
Abstract
In this article, we describe representative contributions in several major application areas of data analytics in operations management to summarize the recent development, discuss the common themes, identify the current trends, and speculate the future directions. Certainly, many important contributions have been made in various application areas that are either directly or indirectly related to data analytics, and there are important theoretical developments made by scholars in our field. It is not our intention to provide a complete survey for data‐analytics work in our field. Instead, we focus only on the aspect of data integration in operational decision‐making by describing the most popular applications of data analytics.
INTRODUCTION
The research in operations management has focused on efficient decision‐making to achieve high operational performance. For decades, the effort is expended to formulating models that capture trade‐offs in strategy designs, developing methodologies that facilitate characterizations of operating structures, designing algorithms that efficiently compute implementable solutions, and generating insights that provide guidance to policy making. In recent years, increasing attention has been paid to the use of data, generating a rapidly growing body of research that builds data awareness in both modeling and analysis.
Generally speaking, the choice of modeling approaches and analytical techniques depends on our knowledge of the system under consideration. In the modeling language, the knowledge is translated into either statistical assumptions or structural assumptions of a model, which determine the domain of validation of the analysis. Conventionally, we may apply different approaches to model and analyze a system of interest, depending on the preciseness of the statistical and structural knowledge of the system; see Figure 1.
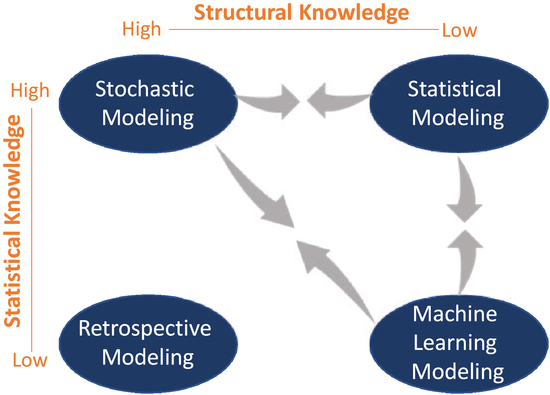
Conventional modeling approaches and the trends
When we are confident in the structural relationships between the inputs and outputs and in the statistical characterizations of uncertain factors, stochastic models are often developed to identify the decision that generates the optimal system performance. Most of the research in operations management falls into this category. For example, when applying the classical newsvendor model, we believe that the structure of the system is fully described by the facts that the amount of sales is the minimum of the demand and the order, that the price charged for all sold units is the same, and that the cost of all ordered units is the same. The statistical characterization (i.e., the distribution) of the uncertain demand is known. When we do not have much structural characterization of the system, we may impose statistical assumptions that we believe are appropriate, and adopt statistical models to analyze the system. For example, there may be multiple suppliers following different delivery processes, leading to a complex relationship between the procurement cost and the order quantity. In such a situation, we may apply an econometric model to understand the relationship between the earnings and the inventory levels by fitting some regression models that we believe are appropriate. Oftentimes, practitioners may have good structural knowledge (e.g., the amount of sales is limited by the inventory, or the procurement cost is linear), but may not have a good understanding of the statistical properties (e.g., the distribution family of the demand). In practice, retrospective models are often used to evaluate the decision performance and to identify improvement opportunities. When we do not have sufficient structural and statistical characterizations of the system, machine learning techniques are often applied.
There are certainly shades of gray, and Figure 1 does not specify all possible scenarios. For example, it is rare that we know nothing about the system. In reality, practitioners have their own experiences of how the system has worked and thus have some understanding of how the system may work in the future, though their knowledge may not be precise due to the changing environment. Thus, we make assumptions that are likely to reflect the reality, while enabling analytical tractability, and evaluate the robustness of the results obtained to understand the implication of the assumptions.
Arguably, complete structural and statistical characterizations of the system are unlikely to be obtained in reality. Data then become useful to understand the system and improve decision quality. The research trend we see recently is that a rapidly growing body of data‐integration work lies between the stochastic models and the statistical or machine learning models. And the emphasis has been given to relaxing the statistical assumptions and using data to supplement the knowledge gap. The approaches developed for specific problems are determined by both the domain of validation and the data generation model. The domain of validation is the collection of models, within which we believe the true model is. This domain is certainly determined by the structural and statistical assumptions of the true model. The data generation model determines the amount of information contained in the available data. For example, in a static or offline learning context, the data may be independent draws from some common distribution, and decisions are made after the realization of the random events associated with the data. In a dynamic or online learning context, the data may exhibit temporal dependence because of the learning strategy deployed. Moreover, observations may be censored by the chosen decisions, or feature variables may be useful to explain the observed variabilities.
