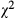Abstract
Traditional approaches in inventory control first estimate the demand distribution among a predefined family of distributions based on data fitting of historical demand observations, and then optimize the inventory control using the estimated distributions. These approaches often lead to fragile solutions whenever the preselected family of distributions was inadequate. In this article, we propose a minimax robust model that integrates data fitting and inventory optimization for the single‐item multi‐period periodic review stochastic lot‐sizing problem. In contrast with the standard assumption of given distributions, we assume that histograms are part of the input. The robust model generalizes the Bayesian model, and it can be interpreted as minimizing history‐dependent risk measures. We prove that the optimal inventory control policies of the robust model share the same structure as the traditional stochastic dynamic programming counterpart. In particular, we analyze the robust model based on the chi‐square goodness‐of‐fit test. If demand samples are obtained from a known distribution, the robust model converges to the stochastic model with true distribution under generous conditions. Its effectiveness is also validated by numerical experiments.
Introduction
The stochastic lot‐sizing model has been extensively studied in the inventory literature. Most of the research has focused on models with complete information about the distribution of customer demand. However, in most real‐world situations, the demand distribution is not known; only historical data are available. A common approach is to hypothesize a family of demand distributions and then to estimate the parameters specifying the distribution using the historical data. Once the probability distribution has been identified, the inventory problem is solved following this estimated distribution. This implies that the inventory policy is determined under the assumption that the fitted distribution adequately characterizes the demand to be realized in the future.
The estimated demand distribution may not be accurate, and, hence, the approach of fitting the distribution and optimizing the inventory decisions sequentially may not work as expected. As shown in Liyanage and Shanthikumar (2005) for the newsvendor model, such an approach may generate suboptimal solutions. Besides, in distribution fitting, one needs to assume a parametric family of a demand distribution in the first place, and this hypothesis may also go awry. For instance, we may fit the historical data to a lognormal distribution while it actually follows a uniform distribution.
The robust inventory models, without assuming a parametric family of distributions, provide an approach to address ambiguity in the demand distribution. A brief review of these robust models is provided in section 1.1. These models adopt a minimax approach targeting to minimize the worst case expected cost maximized over the set of distributions. Without exception, the existing literature either considers a prespecified set for demand distributions without detailed discussions about how to generate the set, for example, Notzon (1970), or derives the set of distributions based on certain statistics of the historical data such as the sample mean and variance, for example, Bertsimas and Thiele (2006) and See and Sim (2010). Compared with the classical approach with separate fitting and optimization, the robust models based on historical statistics may miss important information about the demand distribution conveyed in the historical data set, for example, the shape of the distribution, which, in the separate, two‐phase approach, is usually used to determine the parametric family of the distributions.
In this article, we merge the merits of both approaches, namely (i) to fully utilize historical data as in the classical approach and (ii) to concurrently optimize the demand distribution and the inventory decision without assuming a distribution family as in the robust models. We analyze the single‐item stochastic finite‐horizon periodic review lot‐sizing model under the assumption that the demand is subject to an unknown distribution and only historical demand observations (given by histograms) are available. As all practitioners in inventory control start with histograms and then fit an underlying demand distribution, this assumption reflects the practical value of this research.
By adopting the minimax robust optimization approach, rather than first estimating the demand distribution and then optimizing inventory decisions, we combine these two steps to minimize the worst case expected cost over a set of demand distributions, which is defined as all possible distributions satisfying the chi‐square goodness‐of‐fit test. The advantage of this approach is twofold. First, the historical data are used in the same manner as in the goodness‐of‐fit test; thus, we use all the information conveyed by the historical data that can be utilized by the goodness‐of‐fit test in distribution fitting. Second, we avoid the assumption about the parametric family of distributions, which is a must in distribution fitting. We show that the (s,S) policy remains optimal, discuss the behavior of the model as the number of samples increases, and demonstrate through a numerical study that this model outperforms (i) the classical approach where distribution estimation and inventory optimization are separate and (ii) a robust model where the set of distributions is defined by sample mean and variance.
Our two main contributions are as follows. First, we develop a robust minimax model that only requires historical data and allows correlated demand. Note that most minimax models (see, e.g., Ahmed et al. 2007, Notzon 1970) and Bayesian inventory models, for example, updating demand distributions as suggested in Iglehart (1964), in the literature can be interpreted as special cases of our framework.
Unlike the classical inventory model, which solves a single‐variate optimization problem in each period, the robust model needs to identify the ordering quantity and probability distribution represented by a vector of decision variables simultaneously. Despite this complexity, the optimal policy of the robust model still shares the same structure as the corresponding policy in the classical stochastic lot‐sizing model. In particular, the optimal policy is a state‐dependent base‐stock policy for the multi‐period inventory problem without fixed procurement costs, and a state‐dependent (s,S) policy if the fixed procurement cost is considered.
