
Abstract
The question of whether or not figure-ground segmentation can occur without attention is unresolved. Early theorists assumed it can, but the evidence is scant and open to alternative interpretations. Recent research indicating that attention can influence figure-ground segmentation raises the question anew. We examined this issue by asking participants to perform a demanding change-detection task on a small matrix presented on a task-irrelevant scene of alternating regions organized into figures and grounds by convexity. Independently of any change in the matrix, the figure-ground organization of the scene changed or remained the same. Changes in scene organization produced congruency effects on target-change judgments, even though, when probed with surprise questions, participants could report neither the figure-ground status of the region on which the matrix appeared nor any change in that status. When attending to the scene, participants reported figure-ground status and changes to it highly accurately. These results clearly demonstrate that figure-ground segmentation can occur without focal attention.
Figure-ground segmentation is the process by which the visual system organizes a visual scene into figures and their backgrounds. This is one of the most important visual processes because figure-ground distinctions are fundamental to the visual perception of objects and to visuomotor behavior.
Gestalt psychologists, who were the first to recognize the importance of figure-ground segmentation, distinguished figures and grounds in terms of their phenomenal appearance (Koffka, 1935; Rubin, 1915/1958). Figures appear to have a definite shape, so that their bounding contours are assigned as belonging to them. Grounds are shapeless near the contours they share with figures and appear to continue behind the figures near those contours. Much of the research on figure-ground perception has been concerned with identifying the properties that determine which regions will appear as figures. For example, smaller regions are likely to be perceived as figures (Rubin, 1915/1958), as are symmetrical regions (Bahnsen, 1928), convex regions (Hoffman & Singh, 1997; Kanizsa & Gerbino, 1976), regions with higher spatial frequency (Klymenko & Weisstein, 1986), lower regions (Vecera, Vogel, & Woodman, 2002), regions with a wide base (Hulleman & Humphreys, 2004), and regions depicting familiar objects (Peterson & Gibson, 1994a, 1994b).
An important, yet unresolved, issue concerns the relation between figure-ground segmentation and attention. The study reported in this article addressed one aspect of this issue: Can figure-ground segmentation occur without attention?
Many modern theories of perception have assumed that figure-ground segmentation operates preattentively to deliver the perceptual units to which focal attention is allocated for further processing (e.g., Julesz, 1984; Marr, 1982; Neisser, 1967; Treisman, 1986). Although this view has been widely accepted, researchers have also suggested that deliberate attention (Koffka, 1935; Rubin, 1915/1958) and the location of fixation or spatial attention (Hochberg, 1971; Sejnowski & Hinton, 1987) can influence figure-ground organization. Few studies, however, have directly examined the relation between figure-ground segmentation and visual attention. Peterson and Gibson (1994b) showed that fixation location can contribute to figure-ground segmentation. Baylis and Driver (1995; Driver & Baylis, 1996) examined performance on a contour-matching task with ambiguous displays and showed that endogenous attention influenced figure-ground assignment; their experiments suggested that exogenous attention did not influence figure-ground perception. However, recent research by Vecera, Flevaris, and Filapek (2004), using the same contour-matching task with similar ambiguous displays, demonstrated that exogenous attention can influence figure-ground assignment, provided that the exogenous cues are located inside the figure-ground display. These results demonstrate that exogenous spatial attention can act as a cue for figure-ground assignment, but do not speak to the question of whether or not attention is required for figure-ground segmentation to occur.
Recently, Nelson and Palmer (2007) examined the effects of figural cues (i.e., familiarity) on attention. They used bipartite displays in which the central contour sketched a familiar shape on one side but not the other, and presented detection-discrimination targets equally often on the two sides of the central contour. They found a perceptual advantage for targets presented on the figure, a result suggesting that a figural cue can attract attention to the region that is biased to be perceived as figure. However, it cannot be determined from Nelson and Palmer's experiments whether the figural advantage was due to direct influence of the figural cue on attention or to attraction of attention to the region perceived as figure (see also Weisstein & Wong, 1987). Nevertheless, the possibility that figural cues per se can attract attention and that exogenous attention can influence figure-ground assignment (Vecera et al., 2004) suggests a potential reinterpretation of research by Driver, Baylis, and Rafal (1992) that is often cited (e.g., Barenholtz & Feldman, 2006; Mazza, Turatto, & Umiltà, 2005) as providing evidence that figure-ground segmentation is preattentive.
Driver et al. (1992) studied a patient with right-hemisphere damage and severe left neglect. The patient was presented with a display divided by a contour into a small, bright, green section and a larger, dimmer, red section; the green section could be on the far left or the far right of the display. His task was to decide whether the dividing contour matched a probe line. The patient performed well above chance when the green section appeared at the far left, that is, when the dividing contour fell to the right of the green section, although the contour appeared in his contralesional field, but he performed at chance when the green section appeared at the far right, that is, when the dividing contour fell to the left of the green section, although the contour appeared in his ipsilesional field. According to Driver et al., these results indicate that the patient retained intact figure-ground segmentation despite his pathological bias in spatial attention and thus imply that figure-ground segmentation is preattentive. Although these results clearly indicate that the patient's neglect was applied to the contralesional side of the green figure rather than to the contralesional field as a whole, the possibility that exogenous attention influenced the figural status of the green section cannot be ruled out. The green section was more salient than the red section because it was brighter. Given that color perception can be preserved in the contralesional field in some patients (Cohen & Rafal, 1991), attention could have been drawn automatically to the green section by virtue of its salience, thereby increasing its likelihood of being perceived as figure, much as exogenous cues can influence figure-ground assignment (Vecera et al., 2004). Thus, despite the ingenuity of this study, it does not provide unequivocal evidence that figure-ground segmentation can occur without attention.
In this article, we report new evidence demonstrating that figure-ground segmentation can occur for unattended stimuli. This evidence was obtained using an inattention paradigm with indirect on-line measures of unattended processing (devised by Russell & Driver, 2005; see also Kimchi & Razpurker-Apfeld, 2004).
