
Abstract
We consider a model where a monopolist can profile consumers in order to price discriminate among them, and consumers can take costly actions to protect their identities and make the profiling technology less effective. A novel aspect of the model consists in the profiling technology: the signal that the monopolist gets about a consumer’s willingness‐to‐pay can be made more accurate either by having more consumers revealing their identities, or by spending larger amounts of money (e.g., on third‐party complementary data or data analytics capabilities). We show that both consumer surplus and social welfare are convex in the ability of consumers to conceal their identities. The interest of this result stems from the fact that consumers’ concealing cost can be interpreted as a policy tool: a stricter privacy law would make the concealing cost lower, and vice‐versa. Consequently, a policymaker who promotes total welfare should either make data protection very easy or very costly. The right direction of data regulations depends on data requirements. In particular, a higher (lower) data requirement is an instance when more (less) consumers are needed to achieve the same signal precision. We show that a strict data privacy law is preferable under a high data requirement so that firms are less likely to invest in profiling inefficiently, whereas there is less concern with little or no data regulations under a low data requirement. We also discuss when greater data protection may be beneficial to the firm.
Introduction
The explosion of information technologies has provided unprecedented ways for firms to collect data about their consumers. For instance, communications between web browsers and web sites allow firms to gather information including IP address, the web browser type, the computer model, as well as its operating system—all of which can be used in consumer profiling. Web sites can also assign and read unique identifiers, called cookies, which are used to compile records of individuals’ browsing histories. Retail web sites like Amazon use cookies to keep track of what a consumer has shopped for and bought, and tailor web sites with products that the firm suspects that the consumer is the most interested in. Dansk Supermarked, Denmark’s largest supermarket chain, partnered with Infosys—a leading IT consulting company—in order to use address data of its repeated consumers and tailor offers of products relevant to where they live.
1
Uber introduced a new fare system called “route‐based pricing,” where fares are personalized based on its prediction of how much a customer is willing to pay.
2
All these examples demonstrate that technological developments have enhanced a firm’s ability to profile consumers and make them targeted offers. On the other hand, consumers have become more wary with respect to how their information is being collected and used by firms. Singer (2015) reports several instances where consumers are aware of the many trade‐offs associated with giving companies access to their data. Ultimately, the data can be supplied only by consumers themselves. The very same technologies that allow a firm to profile can also be used by consumers to counteract the effectiveness of profiling. Consumers can remove their traces online by blocking third‐party cookies, or purging cookie files. Some privacy‐wary consumers even take further steps and pay third parties to protect their data. For example, Reputation.com charges individuals $9.95 per month to remove personal data from on‐line data markets. The search engine DuckDuckGo addresses searchers’ privacy concerns by committing never to collect or share any individual information and search history. Drawing upon this increasing tension between firms and consumers, we study data profiling in the context of price discrimination. While a large literature has analyzed consumer profiling and price targeting, which we review in section 2, in this study, we consider the novel aspect of the accuracy of profiling. There are two entangled premises of our model, one related to actions that can be taken by the firm (data precision) and one related to actions that can be taken by consumers (data protection). Suppose that a firm wants to profile its consumers by gathering and analyzing a dataset about them. The degree of precision of consumer’s information is an endogenous choice of the firm, which can be improved in two complementary ways. On one hand, the precision of the information that can be extracted directly from consumers depends on the sample size. The relation between accuracy of statistical inference and sample size is well documented. For instance, in the classical linear regression, standard errors of ordinary least squares estimators shrink at a rate of
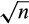
Turning to the second aspect of our model, consumers make endogenous choices whether to allow the firm to use information about them. A consumer can take a costly action to conceal his/her identity. This opens various interesting aspects that we contemplate. First, related to the point about sample size and accuracy, the firm needs to make sure that consumers endogenously prefer not to conceal their identities—otherwise the profiling techniques will be ineffective. This can be done either by offering them a good price in case they allow data disclosure, or by penalizing them in case they do not. Second, as information concealing is costly, there are welfare and policy questions arising. Regulators could make the cost of concealing smaller, for instance by imposing a full disclosure policy on the use of cookies. Conversely, this cost could be made larger if the firms are allowed to trade consumers’ data, so that consumers would need to request potentially many websites to erase their data. Hence we can also address, in a meaningful way, the question that is at the core of current debate on consumer privacy. How easy should access to consumers’ information be?
Taking into account the factors described above, in this study, we consider a model where a monopolist seeks to price discriminate consumers through data profiling. Consumers can take costly actions to protect and anonymize their identities. Otherwise, a signal about a consumer’s willingness‐to‐pay is received by the firm. The signal can be made more accurate either by having more consumers revealing their identities, or by investing larger amounts of money (e.g., on third‐party data or data analytics capabilities).
We show that both consumer surplus and social welfare initially decrease as it becomes more difficult for consumers to anonymize their identities, however the relation is reversed when the cost of concealing becomes sufficiently large. The rationale is as follows. When it is very easy for consumers to conceal, it is sensible that consumer surplus would be relatively high because consumers can prevent the firm’s profiling easily with a small cost. As concealing becomes more costly, more consumers would choose to reveal their identities, allowing the firm to profile them perfectly. However, at the same time, the firm would charge a lower price to anonymous consumers, as this market becomes smaller with a greater proportion of low valuation consumers. So when the concealing cost becomes sufficiently large, the gain in surplus for anonymous consumers dominates the loss of surplus from those who reveal their identities, leading to an increase in consumer surplus in the concealing cost. Following a similar logic, social welfare also initially decreases, reaches its minimum, and then increases in the ability of consumers to conceal. In practice, consumers’ concealing cost can be interpreted as a policy tool: a stricter privacy law would make the concealing cost lower, and vice‐versa. Consequently, our result suggests that a policymaker who promotes total welfare should either make data protection very easy or very costly. The result that consumers may benefit from a very strict privacy law provides theoretical justification for the recent adoption of strict privacy regulations in many countries/regions. For instance, the General Data Protection Regulation (“GDPR”) is a recent regulation in EU law on data protection and privacy, which significantly strengthened rights of individuals by making sure that individuals need to give explicit consent whenever businesses collect their data, and withdrawal of consent is as easy as giving consent. 5 Somewhat more surprisingly, our result also suggests that total welfare can also be high at the other end of the spectrum when policymakers take little or no action over data privacy, which is the stance some countries are taking right now. Having said that, privacy laws have significant impact on how consumer surplus is allocated across consumer segments. A strict privacy law mainly benefits those repeated customers who may participate in the firm’s loyalty program, whereas new/switching customers are the main beneficiaries from the lack of privacy regulations.
