
Abstract
We study a risk‐averse newsvendor problem where demand distribution is unknown. The focal product is new, and only the historical demand information of related products is available. The newsvendor aims to maximize its expected profit subject to a profit risk constraint. We develop a model with a value‐at‐risk constraint and propose a data‐driven approximation to the theoretical risk‐averse newsvendor model. Specifically, we use machine learning methods to weight the similarity between the new product and the previous ones based on covariates. The sample‐dependent weights are then embedded to approximate the expected profit and the profit risk constraint. We show that the data‐driven risk‐averse newsvendor solution entails a closed‐form quantile structure and can be efficiently computed. Finally, we prove that this data‐driven solution is asymptotically optimal. Experiments based on real data and synthetic data demonstrate the effectiveness of our approach. We observe that under data‐driven decision‐making, the average realized profit may benefit from a stronger risk aversion, contrary to that in the theoretical risk‐averse newsvendor model. In fact, even a risk‐neutral newsvendor can benefit from incorporating a risk constraint under data‐driven decision‐making. This situation is due to the value‐at‐risk constraint that effectively plays a regularizing role (via reducing the variance of order quantities) in mitigating issues of data‐driven decision‐making, such as sampling error and model misspecification. However, the above‐mentioned effects diminish with the increase in the size of the training data set, as the asymptotic optimality result implies.
Introduction
Demand forecasting for new products can be very difficult. Christensen (2011) illustrates that 30,000 new consumer products are launched each year, with each product intended to be a success, but 95% of them fail. Even sophisticated firms can make mistakes when launching new products. For instance, Microsoft wrote off $900 million for its overstocked Surface RT (about 6 million units) back in 2013 due to its inaccurate demand forecasting for the then newly launched tablet (Anthony 2013). Unlike existing products, whose historical sales may be indicative of future demand, a new product does not have such data to learn from. Instead, a firm may have to glean clues from previous products that share similar features. For example, in the case of fashion clothing, when forecasting the demand for new products, a firm may look at the sales and feature information of previous products, including sales, price, color, item type (e.g., shirt or pant), fabric, design style (e.g., casual or sporty), store type, and season. With such covariates and demand information of other products, the firm may generate a demand forecast for the new product, which will be used to guide its procurement and other decisions.
Given the inherent uncertainty of demand and the limited ability associated with its prediction, inventory management of new products is challenging and risky. This is particularly the case for products with a short life cycle and a long lead time. A firm may need to prepare its inventory a long period before the product launch and have no inventory adjustment opportunity afterward. Accordingly, the firm acts like a newsvendor. The widely adopted criterion for data‐driven newsvendor decision‐making is to maximize the expected profit. However, an essential responsibility of supply chain managers is to strike a balance between profitability and financial risks (Kouvelis and Li 2019). Managers often have profit risk concerns because their compensation may be attached to the realized profit levels (Culp et al. 1998, Yan et al. 2019). Many public firms manage their projects to hit and beat analysts’ earning expectations with a high probability to avoid harming their stock price (Chen et al. 2015, Graham et al. 2005). Furthermore, under data‐driven decision‐making, the firm is subject to the risk of wrong data models. In case historical data are limited, the typical problems of sampling error and model misspecification can amplify the magnitude of wrong ordering decisions. For these reasons, and given the potential substantial losses resulting from wrong decisions, the firm often wants to restrict the downside risk of its inventory decisions.
In this work, we study a risk‐averse newsvendor model where demand distribution is unknown. We model the profit risk concern of the firm with a chance constraint and develop a data‐driven approach to solve this problem efficiently and effectively. In the rest of the Introduction, we provide an overview of our model and the data‐driven approach, summarize our major contributions, and review the relevant literature.
Model and Approach Overview
The firm aims to maximize its expected profit while satisfying a value‐at‐risk (VaR) constraint by choosing the order quantity. The VaR constraint is a chance constraint (Kouvelis and Li 2019) that requires meeting a pre‐set profit target at a confidence level. Specifically, for a new product with covariate information
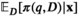
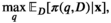
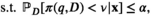
Notably, the distribution of demand D is unknown, and the model above cannot be directly solved. Given that similar or related products often have similar or correlated possibilities of success or failure, we use covariate information to link the new product with similar ones that have been sold historically. Based on historical data, a local machine learning (ML) method (e.g., k‐nearest neighbors (kNN) and random forest (RF)) is employed to construct the weights that measure the similarities between the new product and the historical ones. We construct an approximation to the previous theoretical model with such sample‐dependent weights. We have
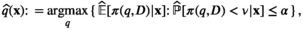
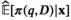
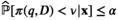
The major contributions of the study can be summarized as follows.
Model and tractability. We show that the data‐driven approximation model can be written as a mixed‐integer program, which can be further transformed into a linear program by using the quantile structure of the problem. Thus, the model can be efficiently solved.
Consistency. We prove that the solution to the data‐driven approximation, which features a sample‐dependent VaR constraint, is asymptotically optimal.
