
Abstract
Abstract
The prevalence of acquired hyperlipidemia has increased due to sedentary life style and lipid-rich diet. In this work, a lipid–protein–protein interaction network (LPPIN) for acquired hyperlipidemia was prepared by incorporating differentially expressed genes in obese fatty liver as seed nodes, protein interactions from PathwayLinker, and lipid interactions from STITCH4.0. Cholesterol, diacylglycreol, phosphatidylinositol-bis-phosphate, and inositol triphosphate were identified as core lipids that influence the signaling pathways in the LPPIN. RACα serine/threonine-protein kinase (AKT1) was a highly essential central protein. The gastrin–CREB pathway was greatly enriched; all enriched pathways in the LPPIN showed crosstalk with the phosphatidylinositol-3-kinase–Akt pathway, correlating with the central role of AKT1 in the network. The disease clusters identified in the LPPIN were cardiovascular disease, cancer, Alzheimer's disease, and Type II diabetes. In this context, we note that the commercially approved drug targets for hyperlipidemia in each disease cluster may potentially be repurposed for treatment of the specific disease. We report here top 10 potential drug targets that may mediate progression from hyperlipidemia to the respective disease state. ToppGene Suite was employed to identify candidates followed by a) discarding high closeness centrality nodes, and b) selecting nodes with high bridging centrality. Three potential targets could be mapped to specific disease clusters in the LPPIN. Lipids associated with acquired hyperlipidemia and each disease cluster identified may be useful as prognostic fingerprints. These findings provide an integrative view of lipid–protein interactions leading to acquired hyperlipidemia and the associated diseases, and might prove useful in future translational pharmaceutical research.
Introduction
H
The common causes of acquired hyperlipidemia (AH) are lipid-rich diet, obesity, glucose intolerance, hypothyroidism, liver diseases, cigarette smoking, and alcohol consumption. Increase in urbanization is accompanied by the increase in consumption of lipid and energy-rich food, as well as decrease in physical activity, leading to AH (Evans et al., 2004; Yusuf et al., 2001). Liver plays an important role in lipid metabolism (Nguyen et al., 2008). As a result, fatty liver is an important player in the pathogenesis of hyperlipidemia, with strong correlation existing between liver fat, insulin resistance, and overproduction of triglyceride laden large VLDL particles (Stahlman et al., 2012).
The key players in pathogenesis of hyperlipidemia are the elevated lipid levels. Therefore, there is increasing interest in the use of lipidomics techniques to determine the levels and type of lipids under physiological/pathological conditions. Lipidomics studies show that human plasma contains lipid species belonging to six broad lipid classes, namely: fatty acyls (FA), glycerolipids (GL), glycerophospholipids (GPL), sphingolipids (SL), sterols, and prenols (Quehenberger et al., 2010). GL-like diacylglycerols (DAG) and phosphatidylcholine (PC) are elevated in dyslipidemic individuals. Cholesterol-derived cholesteryl esters (CE) are also increased during lipid imbalance. Similarly, palmitic and vaccenic acid contribute to increased levels of triacylglycerol (TAG) (Stahlman et al., 2012).
Apart from their role in energy metabolism and cell membrane structure, lipids (e.g., phosphinositides, eicosanoids, SL, and fatty acids) affect diverse cellular processes such as apoptosis, cell proliferation, metabolism, and migration (Wymann et al., 2008). Abnormalities in components of the lipid signaling cascade constitute an important component of pathophysiology in a number of diseases (Chen et al., 2015; Feng et al., 2015; Henk et al., 2015; Schmitz et al., 2015; Watson, 2006). The effect of lipids in formation, stability, and disruption of atherosclerotic plaque is also well established (Meikle et al., 2011). In atherosclerotic plaque, nearly 24 different lipid species belonging to CE, sphingomyelin (SM), PC, lysophosphatidylcholine (lPC), lysophosphatidylethanolamine (lPE), phosphatidylethanolamine (PE), lysophosphatidylserine (lPS), phosphatidylserine (PS), and TAG species were identified (Stegemann et al., 2011).
Microarray studies conducted on familial forms of hyperlipidemia showed that genes involved in uptake, synthesis, cellular outflow, and disposal of cholesterol were differentially expressed. An increase in lipid accumulation in monocytes due to rise in uptake of oxidized/native LDL was observed during these studies (Mosig et al., 2008; Watson, 2006). However, till date, studies on AH have been carried out in animal models only (Kim et al., 2005; Puskas et al., 2004; Takahashi et al., 2012).
Several systems biology studies integrating the interplay between small molecules and proteins have played a crucial role in the study of drug treatment, signal transduction, and metabolism (Bhattacharya et al., 2013; Butcher et al., 2004; Cheng et al., 2012; Schadt et al., 2006). However, till date, there is no study that integrates differentially expressed genes with protein–lipid interactions to provide an integrated view of the protein–protein and protein–lipid interactions in AH.
In view of this, we employed the publicly available Differentially Expressed Gene (DEG) data from human fatty liver with protein–lipid interaction information to develop a lipid–protein–protein interaction network (LPPIN) of AH by two-tier data integration. Further, topological and pathway analysis of the LPPIN was performed to identify choke points, enriched pathways, and central effectors in AH.
The gastrin-CREB (cAMP response element binding protein) pathway was most significantly overrepresented in the LPPIN. CVD, Type II diabetes (T2D), Alzheimer's disease (AD), and cancer disease gene clusters figured prominently in the LPPIN. Critical nodes for the development of AH-based complications and candidate drug targets were identified in each disease cluster. Thus, the constructed LPPIN provides a comprehensive model for the effect of lipids in health and disease. Further, several approved drug targets for the treatment of AH could be mapped to every disease cluster identified, and have implications for the polypharmacology of these disorders.
The top ten potential candidate drug targets were mined from the LPPIN with the target prioritization software ToppGene using the approved drug targets as training set, and further refined using the computed topological parameters. Three of the potential drug targets were first interactors of the disease clusters identified. Literature search also showed the role of these targets in disease pathogenesis. Seven common lipid species associated with AH and unique lipids in each disease cluster may act as useful markers for the development of AH and its associated diseases.
Materials and Methods
Data mining
Seed nodes were mined and data was integrated from two sources: a) Expression profile of GSE15653 (Pihlajamaki et al., 2009) was downloaded from Gene Expression Omnibus (GEO) database consisting of fatty liver sample obtained from five lean controls and four obese test subjects. Identification of DEGs was done by comparing lean and obese groups using GEO2R. GEO2R carries out comparisons on original submitter-supplied processed data tables using the GEOquery and Limma R packages from the Bioconductor project (http://www.bioconductor.org). To adjust p values for multiple testing, the Benjamini and Hochberg false discovery rate method was used. The DEGs were selected based on cut-off value, |logFC| >1.5 and p < 0.05. b) There are numerous lipid species in human plasma that belong to six major lipid classes. To develop a LPPIN, lipid species belonging to the following lipid classes were used as initial seeds: FA, GL, GPL, SL, sterols, and prenols. A total of 67 lipid species were used for network construction through STITCH 4.0 [http://stitch.embl.de/] (Kuhn et al., 2014).
Construction of an integrated LPPIN
First, a protein–protein interaction network (PPIN) was constructed by DEGs and their immediate first interactors using the PathwayLinker tool (Farkas et al., 2012). PathwayLinker assembles validated physical and genetic interaction data with pathway information. PathwayLinker uses BioGrid (Farkas et al., 2012) and Search Tool for Retrieval of Interacting Genes/Proteins (STRING) (Franceschini et al., 2013) to retrieve small-scale and high throughput physical interaction, while data for small scale physical interaction is acquired from the Human Protein Resource Database (Peri et al., 2004). Pathway information is obtained from Kyoto Encyclopedia of Genes and Genomes (KEGG) (Kanehisa et al., 2000), Reactome (Jupe et al., 2015) and SignaLink (Korcsmaros et al., 2010) databases.
