
Abstract
Research on drug-drug interaction (DDI) prediction, particularly in identifying DDI event types, is crucial for understanding adverse drug reactions and drug combinations. This work introduces a Bidirectional Recurrent Neural Network model for DDI event type prediction (BiRNN-DDI), which simultaneously considers structural relationships and contextual information. Our BiRNN-DDI model constructs drug feature graphs to mine structural relationships. For contextual information, it transforms drug graphs into sequences and employs a two-channel structure, integrating BiRNN, to obtain contextual representations of drug-drug pairs. The model’s effectiveness is demonstrated through comparisons with state-of-the-art models on two DDI event-type benchmarks. Extensive experimental results reveal that BiRNN-DDI surpasses other models in accuracy, AUPR, AUC, F1 score, Precision, and Recall metrics on both small and large datasets. Additionally, our model exhibits a lower parameter space, indicating more efficient learning of drug feature representations and prediction of potential DDI event types.
INTRODUCTION
The field of computer-aided drug discovery has placed significant emphasis on the prediction of drug-drug interactions (DDIs) (Dou et al., 2024), which are crucial for understanding drug reaction side effects (Das and Mazumder, 2023; Ding et al., 2023a; Qian et al., 2022; Sachdev and Gupta, 2020; Wang et al., 2023b; Wang et al., 2021) and facilitating drug repositioning (Jarada et al., 2020). The advent of deep learning, particularly graph-based models, has markedly influenced recent developments in DDI prediction, as evidenced by the works of Kastrin et al. (2018), Yu et al. (2018). These models are broadly categorized into graph representation learning, knowledge graph representation learning, and mixed graph structures.
Graph representation learning models usually consider drug features as node features in the drug-drug interaction graph including simplified molecular input line entry system (SMILES), enzyme, and target. Among them, substructure-substructure interaction for DDI prediction (SSI-DDI) (Nyamabo et al., 2021), an accurate and generalized framework for DDIs prediction by dual-view representation learning (DSN-DDI) (Li et al., 2023), a DDIs model based on line subgraph generation strategy (DDI-LSG) (Bai et al., 2023), a model using graph auto-encoder and residual graph convolutional network to predict DDIs based on multi-source drug features (MSResG) (Guo et al., 2023) are representative models. Knowledge graph representation learning aims to construct a biomedical knowledge graph and uses knowledge graph representation learning models to learn knowledge from the knowledge graph. Among those models, an attention-based knowledge graph representation learning for DDIs prediction (DDKG) (Su et al., 2022), the chemical structure features of drugs, the extra label features of drug pairs’ and the KG features of drugs were effectively fused to predict the multi-typed DDIs (MCFF-MTDDI) (Han et al., 2023), a knowledge graph neural network for DDIs prediction (KGNN) (Lin et al., 2020), and a knowledge graph embedding framework by introducing adversarial autoencoders based on Wasserstein distances and Gumbel-Softmax relaxation for DDIs prediction (Dai et al., 2021). Mixed graph-based models incorporate various graph neural networks (Wang et al., 2023a), often combining multi-view structures (Wang et al., 2021) and heterogeneous graphs (Bongini et al., 2023).
Despite these advancements, most DDI prediction models focus primarily on the interactions themselves, often overlooking the significance of DDI event types, particularly in the context of adverse drug events. This gap has been addressed by models like DeepDDI (Ryu et al., 2018), similarity-based models (Lee et al., 2019), and the DDIMDL, a multimodal deep learning model for DDI prediction proposed by Deng et al. (2020), which considers various drug features to predict DDI-related events. Other notable contributions in this area include the MDF-SA-DDI model by Lin et al. (2022b), focusing on multi-source drug fusion and transformer self-attention mechanisms; the MDDI-SCL model by Lin et al. (2022a), employing supervised contrast learning; and the GNN-DDI model by Al-Rabeah and Lakizadeh (2022), utilizing graph neural networks for DDI type prediction. Zhang et al. (2022) introduced CNN-DDI, based on convolutional neural networks, while Yang et al. (2023) proposed the CNN-Siam, a twin convolutional neural networks-based model. Further, Huang et al. (2023) developed a multi-modal drug feature fusion method using a score calculation module for predicting DDIs. Dou et al. (2022) proposed the BP-DDI model, integrating biological information and pharmacological text. Xiong et al. (2023) used a hierarchical integration of drug molecular graph structure information and DDI events graph interaction information, employing a multi-relationship contrast learning graph neural network. Ma and Lei (2023) focused on learning drug molecular features based on key molecular structural features interactions and chemical substructures, using dual-graph neural networks. Xu et al. (2023) integrated biomedical knowledge graph information with drug structural information for DDI event type prediction using comparison learning. However, a common limitation among these models is their lack of focus on the contextual information behind drug features (Wu et al., 2024).
To address this gap, we propose the BiRNN-DDI, a bidirectional recurrent neural network tailored for DDI event-type prediction. This approach differs from previous models by converting drug feature relationships into drug sequence representations through Graph2Seq representation. Our methodology involves creating three distinct homogeneous drug feature graphs corresponding to drug targets, enzymes, and SMILES, subsequently merging these features into a singular serialized drug feature. Furthermore, to capture the contextual interplay between two such serialized drug features, we utilize a Bidirectional Recurrent Neural Network. Experimental evaluations on a DrugBank-based benchmark reveal that our BiRNN-DDI model achieves superior F1 score and operates with a lower parameter space compared to the current state-of-the-art mode.
This work is an expanded version of the conference article of the 19th International Symposium on Bioinformatics Research and Applications (ISBRA 2023). Compared to the conference version, we have added more details.
RELATED WORK
Bidirectional gated recurrent unit
The Recurrent neural network is a kind of neural network architecture. Due to the long-term dependence problem, Long Short-Term Memory (LSTM) is proposed, and Gated Recurrent Unit (GRU) is another improved Recurrent neural network proposed after LSTM. The formula of GRU is calculated as follows:
GRU has two key gating units: an update gate and a reset gate. First, define the input sequence:
The framework of our Bidirectional recurrent neural network for drug-drug interaction event type prediction (BiRNN-DDI) model is shown in Figure 1. Our model consists of two main steps. First, our model constructs homogeneous drug feature graphs including SMILES relation graph, target relation graph, and enzyme relation graph, then our BiRNN-DDI model converts the three-drug feature graphs into a drug-drug pair sequence representation through Graph2Seq representation learning. Finally, our BiRNN-DDI model uses the BiRNN model to learn contextual information between drugs and get drug-drug interaction representation. Our BiRNN-DDI model uses a multilayer perceptron (MLP) to classify event types of drug-drug interaction.
