
Abstract
Staffing decisions are crucial for retailers since staffing levels affect store performance and labor‐related expenses constitute one of the largest components of retailers’ operating costs. With the goal of improving staffing decisions and store performance, we develop a labor‐planning framework using proprietary data from an apparel retail chain. First, we propose a sales response function based on labor adequacy (the labor to traffic ratio) that exhibits variable elasticity of substitution between traffic and labor. When compared to a frequently used function with constant elasticity of substitution, our proposed function exploits information content from data more effectively and better predicts sales under extreme labor/traffic conditions. We use the validated sales response function to develop a data‐driven staffing heuristic that incorporates the prediction loss function and uses past traffic to predict optimal labor. In counterfactual experimentation, we show that profits achieved by our heuristic are within 0.5% of the optimal (attainable if perfect traffic information was available) under stable traffic conditions, and within 2.5% of the optimal under extreme traffic variability. We conclude by discussing implications of our findings for researchers and practitioners.
Introduction
Effective management of store labor is important to successful retail operations as store labor performs all service‐related tasks (e.g., check‐out, returns, shopping assistance) (Fisher et al. 2006), production‐like tasks (i.e., in‐store logistics) (Fisher 2004, Ton 2009) and labor costs are among the largest costs retailers incur in day‐to‐day operations. The retail environment is characterized by volatile store traffic, which complicates the process of determining staffing levels and affects retailers’ ability to provide consistent service quality. Therefore, the ability to match store labor with incoming customer traffic in an efficient manner is a critical driver of retailers’ store performance. In this study, we explore the relationship among sales, labor, and traffic. The exploration prompted development of a heuristic that enables retailers to use customer traffic patterns to determine their labor requirements.
Traditional staffing practices in retailing are primarily sales‐driven and depend on store budget allocation. A typical sales‐based staffing rule is to match a constant ratio of expected store sales to the number of store associates [refer to Lam et al. (1998, p. 62) for a detailed discussion of traditional staffing practices]. A staffing policy primarily driven by sales, however, ignores the fact that retail sales are also affected (among other factors) by store traffic and might result in labor‐to‐traffic‐mismatches, which can have a negative impact on sales revenue (Netessine et al. 2010, Perdikaki et al. 2012). Retailers cannot fully exploit their sales potential if they follow such staffing policies because the scheduled labor may not be enough to accommodate customer traffic flows. In addition, latent shopper demand may be very different from past sales, since past sales include only customers who purchased and not those who had an intention to purchase but left the store due to lack of sales associate assistance. The proportion of customers who typically leave a store because of poor service is not negligible. Extensive interviews with American customers reveal that “33% who experienced a problem could not find sales help when they required assistance. At the end of the day 6% of all shoppers are lost due to lack of sales associate availability” (Baker Retail Initiative 2007, p. 3). Inevitably, such staffing practices have negative short‐term and long‐term implications for retail store performance.
Recently, retailers have been making better use of information available at the store level to improve traditional staffing practices. Specifically, retailers invest heavily in different types of in‐store technology such as sales‐tracking systems, workforce‐planning systems, and traffic‐counting systems to ensure that stores are staffed with the right number of sales associates. Utilizing such technologies enables retailers to generate traffic forecasts for their stores and consider several store specific characteristics to determine the aggregate labor hours required for each store. Even though this approach is an improvement from traditional labor‐planning practices that rely mainly on sales forecasts, it has a strong focus on within‐store performance. Going beyond the focus on individual stores, retailers could better leverage the information available to them by also considering the performance across different stores in their retail chains. In this study, we present an approach that enables retailers to derive aggregate labor requirements by utilizing traffic data, point‐of‐sale (POS) data, and labor data across stores with similar attributes (e.g., store format, product mix, and market demographics). We show that such an approach leads to robust performance while identifying average differences across stores in the chain.
We analyze proprietary data on labor, traffic, and sales collected from 46 stores of a high‐end women's apparel retailer. We investigate the apparel sector because, unlike other retail settings (e.g., grocery stores) that have a close to 100% conversion rate of turning shoppers into buyers (Netessine et al. 2010), apparel stores exhibit considerable heterogeneity in conversion rates and thus staffing levels have a stronger influence on converting traffic into sales (Perdikaki et al. 2012). Our modeling effort focuses on panel data to leverage the between‐store variation in sales, traffic, and labor in addition to the within‐store temporal variation used by existing staffing approaches (e.g., Kabak et al. 2008, Lam et al. 1998). We develop a sales response function with the appropriate characteristics to make reliable staffing decisions and demonstrate that the function has strong explanatory power of sales variation. Using the estimated parameters of the sales response function, we formulate a profit‐maximizing problem and propose a traffic‐based heuristic to help managers determine weekly staffing levels. We assess the performance of the heuristic's staffing recommendations by performing counterfactual experiments (Kydland and Prescott 1996), and find that the heuristic performs close to the optimal based on the sales response function, and generates higher profits than the observed staffing levels.
While our study is not the first in the literature that proposes a traffic‐based labor‐planning approach, our study makes improvements in the following dimensions. First, we formulate a sales response function based on labor adequacy (the ratio of labor to traffic) that exhibits the expected variable elasticity of substitution between traffic and labor in the retail space—while it might be easy to maintain a level of sales by bringing in additional traffic to replace lost labor when the staffing levels are adequate, increasing store traffic should not have as high of an impact when labor is already utilized to capacity. Second, we employ panel estimation methods—widely used fixed effects modeling as well as recently promoted random effects modeling with Mundlak's correction (Bell and Jones 2015, Mundlak 1978)—that allow us to leverage information available from the performance across stores, as opposed to just the within‐store performance variability, resulting in much more efficient and robust estimates for our sales function. We show that our proposed sales response function exploits the information content from the fit sample more effectively and predicts sales under extreme input conditions better than the function in related literature. Furthermore, the proposed formulation and estimation could potentially allow management to isolate time‐invariant store differences that affect the stores’ ability to turn traffic into sales. Third, we use the sales function to develop a data‐driven staffing heuristic that incorporates the prediction loss function (Granger 1969, West 1996) and uses past traffic to predict optimal labor, as opposed to attempting to forecast volatile traffic. The optimal labor prediction yields staffing levels that are commensurate to other stores’ staffing levels as opposed to levels that are just continuation trends of a store's current practices. In counterfactual experiments, we show that the heuristic achieves profits that are within 0.5% of the optimal (attainable if perfect traffic information was available) under stable traffic conditions and within 2.5% of the optimal under extreme traffic variability.
The rest of this article is organized as follows. Section 2 summarizes the relevant literature; Section 3 describes the research setting and the panel data used for analysis. In section 4, we propose a sales response function, discuss its theoretical properties, and present estimation results of the function. In section 5, we present a traffic‐based staffing heuristic and in section 6 we assess its performance and conduct sensitivity analyses. We conclude by discussing managerial implications of our findings and potential extensions of our work.