Separately, small lipid–protein interaction networks were constructed for each of the lipid species. The parameters used to run STITCH (Kuhn et al., 2014) software were: all prediction methods enabled, medium confidence score of 0.400, and 10 interactors allowed. Each of the constructed networks was analyzed in Cytoscape 3.2.0 (Shannon et al., 2003) The PPIN obtained from PathwayLinker was merged with the multiple lipid–protein networks obtained from STITCH using the Advanced Merge Function implemented in Cytoscape 3.2.0 (Shannon et al., 2003).
Validation of the network
Network validation was done by comparing the LPPIN to 100 random networks. The random networks were generated using shuffling of the graph with degrees preserved as implemented in the randomized network plugin in Cytoscape2.6.3 (Shannon et al., 2003). The algorithm randomly selects two edges (u, v) and (s, t) such that u ≠ v ≠ s ≠ t where (u, t) or (s, v) do not exist in the network. At the next step, (u, v) and (s, t) are removed from the network with insertion of (u, t) or (s, v). Finally, average clustering coefficient of the 100 randomized networks was calculated and compared with the clustering coefficient of the LPPIN.
Topological analysis of the network
Topological analysis has been used in various studies to characterize the biological network structure and properties (Assenov et al., 2008). Topological properties of the network were analyzed using NetworkAnalyzer 1.0 and CentiScape1.2.1 plugin (Scardoni et al., 2009) fully implemented in Cytoscape 3.2.0.(Shannon et al., 2003). The following parameters were computed:
Diameter: A network diameter is the largest distance between a pair of network nodes.
Shortest path length: It is the shortest distance or path length between a pair of network nodes.
Neighborhood connectivity: The number of neighbors of a node defines its connectivity. The neighborhood connectivity is average of all neighbors of node n.
Connected components of the network: All the nodes that pairwise connect each other constitute the connected component of a network. The fewer the number of connected components, more is the connectivity.
Clustering coefficient of a node is a measure of its tendency to form a collection with other nodes. The clustering coefficient of a network is a measure of the tendency of network nodes to form a cluster. The average clustering coefficient is the average of clustering coefficient of all n nodes constituting the network.
Biological networks follow Power law degree distribution and are scale free. Hence, fitting of Power law to network structure was also checked. The power law states that there exist few numbers of highly connected nodes called hub nodes in a network.
Choke point analysis was performed to identify protein nodes that had maximum number of lipid interactors. Choke point nodes specifically occupy peripheral region of the network. Their inhibition may lead to either deficiency or accumulation of metabolites (Singh et al., 2007; Yeh et al., 2004).
Centrality analysis has been used in various studies on biological networks to rank different nodes according to their essentiality and disease relevance in biological processes (Koschutzki et al., 2008). Studies demonstrated a correlation between centrality values and essentiality of the node, thus posing central nodes as suitable drug targets (Jeong et al., 2001). While centrality analysis assists in identifying potential drug targets in case of pathogens, the central nodes may not be suitable as drug targets in human system due to the induction of possible side effects (Lounkine et al., 2012). For all centrality analyses, average and standard deviation were calculated, and values >2σ were taken to be significant.
The following parameters of centrality were computed:
The degree of a node is the number of other nodes connected to it. Nodes with large degree are called hub nodes and have crucial regulatory function in the cell.
Betweenness centrality (BC) of a network is a measure of number of shortest paths passing through that node. A node with high BC value controls flow of information through the network and is called a bottleneck node. Nodes having high degree and BC values are significant in scale-free biological network, and are termed as Hub-Bottlenecks (HBNs). These nodes are likely to be essential (Hahn et al., 2005; Joy et al., 2005) to the system and often coincide with high degree hub nodes (Goh et al., 2003).
The Closeness Centrality (CC) analysis selects nodes having minimum average distance to all other nodes in the network. The CC value evaluates the probability that a node (protein/lipid) is functionally relevant to several other nodes (protein/lipid) in the network. CC analysis has been used to determine core central nodes of the network (da Silva et al., 2008; Scardoni et al., 2009). Nodes possessing high CC have also been used to identify central metabolites in a large metabolic network (Ma et al., 2003). Usually, the essential nodes of the network are centrally located and have high degree CC and BC (Hahn et al., 2005).
Bridging Centrality (BrC) is a new centrality measure that is used to identify nodes that are situated between highly connected modules, and thus transduce a large amount of information. BrC of a node is calculated as the product of its BC and bridging coefficient; where bridging coefficient is a measure of how well a node is located between highly connected components of the network (Hwang et al., 2008). Bridging nodes are noticeably different from nodes having high degree and BC as they are less lethal, and are regulated independently. Owing to their importance in information flow combined with low lethality, bridging nodes are good candidates for drug targets, especially in the human system (Hopkins, 2008).
Functional annotation and disease gene identification
In order to identify overexpressed pathways, processes and disease genes in the lipid–protein network, KOBAS 2.0 (http://kobas.cbi.pku.edu.cn) (Xie et al., 2011) web server was employed. KOBAS 2.0 server integrates information for 1327 species from five pathway databases (PID, Reactome, KEGG PATHWAY, Panther, and BioCyc) and utilizes information from OMIM, KEGG DISEASE, GAD, FunDO, and NHGRI GWAS Catalog for human disease annotation. For functional annotation, the entire list of network proteins was submitted and parameters used were: annotate and identify, Homo sapiens as the species background, and all databases enabled. Statistically significant hits were identified by applying hypergeometric test, Benjamini-Hochberg FDR correction, and p ≤ 0.05.
Disease cluster analysis
The core disease genes (p < = 0.05) were identified through KOBAS 2.0 server in the lipid–protein network, and extended disease clusters were prepared by taking into account their protein and lipid first interactors. Each extended disease cluster was analyzed in Cytoscape 3.2.0 to demarcate the major lipids and proteins likely to be involved in the propagation of disease. We also mapped approved and candidate drug targets on each extended cluster to identify common potential drug targets to control hyperlipidemia associated pathologies.
Identification of potential drug targets
Two approaches were employed to identify potential drug targets in the LPPIN:
a) The approved commercially successful drug targets of hyperlipidemia were mapped to the disease clusters identified and centrality was evaluated. The presence of an approved drug target in the cluster presents a clear evidence of its involvement in the disease and an avenue for therapeutic modulation of that disease condition. Also, some of the targets present in multiple disease clusters may be useful for polypharmacology. Conversely, drug targets uniquely present in a single cluster can be used for targeted therapy of the specific disease while approved drug targets with high centrality values are likely to be associated with side effects. In order to explore the topological and disease correlation of the approved drug targets in the LPPIN, approved drug targets for lipid disorders were downloaded from DrugBank 4.2 (Knox et al., 2011; Law et al., 2014; Wishart et al., 2006; 2008). The approved drug target list was further refined manually by considering those targets that were for hyperlipidemia (targets for lipid lowering) and were mapped on the LPPIN. b) A number of candidate gene prioritization softwares are currently available. Toppgene (https://toppgene.cchmc.org/) (Chen et al., 2009) is one such publicly available software that allows use of functional annotations and network analysis for candidate gene prioritization. Initially, over-represented terms from the training genes are identified to construct their profile. Using ToppGene, network nodes that possess a high similarity score to the training set based on Gene Ontology annotations, semantics, phenotypes, pathways, and gene expressions are identified. In our study, approved drug targets that were present in the LPPIN were used as training data set and rest of the network genes as test set. During analysis, all training parameters were enabled, FDR correction was applied, p cutoff of 0.05 was set, 1500 random sampling were applied, and minimum feature count was 2. Further, nodes with high centrality were discarded as they are likely to cause side effects (Lounkine et al., 2012), while nodes with high BrC were given higher ranking to shortlist the top ten potential drug targets using the LPPIN. Nodes with high BrC connect the densely connected backbone of high CC nodes to the disease clusters and are likely to be important for progression of the underlying AH to its associated diseases. Potential drug targets were also mapped to the extended disease clusters. Literature search was carried out to find the known role of the potential drug targets that mapped to the disease clusters.
