
Abstract
Non-negative matrix factorization (NMF) is a fundamental matrix decomposition technique that is used primarily for dimensionality reduction and is increasing in popularity in the biological domain. Although finding a unique NMF is generally not possible, there are various iterative algorithms for NMF optimization that converge to locally optimal solutions. Such techniques can also serve as a starting point for deep learning methods that unroll the algorithmic iterations into layers of a deep network. In this study, we develop unfolded deep networks for NMF and several regularized variants in both a supervised and an unsupervised setting. We apply our method to various mutation data sets to reconstruct their underlying mutational signatures and their exposures. We demonstrate the increased accuracy of our approach over standard formulations in analyzing simulated and real mutation data.
1. INTRODUCTION
Non-negative matrix factorization (NMF) is a popular and useful decomposition tool for high-dimensional data. It is widely used in signal and image processing, text analysis, and in analyzing DNA mutation data. NMF is NP-hard (Vavasis, 2010) in general, and is commonly approximated by various iterative algorithms such as multiplicative updates (MUs) (Lee and Seung, 2000) and alternating non-negative least squares (ANLS) (Lin, 2007). Almost all NMF methods use a two-block coordinate descent scheme, which alternatively optimizes one of the
Recently, architectures based on deep learning were suggested for NMF (Hershey et al., 2014; Wisdom et al., 2017) as part of a general unfolding (or unrolling) framework (Monga et al., 2021). Unrolling techniques connect between iterative methods and deep networks by viewing each iteration of an underlying iterative algorithm as a layer of a network, such that concatenating the layers forms a deep neural network where the algorithm parameters transfer to the network parameters. The network is trained using backpropagation, resulting in model parameters that are learned from real-world training sets. However, these previous unrolling methods for NMF were limited to supervised settings where one of the matrix factors is known and can be used for training.
In this study, we develop a deep unrolled network architecture, which we call deep non-negative matrix factorization (DNMF), for regularized variants of NMF for both the supervised and unsupervised settings. In our model, we learn two types of weight matrices for added flexibility in learning complex patterns and design the network so that conventional backpropagation tools such as the auto gradient in Pytorch can be used to allow for large-scale implementation. We implement the resulting networks and show their utility over standard iterative formulations. In particular, we apply our constructions to analyze a diverse collection of simulated and real mutation data sets, and show that they lead to better reconstructions of unseen data compared with the MU scheme. In the supervised setting, we train the network based on given input vectors V and their corresponding coefficients H, without the need of knowing the underlying dictionary (corresponding to mutational signatures) W. In the unsupervised setting, our network operates with the input non-negative data matrix V only.
2. METHODS
2.1. Problem formulation and current approaches
NMF receives as input a non-negative matrix 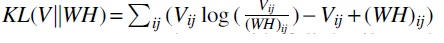 . In the presentation hereunder we mostly focus on the reconstruction error case but provide full details on the KL divergence optimization in Appendix A2.
. In the presentation hereunder we mostly focus on the reconstruction error case but provide full details on the KL divergence optimization in Appendix A2.