Observers were presented with two successive displays, each of which included a small target matrix (made up of random black and white squares) that appeared on a task-irrelevant scene of alternating regions organized into figures and grounds by convexity. The task was to judge whether the matrices in the two displays were the same or different. When the matrices differed, only one black square changed its location, rendering the task sufficiently demanding to absorb attention. The figure-ground organization of the scene backdrop stayed the same or changed across the two displays, independently of whether or not the target matrix changed. The edges in the backdrop always changed from the first to the second display regardless of whether or not the figure-ground organization changed, to control for the possibility that a change in backdrop organization could be detected from local changes in edges per se. We examined whether the figure-ground organization of the scene backdrop influenced performance on the matrix-change task. We hypothesized that if the unattended backdrop was segmented into figures and grounds, then congruency effects would be obtained; that is, responses to same targets would be faster or more accurate when the backdrop organization stayed the same than when it changed, and responses to different targets would be faster or more accurate when the backdrop organization changed than when it stayed the same. After the last experimental trial, observers were probed with surprise questions asking whether the region on which the target was presented in the preceding display appeared to be figure or ground and whether the figure-ground status of that region had changed between the two displays on that trial.
In Experiment 1, we found that changes in the figure-ground organization of the backdrop produced congruency effects on performance of the target-change task, even though accuracy in reporting these changes was no better than chance. In Experiment 2, we instructed participants to attend to the scene backdrops and ignore the matrices; in this case, explicit reports about the figure-ground organization of the backdrop were highly accurate.
EXPERIMENT 1
Method
Participants
Forty-six students at the University of Haifa (39 females, 7 males; age range: 19–28 years) participated in this experiment. All had normal or corrected-to-normal vision. Four observers performed at chance level in at least one of the conditions, and they were replaced.
Stimuli
Each display consisted of a small target matrix presented on a scene of alternating regions organized into figures and grounds by local convexity (Fig. 1). The displays were presented on a gray field at a viewing distance of 60 cm. Each target was made up of 12 black and 13 white small (0.19°) squares, randomly located in a 5 × 5 matrix subtending 0.95° × 0.95°.
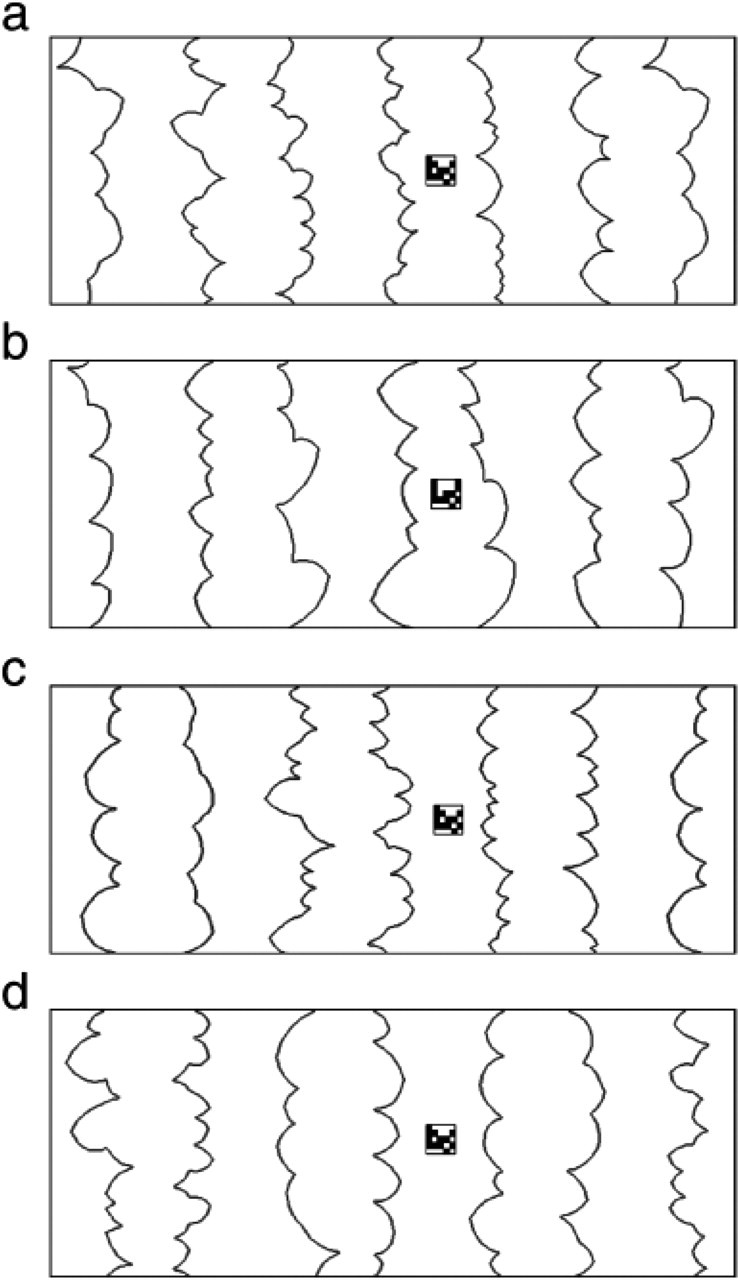
Examples of the displays used in this study. In the experiments, displays were presented on a gray field, and no frame was used. For illustrative purposes, the backdrop edges are somewhat darker than in the actual stimuli. The matrix always appeared on the backdrop region to the right of the central edge (i.e., the fifth region from the left). This region could be convex (figure, or F) or concave (ground, or G), and the number of parts in this region could be small or large. The examples here illustrate (a) the F type with a large part number, (b) the F type with a small part number, (c) the G type with a large part number, and (d) the G type with a small part number. The matrices in (a) and (b) depict an example of a change in matrix (a change in the location of one small black square).
Each trial consisted of two successive displays. The target sometimes changed from the first to the second display (different-target trials) and sometimes remained the same (same-target trials). A change was made by switching the location of one small black square in the matrix with that of a white one.
