
Abstract
The goal of health equity is for all people to have opportunities and resources for optimal health outcomes regardless of their social identities, residence in marginalized communities, and/or experience with oppressive systems. Social determinants of health (SDOH)—the conditions in which we are born, grow, live, work, and age—are inextricably tied to health equity. Advancing health equity thus requires reliable measures of SDOH. In the United States, comprehensive individual-level data on SDOH are difficult to collect, may be inaccurate, and do not capture all dimensions of inequitable outcomes. Individual area-based indicators are widely available, but difficult to use in practice. Numerous area-level composite indices are available to describe SDOH, but there is no consensus on which indices are most appropriate to use. This article presents an analytic taxonomy of currently available SDOH composite indices and compares their components and predictive ability, providing insights into gaps and areas for further research.
Introduction
Background
Health equity is the attainment of the highest level of health for all people, where everyone has a fair and just opportunity to attain their optimal health. 1 The Biden administration has tasked every agency in the US Department of Health and Human Services to prioritize health equity in every project. 2
Social determinants of health (SDOH) are the conditions in the environments where people are born, live, learn, work, play, worship, and age that affect a wide range of health outcomes. 3 The field of public health has long been interested in composite measures of SDOH. 4 Many countries have developed single comprehensive, multidomain area-level composite measures for their population health and quality improvement efforts. 4 In contrast, the United States has many competing SDOH composite measures and indices comprising different factors, focusing on varying populations of interest.
How can we choose the best SDOH composite index for our purposes? The arguments for and against any particular index are complex and require background knowledge and measurement expertise to understand. This clear and pressing need demands an up-to-date practical focused analytic summary to guide researchers and practitioners through a challenging measurement landscape, which is now more important than ever.
Recent publications published by ASPE, 5 Health Affairs, 6 and RTI Press, 7 among many others, have provided information about SDOH composite indices in current use in the United States. Such information is based on the authors' specific knowledge, use cases, and research needs, but the field is nuanced. In this analytic review, the aims are to broaden the conversation to discuss methodological concerns that have not been addressed elsewhere.
Strengths and drawbacks of composite indices
Area-level composite indices of SDOH can be helpful to population health research and practice in numerous ways. For example, they
allow for targeted delivery of efforts, such as interventions, surveys, and/or funds, to improve conditions in areas that have the greatest need or highest risk of poor health outcomes;
offer parsimony by distilling the characteristics of an area into a single numeric summary;
are useful in mapping and other visual displays of quantitative information to tell stories about a place that are informed by local data; and
are easier to visualize than multiple sequential maps or charts using single-item indicators.
Composite SDOH indices have been criticized for a number of reasons. 8 They are, by definition, reductive and can lead people to draw simplistic analytic or policy conclusions. 9 They add increased methodological complexity and require substantial testing and analysis. Unsound methods can affect the validity of conclusions drawn from analyses that may or may not generalize across time and space. For instance, weighted averages have been criticized, especially when they use arbitrary weights that do not capture the true main effects of the components. 10 The subjective nature of some approaches to creating composite indices, and the resulting loss of information, means that using a composite index may not be the right approach for every analysis.
Single-item measures may provide more useful contextual data on SDOH than a composite index, but they can be cumbersome to handle in practice. Individual indicators related to SDOH can be obtained from the US Census and other sources, but the data must be selected, downloaded, cleaned, and processed (eg, by linking to the appropriate geographic unit). Multivariable regression models require certain distributional assumptions, which may necessitate additional manipulation, and models may fail to converge when multiple single-item measures are collinear. In contrast, it is sometimes easier for the general public to understand and interpret familiar single-item measures, such as the percentage with low income. If desired, individual indicators can also be provided alongside composite indices, for context (as shown in Fig. 1).
