
Abstract
Corporations gather massive amounts of personal data to predict how individuals will behave so that they can profitably price goods and allocate resources. This article investigates the moral foundations of such increasingly prevalent market practices. I leverage the case of credit scores in car insurance pricing—an early and controversial use of algorithmic prediction in the U.S. consumer economy—to unpack the premise that predictive data are fair to use and to understand the conditions under which people are likely to challenge that moral logic. Policymaker resistance to credit-based insurance scores reveals that contention arises when predictions depend on mathematical distinctions that do not align with broader understandings of good and bad behavior, and when theories about why predictions work point to the market holding people accountable for actions that are not really their fault. Via a de-commensuration process, policymakers realign the market with their own notions of moral deservingness. This article thus demonstrates the importance of causal understanding and moral categorization for people accepting markets as fair. As data and analytics permeate markets of all sorts, as well as other domains of social life, these findings have implications for how social scientists understand the novel forms of stratification that result.
Markets are fast changing as corporations increasingly harness large amounts of personal data to predict how individuals will behave. Companies are awash in digital information from consumer data brokers, technologies like mobile phones that record behavior in real-time, and customer interactions. With these data, companies create algorithms to predict a broad range of behaviors—who will pay a higher price, be swayed by a marketing offer, rack up penalty fees, be a loyal shopper or a pesky one, and so on. Companies then give different people different prices, services, and terms to maximize the profit derived from each customer (Poon 2016; Zuboff 2019). Data-fed predictions thereby allocate the costs, opportunities, and burdens of the market, resulting in a form of stratification operating on the consumption side of the economy (Fourcade and Healy 2013; Gandy 2009).
Sociologists have shown that moral understandings allow markets to develop in particular ways, and that new market practices often involve contestation about normative standards (Fourcade and Healy 2007; Livne 2015; Quinn 2008; Zelizer 1979, 1985). This article examines the moral understandings justifying the use of personal data and algorithmic prediction in deciding who gets what, and the conditions under which stakeholders are likely to challenge those justifications. These are important questions because moral understandings, once solidified, play a significant role in perpetuating market arrangements, including those that produce vast inequality. Consider the way the idea of meritocracy acts as a seawall against attempts to address income inequality in the United States (Cech and Blair-Loy 2010; Kluegel and Smith 1986).
Fourcade and Healy (2017) argue, in an agenda-setting depiction of how corporations use personal data to score and rank consumers, that this new system inculcates “an economy of moral judgment”: people seem to get what they deserve based on their past behavior. In their telling, this ethos rests on the assumption that data capture how people decide to behave (choices for which they can be held accountable), as well as the perception that calculative methods of sorting and ranking are dispassionate and rational. In the case of algorithmic prediction, data are further fashioned as fair by virtue of their predictive usefulness (Poon 2012; Zuboff 2019). That predictions “work” is an argument companies invoke to defend controversial practices, such as using where people shop to set limits on their credit cards (e.g., Teegardin 2008).
Broad-based calls for “algorithmic transparency” suggest visibility is an important first step in engaging with the moral bases of algorithmic prediction (Rainie and Anderson 2017). Indeed, it often takes great effort to pierce the veil of companies’ proprietary algorithms, even when they are used for public purposes, such as predicting criminal re-offense (Angwin et al. 2016). But if algorithms are visible, what then? Under what conditions and in what ways might they be seen as morally problematic? Computer scientists are leading an interdisciplinary debate about what makes algorithms “fair” (Kleinberg, Mullainathan, and Raghavan 2017; Verma and Rubin 2018). Sociologists can add empirical evidence and a theoretical understanding of how social actors in real-world settings construct moral boundaries around predictions.
Case and Argument
To address these questions, I turn to a rare case of extended public debate about a particular type of algorithmic prediction: the credit scores car insurance companies use to set prices. Credit scores are statistical estimates of how people will behave in the future based on data about their past credit use. Scholars often take them to be the paradigmatic example of algorithmic prediction (e.g., Fourcade and Healy 2017; Pasquale 2015). Credit scores can prove useful in domains far removed from borrowing and lending. Since the early 1990s, car insurance companies in the United States have used credit scores to decide which drivers to insure and what premiums to charge (Rona-Tas 2017). As it turns out, credit scores are quite good at predicting which consumers will file insurance claims and otherwise cost companies money (American Academy of Actuaries 2002; Miller and Smith 2003). Even so, credit-based insurance scores, as they are known, have been the subject of intense regulatory and legislative scrutiny. This includes large-scale investigations in at least 17 states, five congressional hearings, four extended reviews by the professional association of state insurance regulators, and the passage of dozens of state laws restricting how the scores can be used.
The forcefulness of policymakers’ resistance is surprising considering that the field of property and casualty insurance is dominated by the idea that it is fair to use data for pricing if the data actuarially relate to loss insurers expect to incur. In other words, car insurance closely hews to the idea that companies rightly offer different people different things based on predictions about how individuals will behave in the future. This is the mentality rapidly spreading throughout the consumer economy. In insurance, this is called “actuarial fairness” and it is codified in insurance law, regulation, and practice (Baker 2003; Hellman 1997). The debate over credit-based insurance scores is therefore a strategic case for understanding moral disambiguation in companies’ use of personal, predictive data, because anyone pushing back must address why the current moral logic falls short. In the empirical analysis, I draw on more than 6,600 pages of documents and 28 hours of recordings produced during regulatory and legislative debates.
I will show that despite a first-order commitment to actuarial fairness, policymakers consistently called upon a competing idea about what constitutes a moral market. By mobilizing notions of moral deservingness—the sort sociologists have primarily observed in debates about poverty relief (Watkins-Hayes and Kovalsky 2016)—policymakers assigned responsibility and blame for the events in people’s lives in order to decide whether individuals with low credit scores really did deserve to pay more for car insurance. Policymakers did not want the market treating people they saw as good as if they were bad. The problem was, the mathematical mechanics of prediction occluded the sorts of information policymakers needed to morally reason in this way.
To recover information, policymakers engaged in two processes that shaped the law and regulation that followed. In causal theorizing, they sought to understand why credit scores predicted insurance claims and what led to low scores in the first place. These questions were irrelevant from the perspective of actuarial fairness, but they proved crucial to those operating in a deservingness mindset, because how events unfold over time can reveal who is responsible for those events (Bruner 1990; Guetzkow 2010; Scott and Lyman 1968). In de-commensuration, policymakers challenged the way credit scores categorized people and reduced them to a common metric (Espeland and Stevens 1998, 2008), because the distinctions industry found mathematically useful did not always align with how policymakers categorized consumers on moral grounds.
From this case, I offer a theory of when algorithmic prediction will be seen as a morally valid way for companies to set prices and shape how consumers experience markets, and when algorithmic prediction will trigger moral objections. The least controversial predictions, I propose, will satisfy two conditions. First, they will lend themselves to causal theories that various types of social actors find morally palatable. Second, they will mathematically group consumers in ways that resonate with common understandings of good and bad behavior. Spillman (1999) asks what counts as a “proper” market exchange, and here the answer is one in which the moral foundations of the market align with broader shared understandings of what makes people blameworthy and virtuous.
As algorithmic prediction takes hold across domains that bear on stratification and inequality—from employment to education to criminal justice (Barocas and Selbst 2016; Brayne 2017; Eubanks 2017; O’Neil 2016)—this article demonstrates the value of investigating not only predictions’ effects but also their moral defenses.
