
Abstract
In the current studies, we tested the prediction that learning of novel patterns of association would be enhanced in response to unrelated meaning threats. This prediction derives from the meaning-maintenance model, which hypothesizes that meaning-maintenance efforts may recruit patterns of association unrelated to the original meaning threat. Compared with participants in control conditions, participants exposed to either of two unrelated meaning threats (i.e., reading an absurd short story by Franz Kafka or arguing against one's own self-unity) demonstrated both a heightened motivation to perceive the presence of patterns within letter strings and enhanced learning of a novel pattern actually embedded within letter strings (artificial-grammar learning task). These results suggest that the cognitive mechanisms responsible for implicitly learning patterns are enhanced by the presence of a meaning threat.
When evaluating the ambiguity of Franz Kafka's writing, Albert Camus (1955) concluded:
In this fundamental ambiguity lies Kafka's secret. These perpetual oscillations between the natural and the extraordinary, the individual and the universal, the tragic and the everyday, the absurd and the logical, are found throughout his work and give it both its resonance and its meaning. (p. 94)
Of course, it would be an understatement to say that not everyone comes to find meaning in the work of Kafka. In truth, it is the assault on meaning that characterizes Kafka for most readers, insofar as he violates fundamental assumptions of the narrative form—and the reader's existential worldview. In recognition of this “talent,” Camus trumpeted Kafka's ability to elicit a sense of the absurd: “What is absurd is the confrontation of the irrational and the wild longing for clarity whose call echoes in the human heart” (p. 15). According to Camus, this longing for clarity, for associations that are internally coherent and consistent with one's environment, underlies the construction of all meaning frameworks, whether they organize scientific observation, religious observance, or plans for a weekend barbeque (also see Kuhn, 1962/1996; Peterson, 1999).
Camus's general claim is that meaning threats, whatever their origin, motivate people to seek out meaning elsewhere. To date, research in social psychology has borne out this existentialist conceit, with literally hundreds of published studies demonstrating meaning affirmation among participants following threats to their self-esteem (e.g., Steele, 1988), threats to their political worldview (e.g., Jost, Banaji, & Nosek, 2004), threats to their sense of situational certainty (e.g., van den Bos, Euwema, Poortvliet, & Maas, 2007), threats to their existence (e.g., Greenberg, Simon, Pyszczynski, Solomon, & Chatel, 1992), threats to goal attainment (e.g., Martin, 1999), or threats to their existence construed as threats to goal attainment (Renkema & Stapel, 2008). More recently, a study following from the meaning-maintenance model (MMM; Heine, Proulx, & Vohs, 2006; Proulx & Heine, 2006) expanded the affirmation literature by directly demonstrating that the meaning frameworks people will affirm following a meaning threat need not be conceptually related to the meaning framework that was originally violated (Proulx & Heine, 2008).
In the current study, we intended to move from the expansive literature on meaning affirmation and demonstrate a response to meaning threats that does not involve the affirmation of previously learned, unrelated meaning frameworks. Specifically, we aimed to test the hypothesis that either of two unrelated meaning threats (i.e., reading a bizarrely illustrated short story by Kafka or arguing that one is a disunified self) would enhance the learning of unrelated patterns of associations in a novel environment (i.e., improve performance on an artificial-grammar learning task).
THE MEANING-MAINTENANCE MODEL
Using less poetic language than Camus, psychologists have outlined people's efforts toward reducing disequilibrium (Piaget, 1960) and cognitive dissonance (Festinger, 1957), and have explored people's need for coherence (Antonovsky, 1979), need for cognitive closure (Kruglanski & Webster, 1996), and personal need for structure (Neuberg & Newsome, 1993). Following from these frameworks, the MMM posits that people naturally assemble mental representations of expected associations that organize their beliefs and perceptions, and provide them with a general feeling that their lives make sense. Research has provided a remarkably convergent picture of how people respond to experiences that violate expected associations in disparate cognitive and perceptual domains, including the speech prototypes that shape the human perception of vowel sounds (Kuhl, 1991), the scripts that allow people to anticipate future events (Baumeister, 1991), and the worldviews that aid people in coping with tragedy and trauma (Vallacher & Wegner, 1987; see Heine et al., 2006, and Proulx & Heine, 2006, for more theoretical elaboration).