Whether the firm’s investment in profiling is aligned with social welfare is closely related to the ability of consumers to conceal their identities as well as to data requirements. In particular, we define a higher (lower) data requirement as an instance when more (less) consumers are required to achieve the same signal precision, for a given investment from the monopolist. When policymakers introduce very strict privacy laws such that consumers can easily conceal their identities, any of the firm’s investment is rendered unprofitable, and the firm’s decision not to profile is socially optimal, regardless of data requirement. Arguably, this is an extreme case in the sense that, by making it ineffective, it is as if profiling is being banned completely. In many cases, however, it is not realistic that a policymaker can affect the entire range of values of privacy cost. Often only piecemeal policy changes are implementable, and thus the policy maker could only affect privacy costs incrementally. Then, the optimal policy crucially hinges on data requirement of the business/application. For applications with relatively high data requirements, the policymaker shall introduce a relatively strict privacy law, which allows consumers to conceal easily. Coupled with the fact of high data requirements, it would more likely dissuade firms from inefficient investment in profiling, leading to socially optimal investment decisions from the firm. On the other hand, firms are already inclined to invest in profiling when data requirement is relatively low. In this case, policymakers should take little or no action over data privacy, such that consumers become less likely to spend inefficient effort trying to remove their information.
We further consider two extensions of our base model. First, we consider the case where consumers’ concealing costs are heterogeneous. We show that, somewhat surprisingly, the firm’s profit may decrease when a greater proportion of consumers have a high concealing cost. This is because the anonymous market becomes smaller with a greater concentration of low valuation consumers as the proportion of consumers with a high concealing cost increases, leading to a lower price for the anonymous market. As a result, the firm’s profit from the anonymous market is maximized with a moderate proportion of consumers with a high concealing cost. So, even though the firm’s profit from profiling always increases when more consumers find it costly to conceal their information, the reduction in profit from the anonymous market may outweigh the benefit from profiling, leading to a lower profit for the firm. In many cases, the firm itself is able to directly control the cost of maintaining anonymity. For instance, online retailers can determine how easy it is for consumers to delete cookies planted on their computers, or offer to delete consumer data periodically, as suggested in GDPR. Our result indicates that such practices may sometimes benefit the firm.
As a second extension, we consider the case when the firm’s investment level is unobservable to consumers. Compared to the base model where the firm’s investment level is observable, we show that either the two cases yield the same expected profit for the firm, or equilibrium exists only if the firm’s investment level is observable. This is because, by committing to a certain investment level, the firm forces consumers to play along and respond optimally to a committed investment level.
Literature Review
Our paper relates to two broad streams in the literature. First, our paper is linked to the literature on behavior‐based price discrimination. In the seminal work by Fudenberg and Tirole (2000), they study the effects of behavior‐based price competition in the framework of a two‐period Hotelling model. Firms are able to profile a consumer’s preference on the Hotelling line based upon his/her purchase decision in the first period. Past behavior is then used in the second period to design a discriminatory pricing scheme by the firm. The research on behavior‐based pricing has been extended to various settings and applications (Chen and Zhang 2009, Pazgal and Soberman 2008, Shin and Sudhir 2010, Villas‐Boas 1999,2004, Zhang 2011). 6 Comprehensive literature reviews can be found in Fudenberg and Villas‐Boas (2006) and Esteves (2009). Most of the literature on behavior‐based price discrimination does not consider privacy issue explicitly. The common recurring assumption in the literature is that a consumer has no option to remain anonymous once s/he purchased from the firm. In the context of our framework, it is equivalent to the case when consumers’ concealing cost is extremely high, that is, c = 1/2, and thus it becomes prohibitive for a consumer to conceal his/her identity. Our work also differs from this stream of literature in that the granularity of profiling is an endogenous decision by the firm, whereas consumers can only be differentiated based on their purchasing history in the literature on behavior‐based price discrimination.
The second stream of literature we are related to examines the implications of consumer privacy on pricing and privacy regulation, as well as their consequences on welfare (see Acquisti et al. 2016 for a comprehensive review of this literature). The majority of this stream of literature assumes that consumers’ privacy decisions are exogenously determined (see, e.g., Acquisti and Varian 2005, Shy and Stenbacka 2016, Taylor 2004, Taylor and Wagman 2014). That is, discussions are typically centered around two special cases when it comes to privacy, namely, consumers either have no option to remain anonymous, which is the same as that in the literature on behavior‐based price discrimination, or they can conceal/erase their data costlessly. In the context of our framework, the latter is equivalent to the case when concealing cost is extremely small, that is, c = 0. We contribute to the literature by exploring the entire spectrum of consumers’ privacy cost, and show that, somewhat surprisingly, both consumer surplus and social welfare are convex in the privacy cost, implying that either a very strict privacy law or lack thereof can be good for consumers. We further explore the case when privacy costs are heterogeneous, and reveal that, surprisingly, the firm’s profit may decrease when a greater proportion of consumers find it very costly to conceal their identities.