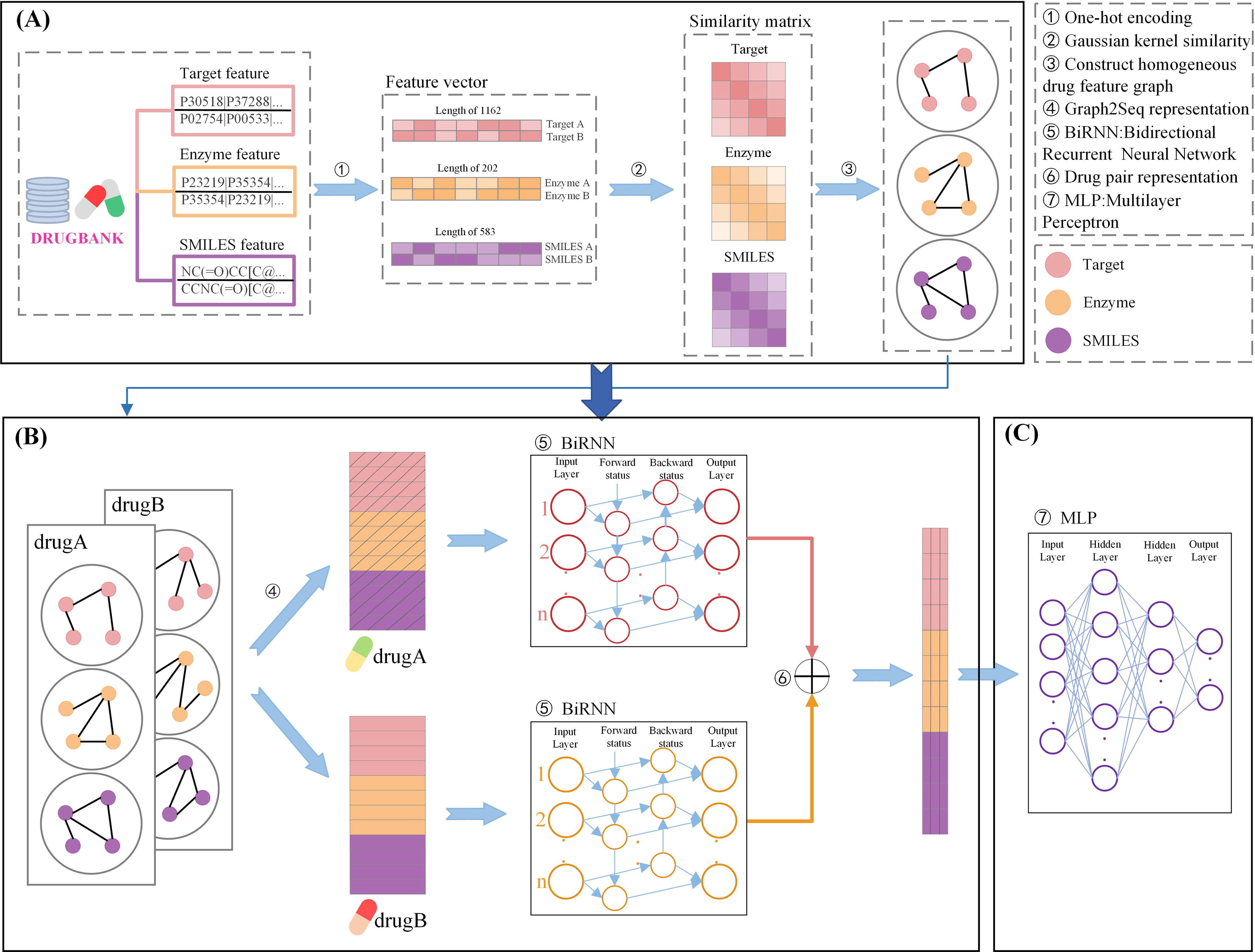
Framework of our BiRNN-DDI model.
The construction process of the drug feature graph is depicted in Figure 2. We utilize the Gaussian kernel, an algorithm renowned for its effectiveness in measuring similarity between two entities in a feature space. This approach enables the nuanced capture of intricate relationships within features, a method that has gained widespread use in various studies (Cao et al., 2021; Cao et al., 2022; Wang et al., 2024). To extract features from drug properties, we apply Gaussian kernel similarity methods to extract features from drug properties. Given two samples A and B, the Gaussian kernel similarity is calculated as follows.
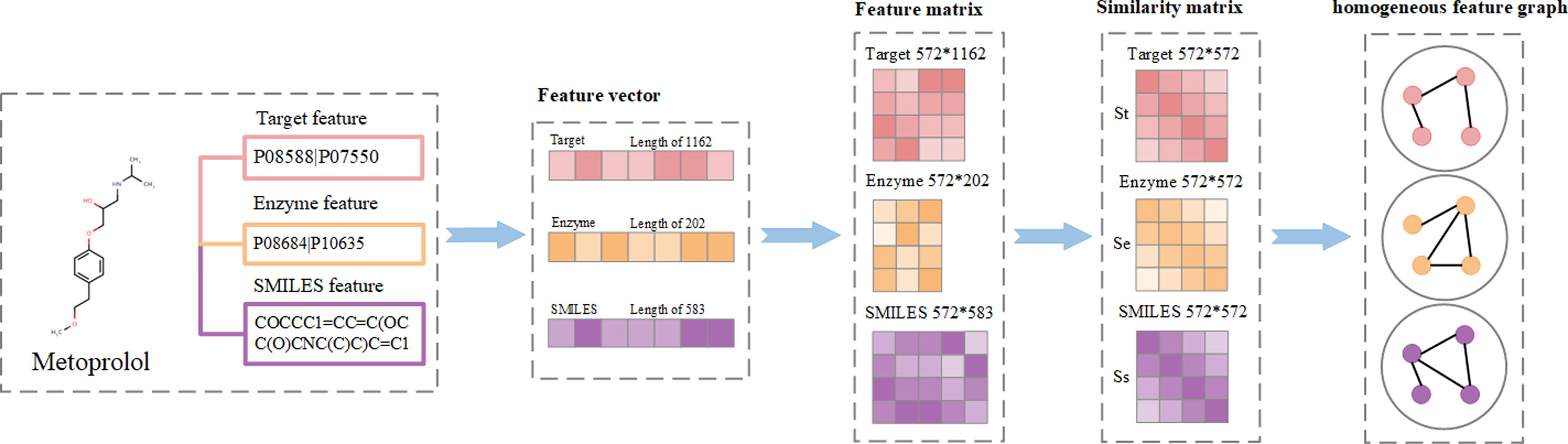
Example of drug feature graph construction process.