Insights from the experiments. Under data‐driven decision‐making, a stronger aversion to risk does not necessarily sacrifice the average profit. In fact, for a given training data set, there appears to be an optimal risk aversion level that can maximize the average profit. This notion means that even a risk‐neutral newsvendor can benefit from incorporating a risk constraint under data‐driven decision‐making. This is largely due to the regularizing role that the constraint plays in mitigating the adverse effects of sampling error and model misspecification. Nevertheless, the above‐mentioned effects diminish with the increase in sample size because our approach guarantees asymptotic optimality. Numerical extensions and associated discussions, including alternative regularization‐based approaches, alternative risk measures, and the pricing‐setting newsvendor, further confirm the aforementioned key insights.
Related Literature
In this part, we review some of the most relevant research streams in the literature, including risk‐averse newsvendor problems with known demand distributions, data‐driven inventory management, interface between ML and OR, and new product forecasting.
Risk‐averse newsvendors. Risk‐averse newsvendor models, as variants of the classical newsvendor problem, have received extensive attention in the literature. These models reflect the fact that decision‐makers often have a strong distaste toward profit losses or missing profit targets. Assuming a given demand distribution or a known set of its parameters, many different models have been proposed (Agrawal and Seshadri 2000, Katariya et al. 2014, Kazaz and Webster 2015), such as mean‐variance (Choi et al. 2008), mean‐conditional value at risk (mean‐CVaR) (Chen et al. 2009), and mean‐VaR (Kouvelis and Li 2019). Kouvelis and Li (2019) investigate a newsvendor model with and without financial hedging under a VaR constraint, assuming demand to correlate with the price of some tradable financial asset. One of the several significant findings is that the firm does not need to rely on inventory decisions to meet the VaR constraint and does not have to sacrifice mean profit for risk control when financial hedging is available. In this work, we adopt a mean‐VaR model without financial hedging. However, we do not assume the demand distribution to be known as in Kouvelis and Li (2019). Interestingly, we show that risk concerns may not have to trade‐off with mean profit under our data‐driven setting, even in the absence of financial hedging.
Data‐driven inventory management. As data become widely available, data‐driven operational decision‐making (Mišić and Perakis 2020), especially data‐driven inventory management, has received growing research interest (Feng and Shanthikumar 2018, Qi et al. 2020). We mainly focus our review on data‐driven newsvendor models. This research can be broadly classified into two groups, namely, models with and without covariate information.
Models without covariate information. This is essentially the case where data in the form of n independent historical observations of D are available (i.e.,
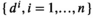
Models with covariate information. With regard to newsvendor problems with covariate information, observable features (e.g., seasonality and brands of products) help predict the future demand and prescribe order quantities. The data are available in the form of
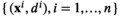
Several studies have integrated ML with newsvendor's ordering decisions. Meller and Taigel (2019) integrate the newsvendor logic into the learning algorithm of the decision tree. Bertsimas et al. (2016) consider a multi‐item inventory problem with the objective of maximizing sell‐through subject to limited shelf space. They report a case study applying the techniques developed in Bertsimas and Kallus (2020) (to be reviewed below). Based on the hypothesis of a linear (parametric) decision rule, Ban and Rudin (2019) first consider ERM‐based models with and without regularization for the newsvendor problem. They then consider a nonparametric approximation model motivated by kernel regression (KR). Within this stream of research, Ban and Rudin (2019) is the most relevant to the current work: we also employ nonparametric local averaging methods (including KR weights) for approximation. However, we study a different problem, in which as to be articulated below, the presence of a VaR constraint has imposed particular challenges in establishing asymptotic optimality. Moreover, we will derive new managerial insights.
Interface between ML and OR. We review some recent data‐driven studies that develop methodological advances linking ML with operations research (OR). Some studies have integrated ML with OR via embedding decision structure into the objective of learning a predictive model. Elmachtoub and Grigas (2021) develop a smart predict‐then‐optimize framework for linear optimization problems in which an ML model is trained to minimize the decision cost. El Balghiti et al. (2021) derive generalization bounds for the smart predict‐then‐optimize loss function. Some studies have also integrated ML with optimization via a nonparametric framework, that is, the weighted sample average framework (Bertsimas and Kallus 2020, Bertsimas and McCord 2018), which can use different local ML methods (e.g., kNN, RF, and KR) to assign weights to the historical data based on covariates and establish that the resulting approximations are statistically consistent.
The above‐mentioned data‐driven framework has been extended to more general settings (Bertsimas and McCord 2019, Bertsimas and Van Parys 2017, Bertsimas et al. 2019, Ho and Hanasusanto 2019). In particular, attention has been given to addressing certain issues, such as overfitting. Ho and Hanasusanto (2019) propose a kernel‐based approach with regularization, which is constructed based on sample variance. In section EC.5.1, we discuss the application of such an approach to our problem and show that the variance term constructed introduces computational challenges.
In terms of asymptotic optimality analysis, the current work is mostly related to Bertsimas and Kallus (2020) and Bertsimas and McCord (2019). They focus on general unconstrained decision‐making models. Some intermediate steps of our asymptotic analysis are established based on their results. The most salient difference in this study is the presence of a data‐driven VaR constraint in our model. With a sample‐dependent constraint as in our model, the feasible region of the related data‐driven optimization problem will change due to the adaptively changing similarity weights with the increase in the sample size. Hence, extending their asymptotic optimality analysis to the current context is not trivial. Certain new results are required to bridge the gap, as shown in the sequel.