Several articles, including Bastani et al. (2022b), Bertsimas and Kallus (2020), Mĭsić and Perakis (2020), Qi et al. (2020), and de Véricourt and Perakis (2020), have provided thorough surveys, insightful discussions, and visionary thoughts on data‐analytics research in operations management. It is certainly challenging to go beyond and unnecessary to repeat what has been discussed. Therefore, we attempt to focus on a niche by underscoring the aspect of data integration in operational decision‐making. We will describe a small subset of recent contributions in four major application areas to analyze what the common themes are, what the new philosophies are, where this research is heading, where the gaps are, and where POMS may provide leadership in the next decade.
DYNAMIC PRICING AND REVENUE MANAGEMENT
Arguably, the most researched application of data analytics in operations management is the design of pricing strategy; see Araman and Caldentey (2011) and den Boer (2015a) for excellent summaries. We choose to start our discussion from this application area because the key building block of modeling, the revenue function, has a simple structure (i.e., price multiplied by demand). The main ideas and intuitions behind the data‐integration approaches developed in this area can set the stage for understanding and comparing the developments in other application areas.
This line of studies focuses on situations with complete structural characterizations. Specifically, when a price p is charged, the subsequent demand is a random variable
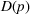
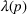
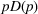
The statistical characterizations of the random demand
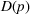
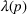
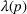
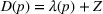
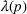
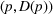
Stationary price–demand relationship
When the demand is unknown, and data are progressively generated and observed, one may sequentially estimate the demand model using the available data and then optimize the price based on the estimated demand model. Such a solution, widely adopted in practice, is often termed the myopic policy in the literature. For example, Bertsimas and Perakis (2006) describe a stationary linear demand model with additive normal noise and unknown coefficients. They iteratively estimate the unknown coefficients using the observations so far, based on which the price is optimized. A myopic policy, while ensuring a high instantaneous profit (or revenue), can lead to incomplete learning (e.g., den Boer & Zwart, 2014; Rothschild, 1974). That is, there is a positive probability that the price path does not converge to the true optimal price. Moreover, depending on the pricing policy implemented, the estimated parameters may depend on the past price, which in turn depends on the demands observed up to then, creating price endogeneity.
To address the issue of incomplete learning, many authors have developed learning algorithms to obtain consistent solutions. We name a few examples. Harrison et al. (2012) demonstrate, using a Bernoulli demand, that incomplete learning can occur in the Bayesian dynamic programming model, which updates the distribution upon observing a demand and then optimizes the price based on the posterior distribution. They resolve the issue of incomplete learning by incorporating price experiments to create deviations from the myopic policy. Besbes and Zeevi (2009) consider a Poisson demand with an unknown random rate. Their algorithm divides the horizon into a learning phase and an earning phase. A sequence of pre‐selected prices is tested during the learning phase, at the end of which the mean demand rates are estimated using the sample averages. In the earning phase, the optimal price is selected based on the estimated demand rates. Besbes and Zeevi (2015) analyze an additive‐noise demand with unknown mean demand function and noise distribution. They divide the planning horizon into episodes, each containing a learning phase and an earning phase. During a learning phase, the myopic price and its perturbation are experimented. A linear demand is estimated using the least‐square estimation. The myopic price is then recomputed and implemented during the subsequent earning phase. Z. Wang et al. (2014) refine the algorithm by reducing the perturbation of the tested price over time. den Boer and Zwart (2014) consider a demand whose mean is a known increasing transformation of an unknown linear function (i.e.,
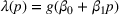
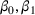
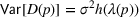
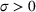
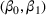
As a common theme, these studies attempt to combine the statistical estimation for the unknown demand function with the optimization of the pricing decision. This is done by balancing learning through exploring the suboptimal prices (i.e., price experiment) and earning through exploiting the revenue under the myopic price. The validation of the asymptotic efficiency under the designed policy (or, interchangeably, algorithm) is through regret minimization. That is, reducing the distance between the true optimal revenue and the revenue earned under the designed policy. The form of regret calculation depends on the price–demand relationship. With the Poisson demand, measuring the regret using the revenue ratio is appropriate as the mean rate equals the variance. With the additive‐noise demand, computing the regret as the revenue difference is natural, as the price only affects the mean of the demand distribution. To obtain a desirable regret bound, the algorithms proposed in the aforementioned studies attempt to achieve two conditions, in the language of Keskin and Zeevi (2015) (Theorem 2). First, the price experiments in the learning periods must create enough price dispersion. Second, the deviation of the implemented prices from the myopic price should be sufficiently infrequent. The first condition ensures that the estimation procedure discovers the true model quickly enough, and the second condition ensures that the revenue loss due to exploration reduces quickly enough.