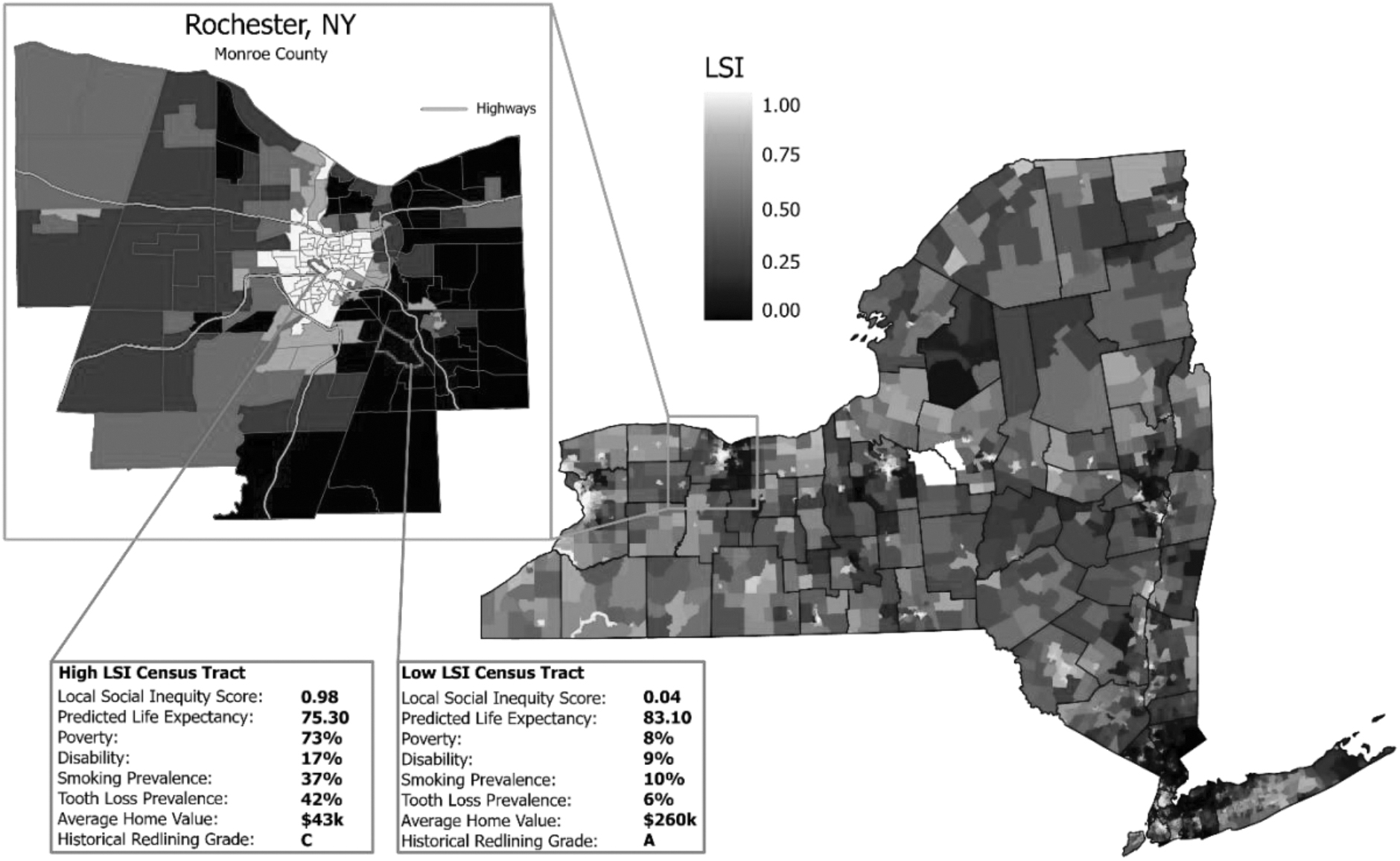
The LSI visual indicating the indicators for local social inequity. Local social inequity scores ranging from 0 to 1 when greater numbers indicate higher social inequity and lesser numbers indicate lesser social inequity.
In this analytic essay, the literature describing different composite measures of SDOH under comparison is summarized, as is each index's development. The indices are also compared in terms of SDOH domains included. Results of an analysis focused on comparison of indices in relation to their ability to explain variance in the core public health outcome of life expectancy at birth at the Census tract level are presented.
Methods
Indices included in this article
The goal was to select indices that are comprehensive measures of SDOH, excluding those narrowly focused on 1 area (such as food). The authors were interested in including multifactorial, US-focused SDOH composite measures that capture multiple aspects of neighborhoods that could synergistically influence population health, such as food, transportation, housing, income, and education. In addition, only composite measures available at a substate (county, ZIP, tract) geographic level, those that covered both rural and urban areas, and those based on published population-level estimates rather than individual data were included.
