
Abstract
Abstract
Cancer and cardiovascular disease (CVD) have a common co-occurrence. Both diseases display overlapping pathophysiology and risk factors, suggesting shared biological mechanisms. Conditions such as obesity, diabetes, hypertension, smoking, poor diet, and inadequate physical activity can cause both heart disease and cancer. The burgeoning field of onco-cardiology aims to develop diagnostics and innovative therapeutics for both diseases through targeting shared mechanisms and molecular targets. In this overarching context, this expert review presents an analysis of the protein–protein interaction (PPI) networks for onco-cardiology drug discovery. Several PPI complexes such as MDM2–TP53 and CDK4–pRB have been studied for their tumor-suppressive functions. In addition, XIAP–SMAC, RAC1–GEF, Sur–2ESX, and TP53–BRCA1 are other PPI complexes that offer potential breakthrough for onco-cardiology therapeutics innovation. As both cancer and CVD share biological mechanisms to a certain degree, the PPI network analyses for onco-cardiology drug discovery are promising for addressing comorbid diseases in the spirit of systems medicine. We discuss the emerging architecture of PPI networks in cancer and CVD and prospects and challenges for their exploitation toward therapeutics applications. Finally, we emphasize that PPIs that were once thought to be undruggable have become potential new class of innovative drug targets.
Introduction
Most biological processes include protein interaction networks. Protein–protein interactions (PPIs) serve as the backbone of signal transduction pathways and networks in a variety of physiological processes. PPIs that were once thought to be undruggable have become a potential new class of targets due to their significant roles in both normal as well as diseased conditions. The nature of PPI networks has been analyzed to obtain disease-related information (Ideker and Sharan, 2008; Jonsson and Bates, 2006; Waksman and Samson, 2005). More recently, highly useful PPI interactomes have been identified by exploiting a variety of proteomic analysis for understanding the role and function of proteins (Dobson et al., 2014). As an example, interaction network of TP53 is shown in Figure 1 (Oughtred et al., 2018; Stark et al., 2006).
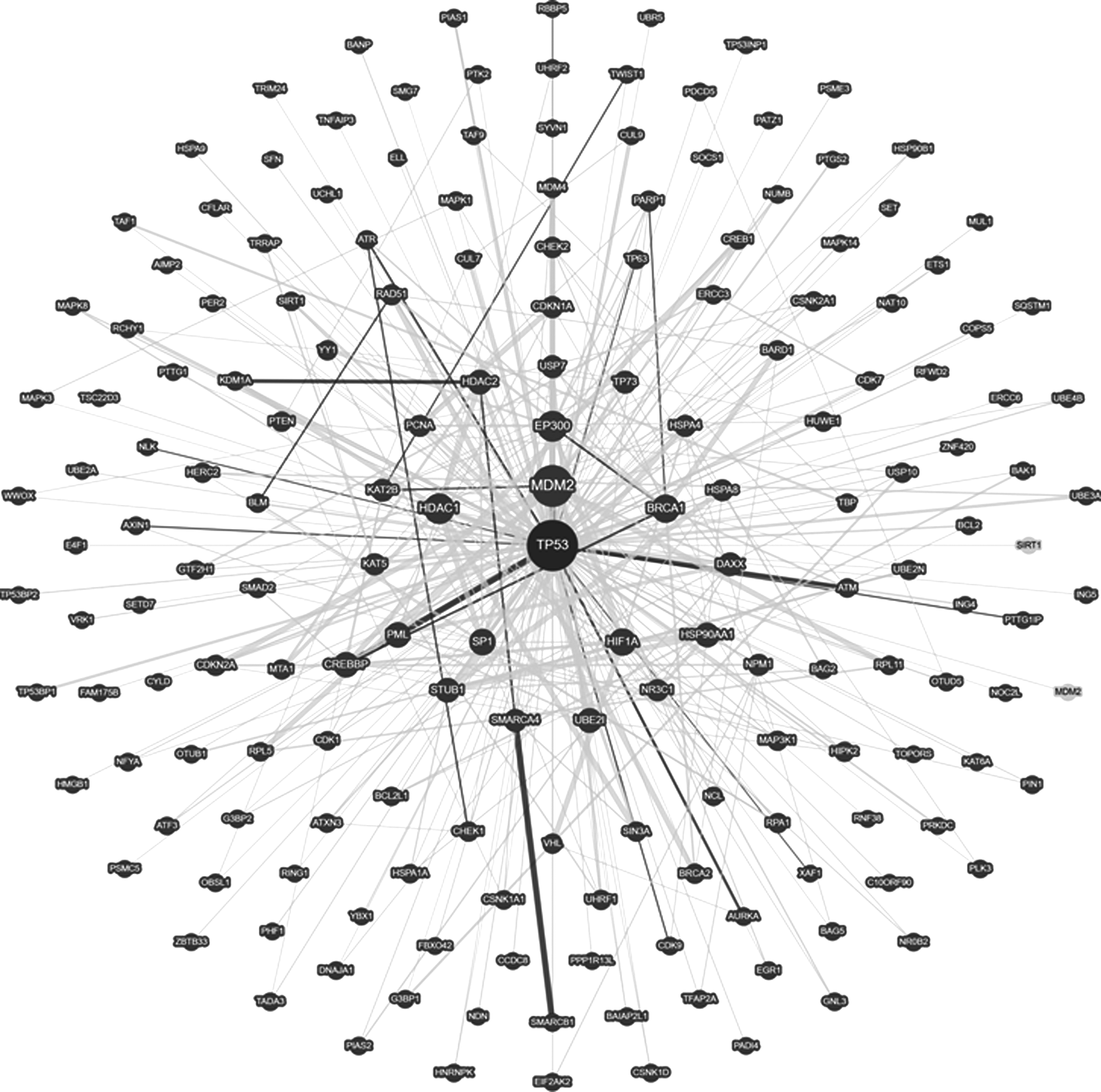
It has been found that genes related to similar disorders demonstrate higher expression profiling similarity among the transcripts as well as a higher likelihood of physical interactions between the encoded proteins. Furthermore, many essential human genes have been reported to encode hub proteins, which are expressed widely in most tissues. These observations are suggestive of the existence of distinct disease-specific functional modules having a pivotal role in the human interactome (Lage, 2014; Li et al., 2010).
Cancer and cardiovascular disease (CVD) have a common co-occurrence. Both diseases display overlapping pathophysiology and risk factors, suggesting shared biological mechanisms. Conditions such as obesity, diabetes, hypertension, smoking, poor diet, and inadequate physical activity can cause both heart disease and cancer.