A popular iterative method to approximate the reconstruction error is Lee–Seung's MU scheme (Lee and Seung, 2000):
where
2.1.1. Regularized variants
Hoyer (2002) extended the classical MU scheme for the case of an L1 penalty imposed on the coefficients of H. Other works have also developed formulations for L2 regularization (Wang et al., 2016). For completeness, we redevelop a regularized variant with both penalties in Appendix A1. Fixing W and looking at one sample v and one column h of H at a time, we consider the problem:
This leads to the following MU equation (see Appendix A1):
Note that if
2.2. Unrolling the iterative algorithm
To obtain our suggested unrolled network, it will be convenient to consider one input sample
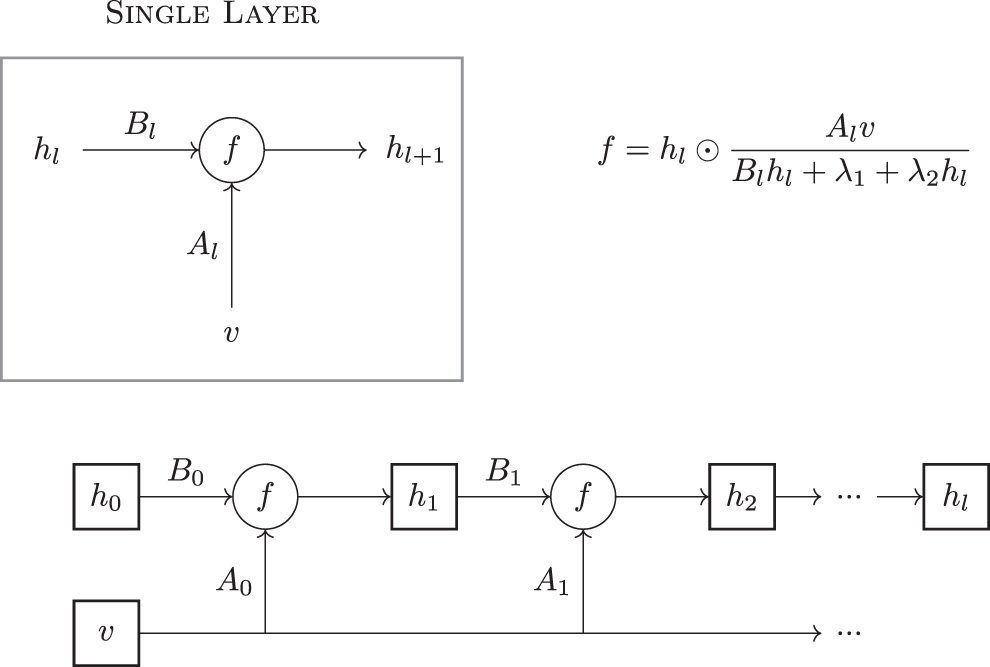
A sketch of the proposed supervised unrolled network for non-negative matrix factorization.
Notably, a similar unrolling architecture applies to the KL divergence case with the main differences being the loss function used and the MU function, which involves two learned matrices that represent W and WT in the update formula (see Appendix A2).
To test the resulting network, we used 10 layers (see Section 3 for performance across varying depth values) and implemented backpropagation using Pytorch. Training was performed through minimizing the MSE loss function
The model parameters including the
2.3. An unsupervised variant
Typically, we do not know the decomposition matrices H and/or W in advance, in which case supervised training is not feasible. Instead, we propose to evaluate a solution by its ability to reconstruct the original matrix V. To this end, after obtaining the network output h for each of the data columns, we use non-negative least squares (NNLS) to reconstruct W (Lawson and Hanson, 1995) and adjust the cost function accordingly. In detail, we start by initializing h0 to fixed values for every column of V, the two columns are forward propagated in the network, and the resulting
