
Abstract
Background:
Accurate estimation of glycated hemoglobin (HbA1c) from continuous glucose monitoring (CGM) remains challenging in clinic. We propose two statistical models and validate them in real-life conditions against the current standard, glucose management indicator (GMI).
Materials and Methods:
Modeling utilized routinely collected data from patients with type 1 diabetes from central Poland (eligibility criteria: age >1 year, diabetes duration >3 months, and CGM use between 01/01/2015 and 12/31/2019). CGM records were extracted from dedicated Medtronic/Abbott databases and cross-referenced with HbA1c values; 28-day periods preceding HbA1c measurement with >75% of the sensor-active time were analyzed. We developed a mixed linear regression, including glycemic variability indices and patient's ID (glucose variability-based patient specific model, GV-PS) intended for closed-group use and linear regression using patient-specific error of GMI (proportional error-based patient agnostic model, PE-PA) for general use. Models were validated with either new HbA1cs from closed-group patients or separate patient-HbA1c pool. External validation was performed with data from clinical trials. Performance metrics included bias, its 95% confidence interval (95% CI), coefficient of determination (R 2), and root mean square error (RMSE).
Results:
We included 723 HbA1c-CGM pairs from 174 patients (mean age 9.9 ± 4.4 years and diabetes duration 3.7 ± 3.6 years). GMI yielded R 2 = 0.58, with different bias between Medtronic and Abbott devices [0.120% vs. −0.152%, P < 0.0001], and overall 95% CI = −0.9% to +1%, RMSE = 0.47%. GV-PS successfully captured patient-specific variance (closed-group validation: R 2 = 0.83, bias = 0.026%, 95% CI = −0.562% to 0.591%, RMSE = 0.31%). PE-PA performed similarly on new patients (R 2 = 0.76, bias = −0.069%, 95% CI = −0.790% to 0.653%, RMSE = 0.37%). In external validation GMI, GV-PS, and PE-PA produced 73.8%, 87.5%, and 91.0% predictions within 0.5% (5.5 mmol/mol) from the true value.
Conclusion:
Constructed models performed better than GMI. PE-PA provided an accurate estimate of HbA1c with fast and straightforward implementation.
Background
Short-term overall glycation burden is most commonly assessed by measuring the glycated fraction of hemoglobin A1 (glycated hemoglobin, HbA1c), which reflects mean blood glucose levels over the erythrocyte lifespan (usually 2–3 months). Thanks to the evidence-based relationship with long-term vascular complications and cardiovascular risk, HbA1c has been the standard for gauging glycemic control in diabetes care and one of the main therapeutic targets. 1,2 Unfortunately, despite HbA1c's strong relationship with blood glucose levels demonstrated by A1C-Derived Average Glucose (ADAG) and other studies, 3 –9 it is still challenging to estimate HbA1c using patient's data from self-monitoring of blood glucose or continuous glucose monitoring (CGM) in clinical practice. Such real life-based records are usually shorter than 90–120 days and often suffer from missing data. 10 –12 In addition, there are reported differences in individual red blood cell turnover that might affect the relationship between mean glucose and HbA1c and speculations about patient-specific glycation rates, which further invalidate the one-equation-fits-all approach. 13 –15 As a result, currently most average-based and static attempts that are easily implementable yield over 0.5% (5.5 mmol/mol) difference in 1 out of 4 estimated HbA1cs. 8,16 The discordance between estimated and laboratory-measured HbA1c resulted in confusion among patients and forced Food and Drug Administration (FDA) together with leading experts to address the issue. In effect, the HbA1c estimation based on mean CGM glucose was renamed as glucose management indicator (GMI) and, after equation refinement, is incorporated into ambulatory glucose profiles report. 17 –19 The previously used term of estimated HbA1c was dropped as to not imply a precise match with a contemporaneous laboratory A1C. However, in its current form, it carries no additional clinical information as mean glucose is already exposed in CGM.
The aim of the study was to develop a comprehensive, easy-to-use statistical tool for HbA1c estimation based on CGM data and to compare it with the currently used standard of GMI in real-life conditions. 18
Research Design and Methods
For this study, we retrospectively collected real-life CGM data from outpatients with type 1 diabetes (T1D) treated in the Department of Pediatric Diabetology, Endocrinology and Nephrology in Medical University Hospital in Lodz between January 1, 2015, and December 31, 2019. The study population comprised Polish children and adults, that is, people of Central and East-European origin. Only patients older than one year and with diabetes duration >3 months were included to rule out the impact of fetal hemoglobin and to avoid the effect of prolonged hyperglycemia before diabetes diagnosis on HbA1c measurements. Exclusion criteria were as follows: diabetes other than type 1, HbA1c <5% (suspected laboratory error), HbA1c >11% at the time of CGM data collection (although in retrospect, no patients met this criterion), severe nonadherence to diabetes management, or anemia that could affect HbA1c measurement. All patients treated in the Department, whose data were included in the study, agreed to have their sensor and clinical records used for research purposes. Furthermore, all proceedings were in accordance with the Declaration of Helsinki as revised in 2013.