An organized investigation of the proteins encoded by cancer genes (cancer proteins) in the human interactome may help in the identification of new candidate genes, and consequently an intense understanding of the genetic landscape of cancer (Sun and Zhao, 2009). Due to the emergence of cancer genomics, extensive biological and clinical studies have made way for identification of many protein interaction hubs. Such cancer-causing PPIs have become promising therapeutic targets. In view of cancer gene/protein interactome, multidimensional, high-throughput functional genomics/proteomics methods are required to connect sequence information to biochemical and medical information (Dobson et al., 2014; Goh et al., 2007). Thus, an organized investigation of cancer proteins in the human PPI network is helpful in obtaining significant biological information for detecting the molecular mechanisms of cancer (Ivanov et al., 2013).
Along with cancer, CVDs are a group of diseases of the heart and blood vessels and one of the foremost global causes of death. Monitoring their complex pathogenesis, which is influenced by genetic, environmental, and lifestyle factors, has grown substantial consideration. The structure of the human PPI network has been exploited to find important CVD genes that could be targeted for therapeutic applications (Sarajlić et al., 2013). Thus, cancer and CVD, taken together, are common causes of sickness and death, and analysis and understanding of their co-occurrence rate have important implications for public health and patient care (Duarte et al., 2017). Both the diseases, commonly considered two separate disease entities, suggest a shared biological mechanism, as they possess various similarities and possible interactions, including several similar risk factors (Johnson et al., 2016).
Even though chronic inflammation is a crucial feature of the pathogenesis and progression of both cancer and CVD, several other mechanisms can be found at their node. Nowadays research is focusing on efforts in onco-cardiology for disease prevention and treatment, in terms of balancing the potential effects from one disease to the other (Koene et al., 2016; Li et al., 2017).
This expert review presents the emerging architecture of PPI networks in cancer and CVDs, and the implication of these networks in current attempts for interpretation and intervention of therapeutic drug by exploring the relationship between the connecting around proteins in PPI networks of both cancer and CVDs.
Role of PPI in Cancer Therapeutics
PPIs play essential roles in cancer by linking networks that allow the attainment of characteristic features and have varied roles in driving and maintaining the growth of cancer cells. In this regard, Kar et al. (2009) analyzed cancer and hub proteins in human PPI networks from a structural as well as behavioral point of view at the global level. Cancer-related proteins tend to interact with their partners through multi-interface hubs, which consists about 56% of cancer-related proteins, while 44% being single interface. These findings made way for discovering new cancer targets as well as the details of binding regions of putative cancer drug candidates. A number of PPI complexes, including MDM2–TP53 and CDK4–pRB, have been reported to play key roles in neutralizing tumor-suppressive functions (Hanahan and Weinberg, 2011; Ivanov et al., 2013).