Among it,
In the homogeneous drug feature graph construction process, we first extract target, enzyme, and SMILES features from drugbank. Then, we use one-hot encoding to encode those three features and get feature vectors. Thirdly, we calculate target, enzyme, and SMILES feature similarity matrixes through the Gaussian kernel similarity method. According to the Gaussian kernel, we can get three Gaussian kernel similarity matrixes which are
We use the drug Metoprolol on Deng et al.’s dataset as an example shown in Figure 2 to illustrate the drug feature graph construction process. The length of one-hot feature vectors corresponding to the target, enzyme, and SMILES features are separately 1162, 202, and 583 shown in Figure 2. We get three feature matrixes corresponding to target, enzyme, and SMILES whose dimensions are separately
After the drug feature relation graphs are constructed, we construct initial drug sequence representations from the three-drug feature graphs. Converting graphs into sequences helps the model better understand global communications between nodes. Hence, in the Graph2Seq representation learning process, we first initialize the node sequence representation. As shown in Figure 3, we extract all weights linked with the given node i in the given graph G. We iterate the SMILES relation graph, enzyme relation graph, and target relation graph sequentially. After that, we get an initialized drug sequence representation of the given node i. Repeatedly, we iterate all nodes in those graphs and get all initialized drug sequence representations. Then, to learn contextual information between drug-drug pairs, we use a two-channel structure to learn drug-drug pair representations in Figure 4. As shown in Figure 4, each channel contains a BiRNN to deal with a single drug sequential features representation. After the two-channel sequence representation learning, we add the two single-drug sequence representations to get contextual drug-drug pair representation.
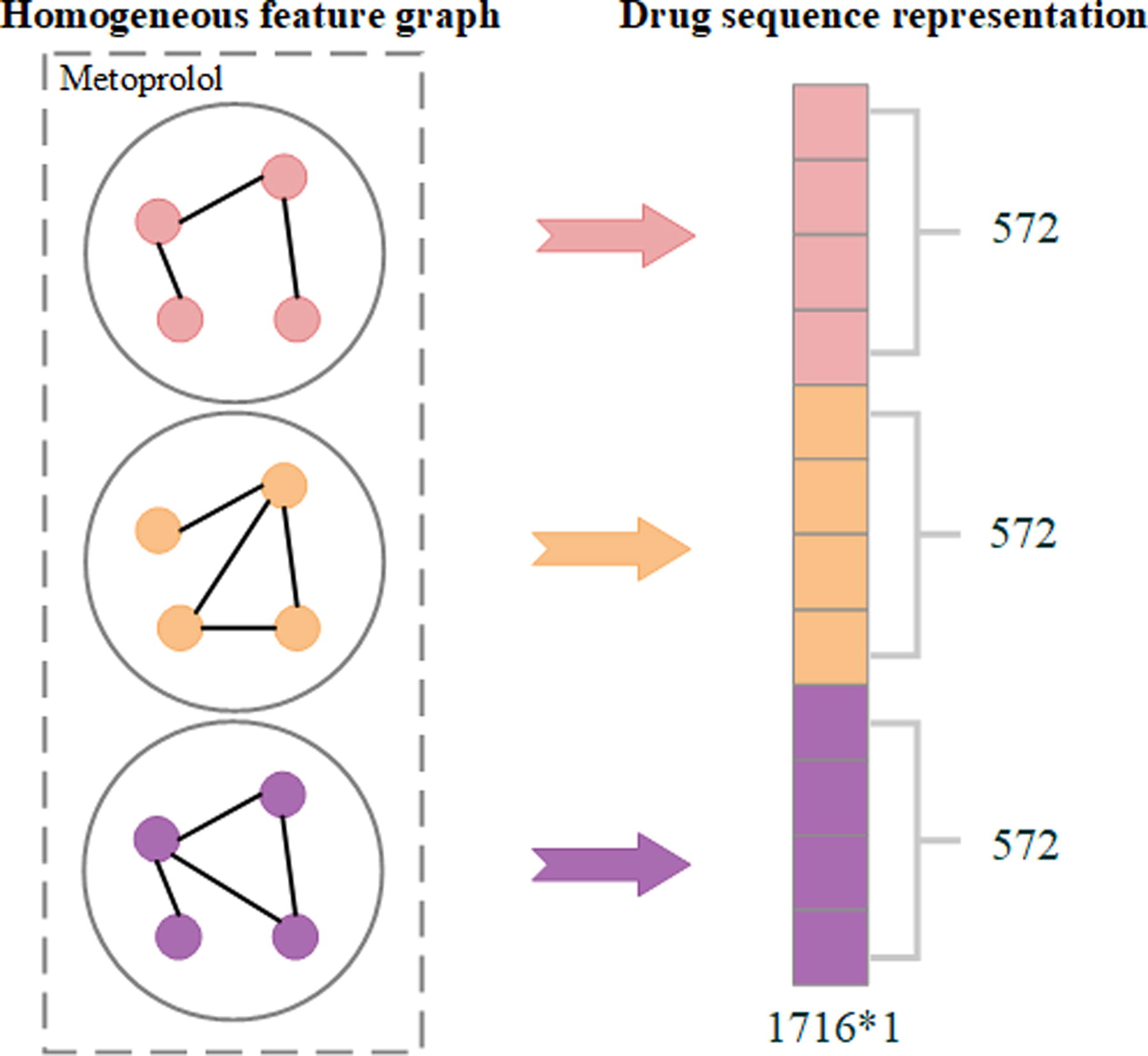
Example of an initial Graph2Seq representation.