The design of price experiments is essential to the performance of the learning algorithm. In reality, experiments do not come free. Cheung et al. (2017) impose a budget of price experiment (expressed as a maximum number m of price change) when the mean demand function comes from a known finite family. The algorithm divides the horizon into m episodes with the length iterated‐exponentially increasing. The first

Incorporating demand features
When the demand exhibits dependence on some observable features (i.e., contextual information), the feature data can be used to improve the decision quality. For example, the search data from GoogleTrend may be used to understand the demand surge of certain consumer products. Consumers' browsing history on related webpages or consumers' past posts of product reviews may be related to their purchasing decisions. Such data can be incorporated into the demand model as a vector of observed feature variables (or covariates), denoted by
A commonly used measure for identifiability is the smallest eigenvalue of the empirical Fisher information matrix. When this eigenvalue is strictly positive, the matrix is invertible and thus the estimates can be computed. For example, Broder and Rusmevichientong (2012) consider a Bernoulli demand with the mean demand
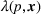
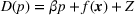
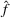
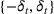
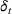
When the feature observations are sparse, price experiments, regularization terms, or clusters are often used to address the identifiability issue in estimation. Javanmard and Nazerzadeh (2019) analyze a Bernoulli demand with success probability
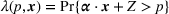
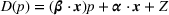
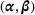
From a very different angle, Cohen et al. (2020) analyze the effect of demand feature by focusing on a special demand model, in which the customers' preference is deterministic but unknown. Specifically, a customer exhibiting feature

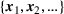

Multiproduct and cross‐learning
The relationships among different products, though increasing the complexity of analysis, allow for leveraging the knowledge from one to understand the other. Cross‐learning happens when we have some partial characterization of the relationships among
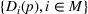
For example, Ferreira et al. (2016) consider multiple products and a finite set of feasible price vectors. The joint distribution of the product demands depends on the chosen price vector and some unknown parameters. The proposed algorithm adapts the Thompson sampling for parametric Bayesian learning (i.e., the multiarm bandit), which ensures price dispersion by probabilistically choosing suboptimal prices derived based on randomly sampled parameters from the posterior distribution. Bastani et al. (2022a) consider the multiproduct demand model
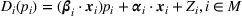
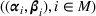
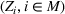
Connections among products can often be identified through cross price elasticities or through common features. Keskin et al. (2021b) analyze the demand model
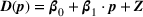

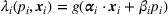
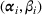
Simchi‐Levi et al. (2021) discuss a problem with primary products and associated add‐on products, both having Bernoulli demands. In addition to selecting a price vector from a finite set, a discount may be offered to an add‐on product when the primary product is purchased. The proposed algorithm divides the horizon into episodes. In each episode, the upper‐confidence bounds on the average demands are constructed, based on which the prices within the episode are determined. To reduce performance loss, a terminal condition (i.e., enough observations for the selected add‐on product at the current price) is imposed which may end an episode before its planned length.
Many studies analyze multiproduct pricing decisions for choice‐based demands, we will postpone the discussion of these studies to Section 3, the section dedicated to choice‐based models.
Nonstationary environment
In reality, the demand distribution may change due to varying market conditions and customer tastes. The change may be reflected by different statistical properties, namely, demand variability (e.g., den Boer, 2015b), price sensitivity (e.g., Keskin & Zeevi, 2017), or feature‐based preference (e.g., Javanmard, 2017).
den Boer (2015b) studies the demand model
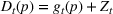
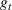
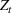
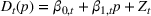
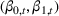
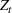
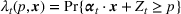
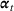
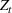
In a different application, Zhang et al. (2022) study a Markovian Bass demand model. The proposed algorithm calls for setting a low price in the introductory stage when the initial data are collected. Then, iteratively, the parameters of the Bass model are estimated using the observed cumulative sales, based on which the price is optimized.
Remarks
The asymptotic performance of the policy has been the major focus of this research recently, which sets important theoretical foundations for understanding the associated dynamic pricing and revenue management problems. A regret bound of the order
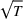
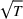
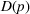
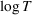
The presence of the uninformative price may increase learning complexity. For example, in the problem studied by Harrison et al. (2012), the uninformative price is the crossing point of the two possible mean demand curves. Incomplete learning may occur under the myopic price unless the uninformative price is not optimal for any Bayesian prior. Another example is discussed by Javanmard and Nazerzadeh (2019). The mean demand comes from a parametric family within which all demand curves intersect at a common price, and the common price is optimal for some feature values. A fast learning algorithm must produce significant deviations from the uninformative price, leading to a potential regret gap. A related concept is the discriminative price, at which all the mean demands are distinct. Knowledge of discriminative prices can reduce the learning complexity (see the related discussion in, e.g., Cheung et al., 2017).
