
Abstract
Antimicrobial resistance (AMR) poses a significant global health threat, with projections indicating it could surpass cancer in mortality rates by 2050 if left unaddressed. Optimizing antimicrobial dosing is critical to mitigate resistance and improve clinical outcomes. Traditional approaches, including population pharmacokinetics (PK) models and Bayesian estimation, are limited by mechanistic hypothesis requirements and complexity. Artificial intelligence (AI) and machine learning (ML) offer transformative solutions by leveraging large datasets to predict drug exposure accurately, refine sampling strategies, and enable real-time dose adjustments through therapeutic drug monitoring. This review highlights the role of ML models, in managing PK and pharmacodynamic variability across diverse patient populations. AI models often equal or outperform traditional methods in achieving therapeutic targets while minimizing toxicity, as demonstrated in some case studies involving ganciclovir, vancomycin, and daptomycin. Despite challenges such as data quality, interpretability, and integration with clinical workflows, AI’s dynamic adaptability and precision underscore its potential. Future directions emphasize integrating multi-omics data, developing bedside decision-support tools, and expanding AI applications to broader drug categories and populations. Continued research and clinical validation are essential to harness AI’s full potential in advancing precision medicine and combating AMR effectively.
Introduction
Antimicrobial resistance (AMR) represents one of the most critical threats to global public health with a staggering impact on morbidity, mortality, and health care costs. In 2019, AMR was directly responsible for an estimated 1.27 million deaths worldwide and contributed to nearly 5 million fatalities. Without urgent intervention, projections indicate that by 2050, AMR-related mortality could surpass that of cancer, potentially reaching 10 million deaths (Fig. 1).1,2 The World Health Organization (WHO), the United Nations (UN), and national health agencies have implemented strategic action plans, such as the Global Action Plan on AMR, to curb the spread of resistant pathogens. However, despite these initiatives, the overuse and misuse of antimicrobials—alongside suboptimal dosing regimens—continue to accelerate and exacerbate resistance, threatening the efficacy of life-saving treatments.
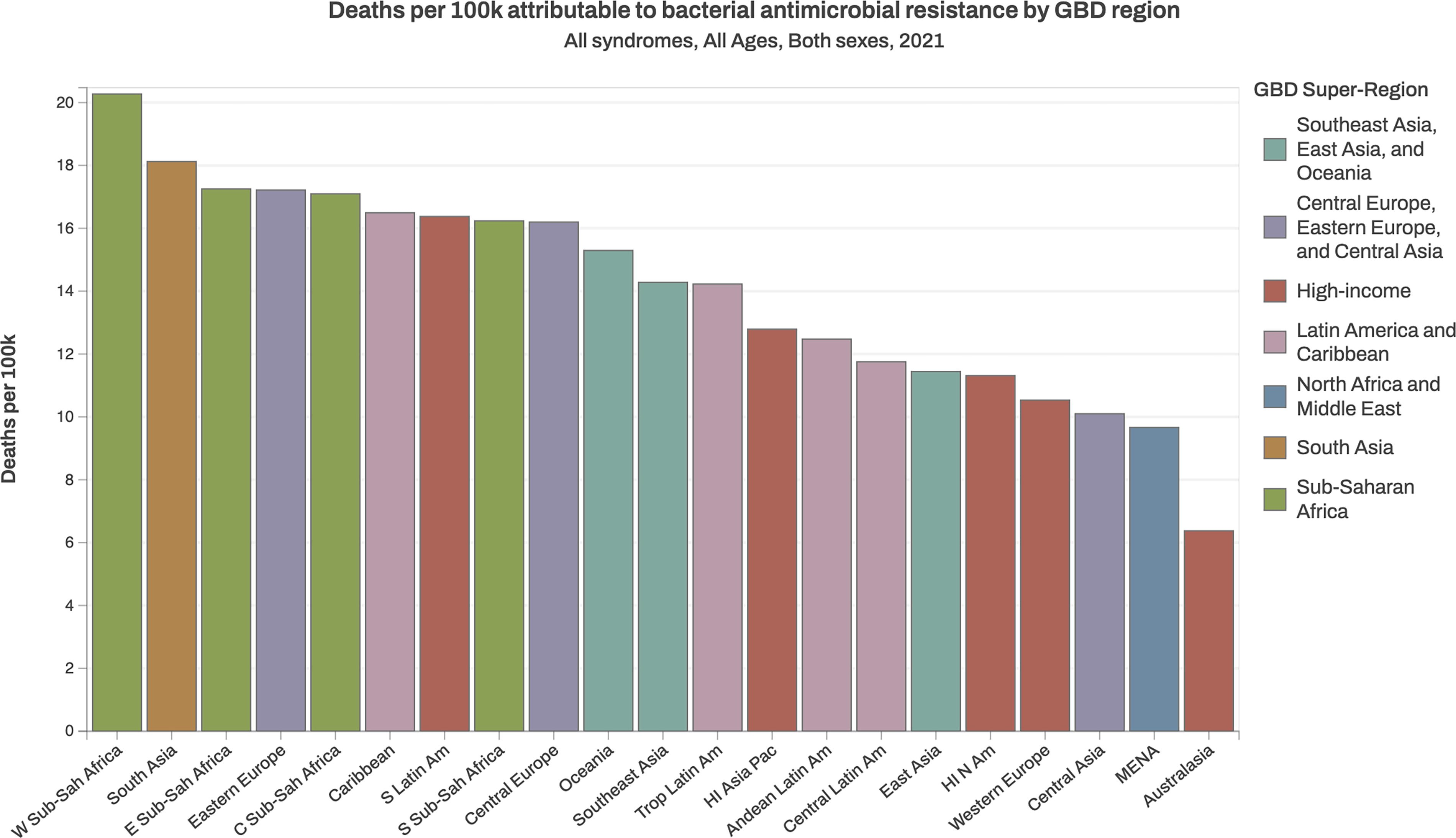
Antimicrobial resistance-related mortality. All-age rate of deaths attributable to and associated with bacterial antimicrobial resistance by GBD region, 2021. Source: Institute for Health Metrics and Evaluation (IHME), University of Oxford. MICROBE. Seattle, WA: IHME, University of Washington, 2024. Available from https://vizhub.healthdata.org/microbe/. (Accessed 5th May 2025).
