
Abstract
It is known that both RNA secondary structure and protein contact map can be presented using combinatorial diagrams, the combinatorial enumeration and related problems of which have been studied extensively. Motivated by previous enumeration works on saturated RNA secondary structures and extended stack structures of protein contact maps, we are interested in the enumeration problems of saturated and optimal extended stacks in the Nussinov–Jacobson energy model, in which each base pair contributes energy −1. Then optimal structures are those with most arcs, and locally optimal structures are exactly the saturated structures, in which no more arcs can be added without violating the structure definition. For saturated extended 2-regular simple stacks, whose degree configuration is related to the protein fold in two-dimensional honeycomb lattice, we obtain generating function equation and asymptotic formula for its number. Moreover, an explicit formula for the number of optimal extended 2-regular simple stacks is also obtained.
INTRODUCTION
It is well known that the function of RNA depends on its 3D structure and dynamics, and the RNA 3D structure is largely determined by the secondary structure (Banerjee et al., 1993). The case of protein is analogous, and the contact map of protein can be seen as a counterpart of the secondary structure of RNA. Contact plays a fundamental role in the well-known hydrophobic-hydrophilic (HP) model for protein folding (Dill, 1990), and recently, contact map also plays an extremely important role in the high accuracy prediction of protein structure through the deep learning method (Xu, 2019; Yang et al., 2020).
Due to the pioneer work of Waterman and Schmitt (1978), combinatorial theory and method were introduced into the field of computational molecular biology, and the combinatorial enumeration of various RNA secondary structures and protein contact maps have attracted extensive study since then. Schmitt and Waterman (1994) provided an explicit formula for the number of RNA secondary structures on n vertices and k arcs by establishing a bijection between RNA secondary structures and linear trees. Nebel (2002) derived the generating function of m-regular RNA secondary structures by using the binary trees and the Horton–Strahler number. Clote (2006) obtained recurrence relations and asymptotic formulas for combinatorial problems related to the number of saturated secondary structures.
Jin et al. (2008) derived the recursion formulas of 3-noncrossing RNA structures. A collection of new combinatorial and computational approaches in the study of RNA structures with pseudoknots were presented in a monograph (Reidys, 2011).
Recently, enumerative combinatorics has also made progress in the study of protein contact map. Based on the classic HP model (Dill, 1990), protein fold can be considered as a self-avoiding walk in some lattice model. Lattice models usually retain important features of protein structures, and enable us to focus on dominant aspects of the structure. Goldman et al. (1999) showed that for any protein fold in a two-dimensional (2D) square lattice self-avoiding walk HP model, the contact map can be decomposed into (at most) two stacks and one queue. Actually, this decomposition also holds for the case of 2D honeycomb lattice, which will be shown in Section 2. Agarwal et al. (2007) found a similar decomposition result for the contact maps of protein folds in the 3D cubic lattice self-avoiding walk HP model.
In combinatorial terms, a stack is a noncrossing diagram and a queue is a non-nesting diagram; they are the two elementary structures of protein contact map. When folding a protein in the lattice model, different lattice models will introduce different degree and arc length constraints to the corresponding contact map. For instance, on the 2D square lattice, each internal vertex in the contact map has maximum degree 2, while the two terminal vertices can have maximum degree 3, and the arc length is at least 3. On the 2D honeycomb lattice, the degree of each internal vertex and terminal vertex is at most 1 and 2, respectively, while the length of each arc is at least 5. For a survey of various lattice models used for protein folding see Pierri et al. (2008). A stack with arc length at least m is called m-regular, and a stack with degree of each vertex bounded by one is called simple. Clearly, RNA secondary structures can be viewed as 2-regular simple stacks.
Istrail and Lam (2009) proposed the question concerning generalizations of the Schmitt–Waterman counting formulas for RNA secondary structures (Schmitt and Waterman, 1994) to enumerating protein stacks and queues, and they pointed out that the enumeration of stacks and of queues could provide insights into computing rigorous approximations of the partition function of protein folding in HP models.
