
Abstract
In the United States, the housing search process has largely moved online for urban residents, yet little work has examined if and how the information homeseekers are exposed to on housing websites matters for their assessments of potential destinations. We designed a unique, geographically contextual survey experiment that uses real neighborhood names and actual online housing advertisement text to test if residents’ ratings of neighborhoods as desirable are affected by novel information. We find that online housing information—descriptions of housing units, neighborhoods, and how to apply for leases—largely reproduces the existing racial-spatial hierarchy, where non-poor White neighborhoods are rated as the most desirable, and poor Black and Latinx neighborhoods are rated as the least, with Asian neighborhoods in between. Residents’ prior familiarity with neighborhoods in their metro attenuates but does not fully explain away these effects, and the effect varies by race/ethnicity, with White residents the most sensitive to novel information. We offer a sophisticated model of the digital information environment in which an ethnoracially diverse population is exposed to neighborhood options, and we detail how our methods improve survey experiment design more broadly. Our results show that relatively small amounts of seemingly race-neutral information can affect residential preferences.
Keywords
Introduction
Scholars of residential mobility have increasingly turned their attention to the housing search and selection process, identifying unequal access to information as a key mechanism in the reproduction of the racial-spatial hierarchy (Bruch and Swait 2019; DeLuca, Wood, and Rosenblatt 2019; Krysan 2008; Krysan and Bader 2009; Krysan and Crowder 2017). Yet our understandings of how the information homeseekers are exposed to during the search influences neighborhood desirability and potential mobility remains limited, particularly as search and selection processes have moved online. The majority of urban residents in the United States report using the internet as a main tool for finding housing, but conceptual models and empirical approaches have been slow to reflect this reality (Brannon 2017; Rosen, Garboden, and Cossyleon 2021; Schachter and Besbris 2017). Indeed, because housing websites aggregate and make searchable many listings, it is possible the internet may distribute information on neighborhoods in less racialized ways than do traditional offline sources of information like social networks and real estate professionals, expanding the sets of neighborhoods homeseekers might consider (Krysan and Crowder 2017; McLaughlin and Young 2018). But we know little about the online housing information environment despite its growing prominence.
Our study explores how two types of information readily available through online housing websites—neighborhood names and housing advertisement text—independently influence residents’ perceptions of neighborhoods within their metros. Past work shows that a neighborhood’s racial demographics are central to the collective interpretation of whether that neighborhood is considered a desirable place to live (Bader and Krysan 2015; Evans and Lee 2020; Galster 2019; Harris 1999). But much of the information homeseekers are exposed to during the housing search, including neighborhood names and the text in housing advertisements, is overtly race-neutral. So, we ask how these two forms of information might influence the search process.
First, we focus on neighborhood names because prior research demonstrates that knowledge of particular neighborhood names among metro residents is not only unevenly distributed by race/ethnicity, but neighborhood names can act as a signal for neighborhood desirability (Krysan and Bader 2009; Schachter et al. 2024). 1 Second, we look at the effects of housing advertisement text. Recent analyses reveal that, while advertisements for rental housing in metropolitan America rarely contain racially discriminatory language, the descriptions of desired tenants, housing unit characteristics, and the local environment vary substantially depending on the demographics of the neighborhood advertised (Besbris, Schachter, and Kuk 2021; Boeing, Besbris, Schachter, and Kuk 2021; Costa et al. 2021; Hess et al. 2021; Kennedy et al. 2021). Yet none of this past research has examined whether these differences affect residents’ assessments of neighborhood desirability.
To do so, we use a large corpus of real online housing advertisements and computational techniques to generate a set of metro-specific advertisements that represent the variation in advertisements across neighborhoods with different racial/ethnic and poverty compositions. We randomly pair these ads with real neighborhood names within the respondent’s metro that vary in terms of their ethnoracial and socioeconomic composition. Critically, our experimental design allows us to eliminate the documented link between housing advertisement content and neighborhood demographics. We can thus determine, for example, what would happen to the perceived desirability of poor Black neighborhoods if their housing advertisements were written like those from non-poor White neighborhoods.
More generally, we ask: Does the information widely available online change residents’ perceptions of local neighborhoods as desirable places to move to? Do the effects of this information remain even after accounting for residents’ preexisting knowledge of local neighborhoods? And do these processes vary by residents’ racial/ethnic identity? These questions test existing theories that posit the unequal availability of information as key for understanding racially segregated mobility patterns, and we answer them using a novel research design with more external validity than any work to date. We fielded our survey experiment in five large U.S. metros—Chicago, Houston, Los Angeles, New York, and the San Francisco Bay Area. In each, we asked a representative sample of residents, as well as an oversample of non-White residents, about their familiarity with a wide set of local neighborhoods before they participated in our experiment. Our sample reflects the growing diversity of urban America and allows for comparison across the four largest ethnoracial groups in the United States.
We find that both individual housing advertisements and neighborhood names are indeed influential forms of information that shape residents’ perceptions of neighborhoods’ desirability. Both sources of information largely serve to replicate the existing racial-spatial hierarchy. When residents view ads that are modeled from ones for housing in local Black and Latinx neighborhoods—even when they are assigned to a local neighborhood name that is mostly White and non-poor—they tend to rate the neighborhood as less desirable, especially if the ads are modeled on ones from poor Black and Latinx neighborhoods. Residents’ prior familiarity with local neighborhood names attenuates but does not fully explain away these effects. Similarly, names of neighborhoods with mostly non-poor White residents—regardless of the text of housing ads—were rated the most desirable, and the names of neighborhoods with higher shares of poor and Black residents elicited the lowest desirability ratings. We also find that respondent race/ethnicity matters for the strength of the effects of neighborhood names and housing advertisement text, although the racial-spatial hierarchy, which places non-poor White neighborhoods at the top and poor Black and Latinx neighborhoods at the bottom, is consistent across all racial/ethnic groups.
Our findings bring the literatures on housing search, neighborhood desirability, and mobility decision-making into the digital age. We argue that neighborhood preferences are the product of longstanding patterns of segregation that engender racial animus and are quite mutable. Our results show that relatively small amounts of seemingly race-neutral information can affect residential preferences—although new information has the greatest effect when it resonates with existing stereotypes about race and place. Neighborhood preferences should therefore be understood as the result of (1) entrenched racial-spatial hierarchies, (2) the information environment in which searchers make decisions, and (3) the immediate cues searchers receive when their preferences are elicited. More generally, our findings reveal that contemporary theories are correct in positing disparate information as a key source of racially segregated mobility patterns. Even small, ostensibly race-neutral pieces of information gleaned during the search can reify neighborhood reputations and reproduce the racial-spatial hierarchy social-psychologically.
The Residential Search Information Environment and Residential Mobility
Contemporary models of residential search and selection underscore how the socio-cognitive processes marking only some neighborhoods as desirable are a fundamental cause of racially distinct mobility patterns and enduring racial segregation (Krysan and Crowder 2017). This work argues that decades of segregation have produced a segmented, ethnoracially-stratified information environment in which residents have unequal familiarity and experience with limited sets of neighborhoods in a given metropolitan area. When households move, they are choosing desired neighborhoods from a narrowed set of familiar places—places made familiar and desirable on the basis of shared ethnoracial identity. In other words, race/ethnicity is the prism through which residents see their cities, as it determines their preexisting knowledge about neighborhoods when they begin to consider their potential destinations (Krysan and Bader 2007; Zubrinsky and Bobo 1996). 2
Moreover, the information residents are exposed to during the search tends to be quite distinct by race/ethnicity, reinforcing blinkered and narrowed visions of appropriate neighborhoods to consider. This includes information searchers receive from their social networks (Lacy 2007; Lareau 2014; Rhodes and DeLuca 2014), from social media algorithms that target housing advertisements by race (Boeing, Besbris, Wachsmuth, and Wegmann 2021), and from housing market intermediaries like real estate agents (Besbris and Faber 2017; Besbris and Korver-Glenn 2023; Galster and Godfrey 2005; Hall, Timberlake, and Johns-Wolfe 2023), public housing agencies and local community groups that facilitate housing searches (Rosen 2014, 2020), and other financial actors and search technologies (Korver-Glenn, Bartram, and Besbris 2023; Korver-Glenn, Lee, and Crowder 2024).