Dose individualization is a pivotal strategy to enhance clinical outcomes while limiting resistance. By tailoring doses to patient-specific factors such as weight, renal function, and pharmacokinetic (PK) and pharmacodynamic (PD) responses,3,4 clinicians can achieve therapeutic targets such as the area under the curve to minimum inhibitory concentration (AUC/MIC) ratio while minimizing toxicity.5,6
Traditional approaches, including population PK (POPPK) and Bayesian estimators, require expertise and strong hypotheses about mechanistic processes, limiting their routine clinical use. 7
To address AMR, machine learning (ML), a branch of artificial intelligence (AI), is increasingly being applied in medical research to improve clinical decision-making. A recent review by Sakagianni et al. comprehensively outlined the diverse applications of ML in combating AMR and managing infections caused by multidrug-resistant pathogens.
8
Building on these foundations, AI and ML algorithms offer several promising avenues for enhancing antimicrobial therapy, particularly by:
Optimizing data utilization: AI analyzes large datasets to predict drug exposures accurately.9,10 Refining sampling strategies: AI develops limited sampling protocols, allowing precise predictions with fewer measurements.11–13
Supporting real-time clinical integration: AI tools integrate with therapeutic drug monitoring (TDM) to guide dose adjustments in real-time.14,15
AI has shown particular promise in antimicrobial therapy, where precise dosing is essential. For example, ML models such as XGBoost equal or outperform traditional methods in predicting drug exposure leading to decreased toxicity, and improving therapeutic efficacy.
This review examines the role of AI in combating AMR through dose individualization, focusing on three critical antimicrobial agents such as daptomycin, used in treating infections caused by resistant Gram-positive bacteria and characterized by exposure variability, Vancomycin, a cornerstone antibiotic for severe Gram-positive infections, requiring careful monitoring due to its narrow therapeutic index and ganciclovir (GCV), employed in managing cytomegalovirus (CMV) infections in immunocompromised patients.
We will explore methodological innovations, clinical outcomes, and the potential of AI-based dose optimization in advancing precision medicine and antimicrobial stewardship.
Overview of Dose Individualization
Dose individualization is central to precision medicine, aiming to optimize therapeutic outcomes while minimizing toxicity and resistance. This approach tailors drug regimens to account for significant inter-individual variability in drug metabolism, distribution, and elimination. It relies on two primary strategies: a priori dose optimization before treatment and a posteriori adjustment based on real-time monitoring (Fig. 2).
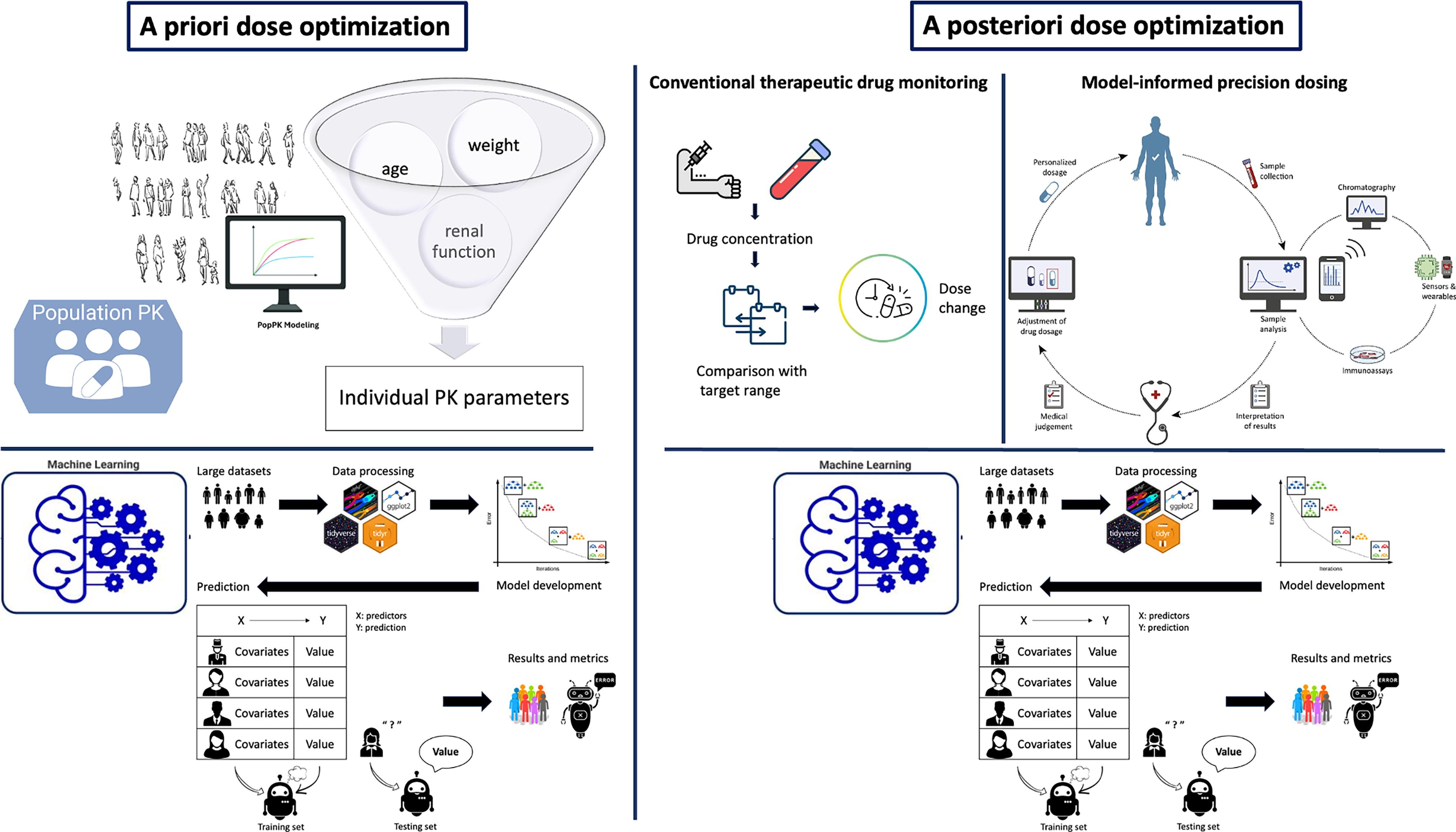
Overview of dose optimization.