The backdrop stimuli were chosen from the set of eight-region outline displays created by Kim and Peterson (2002; for details, see Peterson & Salvagio, 2008). Each backdrop stimulus subtended 7.31° in height and 18.43° in width and consisted of four locally convex regions (i.e., regions with multiple convex parts) alternating with four locally concave regions (i.e., regions with multiple concave parts). The convex and concave regions in a display were equal in area; no two regions, whether within or across displays, were the same shape. The matrix in each display was presented on the backdrop region to the right of the central edge (i.e., the fifth region from the left). We included 20 different backdrop stimuli in which the fifth region was convex (figure-type backdrops, or F; see Figs. 1a and 1b) and 20 different backdrop stimuli in which this region was concave (ground-type backdrops, or G; see Figs. 1c and 1d). In half of the backdrops of each type, the fifth region had a relatively large number of parts (8–13; Figs. 1a and 1c), and in the other half, this region had a relatively small number of parts (3–7; Figs. 1b and 1d).
These 40 backdrop stimuli were randomly paired (with the constraint that a backdrop with a small number of parts was paired with a backdrop with a large number of parts) so as to produce 20 pairs of each of four types (the first letter denotes the first backdrop type, and the second letter denotes the second backdrop type): FF, GG, FG, and GF. Eighty additional pairs were produced by reversing the order of the stimuli in each pair (reversed FG and GF pairs turned into GF and FG pairs, respectively). Altogether, there were 160 pairs, 40 pairs of each type; in half of the pairs of each pair type, the first stimulus had a small number of parts, and in the other half, the first stimulus had a large number of parts. Each individual backdrop stimulus was repeated eight times. For the practice trials, 8 additional backdrop stimuli (4 F, 4 G) were paired to produce 16 different pairs, 4 of each type.
Design and Procedure
The participants completed 160 experimental trials in two blocks of 80 trials each, preceded by one practice block of 16 trials. A 2 (target: same, different) × 2 (backdrop organization: same, different) × 2 (starting backdrop organization: F, G) within-subjects design was used, producing eight different conditions. Half of the trials were same-target trials, and half were different-target trials. Independently of whether the target changed or remained the same on each trial, the figure-ground organization of the scene backdrop also changed or remained the same. Half of the same-backdrop trials were FF trials, and half were GG trials; half of the different-backdrop trials were FG trials, and half were GF trials. The order of the trials within each block was randomly permuted. The fixation cross was always aligned with the center of the fifth region of the backdrop to be presented, and the target was always centered in the place where the fixation cross had been.
The event structure of each trial is shown in Figure 2. Each trial started with a fixation cross that appeared for 750 ms. After a 250-ms interval, the first display appeared for 200 ms. It was followed by a 150-ms interval, and then the second display appeared for 200 ms. At this point, participants had to decide, as rapidly and as accurately as possible, whether the two successive targets were the same or different. They indicated their decision by pressing one of two response keys. An auditory tone provided immediate feedback after an incorrect response. The intertrial interval was 1,000 ms.
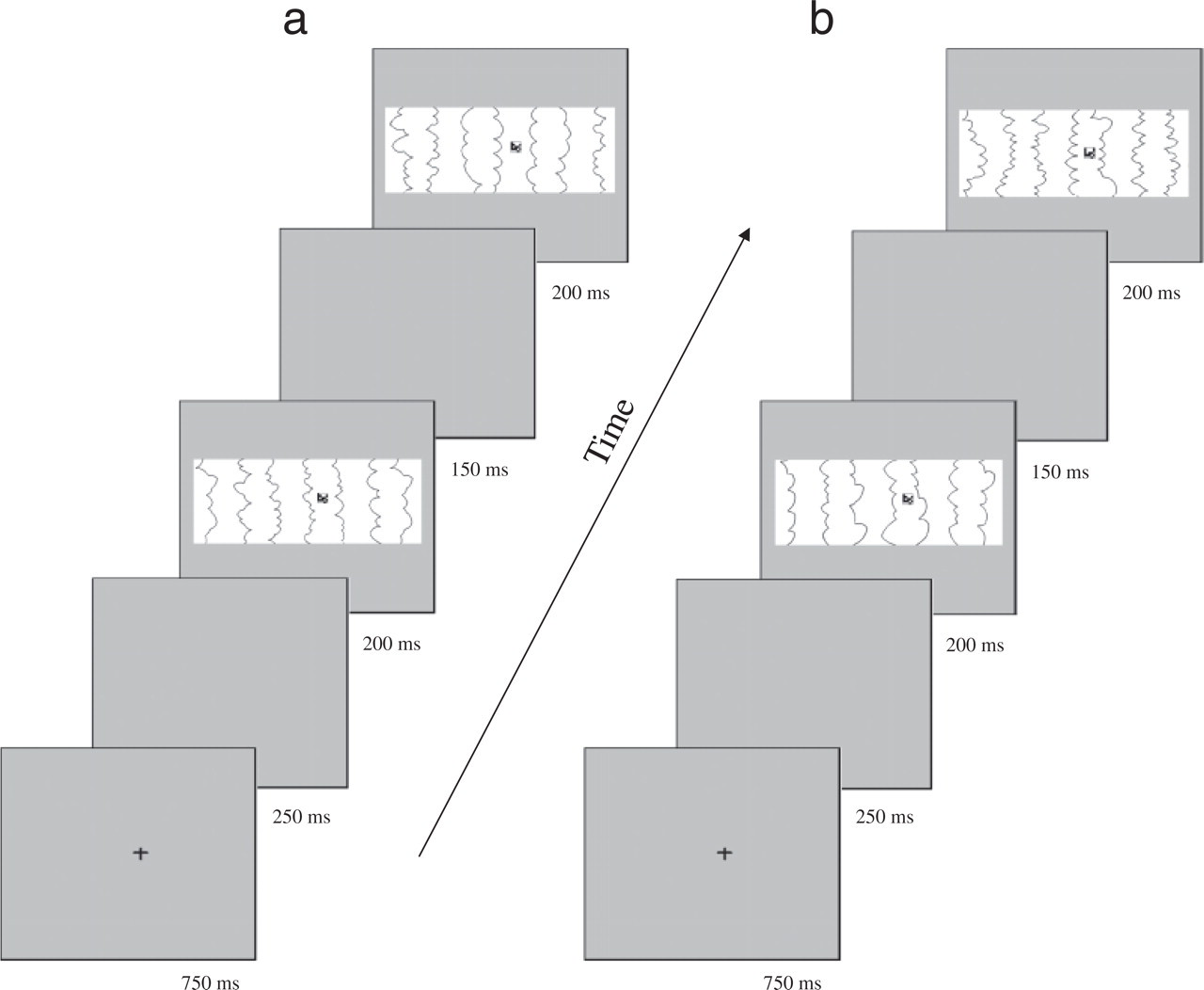
Sequence of events in a trial. The illustration depicts two examples: (a) a same-target trial (matrix is unchanged) on a backdrop that changes from figure to ground and (b) a different-target trial (matrix changes) on a backdrop that stays figure.