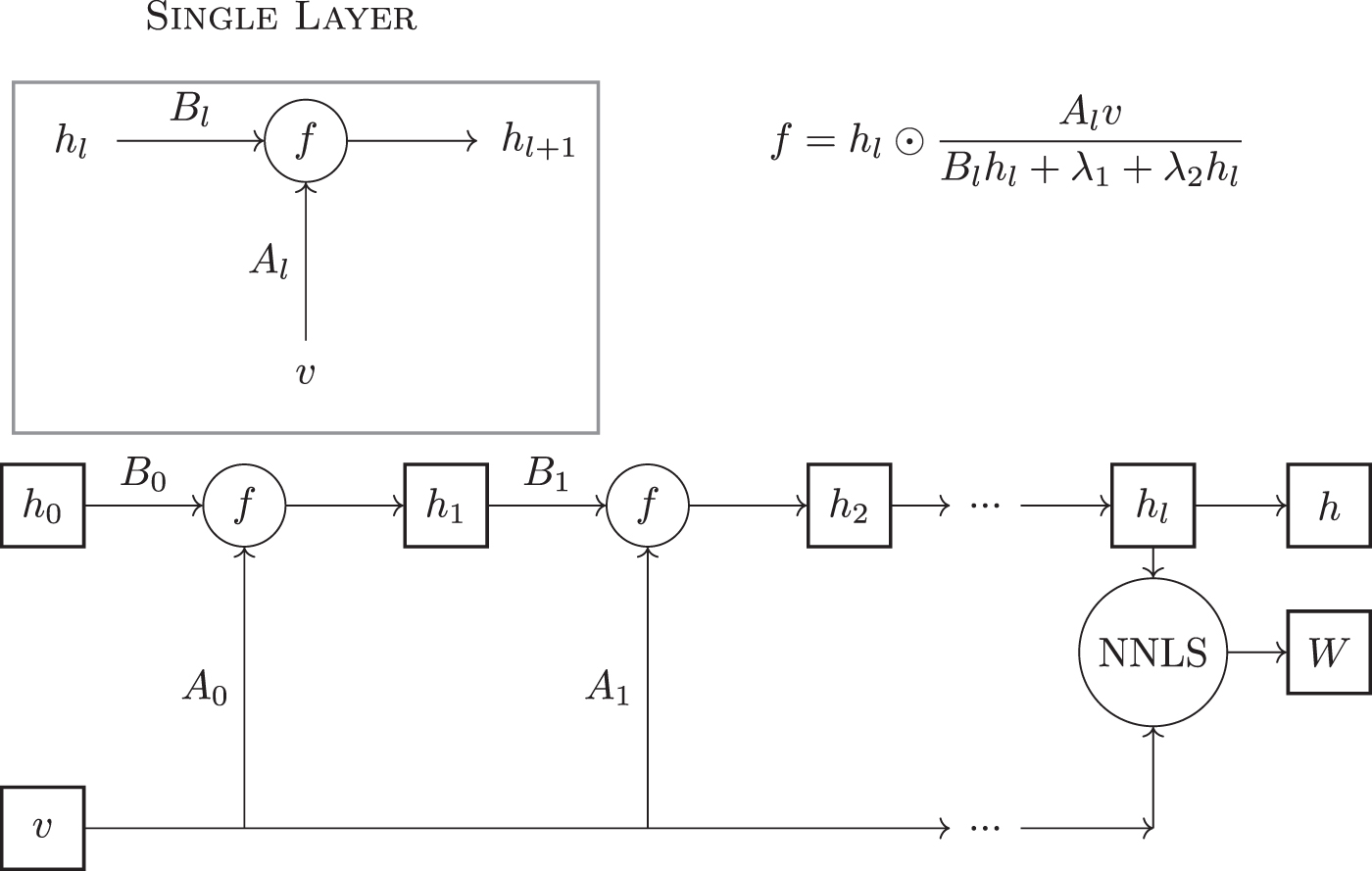
A sketch of the unrolled deep network for the unsupervised variant. NNLS, non-negative least squares.
In the unsupervised case we cannot learn the regularization parameters as they affect the cost function and if we would omit them from the cost function, their optimal value will be zero (corresponding to no regularization). Hence, in this variant we use
2.4. Data description and performance evaluation
We used two types of mutation data sets: simulated and real ones. In all cases the number of rows in the observed (count) matrix V was 96, representing the 96 standard mutation categories (Alexandrov et al., 2019). For such data, V is assumed to be the result of the activity of certain mutational processes whose signatures are given by the dictionary W and whose exposures are given by the coefficient matrix H. We describe these data sets as follows.
2.4.1. Simulated data
The simulated data were taken from Alexandrov et al. (2019) and includes multiple mutation data sets with varying numbers of underlying signatures and degrees of noise. For each data set we are given an observed matrix of mutation counts (denoted V earlier) and its decomposition into signature (W) and exposure (H) matrices. In total, we used 12 different simulated data sets with at least 1000 samples each as detailed in Appendix A3.
2.4.2. Real data
We analyzed a breast cancer (BRCA) mutation data set of whole-genome sequences from the International Cancer Genome Consortium. The data set has 560 samples and believed to be the result of the activity of 12 mutational processes as cataloged in the Catalogue of Somatic Mutations in Cancer (COSMIC) database.