A priori dose optimization estimates initial drug doses using population-based models and ML predictive tools.
POPPK leverages data from diverse populations to model typical PK behavior, integrating patient-specific factors such as age, weight, and renal function to predict individual PK parameters.
16
This approach is mechanistic and relies on various theoretical compartment models. ML enhances these predictions. Models such as XGBoost and neural networks, trained on large datasets, predict drug exposure metrics such as AUC and Cmax with high accuracy. Unlike traditional POPPK models, ML can capture complex, nonlinear relationships between predictors, improving predictions in diverse patient populations. For instance, ML has optimized GCV dosing in pediatric transplant patients,
17
and individualized vancomycin and daptomycin doses in critically ill patients.14,18
A posteriori dose adjustment optimizes dosing through TDM, which is a clinical practice that involves measuring drug concentrations in a patient’s blood to optimize dosing and enhance efficacy while minimizing toxicity. TDM is particularly important for drugs with narrow therapeutic indices, such as vancomycin, where small changes in concentration can significantly affect safety and efficacy.
An advanced form of TDM, known as model-informed precision dosing (MIPD), uses computer-based models to integrate population-level PK data with individual patient measurements. By incorporating patient-specific factors such as age, weight, renal function, and measured drug levels, MIPD can predict future drug exposure and refine dosing with greater accuracy. The advantages of MIPD over traditional TDM have been highlighted by Wicha et al. in the context of antibiotic therapy, where individualized dosing is critical. 19
To guide these decisions, clinicians rely on specific PK/PD indices, which link drug exposure to antibacterial activity:
19
AUC/MIC (area under the concentration-time curve over MIC) is often used for antibiotics such as vancomycin or daptomycin, where overall exposure is critical for effectiveness. Cmax/MIC (peak concentration over MIC) is more relevant for concentration-dependent antibiotics like aminoglycosides, where high peak levels drive bacterial killing. Ctrough/MIC (trough level over MIC) may be used for time-dependent antibiotics like β-lactams in certain settings, although maintaining time above MIC (T > MIC) is often the main goal.
AI and ML can improve these strategies by enabling real-time dose adjustments. ML models trained on TDM data can identify patterns across multiple patient factors and predict how doses should be adjusted to reach therapeutic targets. For example, AI models have shown similar performance than traditional methods in estimating vancomycin AUC/MIC ratios and optimizing daptomycin dosing to avoid toxicity. 11 By combining pre-treatment (a priori) and during-treatment (a posteriori) approaches, AI-powered tools offer a dynamic and personalized way to ensure that each patient receives the right dose at the right time tailored to the characteristics of the patient and the infection. 20
Methodological Innovations in AI-Based Dose Optimization
AI-driven dose optimization leverages advanced ML techniques to address inter-individual variability in PK/PD responses and improve precision dosing. Key innovations in this field include ML models developed using either supervised or unsupervised learning paradigms.
Supervised learning, which requires labeled data, is commonly used for regression (e.g., predicting AUC/MIC) or classification tasks (e.g., resistance: yes/no). For example, XGBoost builds sequential decision trees to capture nonlinear interactions between patient features such as age, renal function, and weight, while Random Forest enhances prediction robustness by averaging multiple trees.21,22 Neural networks are particularly useful for modeling complex PK/PD relationships due to their ability to learn hidden patterns in large datasets. 23 When experimental or clinical data are limited, models can also be trained on simulated datasets generated via Monte Carlo simulations from published POPPK models. This approach creates virtual patient cohorts by sampling from joint distributions of PK parameters, expanding the diversity of training data and improving model performance.24,25
In contrast, unsupervised learning does not rely on outcome labels and can be leveraged to uncover latent structures in the data. Two key techniques are: (1) clustering, which groups patients based on similar PK/PD characteristics to identify subpopulations with distinct dosing needs, and (2) dimensionality reduction, such as principal component analysis (PCA), which transforms high-dimensional data into lower-dimensional representations while preserving variance.
A practical application of these unsupervised approaches is demonstrated in the PanRes dataset analysis, where clustering and PCA were used to classify bacterial isolates based on resistance patterns, offering new avenues for identifying emerging AMR phenotypes. 26 Such methods could similarly be applied to stratify patients for individualized dosing.
While these innovations enhance model capabilities, overfitting remains a concern, especially when models learn specific patterns from training data that fail to generalize to new populations. Careful validation is thus essential. Model performance is typically evaluated using task-specific metrics:
Regression: Root mean square error (RMSE) and mean prediction error assess accuracy and bias. Classification: Accuracy, sensitivity, specificity, and area under the receiver operating characteristic (ROC) curve provide insight into clinical applicability.
27
Another advantage of AI-based models is their ability to integrate diverse data sources, including electronic health records (EHRs), laboratory values, and genetic data. Through feature engineering, these inputs are transformed into meaningful predictors, enabling personalized dosing even in complex scenarios such as renal impairment, obesity, or pediatrics.
Finally, hybrid models that combine mechanistic POPPK frameworks with ML algorithms can enhance prediction accuracy by leveraging the strengths of both approaches, offering improved exposure estimation and dose recommendations.28–30
To conclude this chapter and before moving to examples, AI-based dose optimization can replace or enhance traditional pharmacometric models leading to enhanced precision dosing. These innovations not only improve therapeutic outcomes but also support antimicrobial stewardship by reducing toxicity and limiting resistance development.
