
Abstract
Word frequency is an important predictor of word-naming and lexical decision times. It is, however, confounded with contextual diversity, the number of contexts in which a word has been seen. In a study using a normative, corpus-based measure of contextual diversity, word-frequency effects were eliminated when effects of contextual diversity were taken into account (but not vice versa) across three naming and three lexical decision data sets; the same pattern of results was obtained regardless of which of three corpora was used to derive the frequency and contextual-diversity values. The results are incompatible with existing models of visual word recognition, which attribute frequency effects directly to frequency, and are particularly problematic for accounts in which frequency effects reflect learning. We argue that the results reflect the importance of likely need in memory processes, and that the continuity between reading and memory suggests using principles from memory research to inform theories of reading.
What determines how quickly a word can be read? Empirically, in both word-naming and lexical decision tasks, frequency of occurrence is among the strongest known influences: Frequent words are read more quickly than infrequent words (Balota, Cortese, Sergent-Marshall, Spieler, & Yap, 2004; Forster & Chambers, 1973; Frederiksen & Kroll, 1976). Thus, it appears that repeated experience with or exposure to a particular word makes it more readable or identifiable. A key assumption of theoretical explanations of the word-frequency (WF) effect is that it is due to the number of experiences with a word—that each (and every) exposure to a word has a long-term influence on its accessibility.
In learning-based accounts of reading, such as connectionist models (e.g., Plaut, McClelland, Seidenberg, & Patterson, 1996; Seidenberg & McClelland, 1989; Zorzi, Houghton, & Butterworth, 1998), learning occurs upon each experience of a word, strengthening the connections needed to process that word and allowing it to be processed more quickly. In lexicon-based models, the accessibility of individual lexical entries (words) is governed directly by frequency, either by thresholds of activation based on WF (e.g., Coltheart, Rastle, Perry, Langdon, & Ziegler, 2001) or by a serially searched frequency-ranked list (e.g., Murray & Forster, 2004).
Research on memory, however, has found that the extent to which the number of repeated exposures to a particular item affects that item's later retrieval depends on the separation of the exposures in time and context (Glenberg, 1976, 1979). Indeed, under some conditions, if neither time nor context changes substantially, there may be no benefit of repetition at all (Verkoeijen, Rikers, & Schmidt, 2004). If the memory for words that subserves word recognition operates in the same fashion, then the effect of repetitions (i.e., WF) will be diminished or eliminated when these repetitions occur in the same context. Accordingly, the number of contexts in which words are experienced, their contextual diversity (CD), should determine their accessibility and hence response times (RTs) in word naming and lexical decision.
A normative measure of a word's CD may be obtained by counting the number of passages (documents) in a corpus that contain that word; measured this way, CD has been shown to have effects on recognition memory that are distinguishable from WF effects (Steyvers & Malmberg, 2003). In the study reported here, we compared the ability of CD and WF to predict six existing sets of data regarding RTs in word naming and lexical decision, basing our analyses on measures of CD and WF from each of three corpora.
METHOD
Dependent Variables
The dependent variables were mean RTs for word naming (reading aloud) and lexical decision (judging whether or not the stimulus is a word) in six data sets. Two of these data sets contain word-naming data for 2,820 uninflected one-syllable words (data for 2,776 words were analyzed in the present study) from studies of young adults (Spieler & Balota, 1997) and older adults (Balota & Spieler, 1998). Another two data sets contain lexical decision data for the same words; again, one set contains data obtained with a young-adult group, and the other contains data obtained with an older-adult group (Balota, Cortese, & Pilotti, 1999). The last two data sets, from the Elexicon project, contain both word-naming and lexical decision data obtained from young adults using a broader selection of 40,481 words (Balota et al., 2000; data for 39,383 words were analyzed in the present study).
Independent Variables
The independent variables were WF (number of occurrences) and CD (number of passages or documents in which a word occurs), calculated from three corpora. First, we used Kučera and Francis's (1967; KF) counts for the Brown corpus, which contains 500 samples (target length of 2,000 tokens) from distinct documents spread evenly over 15 genres. The samples have a mean length of 2,030 tokens (SD = 42). Second, we calculated WF and CD in the 12th-grade portion of the LSA/TASA (Latent Semantic Analysis from Touchstone Applied Science Associates) corpus (Landauer, Foltz, & Laham, 1998), which consists of most of the texts used in the compilation of Zeno, Ivens, Millard, and Duvvuri's (1995) frequency norms; these norms are designed to reflect the likely experience of students schooled in the United States. 1 This section of the corpus has 28,882 samples (from distinct documents) with a mean length of 286 tokens (SD = 25). Third, we also compiled counts from the written portion of the British National Corpus (BNC; British National Corpus Consortium, 2000). This corpus is designed to have the largest possible samples—ideally, whole texts. This portion of the BNC contains 3,144 samples, of various forms and lengths, drawn from documents ranging from pamphlets through book chapters to whole issues of newspapers. 2 The mean number of tokens in each passage is 26,892 (SD = 25,914).
When calculating logarithm and power-law fits, we increased all counts by 1, to avoid problems from zero counts. Items with zero counts were excluded from the rank analyses.
The following measures from CELEX 3 (Baayen, Piepenbrock, & Gulikers, 1995) were included as covariates in the analyses: word length (number of letters), orthographic neighborhood size, rime consistency (for the monosyllabic databases only), number of syllables (when applicable), and initial phoneme (for word naming only).
RESULTS
In this section, we show that CD predicts word-processing times independently of WF and, moreover, that there is no evidence for a facilitatory effect of WF independent of CD. We also discuss a number of possible explanations of the results that are inconsistent with our contention that CD per se determines accessibility, and provide evidence for the validity of the measure of CD that we use here.
