
Abstract
Numerous biological experiments have demonstrated that microRNA (miRNA) is involved in gene regulation within cells, and mutations and abnormal expression of miRNA can cause a myriad of intricate diseases. Forecasting the association between miRNA and diseases can enhance disease prevention and treatment and accelerate drug research, which holds considerable importance for the development of clinical medicine and drug research. This investigation introduces a contrastive learning-augmented hypergraph neural network model, termed CLHGNNMDA, aimed at predicting associations between miRNAs and diseases. Initially, CLHGNNMDA constructs multiple hypergraphs by leveraging diverse similarity metrics related to miRNAs and diseases. Subsequently, hypergraph convolution is applied to each hypergraph to extract feature representations for nodes and hyperedges. Following this, autoencoders are employed to reconstruct information regarding the feature representations of nodes and hyperedges and to integrate various features of miRNAs and diseases extracted from each hypergraph. Finally, a joint contrastive loss function is utilized to refine the model and optimize its parameters. The CLHGNNMDA framework employs multi-hypergraph contrastive learning for the construction of a contrastive loss function. This approach takes into account inter-view interactions and upholds the principle of consistency, thereby augmenting the model’s representational efficacy. The results obtained from fivefold cross-validation substantiate that the CLHGNNMDA algorithm achieves a mean area under the receiver operating characteristic curve of 0.9635 and a mean area under the precision-recall curve of 0.9656. These metrics are notably superior to those attained by contemporary state-of-the-art methodologies.
INTRODUCTION
MicroRNAs (miRNAs) are short, single-stranded noncoding RNA molecules, typically consisting of 21–25 nucleotides. Substantial research has shown that dysregulated miRNA expression is involved in the pathogenesis of various complex diseases, including cancers, cardiovascular diseases, and neurological disorders, highlighting their critical role in disease mechanisms (Barut et al., 2024; Bozzarelli et al., 2024; Li et al., 2024; Pantaleao et al., 2024). Therefore, investigating the relationships between miRNAs and diseases is essential for understanding molecular disease mechanisms and improving diagnostic and therapeutic strategies.
Early studies exploring miRNA–disease relationships primarily relied on biological experiments, which, while accurate and reliable, suffer from significant limitations such as long durations, high costs, and time-intensive procedures. The advent of next-generation sequencing has led to the development of several miRNA–disease databases, including dbDEMC (Yang et al., 2010), HMDD (Huang et al., 2019), and miR2Disease (Jiang et al., 2009), which have become valuable resources for predicting miRNA–disease associations. In recent years, computational approaches have been increasingly employed to forecast miRNA–disease associations, yielding substantial progress (Chen et al., 2018b, 2019; Huang et al., 2022a, 2022b). These methodologies for analyzing miRNA–disease connections can be broadly categorized into three groups: similarity-based approaches (Lan et al., 2018; Li et al., 2020, 2021; Sujamol et al., 2023; Sun et al., 2016; Wang et al., 2023a), machine learning-based techniques (Chen et al., 2018a; Liu et al., 2021; Wu et al., 2021), and deep learning-based strategies (Chen et al., 2017; Qu et al., 2019; Sheng et al., 2024; Zhang et al., 2019; Zhou et al., 2023).
In recent years, deep learning techniques have significantly advanced in predictive classification tasks, particularly in complex applications such as multi-task learning (Yang et al., 2024) and multi-view learning (Pan et al., 2024). Deep learning, which excels in processing unstructured data, has been widely adopted in bioinformatics (Lan et al., 2022a, 2022b, 2023, 2024; Liu et al., 2020, 2024; Sun et al., 2022; Wang et al., 2022b; Zhu et al., 2024a, 2024b), with graph neural networks (GNNs) demonstrating superior performance in capturing topological information from biological networks (Liang et al., 2023; Liu et al., 2023; Mastropietro et al., 2023; Peng et al., 2023a). In miRNA–disease association prediction, researchers have leveraged GNNs to improve the accuracy of predictions by utilizing the graph-based nature of the problem (Wang et al., 2021). For example, Li et al. (2019) introduced the heterogeneous graph convolutional network (HGCNMDA), which extracts multi-scale vertex features across different networks, while Tang et al. (2021) developed the MMGCN, a graph convolutional neural network based on multi-view multi-channel attention mechanisms.
Hypergraphs have emerged as crucial tools for modeling complex relationships among entities in systems such as biological networks, data structures, and disease prediction (Gao et al., 2022; Liu et al., 2017; Zheng et al., 2019). The hypergraph neural network (HGNN), developed by Feng et al., was the first deep learning model designed to learn from hypergraph structures, using a k-nearest neighbor strategy to construct the hypergraph and employing hyperedge convolution for feature transformation and aggregation (Feng et al., 2019). However, the attention mechanism in HGNN is static and untrainable. To address this, models such as HyperGCN (Yadati et al., 2019), which approximates hypergraph learning as a graph problem using paired edges, and dynamic HGNN (DHGNN) (Jiang et al., 2019), which introduces dynamic hypergraph structures and hypergraph convolution, have been proposed.
In current research, there are still few studies on using HGNN for miRN–disease association prediction tasks. In this study, we introduce a novel prediction method, termed CLHGNNMDA, which harnesses the potential of HGNNs in conjunction with contrastive learning. Our contributions are distinguished by the following advancements:
We devise multiple hypergraphs and execute hypergraph convolution for each, enabling the capture of high-order relationships between miRNAs and diseases. This approach facilitates the learning of miRNA and disease feature representations from varied perspectives. In the process of building a hypergraph based on KNN, we use Jaccard similarity for distance measurement to simplify model complexity and improve model robustness. By employing HGNNs, we address high-order relationships more effectively, endowing the model with superior expressive capabilities. HGNNs offer a more nuanced data representation, which empowers the model to capture the intricate and diverse relationships between entities with greater accuracy, thereby augmenting prediction accuracy and model generalization. The CLHGNNMDA method integrates contrastive learning to consider interactions between views and ensure feature consistency, further refining the model’s effectiveness. We apply the CLHGNNMDA model to the task of predicting miRNA–disease associations, with all experimental outcomes indicating that CLHGNNMDA delivers a commendable performance. Thus, CLHGNNMDA represents a novel and promising approach for the prediction of miRNA–disease associations.
