
Abstract
Objectives:
We sought to validate the use of crowdsourced surgical video assessment in the evaluation of urology residents performing flexible ureteroscopic laser lithotripsy.
Methods:
We collected video feeds from 30 intrarenal ureteroscopic laser lithotripsy cases where residents, postgraduate year (PGY) two through six, handled the ureteroscope. The video feeds were annotated to represent overall performance and to contain parts of the procedure being scored. Videos were submitted to a commercially available surgical video evaluation platform (Crowd-Sourced Assessment of Technical Skills). We used a validated ureteroscopic laser lithotripsy global assessment tool that was modified to include only those domains that could be evaluated on the captured video. Videos were evaluated by crowd workers recruited using Amazon's Mechanical Turk platform as well as five endourology-trained experts. Mean scores were calculated and intraclass correlation coefficients (ICCs) were computed for the expert domain and total scores. ICCs were estimated using a linear mixed-effects model. Spearman rank correlation coefficients were calculated as a measure of the strength of the relationships between the crowd mean and expert average scores.
Results:
A total of 30 videos were reviewed 2488 times by 487 crowd workers and five expert endourologists. ICCs between expert raters were all below accepted levels of correlation (0.30), with the overall score having an ICC of <0.001. For individual domains, the crowd scores did not correlate with expert scores, except for the stone retrieval domain (0.60 p = 0.015). In addition, crowdsourced scores had a negative correlation with the PGY level (0.44, p = 0.019).
Conclusions:
There is poor agreement between experts and poor correlation between expert and crowd scores when evaluating video feeds of ureteroscopic laser lithotripsy. The use of an intraoperative video of ureteroscopy with laser lithotripsy for assessment of resident trainee skills does not appear reliable. This is further supported by the lack of correlation between crowd scores and advancing PGY level.
Introduction
U
Global assessment scales have been widely adopted as validated, efficient, and discriminating tools for surgical assessments. 4,5 Although global assessments were initially described for use in simulation settings, they have been adopted for in vivo surgical skills, including robot-assisted prostatectomy. 3,6 A global assessment tool exists for ureteroscopy with laser lithotripsy (URS-LL), which was validated in a urology skill simulation curriculum. 3
To add efficiency to the evaluation of surgical skills, crowdsourced assessments of surgical videos have been introduced as a validated tool for evaluation and quality improvement. 7 Lay public evaluations of surgical skills rely on the assumption that the large number of evaluators possible through crowdsourcing overcomes their lack of specific knowledge or experience in a specific domain. The private company, Crowd-Sourced Assessment of Technical Skills (C-SATS, Inc., Seattle, WA), developed a platform where surgical videos are scored using custom assessment tools by selected experts and crowd workers. Application of the C-SATS crowdsourced evaluation platform has been incorporated into several robotic training programs in various surgical fields. 8 The use of this platform is appealing in surgical education because of the added efficiency and objectivity of crowd workers. In addition, time-efficient surgical evaluation has widespread appeal given growing productivity pressures at teaching hospitals that can conflict with mentorship and teaching obligations.
Our objective was to provide construct validation of the C-SATS crowdsourced evaluation platform in assessment of flexible URS-LL procedures by utilizing endoscopic videos captured during live surgery. 9 Our primary aim was to test whether lay crowd assessments were concordant with expert video scoring. Our secondary aims included (1) evaluation of scoring reliability between experts and (2) score correlation with experience and previously evaluated skill level defined as postgraduate year (PGY) of residency and endourology milestone scores for each respective resident trainee.
Methods
Setting
This study was conducted between January 2017 and June 2017 in an academic hospital in northern California and an affiliated veterans hospital. We included cases if they met the following inclusion criteria: (1) intrarenal ureteroscopy procedures without complicated anatomy (tight ureter and stenotic infundibula limiting ureteroscope manipulation were excluded); (2) stones 1.5 cm or smaller; (3) stones in the renal pelvis, central region, or upper pole; (4) cases where a ureteral access sheath was used; and (5) cases that were performed with a trainee and a single supervising attending surgeon.
