
Abstract
In a hierarchical stage account of vision, figure-ground assignment is thought to be completed before the operation of focal spatial attention. Results of previous studies have supported this account by showing that unpredictive, exogenous spatial precues do not influence figure-ground assignment, although voluntary attention can influence figure-ground assignment. However, in these studies, attention was not summoned directly to a region in a figure-ground display. In three experiments, we addressed the relationship between figure-ground assignment and visuospatial attention. In Experiment 1, we replicated the finding that exogenous precues do not influence figure-ground assignment when they direct attention outside of a figure-ground stimulus. In Experiment 2, we demonstrated that exogenous attention can influence figure-ground assignment if it is directed to one of the regions in a figure-ground stimulus. In Experiment 3, we demonstrated that exogenous attention can influence figure-ground assignment in displays that contain a Gestalt figure-ground cue; this result suggests that figure-ground processes are not entirely completed prior to the operation of focal spatial attention. Exogenous spatial attention acts as a cue for figure-ground assignment and can affect the outcome of figure-ground processes.
In visual scenes that contain multiple objects, the ability to visually segregate objects from one another becomes critically important: If different objects were not isolated, high-level visual processes such as object recognition would not know where one shape ended and another began. Figure-ground assignment processes allow shapes (figures) to be segregated from backgrounds. These visual processes are important because figures form the basis of much visual processing—humans are more likely to recognize and act upon figures than backgrounds.
The visual cues that influence figure-ground assignment were studied extensively by the Gestalt psychologists (Bahnsen, 1928; Koffka, 1935; Metzger, 1953; Rubin, 1915/1958), who identified the stimulus characteristics that allow one region to appear as the figure and another to appear as the ground. For example, Rubin reported that in most cases a smaller region is generally reported as figure and a larger region reported as the ground. Bahnsen reported that symmetric regions are more likely to be perceived as figure than asymmetric regions. Convex regions are more likely to be perceived as figures than concave regions (Hoffman & Singh, 1997; Kaniza & Gerbino, 1976). Regions that fall below a horizon line are more likely to be perceived as figure than regions that fall above a horizon line (Metzger, 1953; Vecera, Vogel, & Woodman, 2002).
Figure-ground assignment is considered a preattentive process that operates in parallel across the visual field before focal attention processes (e.g., Julesz, 1984). What is the relationship between preattentive segregation processes and focal spatial attention? A straightforward account, endorsed by several theories, is a hierarchical stage account in which figure-ground assignment is completed before other high-level visual processes, such as focal attention or object identification (e.g., Biederman, 1987; Julesz, 1984; Kosslyn, 1987; Marr, 1982; Neisser, 1967). Under this account, spatial attention would not influence figure-ground assignment automatically because attention would not operate until figure-ground processes were completed. Voluntary, or strategic, attention might influence figure-ground assignment, but only when a figure-ground stimulus was ambiguous and the two regions could be perceived as figure equally easily. In this latter case, figure-ground processes would fail and allow voluntary spatial attention to resolve the perceptual ambiguity (see Peterson, 1999, for relevant discussion). Recent findings support these predictions and support the hierarchical stage view of segregation and attention.
Baylis and Driver (1995; Driver & Baylis, 1996) demonstrated that exogenous (automatic) spatial precues do not influence figure-ground assignment, although endogenous (voluntary) precues do influence figure-ground processes. 1 Exogenous and endogenous attention were distinguished by manipulating the predictability of a spatial precue. Previous research had demonstrated that uninformative precues tap exogenous attention whereas predictive precues tap endogenous attention (e.g., Jonides, 1981; Klein, Kingstone, & Pontefract, 1992). Observers viewed ambiguous figure-ground displays (similar to the figure-ground stimuli shown in Fig. 1) in which either of two regions could be perceived as the figure. Prior to the figure-ground display, a spatial precue was flashed briefly on one side of where the figure-ground display would appear. The figure-ground display then appeared for a short duration, followed by a blank screen. A test display followed the blank screen; the test display contained two shapes, and observers were asked to decide which of the two contours matched one of those from the figure-ground display. The direction of the test contours was manipulated so that the two contours matched either the cued region (Fig. 1a) or the uncued region (Fig. 1b). If the attentional precue influenced figure-ground assignment, then the precued region would be perceived as figure, and this region would be discriminated rapidly in the test display.