Immediately after participants completed the last experimental trial, they were asked two forced-choice questions. The first question asked, “Did the matrix in the previous display appear to lie on a shape bounded by black borders or on a space between shapes?” An example was presented for each alternative (“shape” or “space between shapes”), and participants indicated their choice by pressing one of two response keys. The second question asked, “Was there a change in the region the matrix appeared to lie on across the two displays in the previous trial (from a shape to a space between shapes or from a space between shapes to a shape)?” The two alternatives were “change” and “no change,” and participants indicated their choice by pressing one of two response keys.
Results and Discussion
On-Line Performance on the Matrix Task
All reaction time (RT) summaries and analyses are based on participants' mean RTs for correct responses. RTs less than 150 ms and greater than 1,500 ms were discarded (2.04% of all trials). Table 1 presents mean RT, mean percentage correct, and mean inverse-efficiency (IE) score for each type of trial. The IE score was determined for each condition for each participant by dividing the mean RT by the proportion correct for that condition (Townsend & Ashby, 1983). Because analyses showed that the backdrop significantly influenced RTs for different-target trials and accuracy for same-target trials, we focused on IE, which combines speed and accuracy, and therefore allowed us to evaluate congruency effects with a single measure.1
Mean Reaction Time (RT) on Correct Trials (in Milliseconds), Mean Percentage of Correct Responses, and Mean Inverse Efficiency in Experiment 1
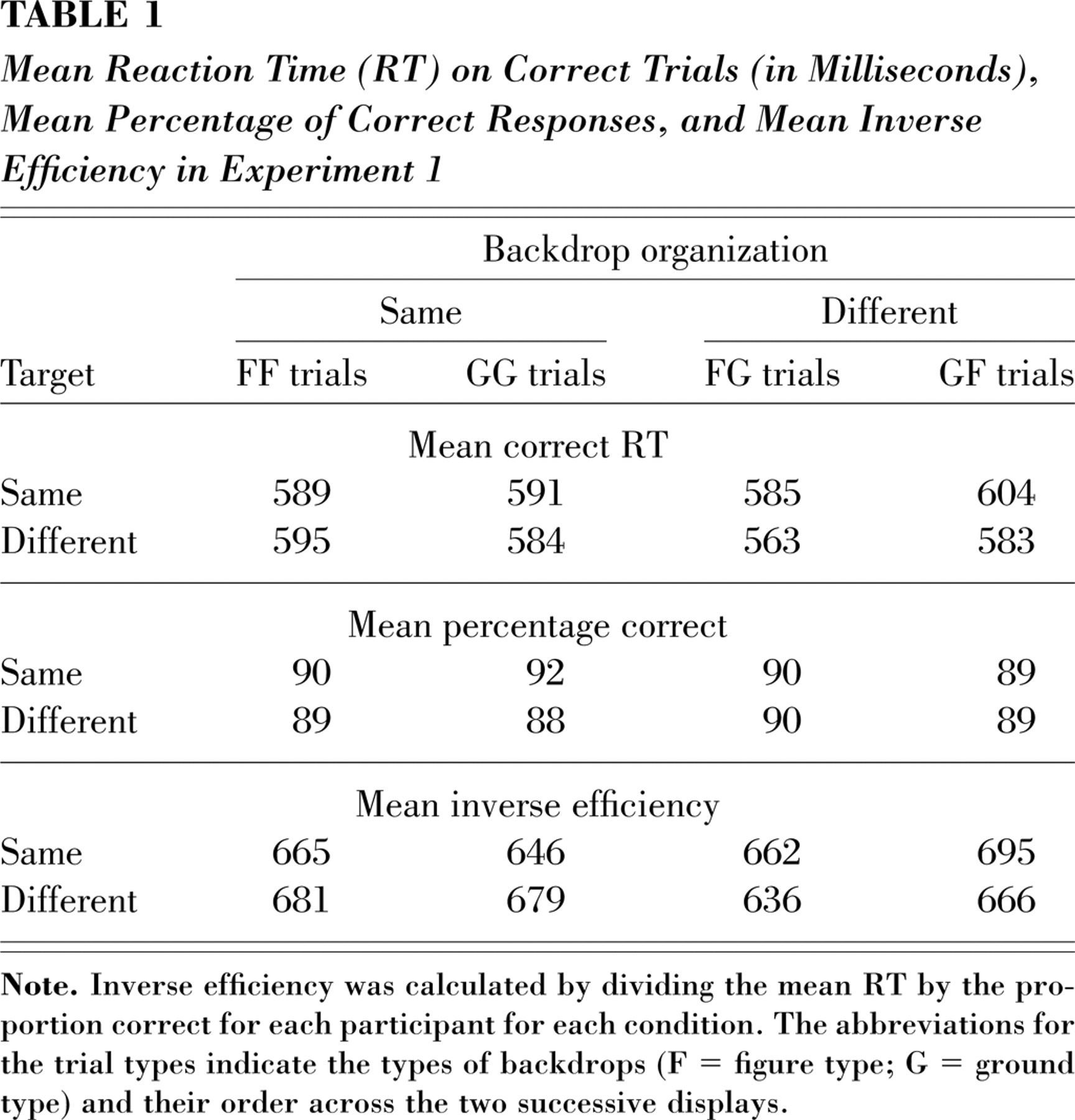
Figure 3 depicts mean IE scores for same and different targets as a function of backdrop organization (same, different). These results show congruency effects arising from changes in the figure-ground organization of the backdrops: On different-target trials, judgments were more efficient (i.e., IE scores were lower) when backdrop organization changed across the two displays than when it remained the same, and on same-target trials, judgments were more efficient when backdrop organization stayed the same than when it changed. A 2 (target) × 2 (backdrop organization) × 2 (starting backdrop organization) analysis of variance confirmed these results. The interaction between target and backdrop organization was significant, F(1, 45) = 13.90, p < .0005, η p 2 = .24, and did not vary with starting organization, F < 1. Analysis of simple effects showed that responses to different targets were significantly more efficient when backdrop organization was changed than when it was unchanged, F(1, 45) = 10.47, p < .005, η p 2 = .29, and responses to same targets were significantly more efficient when backdrop organization was unchanged than when it was changed, F(1, 45) = 4.47, p < .05, η p 2 = .09.