Case Studies
Ganciclovir
GCV and its oral prodrug, valGCV (VGCV), are essential for preventing and treating CMV infections, especially in immunocompromised pediatric patients. These drugs show large inter-individual PK variability, particularly in children and dosing is challenging due to significant variability in PK influenced by factors such as age, weight, and renal function.
AI contributions: Ponthier et al. developed both ML algorithms trained on simulated PK profiles obtained by Monte Carlo simulations to estimate the best GCV or VGCV starting dose in children. They then compared its performances on real-world profiles with previously published equations derived from literature POPPK models. 17 Additionally, they constructed an ML model using the XGBoost algorithm to predict GCV/VGCV exposure in children based on limited sampling strategies (LSS). 13
To predict the best starting dose, Ponthier et al. used the PK parameters of four literature POPPK models in addition to the WHO growth curve for children to simulate 10,800 PK profiles. ML algorithms were developed and benchmarked to predict the probability to reach the steady-state, AUC target (AUC0–24 within 40–60 mg × hr/L) based on demographic characteristics only. The best ML algorithm was then used to calculate the starting dose maximizing the target attainment. Performances were evaluated for ML and literature formula in a test set and in an external set of 32 and 31 actual patients (GCV and VGCV, respectively). A combination of Xgboost, neural network, and Random Forest algorithms yielded the best performances and highest target attainment in the test set (36.8% for GCV and 35.3% for the VGCV). In actual patients, the best GCV ML starting dose yielded the highest target attainment rate (25.8%) and performed equally for VGCV with a POPPK model-derived formula (35.3% for both) (Table 1). 17
Performances (in %) of the Machine Learning Algorithms in the Train Dataset Ganciclovir and Valganciclovir to Predict AUC0–24 in the Target
From Ponthier et al. Clin Pharmacokinet 2024. 16
AUC, area under the curve; NPV, negative predictive value; PPV, positive predictive value; ROC, receiver operating characteristic.
To predict GCV/VGCV exposure on LSS in children, the same group simulated over 10,000 pediatric profiles and developed an ML algorithm based on two-sample combinations (e.g., 0 and 2 hr post-dose for IV GCV, and 2 and 6 hr for oral VGCV). The model achieved superior performance compared with literature POPPK and Bayesian estimators, with an RMSE of 5.7% for VGCV (Figs. 3 and 4). 13
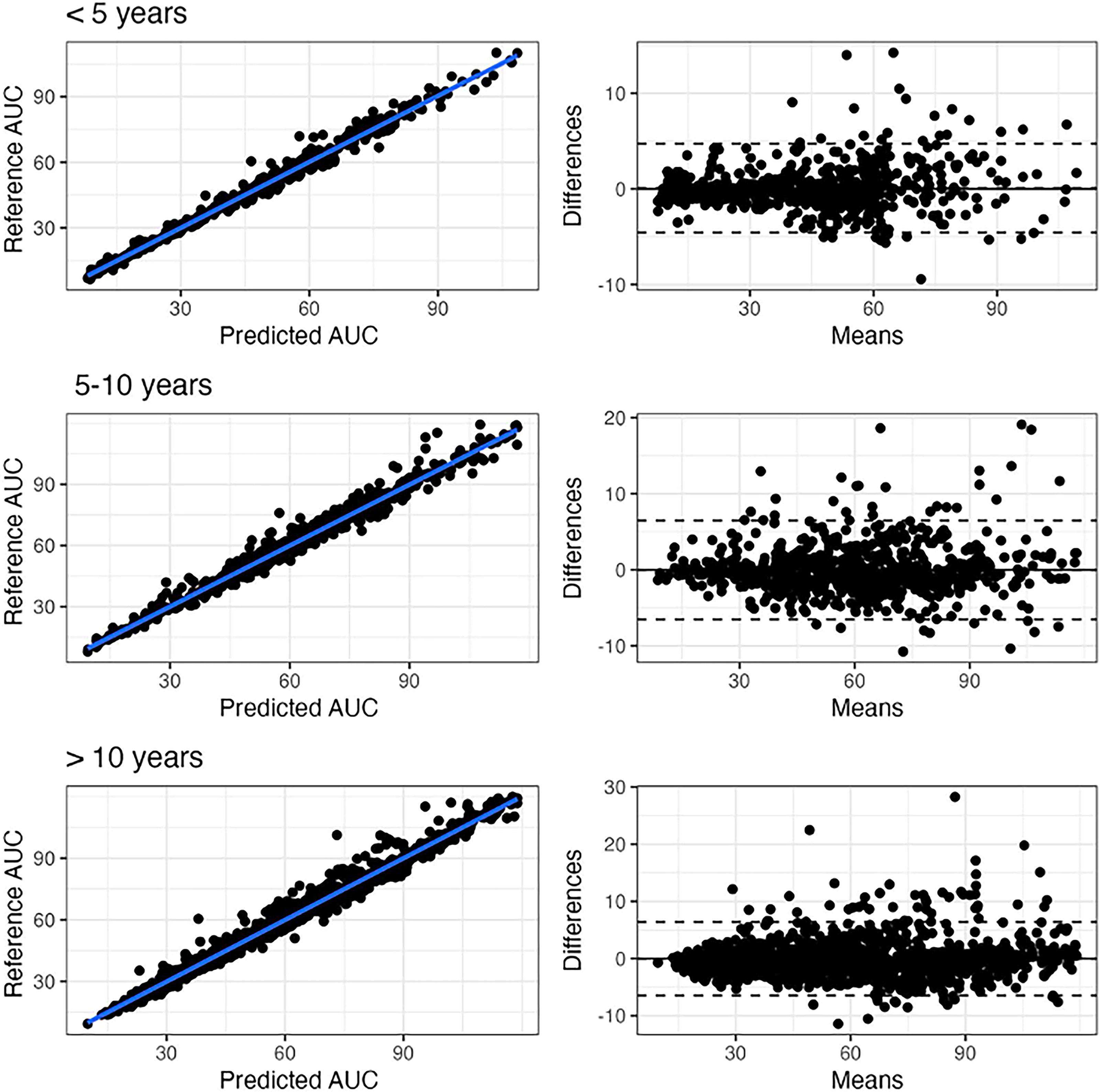
Scatter plot of AUC0–24s estimated using the Xgboost algorithm based on two points at 2 and 6 hr vs. reference trapezoidal AUC0–24 in the test set for valganciclovir, and corresponding Bland–Altman plots for different classes of age (<5, 5–10, and >10 years old). The difference is the difference between the reference and the Xgboost. AUC0–24s and the mean is the average of both. From: Ponthier et al. AAC 2024. 13 AUC, area under the curve.