Overexpression of the MDM2 protein reduces the ability of cell to activate the TP53 pathway under stress conditions. Identifying compounds that prevent the interaction between TP53 and MDM2 is therefore a striking strategy for the treatment of human cancers (Chène, 2003; Shangary and Wang, 2009; Vassilev et al., 2004). Among other protein complexes that expand the list of promising protein–protein targets are TP53–BRCA1, XIAP–SMAC, RAC1–GEF, Sur–2ESX, and so on (Arkin, 2005). Thus, PPI analysis in cancer is emerging as a promising approach for the identification of targets for drug development. Furthermore, the analysis of these proteins may also be an efficient way to discover novel cancer genes and biomarkers (Auffray et al., 2009; Clermont et al., 2009; Sanz-Pamplona et al., 2012; Xu and Li, 2006).
Interaction of the mutant and wild-type TP53 with that of wild-type BRCA1 (breast cancer-associated protein 1) as novel and promising target against breast cancer has been reported (Tiwari et al., 2018). The study revealed that interaction of BRCA1 with mutant TP53 was more noticeable and resulted in elevated expression level of mutated TP53, displaying a dominant negative gain of function and obstructing the function of wild-type TP53, leading to tumor progression (Fig. 2).
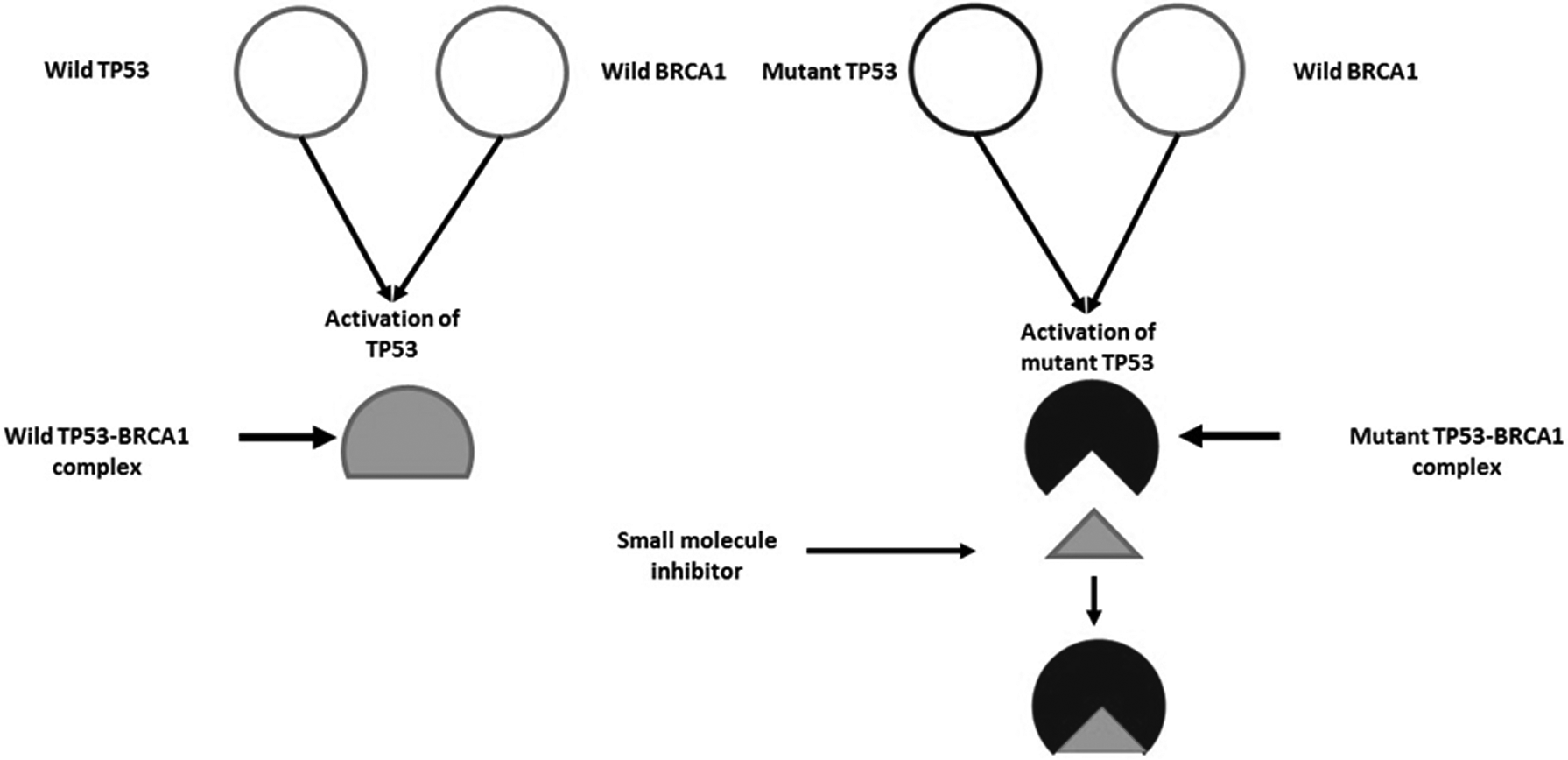
TP53 and BRCA1 interaction in wild and mutant state and its inhibition with small molecule inhibitor. BRCA1, breast cancer associated protein 1.