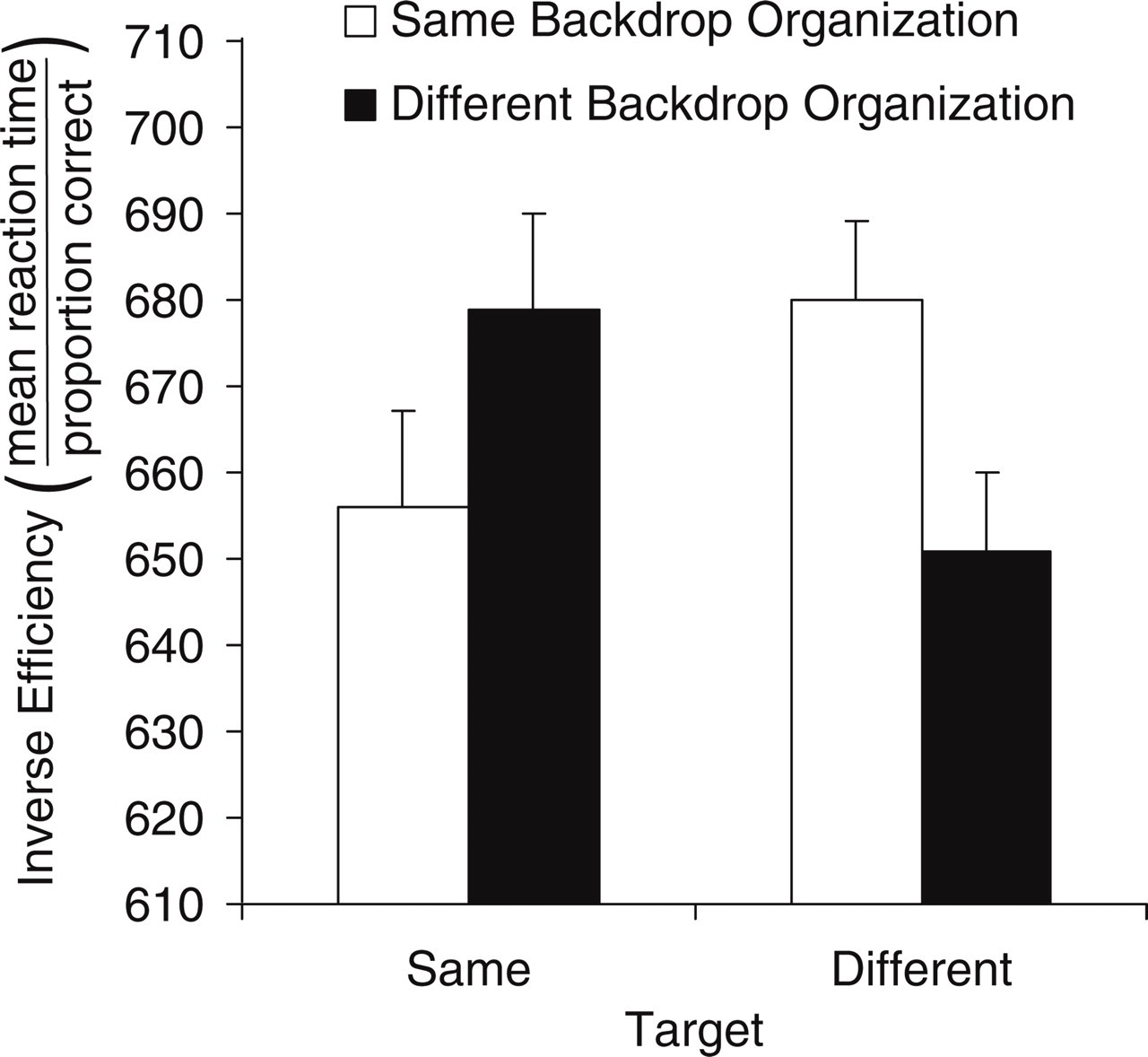
Results from Experiment 1: inverse-efficiency scores for same and different targets as a function of the backdrop's organization (same, different). Error bars indicate standard errors of the means.
The only other significant result was an interaction between starting organization and backdrop organization, F(1, 45) = 6.81, p < .02, η p 2 = .13. Analysis of simple effects revealed two important results. First, performance was more efficient on FG trials (IE = 649) than on GF trials (IE = 681), F(1, 45) = 9.13, p < .005, η p 2 = .17. The FG and GF trials differed in an important way: On the GF trials, the backdrop region on which the matrix appeared changed from ground to figure, so that a new figure (a “new object”) appeared in the target's backdrop region; no new figure appeared in this region on FG trials. Presumably, the implicit processing of a new figure on the GF trials produced less efficient responses to the target. This result indicates that changes in figure-ground organization, and not simply changes in convexity versus concavity of the backdrop regions, were registered by the visual system. Changes in convexity/concavity per se would not predict a difference between these two types of trials, because in both types convex and concave regions changed their location across successive displays. The direction of change would have mattered only if the convex regions were designated as figures, such that a new figure appeared when the backdrop region on which the target appeared changed from concave to convex (GF trials), but not when it changed from convex to concave (FG trials).