The focus was on indices developed or updated in the past 10 years. The authors selected publicly available SDOH indices that could be identified through a targeted literature review of English-language peer-reviewed publications from electronic databases (Google Scholar and PubMed) as well as gray literature. Also included was a subset of proprietary indices of interest developed by public- and private-sector organizations. Eleven US national composite indices of SDOH that met the inclusion criteria were included; data could be obtained for 9 of them.
Statistical analyses
For this study comparison, a file was created that merged each of the indices onto Census tracts across the 50 US states (data for Washington, DC, Puerto Rico, and other territories were not consistently available). The authors produced a correlogram depicting pairwise correlations between each of the indices and life expectancy at the Census tract level. The data were managed using R, version 4.1.2 (R Foundation, Vienna, Austria).
Stata MP v16 (StataCorp, College Station, TX) was also used to calculate a series of simple linear regressions, with life expectancy as the outcome measure (Y) and each individual SDOH composite measure as the predictor (X), to understand how much of the variance in life expectancy is explained by each index. Adjusted R-squared values were interpreted as the percentage variance explained. Appendix A in Supplementary Data contains additional information on methods, including information about geographic units, scale development, and validation.
Summaries of Selected SDOH Composite Indices
Publicly available national indices
University of Wisconsin: area deprivation index
As of this writing, the latest version of the Area Deprivation Index (ADI) is based on 18 measures from 2019 data, including American Community Survey (ACS) 5-year estimates, Behavioral Risk Factor Surveillance System (BRFSS) data, and data from the National Center for Health Statistics (NCHS). 11 The scores are available at Census block group, tract, and county levels. The developers recommend using only the ADI at these levels, as other small geographic units (including 5-digit ZIP codes, Zip Code Tabulation Areas (ZCTAs), and others) may not be valid.
The index was originally developed in the 1990s. In 2003, Gopal Singh published an examination of US mortality by ADI between 1969 and 1998. 12 In the seminal 2003 publication, more deprived areas had higher mortality rates than less-deprived areas during each year examined, and the gradient increased from 1970 to 1990, especially for men. Mortality rates for all deprived groups declined, but the more-deprived groups experienced slower mortality declines. Singh found no statistically significant interaction between race and the ADI. 12 At the time, the lack of Census tract or block group estimates made it impossible to analyze national mortality data at a geographic level smaller than county.
University of Wisconsin: county health rankings
The county health rankings (CHR) measure and rank the health of counties in each state. 10 Data are from 18 national publicly available data sets, including ACS 5-year estimates, BRFSS data, and data from the NCHS. Updated annually, the CHR use more than 30 measures that help communities understand how healthy their residents are today (ie, health outcomes) and what will impact their health in the future (ie, health factors). 13,14
The measures are standardized at the county level and ranked from lowest to highest, then assigned to equally sized quartiles. 13,14 This methodology supports comparisons of counties across each state. The summary CHR is based on conceptual weights assigned to each domain: physical environment (10%), social and economic factors (40%), clinical care (20%), and health behaviors (30%). Confirmatory research provides empirical support for the CHR model and weightings. 15
Brandeis University: child opportunity index
The child opportunity index (COI), developed by researchers at Brandeis University, measures and maps the quality of resources and conditions that matter for children to develop in a healthy way in the neighborhoods where they live. 16 Developed in 2014 and updated in 2020, the COI includes 29 indicators that measure neighborhood-based opportunities for children in 3 domains (education, health and environment, and social and economic resources) at the Census tract and ZIP code levels. 17 Data are drawn from numerous public sources including the US Census Bureau and the Centers for Disease Control and Prevention.
