
Abstract
Can skilled performers, such as artists or athletes, recognize the products of their own actions? We recorded 12 pianists playing 12 mostly unfamiliar musical excerpts, half of them on a silent keyboard. Several months later, we played these performances back and asked the pianists to use a 5-point scale to rate whether they thought they were the person playing each excerpt (1 = no, 5 = yes). They gave their own performances significantly higher ratings than any other pianist's performances. In two later follow-up tests, we presented edited performances from which differences in tempo, overall dynamic (i.e., intensity) level, and dynamic nuances had been removed. The pianists' ratings did not change significantly, which suggests that the remaining information (expressive timing and articulation) was sufficient for self-recognition. Absence of sound during recording had no significant effect. These results are best explained by the hypothesis that an observer's action system is most strongly activated during perception of self-produced actions.
One important characteristic of human mental life is the experience of being an entity that remains stable over time and that stands in a certain relation to events, objects, or persons that have been encountered in the past or that are being encountered currently (Metzinger, 2003). Accordingly, the self is often regarded as a special concept that is associated with certain personality traits (Baumeister, 1998), episodic and autobiographical memories (cf. Tulving, 2002), narratives (Dennett, 1992), or representations of personal anatomical features (Van den Bos & Jeannerod, 2002)—especially of one's face (Keenan, Nelson, O'Connor, & Pascual-Leone, 2001; Kircher et al., 2001). However, only a few studies have addressed the issue of how action knowledge—the ability to recognize the immediate consequences of one's own actions as self-produced (Frith, Blakemore, & Wolpert, 2000; Jeannerod, 1999; Wegner, 2002)—might contribute to the self-concept by encompassing actions carried out in the past. This issue may pertain especially to skilled performers such as musicians, dancers, or athletes, whose actions often have distinctive individual characteristics from which the actor can be identified, especially by the actor him- or herself. One way in which self-recognition from past actions and their consequences could occur is through recognition that they are very similar to potential present actions and their consequences, respectively. We refer to this similarity as action identity (Knoblich & Flach, 2003).
The Action System's Contributions To Perception
The ability to recognize one's own earlier actions requires a close link between perception and action. Although such a link was postulated by earlier authors (e.g., Gibson, 1979; Liberman & Mattingly, 1985), it has attracted much attention in recent years as a result of developments such as the common-coding theory of perception and action (Hommel, Müsseler, Aschersleben, & Prinz, 2001; Prinz, 1997) and the closely related concept of action simulation in neuroscience (Blakemore & Decety, 2001; Dokic & Proust, 2002; Gallese & Goldman, 1998; Jeannerod, 2001).
The common-coding theory assumes that actions are coded in terms of the resulting perceptual events (Prinz, 1997; see also Greenwald, 1970). Conversely, whenever an observer perceives events resulting from an action, corresponding motor codes are also activated, to the degree that the perceived events are connected with actions in the individual's repertoire (Prinz, 1997). Recent neurophysiological evidence provides ample support for these assumptions. There are a number of areas in the brain that are active both when planning and performing actions and when perceiving the actions of others (Blakemore & Decety, 2001; Decety & Grèzes, 1999). Rizzolatti and his colleagues (Gallese, Fadiga, Fogassi, & Rizzolatti, 1996; Rizzolatti, Fogassi, & Gallese, 2001) have discovered mirror neurons in the premotor area of the macaque monkey that discharge not only when the monkey carries out goal-directed actions, such as grasping a raisin, but also when the monkey observes the experimenter carrying out the same specific action. Recent brain-imaging studies suggest that humans possess a similar mirror-neuron system (Iacoboni et al., 1999; Koski et al., 2002).
The common-coding theory suggests a basis for recognizing one's own actions. Different people carry out the same actions in different ways because their bodies define different anatomical constraints and, more important, because they have different learning histories. When a person perceives events that are the products of his or her own actions, there is a particularly strong connection between these event codes and the corresponding motor codes. If the strength of this connection can be sensed—either as an increased tendency to carry out the same action or, if the action is simulated internally during perception, as a close match of anticipated and perceived action effects—then self-recognition may occur.