Related Literature
Labor planning has been a traditional area of research in operations management and a large body of literature has focused on mathematical modeling to facilitate labor‐planning decisions. The emerging stream of empirical research on retail labor management is primarily motivated by Raman et al. (2001) who posit that store labor is key to resolving execution issues such as inventory record inaccuracy (DeHoratius and Raman 2008) and phantom stockouts (Ton and Raman 2010). Fisher et al. (2006) examine the impact of execution issues on customer satisfaction and sales and propose labor reallocation across stores to enhance sales. Since experienced store associates are usually more capable of executing prescribed tasks correctly, one critical issue of retail labor management is to reduce employee turnover and the associated loss of accumulated experience (Cascio 2006). Ton and Huckman (2008) find employee turnover is negatively associated with profit margin and customer service in a US retail chain. Because high employee turnover is often caused by working overtime, pressure, and fatigue, increasing staffing levels is an effective way to relieve workload and enhance service quality (Oliva and Sterman 2001). In addition to the well‐known effect of labor on service quality, Ton (2009) finds that increasing the amount of labor leads to profit increases through labor effects on conformance quality and Chuang and Oliva (2015) find a positive impact of staffing levels and labor‐mix on inventory data quality. Netessine et al. (2010) examine the impact of labor planning and labor execution on store performance and find that matching store labor to traffic is associated with greater basket values. Their study, which does not possess actual traffic data but uses monthly data on the number of transactions as a proxy for traffic, suggests that better labor planning and execution would lead to superior store performance. Our study is different from the above descriptive body of literature in its research question and data. We study labor together with actual store traffic to develop a traffic‐based labor‐planning heuristic for retail environments.
While the impact of labor on retail performance has been extensively analyzed in the aforementioned studies, traffic has been comparatively understudied because of the difficulty to measure and record actual store traffic. Few studies obtain actual traffic data to assess the effect of traffic and labor on store performance (Perdikaki et al. 2012) and utilize such data to improve/support store labor‐planning decisions (Kabak et al. 2008, Lam et al. 1998, Mani et al. 2015). Lam et al. (1998) propose a sales response function‐relating store sales to traffic and labor and use traffic forecasts to plan labor in a single store. Kabak et al. (2008) adopt Lam et al.'s function to determine hourly staffing requirements, which are used as inputs of a mixed integer program to optimize daily shifts. Our study differs from Kabak et al. (2008) in that their staffing requirements are based on forecasted sales revenue as opposed to store traffic. In addition, while Kabak et al. (2008) focus on optimizing the hourly labor plan, given the sales forecast, our goal is to develop a methodology that effectively uses traffic information to perform weekly labor allocation. Mani et al. (2015) provide a methodology that identifies the extent of understaffing in retail stores and its impact on sales and profitability. Our study is different from Mani et al.'s (2015) in the following dimensions. Mani et al.'s (2015) objective is to develop a methodology to assist labor planning by identifying periods during the day where overstaffing and understaffing occur. We, on the other hand, view planning at a higher level and are interested in determining the aggregate requirements of labor hours at a store on a weekly level. Moreover, the optimal staffing rule proposed by Mani et al. (2015) is technically more complicated in that it requires imputation of unobserved labor costs. Although econometricians do not typically have access to employee wages, store managers have labor cost information when making their staffing decisions. Thus, our heuristic, which does not require labor cost imputation, is easier for retailers to implement. Finally, Perdikaki et al. (2012) empirically examine how traffic and labor affect store performance. They find that sales exhibit diminishing returns to scale with respect to traffic; labor moderates the impact of traffic on sales; and conversion rate declines with increasing traffic. Our objective differs from Perdikaki et al.'s (2012) in that we are interested in providing a framework to support store labor‐planning decisions. To that end, we propose and assess the performance of a simple heuristic using counterfactual experimentation.
Our study is closest to Lam et al. (1998) who propose a traffic‐based labor‐planning methodology based on traffic forecast. We improve on their paper in three important ways. First, we develop a formulation and estimation method that allows us to leverage information across multiple stores and utilize the performance variability across stores. Second, our sales response function is based on labor adequacy (the ratio of labor to traffic) and exhibits variable elasticity of substitution between traffic and labor. From an information theory perspective, our sales response function exploits the information content from the fit sample more effectively than Lam et al.'s. Finally, unlike Lam et al.'s (1998) labor‐planning approach that relies on traffic forecast, we propose an approach that exploits only past traffic information and still performs within 2.5% of the optimal even under extreme traffic conditions.
Research Setting and Data Description
Our research site is a large US retail chain that specializes in women's high‐end fashion apparel. As of 2013, the retailer had more than 200 stores located in the United States, the District of Columbia, Puerto Rico, the U.S. Virgin Islands, and Canada. The retailer's stores are located mainly in shopping centers and malls.
The retailer had installed customer traffic counters in 60 of its US stores during our study period. Those traffic counters were purchased from a company that develops advanced traffic counting systems and guarantees a very high percentage of performance accuracy. This technology has several capabilities such as counting groups of people; distinguishing between incoming and outgoing customer traffic; and differentiating between adults and children, while not counting shopping carts or strollers. This traffic counting system also responds well to different levels of light in the store and can prevent certain types of counting errors such as customers entering but immediately exiting the store.
We obtained the following daily data for the retailer over a whole calendar year (52 weeks): (i) store sales volume (total revenue in $), (ii) labor data (employee hours), and (iii) traffic data (total number of customers). The stores were open 7 days a week and their operating hours were different among locations and days of the week, for example, weekends and weekdays. Out of 60 stores, there were nine stores for which we did not have traffic information for the entire 52 weeks. Those stores had either opened later during that year or had not installed traffic counters at the beginning of the year. Moreover, there were five stores that were in malls that did not have a working website so we could not obtain their operating hours. Thus, we restricted our analysis to the remaining 46 stores for which we could obtain complete information with respect to our variables of interest.
The retailer uses a proprietary labor‐planning system to perform in‐store labor allocation. The tool is run centrally (i.e., at corporate headquarters), and provides weekly labor requirements to store managers who use this information as an input to make more detailed staffing scheduling decisions (i.e., day‐by‐day and hour‐by‐hour), taking different constraints into account such as employees’ preferred schedules and vacations.
While the data were available on a daily basis, we analyzed weekly labor capacity following Oliva and Sterman (2001) and Siebert and Zubanov (2010). Although we also check the effectiveness of our analysis based on a daily data aggregation (see subsection 4.3), several structural elements better justify the weekly data aggregation. First, the weekly aggregation is consistent with staffing planning practices in the apparel retail sector that determines weekly capacity requirements and later decides on day‐to‐day scheduling decisions (Pastor and Olivella 2008). Second, this approach is also consistent with this retailer's labor planning practices. Weekly labor requirements are provided as a recommendation to local store managers by the centralized labor‐planning system, while detailed workforce scheduling decisions (e.g., day‐by‐day, hour‐by‐hour) are more appropriate for local store managers who have better knowledge about constraints pertaining to local contracts and labor availability. Finally, the fraction of a store's weekly traffic that occurs in any given day of the week does not vary much for each store (e.g., 15% of the week's traffic occurs on Friday, 10% on Mondays, etc.) and explains 70% of the variation of sales within a week, making the translation from weekly labor requirements to daily requirements a simple exercise, again, best informed by the local store constraints.