Across literatures, people's most commonly reported reactions to anomalies involve the assimilation of anomalous experiences so that they no longer violate an existing framework (e.g., the McGurk effect in auditory perception—McGurk & MacDonald, 1976) or the accommodation of existing frameworks to account for the anomalies (e.g., dissonance-reduction efforts in the face of apparently inconsistent attitudes—Festinger, 1957; for other theories on meaning maintenance that incorporate assimilation and accommodation, see Kuhn, 1962/1996; Park & Folkman, 1997; Piaget, 1960). In social psychology, a growing literature has demonstrated a third reaction: In the face of a variety of meaning threats (e.g., threats to people's desire for immortality, self-esteem, political beliefs, and certainty about the outcome of events), people will affirm alternative meaning frameworks that are related to the meaning framework that was originally threatened; this process has been termed fluid compensation (cf. McGregor, Zanna, Holmes, & Spencer, 2001; Steele, 1988).
Several recent studies have suggested that people will also fluidly compensate for meaning threats by affirming unrelated meaning frameworks (e.g., Burris & Rempel, 2004; McGregor et al., 2001; Navarrete, Kurzban, Fessler, & Kirkpatrick, 2004). In response to these studies, we have directly tested and supported the hypothesis that the meaning frameworks people affirm in meaning-maintenance efforts are radically substitutable, such that one meaning framework (e.g., moral beliefs) or another meaning framework (e.g., group affiliation) may be called upon when an unrelated meaning framework (e.g., a perceptual schema) is violated (Proulx & Heine, 2008).
ABSTRACTION: AN ADDITIONAL RESPONSE TO MEANING THREATS?
Much of the current research on meaning-maintenance efforts falls within the affirmation literature. In these studies, people are given the opportunity to affirm meaning frameworks that are either related or unrelated to a threatened meaning framework. In all cases, the meaning frameworks that are affirmed consist of associations learned long before participants entered the lab, and to which participants had presumably been committed for quite some time (e.g., moral beliefs, self-esteem, political worldview). What would happen if, following a meaning threat, participants were not given the opportunity to affirm a previously learned meaning framework? Would this increase participants' motivation to perceive unrelated patterns in their environment? More provocatively, would participants be better able to learn unrelated patterns that are actually present in their surroundings?
A recent study by Whitson and Galinsky (2008) demonstrated the first of these possible responses to meaning threats. Using several related experimental manipulations, Whitson and Galinsky challenged a fundamental framework of expected associations—the belief that one can interact effectively with one's environment (Bandura, 1982). Participants who experienced this meaning threat were more likely than those in a control condition to perceive illusory patterns of association in a variety of stimuli, from visual static to unrelated group behaviors. Although these findings may provide evidence that meaning threats enhance a motivation to perceive signals in noise, as Whitson and Galinsky proposed, it is important to note that the associations participants perceived were illusory, not objectively present in the stimulus materials. Put differently, Whitson and Galinsky's participants did not actually learn from their environment, as the task they engaged in did not give them the opportunity to encode objectively present patterns of association in the stimulus materials, or to subsequently demonstrate an enhanced ability to retrieve or recognize any learned material. What would happen, then, if participants were presented with a complex array of stimuli that contained an actual pattern of associations? Would any enhanced motivation to perceive signals in noise carry over to an enhanced ability to actually learn the patterns hidden in the array?