Prior Studies Of Action Identity
The first study of self-recognition from action was conducted by Wolff (1931), who filmed individuals while they were walking. All were dressed in the same loose clothing, and their faces were disguised. When Wolff showed these films to the walkers, they could recognize themselves much better than they could recognize their acquaintances. Two later studies on walking used Johansson's (1973) point-light technique, which isolates the kinematic information from differences in form. One found evidence of successful self-recognition (Beardsworth & Buckner, 1981), although the other did not (Cutting & Kozlowski, 1977).
Recently, Knoblich and Prinz (2001) investigated whether individuals can identify their own handwriting from the kinematics alone, without receiving information about letter shape that might be compared with an internally stored visual template without engaging the action system. Individuals produced writing samples, and the pen trajectories were recorded. One week later, the same individuals viewed self-produced and other-produced trajectories and tried to identify their own writing. Although shape information was neutralized and no feedback was provided, individuals were successful in this task. However, when velocity information was neutralized, participants could not identify their writing any more. Further experiments demonstrated that individuals generated more accurate predictions about the future course of handwriting trajectories when these trajectories had been produced by themselves than by other people (Knoblich, Seigerschmidt, Flach, & Prinz, 2002). Analogous results were obtained in a study of dart throwing: Participants were better able to predict the landing position of a dart when observing their own throwing movements than when watching someone else throwing the dart (Knoblich & Flach, 2001).
Some studies have investigated self-recognition from recordings of the acoustic consequences of actions. Repp (1987) instructed individuals (all known to each other) to clap at a self-selected rate and later asked them to identify each other from the recordings. Participants could identify their own clapping much better than the clapping of their acquaintances. Although Repp thought that this recognition performance was based mainly on the acoustic consequences of hand configuration during clapping, Flach, Knoblich, and Prinz (in press) have recently shown that tempo and timing are also important: When individuals listened to beep sequences that reproduced the temporal pattern of the claps, they could identify themselves as accurately as when listening to the original recordings.
The Present Study
We are unaware of any systematic study of self-recognition from action in expert performers, such as artists or athletes. Expert performers have a firmly established and carefully controlled action repertoire within a certain domain, which means that the connections between their actions and the resulting events are particularly strong and differentiated. Artists and athletes also have a strong tendency to activate the corresponding motor codes when perceiving events resulting from actions in their domains of expertise (e.g., Haueisen & Knösche, 2001). Consequently, there may be a solid basis for self-recognition in these domains. We addressed this issue by investigating self-recognition from music performance in pianists.