Role of PPI in CVD Therapeutics
Similar to PPI in cancer, in CVDs also, the knowledge of the interacting proteins allows us to characterize the molecular and cellular mechanisms of the disease. A number of studies have been performed in this direction (Dekkers et al., 2010). Thus, a study involving association across several pathway members, using network-based approaches, revealed a genome-wide association (GWA) of coronary heart disease (CHD). They observed that networks of genes that signified experimentally determined PPIs are also complimented with genes associated with the risk of CHD. They used a database of PPIs to accumulate 8351 unbiased protein complexes and matching gene sets. By incorporating a GWA study with PPI data, they were able to successfully identify a set of candidate susceptibility genes for occurrence of CHD, which would not have been possible with a single-marker GWA analysis (Jensen et al., 2011).
In another study, Sarajlić et al. (2013) proposed a methodology that examined the PPI network along with corresponding genes involved in CVDs. Li et al. (2014), analyzed multilayer interactions in cardiovascular system biology, which included cardiovascular drugs, targets, genes, and disorders. It was revealed that cardiovascular disorders share more etiological similarities with each other in global disease-disease network. Furthermore, a close relationship between hypoxia and CVDs in the human interactome has been demonstrated (Wang et al., 2014). It was observed that hypoxia genes are much closer to CVD genes in the human protein interactome. It was also observed that hypoxia genes play significant bridging roles in connecting different CVDs.
Currently, there are several treatment strategies for CVD that interfere with cyclic adenosine monophosphate (cAMP) signaling in the heart. The existence of specific complexes governing PPIs gives an opportunity for developing new therapeutic strategies to control cAMP-dependent signaling that is involved in CVD pathologies. Thus, directly altering a specific cAMP signalosome by targeting PPI in complexes is an effective strategy due to its firm roles in the functioning of heart, for example, Ca2+ handling and excitation-contraction coupling, hypertrophic stress responses, and controlling electrical signaling (Calejo and Taskén, 2015).
Similarly, Jiao et al. (2018), investigated PPIs associated with myocardial infarction (MI) using a computational approach. By analyzing gene expression profiles associated with MI, several dysfunctional complexes were identified. Out of 24 identified complexes, 22 protein complexes exhibited interactions with MI-related genes, thus indicating a role in MI development. These protein complexes may help in improving our understanding of the molecular mechanisms of MI and can also be used as biomarkers in the future.
Why Study Cancer and CVD Simultaneously?
As mentioned above, cancer and CVD possess a number of similar risk factors and a widespread connection between the risk factors. Thus, there are millions of cancer survivors who are at risk of developing CVD (Farmakis et al., 2016; Koene et al., 2016). There are epidemiological reports that suggest smoking, obesity, poor diet, and inactivity can cause both CVD and cancer (Fig. 3). CVDs and their risk factors are adversely affecting oncological results, leading to increased cancer mortality. One of the risk factors, obesity, is mediated by several other factors such as diet, body fat distribution, physical activity, hormones, chronic inflammatory burden, and oxidative stress. All these factors have also been reported to have an intricate relationship with cancer and CVD.
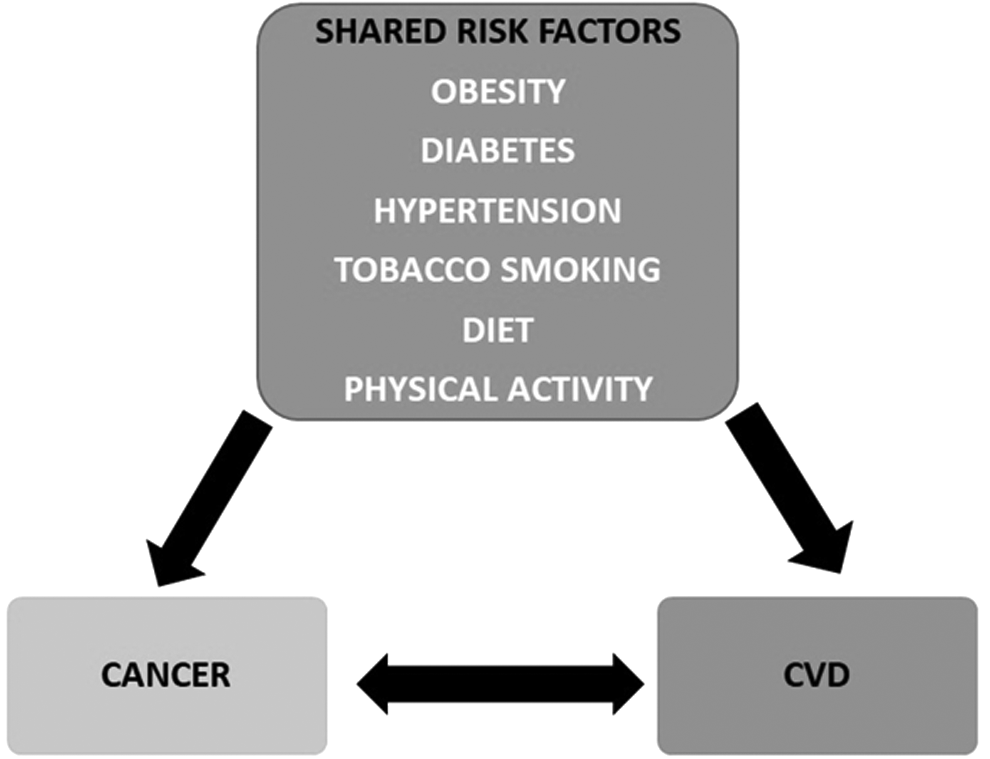
Obesity, diabetes, hypertension, tobacco smoking, diet, and physical activity as two-way risk factors in cancer and CVD. CVD, cardiovascular disease.