Does CD or WF Predict Word-Naming and Lexical Decision Times?
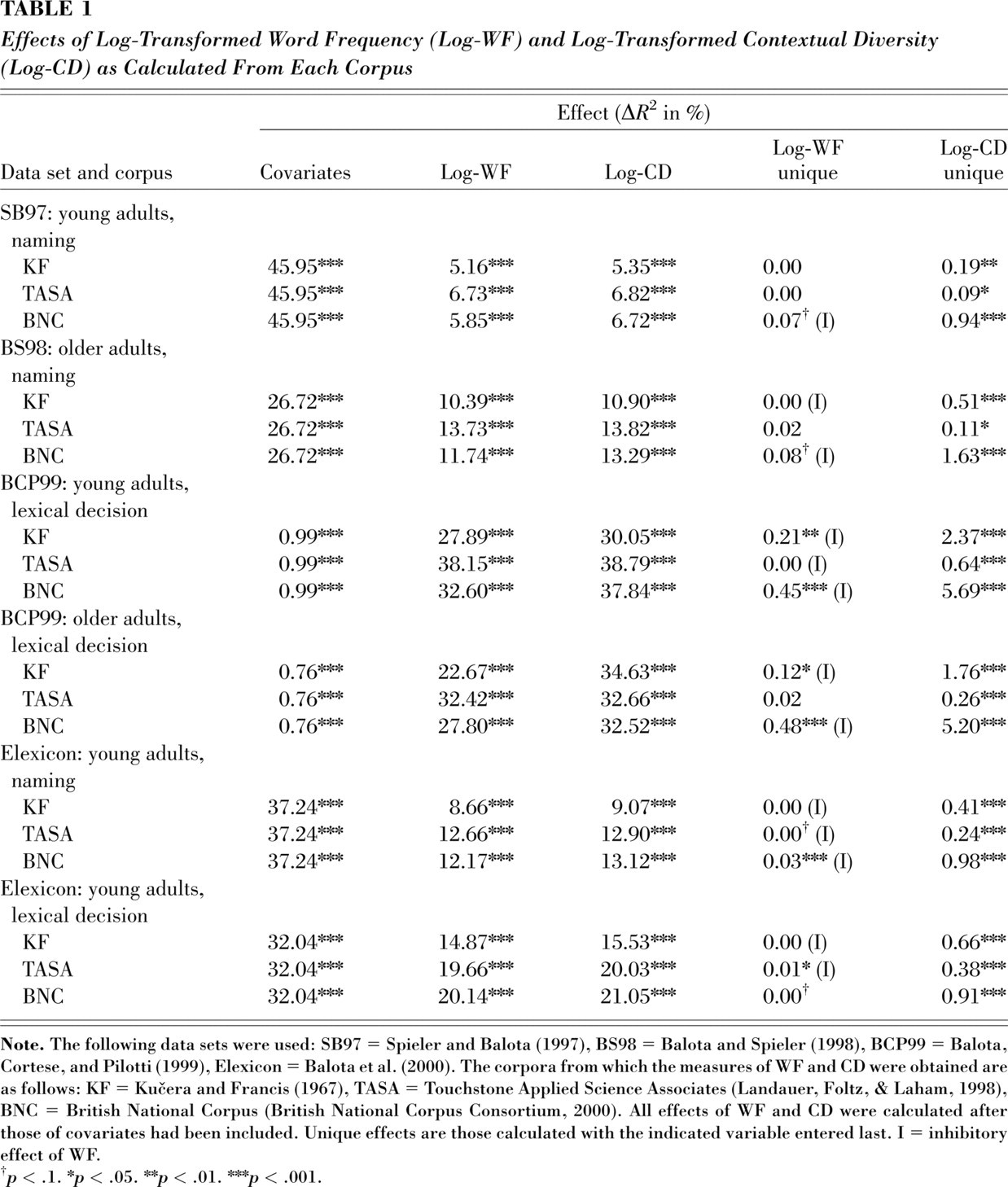
Table 1 presents the results of the 18 analyses (6 data sets × 3 corpora) using log-transformations of WF and CD; log-WF is generally agreed to approximate a linear predictor of naming and lexical decision RTs. After the covariates were entered into the analysis, introducing either WF or CD accounted for significant additional variance, with high WF and high CD both being associated with faster RTs. Moreover, the improvement in prediction was always greater for CD than for WF. In all 18 analyses, there was a unique effect of CD. Six analyses showed a unique effect of WF; in every case, high WF led to slow RTs, meaning that WF acted as a suppressor variable. These results suggest not only that CD is a better predictor of lexical decision and word-naming times for both young and older participants, but also that WF does not contribute to such RTs, except insofar as it is correlated with CD and the covariates.
Effects of Log-Transformed Word Frequency (Log-WF) and Log-Transformed Contextual Diversity (Log-CD) as Calculated From Each Corpus
† p < .1.
∗ p < .05.
∗∗ p < .01.
∗∗∗ p < .001.