To attack this question, Chen et al. (2014) proposed the primary decomposition method to study the combinatorial enumeration of m-regular (with arc length at least m) linear stack (with the degree of each vertex bounded by two), which is a generalization of the classic RNA secondary structure, and got enumeration results in the form of generating function equation, recurrence relation, and asymptotic formula. Furthermore, combinatorial enumeration results were obtained for extended (with the degree of two terminal vertices bounded by three) m-regular linear stacks (Guo et al., 2016), m-regular linear stacks with n vertices and k arcs (Guo and Sun, 2018), and 2-regular and 3-regular simple (with the degree of each vertex bounded by one) queues (Guo et al., 2017).
The RNA and protein folding problems can be formulated as energy minimization problems in some energy model, for example, in the classic Nussinov–Jacobson free energy model (Nussinov and Jacobson, 1980), the energy function is the negative of the number of base pairs (for RNA) or contacts (for protein), and the structures with minimum energy are called optimal. Another concept closely related to the optimal structure is saturated structure, which means no base pairs (contacts) can be added without violating the definition of the structure (Clote, 2006). Saturated structures are actually local minima in the energy landscape. The combinatorial problems related to the number of saturated RNA secondary structures have attracted much interest (e.g., Clote, 2006; Clote et al., 2009, 2007; Fusy and Clote, 2014).
Stimulated by the enumeration works on saturated and optimal RNA secondary structures and extended stacks of protein contact map, we are interested in the problem of enumerating saturated and optimal extended 2-regular simple stacks, in which the degree of two terminal vertices bounded by two, and the degree of the internal vertices bounded by one. This degree configuration is related to the protein fold in the 2D honeycomb lattice. The honeycomb lattice alleviates the “sharp turn” problem and models certain aspects of the protein secondary structure more realistically with reduced combinatorial complexity (Jiang and Zhu, 2005; Guo et al., 2018). Denote the number and the generating function of all saturated extended 2-regular simple stacks with n vertices by
where
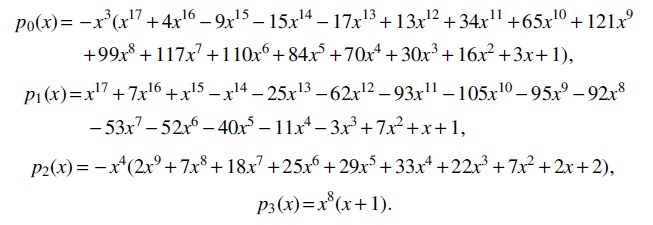
Based on Equation (1), we furthermore obtain the following asymptotic formulas for
The explicit expression for
This article is organized as follows. In Section 2, we give basic definitions and notations, and some previous results that are the foundation of this article. In Section 3, we study the combinatorial enumeration problem of the saturated extended 2-regular simple stacks. At last, Section 4 focuses on the number of optimal extended 2-regular simple stacks.
2. BASIC DEFINITIONS AND NOTATIONS
First, we recall the definition of RNA secondary structure and protein contact map in a combinatorial way. A secondary structure on RNA sequence
For the case of protein, when two nonconsecutive amino acid residues in a protein fold come very close to each other, say, closer than a predetermined threshold, they presumably form some kind of bond, which is called a contact. A protein contact map on protein sequence
In combinatorics, both RNA secondary structure and protein contact map can be presented by a diagram, that is, drawing vertices
Stack and queue are the two elementary structures of protein contact map. Following Chen et al. (2014) and Guo et al. (2017), a structure (stack or queue) with arc length at least m is called m-regular, a structure with degree of each vertex bounded by one is called simple, and a structure with degree of each vertex bounded by two is called linear. Furthermore, an m-regular simple stack with the degrees of the two terminal vertices bounded by two is called an extended m-regular simple stack. Note that this degree of configuration is related to the protein contact map in the 2D honeycomb lattice.
Recall that the contact map of any protein fold in 2D square lattice can be decomposed into (at most) two stacks and one queue (Goldman et al., 1999). We claim that the same decomposition also holds in the 2D honeycomb lattice.