Data preprocessing
Various data used in the experiments of this article come from the HMDD v3.2 database (Huang et al., 2019), mirTarbase database (Huang et al., 2022b), DisGeNET database (Pinero et al., 2020, 2021), and miRBase database (Kozomara et al., 2019). All experimental data were obtained from the literature (Peng et al., 2023c).
In the data preprocessing stage, association similarity for miRNA–disease, MiRNA sequence second-order similarity, diseases mantic second-order similarity, MiRNA cotarget genes similarity, and disease co-association gene similarity were calculated and obtained. The calculation method comes from the literature (Peng et al., 2023c). For detailed calculation formulas, please read the literature (Peng et al., 2023c).
Hypergraph neural networks
Hypergraphs (Gao et al., 2022) extend traditional graph theory by permitting a single edge to connect more than two vertices. This generalization allows for a more flexible and comprehensive representation of relationships among vertices, as it is not limited to pairwise connections, unlike conventional graphs. Hypergraphs are well suited for representing multivariate relationships. HGNNs utilize the hypergraph’s correlation matrix to learn vertex representations, effectively capturing complex relationships in data. They employ a normalized incidence matrix H to propagate vertex features and use an association matrix to capture both direct and indirect connections through common hyperedges, surpassing traditional GNNs in tasks like classification, clustering, and prediction. Key components include node feature aggregation, hyperedge feature learning, and convolution operations, all designed to leverage high-order relationships (Liu et al., 2017; Nguyen and Mamitsuka, 2021; Wang et al., 2022a, 2023c).
The task of semi-supervised learning using HGNN is usually to learn a function
Current research on HGNNs categorizes hypergraph construction into four main types: KNN-based methods, clustering techniques, attribute-centric approaches, and network structure-oriented strategies, with this study utilizing the KNN method. Convolution operators, typically based on spectral convolution theory, are key in HGNNs for effective node feature aggregation tailored to hypergraphs’ unique characteristics.
The HMDD v3.2 database reveals significant disparities in miRNA–disease associations, with research heavily concentrated on common diseases like cancer and cardiovascular conditions, while rare diseases remain underexplored. This imbalance also extends to miRNAs, where a few well-studied miRNAs dominate the dataset, limiting the identification of new biomarkers. Challenges such as reliance on experimental validation and inconsistent data further exacerbate these issues. Contrastive learning, rooted in information theory and metric learning, addresses these limitations by improving model generalization and robustness in uneven datasets, facilitating the discovery of novel miRNA–disease associations and therapeutic targets. Notably, advancements like momentum contrast enhance self-supervised learning through dynamic dictionaries for effective utilization of negative samples, thereby improving learning efficiency (He et al., 2020; Long et al., 2024).
Overfitting is a common issue in deep neural network training. Contrastive learning helps by encouraging models to learn generalized features, especially with limited data. It improves classification accuracy and mitigates data imbalance by focusing on sample similarities and differences rather than category labels. Contrastive loss, a key part of this process, minimizes the distance between positive pairs and maximizes it between negative pairs, enhancing model performance.
The temperature-scaled cosine similarity method adjusts similarity scores, aiding in effective feature learning and generalization to new data. The formula for calculating cosine similarity between two vectors is
Combining the cosine similarity with the temperature parameter, the calculation formula for the temperature-scaled cosine similarity is
The calculation formula for calculating the contrastive loss based on the temperature-scaled cosine similarity matrix can be expressed as follows:
The framework flow chart of model CLHGNNMDA is shown in Figure 1. Figure 1 illustrates the procedural workflow and sequential steps encompassed within the CLHGNNMDA framework. This model architecture incorporates several critical components, detailed as follows: (1) The construction of multiple hypergraphs is based on varied similarity metrics, including miRNA–disease association similarity, miRNA sequence second-order similarity, disease semantic second-order similarity, miRNA co-target genes similarity, and disease co-association gene similarity. (2) Latent representations are derived using node and hyperedge encoders, with latent variables sampled via the sample_latent method. A graph neural network (GNN) layer is applied to each hypergraph to process the attributes and structural information of distinct nodes and hyperedges, thereby yielding updated representations for both nodes and hyperedges. (3) Decoders are utilized to reconstruct information from the latent representations, encompassing both node- and hyperedge-centric representations alongside task-specific multifaceted feature representations. The outcome includes multiple reconstruction outputs and feature representations, amalgamating various miRNA and disease features elucidated from the hypergraph. (4) A joint contrastive loss function is employed to refine the model and facilitate the learning of parameters, aiming to accurately predict the associations between miRNAs and diseases.
The flow chart of CLHGNNMDA.
The hypergraph in this article is denoted as
Taking miRNA as an example, the miRNA hypermap obtained from the perspective of miRNA and the disease hypermap obtained from the perspective of disease is based on the known association matrix between miRNA and disease.
The constructed miRNA hypergraph is represented as
The calculation formula of the correlation matrix
The calculation formula of SSM is defined as follows:
Similarly, the calculation formula of the correlation matrix
This article uses the KNN strategy to construct multiple hypergraphs. Adjust the similarity threshold and K value as needed to optimize the hypergraph’s performance and interpretability.
HGNN utilizes forward propagation to compute outputs and backpropagation to adjust weights and biases, enhancing model expressiveness. The optimization strategy focuses on designing an effective architecture and minimizing the loss function to reduce prediction errors. A composite loss function, integrating KL divergence, contrastive loss, and binary cross-entropy, captures both data structure and attributes, improving model performance.