Race remains one of the strongest predictors of where households consider moving and where they do in fact move to, but other demographic characteristics matter for both when mobility occurs and how strongly neighborhood racial composition affects mobility decisions. White households—particularly ones with children—are the most avoidant of neighborhoods with higher shares of Black residents, and more likely to move out of diverse neighborhoods (Clark 1992; Goyette, Iceland, and Weininger 2014). These discriminatory preferences hold even when accounting for the potential that White households use race as a proxy for neighborhood socioeconomic characteristics and school quality (Krysan et al. 2009). This past work notes that preferences “are but one factor shaping residential segregation by race, but they are a powerful factor” (Emerson, Yancey, and Chai 2001:933). As such, it is possible that making more residents more familiar with neighborhoods where their own ethnoracial group is not the majority could foster more expansive patterns of residential mobility and increase integration—although this may be more the case for non-White residents who consistently state they prefer residence in more integrated neighborhoods relative to White respondents (Charles 2006; Howell and Emerson 2018; Lewis, Emerson, and Klineberg 2011; see also Krysan 2002).
Does the Internet Provide Access to More Housing Information?
Some researchers have been broadly optimistic that recent changes in housing search and selection technologies may provide more information on a larger set of desirable destination neighborhoods and might reduce racial differences in mobility. Across all ethnoracial groups living in urban areas, internet housing websites have become one of the most common methods for finding new homes. Online search tools could, in theory, reduce information inequalities (McLaughlin and Young 2018; Palm and Danis 2001), but some researchers have expressed skepticism about the potential of housing websites and other novel technologies to alter housing search dynamics (Boeing, Besbris, Wachsmuth, and Wegmann 2021; Brannon 2017; see also Cottom 2020; Noble 2018).
Empirical work reveals that the internet is not a panacea for equalizing information on neighborhoods. For example, Boeing and colleagues (Boeing 2020; Boeing, Besbris, Schachter, and Kuk 2021; Boeing and Waddell 2017) have found that housing websites tend to underrepresent available housing in disadvantaged neighborhoods, and listings from poorer and less-White neighborhoods tend to have less information about the advertised unit relative to listings in majority White and non-poor neighborhoods (see also Hess et al. 2021; Somashekhar et al. 2024). In a study of online housing ads in Seattle, Kennedy and colleagues (2021) found that ads from Whiter neighborhoods were more likely to mention neighborhood history and neighborhood trust. In an analysis of online housing ads from the 50 largest U.S. metros, Besbris and colleagues (2021) found that ads from Whiter and less-poor neighborhoods were more likely to contain information on local amenities and the quality of the housing unit, whereas ads from non-White and poorer neighborhoods were far more likely to contain language about tenant requirements and logistics regarding application (see also Adu and Delmelle 2022; Stewart et al. 2023). These logistics include demands for proof of income, credit scores, and past residential histories, as well as prohibitions against applicants with eviction or criminal records.
Why Measure Neighborhood Desirability?
What is clear from this work is that the online information environment is segmented in similar ways to offline sources—that is, by neighborhood race/ethnicity. These differences in the amount and type of information likely create unequal search costs across homeseekers by race and income (Besbris et al. 2022; Hess et al. 2023). But how residents interpret this information has not been examined, so it remains unclear if and how the information provided on housing websites becomes useful and acted on in particular spatial contexts (Bruch and Feinberg 2017). For example, does seeing language in a housing advertisement indicating a preferred applicant should have no past evictions lead residents to rate the surrounding neighborhood as undesirable? Does it matter if the ad is for housing in a White, Black, Latinx, or Asian neighborhood? Or for housing in a neighborhood that residents are very familiar with?
As Kennedy and colleagues (2021) suggest, answering these types of questions is key for understanding how residents form choice sets of desirable neighborhoods (see also Bruch and Mare 2012). First, these informational differences influence neighborhood selection during mobility, especially for homeseekers with less information about neighborhoods in a given metro. As such, analyses of how information affects potential homeseekers’ assessments of neighborhoods help explain the intransigence of segregated mobility patterns. Second, information that reflects material and geographic differences by race/ethnicity is presented in a way that obscures the causes of such differences and reifies the racial-spatial hierarchy, “making it seem that less White neighborhoods are not only more dangerous . . . but also that such a discrepancy is natural, not worth understanding” (Kennedy et al. 2021:1449–50). Third, these variations in the quantity and quality of information by neighborhood race/ethnicity may contribute to the formation of place reputations, particularly when they act in concert with existing racial stereotypes (Quillian and Pager 2001; Sampson 2012; Sampson and Raudenbush 2004). Information differences can reinforce existing biases against certain racialized neighborhoods, influencing residents’ assessments of places as more or less desirable, which, in turn, reproduces racially segregated mobility patterns. In other words, understanding why mobility patterns remain so segregated necessitates understanding what kinds of information residents use in forming their impressions of places as raced and desirable/undesirable.
Expanding Research to Reflect Multiracial Metropolitan America
Even as scholarship on residential mobility has moved toward understanding the information environment in which mobility takes place, the literature still often focuses on the preferences and decisions of White and/or Black residents (Adelman 2005; Emerson et al. 2001; Krysan and Farley 2002; Krysan et al. 2009; but see Charles 2006; Clark 1992; Swaroop and Krysan 2011). On the one hand, this makes sense as Black-White segregation remains high in U.S. metros (Hwang and McDaniel 2022; Kye and Halpern-Manners 2023). On the other hand, it does not reflect an increasingly diverse metropolitan context in which Latinx and Asian residents are growing in absolute and relative population size (Frey 2021; Kye 2023; Lee et al. 2017).
As metropolitan U.S. neighborhoods have diversified, more research is needed on how signals of race/ethnicity beyond a Black-White binary affect the formation of neighborhood reputations. Latinx and Asian neighborhoods may be especially prone to racialization and subsequent stigmatization via language signals. That is, seeing non-English language in housing advertisements may be a uniquely strong signal for residents’ assumptions about a neighborhood’s ethnoracial composition and therefore its desirability (Hall and Krysan 2017; Schachter et al. 2023). By examining the reactions of Black, White, Latinx, and Asian residents to advertisements from Black, White, Latinx, and Asian neighborhoods, our analysis better reflects the multiracial/ethnic reality of contemporary U.S. metropolitan areas (Jiménez 2017; Jones 2019).
The Potential Mutability of Neighborhood Preferences
Our study also accounts for two consistent findings in recent scholarship on housing and neighborhood preferences that challenge typical research designs. First, decision-making in the context of neighborhood selection and mobility must be contextualized and cannot be conceptualized as optimal (Bruch and Feinberg 2017). In other words, no one neighborhood can be designated as most desirable, because homeseekers vary not only in their stated needs/goals, but also in how they decide where to live (Carrillo et al. 2016; Darrah and DeLuca 2014; Harvey et al. 2020; Lacy 2007; Rhodes and Besbris 2022; Rosenblatt and DeLuca 2012). In fact, past work shows that selecting housing or a neighborhood cannot be defined as a rational or even boundedly rational choice, as information is extremely limited and influenced by various non-market, social psychological factors (Besbris 2016; Hayes and Besbris 2023; Krysan and Bader 2009; Krysan and Crowder 2017).
Second, and relatedly, preferences for housing and neighborhoods are highly malleable during the search process as searchers are exposed to new information. Ethnographic accounts of search and mobility reveal that homeseekers’ decisions are determined in large part by the advice of housing market intermediaries, like real estate agents, who use heuristics to steer individuals toward particular places (Besbris 2020; Korver-Glenn 2021). More generally, homeseekers’ interactions with others provide in-the-moment cues that affect their decision-making (Besbris and Fine 2023). 3 A good deal of past work demonstrates that neighborhoods are determined to be desirable or not based on immediate forms of information homeseekers glean during the search process, including seemingly minor aspects of housing advertisements, like whether the ad contains a specific neighborhood name (Schachter et al. 2024). What remains unclear is how mutable residents’ assessments of neighborhood desirability are. No work has tested whether the information contained in online housing ads affects neighborhood desirability. Our study pays close attention to the effect of novel information on the assessments of neighborhoods for residents who express both high levels of knowledge and unfamiliarity with actual neighborhoods in their metro. We do so with pre-treatment measurement of our respondents’ familiarity with actual neighborhoods in their metros and then using real neighborhood names as treatments, which allows for investigation of the potential plasticity of neighborhood preferences.