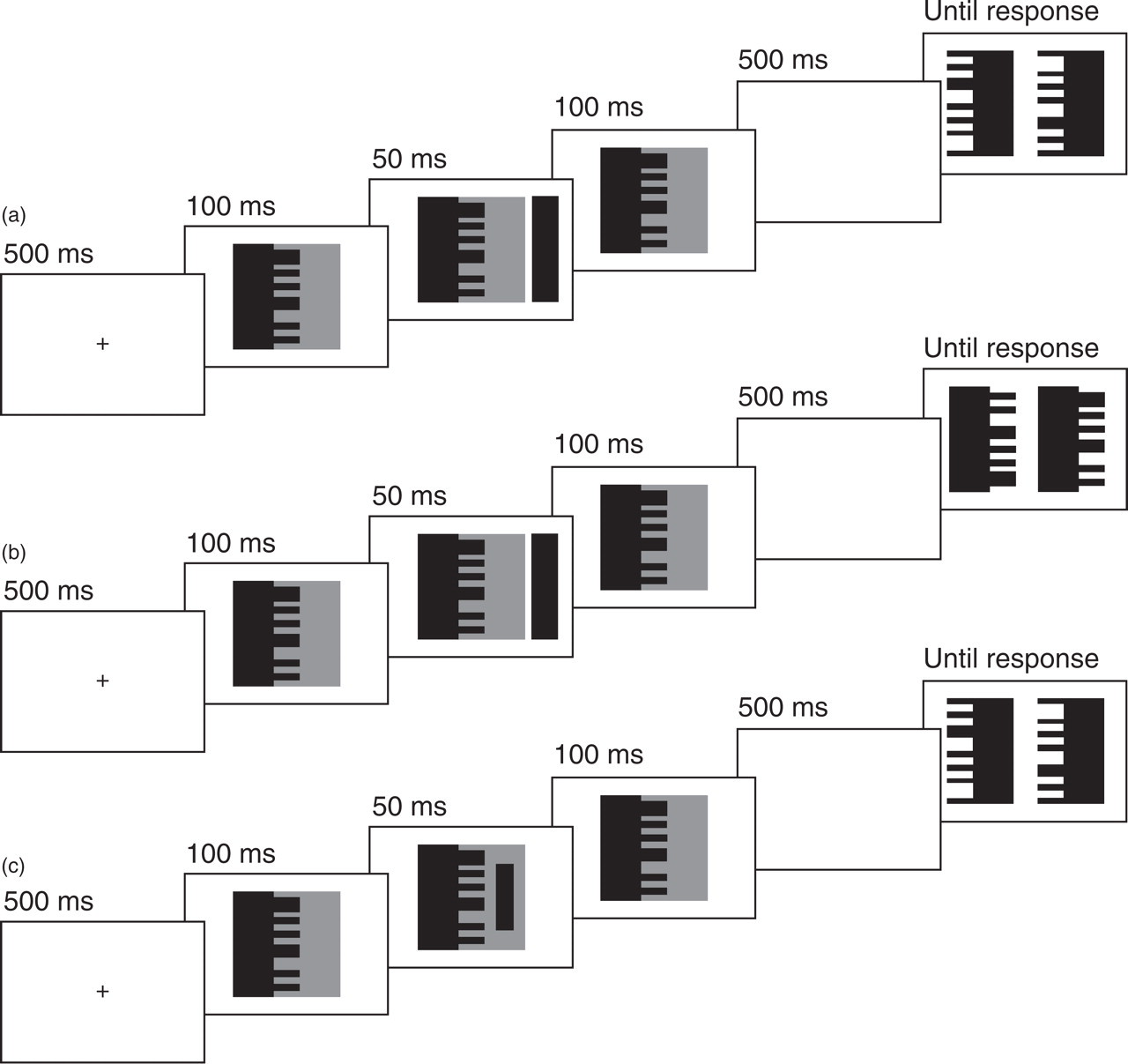
Illustration of the sequence and timing of displays in the experiments. On each trial, a figure-ground display was presented with an attentional precue, and the task was to indicate which of two probe stimuli matched one of the regions that had appeared in the figure-ground display. In Experiment 1 (a and b), the uninformative precue appeared outside the figure-ground stimulus; the tested region was on the same side as the spatial precue (a) and on the side opposite the spatial precue (b) equally often. Experiment 2 (c) followed the procedure of Experiment 1 except that the attentional precue appeared directly in one of the regions of the figure-ground display. In all the test trials depicted, the probe on the right is the matching shape. The stimuli in this illustration are not drawn to scale; in the experiments, the figure-ground displays were red and green against a black background, the attentional precues were white, and the probe stimuli were gray.