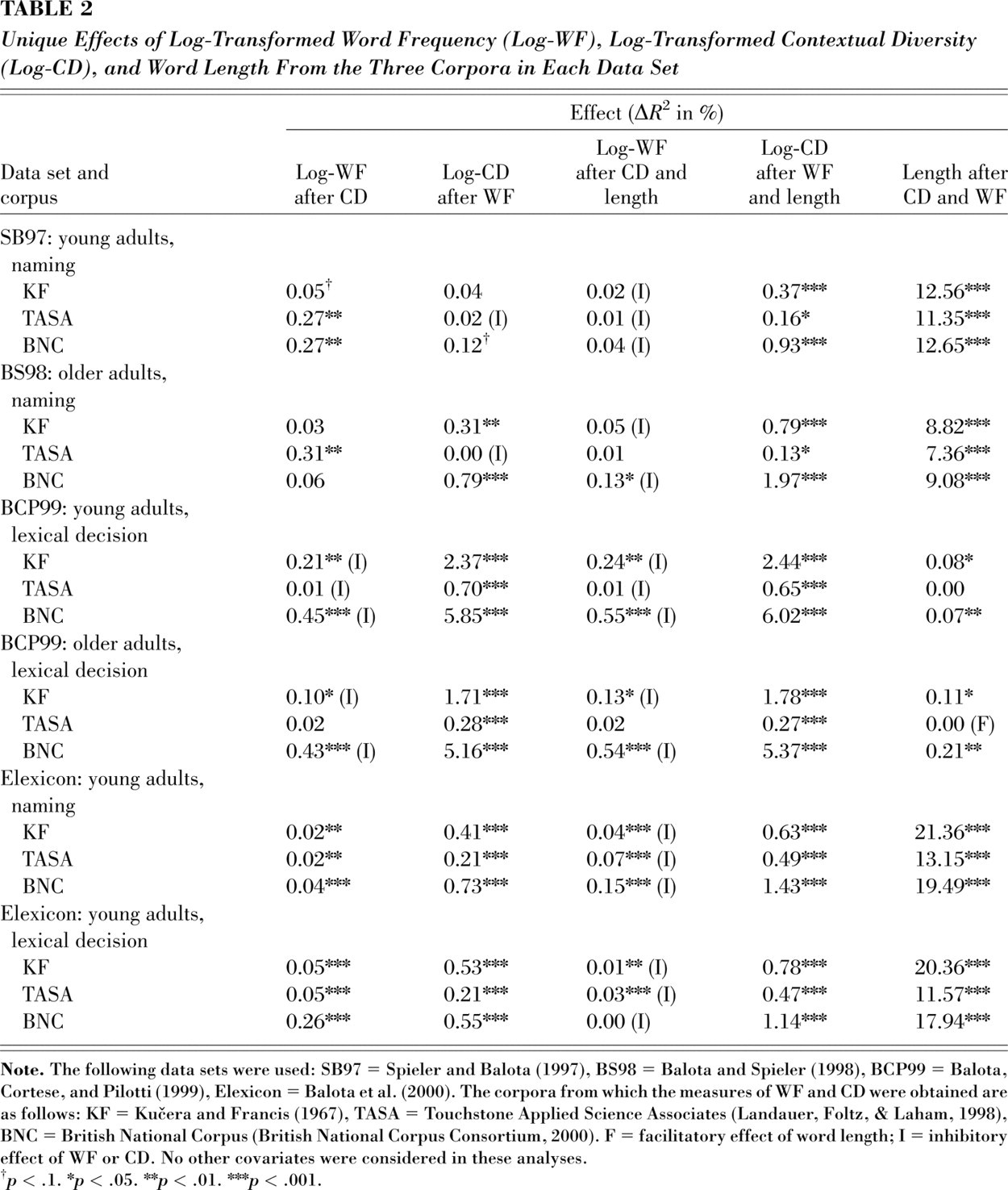
Because the addition of CD to the regression equation eliminated the unique effect of WF, CD must be a critical component of a confound that creates an artifactual effect of WF. However, it need not be the only component. When only log-WF and log-CD were entered into the equation, there was always a facilitatory effect of CD, but in some cases there was also a facilitatory effect of WF. The raw correlations among the variables 4 suggest that word length (in letters) is a likely contributor to the confound, as its correlation with log-WF is greater than its correlation with log-CD. The results summarized in Table 2 are consistent with this idea: In analyses including only log-WF, log-CD, and length as predictors, log-WF showed no unique facilitatory effect, but log-CD did. Moreover, for the critical analyses in which log-WF had appeared to have an effect when length was omitted, there was evidence of a unique (inhibitory) effect of length when it was introduced. Figure 1a illustrates the semipartial correlations of log-WF and log-CD with response time as a function of word length for the Elexicon data. Facilitatory effects are consistently present for CD, but not for WF.