The research subjects included urology residents performing ureteroscopic procedures. These were urology residents, PGY two through six, during the second half of the academic year. Two additional videos were performed by endourology faculty as controls. This study received an exemption from the Stanford University and Johns Hopkins University Internal Review Board for Human Subjects Research.
Intervention
Video capture
We captured sequential URS-LL cases that met inclusion criteria for video analysis. All videos included a full pyeloscopy, stone lasering, basketing of the stone, and withdrawal of the endoscope down the ureter. We captured videos from URS-LL procedures using the Karl Storz® video endoscopy recorder and transferred case videos to an encrypted, secure, and deidentified database. All ureteroscopy procedures were performed using the Olympus® URF-V2 or URF-P6 ureteroscope. The ureteroscopy videos were transferred to the C-SATS platform. We annotated 2-minute clips of four different parts of the procedure (pyeloscopy, laser lithotripsy, stone basketing, and endoscope withdrawal) on the C-SATS platform and compiled these into an 8-minute clip for review. Any intervention by attending physicians had been previously noted with a time mark and was not included in the 8-minute clip submitted for review.
Assessment tool
Procedural videos were assessed using a modification of the previously validated Ureteroscopy Global Assessment Tool (mUGAT) (Fig. 1). 3 The global assessment tool required modification to fit our mode of assessment since video only from the endoscopic portion of the case was being used, and the original tool contained domains that could only be assessed by an in-person observer. The maximum score of the mUGAT was 35. Other domains in the validated tool (knowledge of steps of the procedure and use of fluoroscopy) could not be assessed through video and were not included in the modified version.
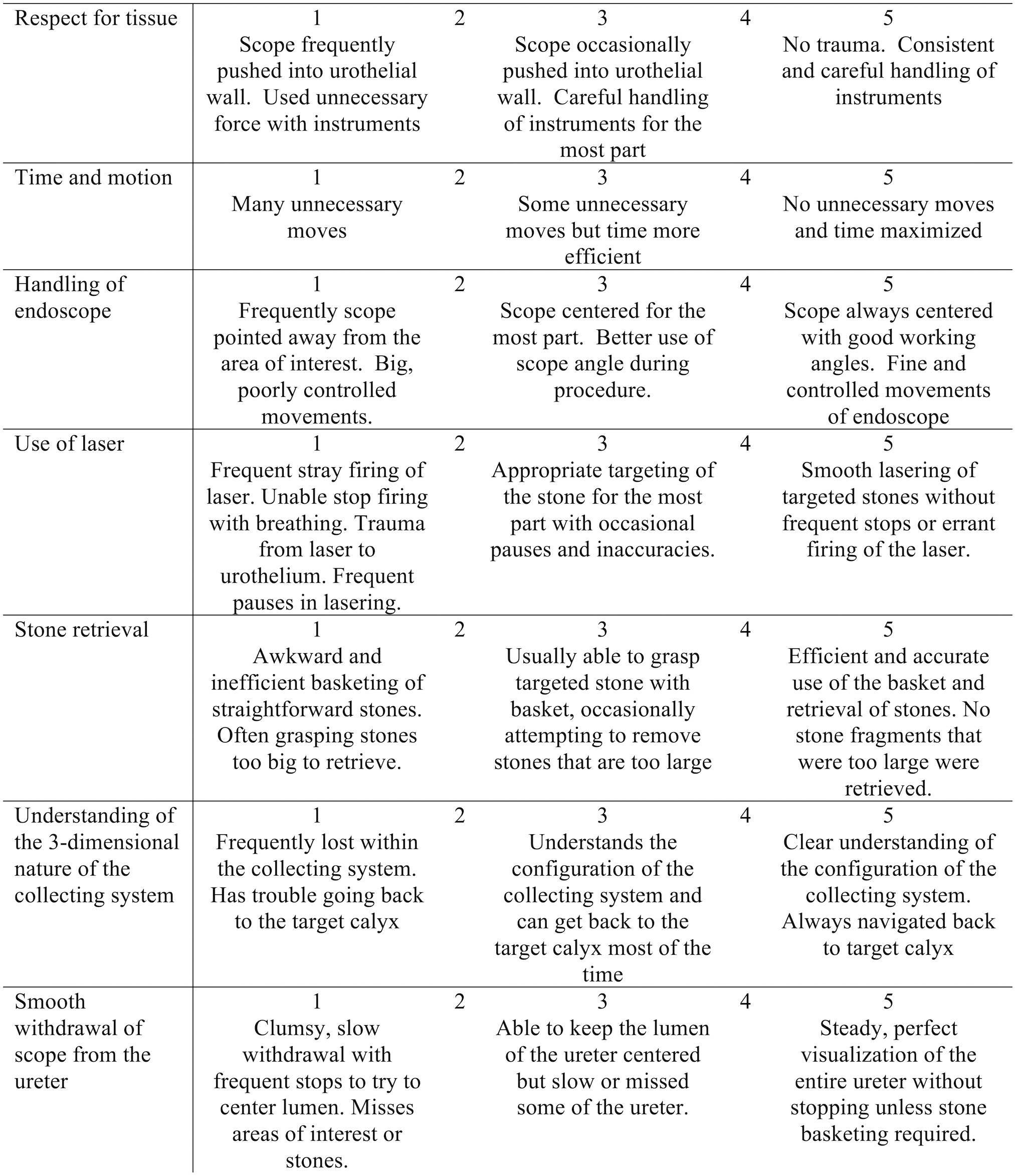
Global rating scale for ureteroscopy laser lithotripsy video feeds: modified ureteroscopy global assessment tool.
Video evaluation
