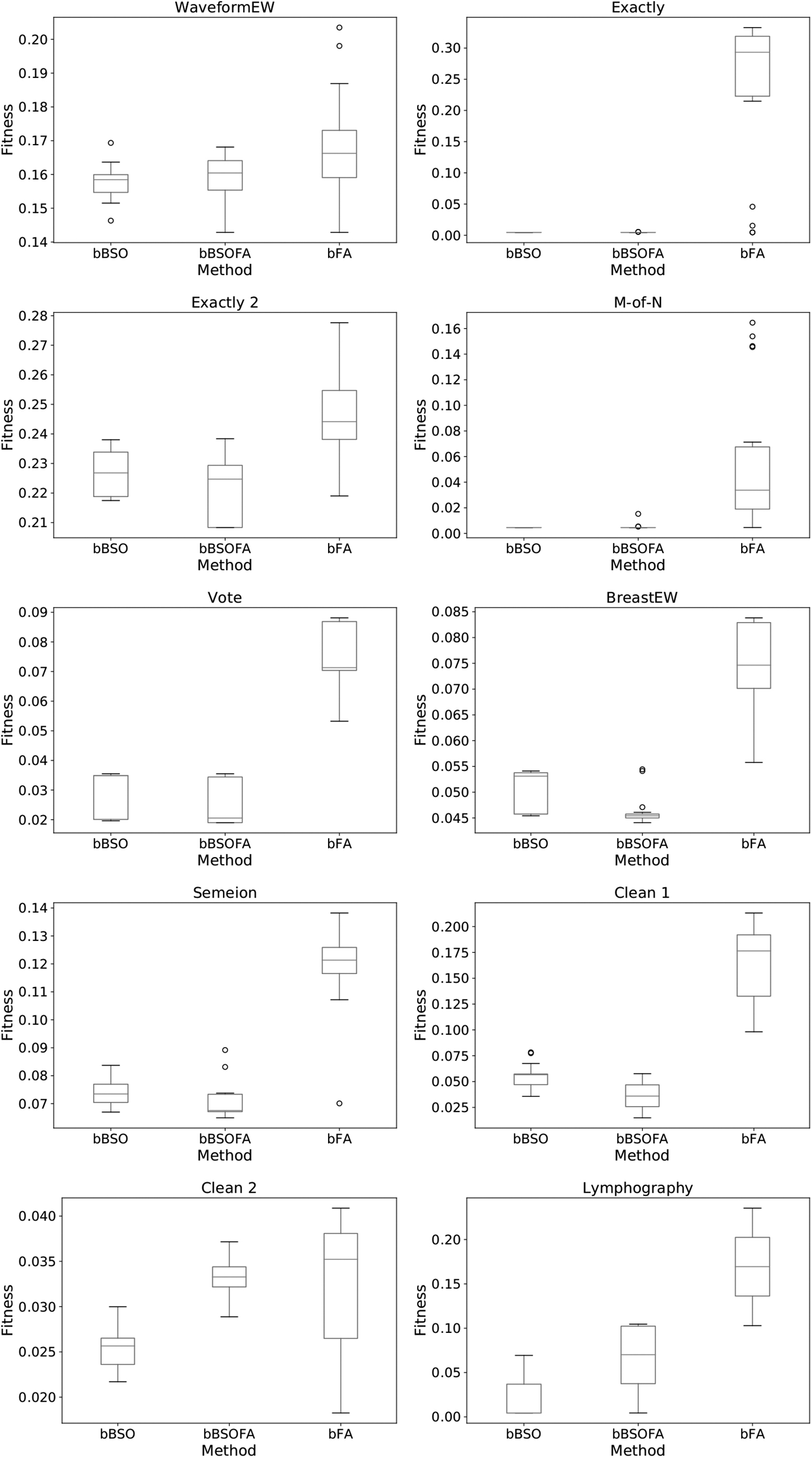
Box plot of the original BSO, original FA, and the proposed hybrid BSO.