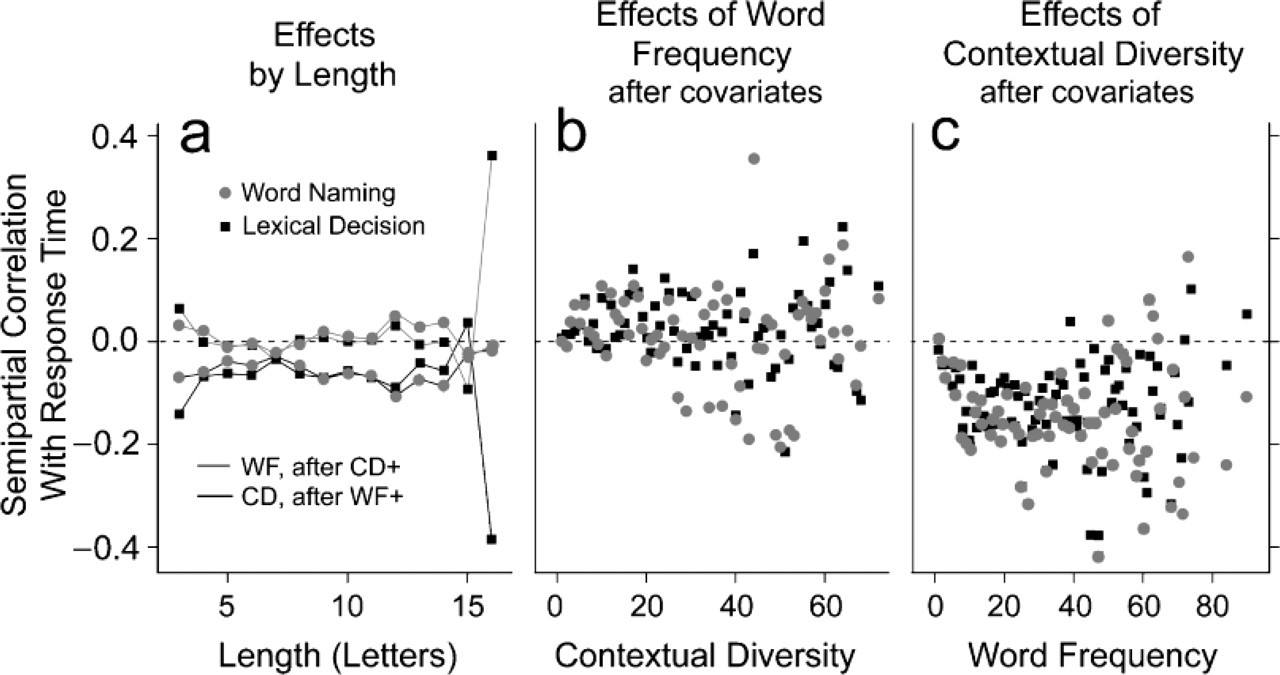
Semipartial correlations of TASA (Touchstone Applied Science Associates) log-word frequency (WF) and log-contextual diversity (CD) with response times in word naming and lexical decision in the Elexicon data, with orthographic neighborhood size, number of syllables, and onset (for naming only) partialed out. Points based on fewer than 50 words are omitted. The graph in (a) presents the correlations of both log-WF and log-CD as a function of word length; the correlations of log-WF have log-CD partialed out, and vice versa. The graph in (b) presents the correlations for log-WF for each value of log-CD, and the graph in (c) presents the correlations for log-CD for each value of log-WF.
Unique Effects of Log-Transformed Word Frequency (Log-WF), Log-Transformed Contextual Diversity (Log-CD), and Word Length From the Three Corpora in Each Data Set
† p < .1.
∗ p < .05.
∗∗ p
∗∗∗ < .01.
Do Semantic Variables Account for the Effect of CD?
Of course, CD may itself be confounded with some variable that was not controlled in this analysis. Whereas WF is subject to effects of structural variables, CD seems more likely to be influenced by semantic variables. Ambiguity, for instance, might be important in the present case, as words with multiple meanings should be used in multiple contexts. Abstract words are also likely to be used in a larger number of contexts than concrete words are. Indeed, Galbraith and Underwood (1973) found that abstract words are rated by undergraduates to have more different contextual uses than concrete words, and Schwanenflugel and Shoben (1983) found that context availability (ease of remembering a context for a word) and diversity of contexts are negatively correlated with concreteness and predict lexical decision RTs. Imageability is conceptually related to concreteness, and often substituted for it in experimental designs.
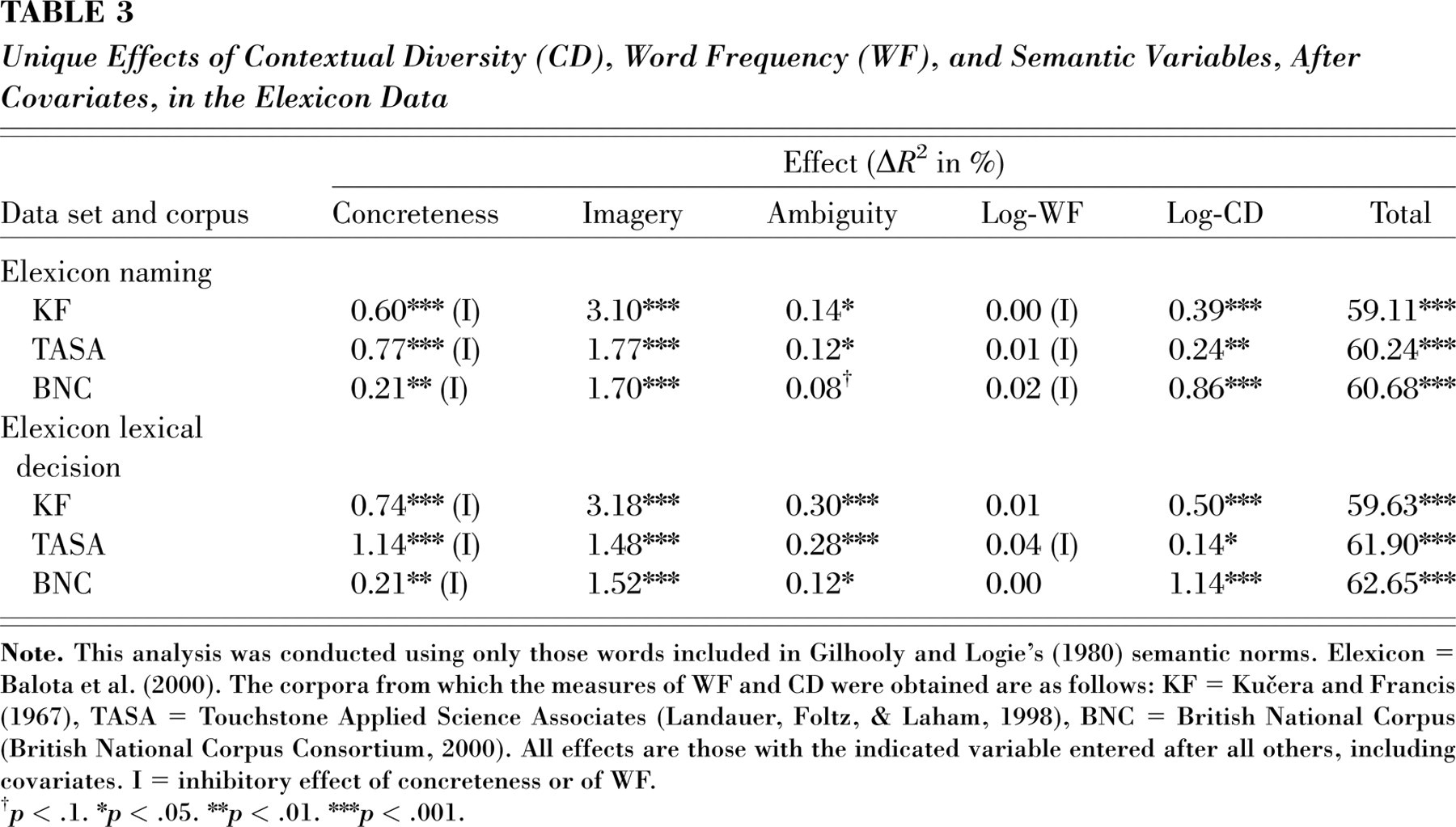
We conducted analyses using the concreteness, imagery, and ambiguity norms from Gilhooly and Logie (1980) for the 1,812 words also found in the Elexicon database. The correlations 5 between concreteness and CD appeared to be more negative than those between concreteness and WF, although TASA appeared to have greater proportions of types and tokens that were concrete (and