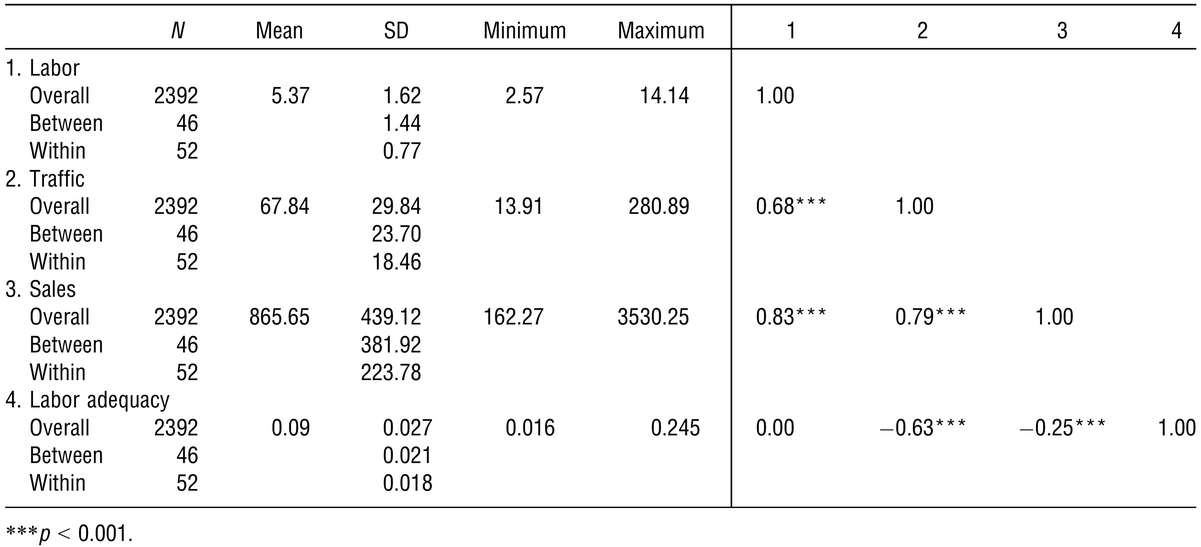
As discussed earlier, the stores’ operating hours were different among locations and days of the week. To avoid any potential spurious correlation that could arise due to systematic differences in stores’ business hours, we normalized our variables. Specifically, we divided weekly sales, weekly traffic, and weekly labor by the regular business hours of each store on each week to obtain average sales per hour, average traffic per hour, and average labor hours per hour for each store on each week. This approach has been adopted by prior literature in similar contexts (e.g., Perdikaki et al. 2012). We report the summary statistics, pairwise Pearson correlations, and within‐ and between‐store variance of the normalized variables and the labor adequacy—(ϕ = L/N) see the following section—calculated from the normalized variables traffic (N) and labor (L) in Table 1. To test the validity of our analysis, we split the data set of 46 stores into a fit sample (weeks 1–40) and a test sample (weeks 41–52).
Summary Statistics and Correlation Coefficients of the Normalized Variables
Sales Response Function
We formulate a sales response function that is grounded on production theory to capture the dynamics of labor, traffic, and sales revenue in our setting. After discussing the rationale of the proposed function, we present the estimation results of the function using the store‐level data described above.
Formulation
Following previous studies (e.g., Kabak et al. 2008, Lam et al. 1998, Mani et al. 2015) that use a production function approach to capture sales generation in apparel retail stores, we model sales as a production function with two factors—traffic (N) and labor (L). However, we revised this frequently used production function to address two issues unique to our approach. First, we wanted to develop a formulation that would allow us to leverage the information across multiple stores (i.e., panel estimation), a salient possibility since the retailer has centralized capacity planning. As reported in Table 1, the variance between stores is much greater than the variance within stores for all our relevant variables. We believe there is valuable information in that variance. The reason why we decided to use panel data to estimate the model parameters, as opposed to using data from one store at a time, is due to the benefits that are associated with panel data analysis vis‐à‐vis a time‐series analysis, among them: panel data models (i) can control for individual heterogeneity; (ii) incorporate more data, that is, more variability, that results in less collinearity among variables, more degrees of freedom, and higher efficiency of estimates; and (iii) are able to identify and measure effects that are simply not detectable in pure‐cross‐section or pure time‐series data (Baltagi 2001, Hsiao 2003, Klevmarken 1989).
The second concern that we had in developing a formulation of the sales response function was the intended use that we had for it, namely, the estimation of store labor requirements in ranges that might be outside of the observed sample for each store. While the papers cited above have used the estimated response function outside of the sample range, we believe that the formulation has characteristics that may make this extrapolation unreliable. Specifically, the sales response function to traffic and labor originally proposed by Lam et al. (1998) is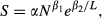
The formulation, however, assumes a constant elasticity of substitution between labor and traffic. The elasticity of substitution measures how easy it is to substitute one input for another. For equation 1, the elasticity of substitution is given by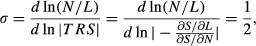
To address this issue, we adopt a formulation that assumes that the output and elasticity of substitution are a function of the ratios of input factors (Karagiannis et al. 2005, Revankar 1971). Specifically, we posit that the labor‐to‐traffic ratio (ϕ = L/N) constitutes labor adequacy and drives sales generation. In other words, what matters is not labor available per se, but how labor compares to store traffic. While ϕ will normally take small values—in many store formats customers can find merchandize without the support of a sales representative—formulating the ratio as L/N makes it an increasing function of labor. Using the log‐reciprocal specification (Lilien et al. 1995) to capture the saturation effects on this ratio, the sales response function is specified as: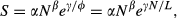
The functional form is grounded on the generalized power production function that subsumes the well‐known Cobb–Douglas function and the transcendental function used by previous studies on apparel retail staffing (Kabak et al. 2008, Lam et al. 1998, Mani et al. 2015). The generalized power production function is flexible in that it does not require constant elasticity of substitution (Janvry 1972) and shows the variable elasticity of substitution that we anticipate. The elasticity of substitution of equation 2 is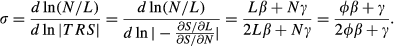
Since γ < 0, the elasticity of substitution of this production function is lower than the one for Lam et al.'s (1998), that is, it has an upper limit of 1/2 when the labor adequacy is high. 1 More importantly, the elasticity of substitution is increasing in ϕ (dσ/dϕ > 0), suggesting that for the expected operating range ϕ < 1 it is more difficult to replace traffic with labor when the two inputs are out of balance. Such behaviors are expected when even more customers arrived in a situation where labor was already working at capacity.