A growing body of research has identified the role that motivational states, more generally, may play in enhancing the accuracy with which people are able to abstract signals from noise. That is, priming motivational states has been found to improve performance on implicit-learning tasks. For example, Schultheiss et al. (2005) found that when participants high in power motivation were given success feedback, they subsequently demonstrated improved performance in predicting the orientation of visual objects. Similarly, Eitam, Hassin, and Schul (2008) found that priming participants with goal-related words improved performance on a serial reaction time task. To date, no published data have demonstrated that meaning threats may motivate enhanced learning of patterned associations in an implicit-learning paradigm (an unpublished study by Dechesne & Wigboldus, 2001, cited in Dechesne & Kruglanski, 2004, found enhanced learning following a mortality-salience prime). To directly examine this possibility, we turned to the most replicated example of implicit learning: artificial-grammar learning (Reber, 1967). Dozens of studies have employed this paradigm to determine whether participants implicitly learn complex transitional probabilities while copying letter strings, as indexed by their ability to recognize subsequent letter strings that adhere to the same “grammar rules” (for a review, see Pothos, 2007).
For the purposes of the present study, what is especially advantageous about the artificial-grammar paradigm is that it provides two separate measures, each uniquely relevant in determining whether meaning threats prompt individuals both to perceive associations in their environment (measured by the total number of letter strings correctly or incorrectly perceived as pattern congruent: hits + false alarms) and to learn patterns of association that are objectively present in the stimulus materials (measured by the number of letter strings accurately identified as pattern congruent: hits − false alarms). We expected that participants exposed to meaning threats, compared with participants in control conditions, would perceive that a greater number of test letter strings contained a training pattern and would also demonstrate enhanced pattern learning by being more accurate in recognizing those letter strings that actually contained this pattern rather than another pattern.
The primary aims of the experiments we report here were twofold. First, we aimed to demonstrate a response to meaning threats that does not involve the affirmation of meaning frameworks to which people are committed or the perception of patterned associations in environments where they do not objectively exist. We hypothesized that participants who had experienced a meaning threat, compared with those who had experienced no meaning threat, would demonstrate superior accuracy in learning patterned associations. To test this hypothesis, we exposed participants to a meaning threat and assessed their performance on a subsequent artificial-grammar implicit-learning task, relative to the performance of participants who were not exposed to a threat. We expected that participants in the meaning-threat condition would demonstrate enhanced learning of a pattern actually embedded within the training letter strings, in addition to a generally heightened motivation to perceive the presence of patterns in the test letter strings.
Second, we aimed to demonstrate that different, unrelated meaning threats would similarly affect performance on the artificial-grammar task. To do this, we had participants in Study 1 read an absurdly illustrated short story by Kafka and participants in Study 2 argue against their own self-unity. We expected that, in both studies, participants who had been exposed to the meaning threat would demonstrate a heightened ability to learn the embedded grammar pattern in the training strings and a generally elevated propensity to perceive the existence of congruent patterns within the test letter strings, compared with participants in control conditions that presented no meaning threat.
STUDY 1
This study explored whether encounters with meaning threats enhance people's ability to learn novel patterns. The meaning threat employed in Study 1 follows directly from existentialist and early psychological theorists (e.g., Camus, 1955; Freud, 1919/1990) who addressed the meaning threats evoked by absurdist imagery and literature. If the breakdown of expected associations found in absurdist art constitutes a meaning threat, then we would expect instantiations of absurdity to evoke efforts toward compensatory abstraction of novel patterns. In selecting our absurdist stimulus materials, we deferred to Camus's (1955) praise of Kafka, and presented participants with a bizarrely illustrated story by Kafka.