KL divergence, often used in variational autoencoders, measures the divergence between two probability distributions, such as the encoder’s output and a prior distribution. Minimizing KL divergence ensures continuity and completeness in the latent space, enhancing the diversity of generated data (Yin et al., 2023).
The formula for computing KL divergence loss is as follows:
Contrastive loss, widely recognized in deep learning and computer vision, improves feature representation by minimizing distances between positive sample pairs and maximizing separations between negative pairs, with this study employing the cosine similarity matrix method with temperature scaling (Long et al., 2024).
In our model, the cosine similarity matrix between two sets of representations is calculated, scaled by a temperature parameter, and used to compute the contrastive loss by summing similarities and averaging the negative log-likelihood, with four sets of contrastive losses combined for the total loss.
Binary cross-entropy loss (Guo et al., 2022), essential for binary classification tasks, measures the difference between predicted probabilities and actual labels, with our model utilizing PyTorch’s binary_cross_entropy_with_logits function to enhance numerical stability and mitigate vanishing gradients.
The overarching loss function in our model is determined as follows:
Experimental setting
All experiments were conducted using the Python language, based on the Pytorch deep learning framework. The running machine CPU is Intel(R) Core(TM) i7-4790 CPU @ 3.60 GHz, the memory is 24G, and the GPU is NVIDIA RTX 4070 with 12G memory.
K-fold cross-validation (CV) is especially suitable for limited data scenarios, as noted by Huang et al. (2022c) and has been widely used to evaluate model performance. In our study, we employed fivefold CV repeated 10 times, using the mean results for final evaluation. Performance was assessed using receiver operating characteristic (ROC) curves and area under the ROC curve (AUC) as the primary indicators, with additional metrics including accuracy, precision, recall, F1-score, and area under the precision-recall curve (AUPR) (Sokolova and Lapalme, 2009).
The formulas used to calculate the evaluation metrics in this experiment are provided below.
Preliminary hyperparameter values for the CLHGNNMDA model were determined based on prior research insights, followed by the execution of a fivefold CV on the CLHGNNMDA model. Table 1 provides the initial experimental settings for the key hyperparameters used in the CLHGNNMDA model.
Main Hyperparameters of CLHGNNMDA Model
In Table 1, “lr” indicates the learning rate, which controls the magnitude of parameter updates, while “weight_decay” serves as the coefficient for L2 regularization, designed to reduce overfitting by discouraging large parameter values. The parameter “p” modulates the relative contributions of the three loss functions in predicting miRNA–disease associations, and “k” defines the number of neighboring points considered in hypergraph construction, influencing both the sparsity and effectiveness of the algorithm. The “Temperature” parameter, typically ranging from 0.1 to 1, plays a key role in the computation of contrastive loss by shaping learning dynamics and overall model performance. Identifying the optimal value for this parameter often requires empirical experimentation through multiple iterations of testing and fine-tuning, as it can significantly affect model accuracy.
A fivefold CV experiment was performed on the CLHGNNMDA model using the HMDD v3.2 database, with hyperparameters specified in Table 1. The experimental results are depicted in Figure 2, where Figure 2a illustrates the accuracy line graph, and Figure 2b shows the corresponding ROC curve.
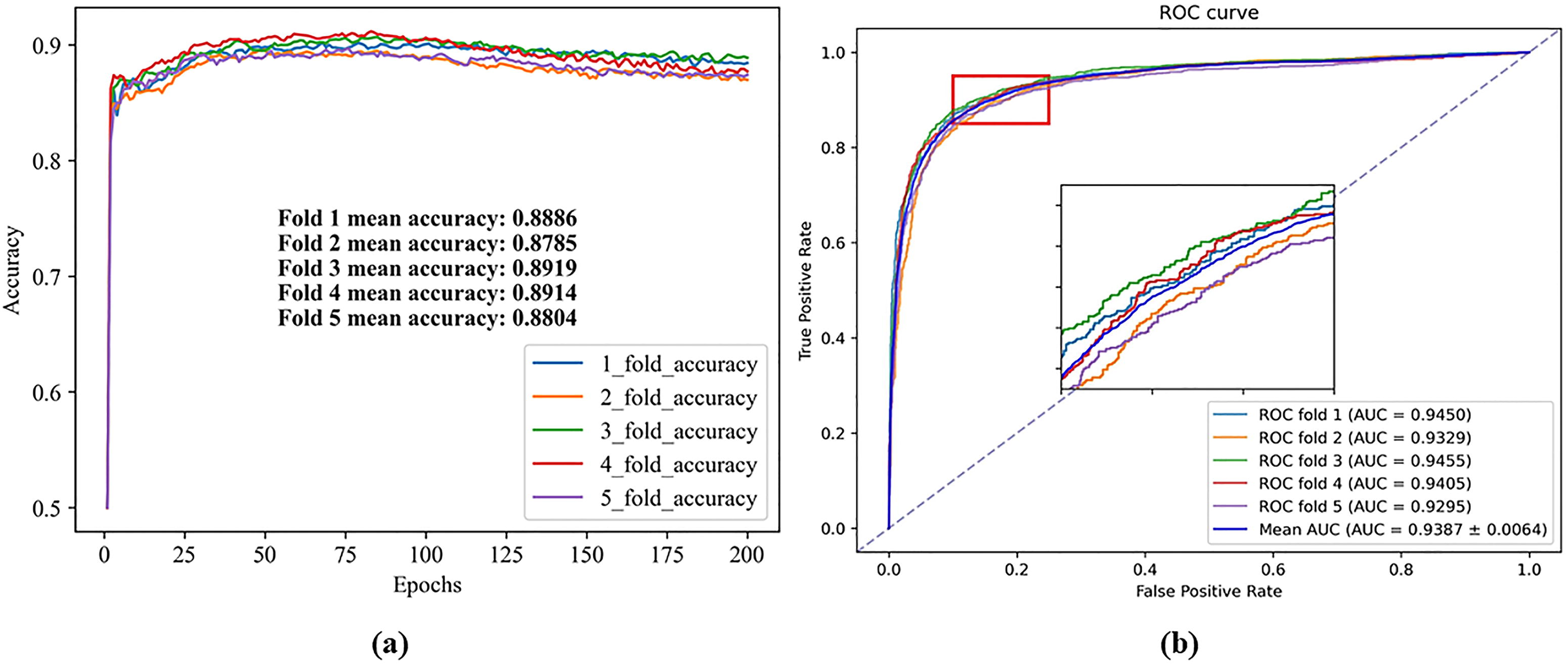
Initial experimental results.