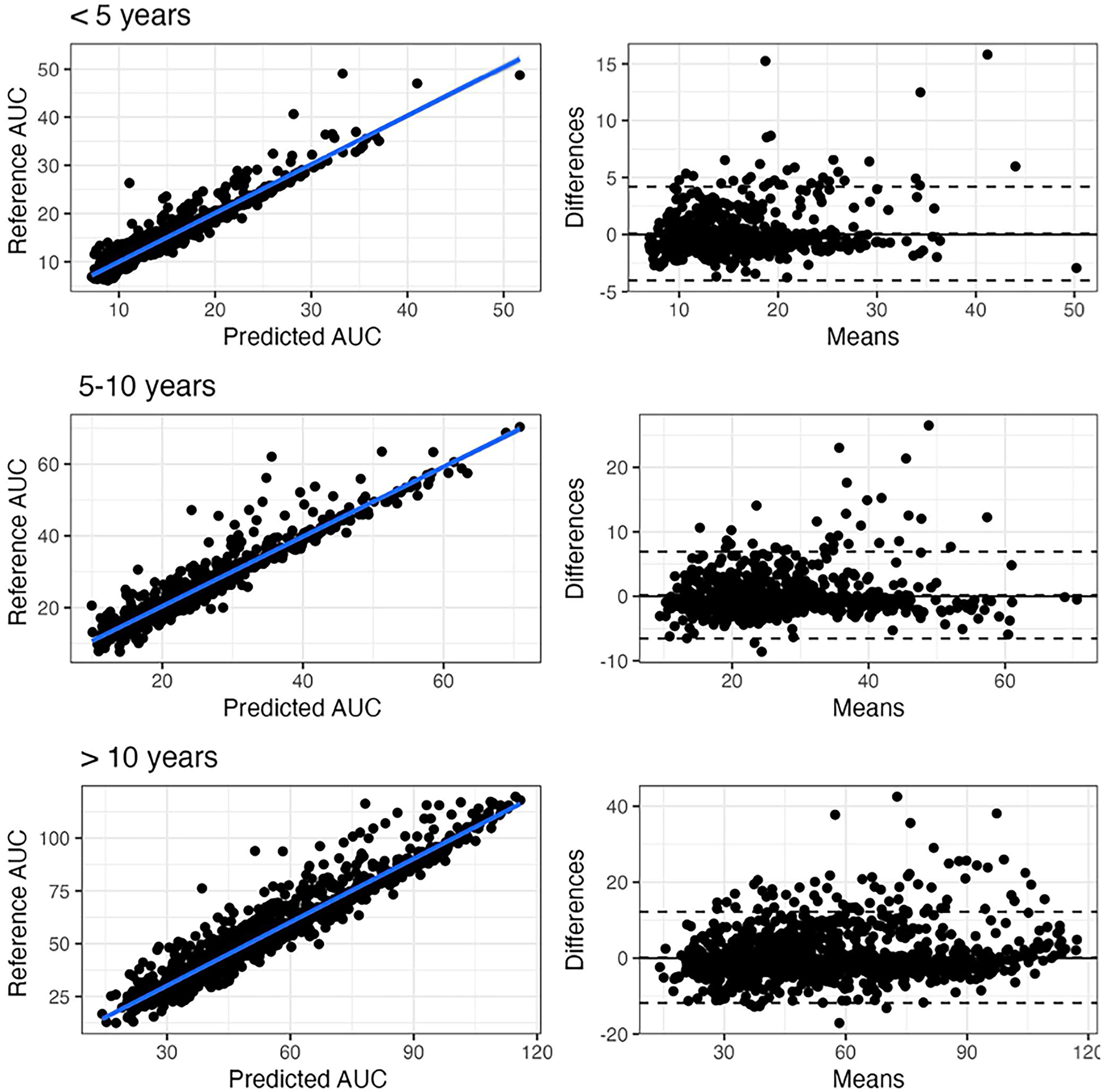
Scatter plot of AUC0–24s estimated using the Xgboost algorithm based on two points at 1 and 6 hr vs. reference trapezoidal AUC0–24 in the test set for ganciclovir, and corresponding Bland–Altman plots for different classes of age (<5, 5–10, and >10 years old). The difference is the difference between the reference and the Xgboost. AUC0–24s and the mean is the average of both. From: Ponthier et al. AAC 2024. 13
Vancomycin
Vancomycin, a cornerstone antibiotic for severe Gram-positive infections, presents significant dosing challenges due to its narrow therapeutic index. The high inter-individual variability in neonates further complicates achieving therapeutic targets such as AUC/MIC ratios.
AI contributions: Two studies by Bououda et al. and Ponthier et al. explored ML models for vancomycin dose optimization in adults 25 and neonates. 18
Bououda et al. successfully developed the XGBoost algorithm from 6,000 simulations performed from six different POPPK models to predict vancomycin AUC from early concentrations (2, 4, or 6 samples) and a few features (i.e., patient information). Finally, the two-sample algorithm was externally evaluated on 28 real patients and compared with a state-of-the-art POPPK model-based averaging approach. 31 The XGBoost algorithm trained from simulation and evaluated in real patients allows accurate and precise prediction of vancomycin AUC. It can be used in combination with POPPK models to increase the confidence in AUC estimation. 25
Ponthier et al. aimed to develop an ML algorithm based on PK profiles obtained by Monte Carlo simulations using a POPPK model from the literature, in order to derive the best vancomycin initial dose in preterm and term neonates. They then compare the ML performances in terms of target attainment with those of a literature equation (LE) derived from a POPPK previously published. Performances were evaluated in a second simulation set and in an external set of 82 real patients and compared with those of the LE. They simulated 1,900 PK profiles and the XGBoost algorithm yielded target attainment rates of 46.9% in the second simulation set of 400–600 AUC/MIC ratio versus 41.4% for the LE model (p = 0.0018); and 35.3% versus 28% in real patients (p = 0.401), respectively. The XGBoost model resulted in less AUC/MIC >600, thus decreasing the risk of nephrotoxicity (Table 2). 18 The algorithm will be prospectively evaluated in a randomized clinical study.