The mUGAT was submitted to the C-SATS platform for scoring by lay crowdsourced raters and expert raters. Crowd workers were recruited by C-SATS through Amazon's Mechanical Turk platform. The goal was to recruit at least 32 crowd workers to evaluate each video based on prior crowdsourced assessment validation studies using the C-SATS platform for other surgical modalities. 7 Five experts in endourology were also asked to rate the videos through the C-SATS platform. Experts were urology faculty with academic appointments and fellowship training in endourology or, in one case, an expert who had recently moved on from academic practice to local community practice.
The C-SATS platform included layperson training material and one comprehension test question. The custom training suite was created by C-SATS, Inc., to educate the crowd reviewers about ureteroscopy and the indications for such a procedure. A correct response to the comprehension question in the training suite was required for inclusion in the data analyses in this report. The experts received similar training to the crowd to similarly orient them to the platform and our evaluation tool.
Measures
Primary aim—lay crowd assessment correlation with expert video scoring
Crowd-based mean scores for each video were generated using a linear mixed-effects (LME) model. The LME model incorporates adjustment for clustering by crowd worker ID. Crowd LME means are provided for each of the global assessment scale's seven domains (respect for tissue, time and motion, handling of the endoscope, use of laser, stone retrieval, understanding of the three-dimensional collecting system, and smooth withdrawal of the endoscope) and for the total (the sum of seven domains). Average video scores for each domain and a total were similarly calculated for the subset of videos reviewed by expert endourologists, which contained videos from each quartile of scoring by the crowd.
Secondary aim 1: evaluation of scoring reliability between experts
Experts used the mUGAT to score each of the global assessment scale's seven domains and the total score was recorded.
Secondary aim 2: score correlation with experience and previously evaluated skill level
Each participating trainee PGY level and their specific endourology milestone score were recorded. Urology milestones (a required evaluation framework for resident evaluation put forth by the ACGME) have a specific domain for endoscopic skills such as ureteroscopy. 10 This score offers an independent secondary measure of trainee endourology skill as the PGY level may not always be predictive.