New product forecasting. Given its critical importance, many studies have examined demand forecastings, such as Urban et al. (1996), Fader et al. (2004), Ching‐Chin et al. (2010), Chung et al. (2012), and Hu et al. (2018). Baardman et al. (2018) leverage comparables for new product sales forecasting and develop a scalable algorithm that generates a forecasting model with good analytical guarantees on the prediction error. For our purpose, we require more than a point forecast under our nonparametric decision‐making framework. In particular, some studies have integrated forecasting with procurement decisions (Ban et al. 2019, Kurawarwala and Matsuo 1996). We use nonparametric local averaging approaches to approximate the expected quantities associated with demand based on the covariates and historical sales data of similar products.
In summary, this study is closely related to the latest development in data‐driven operational decision‐making, especially to studies that focus on newsvendor models and those that integrate ML and OR. We study a risk‐averse newsvendor where the data‐driven risk constraint introduces some technical challenges. With regard to the problem examined in this work, the aspect of data‐driven decision‐making brings insights that are distinct from those of its theoretical counterpart.
The rest of the paper is organized as follows. Section 2 presents our risk‐averse model, followed by a data‐driven approximation and structural analysis. Section 3 presents the main theoretical results. Section 4 presents experimental studies with some important managerial insights and extensions. Section 5 concludes the paper.
Data‐Driven Risk‐Averse Newsvendor Model and Solution
Model and Approximation
We now elaborate model (1)–(2). Let p,
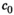
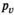
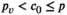
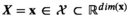
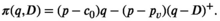
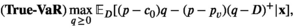
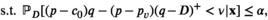
The conditional distribution of D on
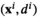
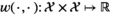
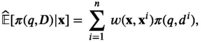
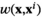
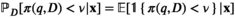
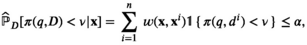
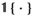
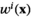
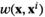
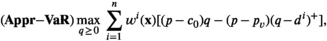
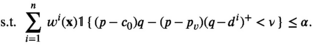
Model
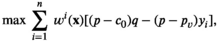
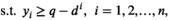
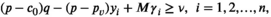
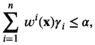
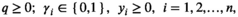
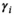
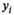
Our approximated model
The kNN weight functions are given by
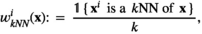
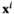
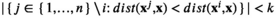
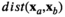
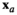
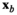
Conceptually, kNN will find out the kNN that are closest (i.e., most similar) to the given new product.
The KR weight functions are given by
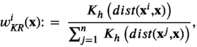
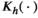
KR is weighted average estimators that use kernel functions as weights. Examples of kernel functions include the Gaussian and triangular kernels.
The CART weight functions are given by
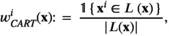
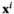
In a tree structure, a leaf is a collection of products that are labeled as the same group, and branches represent conjunctions of covariates (i.e., features) that lead to those labels. CART partitions the input feature space by recursively looking for a feature and a split value leading to a new branch of a tree.
The RF weight functions are given by
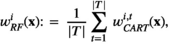
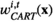
RF constructs a multitude of decision trees. The “forest” it builds, is an ensemble of trees. RF, as a local averaging approach, takes an average of the weights in different decision trees.
The aforementioned four weight functions are general ML methods used as nonparametric techniques to estimate the conditional expectation of a random variable. (An overview of local averaging approaches can be found in Györfi et al. 2006 and associated ML approaches in Friedman et al. 2001.) They are very flexible because they can learn the complex relationship between covariates and the response variable without requiring any explicit parametric form.
The greater the weight value of each historical product, the more similar it is to the focal new product. The historical products with resulting positive weight values are similar products to be used to aid decision‐making for the focal new product. Take kNN as an example: kNN selects k similar products according to some pre‐specified distance measure (e.g., Euclidean distance). As a high‐level interpretation, tree‐based methods (i.e., CART and RF) can be thought of as nearest neighbor methods with an adaptive neighborhood metric where similarity is defined with respect to a decision tree. Similar products are those that fall into “the same” leaves of decision trees for the new product. The weights in Definitions 1–4 are non‐negative, and in some sense, they can be regarded as approximations to the conditional distribution of demand D with covariate
Once the weights in the MIP are obtained, we can solve the optimization problem and derive the optimal quantity via standard solvers (e.g., Gurobi). However, the data‐driven formulation actually has a closed‐form optimal solution with a quantile structure and can thus be efficiently solved without necessarily solving the MIP, as shown below.