While the first contribution mainly serves as an extension to existing models, the second major contribution regards combining the statistical test in distribution fitting within a single inventory control model. We consider a special case of the general robust framework when the set of demand distributions is directly related to the chi‐square goodness‐of‐fit test. Such a distribution set can be defined by a set of second‐order cone constraints, and, hence, it is tractable to compute the (s,S) levels for each period. To the best of our knowledge, this is the first endeavor to integrate the goodness‐of‐fit statistical test with inventory optimization and to explicitly consider the shape of the distribution in a robust framework.
We also prove that the robust model based on the chi‐square test converges to the stochastic model with true demand distribution under generous conditions if samples are drawn from this distribution and they grow indefinitely. In particular, if the demand distributions are discrete, the robust model converges to the stochastic model with the true demand distribution as the number of independent samples drawn from the true distribution for each period tends to infinity. Moreover, the rate of convergence is in the order of
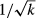
When the sample size is relatively small, the performance of the robust model is illustrated by means of computational experiments. We argue that the robust model based on the chi‐square test outperforms the traditional approach, which optimizes the inventory decisions by using fitted distributions, as well as the minimax robust model where the set of distributions is based on the set proposed by Delage and Ye (2010). We also provide insights on the performance of the robust model with different parameters and sample sizes.
In section 2, we describe our robust model, which incorporates historical data, and present the optimality equation in a compact form. The structure of the optimal policies is characterized in section 3. Section 4 considers a special case with robustness defined by the chi‐square goodness‐of‐fit test. We also discuss selected convergence results for the chi‐square test‐based models in the same section. The computational results are presented in section 5. Finally, additional extensions are presented in section 6. We conclude the introduction with the literature review.
Literature Review
This work is built on two streams of literature: stochastic inventory control and robust optimization. The discrete‐time stochastic inventory model has been studied since the 1950s. Scarf (1960) proposes the concept of K‐convexity and proves that the (s, S) policy is optimal in the presence of a fixed ordering cost. Since then, the research in this area has flourished. We refer the reader to Zipkin (2000) for a detailed review. The concept of K‐convexity has been generalized to attack various problems related to inventory control, for example, Chen and Simchi‐Levi (2004). Efficient algorithms, for example, Guan and Miller (2008) and Halman et al. (2009), have also been proposed to solve other more general stochastic inventory problems.
Robust optimization was pioneered by Soyster (1973), which proposes robust linear programming formulations for linear programs with coefficient uncertainty. This line of research has enjoyed popularity in recent years. Some of the important works include but are not limited to Ben‐Tal and Nemirovski (2000) and Bertsimas and Sim (2004) for robust linear programming, Ben‐Tal and Nemirovski (1998) for robust convex optimization, and Kouvelis and Yu (1997) and Bertsimas and Sim (2003) for robust discrete optimization. More relevant to this research, Iyengar (2005) and Nilim and El Ghaoui (2005) develop a robust optimization framework for dynamic programming models, extend the Bellman recursion to the robust counterpart, and investigate its computational complexity. Delage and Ye (2010) propose a data‐driven robust framework for any single‐stage optimization problem, which minimizes the maximum expectation over a set of distributions defined by the sample mean and variance. They identify sufficient conditions under which the corresponding robust problem is polynomially solvable and provide probabilistic arguments for using this model by considering a confidence region for the mean and variance as a random vector.
In this article, we apply the idea of robust optimization to inventory control models. This notion of robust inventory control is not new in the literature. The earliest work in minimax inventory control is attributed to Scarf (1958), where minimization of the maximum expected cost of the newsvendor model over all distributions with a given mean and variance is considered. Gallego and Moon (1993) present another proof of Scarf's result and consider various extensions of the model. The recent work by Natarajan et al. (2008) extends the result of Scarf (1958) by considering the set of distributions with a given mean, variance, and semivariance information. Perakis and Roels (2008) minimize the maximum regret of the newsvendor model over a convex set of distributions with certain moments and shape.
Notzon (1970) is among the earliest works that considers a minimax multiple‐period inventory model. The demand in each period is assumed to be independent, and its distribution function is ambiguous but within a specified class of distribution functions. The minimax control policy minimizes the maximum expected cost. The optimality of the (s, S) policy is proved.
Bertsimas and Thiele (2006) analyze distribution‐free inventory problems, in which demand in each period is assumed to be a random variable that takes values in a given range. The demand is assumed to be a random variable controlled by only two values: the lower and upper estimators. To capture the trade‐off between robustness and optimality, a parameter is defined to control the budgets of uncertainty at every time period. They show that for a variety of problems, the structures of the optimal policy remain the same as in the associated model with complete information about the distribution of customer demand. A related model from the base‐stock perspective is analyzed in Bienstock and Özbay (2008).
See and Sim (2010) consider a factor‐based demand model with given mean, support, and deviation measures. To obtain tractable replenishment policies, the worst case expected cost among all distributions satisfying the demand model is minimized by solving a second‐order cone optimization problem.
Ahmed et al. (2007) propose an inventory control model that minimizes a coherent risk measure instead of the overall cost function. They show that risk aversion treated in the form of coherence risk measures is equivalent to the minimax formulations, and it is proved that the optimal policies conserve the properties of the stochastic dynamic programming counterparts. They do not consider demand‐dependent evolutions.