Moreover, the bBSOFA approach is employed for COVID-19 and compared with the other state-of-the-art methods, where the proposed method is overperformed by the other approaches. The accuracy of bBSOFA is 93.57%, whereas the second best performing approach is HLBDA, with a classification accuracy of 92.21%. In the case of the total selected features, both approaches selected two to three features on average, and the feature size comparison is depicted in Figure 4. Based on the analysis of the selected features, we can draw a conclusion that specific features are not important for the prediction, and symptom4, symptom5, and symptom6 are never selected by the algorithm in the experiments.
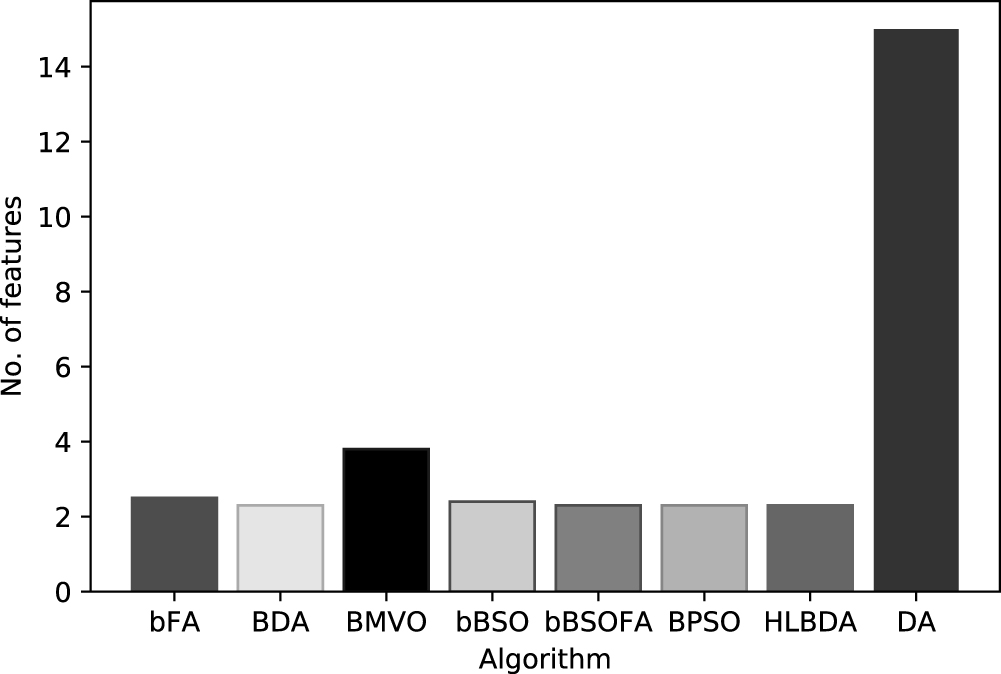
Feature size of comparable methods.
Feature selection is a very important preprocessing method in data mining for reducing the dimensionality of data, which leads to computation time reduction and also can positively affect the classification accuracy. In this article, a novel approach is proposed for the feature selection problem by employing the hybridized BSO algorithm with the FA. The hybrid algorithm overcomes the lack of exploitation in the original BSO algorithm. For the purpose of performance evaluation, 21 data sets are utilized from the UCI Machine Learning repository. Moreover, the method is employed for COVID-19 classification.
The obtained statistical results prove the efficiency and robustness of the proposed method over other state-of-the-art approaches.
For future study, we plan to incorporate the bBSOFA method for other machine learning problems and predictions, such as neural network weight and architecture optimization, as well as to experiment with more different data sets.
Footnotes
AUTHOR DISCLOSURE STATEMENT
The authors declare they have no conflicting financial interests.
FUNDING INFORMATION
This research is supported by the Project Grant No. III-44006 by Ministry of Education, Science, and Technological Development of Republic of Serbia.