Structure of the Optimal Solution
The main difficulty in solving the MIP is due to the n integer decision variables (
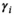
Let
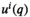
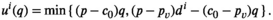
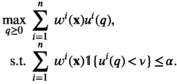
For a sample point i to attain the profit target
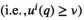
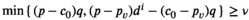
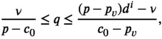
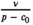
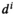
Solving the model
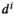
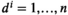
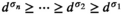
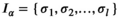
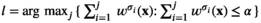
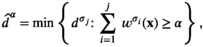
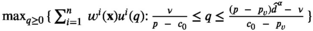
Notably, compared with the data‐driven risk‐neutral newsvendor problem, the VaR constraint only introduces a new interval constraint for q, that is,
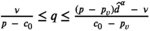
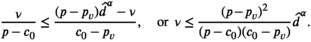
Let
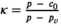
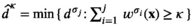
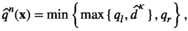
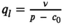
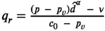
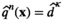
Proposition 1 brings us an important insight: as the solution of
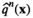
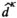
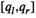
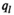
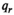
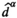
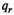
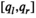
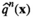
Asymptotic Optimality
There are two approximations from model
Preliminaries
We use R(q) and
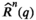
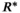
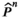
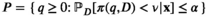
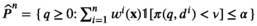
We say the approximated profit of the true profit of
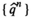
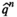
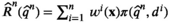
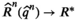
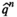
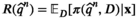
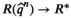
We introduce the following technical assumptions to ensure the asymptotic results:
Model Existence
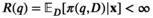
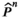
No atom
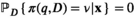
For any given Slater condition
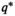
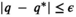
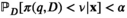
Assumption 1 always holds in practical settings.
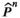
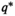
A common assumption for all oracles is that the observations
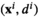
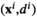
Suppose r( Consistency result of kNN
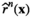
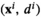
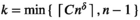
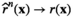
Asymptotic Results
To prove the asymptotic results of the resulting solution and objective value, we first establish uniform convergence over the decision for the function of the VaR constraint and the objective. All the proofs can be found in section EC.3.
A remark is in order. Bertsimas and McCord (2019) and Bertsimas and Kallus (2020) also integrate ML approaches with decision‐making problems and show the asymptotic optimality of resulting data‐driven solutions. However, they focus on general unconstrained decision‐making problems. Their consistency results can only be utilized here in intermediate steps of our asymptotic analysis because the data‐driven VaR constraint in our newsvendor setting entails new challenges. Similarity weights will adaptively change with the increase in sample size. Naturally, the sample‐dependent feasible region admitted by the sample‐based VaR constraint will vary as well. Our new theoretical results can be found in Lemma 2, Theorem 1, Proposition 2, and Theorem 3.
Suppose that function
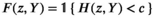
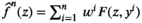
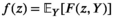
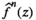
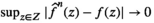
Note that
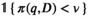
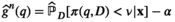
For any given
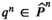
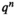
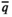
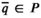
In addition to Theorem 1, we also need Assumption 3 to ensure the existence of a sequence
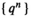
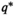
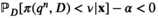
For any given
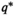
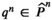
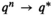
For any given
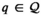
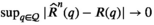
Theorem 2 is established on the basis of any fixed compact set of q (i.e., Q). It stipulates that the objective value without a risk constraint uniformly converges. Thus, this theorem does not involve the issue of infeasibility. A similar result also appears in Bertsimas and Kallus (2020), where there is no risk constraint.
Suppose that the conditions of strongly (weakly, resp.) universal consistency for the local averaging oracles hold. We have
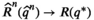
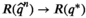
The asymptotic optimality does not require the local averaging oracles used for computing the objective function and the VaR function to be the same. Therefore, we can opt to different local averaging approaches for these functions; for example, RF for the objective function and kNN for the VaR constraint, which still ensures the asymptotic optimality. (A tractable formulation can be found in section EC.1 for such a case.)
Experiments
We now conduct experimental analysis on the performance of our data‐driven approach. We are particularly interested in the properties and managerial insights pertinent to data‐driven decision‐making.
Data and Solution Methods
We conduct our experiments on two data sets. The first data set is obtained from an online retailer based in Hong Kong that specializes in entertainment digital products, such as games for XBox, Playstation, and other Asian (particularly Japanese and Korean) games in the form of memory cards or online downloads. The retailer's products follow the 80/20 rule, that is, 20% of the products account for 80% of the retailer's revenue. Those products with high potential revenue are supplied by major suppliers such as Sony and Microsoft, which do not accept orders during the 2 weeks before and after the product launch date. The demand during the first 2 weeks typically accounts for about 60% of the life cycle demand of these short‐lived products. The business after the first 2 weeks of the product launch can be easily gauged based on the first 2 weeks’ sales. Therefore, the major challenge for the retailer is to manage the first 2 weeks after the product launch by placing a proper order 2 weeks before the product launch, which can be framed as a newsvendor problem. The wholesale price and initial retail price are dictated by the suppliers, and the gross margins are rather moderate.
The retailer has to rely on the historical information of related products to predict a new products demand. Such information includes the demand and features of products with similar features, and in some cases, the demand for the previous edition of these products. We obtain observations of 1429 products, with each observation having the following information: demand (the demand was not censored because customers ordered online), game type, release date, platform, price, and ratings. The detailed description is given in section EC.4.1 (see Table EC.1). The products are randomly split into two subsets: training set (n = 1143, 80%) and test set (m = 286, 20%). The training set is used for model learning, and the test set is used to evaluate model performance. In our study, we validate the final models through a fivefold cross validation (see the detailed description in section EC.4.2).
The second data set is synthetic, which is generated from a known distribution. The underlying demand model and parameter setting can be found in section EC.4.1. This data set will be used for more controllable analysis.