We remark that our discussion in this section has omitted an important consideration, potentially limited inventories (e.g., Araman & Caldentey, 2011; Cheung et al., 2017). This consideration requires rather nonfundamental modifications of the learning process (e.g., including a shut‐off price at which the demand is zero almost surely), as the quantity is exogenously given. In Section 4, we will discuss the data‐integrated quantity decision and its critical differences from the price decision.
CHOICE, OPTIONS, AND PRICING
The axiom‐based mathematical modeling of choice dates back to the 1950s. Since then, the choice models have been extensively researched and continuously finding numerous applications in psychology, economics, marketing, and operations. With the wave of data analytics, many new contributions have been made recently in operations management.
Modeling, estimation, and identification
In general, a choice model describes how people would select a single element from a given set of options. Such a choice preference can be described by a probability vector
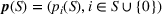
The four categories of structural models are the attraction models, utility‐based models, temporal models, and rank‐list models, each describing the consumers' preference from a different angle. The attraction model assigns an attraction value to each option under the axiom of independence of irrelevant alternatives (Luce, 1959). These values represent the unnormalized choice probabilities. An attraction model is equivalent to a multinomial logit (MNL) model, though the latter is developed from the random utility model. A random utility model assigns a random consumption utility to each option. A consumer's utility vector is an independent random realization, and the consumer chooses the maximum‐utility option within the available set. Extensions of MNL (e.g., nested logit, mixed logit, and latent MNL) models, probit models, and exponomial models belong to this category. A temporal model assumes that the consumer's preference is described by the occurrence of some random events, one related to an option. The consumer would choose the option corresponding to the earliest event among the available options. The Markov‐chain choice model developed by Blanchet et al. (2016) and Gupta and Hsu (2020), the single‐transition model by Nip et al. (2021), and the k‐attempt model by Chung et al. (2019) are examples of temporal models. Under a rank‐list model, each consumer has a rank order of all the options and would choose the highest ranked option from the available ones. A consumer's type is a random draw from a discrete random variable (index), which determines the rank list of that consumer. It turns out that the last three categories of models coincide—A model in one category has an equivalent representation in each of the other two categories (Feng et al., 2022). Thus, the estimation method developed for one can be applied to others.
The estimation and identification of a structural choice model with data are nontrivial as the number of potential offering sets can be large. Even in the parametric setting, the likelihood function may not be well behaved and a considerable effort is made to develop efficient estimation approaches like expectation maximization (e.g., Train, 2008; van Ryzin & Vulcano, 2017).
A major focus in recent research is to identify the right choice model using data with relaxed structures (e.g., partially nonparametric) or additional structures. A relaxation can significantly increase the complexity in model estimation, requiring the development of optimization techniques. For example, Ho‐Nguyen and Kılınç‐Karzan (2021) formulate a min‐max (saddle point) model to estimate the rank‐list distribution and analyze the sparsity of the estimates. Farias et al. (2013) use a pairwise preference matrix to represent rank lists, which account for the censored observations of the full rank list. Based on this representation, the potential models that can generate the observed data are characterized through linear constraints, and then the pessimistic (worst‐case) revenue is estimated. van Ryzin and Vulcano (2015) analyze a similar problem and apply column generation to reduce the computational burden in estimation. Specifically, the maximum‐likelihood estimates are computed over a subset of rank lists. Then the algorithm explores additional rank lists to improve the estimates. Chen and Mišić (2022) relax the rationality assumption of many random utility models by allowing the choice probability to increase when additional options are added to the offered set. A customer's type is described as a binary‐choice tree. The consumer starts from the root of the tree, moves down to the left or right child depending on whether the option associated with the current node is offered, and chooses the option associated with the leaf node. This paper discusses the complexity of model identification and proposes techniques (column generation and randomized tree sampling) for estimation.
Several studies analyze elaborated consumer behaviors that are not captured in conventional models. Jagabathula and Vulcano (2018) refine the choice model using the fact that the consumer may have a random consideration set. Options outside of the consideration set, even offered, would not be chosen. They use a set of acyclic directed trees to identify consumers' partial preferences based on data, and analyze an integer program to obtain the estimates. Jagabathula et al. (2021) consider a general model of the consumer's consideration set. They develop an approach to solve the mixed‐integer nonlinear optimization problem for the maximum‐likelihood estimation. The model proposed by Ferreira et al. (2022) (see Section 3.2) is another representative example.