Observers in Baylis and Driver's (1995) study were faster to discriminate the test shape when the spatial precue predicted the region to be tested (endogenous precue), indicating that endogenous spatial attention influenced figure-ground assignment. When the precue did not predict the to-be-tested region (exogenous precue), spatial attention did not influence figure-ground assignment. Thus, voluntary attention influenced segregation, but this attentional influence did not occur automatically, a result consistent with a hierarchical stage view of segregation and attention.
In the present study, we investigated whether exogenous attention might influence figure-ground assignment if attention was allocated directly to the space occupied by one of the shapes in the figure-ground display. Baylis and Driver's (1995) study may have obscured the effects of exogenous attention in two ways. First, the spatial precue appeared outside the figure-ground stimulus, thereby preventing attention from operating directly on a potential figure. Second, the figure-ground stimulus appeared after the precue; the abrupt onset of the figure-ground stimulus could have captured attention away from the precued location (Yantis, 1998; Yantis & Jonides, 1984). In Experiments 1 and 2, we demonstrated that unpredictive, exogenous spatial precues influence figure-ground assignment when attention is allocated within the boundaries of a potential figure.
EXPERIMENTS 1 AND 2
In these experiments, observers reported which of two probe shapes had the same shape as a corresponding region in an ambiguous figure-ground display in which either region could be perceived as figure (Fig. 1). Our procedure differed from previous studies in two respects: First, we manipulated the location of the spatial precue so that in one condition it was presented inside the figure-ground stimulus. Second, the precue was presented after the onset of the figure-ground stimulus. If exogenous spatial attention influences figure-ground assignment, then reaction times (RTs) to the test displays would be faster for previously cued regions than for previously uncued regions. The spatial precues were unpredictive and thus tapped exogenous spatial attention; half of the time the precue summoned attention to the to-be-tested region, and half of the time the precue summoned attention to the other region.
In Experiment 1, we followed previous research and placed the precue outside the figure-ground stimulus (the cue-outside condition; Figs. 1a and 1b). In Experiment 2, we placed the precue within the figure-ground stimulus, which focused attention directly on one of the two regions (the cue-inside condition; Fig. 1c). Because the precue was located further in the visual periphery in the cue-outside condition than in the cue-inside condition, we increased the size of the precue in the cue-outside condition in accordance with the cortical magnification factor (Rovamo & Virsu, 1979) to ensure that the precues were represented equivalently in the visual system when located inside and outside the figure-ground display.
Method
Participants
The participants were 36 University of Iowa undergraduates (18 per experiment) who received course credit; all reported having normal or corrected vision.
Stimuli
The figure-ground displays were similar to those used in previous research. Each ambiguous figure-ground display comprised a square separated into two distinct colored regions by a jagged contour (Fig. 1). The two regions in each display were equal in area and convexity. One region was red and the other green, and each color was equally likely to appear on the left side or the right side in the display. We used six different contours, all of which produced ambiguous figure-ground displays (i.e., neither region had a bias to be perceived as figure). The stimuli were viewed from a distance of approximately 80 cm. From this viewing distance, each display measured 7.24° by 7.24° of visual angle. All stimuli were drawn on a black background.
In the cue-outside condition (Experiment 1), the precue was a white rectangle that measured 10.27° by 3.13° and appeared just outside the figure-ground stimulus, falling 1.57° to the left or right edge of the figure-ground display. In the cue-inside condition (Experiment 2), the precue was a white rectangle that measured 3.48° by 0.99° and was located inside one of the two regions of the figure-ground stimulus; these precues appeared 2.28° to the left or right of fixation. The precue appeared equally often to the left and right of fixation and equally often inside or adjacent to red and green regions.
At the end of each trial, two gray probe shapes appeared, and observers were instructed to determine which probe shape had appeared in the previously viewed figure-ground display. The probes were presented 2.28° of visual angle to the left and right of fixation and measured 7.24° by 4.54°. The correct probe—the region that had appeared in the figure-ground display—appeared equally often to the left and right of fixation in the probe display. There were two types of probe displays: Cued-probe displays required observers to remember the region that was either directly precued (cue-inside condition) or adjacent to a precue (cue-outside condition); uncued-probe displays required observers to remember the region that was not directly cued or not adjacent to the precue. The spatial precue was uninformative regarding the region that would be probed; half the trials were cued-probe trials and half were uncued-probe trials.