Algorithmic Prediction as a Framework of Market Fairness
Algorithms and Classification Situations
Scholars have long studied the moral underpinnings of seemingly amoral market activity. Market enthusiasts often portray markets as normatively neutral institutional arrangements based on rational calculation, but sociologists show that socially constructed conceptions of good and bad provide the foundation and ongoing justification of various forms of market exchange (Fourcade and Healy 2007; Healy 2006; Livne 2015; Thompson 1971; Zelizer 2011). 1
Particular renderings of what is moral and immoral enable the rise of new markets, as in the case of life insurance (Quinn 2008; Zelizer 1979), and help destroy widely accepted ones, as in the case of child labor (Zelizer 1985). Such transformations involve substantial cultural work, as actors battle to establish their views as legitimate. Markets are thus “explicitly moral projects,” in that they “involv[e] more or less conscious efforts to categorize, normalize, and naturalize behaviors and rules that are not natural in any way, whether in the name of economic principles (e.g., efficiency, productivity) or more social ones (e.g., justice, social responsibility)” (Fourcade and Healy 2007:299–300). Successful actors shape understandings of how the market is and should be, thereby institutionalizing assumptions and beliefs that promulgate their values and interests (Dobbin 1994; Hirschman 1977).
Consumer markets today are at an inflection point, as corporations capitalize on newfound abilities to gather massive amounts of data about individuals (Fourcade and Healy 2013, 2017; Poon 2016; Zuboff 2019). Data come from a variety of sources. These include third-party brokers that collect and re-sell personal information, technologies like mobile phones and web browsers that record behavior moment by moment, and companies’ own interactions with customers including sales records and customer service calls. These data allow for computationally sophisticated predictions about how people will behave in the future, a crisp example of the calculative rationality Weber (1978) noted was taking over modern society.
Predictions give companies insight into the maximum amount of money individuals will pay for goods and services, who will prove to be a costly or troublesome customer, and other profit-oriented outcomes. Corporations then treat people differently based on these predictions. Less desirable customers might wait on hold longer for customer service, go through a more stringent vetting process, pay more for products, and so on (Moor and Lury 2018; O’Neil 2016). Markets thus slot individuals into “classification situations” that determine how a person experiences the market and the market’s influence on life chances (Fourcade and Healy 2013). This may act as a social leveler—for example, by enticing companies to sell to people they previously shunned—but it also engenders novel patterns of cumulative advantage and disadvantage (Gandy 2009).
These new market arrangements embody particular moral understandings that can be used to justify the system as well as any inequality it produces. Key among these is the idea that algorithmic predictions help allocate economic resources in a manner that provides consumers with the right prices and opportunities (Mayer-Schönberger and Cukier 2013). Companies explain data mining and prediction as a way to customize what individuals get—a way to anticipate people’s preferences, needs, and wants, and present what is most relevant (Cohen 2013; Seaver 2015; Zwick and Knott 2009).
Yet right means more than well-matched. The data fed into algorithms are tied to individuals and their “behavior,” a way of understanding action that implies deliberate decisions for which people can be legitimately held to account (Boltanski and Thévenot 2006). Fourcade and Healy (2017:24) argue that the mass use of personal data therefore inculcates an “economy of moral judgment” in which “outcomes are experienced as morally deserved positions based on prior good actions and good tastes.” An individual rightly reaps the rewards or suffers the ill effects of her data because it is her data. Moreover, the method of moving from data to decision—computation—“seems dispassionate, impartial and objective” (Fourcade and Healy 2017:17), bolstering the sense that predictions indicate not only what people will want, but also what they ought to get.
The Case of Car Insurance Pricing
To better theorize how algorithmic prediction functions as a framework of market fairness—and the conditions under which it may be challenged—it is useful to start digging into the case of car insurance pricing. This is a domain in which predictive usefulness has long operated as a moral justification. In the United States, car insurance companies gather data about individuals to actuarially predict how likely they are to file insurance claims and otherwise cost companies money. Insurers then charge different people different prices in line with these expected costs.
That this is a fair way to price insurance is institutionalized in law, regulation, and the standards of the actuarial profession. In the early twentieth century, most states adopted statutes to govern property and casualty insurance, of which auto policies are one type (homeowners’ insurance is another). These statutes prohibit “unfair discrimination,” which exists if “price differentials fail to reflect equitably the differences in expected losses and expenses” (NAIC 2010:5; see also Schneiberg and Bartley 2001). 2 In other words, for insurance to be fair, companies must charge customers for their predicted costs. These laws evolved from industry efforts to prevent insurers from destructively undercutting each other on price (i.e., from engaging in unfair competition). Over time, regulators, actuaries, and members of industry embraced the idea that pricing in line with predicted costs was also a form of fairness to consumers (Crane 1972; Wortham 1986b). Scholars of insurance refer to this as “actuarial fairness,” a term that companies, regulators, and other practitioners occasionally use as well. 3
As a moral construct, actuarial fairness relies on a particular cultural scaffolding, one that foregrounds individuals and automates accountability (Baker and Simon 2002). People who companies calculate to be low-risk pay less, and people who companies calculate to be high-risk pay more. This is considered fair because high-risk people are likelier to draw from the pools of money insurers gather through the collection of premiums. To charge otherwise would be an improper subsidization of people predicted to file expensive insurance claims by those predicted to file few if any. Why some people register as low-risk and others as high-risk is irrelevant (Baker 2003; Hellman 1997). Making people responsible for the risk they bring into the insurance system may mean some cannot afford coverage, but others may “feel morally comfortable” with this outcome by understanding that the allocation of insurance is the result of dispassionate actuarial calculation (Stone 1993:309). 4 As with quantification more broadly, mathematical prediction is “a way of making decisions without seeming to decide” (Porter 1995:8).
This, however, is not the only moral understanding of insurance. Actuarial fairness runs counter to an older, some would say definitional, conception of insurance as a way to spread risk across a population. In this “solidaristic” approach, money from those lucky enough to avoid misfortune helps cover the costs of those unlucky enough to have to submit claims. Some policyholders effectively pay for others, but that is the entire point (Baker 2003; Ewald 2002). In the United States today, different types of commercial and social insurance continue to embrace this approach to varying degrees. But in the early twentieth century, actuarialism gained a dominant foothold as profit-seeking corporations using risk-based pricing worked to de-legitimize the solidaristic models of competitors, such as mutual aid societies and fraternal organizations (Baker and Simon 2002; Levy 2012).
Yet, the notion that actuarial pricing lets insurers charge people only for their own risk is misleading. Data may be about individuals, but mathematical predictions are not. Predictions rely on comparison across individuals to generate knowledge (Hacking 1990; Heimer 2001; Schauer 2003). This proves crucial for understanding the broader moral economy of algorithmic prediction. To predict whether a person will file a claim, an insurer needs data on hundreds if not thousands of other people, some of whom have filed claims and some of whom have not, in order to parse which patterns of data correlate with claims and which do not. Algorithmic prediction relies on variation in an outcome of interest, and a single person does not produce enough observations on her own. An insurer’s calculation of a person’s risk—and the price she ought to receive—is therefore always a function of how other, somehow similar, people have behaved.
Historically, this has led to controversy when mathematically useful similarity overlaps with socially and politically salient ways of grouping people, such as by race, sex, marital status, occupation, education, or zip code (Starr 1992; Wortham 1986b). On many occasions, advocates and policymakers have pushed back against the use of such rating factors, especially immutable traits such as race and sex that carry the weight of historical injustice. As early as the 1880s, some states banned life insurers from charging African American policyholders higher prices than white policyholders, even though black individuals did not live as long on average (meaning insurers had fewer years over which to collect premiums) (Bouk 2015).
Many similar efforts, however, have been unsuccessful. These include attempts in the 1970s and 1980s to curtail car insurers’ use of sex and marital status as rating factors, and more recent attempts to limit the use of education and occupation. Courts and legislators have routinely rejected civil-rights-style claims about equal treatment in favor of the argument that when data help predict costs, they are fair to use (Avraham, Logue, and Schwarcz 2014; Horan 2011; Wortham 1986b). This is a testament to how entrenched actuarial fairness is in U.S. insurance law.