Results
In order to study the pathogenesis of AH and its associated disorders, a network was first constructed from 785 DEG obtained from a publicly available microarray data set of fatty liver of obese versus lean subjects. The first interactors of the proteins were included during network construction using PathwayLinker to yield a PPIN. Separate small lipid–protein interaction networks for 67 lipid species (listed in Supplementary Table S1; supplementary material is available online at www.liebertpub.com/omi) were constructed using STITCH. The multiple lipid–protein networks obtained were again merged, and disconnected components were discarded to obtain a final network consisting of 4088 proteins, 67 lipid nodes, and 20,259 edges. In all, the lipids interacted directly with 438 protein nodes and were localized at one corner of the network as shown in Supplementary Figure S1.
GO and pathway analysis for first interactors of lipids showed that most of the proteins were involved in GPL metabolism, organophosphate metabolism, lipid biosynthesis, GL metabolism, and lipid degradation processes. The over-represented pathways (corrected p < = 0.02) included metabolism of lipids and lipoproteins, GPL metabolism, phosphatidylinositol (PI) metabolism, PI signaling pathway, ether lipid metabolism, arachidonic acid (AA) metabolism, GL metabolism, gastrin-CREB signaling pathway, peroxisome proliferator-activated receptor (PPAR) signaling pathway, platelet activation, signaling and aggregation, Fc gamma receptor (FcγR) mediated phagocytosis, and vascular endothelial growth factor (VEGF) signaling pathways.
Phosphatidylinositol-bis-phosphate (PIP2), cholesterol, and inositol-tri-phosphate (IP3) act at the heart of the network
The LPPIN obtained followed the Power law (Supplementary Fig. S2) with a degree exponent (γ) of −1.696 and R2 value of 0.930. Comparison of the LPPIN with the random networks showed an average clustering coefficient of 0.453 as compared to that of 0.018 in the random networks. Detailed examination of centrality values of LPPIN elements revealed that three lipids and 85 proteins of the LPPIN had high CC values, while two lipids and 52 proteins were identified as HBNs. Supplementary Tables S2 and S3 list the high CC nodes and the HBNs in the LPPIN respectively. 44 high CC nodes were also found to be HBNs. Lipids having high CC values were PIP2, cholesterol and IP3. Together, these three lipids directly interacted with 27 of the high CC protein nodes.
The top CC nodes consisted of RACα serine/threonine-protein kinase (AKT1), tumor protein P53 (TP53), estrogen receptor 1 (ESR1), dual-specificity protein phosphatase PTEN (PTEN), and phosptidylinositol-3-Kinase regulatory subunit α (PIK3R1). Of the proteins having highest CC, ESR1 interacts with cholesterol, PTEN interacts with both IP3 and PIP2, PIK3R1 interacts with IP3, indicating the influence of lipid species on central nodes of the LPPIN. Cholesterol and DAG were lipid HBNs while AKT1, Mothers against decapentaplegic homolog 4 (SMAD4), PIK3R1 and 1-phosphatidylinositol 4,5-bisphosphate phosphodiesterase gamma-1 (PLCG1) were protein HBNs. Supplementary Figure 3 represents CentiScape plots for high CC nodes and HBNs; proteins and lipids for extracting high CC proteins and lipids of the LPPIN, respectively. The nodes that occupy the top right region of the line graph are the high CC proteins of the network
A sub-network constructed from the high CC nodes showed that they were densely connected with each other. No additional nodes were added during sub-network construction of high CC nodes. The sub-network of HBNs was also densely connected, and required the addition of only one additional node. The intersection of high CC nodes and HBNs contained 44 nodes. Figure 1 shows the sub-network of high CC nodes, HBNs, their intersection, and their interacting lipids. GO analysis of proteins constituting the sub-network showed that most of them were involved in response to stimulus processes, and were in direct interaction with PIP2, cholesterol, IP3 and DAG, which are major signaling lipids (PIP2, IP3, and DAG).
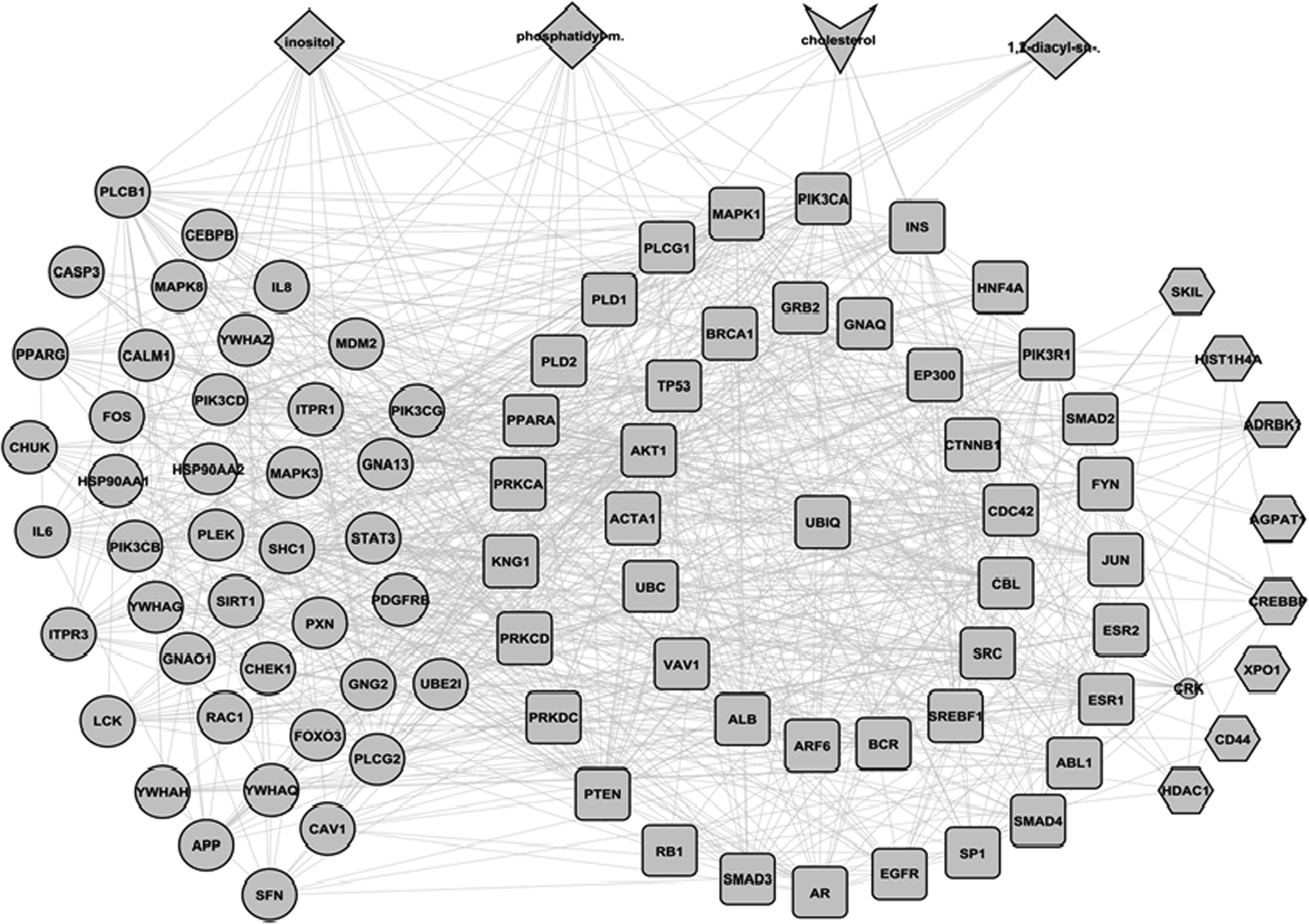
A sub-network of high CC nodes, HBNs, and their interacting lipids: The large circles represent the high CC nodes, hexagons represent HBNs, while yellow squares represent intersection of high CC and HBN nodes. The sub-network was densely connected and required addition of only one additional node (small circle). The lipids that interacted with high CC nodes are shown as diamond, while cholesterol that interacted with the intersection of high CC and HBNs is shown as V.