The sales function 2 can be linearized on the inputs by taking the natural log: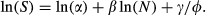
We turn the above function into an empirically estimable fixed effects model (Wooldridge 2010) for store i at period t, in which D
i
are store dummies that denote time‐invariant store characteristics such as store location and store size among others.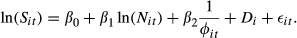
We propose a fixed effects model, as opposed to a random effects model, as we believe that each store in our sample will be different in a unique way, not controlling for store characteristics will produce biased estimates of the coefficients.
We can employ the estimated coefficients to recover structural parameters α, β, and γ. Using equations 3 and 4, we obtain the following relationships after dropping the random noise 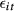
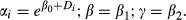
The above specification provides estimates for traffic elasticity (β) and the response to labor adequacy (γ) that takes into account all the available data (across stores and weeks), thus providing more efficient and reliable estimates for the interaction parameters. The fixed effects estimate (α i ) accounts for the fact that stores differ in some intrinsic aspects such as location, demographics, or store size, and capture the ability to monetize the interactions between traffic and labor. Since our model includes store dummies to capture all time‐invariant aspects of a particular store, additional time‐invariant controls would be dropped from the model for being collinear to the store dummies. While a more detailed breakdown of the impact of time‐invariant effects might be desired for designing improvement strategies, the breakdown is not required for staff planning purposes. Finally, the specification in equation 4 can easily be expanded to include heterogeneity in the labor force and traffic, or to capture time variant effects by adding dummies (e.g., promotions, sales periods, etc.). Appendix A provides the specification assuming labor with two different productivity levels.
Sales Function Estimation
Using the fit sample (weeks 1–40), we adopted fixed effects modeling and include 45 dummy variables to estimate 4 (in which the base store has D i = 0) (Cameron and Trivedi 2010). To account for AR(1) serial correlation (p < 0.001 based on a Wooldridge autocorrelation test for panel data), heteroskedasticity (p < 0.001 based on a modified Wald test for group‐wise heteroskedasticity), and cross‐sectional dependence (p < 0.001 based on three different tests for cross‐sectional independence), we adopted Driscoll and Kraay standard errors, which are robust to all three issues listed above (Hoechle 2007).
Another issue that needed to be addressed was the potential endogeneity between contemporaneous labor and sales. In a simple regression of sales and labor the coefficient of labor could be endogenously biased as (i) labor could be planned based on expected future demand, and (ii) managers could potentially observe sales and change labor accordingly. However, three separate reasons led us to believe that the endogeneity bias was mitigated in our setting. First, the fact that we use actual labor instead of planned labor should mitigate the endogeneity bias as actual labor is expected to randomly vary from planned labor due to unanticipated absenteeism. Second, controlling for traffic should also mitigate the endogeneity bias between sales and labor since actual traffic can control for unobserved events such as promotional periods when retailers would tend to schedule more labor (Perdikaki et al. 2012 have also used this approach). Finally, interviews revealed that stores plan labor based on expected traffic and that the sales associates were typically informed of their schedules a week ahead of time. As a result, the retailer does not change its staffing plans later in the week based on sales observed in the early part of the week, thus reducing the possibility of reverse causality. To verify our assumption, we ran the C‐statistic endogeneity test, which is superior to the Hausman endogeneity test as it does not require conditional homoscedasticity (Baum et al. 2003), and the Davidson‐MacKinnon test (Cameron and Trivedi 2005). We found that the null hypothesis of exogeneity is not rejected in either test (p = 0.85 and 0.65 respectively). Finally, as a robustness check, we conservatively assumed that the endogeneity bias was present and used the first and fourth lags of labor as instruments—lagged labor has been used in previous studies as a valid instrument (e.g., Perdikaki et al. 2012, Siebert and Zubanov 2010, Tan and Netessine 2014)—and found that the instrumentation makes little difference to the estimates.
Model I in Table 2 shows parameter estimates from equation 4 and their corresponding robust standard errors. Model Ia shows the estimation with the instrumental variables. We also checked the variance‐inflation‐factors (VIFs) and find no severe multicollinearity using VIF > 10 as a cutoff point (Mela and Kopalle 2002).
Panel Data Estimates of the Sales Response Function
Model I shows the fixed effects estimates of our model. Model Ia treats labor as endogenous variable and shows the estimates of our model using the first and fourth lags of labor as instruments. Model II shows the Mundlak's correction estimates of our model. Models III and IV show the fixed effects and Mundlak's correction estimates of the Lam et al.'s model.
Standard errors are in parentheses. *, **, and *** denote statistical significance at the 10%, 5%, and 1% levels respectively. ρ is the share of estimated error variance accounted for by fixed effects.
The regression and all parameters are highly significant, and all estimated parameters have the expected sign and magnitude. Although simple, the proposed function is able to capture sales variation well without any additional controls. The high R
2 (0.90), as well as the small root mean squared error (RMSE = 0.145), provide strong evidence that the function captures salient features of store operations and helps us build confidence in using the formulation for further analysis. Furthermore, 74% of the explained variance is due to the variance of the fixed effect estimates, suggesting that the model does an adequate job of capturing the within‐store variance over time. As a way to further assess our proposed functional form from an information theory perspective, we introduced Mundlak's correction (Mundlak 1978) that allows the use of random effects methods to estimate the model. Given a properly specified model, Mundlak's correction does not affect the parameter estimates of the fixed effect model nor the predicted outcomes. Mundlak's correction, however, permits the model to be estimated through maximum likelihood estimation (MLE) and generates robust estimates that are more efficient than fixed effect estimates (Bell and Jones 2015). Mundlak's correction incorporates store‐specific means of all time‐variant regressors as extra controls, (i.e., 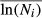
Figure 1 plots the estimated response (with 95% confidence interval) for the range covering the lower 99% of the traffic and labor adequacy values observed in our sample. The left panel shows the diminishing returns to traffic that we expect from stores being increasingly crowded (dashed line is N and is provided as reference). The right panel shows the saturation effect of labor adequacy beyond the point where the store is staffed to a level where each employee sees an average of five customers per hour (1/ϕ = 5).