Proof. For each vertex in the walk, we assign a label O or U to its adjacent edges in the lattice, which are not edges in the walk. Edges in the lattice will then have multisets of labels consisting of 0, 1, or 2 members. Labels are assigned inductively as follows:
Label nonwalk edges adjacent to vertex 1 as follows: assign O to one of the edges and assign U to the other. Label nonwalk edges adjacent to vertex i, where
After the labeling procedure, the edges in the contact map will be assigned exactly two labels. Following the similar arguments of Goldman et al. (1999), the graph consisting of edges labeled by
See Figure 1 for an illustration.
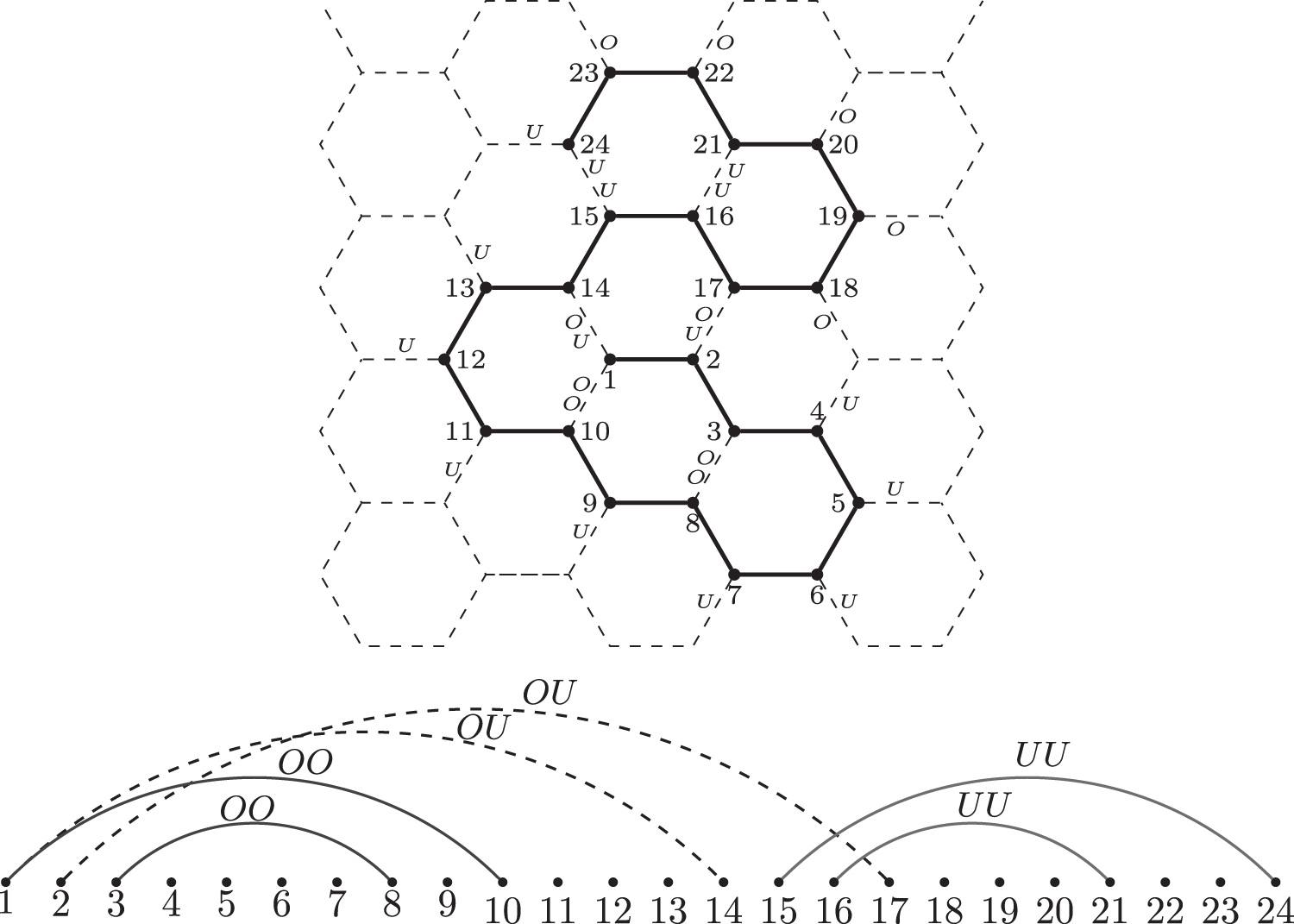
The contact map of a protein fold in two-dimensional honeycomb lattice. The graph consisting of arcs (solid) labeled by
Next, let us recall some previous results by Clote (2006) on the enumeration of saturated and optimal RNA secondary structures. Call a vertex
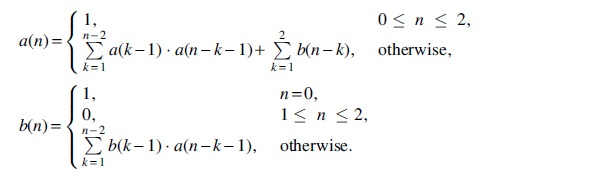
Denote the generating functions of
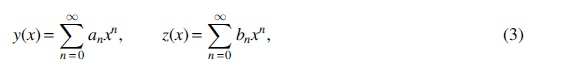
respectively, they satisfy the following relations.