The Number of Patients with Theoretical AUC Below, Within, or Above the Therapeutic Range Was Calculated Using the References Doses, Machine Learning (ML) Doses, and Literature Equation (LE) Doses in the Independent Simulated Set No. 2
From Ponthier et al. Pharm Res 2022. 17
AUC, area under the curve.
Daptomycin
Daptomycin is used to treat multidrug-resistant Gram-positive infections. Its dose administration usually depends on the patient’s weight and its monitoring is highly variable, influenced by patient-specific factors such as renal clearance and obesity, necessitating precise dose adjustments to achieve PK/PD targets such as AUC/MIC. PK/PD has been proposed for daptomycin’s antibacterial effect (AUC/CMI >666) and toxicity (C0 > 24.3 mg/L) or more recently AUC >939 mg × hr/L.32–34
AI contributions: Rivals et al. developed ML models that predict the initial daptomycin dose required to meet therapeutic goals. About 5,000 PK profiles were simulated from the Dvorchik POPPK model with doses ranging from 4 to 12 mg/kg. Four ML algorithms were trained to search the optimal dose of daptomycin maximizing the event (AUC/CMI >666 and C0 < 24.3 mg/L). The best model was evaluated in simulations and then in an external database of real patients in comparison with POPPK. The XGBoost algorithms developed to predict the event (ROC-AUC) in the training and test set were 0.762 and 0.761, respectively. In the external database of real patients, the starting dose administered based on the ML algorithm significantly improved the target attainment by 7.9% (p value = 0.02929) in comparison with the dose administered based on body weight. The developed algorithm improved the target attainment for daptomycin in comparison with weight-based dosing. A Shiny app was built to calculate the optimal starting dose and is available on the website https://daptomycinstartingdose.shinyapps.io/application/ (Fig. 5). 14
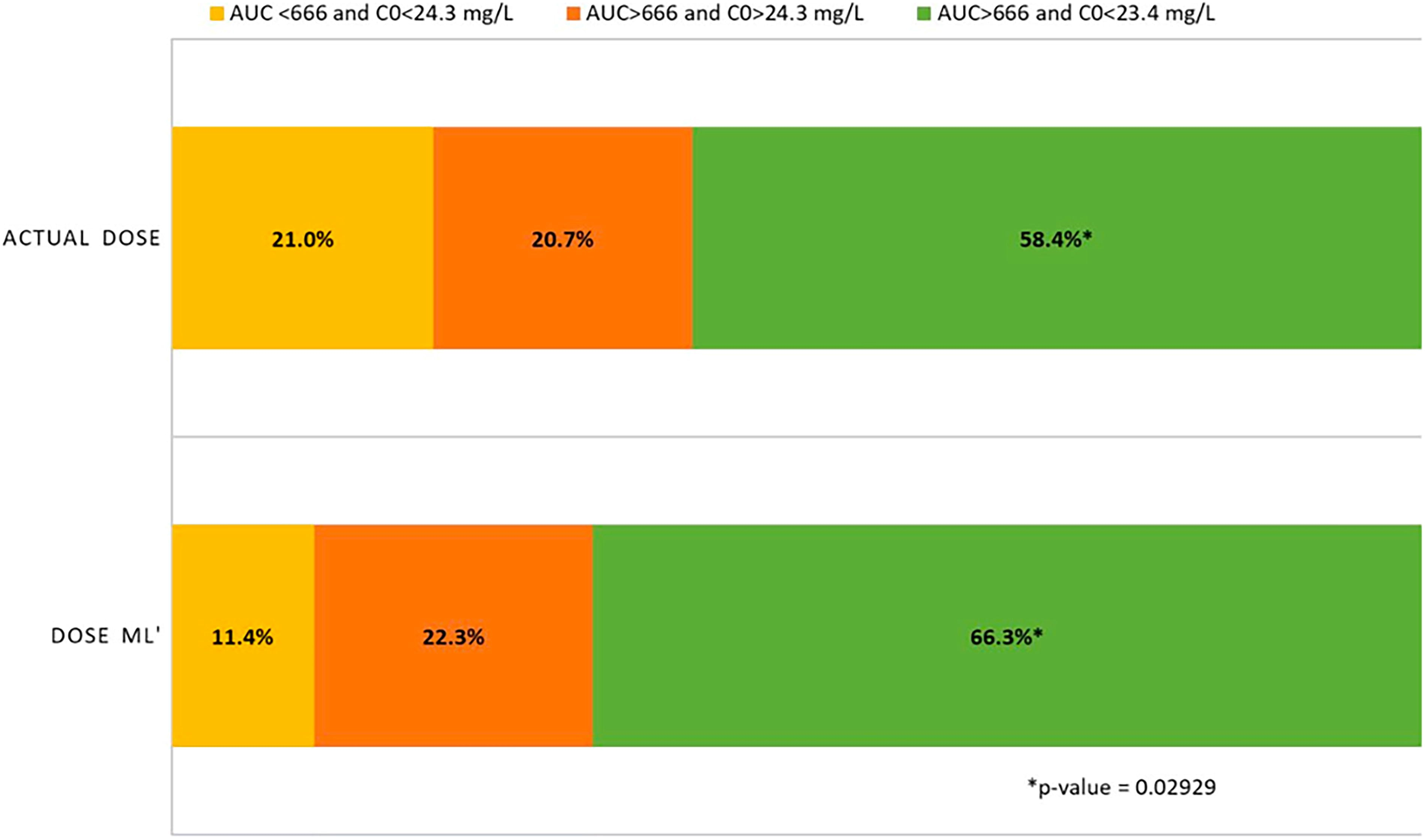
Proportions of events for the actual doses administered to patients in the external database and after theoretical administration of the dose proposed by the machine learning parameters (doseML). From: Rivals et al. Clin Pharmacokinet 2024. 14
We also aimed to predict the area under the blood concentration curve (AUC) of daptomycin from two samples and a few covariates using the XGBoost ML algorithm trained on Monte Carlo simulations. 11 Five thousand one hundred fifty patients were simulated from two literature POPPK models. The ML model based on two concentrations (C0 and C1h post dose), the differences between these concentrations, and five other covariates (sex, weight, daptomycin dose, creatinine clearance, and body temperature) yielded accurate AUC estimation in the test set (relative bias/RMSE = 0.43/7.69%) and external validation sets (relative bias/RMSE = 4.61/6.63%) (Fig. 6). A Shiny app was built to predict daptomycin exposure and is available in the website https://ccodde.shinyapps.io/Daptomycin_AUC/.