Single-item indicator values are standardized using z-scores and combined into the 3 domains using weights that reflect the strength of association between each indicator and related health and socioeconomic outcomes. Domain scores are then aggregated into an overall score. 17 Dolores Acevedo-Garcia and colleagues who created the COI, published an article using the COI to demonstrate the 40% of Black and 32% of Hispanic children live in low-opportunity neighborhoods compared with 9% of White children. They suggest that the COI can be used to inform strategies for place-based community development to improve opportunities for children. 18
US Census Bureau: community resilience estimates
The community resilience estimates (CRE) index, developed by the US Census Bureau in the summer of 2020, was designed to assess the potential resiliency of communities across 10 individual- and household-level risk factors obtained from Census Bureau products (ACS, Population Estimates Program). 19 The CRE uses microdata and small-area modeling techniques and draws on detailed demographic and economic data about individuals that is aggregated to the geographic scale of choice: Census tract, county, or state. Utilizing restricted microdata results in a composite index with a lower sampling error than indices that rely on publicly available data, especially in rural areas. 19 The result is an index that produces aggregate level small area estimates of the number of people with a specific number of risks: zero risks, 1–2 risks, or 3+ risks. 19
Opportunity nation: opportunity index
The opportunity index (OI), jointly developed by Child Trends and the Forum for Youth Investment's Opportunity Nation Campaign, measures conditions that can identify and improve access to opportunity in communities. 20 Released annually since 2011, the OI is a snapshot of 20 indicators combined to yield a score from 1 to 100 in each of 4 dimensions of community well-being (ie, economy, education, health, community). Data are predominantly from the ACS along with other national data sets (eg, CDC Wonder, Bureau of Labor Statistics, Federal Bureau of Investigation (FBI) Uniform Crime Reporting data, Health Resources and Services Administration [HRSA] data). 21
There are OI scores for all 50 states and the District of Columbia, along with a county-level index for 2065 counties. If a county is missing data for more than 2 indicators, an opportunity grade is not calculated for that county. Instances of missing data were highest for indicators of low birthweight and broadband internet. 21 Index development included rescaling observed values and aligning directionality, then averaging scores to calculate a summary score for each dimension. All 4 dimensions are then averaged with equal weighting, with standard deviations used to score states or counties from A+ to F. 21
Robert Graham Center: social deprivation index
The social deprivation index's (SDI's) most recent version is based on data from 2015. Available at county, Census tract, ZCTA, or primary care service area (PCSA) levels, the index was initially developed by Butler and colleagues, of the American Academy of Family Physicians' Graham Center. 22 Their aim was to develop a measure that could be useful to family medicine and other primary care physicians. Variables available at the block group were aggregated to PCSAs, which are generally larger in area than ZCTAs. The original health outcome measures included mortality, infant mortality, low birth weight rates, and prevalence of diabetes, all converted to centile rankings (estimates based on county measures).
They conducted a population-weighted factor analysis on 9 social deprivation measures, retaining items that had a partial correlation above 0.60. They used the factor loadings to construct weighted factor scores for each index. The SDI was positively and significantly (P < 0.01) associated with mortality, low birth weight, infant mortality, diabetes prevalence, and ambulatory care sensitive hospitalization rates. 22 However, the SDI explained only 20% of the variance in mortality rates. They found a high correlation between SDI and poverty (r = 0.86), but reported that SDI explained more variance in health outcomes than poverty alone. 22
University of South Carolina: social vulnerability index
The social vulnerability index (SoVI), developed by researchers at the University of South Carolina, intends to measure the social vulnerability of US counties to environmental hazards. 23 Last updated in 2014, the SoVI synthesizes 29 socioeconomic variables primarily from the US Census Bureau (eg, 5-year estimates and model-based Small Area Health Insurance Estimates) and from the Geographic Names and Information Systems data. The variables were chosen based on research suggesting they contribute to reductions in a community's ability to prepare for, respond to, and recover from environmental hazards.