Yet little of this accounts for credit-based insurance scores being so contentious. The case is thus a good one for understanding how algorithmic prediction can function as a moral justification—and the conditions under which people are likely to refuse to accept it as such. Credit scores are decidedly not a socially salient way to group people. What does it mean to look and feel like a 724? Indeed, the way credit scoring algorithms scramble information about individuals actively prevents people from being able to recognize and act on social identities (Krippner 2017; Krippner and Hirschman 2019; Simon 1988). Moreover, car insurance as a field strongly adheres to the actuarial paradigm. Unlike in other realms, such as health insurance, there are not ongoing conversations about the virtues of solidaristic subsidization—there is no equivalent to debates about who should pay for preexisting health conditions. Perhaps more so than in any other industry, car insurance is ruled by the idea that data that mathematically predict how people will behave are fair to use. Credit scores predict insurance claims. So how have they drawn such intense scrutiny for so long?
Credit-Based Insurance Scores as a Case of Resistance
To understand credit scores—algorithmic predictions about how likely people are to do certain things, such as repay loans or file insurance claims—we must start with raw credit data. Credit bureaus have long found insurers to be eager buyers of the information they compile about individuals’ financial pasts, including how timely people have been with loan repayments, the total amount individuals have borrowed, how often they have inquired about obtaining new credit, and much more (Bouk 2015; Lauer 2017). When the U.S. government regulated credit bureaus for the first time in 1970, insurance underwriting was codified as a permissible use of credit data. The law eventually required companies to tell people when credit records led to “adverse action,” such as a higher price for insurance or credit. Decades later, this rule let people know credit scores were to blame for their suddenly higher car insurance rates.
The databases credit bureaus maintain, like those all sorts of companies compile today, capture personal information in rationalized form. Thousands of fields of data render events, such as opening a new credit card or filing for bankruptcy, in uniform, largely numeric ways. Standardized categories and codes, such as ones that mark loan payments as 30, 60, or 90 days late, make it easier to share data among companies and funnel information into a format conducive to quantitative manipulation (Kiviat 2017).
As with other systems of quantification, the categories used to measure and record behavior can appear self-evident and value-neutral (Hirschman, Berrey, and Rose-Greenland 2016). Yet a mathematical “view from nowhere” is a chimera (Daston 1992; Porter 1994). As Bowker and Star (2000:5) write, “each standard and each category valorizes some point of view and silences another” (see also Desrosières 1998). Technical decisions about how to construct data are “ethical choice[s]” (Bowker and Star 2000:5). These decisions reflect judgments about which details are important to pay attention to, which details are fine to ignore, and which qualitatively different phenomena ought to be grouped together. In markets built on personal data, corporate values like profit maximization shape how consumer behavior gets selected for measurement and slotted into categories (Krenn 2017; Seaver 2015).
To move from raw credit information to credit scores, companies mine data to statistically link pieces of credit records to outcomes of business interest, such as loan defaults or insurance claims (Guszcza and Wu 2003). This involves collapsing information from individuals’ credit files into a single set of numbers, facilitating interpersonal comparisons. Credit scoring, like other types of predictive scoring companies use, is thus a form of commensuration, or the “transformation of different qualities into a common metric” (Espeland and Stevens 1998:314).
A core feature of commensuration and the categorization that precedes it is that the amount of information communicated is greatly reduced (Beniger 1986; Espeland 1998). Turning lived experience into metrics involves stripping away context that may be telling but is difficult to measure or compare across cases (Espeland and Stevens 2008; Heimer 2001). Struggling to repay a loan, for example, involves people having thoughts and feelings and events unfolding over time. When compressed into a credit score, all those details disappear. The broader social environment in which people live and make decisions also becomes invisible. A credit score is assigned to a single person, even though family, geography, and history may have played roles in the score turning out the way it did (Wherry 2019).
Getting rid of large amounts of information is not incidental. Credit scoring and other forms of algorithmic prediction would not work were each person portrayed with idiosyncratic nuance. The mechanics of mathematical prediction necessitate the creation of comparable cases (Guseva and Rona-Tas 2001).This means credit scores present people as simpler than they really are, a fact that has had immense bearing on how policymakers reacted to credit-based insurance scores.
At least some insurers looked at consumer credit files as early as the nineteenth century, but credit scores were an invention of the late twentieth century (Bouk 2015; Lauer 2017). In the 1980s, data analytics firm Fair Isaac introduced the first general-purpose credit scores for lenders (today’s FICO scores), a big step in a decades-long trend of lenders using credit data in increasingly quantitative ways (Marron 2009; Poon 2007). By the early 1990s, Fair Isaac also figured out how to use credit data to predict outcomes of interest to car insurance companies, as did its competitor ChoicePoint and a handful of large insurers such as Allstate and Progressive. As insurance companies began using credit scores to set prices, state insurance regulators found out about the practice through routine rate filings and complaints from consumers who saw their insurance prices increase, at times doubling or more.
Within a few years of credit scoring’s introduction, most parties agreed that credit scores predicted risk of loss and other measures of how costly customers would be to insurers. Given the field’s guiding principle of actuarial fairness and federal law allowing insurers to consider credit records, one might expect credit scores were uneventfully accepted.
Instead, credit-based insurance scoring was subject to decades of regulatory and legislative scrutiny. This includes five congressional hearings, at least 17 full-scale state investigations (often requiring in-person testimony from industry executives), four intensive reviews by the professional association of state insurance regulators, and the passage of dozens of state laws restricting credit score use. Today, all states have laws or regulations limiting how companies can use credit scores in property and casualty insurance, although only four ban it outright (NAIC 2016). The policy debate touched on many issues, but the central concern time and again was the fairness of using credit scores to raise insurance rates—the thing that, given actuarial fairness, should have been self-evident. 5 Put to the test, algorithmic prediction failed as a moral defense. How it did so casts light on the moral limits of predictive practices.
Data and Methods
In this article, I investigate the moral economy of algorithmic prediction by studying public policy debates. The value of studying such debates is that as social actors justify their actions and ideas and challenge those of others, they draw on taken-for-granted understandings, thus articulating assumptions and worldviews that otherwise might remain in the background (Boltanski and Thévenot 2006; Swidler 1986). The discourse of debate thereby makes visible moral understandings, as well as how different understandings come into conflict. As Massengill and Reynolds (2010:486) write: “Focusing on the ways that individuals and groups use moral language to describe market phenomena offers a unique perspective into both the larger cultural framework that informs economic exchange, as well as the strategic ways that individuals use those cultural resources to create moral order in market contexts” (see also Spillman 1999).
This research draws on a qualitative case study of policy debates about the use of credit scores in car insurance pricing. Credit-based insurance scores are a strategic case for understanding how actors negotiate the moral basis of algorithmic prediction because the idea that predictive data are fair data is well-institutionalized in car insurance. Anyone arguing otherwise must address why the standard falls short—thus producing discourse for study. Moreover, laws and regulations governing insurance and credit reporting provide pathways for contestation to arise. Regulators see how prices are set; drivers know when rates increase because of credit scores; and insurance departments have channels for consumers to complain. This helps reveal disagreement that in other markets may remain unarticulated.
I rely on documents produced during debates that started in the early 1990s and continue to the present. These documents include transcripts and recordings of hearings held by regulators and legislators, policy reports, actuarial and other studies, minutes from regulatory meetings, and texts of state laws. Hearings and meeting minutes are particularly valuable, because they reveal how actors work to convince each other that their way of thinking is the right one (Guetzkow 2010). I analyzed more than 6,600 pages of documents and 28 hours of recordings.