Solution Methods
Four alternative local ML methods (i.e., Definitions 1–4) are used to construct the weight functions and are embedded into our data‐driven model. We use kNN‐VaR, KR‐VaR, CART‐VaR, and RF‐VaR to refer to our approximated risk‐averse model with corresponding weight functions.
We compare our methods with four benchmarks. The first benchmark method is SAA, which does not incorporate covariate information. The other three methods incorporate covariate information. We first use a predictive model to estimate the demand distribution and then use estimated distribution for computing the optimal order quantity. Three predictive models are tested: linear regression (LR), log‐linear regression (LLR), and RF. We refer to the last benchmark as separate RF with optimization (SRF) to differentiate from our nonparametric model RF‐VaR. We also consider the VaR constraint for them. The resulting benchmarks are then denoted as SAA‐VaR, LR‐VaR, LLR‐VaR, and SRF‐VaR. A detailed description of their solution methods together with corresponding formulations can be found in section EC.1.
Performance Comparison
To evaluate the performance of these approaches, we use the average realized profit (ARP) as a performance measure, which takes the average out‐of‐sample profit of all the products from the test data set. Table 1 reports the results of different methods. The first column presents different values of risk‐aversion parameters (ν, α). The row with α = 1 is the risk‐neutral case. First, our four methods outperform all benchmarks in terms of ARP. For each pair (ν, α), the (overall) best result is highlighted in boldface. The SAA‐VaR method suffers from ignoring covariate information. The other three benchmark methods are parametric and may suffer from model misspecification. LLR‐VaR uses LLR for demand prediction and fits the data better than the other two; thus, it is the best among the three benchmarks that consider covariate information. By contrast, our methods are nonparametric and use covariate information. Note that RF‐VaR is an aggregation scheme that helps reduce variances and smoothen sharp decision boundaries, thereby yielding highly robust and stable results. Indeed, among our four models, RF‐VaR demonstrates an overall superior performance. When the firm is more risk‐averse (with a smaller α), kNN‐VaR tends to outperform others because kNN‐VaR often selects the most representative and similar products for decision‐making. Based on these results, we can conclude that covariate information helps make better decisions and that our models are more robust against model misspecification.
Comparison of Average Realized Profit on Real Data
*Note: As an example to show the percentage improvement over the risk‐neutral case.
For each pair (ν, α), the (overall) best result is highlighted in boldface.