Data and Methods
To better reflect the information available to residents when they search for housing online, we designed a complex survey experiment with treatments derived from a large-scale data collection and text analysis effort. We then used YouGov, an established internet-based survey firm, to implement the survey in five large, diverse metropolitan areas. YouGov uses a proprietary matching algorithm to draw representative samples from its large, online panel of respondents. YouGov is commonly used for survey-based research in the social sciences, and its samples perform well relative to other established survey firms (Kennedy et al. 2018).
Design
To examine the weight of novel pieces of information in fostering neighborhood desirability, our study needed to not only approximate the kinds of information available online, but do so in real geographic contexts. That is, residents already have information about some local neighborhoods that may affect whether or not new information changes their perceptions. We thus selected particular places where we could first ask residents about the extent of their existing information about neighborhoods. We then randomly assigned neighborhood names to different types of advertisements to test the relative effects of preexisting and novel signals. Our 9 x 8 factorial design (nine neighborhood name types by eight advertisement types) thus eliminates the correlation between neighborhood names and typical advertisement content. By randomly matching names and types of ad text, we are able to see to what extent either one affects neighborhood desirability independently. Additionally, by using real neighborhood names and real advertisements from each of our metros, our design better simulates the neighborhood selection process with more external validity than prior vignette experiments (Egami and Hartman 2023; Findley, Kikuta, and Denly 2021). We chose the Chicago, Houston, Los Angeles, New York City, and San Francisco metropolitan areas for multiple reasons, including their size and varying types of diversity, which allowed for oversamples of the three largest non-White enthoracial groups in the United States.
We fielded a representative sample of 1,000 residents in each metro and, in each metro, an oversample of 100 to 675 non-White residents: Asian residents in the San Francisco Bay Area, Black residents in New York and Chicago, and Latinx residents (including Spanish-speakers) in Los Angeles, Chicago, and Houston, for a total of 6,132 respondents. For more information on the sample, see Table S1, panel A, in the online supplement.
To first establish residents’ existing neighborhood knowledge, respondents began the survey by reporting their familiarity with a list of 16 to 18 locally specific neighborhood names. The neighborhood names were selected to represent eight different neighborhood typologies drawn from prior work: White poor/non-poor, Black poor/non-poor, Latinx poor/non-poor, and Asian poor/non-poor. 4 Using 2019 five-year ACS estimates, a neighborhood name was categorized as representing a particular raced neighborhood if it had a plurality of White/Black/Latinx/Asian residents, and it was deemed poor or non-poor if that neighborhood was in the top quartile of households in poverty in its metro (Kuk et al. 2021; Wang et al. 2018). To measure preexisting knowledge of each neighborhood, respondents were asked, “How well do you know [neighborhood]?” Response categories ranged from “not at all well” to “extremely well.” We also included two fictitious neighborhood names for each metro, which serve as control conditions, leading to nine total categories of neighborhood name types. For more information on neighborhood names and preexisting knowledge among all respondents, see Table S1, panel B, in the online supplement.
We then incorporated information about neighborhood name familiarity into the randomization scheme for our first treatment—neighborhood name type. Respondents were randomly assigned one of the nine possible neighborhood name types based on our pre-treatment measures of neighborhood familiarity: (1) a fictitious neighborhood name (fake), (2) a neighborhood name randomly selected among the neighborhoods respondents reported knowing relatively well (familiar), and (3) a neighborhood name randomly selected among the neighborhoods they reported knowing relatively not well (unfamiliar). 5 Each respondent was randomly assigned three neighborhood name types, because each respondent repeated the survey experiment three times. The order in which respondents viewed names was randomized, so some saw the fake name first, others saw their familiar name first, and so on. We followed this randomization scheme to ensure we had sufficient statistical power to test for heterogenous treatment effects by preexisting neighborhood knowledge.
Importantly, our neighborhood name treatment does not capture the effects of specific neighborhood names (e.g., East Side, a Chicago neighborhood), but instead types of neighborhood names (East Side is classified as a Latinx poor neighborhood). Using the neighborhood name type as our treatment, rather than the name itself, allows us to generate sufficient statistical power and identify the average effect of different types of neighborhood names, rather than the specific effects of particular neighborhood names. For a more detailed explanation of our factorial design and treatment assignment strategy, see the “Factorial Design” subsection in the online supplement.
Our second treatment is advertisement type. We use the same eight neighborhood types for ads as we do for names (White poor/non-poor, Black poor/non-poor, Latinx poor/non-poor, Asian poor/non-poor). We identified the most representative advertisement text for each neighborhood type by extending the intuition from Topical Inverse Regression Matching, a text matching method (Roberts, Stewart, and Nielsen 2020). We gathered and geocoded millions of advertisements for rental housing from Craigslist across our five metros. Once the ads were grouped by neighborhood type, we ran structural topic models (STM) to observe word choices that vary by neighborhood type. This resulted in a low-dimensional summary of text data. To extract topic proportions, or the distribution of different types of language we uncovered in our STM across ads, we refit each ad into each neighborhood type via a predicted probability regression. Finally, we fit a multinomial regression model where the outcome is an eight-way interaction that represents each neighborhood type’s treatment projection. This allows us to measure each advertisement’s likelihood of being in each neighborhood type. In other words, we can obtain a predicted probability or treatment propensity of each advertisement—if an ad is from a Black non-poor neighborhood, we should expect the propensity for Black non-poor ad language to be highest. We used this propensity score to select the most representative advertisements for each neighborhood type, which we then edited for typos and clarity to use as our treatments. This process allowed us to create sets of eight to ten representative ads for each neighborhood type within each of our metros. (For further details, see the “Experimental Design” section of the online supplement.)
Once each of the three neighborhood names was randomly matched with a randomly selected neighborhood ad type, respondents viewed three randomly selected ads corresponding to their assigned neighborhood ad type and were told the ads were located in their assigned neighborhood name. After viewing the first three ads, respondents were asked if they would like to see more ads from the neighborhood. If they selected yes, they were shown three more of the same neighborhood type ads. 6
Respondents then answered a series of questions about the neighborhood that were derived from prior studies of neighborhood reputations and neighborhood knowledge (see Bader and Krysan 2015; Farley et al. 1994; Krysan 2002; Krysan et al. 2009). Here, we restrict our analysis to responses to the first question all respondents were given after viewing the ads in their assigned location, which asked whether or not the neighborhood is a desirable place to live (measured on a Likert scale from 1 = not at all desirable to 5 = extremely desirable). After completing the full set of questions about the first randomly assigned neighborhood name and set of advertisements, respondents then repeated the full experiment two additional times with randomly selected neighborhood names, ad types, and ads. Because our 9 x 8 factorial design requires substantial statistical power, each respondent repeated the experiment three times, similar to the logic of repeated profile evaluations in conjoint experiments (e.g., Flores and Schachter 2018). As a robustness test, we looked for evidence of any order effects based on whether the ad types and neighborhood names were viewed first, second, or third. We found no order effects for our ad type treatment, but we found some differences based on order for our neighborhood name type treatment (see Table S3 and Figure S2 in the online supplement). 7
Analyses
Although respondents repeat the experimental task three times to increase statistical power, our design is between-subjects; all models include clustered standard errors to account for repeated observations of each respondent. We use OLS models predicting neighborhood desirability to evaluate the main effects of our two key treatments: neighborhood name type and neighborhood ad type. We estimate the effects of neighborhood name type and neighborhood ad type using the following model:
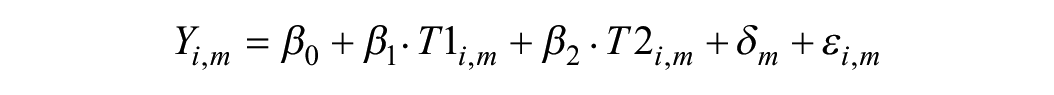
where
In addition to our main analyses, we examine several possible sources of variation and conduct extensive robustness tests. First, to understand how respondent race/ethnicity or preexisting knowledge of neighborhood names moderate our treatment effects, we estimate global interactions (separate models). We also formally evaluate the statistical significance of any differences by estimating pooled models with interaction effects (see Table S2 in the online supplement). We estimate three-way global interactions among respondent race/ethnicity, preexisting knowledge, and treatments to test whether preexisting knowledge differentially moderates responses to our treatments by respondent race/ethnicity (see Tables S4a–S4d in the online supplement).