Liyanage and Shanthikumar (2005) first provide concrete examples in a single period (newsvendor) setting, which illustrate that separating distribution estimation and inventory optimization, as is done in the classical approach, may lead to suboptimal solutions. They propose the use of operational statistics where it is assumed that the demand distribution function belongs to a specific (predetermined) family and estimate the (single) parameter of the family within an inventory optimization model.
In addition, selected recent papers also consider lost‐sale inventory problems with censored demand data, that is, the observed historical demand data excludes the lost‐sale information as the lost sales are not observable. Huh and Rusmevichientong (2009) propose nonparametric adaptive policies to solve this problem and provide a bound for the asymptotic performance, which, interestingly, is the same as the convergence rate of our model under discrete distributions.
The models by Notzon (1970) and Ahmed et al. (2007) do not take the historical data into account, and they predefine the class of distribution functions. The robust optimization approaches from Bertsimas and Thiele (2006) as well as See and Sim (2010) do not use any historical data except to determine the support, expectation, and deviation measures. On the other hand, Liyanage and Shanthikumar (2005) use historical data but predetermine the family of distributions. In fact, they consider only distributions characterized by a single unknown parameter. This is the only work besides the one proposed in this article that concurrently optimizes the ordering quantity and applies techniques in distribution fitting to determine the demand distribution. Our research combines both strategies by integrating distribution fitting with robust optimization. Specifically, we consider the set of demand distributions that satisfy a certain data fitting criterion with respect to historical data and characterize an optimal policy that minimizes the maximum expected cost.
Formulation of Robust Stochastic Lot‐Sizing
The classical multi‐period inventory problem considers a finite planning horizon of T periods. We assume that all shortages are backlogged. For each period t = 1,…,T, let
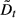
At the beginning of each period t, the decision maker reviews the net inventory level
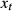
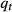
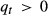
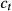
Assuming zero lead time, this order arrives immediately and increases the inventory level up to
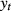
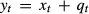
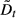
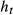
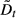
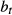
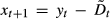
Thus, the total cost for period t given the net inventory levels before and after ordering (
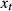
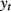
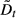
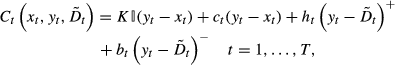
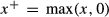
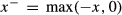
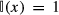
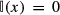
In the standard dynamic programming formulation, we consider
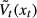
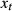
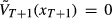
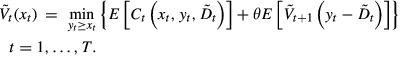
Note that the distribution of
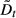
In practice, the demand distribution is not known. Rather, an inventory manager has at his or her disposal only historical data. Depending on the realized past demand in the planning horizon, the manager may choose different aggregations of historical data to forecast the demand distribution. For example, the demand data of the last n observations are considered, which is analogous to the moving average forecast, or the realized demand in periods 1 to t − 1 is accounted for when forecasting the demand in period t.
Historical observations are often aggregated to a histogram with respect to unknown distribution
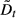
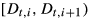
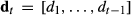
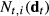
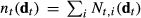
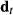
We assume that
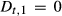
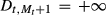
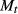
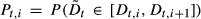
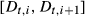
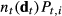
The classical approach to identify the best distribution representing the observed data is to use a goodness‐of‐fit test. The objective is to fit a distribution that “closely” follows the observed data. Under this criterion, there should be a set of distributions depending on
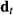
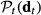
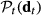
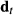
As defined in the dynamic programming field, a decision rule
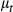
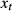
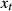
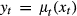
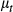
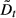
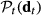
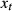
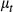
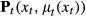
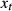
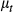
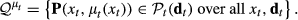
In
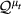
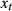
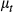
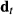
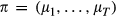

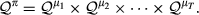
As the second player will maximize his or her reward, given policy π, net inventory
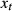
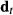
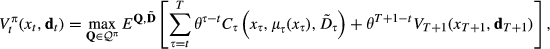
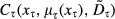
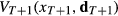
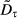
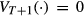
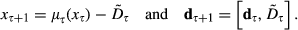
Since the first player will choose a policy that minimizes the cost, the optimal cost from period t to T given net inventory
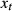
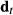
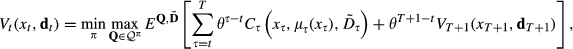
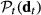
The optimality equation of the robust model is
for t = 1,…,T, where
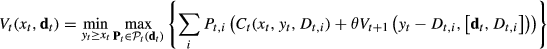
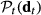
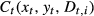
It follows from Theorem 2.1 in Iyengar (2005) when
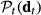
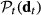
An immediate observation from Proposition is that we minimize the worst case expected cost over a set of distributions. Therefore, our robust stochastic model may not be as conservative as the classical minimax models, where the worst case is defined by the realized demand instead of distribution, for example, the minimax model discussed in section 2.4 in Notzon (1970).