More recently, a growing number of works have considered the implications of consumers’ endogenous decisions regarding how much information to be revealed to the firm. Casadesus‐Masanell and Hervas‐Drane (2015) consider a duopoly setting where consumers can choose the amount of information being provided to the firms. This information can help the firms to improve the quality of their products. Firms derive revenues from both consumer purchases and disclosure of consumer information in a secondary market. Montes et al. (2019) study the effects of price discrimination with endogenous consumers’ privacy choices in the context of a duopoly Hotelling model. There is a data broker who collects consumers’ information and can sell data to the two competing sellers. They show that the optimal selling strategy for the owner of consumer data is to deal with one firm exclusively. In the specific context of the auto insurance market, Chen and Jiang (2019) study the impact of in‐vehicle monitoring technology on the insurance firms and drivers. The work closest related to ours is Conitzer et al. (2012), who study a monopolist’s pricing problem in the framework of a two‐period model. The monopolist is able to price discriminate consumers in the second period, depending on consumers’ decisions regarding whether or not to purchase and whether or not to conceal their identities in the first period. Motivated by recent advance in data analytics, our work adds an important aspect to this discussion by allowing the firm to offer personalized prices to those identifiable consumers. This aspect considerably changes the impact of privacy cost on consumer surplus, as well as social welfare. On one hand, we obtain a result similar to Conitzer et al. (2012) that consumers may sometimes benefit from a high privacy cost. This is because, as privacy cost increases, the size of the anonymous market would become smaller with a greater proportion of low‐valuation consumers. Consequently, the firm charges the anonymous market with a lower price, leading to higher consumer surplus as a result. However, unlike Conitzer et al. (2012), we show that consumer surplus may also decrease in the concealing cost, especially when the cost is very small. This decrease in consumer surplus is mainly driven by personalized prices offered by the firm, as the benefit from the ability of concealing with a lower cost becomes much larger.
To the best of our knowledge, two papers consider explicitly profiling technology in the context of price discrimination. In Koh et al. (2017), consumers can choose to disclose their private information to a monopolist in return for reduced search cost due to more accurate product recommendation. They face a trade‐off between better product‐fit and potential price discrimination. Belleflamme and Vergote (2016) study the optimal pricing of a monopolist who is able to profile consumers, while consumers are able to counteract by maintaining anonymity. What these two models have in common is that the signal received by the firm is assumed to follow a Bernoulli distribution when a consumer’s true valuation is revealed with probability β, and no new information with probability (1 − β). Unlike the exogenously given profiling technology in Koh et al. (2017) and Belleflamme and Vergote (2016), our paper accounts for the firm’s endogenous and costly investment in the precision of the signal. Coupled with the fact that consumers choose endogenously whether or not to reveal information, our framework adds an important dimension related to privacy regulation by accounting for the dynamics between data requirements and privacy cost. We show that the right privacy regulation hinges crucially on data requirements: total welfare typically benefits from a strict privacy law when data requirements are high, whereas lack of privacy law can be good for applications with low data requirements.
The Model
The Setup
A monopolist sells a product to a continuum of consumers with a total mass of one. There are two market segments, namely an “old market” and a “new market.” The difference is that, in terms of consumer valuations, the firm only knows the aggregate distribution of the new market, while information can be obtained about individual consumers in the old market. We assume that the size of the old market is λ and the size of the new market is 1 − λ, known to both the firm and consumers. In the following analysis, we use the subscripts o and n to denote the old market and the new market, respectively. We use the “old” vs “new” markets as a simple but flexible device to model different segments of consumers. The existence of the new market is crucial in our analysis. As we will show below, there exists a cutoff
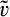
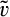
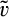
A consumer’s valuation is determined by the realization of a random variable, which we assume to be uniformly distributed over the unit interval in both the new and the old market. A consumer in the old market can choose to perfectly conceal her identity to prevent the firm from profiling her valuation towards the product. A cost of c(>0) is incurred if a consumer spends the effort to conceal her identity. We assume that, if a consumer is indifferent between revealing or concealing, she would choose to reveal her identity. 7 Consumers in the new market and those consumers in the old market who conceal their identities constitute an anonymous market. That is, we assume that the monopolist cannot distinguish between new consumers (for whom no information is available) and old consumers who remove all available traces of their activities by paying the privacy cost. As a result, the firm can only offer one common uniform price to the anonymous market.
To put things into context, we can think of the firm as an online retailer. The new market can represent those consumers who are buying from the retailer’s competitors, and thus have never shopped at the firm before. As such the retailer knows nothing about this segment of consumers. On the other hand, consumers in the old market can be repeated shoppers, who may also have joined the retailer’s loyalty rewards program. For this segment, the firm is able to keep track of any individual’s purchase history, her demographic information, etc., which can be used for profiling by the retailer. However, a repeated shopper can spend time and effort, for instance, registering a new account to remove her traces online. By doing so, the retailer will not be able to differentiate her from those consumers who may recently switch from competitors.