Moreover, the number of optimal 2-regular simple stacks of length n is given by the following formula.
where
In this section, we use the method of combinatorial structure decomposition method to study the generating function for the number of saturated extended 2-regular simple stacks.
Following the structure decomposition idea proposed by Chen et al. (2014), we call the component containing both vertices 1 and n the primary component. For the primary components of the saturated extended 2-regular simple stacks with n vertices, we distinguish six classes according to the degrees of the two terminal vertices and whether they form an arc or not (Fig. 2).

The six cases of the primary components of the saturated extended 2-regular simple stacks.
Let 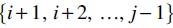 . We use this notation
. We use this notation
As shown in Figure 2, the primary component splits
T1: an isolated vertex followed by an arbitrary saturated structure with no visible vertex, or just an arbitrary saturated structure with no visible vertex; For a structure of type T1, its reverse order structure is denoted of type
T2: an arbitrary saturated structure;
T3: an arbitrary nonempty saturated structure;
T4: an isolated vertex followed by an arbitrary saturated structure with no visible vertex, or just an arbitrary nonempty saturated structure with no visible vertex;
T5: an arbitrary saturated structure with no visible vertex;
T6: an isolated vertex, or an arbitrary nonempty saturated structure with no visible vertex.
Note that, the substructures of types
Let
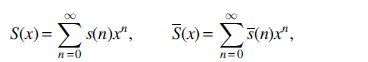
respectively. Denote the number of the structures with n vertices of Case
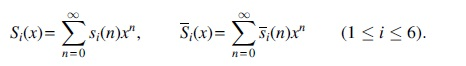
Using the method of primary component decomposition, we obtain that
Proof. For a saturated extended 2-regular simple stack with n vertices, suppose that its primary component splits
Obviously, Case (1) and Case (1′) are symmetric, and we thus consider only Case (1). As shown in Figure 2, there are three intervals
We have two cases for the substructures on I1. For the case of an isolated vertex followed by an arbitrary saturated 2-regular simple stack with no visible vertex, there will be