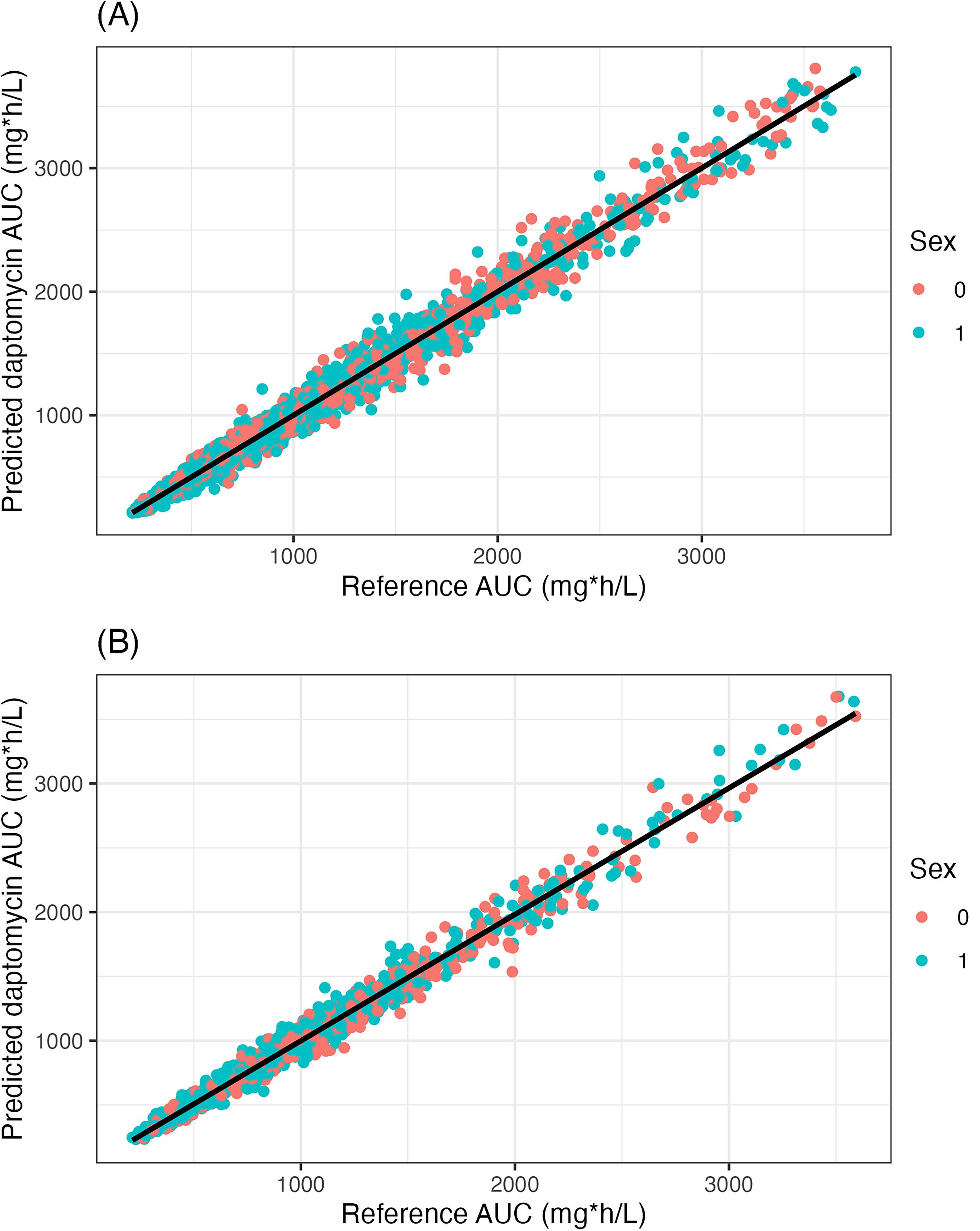
Scatterplots of ML predicted vs. reference daptomycin AUCs in the training
Discussion
This review highlights how ML contributes to optimizing antimicrobial dosing strategies and supports the broader fight against AMR through data-driven, individualized approaches. Coupled with pharmacological data, AI-driven models offer transformative advantages in optimizing antimicrobial dosing strategies, making them invaluable in combating AMR.
The strengths of AI in antimicrobial stewardship include variability management. AI algorithms, such as XGBoost, Random Forest, and neural networks can handle complex, nonlinear relationships in PK and PD data. This allows for accurate dose predictions across diverse patient populations, including neonates, pediatric, and critically ill patients. LSS are employed in clinical settings to reduce the number of blood samples needed for accurate estimation of the AUC applied to drug concentration-time profiles. Indeed, AUC is largely used in infectious diseases as a surrogate PD marker of efficacy and its accurate estimation allows to optimize dosing regimens. Traditionally, maximum a posteriori Bayesian estimation has been the standard method for AUC estimation based on limited samples. But ML is emerging as a promising alternative for it as described in the review of Asultan et al. 12
ML can serve as a valuable complement to traditional approaches, such as mechanistic models and POPPK, in guiding clinical decisions. When integrated with TDM, ML enables real-time dose adjustments based on patient-specific data. This helps clinicians make faster, more informed decisions that improve treatment outcomes and reduce the risk of AMR. Tools such as Shiny apps demonstrate how AI can be translated into user-friendly platforms for routine clinical use. 35 These intuitive applications support practical implementation, simplify workflows, and promote wider adoption in everyday care.