The firm invests a total amount of K in collecting old consumers’ information and profiling consumers. The investment in consumer profiling allows the firm to receive a signal, denoted as s, for each consumer in the old market who reveals her identity. The signal represents a mapping from the information about a consumer collected by the firm to a noisy prediction of the consumer’ willingness to pay. The accuracy of the signal is assumed to be dependent on the firm’s investment K, as well as the fraction of consumers choosing to reveal their identities, γ. That is, the degree of precision of the firm’s prediction of consumers’ willingness to pay can be improved in two complementary ways. On one hand, the firm is able to get more accurate signals when a greater proportion of consumers in the old market choose to reveal their valuations, which constitute the dataset that can be analyzed with statistical techniques. The justification of this assumption can be traced to the root of statistical inferences. A larger sample reduces the variation of sampling distribution, and thus predictions are more likely to be close to true values. With this assumption, we implicitly assume that there exists an externality in consumer profiling, because a consumer’s decision of revealing her identity has implications for the rest of consumers in the dataset. This assumption also echoes many practitioners’ observation (e.g., Norvig 2011) that the scale of data needs to reach a minimal threshold to be sufficiently informative. Typically, the relationship between the accuracy of signals and the amount of data available is S‐shaped. On the other hand, more accurate signals are received with a higher investment K. The firm can invest in either obtaining additional data from third parties to supplement their consumer data, or more advanced data analytics for more accurate inferences. Note that these modeling features allow us to describe the process whereby digital platforms collect large amount of browsing data and process it through machine learning techniques. Perhaps the limit point of the long‐term trajectory of this technological progress is best described by Larry Page, one of the founders of Google, in 2000: “Artificial intelligence would be the ultimate version of Google. The ultimate search engine that would understand everything on the web. It would understand exactly what you wanted, and it would give you the right thing. We are nowhere near doing that now. However, we can get incrementally closer to that, and that is basically what we work on.” 8 Instead, no profiling can be conducted in the new market, as no individual information is known to the firm.
The game unfolds in several stages. First, each consumer realizes her valuation v. The firm does not observe v; however, the uniform distribution of customers’ valuations is common knowledge, known to both the firm and consumers. Second, the firm decides an investment level K in consumer profiling. In the third stage, each consumer in the old market decides whether or not to conceal her identity. A cost of c is incurred when concealing her identity. Next, the firm sets a base price to consumers in the new market, as well as to those in the old market who conceal their identities. The firm also offers a tailored price to each consumer in the old market who chooses to reveal her identity, based on the firm’s belief of the consumer’s valuation. Finally, each consumer makes the purchase decision, and she will purchase the product if and only if her utility from purchasing the product is non‐negative.
Operationalization of Signal Accuracy
Next we formalize the definition of accuracy of signals, which is operationalized by the conditional distribution of signals. Let G(s|v) be the conditional cumulative distribution of signals from a type‐v consumer in the old market who chooses to reveal her identity. Its corresponding density function is denoted as g(s|v). No signals would be received from those consumers who conceal in the old market, or in the new market. We specify the conditional density of signals from a type‐v consumer who reveals her identity as follows. For any
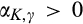
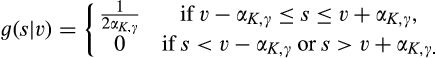
That is, the conditional distribution of signals still follows a uniform distribution. The mean of random signals equals to the consumer’s valuation v, which is independent of the firm’s investment as well as others’ decisions. However, the conditional distribution rotates around the mean v as K and γ varies.
9
Consequently, the accuracy of the signal is determined solely by
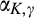
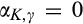
In our main analysis in section 4,
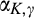
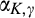
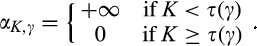
The use of step functions is common in statistical analysis. One example is the classical hypothesis testing. In hypothesis testing, researchers first decide on a significance level, say 1% or 5%, and then the test statistic is compared against the critical value corresponding to the chosen significance level. The null hypothesis is rejected if and only if the probability of observing more extreme values than the test statistic is less than the significance level, assuming that null is true. The firm’s problem of consumer profiling can be considered as a variation of hypothesis testing problems, where the null hypothesis is that a consumer’s valuation is equal to a pre‐specified value. A more accurate estimate is obtained by having a larger sample. Or alternatively, the firm can invest to improve the statistical power of the test by controlling for more confounding variables or using more sophisticated methods. The assumption of α as a step function implies that the firm will act on the result of profiling if and only if the firm is sufficiently confident about the result.
We assume that τ(γ) is non‐increasing and concave in γ. The non‐increasing property of τ(·) is consistent with the intuition that the firm’s investment required to profile consumers perfectly decreases (weakly) in the fraction of consumers choosing to reveal their identities. The concavity of τ(·) suggests that the required investment level decreases slowly when γ is small, however the marginal effect of the size of dataset on the required investment increases when the dataset becomes larger. One way to understand the concavity of τ(γ) in γ is as follows. The difference between
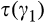
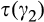
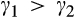

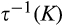
Results
In this section, we characterize the equilibrium, show comparative statics, and discuss implications of consumer profiling on consumer surplus and social welfare. We use Perfect Bayesian Equilibrium as the solution concept. Throughout the analysis, we impose the following assumption on the concealing cost to avoid the trivial equilibrium where concealing is so expensive that all consumers in the old market would choose to reveal their identities.
(C C
Characterization of Equilibrium
With
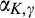
(C (P a consumer in the old market chooses to conceal her identity if and only if the price the firm charges to the anonymous market is the firm receives a perfect signal for any consumer in the old market who chooses to reveal her identity (i.e., α = 0), and charges an individual price equal to the signal. (N a consumer in the old market chooses to conceal her identity if and only if the price the firm charges to the anonymous market is signals from those who choose to reveal are non‐informative (i.e., α = +∞), and thus the firm offers one price to those who reveal their identities, which is given by If K < τ(1), all consumers in the old market would choose to conceal their identities. Signals are non‐informative (i.e., α = +∞), and the firm would offer the optimal monopoly price 1/2 to both the new market and the old market.