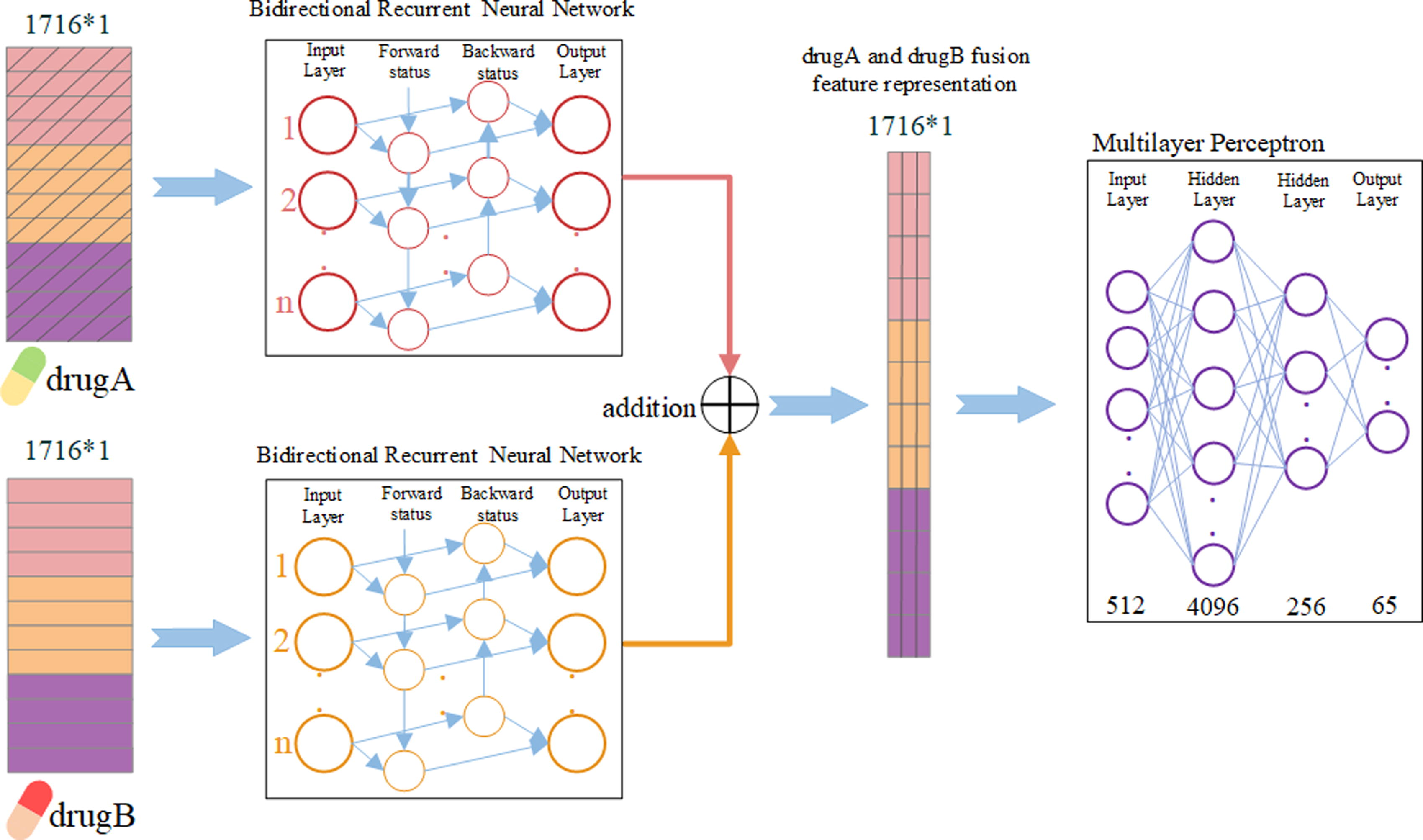
Example of drug-drug pair representation.
An example is drawn in Figure 3 and Figure 4. In Figure 3, a drug is represented as a 572-dimensional vector to measure relationships with other drugs. We combine the features of the same drug in three graphs and get an initial sequence representation whose dimension is 1716. Then we add the two drug contextual representations and get a drug-drug pair representation as shown in Figure 4.
After drug-drug pair representations are gotten, we use a multilayer perceptron consisting of three linear layers and layers of activation functions to predict the type of drug-drug interaction event. As shown in Figure 4, the number of the nerve cells corresponding to the input layer, two hidden layers, and output layer are separately 512, 4096, 256, and 65.
EXPERIMENTS AND RESULTS
Datasets
In our experiment, we use two datasets. The first dataset is proposed by Deng et al. (Deng et al., 2020) which is collected from drugbank. It contains 572 drugs and 74528 pairwise DDIs, which are associated with 65 types of events. The second dataset is proposed by Lin et al. (2022b) which is also collected from drugbank. It contains 1258 drugs and 323539 pairwise DDIs, which are associated with 100 types of events. In Deng et al.’s dataset, each drug has four features: target, SMILES, enzyme, and pathway. It contains 65 event types of DDIs in the dataset. According to the experiments of Deng et al. (2020), among all feature combinations, the combination of SMILES, target, and enzyme performed best, so we only used these three features for analysis. The information for the two datasets is shown in Table 1.
Details of Deng et al.’s Dataset and Lin et al.’s Dataset
Details of Deng et al.’s Dataset and Lin et al.’s Dataset
To better set our BiRNN-DDI model parameters, we test different parameter settings in our model including training epoch, learning rate, batch size, num layers, activation function, and cross-validation on Deng et al.’s dataset. The experimental parameter setting results are shown in Figure 5. According to the results shown in Figure 5, we chose 7-fold cross-validation, 256 for batch size, 1e-3 for learning rate, 80 for training epoch, and 2 for the number of GRU layers.