For example, interleukin 6 (IL-6), TNF-α, leptin, angiotensinogen, resistin, and C-reactive protein (CRP) possess antiapoptotic and proangiogenic properties. Cytokine produced by adipose tissues is IL-6; it increases blood pressure and stimulates hepatic production of CRP, which is also an inflammatory marker of CVD. Overexpression of IL-6 inhibits cancer cell apoptosis, stimulates angiogenesis, and has a role in drug resistance, causing tumor progression. Along with this, cardiovascular risk factors like hypertension in a cancer survivor pose greater risk than hypertension in an individual without cancer. Each added risk factor found in a cancer survivor appears to increase CVD risk to a greater magnitude (Ridker, 2000; Roy et al., 2015; Steppan et al., 2001; Whelton et al., 2014).
Cancer treatment consists of chemotherapy, radiotherapy, and surgery to prolong life and provide cure. This combination of therapies causes cardiotoxicity that has shown significant impact on prognosis and survival of cancer patients. This has laid the foundation of a new interdisciplinary field of cardio-oncology (Cubbon and Lyon, 2016; Mozaffarian et al., 2016). Thus, due to cardiotoxicity, there is an increasing group of patients with cancer and co-occurring CVD (Clark et al., 2017; Mehta et al., 2018). This combination of therapies for cancer treatment has been reported to cause direct cardiovascular damage or due to accelerated atherosclerosis (Aleman et al., 2014). Bradshaw et al. (2016) conducted a study on breast cancer patients and concluded that breast cancer survivors are more prone to CVD-related death compared to women without breast cancer and this increase in risk is demonstrated about 7 years after diagnosis.
In addition to this, breast cancer patients with BRCA1/2 mutation, treated with anthracycline, tend to have cardiac dysfunction (Barac et al., 2016). Stratifying CVD risk at the time of cancer and having knowledge of the pathways developing CVDs in cancer patients to maintain an equilibrium between both the diseases is a vibrant approach (Schoormans et al., 2016). This calls for efforts to identify risk factors and interferences that can be utilized during this treatment period to reduce the excess burden of CVD in cancer patients.
The common risk factors between cancer and CVD correspondingly manifested at the molecular level in the form of PPI. The studies pertaining to proteins commonly involved in cancer and CVD are very limited. A description of the key PPI involved in cancer and CVD is given in the following section.
Proteins Commonly Involved in Cancer and CVD
Tumor suppressor protein 53
TP53 is a powerful tumor suppressor whose functions are induced by a vast range of stress signals, showing its effect in maintaining genome integrity and proper cell proliferation. Activation of TP53 leads to cell cycle arrest, deoxyribonucleic acid (DNA) repair, senescence, or programmed cell death (Collavin et al., 2010). More than half of human tumors have been reported to carry TP53 mutations. TP53 accumulation has been reported to possess antiangiogenic property, showing a vital function in the changeover from cardiac hypertrophy to heart failure (Sano et al., 2007). In this direction, interaction of TP53 and Hif-1 and negative way (inhibition) has been reported to play a crucial role in impaired cardiac angiogenesis and systolic function. Contrarily, inhibiting TP53 accumulation alone (by angiogenic factors) may restore cardiac dysfunction but at the same time risk for cancer is possible. Therefore, the approaches involving PPI, such as TP53 and Hif-1, are more advantageous.