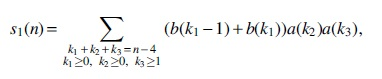
from which we can obtain the generating function as follows:
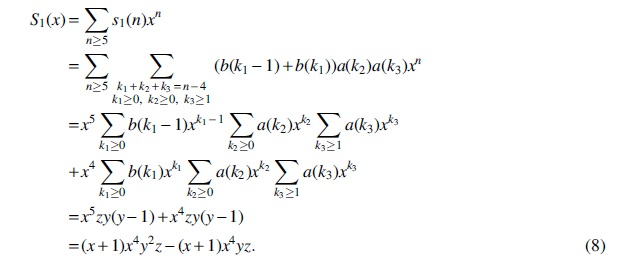
Case (2) and Case (2′) are also symmetric, and so, we only consider Case (2). Following the similar discussions in Case (1), we have
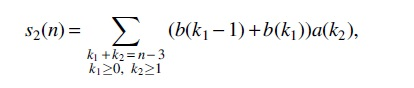
whose generating function is
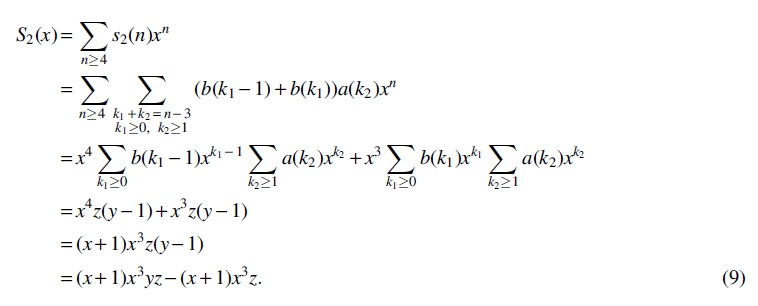
Case (3) and Case (3′) are symmetric, and so, we only consider Case (3). There are four intervals
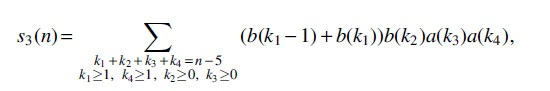
whose generating function is
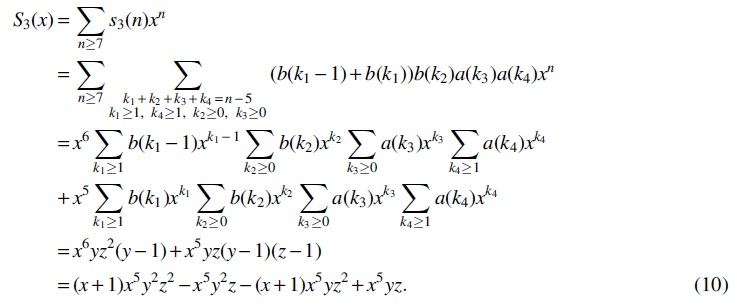
For Case (4), there is only one interval of type T6. Obviously,
with generating function
For Case (5), there are three intervals
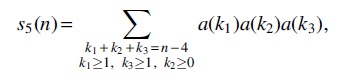
from which we can get the generating function as follows:

For Case (6), there are five intervals
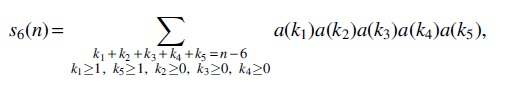
whose generating function is
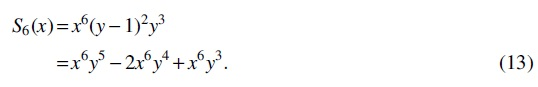
Above all, substituting Equations (8)—(13) into
we obtain Equation (7), which completes the proof.
Now, we are ready to prove Theorem 1 by eliminating the variables y and z from Equations (4), (5), and (7).
Substituting Equation (14) into (7), we obtain
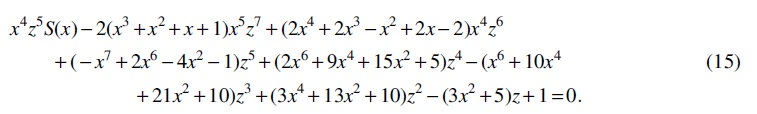
By computing the resultant of Equations (4) and (5) with respect to y, we have
Then eliminating z by computing the resultant of Equations (15) and (16), we obtain (1).
From the functional equation (1) of

in which
The first 29 initial values of
Next, we use the singularity analysis method to derive the asymptotic formula of
First, by Equation (1), we find the dominant singularity of
where
At last, leveraging the transfer theorem, we transfer the approximation of
where
Finally, we arrive at
The Maple source codes of the above procedures can be found at https://github.com/aimerbam/asymptotic_formulas_RNA/tree/master.
For the saturated extended 2-regular simple stacks of length n with no visible vertex, we obtain the following expression for the generating function

The saturated extended 2-regular simple stacks of length five.