Striking observation. We observe that incorporating a VaR constraint often increases the average realized profit compared with the risk‐neutral cases (shown in the row (ν, α) = (0, 1.0)); specifically, all the nonparametric methods and benchmarks improve the average profit under a majority of combinations of the values of risk‐aversion parameters (ν, α). Moreover, the improvement in profitability is rather significant for certain combinations. Take the row (0, 0.2) (i.e., ν = 0 and α = 0.2) in Table 1, for example, the VaR constraint can help the firm earn much more (or lose much less) profit: the improvement ranges from 79% to 953%, over the risk‐neutral case. Figure 1 exhibits the results for the four different local averaging methods, where the horizontal axis is 1 − α. For a theoretical risk‐averse newsvendor (who faces a known demand distribution), risk aversion will compromise the expected profit (Chen et al. 2009, Kouvelis and Li 2019), that is, the profit is non‐increasing in 1 − α: a larger value of 1 − α means a stronger risk aversion. However, for our data‐driven risk‐averse newsvendor, Figure 1 shows that the average realized profit peaks between 0.5 and 0.9 of (1 − α) (i.e., at some intermediate risk‐aversion levels).
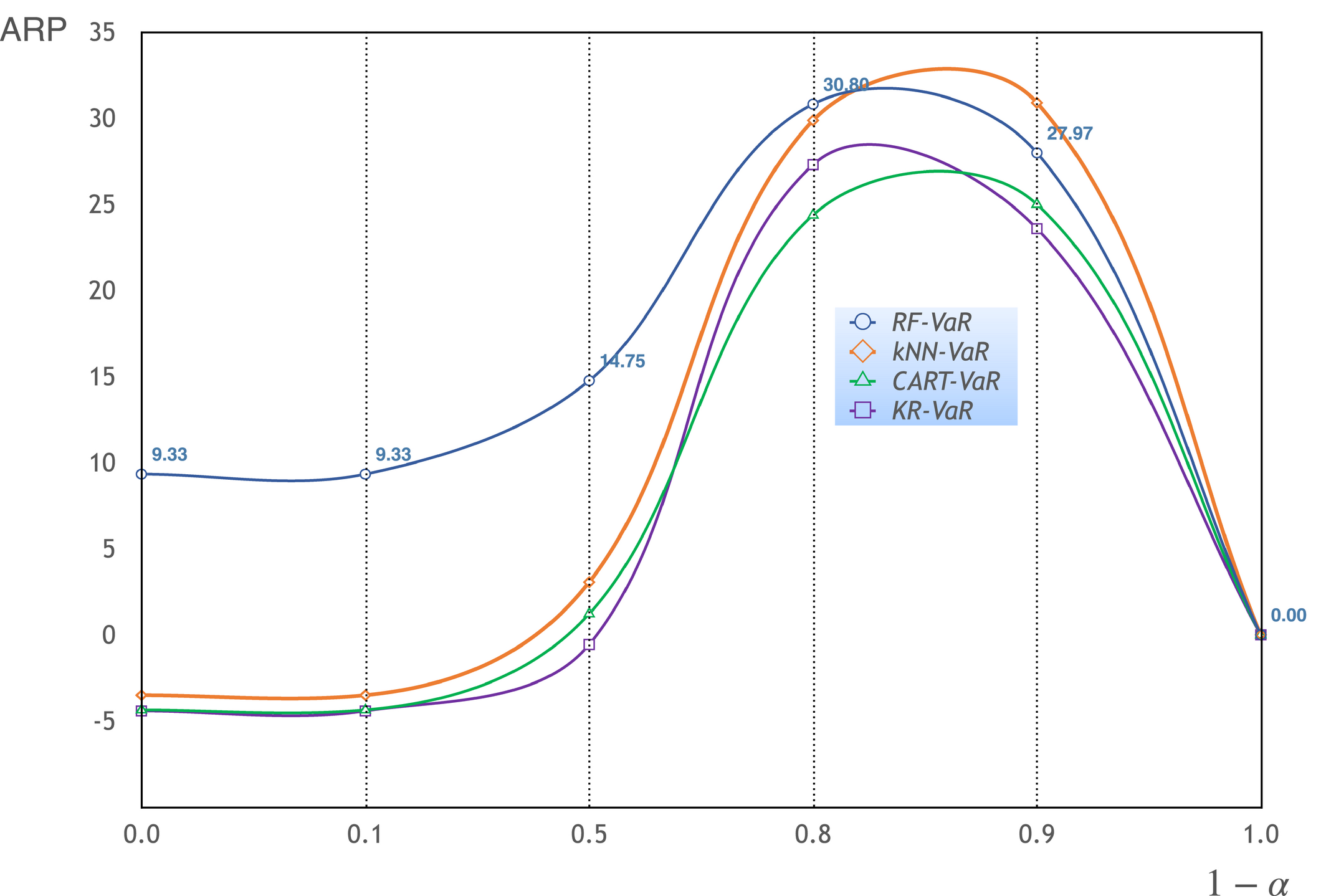
Average Realized Profit in Risk Aversion (real data, ν = 0) [Color figure can be viewed at
Comparison between Data‐Driven and Full‐Information
Is the above striking observation from the data‐driven approach robust? That is, does it exist with other data? How will the data‐driven approach perform as the sample size varies? To answer these questions, we run experiments with synthetic data, which can be generated from known demand distributions. The underlying demand models can be found in section EC.4.1, which allow us to compute the optimal order quantities and profits under full information (i.e., when demand distributions are known) and see if the striking observation repeats under the synthetic data. Figure 2 reports the average realized profits against different levels of risk aversion (i.e., 1 − α) and sample sizes (i.e., n). The top curve in Figure 2 corresponds to the case under full information, where α = 1 (i.e., 1 − α = 0) corresponds to the risk‐neutral case.
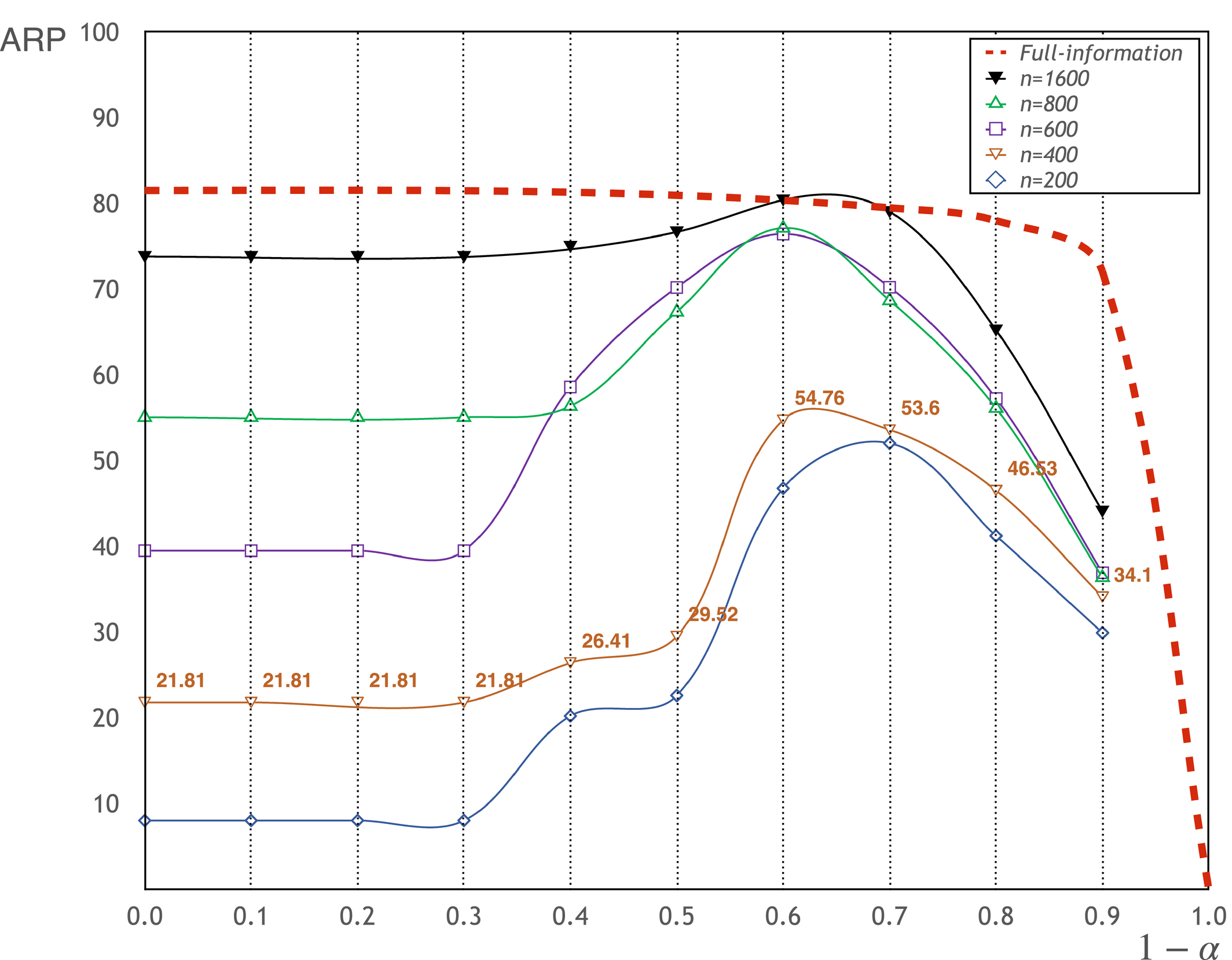
Average Realized Profit in Different Sample Sizes n and α (synthetic data, RF‐VaR, v = 0) [Color figure can be viewed at
We have the following observations: As expected, the full‐information result is consistent with the theoretical result: there is a trade‐off between average profit and risk aversion for a risk‐averse newsvendor. When the sample size is limited, the data‐driven risk‐neutral newsvendor earns far less profit than the one with full information; for example, in the case of n = 400 and 1 − α = 0, the gap can be as large as 272% (i.e., 21.81 vs. 81.11). However, the gap is reduced to 48% (i.e., 54.76 vs. 81.11) with a VaR constraint at 1 − α = 0.6. The risk‐neutral solutions performance further improves with the increase in sample size (see 1 − α = 0) and the benefit arising from the VaR constraint becomes smaller, as readily visualizable by comparing the three cases of n = 600, 800, and 1600. Another observation is also worth noting: at 1 − α = 0.6, even for n = 