Method
Participants were 40 Canadian-born psychology undergraduates (29 females and 11 males). They were randomly assigned to one of two experimental conditions. In the meaning-threat condition, participants read an absurd short story called “The Country Dentist.” The story is a modified1 version of Kafka's 1919 short story “The Country Doctor.” In the story, a rural dentist sets out during a snowstorm to help a young boy with a toothache. As the story progresses, the narrative gradually breaks down and ends abruptly after a series of non sequiturs. We also included a series of bizarre illustrations that were unrelated to the story. In the no-meaning-threat condition, participants read a different story that we wrote. This story, also titled “The Country Dentist,” is parallel to the Kafka tale, but contains no non sequiturs and follows a conventional narrative. It contains illustrations that relate to the story. (The stories are available on-line at http://www.psych.ubc.ca/~heine/ImplicitLearningStories.doc.)
Participants were administered the Positive and Negative Affect Schedule (PANAS; Watson, Clark, & Tellegen, 1988) as a measure of their affect after reading the stories. They also performed a word-completion task containing several word fragments that could be completed with death-related or non-death-related words (e.g., “coff_ _” could be completed as “coffin” or “coffee”). If participants completed more of the word fragments as death-related words in the meaning-threat condition than in the control condition, this might indicate that death-related thoughts were primed in the meaning-threat condition and were responsible for any subsequent meaning-maintenance efforts (Schimel, Hayes, Williams, & Jahrig, 2007). We aimed to rule out this possibility.
Participants were then presented with an artificial-grammar task. They were shown a series of 45 training letter strings, one at a time. Each string was six to nine letters long (e.g., X M X R T V T M, V T T T T V M; Dienes & Scott, 2005), and the arrangement of the letters conformed to an artificial grammar (Grammar A) that dictated the transitional probability of each letter appearing adjacent to each other letter. Participants were asked to copy down each letter string verbatim and were not told that the strings contained a pattern or that they would be tested on the strings at a later time. Next, participants were given a sheet of paper containing 60 novel letter strings, 30 of which conformed to the same transitional probabilities of the training strings (Grammar A), and 30 of which did not (Grammar B). Participants were given the following instructions:
The strings of letters you just copied contained a strict pattern. Some of the letter strings below follow the same pattern. Some of these letter strings do not. Please place a check mark beside the letter strings you believe follow the same pattern as the letter strings you just copied.
We expected that participants in the meaning-threat condition, compared with those in the no-meaning-threat condition, would more accurately identify those test letter strings that were pattern congruent with the training letter strings (i.e., hits – false alarms) and would also perceive a greater number of the test strings as being pattern congruent with the training strings (hits + false alarms).
Results
Participants in the meaning-threat condition more accurately identified Grammar A letter strings (hits − false alarms; M = 12.2, SD = 4.74) than did participants in the no-meaning-threat condition (M = 7.5, SD = 5.11), F(1, 38) = 9.08, p < .01, η2 = .19. Overall, participants in the meaning-threat condition selected a higher total number of letter strings as being congruent with Grammar A (hits + false alarms; M = 21.95, SD = 7.46) than did participants in the no-meaning-threat condition (M = 16.5, SD = 9.45), F(1, 38) = 4.17, p < .05, η2 = .10 (see Fig. 1).