Breast cancer associated protein 1
BRCA1 is another important tumor suppressor protein that physically associates with TP53, leading to stimulation of TP53-dependent transcription (Jiang et al., 2011; Rasti and Azimi, 2015; Zhang et al., 1998). It acts as TP53 co-activator, leading to increased TP53-dependent gene expression, thus easing its role as tumor suppressor (Ouchi et al., 1998). About 50% of inherited breast cancer cases and 80% of families susceptible to both breast and ovarian cancer carry BRCA1 mutation (Zhang et al., 1998). In addition to breast, ovarian, and prostate cancer in women and men, BRCA1 has also shown its role in other malignancies like colorectal and pancreatic cancer (Levy-Lahad and Friedman, 2007).
BRCA1 also has a role as a guard of cardiac function and survival. It has been reported that in mice, loss of BRCA1 in cardiomyocytes resulted in increased cardiomyocyte apoptosis. It has been found that ischemia induces double-strand breaks and upregulates BRCA1 expression in human adult and fetal cardiac tissues. Such data designate BRCA1 as an essential adaptive response protein with its role in protecting cardiomyocytes from DNA damage, apoptosis, and heart dysfunction (Shukla et al., 2011).
RAD51 recombinase
RAD51, which plays a major role in homologous recombination of DNA during double-strand break repair (DDR), has been reported to be involved in many cancers, for example, breast cancer and pancreatic cancer. RAD51 depicts an important link between its subcellular localization and clinicopathological and molecular features. Its outcomes suggest that the cytonuclear trafficking of DDR proteins might play a role in breast cancer development and progression. Thus, cytoplasmic overexpression and lack of nuclear expression of RAD51 have been reported to be associated with aggressive tumor progression, together with aberrant expression of key DDR proteins, including BRCA1. An opposite trend of expression of RAD51 (i.e., nuclear overexpression and lack of cytoplasmic expression of RAD51) has been correlated with high rate of breast cancer survival (Alshareeda et al., 2016; Nagathihalli and Nagaraju, 2011).
It has been reported that BRCA1 physically interacts with RAD51 to regulate its nuclear transport for DSB repair. A study conducted by Shukla et al. (2011) demonstrated that deletion of exon 11 (responsible for interaction and co-localization of RAD51) of BRCA1 in mice compromised RAD51-dependent DNA repair system and led to death by congestive heart failure compared to the live wild ones (consisting of exon 11). Furthermore, RAD51 foci formation was also found to be upregulated with MI- and ischemia-induced BRCA1 upregulation due to increased DSB repair, suggesting its foreseeable role in CVDs as well.
Serum TGF-β1 and mothers against decapentaplegic homolog 3/transforming growth factor beta
SMAD3 is essential for TGF-β-mediated cancer progression, as both genetic deletion and pharmacological inhibition of SMAD3 lead to a significant inhibition of cancer growth, invasion, and metastasis. However, it has been shown that TGF-β signaling pathway has contrasting effects on cancer cells by acting as either a tumor promoter or a tumor suppressor. It is due to some distinct epigenomes and transcription factors that instruct the gene targets downstream of TGF-β signaling in deciding its cell type-specific effects. Genome-wide mapping of SMAD3 binding patterns in breast tumor initiating cells suggested the role of distinct epigenetic states responsible for opposing effects of TGF-β (Tang et al., 2017; Tufegdzic et al., 2015; Van Der Linde et al., 2012).
Furthermore, in connection with CVDs, a study conducted by Chen et al. (2014) evaluated serum TGF-β and SMAD3 concentration in 279 patients with coronary artery disease and 268 controls without coronary artery disease. The data suggested that serum TGF-β and SMAD3 levels were closely associated with coronary artery disease. Thus, TGF-β and SMAD3 may serve as useful markers for commonality between cancer and CVD.
Cyclin-dependent kinase inhibitor 2A
CDKN2A gene is found to be mutated or inactivated in many types of human cancers, thus bearing a resemblance to many classic tumor suppressor genes. CDKN2A may prove to be as important a regulator of cell growth as TP53. Lymphoma, skin cancer and melanoma, pancreatic cancer, lung cancer, and gastric cancer are a few examples in which its activation or inhibition has been studied. Therefore, reactivation of silenced CDKN2A or the inhibition of epigenetic suppression of the gene could be a rational strategy for the prevention or treatment of cancers. The regulation of gene expression on CDKN2A has been found to be associated with many other proteins such as TP53, BRAF, ATM, PTEN, KRAS, and PI3-K (Foulkes et al., 1997; Zhao et al., 2016). The function of CDKN2A gene and protein products has also been mechanistically linked with CVDs (Hannou et al., 2015).
A study conducted by Wouters et al. (2017), revealed that the modulation of epicardial adipose tissue development by CDKN2A establishes a possible link between the genetic association of the CDKN2A locus and CVD risk. It was shown that CDKN2A protein was expressed in normal as well as atherosclerotic human coronary arteries.