2.4.3. Performance evaluation
We evaluated our method on each data set using fivefold cross-validation and compared with the standard MU method under various regularization schemes. All model parameters in both methods were initialized to one, unless specified otherwise. In the supervised case, we report the MSE between the true H and the estimated matrix Hl over a test set (20% of the samples), where the MSE is averaged over the columns of H. In the unsupervised case, we report the MSE between V and its reconstruction WH over a test set (20% of the samples), where the MSE is averaged over the columns of H. For both DNMF and MU, W in inferred using the training samples and H is estimated on the test samples. For DNMF, the estimation of H is done by propagating the columns of V in the learned network. For MU, it is done by fixing W and using the iterative update rule to compute H.
2.5. Implementation and runtime details
All reported runs were done in Google Colab using a 2-core CPU (x86_64). Code is available at https://github.com/raminass/deep-NMF. The inference time of supervised/unsupervised DNMF with 10 layers was 0.0019 seconds, similar to a 10-iteration MU inference in the supervised case (0.0021 seconds), and an order of magnitude faster than a 100-iteration MU inference in the unsupervised case (as used in this study, 0.016 seconds).
3. RESULTS
We developed a deep learning based framework for NMF, which we call DNMF. The DNMF framework imitates the classical MU scheme for the problem by unrolling its iterations as layers in a deep network model. We further developed regularized variants for MU and DNMF. We apply our framework in both a supervised setting, where training data regarding the true factorization is available, and in an unsupervised setting. Full details on the different models appear in Section 2.
We start with testing the different model formulations using simulated data. First, we compare the regularized with the nonregularized variant in the supervised case. As expected, the results, summarized in Figure 3, show that the regularized variant performs best in terms of MSE, hence we focus on it in the sequel.
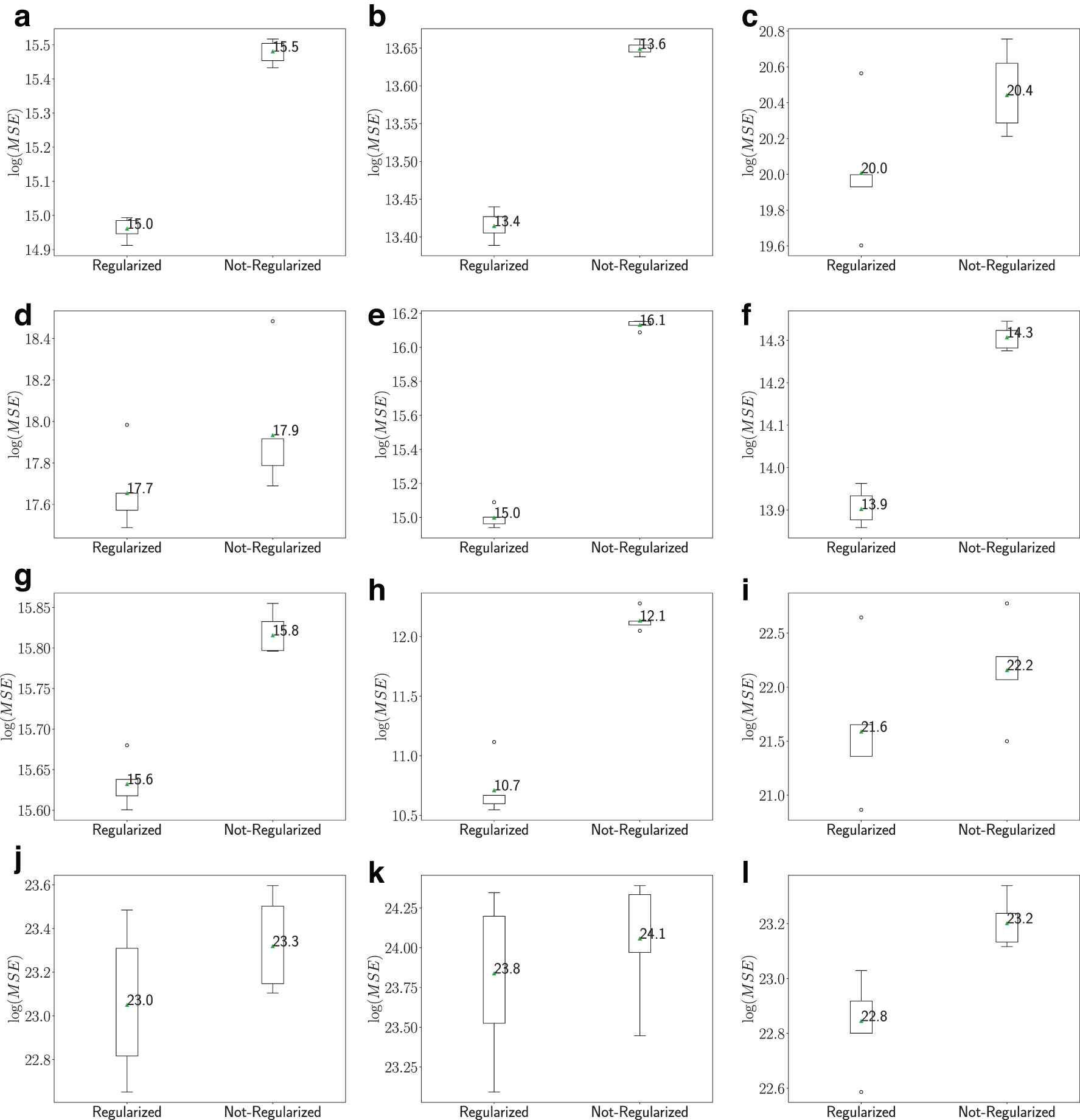
The effect of regularization on DNMF performance in the supervised case.
Next, we tested the effect of the depth of the unrolled network on the algorithm's performance. The results, depicted in Figure 4, show that after 10–15 layers the performance reaches a plateau, hence we focus in the following on depth-10 networks. Notably, as our network borrows from the MU update scheme and does not rely on activation functions, it is less affected by the problem of gradient decay for deep architectures.
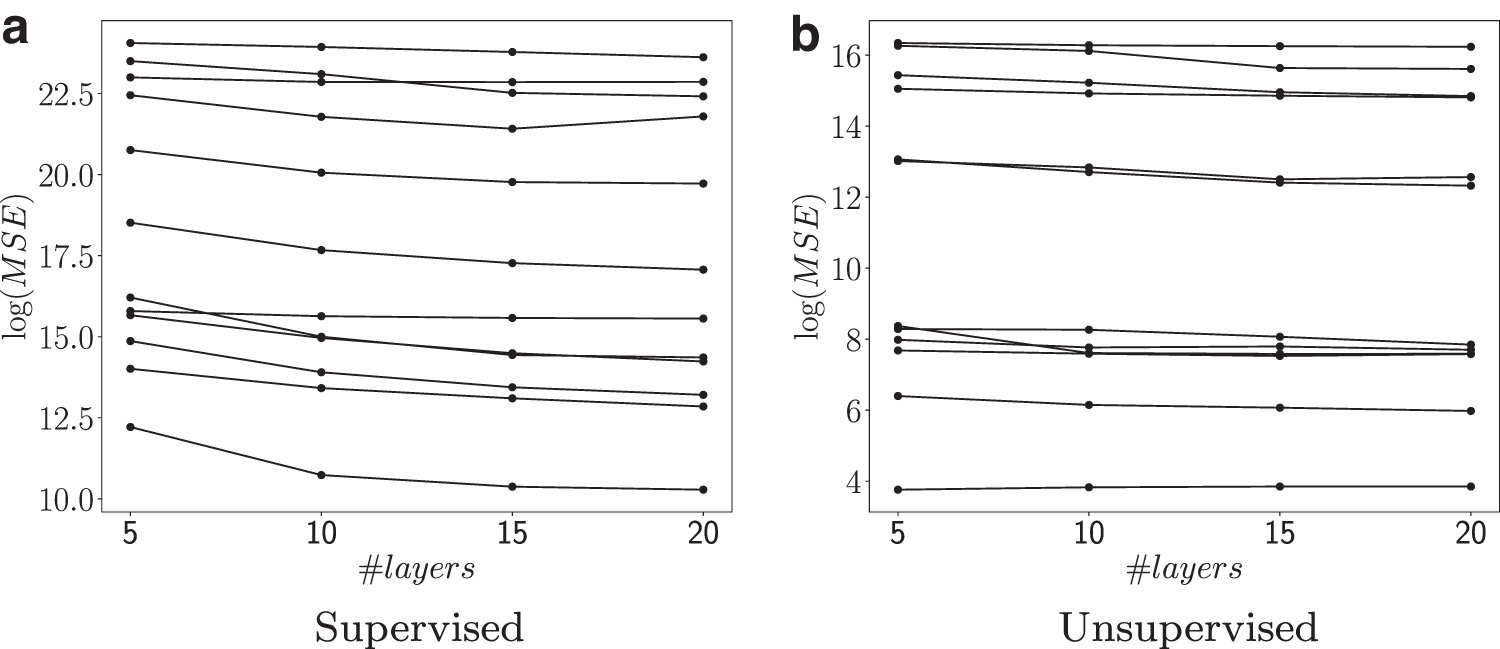
The effect of number of layers on algorithm's performance. Each line corresponds to one of the simulated data sets.