Method
Participants
Twelve classically trained pianists possessing advanced skills (8 women, 4 men) were paid for their participation. They included 4 graduate students of piano performance at the Yale School of Music and 8 undergraduates from Yale College who were recommended by the faculty pianist they were studying with.
Materials
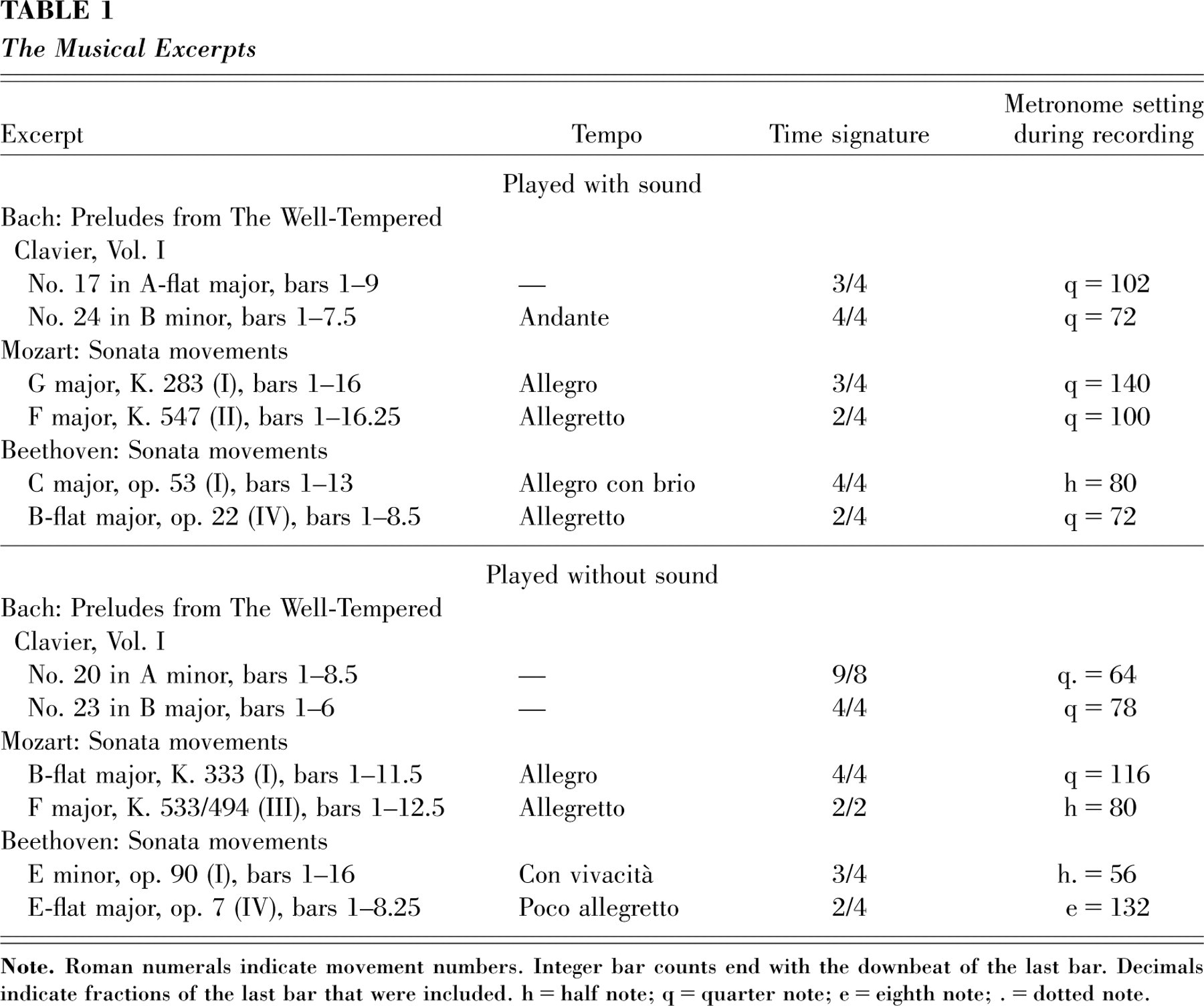
We chose 12 excerpts from the standard classical piano literature, 4 by each of three composers (see Table 1). The excerpts were not technically challenging, did not require pedaling, did not contain ornaments that could be interpreted in different ways, exhibited final closure, and had a duration of 15 to 20 s. An effort was made to find pairs of excerpts of similar character, to be performed with or without sound, respectively. The score of each excerpt was copied onto a separate sheet, together with a suggested metronome setting.
The Musical Excerpts
Procedure
Recording Session
While looking at the printed scores, participants first completed a questionnaire about their familiarity with the musical materials. Then they were informed that, after brief practice, they would have to play each excerpt from the score at a prescribed tempo, without using the pedals, and without hearing any sound during the second half of the session.
The instrument was a Yamaha Clavinova CLP-611 digital piano, with “Piano 1” sound delivered over headphones. After setting the piano's built-in metronome to the suggested tempo, pianists practiced each excerpt until they felt ready to record it and then played it three times (more often, if necessary) with the metronome turned off. The performances were recorded by a computer in musical-instrument-digital-interface (MIDI) format. After the sixth excerpt, the headphones were disconnected and removed, so that the pianists could no longer hear the sound of the digital piano and had to rely on a visual metronome on the piano console during practice. No pianist had any serious difficulties with this task. Participants were not informed about the purpose of the study until they returned for the second session.
Author B.H.R. (an experienced amateur pianist) subsequently listened to all recordings and selected what seemed to him the most accurate performance among each pianist's repetitions of each excerpt. The MIDI files of the selected 144 performances (12 participants × 12 excerpts) were subsequently edited to remove obvious pitch errors that might have biased responses in the self-recognition tests. Altogether, about 85 errors were corrected (39 were committed by 1 pianist). They consisted mainly of pitch substitutions, omissions (in which case the correct pitch was filled in, together with an appropriate onset time and MIDI key velocity), and additions (which were deleted).