Ataxia telangiectasia mutated
The ATM gene is activated by DNA damage and involved in cell cycle arrest, apoptosis, and DNA repair. Polymorphisms carried by ATM gene are found to be important factors for predicting individual susceptibility to lung cancer (Kim et al., 2006). Several studies have associated single-nucleotide polymorphism of the ATM gene with increased incidence of lung cancer. The ATM gene/protein has been found to predict the response to radiotherapy, chemotherapy, and prognosis of lung cancer, thus confirming its role as a new potential target for the diagnosis and treatment of lung cancer. As investigated by Xu et al. (2017), ATM gene mutation can lead to multiple system impairment and increased tumor progression. Along with this, ATM is involved in many cytoplasmic processes and responses, which may induce metabolic and cardiovascular problems (Espach et al., 2015).
Recent studies have provided insight into the role of ATM in cardiac remodeling, following β-AR stimulation and MI, providing evidence that ATM modulates cardiac remodeling by affecting inflammatory response, apoptosis, fibrosis, and hypertrophy in the heart (Thrasher et al., 2017). Thus, therapeutic activation of ATM could possibly be a novel approach for the prevention or treatment of CVD as well.
Computational Approaches for Targeting PPIs
In view of significance of PPI in many aspects of cellular processes under healthy and diseased conditions, several high-throughput experimental methods such as yeast two-hybrid system, immunoprecipitation, mass spectrometry, and protein microarray have been developed to analyze such interactions (Rao et al., 2014). These methods, although useful, offer disadvantages such as too high cost as well as high rates of errors, in terms of false negatives and false positives. To overcome these drawbacks, complex properties of PPI data have been addressed using computational techniques (Goh et al., 2016; Yu and Fotouhi, 2006). In addition to analyze interactions of two proteins, computational methods have also been applied to predict protein–peptide interactions to find out interacting motifs involved in various biochemical processes as well as to design pharmaceutical peptides (Fallaha et al., 2017).
Many computational methods for PPI analyses have been applied that range from comparative genomics-based methods to those of data integration. Thus, few examples of these include gene neighboring, gene fusion, phylogenetic profiling, co-expression analysis, protein–protein docking, and molecular dynamics (MD) simulation (Fig. 4) (Browne et al., 2010; Ding and Kihara, 2018; Li et al., 2010; Zahiri et al., 2013).
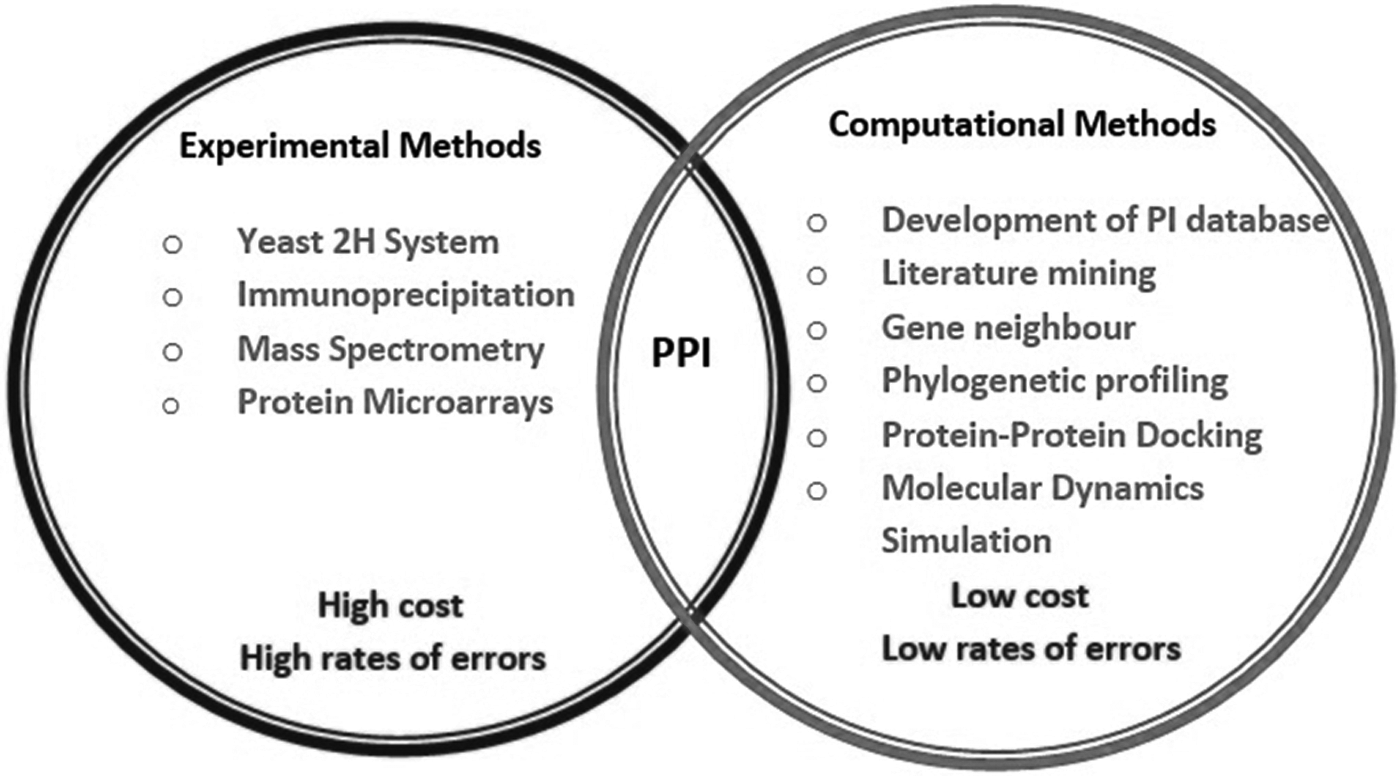
Various experimental and computational methods for PPI analysis. PPI, protein–protein interaction.