Second, performance was equally efficient on FF (IE = 673) and GG (IE = 663) trials, F < 1. This result indicates that the congruency effects produced by backdrop organization could not have been due to implicit capturing of attention by backdrop convexity, as per Nelson and Palmer's (2007) suggestion that a figural cue can attract attention automatically. Had attention been captured by backdrop convexity, then performance efficiency on the matrix task should have differed between trials on which the matrix appeared on convex regions (FF trials) and trials on which it appeared on concave regions (GG trials), but no such difference was observed.2
Response to Surprise Questions
Table 2 presents the percentage of participants who responded correctly to each surprise question. Overall, only 21 participants (46%) correctly reported the region on which the target appeared in the preceding display; this percentage was not different from chance. Of the 22 participants who were presented with a figure on the last display (FF or GF), 15 (68%) reported seeing a “shape,” χ2(1) = 2.9, n.s. Of the 24 participants who were presented with a ground (GG or FG), only 6 (25%) reported seeing a “space between shapes,” χ2(1) = 6.0, p < .025; this finding suggests some bias to respond “shape.”
Percentage of Participants Who Responded Correctly to Each Forced-Choice Question in Experiment 1
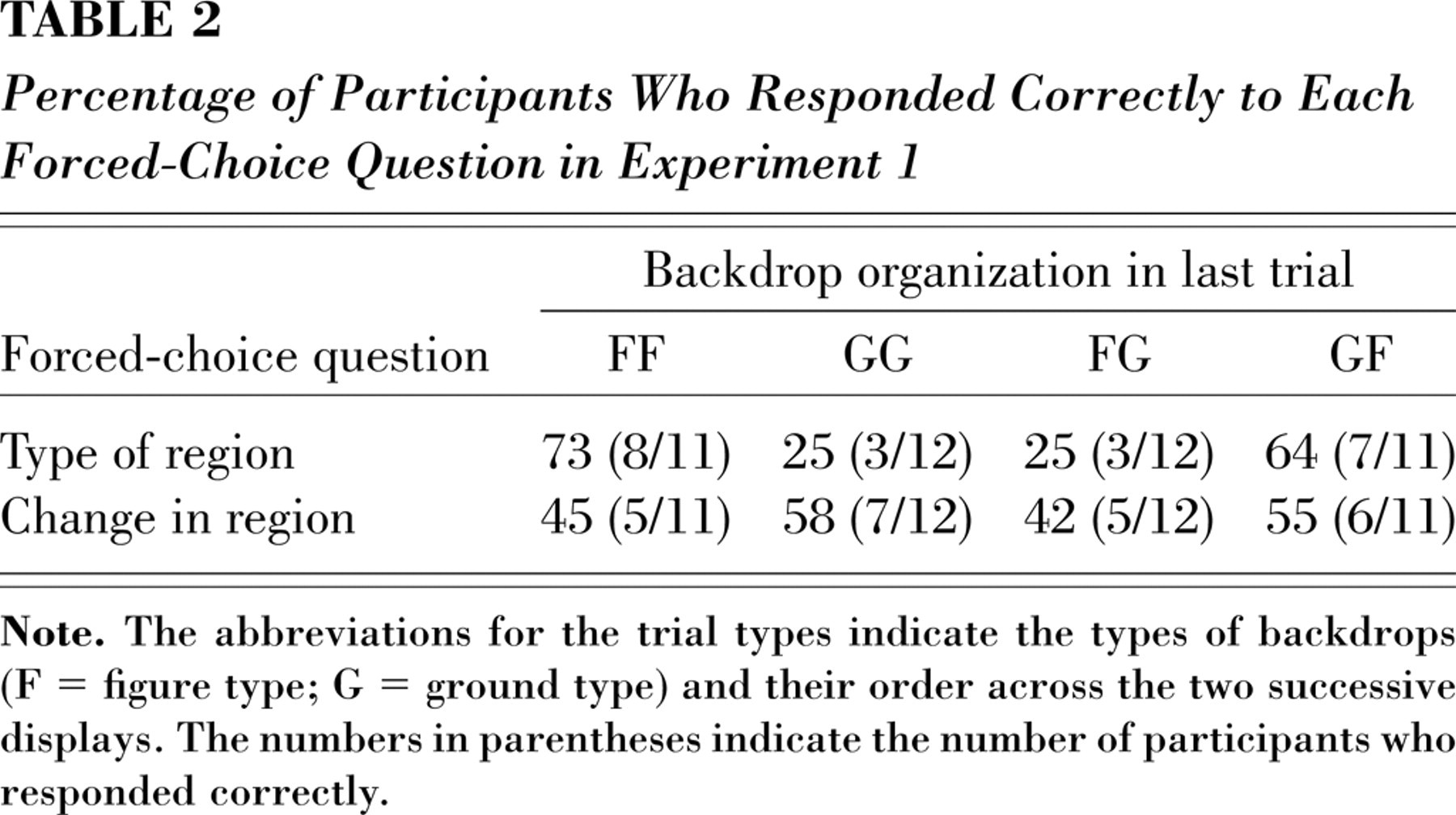
Only 23 participants (50%) correctly reported whether or not the figure-ground status of the region had changed on the preceding trial; no bias was detected in change responses.
These results show that participants performed at chance in reporting the figure-ground status of the region on which the target appeared in the preceding display and in reporting whether its figure-ground status had changed during the trial. An informal postexperimental debriefing further revealed that participants in this experiment were unaware of the nature of the backdrop scene and of changes in its organization.