After determining the architecture of the developed framework, we turn to examine it in the supervised case and compare with the MU approach on the simulated data. To this end, we apply MU to the training data to estimate W, and then use MU with the learned W to estimate H on the test data. The results, summarized in Figure 5, show that DNMF outperforms MU across a wide range of regularization values for the latter (note that DNMF learns the regularization parameters automatically from data in this case).

Comparative performance on simulated data in the supervised setting.
Next, we evaluate DNMF in the unsupervised case. In this case, the regularization parameters are part of the objective function and cannot be learned by the model, hence we compare DNMF with MU under different regularization settings. As evident from the results in Figures 6 and 7a, DNMF outperforms MU across a wide range of data sets and regularization values on both simulated and real data.
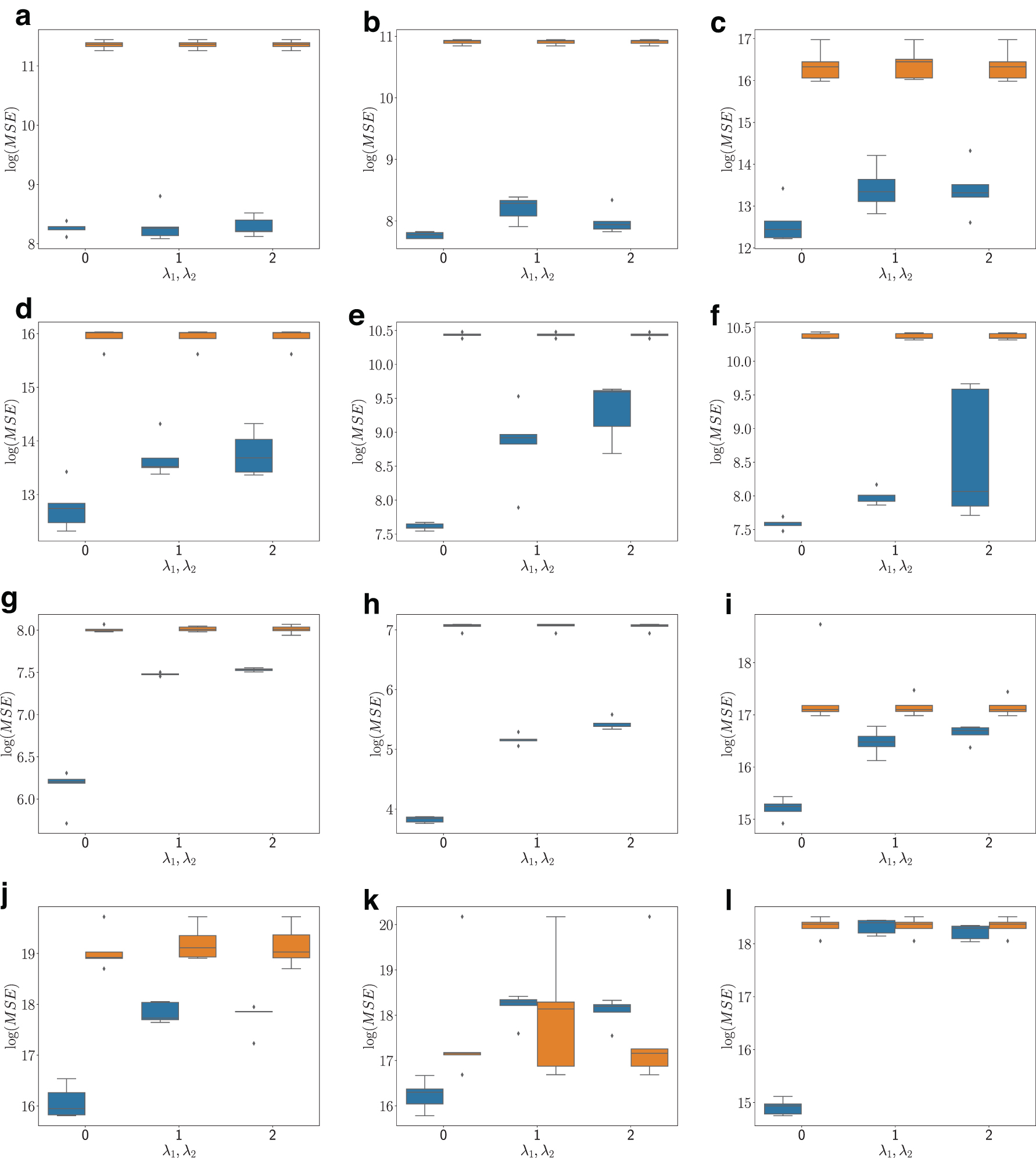
Comparative performance in the unsupervised setting on simulated data. Blue: DNMF; orange: MU.
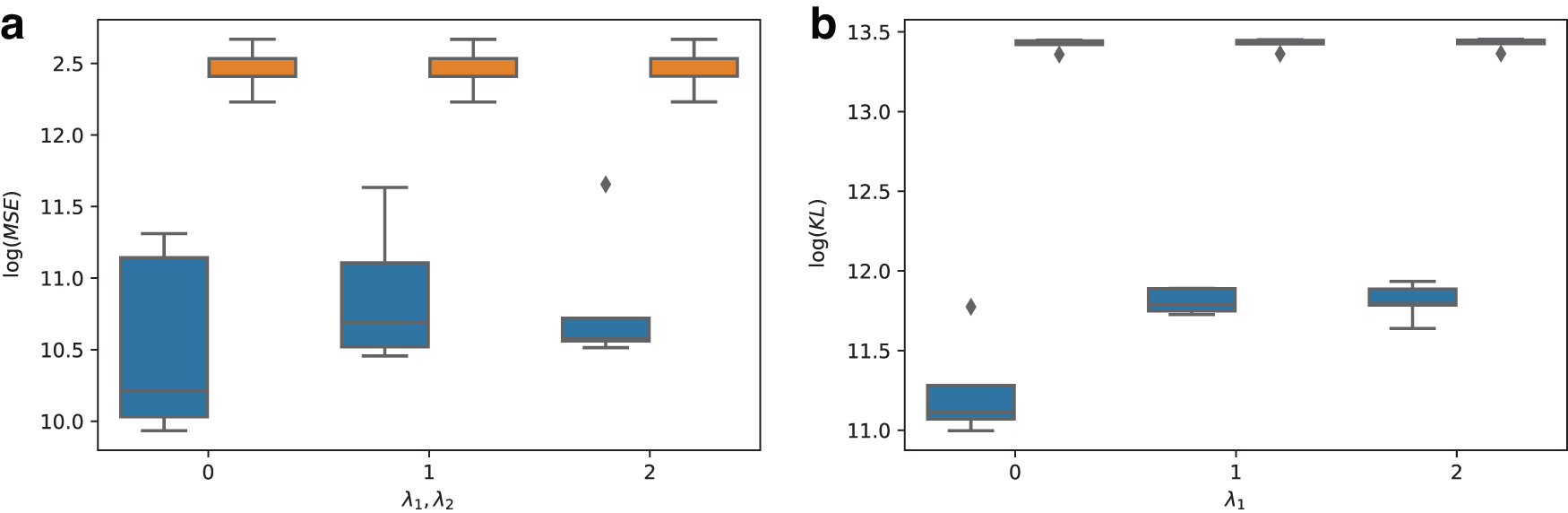
Comparative performance in the unsupervised setting on real data for both Euclidean
For the real mutation data, we also evaluate the KL divergence variant of DNMF as this type of optimization is commonly applied to such data (Kim et al., 2016). The results, depicted in Figure 7b, again show the superiority of DNMF over MU.