Feng et al. (2022) apply a framework, called operational data analytics, developed by Feng and Shanthikumar (2022), to bridge the gap between parametric and nonparametric estimations. This approach takes into account possibly imprecise (“roughly correct”) structural assumptions in validating the estimated model. A class of estimation functions (i.e., operational statistics) is developed to leverage the structure implied by the domain knowledge and the information contained in the observed data. The optimal estimation function is derived by validating the regret of the estimation error over a set of models that may or may not satisfy the structural assumptions. This approach not only produces an estimate of the choice model but also identifies the true structure if the underlying model comes from a collection of structural models.
All these studies perform static learning of the choice model by assuming that the data generation is independent of the estimation approach adopted. An important aspect of model identification, currently underresearched, is how to design the experiment (by selecting a sequence of offered sets) so that the “most useful” data are generated under a limited learning budget. It is worth mentioning that Fisher et al. (2018) conduct a field experiment and make several interesting observations empirically, though their focus is not to provide guidance for experimental design.
Choice‐based product assortment, display, and pricing
The consumer choice model has been the building block for price and revenue optimization (Strauss et al., 2018) and assortment planning (Chernev, 2011; Karampatsa et al., 2017).
A natural way of data‐integrated decision‐making is the learning‐then‐earning approach, with which the choice model is estimated from historical data and the decisions are then optimized based on the estimated model. Yan et al. (2022) design price experiments to estimate the random utility model and develop algorithms to optimize the product prices. Jena et al. (2020) consider assortment planning under partially ranked consumer preference in the spirit of Farias et al. (2013), which allows the consumer to be indifferent among a subset of options. Using a column‐generation approach similar to that developed by van Ryzin and Vulcano (2015), they solve for the optimal assortment decision from an integer program. Jagabathula and Rusmevichientong (2017) analyze the optimization of assortment and prices when consumers' choices are limited to their own consideration sets. They develop an expectation maximization approach to obtain the maximum‐likelihood estimate of the choice model and design an algorithm to compute profit‐maximizing decisions. Paul et al. (2018) use a tree representation of consumer choice. Based on historical sales data, a greedy heuristic is deployed to identify possible rank lists that could have possibly generated the data. The fitted trees and consumer type distribution (over all possible rank lists) are estimated using maximum likelihood. Then, the dynamic assortment and pricing decisions are optimized.
Different approaches for dynamic learning and earning have been explored by several authors. Bernstein et al. (2019) apply a dynamic Bayesian framework with a Dirichlet prior on the consumer's preference. The planning horizon is divided into episodes with equal length. In each episode, the clusters of consumer types are updated based on the observations from the last episode. The estimated choice probabilities are updated, and a multiarm bandit algorithm is deployed to select the assortment. Chen et al. (2022a) consider feature‐based dynamic pricing under an MNL choice model. They use a constrained maximum‐likelihood estimation to account for the potential sparsity of the coefficients. Chen et al. (2020b) examine dynamic assortment decisions in a similar setting. During the initial learning phase, the assortment is chosen by uniformly sampling all possible offerings. Then the maximum‐likelihood estimators are computed for the choice model. In the remaining periods, the estimated choice model is updated based on the observed features and revenues using a constrained maximum‐likelihood estimation and the upper‐confidence bounds are constructed to determine the assortment.
Consumer choice models have been applied to analyze offering decisions in related, but different contexts. For example, Ferreira et al. (2022) model the consumer's choice of clicking on products. The choice probability can be shifted (by an additive term) based on the products clicked before. Each consumer is associated with a display window beyond which the consumer would not browse. The focus is to design a display sequence (a ranked list) that maximizes the number of consumers who click on at least one product. The proposed algorithm iteratively adds a product to the current list, experiments with the display to obtain response data, and then decides, based on a threshold response rate, whether or not to keep the newly added product on the list. In a related context, Gao et al. (2022) consider a cascade‐click model for the consumer purchase choice. They develop contextual‐based (i.e., click‐based) upper confidence bounds for dynamic learning and price optimization.
Remarks
Structural models that exhibit nice properties may not fit data, while fully nonparametric models are complex to identify (Chen et al. 2021c). In particular, the number of parameters needed to be estimated for a full rank‐list model is
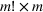
Implementing choice‐based models and solutions in practice requires a careful treatment of many details. An insightful discussion can be found in Vulcano et al. (2017), which demonstrates empirical considerations in the choice‐model design for revenue maximization.
PROCUREMENT, INVENTORY, AND PRICING
Managing material flows to meet the uncertain demands has been the forever puzzle faced by practitioners. Many approaches for data‐based decision‐making have been developed in the operations management research.