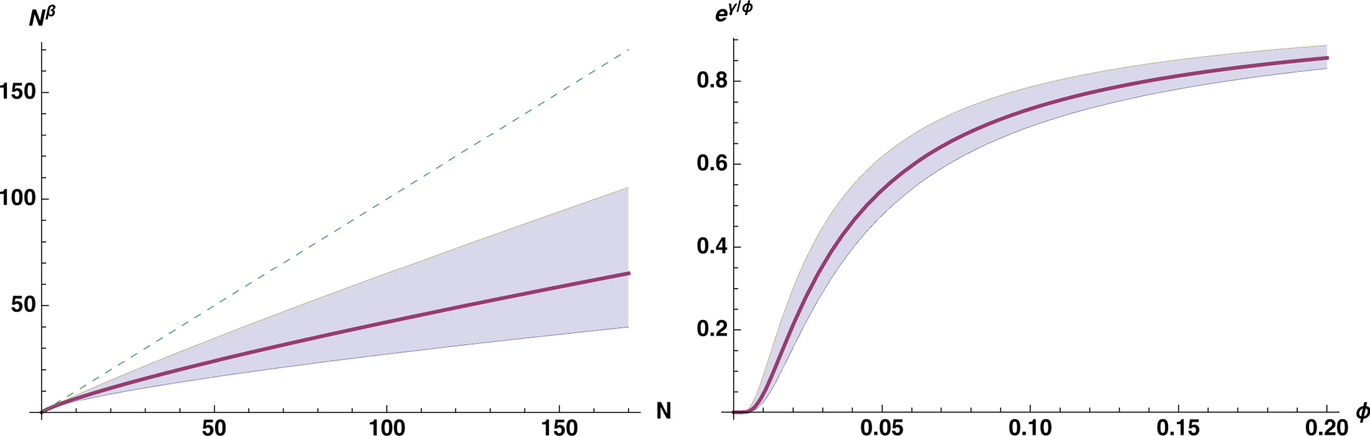
Estimated Response to Traffic and Labor Adequacy (95% CI)
Finally, the distribution of the store potentials (α i ) under Model II has a mean of 5.620 and a standard deviation of 0.858. The distribution is fairly compact (range [3.994, 7.242]) and we found no evidence to reject that it was normally distributed (p = 0.378 Shapiro–Wilk W test). It should be noted that, having controlled for average traffic and labor adequacy, these α i isolate all the stores’ time‐invariant factors that affect profitability. It could be possible to perform detailed analyses of the drivers of the stores’ abilities to monetize traffic and labor by treating α i as dependent variables on regressions with hypothesized factors (e.g., store demographics, store size, competition, location). Such an analysis, however, is beyond the scope of this study.
Assessment of Sales Function
To assess the robustness of the estimated sales function, we used it to predict the realized sales in our test sample (weeks 41–52) while making smearing correction (Duan 1983) to account for errors incurred by directly exponentiating predicted ln(S it ). Despite the fact that the test sample included significantly higher traffic periods (see discussion in subsection 6.1 and Figure 5), the function had a solid out‐of‐sample performance explaining 82.4% of the realized sales across the 46 stores and with only a 0.140 Mean Absolute Percent Error (MAPE).
To illustrate the benefits of panel estimation, we compared the performance of our estimated sales function to the store‐by‐store estimation of the Lam et al.'s (1998) formulation employed by Mani et al. (2015). In addition to the structural components in equation 1, we added time series components to account for the sales autocorrelation used by Lam et al. (1998)—see Appendix B for details. Two of the stores yielded unrealistic parameter values (β 1 < 0 or β 2 > 0), suggesting a specification error, and they were excluded from our comparison sample. For the remaining 44 stores, the average R 2 per store was 0.70 with a standard deviation of 0.11. Considering all of the available estimates across all stores (n = 1760), the store‐by‐store estimation explained 96% of the observed sales variance (the squared correlation between actual and predicted sales). While these numbers compare well to the variance explained by our sales function (90% overall, of which 74% is explained by the store fixed effects), this marginal increase in R 2 comes at a very high loss of estimation efficiency. Whereas store‐by‐store estimation with local information required 312 parameters for 44 stores, our model only required 48 parameters for 46 stores.
When using the full panel data to estimate the Lam et al.'s (1998) specification, the elasticity estimates are significant and have the expected signs and magnitudes (Model III and IV in Table 2 report the FE and Mundlak's correction estimates of the Lam et al.'s formulation). Furthermore, the model's ability to explain sales is not significantly different than that of our proposed formulation within the fit sample (weeks 1–40) (F = 0.960 and p = 0.193 for H 0 : Difference of In‐Sample Fit = 0), nor within the test sample (weeks 41–52) (t = 0.048 and p = 0.962 for H 0 : Difference of MSE = 0). However, assessment of the two functional forms from an information theory perspective, the established paradigm for model selection (Burnham and Anderson 2002), reveals some differences. According to Burnham and Anderson (2002), when selecting among model specifications/functional forms one should select the model with the highest information content. We use the Akaike Information Criterion (AIC)—2k − 2ln(L), where k is number of parameters in a model and ln(L) is its log likelihood—to assess the model's ability to exploit information content from the fit sample. Model II and Model IV have AICs of −1695.55 and −1646.17, respectively, indicating that model II makes better use of the information content (lower AIC) and that the relative probability of Model IV minimizing the (estimated) information loss is virtually zero (exp((AIC II − AIC IV )/2) (Burnham and Anderson 2002). We speculate that this difference in information content is in part reflected in the coefficient for the means for traffic (β 3 ) having an opposite sign to the traffic elasticity (β 1 ), suggesting that Lam et al.'s functional form is too sensitive to changes in traffic for this data set.
As discussed in the previous section, the two models differ on the assumed elasticity of substitution between production factors, that is, labor and traffic. Figure 2 plots the isoquants of the two functions as estimated using the full panel structure for the median sales ($742) in the base case store. Our formulation (solid line) shows a lower elasticity of substitution, and indicates that higher levels of staffing would be required to maintain the same levels of sales throughout the range of observed traffic. While these isoquants represent the inputs required to achieve the median sales data observed in our sample, the two functions are indistinguishable in the regions close to the medians of the fit sample. The functions, however, differ when either labor or traffic is relatively low.
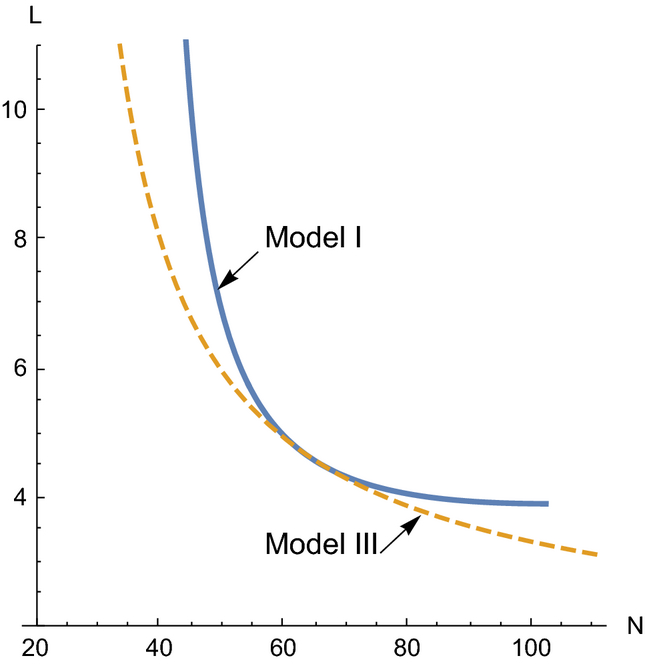
Isoquant for Median Sales on Base Case StoreNotes. Curves estimated from the parameters of Models I and III in Table 2, for a sales level of $742/week
As a final test, we estimated our model using data aggregated daily (as opposed to weekly). The model is still capable of explaining 78.6% of the daily sales variance, and does so with parameter estimates that are significant (p < 0.001) and all have the signs and magnitudes similar to the values estimated from the weekly data.