600 (and 800), the average profit becomes close to the risk‐neutral profit of the full‐information case. However, this is not a general pattern as more examples will reveal in section EC.4.2. We observe that the case of n = 1600 earns the same profit as the full‐information case at 1 − α = 0.6 or 0.7, and the gap with the full‐information case is much smaller than all cases of smaller sample sizes at all other values of (1 − α). This pattern is consistent with the earlier asymptotic analysis.
In summary, the profit gain from the introduction of VaR constraint as observed under the real data (in Figure 1) recurs under the synthetic data. On the one hand, the profit gain moderately diminishes with the increase in sample size. On the other hand, even with a relatively small sample, a properly chosen α value may greatly elevate the profit. For more supplementary results, refer to section EC.4.2.
Risk aversion as regularization. Here, we try to offer an explanation for the above striking observation (i.e., the risk aversion does not necessarily compromise the average profit). When the sample size is not large, data‐driven decision‐making is vulnerable to the issues of sampling error and model misspecification. The “model misspecification” issue under our framework may be due to misspecifying the similarity metric by a local averaging method.
The patterns observed in Figures 1 and 2 can be explained by the interplay between the effects of variance reduction and profit‐constraint trade‐off. On the one hand, as explained when interpreting Proposition 1, (1) the risk‐aversion as expressed by a VaR constraint can regularize order quantities through reducing their variance (in relative to the risk‐neutral case); (2) the optimal order quantity of a more risk‐averse newsvendor (with a larger value of 1 − α) will be chosen within a smaller range of interval 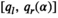
An important managerial insight can readily be drawn from the experiments, based on real and synthetic data: under data‐driven decision‐making, even if the decision‐maker is risk‐neutral, incorporating a VaR constraint can be beneficial, as it could mitigate the sampling and modeling issues inherent in the data‐driven approach. In fact, a consistent pattern is exhibited in Figures 1 and 2: the average profit achieves its maximum at a certain level of risk aversion (i.e., α). In other words, when adopting a data‐driven approach, even a risk‐neutral newsvendor can have a profit gain simply by becoming risk‐averse, that is, choosing a proper level of risk aversion through cross validation.
Alternative Risk Measures and Price‐Setting Newsvendor
As our VaR constraint plays a regularizing role, it is worth discussing and comparing with alternative regularization‐based models (e.g., regularization with variance and robust optimization) and other risk measures (e.g., CVaR and a service level target). The detailed solution methods and numerical results can be found in section EC.5. We summarize our key observations regarding these alternatives below.