to a lesser degree imageable) words than the other corpora did. Despite this relationship, including these variables in the analysis did not eliminate the effect of CD: As shown in Table 3, after these variables' effects were accounted for, CD still had a significant facilitatory effect, and WF still did not. Also, in these analyses, the BNC counts accounted for more variance than the TASA counts, a result consistent with the BNC being a larger corpus (by tokens); this may indicate that an apparent advantage for TASA in predicting the RTs in Table 1 comes from its relationship to concreteness and imageability, not its greater number of passages. These analyses show that high CD is associated with faster responses regardless of imageability, concreteness, ambiguity, and other lexical measures, and high WF is not.
Unique Effects of Contextual Diversity (CD), Word Frequency (WF), and Semantic Variables, After Covariates, in the Elexicon Data
† p < .1.
∗ p < .05.
∗∗ p < .01.
∗∗∗ p < .001.
Can the Results Be Explained by the High Correlation Between WF and CD?
The obviously high correlation between log-WF and log-CD might cause concern to some readers in the context of our regressions, although the inferential logic of these analyses is unaffected by this collinearity. 6 One way to show that this correlation is not responsible for the results is to remove it by examining the effect of one variable while holding the other constant. Figure 1b shows the effect of log-WF on RT for individual values of CD; there is little or no evidence for a unique effect of WF. By contrast, Figure 1c, which shows the effect of log-CD for individual values of WF, demonstrates a consistent (and necessarily unique) facilitatory effect. Moreover, all the analyses summarized in Table 1 give evidence for a unique facilitatory effect of CD. Such a pattern would be unlikely even if Type I errors occurred at random in every analysis (because the signs would be inconsistent across analyses).
Nonetheless, the high correlations between measures of WF and measures of CD raise the possibility that WF is the better predictor, but log-CD shows a unique facilitatory effect because log-CD correlates better (more linearly) than log-WF with the most appropriate transformation of WF; both Balota et al. (2004) and Murray and Forster (2004) have found evidence of nonlinearity in the prediction of reading latencies from log-WF.