Many of these documents come from the National Association of Insurance Commissioners (NAIC), a professional organization of state insurance regulators who oversee the industry. The NAIC frequently brings together policymakers, members of industry, and others to discuss emerging issues in insurance. Through the NAIC, regulators establish standards, set best practices, and coordinate oversight. The organization thus plays a substantial role in shaping U.S. insurance law and regulation. The NAIC records and publishes detailed minutes of its meetings in its official Proceedings, and it retains supplemental materials, such as audio recordings, submitted testimony and comments, and presentations. On the issue of credit-based insurance scores, the NAIC has also collected information from individual states. I gathered documents through a series of keyword searches in the Nexis Uni database, which contains the NAIC Proceedings back to 1950, as well as from NAIC web sites and staff members. I supplemented these documents with others mentioned in the NAIC archives, including transcripts and recordings from hearings held in Florida, Georgia, Michigan, and Wisconsin. I obtained these materials directly from those states.
To this corpus, I added two other types of documents. First, I added five congressional hearings that were entirely or largely about credit scores in insurance, including one titled, “Credit-Based Insurance Scores: Are They Fair?” I identified these by keyword searching the Proquest congressional database. Second, I gathered existing meeting minutes from the National Council of Insurance Legislators (NCOIL), an association of state legislators that wrote a model law on credit-based insurance scores in 2003. NCOIL has not preserved all materials related to the creation of this model law, so I also interviewed state legislators involved in its development.
A potential drawback of the documents used in this article is that they almost exclusively capture “front stage” behavior (Goffman 1959), because actors are articulating arguments in venues where other people are obviously paying attention. In a way, that is the point: to witness the public, social construction of market morality. Yet it does mean underlying motives, especially motives actors would rather keep to themselves, are not necessarily evident in the materials. This means I can make stronger claims about how insurance companies fight for actuarial fairness than I can about why they do so.
In case studies, researchers proceed sequentially through data, honing their understanding as they go, until they reach a point of saturation, when continued analysis brings no new insight (Small 2009; Yin 2009). In analyzing the data, I started with the broad question of how credit-based insurance scoring was contentious; that is, what people disagreed about when they disagreed. I spent time closely reading documents and listening to recordings to uncover how participants in the debate articulated why it was or was not desirable to use credit scores to price car insurance. At times, it took some unpacking to understand the nature of the disagreement, such as when policymakers and members of industry used the same word (e.g., “risk”) to refer to different concepts.
To organize my thoughts, I took notes and wrote memos (Charmaz 2012; Glaser and Strauss 2007). These memos, a key aspect of my analytic approach, summarized arguments, developed emergent themes, and abstracted away from explicit statements to excavate the underlying principles animating the debate (Gibson 2016; Lofland et al. 2006; Miles and Huberman 1994). My approach can be described as abductive (Tavory and Timmermans 2014). Theoretically-informed questions guided the initial case selection, but specific ideas emerged from the data, rather than from a particular theory used as an a priori framework. As my analysis progressed, I returned to theory to make sense of my observations, iterating between data and extant research.
Alongside this process, I used the data analysis software MaxQDA to assign codes to documents. These codes helped systematically connect actors (e.g., regulators, insurers, credit scoring outfits) with arguments made and questions raised (e.g., why a person would have bad credit). This part of the analysis let me test the ideas I developed during the more inductive phase and check for explanations I may have missed or underplayed.
Findings
Correlation, Causation, Explanation
Since the first hearing of the National Association of Insurance Commissioners (NAIC) in 1995, insurance companies and credit scoring outfits have argued that credit-based insurance scores are fair to use because they predict risk of insurance loss. This is the core of actuarial fairness: people should pay according to how much companies expect them to cost. Industry often holds that charging people with lower credit scores higher premiums is not only something they should be allowed to do, but something they must do. 6 Otherwise, people with high credit scores will be forced to pay more than their fair share.
Such arguments depend on credit scores being predictive of insurance loss, but in the early years of credit-based insurance scoring, regulators questioned whether that was the case. In testimony submitted for the NAIC hearing, a lawyer from Texas’s Office of Public Insurance Counsel wrote that he was “unaware of any convincing study or data that satisfactorily links risk of loss to credit history” (NAIC 1995). At the hearing, representatives from the credit scoring outfit Fair Isaac and the insurer Allstate discussed how those companies had built their models, but it would take a few more years for most regulators to be satisfied with the idea that credit-based insurance scores predicted insurance loss (NAIC 1997).
A key factor drawing out the process was the nature of credit scoring models. Insurance companies had long had to show regulators that their rating factors were actuarially justified by filing information on their pricing plans, but insurers and scoring outfits considered scoring models to be trade secrets and not sharable in the normal ways (NAIC 1997). Insurance regulators were faced with their first algorithmic “black boxes.” Eventually, via a series of statistical studies, including one commissioned by Fair Isaac, and visits between regulators, credit scoring outfits, and insurance companies—there was a lot of flying around the country—regulators became generally convinced that credit scores correlated with insurance outcomes.
This was an important step for regulators. In line with the field’s dominant logic of actuarial fairness, they were deeply invested in whether credit scores predicted insurance loss. Yet much to the chagrin of insurance companies, that was not all they cared about. Regulators—and the state and federal legislators who turned their attention to the issue in the years that followed—also wanted to know why credit scores predicted loss. They wanted an explanation. Insurance companies and trade associations balked at such requests, which, they said, were unlike anything they had received before. At a 2003 congressional hearing, an Allstate attorney testified: Allstate’s use of insurance scoring as a risk evaluation tool is based on the fact of its predictive power, not on the explanation for its predictive power. Insurance pricing based upon valid and credible data and actuarially sound methodology has never been asked to support
Industry members were even more disgruntled by discussions about causal explanation. When the NAIC added a section on spurious correlations and causal relationships to a draft of a white paper regulators had been working on with members of industry and consumer advocates for the better part of two years, representatives from industry trade groups strongly protested the “radical departure,” and the American Insurance Association withdrew its support (NAIC 1996). In a 2009 Florida hearing, Michael Miller, an actuary who co-authored an influential industry-funded report on the predictive validity of credit scores, expressed frustration at talk of a causal link: Credit-based insurance scores do not cause accidents. Neither is there a cause and effect relationship with any other rate factor used to assess risk. Past accidents do not cause future accidents. Past driving tickets do not cause future driving accidents. It’s the correlation, the predictive power of these risk factors that we are relying on, not whether they cause accidents.
Later in the hearing, Steve Parton, general counsel for Florida’s Office of Insurance Regulation, returned to the issue:
It’s clear to me the industry really doesn’t know what credit scores are doing other than it appears to correlate with claims history. End of story. You don’t know why . . .
It’s not fair to accuse industry for not knowing why, because that’s not really knowable for any risk factor.
I’m not accusing the industry. It’s what they tell me all the time, Mr. Miller, that they don’t know why this is occurring. I’m not accusing, I’m merely making a statement that they don’t know why it correlates, and you’re telling me they don’t know why anything else correlates, and I understand that. I’m just saying they don’t know.
The reason I am sensitive to this statement is because it’s made in a way that implies that that’s a fault of credit-based insurance scores, and I’m just pointing out that what you think is a weakness in not knowing why there is a correlation is not a knowable thing, and it’s not knowable for any risk factor. If you were going to say the test of whether you can use a particular risk factor is if you can prove to us why it’s correlated, then every risk factor would fail that test. (Florida Office of Insurance Regulation 2009)
A close examination of the written record reveals that most regulators and legislators who asked for an explanation of why credit scores predicted insurance loss were not asking for the sort of statistical causal identification that, given the complexities of the social world, would almost surely be impossible to produce, as Miller and plenty of others—including the American Academy of Actuaries—pointed out (American Academy of Actuaries 2002). Rather, as policymakers repeatedly asked on what basis credit scores were “relevant,” “logical,” and “related” to insurance claims, and how the results of correlational analyses were “reasonable,” “plausible,” and reflected “common sense,” what they were really seeking was causal theory. 7
The reason: even in a world permeated by the idea that prediction is a form of moral justification, policymakers drew on another standard of right and wrong. In this competing moral calculus, whether predictive data were fair rested on a careful assessment of responsibility, blame, and virtue. Not only math, but moral deservingness factored into policymakers’ thinking in that they evaluated what people ought to receive by considering the goodness of their past actions (Feinberg 1970; Rachels 1991). 8 Policymakers wanted to understand why credit scores predicted insurance loss in order to determine if any links in the causal chain held the wrong people to account, and as a consequence gave them prices they did not deserve.