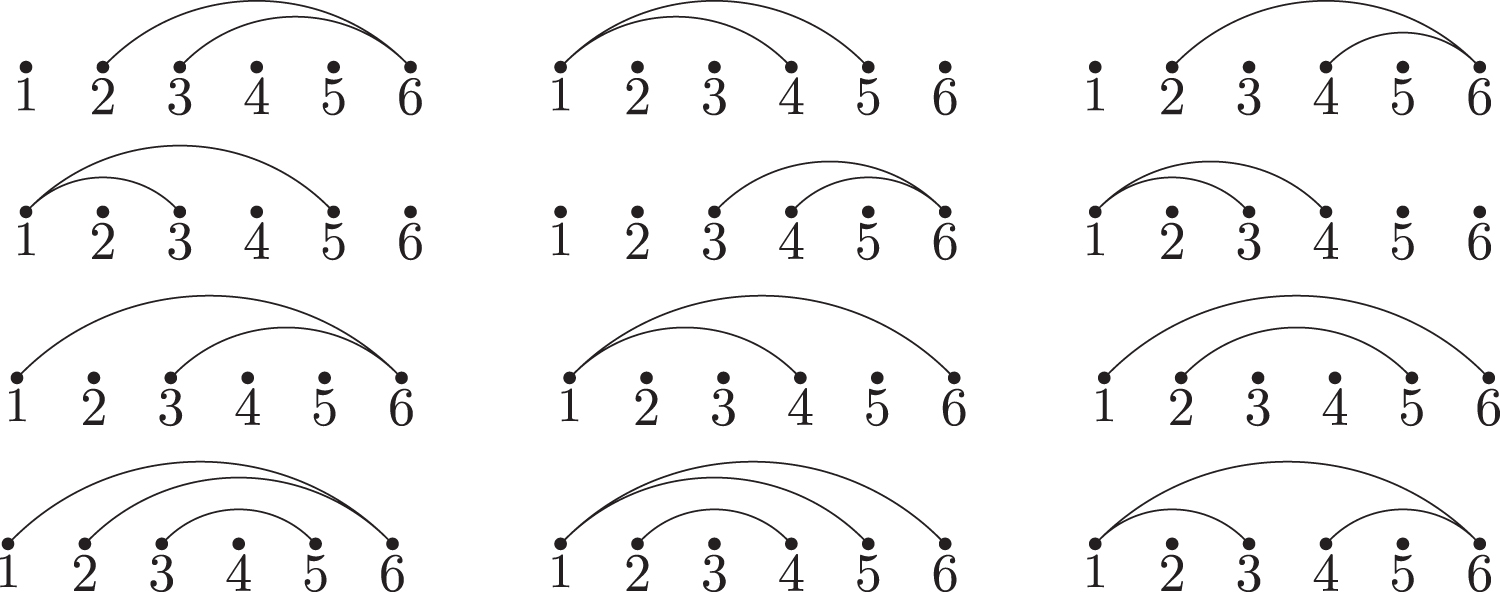
The saturated extended 2-regular simple stacks of length six.
The First 29 Values of
Proof. Similar to the proof of Theorem 4, we continue to use the method of primary component decomposition and discuss the six cases as shown in Figure 2.
Obviously, it is impossible for Case (1) to build a stack with no visible vertex. According to the proof of Theorem 7, we can see that the structures of Cases (2), (2′), (3), (3′), (4), and (5) are all saturated 2-regular simple stacks with no visible vertex. Thereby for
For Case (6), the interval I3 of type T2 must have no visible vertex. So the number of saturated extended 2-regular simple stacks of this case is
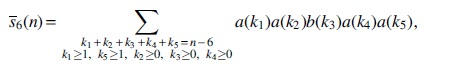
whose generating function is

Substituting Equations (9)–(12) and (19) into
we obtain Equation (18), which completes the proof.
Similarly, by eliminating y and z from Equations (4), (5), and (18), we obtain the following functional equation satisfied by
where
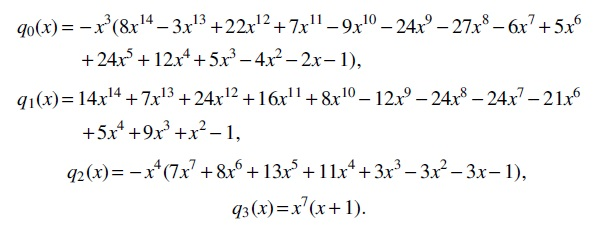
Consequently, the asymptotic formula of
In this section, we consider the enumeration of optimal extended 2-regular simple stacks, which correspond to the structures with the maximum number of arcs in the Nussinov–Jacobson energy model.