Data collection, pairing, and filtering
To model the HbA1c-CGM relationship, 28-day-long records that comprised >75% of CGM data were collected. The quality threshold was based on the International Consensus recommending data sufficiency threshold of 70%–80% of possible CGM readings. 10 Record length was selected after initial analysis of data (for details, see Supplementary Data S1 and Supplementary Fig. S1) and was coherent with the CGM data collection periods recommended for analyses in individuals with more variable glycemic control. 20 In short, record length was selected based on the assessment of the fit of the regression between GMI and HbA1c in paired high-quality (>75% complete in whole observation) records of duration ranging from 7 to 91 days. The inflection point, after which longer records provided only a marginal increase in R 2, was found for records of 21-day duration. For the set construction, we used 28 days of record length due to it being the first without a significant increase in the expected accuracy of GMI estimation in the context of HbA1c. At the same time, such period is often available for analysis during routine outpatient visits. Next, we extracted as many pairings of CGM record and HbA1c per individual patient as possible. To facilitate later modeling and validation, we only included subjects for whom at least 2 HbA1c-CGM pairs were available. Collected clinical data included patient age and diabetes duration at the point of HbA1c measurement.
The stages of data collection and refinement are summarized on Figure 1. First, we searched the Department's repositories (CareLink Professional database for Medtronic devices and LibreView database for Abbott device) for all patients who reported using Medtronic real-time CGM systems (devices: MiniMed Veo, MiniMed Paradigm REAL-Time (722), and MiniMed 640G, Guardian Connect; Medtronic MiniMed, Inc., Northridge, CA) or Abbott intermittently scanned CGM system (device: FreeStyle Libre; Abbott Diabetes Care Ltd., Oxon, UK) and had data available in the studied period. Other CGM systems and devices were used by <1% of patients treated in the clinic, and to maintain data integrity, we did not retrieve such recordings. CGM data were exported as .csv files and processed with custom tools. Briefly, all patients' files were divided into directories and collapsed into a single record for each patient, and then checked for possible corruption using scripts prepared in Python (for detailed description of data preprocessing, please see the Supplementary Data). After initial assessment, all records were subjected to technical quality checkup. Old-generation sensors (associated with Medtronic 722) were discarded. If a patient used both Abbott and Medtronic CGMs, records from the most recent one were retained.

The flowchart of recruitment, data processing, and modeling procedures. First, we collected all available patient electronic CGM data from dedicated software in the outpatient clinic. After technical control, CGM files were matched with users, their clinical data, and HbA1c measurements. Each stage was followed by clinical and quality control to exclude patients/measurements not suitable for subsequent modeling. As exclusions were made both at patient and measurement level, for clarity, we used N to denote the number of patients excluded or retained at each step, and m to indicate the number of associated HbA1c measurements available. After data collection, we allocated the patients and their measurements (depicted as droplets) into the sets for model training and validation. Briefly, those with at least three HbA1c measurements were assigned to the modeling group, with one HbA1c withheld at random for closed-use validation. Separate patients with two HbA1c measurements each were treated as open-use validation. Last stage of models' development included their validation on an external set of publicly available HbA1c-CGM pairs collected by clinical trials. CGM, continuous glucose monitoring. T1D, type 1 diabetes.
Records with CGM data were matched with patients' clinical files and, after exclusions, cross-referenced by personal identification number (ID) with HbA1c records held by diagnostic medical laboratory (DIAGNOSTYKA Sp. z o.o., Kraków, Poland), the only provider of the test for the outpatient clinic during the observation period. All HbA1c concentrations were measured using the reference HPLC method with traceable agreement to the Diabetes Control and Complications Trial according to the NGSP program (D-10 Hemoglobin A1c Program; Bio-Rad Laboratories, Hercules, CA; Bio-Rad, Marnes-la-Coquette, France). We used a dual-reporting standard for HbA1c as % and mmol/mol for figures and tables, and % in the written descriptions. Next, we aligned the CGM files with HbA1c measurement time and cut the records to the last 28 days preceding measurement. We excluded rare cases of two HbA1c measurements taken on the same day or erroneously matched with the wrong patient.
The resulting data set was used to assess the fit between GMI and HbA1c. To this end, we used a modified Bland-Altman plot to assess possible bias between estimated and measured HbA1c, its 95% confidence interval (95% CI), root mean square error (RMSE), and coefficient of determination R 2. For these calculations, we treated each HbA1c measurement as an independent one, similar to the current version of GMI.
We then attempted to produce an improved estimation of HbA1c concentrations based on CGM data.
Model development and validation sets
To enforce the best practices, we followed the TRIPOD checklist for Prediction Model Development and Validation. 21 We trained our models on a major subset of collected data, while retaining the rest for internal validation. To construct our models, we used data from patients who provided at least three HbA1c-CGM pairs, which corresponded to ∼2/3 of the initial group. Among their measurements, we randomly retained one HbA1c from each patient's pool, which would not be used in model development. The rest became the training set used to develop our tools (Fig. 1).