Note that the Bayesian inventory models assume a prior demand distribution, and the posterior distribution at time t is obtained by updating the prior distribution using
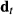
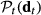
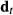
Proposition also gives us an interpretation of the robust model from a risk measure perspective when set
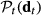
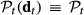
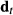
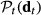
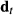
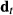
In addition, let constant
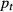
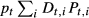
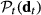
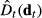
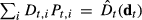
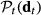
In this section, we study optimal policies of the general robust stochastic model . Notzon (1970) and Ahmed et al. (2007) show the optimality of (s, S) policy when the set of distributions in the minimax model is independent of the realized demand
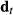
We assume that the reader is familiar with standard concepts in inventory theory such as K‐convexity and (s, S) policies (see, e.g., Porteus 2002, Zipkin 2000).
Let us define
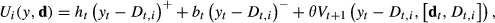
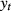
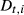
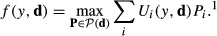
Since optimality of the (s, S) policy follows directly from K‐convexity, first we are going to establish that the function f(y,
If
Please refer to the Online Supplement.
Lemma shows that K‐convexity is preserved under maximization over a set of distributions. On the basis of this property, we show the K‐convexity of the cost‐to‐go functions.
If
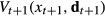
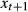
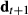
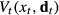
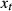
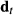
The proposition is trivially true for t = T + 1. Suppose that the proposition holds for period t + 1, and consider period t. To simplify the notation, let us define Therefore, the optimality equation in is equal to According to Lemma , if From the structure of
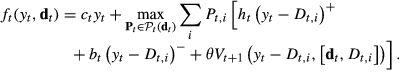
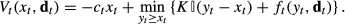
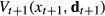
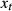
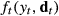
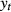
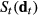
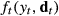
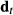
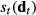
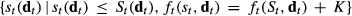
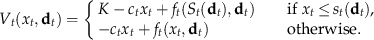
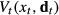
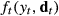
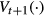
A state‐dependent (s, S) policy is optimal for the robust stochastic model. More precisely, for any t and
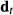
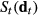
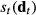
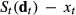
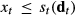
The structure of the policy follows directly from the proof of Proposition and general theory of K‐convexity (see, e.g., Porteus 2002, Zipkin 2000).
If there is no fixed cost, then
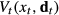
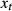
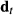
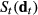
A drawback from the practical point of view is the fact that
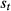
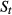
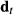
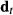
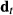
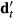
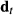
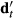
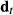
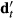
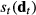
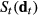
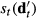
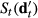
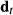
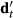
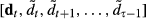
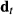
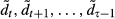
Let
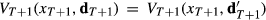
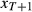
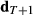
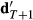
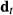
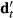
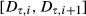
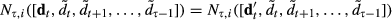
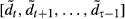
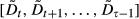
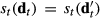
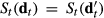
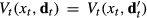
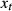
Consider period T. According to the assumption stated, Suppose that the proposition is true for any period τ > t. Hence,
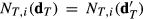
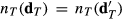
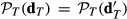
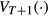
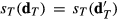
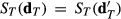
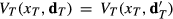
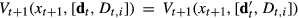
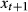
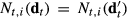
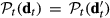
Suppose that we use the same bin intervals
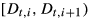
The most widely used goodness‐of‐fit test is the chi‐square test (see, e.g., Chernoff and Lehmann 1954) with the statistical test
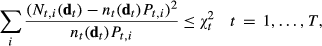
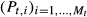
More specifically, suppose that k is the number of bins, c is the number of estimated parameters for the fitted distribution (e.g., c = 2 for normal distributions due to the mean and variance), and consider the null hypothesis
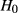
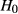
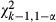
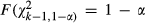
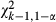
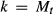
Since
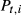
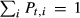
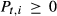
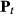
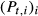
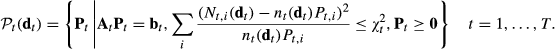
The linear constraints
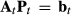
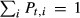
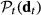
We next give an alternative optimality equation that exploits the structure of Equation . We first provide an alternative characterization of
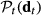
The set of demand distributions on the space of
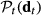
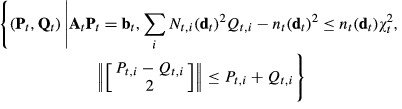
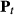
Since As Obviously, we have Note that the eigenvalues of the matrix
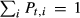
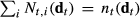
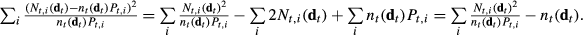
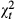
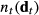
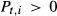
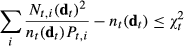
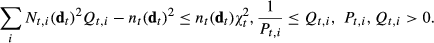
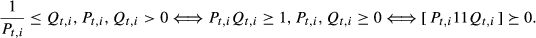
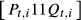
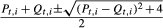
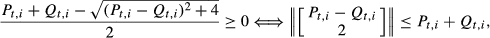
Lemma shows that the set
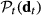
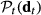
The optimality equation of the robust stochastic model is equivalent to for any t = 1,…,T.
Please refer to the Online Supplement.