All models include metro fixed effects to adjust for baseline differences among our five metro areas, and in Table S5 in the online supplement, we present results of a sensitivity analysis demonstrating that our findings are largely consistent across metros. We follow best-practices and do not include controls for respondent characteristics or survey weights, as our treatments are randomly assigned (Berk et al. 2013; Mutz, Pemantle, and Pham 2018; Schachter and Weisshaar 2025). In Table S6 in the online supplement, we re-estimate our main analyses including common controls used in studies of neighborhood desirability (e.g., Emerson et al. 2001; Krysan et al. 2009); results are unchanged (see also Figure S3 in the online supplement). Given the likely differences in how homeowners and renters may have approached our experiment (see Harvey et al. 2020), as a further robustness test we interact homeownership status with our treatments to test whether homeowners and renters respond differently to our treatments; we find no statistical nor substantive differences (see Table S7 in the online supplement).
Results
To reiterate, our questions are, first, whether and how viewing different types of housing advertisements and viewing real neighborhood names affect the desirability of a neighborhood. After presenting these results, we turn to our second question, whether residents’ preexisting familiarity with neighborhoods attenuates the effects of seeing ad text and names. Finally, we show how residents’ race/ethnicity matters for their responses to ad text and neighborhood names.
Main Effects
We begin by estimating the independent effects of our two treatments, neighborhood ad type and neighborhood name type. Table 1 reports the effects relative to their respective reference categories, White non-poor ads/names. Starting with the base model results, which include the entire pooled sample, we see that viewing just a small set of similar Craigslist ads meaningfully affects perceptions of neighborhoods within one’s own metro area. Relative to White non-poor advertisements, all other ad types have a negative, statistically significant effect on perceived neighborhood desirability. The effect sizes range from a −0.13 (p < 0.001) point decrease in perceived desirability for non-poor Asian ad types, to a −0.55 (p < 0.001) point decrease in desirability—an over four times greater effect size—for poor Latinx ad types. Turning to the main effects of neighborhood name type, we similarly see that among the entire pooled sample, all neighborhood name types have a negative, statistically significant effect on perceived neighborhood desirability compared to non-poor White neighborhood names. Here the effect sizes range from −0.27 (p < 0.001) for poor Asian neighborhood names to a little more than two times greater, at −0.59 (p < 0.001) for poor Black neighborhood names.
Overall Ad Type and Name Type Treatment Effect by Preexisting Knowledge.
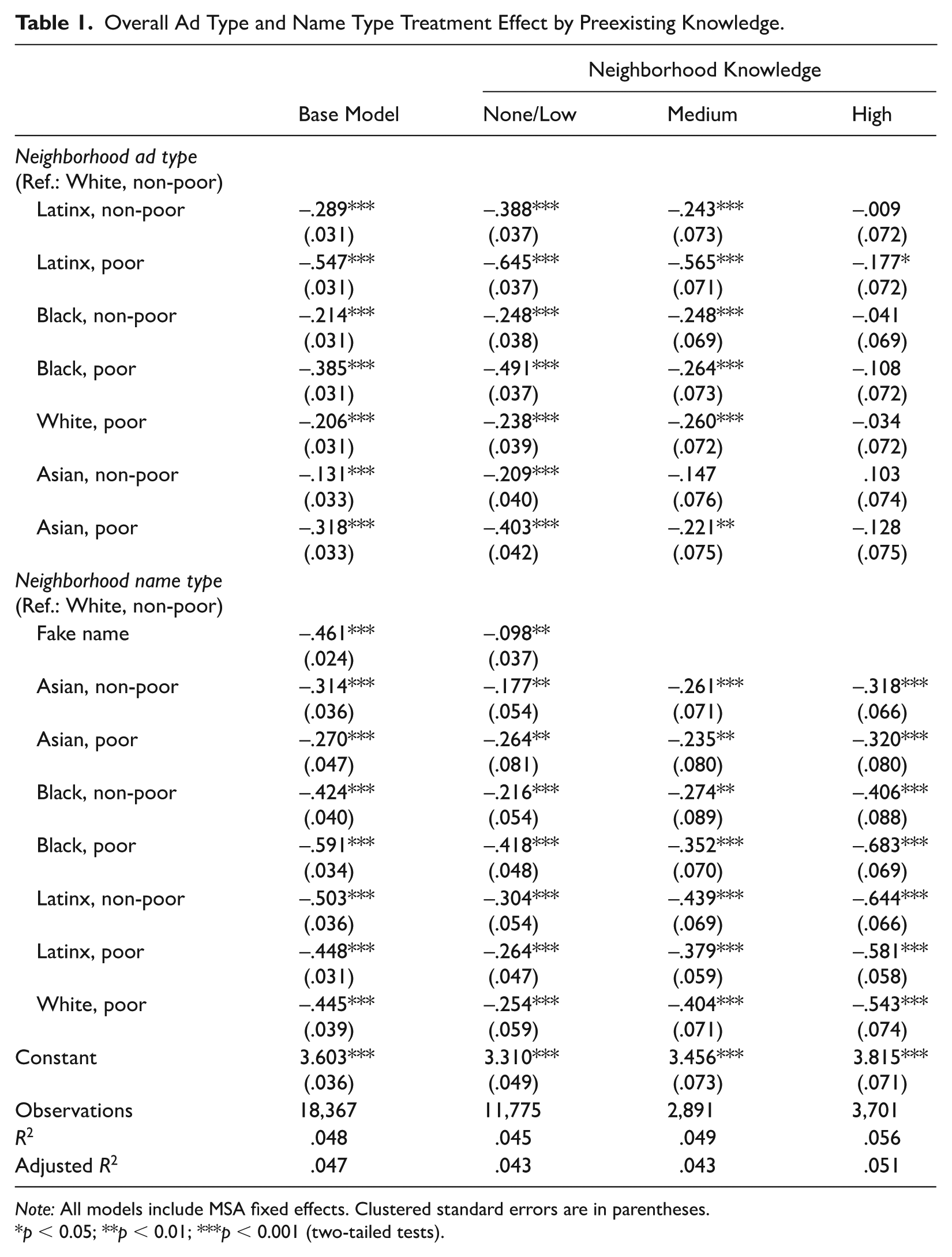
Note: All models include MSA fixed effects. Clustered standard errors are in parentheses.
p < 0.05; **p < 0.01; ***p < 0.001 (two-tailed tests).
To further understand the relative influence of housing advertisements and neighborhood names on perceived neighborhood desirability, in Figure 1 we plot predicted desirability by neighborhood ad type (top panel) and neighborhood name type (bottom panel). Beginning with the ad type effects in the top panel, we see a clear hierarchy of neighborhood desirability. On average, respondents assigned White non-poor ads rated the neighborhood as the most desirable (3.2 on a scale of 1 to 5). Respondents assigned ads from non-poor Latinx, Black, and Asian neighborhoods ranked the neighborhood in the middle in terms of desirability, ranging from scores of 2.9 to 3.1, and on par with neighborhoods assigned ads from poor White neighborhoods (scored 3.0). Finally, respondents assigned ads from poor Black (score 2.8) and especially poor Latinx (scored 2.6) neighborhoods rated these neighborhoods as the least desirable.