As shown in Figure 2, the CLHGNNMDA model achieves an average AUC of 0.9387. Through iterative training, the model learns patterns and features, with each epoch refining the model’s parameters to minimize the loss function. Determining the optimal number of epochs requires experimentation, often combined with early stopping to avoid overfitting. In this study, 200 epochs were established as optimal for the CLHGNNMDA model through extensive testing. Dropout regularization, which randomly omits neurons during training, enhances model robustness by preventing reliance on specific neurons. We use a dropout rate of 0.5, in line with common practice in the literature.
This section uses the Optuna hyperparameter automated tuning framework to optimize the five hyperparameters of lr, weight_decay, k, p, and temperature in the CLHGNNMDA model. Optuna is an advanced framework designed for the automated tuning of hyperparameters, compatible with a plethora of machine-learning libraries. Utilizing Optuna facilitates the expedient identification of the optimal hyperparameter combination, thereby augmenting model efficacy.
Initially, the hyperparameter search space within the Optuna framework is defined, as delineated in Table 2.
Optuna Hyperparameter Tuning Search Range
Optuna Hyperparameter Tuning Search Range
Based on the hyperparameter search range outlined in Table 2, we employed Optuna’s median pruning decision tree algorithm to conduct 100 hyperparameter searches. This optimization process yielded a maximum AUC value of 0.9635, with the results illustrated in Figure 3. The optimal parameters identified through Optuna’s hyperparameter optimization framework are listed in Table 3.

Hyperparameter optimization using the Optuna framework.
The Optimal Value of Optuna Search for the Main Hyperparameters of CLHGNNMDA
Slight variations in results may occur across different executions when using the Optuna framework for hyperparameter tuning. Therefore, in the experiment, this procedure was iterated 10 times, with the results presented in Table 3 representing the tuning outcome that achieved the highest AUC value among the 10 experimental iterations.
As illustrated in Figure 3d, the application of the Optuna framework for hyperparameter optimization elevated the experimental average AUC of the CLHGNNMDA model to 0.9635, marking an improvement of approximately 2.33% over the pretuning performance. This enhancement underscores the efficacy of the Optuna hyperparameter optimization framework in identifying an optimal set of hyperparameters, thereby significantly augmenting the performance of the CLHGNNMDA model.
In the previous experimental phase, broad value ranges were initially set for the hyperparameters lr and weight decay, based on prior research. This section focuses on refining these ranges by narrowing them, guided by the optimal values identified earlier, to better examine their effects on model performance.