Procedure
The sequence and timing of events are depicted in Figure 1. Each trial began with a fixation point, visible for 500 ms. The figure-ground display was then presented for 100 ms before the precue was added to the display for 50 ms; after the precue disappeared, the figure-ground display remained visible for another 100 ms. The time between the onset of the cue and the offset of the figure-ground display was 150 ms, too brief to permit eye movements to the cued region. After the figure-ground display disappeared, the screen was blank for 500 ms before the probes appeared. The probes remained visible until the observer made a response.
Observers reported which of the two probe shapes had the same shape as one of the regions in the figure-ground display. Observers were instructed to respond as quickly and accurately as possible by pressing one key on a button box to indicate that the left probe shape matched or another key to indicate that the right probe shape matched.
Each observer received a block of 96 practice trials, which were not analyzed, followed by five blocks of 96 trials. Observers were instructed that the red and green regions in the figure-ground displays would be tested equally often. To minimize the role of voluntary (endogenous) orienting to the spatial precue, we told observers only that the precue would appear and that it had no relationship to the region that would need to be matched at the end of the trial.
Results and Discussion
Only correct RTs were analyzed. Participants' median RTs were analyzed with a two-factor, mixed-model analysis of variance (ANOVA) with cue location (cue outside and cue inside) and probe type (cued region probed and uncued region probed) as factors. The RT and error data are shown in Figure 2; the RTs show a smaller effect of the precue when it was located outside the figure-ground stimulus than when it was located inside the stimulus. There were no statistically significant effects in the error data.
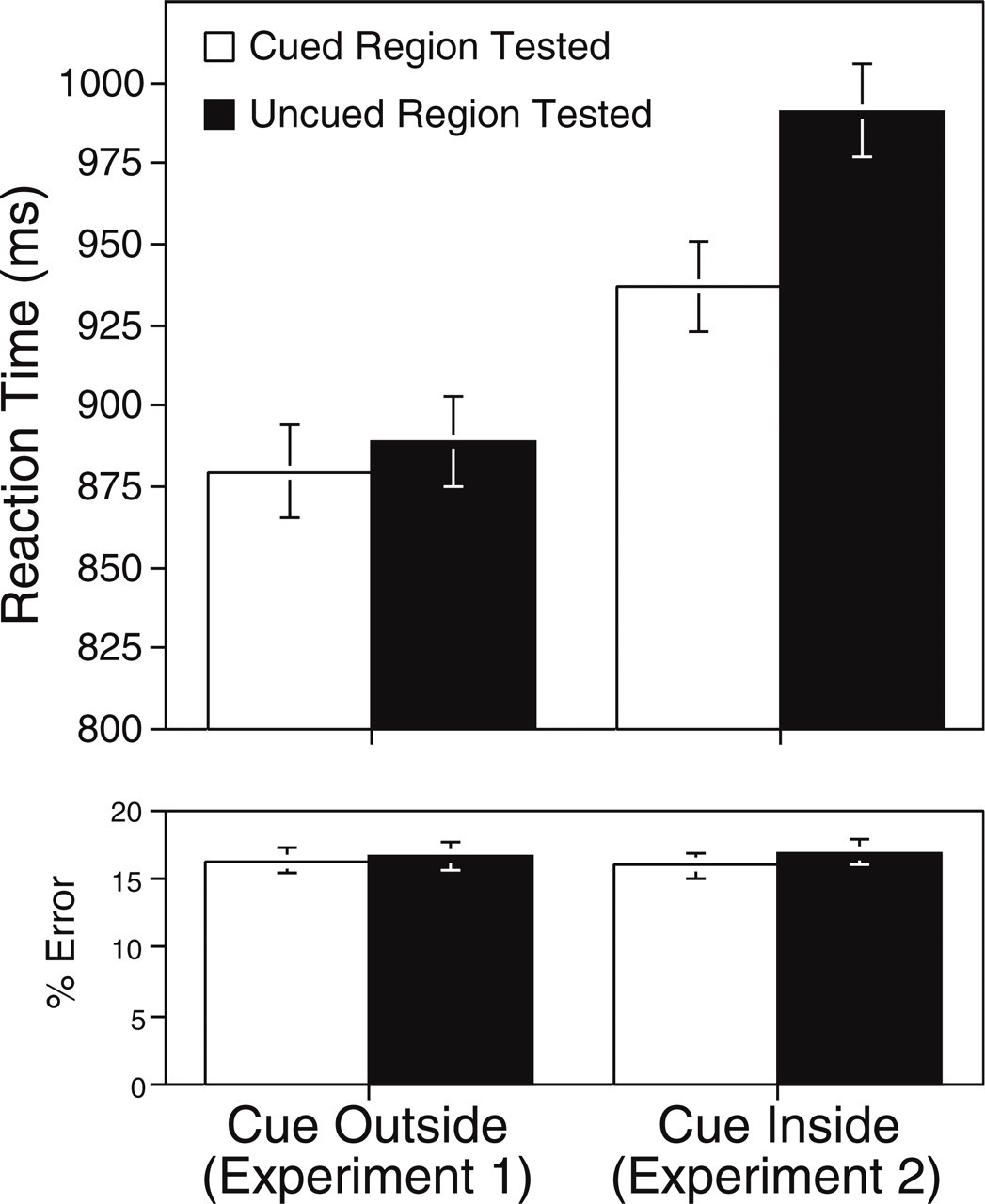
Reaction times and percentage of errors in Experiment 1 (cue outside) and Experiment 2 (cue inside). Results are shown separately for trials on which the probe matched the cued and uncued region. Error bars show within-subjects 95% confidence intervals.