Let us first consider the number of arcs in the optimal structures.
Proof. We follow the six cases as shown in Figure 2 to discuss the number of arcs in the optimal structures.
We first consider the case when n is odd. Suppose that
In Case (3), the primary component splits
When n is even, suppose that
Above all, the number of arcs of the optimal extended 2-regular simple stacks with n vertices is
Now, we are ready to prove Theorem 2.
For Case (1), we see that
For Case (2),
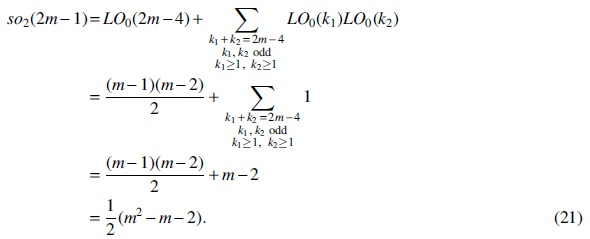
For Case (3),
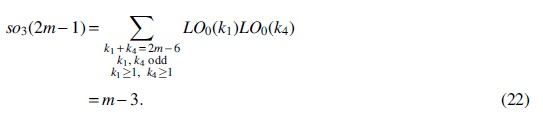
For Case (4),
For Case (5),
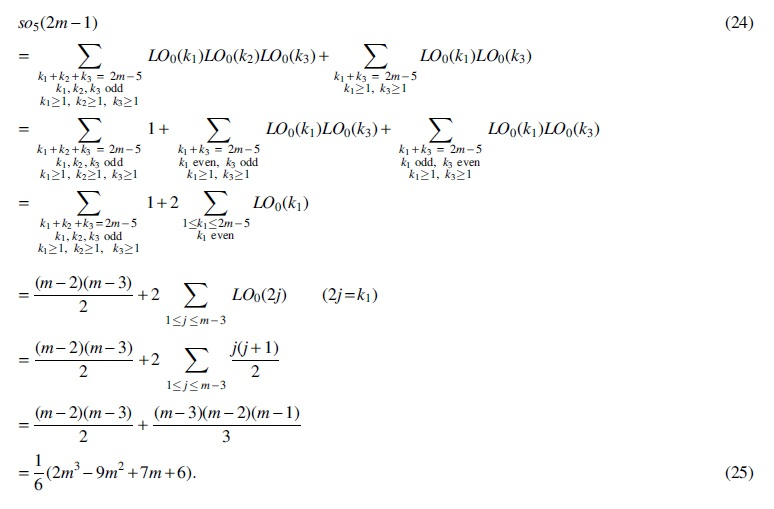
For Case (6),
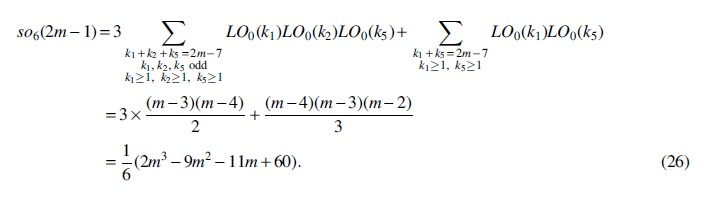
Substituting Equations (4)–(26) into
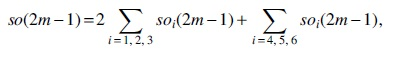
we obtain
Thus, for n being odd, we have that
When n is even, suppose that
For Case (2),
For Case (5),
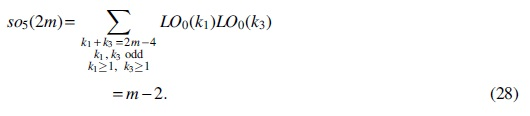
For Case (6),
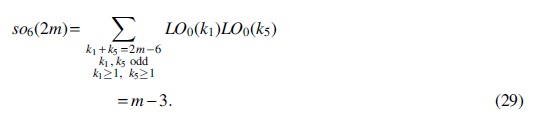
Substituting Equations (27)–(29) into
we obtain
Thus, for n being even,
We complete the proof of Theorem 2.