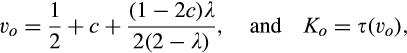
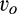
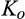
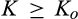
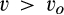
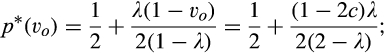
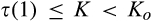
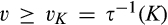
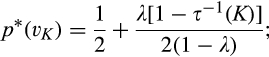
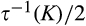
Consumers’ optimal response as a function of the firm’s investment level is illustrated in Figure 1. In particular, the firm’s investment levels can be divided into two regimes, depending on accuracy of signals from consumers who reveal in the old market. For any
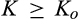
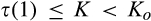
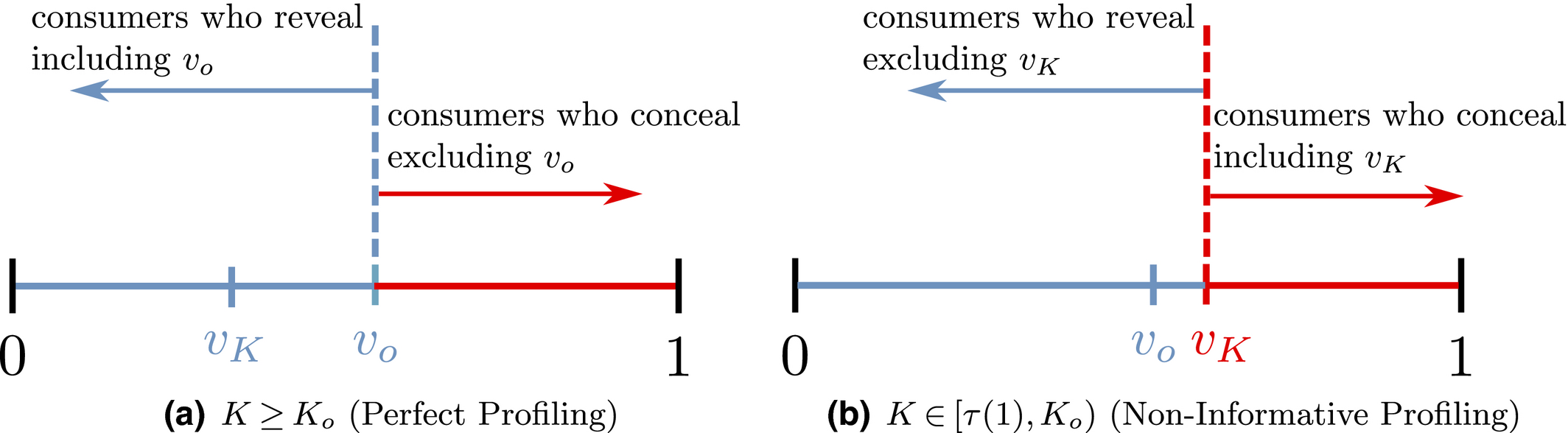
Consumers’ Optimal Responses under Various Investment Levels [Color figure can be viewed at
A few comments are in order. First, recall that a consumer from the old market needs to spend effort c in order to conceal her identity. Intuitively, any consumer with a valuation lower than c would find it unattractive to conceal her identity, and choose to simply reveal her identity. However, as we show in the proof of Lemma 1, at least a fraction
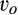
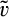
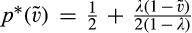
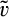
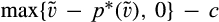
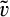
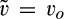
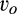
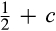
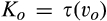
On the other hand, when the firm invests less than
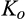
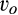
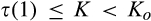
Second, and perhaps surprisingly at first sight, no matter whether the firm is able to profile those who reveal perfectly, the price the firm charges to the anonymous market is always greater than 1/2, which is the optimal monopoly price for the new market. The rationale is as follows. High valuation consumers from the old market would fear of being price discriminated as a result of the firm’s profiling, and thus choose to conceal their identities. As a result, the valuation distribution of consumers in the anonymous market stochastically dominates the valuation distribution from the new market, leading to a higher price for the anonymous market.
Next we study the firm’s optimal investment level in the first stage. Let
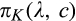
(F
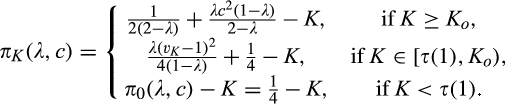
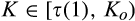
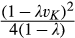
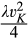
On one end of the spectrum, for any
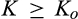
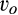
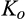
The most interesting case is when
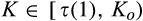
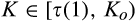
Lemma 2 indicates that the firm’s optimal investment level depends on curvature of τ(·) function. However, as we show in the lemma below, it is reduced to two points, either 0 or
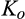
(O
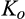
Lemma 3 indicates that when the required level of investment is concave and decreasing in the fraction of consumers choosing to reveal their identities, the optimal solution is to either invest the minimum amount
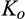
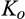
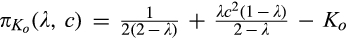
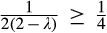
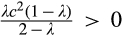
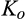
Welfare Implications
Whether or not the firm chooses to invest has different implications on consumer surplus (CS) and social welfare (SW). With an investment of
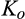
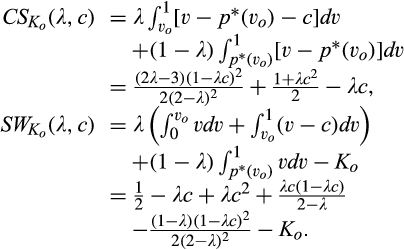
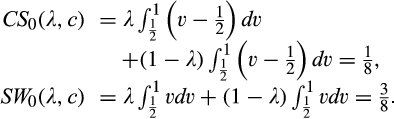
Neither λ nor c plays a role in consumer surplus or social welfare when the firm invests zero. The reason is that with no investment from the firm, the signal from a consumer is non‐informative. That is, the firm’s posterior belief of a consumer’s valuation is exactly the same as the prior belief. Consequently, any consumer in the old market would be better off revealing his identity, and the firm faces two identical markets in terms of the distribution of consumer valuations. However, if the firm invests, prices will differ and thus both λ and c affect the equilibrium. The impacts of λ and c on profit and consumer surplus are summarized in the lemma below.
(S
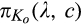
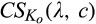
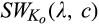
A few comments are in order. First, Proposition 1(i) indicates that the firm’s profit increases in both λ and c. This is intuitive in the sense that, when the size of the old market λ increases, the firm is able to profile a larger proportion of the market, leading to a higher profit. Similarly, when consumers find it more difficult to conceal, a greater proportion of consumers in the old market would choose to reveal their identities, allowing the firm to extract greater surplus from them. A direct consequence of Proposition 1(i) is that the firm is more likely to invest in consumer profiling with either a higher c or a higher λ.