Note that this is not the standard optimality equation since
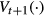
Next, we give a computational approach to compute
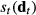
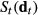
Let and let where A state‐dependent (s, S) policy is optimal for the robust stochastic model with
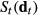
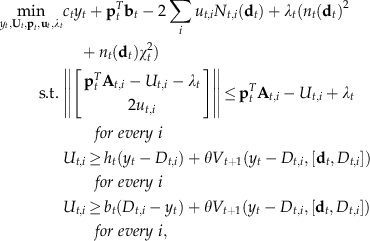
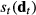
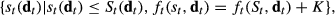
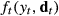
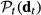
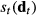
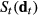
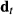
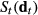
The minimization problem to calculate
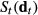
Consider the models where the historical data used for period t is independent of the realized demand from periods 1 to t − 1, that is, the number of observations
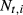
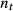
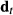
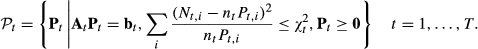
In this case, the optimality equation of the robust model is reduced to
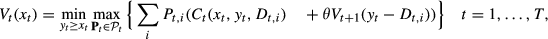
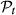
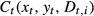
Alternatively, it can be written as
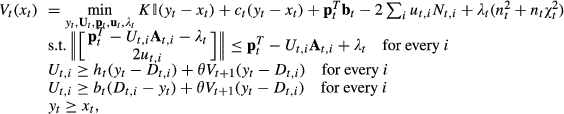
The corresponding optimal (s, S) policy levels are also independent of the realized demand
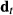
The (s, S) policy is optimal for the robust stochastic model (11). In particular, let and let where The policy is to order Without fixed procurement cost, a base‐stock policy is optimal, that is,
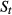
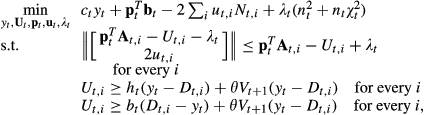
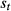
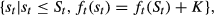
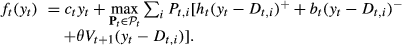
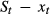
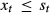
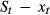
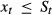
In this subsection, we explore the case of the bins in the histogram being defined by distinctive values in the sample data, and we study the performance of the robust model when the number of samples increases. The important results are summarized in the remaining part of this subsection, and the details of the analysis are presented in Appendix A.
The majority of the results are built on the following convergence property: as
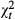
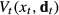
If there exists no fixed procurement, then based on Proposition , if (i)
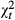
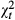
For the models with both fixed and variable procurement cost, we consider the case where the demands follow a discrete distribution over a finite set. Similar to Proposition , the cost‐to‐go function of the robust model converges to that of the stochastic model with the true demand distribution under the conditions that (i)
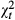
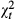
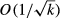
The convergence study not only provides the asymptotic performance of the robust model when the sample size approaches infinitely but also guarantees that the robust models with small bin sizes and small
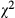
Computational Results
In this section, we describe computational experiments and present numerical results to support the effectiveness of the minimax robust model based on the chi‐square test. In particular, the robust model proposed in section 4 is compared with (i) the approach which first fits the historical data and then solves the inventory optimization model using the fitted distribution and (ii) the robust model based on Delage and Ye (2010). These two comparisons are presented in the following two subsections, respectively.
Comparison with Separated Data‐Fitting and Inventory Optimization
As we have mentioned in the previous sections, the traditional approach is to fit the historical data with a distribution and then apply stochastic inventory optimization using the fitted distribution. The main objective of our experiments is to compare performances of this separated approach and the studied minimax robust model with respect to optimality and robustness. At the same time, we would like to assess sensitivity of the robust model to the choices of the bin sizes and
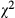
We consider inventory control problems without fixed ordering costs. Following the notation in the previous sections, we let T denote the planning horizon and
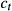
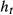
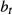
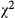
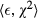