The first 22 initial values of
The First 22 Values of
For
At last, the growth curves of the numbers of saturated and optimal extended 2-regular simple stacks are drawn together in Figure 5.
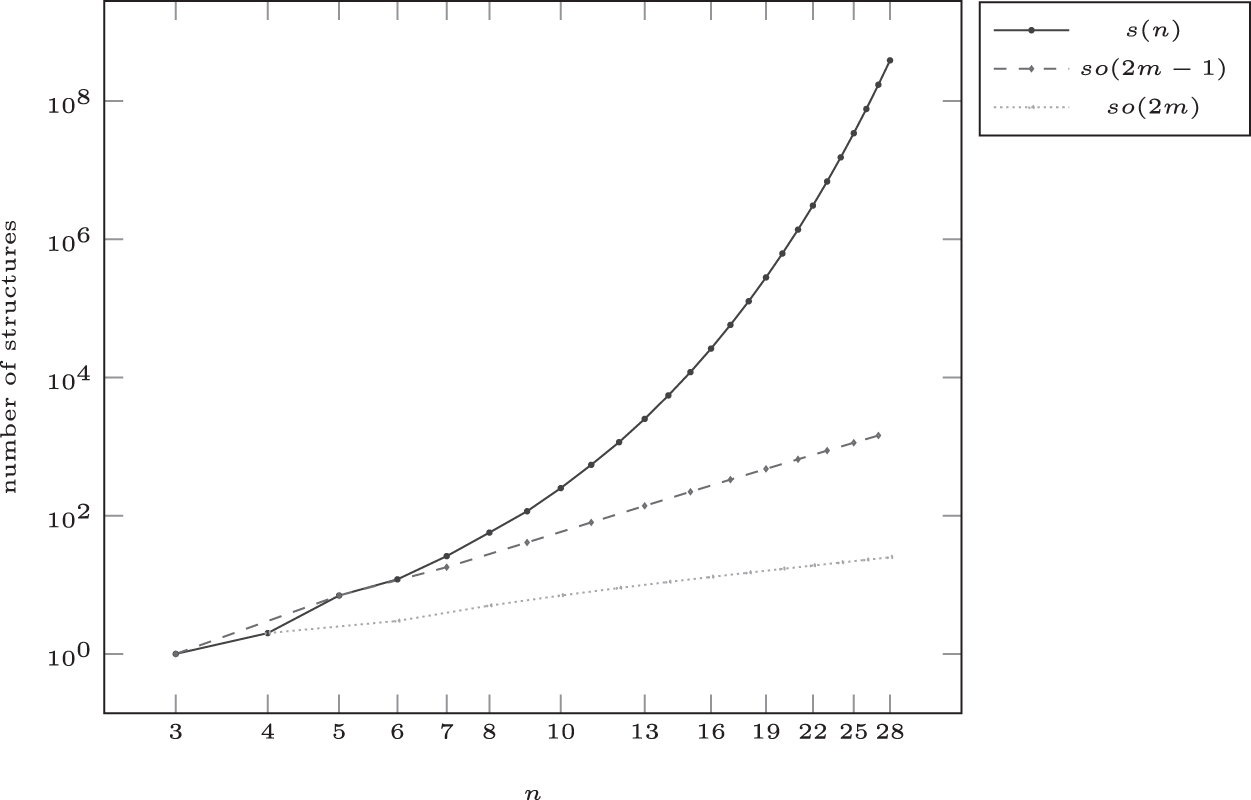
The growth curves of the numbers of saturated and optimal extended 2-regular simple stacks.
Footnotes
ACKNOWLEDGMENTS
We would like to thank the anonymous referees for valuable comments and suggestions.
AUTHOR DISCLOSURE STATEMENT
The authors declare they have no competing financial interests.
FUNDING INFORMATION
This work was supported by the National Natural Science Foundation of China (Grant Nos. 12071235, 11771222, and 11501307), the Fundamental Research Funds for the Central Universities, and the Natural Science Foundation of Tianjin (Grant No. 16JCQNJC09400), China.