Analysis
Primary aim—lay crowd assessment concordance with expert video scoring
Spearman rank correlation coefficients (Spearman's rho) were calculated as a measure of the strength of the relationships between the crowd LME mean and expert average scores. Spearman's rho is a nonparametric statistic that can detect any form of monotonic (strictly increasing or strictly decreasing) relationship between two measures. In the context of crowdsourced vs expert ratings, rho values of >0.8 indicate very strong agreement, 0.6–0.8 moderately strong agreement, 0.3–0.5 fair agreement, and <0.3 poor or no agreement.
Secondary outcome 1: evaluation of scoring reliability between experts
Intraclass correlation coefficients (ICCs), a measure of inter-rater reliability, were computed for the expert domain and total scores. ICCs were estimated using a linear mixed-effects model, which can accommodate varying numbers of reviewers per subject. An acceptable ICC coefficient would be >0.5 with good correlation being >0.8–0.9.
Secondary outcome 2: score correlation with experience and previously evaluated skill level
Spearman rank correlation coefficients were also calculated for the crowd and expert scores for video scores and PGY level. A similar analysis was performed with each resident participant's ACGME milestone score for endourology. Spearman's rho was calculated for the PGY level vs milestone score for each resident.
Results
We collected 30 ureteroscopy videos, which were evaluated by crowd workers (2488 times). Evaluations were performed by 487 individual crowd workers. The overall percentage of evaluations that met the comprehension criterion was 96%.
Five experts reviewed a subset of 10–16 videos each. Experts reviewed only a subset of videos that represented each quartile of crowd scores to aid in the expedited completion of expert evaluation. Crowd workers completed 2488 evaluations in 36 hours. Expert evaluation turnover ranged from 1 week to 9 weeks.
Primary aim—lay crowd assessment concordance with expert video scoring
Crowdsourced scoring of each video ranged between a total score of 23.3 and 27.0. Expert scoring ranged between 17.0 and 33.0 (Table 1). Crowd scores showed poor correlation with expert scores (Fig. 2). Poor correlation was also seen when analyzed by individual domains from the assessment tool and the total sum score of the video, with the notable exception of the stone retrieval domain (Spearman's rho value of 0.60, signifying moderate correlation between crowd and experts [p = 0.015]).
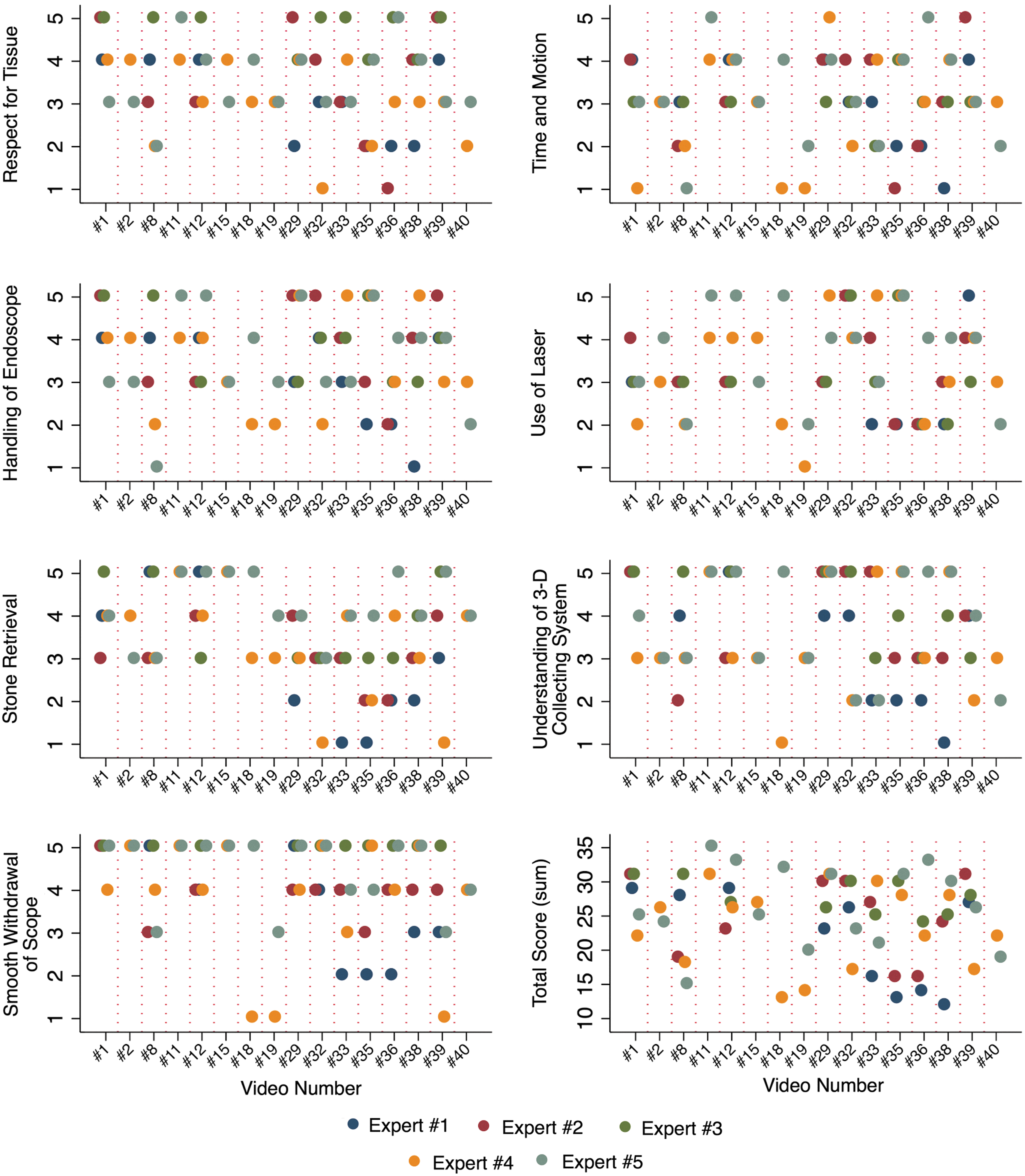
Expert scoring by domain and total score.
Individual Total Sum of Video Scores and Number of Expert and Crowd Reviewers
PGY = postgraduate year.
Secondary aim: evaluation of scoring reliability between experts
Among experts rating the same video, ICCs were all below 0.30, indicating poor agreement (Table 2). Expert responses to selected videos in each domain demonstrated highly variable responses to the same video, as demonstrated in Figure 3.