Afterward, we aimed to validate our models in two scenarios. The first would be predicting a new HbA1c for a patient who took part in model creation, reflecting the tool's usefulness for a closed group of patients followed prospectively, such as in clinical trials. Such closed-use validation was performed on the HbA1cs retained previously from patients introduced to the training set.
In the other scenario, the model might be used to predict HbA1cs for new patients who were not present at the time of model development. Such use would be most desired in real-life practice. To assess the performance of our tools in such environment, we used 1/3 of patients who provided only two HbA1cs per patient. As our approach was focused on using patient's clinical history to improve future prediction, older of two HbA1cs was used as “past information” and the most recent one as prediction test (open use validation).
Although this group allocation was not completely random, it was necessary to create a training set big enough to reflect population structure and a validation set allowing for reliable assessment of the model's predictive power.
To assess the generalizability of our models and their utility outside of our clinic, we performed external validation using publicly available data sets recorded during clinical trials obtained from Jaeb Centre For Health Research (URL:
To assess the effect of number of previous patient's observation on the estimation accuracy, we defined another superset with 6 HbA1c-CGM pairs for each patient (in cases where more HbA1c-CGM pairs were available, we used the chronologically first 6; thus, the 6th HbA1c should correspond to the same study period for all patients within the original external dataset). We provided the error for predictions for the last HbA1c using N chronologically previous HbA1cs (1–5) for each patient, as well as description of past history-based parameter values.
Model development
We designed, calibrated, and evaluated two predictive tools to estimate HbA1c from routine CGM data. Their performance was measured with the same metrics as GMI. Statistical comparisons between GMI and competing models were made using repeated-measures ANOVA for bias. For consistency, the tests were performed on a subset of HbA1cs from a validation group that could be estimated by all the tools.
Model 1: Patient-specific linear regression based on glucose variability indices (glycemic variability-based patient specific model)
In the first attempt, we constructed a two-level mixed linear model. HbA1cs were grouped by patient's ID number (categorical variable), which was treated as a random effect. Therefore, the linear regression not only estimated a general regression line between HbA1c- and CGM-based predictors (as is the case for mean-based GMI) but also accounted for patient-specific effects by shifting the line to better fit each individual. Due to low number of HbA1c per patient, relatively high number of patients, and low intrapatient variance, the individual adjustment was only achieved by parallel shifting of the relationship line 22 —mathematically this corresponds to creating a random intercept βind estimated for each patient. The random part of the model assumes that all patients come from a broader general population (here: young people with T1D) and thus should have βind following a normal distribution, which was subsequently forced for all patients around mean of 0. All in all, such approach helped to avoid false overestimation of parameter errors (which would happen if HbA1cs were treated as independent) and better estimate patient-specific effects with as few as 2 HbA1c-CGM pairs per patient in some cases.
The candidate predictors for the model included type of CGM used (Medtronic vs. Abbott) and CGM glucose variability (GV) indices: mean, median and standard deviation (SD) of glycemia, coefficient of variation (CV), indices of low and high blood glucose, time below 54 mg/dL, time below 70 mg/dL, time in range (TIR) (70–180 mg/dL), time above 180 mg/dL, time above 250 mg/dL, and additional features of glycemic variability—continuous overall net glycemic action for 6-h intervals (CONGA6h—chosen arbitrarily based on previous experience), J-index, M100, Mean of Daily Differences. We calculated the indices using in-house software, with nonstandard features following equations provided by their creators.
23
–25
Feature selection was performed in R studio software, using StatisticalModels (
After feature selection, we constructed the final mixed regression models in Python with the pymer427 and statsmodels 28 libraries, using residualized maximum likelihood as a fitting algorithm.
Model 2: Patient-agnostic linear regression model based on past patient's proportional HbA1c-to-GMI error (proportional error-based patient agnostic model, PE-PA)
We acknowledge that currently used GMI might poorly estimate HbA1c partly due to unaccounted factors related to an individual patient. However, as such bias is systemic, we might adjust GMI estimation by the usual bias the patient has experienced so far.
29
We followed the logic that the proportion between measured HbA1c and GMI should be stable in all time points, and at the same time more robust for extreme values of HbA1c (compared to simple difference between GMI and HbA1c, which was reported to have increased variance for higher values of HbA1c
30
):
Based on patient's past HbA1c measurements paired with CGM data, PE can be estimated as mean ratio of historic HbA1c/GMI pairs. Then, model based on PE should allow for estimation of new HbA1c from:
Such adjustment would provide the information on how much HbA1c is overestimated or underestimated with GMI and might represent the patient's individual input—that is, using the patient's ID to improve prediction would likely be unnecessary. To quantify this, for each HbA1c, we calculated the GMI according to the standard equation, as the formula has already been optimized on much larger datasets than ours.