One possible reason that the logarithmic transformation might lead to misleading results is that the rank of a word's WF is a more linear predictor of these RTs than the logarithm of the word's WF. Murray and Forster (2004) provided some evidence that rank-WF is a better predictor than log-WF for lexical decision times when KF is used to derive these values; this is what they predicted from their model of lexical access, as it serially searches for lexical entries in lists that are frequency ordered. However, rank-WF 7 accounted for more variance than log-WF for only 8 of the 18 combinations of data sets and corpora examined here. These 8 included all 6 analyses involving KF measures of WF; this corpus gives the least reliable estimate of WF because of its size, is the least predictive of RTs, gives the smallest range of CD values, and is most subject to negative bias in the estimation of ranks of low-frequency words. 8
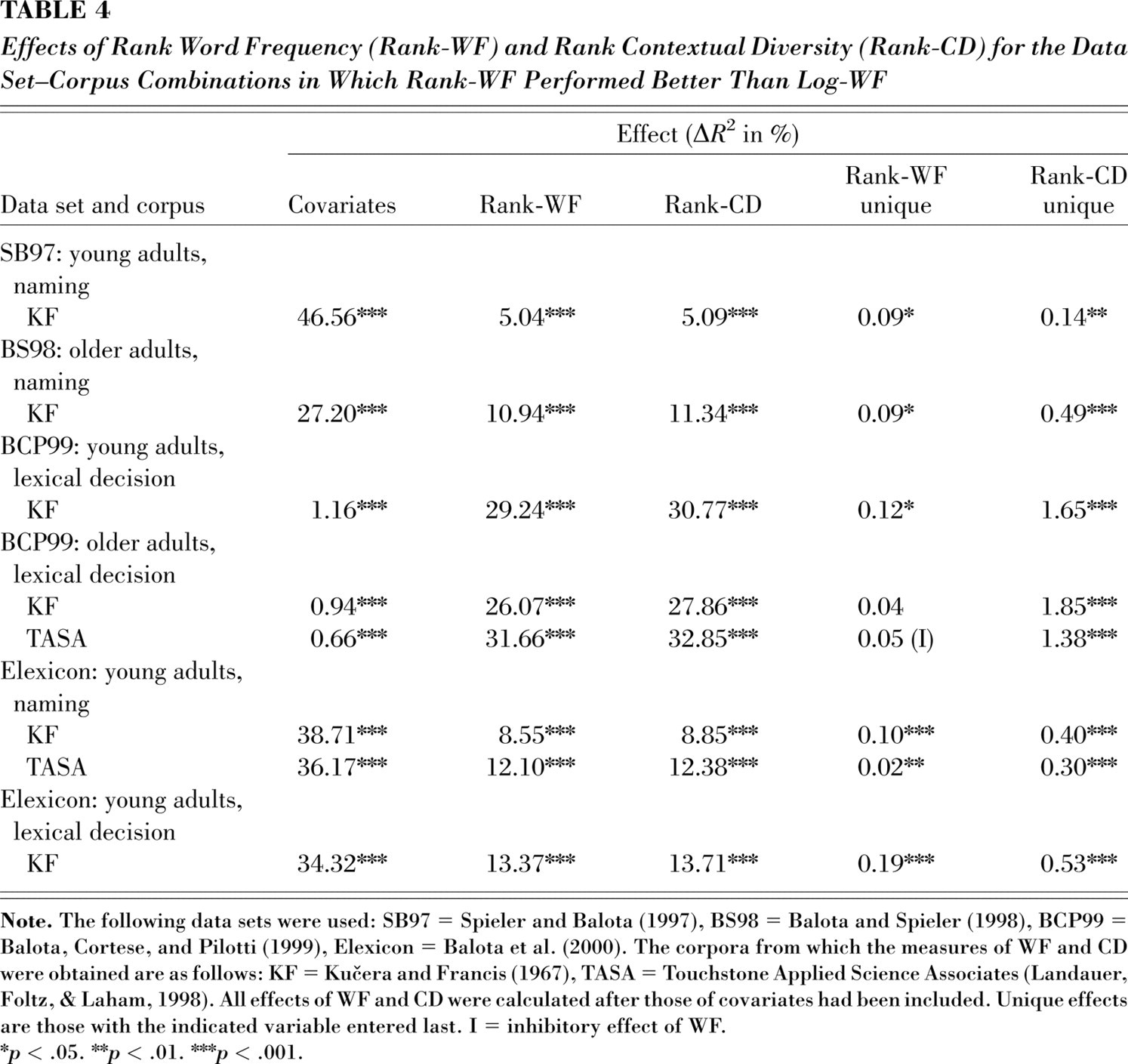
Table 4 presents the results for rank-WF and rank-CD for the eight analyses in which rank-WF accounted for more variance than log-WF. In all eight cases, there was a unique effect of rank-CD, such that high rank-CD led to fast responses. Six of these analyses yielded a significant unique effect of rank-WF. The three of these involving monosyllabic data used KF frequency counts, but for these data TASA accounted for more variance than KF, even when WF was ranked, and log-WF from TASA accounted for even more variance. This suggests that the counts from KF and a ranking transformation were both inappropriate. Moreover, the power transformation we discuss next accounted for much more variance in all cases. Furthermore, because rank-WF did not in any of these instances eliminate a unique effect of rank-CD, the resulting regression formulas did not correspond to any simple (or readily interpretable) version of a rank-hypothesis serial-search model. Moreover, in every case, CD was a stronger predictor than WF, even when ranked measures were used.
Effects of Rank Word Frequency (Rank-WF) and Rank Contextual Diversity (Rank-CD) for the Data Set–Corpus Combinations in Which Rank-WF Performed Better Than Log-WF
∗ p < .05.
∗∗ p < .01.
∗∗∗ p < .001.