Although RTs were shorter in the cue-outside condition (884.2 ms) than in the cue-inside condition (964.1 ms), this main effect was not significant, F(1, 34) = 1.78, n.s. There was a main effect for the region probed, with faster RTs when the cued region was probed (908.3 ms) than when the uncued region was probed (940 ms), F(1, 34) = 10.64, p < .005. This main effect was subsumed by a two-way interaction, F(1, 34) = 5.45, p < .03, indicating that the effect of the region probed depended on whether the cue was inside or outside the figure-ground stimulus. In short, the exogenous precue influenced figure-ground assignment when it appeared inside the figure-ground display, but not when it appeared outside the display.
This conclusion was corroborated with planned comparisons between the cued-probe and uncued-probe conditions. In the cue-outside condition, there was no difference between RTs when the cued region was tested (879.7 ms) and when the uncued region was tested (888.7 ms), t(17) < 1. In the cue-inside condition, RTs when the cued region was tested (936.9 ms) were significantly faster than RTs when the uncued region was tested (991.3 ms), t(17) = 3.63, p < .005. These results demonstrate that exogenous spatial attention can influence figure-ground assignment, provided that attention is focused within the boundaries of a potential figural region. In the cue-outside condition, we replicated previous failures to find an attention effect when precues were outside a figure-ground stimulus.
Although our results suggest that directly precuing a region in a figure-ground display allows attention to influence figure-ground assignment, these findings could be explained with a hierarchical stage account of figure-ground processes and attention. Because our figure-ground displays were ambiguous (i.e., either region could be perceived as figure), figure-ground processes may have failed to assign figural status to either region (see Peterson, 1999, and Vecera & O'Reilly, 2000, for discussion). In such a case, both regions might be fed forward to attentional processes, which can select the cued region if either the precue is highly predictive (Baylis & Driver, 1995; Driver & Baylis, 1996) or the precue is unpredictive but a region is cued directly (the present Experiment 2). More convincing evidence against a hierarchical stage account would involve demonstrating that exogenous spatial attention can partially override an unambiguous bottom-up, or Gestalt, cue for figure-ground assignment. For example, if one region in a figure-ground display has a bias to be perceived as figure based on the Gestalt cue of convexity, could exogenously precuing the concave region reduce or override the bias to perceive the convex region as figure? We addressed this question in Experiment 3.
In Experiment 3, observers viewed figure-ground displays that contained a convexity cue that influenced figure-ground assignment (Hoffman & Singh, 1997; Kaniza & Gerbino, 1976). A nonpredictive spatial precue summoned attention to either the convex region or the concave region. In this design, when the convex region is precued, both attention and convexity operate to assign figural status to this region. However, when the concave region is precued, attention and convexity compete with one another for figural status. If figure-ground processes are completed prior to the operation of exogenous attention as assumed under a hierarchical stage account, then the convex region should continue to be perceived as figure as readily as it is when the convex region is precued. Specifically, the region that is cued (convex vs. concave) and the region tested (convex vs. concave) should produce additive effects on the RTs. In contrast, if figure-ground processes and attention mutually constrain one another, then convexity should have a smaller effect on figure-ground assignment when the concave region is precued than when the convex region is precued. This latter account predicts an underadditive interaction between the region cued and the region tested; the convex region will not be perceived as figure as readily when attention has been summoned to the concave region as when the convex region receives attention.