For lr, Optuna’s optimization determined 0.0009 as the best value. Thus, experiments were conducted over the range (0.0005, 0.0006, 0.0007, 0.0008, 0.0009, 0.001, 0.002, 0.003, 0.004, 0.005). As shown in Figures 4a and 4b, the value lr = 0.0009 yielded the highest AUC (0.9634) and AUPR (0.9646), validating Optuna’s prior results. Consequently, lr = 0.0009 was chosen for further testing.
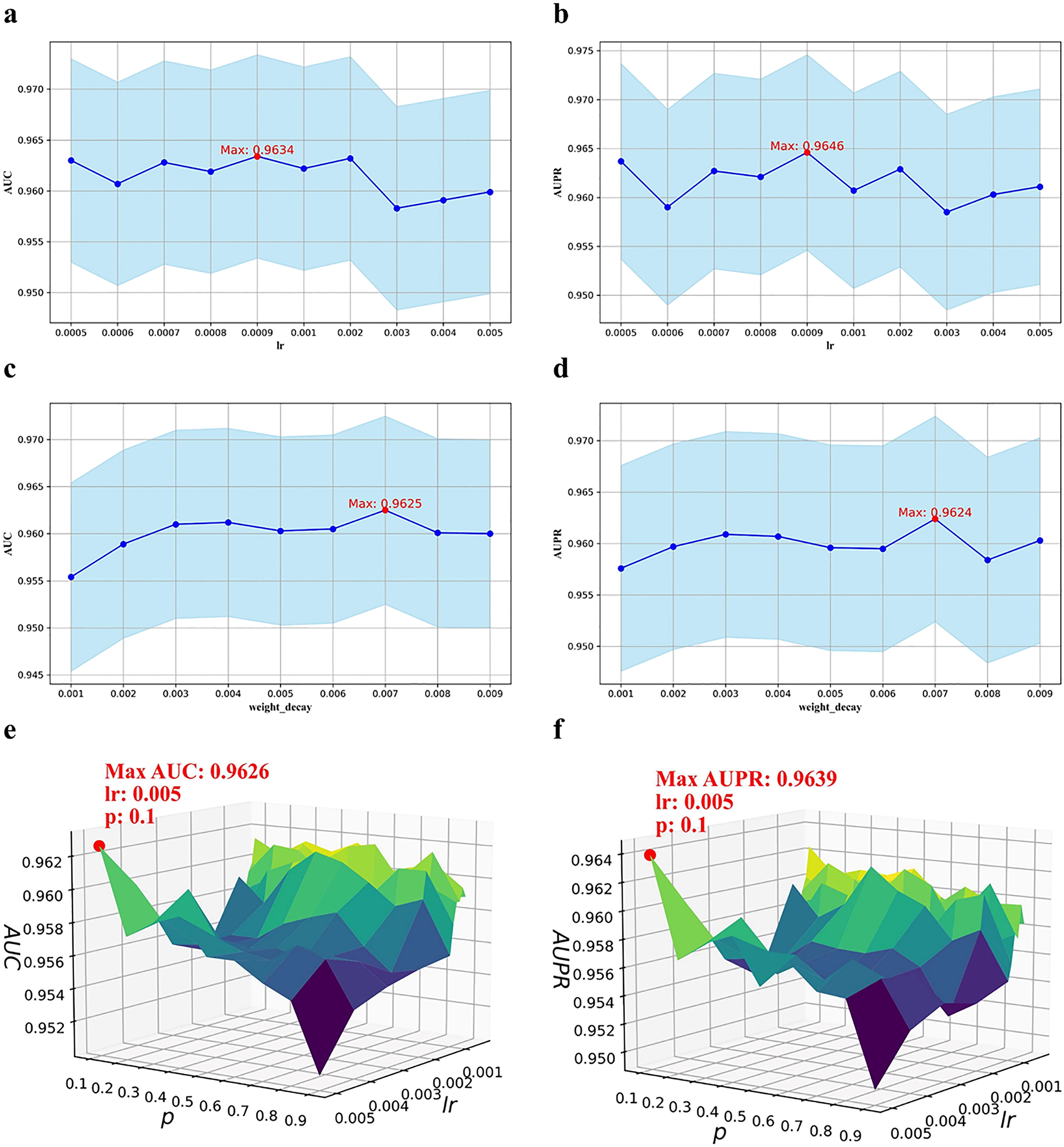
Parameter analysis. Building on previous experimental results, we further refined the hyperparameter ranges for learning rate (lr) and weight decay, conducting extensive experiments to identify the optimal settings. Panels
Similarly, based on the weight decay value of 0.004 suggested by Optuna, the range (0.001 to 0.009) was explored. Figures 4c and 4d demonstrate that weight decay = 0.007 provided the best AUC (0.9625) and AUPR (0.9624), though slightly different from the previous value. After averaging results from 10 additional trials, weight decay = 0.005 was selected for future use.
Additionally, the joint effects of lr and p on model performance were examined. Figures 4e and 4f reveal that the combination of lr = 0.005 and p = 0.1 produced the optimal AUC (0.9626) and AUPR (0.9639). After extensive experimentation, the final settings chosen for subsequent studies were lr = 0.0009 and p = 0.1.
This section presents an evaluation of the CLHGNNMDA model’s performance through a comparative analysis with four established computational techniques. The assessment utilizes fivefold CV on the HMDD v3.2 database. The methods considered in this analysis include MHCLMDA (Peng et al., 2023c), HGCNMDA (Peng et al., 2023b), MSHGANMDA (Wang et al., 2023b), and AGAEMD (Zhang et al., 2023). The methods we have selected are widely recognized and extensively validated as effective within our field, making them highly representative. Table 4 presents the evaluation metrics for the various methods, while Figure 5 depicts the ROC curves generated from the fivefold CV of these methods. The hyperparameter configurations for the various experimental methods are presented in Table 5.
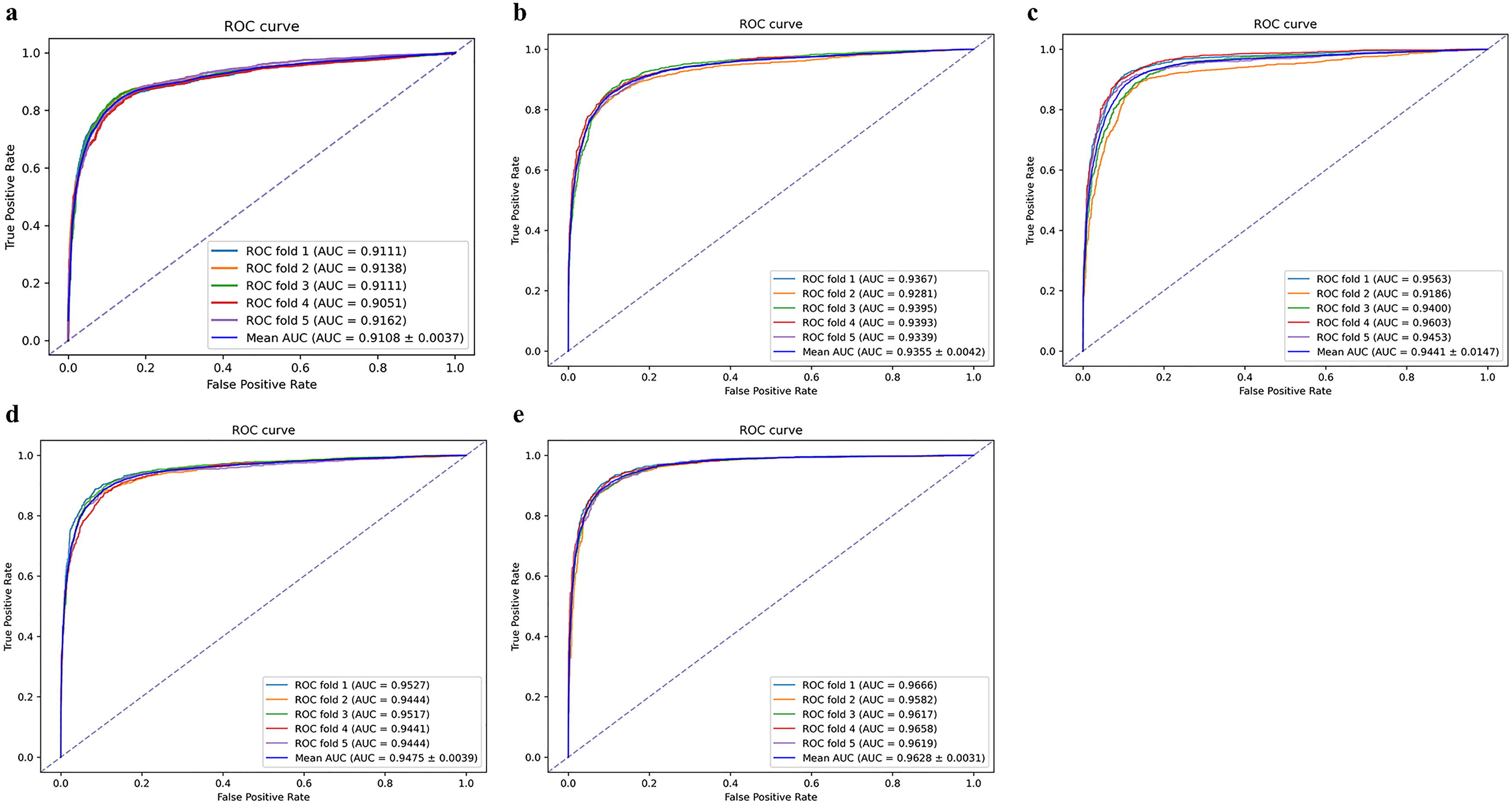
ROC curves for fivefold cross-validation of various models. This figure compares the performance of the CLHGNNMDA model with four established computational methods using fivefold cross-validation on the HMDD v3.2 database. The methods evaluated include
Comparison of Prediction Results of Various Models
Hyperparameter Settings of Various Models
To compare different methods in pairs, the Wilcoxon signed rank test was utilized, and the results are presented in Table 6. This test is a nonparametric statistical tool commonly used for paired data, particularly advantageous when dealing with small sample sizes or data that deviate from normality. In this study, comparisons with p-values below 0.05 indicate statistically significant differences between two algorithms, while p-values above 0.05 suggest no significant difference.