The conserved gene sequences across the species are found to be functionally correlated during the course of evolution. Genome-wide analysis methods exploit this complete genome sequence information for interaction prediction (Pitre et al., 2008). The conservation of gene sequence across species yields information about the evolution of the genome, and hints at which genes may be functionally correlated. Keeping this in view, Jensen et al. (2011) conducted a protein network-based genome-wide analysis for CHD by using genome-wide analysis data from two individually homogeneous studies and integrated the gene-wise p-values with a large database of PPIs. A gene complex of 19 candidate genes, which has been suggested to play a role in incident CHD, was identified benefiting from the complementary nature of genetic variation and biochemical data.
With regard to cancer and CVD, Dobson et al. (2014), used biostatistical and genome-wide analysis methods to compare the PPI network properties, focusing on two sets of network descriptors namely network centralities and network clusters. The results showed that there are some network properties common to both cancer and CVD, which can also be found in other diseases. It was suggested that there are several proteins associated with both cancer and CVD and may act as disease mediators.
The phylogenetic profiling portrays the presence of homologous regions across a series of organisms. Support vector machine has improved the accuracy of function prediction, while analyzing proteins with similar phylogenetic profiles, and may be functionally linked (Vert, 2002).
MD simulations are useful for analyzing conformational flexibility of the complex and assessment of PPIs in a dynamic environment in full atomistic molecular mechanics force-field background. Molecular docking, on the other hand, is suitable for creating a hypothesis about the mode of molecular interactions (Mulholland et al., 2016). Thus, MD simulations allow for an in-depth analysis of structural and functional aspects of PPIs and provide valuable insights into PPI mechanisms as well as helps in the design of PPI modulators.
By using high-performance computing resources and improving algorithms and software, the use of MD simulation can prove to be a promising approach to understand PPIs and design molecules for their modulation (Hospital et al., 2015; Perilla et al., 2015; Rakers et al., 2015). In cancer, TP53-azurin complex, TP53-MDM2 complex, and TP53-BRCA1 complex have been studied using MD simulation approach. The proteins such as TP53 and BRCA1 have also been studied for their role in CVD (Chen and Luo, 2007; Taranta et al., 2009; Tiwari et al., 2018).
Conclusions and Outlook
PPIs provide a strong platform for compiling and analyzing large and densely connected networks based on their biological function and cellular mechanism. Several PPI network-based methods focusing on human diseases have suggested a frequently shared interaction between disease-associated proteins with other disease proteins. A continuously developing pattern highlighting a link between cancer and CVD through shared risk factors calls for more effective and preventive health care strategies for both the diseases. An elevation in co-occurrence of a number of CVD conditions such as heart failure, CHD, and MI, seen widely across various types of cancers, came into spotlight by using network methods. As per their shared risk factors, along with the susceptibility carried by cancer patients, becoming prone to CVDs makes such type of study more significant.
Several computational techniques such as genome-wide analyses, protein–protein docking, and MD simulations for such protein interaction analysis have been developed for speeding up such high-throughput studies. Therefore, PPI interaction analysis, taking both cancer and CVD into consideration, could be a breakthrough in the field of therapeutic interventions for both diseases that are not only often comorbid but also deadly. The understanding of PPI networks as therapeutic targets offers significant prospects as a new drug discovery strategy that addresses comorbid diseases broadly.
Footnotes
Acknowledgments
Funding support from Department of Higher Education, Government of U.P., Lucknow, under Institute for Development of Advanced Computing and Centre of Excellence Scheme; Department of Biotechnology (DBT), New Delhi, under Bioinformatics Infrastructure Facility and Department of Science and Technology, New Delhi, under Promotion of University Research and Scientific Excellence (DST PURSE) program are gratefully acknowledged.
Author Disclosure Statement
The authors declare there are no conflicting financial interests.