Choke points (i.e., protein nodes that interacted with a large number of lipids) were also identified from the LPPIN. Like lipids, most of the protein choke points occupied the peripheral region of the LPPIN. Protein choke points in the LPPIN include 1-phosphatidylinositol 4,5-bisphosphate phosphodiesterase beta-3 (PLCB3), Acyl-coenzyme A thioesterase (ACOT) family proteins, and 1, 2, and 4-trans-2-enoyl-CoA reductase (MECR). A complete list of protein choke points and their interacting lipids is provided as Supplementary Table S4.
A novel role for gastrin-CREB pathway in AH
As expected, the LPPIN showed several over-represented pathways related to metabolism of lipids and lipoproteins, notably GPL, GL, and PI metabolic pathways. However, lipids also drive numerous signaling processes via direct and indirect interaction. As metabolism remains an inherent, constituent, and physiological part of the processing of lipids in the biological system, we concentrated on the signaling pathways over-represented in the LPPIN. It can be conceived that an increase in lipid levels under hyperlipidemic conditions leads to impaired signaling pathways comprising of: 1) gastrin-CREB signaling pathway via protein kinase C (PKC) and mitogen activated protein kinases (MAPK); 2) platelet activation, signaling, and aggregation; 3) signaling by interleukin (IL); 4) transcriptional regulation of white adipocyte differentiation; 5) Fc epsilon receptor (FcɛR) signaling; 6) signaling by nerve growth factor (NGF); 7) Fc gamma receptor (FcγR) mediated phagocytosis; and 8) Toll-like receptor (TLR) signaling pathway. Thus, highest pathway enrichment was noted for the gastrin-CREB pathway, which also had the largest number of interactions with lipids. 93 of the gastrin-CREB pathway proteins were present in the network. Of these, 30 nodes had a total of 19 lipids as first interactors, indicating a role for this pathway in AH.
All enriched pathways of the LPPIN show cross-talk with phosphatidylinositol 3-kinase (PI3K)-Akt pathway
The molecular crosstalk between signaling pathways drives signal transduction in order to enable cells, proteins, and molecules to respond to varied stimuli in a unique context (Hartwell et al., 1999). Therefore, crosstalk analysis is necessary for understanding the underlying complexity in complex diseases. As shown in Figure 2, all of the enriched pathways in the LPPIN were involved in molecular crosstalk with the PI3K-Akt pathway. All the enriched pathways included high CC nodes (big red circles). The highest number of high CC nodes was also part of the PI3-Akt pathway. Direct interaction of each pathway with lipid species was also evident (Fig. 2). The list of proteins involved in each pathway is provided in Supplementary Table S5, while the list of interacting lipids in each of the pathways is given in Supplementary Table S6. The systemic role of lipids in pathogenesis of AH can thus be illustrated.
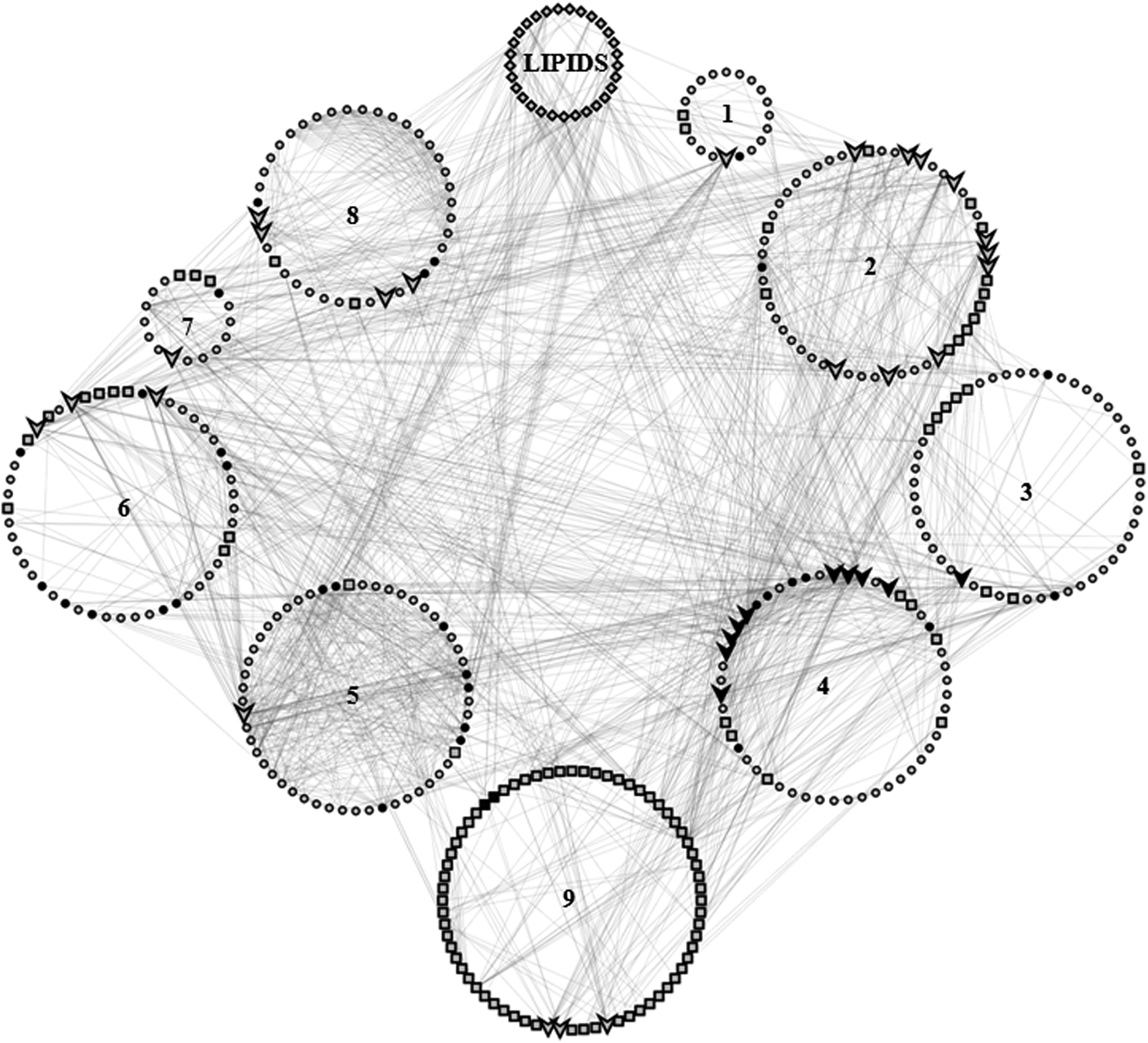
Crosstalk in the LPPIN and convergence on the PI3K-Akt pathway. Each of the circles represents a particular pathway: 1) Toll-like receptor signaling pathway; 2) Signaling by NGF; 3) Fc
Disease clusters CVD, cancer, AD, and T2D figure prominently in the LPPIN and are associated with unique lipids
Numerous studies have established the role of hyperlipidemia in several types of cancer, AD, and T2D (Boden et al., 2004; Chen et al., 2015; Mutoh et al., 2006; Refolo et al., 2000; Sako et al., 2004). Therefore, disease cluster analysis was carried out to determine the disease clusters present in the LPPIN. Proteins related to four main diseases were found to be over-represented in the LPPIN, namely: CVD (682 nodes), cancer (1398 nodes), AD (476 nodes), and T2D (512 nodes). The most common category of CVD was atherosclerosis, while the most common subtype of cancer identified was breast cancer. Forty high CC proteins were found to be common to all the disease clusters, thus linking AH and the four diseases. Of these, 25 high CC proteins had lipids as their first interactors.