16,19,29
Afterward, for each HbA1c in the training set, we calculated PEi. Please notice the difference between PE (ratio of HbA1c [%] to GMI [%]) and Glycation Index (ratio of HbA1c [%] to mean glucose [mmol/L] in rolling 28-day window)
31
and hemoglobin glycation index (HGI—the difference between HbA1c and GMI) introduced in previous works.
30
For each time point, we calculated mean PE for the given patient using PEi from all time points save the current one (to avoid using data on current HbA1c for modeling it). Next, we transformed equation (2) to fit a linear model:
We then fit the linear regression model for log10(HbA1c), log10(current GMI), and log10(mean PE)—first with patient's ID included as a random factor and then without ID to assess the possible loss of information. The validation of the created model was performed as previously described.
Results
Among ∼800 children and 500 young adult patients under the Department's care, we identified 406 as long-term CGM users (∼31.5%) (for details see Fig. 1). Five individuals (1.2%) had to be excluded due to clinical reasons. However, the strict quality cutoff for the HbA1c-CGM pairs caused a significant portion (n = 208, 51.9%) of patients to drop out. As a result, the final group consisted of 174 patients with 723 HbA1c-CGM pairs, with the majority using Medtronic CGM (n = 116, 66.7%) (Fig. 1). The mean age of subjects (calculated first as mean for each patient over the observation period and then mean for the whole group) was 9.9 ± 4.4 years and mean diabetes duration (calculated similarly) was 3.7 ± 3.6 years (Table 1). However, the group included a minority of young adults (n = 8, maximum age 32.4 years), some of whom turned 18 during the observation period. Total observation/follow-up time for the group was 400 ± 272 days, with median time between successive HbA1cs of 4.0 months (interquartile range of 3.4–4.7, more details in Supplementary Table S6). For each of the 723 HbA1c measurements, we calculated a corresponding GMI based on the CGM-derived mean glucose and compared them with Bland-Altman analysis (Fig. 2A and Table 2). Although the mean bias was close to 0 (0.054%), GMI demonstrated a high spread of errors with 95% CI for bias ranging from −0.891 to +0.956%. The RMSE between HbA1c and GMI was 0.47%. Moreover, we noted two systemic sources of bias:
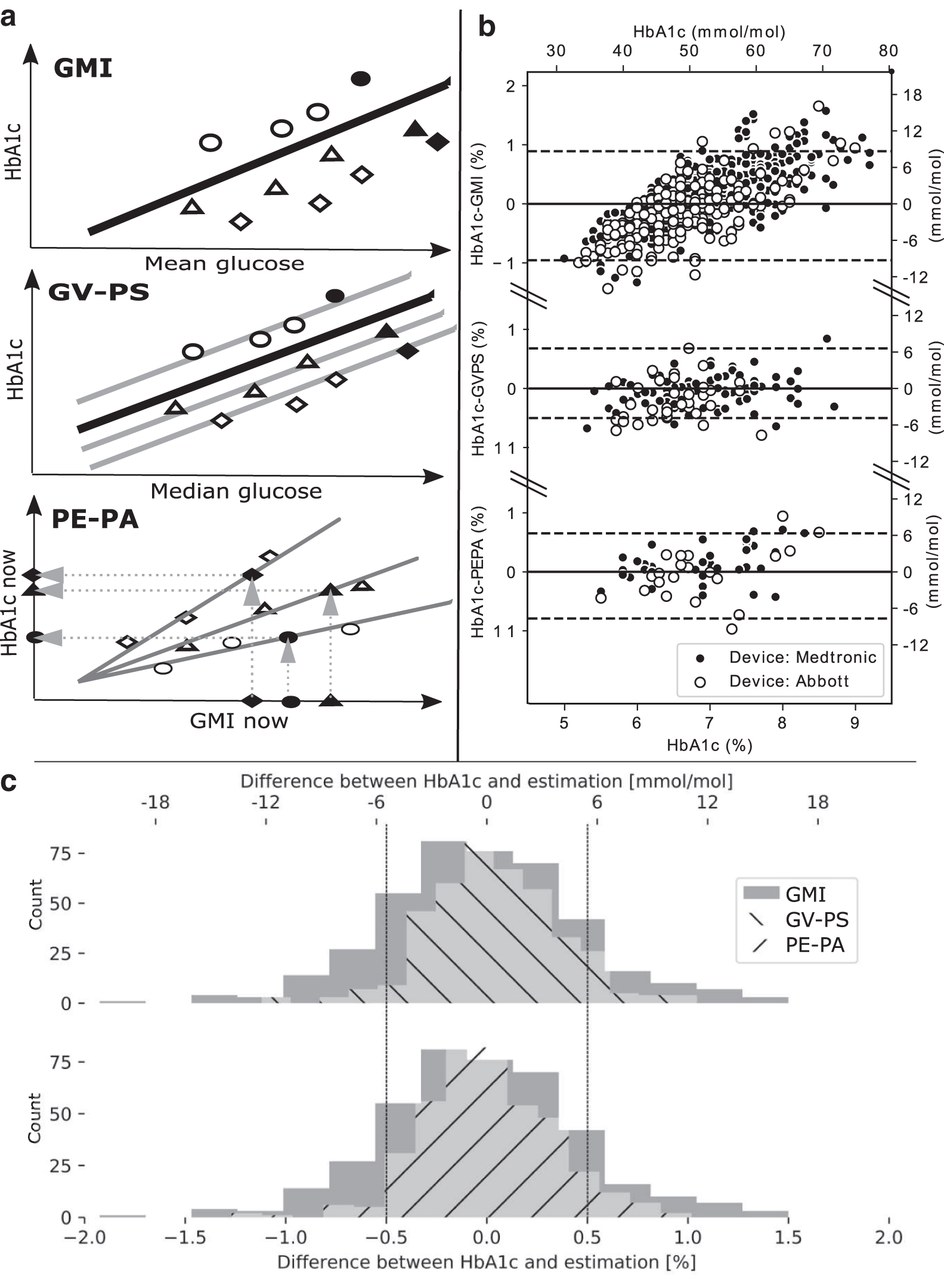
The summary of statistical tools used to predict HbA1c using CGM developed in our study (GV-PS and PE-PA) and current standard (GMI).