Traffic‐Based Staffing Heuristic
The estimated sales response function in subsection 4.2 provides a basis for our staffing heuristic. We treat other decisions (e.g., inventory selection, service levels, advertising) as given, and focus exclusively on labor and its impact on sales revenue by formulating an optimization problem in which labor (L
it
) is the decision variable. Consistent with prior literature (Lam et al. 1998, Mani et al. 2015), we assume that managers aim to maximize profit under constant marginal cost of labor. Even though these are common assumptions made in the literature, we acknowledge that store managers may actually take additional factors into account, yet we are not aware of the exact model they use to make their labor‐planning decisions. Our profit function is the difference of sales times the gross margin, minus the labor cost: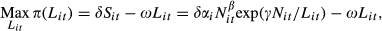
A closed‐form optimal solution for L
it
is obtained by solving the first‐order condition of equation 6: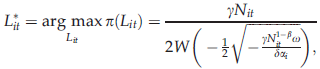
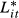
The profit function is concave in labor (L
it
), i.e.,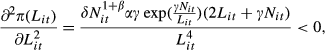
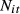
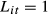
The optimal labor 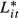
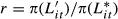
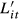
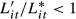
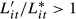
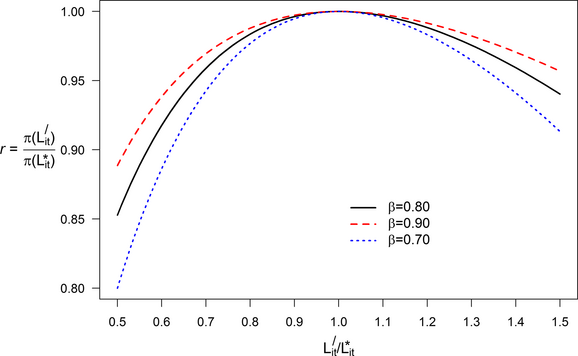
Impact of Suboptimal Staffing on Profit
Given that deviations in 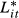
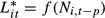
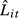
To test our conjecture that the optimal staffing level can be estimated with historical traffic, we first calculate 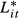
Since 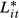
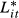
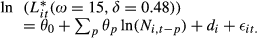
The idea of equation 8 is to empirically characterize optimal labor 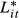
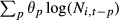
Table 3 shows the fixed effects estimates and robust standard errors (in parentheses) of equation 8 (across 46 stores). We adopt the Driscoll and Kraay standard errors to account for autocorrelation, heteroskedasticity, and cross‐sectional dependence (Hoechle 2007). We consider weekly traffic lags up to four periods and find no severe collinearity as all VIFs are less than 10.
Panel Data Estimates of Equation 8
*p < 0.10; **p < 0.05; ***p < 0.01; The fraction of unexplained variance due to store fixed effects is 0.89.
The high (adjusted) R
2
implies that past traffic is a good predictor of 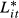
Since fixed effects modeling enables us to capture the relationships between optimal labor and past traffic in a reliable fashion, our heuristic simply capitalizes on those empirical estimates of (θ
0
, θ
p
, d
i
). Therefore, following the premise of traffic‐based (as opposed to sales‐based) labor planning, our heuristic defines weekly staffing requirements for given ω and δ as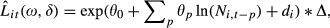
Assessment of Staffing Heuristic
In this section, we assess the performance of our traffic‐based labor‐planning heuristic. By combining the two empirically verified structures (equations 4 and 8), we perform a counterfactual analysis (Kydland and Prescott 1996) to compare our heuristic's labor plans with the retailer's actual labor decisions. In addition, we assess our heuristic's sensitivity to parameter values and compare our heuristic's performance with the performance of an individual store traffic forecast‐based approach.
Heuristic Performance
Figure 4 illustrates the logic of our counterfactual analysis, in which, as in section 5, we set ω = 15 and δ = 0.48. From the fit sample (weeks 1–40) we derived estimates of (α, β, γ) in subsection 4.2 and estimates of (θ
0
, θ
p
, d
i
) in Section 5. Using those estimates and the test sample (weeks 41–52) actual traffic realizations for each store, we compute the heuristic staffing level (
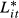
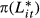

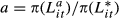
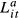
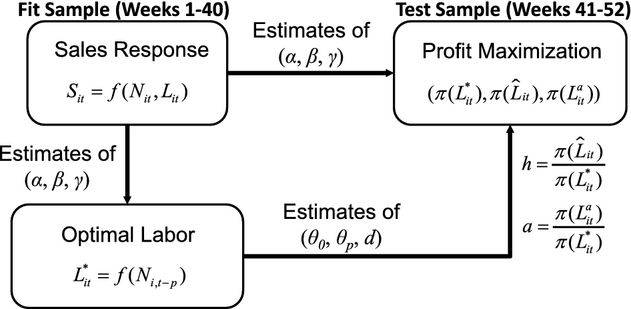
Procedure for Counterfactual Analysis
Figure 5 shows the average of h versus the average of a across 46 stores over the test sample period (weeks 41–52). In the first half of the sample (weeks 41–46), the average performance of the traffic‐based staffing heuristic is very close to optimal staffing (average performance gap (1 − h) = 0.33%). The heuristic performs better than the actual labor realization (a) by achieving significantly smaller performance gap relative to the optimal level (average performance gap (1 − a) = 3.20%, t = 12.21, p < 0.01) and lower performance variability (F = 32.45, p < 0.01). In the last 6 weeks (47–52), the heuristic's performance reveals a slight fluctuation (average performance gap (1 − h) = 2.48%) while the actual exhibits substantial performance degradation (average performance gap (1 − a) = 10.68%). Nevertheless, the heuristic still performs better than the actual in terms of a smaller gap relative to the optimal profitability (t = 13.78, p < 0.01) and lower variability (F = 14.21, p < 0.01).