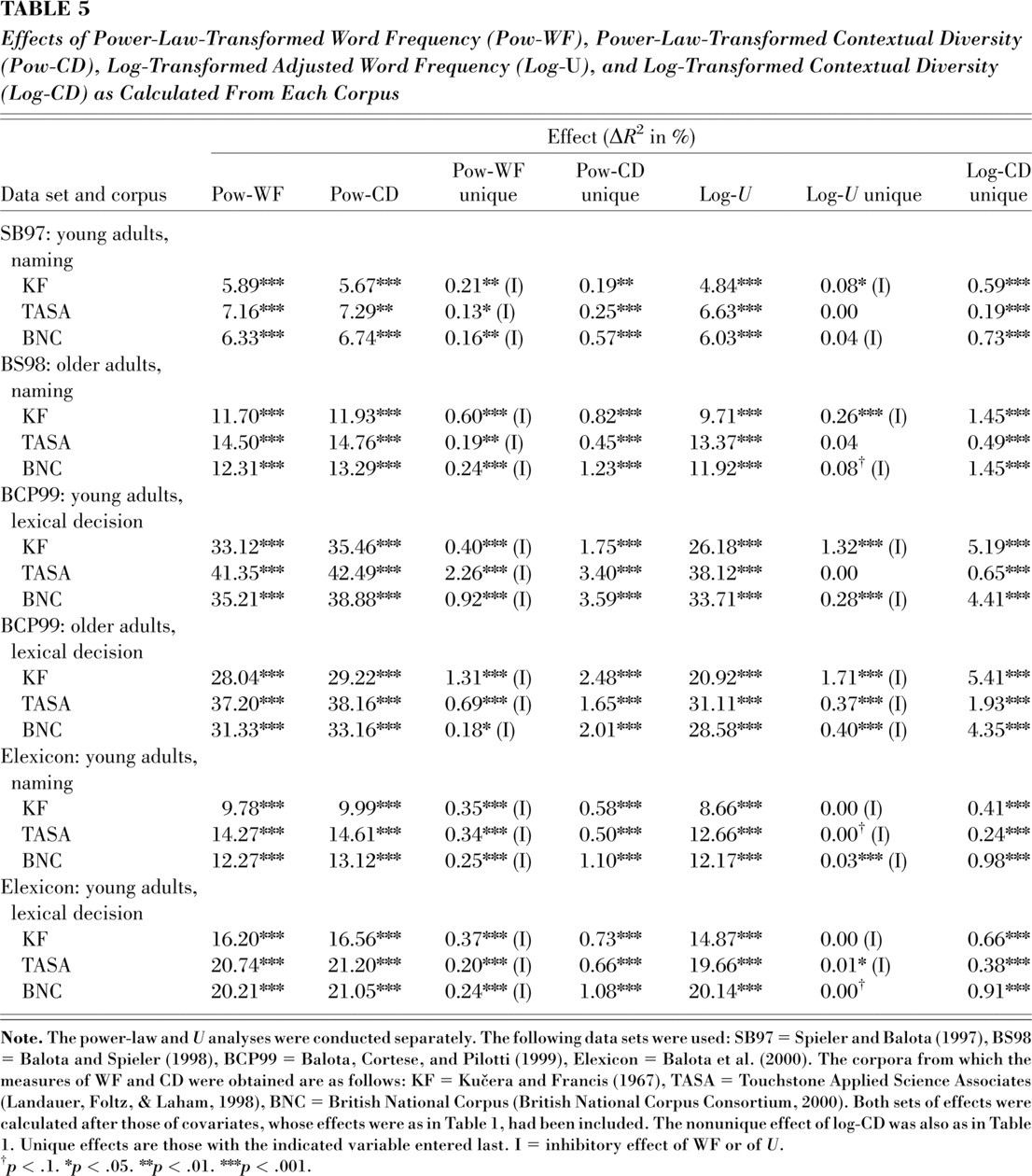
The power law of practice (e.g., Newell & Rosenbloom, 1981) represents a further possibility for an appropriate transformation of frequency for predicting word-processing times (Kirsner & Speelman, 1996). That is, the most appropriate transformation of WF might be some power function (with a negative exponent). The analyses presented in Table 5 tested the possibility that the advantage of CD over WF would disappear when both measures underwent a power-law transformation (with the exponent always a negative free parameter). Broadly speaking, using this transformation led to large increases in the variance accounted for by WF and CD. As Table 5 shows, in 17 of the 18 analyses, CD accounted for more residual variance than WF. In all 18 analyses, including CD led to a significant increase in R 2, with high CD predicting fast responses; although including WF led to significant increases in R 2 in all 18 analyses, low WF was predictive of fast responses in every case.
Effects of Power-Law-Transformed Word Frequency (Pow-WF), Power-Law-Transformed Contextual Diversity (Pow-CD), Log-Transformed Adjusted Word Frequency (Log-U), and Log-Transformed Contextual Diversity (Log-CD) as Calculated From Each Corpus
† p < .1.
∗ p < .05.
∗∗ p < .01.
∗∗∗ p < .001.
Is Corpus CD Just a Better Indicator of Real-World WF?
A final possibility that we consider is that the results suggesting that CD is the cause of apparent WF effects were due to the CD measure from a corpus being more correlated with real-world WF (the frequency in the language as a whole) than is the WF measure from the same corpus. 9 This could occur as a result of WF being more influenced than CD by idiosyncratic properties of individual passages, as one obscure word might occur many times in one passage, 10 inflating WF greatly, but CD only slightly.
To take an extreme example of how corpus CD could be a better reflection of real-world WF than corpus WF is, suppose words did cluster, but not to differing degrees. That is, suppose that the probability that each word occurs in a particular document at all is proportional to the word's real-world frequency, and if the word does occur, it occurs with equal probability either once or 25 times. In this scenario, (proportional) real-world WF and CD are the same thing, and (proportional) corpus WF and CD are both unbiased estimators of real-world WF, but corpus CD has much lower variance, 11 because it is not distorted by low-frequency words that by chance occur 25 times in more than half the passages that they occur in. Consistently different levels of clustering between words are necessary for CD to be conceptually distinct from WF. The ratio of CD to WF can be used as an index of clustering. This index correlates well between the different corpora in this study (correlations calculated for words in the Elexicon data were as follows: KF-TASA, .362; KF-BNC, .485; TASA-BNC, .414), indicating that much of the clustering at play is not idiosyncratic to any particular corpus; that is, CD is reliable for reasons unrelated to corpus WF.