The procedure of the computational experiments is as follows. Suppose that the underlying demand distribution has support Generate n random samples according to the true distribution selected in Step 1. Fit the samples obtained in Step 2 using Crystal Ball and then choose the l best‐fitted distributions according to the Solve the standard stochastic inventory control problem with distributions generated in Steps 1 and 3. Solve the robust inventory control model using a set of bin size and Evaluate the total expected cost with respect to the true distribution The n samples generated in Step 2 define the empirical distribution


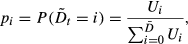
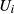
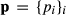
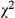
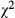
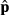
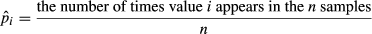
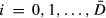
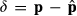
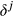
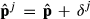
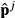
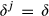
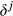
For each distribution defined by vector
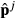
Let us consider a 10‐period problem. The support for the demand distribution is assumed to be the set {0,1,…,29}, that is,
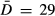
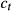
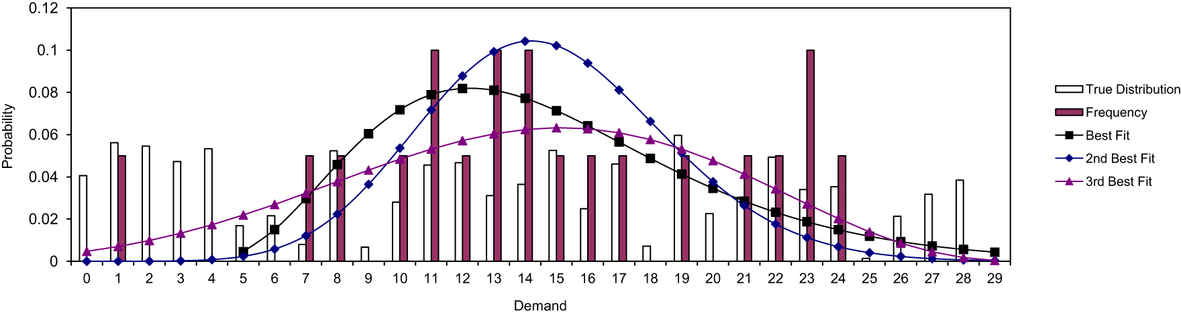
True Distribution, Frequency, and Fitted Distributions With 20 Samples
In Steps 4 and 5 of our procedure, we compute the base‐stock levels corresponding to different models: the stochastic model using the true distribution, the stochastic model using the three best‐fitted distributions, and robust models with different bin size and
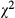
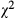
As stated in our analysis, the robust model picks the demand distribution based on the on‐hand inventory after the order is received, that is, the order‐up‐to level
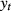
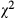
In Figures and and Table , we use a simple representative sample of cost parameters. Figure shows the robust distributions for the last period t = 10 and the first period t = 1 when the inventory levels after receiving the order
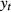
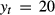
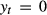
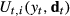
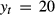
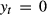
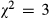
Demand Distributions Returned by the Robust Model With Bin Size = 3 and
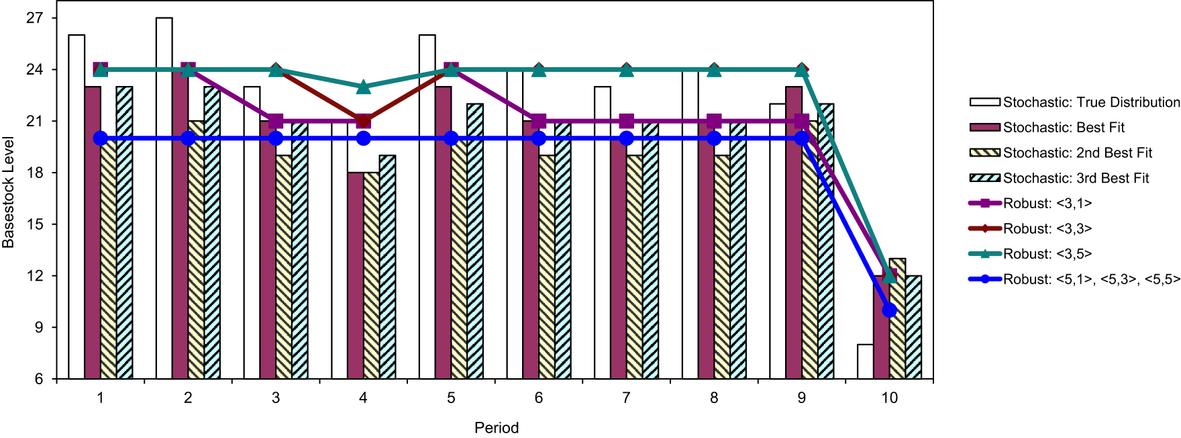
Base‐Stock Levels Computed Using Different Models
If we compare the robust distributions when 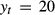
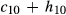
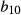
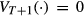
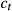
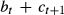
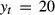
On the other hand, the robust distributions when 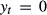
The base‐stock levels computed in Steps 4 and 5 are displayed in Figure . For any of the stochastic or robust models, the base‐stock level for period 10 is significantly lower than the remaining periods. As explained before, this is caused by the fact that the over‐order cost is much higher while the under‐order cost is lower in period 10 because of 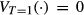
For the three robust models with the bin‐size 3, the base‐stock levels are nondecreasing with respect to the 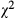
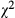
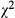
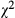
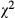
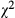
We use Steps 6 and 7 to understand the performance of different models. The results are summarized in Table . The first four columns correspond to the results for the stochastic models using true distribution 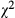
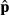

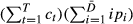
Obviously, the stochastic model using the true distribution gives the lowest expected cost. The output of Step 7, CVaR, also indicates that this model is robust with respect to perturbations in the input distribution as it has the third lowest CVaR, which is only 2.61% higher than the lowest CVaR.
For the three stochastic models using fitted distributions, the models using the first and third best‐fitted distributions have a very similar performance. The best‐fit case has the best performance among the fitted stochastic models as its CVaR is 0.25% better than the third best‐fit stochastic model, and the cost is only 0.13% higher than that. The performance of the model using the second best distribution is much worse compared with the other two. Its cost and CVaR values are at least 12% higher than those of the remaining two models.