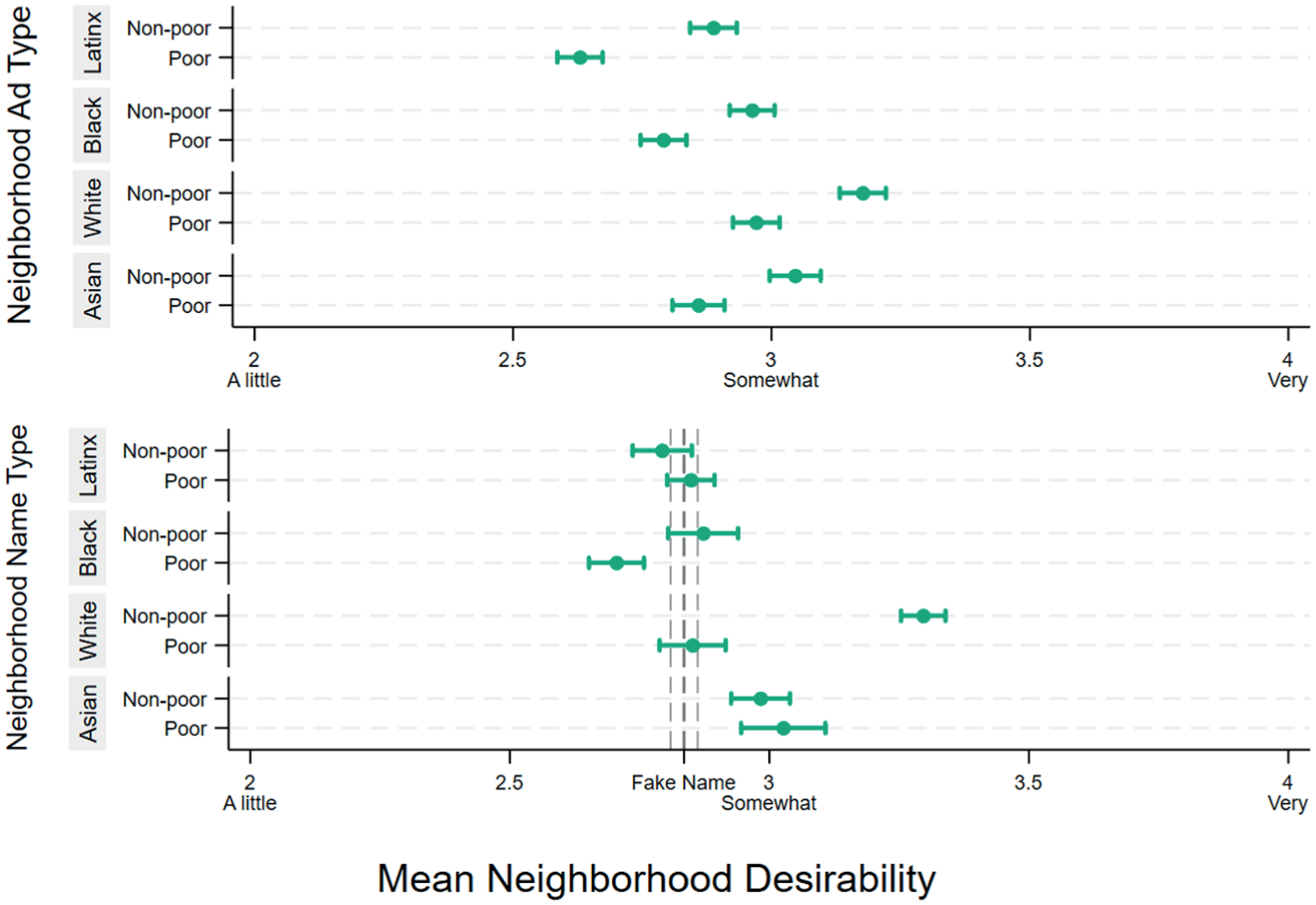
Predicted Desirability Ratings by Neighborhood Ad and Name Treatments for Pooled Sample.
Neighborhood names also affected perceived desirability. As shown in the bottom panel of Figure 1, White non-poor neighborhood names receive a desirability premium relative to all other neighborhood names, including fake names. That is, the names of neighborhoods in respondents’ metros where the majority of residents are White and non-poor are rated as the most desirable (score of 3.3 on a scale from 1 to 5). Overall, the magnitude of the effect sizes is the same or slightly larger than those of the ads, suggesting that both forms of information are similarly effective in shaping perceptions of neighborhoods. We also observe a small but statistically significant desirability premium for poor and non-poor Asian neighborhood names relative to our fictitious name (both rated about 3.0). In contrast, names of non-poor Black and poor and non-poor Latinx neighborhoods are perceived to be about as desirable as poor White neighborhood names and equivalent to the fake neighborhood name (rated 2.8 to 2.9). And poor, Black neighborhood names are rated the least desirable (score of 2.7 out of 5), a statistically significant difference with our fictitious neighborhood name (rated about 2.8).
Our findings underscore the power of both neighborhood names and housing advertisements to shape local residents’ perceptions of neighborhood desirability. Both types of information reinforce a racial-spatial hierarchy, with non-poor White neighborhoods at the top and Asian and non-poor Black and Latinx neighborhoods in the middle. White neighborhoods seem to enjoy a reputational premium that works in tandem with other material advantages to keep them as the most desirable locales (Besbris, Robinson, and Angelo 2024; Robinson, Korver-Glenn, and Besbris 2023).
However, we observe some disagreement over which neighborhoods are the least desirable across treatment type. Viewing housing advertisements representative of ads from poor Latinx neighborhoods, and viewing the names of poor Black neighborhoods, led respondents to rate neighborhoods as the least desirable. Names and advertisement text may affect neighborhood desirability differently for a few key reasons. Neighborhood names tend to operate as short-hand heuristic stand-ins for a larger racialized collection of information about a neighborhood (Evans and Lee 2020). If they are familiar with a neighborhood name, residents tend to make assumptions about the racial demographics and desirability of that neighborhood. Black neighborhoods also tend to be more longstanding as majority non-White, relative to Latinx and Asian neighborhoods, and are more often mentioned in local media (Krysan and Crowder 2017; Stuart et al. 2025), likely increasing the chances residents may be familiar with them. Furthermore, people often suspect names associated with Black neighborhoods will be high-crime and low-amenity places (Jones and Jackson 2012; Wacquant 2008). Black neighborhood names evoke negative reactions because longstanding patterns of segregation and unequal resource distribution have hardened residents’ perceptions of Black places as undesirable.
For advertisement text denoting Latinx neighborhoods, respondents are likely reacting to seeing Spanish-language text. Some of our ad treatments—which again come from large samples of text from real ads posted on Craigslist for housing in each of our metros—contain Spanish. Additionally, some of the ad treatments from poor and non-poor Asian neighborhoods include Chinese text. As noted earlier, given the growing diversity of metropolitan areas in the United States, the fact that languages other than English are found in housing ads is unsurprising. But the effects of Spanish or Chinese in the context of housing search and residential mobility are underexplored, and it is possible that the particularly low desirability rating of poor Latinx neighborhoods we find in our main effects is due to seeing Spanish. Indeed, past work shows that seeing or hearing Spanish in other contexts (e.g., political advertisements, in public) can evoke anti-Latinx sentiments (Enos 2014; Hopkins, Tran, and Williamson 2014).
To test the effect of non-English languages in housing ads, we next examine whether Spanish or Chinese moderate the neighborhood ad type treatment effect. Note that due to sample construction, we restrict this analysis to observations assigned to poor or non-poor Asian and poor Latinx advertisement texts. To test the effects of non-English languages, we estimate separate models for each ad type (Asian poor, Asian non-poor, and Latinx poor) and add a binary measure indicating whether any Chinese/Spanish appeared in the ads (= 1) compared to no non-English text in the ads (= 0).
As shown in Table 2, residents generally react negatively to seeing Spanish or Chinese language in advertisements. Interestingly, the effect of non-English language is similar for both poor Asian ads and poor Latinx ads but the effect of Chinese is less than half the size and does not reach statistical significance for non-poor Asian ads. Our findings are consistent with prior work examining the effects of Spanish in housing advertisements (Schachter et al. 2024) and suggest other languages may also be stigmatized, but the effects of languages depend on other neighborhood characteristics, such as poverty status. While more work is needed to fully understand the role of language in driving perceptions of neighborhood desirability, our findings suggest both Spanish and Chinese can contribute to negative neighborhood perceptions.
Effects of Chinese or Spanish Language in Ads.