To get an intuition for the improved performance of DNMF compared with MU, we looked at the cost function being optimized across algorithmic iterations when considering the real data set and multiple regularization parameters. We observed that MU converges to a local minimum after a few iterations only, hence we attempted different random initializations for it and report the best one. Nevertheless, DNMF remains the best performer under all settings (Fig. 8).
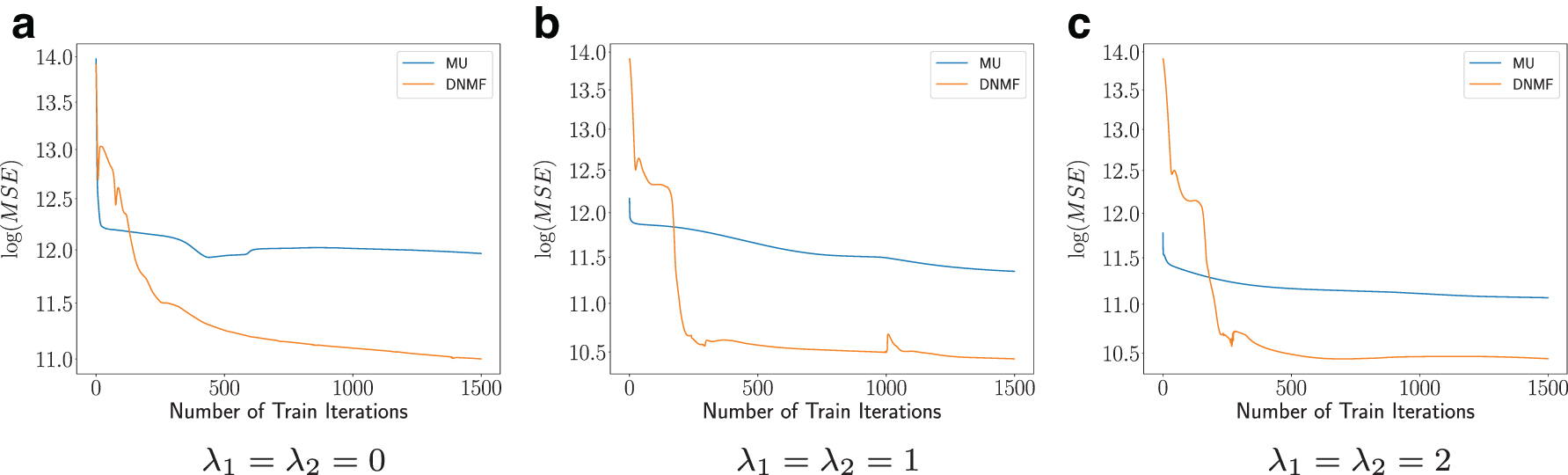
Unsupervised reconstruction error during training on real data for MU and DNMF. Values of λ1 and λ2 from left to right:
4. CONCLUSIONS
We provided a detailed deep learning framework for NMF that is applicable in both supervised and unsupervised settings. The framework outperforms classical approaches to this problem and greatly improves the reconstruction error of the factorization across a wide range of data sets and regularization schemes. We demonstrated the utility of our framework in analyzing mutation data from simulated and real data sets and expect it to greatly improve our ability to reconstruct mutational signatures and their exposures.
For future study, we intend to explore different strategies for initializing the DNMF model and to select its regularization parameters in the unsupervised case.
Footnotes
ACKNOWLEDGMENTS
We thank Itay Sason for his helpful feedback on the article.
AUTHOR DISCLOSURE STATEMENT
The authors declare they have no conflicting financial interests.
FUNDING INFORMATION
R.S. was supported by a grant from the United States-Israel Binational Science Foundation (BSF), Jerusalem, Israel.