The three robust models with bin size 3 outperform all of the stochastic models using fitted distributions in terms of both optimality (cost) and robustness (CVaR). The robust models with bin size 5 also have better values of the cost and CVaR than the stochastic model using the second best‐fitted distribution. In particular, the robust models with bin size/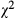
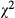
There are mainly two reasons why the robust model outperforms the stochastic model with the best‐fit distribution. First, the sample size is relatively small, and hence, the fitted distributions could be significantly different from the true distribution. The robust model, on the other hand, recognizes the difference between the samples and the true distribution and corrects the error by considering a set of distributions close to the empirical histogram. Second, although Crystal Ball considers 16 families of commonly used parametric distributions, it is still possible that the true distribution does not follow any one of these 16 families of distributions. In fact, most distribution encountered in practice cannot be described using parametric families such as the uniform or Poisson distributions. Therefore, as long as the true distribution does not belong to any parametric family of distributions, the best‐fit distribution does not match the true distribution even if the sample size goes to infinity. The robust approach based on the chi‐squared test, which does not make any assumption regarding the parametric family of the underlying distribution, is much more flexible in this perspective.
Next, we repeated the experiment 10 times from Step 1 to Step 7, that is, each time with a different true distribution, demand data, and cost parameters. Table shows the average and standard deviation of the cost and CVaR values for the 10 data samples for the stochastic model using the true distribution, the stochastic model using the best‐fitted distribution, as well as the six robust models already considered. All robust models have lower average and standard deviation of cost and CVaR compared with the stochastic model using the best‐fitted distribution. In terms of both optimality (cost) and robustness (CVaR), the performance of our robust models is better on average (smaller average) and more stable (smaller standard deviation) than the stochastic model using the best‐fitted distribution.
Performance of Different Models in 10 Instances
The robust models with bin size 3 have lower values of average and standard deviation of both measures than the robust models with bin size 5. Moreover, the robust models with higher 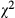
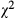
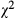
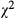
The robust model with bin size 3 and 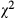
Figure shows the cost and CVaR values for the stochastic model using the best‐fitted distribution and the ‹3,3› robust model in each of the 10 instances. The cost values of the ‹3,3› robust model are at least 7.5% lower than the stochastic model with the best‐fitted distribution for instances 5, 8, 9, and 10. The improvement in instances 9 and 10 even exceeds 20%. The cost values of instances 2 and 3 are almost the same for both models. Instance 7 is the only case where the cost of the robust model is more than 2% (2.04% to be exact) higher than the cost of the stochastic model.
The Stochastic Model Using Best‐Fitted Distribution vs. the Robust Model With Parameters ‹3,3› for 10 Instances
The values of CVaR for the robust model are < 1 for 7 of the 10 instances, they are very close to 1 (at most 0.04% higher than one) for the other two instances, and the largest value is 1.0150. On the other hand, the values of CVaR for the stochastic model with the best‐fitted distribution are < 1 only for three instances and the largest value is 1.2923. We conclude that the ‹3,3› robust model is much more robust compared with the stochastic model using the true distribution.
To understand the sensitivity of different models with respect to the number of samples drawn from the true distribution, we ran 10 additional experiments in which we generated n = 40 samples from the true distribution in Step 2.
Table summarizes the main statistics of the stochastic model using the best‐fitted distribution and our robust models. Similar to the result in Table where we have 20 samples from the true distribution, all the robust models outperform the stochastic model with the best‐fitted distribution in both the average and standard deviation of the two measures.
Performance of Different Models for 10 Instances and 40 Samples
As expected, the average cost of all robust models and the best‐fit stochastic model improve when the sample size increases from 20 to 40. The robust models with bin size 5 have a slightly greater improvement than the remaining models. For the other three statistics, we also observe improvements for the stochastic model using the best‐fitted distribution as well as the robust models with bin size 5 when the sample size is increased to 40. Again, the robust models with bin size 5 show slightly better improvements in these statistics.
If we compare the robust models with different bin sizes, those with bin size 3 still perform better than those with bin size 5. However, compared with the case of 20 samples, the differences are slightly smaller for all statistics, which suggests that the robust models with bin size 5 improve faster as the sample size increases. Similar to the experiments with 20 samples, the increase in 
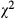
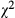
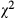
The robust model with parameters ‹3,3› has the lowest average cost, the second lowest average CVaR, and the second lowest standard deviation of the cost. Besides, its standard deviation of CVaR is < 3%. We still consider it as the most efficient model among all the robust models and the stochastic model using the best‐fitted distribution.