Figure 3 shows a clear path between lipids, high CC nodes, and the four disease clusters. The increase in lipid level during AH may directly affect the high CC proteins, thus leading to disease. A list of the proteins present in each disease cluster is provided as Supplementary Table S7.
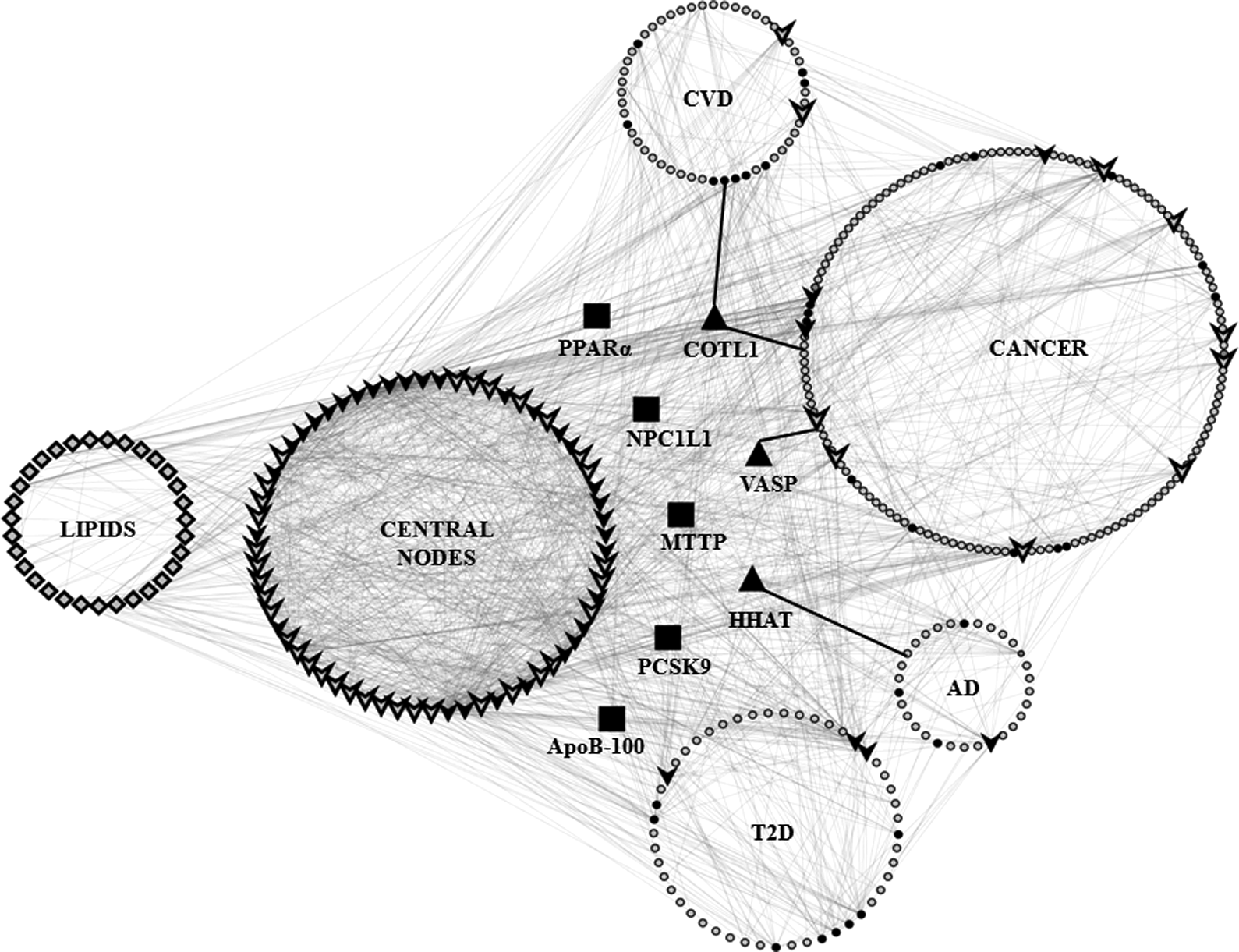
Interactions between lipids, high CC nodes, and four disease clusters in the LPPIN (CVD, cancer, AD, and T2D). The cluster corresponding to lipids (diamond shaped) has interactions with nodes in the high CC (V-shaped) cluster and all the disease clusters (circle). High CC nodes in each cluster are shown as V, and solid black V represent first interactors of lipids. First interactors of lipids in each disease cluster are shown as solid black circles. Approved drug targets common to multiple disease clusters are shown as solid black squares to signify their direct interaction with lipids. Bridging nodes included in the disease clusters are shown as solid black triangles. The nodes present in each cluster are listed in Supplementary Table S7.
An analysis of the interacting lipids in each disease cluster showed the presence of seven lipids common to all the extended disease clusters. The lipids common to all the clusters were TAG, cholesterol, oleic acid, AA, palmitate, SM, and myristate. Additionally, the eicosanoids leukotriene B4 (LTB4), LTC4, LTD4 prostaglandin E2 (PGE2), PGH2, and prostacyclins were found to interact with the proteins in all the extended disease clusters. Our analysis also revealed certain unique lipids occurring in each cluster. Sphingosine-1-phosphate (S1P) and platelet activating factor (PAF) were unique to CVD, while inositol-4,5-bisphosphate was uniquely present in AD. Eleven lipids were specially present in cancer namely; PIP2, IP3, PI, PA, DAG, lauric acid, propionyl-CoA, inositol-1,4-bisphosphate, lysophosphatidic acid, PI-4-phosphate, and PI-3-phosphate.
Pathway analysis of each disease cluster showed that pathways related to lipid and lipoprotein metabolism were over-represented in each disease cluster (except cancer) justifying a link between lipid metabolism and the respective disease (Supplementary Table S8). Comparison of disease pathways with those overrepresented in the entire network identified signaling pathways that drive the AH state to the respective disease cluster. TLR signaling pathway, signaling by IL, and platelet activation, signaling, and aggregation are likely to be involved in the progression of AH to CVD. FcɛR and NGF signaling pathways are likely to be involved in cancer due to AH. The IL signaling pathway is likely to be important for development of AD while transcriptional regulation of white adipocyte differentiation may play an important role in development of T2D due to AH.
Mapping of approved drug targets for polypharmacology of AH-induced diseases
In order to identify targets for the treatment of AH-induced disorders, successful drug targets (of FDA approved drugs) of hyperlipidemia were mapped to the disease clusters identified in the LPPIN. Six successful drug targets for hyperlipidemia were identified from DrugBank, namely proprotein convertase subtilisin Kexin Type 9 (PCSK9), 3-hydroxy-3-methyl-glutaryl-CoA reductase (HMGCR), microsomal triglyceride transport protein (MTTP), peroxisome proliferator activated receptor α (PPARα), Niemann-Pick C1-Like 1 (NPC1L1), and apolipoprotein B-100 (ApoB-100). All the six drug targets were mapped to the LPPIN and the identified disease clusters. Each of the four disease clusters contained at least three successful drug targets for hyperlipidemia, thus showing a clear link between lipid abnormalities and prevalence of these diseases. A complete list of the diseases and the successful drug target associated is provided in Table 1.
Mapping of approved drug targets on the LPPIN showed that PPARα, an approved drug target for AH, constituted one of the high CC proteins of the network. All the approved drug targets of hyperlipidemia were found to be first interactors of lipids. Accordingly, these were involved either in lipid metabolism, regulation of lipid metabolism, lipid transport or synthesis. Especially notable were targets such as MTTP, ApoB-100, and PPARα that were common to all disease clusters and were first interactors of lipids. NPC1L1 was present only in the cancer disease cluster and can potentially be a drug target specifically against AH-induced cancerous condition. Also, PCSK9 was found to occur in the CVD, AD, and T2D disease clusters, indicating its use for polypharmacology of these diseases.