Researchers used principal component analysis to reduce an initial set of variables into a smaller set of “statistically optimized components.” 24 SoVI is a comparative index, classified using standard deviations (SDs), where scores greater than 1.5 SDs above the mean are considered the most socially vulnerable and those 1.5 SDs below the mean are the least vulnerable. Because the SoVI is a relative score, not absolute, counties cannot be directly compared with each other. 24 The creators of the index found 8 significant components explained 78% of the variance in the data. The components include wealth, race (Black) and social status, elderly residents, Hispanic ethnicity and residents without health insurance, individuals with special needs, service industry employment, Native American populations, and gender (female). 24
CDC/ATSDR: social vulnerability index
The latest version of the CDC/ATSDR social vulnerability index (SVI) was released in 2020 and contains data from 2018. It is available at the Census tract or county levels. The original index was produced in 2000. 25 This SVI is based on 15 Census and ACS variables, which were ranked from highest to lowest across all Census tracts in the United States with a nonzero population. Rankings range from 0 to 1, with 1 indicating the highest vulnerability. The 15 variables for each tract were also grouped into 4 thematic domains (socioeconomic, household composition/disability, minority status/language, and housing/transportation)—and 4 domain rankings were calculated for each tract. An overall mean SVI ranking was calculated from the 4 domain rankings both across the United States and within each state.
Pump handle LLC: Yost index
The Yost index (YI) is a composite measure of socioeconomic status that includes 7 Census variables intended to capture the economic status of a geographic area. 26 The index was initially developed to examine instances of breast cancer in California and has been used extensively in the field of cancer surveillance at the Census tract level. 27 To capture SDOH, the index includes variables measuring the average educational level, median income, poverty rate, median housing value, median rent, unemployment rate, and employment mix. 28 These variables are randomly ordered at the block group level, and then scores are generated through a factor analysis.
One study comparing the YI with the ADI found that, although they were derived from similar data, the YI was more parsimonious, adaptable, and adept at handling missing data than the ADI. 26 Some critics have argued that these 7 measures may not fully capture the SES of the community. 29
Selected proprietary national indices
Economic innovation group: distressed communities index
The distressed communities index (DCI), developed by the Economic Innovation Group, was first launched in 2015 to provide a picture of the uneven economic conditions across the country. 30 The current (4th edition) DCI uses 2015–2019 ACS estimates on 7 indicators at the ZIP code, county, city, and congressional district levels. The 7 variables are percentage of adults without a high school diploma, poverty rate, percentage of adults not working, housing vacancy rate, median household income, the change from 2014 to 2018 in the employment rate, and the change from 2014 to 2018 in the number of business establishments located in the area. 30
Each community's score equals its percentile rank across all 7 measures combined. To generate this score, each community's 7 rankings are averaged and weighted equally to create a preliminary score, which is then normalized into the final score that ranges from 0 (most prosperous) to 100 (most distressed). Communities are categorized into 5 quintiles described as prosperous, comfortable, mid-tier, at risk, and distressed.
RTI international: local social inequity scores
Local social inequity (LSI) scores, developed by the independent nonprofit research institute RTI International, draw on more than 150 neighborhood-level variables across 10 domains of SDOH to explain variation in health outcomes. 31 The score is derived using an “artificially intelligent” approach: using random forests (a type of supervised machine learning) to predict life expectancy at birth, as well as other health outcomes, at the Census tract, ZIP code, and county levels across the country. 31 –33 The resulting LSI scores—taking the form of predicted estimates and/or percentile-rank scores—provide a comprehensive health equity-focused index of neighborhood-level social inequity.
The development phase, in 2020–2021, started with a conceptual model, curating data, and pilot testing in Ohio and 4 comparison states. The team validated the within-state and cross-state model results in 2022. Linked with individual-level data, the scores have been used in evaluations of interventions to understand the effects of area-level SDOH. These robust, cross-disciplinary, and spatially refined scores allow researchers, analysts, and policy makers across the research-to-practice spectrum to understand the co-occurrence of social and behavioral determinants of health and assess how best to intervene.
Table of components
These indices were compared using a comprehensive conceptual framework of SDOH adapted from the CDC's Healthy People framework (Figure A-1 in Supplementary Data). 3 The figure shows the 5 broad domains from Healthy People expanded into 10 domains to allow for more granularity in the areas of interest. These domains, along with examples of indicators that fall into them, are further described in Appendix A in Supplementary Data.
Table 1 indicates whether each of the 11 indices examined includes measures in each domain, including 10 domains of SDOH and an 11th domain for basic demographic characteristics (age, sex, and race). In this way, the authors distinguish between simply describing the racial/ethnic makeup of an area versus describing the effects of structural racism in an area. The first type of measure was placed in the Demographics column and the second in the “Stress” domain. See Table A-1 in the Appendix for further details in Supplementary Data.