To summarize the numerical results, the computational experiments show that the robust models outperform the stochastic models using fitted distributions in terms of both optimality and robustness. The robust models with a lower bin size perform better than those with a larger bin size, but an increase in sample size may decrease the difference in performance caused by the choice of the bin size. In addition, a higher 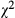
Delage and Ye (2010) propose a robust formulation for single‐stage optimization problems, which minimizes the worst‐case expectation over a set of distributions defined by the estimates of the mean 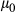
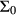
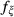
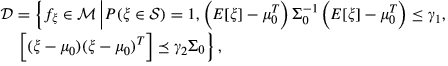
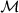
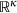
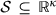
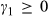
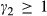
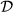
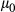
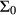
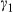
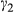
Obviously, the set defined in Equation is also applicable to the robust inventory model discussed in section 2. Similarly to the computational settings in the previous part, suppose that the demand distribution is stationary and we have n samples drawn from the true distribution. Let 
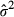
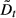
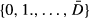
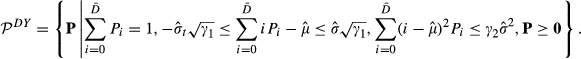
Replacing 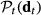
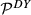
An important issue when applying the robust model based on Delage and Ye (2010) is to determine the values of the parameters 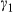
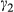
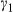
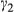
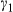
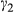
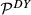
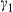
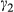
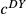
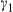
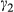
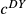
Values of
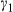
and
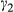
for the Robust Model Based on Delage and Ye (2010)
Values of
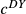
For the example discussed in Figure , we apply the robust model based on Delage and Ye for different 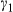
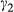
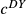
Performance of the Robust Model Based on Delage and Ye (2010) for the Instance in Figure
In general, the expected cost, which measures the optimality of the model, is decreasing in the confidence level 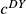
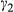
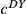
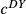
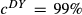
Compared with Table , for most parameters, except for 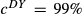
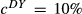
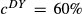
The robust model based on Delage and Ye (2010) with parameters in Table is also applied to the 20‐ and 40‐sample instances in Tables and . The statistics corresponding to these are presented in Tables and , respectively.
Performance of the Robust Model Based on Delage and Ye (2010) for the 20‐Sample Instances in Table
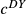
Performance of the Robust Model Based on Delage and Ye (2010) for the 40‐Sample Instances in Table
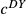
First, we compare the performance of our robust model in section 4 with the robust model based on Delage and Ye (2010) for the 20‐sample instances. The average cost of the latter is from 1.110 to 1.135 while the corresponding cost in Table is less than 1.073. On the other hand, the model based on Delage and Ye (2010) has lower average CVaR, which varies from 0.951 to 0.969, than our robust model, whose average CVaR is from 0.975 to 1.065. As for the standard deviations, our robust model has a lower standard deviation in CVaR, and its standard deviation in cost is comparable to the model based on Delage and Ye (2010).
We now discuss the 40‐sample instances. The average cost of the model based on Delage and Ye (2010) is almost the same as the 20‐sample instances, but these statistics of our robust model are on average 1.9% lower in the 20‐sample instances. Moreover, our robust model has similar values of CVaR for both 20‐ and 40‐sample instances, while the CVaR of the robust model based on Delage and Ye (2010) increases 4.6% on average when the sample size increases to 40. The two types of robust models have similar standard deviations in cost, but our robust model has a lower standard deviation in CVaR.
The numerical results indicate that our robust model outperforms with respect to the solution quality, which is mainly due to the distributional set derived from the chi‐square test carrying more information about the shape of the distribution compared with the distributional set Equation defined only by the sample mean and variance. The model based on Delage and Ye (2010) is more robust, but the difference in robustness of these two models decreases as we increase the sample size from 20 to 40.
In addition, we identified that the ‹3,3› robust model based on the chi‐square test has the best performance among all of the six combinations of the parameters. For 20‐sample instances, its average cost is 7.3% lower than the lowest cost for the model based on Delage and Ye (2010) (when 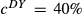
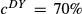
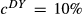
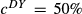
In this study, we propose a robust stochastic model for the multi‐period lot‐sizing problem, in which the demand distribution is unknown and the only available information is historical data. The convergence results for the chi‐square test based models suggest that the solutions to the robust approach are very close to the optimal stochastic programming solutions when the sample size is sufficiently large. When the sample size is relatively small, the extensive numerical results show that the robust model still obtains a close‐to‐optimal solution whose performance is insensitive to the disturbances in demand distributions. This robust framework based on historical data can be extended to many more general finite‐horizon dynamic programming problems, and the convergence properties can also be extended to more general problems.
Although we consider backorder models, most of our results can be extended to lost‐sales models. In particular, for lost‐sales models with only linear procurement cost and under the same technical assumptions, the optimal policy under the robust model is a state‐dependent base‐stock policy.
Footnotes
Appendix A.
Acknowledgments
The authors thank the senior editor and two anonymous referees for their comments to improve the paper. The authors were supported by NSF contract CMMI‐0758069, NASA's Interplanetary Supply Chain Management and Logistics Architectures project, Masdar Institute of Science and Technology (MIST), and grants from Ford, GE, and SAP. The last author was also supported by Hong Kong RGC GRF grant 717111.
1
Note that here we drop subscript t to simplify the notation.
2
If
3
Given random variable X, the conditional value‐at‐risk at a quantile‐level q is defined as E[X | X < μ] where μ is defined by P(X < μ) = q.
4
In this section, the over‐order (under‐order, respectively) cost includes not only the inventory holding cost