First Self-Recognition Test
The first self-recognition test took place about 2 months after the recording session. Pianists were given written instructions and a booklet of 12 answer sheets, 1 for each excerpt. The order of the answer sheets was different for each participant and was determined by four interleaved 6 × 6 Latin squares, so that across the 12 participants each excerpt occurred in each ordinal position, and excerpts originally played with sound alternated with excerpts originally played without sound. Each answer sheet contained the question “Is that me playing?” followed by five response options for each of the 12 performances of the corresponding excerpt. The options were “yes,”“probably,”“don't know,”“probably not,” and “no.” The order of the 12 performances of each excerpt was fixed for all participants according to a 12 × 12 Latin square, so that across all excerpts each pianist's own performance appeared in each ordinal position.
The performances were played back on the digital piano on which they had been recorded and were heard over headphones, with no musical scores in view. Participants clicked a box on the computer screen containing the name of the excerpt given on the answer sheet, and then clicked a “next” button to listen to each performance in succession. The instructions informed them that only 1 of the 12 performances was their own, but that it was all right to give more than one “yes” response.
Preparation of Materials for Follow-Up Tests
Although a metronome had been used in the recording session, there were still some tempo differences among performances of the same excerpt. Also, different pianists played the same excerpt at different dynamic (i.e., intensity) levels. These individual differences were removed in the materials for the follow-up tests. Tempo differences were eliminated by determining the mean performance duration of each excerpt (from the first to the last note onset) and then multiplying all note onset times in each performance by the ratio between the mean duration and that individual performance's duration, rounding to the nearest millisecond. (In two Beethoven excerpts containing a final ritard, the ritard was excluded from this tempo scaling.) The mean dynamic levels of the performances were similarly equalized by scaling the MIDI key depression velocities to yield a constant mean velocity. The materials produced in this way were employed in one test, referred to as the ATD test because the remaining individual difference information included articulation (A), timing (T), and dynamic variation (D). In the other follow-up test, referred to as AT, the dynamic variation was also eliminated by setting all MIDI velocities to a constant value.
Follow-Up Self-Recognition Tests
The ATD and AT tests were administered 2 to 3 months after the first self-recognition test. Their order was counterbalanced, and they were separated by at least 1 week. The procedure was the same as used for the first test. Participants were informed about the modifications made in the recordings.
Results
We coded the self-recognition judgments numerically, from 5 for a “yes” response to 1 for a “no” response. Figure 1 compares self-ratings with highest other-ratings (i.e., the highest average rating given to another individual pianist's performances) and mean other-ratings (averaged across all other pianists) for each of the three tests. A 2 × 3 repeated measures analysis of variance (ANOVA) confirmed that self-ratings were significantly higher than mean other-ratings, F(1, 11)=75.9, p<.0001, η2=.71. Although this difference decreased somewhat across the three tests, the interaction was not significant, F(2, 22)=2.1, p<.16. Similar results were obtained in an ANOVA in which excerpts rather than participants were considered the sampling unit.