Domains of Social Determinants of Health Included in the Reviewed Composite Social Determinants of Health Measures
Source: Authors' analysis of selected SDOH composite measures. The first column provides the abbreviated index name and the total number of measures included in the composite. The X's indicate at least 1 included measure is captured in the specified SDOH domain. See Appendix A in Supplementary Data for full domain names and examples of measures in each domain.
ADI, area deprivation index; CHR, county health rankings; COI, child opportunity index; CRE, community resilience estimates; DCI, distressed communities index; LSI, local social inequity; SDI, social deprivation index; SDOH, social determinants of health; SoVI, University of South Carolina Social Vulnerability Index; SVI, social vulnerability index; YI, Yost index.
As shown, the most comprehensive of the indices—in terms of coverage across all the SDOH domains—are the CHR and the LSI, which have measures in all of the domains. The least comprehensive are the DCI and YI, which cover the same 4 domains.
The least-represented domains are Environment and Justice, which were included in only three of the indices analyzed. In contrast, Housing and Poverty metrics were included in all of the indices examined.
Correlations
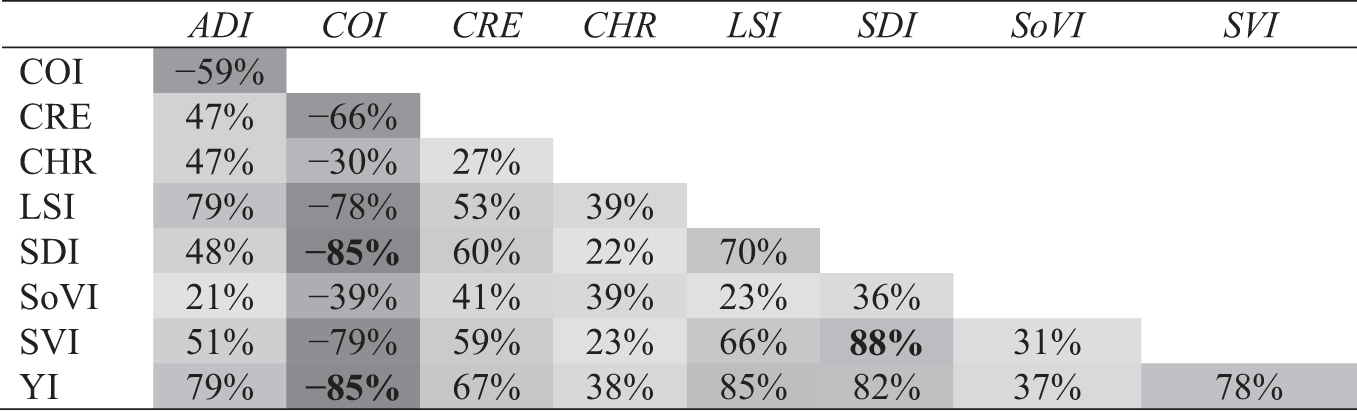
Table 2 shows the pairwise correlation coefficients among the 9 composite indices that the authors could obtain. Because the COI is scaled such that higher values are better, it is negatively correlated with all the others, which are scaled such that higher values are worse. The SDI and SVI were the most highly positively correlated (88%), whereas the COI had the highest negative correlation (−85%) with the SDI and YI. The SoVI and CHR have the lowest correlations with the other indices analyzed.
Pairwise Pearson Correlation Coefficients Among Available Social Determinants of Health Composite Indices
Source: Authors' analysis of selected SDOH composite measures.
Bold values indicate the greatest positive and negative correlations.
Variance explained in life expectancy by each of the available SDOH indices
As shown in Figure 2, the 9 SDOH indices for which data were available at the Census tract level were able to explain a range of variance in tract-level life expectancy at birth. The SoVI explained the least variance (6%), whereas the LSI explained the most (70%). Interestingly, the CHR performed substantially worse than the LSI (9% vs. 70% of variance explained), despite having similarly comprehensive inclusion of metrics across all the evaluated domains of SDOH. One explanation for the difference could be the level of geography, as the CHR includes only county-level metrics, whereas the LSI uses tract-level metrics.