Novel drug candidates for treatment of AH-related diseases
The set of candidate potential drug targets obtained using ToppGene suite was further refined by discarding high CC nodes of the network, as targeting them could be lethal. Instead, nodes that had high BrC value were taken into consideration. The top 10 potential drug targets obtained by using this approach are shown in Table 2. Three of the potential drug targets identified using this approach could also be mapped to the extended disease clusters identified in the LPPIN.
The three potentials targets mapped to the extended disease cluster are coactosin-like binding protein 1 (COTL1), vasodilator-stimulated phosphoprotein (VASP), and hedgehog acyltransferase (HHAT). These three targets have low CC, high BrC, and are first interactors of the core disease genes identified in the network. They demarcate a clear path from the central controlling high CC nodes of AH to the specific disease cluster. Signaling through these nodes is therefore thought to be important for disease progression. The path from the central high CC nodes through these three potential drug targets to the specific disease clusters is shown in Figure 3. Candidate drug targets were located in all clusters except the T2D cluster. Unlike the approved targets, none of the candidate drug targets predicted in this study was first interactors of lipids. The predicted targets for each of the disease conditions are listed in Table 1.
We found that the current set of approved drug targets for hyperlipidemia consists of first interactors of lipids. However, a more fine control of lipid metabolism or synthesis could be achieved by the second/third interactors that essentially act by regulating the activity of the first interactors. The candidate drug targets proposed in this work were found to be critical regulators of lipid signaling. VASP and COTL1 are second interactors of lipid, while HHAT is third interactor of lipid. However, the novel potential drug targets need further study and validation for their role in controlling hyperlipidemia-related diseases.
Discussion
The LPPIN constructed consisted of 4155 (4088 proteins, 67 lipids) nodes and 20,259 edges, of which lipids interacted with only 11% of the protein nodes at the periphery of the LPPIN. Network validation showed that LPPIN followed power law and had topological parameters similar to that of other biological networks. Smaller γ values (−1.696) indicated the important role of highly connected nodes in the network. The R2 value of 0.930 (closer to 1) indicated strong correlation and significant linear relationship between data variables (Sengupta et al., 2009). The clustering coefficient of LPPIN was much higher than that of random networks, indicating higher compactness and biological significance of the LPPIN in comparison with the random networks. Further, the GO and pathway analysis of first interactors of lipids showed that, apart from metabolic pathways, lipids directly activate a large number of signaling processes. This indicates that lipids interact with few proteins but have a wide range of effects as shown by further pathway and disease cluster analysis.
Centrality measures disclosed important proteins and lipids that constitute the core region of the LPPIN and had thus an essential role in AH pathogenesis. Most of the core proteins (AKT1, TP53, ESR1, PTEN, PLCG1, etc.) were in direct contact with core lipids (cholesterol, DAG, IP3, PIP2). Our analyses showed that most of the lipid species interact with metabolic pathways, and were located at the periphery. However, cholesterol, PIP2, IP3, and DAG interact with the central signaling pathways and thus are essential for central control in the LPPIN.
Choke point analysis was done to find protein nodes that consume the highest number of lipid metabolites because their aberrant functioning is likely to be associated with system-wide disturbances. Accordingly, a literature search established the relevance of the choke points identified. Studies on animal models have shown that mice lacking PLCB3 developed skin ulcers (Li et al., 2000). Further, PLC activity was found necessary for macrophage survival in atherosclerotic lesions (Wang et al., 2008). ACOT family members have an essential role in maintaining balance between coenzyme A ester of various lipids and free fatty acids (FFA) (Hunt et al., 2006), which may cause development of dyslipidemia.
Pathway analysis unveiled several signaling pathways involved in pathogenesis of AH, each of which had direct interaction with lipids. The most highly enriched signaling pathway in the LPPIN was the gastrin-CREB signaling pathway via PKC and MAPK. Gastrin is a peptide hormone that has an essential role in proliferation of gastric mucosa (Koh et al., 2000; Sinclair et al., 2004). Upon forming a complex with its cognate receptor, gastrin initiates a signaling cascade that performs many cellular functions such as differentiation, proliferation, growth, apoptosis, secretion, and angiogenesis (Doni Jayavelu et al., 2014).
Serum gastrin levels were reduced in experimental rats fed a high fat diet, thus indicating a link between gastrin and lipid metabolism (Shaodong et al., 2013). While CREB is known to regulate hepatic lipid metabolism through nuclear hormone receptor peroxisome proliferator-activated receptor gamma (PPARγ), the role of the interaction in hyperlipidemia remains to be elucidated (Herzig et al., 2003). The exact role of the Gastrin-CREB signaling pathway is not known.
The established role of other overrepresented pathways in the LPPIN of AH is discussed below:
Platelet activation, signaling, and aggregation
Eighty-five proteins in the LPPIN mapped to this pathway; 23 of the pathway proteins interacted directly with 18 lipids. Dyslipidemia gives rise to a prothrombotic phenotype due to the accumulation of oxidized lipids (Carvalho et al., 1974; Davi et al., 1998). Platelet activation and blood coagulation processes play an important role in hemostasis and thrombosis. Dyslipidemia is associated with platelet hyperactivity, hypofibrinolysis, and hypercoagulability. The increased efflux of non-esterified fatty acids promotes platelet aggregation and thrombus formation (Heemskerk et al., 2002; Wang et al., 2011).
Activated platelets produce membrane blebs and microvesicles that expose PS on their outer surface. Surface exposure of PS enhances the formation and activation of tenase and prothrombinase complex, thus initiating coagulation (Juhan-Vague et al., 1990). A role for the major secreted platelet glycoprotein CD36 in activation of platelets due to oxidized lipids has also been established (Podrez et al., 2007). Therefore the cardiovascular risk associated with hyperlipidemia is as much due to thrombosis as it is due to atherogenesis (Lacoste et al., 1995).
Signaling by interleukin
Fifty-seven proteins of IL signaling pathway were mapped in the LPPIN. Of these, six proteins interacted directly with eight lipids. ILs are a group of cytokines that have immunomodulatory effects on white blood cells (Brocker et al., 2010). IL1 and IL6 are known to increase the hepatic de novo fatty acid synthesis, while IL1 also increases lipolysis (Feingold et al., 1992). IL2 could induce severe chronic hypercholesterolemia through inhibition of lecithin:cholesterol acyltransferase enzyme (Kwong et al., 1997). The members of the IL family perform multiple functions that are regulated by lipids. There are several lines of evidence that show role of IL1, IL2, IL6, and IL17 in hepatic lipid metabolism and chronic inflammatory diseases (Hassan et al., 2014; Netea et al., 2011; Yu et al., 2014). The interplay between inflammation and lipid levels leads to atherogenesis (Getz, 2005).
Transcriptional regulation of white adipocyte differentiation
Forty-one proteins of the LPPIN were mapped to transcriptional regulation of white adipocyte differentiation pathway, of which five proteins were in direct contact with six lipids. Adipocytes have a central role in lipid metabolism by storing FFA as TAG and in glucose metabolism due to the presence of glucose transporter type 4 (Glut4), an insulin-dependent glucose transporter. Additionally, adipocytes possess a large number of secretory and endocrine functions. Cytokines released from adipocytes also take part in a number of inflammatory responses that are responsible for CVD (Morrison et al., 2000).
Studies have shown that FFAs regulate certain steps involved in adipogenesis such as activation of PPARγ, stimulation of adipocyte related genes, and development of preadipocytes to heterogenous adipocytes having lipid droplets of varying sizes (Abbott et al., 1987; Olefsky, 1976). Differentiation of adipocytes can cause the restriction or expansion of adipocyte depots and their functions. Brown fat expansion is beneficial while visceral white adipose tissue expansion is associated with dyslipidemia, insulin resistance, low grade inflammation, and risk of CVD. The largest depot of fat is subcutaneous. It has a role in lipid storage, and secretion of adipokines with beneficial metabolic effects (Ma et al., 2015).