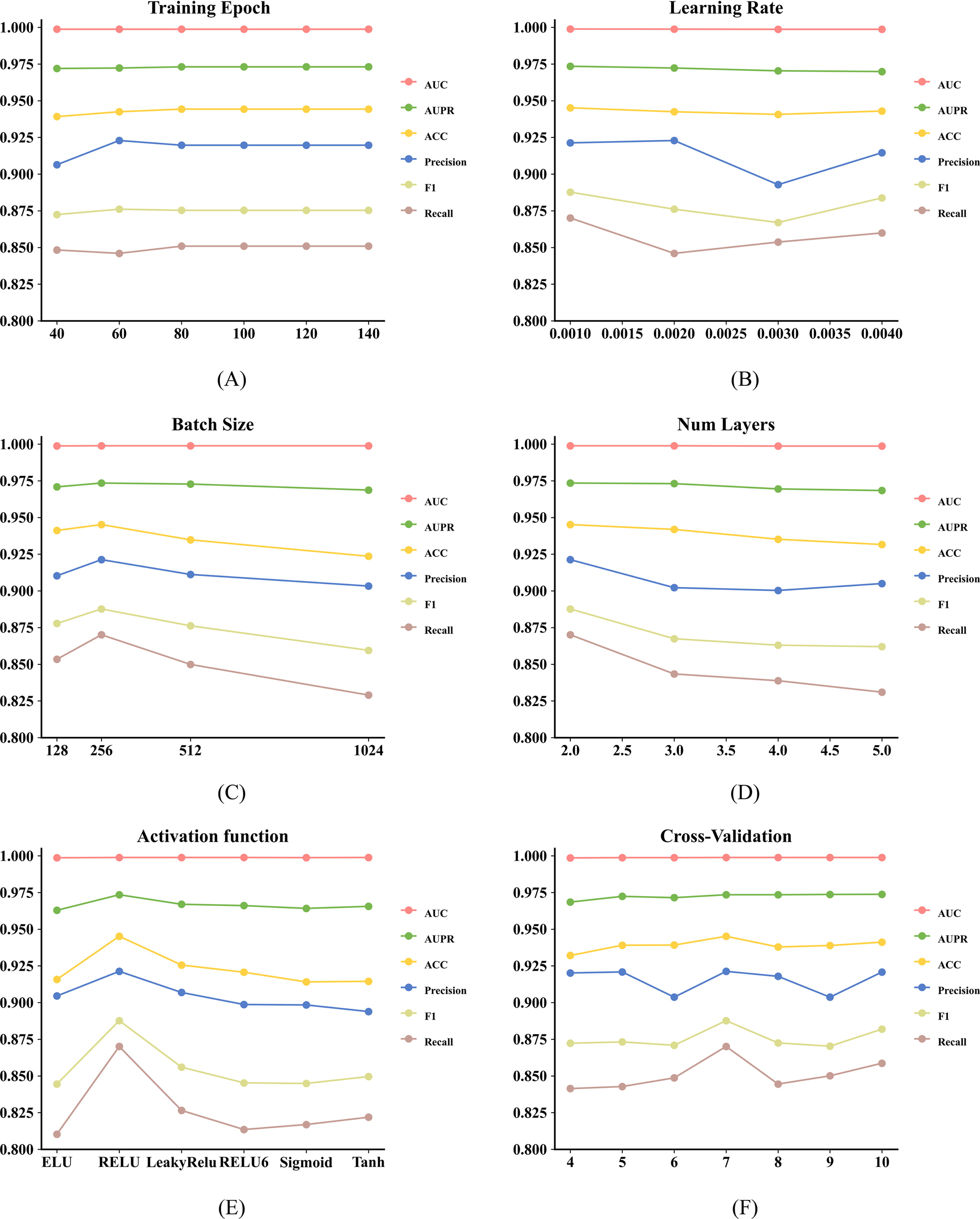
Performance charts with different hyperparameters.
According to the reference of Deng et al., we select SMILES, target, and enzyme as final features. For the SMILES, we use the RDKit toolkit to get the Morgan fingerprint of the chemical substructure SMILES. Then, we use a binary vector to represent the Morgan fingerprint. After that, we got a 583-dimensional SMILES representation vector. Similarly, for the target feature and enzyme feature, the representation vectors are separately an 1162-dimensional vector and a 202-dimensional vector.
To evaluate DDI event types obtained by different models, we use six evaluation metrics including accuracy (ACC), area under the precision-recall-curve (AUPR), area under the ROC curve (AUC), F1 score, Precision, and Recall. As the prediction results are divided into four types: TN (true negative), FN (false negative), FP (false positive), and TP (true positive), those evaluation metrics are calculated as follows:
TP indicates that the model correctly predicts the number of samples for that category. In our model, TP indicates that the model correctly predicted a certain drug-drug interaction event type. TN indicates that the model correctly predicted the number of samples from other classes or negative classes from the model. In our model, TN means that the model correctly predicts samples of non-certain drug-drug interaction event type as other types of events. FP indicates that the model incorrectly predicted the number of samples from other classes or negative classes to the number of samples in that class. In our model, FP means that the model incorrectly predicts a sample of other types of drug-drug interaction event type as a particular event type. FN indicates that the model incorrectly predicted the sample size of that class as a sample of a different class or a negative class. In our model, FN indicates that the model incorrectly predicts a sample of a drug-drug interaction event type as other types of events.
To validate the effectiveness of our BiRNN-DDI model, we compare our model with deep learning models and machine learning models. In deep learning models, we choose five start-of-the-art drug-drug interaction event type prediction models including MDDI-SCL (Lin et al., 2022a), MDF-SA-DDI (Lin et al., 2022b), CNN-Siam (Yang et al., 2023), and DDIMDL (Deng et al., 2020). In machine learning models, we choose random forest (RF), k-nearest neighbor (KNN), and logistic regression (LR).
RESULTS
The experimental results of Deng et al.’s dataset are shown in Table 2. The experimental results of Lin et al.’s dataset are shown in Table 3. When testing the CNN-Siam model on Lin et al.’s dataset, our server was unable to successfully run the model due to the high demand for GPU resources on Lin et al.’s dataset, failing to obtain the expected results. We can see that our BiRNN-DDI model achieves the four best evaluation metric values including ACC, AUC, F1 score, and Precision in both Deng et al.’s dataset and Lin et al.’s dataset. In Deng et al.’s dataset, the AUPR and Recall values obtained by our BiRNN-DDI model achieve the third-best values. the AUPR and Recall values are only 0.050 and 0.068 lower than the MDDI-SCL model which achieves the best values in the two evaluation metrics. In Lin et al.’s dataset, the AUPR and Recall values are only 0.0031 and 0.0278 lower than the MDDI-SCL model which achieves the best values in the two evaluation metrics. To further show the results on each DDI event type, we use the AUPR and F1 score evaluation metrics obtained from Deng et al.’s dataset to draw Radar maps as shown in Figure 6 and Figure 7. In Figure 6 and Figure 7, we can see the AUPR and F1 score of each DDI event type predicted by different models. Our BiRNN-DDI model achieves separately 32 best values among 65 DDI event types in terms of F1 score evaluation metrics. Figure 8 and Figure 9, show the AUPR and F1 score for each DDI event type predicted by different models on the Lin et al.’s dataset.
The Performance of Different Methods on Deng et al.’s Dataset
The Performance of Different Methods on Deng et al.’s Dataset
The best results are displayed in bold.
The Performance of Different Methods on Lin et al.’s Dataset
The best results are displayed in bold.
No run result is displayed in — .