Offline‐learning newsvendor
The newsvendor model is probably the most studied model in the operations management literature. It is probably the one with the earliest development in data‐integrated decision‐making that departs from the paradigms of learning‐then‐earning (i.e., predetermined learning phase and earning phase) and learning‐or‐earning (i.e., probabilistically determined learning or earning period by applying, e.g., Thompson sampling or upper‐confidence bounds). This departure leads to a direct data‐integration approach that does not separate learning (i.e., parameter estimation) and earning (i.e., decision optimization).
Hayes (1969) first describes a data‐integrated newsvendor solution by defining the mismatch cost as the loss function and the ordering decision as a statistics. Pointing out the asymmetry of the loss function, he argues that the data‐integrated solution is naturally biased. This observation is further elaborated by Siegel and Wagner (2021) in their analysis of exponentially distributed demands. Several authors (Akcay et al., 2011; Janssen et al., 2009) have proposed solutions to adjust the safety stock factor derived from the estimated demand, leveraging both the sample information and the profit optimization. A general data‐integrated solution is developed by Chu et al. (2008), who define the decision as a direct function of data using the concept of operational statistics proposed by Liyanage and Shanthikumar (2005). This approach produces a uniformly optimal ordering decision as a statistics of the demand data.
All the above studies assume a known distribution family of the demand. When there is no knowledge about the demand distribution (i.e., in nonparametric settings), the estimation of the distribution parameters needs to be expanded to that of the distribution function, as the optimization of the newsvendor model requires the input of demand distribution. One learning‐then‐earning approach here is to apply quantile regression (see, e.g., Amrani & Khmelnitsky, 2017; Harsha et al., 2021) and optimize the decision based on the quantiles.
To break the separation between learning and earning in a nonparametric setting, a natural approach is to examine the average profit computed by replacing the random demand with the demand samples. This is the sample‐average approximation (SAA), which, under the standard structural assumptions of the newsvendor model, is equivalent to the retrospective analysis and the approximation using empirical distribution. Certainly, a pure SAA would result in overfitting. The common approach is to either add a regularizer to the estimated profit or impose a constraint to control the variability of the estimated profit (see, e.g., Cheung & Simchi‐Levi, 2019; Homem‐de‐Mello & Bayraksan, 2014; Levi et al., 2007, 2015; Qin et al., 2022).
Recognizing that the (unregularized) SAA solution corresponds to a specific order statistics of the demand data, Besbes and Mouchtaki (2021) focus on a class of operational statistics that are mixtures of order statistics. They demonstrate the superiority of the resulting solution against the existing ones in the small‐sample regime. Taking a different angle, Lin et al. (2021) modify the empirical profit, instead of the empirical solution, by computing a weighted retrospective profit. The weights are estimated using clustering techniques (i.e., the k‐nearest neighborhood, kernel regression, or classification and regression tree). Ban and Rudin (2019) incorporate demand features into the analysis and apply Kernel regression to estimate the mean demand.
Research considering the endogenous pricing decision often assumes a demand model with an additive noise, that is,
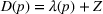
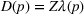
An alternative approach for data integration is robust optimization (Bertsimas & Thiele, 2006; Bertsimas & Vayanos, 2017; Lu & Shen, 2021). For example, Hu et al. (2019) define a candidate set of mean demand functions by bounding the squared deviation when fitted from the observed data. The mean demand is used to replace the random demand in approximating the profit function, based on which the worst candidate demand function is chosen under the optimal pricing and inventory policy.
Dynamic learning
When considering dynamic learning, many studies also relax the structural assumptions of the newsvendor model by allowing (partial) inventory carryover, positive delivery lead times, or fixed ordering costs. Most of the learning algorithms use episodic update and re‐optimization, like those in the pricing and revenue management literature, and focus on balancing the estimation error, approximation error, and profit generation.
For the classical period‐review inventory problem, Chen et al. (2019) design an algorithm similar to that of Besbes and Zeevi (2015) by experimenting on two prices and their corresponding order‐up‐to levels during the learning phase. They use a linear approximation to estimate the mean demand and compute the noise. A potential challenge in data‐integrated inventory planning is the possibility of censored demand observations. Indeed, Ban (2020) suggests that the bias‐corrected demand estimates from the censored observations may lead to inconsistent inventory decisions. She adjusts the profit estimation using the censored observations instead. Zhang et al. (2020) propose that, in parallel to the actual system, a shadow system is simulated with a base‐stock level lower than its counterpart in the actual system. The shadow system only runs in periods when the inventory is sufficient to meet the demand. The parallel system allows for best utilizing the observed data and facilitating the evaluation of the cost gradient, which is used to update the base‐stock level to be implemented in the next episode. To address the issue of demand censoring in making price and inventory decisions, Chen et al. (2021a) use a spline approximation for the unknown mean demand function with spline coefficients computed from the data in the learning phase.