FcɛR signaling and FcγR mediated phagocytosis
Sixty-eight proteins of the LPPIN were mapped to the FcɛR signaling, and 49 proteins mapped to the FcγR-mediated phagocytosis pathways, respectively. In these pathways, nine lipid moieties were found to be directly interacting with 10 and 16 proteins FcɛR signaling and FcγR mediated phagocytosis, respectively. Fc receptors for immunoglobulin are present on the cell membrane of leukocytes and mediate a range of cellular processes consisting of phagocytosis, production/secretion of molecules involved in inflammation, and variation in immune responses.
Upon interaction with FcɛR1, IgE activates mast cells and elicit allergic responses. Many cell types such as macrophages, dendritic cells, eosinophils, and monocytes express FcɛR1 during inflammatory diseases such as atherosclerosis. Signals downstream of FcɛR1 are proliferated through spleen tyrosine kinase (Syk), which includes tyrosine phosphorylation of PLC-γ for IP3 production, subsequent increase in calcium ion concentration, and release of inflammatory mediators from mast cells (Holowka et al., 2000; Zhang et al., 1996). In mice, deficiency of FcɛR1α (a subunit of FcɛR1) led to reduced apoptosis in atherosclerotic plaques and reduced complications of the disease (Wang et al., 2011).
On the other hand, FcγR is also involved in removal and destruction of IgG coated antigens, mast cell degranulation, and antibody-induced cytotoxicity (Sanchez-Mejorada et al., 1998). Oxidized LDL-antibody complex is rapidly taken up by macrophages and monocytes through Fc receptors, leading to formation of foam cells. Many lipid molecules concentrate around the growing phagosome and begin the signaling cascade for phagolysosome formation. FcRI expression and FcR-mediated phagocytosis is regulated by LDL (Bigler et al., 1990; Crowley et al., 1997; Garcia-Garcia et al., 2002). Thus, Fc receptors either through FcɛR1signaling or FcγR-mediated phagocytosis play a key role in pathogenesis of hyperlipidemia.
Signaling by NGF
106 proteins of NGF signaling pathway were mapped on the LPPIN model, of which 11 proteins interacted directly with 12 lipids. NGF, a member of the neurotrophin family, is important for survival and differentiation of neuronal cells. Studies have also shown NGF involvement in the immune and endocrine system (Bonini et al., 2003; Levi-Montalcini et al., 1997). Studies on animal models have confirmed that NGF caused activation of PI3K and followed by increase in intracellular level of lipids species such as phosphatidylinositol-3,4,5-triphosphate (PI-3,4,5-P(3)) and phosphatidylinositol-3,4-bisphosphate (PI-3,4-P(2)) (Carter et al., 1992). NGF activation of sphingosine kinase and synthesis of sphingosine-1-phosphate or ceramide is involved in survival and differentiation of pheochromocytoma cells (Bonini et al., 2003).
TLR signaling pathway
Fifty-five of the LPPIN proteins mapped to the TLR signaling pathway, of which, 5 proteins interacted directly with 9 lipids. Dyslipidemia increases the level of oxidized LDL that affect expression and signaling of TLRs (Su et al., 2011; Xu et al., 2001). TLR2 and 4 play a crucial role in innate immune and inflammatory responses. TLRs are pattern recognition receptors of the immune system that elicit inflammatory reactions in response to exogenous (microbial agents) and endogenous ligands (e.g., components of oxidized LDL). Saturated fatty acids can also excite inflammatory pathways via TLR4 dependent pathway (Holland et al., 2011; Wong et al., 2009). Studies have also shown that expression of TLR4 also increases in macrophages of atherosclerotic plague due to oxidized LDL (Xu et al., 2001). Deregulation of TLR signaling results in number of human diseases. Studies on animal models have shown that TLRs link hyperlipidemia and atherosclerosis as TLR deficiency in LDLr−/− hypercholesterolemic mice reduced atheroma formation (Curtiss et al., 2009; Mullick et al., 2008).
The enriched pathways in LPPIN were found to have molecular crosstalk with PI3K-Akt pathway. PI3K, is a member of the lipid kinase family and generates a secondary messenger PI-3,4,5-P(3) by phosphorylating inositol phospholipids (Fresno Vara et al., 2004). AKT, upon interaction with PI-3,4,5-P(3) is translocated to the plasma membrane where it is phosphorylated and activated by phosphoinositide-dependent kinase (PDK)1 and PDK2 (Osaki et al., 2004). Downstream of AKT, the Mammalian Target of rapamycin kinase (mTOR) triggers a number of metabolic processes. The PI3K/Akt/mTOR pathway is involved in lipid biosynthesis through sterol regulatory element-binding protein (SREBP) dependent transcription of enzymes such as ATP citrate lyase (ACL) and fatty acid synthase (FAS) (Krycer et al., 2010; Yang et al., 2002). Several lines of evidence support the role of the PI3K-Akt pathway in different human diseases (Brugge et al., 2007; Carnero et al., 2008; Hers et al., 2011; Liu et al., 2009; Matsuda et al., 2013).
Disease cluster analysis also provided the lipid profiles that are related to diseases associated with AH. The lipids common to all the extended disease clusters (TAG, cholesterol, oleic acid, AA, palmitate, SM, and myristate) may act as a fingerprint for detection of AH-induced disease states. Our analysis is in accordance with previous lipidomics studies showing that lipids belonging to FA, sterol (Stahlman et al., 2012), GL (Stahlman et al., 2012), and SL groups play key roles in the progression of AH to multiple associated disorders. The analysis further provides possible unique lipid prifiles related to a particular disease cluster.
Two lipids S1P and PAF were distinctly associated with CVD cluster. S1P plays an important role in maintaining cardiac and vascular homeostasis and has a causative role in pathogenesis of various cardiovascular disorders (Levkau, 2013). Similarly, PAF, a phospholipid mediator, is associated with fluctuations in blood pressure and cardiac dysfunction (Montrucchio et al., 2000). Inositol-4,5-bisphosphate was found to be uniquely associated with the AD cluster. Inositol lipids have been implicated in growing cases of AD (Di Paolo et al., 2011). Impaired lipid metabolism is involved in several features of tumourigenesis (Santos et al., 2012). The analysis has identified 11 distinct lipid moieties in cancer, namely: PIP2, IP3, PI, PA, DAG, lauric acid, propionyl-CoA, inositol-1,4-bisphosphate, lysophosphatidic acid, PI-4-phosphate, and PI-3-phosphate.
A comparative analysis between enriched pathways in LPPIN and the disease clusters revealed the major pathological pathways associated with progression of AH to other diseases. Interestingly, literature evidence also supports the involvement of TLR signaling (de Kleijn et al., 2003; Moghimpour Bijani et al., 2012), IL signaling (Fearon et al., 2008; Yamauchi-Takihara et al., 2000), and platelet activation, signaling, and aggregation (Bhatt et al., 2003) in CVD. Similarly, FcɛR (Newton et al., 2012) and NGF signaling (Molloy et al., 2011) pathways have a role in cancer development. Studies also support involvement of IL signaling (Bishnoi et al., 2015; Shaftel et al., 2008; Vom Berg et al., 2012; and transcriptional regulation of white adipocyte differentiation (Lonn et al., 2010; Weyer et al., 2000) in AD and T2D.
As metabolic disorder typified by hyperlipidemia is the basis for the development of a cluster of disease such as CVD, cancer, and AD, the presence of approved hyperlipidemic drug targets in the identified disease clusters may also have implications for polypharmacology of CVD, cancer, AD, and T2D. An approved drug target, PPARα, had high CC value and was constituent of core elements of LPPIN. The use of PPARα agonists for the treatment of dyslipidemia is associated with off target effects such as tumorigenesis (Gross et al., 2007; Roberts-Thomson, 2000). As targeting high CC nodes for therapeutic treatment is likely to induce side-effects (Hopkins, 2008), this provides a possible reason for the drug-induced side effects of PPARα.