The observed congruency effects arising from changes in the backdrop's figure-ground organization suggest that figure-ground segmentation can occur under conditions that satisfy criteria for inattention (Mack & Rock, 1998; Moore, Grosjean, & Lleras, 2003). The target-change task was sufficiently demanding to absorb attention (mean accuracy = 89.5%), the backdrop's figure-ground organization was irrelevant to the task, and participants performed poorly in reporting the figure-ground status of the backdrop or any change in it; these considerations strongly suggest inattentional blindness to the scene backdrop. In the next experiment, we examined whether the figure-ground organization of the backdrop stimuli could be perceived when attention was allocated to them.
EXPERIMENT 2
Method
Participants
Twenty-three new individuals (18 females, 5 males; age range: 19–27 years) participated in this experiment.
Stimuli, Design, and Procedure
The stimuli, design, and procedure were the same as in Experiment 1, except that participants were instructed to attend to the region on which the matrix appeared while ignoring the matrix itself, and to answer two forced-choice questions immediately after the second display in each trial disappeared. The two questions were identical to the two surprise questions in Experiment 1. The complete questions were presented and explained to the participants in the beginning of the experiment. Immediately following the second display in each trial, the two alternatives for the region question (“shape,” “space between shapes”) appeared on the screen. Following participants' response, the two alternatives for the change-detection question (“change,” “no change”) appeared on a new screen. Responses were made by pressing one of two keys.
Results and Discussion
Table 3 presents the mean percentage of correct choices for each question. Overall, participants correctly reported whether the region on which the matrix appeared in the preceding display was a “shape” (figure) or a “space between shapes” (ground) on 96% of all trials. An analysis of variance showed no difference in accuracy between trial types, F < 1. Thus, when attention was allocated to the backdrop region on which the matrix appeared, observers were aware of its figure-ground status, perceiving the convex region as figure and the concave region as ground. These results are consistent with previous results, which demonstrated that when observers were presented with the same eight-region displays and asked to report the figural status of a probed region, they were likely to see the convex regions as figures (Kim & Peterson, 2002; Peterson & Salvagio, 2008).
Mean Percentage of Correct Region Detection and Change Detection for Each Trial Type in Experiment 2
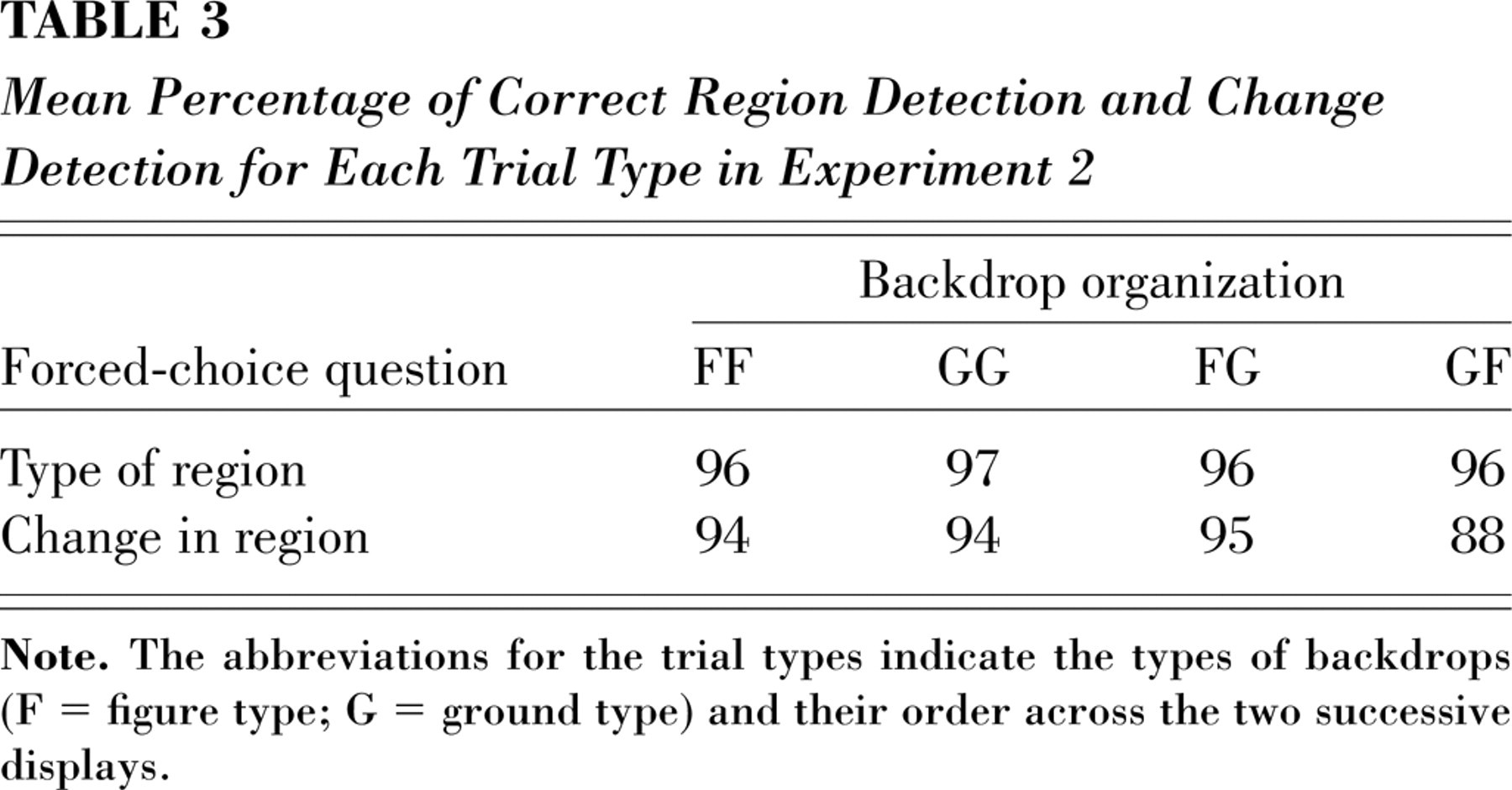
Overall, participants were also accurate in reporting whether or not the figure-ground status of the region on which the matrix appeared had changed during the preceding trial, correctly responding on 93% of all trials. This result, indicating that participants were aware of figure-ground changes in the attended backdrop region, is compatible with previous findings demonstrating that when presented with foreground items lying on a background display, observers could detect background changes only when attention was allocated to the background (Mazza et al., 2005; Turatto, Angrilli, Mazza, Umiltà, & Driver, 2002).