Second, Proposition 1(ii) indicates that consumer surplus decreases in λ, as the firm can extract more surplus from consumers in the old market than the new market. Interestingly, consumer surplus is non‐monotone in c. When c is close to zero, consumers in the old market can conceal their identities easily, leading to relatively high consumer surplus. As c increases, more consumers in the old market would choose to reveal their identities (as
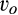
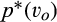
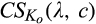
The interest in this discussion stems from the fact that c could be interpreted as a policy tool: a stricter privacy law would make c lower, and vice‐versa. From this perspective, a policy maker that promotes total welfare should either make data protection very easy (low c) or very difficult (high c). The result that consumers may benefit from a very strict privacy law seems intuitive, and, as shown by Proposition 1 , total welfare may also be relatively high as a result. This result provides theoretical justification for the recent adoption of strict privacy regulations in many countries/regions, such as GDPR in the EU, as discussed in the introduction. Somewhat more surprisingly, Proposition 1 suggests that total welfare can also be high at the other end of the spectrum when policymakers take little or no action over data privacy, which is the stance a few countries are taking right now. For instance, China has taken little action over data privacy compared to the west. Based on a survey released by the China Consumers Association, around 85% people had suffered some sort of data leak—ranging from their phone number being sold to spammers to their bank account details being stolen (Yang 2018). Even though total welfare can be relatively high with either very strict or no privacy laws, its implication on the allocation of consumer surplus across consumer segments differs significantly. From a consumer’s perspective, a strict privacy law mainly benefits the old market (e.g., repeated customers who may participate in the firm’s loyalty program), whereas the new market (e.g., new/switching customers) is the main beneficiary from the lack of privacy regulations. It follows that privacy laws can potentially be used as a policy tool to influence consumer behavior. For instance, the government of Japan is aiming to double Japan’s cashless payment rates by 2025 due to reasons such as costly handling of cash, potential tax evasion with cash transactions, and etc. (Lewis 2019). However, Japan traditionally has a cash culture as people love the sense of security, ownership, as well as anonymity that cash can bring to them. To facilitate its shift toward a cashless society, our result suggests that strict privacy enforcement with cashless payments is needed.
The impact of the firm’s profiling investment on consumer surplus and social welfare is summarized in the corollary below.
(I Comparing consumer surplus and social welfare under investment levels of 0 and for any λ and c, for any λ > 1/4 and c,
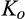
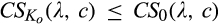
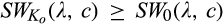
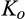
It is not surprising that investment in profiling enables the firm to capture more consumer surplus than it would otherwise without the investment. However, this investment is not necessarily socially optimal. If the firm chooses to invest in profiling consumers, the firm is able to sell to more consumers in the old market, especially to those with relatively low valuations due to personalized pricing. This is good for efficiency. At the same time, consumers with higher valuations would choose to spend effort to avoid price discrimination from the firm, leading to a loss in efficiency. Consequently, if the size of the old market is small, or the investment required to profile consumers perfectly, that is,
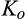
Having described how the equilibrium looks like, and having identified possible inefficiencies, we now ask a natural follow up and central question. What determines the extent to which the investment is socially optimal? Imagine a situation where prices to consumers are always set by the firm, but the investment level could be set by a social planner that maximizes total welfare instead of just the firm’s profit. How does the investment level compare to that chosen by the firm? It turns out that whether the firm’s investment is socially optimal depends critically on λ and c. As shown in Lemma 4 below, if the required investment to perfectly profile consumers
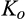
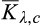
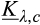
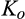
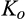
(O when when when where
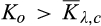
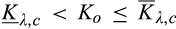
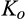
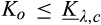
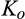
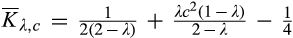
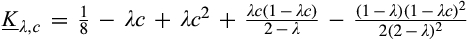

As shown in Lemma 4, the interval where the firm’s investment is inefficient becomes larger for a relatively larger old market. That is, when the size of the old market is large, the option of knowing consumers’ valuations perfectly becomes more attractive for the firm because the firm is able to price discriminate a larger fraction of the market. Consequently, the chance of excessive investment becomes higher, especially when the investment required is high.
Lemma 4 also shows that the interval

Impact of Data Requirements
The final step in this section concerns the properties of the sampling technology that is used to profile consumers. We study how the firm’s investment decision and profit will be affected by the different scenarios with respect to data requirement. There are situations when only “small data” are enough to generate statistically relevant information about consumers, as opposed to truly “big data” instances whereby databases should include abundant information from many consumers. A way to think about a small‐data case is one where there is a relatively simple and general statistical relationship in the population of consumers based on a few observables (think of gender and age, for instance). A few hundreds observations may suffice for the firm to unravel the relationship and understand its consumers with a very good degree of precision. Conversely, a situation about big data is one where there could be thousands of profiles, and the data requirements are orders of magnitude larger. 10
The definition below sets the stage for our discussion. In particular, we say one scenario
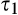
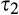
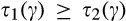
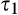
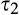
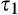
(H
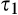
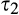
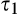
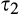
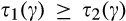
The implications of higher data requirement on the firm’s profit, consumer surplus and social welfare are summarized in the proposition below. Given the same fraction of consumers who choose to reveal their identities, the amount of investment required is lower with lower data requirement: hence the firm is more likely to invest in consumer profiling, and the firm’s profit is always higher under a scenario with lower data requirement. On the other hand, because the firm’s investment always leads to lower consumer surplus as shown in Corollary 1, consumer surplus is thus lower when the data requirement is lower.