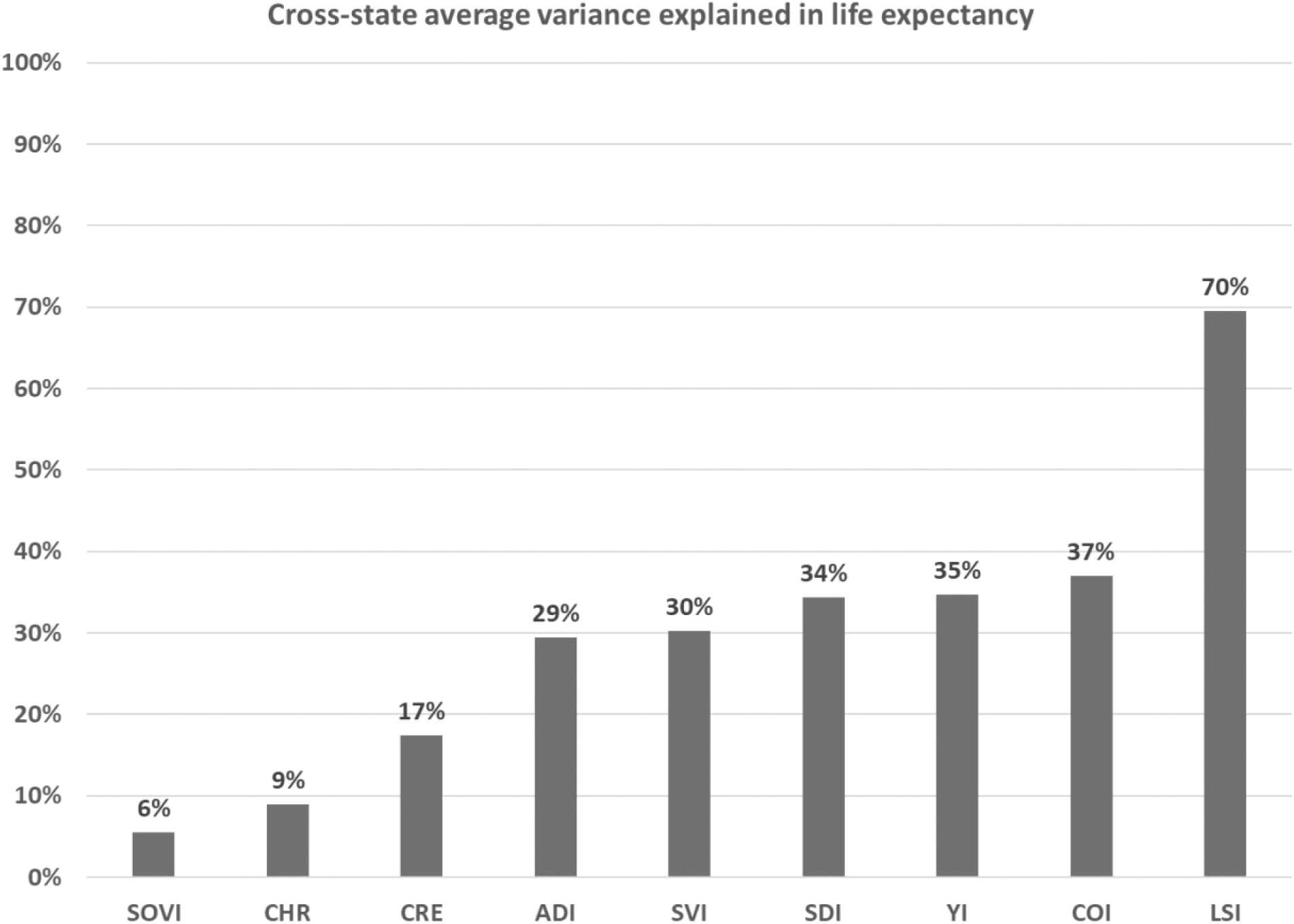
Indicating that the bars are the percent of variance explained in life expectancy for each index.