Despite its potential, data-driven approaches come with inherent limitations that must be addressed to fully realize their clinical impact.
One major challenge lies in the accuracy and generalizability of AI models, which are highly dependent on the availability, quality, and diversity of training datasets. Models trained on multicentric data gathered across hospitals, laboratories, and geographic regions, must contend with significant variability in patient demographics, microbial ecology, and therapeutic practices. Inconsistencies in data collection methods, laboratory standards, and reporting formats can further compromise model robustness. Therefore, standardizing data structures and implementing robust harmonization strategies are essential for ensuring reliable AI performance across varied clinical contexts. 36
Another key concern is the frequent reliance on simulated or retrospective data, which may not capture the full complexity of real-world clinical variability. This can particularly affect model performance in underrepresented populations, such as patients in low-resource settings or those with rare comorbidities. For example, Theodorakis et al. have highlighted how age-related factors—including immunosenescence, comorbidity burden, and PK changes—significantly influence AMR and may not be adequately represented in current training datasets. 37 When AI models are developed using simulated populations, such as those derived from Monte Carlo methods, they may not fully account for such patient-specific nuances. This discrepancy can lead to biased predictions and reduced clinical utility, particularly in vulnerable groups such as the elderly.
While AI presents promising opportunities in AMR management, its deployment also raises critical ethical and operational concerns that must be addressed to ensure safe, fair, and effective clinical integration.
Algorithmic transparency: Many ML models, particularly complex architectures such as neural networks, are perceived as “black boxes,” making it difficult for clinicians to understand the basis of specific predictions. This lack of interpretability can undermine trust and hinder clinical adoption. To address this, the integration of explainable AI techniques such as feature importance scores, SHapley Additive exPlanation (SHAP) values, or decision tree surrogates can provide clinicians with clearer insights into model behavior and foster greater confidence in AI-assisted decisions.38,39 However, achieving a balance between model performance and interpretability remains an ongoing challenge. Data privacy: AI-driven AMR surveillance and treatment optimization depend on access to large-scale patient datasets, raising concerns about data security, consent, and regulatory compliance, especially under frameworks such as the General Data Protection Regulation.
40
Emerging solutions, including federated learning and privacy-preserving data-sharing infrastructures, offer promising ways to enable model training across decentralized datasets without compromising patient confidentiality. Equity and bias in health care access: AI models must be designed to avoid systemic bias and ensure equitable treatment recommendations across all patient groups. Underrepresentation of certain populations such as the elderly, ethnic minorities, or individuals from low-resource settings can lead to skewed predictions and exacerbate existing health disparities. Strategies such as diverse data sourcing, bias detection metrics, and fairness audits are essential to mitigate these risks and promote inclusive AI development. Model integration and adaptability: For AI tools to be truly useful in clinical settings, they must integrate seamlessly with EHRs and laboratory systems. However, heterogeneity in health care IT infrastructure and the lack of standardized interoperability protocols present practical barriers. Furthermore, AI models need to be continuously updated to reflect evolving resistance patterns, guideline changes, and patient population shifts. Real-time validation pipelines and automated model updates are therefore key to sustaining long-term clinical relevance.
Looking ahead, hybrid approaches combining the strengths of data-driven ML models with traditional pharmacometrics methods offer a promising path to enhance robustness and generalizability. Leveraging multi-omics data, real-world evidence (e.g., EHRs and wearable sensor data), and conducting prospective validation in diverse populations will be critical for refining model accuracy and clinical applicability. Additionally, the development of user-friendly bedside tools that support real-time, AI-assisted dose adjustment could facilitate seamless adoption in routine care, empowering clinicians to optimize antimicrobial therapy efficiently.
Overcoming current limitations will require sustained interdisciplinary collaboration among infectious disease specialists, microbiologists, pharmacologists, data scientists, regulatory bodies, and policymakers. Such cooperation ensures that AI-based solutions remain clinically meaningful, ethically sound, and technically robust. For instance, the integration of ML with epidemiological models has already shown potential in identifying resistance trends and predicting outbreaks, including those involving carbapenem-resistant pathogens. 41
These converging challenges and opportunities have been increasingly highlighted in recent literature. As discussed by Stankevičiūtė et al., 38 bridging pharmacometrics and ML is essential to advance precision medicine. 42 While pharmacometrics offers mechanistic insight into drug behavior, ML brings flexible computational frameworks for modeling individualized treatment responses. However, methodological complexity and domain-specific silos often hinder collaboration. Facilitating dialogue between disciplines is therefore key to developing more integrative, scalable tools. Finally, expanding AI applications to underserved populations and less-studied antimicrobial classes will be critical to maximizing the global impact of these technologies in the fight against AMR.
Conclusion
AI has significant potential to advance antimicrobial dose individualization by enhancing the precision of PK and PD predictions. Realizing this potential requires access to large, high-quality clinical datasets, including real-world and multi-omics data, to improve model robustness and generalizability. Successful clinical translation depends on seamless integration into TDM workflows and the development of user-friendly, bedside tools to support real-time dosing decisions. To facilitate adoption, strategies that enhance model interpretability, such as explainable AI and clinician-in-the-loop systems, are essential. Ultimately, bridging AI innovation with clinical pharmacology will require rigorous validation, transparent algorithms, and close alignment with existing dosing practices to support its routine use in individualized antimicrobial therapy.
Footnotes
Authors’ Contributions
C.C. and J.-B.W.: Conceptualization. C.C.: Methodology. C.C., J.-F.F., and J.-B.W.: Writing—original draft. C.C. and J.-B.W.: Writing—review and editing.
Disclosure Statement
All authors have no interests to disclose.
Funding Information
No funding was received for this article.