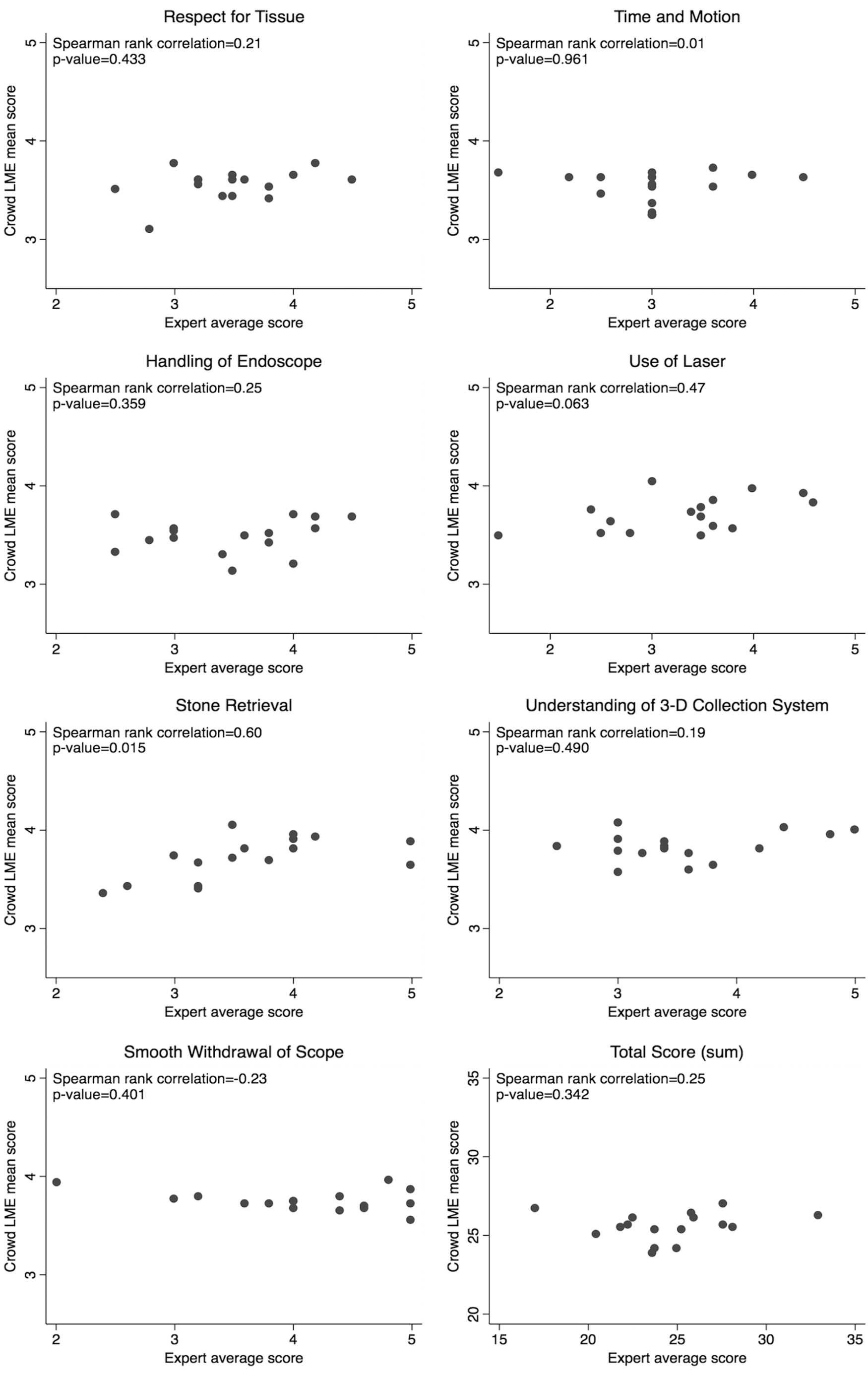
Association between mean crowd score and expert scores.
Intraclass Correlation Coefficients for Expert Raters By Evaluation Domain and Sum Score
3D = three-dimensional; ICC = intraclass correlation coefficient.
Secondary aim: score correlation with experience and previously evaluated skill level
Despite milestone scores and the PGY level showing a strong positive correlation (0.84, p < 0.001), there was no correlation of milestone scores or PGY level compared with the expert or crowd scoring (Fig. 4). Crowd total scores showed a significant negative correlation with the PGY level (−0.44, p = 0.019). Interestingly, procedures performed entirely by attending-level endourologists were graded with similar scores to resident trainees (crowd LME means 25.5 and 26.1, expert mean 21.8). Given that attending experience was felt to be more than a linear step above PGY six, we did not include these data in our statistical analysis.