Causal Theorizing as Moral Adjudication
As policymakers sought to understand credit-based insurance scoring, they asked two distinct but related “why” questions. First, they wanted to know why there was a correlation between credit scores and insurance claims. Or, more generally: Why does the prediction work? Second, they wanted to know why people had low credit scores in the first place: Why do people show up in the data the way they do? Coming up with plausible (if not empirical) answers to these questions helped policymakers decide if consumers were being improperly penalized or punished—words used throughout the debate—with higher insurance prices.
Industry representatives got an early jump on suggesting why prediction worked, even as they continued to argue such explanation did not matter. Some people, they held, were irresponsible, and this irresponsibility simultaneously led to failing to repay one’s loans on time and the sort of careless car ownership and driving that resulted in needing to file insurance claims. As Fair Isaac explained in written testimony for an Iowa investigation: “In general, people with good credit habits demonstrate careful behavior overall. This crosses over into their driving habits, care of their automobiles, and care taken in the maintenance and safety of their homes” (Robinson 2011). Or, as an insurance company executive explained at a 2002 Michigan hearing, people who demonstrate no responsibility in repaying debts are likely the same people who fail to stop at stop signs and red lights (Michigan Office of Financial and Insurance Services 2002a). This causal theory is represented in Figure 1. Variants of this theory relied on other essentializing traits, including inattentiveness, carelessness, aggressiveness, instability, and distractedness.
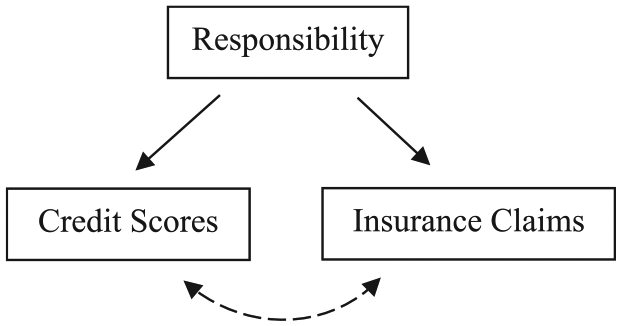
Representation of a Theory Policymakers Invoked to Make Sense of the Correlation between Credit Scores and Insurance Claims
A different theory of why prediction worked hinged on what, exactly, credit scores predict. Insurance companies used many terms: insurance claims, loss experience, loss ratio, risk of loss, frequency of loss, severity of loss, loss potential, and pure premium. Yet they never said credit scores predicted car accidents. This turned out to be a sticking point. In a 2010 House hearing, Congressman Al Green of Texas questioned a panel consisting of David Snyder from the industry trade group American Insurance Association, John Wilson from the data provider LexisNexis (which sold credit-based insurance scores), and Illinois insurance commissioner Michael McRaith:
Let’s first review some intelligence that I have received. The intelligence indicates that credit-based insurance scores are not, “n-o-t,” held out as being predictive of an individual’s likelihood to have an automobile accident. . . . Is this true?
They are predictive of making a claim.
Is it true that they do not predict that a person is likely to have an accident?
Models perform for groups of individuals rather than for individuals.
Do you know whether it is predictive of whether a person will have an accident? I am not hearing you say yes or no. I do not know.
It is predictive of having an accident and making a claim; yes.
A credit score can predict whether a person will have an accident?
It is my understanding, Congressman, that a credit score indicates a likelihood of submitting a claim.
I am not there yet. I am talking about the likelihood of having an accident, which I thought was going to be the easy question, by the way. Let me ask again: Will a credit score predict whether a person will have an accident?
I have not seen any study that indicates that to be true. (U.S. Congress 2010)
As illustrated by this exchange, industry rhetorically conflated insurance claims with car accidents. However, many people who have accidents do not file claims. This could be because their deductible exceeds the amount of damage, because they would rather pay out of pocket than file a claim and see their rates go up the following year, or for another reason (Robinson 2011). What credit scores measure—what “risk” means when companies use that word—is not the probability of something bad happening, but the probability of something bad happening and a policyholder asking the insurance company to pay for it.
This distinction grabbed the attention of policymakers because of what they understood to be the reason some people would forgo submitting claims and others would not. As Jay Bradford, the insurance commissioner of Arkansas, said at a 2009 NAIC hearing: What concerns me is the fact that people who are in a lower economic status, due to no fault of their own, they have lower deductibles and don’t have the means to absorb losses so they use their insurance. That is what they purchase it for. People of lower economic status are higher risk because they can’t self-insure themselves, they have loans on their vehicles and they have to fix them. I come from the producer [insurance agent] side, and people who have higher incomes have fewer claims because they have higher deductibles and their brokers tell them they shouldn’t submit the claim if it is $400–700. But if someone is working at minimum wage he has to. (NAIC 2009b)
This causal theory is represented in Figure 2. Here, income, not personal responsibility, simultaneously leads to both lower credit scores and more insurance claims. From the standpoint of actuarial fairness, the distinction is irrelevant, but for policymakers thinking in a framework of moral deservingness, the difference was incredibly important. Policymakers were generally willing to accept that consumers might deserve to pay more for insurance by virtue of their general irresponsibility in life, but many were less willing to accept that consumers might deserve to pay more by virtue of their low earning power. It was fine to hold people to moral (and financial) account for one quality but not for the other.
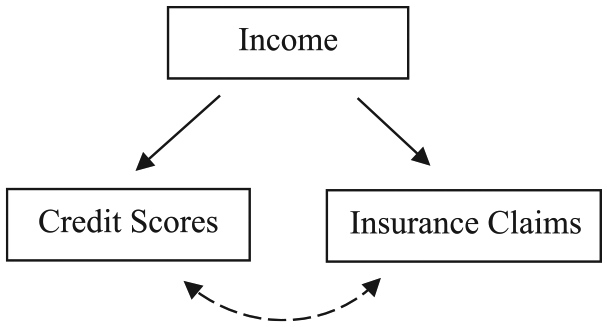
Representation of a Competing Theory Policymakers Invoked to Make Sense of the Correlation between Credit Scores and Insurance Claims
In other words, depending on a person’s theory of why credit scores predict insurance claims, credit-based insurance scores can register as either fair or unfair. This distinction is impossible to make when the only issue is whether the data accurately predict the outcome. Research from psychology shows that moral reasoning often takes the form of causal thinking and narrative (Malle, Guglielmo, and Monroe 2012; Martin and Cushman 2016). Stories are thick forms of understanding in which events unfold over time in particular contexts. Actions can therefore be understood in terms of intentions and trade-offs, which helps people hearing the story decide how harshly to judge a person who has behaved a certain way (Bruner 1990; Scott and Lyman 1968; Stone 1989). Simply saying that credit scores and insurance claims are correlated provides none of this information. Categorization and commensuration reduce information, and the narrative details people rely on to assign blame are among the bits of information wiped away as consumers’ lived experiences are collapsed into a single number.