Results of Wilcoxon Signed-Rank Test
According to Table 6, CLHGNNMDA emerges as the best-performing algorithm. It exhibits statistically significant differences when compared with MSHGANMDA, HGCNMDA, and MHCLMDA, all with p-values under 0.05, suggesting its superior performance across multiple evaluation metrics. Although there was no significant difference ( p-value > 0.05) between CLHGNNMDA and AGAEMD, AGAEMD did not show any substantial disadvantage in comparison to other algorithms. Moreover, no significant differences ( p > 0.05) were observed between MSHGANMDA, MHCLMDA, and HGCNMDA.
In conclusion, the Wilcoxon signed rank test results demonstrate that CLHGNNMDA performs significantly better than most other algorithms, particularly when compared with MSHGANMDA, HGCNMDA, and MHCLMDA. While no significant difference was detected between CLHGNNMDA and AGAEMD, CLHGNNMDA still showcases superior performance across various evaluation metrics.
To further evaluate the performance of the CLHGNNMDA model, we carried out additional validation experiments using the HMDD v2.0 dataset (Li et al., 2014). We utilized this dataset to conduct a fivefold CV on the models listed in Table 4, while keeping the hyperparameters consistent with those outlined in Table 3. The results of these experiments are presented in Figure 6.
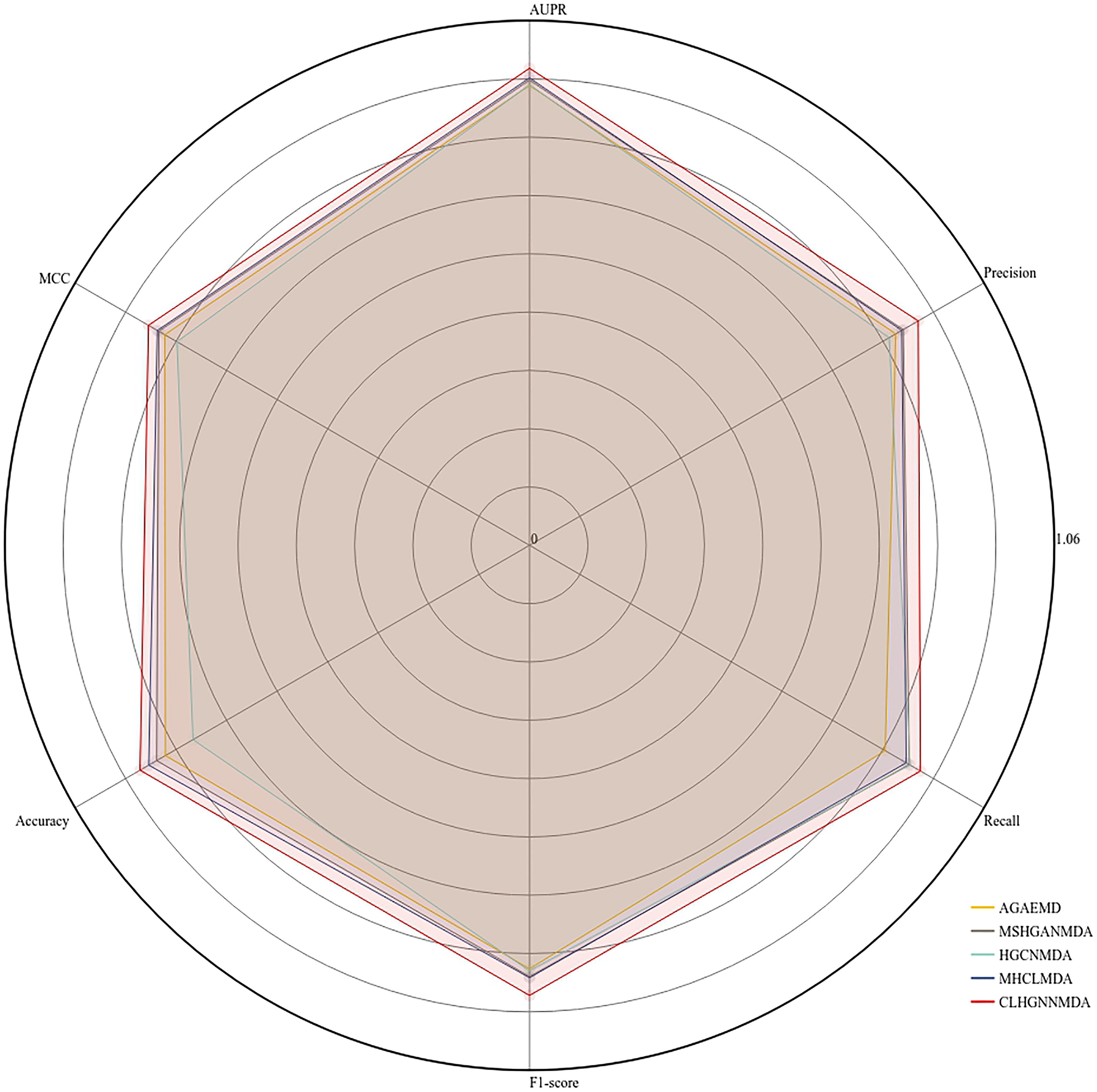
Experimental results on HMDD v2.0 database. This figure compares the performance of the CLHGNNMDA model with four established computational methods using fivefold cross-validation on the HMDD v2.0 database.