EXPERIMENT 3
Method
Participants
The participants were 36 University of Iowa undergraduates who received course credit; all reported having normal or corrected vision.
Stimuli
The figure-ground displays contained a convexity cue and were similar to those developed by Hoffman and Singh (1997). A sample display appears in Figure 3a. In this display, the left region is more convex than the right region, according to Hoffman and Singh's (1997) part-salience analysis. That is, given the local geometry around the shared contour, the left region, compared with the right region, produces more salient convex parts that influence figure-ground assignment. As in Experiments 1 and 2, the two regions were equal in area. One region was red and the other green, and each color was equally likely to appear on the left side or the right side in the figure-ground display. All stimuli were drawn on a black background and viewed from a distance of approximately 80 cm. From this viewing distance, each display measured 5.8° by 5.8° of visual angle.
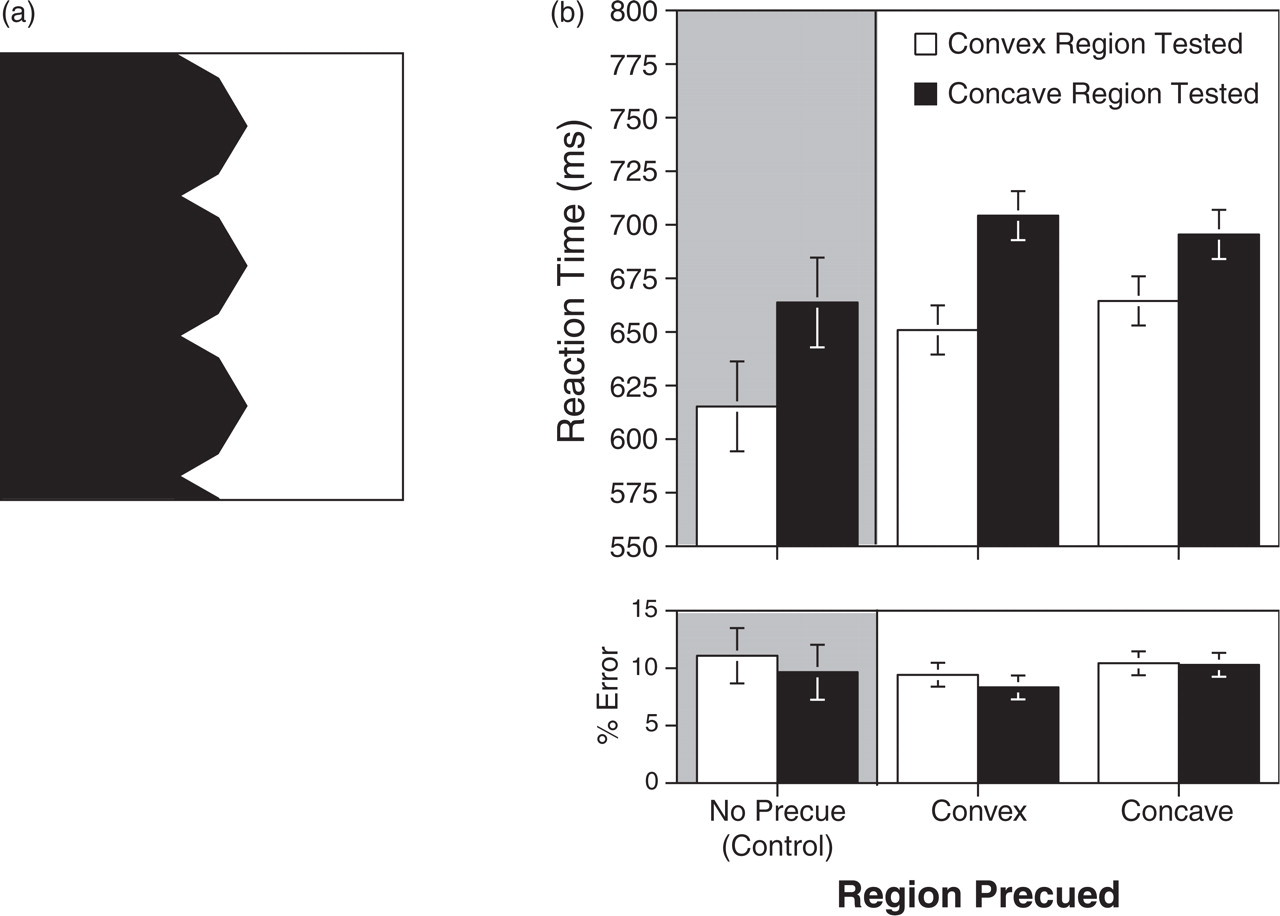
Sample display (a) and results (b) from Experiment 3. In this experiment, each figure-ground display comprised a convex region (depicted here in black) and a concave region. In the experimental trials, either the concave or the convex region was cued; in a control condition, there was no precue. Reaction times and results are shown separately for trials on which the probe matched the concave and the convex region.