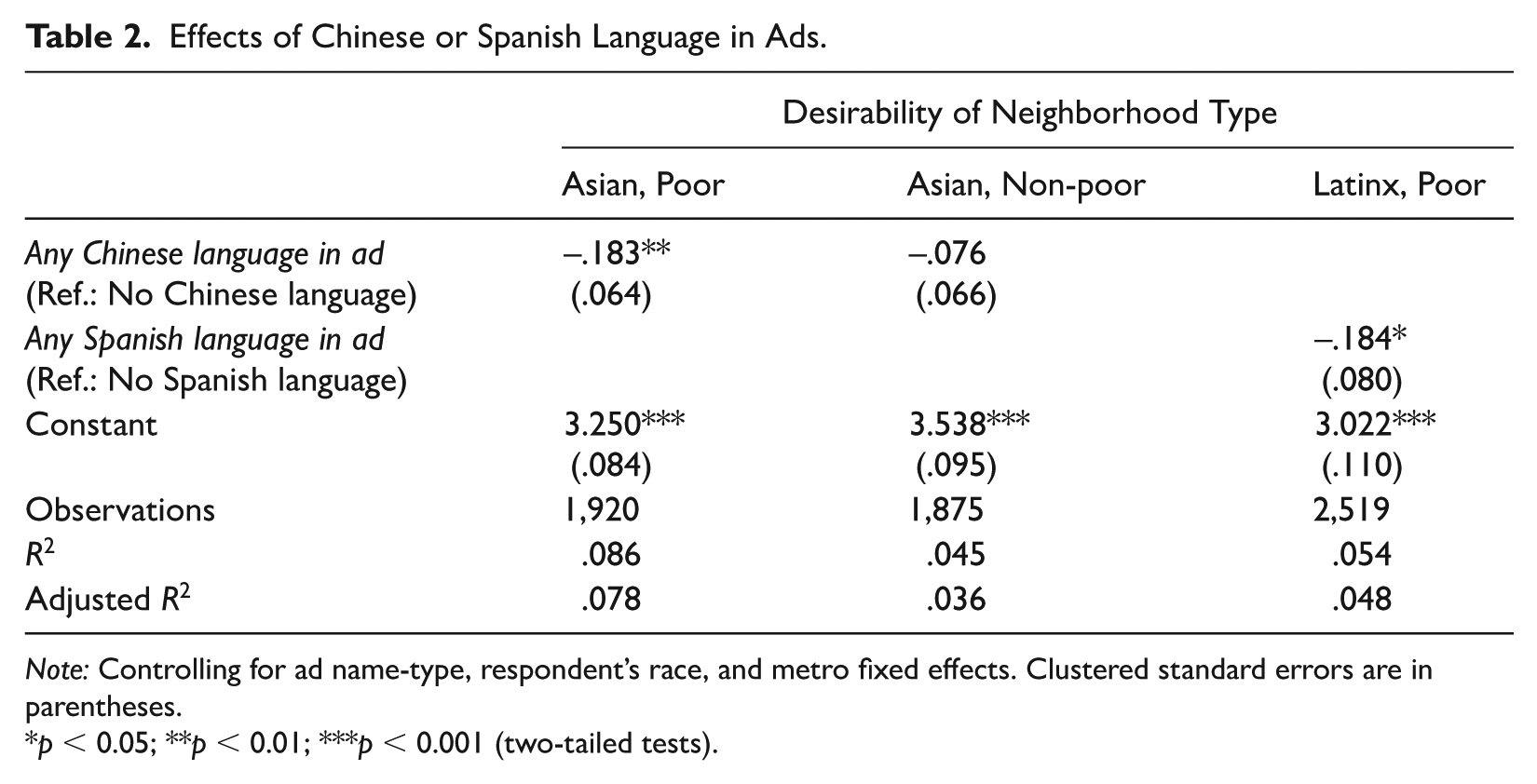
Note: Controlling for ad name-type, respondent’s race, and metro fixed effects. Clustered standard errors are in parentheses.
p < 0.05; **p < 0.01; ***p < 0.001 (two-tailed tests).
Does Preexisting Knowledge Moderate the Effects of Information?
Neighborhood names and housing advertisement text appear to be key sources of information shaping residents’ perceptions of neighborhood desirability, but residents are also likely influenced by factors external to the online search process. In particular, preexisting knowledge about neighborhoods within one’s metro likely moderates the effects of any new information contained in ads from Craigslist—neighborhood reputations may be hardened, as patterns of ethnoracial segregation have generally existed for decades (Faber 2020; Massey and Denton 1993). Preexisting information may be so powerful that the effect of information presented online is minimal.
To examine the effects of preexisting knowledge, we identify three subgroups of respondents based on their self-reported familiarity with the neighborhoods they were randomly assigned in the experiment. 8 We estimate global interactions between preexisting knowledge, our advertisement types, and neighborhood names to test for differences in treatment effects. (For formal tests of interaction effects, see Table S2 in the online supplement.)
As shown in columns 2, 3, and 4 of Table 1, preexisting knowledge is an important driver of neighborhood desirability. First, overall, we observe higher perceived desirability among respondents who report more preexisting knowledge (as shown in the model intercepts; for formal tests of coefficients, see Table S2 in the online supplement). This suggests familiarity is an independent driver of perceptions of neighborhood desirability. In other words, residents who have some knowledge or experience with a wider set of places are more catholic in their neighborhood preferences. Second, preexisting knowledge moderates our treatments. Compared to respondents with low or no preexisting knowledge of a neighborhood, we tend to observe smaller effects based on neighborhood ad types among those with high preexisting knowledge. In contrast, we tend to see greater effects of neighborhood names among respondents with high preexisting knowledge compared to those with low/no preexisting knowledge. Advertisements appear to be most influential in determining neighborhood perceptions among individuals with the least self-reported preexisting knowledge, and neighborhood names are the most influential among those with the highest levels of preexisting knowledge. This pattern is expected: neighborhood names are more informative for people who already have some impression of the neighborhood. In contrast, advertisements are more informative for those with little information.
In Figure 2 we plot predicted desirability by our ad type (top panel) and name type (bottom panel) treatments separately for respondents with self-rated high, medium, and low/none preexisting knowledge of a neighborhood’s name. With respect to the ad type treatment (top panel), among respondents with self-rated “high” knowledge of the neighborhood they were randomly assigned in the experiment (depicted with green triangles), we find only minimal differences by ad type, as shown by the overlapping point estimates and confidence intervals among the neighborhood ad type treatments for those with high-knowledge. We also find no clear desirability premium for White non-poor ads, again depicted by the tightly clustered neighborhood ad type effects we estimate for respondents with high knowledge in the top panel of Figure 2. In contrast, among respondents with no or low self-rated knowledge of the randomly assigned neighborhood (orange circles), we observe significantly larger treatment effects compared to those with high self-rated knowledge, and thus a stronger desirability premium for non-poor White advertisements. Respondents reporting medium preexisting knowledge (blue diamonds) fall in between (for formal interaction tests, see Table S2 in the online supplement). 9 These findings underscore that preexisting knowledge conditions the effect of neighborhood ads; ads shape perceived desirability mostly among people with little to no preexisting knowledge of the neighborhood.