When fixed ordering costs are paid, Yuan et al. (2021) propose an algorithm to find the optimal
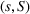
Considering nonstationary demands, Keskin et al. (2022a) model time‐varying demand coefficients and i.i.d. additive noise. Their algorithm divides the horizon into episodes of equal length, each consisting of a learning phase and an earning phase. To account for the nonstationarity in the demand, change detection is performed on the deviation among average demands after conducting price experiments in each learning phase to determine whether historical data should be discarded. Keskin et al. (2021) study a similar problem in a nonparametric setting. They deploy a time‐window policy, in a spirit similar to that used by den Boer (2015b) and Keskin and Zeevi (2017) and discuss the difference in the learning complexity between the pricing decision and the ordering decision. Chen (2021) considers inventory control under unknown discrete demand distributions and derives performance bounds for exploration‐heavy or exploitation‐heavy learning algorithms.
Remarks
Learning of pricing decisions and inventory decisions can be very different when we compare the developments discussed in this section with those in Section 2. For a pure pricing policy, the focus is to discover the mean demand curve. Many statistical methods (e.g., least square, maximum likelihood) used for learning the mean demand curve may not be sufficient to make an inventory decision. Instead, estimation of the distribution function (e.g., empirical distribution, quantile, order statistics) is needed.
We also note that there are studies of more sophisticated structural models, including capacitated production (Chen et al. 2020a) and dual sourcing (Chen & Shi, 2021).
HEALTHCARE OPERATIONS
Healthcare is gaining significant attention in many fields. Research in our field centers around issues associated with understanding, predicting, and optimizing the performance of resource planning (e.g., staffing, bed occupancy, drug approval), resource allocation (e.g., admission, diversion, discharging, organ matching, scheduling), and quality management (e.g., treatment outcome, test accuracy, readmission, drug safety). The applications are diverse, and each brings unique considerations in modeling and analysis. These are evident from recent surveys by several experts in our field (Anderson et al., 2022; Baron, 2021; Betcheva et al., 2020; Diwas Singh et al., 2020; Hopp et al., 2018; Keskinocak & Savva, 2020).
The current status and recent trends
The studies on healthcare operations are heavily centered on the two corners in Figure 1, namely, statistical modeling and stochastic modeling. For the former, empirical approaches (e.g., econometric models, hypothesis testing) are applied to analyze real data (recent examples include Bobroske et al., 2022; Lan et al., 2022; Niewoehner & Staats, 2022). In these studies, the input–output relationship is often modeled at a high level with time aggregation, without the detailed structures to enable decision optimization. In the second stream of healthcare research, analytical models are formulated and techniques including stochastic program, approximate dynamic program, Bayesian dynamic program, queuing analysis, and equilibrium analysis are used to derive the decisions (recent examples include Adida, 2021; Ahuja et al., 2021; Ata et al., 2020; Bavafa et al., 2022; Carew et al., 2021; Slaugh et al., 2018; Tian et al., 2022). In these studies, data are often not explicitly modeled as an input to the decision models, though some demonstrate how to apply the model to real data (e.g., Aswani et al., 2019).
Both research streams, though appearing separately from each other, exhibit a trend of adopting machine learning techniques. To draw inferences from empirical studies, machine learning techniques are used to replace traditional econometrics methods to relax relational assumptions or to deal with high dimensionality. For example, Schiele et al. (2021) use features extracted from data to formulate an estimation model using a neural network and apply gradient descent to obtain estimates for bed occupancy. Wang et al. (2022) adopt casual trees with instrumental variables to identify heterogeneous treatment effects. Xu et al. (2021) apply text mining to understand how online reviews impact the patient choice of care providers.
In stochastic modeling, a recent focus is on combining machine learning methods with conventional approaches to facilitate data integration and address the computational complexity. For example, Shi et al. (2021) use clustering, expectation maximization, and instrumental variables to estimate patient readmission time based on patient features. The estimates are used as inputs to an approximated Markov decision process from which the patient discharging policy is optimized. Grand‐Clément et al. (2021) examine a Markov decision process for cost‐efficient resource allocation based on patients' health states. They use classification trees to identify an allocation policy and demonstrate the application of the approach using the retrospective data of COVID‐19 hospitalization cases. Bravo et al. (2022) propose a queuing network framework to model clinical trials for new drugs and estimate the model parameters from data to demonstrate the implementation of the drug‐specific approval policy. Xie et al. (2022) examine patient overflow by defining a bed shortage measure using a notion similar to the quasi‐convex risk measure. This measure can be computed using the patient flow data. Based on this measure, they formulate an optimization model to plan bed capacity.