The spatial precue was a white rectangle that measured 0.60° wide by 3.5° tall and was located inside one of the two regions of the figure-ground stimulus. Each precue appeared 1.3° to the left or right of fixation. The precues appeared equally often to the left and right of fixation and equally often inside and adjacent to red and green regions.
At the end of each trial, two gray probe shapes were presented, and observers were instructed to determine which probe shape had appeared in the previously viewed figure-ground display. The centers of the probes were 2.6° of visual angle to the left and right of fixation, and each probe measured 5.8° tall by 2.9° wide. The correct probe—the region that had appeared in the figure-ground display—appeared equally often to the left and right of fixation in the probe display. The region that was probed was either convex or concave, and this region could have been cued or uncued. As in the previous experiments, the spatial precue was uninformative regarding the region that would be probed; cued- and uncued-probe trials appeared equally often.
Procedure
Observers performed the matching task used in Experiments 1 and 2. One group of 18 participants viewed the figure-ground displays without precues; this control condition ensured that the convex regions were perceived as figure in our stimuli. The remaining 18 participants viewed the figure-ground displays with precues that appeared within either the convex or concave region (this condition was similar to the cue-inside condition in the previous experiments). In the control condition, each trial began with a 500-ms fixation cross, followed by the figure-ground display for 180 ms. A blank screen then appeared for 500 ms before the probes appeared; the probe shapes remained visible until a response was made. In the precue condition, the sequence and timing of events were identical to those in Experiment 2. In this condition, two variables were factorially manipulated: the convexity of the region cued (convex or concave) and the region probed (convex or concave).
Results and Discussion
Only correct RTs were analyzed. In the control condition (Fig. 3b), participants' median RTs were significantly faster when convex regions were probed (615.2 ms) than when concave regions were probed (663.7 ms), t(17) = 3.6, p < .005. This result indicates that our convex regions influenced figure-ground assignment. There were no systematic effects in the error data.
In the precue condition, participants' median RTs were analyzed with a two-factor within-subjects ANOVA with precued region (convex or concave) and probe type (convex region probed or concave region probed) as factors. The RT and error data are shown in Figure 3b; there were no statistically significant effects in the error data. As is evident in Figure 3b, convex regions were matched faster than concave regions. Most important, however, was the finding that convexity had a 40% smaller effect on figure-ground assignment when the concave region was precued than when the convex region was precued.
These observations were supported by the ANOVA. There was no main effect of the region that was precued; RTs were similar when the convex region was precued (677.6 ms) and when the concave region was precued (680 ms), F(1, 17) < 1. There was an effect of probe type: Overall, convex regions were matched faster than concave regions (657.7 ms vs. 699.9 ms, respectively), F(1, 17) = 18.2, p < .0005. Most important, these two factors interacted, F(1, 17) = 4.5, p < .05. The difference between matching convex and concave regions was significantly smaller when the concave region was precued than when the convex region was precued.
The interaction between spatial precuing and convexity indicates that exogenous spatial attention can compete with image-based Gestalt cues in figure-ground assignment. Further, these results are specific to figure-ground processes: In an additional 18 participants, we found that if the convex and concave regions are separated and do not share a central contour, the spatial precue is the predominant influence on responses; cued regions are matched faster (678.8 ms) than uncued regions (708.6 ms). This attentional effect is much larger than that observed in Experiment 3, in which cued regions were matched only slightly faster (673.2 ms) than uncued regions (684.3 ms), because figural status also affected responses. Thus, the results of Experiment 3 are not merely due to attentional cuing, but also depend on the figural status of one of the regions. In general, the results of Experiment 3 are at odds with a hierarchical stage account of figure-ground assignment, which predicts that figure-ground assignment would be based on image-based cues only.