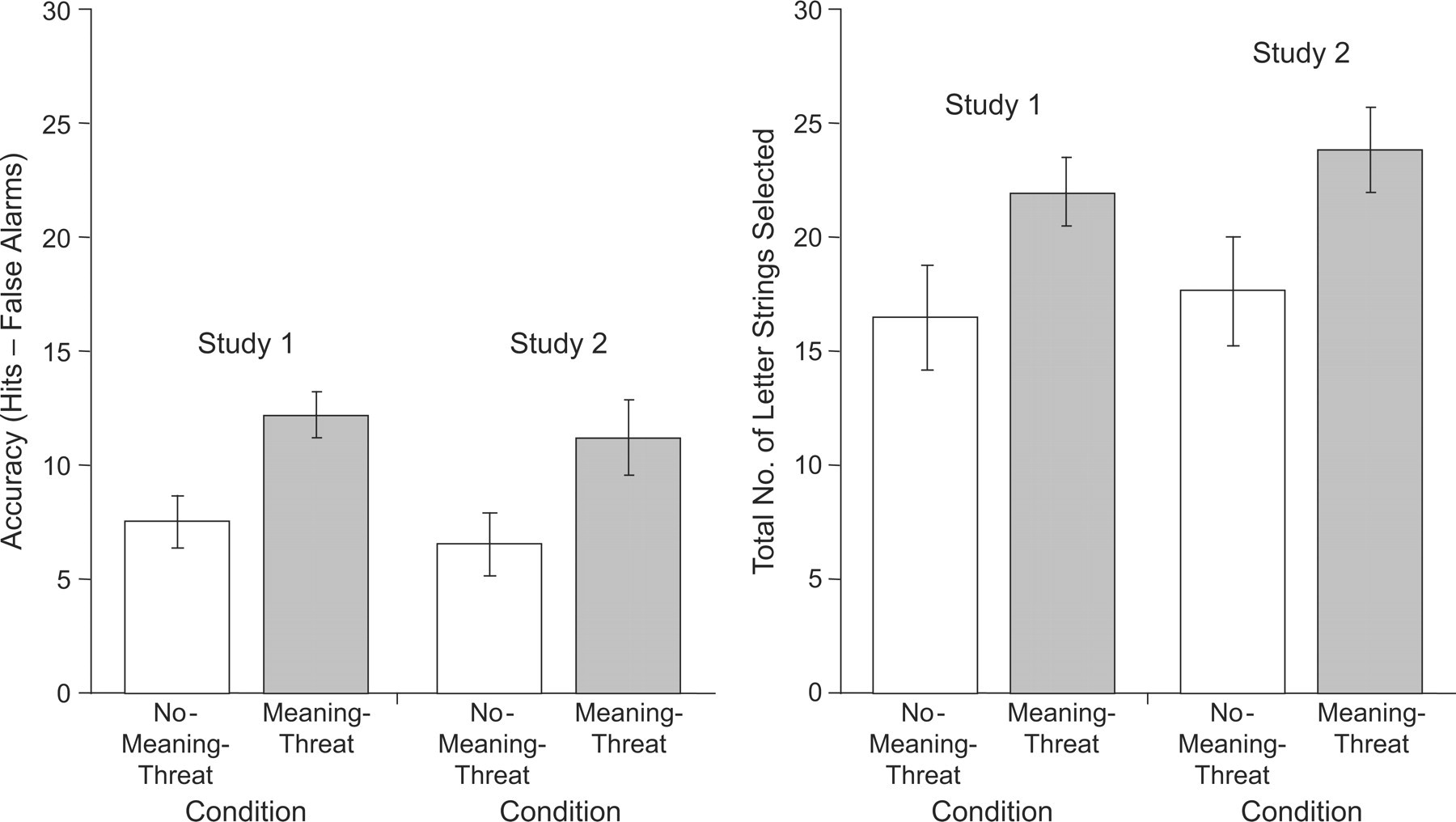
Performance on the implicit-learning task as a function of condition (meaning threat: absurd Kafka story in Study 1; threat to self-unity in Study 2; no meaning threat: control condition in both studies). The graphs show mean accuracy of performance (hits – false alarms) and mean total number of letter strings selected as consistent with the grammar (hits + false alarms). Error bars indicate standard errors of the mean.
The conditions did not differ significantly in the frequency of death-related words produced in the word-completion task, F(1, 38) = 1.04, p > .20, which suggests that death thoughts were not made more accessible in the meaning-threat condition than in the no-meaning-threat condition. There was no significant difference between conditions in participants' scores on either subscale of the PANAS (ps > .05).