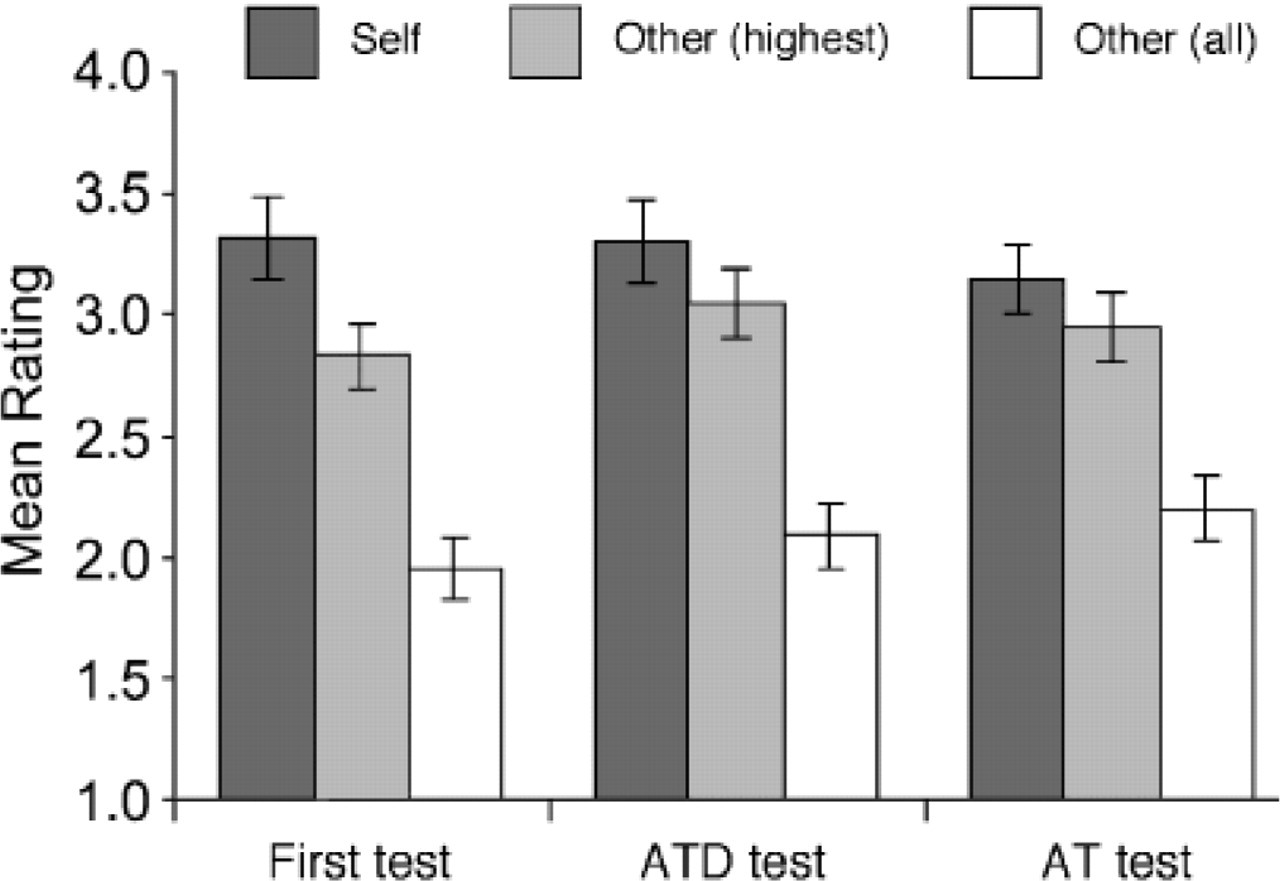
Mean self-ratings, highest other-ratings (one other pianist), and mean other-ratings (all other pianists) in three self-recognition tests. The first test used the original recordings; the ATD test retained information about articulation (A), timing (T), and dynamics (D); the AT test retained articulation and timing only. Error bars show standard errors.
Another 2 × 3 ANOVA compared the self-ratings with the highest other-ratings. The highest other-rating for each participant was the highest of the mean ratings (across the 12 excerpts) given by that participant to the 11 other pianists. The pianist receiving the highest other-rating varied across participants. Although the difference between self-ratings and highest other-ratings was much smaller than that between self-ratings and mean other-ratings, it did reach significance overall, F(1, 11)=7.6, p<.02, η2=.13, and the interaction with test was again nonsignificant, F(2, 22)=0.8. Thus, on average, pianists rated their own performances more highly than any other individual pianist's performances.
To determine whether playing with or without sound in the recording session made any difference, we computed self-ratings and mean other-ratings separately for the excerpts played with and without sound, and repeated the ANOVA with that additional variable in the design. In the first test, there was a tendency toward higher self-ratings for excerpts played with sound than for excerpts played without sound, but this tendency disappeared in the later tests. No effect involving the sound variable reached significance.