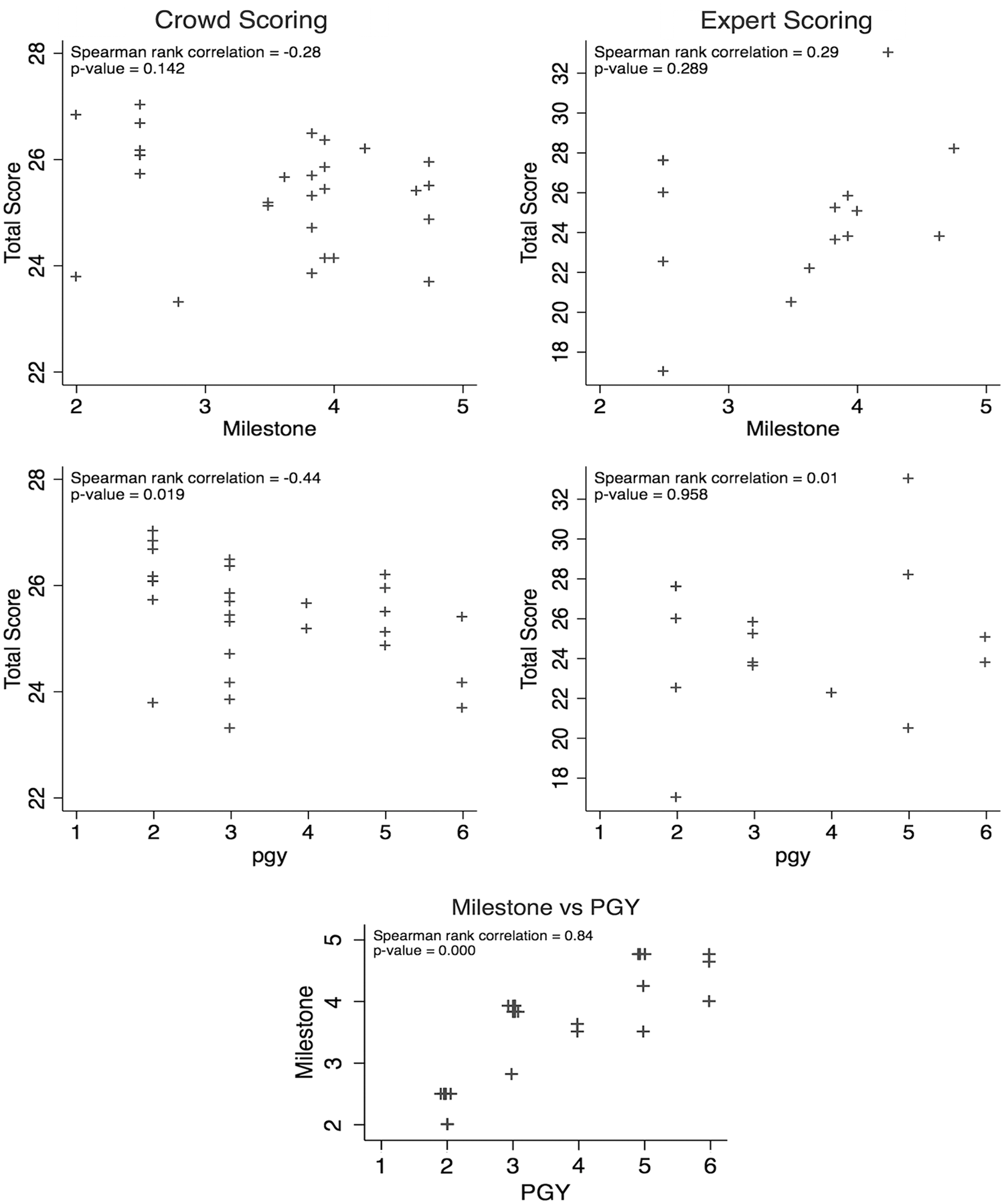
Association of crowd and expert scoring with milestone score and PGY level. PGY = postgraduate year.