(I the firm is more likely to invest in profiling under consumer surplus is (weakly) lower under with small c, the firm’s investment decision is socially optimal under both scenarios; with large c, the firm’s investment decision is more likely to be efficient under
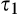
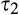
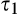
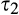
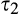
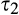
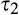
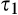
The impact of data requirement on social welfare is the most involved and deserves further comment. Recall that the firm’s profit when investing in consumer profiling is always increasing in c. Consequently, with small c , the firm does not invest under either a high‐data‐requirement scenario or a low‐data‐requirement scenario, and the firm’s decision is efficient under both scenarios. With large c, the firm invests under both scenarios, and its investment decision is more likely to be socially optimal under a scenario with lower data requirement due to the lower amount of investment required. With moderate c, the firm will invest when the data requirement is low, but does not invest otherwise. In this case, the decision of no investment under high data requirement is guaranteed to be efficient, while the decision of investment may be excessive if the condition shown in Lemma 4(ii) is satisfied.
Proposition 2(iii) has important policy implications. In the case when a policymaker introduces very strict privacy laws, any of the firm’s investment is rendered unprofitable, and the firm’s decision of not profiling in this case is socially optimal, regardless of data requirement. Arguably, this is an extreme case in the sense that it is as if profiling is being banned completely. Some policymakers are indeed adopting this view regarding privacy. An example is the recent ban on the use of facial recognition technology by police and other agencies in San Francisco (Conger et al. 2019). This ban essentially reduces c to 0, and thus all individuals can remain anonymous costlessly. Having said that, in many cases, it is not realistic that a policymaker can affect the entire range of values of c. Often only piecemeal policy changes are implementable, and thus the policy maker could only affect privacy costs incrementally. Proposition 2(iii) shows that the optimal policy crucially hinges on data requirements of the particular business/application. For applications with high data requirements, the firm’s action is more likely aligned with that of the central planner under strict privacy laws. On the other hand, policymakers can get away with little or no privacy regulations for applications with a relatively low data requirement.
Extensions
Heterogeneous Concealing Costs
In the base model, we assume that all consumers in the old market incur an identical cost if they choose to conceal their identities. Arguably, this assumption is restrictive. For instance, consumers may differ in their capabilities of removing their traces online. Some tech‐savvy consumers might find it easier to delete cookies implanted on their PCs or use proxy software to mask their IP addresses. This cohort of consumers effectively face a lower concealing cost than others. In this section, we extend our base model by accounting for consumers’ heterogeneous concealing costs.
The setup of the model is the same as the base model, with the only exception that there are now two segments of consumers in the old market. In particular,
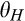
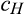
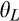
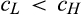
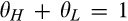
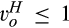
(H
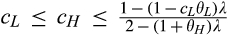
We first study consumers’ optimal responses and the firm’s pricing strategy, given any investment level K. Results are summarized in the lemma below. Proofs of results in this section are available in Online Appendix.
(C (P for any consumer with concealing cost the price the firm charges to the anonymous market is the firm receives a perfect signal for any consumer in the old market who chooses to reveal her identity, and charges an individual price equal to the signal. (N for any consumer with concealing cost the price the firm charges to the anonymous market is signals from those who choose to reveal are non‐informative, and thus the firm offers one price to those who choose to reveal, which is given by (N all consumers with high concealing cost would reveal their identities, that is, a consumer with low concealing cost would conceal her identity if and only if the price the firm charges to the anonymous market is signals from those who choose to reveal are non‐informative, and thus the firm offers one price to those who choose to reveal, which is given by If K < τ(1), all consumers in the old market would choose to conceal their identities. Signals are non‐informative, and the firm would offer the optimal monopoly price 1/2 to both the new market and the old market.
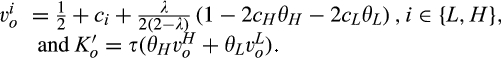
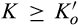
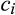
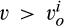
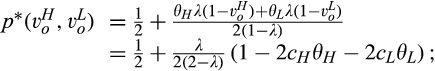
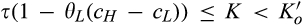
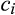
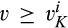
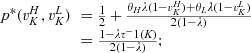
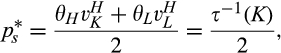
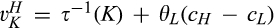
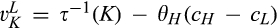
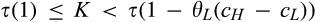
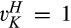
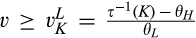
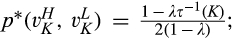
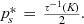
Comparing Lemma 5 against consumers’ optimal responses in the base model, as characterized in Lemma 1, we notice that consumers’ optimal responses are similar in structure under the two cases. When the firm’s investment is greater than
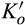
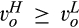
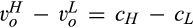
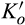
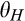
When
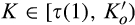
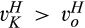
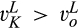
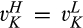

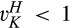
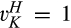
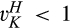

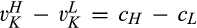
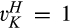
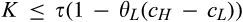
Lastly, there is also a trivial case when K < τ(1). This case is exactly the same as that of the base model, where all consumers in the old market would reveal their identities, and the firm offers the optimal monopoly price 1/2 to both the new market and the old market.
(F
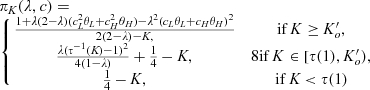
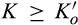
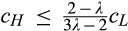
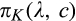
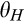
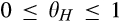
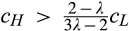
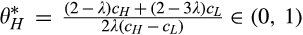
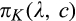
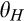
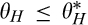
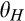
Proposition 3 summarizes the firm’s optimal expected profit given any investment level K. When
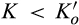
When
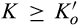
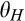
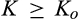
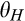
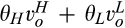
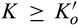
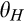
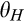
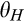
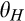
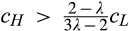
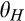
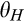
In many cases, the firm itself is able to directly control the cost of maintaining anonymity. For instance, online retailers can determine how easy it is for consumers to delete cookies planted on their computers, or offer to delete consumer data periodically as suggested in GDPR. Proposition 3 shows that the firm may sometimes be better‐off if it allows more customers to remain anonymous more easily. This is great news for firms, especially those operating under the conditions specified in the preceding paragraph. By allowing consumers to control their privacy more easily, the firm not only establishes a good corporate image by showing that it really cares about consumer privacy, but also earns a higher profit at the same time.