Finally, we examined whether familiarity with the pieces played a role. We coded the responses to the familiarity questionnaire numerically (4=most familiar, 1=least familiar). On average, the pianists were rather unfamiliar with the excerpts; the mean rating was 2.2. The correlation between familiarity ratings and self-recognition scores (self-rating minus mean other-rating for a given excerpt) across all excerpts and pianists (n=144) was .13 (n.s.) in the first test and .18 (p<.05) in both the ATD and the AT tests. Thus, there was a tendency toward better self-recognition in pieces that were more familiar, but it accounted for only a very small proportion of the variance.
Discussion
The results of this study demonstrate that pianists can reliably recognize their own performances of relatively unfamiliar musical excerpts after a delay of several months. Not only did the participants rate their own performances more highly, on average, than those of other pianists, but they also usually gave their own performances a higher average rating than any other individual pianist's performances. This does not mean, however, that they always gave the highest rating to their own performance of a particular excerpt. Self-recognition was not that easy, and participants quite often gave their own performances low ratings. Also, high ratings for other pianists' performances were quite common.
Some participants adopted a very high criterion of acceptance, giving low ratings to nearly all performances, including some of their own. This strategy explains the relatively low absolute mean self-rating. The strategy could be interpreted as evidence of active anticipation of action effects during listening and participants' rejection of a performance as their own if any noticeable mismatch between anticipated and perceived effects occurred.
The absence of a reliable difference among the results for the three self-recognition tests and the finding of reliable self-recognition even in the AT test lead us to conclude that the most salient information for self-recognition was provided by articulation and timing. These two expressive devices are associated especially (but not exclusively) with phrasing, that is, the delineation of structural units in the music (Clarke, 1988). Dynamic variation may have conveyed information for some participants, as indicated by the nonsignificant decrease in self-recognition accuracy between the ATD and AT tests. The fact that there was hardly any difference between ratings for the first self-recognition test and the ATD test suggests that tempo and overall dynamic level did not play an important role. 1 We should note, however, that tempo choices were deliberately constrained in the recording session, because we were most interested in the role of articulation, timing, and dynamics. Individuals can recognize their personal tempo in nonmusical contexts (Flach et al., in press; Rimoldi, 1951), and tempo probably would have contributed to self-recognition if the pianists had been free to play at their preferred tempi.
The results support our hypothesis that self-recognition in pianists results from perception of action identity. That is, pianists seem to recognize their own performances because those performances create a stronger resonance in their action system than other performances do; this stronger resonance implies that there is a closer match between anticipated and perceived action effects. The self-recognition ability observed in the present study was more pronounced than that found in earlier studies (e.g., Beardsworth & Buckner, 1981; Knoblich & Flach, 2003). This difference is in line with our assumption that expert performers have an especially elaborated action repertoire within a certain domain, which implies strong and differentiated links between their actions and the events resulting from them (Haueisen & Knösche, 2001; Münte, Altenmüller, & Jäncke, 2002). However, we also need to consider possible alternative explanations.
One alternative explanation might be familiarity with the pieces performed: The pianists may simply have known what their performances of familiar repertoire sound like. Indeed, self-recognition rates tended to be higher the more familiar the pieces were, but this relationship was weak. Clearly, the pianists were also able to recognize their performances of pieces that had been completely unfamiliar prior to the recording session. Moreover, the action-identity hypothesis actually predicts better self-recognition with familiar pieces. When a pianist spends many hours refining the performance of a particular piece, specific links between auditory events and motor programs that should facilitate self-recognition are acquired. When a pianist knows what his or her performance of a piece sounds like, that knowledge concerns specific actions connected with the piece and their auditory consequences. That is exactly the knowledge that is involved in establishing action identity when listening to a performance. Therefore, familiarity is not really an alternative explanation but part and parcel of the action-identity hypothesis.