The second “why” question that policymakers repeatedly theorized an answer to was why people have low credit scores in the first place. To decide if it was fair to hold people to account for how they showed up in the data, policymakers sought to understand why they showed up that way. They therefore turned their attention to factors that might have bearing on loan repayment and credit quality, as shown in Figure 3. In moments when policymakers discussed personal irresponsibility as the likely cause, they did not express nearly as much reservation about credit-based insurance scores as when they theorized other causes. Key among these were various misfortunes, including medical travesty, divorce, and job loss. Consideration of what came to be codified in many state laws as “extraordinary life circumstances” routinely returned to the idea that these events had occurred to people through no fault of their own.

Representation of Another Policymaker Preoccupation: What Causes Low Credit Scores
Race and ethnicity appeared in the debates in a similar way. In a 2007 report to Congress, the Federal Trade Commission (FTC) concluded that minorities had significantly lower credit-based insurance scores than did white individuals. More than a quarter of African Americans in the FTC’s sample had scores in the lowest decile of the distribution, whereas only 3 percent had scores in the top decile (Federal Trade Commission 2007; see also Texas Department of Insurance 2004). Those invoking the idea of actuarial fairness focused on the fact that credit scores predicted insurance loss within racial and ethnic groups, and concluded that because prediction worked for all groups, it was fair to use for all groups. Yet some regulators and legislators argued that the issue was what led to the skewed distribution of scores. If low scores stemmed from long-standing inequities, such as exclusion from mainstream credit markets, predatory lending practices, and residential segregation that made it tougher to find good-paying jobs and build housing wealth, then one could argue—and many did—that it was not fair to penalize minorities for their lower scores with higher prices. 9 Minorities could not deserve higher prices by virtue of the discriminatory actions of others.
Concerns about why some people had low credit scores also arose during hearings as regulators and legislators dug into the mechanics of credit scoring and discovered the sorts of information models relied on. Policymakers found many factors intuitive—the number and severity of loan delinquencies, the presence of bankruptcies—but others they did not. For example, at multiple hearings policymakers questioned companies about using the fact that data were missing from credit files as a meaningful piece of information in and of itself. That is to say, when data were missing—when there was a space, say, for total amount owed on a loan and it had been left blank—people were more likely to file claims.
Yet as Georgia insurance commissioner John Oxendine asked in a 2001 hearing: “If you don’t know how much someone owes, how can you say that’s a strike against them?” (Georgia Office of Insurance 2001). The problem for many regulators was that consumers had nothing to do with the fact that data were missing. Missing data meant creditors had failed to report complete information. As a 2002 Florida report put it: “Excessive or unknown amount owed on accounts (Is that the fault of the consumer or the reporting entity?)” (Florida Department of Insurance 2002). The implication being, rates should not increase if consumers were not to blame.
Industry understood the importance of fashioning low credit scores as a function of consumers’ own actions and not those of financial institutions. During the 2007 to 2008 financial crisis, some lenders cut the credit limits of borrowers as a precautionary measure. This drove up the ratio of outstanding balances to credit limit (a person’s “credit utilization”), which drove down credit scores even if borrowers behaved the same. Policymakers criticized industry for letting something consumers could not control affect their insurance prices. Industry’s response was to explain how consumers were, in fact, still in control. In testimony submitted for a 2009 NAIC hearing, Lamont Boyd, Fair Isaac’s head of insurance scores, wrote: “While, in many cases, credit cardholders don’t control their credit limits, they can control their account balances. Recent data shows that a notable number of consumers have reduced their revolving credit usage, helping to minimize any effect from lenders reducing their account limits” (NAIC 2009a). The logic was that because consumers could take steps to avoid a lower score, they were accountable for whatever their score may be.
Control, however, was not always a bright line. In certain circumstances, even if people could take action to improve their scores, policymakers were loath to let a failure to do so influence insurance rates. For example, state investigations often included testimony from consumers who had a low credit score, or none at all, because they had chosen to borrow little to no money, and therefore lacked a robust record of timely repayment. At a 2002 Michigan hearing, state representative David Woodward, sponsor of a bill to ban the use of credit scores, testified: “My grandfather and grandmother . . . they paid by cash for everything. They did not have a lengthy credit report. Now, is it fair to say that they . . . have to pay higher rates because they’re not using credit cards or they’re not taking out loans? [That] is . . . absolutely absurd” (Michigan Office of Financial and Insurance Services 2002b).
In the consumer credit world, failing to repay borrowed money on time is bad, but so is not borrowing enough. Both lead to lower scores. Yet for many policymakers, staying debt-free was a good and worthy act—one that should not lead to higher insurance rates, no matter what an algorithm might say. 10
De-commensuration as Policy Response
One way of understanding the issues policymakers had with credit-based insurance scoring is that scores grouped together meaningfully different behaviors from the perspective of moral evaluation. Insurance companies and credit scoring outfits sorted people in a way that was appropriate to their task: predicting insurance claims. But policymakers were engaged in an additional task. As they worked to establish a type of market fairness that only held the morally fallible to account with higher prices, they found that the sorting and scoring work of industry misclassified certain people. Individuals who fail to pay credit card bills because they lose a job and those who fail to pay their bills because they do not take financial obligations seriously are interchangeable to a credit scoring algorithm, but policymakers did not see them as morally equivalent. Credit scores may properly commensurate human behavior for purposes of mathematical prediction, but they create false equivalences for purposes of moral adjudication. 11
Many of the policies established to regulate credit-based insurance scoring aimed to undo industry’s classificatory work and put consumers back into what policymakers saw as the right categories, so that blameless consumers would not be penalized with higher rates. 12 To do this, policymakers undertook what I call de-commensuration—the deconstruction of a metric to reveal qualitative differences in objects being evaluated. 13 For example, a model law drafted by the National Council of Insurance Legislators (NCOIL), a professional association of state lawmakers, and adopted in whole or in part by 29 states, included a list of “extraordinary life circumstances”—times when insurers should make exceptions for consumers with low credit scores. These included:
Catastrophic event, as declared by the federal or state government
Serious illness or injury, or serious illness or injury to an immediate family member
Death of a spouse, child, or parent
Divorce or involuntary interruption of legally-owed alimony or support payments
Identity theft
Temporary loss of employment for a period of 3 months or more, if it results from involuntary termination
Military deployment overseas
Other events, as determined by the insurer (NCOIL 2009)
Some states included additional circumstances. For example, after hurricanes Katrina and Rita ravaged Louisiana in 2005, that state’s insurance department issued a bulletin to ban insurers from considering negative credit history that could be tied back to people being displaced or economically affected by the storms (Louisiana Department of Insurance 2006).
In writing such lists into law, policymakers codified situations in which they thought the market ought not hold people accountable for their data. Some situations, such as serious injury and death of a spouse, are almost certainly things that happen to people and are arguably beyond the control of consumers. Others, however, involve deliberate actions individuals presumably could have avoided. People may feel constrained in the decisions they make, but they do ultimately choose to get divorced or join the military knowing that deployment follows. The inclusion of these situations shows that policymakers were concerned not only with how people might be disadvantaged for circumstances over which they had no control, but also with how people might be disadvantaged for making morally justified choices.