Discussion
We failed to show that crowdsourced evaluation of endourologic surgical videos has construct validity as an educational assessment and quality assurance tool despite prior validation of video evaluation in open, laparoscopic, and robotic surgery. Crowdsourced evaluation offers efficient and unbiased scoring compared with traditional evaluation models. Expert reviewers had poor agreement on what represented a high-scoring video. There was poor expert correlation with crowd scores and there was actually an inverse correlation between crowd scores and the PGY level. Milestone endourology scores and mean expert score also did not have a significant correlation with crowd scores. The efficiency of the crowdsourcing platform was evident in this study as the crowd performed video reviews in a small fraction of the time that the experts took.
Given that the C-SATS platform has been effective for other surgical videos and case types, there are several potential explanations for the lack of transferability. It is possible that our modified assessment tool and its anchors were not appropriate for this particular application. Matsumoto and colleagues 3 designed the tool initially to be used for evaluation of technical skills in a simulation session. Recently, a global assessment tool based on the same original ureteroscopy assessment tool was examined with the C-SATS platform using an updated scale with only four domains and was validated in a ureteroscopy simulation session, not live surgeries. 11 The scale has not been validated with intraoperative video footage and may require additional modification for application with live surgery recordings.
The disagreement between expert raters may also indicate that there is a wide range of expectations and opinions as to what exemplifies a properly performed URS-LL. While URS-LL is a straightforward procedure, there are variables that affect case difficulty. Extrinsic factors, apart from surgical skill level, such as clarity of visualization, bleeding, endoscope quality (digital vs fiber optic), and patient anatomy may affect how the video is rated by an unbiased observer. It could be that more information can be gleaned by parts of the case not captured by video feed, such as ergonomics and knowledge of the steps of the procedure. An additional video of the surgeon's body and hands may augment the accuracy of a video assessment by crowdsourcing.
Our data further show that crowd scores were negatively correlated with the PGY level (Spearman rank coefficient of −0.44, p = 0.019). This would suggest that PGY two residents are more skilled in ureteroscopic surgery than PGY six residents. One potential explanation for this flawed finding is that faster movements of the ureteroscope by more advanced trainees may have been perceived by raters as erratic. Other issues such as increased levels of active coaching from faculty may have occurred for trainees with less experience or that sampling error led to more technically advanced junior trainees participating in the study.
There are several limitations to our findings. First, the video platform may be limited, in that only a small portion of the overall procedure is available for viewing. It is possible that inclusion of longer video clips, or the entire case, might improve scoring consistency, although prior validations of crowdsourced video evaluations have similarly used only small portions of cases. An additional limitation is our use of a private company's platform to facilitate video evaluations. While the platform has been validated in various settings and is user friendly, it comes at a financial cost that may be unattainable for many surgical education settings. Our use of a global assessment tool previously only validated in a simulation setting is an additional limitation that likely requires further construct validation studies.
The strength of our study is our use of a robust platform for crowdsourced and expert surgical video evaluation that has been previously validated in other types of surgical procedures. We captured 30 videos of standard URS-LL with stones in similar anatomic locations to minimize procedural differences that might affect video scoring, and our selected experts were all highly experienced individuals from a wide variety of practices worldwide. Despite these efforts, this assessment modality failed validation.
Conclusions
The lack of agreement among expert raters using the global assessment scale on this set of URS-LL videos and the lack of correlation of crowdsourced scoring of URS-LL videos with trainee experience suggest that assessment of ureteroscopic surgical skill is not adequate using only a video feed. Future studies should consider inclusion of video feed of the operating room to evaluate surgeon ergonomics and economy of motion.
Footnotes
Acknowledgments
This research was made possible by the Stanford School of Medicine Teaching and Mentoring Academy's Teaching Innovation grant to S.L.C. The authors would also like to thank Henry Choi and Kristy Seidel of C-SATS for their contributions to this study.
Author Disclosure Statement
No competing financial interests exist.