Significant trial-dependent differences in change-detection accuracy were observed, however, F(3, 66) = 4.52, p < .02. Post hoc Tukey HSD (honestly significant difference) comparisons revealed that change detection was significantly lower on GF trials (88%) than on the other trials (94–95%). Thus, the appearance of a new figure in the attended location on GF trials interfered to some extent with change-detection accuracy. This result, obtained under conditions of attention, is consistent with the proposal that a change from figure to ground is not equivalent to a change from ground to figure, because only the latter involves processing of a new object, which can interfere with task performance even when the task is change detection (cf. Landman, Spekreijse, & Lamme, 2004). In Experiment 1, in which the backdrop was unattended, the direction of change in the backdrop region on which the target matrix appeared had a similar effect: Performance on the target-change task was significantly less efficient on GF than on FG trials.
Taken together, the results of the two experiments strongly suggest that figure-ground organization occurred in the scene backdrop when it was outside the focus of attention.
GENERAL DISCUSSION
Our results provide clear evidence that figure-ground segmentation can occur for unattended stimuli. When observers performed a demanding change-detection task on a small matrix presented on a task-irrelevant scene of alternating regions organized into figures and grounds by convexity, changes in the scene's figure-ground organization produced reliable congruency effects on performance. As noted earlier, these results cannot be due to implicit capturing of attention by convexity in the scene backdrop, nor to the backdrop's changes in convexity/concavity per se. These congruency effects arose despite inattentional blindness to the scene backdrop. When probed with surprise questions, participants could report neither the figure-ground status of the region on which the target appeared in the preceding display nor whether the figure-ground status of the region had changed during the preceding trial, but when participants attended to the scene backdrop, their answers were highly accurate.
The finding that figure-ground segmentation can occur without attention, together with previous findings indicating that some grouping (e.g., Kimchi & Razpurker-Apfeld, 2004; Russell & Driver, 2005) and surface completion (Moore et al., 2003) occur under inattention, supports the view that at least some perceptual organization processes are preattentive.
Note that our finding does not imply that figure-ground segmentation must always precede the deployment of focal attention, as many models of perception have assumed (e.g., Julesz, 1984; Treisman, 1986). The backdrop stimuli in our study contained eight alternating regions that were equated for all other stimulus factors (such as size, contrast, symmetry, familiarity, and orientation) but convexity. Convexity is a powerful cue for figural assignment in such displays (e.g., Hoffman & Singh, 1997; Kanizsa & Gerbino, 1976; Peterson & Salagio, 2008) and can, for example, override symmetry (Kanizsa & Gerbino, 1976). It is possible that when other, perhaps less potent, figural cues are involved, segmentation requires the scrutiny of focal attention.
Furthermore, in natural scenes, adjacent regions are likely to have multiple competing cues. Figure-ground assignment in this case requires the resolution of cross-edge competition (Peterson & Kim, 2001; Peterson & Skow, 2008), which may demand focal attention. Research on perceptual grouping suggests that attentional demands of organizational processes and the time course of these processes may be related: Grouping that took place without attention was achieved rapidly, whereas grouping that required attention was likely to consume time (Kimchi & Razpurker-Apfeld, 2004; Razpurker-Apfeld & Kimchi, 2007). For example, grouping into columns or rows by common color occurred rapidly and was accomplished without attention (see also Russell & Driver, 2005), but grouping into a shape by common color consumed time and did not occur under inattention. Peterson and Lampignano (2003; Peterson & Enns, 2005) have already demonstrated that when competing figural cues are present, figure-ground assignment is time-consuming. It may well be the case, then, that under such conditions it is also attention demanding (Kimchi & Razpurker-Apfeld, 2004; Trujillo, Allen, & Peterson, 2008).
Evidence that spatial attention can act as a cue for figure-ground assignment (Peterson & Gibson, 1994b; Vecera et al., 2004) also casts serious doubt on the assumption that figure-ground segmentation must necessarily be completed prior to the deployment of focal attention.
In sum, the present results provide strong evidence that some figure-ground segmentation can occur for stimuli that are unattended. Furthermore, the results suggest the exciting possibility that the relationship between attention and figure-ground perception is complex and multifaceted.
Footnotes
1Analyses of variance (Target × Backdrop Organization × Starting Organization) conducted on correct RT and accuracy yielded a significant Target × Backdrop Organization interaction, F(1, 45) = 7.03, p < .02, η p 2 = .14, for RT and F(1, 45) = 5.96, p < .02, η p 2 = .12, for accuracy; there was no significant three-way interaction, F < 1 for RT and F(1, 45) = 1.06, p > .30, for accuracy. Responses on different-target trials were significantly faster when backdrop organization was changed than when it was unchanged, F(1, 45) = 8.52, p < .01, η p 2 = .16, and responses on same-target trials were significantly more accurate when backdrop organization was unchanged than when it was changed, F(1, 45) = 4.73, p < .05, η p 2 = .10.
2Similar results were obtained for correct RT: The Backdrop Organization × Starting Organization interaction was significant, F(1, 45) = 6.85, p < .02, η p 2 = .13, and analysis of simple effects showed a significant difference between FG (574 ms) and GF (594 ms) trials, F(1, 45) = 8.49, p < .01, η p 2 = .16, and no difference between FF (592 ms) and GG (588 ms) trials, F < 1.
Acknowledgements
This research was supported partly by the Max Wertheimer Minerva Center for Cognitive Processes and Human Performance, University of Haifa (R.K.), and partly by National Science Foundation Grant BCS0425650 (M.A.P.). We thank Yafa Lev for programming assistance, and Dannah G. Raz and Allegra Dan for assistance in stimulus preparation and data collection. We are indebted to two anonymous reviewers for their helpful comments.