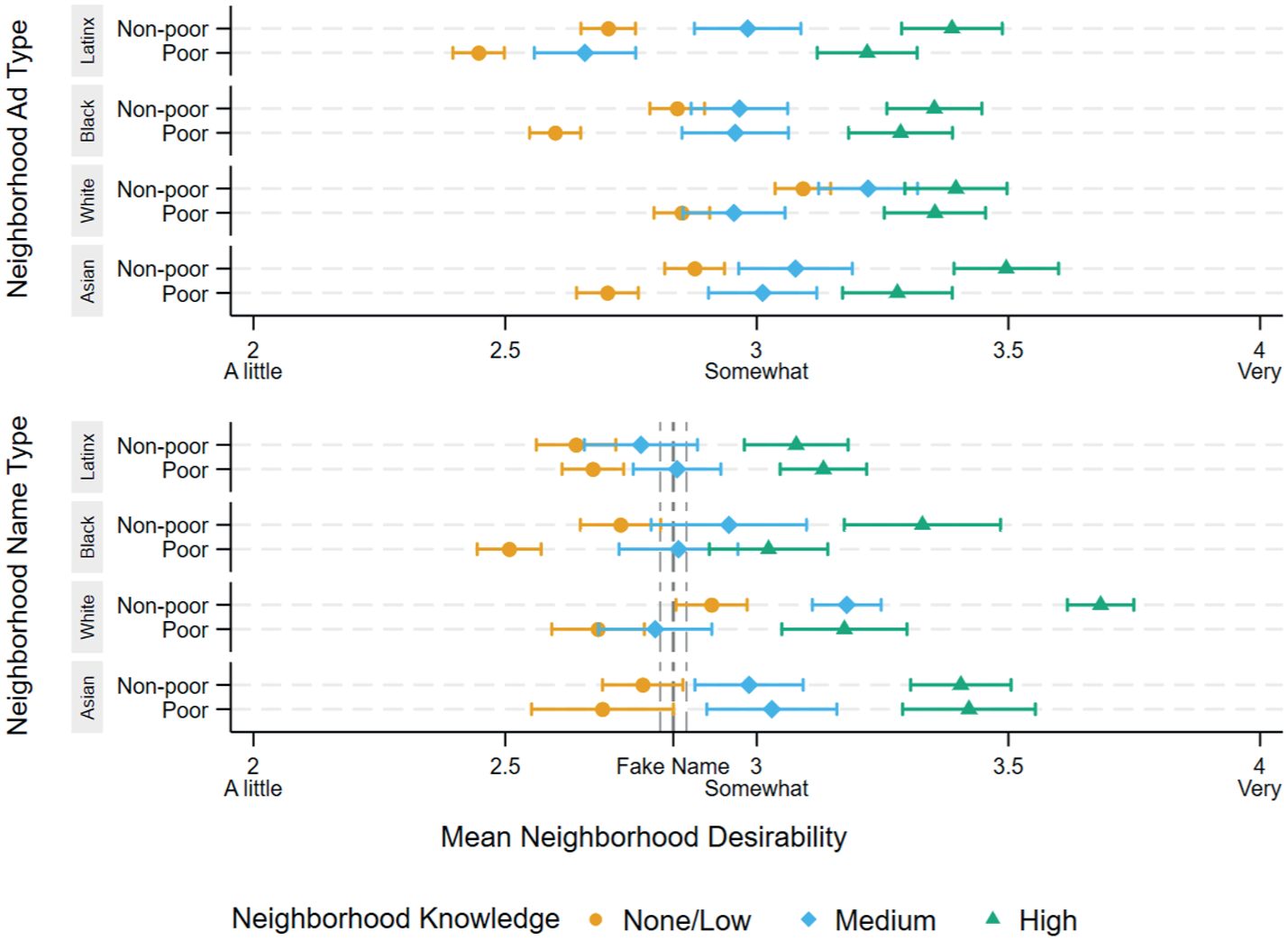
Predicted Neighborhood Desirability by Ad and Name Treatments and Respondent’s Preexisting Knowledge for Pooled Sample.
The bottom panel of Figure 2 depicts predicted neighborhood desirability by neighborhood name type and respondents’ preexisting knowledge (for formal interaction tests, see Table S2 in the online supplement). We find somewhat larger differences by name type among respondents with the highest self-rated preexisting knowledge (again depicted with green triangles) compared to those with little or none (orange circles). In other words, believing you know a lot about a neighborhood makes its name more influential in your evaluation of the neighborhood’s desirability. High preexisting knowledge benefits non-poor White neighborhoods the most in terms of desirability (see Table S2). That is, residents who are particularly familiar with neighborhoods in their metro are more likely to rate non-poor White neighborhood names as more desirable relative to the names of other types of neighborhoods. The moderating effects of preexisting knowledge are reversed relative to the ad type treatment, but the race-class hierarchy of neighborhoods remains consistent: non-poor White neighborhoods receive the highest desirability ratings.
These findings underscore how these two pieces of information—ad text and neighborhood names—are working to (re)create the racial-spatial hierarchy. Whether residents believe they know a neighborhood or not, the information they tend to rely on (names for those with more information, ad text for those with less information) increases their desire for non-poor White neighborhoods and decreases their interest in poor, predominantly Black and Latinx neighborhoods.
Does Respondent Race/Ethnicity Moderate the Effects of Information?
Thus far, our findings suggest that preexisting knowledge plays a critical role in how information affects searchers’ perceptions of neighborhoods, but it is possible the moderating effects of preexisting knowledge are merely proxies for respondent race/ethnicity. Because preexisting knowledge of neighborhoods is racialized (see Table S8 in the online supplement), our knowledge effects could be related to or even explained by differences in how respondents with different racial/ethnic backgrounds interpret and respond to our advertisement and neighborhood name treatments. Table 3 reports treatment effects by respondent race.
Ad Type and Name Type Treatment Effects and by Respondent Race.
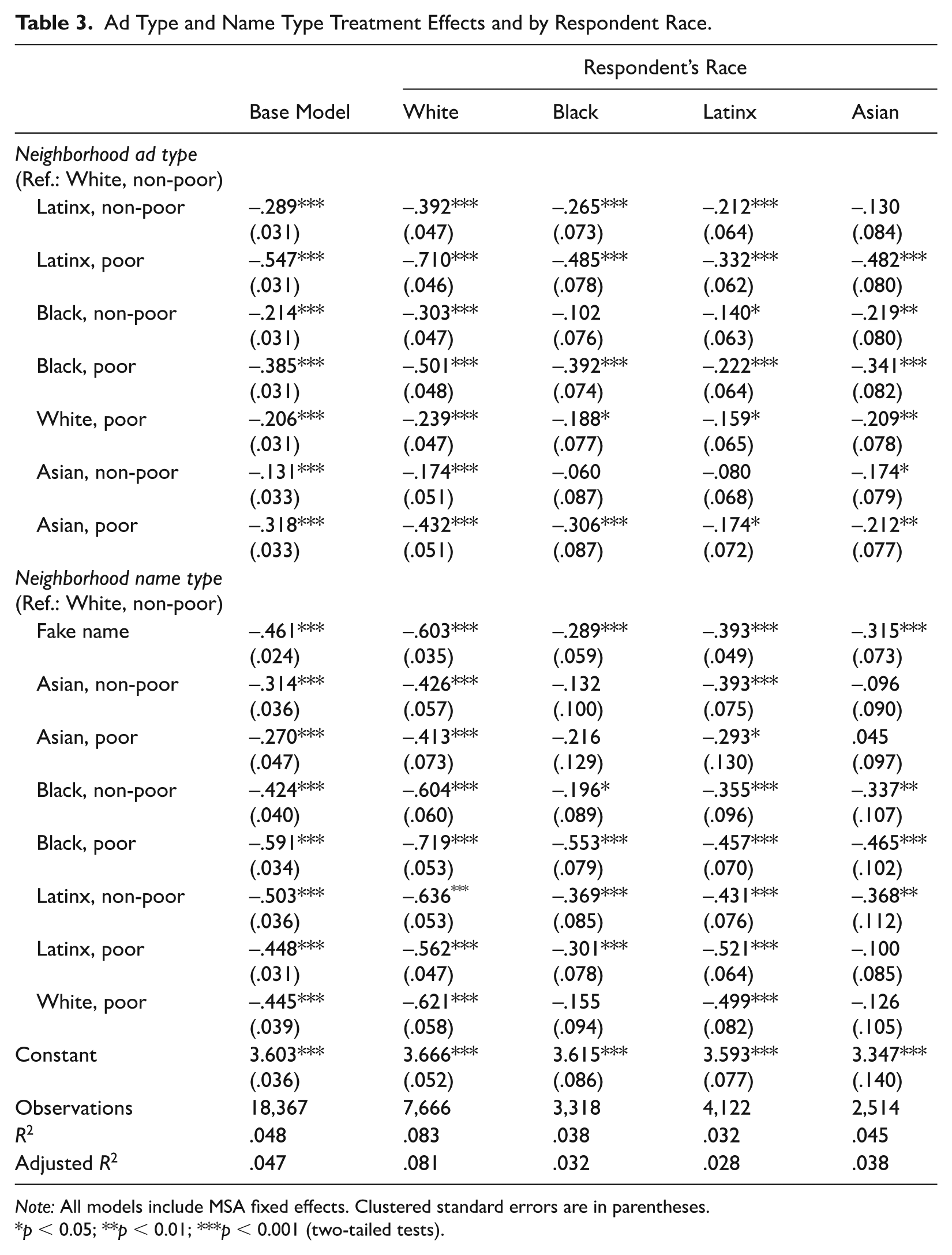
Note: All models include MSA fixed effects. Clustered standard errors are in parentheses.
p < 0.05; **p < 0.01; ***p < 0.001 (two-tailed tests).