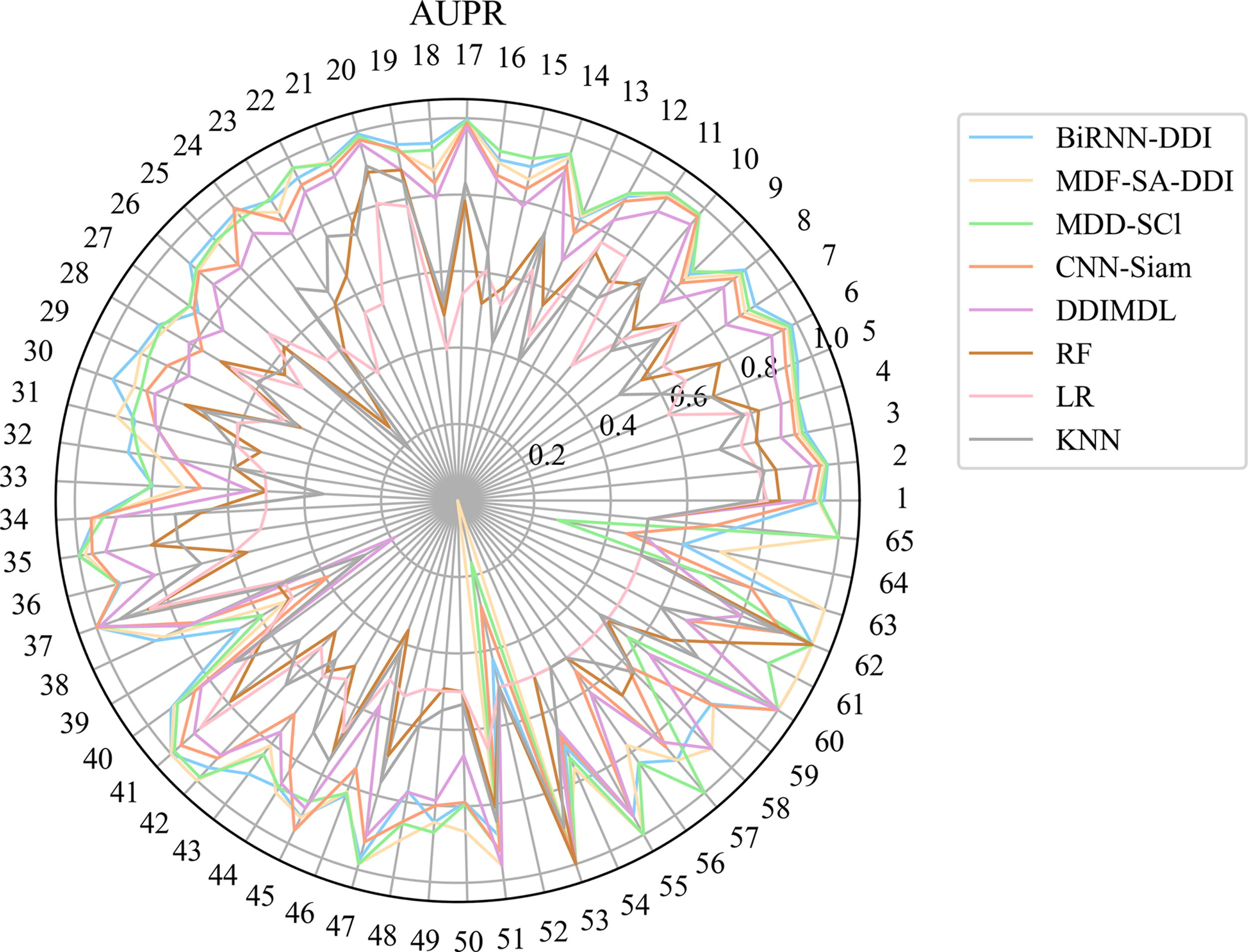
AUPR values of 65 events predicted by different methods on Deng et al.’s dataset.
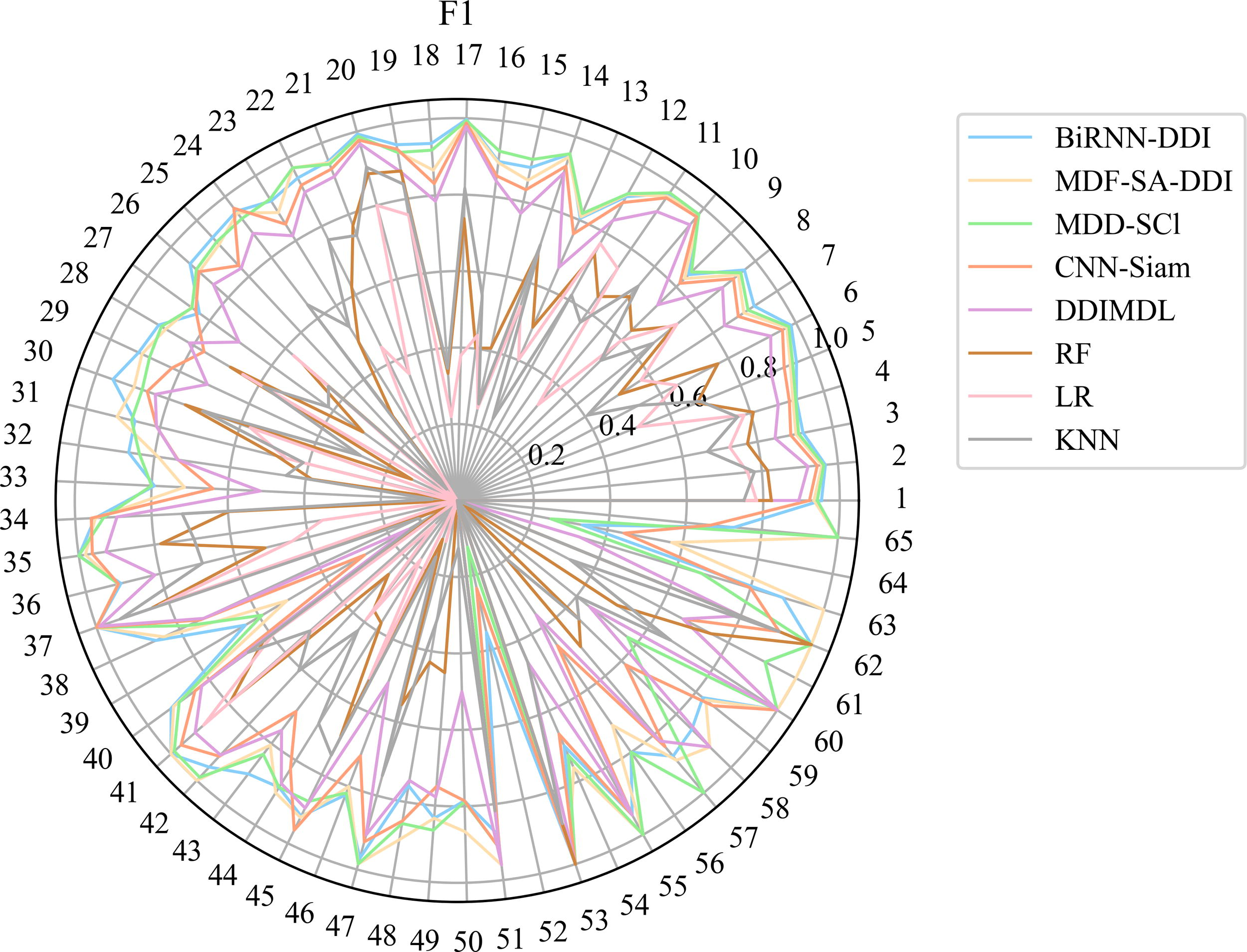
F1 score of 65 events predicted by different methods on Deng et al.’s dataset.