Our analysis showed that approved hyperlipidemia drug targets that are known to lower plasma lipid levels can also be directed for treatment of other diseases. MTTP, ApoB-100, and PPARα were found common to all disease clusters and therefore, may be explored for CVD, cancer, AD, and T2D polypharmacology. Contrary to this, NCP1L1 was found to be present uniquely in the extended cancer disease cluster and can be targeted for treatment of cancer. Evidence for the role of NPC1L1 in cancer is available from a recent study showing that knocking out NPC1L1 reduces chances of colitis associated tumourigenesis (He et al., 2015).
We also identified potential drug targets using a combination of candidate gene prioritization and network topological parameters as described in detail in the Methods section. Of the potential drug targets identified in the LPPIN using this approach, three were present in the extended disease clusters. The known role for the identified potential drug targets in the specific disease identified is as follows:
COTL1: CVD, cancer
COTL1 is an important regulator of 5-lipoxygenase (5LO), an important drug target. 5LO acts by selectively inducing synthesis of proinflammatory leukotrienes (Provost et al., 1999; 2001; Rakonjac et al., 2006), and is implicated in CVD pathology (Funk, 2005). COTL1 is also upregulated in, and is a potential biomarker for, small cell lung cancer (Jeong et al., 2011; Sun et al., 2012).
VASP: cancer
VASP is a member of a conserved family of proteins involved in actin regulation (Krause et al., 2003; Tao et al., 2003). Stimulation by prostaglandins and NO donors caused phosphorylation of VASP in platelets and endothelial cells, leading to inhibition of platelet aggregation and fibrinogen receptor activation. Disruption in VASP resulted in hepatic steatosis by impairment of fatty acid oxidation and VLDL-triglyceride secretion. Fatty acid oxidation and TAG accumulation in hepatocytes was reduced by overexpression of VASP on hepatocytes (Tateya et al., 2013). As VASP is involved in cell motility, actin filament assembly and dynamics, overexpression of VASP in cancer cell also contributed to tumor progression and invasion (Dertsiz et al., 2005). Our analysis shows that VASP has a critical role in cancer signaling and is a potential therapeutic target for AH induced cancers.
HHAT: AD
HHAT, a member of the membrane-bound O-acyl transferase (MBOAT) family is a multipass transmembrane enzyme that catalyzes transfer of palmitate to hedgehog protein (Matevossian et al., 2015). Various members of MBOAT family are known drug targets for human diseases such as atherosclerosis, obesity, cancer, AD and viral infection (Chang et al., 2011). However, a specific role of HHAT in AD is yet to be elucidated.
Drug target identification and validation is the most crucial step in process of drug discovery (Hughes et al., 2011; Isik et al., 2015). The basic step in the process of drug discovery consists of developing proper knowledge about disease mechanism by various genetic and proteomics approach. Target identification also involves determination of differentially expressed protein/mRNA levels, genetic association, loss of function studies and bioinformatics approaches (Hughes et al., 2011; Yang et al., 2012).
High throughput interaction studies have resulted in the development of network biology as a tool to explore both local and global aspects of a disease (Isik et al., 2015; Yang et al., 2012). A number of strategies have evolved for identification of novel drug targets in interaction networks. In pathogenic organisms, central proteins that are essential for the parasite survival and have no homologs in host are good candidate drug targets. Choke point analysis can also be performed to recognize essential proteins (enzymes) that either consume or produce an important metabolite, targeting of which could be lethal for the parasite (Kushwaha et al., 2010). However, in the human system, choke point nodes represent essential proteins, aberrant activity of which may lead to a disease. Network topological parameters such as BC (Gupta et al., 2015; Yao et al., 2008) and BrC (Farkas et al., 2011; Hwang et al., 2008) have also been used to predict potential drug targets. Proteins participating in molecular crosstalk present good prospects for drug target discovery (Farkas et al., 2011).
Prioritization of network proteins/genes involves combination of various features and has been widely applied for identification of novel disease-related genes and drug targets (Chen et al., 2009; Grover et al., 2014; Kaimal et al., 2011; Moreau et al., 2012; Tao et al., 2015). The approach utilizes information of disease genes given as a training set, and prioritizes genes in test set based on their overall proximity with diseased genes (Emig et al., 2013). Various algorithms such as random walk, shortest path, and nearest neighbour have been used for candidate gene prioritization (Csermely et al., 2013; Isik et al., 2015). Many of the current prioritization programs use gene expression, functional annotation, and sequence based features (Freudenberg et al., 2002). Several studies have reported the use of gene prioritization programs (Chen et al., 2006; 2009; Kohler et al., 2008; Wu et al., 2008).
In this work, we have proposed specific reuse of established hyperlipidemia drug targets using disease association analysis. We have also used a combination of protein prioritization and network topology parameters to identify potential drug targets. Our approach is somewhat different as we used approved drug targets for hyperlipidemia as training set and prioritized LPPIN proteins based on their close overall proximity with approved drug targets. The candidate drug targets obtained were further rectified by eliminating core proteins (high CC) and considering proteins that had high BrC values. Further, establishing the proximity of the proposed targets to the disease cluster and literature search for their role in the specific disease provides greater emphasis to their selection as drug targets.
Conclusion
A number of studies have shown that there is relation between the nutritional intake, increased lipid levels, and occurrence of disease. With increase in consumption of lipid-rich food and decrease in physical activity, the incidence of metabolic disease has increased manifold. AH is the basic underlying disorder that causes metabolic disease. However, there is a dearth of studies that specifically address its pathogenesis or associated diseases. Therefore, we constructed a LPPIN model by integrating DEG, lipid–protein interactions and protein–protein interaction data to understand the complexity underlying the AH induced pathogenesis.
Topological analysis identified the HBN, AKT as the node with highest CC. Our analysis also showed that proteins interacting with lipids at the core of the network were related to signaling pathways, while proteins interacting with lipids present at the periphery were involved in metabolism. Several high CC nodes had direct interaction with cholesterol, IP3, PIP2, and DAG, and were thus seen to be of high functional relevance in the control of the network. Further, the most over-represented pathways in the LPPIN included eight signaling pathways. The involvement of the gastrin-CREB signaling pathway via PKC and MAPK in the pathogenesis of AH is a novel finding of our study. Crosstalk analysis showed that all the signaling pathways had crosstalk with the PI3K-Akt pathway, correlating with the topological analysis.
The disease cluster analysis highlighted the presence of CVD, cancer, AD, and T2D-related genes in the LPPIN. Pathway analysis of the disease cluster provided insights into their prominent pathways and lipid interactors. TLR, IL, and platelet signaling pathways were over-represented in the AH-induced CVD disease cluster. FcɛR and NGF signaling pathways were involved in AH-induced cancer cluster while IL signaling was implicated in AH-associated AD disease cluster. The presence of approved hyperlipidemia drug targets such as MTTP, PPARα, and ApoB-100 in disease clusters is potentially useful for their polypharmacology.
The approved hyperlipidemia drug targets were used to prioritize LPPIN proteins for their drug target likeliness. The data obtained were further rectified by network topology parameters, and potential drug targets were identified. COTL1, VASP, and HHAT were promising potential drug targets due to their presence in the extended disease clusters. An advantage of including protein–lipid interactions in the network was that analysis of the lipid interacting properties of the approved as well as the proposed drug targets could be undertaken. All the approved drug targets were first interactors of lipids, while the potential drug targets identified had lipids as second or third interactors. It is possible that a finer control of lipid signaling may be achieved by regulation of these elements. Our work provides novel insight into the systemic role of lipids and possible novel drug targets in pathology of AH and the associated diseases.
Footnotes
Acknowledgments
S.R. acknowledges financial support from Netaji Subhas Institute of Technology.
Author Disclosure Statement
No conflicting financial interests exist.
Abbreviations Used
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.