First, we tested a sample robust model with covariates by Bertsimas et al. (2019). The numerical results can be found in Table EC.7. In general, the out‐of‐sample performance of our approach is significantly better than that of robust optimization. We also observe that for certain values of robustness parameter, the performance improvement from the robust approach against the risk‐neutral one, if any, is rather minor; whereas the improvement by the introduction of a VaR constraint is much greater. We can roughly conclude that the VaR constraint‐based approach can better control tail risks caused by limited sample size than the robust optimization approach does. Another possible alternative we may consider is the regularization‐based method built upon sample variance by Ho and Hanasusanto (2019). Their method incorporates a conditional variance term constructed based on data of similar products. However, such a formulation is intractable under the newsvendor setting because the conditional variance of the profit function constructed based on sample data involves complex nonlinear terms (section EC.5.1 provides a detailed discussion).
We have also considered alternative risk measurements, such as a service level target and CVaR, of which the numerical results can be found in Table EC.7. Under the service level target (i.e., a fill‐rate constraint), the average out‐of‐sample performance becomes worse, and increasing the service level exacerbates the out‐of‐sample profit. Hence, the newsvendor will not benefit from an arbitrary risk‐based constraint. We also observe that the model with a CVaR constraint can obtain performance nearly as good as our approach. However, a direct benefit of the model based on VaR is its computational efficiency: there exists a closed‐form structural result for the optimal solution that only involves computing two quantiles, whereas solving the model with a CVaR constraint is much more involved.
Price‐setting newsvendor. In the above experiments, we assumed the newsvendor price is fixed. Now we consider a price‐setting newsvendor (denoted by PN‐VaR). We consider a discrete set of price choices to make the data‐driven problem tractable and carry out numerical experiments based on the synthetic data. The detailed design of experiments and the numerical results (Table EC.8 and Figure EC.7) are presented in section EC.5.3. We highlight important insights from the experiments here. First, the price‐setting newsvendor does not necessarily earn more profit, actually can be less, than her counterpart with a fixed price. Second, however, incorporating a VaR constraint with a proper α, the price‐setting newsvendor can outperform the fixed‐price newsvendor. Moreover, for the price‐setting newsvendor, the presence of VaR constraint can lead to a higher profit than the risk‐neutral newsvendor. Finally, the benefit of the VaR constraint is more pronounced for the price‐setting newsvendor than for the fixed‐price newsvendor. The above observations may be explained with the same logic as in the basic model. With more flexibility in decision‐making, the firm may become more “vulnerable” to the issues arising from limited sample size (including sample error and model misspecification), which leads to “worse” decisions, whereas the regularization via a VaR constraint could partially mitigate these issues.
Conclusion
In this work, we study a data‐driven risk‐averse newsvendor problem. The demand distribution of the newsvendor is unknown, and the demand has to be learned from the historical information of other products. We develop nonparametric estimations and propose an approximation to the theoretic risk‐averse newsvendor model by using the covariate information. We show that the data‐driven risk‐averse newsvendor solution exhibits a quantile structure and that the problem can be efficiently solved. Furthermore, we establish the asymptotic optimality of the data‐driven solution.
Experimental results obtained using real and synthetic data confirm the effectiveness of our approach, especially in terms of addressing issues due to the small sample size. Interestingly, incorporating the VaR constraint brings some unintended benefits. The experimental and analytical results show that the VaR constraint reduces the variance of the order quantity and subsequently increases the average profit of the decision. In other words, the VaR constraint, which is initially a business constraint that reflects the firm's risk aversion, effectively plays a regularizing role. This finding has some implications. First, a risk‐averse decision‐maker should choose his/her risk aversion cautiously because it can be the case that the realized profit can be further increased by becoming more risk‐averse. This case differs dramatically from the classical trade‐off between expected profit and risk aversion for risk‐averse newsvendors with full demand information. Under data‐driven decision‐making, incorporating the VaR constraint can help in achieving his/her goal, especially when the sample size is limited, even if the decision‐maker is only interested in profit maximization. Cross validation will help determine the proper level of risk aversion.
In our study, we have obtained an interesting insight that the VaR constraint plays a regularizing role. However, this notion is only partially explained by Proposition 1 and observed from intensive numerical experiments, and we cannot analytically establish the finite‐sample result. On the other hand, this situation also provides an opportunity for future research. Another limitation arises from the fact that some covariates, such as prices, might not be completely randomly chosen; however, we assume that they are random variables. Nevertheless, the key insight remains robust, based on the numerical results from the newsvendor facing a fixed price and the price‐setting newsvendor.
In our future work, we seek to extend the single‐period model to a multi‐period dynamic setting, where the initial ordering decision occurs before the launch of a new product, and the remaining decisions are made periodically after some demand has been observed. To consider data‐driven approaches based on covariate information, we may utilize the risk constraint to tackle the issues arising from the limited sample size as well. Kouvelis and Li (2019) address risk hedging via financial instruments. With historical sales and financial market data, a data‐driven approach to revisit their work would be another interesting direction.
Footnotes
Acknowledgments
Max Shen acknowledges the support from the National Natural Science Foundation of China (NSFC) Grant 71991462. Frank Chen and Yanzhi Li acknowledge the support from Hong Kong Research Grant Council's Project No. CityU 11501820 and Project No. CityU 11503418, respectively. The authors are indebted to the department editor, senior editor, and referees for their valuable and constructive suggestions.