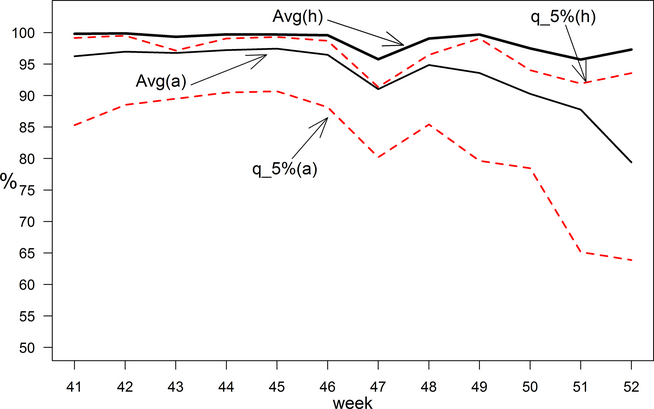
Performance of Heuristic Versus Actual and Optimal Staffing Decisions
To better understand the causes of the performance degradation of h and a during the last 6 weeks we investigate patterns of store traffic over the whole year. As shown in Figure 6, traffic flows remain stationary up to week 46 and a change occurs in the last 6 weeks. Essentially, the holiday season (Thanksgiving to Christmas) shifts the mean of traffic up and amplifies the variability of traffic among stores (not shown in the figure). Our staffing heuristic, which relies exclusively on traffic data in the past p weeks, has limited capability to address those traffic spikes. The effect is more salient because of the asymmetric response of profit to understaffing. Nonetheless, the heuristic still performs within 2.5% of the optimal profits, despite the dramatic traffic surges, for example, 50% increase in week 47 and 90% increase in weeks 51 and 52, corroborating the usefulness of exploiting structural relationships between traffic and optimal labor through across‐store fixed effects.
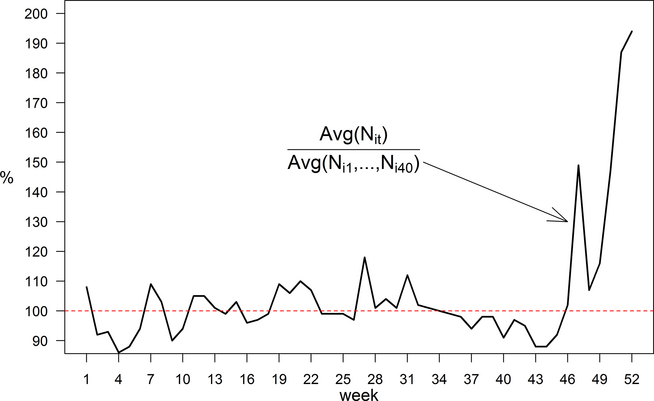
Trajectories of Store Traffic Flows over the Year
Clearly, the performance of the heuristic could be improved if we could use past years’ information to anticipate changes in traffic patterns. For instance, we could modify equation 8 into a two‐way (store and time) fixed effects model: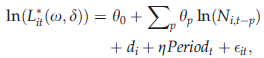
Finally, in terms of dollar values, profits from the heuristic (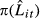
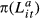
Heuristic Robustness
We first verify that the heuristic is robust to changes in the hourly labor cost ω by testing a wide variety of values from 10 to 25. While the precise cost information would be accessible to the retailer, we conduct the analysis as a means of assessing how the heuristic performance will change if the retailer has different compensation premiums. The left panel of Figure 7 shows the average of h versus the average of a across 46 stores and 6 weeks (weeks 41–46). The average performance of the staffing heuristic is very close to optimal staffing (average performance gap < 0.5%) regardless of the value of ω, while the performance of actual labor (a) is on average lower than the heuristic's performance (h); mainly due to some stores that were severely understaffed (see q_5%(a) line in left panel of Figure 7). In general, the traffic‐based heuristic staffs more aggressively than the retailer for ω in the realistic range of [10, 20]. The improvement of a as ω increases is because the effect of understaffing is mitigated when we assume labor is more expensive, that is, the difference between the two average staffing levels is monotonically decreasing in ω. The performance of the actual staffing practice peaks at ω = 19, but even then is still significantly inferior to h (t = 9.38, p < 0.01 H0:(1 − h) = (1 − a)).
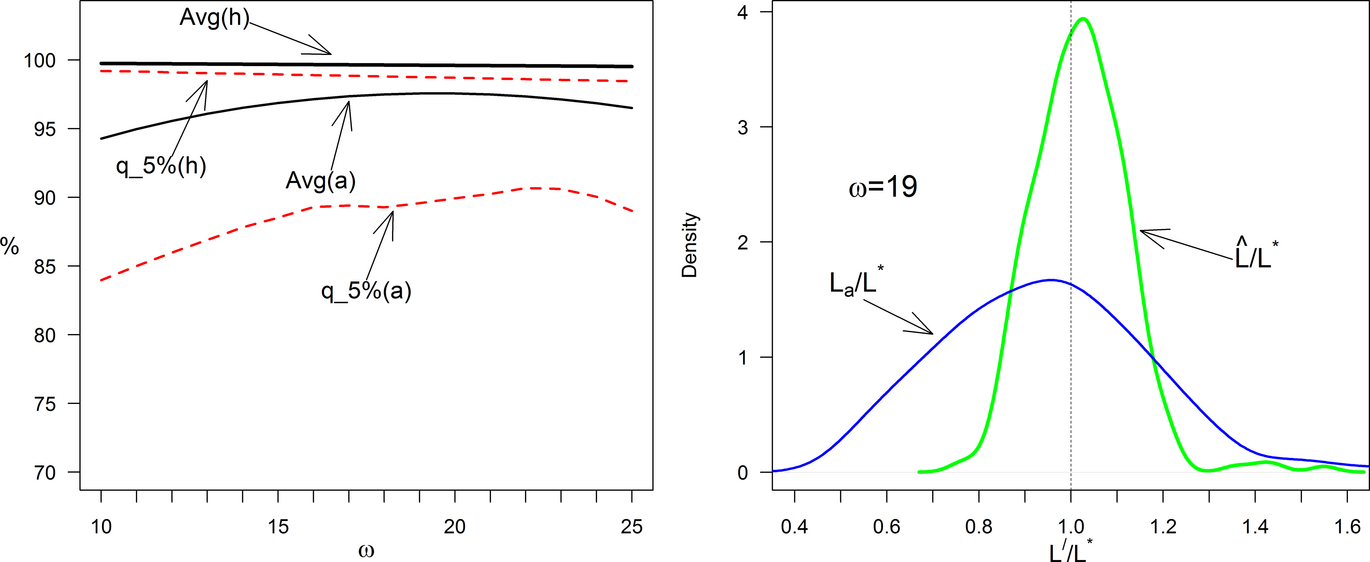
Impact of Wage on Heuristic Performance
Note that one of the advantages of the heuristic is the reduced variability of performance across stores as the full panel information is being used to estimate the sales response and predict the optimal labor. To better articulate this point, we compare heuristic‐generated labor and actually realized labor to optimal labor. The right panel of Figure 7 illustrates estimated probability densities of 
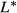
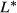
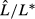
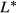
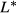
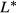
We further evaluate the performance of generating labor plans two weeks ahead, as doing so would allow store managers to have more time making local adjustments of labor schedules. Specifically, we apply the estimated θ 3 and θ 4 (Table 3) to lagged traffic data (N i,t−3 , N i,t−4 ) and compute staffing levels from equation 9. Table 4 shows the performance comparison under different values of ω. The heuristic with either (N i,t−1 , N i,t−2 ) or (N i,t−3 ,N i,t−4 ) performs significantly better than actual labor decisions. Also, the staffing heuristic achieves much lower performance variability across stores and weeks. For instance, for the case where ω = 15, the performance of the labor plan fixed two weeks in advance (N i,t−3 ,N i,t‐4 ) drops only 0.19% from the plan made for the current period, with a minimal increase in variability relative to the (N i,t−1 , N i,t−2 ) case of 0.27%—that is, 0.93–0.66.