Clinical Characteristics of the Studied Group and Comparison Between Training and Validation Group
Patients whose data were used for validation of created models were generally older and had longer diabetes duration. However, adjusting for age or diabetes duration provided no significant increase in prediction accuracy of developed models.
Out of those, 492 were used for model training and 117 (chosen randomly) for model validation in a closed-use setting.
Out of those, 57 older measurements were used to estimate each patient's HbA1c/GMI ratio, and 57 recent HbA1c were used to test PE-PA prediction.
CGM, continuous glucose monitoring; GMI, glucose management indicator; HbA1c, glycated hemoglobin; PE-PA, proportional error-based patient agnostic model.
Summary of Performance of GMI, Models GV-PS (Glycemic Variability-Based Patient Specific) and PE-PA (Proportional Error-Based Patient Agnostic)
GMI was evaluated using all available HbA1c in our cohort and external validation sets. GV-PS was assessed in the “closed-use” validation using HbA1c restricted from the training set, but provided by the same patient, to provide the patient-specific Bind. PE-PA was assessed in “open-use” validation using HbA1cs from 57 patients not included in model parameterization. All tools were subsequently evaluated in an external set of HbA1c-CGM pairs collected during clinical trials.
R 2 —coefficient of determination; Bias—difference between measured and predicted HbA1c for each tool. Positive bias indicates that the predictions underestimate true HbA1c, negative bias indicates overestimation; 95% CI, 95% confidence interval for the bias provided by model estimations; RMSE (% and mmol/mol); r—Pearson coefficient;
P < 0.0001; ** P < 0.001; * P < 0.05;
Nonsignificant.
GV-PS, glycemic-variability based patient specific model; HbA1c, glycated hemoglobin; RMSE, root mean square error.
The type of device significantly affected the direction of difference with Medtronic CGM overestimating and Abbott underestimating HbA1c (similar results were previously described 32 );
The GMI overestimated the lowest values and underestimated the highest ones.
Subsequent modeling and validation were performed as described in Methods. Patients participating in model training and open-use validation were comparable in terms of gender structure, frequency of each type of CGM, and overall glycemic control, with the validation group being slightly older (Table 1).
First, we estimated the glycemic variability-based patient specific model (GV-PS) model. After feature selection, four predictors were chosen in addition to patient ID: median glucose, SD of glucose, CONGA6h index, and type of device. The final model followed the equation (numbers in parentheses denote standard errors or the estimated parameters):
The counterpart of the above equation for alternative HbA1c or glucose units is enclosed in Supplementary Table S4.
βind is the intercept derived from mixed-effects linear regression, which adjusts estimation of HbA1c by including information of patient-specific bias. The βind varied from −0.96 to +1.01 with a variance of 0.12 (±0.01). The residual variance was 0.06 (±0.003), which yielded intraclass correlation as 0.12/(0.12 + 0.06) = 0.66. In remove as redundant closed-group validation, GV-PS performed well (R 2 = 0.83, bias = 0.01%, 95% CI = −0.6% to +0.6%, RMSE = 0.31%, Table 2, Fig. 2A and 2B). In new patients, GV-PS was applied using only the fixed part of the equation (βind = 0) and performed visibly worse (open-use validation: R 2 = 0.65, bias = −0.01%, 95% CI = −0.9% to +0.9%, RMSE = 0.44%).