The majority of these studies belong to the static learning‐then‐earning paradigm, applying statistical machine learning techniques on data to obtain inputs for decision‐making. There are a few recent studies deviating from this paradigm. For example, Bastani and Bayati (2021) develop a LASSO bandit algorithm for problems involving high‐dimensional features and derive the bounds of the expected regret. They demonstrate the application of the algorithm to determine the warfarin dosage based on patients' features. Bastani et al. (2021) use LASSO and empirical Bayes to identify key features for travelers' type and apply reinforcement learning to evaluate COVID‐19 testing policies. Anderer et al. (2022) study clinical trial design. They apply a proportional hazard rate model for the trial outcome and use a Bayesian framework to estimate the effect based on patient‐level data. The patient enrollment level and the target posterior variance are chosen to minimize the expected cost under given type I and type II error requirements. Chan et al. (2022) model patients' journeys in the healthcare system by capturing possible deviations from the reference pathways. Using the data of patients' medical records, they apply inverse optimization to identify the patients' cost structures in the network.
Potential directions and challenges
Though the research on healthcare operations spans over a wide range of topics, the conventional views are often hospital focused (i.e., appointment and resource scheduling, resource planning, and allocation), disease focused (admission, matching, treatment), or medicine focused (development, approval, production, insurance, financing). As detailed patient data become available, there is a movement toward patient‐centric approaches (in, e.g., therapeutic development, information display, self‐management intervention); see the POM special issue edited by Bretthauer and Savin (2018). Such a movement calls for personalized predictive and prescriptive models to improve the precision of medical decision‐making. Though machine learning is finding increasing applications in healthcare, most of the publications appear in medical and computer science journals with an emphasis on performance assessment and predictability. From the operations perspective, there is plenty of room for data‐integrated medical decision‐making and experimental design in various applications.
The research in healthcare, compared with that in other areas, has its unique challenges. Different healthcare providers may maintain different practices, procedures, and protocols. Data sharing across providers remains a difficult task in many situations. Moreover, a solution approach developed for one may not be directly applicable to another, and the results obtained from one application may not be replicable in another, even very similar, application. Anderson et al. (2022) summarize five main barriers to realizing the practical values of research findings, including the resistance from practitioners, the competition among providers, the quality of data, the mismatch of incentive, and the nontransferability of solutions. Fundamental work on general frameworks that address these challenges is yet to be developed.
DISCUSSION AND FURTHER DIRECTIONS
Data analytics is finding increasing applications and making a major shift in the research of operations management. With the consideration of data, researchers are not only developing new models and new approaches for traditional operations problems, but also discovering new problems and issues, for example, privacy‐proof policies (Chen et al. 2022b), personalized bundle pricing (Ettl et al., 2020), reusable resources (Gong et al., 2022), crowd sourcing (Manshadi & Rodilitz, 2022), personalized priority (Hathaway et al., 2022), and racial bias (Samorani et al., 2021). As we have seen from our discussions, there are many ways of data integration, and the choice of the approach must match with the application and the goal of the analysis.
To push the frontier of data analytics in operations management, an increasing amount of theoretical research is the engine. Many scholars have made important theoretical contributions under general frameworks (e.g., Aswani et al., 2018; Besbes et al., 2014; Elmachtoub & Grigas, 2022; Gupta & Kallus, 2022; Gupta & Rusmevichientong, 2020; Zhu et al. 2022). These developments have great potential to generate new understandings in different application domains. The development of new paradigms that blur the boundaries between the conventional modeling approaches would lead to breakthroughs of the research on many operations problems. Moreover, relaxing the technical conditions that are commonly assumed in our analytical and empirical models (e.g., linearity, concavity, log‐linearity, additivity) can enhance the data integration into decision models. For example, many studies assume that the revenue function is smooth and concave in price. Though necessary for analytical elegance, such a condition may not be satisfied and may be difficult to verify in reality. Improving the resilience of the learning approach along this dimension (e.g., Wang et al., 2021) is valuable to practice.
Admittedly, the gap between the research and application exists. Execution of many proposed policies can be challenging in practice unless one has extensive knowledge of the theories. Simple algorithms and easy‐to‐follow implementation procedures can make the research development accessible to the practitioners. For example, in dynamic pricing, the price dispersion needs to be of order
Footnotes
ACKNOWLEDGMENTS
The authors are grateful to Christopher Tang for his helpful suggestions.