This was clear in how states restricted insurers’ use of inquiries, or records of lenders looking at credit files (NAIC 2016; Robinson 2011). Too many inquiries, and a person’s credit score drops. A large number of inquiries can indicate someone is desperately applying for credit, but the same pattern can also mean a person is shopping around for the best rate on a loan. This was something policymakers considered financially responsible and worth praising, not punishing. Because credit scores conflate the two situations, policymakers pulled them apart by requiring that certain clusters of inquiries only count once. Policymakers also saw an important distinction in how an inquiry came about. Sometimes lenders look at credit reports because people ask to borrow money, and sometimes they look on their own to make unsolicited offers. As an NCOIL staffer explained at a 2009 NAIC meeting: [The model law] also states that credit inquiries that a consumer didn’t initiate can’t count. So, when credit card companies, like over the last few years, mine your credit reports trying to decide whether you should get a low or no interest credit offer, that doesn’t count against the consumer because that isn’t the consumer’s fault. It really tries to reward sound financial behavior. It states that inquiries related to the auto lending industry or the mortgage lending industry only count once within the 30-day period. Because often, insurance and credit scores count negatively if you have too many hits on your credit report. Obviously, if you are shopping around for a mortgage, and you go to four lenders in three months looking for the best rate, that is a good decision and that is not something that should count against folks. (NAIC 2009b)
Many other limitations written into law and regulation reflected this dual concern with agency and the moral tone of intentional acts. Policymakers excluded data they saw as not under consumers’ control, such as medical debts and information whose accuracy consumers disputed (NAIC 2016; Robinson 2011). 14 When it came to actions policymakers did see as under consumers’ control, they limited the use of data they thought indicated morally laudable acts (e.g., not opening credit card accounts in the first place), blameworthy acts that now deserved forgiveness (e.g., delinquencies more than a given number of years old), and actions that carried no moral connotation (e.g., having a certain number of credit cards, having a certain type of credit card, or starting to borrow at a particular age).
Notably, imposing restrictions on credit-based insurance scoring was a bipartisan affair. The process of questioning actuarial fairness via causal theorizing and de-commensuration was pretty consistent across party lines, especially in state-level discussions. 15 What did vary by political ideology were ideas about which causal theories were the important ones to pay attention to, and which groups of people had been improperly commensurated. Members of NCOIL, for instance, a heavily Republican body, discussed the fact that credit scoring disproportionately raised prices for low-income individuals and minorities, but they decided not to address the issue in their model law (NAIC 2009b). Predatory lending, to take another example, only made it onto one state’s list of extraordinary life circumstances, even though consumer advocates frequently pointed to the impact such practices had on credit scores and the 2007 to 2008 financial crisis cast a national spotlight on the issue.
Some information was also technically easier to strip from credit scoring algorithms. Individual fields of data in a credit file and life events like job loss are discrete and can easily (if not seamlessly) be adjusted for. Companies can create algorithms to count half a dozen inquiries as just one, and they can tell insurance agents to undo the surcharge of a low credit score if customers provide a letter showing they have been laid off. 16
When the causes of low credit scores are understood to be entangled with structural inequality, undoing the classificatory work of industry is more difficult. Many states prohibit credit scoring models from including information about a consumer’s race and income. Yet, these restrictions are essentially symbolic. Insurers repeatedly said they did not collect such information to avoid allegations of discrimination. Even when models do not include race and income as variables, models can still indirectly pick up on and promulgate the effects of race and income as instantiated in any number of “behavioral” patterns (Barocas and Selbst 2016; Hyman 2011). 17 When an actuarial model reflects engrained social inequities, tweaking around the edges does not accomplish much.
Arguably, the more effective response to these concerns would have been to ban credit-based insurance scoring altogether. This rarely happened. Policymakers have been questioning the fairness of credit scoring in insurance for more than 25 years, and bans have been proposed at the state and federal level on dozens of occasions, largely by Democratic legislators. However, only two bans have ever passed after extended legislative debate, in Massachusetts for car insurance and in Maryland for homeowners’ insurance (National Conference of State Legislatures 2016). 18
A major hurdle to banning credit scoring is that when people with low credit scores do not pay more for insurance, those with high credit scores lose their discount. The allocation of insurance premium across a population is essentially a zero-sum game. Although policymakers successfully argued that not everyone with a low credit score deserves to pay more for insurance, they laid little groundwork for the argument that not everyone with a high credit score deserves to pay less. Whenever it looked like a state might ban credit-based insurance scoring entirely, industry quickly responded.
For example, after polls showed that a 2006 ballot initiative to ban the practice in Oregon would likely pass, the insurance industry spent $5 million on pro-credit-score messaging (NAIC 2009a). When industry lobbied against proposed bans, it was able to flip public opinion by arguing that people with good credit scores should not be forced to subsidize those with bad ones. That is, they appealed to the idea that people with good credit scores deserve low insurance prices.
Actuarial fairness rests on the principle that it is right to hold high-risk people accountable for their high-risk status, whether or not it was of their own doing, and it is wrong to deny low-risk people the financial benefits of their low-risk status, whether or not they had any hand in becoming low-risk (Baker 2003; Hellman 1997). Acknowledging that people should not be penalized with high insurance prices by virtue of bad luck and other morally forgivable circumstances was relatively easy. Acknowledging that people should not be rewarded with low insurance prices by virtue of good luck and other unearned privilege was a political nonstarter. The work of regrouping people into categories of moral deservingness could only go so far.
Discussion
Summary of the Argument and Findings
By introducing credit scores to their pricing models, U.S. car insurance companies inadvertently set off a policy debate that revealed the moral limits of predictive practices. To defend credit scores, industry relied on the idea it always had, an idea that is quickly spreading through the rest of the consumer economy: predictive data are, by definition, fair to use. For policymakers, predictive validity was necessary, but not sufficient, to establish credit scoring as fair. To fill out the picture, policymakers also drew on a competing moral framework, one in which moral deservingness indicated how the market ought to treat people. In this other vision of a just market, consumers who did nothing wrong should not have to pay more just because of how they showed up in a corporate database.
This led to contention in two ways. First, policymakers sought to understand the connection between consumers, credit scores, and insurance claims in non-mathematical, narrative ways. They asked why predictions worked and what caused people to have low scores. These questions led to competing causal theories. This made it difficult to come to a consensus about whether credit scoring was fair, because different causal theories carried different normative implications. Second, as policymakers dug into the mechanics of credit scoring, they discovered that the way industry categorized people for the purposes of prediction did not always align with their understandings of good and bad behavior. At times, the categories industry found to be mathematically useful directly contradicted how policymakers grouped consumers morally.
Using personal data in quantified ways to decide what consumers get can make outcomes seem like “morally deserved positions,” to return to Fourcade and Healy’s (2017) phrase. The institutionalization of actuarial fairness is a testament to that. But the case of credit-based insurance scores reveals that this only works when people agree on the moral validity of underlying causal theories and categories. A “proper” market exchange (Spillman 1999) is one in which the moral orientation of the market comports with broader shared understandings of what makes people blameworthy and virtuous. In line with Thompson (1971), contention arises when the market’s moral foundations betray institutionalized ideas about right and wrong.
The fundamental difference between the two visions of market fairness presented in this article rests in how they sort individuals: as data points or moral beings. That is not to say using math to determine people’s fates is an amoral practice. Actuarial fairness does not avoid the moral minefield. It simply, if implicitly, holds that people are always accountable, regardless of whether the data look the way they do because of personal fault, structural disadvantage, simple chance, or some other factor. Algorithmic prediction is imbued with normative viewpoints—they are viewpoints that suit the goals of corporations. At the same time, treating people as moral beings, as policymakers attempted, does not necessarily preclude the quantification of personal information and lived experience. Policymakers do not, after all, question actuarial practices in toto. It is at least theoretically possible for the two camps to reach common ground.
Implications for Studies of Algorithmic Prediction in Consumer Markets
Thinking about algorithmic prediction in consumer markets going forward, these findings suggest that the least controversial predictions will satisfy two conditions. First, they will lend themselves to causal theories that a broad range of social actors finds morally palatable. Second, they will mathematically categorize and commensurate consumers’ actions in ways that match broader understandings of good and bad behavior. Such matching will be important for both the data fed into algorithms and the decisions coming out. To figure out if these conditions are met and to take action if they are not, actors will have two processes at their disposal: causal theorizing for testing whether the market is unfairly penalizing any morally upright individuals, and de-commensuration for re-sorting consumers according to competing understandings of who ought to receive favorable treatment.