Performance Comparison among Different Staffing Approaches
The analysis (n = 46 * 6 = 276) is across 46 stores and 6 weeks. t‐test H 0 : Mean a‐Mean h = 0. F‐test H 0 : Variance a/Variance h = 1.
† p < 0.05, *p < 0.01.
As mentioned in Section 5, the heuristic relies on estimates from the whole panel data set without extrapolating traffic data. As a final benchmark, we test two extrapolative traffic forecasting approaches. The first approach is exponential smoothing and is selected for comparison because of its recognized performance and popularity in practice (Achabal et al. 2000). We estimate the optimal exponential smoothing coefficient ρ
i
for each store using the fit sample and the starting condition 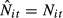
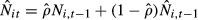
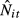
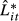
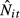
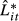
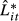
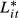
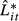
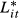
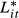
Discussion
Our study takes a grounded approach to develop a retail labor‐planning framework, which avoids the pitfall of allocating labor capacity solely based on a rudimentary calculation of expected sales without fully utilizing knowledge about customer traffic. Our study has several distinct features. First, when formulating the sales response function we introduced the notion of labor adequacy. Our focus on labor adequacy aims to enhance service quality and conformance quality in actual store operations, since adequate/abundant labor capacity is instrumental in reducing work pressure and speeding up customer service (Oliva and Sterman 2001); ensuring correct execution of in‐store logistic tasks (Ton 2014); and maintaining inventory information accuracy (Chuang and Oliva 2015). Second, our proposed sales function exhibits variable elasticity of substitution between traffic and labor, which is expected in a retail setting, and is more capable of explaining sales performance under extreme conditions of input factors. The variable elasticity of substitution between labor and traffic, together with the labor adequacy, shed light on the importance of balancing labor‐to‐traffic ratios in practice. Third, in order to exploit information available across stores, we adopted panel estimation methods for our sales function as well as the staffing rule. Doing so helps us not only isolate time‐invariant store differences that affect the stores’ ability to turn traffic into sales, but also develop labor requirements that are commensurate to other stores’ staffing levels as opposed to levels that are continuation trends of a store's current practices. As a result of the robust and efficient panel estimation, our heuristic performs fairly well under both stable and extreme traffic conditions. Last, our study goes beyond establishing static correlations between variables and contributes to the growing body of empirical research on the effects of labor on retail performance (Fisher et al. 2006, Mani et al. 2015, Netessine et al. 2010, Perdikaki et al. 2012, Ton 2009, Ton and Huckman 2008). Researchers who aim to develop data‐driven and easy‐to‐use staffing rules can refer to our modeling framework and extend our idea to other labor‐intensive service settings such as restaurants, banks, and hospitals. Moreover, researchers who intend to empirically assess retail labor productivity should find the proposed sales response function applicable given the function properties.
Several limitations of our study pinpoint opportunities for future research. First, our analysis assesses a single apparel retail chain, which allows us to implicitly control unobservable firm‐level factors such as pricing policies, manager incentive schemes, and types of merchandise. Analyzing stores of the same firm contributes to a deep understanding of the context but somewhat limits the generalizability of our results. Subsequent studies should attempt to further explore the effects of labor and traffic on performance in other service settings. Second, we adopt a fixed effects estimation to control for several unobservable time‐invariant store‐level factors that could affect sales. We acknowledge that several other factors such as labor experience, employee turnover, and inventory levels, for which we do not possess data, could drive store sales performance. Third, we take an aggregate view on planning labor capacity and derive weekly labor requirements. While the detailed daily/hourly workforce scheduling is not explicitly addressed in our study, we have shown that the proposed sales response function works with that granularity. Lastly, given that we only have data on total labor hours, we cannot differentiate full‐time labor from part‐time labor, which could differ in experiences, attitudes, and productivity. For example, Chuang and Oliva (2015) find that the mix of full‐time and part‐time labor has significant impact on inventory data quality. In Appendix A, we show how our sales response function can be modified to distinguish between full‐time and part‐time labor. Future research may incorporate labor mix into a modeling framework, empirically identify its effect, and develop more comprehensive staffing rules.
Despite these limitations, our modeling efforts carry pragmatic implications for retail practitioners. First, our study proposes a methodology that guides retailers to utilize aggregate information to determine labor requirements. Since many retailers have recently invested in traffic counting technology and have started using such technology to support labor planning, retailers who possess traffic count data could adopt our framework to derive weekly labor hour requirements at their stores. These weekly requirements could then be used by store managers as guidance to identify the mix of labor and perform daily as well as hourly level scheduling. Second, the proposed heuristic is easy to implement in that it merely requires readily available data and does not rely on sophisticated forecasting mechanisms. Our heuristic applies fixed effects estimation to derive weights on past traffic and outperforms an extrapolative approach that requires store‐level traffic forecasting. The weights on observed traffic information can be estimated and updated in a spreadsheet. Third, unlike many existing retail labor management systems that focus on minimizing labor costs and often result in understaffing, our labor‐planning framework provides an alternative to match labor with traffic so as to achieve better sales performance. By aiming for reduction of labor‐traffic‐mismatches, we expect our heuristic's recommended staffing levels not only to positively affect service delivery but also to relieve employee work pressure/fatigue to a certain extent. Last, retailers can take advantage of the robustness of our heuristic to lagged traffic information to develop aggregate labor plans that become input to daily/hourly schedules and apprise their employees of their schedules several weeks in advance. Such an approach can allow retailers to accommodate employees shift requests/preferences without sacrificing profitability. This idea of being accommodative to store labor is actually found to be beneficial for store execution and profits in high‐performance retail companies (Ton 2014).
Footnotes
Estimation Equation for Heterogeneous Labor Productivity
Estimating Lam et al.'s ( 1998 ) Sales Response Function
Traffic Forecasting of Lam et al. ( 1998 )
Acknowledgments
The authors are grateful for the helpful suggestions provided by Nicole DeHoratius, the Senior Editor, and two referees. The authors also thank Gregory Heim, James Abbey, and Ram Janakiraman for their comments and suggestions, which helped improve the content and presentation of the manuscript.
1
The constraint σ > 0 also reduces the viable range for the response to labor adequacy to −βϕ< γ < 0.