A second possible alternative explanation is episodic memory for actions or sounds. Two aspects of our study suggest that this explanation is not viable, however. First, several months passed between the recording session and the self-recognition tests, and during those months the pianists spent many hours playing different repertoire. It seems unlikely that any specific episodic memories of the recording session would have survived this massive interference. Second, there was no significant difference in self-recognition between performances that had been played with sound and those that had been played without sound, which at least rules out episodic memory for the sound of performances. Incidentally, the absence of an effect for the sound variable also suggests that the pianists played about equally well with and without sound, which is consistent with the results of an earlier study (Repp, 1999) showing little effect of auditory feedback deprivation on expressive music performance. Episodic memory would perhaps be most plausible for errors committed during performance, not so much for specific errors but more generally for difficulties encountered in the recording session. However, we eliminated most errors from the materials in the self-recognition tests, and thus they could not serve as a basis for self-recognition of those few pianists who were error prone. We suggest that pianists' knowledge of their own performances is not episodic but generative (Clarke, 1988, 1993): For them, hearing music causes an internal simulation of appropriate actions and their sensory consequences, and this simulation may be more or less in agreement with what they hear. The internal simulation evoked by auditory input may be no different from the one generated in playing from a score or from memory.
A third alternative explanation to consider is that the pianists based their judgments on aesthetic preference and achieved self-recognition simply because they liked their own performances best. There is undoubtedly a close relation between self-recognition and aesthetic preference. However, in principle, it is possible to appreciate a performance that sounds very different from the way one would (or could) play the piece. In practicing a piece, pianists aim for a particular sound image that they have in mind, and they keep adjusting their actions to get ever closer to that ideal. Thus, they are comparing the actual consequences of their actions with desired consequences. Recognition of action identity when listening to a performance pertains to the match between perceived and expected (i.e., internally simulated actual) action consequences, whereas aesthetic judgment concerns the match between perceived and desired consequences. Self-recognition and aesthetic judgments converge if pianists are so accomplished as to have achieved a close match between actual and desired outcomes in their playing. That was surely not the case in our recording session, given the relative unfamiliarity of the pieces, the minimal practice time, and the quality of the instrument used. Moreover, the pianists clearly varied in technical and musical ability, even though all of them were capable of playing advanced repertoire. If aesthetic judgments had prevailed, the weaker pianists in the group (as judged informally by author B.H.R.) should have tended to confuse themselves with the better pianists. However, they tended to confuse themselves with other weak pianists instead, which suggests that they were aware of the weaknesses in their playing and relied on action identity rather than aesthetic appeal in making their ratings. 2
Experts' self-recognition might provide a fruitful approach to studying perception-action links and their development. For instance, further investigation of the relation between familiarity and self-recognition, or of temporal synchronization of pianists' actions with self- and other-produced performances (as when playing a duet), may be informative about how perception and action get connected in expert performance. In addition, neurophysiological methods, and functional magnetic resonance imaging in particular, make it possible to assess directly the extent to which the action system is involved in perceiving and recognizing one's own performances. Certain parts of the action system may be more active when pianists listen to their own performances than when they listen to other pianists play. Alternatively, or in addition, some parts of the action system may be less active when pianists listen to their own performances than when they listen to other pianists' performances because few differences between perceived and internally simulated actions are detected.
Footnotes
Acknowledgements
This research was supported by National Institutes of Health Grant MH-51230 to B.H.R. The Max Planck Society supported G.K. and a visit of B.H.R. to the Max Planck Institute for Psychological Research in Munich in the summer of 2002, when this research was planned. We are grateful to Susan Holleran for help with data analysis and to Rüdiger Flach for helpful comments.
1One exception was a pianist who performed poorly on the first test but did very well on the later tests, when differences in dynamic level were absent. Her original performances happened to be louder than those of all other pianists, and apparently she was not aware of her “strong touch” and found her own performances unappealing when she heard them in the context of the first test.
2Nevertheless, aesthetic appeal may have exerted a bias on self-recognition judgments. To correct for such a bias, we reanalyzed the data for each test by computing the mean rating of each pianist's performances by all pianists, subtracting these mean ratings from the original ratings, and submitting the resulting unbiased self-ratings and highest other-ratings to a 2 × 3 repeated measures ANOVA. Self-ratings were significantly higher than the highest other-ratings, F(1, 11)=22.1, p<.001, η2=.33, and although the difference again decreased across tests, the interaction was not even close to significance, F(2, 22)=0.9. The larger effect size in this analysis than in the original analysis suggests that aesthetic appeal indeed exerted a bias on judgments. Removal of this bias revealed even more clearly that the pianists were able to recognize their own performances.