This theoretical framework helps explain other cases of algorithmic prediction. One of the most intrusive ways insurers collect data, for example, is through telematics tracking devices that capture how individuals drive (e.g., how often they slam on the brakes or turn sharply). Yet insurance regulators have barely questioned using telematics data in price-setting. The framework presented here suggests this is because of a broadly shared and morally palatable theory of why prediction works—people who have driven dangerously in the past are likely to do so in the future—and an alignment of mathematical and moral categorization. People who drive safely, a morally worthy thing to do, register as low-risk and get charged less, and people who drive unsafely, a moral infraction, register as high-risk and get charged more. 19 On the rare occasions when regulators have questioned aspects of telematics—such as tracking when people drive—contestation has played out through causal theorizing and de-commensuration. Some regulators, for instance, have expressed concern that telematics may unfairly penalize people who work night shifts (Karapiperis et al. 2015). These people may be statistically more likely to file claims, but if they are just trying to earn a living, is it right to charge them more?
Algorithmic predictions may also go uncontested simply because companies hide them from view, which they often do (O’Neil 2016; Pasquale 2015), a reality put into sharp relief by the distinctiveness of the credit-based insurance scoring debates. In the United States, insurance regulators oversee pricing decisions, and privacy law governs consumer credit data, two background conditions that paved the way for public debate. Indeed, a key feature of the case studied here is that in the 1960s and 1970s, Congress investigated consumer credit bureaus and established a set of procedural protections, including adverse action notices. An earlier reckoning with issues of procedural fairness made data and algorithms visible for a later reckoning with questions of distributional fairness. For industries that have not had the first sort of reckoning, which is most of them, this article hints at the sort of tension that may sit just below the surface. That is, the sort of debate we might see if efforts to make algorithms transparent succeed. There are certainly non-regulatory ways for people to find out about algorithms—journalistic investigation, consumer advocacy, outspoken data scientists (Angwin et al. 2016; Dixon and Gellman 2014; O’Neil 2016)—but governmental action does the most to enable visibility, and thereby contestation, on a large scale.
Clarifying the Moral Role of Causal Theorizing in Markets
Another contribution of this study is pinpointing what is at stake in debates over causation. Promoters of predictive analytics frequently dismiss efforts to graft causal theories on top of predictions as futile attempts to hold onto less precise ways of thinking (Bowker 2014; Mayer-Schönberger and Cukier 2013). Yet what gets wiped away along with storytelling is an ability to appreciate how bad luck or the inequities of history can set events in motion and cause people to show up in the data in particular ways (Gandy 2009; Simon 1988).
As I have shown, causal theorizing helps people weigh whether predictions appropriately assign responsibility and blame. Indeed, this is often the role of causal claims in other settings (Guetzkow 2010; Stone 1989; Thibodeau, Perko, and Flusberg 2015). Importantly, causal theories are not themselves the goal. The point is not to accept predictions that are plausibly causal and reject those that are not. Rather, people use causal theories as a tool of moral adjudication. Some theories pass moral muster and others do not. Algorithms are “black boxes” not only because it is tough to see how the math works, but also because they deny people the sorts of information they need to develop causal intuitions. When people say questions about causation are irrelevant, they are making a statement about how a certain set of moral concerns do not matter.
The case of credit-based insurance scores also sheds light on how Americans think about markets more broadly. There are multiple ways to challenge the fairness of mathematical prediction (Underwood 1979; Verma and Rubin 2018). Debates about algorithms that predict criminal re-offense, for example, revolve around the relative importance of predictive accuracy, false positives, and false negatives (Kleinberg et al. 2017). Yet policymakers here focused on whether people deserved lower prices. In sociology, the construct of deservingness is generally used to explain the allocation of public benefits and poor relief (Somers and Block 2005; Steensland 2006; Watkins-Hayes and Kovalsky 2016). This article suggests deservingness may also be a useful lens for understanding evaluations of how companies allocate goods and services through markets. As Feinberg (1970) notes in his classic essay on moral desert, economists—and, we can add, sociologists—rarely talk about market phenomena in terms of deservingness (cf. Velthuis 2005), but lay people frequently do. Do bankers deserve their huge paychecks? Do senior citizens deserve the discounts they receive all over town?
For understanding the moral economy of algorithmic prediction, it is important to note that moral deservingness and actuarial fairness are similar in one crucial respect. Both focus attention on the individual, effectively answering the question: how do I decide if this person should get a high or low price? In both cases, the answer depends on classifying people; the difference is the basis of classification, mathematical usefulness or moral virtue. That means both approaches ignore a truly different conception of market morality, one rooted in solidarity that foregrounds sharing costs rather than figuring out what each person should pay. Were efforts to totally ban credit-based insurance scoring successful, the result would be to increase this sort of solidarity, but proponents of such bans nonetheless justify them on individualistic grounds, pointing to people who are misclassified under the current system. Relying on moral deservingness thus reifies rather than undermines prediction’s ethos of differentiation.
For markets beyond insurance, this shows that when people object to the way predictions treat certain people, they obscure the larger moral issue of whether a prediction should be made in the first place. That is, whether a cost is properly socialized or individualized—whether a burden ought to be borne by specific people or a company.
Suggestions for Future Research on Moral Markets
One key question for future research is how certain causal theories and ideas about good and bad behavior come to dominate discourse and belief. If stories and moral categories are the cultural fodder on which the moral permissibility of algorithmic prediction depends, then how do people wind up buying into particular stories and categories? After all, notions about what people can and cannot control are socially constructed (Abraham 1986; Gusfield 1981), as are judgments about forgivable and unforgivable offenses.
In the case of credit-based insurance scores, divorce was broadly construed as a life event for which it would not be right to hold people morally (and therefore financially) accountable, but it is easy to imagine a time in the not-so-distant past when divorce would have been considered a moral trespass. This is the battleground Fourcade and Healy (2007) are getting at when they describe markets as “explicitly moral projects”—as the outcome of deliberate efforts of interested parties to shape how people perceive what is natural and right. This question may be especially relevant given how research on deservingness in non-market settings reveals a strong overlay with racial and gender stereotyping and bias (Quadagno 1994; Steensland 2006; Watkins-Hayes and Kovalsky 2016).
More broadly, this article points to the usefulness of examining the cultural presuppositions sustaining algorithmic prediction and the differential treatment of individuals that follows. Markets, along with every other social domain—from employment to education to criminal justice—are being revolutionized by exponential growth in personal data and the spread of predictive practices. Valuable scholarship is being done on how these changes complicate, exacerbate, and obscure patterns of social stratification (Barocas and Selbst 2016; Brayne 2017; Eubanks 2017; Fourcade and Healy 2013). By unpacking the moral defenses of such systems, we gain insight into how the inequalities that arise might become permanently entrenched, and by studying the moral critiques, we gain insight into how they might be undone.
Footnotes
Acknowledgements
For helpful comments and guidance, the author thanks Laura Adler, Jason Beckfield, Kelsey Berry, Frank Dobbin, Alexandra Feldberg, Dan Hirschman, Sandy Jencks, Carly Knight, Katherine Morris, Rourke O’Brien, Mario Small, Nate Wilmers, Alix Winter, Tom Wooten, Xiaolin Zhuo, members of the Dobbin Research Group, and the ASR reviewers and editors, as well as participants of the Society for the Advancement of Socio-Economics and American Sociological Association’s 2018 annual meetings, the Harvard-MIT Economic Sociology Seminar, and the Edmond J. Safra Center for Ethics’ graduate fellowship workshop. The author deeply thanks members and staff of the National Association of Insurance Commissioners for their time and generosity.
Funding
The author gratefully acknowledges funding from the Edmond J. Safra Center for Ethics, Washington Center for Equitable Growth, Harvard Multidisciplinary Program in Inequality and Social Policy, and the National Science Foundation (Doctoral Dissertation Research Improvement Award 1802286).