The preceding discussion does not, however, address the more subtle possible ways in which corpus CD could be a better estimate of real-world WF than corpus WF is. For instance, if corpus WF is biased as an estimate of real-world WF because of contextual factors, and if corpus CD is more unbiased, CD could be a better predictor. One way to approach the question of whether corpus CD reflects real-world WF better than corpus WF does is to use pairs of corpora to see whether (a) WF is consistently predicted better by CD than by WF and (b) CD consistently predicts WF better than CD; either eventuality would be damaging for the case that CD has true effects. The raw correlations 12 did not yield consistent answers (in three of the six cases, CD predicted WF better than WF did; in two of the six cases, CD predicted WF better than CD). Hence, this analysis neither supports nor disconfirms the suggestion that CD consistently acts as a better measure of WF. However, similar analyses can be conducted with randomly chosen halves (half the passages) of each corpus. We conducted 100 such random splits for each corpus, investigating the predictions of log-WF and of log-CD. WF was predicted slightly (but highly significantly) better by WF than by CD (KF: .7816 vs. .7798, SE diff = .00019; TASA: .9340 vs. .9333, SE diff = .00003; BNC: .9721 vs. .9553, SE diff = .00012), and CD predicted CD somewhat (and highly significantly) better than it predicted WF (KF: .7928 vs. .7812, SE diff = .00019; TASA: .9423 vs. .9338, SE diff = .00003; BNC: .9790 vs. .9549, SE diff = .00011). These results appear to exclude the possibility that CD is a better indicator of WF than are observations of WF itself.
Finally, we used a standard adjustment for clustered sampling of WF estimates, Carroll's U, which adjusts frequency estimates downward for words occurring in few contexts. Table 5 presents results of these analyses, which are analogous to the analyses in Table 1. Essentially, the same pattern of results obtains: All 18 analyses showed a unique facilitatory effect of CD, and none showed a unique facilitatory effect of adjusted WF (U); many showed adjusted WF had unique inhibitory effects.
DISCUSSION
In both word naming and lexical decision, CD was more predictive of RTs than WF was. Moreover, CD had a unique effect, with high CD leading to fast responses, whereas WF had either no unique effect or a suppressor effect, with high WF leading to slow responses. This implies there is a facilitatory effect of CD, but no facilitatory effect of WF per se. This pattern was found even when ambiguity, imagery, and concreteness were controlled; was not an artifact of the strong correlation between the CD and WF variables; and does not appear to be due to the clustering properties of the corpora, both because CD did not predict WF better than WF did and did not predict WF better than CD and because the same pattern of results was obtained even when WF was adjusted for clustering.
According to the rational analysis of memory (Anderson & Milson, 1989; Anderson & Schooler, 1991), number of contexts has an effect because the more contexts an item has occurred in, the more likely that item is to be needed in any new context; and as a result of different words clustering within particular contexts to differing degrees, WF is a relatively poor indicator of likely need. Recently needed items also have high likely need, and recency certainly affects memory (e.g., Rubin & Wenzel, 1996). Because CD is a good indicator of the probable recency of an item, it is feasible that recency, and not CD per se, drives the CD effect. However, when the recency of items is controlled by introducing recent repetitions, the (apparent) WF effect is diminished, but not eliminated (Balota & Spieler, 1999; Kirsner & Speelman, 1996). This would not be the case if recency were the key factor in the CD effect.
Previous attempts to link CD to lexical decision latencies have also used local windows of semantic context to derive (information-theoretic entropy) values based on contextual predictability (McDonald & Shillcock, 2001). Although the variable thus derived did have an effect distinct from that of WF, it did not entirely eliminate the WF effect, possibly because temporal, as well as semantic, aspects of context contribute to the CD effect.
Learning-based models of reading cannot accommodate these results unless they are modified so that learning mechanisms are sensitive to context, not frequency. Models of reading that attribute frequency effects to frequency-sensitive units in dictionary-like lexicons, but do not specify the source of this sensitivity, could be modified so that these units are sensitive to CD. However, such modifications would seem to violate the principle that only orthographic forms are stored in the orthographic lexicon, and only phonological forms are stored in the phonological lexicon (Coltheart, 2004). By contrast, according to a view that reading uses the same kind of memorial resources as recall, the present results are natural. They therefore motivate a theory of reading based on principles from memory research.
Footnotes
1This corpus is also described on the Web at ![]() . We used the 12th-grade level because frequency computed from this level is a better predictor of RTs than frequency counted across the whole corpus, probably because the full corpus is too heavily weighted toward college-level texts to be representative of undergraduate participants or older control subjects education-matched to them.
. We used the 12th-grade level because frequency computed from this level is a better predictor of RTs than frequency counted across the whole corpus, probably because the full corpus is too heavily weighted toward college-level texts to be representative of undergraduate participants or older control subjects education-matched to them.
3CELEX was not used for frequency counts because the corresponding CD values were not readily obtainable. Additionally, the base corpus consists of only 243 documents, and so would yield a relatively coarse measure of CD.
6In instances of high collinearity, estimated coefficients are unbiased, but are subject to higher error than would otherwise be the case. Power is therefore reduced, but Type I error rates are not thereby inflated. The nonindependence of estimates and comparatively high sensitivity to small changes in the data make interpretations of coefficient magnitudes uncompelling, but allow null-hypothesis significance testing. The negative effects on power are mitigated by the large sample sizes used in our analyses.
8The relationship between ranks estimated from different corpora is nonlinear.
9We thank David Balota for highlighting this possibility.
10This issue would be especially problematic for long passages. The BNC is the only corpus examined here that has sizable variability in passage size. We therefore conducted an analysis in which we weighted each occurrence by the reciprocal of the length of the passage, so that all passages contributed equally to the WF count. However, this decreased the correlation with RTs, and the analysis still favored CD.
11It is generally the case that CD estimates are more stable than WF estimates. This is why CD correlates better with itself than WF correlates with itself over split halves of a corpus.
Acknowledgements
This work was supported by a Warwick Postgraduate Research Fellowship to J.S.A. and by Grants RES 000221558 and PTA 026270716 from the Economic and Social Research Council (UK) and Grant F/215/AY from the Leverhulme Trust. We thank Marjolein Merkx, Chris Kent, Elizabeth Maylor, Neil Stewart, and Matthew Roberts for comments on this work.