As illustrated in Figure 6, the CLHGNNMDA model achieves the best performance across all the evaluated indicators compared to the other models.
To substantiate the CLHGNNMDA model’s effectiveness further, ablation studies were executed. These involved comparative analyses between the CLHGNNMDA model and a variant, CLHGNNMDA_1, from which the contrastive loss component was excised.
The comparative outcomes, as depicted in Figure 7, reveal a notable enhancement in model performance subsequent to the incorporation of the contrastive loss function.
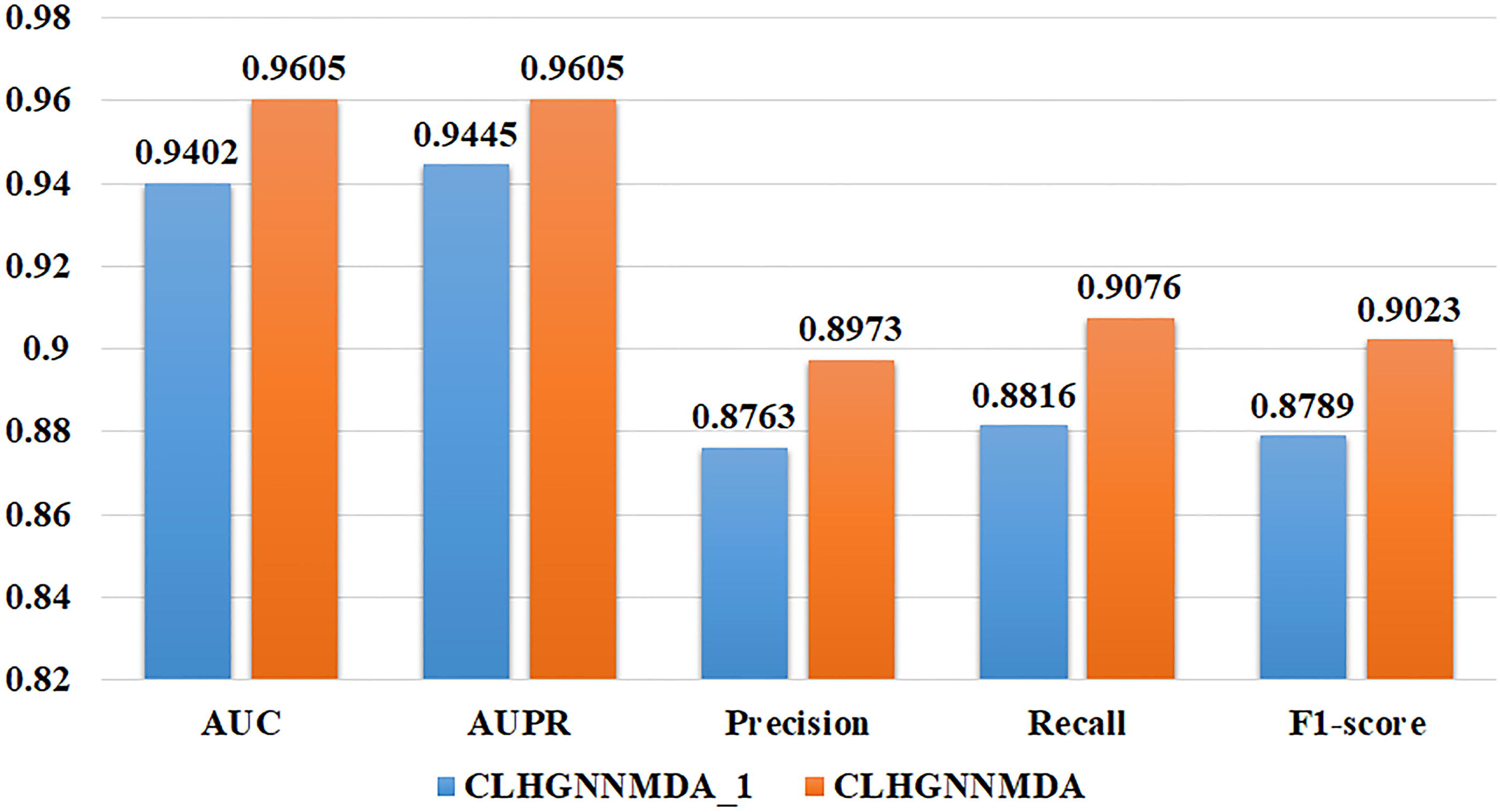
Comparative analysis of performance outcomes from ablation experiments.
Further investigations were carried out by eliminating the KL divergence loss function, maintaining solely the binary cross-entropy loss function. The outcomes of these experiments were significantly inferior, thereby not warranting inclusion herein.
To corroborate the predictive accuracy of the CLHGNNMDA model further, this section conducts a case study on breast tumors. Employing the trained CLHGNNMDA model, the study predicts the top 10 candidate miRNA–disease pairs for breast tumors. These candidates were then scrutinized against the miRNA–disease association database dbDEMC (Yang et al., 2010) to validate the existence and biological experimentally confirmed associations of these candidate miRNAs with the specified diseases.