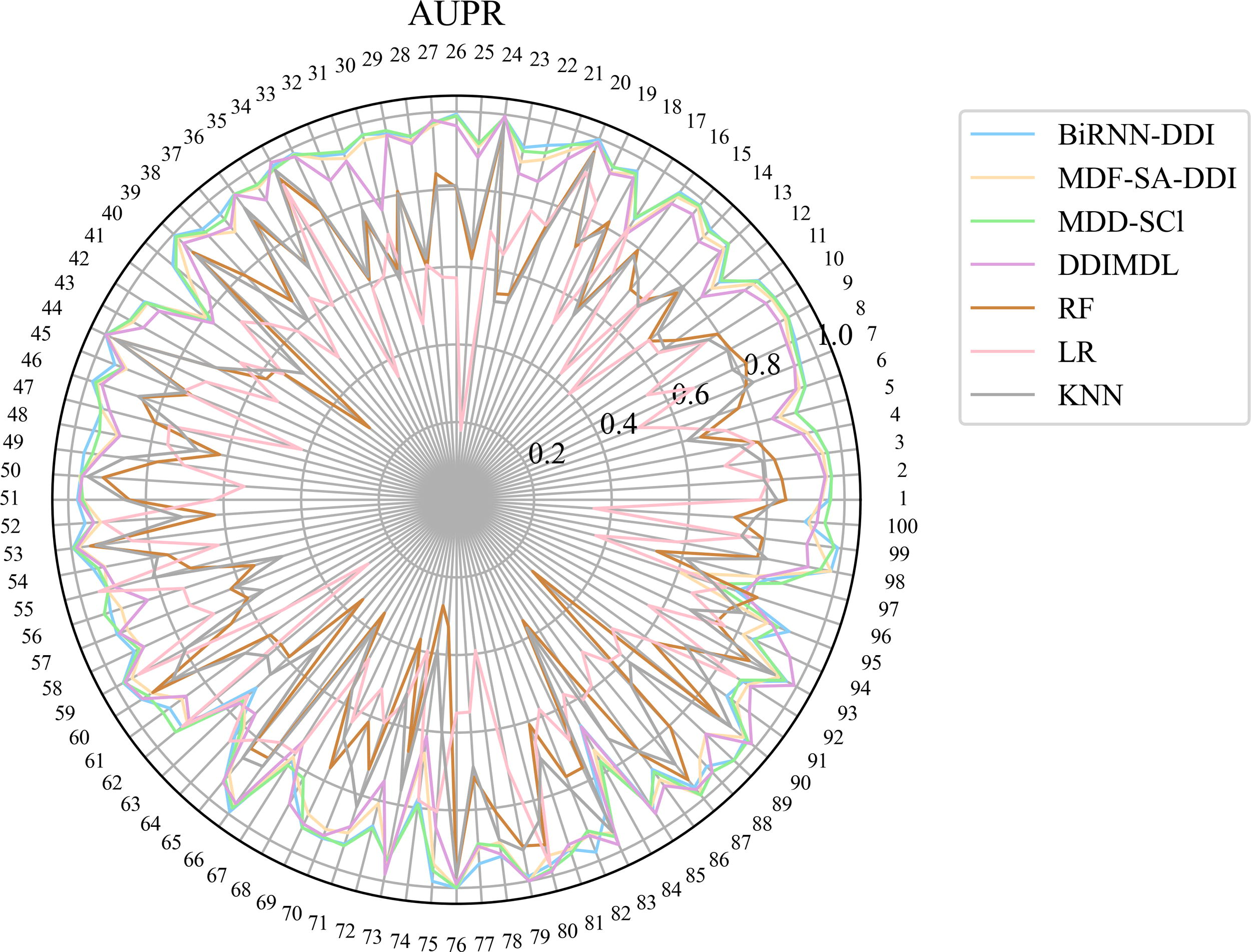
AUPR values of 100 events predicted by different methods on Lin et al.’s dataset.