Discussion
The absurd story constituted a meaning threat for many participants, and these participants responded by perceiving the presence of patterns in their environment and by abstracting patterns of association from their environment. We suggest that two general conclusions can be drawn from these findings. First, the breakdown of expected associations presented in the absurd story appeared to motivate participants to seek out patterns of association in a novel environment. Despite being given no instructions to learn features of the letter strings during the training phase of the task, participants in the meaning-threat condition selected a higher total number of test letter strings as following the Grammar A pattern than did participants in the no-meaning-threat condition. This suggests that the meaning threat enhanced motivation to perceive congruent patterns of association in the test letter strings. Second, and more remarkably, participants in the meaning-threat condition demonstrated greater accuracy in identifying the genuinely pattern-congruent letter strings among the test strings, which suggests that the cognitive mechanisms responsible for implicitly learning statistical regularities in a novel environment are enhanced by the presence of a meaning threat. In the wake of these novel findings, we sought to replicate them using an alternative, unrelated meaning threat (i.e., arguing against one's self-unity).
STUDY 2
In Study 2, we aimed to elicit compensatory pattern-abstraction efforts following a different meaning threat unrelated to the absurdist-literature meaning threat employed in Study 1. The meaning threat we used follows from a sizable literature, beginning with James (1892/1963), suggesting that people generally maintain an expectation that they have a unified self, and do so primarily by attempting to minimize behavioral variations across situations (also see Festinger, 1957). These motivations are especially pronounced among Westerners; studies find that Westerners attempt to maintain much behavioral consistency across situations, associate behavioral consistency with personal well-being, and associate positive evaluations with behavioral consistency (e.g., Campbell et al., 1996; Suh, 2002). On the basis of these findings, we expected that a meaning threat would be evoked if participants were led to focus on their behavioral variations across situations and were asked to argue that these variations proved that they did not have a unified self (meaning-threat condition), but that a meaning threat would not be evoked among participants who were asked to argue that their selves remained unified despite these variations (no-meaning-threat condition; Proulx & Chandler, 2007). Following the manipulation, participants were given the opportunity to both learn unrelated patterns and perceive the existence of unrelated patterns in the same artificial-grammar learning task from Study 1.
Method
Participants were 53 Canadian-born psychology undergraduates (34 females and 19 males). Upon entering the lab, they were randomly assigned to one of two experimental conditions. In the meaning-threat condition, participants completed a three-page workbook. The first page instructed them to describe a situation in which they had behaved in an outgoing manner. The second page instructed them to describe a situation in which they had behaved in a shy manner. The third page instructed them to use what they had described in the previous two pages as evidence to argue that they had two different selves inhabiting the same body. In the no-meaning-threat condition, participants completed a different three-page workbook. The first two pages were identical to those in the workbook given to participants in the meaning-threat condition. The third page instructed participants to argue that, despite the behaviors they had reported in the previous two pages, they nevertheless remained a unified self.
Participants completed the PANAS (Watson et al., 1988) as a measure of their affect following the manipulation. They then performed the same word-completion task employed in Study 1 so that we could assess whether death-related thoughts were primed in the meaning-threat condition and were responsible for any subsequent meaning-maintenance efforts (Schimel et al., 2007). Participants were then given the opportunity to abstract associations from a novel environment by means of the same artificial-grammar task used in Study 1.
Results
Participants in the meaning-threat condition more accurately identified pattern-congruent letter strings (hits − false alarms; M = 11.25, SD = 7.39) compared with participants in the no-meaning-threat condition (M = 6.6, SD = 6.73), F(1, 51) = 5.39, p < .05, η2 = .09. In addition, participants in the meaning-threat condition selected more letter strings as congruent with Grammar A (hits + false alarms; M = 23.83, SD = 10.21) than did participants in the no-meaning-threat condition (M = 17.69, SD = 10.74), F(1, 51) = 4.49, p < .05, η2 = .08 (see Fig. 1).
The conditions did not differ significantly in the frequency of death-related words produced in the word-completion task, F < 1, which suggests that death thoughts were not made more accessible in the meaning-threat condition than in the no-meaning-threat condition. There was no significant difference between conditions in participants' scores on either subscale of the PANAS (ps > .05).