In the next step, we tried to make the predictive tool more clinician friendly by simplifying the input. We therefore tried to capture previously observed patient-specific effect with patient's past data. This way, we restricted the input to historic estimations based on GMI and their respective errors using patient-specific PE. In the training set, PEi varied from 0.79 to 1.30 (mean 1.01, SD 0.09), with small within-patient SD (mean SD <0.01, standard error of SD <0.01). After fitting linear regression, we obtained the following equation:
The intersubject variance was estimated as 0 (±0), whereas residual variance was 0.001 (±0.023), which yields an intraclass correlation of 0. Therefore, the model successfully captured the individual's features with mean PEi, allowed us to drop patient's ID (βind) from the input, and generalize our tool for use outside of the training group. In fact, PE-PA performed effectively in the open-use validation set, where (using only one past HbA1c-GMI pair) it achieved overall R 2 = 0.76, bias = −0.069%, 95% CI = −0.79% to +0.65%, RMSE = 0.37%, Figure 2A and 2B. However, differences in prediction accuracy between Medtronic CGM (R 2 = 0.83) and Abbott CGM system (R 2 = 0.66) were still present.
External validation
We obtained n = 2251 HbA1cs paired with CGM records collected from 4 clinical trials, 33 –36 from which 409 were used for the evaluation of HbA1c estimation (and the rest was used to provide the HbA1c/GMI and Bind). Unfortunately, all were derived from Medtronic CGMs, making validation for Abbott devices impossible. Overall, bias (±95% CI) of GMI, GV-PS, and PE-PA for the superset from all the external datasets were as follows: −0.029% (−0.979 to 0.921%), 0.031% (−0.529 to 0.646%), and 0.008% (−0.627 to 0.644%) (Table 2). The difference between 95% CI for bias between the models was significant, where both GV-PS and PE-PA were more accurate than GMI (P < 0.0001 in post hoc repeated-measures ANOVA). In terms of clinical accuracy, as many as 73.8% (for GMI), 90.0% (for GV-PS), and 91.0% (for PE-PA) of predictions were within the 0.5% of the true value (Fig. 2C). Secondary analysis showed that both GV-PS and PE-PA provide similarly accurate predictions irrespective of the number of HbA1cs per patient used to train GV-PS or estimate individual PE for PE-PA (Supplementary Fig. S2). This said, GV-PS demands at least two HbA1cs per patient to be trained and using at least two HbA1cs for PE-PA might safeguard against external sources of bias (e.g., laboratory error). Moreover, the duration of gap between HbA1c measurements did not affect the accuracy of the prediction.
Detailed summary of the performance of GMI, GV-PS, and PE-PA in all data subsets is presented in Supplementary Table S2.
Discussion
We have developed new methods for estimation of HbA1c based on 28 days of CGM data and patient's clinical features. In patients using CGM, these models could provide clinicians with useful tools to estimate HbA1c, thus reducing the costs of monitoring and the need for blood collections. In addition, it can benefit the era of telemedicine.
It must be kept in mind that HbA1c may not be the best indicator of diabetes control in patients using CGM. It is sensitive to hyperglycemia, but does not reflect brief clinically important hypoglycemic episodes 37,38 and portrays only the mean blood glucose level, disregarding biologically relevant GV. 16,39 –41 Finally, while most patients have no trouble understanding HbA1c meaning as a laboratory measure, their understanding and attitude to HbA1c as therapy target vary greatly. 42 For CGM users, new metrics such as TIR 20,43 might help overcome HbA1c shortcomings. 44 There is already emerging evidence that TIR is associated with neuropathy and microangiopathy 45,46 and a potential primary endpoint for clinical trials. 47 However, to be grounded as a therapeutic target, TIR needs extensive prospective validation, particularly focused on cardiovascular risk and life expectancy. Those changes are already along the way, as evidenced by currently ongoing or recruiting clinical trials such as NCT04411277 and NCT04145804, utilizing TIR among primary endpoints. Even so, the shift from HbA1c, backed up by decades worth of evidence and habit, to TIR is likely to take some time, especially in clinical practice. In the meantime, HbA1c is likely to remain the reference and later equivalent metric of diabetes control. Thus, the tools we propose could be viewed as bridging the gap between HbA1c and CGM perspective on diabetes control.
It is important to note that it was not our attempt to replace the standard average HbA1c transforming equation as developed by ADAG and later adjusted by others. 3,48 –50 Those are based on long feeds of glucose measurements and are implemented using weighted average of glucose captured by either SMBG or CGM, and were validated on both in-vitro and in-vivo hemoglobin glycation models as closely describing biological relationship between mean glucose and HbA1c. However, this approach, despite its great utility for basic research, fails to provide the accurate estimates of HbA1c, especially for patients with less stable glycemic profiles (R 2 = 0.59). 8
Interpatient and intrapatient glycemic variability might be one of the reasons for underperformance of linear models, such as ADAG or GMI demonstrated in various real-life datasets. 32,51,52 Furthermore, previous attempts at estimating HbA1c from CGM data, including GMI, demonstrated a number of issues: differences depending on the sensor type or patient's ethnicity 32,51 and individual factors in terms of variable red blood cell turnover or differences in glycation, 53,54 resulting in increased uncertainty of predictions based on mean glucose. These unrecognized effects might affect the estimation of linear regression equation and skew either its intercept or slope.