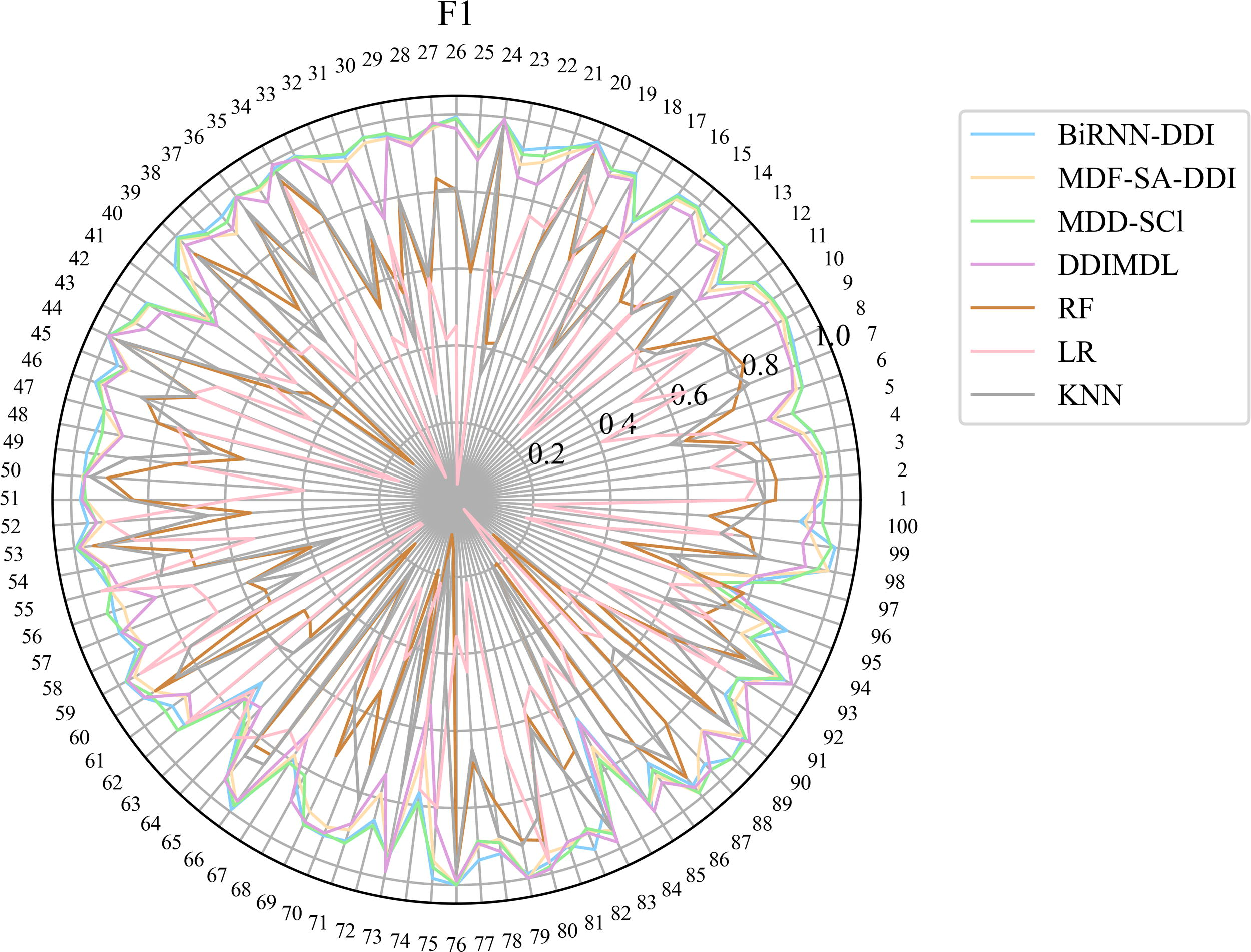
F1 score of 100 events predicted by different methods on Lin et al.’s dataset.
To further explore the performance of deep learning models, we list the parameter space of deep learning models occupied in GPU memory on Deng et al.’s dataset shown in Table 4. According to Table 4, we can see that our BiRNN-DDI model only occupies 1706 MB GPU memory which is significantly smaller than MDDI-SCL, MDF-SA-DDI, and CNN-Siam models. It indicates that our model can achieve relatively higher evaluation metric values while needing less GPU memory.
The Parameter Size of Different Methods Are on Deng et al.’s Dataset
This study embarked on a multi-source fusion approach for drug features, encompassing SMILES, enzymes, and targets. We initiated this by constructing a drug similarity network for each of these features, leading to the development of corresponding drug feature graphs. These were then synthesized into a comprehensive drug sequence representation. The BiRNN model was subsequently employed to learn contextual representations between drugs, aiming to accurately predict DDI event types. Our model was benchmarked against several leading DDI event prediction models and three widely-recognized classification methods. The evaluation encompassed an overall performance score comparison, including the aforementioned models, and a detailed analysis of performance across different DDI event types. Our findings indicate that the proposed model achieves a notable level of performance in these contexts.
However, our approach is not without limitations. Firstly, the SMILES of drugs can be translated into various molecular fingerprint types, yet our study only considered conversion to Morgan fingerprints. Furthermore, in fusing the three drug features, we did not differentiate the relative importance of each feature, opting instead for an equal treatment approach. Future endeavors will explore the conversion of SMILES into other fingerprint vectors. Moreover, we aim to adopt a more holistic method in predicting DDI events, incorporating a broader spectrum of drug features to enhance predictive accuracy (Ding et al., 2023b; Vo et al., 2022). Recognizing the unique importance of different drug features, our forthcoming research will prioritize assigning greater weight to more critical features, thereby refining the predictive model. This expanded approach is anticipated to significantly elevate the efficacy of DDI event type prediction, contributing further to the nuanced understanding of drug interactions.
CONCLUSION
In this research, we introduced BiRNN-DDI, an innovative model for predicting drug-drug interaction (DDI) event types. Our approach involved extracting three key drug features: SMILES, enzymes, and targets. We analyzed drug-drug relationships within these individual feature dimensions, leading to the construction of three distinct homogeneous drug-feature relationship graphs. These graphs were then transformed into drug sequence representations using the Graph2Seq model. For mining the contextual information embedded in these sequences, we employed a dual-channel structure, each channel incorporating a BiRNN model. The final prediction of DDI event types was executed through a multilayer perceptron network.
The efficacy of the BiRNN-DDI model was rigorously tested against various baseline models, evaluation metrics such as ACC, AUPR, AUC, F1 score, Precision, and Recall across two DDI event-type prediction benchmarks. Our experimental results indicated that the BiRNN-DDI model not only achieves higher values in these evaluation metrics but also operates with lower GPU memory requirements compared to other baseline models.
Looking ahead, we plan to incorporate a more diverse range of drug features to further refine and enhance our model’s architecture. Additionally, we aim to validate and test the performance of the model using a broader array of datasets, reinforcing its robustness and applicability in varied bioinformatics contexts.
Footnotes
ACKNOWLEDGMENTS
We thank Prof. Hongmei Wang for valuable suggestions.
AUTHORS’ CONTRIBUTIONS
GW: conception and design; designed the research methodology; writing-review and editing. HF: data analysis and interpretation collected and sorted data; writing original draft. CC: conception and design; validation; writing-review and editing. All authors listed have made a substantial, direct, and intellectual contribution to the work and approved it for publication.
AUTHOR DISCLOSURE STATEMENT
No competing financial interests exist.
FUNDING INFORMATION
The research is supported by the National Natural Science Foundation of China (grant no. 62102068), the Natural Science Foundation of Jilin Province (grant no. YDZJ202201ZYTS424).