GENERAL DISCUSSION
Our results demonstrate that when spatial attention is directed to one of the regions of a figure-ground stimulus, the precued region is perceived as figure and the shared contour is assigned to the precued (i.e., figural) region. However, exogenous spatial attention does not influence figure-ground assignment when spatial attention is directed outside a figure-ground stimulus. Further, exogenous spatial attention can influence the operation of image-based (bottom-up) Gestalt cues for figure-ground assignment. This latter result indicates that exogenous spatial attention can influence figure-ground processes per se, as opposed to operating after figure-ground processes. Although it is well known that voluntary (endogenous) attention can influence figure-ground assignment (see Rubin, 1915/1958), our results are the first to demonstrate that a similar influence can occur with unpredictive, exogenous precues, which do not require observers to voluntarily direct spatial attention. Our results indicate that exogenous spatial attention can be viewed as a cue for figure-ground assignment (also see Palmer, Nelson, & Brooks, 2001): Exogenous spatial attention can disambiguate otherwise ambiguous displays (Experiment 2) and can reduce a bottom-up bias provided by a Gestalt figure-ground cue (Experiment 3).
It is difficult to reconcile our results with a hierarchical stage account of visual processing. Such an account predicts that exogenous spatial attention would, at best, operate to influence only an otherwise ambiguous figure-ground assignment, as we found in Experiment 2. More problematic for the hierarchical stage account are the results from Experiment 3, because this account predicts that figure-ground assignment would be performed using the convexity cue present in these displays. The finding that exogenous spatial attention could reduce the effect of convexity on figure-ground assignment suggests that figure-ground assignment need not be completed prior to the influence of spatial attention. Instead, figure-ground assignment and exogenous attentional processes mutually constrain one another, possibly through recurrent, interactive processes.
This interactive view of attention and figure-ground assignment is consistent with other results showing that high-level visual processes can affect figure-ground processes. For example, object familiarity can reduce or override image-based figure-ground cues. When observers view a figure-ground display in which one region depicts a familiar object, this region is perceived as figure, provided that the familiar object is in its canonical orientation (see Peterson, 1999; Peterson & Gibson, 1991, 1994). We have explained these results with an interactive parallel-distributed-processing model in which orientation-dependent object representations, which occur architecturally late in the model, provide a top-down constraint on figure-ground processes (Vecera & O'Reilly, 1998, 2000).
Because exogenous spatial attention acts as a cue for figure-ground assignment, the distinction between figure-ground processes and attention is blurred. A region or shape may appear more shapelike or may be more memorable than another either because it has been attended or because it has been perceived as figure. One theoretical advantage to a blurred distinction between figure-ground processes and attention is that figure-ground processes might be interpretable within theoretical views developed in the attention literature. For example, the biased-competition account of visual search (Desimone & Duncan, 1995) and related models (e.g., guided search; see Wolfe, 1994) capture the operation of our interactive model of figure-ground assignment (Vecera & O'Reilly, 1998, 2000). In a biased-competition view of figure-ground assignment (Vecera, 2000), figure-ground assignment and spatial attention may interact with one another, with exogenous precues providing a top-down biasing signal that helps resolve the competition between two regions that are competing for figural status. Figure-ground assignment is also biased by bottom-up factors, such as the Gestalt cues. In general, a biased-competition account of figure-ground assignment can explain the multiple constraints on figure-ground processes.
Interactions between attention and figure-ground assignment could allow these visual processes to exhibit similar effects. For example, spatial attention appears to operate as a gain control on sensory information, enhancing attended items relative to unattended items (Hillyard, Vogel, & Luck, 1998). Through its interactions with spatial attention via exogenous precues, figure-ground assignment may exhibit a similar effect, with figural regions being perceptually enhanced relative to grounds. Although interacting processes are difficult to separate (Vecera & O'Reilly, 2000), a close relationship between figure-ground processes and focal attention could help explain other phenomena, such as object-based attention, which might arise from both exogenous spatial attention and Gestalt segregation cues such as symmetry or area.
Footnotes
1Although these results support a hierarchical stage account, Baylis and Driver (1995; Driver & Baylis, 1996) did not attempt to argue for a strict serial stage relationship between figure-ground assignment and spatial attention. They did state that exogenous attention mechanisms do not influence segregation.
Acknowledgements
This research was supported by grants from the National Science Foundation (BCS 99-10727) and the National Insti-tutes of Health (MH60636). The authors thank Greg Davis, Maureen Marron, and Steve Palmer for comments.