An inquiry into dbDEMC for the top 10 predicted candidate miRNAs associated with breast tumors, as identified by the CLHGNNMDA model, yielded retrievable results for all candidates. Subsequent analysis conducted on the dbDEMC analysis page (https://www.biosino.org/dbDEMC/metaProfiling/detail) furnished a Meta-profiling Heatmap, as exhibited in Figure 8.
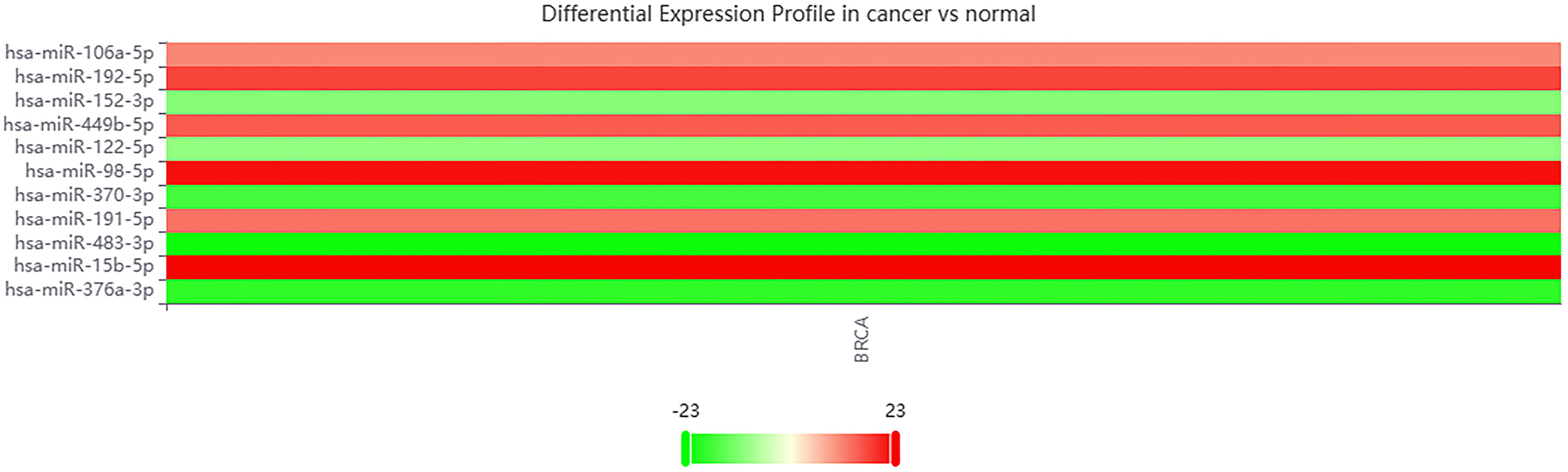
Meta-profiling heatmap in dbDEMC. To validate the predictive accuracy of the CLHGNNMDA model, a case study on breast tumors was conducted. The model identified the top 10 candidate miRNA–disease pairs for breast tumors. This figure presents the resulting meta-profiling heatmap from the dbDEMC analysis page (https://www.biosino.org/dbDEMC/metaProfiling/detail).
The findings from this case study affirm the CLHGNNMDA model’s effectiveness and its commendable predictive prowess.
miRNAs are crucial in various biological processes and are linked to the development of numerous diseases. Investigating miRNA–disease interactions is vital for advancing the prevention, diagnosis, and treatment of complex diseases. With the rise of computational technologies, deep learning has become a valuable tool for efficiently identifying disease-associated miRNAs due to its strong modeling and feature extraction capabilities. This study introduces a novel model, CLHGNNMDA, which integrates contrastive learning within a HGNN framework to predict miRNA–disease associations. The contrastive learning strategy enhances feature representation, generalization, and model interpretability while addressing overfitting and data imbalance issues.
The CLHGNNMDA model’s effectiveness is validated through fivefold CV, achieving an average AUC of 0.9635 and an AUPR of 0.9656, outperforming existing methods. Additionally, a case study on breast tumor-associated miRNAs confirms the top 10 predictions using existing research. Despite its strong performance, there is room for improvement, particularly in incorporating more diverse biological data and integrating heterogeneous information to further enhance predictive accuracy.
CONCLUSION
This research introduces a novel HGNN model, designated CLHGNNMDA, which is enhanced through contrastive learning to forecast miRNA–disease associations. The distinguishing feature of the CLHGNNMDA model resides in its innovative construction of multiple hypergraphs coupled with the integration of contrastive learning techniques. The strong experimental results of the CLHGNNMDA model highlight its potential as an influential tool for advancing miRNA–disease association research, offering valuable insights and practical applications in this domain. The future of miRNA–disease association prediction will likely emphasize the integration of diverse omics datasets, the application of advanced machine learning, and the need for greater model interpretability. By synthesizing data from various biological sources, these predictive models will become increasingly accurate, uncovering new relationships between miRNAs and diseases. The use of cutting-edge algorithms, such as deep learning, will enhance the ability to model complex biological interactions, even in the presence of data imbalances. Ensuring that these models are transparent and interpretable will be crucial for their application in clinical settings. Additionally, collaboration and data sharing will be essential in building robust datasets, refining predictions, and advancing personalized medicine.
Footnotes
AUTHORS’ CONTRIBUTIONS
R.Z. and Y.W.: Conceptualization and methodology. Y.W.: Data curation. R.Z.: Writing. L.Y.D. and Y.W.: Review and editing. All authors have read and agreed to the published version of the article.
AUTHOR DISCLOSURE STATEMENT
The authors declare no conflict of interest.
FUNDING INFORMATION
This work was supported in part by Shandong Social Science Planning Fund Program No. 21BTQJ02 and the National Natural Science Foundation of China under Grant No. 62472250.