We used these drawbacks as targets for our proposed solutions. First, we created a GV-PS model that incorporated more CGM-based parameters than mean. Its final features included median, SD, CONGA6h, and system type (Abbott or Medtronic). Median is the most robust metric of central tendency, especially in case of skewed distributions and deviations from normality. SD is a metric corresponding to the dispersion of the blood glucose values. CONGA6h is a measure of intraday glycemic variation and can be interpreted as a “stability index” of GV. 24 Together, these indices provide more complete image of glucose excursions than mean alone. It is possible that other GV parameters (like CV, times below, in and above range, MAGE) might play a similar role 9,44 —however, in our modeling, this set showed the best results. The type of sensor was also included in the model based on our previous reports on discrepancies in the glycemic variability indices calculated using Medtronic and Abbott devices. 55
GV-PS provided the best results for patients whose data were used to train it and for new HbA1c from these patients. It could be useful in prospective tracking of HbA1c estimates in a closed group of patients, thus relieving the need for frequent HbA1c testing. This is especially attractive for long-term clinical trials that would like to ease the testing burden on themselves or patients. However, such “closed-group” approach could not be utilized in the clinic. Due to the nature of the fitting algorithm, it is not possible to add a patient to the model and estimate his βind without repeated estimation of the whole equation, which might slightly affect the GV-specific parameters. This was evidenced in our external validation procedure, where GV-PS had to be trained anew for the chosen set of predictors before being used for prediction. In the clinic, each new patient would necessitate retraining the model after a run-in period with at least two HbA1c measurements. Setting and maintaining GV-PS for the general population would need massive resources, cooperation from CGM manufacturers, and solutions for safe transfers of CGM data. Therefore, we consider GV-PS as proof of concept that estimation of HbA1c based on short-term CGM records can be improved by including GV-based predictors and incorporating patient-specific effects.
However, GV-PS incorporates several predictors into its structure—and with each variable, its biological meaning is harder to discern. For this reason, in our second attempt, we tried to create a simple model with clear components.
To this end, we followed an assumption that the patient-specific effects observed in GV-PS would also result in the discrepancy measured HbA1c and the one estimated using GMI or other simple equations. Such proportional error should be constant for individual and robust for extreme values of HbA1c and could be easily estimated from past data. Therefore, knowing one's PE might improve subsequent estimates in a similar manner to the usual adjustments diabetologists make when “guesstimating” HbA1c based on patient's GMI and his history, but in a more statistically and mathematically stringent way. This way, the tool does not need to be adjusted for new patients who follow the same equation (5) and only need to provide at least one historic HbA1/GMI ratio. Indeed, the PE-PA performed successfully in the new patients not seen during training, demonstrating its potential for open use.
In our approach, we decided to use proportional error for modeling and not already-introduced HGI, which is based on the difference between estimated and measured HbA1c. While HGI-based model might be simpler (one would need to only add a correction factor to GMI and not multiply it), such tools might underperform for patients with high HbA1c as GMI error was already shown to strongly correlate with underlying HbA1c value. Similarly, variance of HGI is increased for higher values of HbA1c. The proportional method should ensure greater stability at this end of HbA1c spectrum, as the higher GMI error would already be adjusted by higher HbA1c.
Finally, both models were validated for their intended use on the extensive dataset derived from clinical trials. GV-PS was trained on a major portion of each patient HbA1cs, while PE-PA had individual PE estimated as mean from past GMI-HbA1c pairs. Both clearly outperformed GMI, providing as much as 90% and 91% within 0.5% from the true value. This proved that both models are potentially generalizable for use in the general population and did not just capture idiosyncrasies specific to our center group. At the same time, PE-PA could be easily incorporated into currently available diabetes management report software provided by CGM manufacturers (e.g., as “personalized or patient GMI,” “pGMI”).
The underperformance of the current models for Abbott CGM requires further studies as the data we used were collected predominantly from a sensor that was recently replaced on the market by an improved device. The manufacturer claims the new sensor is more accurate in its measurements (reported MARD vs. venous measurements 9.2%), 56 which may improve the reliability of predictions based on this CGM. Moreover, the significant differences between Medtronic and Abbott sensors (used in this study) were found in some of the GV metrics (SD, CV, and CONGA), 55 which may indicate that the inclusion of information on the device type in GV-PS model may not be sufficient to adjust for the differences.
Our attempt was not the first to estimate HbA1c from complex CGM data and should be viewed in the context of previous achievements. The short summary of the previous estimation approaches can be found in Supplementary Table S1, but detailed comparison exceeds the scope of this article.
Our first model, GV-PS, falls into a family of tools designed to individualize HbA1c prediction for a given patient using CGM data. A similar notion was already presented by Malka et al., 57 Xu et al., 58 and most recently, by Fabris et al. 44 The first one incorporated patient variability by including component corresponding to erythrocyte incubation time. In their validation group, the authors reported R 2 = 0.9 and the average deviation from HbA1c of 0.3%.