Discussion
This analysis of selected US-specific SDOH composite indices shows that the performance of these metrics, in terms of explaining the core public health outcome of life expectancy at the Census tract level, varies substantially. This may be due to the fact that these indices were generally not explicitly designed to predict life expectancy, but instead to try to capture the variation in the predictor data alone, without tying the work to any health outcome. The performance does not seem to be strongly related to which variables were included. For example, the 2 most comprehensive measures (CHR and LSI) varied widely in their ability to explain life expectancy. Moreover, metrics with very similar component measures (such as the ADI and YI) performed differently, suggesting differences in methods may be important in assessing the quality of any particular index.
Our analysis identified several important takeaways. First, many of the reviewed SDOH composite indices were developed using either weighted or simple averaging. These approaches have multiple drawbacks, but one of the most important has to do with replicability. 34 Other approaches, including principal component analysis and exploratory factor analysis, summarize a large set of correlated variables into a smaller number of derived features that explain variability in the original data, irrespective of any particular outcome measure. Future developers of SDOH indices should consider more sophisticated approaches, rather than relying on weights and averages.
As an illustration, consider the ADI and SDI, which both include variables capturing household crowding and vehicle ownership. The factor analyses reported by the original developers showed that the factor loadings for these variables were not stable. 12,22 For example, the factor loading for not having a car ranged from 0.43 at the ZCTA level in 1990 to 0.75 in 2008–2012. Similarly, the factor loading for household crowding ranged from 0.40 in 1990 to 0.67 in 2008–2012. With such differences in just these 2 variables, it becomes clearer why differences in data vintages are bound to result in different index values for the same tract. This suggests that they may not be accurately capturing the nuances of SDOH relative to today's circumstances.
Second, factor analysis (almost by design) could never explain a huge amount of variance in the outcome of interest because it involves discarding information on purpose—selecting only factors with high loadings. Simple regression-based predictive models often result in better predictions than factor analysis-based composite indices, and random forest models, which are particularly adept at prediction, regularly outperform regression models.
The choice of outcome should depend on the goal of the analysis. Life expectancy is a core public health outcome that is relevant to all residents and is known to be associated with SDOH, such as smoking, employment, and education rates. 35 However, more specialized analyses may want to explain variation in other outcomes (eg, infant mortality or opioid overdoses).
Third, most of the indices discussed in this article were constructed from US Census data, which generally represent the US population. However, some indices use other data sources, such as Health Resources and Services Administration or FBI data, which only pertain to certain segments of the population. Another issue is that composite measures are themselves obtained from estimates, with uncertainty in their construction. Potential underestimation of uncertainty should be acknowledged in ecological or multilevel analyses that consider these measures for capturing drivers of health inequities.
Conclusion
The field of SDOH measurement needs rigorous validated composite indices to improve health equity. Researchers across academia, the private sector, and government need better ways to measure and account for SDOH. More research is needed to understand the ideal underlying metrics, outcome measures, methods, and approaches.
This article provides a taxonomy of different composite measures of SDOH, including measures based on unsupervised and supervised machine learning. One challenge with supervised learning methods is the choice of the outcome, which determines its applicability in different situations. The Local Social Inequity in Life Expectancy score predicts life expectancy, which is a broadly accepted indicator of community health and well-being. Other scores predicting specific health outcomes (eg, cancer mortality) have also been developed.
These scores can be viewed at
Footnotes
Acknowledgments
The authors are grateful to their reviewers and advisors, including Katherine Karriker-Jaffe and Heidi Guyer, for their invaluable insights and feedback.
Authors' Contributions
Dr. Lines, Mr. Long, Dr. Subramanian; Data collection: Dr. Lines, Mr. Long; Data analysis and interpretation: Dr. Lines, Mr. Long, Dr. Zangeneh, Dr. Humphrey, Dr. Subramanian; Drafting the article: Dr. Lines, Mr. Long, Dr. Zangeneh, Dr. DePriest, Dr. Piontak, Dr. Humphrey; Critical revision of the article: Dr. Lines, Mr. Long, Dr. Zangeneh, Dr. DePriest, Dr. Piontak, Dr. Humphrey, Dr. Subramanian; Final approval of the version to be published: Dr. Lines, Mr. Long, Dr. Zangeneh, Dr. DePriest, Dr. Piontak, Dr. Humphrey, Dr. Subramanian.
Author Disclosure Statement
No competing financial interests exist.
Funding Information
No external funding outside of RTI International was received.
Supplementary Material
Supplementary Data
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.