Unobservable Investment from the Firm
In the base model, the firm’s investment is assumed to be observable to consumers, and, in turn, consumers decide whether or not to conceal their identities in response. This assumption is reasonable in many situations. For instance, as in the examples discussed in section 1, firms’ investments in data analytics are commonly reported by press and media, which are thus made available to consumers. These investment decisions are costly and cannot be adjusted easily. Having said that, as nowadays consumers become more wary with respect to how their information is being collected and used, firms do have an incentive to hide their profiling investment, with the hope that more consumers would reveal their identities. Thus, in this section, we consider a model where the firm’s investment is unobservable to consumers.
In this case, it would be as if the firm and consumers make decisions simultaneously. For any level of firm’s investment K, the best response from consumers is still characterized by Lemma 1. On the other hand, we can characterize the optimal simultaneous choice of investment from the firm as follows. Proofs of results in this section are available in Online Appendix.
(F If If where
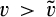
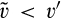
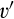
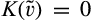
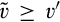
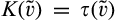
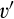
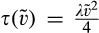
Lemma 6 shows that, anticipating that
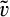
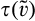
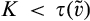
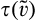
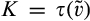
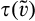
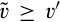
We can derive the equilibrium by studying the best response curves from consumers and the firm, as characterized in Lemma 1 and Lemma 6, respectively. The result is summarized below.
(E When When When
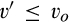
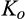
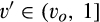
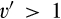
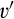
In particular,
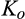
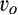
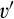
Comparing Proposition 4 against the equilibrium when the firm’s investment is observable, which is characterized by Lemma 1 and Lemma 3, the two cases yield identical outcome when
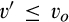
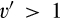
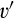
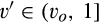
General
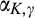
We managed to get several interesting insights analytically in section 4. In this section, we adopt a more flexible logistic specification for
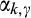
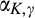
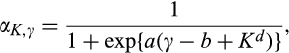
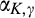
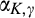
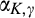
The equilibrium analysis under the general
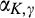
Figure 2 illustrates the impact of b and d on the optimal investment level K, firm’s optimal profit
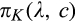
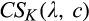
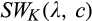
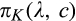
Impact of b and d on Optimal Investment Level K, Firm’s Optimal Profit
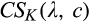
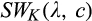
Though K is not monotone in either b or d, Figure 2b suggests that the firm’s profit
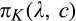
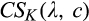
Conclusion
In this paper, we study data profiling in the context of price discrimination. Our main contribution to the literature is the novel focus on two endogenous and related decisions: the firm invests in the precision of the information it gets from consumers, while consumers can take costly actions to protect their privacy. We show that the optimal privacy policies and regulations closely relate to the flexibility of consumers to conceal their identities as well as to data requirements.
A policymaker who promotes total welfare should either make data protection very easy or very costly. Consumers from the old targeted market benefit from stricter data protections, because otherwise they are negatively affected from price discrimination. However, the anonymous market can benefit from little or no data protections, because the firm would charge them a lower price when it becomes more difficult for consumers in the old targeted market to conceal. The optimal policy crucially hinges on data requirement of the business/application. When it is easy for consumers to protect their data, private and social incentives are aligned when data analytics involve a large data requirement. On the other hand, when it is very costly for consumers to conceal their information, a small data requirement induces an investment on the firm’s side that is very close to that would be chosen by a social planner.
We consider a monopoly model in this study. This is a reasonable assumption in many situations with dominant platforms that collect recurring information about their customers, who either do not have other alternatives or face substantial switching costs. Consider Facebook in the online social networking industry, Amazon prime in the retail sector, or Google Adsense in online advertising. They are all close to a monopoly in their respective industries. However, in industries where dominance is not yet established, competition for consumers may potentially alter our analysis considerably. For instance, consumers with higher valuations may be better off revealing their identities to induce head‐to‐head competition and get better prices. We leave the study of consumer profiling under competition for future research.
Footnotes
Proofs.
Acknowledgments
The authors thank the department editor, the senior editor, and two anonymous referees for their guidance and thoughtful comments throughout the review process. The authors also thank Steven Shugan, Miguel Villas‐Boas, Yiangos Pananastasiou, and conference participants at the POMS Annual Conference 2016, Summer Institute in Competitive Strategy 2016, and INFORMS Annual Meeting 2016 for their helpful suggestions on this paper.
1
2
3
Precision can also be obtained by buying another company that holds meaningful data, think of Facebook’s acquisition of Instagram and WhatsApp that are planned to be integrated into a single platform.
4
5
6
The literature on consumer addressability is also closely related (Chen et al. 2001, Chen and Iyer ![]() ).
).
7
Alternatively, we can assume that a consumer always chooses to conceal her identity when she is indifferent between revealing or concealing. This would not change our results qualitatively; however, the firm’s and consumers’ decisions at boundary cases will differ slightly. For instance, in Lemma ![]() , the firm needs to invest more than
, the firm needs to invest more than
8
9
10
According to the Federal Trade Commission, one data broker’s database has information on 1.4 billion consumer transactions and over 700 billion aggregated data elements (Federal Trade Commission ![]() ). Although related to a different setting, a “big data” problem is also the Netflix prize. In 2009, Netflix awarded a $1m prize for the best filtering algorithm to predict user ratings for films. A data set of 100,480,507 ratings that 480,189 users gave to 17,770 movies was provided by Netflix. See
). Although related to a different setting, a “big data” problem is also the Netflix prize. In 2009, Netflix awarded a $1m prize for the best filtering algorithm to predict user ratings for films. A data set of 100,480,507 ratings that 480,189 users gave to 17,770 movies was provided by Netflix. See