The work by Xu et al. uses CGM data and two laboratory HbA1c measurements to incorporate patient-specific kinetic rate constants for red blood cell glycation and turnover. Next, past HbA1c and patient-adjusted equation incorporating glucose data and kinetic constants are used to provide a daily approximation of HbA1c. The authors tested the accuracy of this approach against the laboratory-measured HbA1c ∼100 days after equation fitting. Quantitatively, that model performed slightly better than ours (reported R 2 = 0.88), which is not surprising, given the fact that it estimates kinetic constants for each patient separately. However, its construction demanded much more data and computation power than our approach and advanced numerical optimization to solve for patient-specific kinetic constants. Undoubtedly, the model by Xu et al. provides important insights into patients' biological features, which may facilitate further research on the relationship of individual glycation rate and development of diabetes complications. It would be interesting to compare predictions made by other tools (Glycation index, Hemoglobin Glycation Rate, Glycation Gap, or introduced ratio between HbA1c and GMI) with the method by Xu et al. to see what portion of error variance it may help explain.
Finally, the model proposed by Fabris et al. includes information about TIR to provide an individualized dynamical estimation of HbA1c. This approach is based on their previously published method of dynamic estimation (Kovatchev et al.) 59 with some additional features, mainly the γ parameter corresponding to the patient-specific adjustment of TIR impact on HbA1c. This model can also be used to provide daily approximations of HbA1c value. This approach was designed based on data from clinical trials and patients using CGM in a continuous and uninterrupted manner as per protocol. Reported performance R 2 of 0.87 at month 5 and 0.86 at month 9 was similar for GV-PS.
Most of those individualized tools 44,57,60 are demanding or impossible to introduce in clinical practice without extensive technical resources or time investment of clinicians. An alternative approach would be to simplify the estimation method, allowing for less-than-ideal, but feasible and useful prediction. This was our aim in creating the PE-PA model. However, we are aware that alternative approaches for PE-PA construction could be introduced: forcing the intercept in PE-PA equation as 0 to obtain direct proportionality, using AGAD equation as the reference instead of GMI, or adjusting prediction with difference (HGI) instead of PE. Those approaches were attempted and described in more detail in Supplementary Tables S3 and S5.
The strength of our study lies in a large patient sample followed in real life conditions, which makes the results more similar to that one can expect in clinical practice. Moreover, in the creation of our models, we followed good modeling practices by creating separate training and two validation sets depending on the intended implementation: closed or open use. This allowed us to assess the performance of our tools in different scenarios: new HbA1cs from a patient previously included in the model and for new, previously unknown individuals. We also managed to produce relatively simple models that need a moderate amount of data to accurately predict HbA1c in clinical practice. Finally, we evaluated the performance of those tools using large, independent dataset assembled from trial-derived data. In those new, ethnically distinct patients of various ages, both models performed reasonably well in their intended applications. This proves their potential for general and not only local application.
On the other hand, our approach had shortcomings that must be acknowledged. First, it was based on a sample of solely Central and Eastern European, mostly pediatric patients from a single center. Despite promising results during external validation, this limits the models' generalizability to other populations until their performance can be validated and possibly improved. Although both models provide a good fit on the external validation with multiorigin data collected from adults, the unrecognized patient-specific covariates could limit the applicability of our models on new populations, we cannot guarantee their performance in all specific populations. The tools themselves provide the possible adjustment for unrecognized covariates, as random intercept in GV-PS (for glucose-independent variance) and individualized slope (HbA1c-to-GMI ratio) in PE-PA (for glucose-dependent variance). However, we would still advice preliminary testing between implementation for clinical practice. Moreover, we must acknowledge that Abbott CGM was underrepresented in our CGM sample. Therefore, despite observing clear discrepancy in performance of PE-PA between Medtronic and Abbott CGM, we were unable to create a separate model for each technology—this may be done in future when more HbA1c-CGM datasets are available. Finally, our solution provides only limited insight into biological processes underlying observed discrepancy between GMI and HbA1c. We demonstrated that other GV metrics such as SD or CONGA might affect the relationship between median (or mean) glucose and HbA1c.
Conclusions
We showed that information provided in the glucose sensor traces and past clinical data of the patient should be enough to compute close estimation of the expected HbA1c value and possibly improve GMI. A model that accounts for an estimate of an individual's proportional error between GMI and HbA1c (PE-PA) could be implemented into clinical practice to be prospectively validated in a controlled way.
Footnotes
Data Availability
Anonymized data from our cohort are available on reasonable request from the authors. External validation datasets were obtained from Jaeb Centre For Health Research (URL:
Authors' Contributions
A.M. and
Author Disclosure Statement
A.M.,
Funding Information
This research received no specific grant from any funding agency in public, commercial, or not-for-profit sectors.
Supplementary Material
Supplementary Data
Supplementary Figure S1
Supplementary Figure S2
Supplementary Table S1
Supplementary Table S2
Supplementary Table S3
Supplementary Table S4
Supplementary Table S5
Supplementary Table S6
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.