When we combined the meaning-threat and control conditions of Studies 1 and 2 and compared the mean accuracy results (hits − false alarms), we obtained a significant effect of condition, F(3, 89) = 4.25, p < .01, η2 = .16. A Tukey post hoc analysis pointed to the equivalence of participants' performance within conditions; that is, there was no significant difference between the two meaning-threat conditions (p > .90) or the two no-meaning-threat conditions (p > .90). Similarly, a combined analysis of the two studies' mean results for the total number of letter strings perceived as pattern congruent (hits + false alarms) revealed a significant effect of condition, F(3, 89) = 3.15, p < .05, η2 = .10, and no significant difference between the two meaning-threat conditions (p > .90) or between the two no-meaning-threat conditions (p > .90). The effects of the absurd Kafka story and the self-disunity exercise were highly similar with regard to people's motivation and accuracy in abstracting novel patterns.
Discussion
Two general conclusions can be drawn from these findings: First, the breakdown of expected associations that participants experienced when arguing against their own self-unity appeared to motivate them to seek out patterns of association in a novel environment. As had been the case for participants in Study 1 who read an absurd story, participants who had been exposed to a self-disunity meaning threat perceived a higher total number of letter strings as corresponding to the pattern in the training strings, compared with participants who had not been exposed to a meaning threat. More important, these participants also demonstrated greater accuracy in identifying the pattern-congruent letter strings. Thus, Study 2 provides further evidence that the cognitive mechanisms responsible for implicitly learning novel patterns of association are enhanced by the presence of a meaning threat. Second, in combination, the two studies show that unrelated meaning threats (arguing against self-unity and reading an absurd story) provoke comparable motivations to perceive unrelated patterns in the environment, and similarly enhance the ability to learn unrelated patterns that are present. Whether these findings generalize beyond North American college students remains to be assessed.
GENERAL DISCUSSION
People may wonder what absurdist literature, expectations of self-unity, and implicit grammars have in common. They would appear to share little or no content. They all, however, constitute some manner of meaning, that is, a set of expected associations that are derived from, and impose order upon, one's experiences. According to the MMM, threats to any of these meaning frameworks activate a meaning-maintenance motivation that may call upon any other available associations to restore a sense of meaning. Recent studies exploring meaning-maintenance efforts have dealt mainly with the affirmation of alternative meaning frameworks, whether they are conceptually related (e.g., Jost et al., 2004; Renkema & Stapel, 2008) or conceptually unrelated (e.g., McGregor et al., 2001; Proulx & Heine, 2008) to the meaning framework that was threatened. In the present article, we have proposed an additional, distinct mode of meaning maintenance—the learning of novel patterns of association from one's environment. In two studies, we demonstrated that unrelated meaning threats provoked an increased motivation to perceive patterns in the environment and an enhanced ability to accurately detect patterns that were actually present. These findings significantly broaden the expansive literature exploring responses to meaning threats, as well as the implicit-learning literature.
Further research may address two general questions that arise from these findings. First, participants demonstrated enhanced learning in an implicit-learning paradigm. During the training phase of the task, they were not instructed to learn any patterns in the letter strings they were copying, nor were they informed that these strings contained a pattern. Of course, much of the learning people do is explicit, involving intentional study of materials with the aim of learning the patterns of association that are manifestly present. Would the presence of a meaning threat also enhance performance in explicit-learning situations? Second, these findings point to abstraction as a meaning-maintenance effort that is distinct from the assimilation, accommodation, and affirmation that have been the focus of the meaning-maintenance literature to date. Are there other responses to meaning threats that have yet to be identified in the scientific literature? We anticipate that future research will show this to be the case.
Footnotes
1All references to death and dying were removed to distinguish affirmation following from the absurd nature of the story and affirmation following from mortality-salience meaning threats (see Greenberg et al., 1992).
Acknowledgements
This research was funded by a Social Sciences and Humanities Research Council of Canada grant (410-2008-0155).