We do find differences in treatment effects by respondent race/ethnicity for both advertisement text and neighborhood names. Overall, we find larger treatment effects for White respondents; White respondents display a greater desirability gap between White non-poor and poor Latinx ads, and between White non-poor and poor Black neighborhood names, than do any other group of respondents (for formal tests of interaction effects, see Table S2 in the online supplement).
As shown in Figure 3, we also find that respondent race/ethnicity moderates the treatment effects of ad types. For ease of interpretation, Figure 3 compares results for each ad type for Black, Latinx, and Asian respondents compared to White respondents. In general, Black and Latinx respondents perceive most neighborhood ad types to be more desirable relative to White respondents, regardless of the advertisement type they were randomly assigned to view. In particular, compared to White respondents, Black respondents perceive neighborhoods assigned advertisements from poor Latinx neighborhoods and non-poor Black neighborhoods as more desirable (by about 0.2 points each). Similarly, compared to White respondents, Latinx respondents perceive neighborhoods assigned advertisements from poor Latinx and poor Black neighborhoods as relatively more desirable (by almost 0.4 and 0.3 points, respectively; see also Table S2). This aligns with past work on neighborhood ethnoracial preferences, which tends to find that non-White residents are more open to considering ethnoracially diverse neighborhoods relative to White residents (Charles 2006; Howell and Emerson 2018; Lewis et al. 2011). Nevertheless, the general pattern is similar among White, Black, and Latinx respondents: advertisements from poor Latinx and Black neighborhoods cause the assigned neighborhood to be perceived as the least desirable, and ads from non-poor White neighborhoods lead to the neighborhood being perceived as the most desirable.
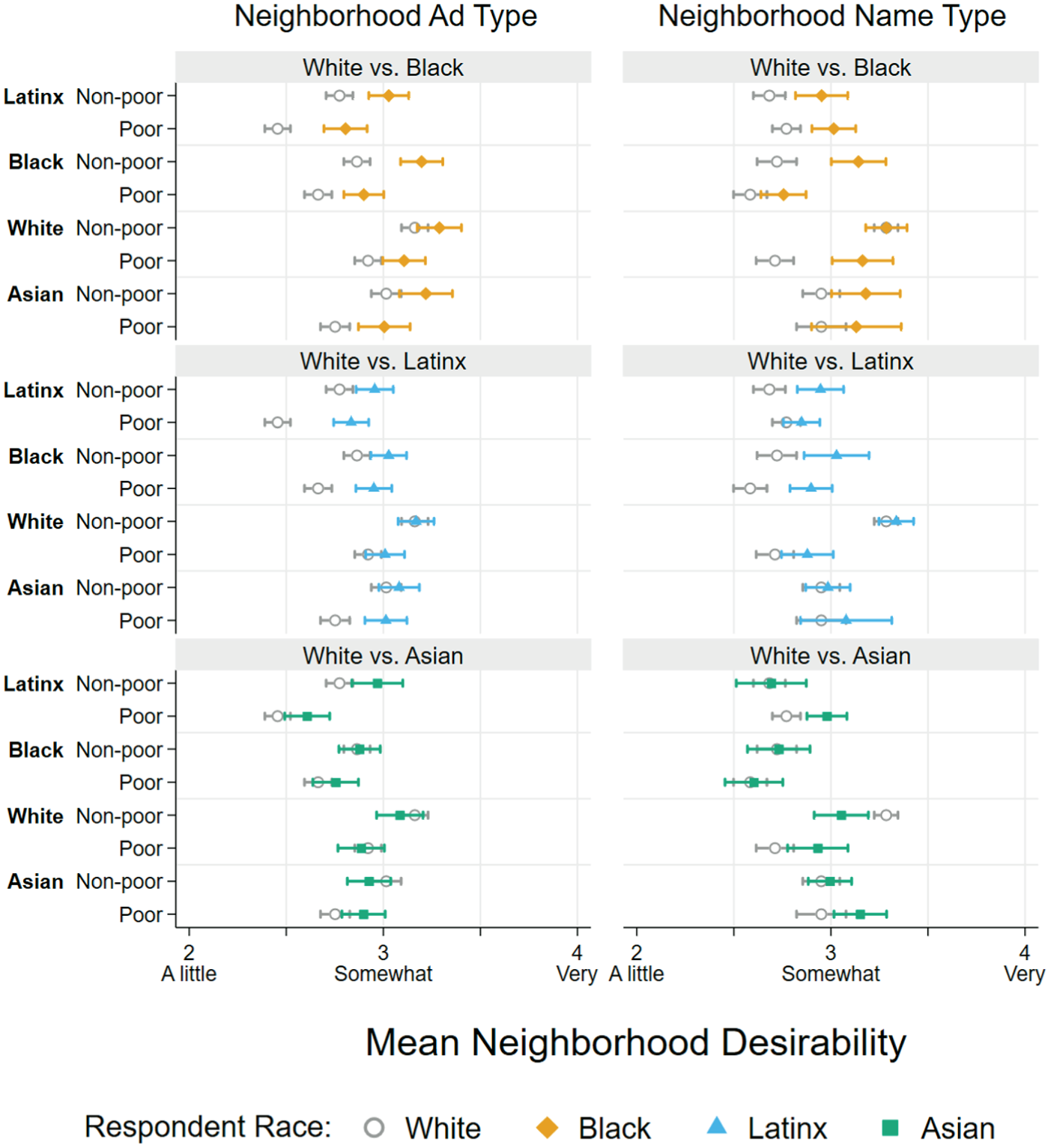
Predicted Neighborhood Desirability by Ad Treatment/Name Type and Respondent’s Race for Pooled Sample.
As shown in Figure 3, we find smaller and fewer statistically significant differences between White and Asian respondents in terms of ad type treatment effects. Relative to White respondents, and similar to Black and Latinx respondents, Asian respondents assign less of a desirability penalty when they view advertisements from poor and non-poor Latinx neighborhoods (by about 0.2 to 0.3 points). Asian respondents are also more positive about ads from poor Asian neighborhoods compared to White respondents (also by about 0.2 points; for details, see Table S2 in the online supplement). Nevertheless, the neighborhood hierarchy in terms of desirability is similar, with ads from non-poor White neighborhoods leading to the highest perceptions of desirability, and ads from poor Latinx neighborhoods leading to the lowest perceptions of desirability.
Overall, we find that while respondent race/ethnicity does moderate the magnitude of the effect of ad type on perceived neighborhood desirability, the hierarchy of perceived neighborhood desirability is very consistent. White, Black, Latinx, and Asian respondents perceive advertisements from non-poor White neighborhoods as conveying the most desirability, and listings from poor Black and Latinx neighborhoods signal the lowest neighborhood desirability.
In contrast, we observe more substantive differences in neighborhood name treatment effects depending on the respondent’s race/ethnicity. As shown in Figure 3 (and Table S2 in the online supplement) respondents similarly rate names from non-poor White neighborhoods as relatively desirable. But while White respondents clearly perceive non-poor White neighborhoods names to be the most desirable by a substantial margin, Black, Latinx, and Asian respondents perceive weaker if any differences by neighborhood name types. As shown in Table 3, unlike White respondents, Black respondents perceive both poor and non-poor White neighborhood names to be similarly desirable and react less negatively to non-poor Black and poor and non-poor Latinx neighborhood names (see also Table S2). Relative to White respondents, Latinx respondents react similarly to poor and non-poor Asian neighborhood names, but significantly less negatively toward poor and non-poor Black neighborhood names. And Asian respondents’ reactions to all neighborhood name types are significantly different from those of White respondents (see Table S2), but they also appear to follow distinct patterns relative to Black and Latinx respondents—indicating that Asian residents’ assessments of neighborhoods are unique relative to other ethnoracial groups.
In summary, like preexisting knowledge, respondent race/ethnicity matters for the interpretation of information and the development of neighborhood perceptions. But preexisting knowledge and respondent race/ethnicity seem to have distinct moderation effects on the treatments. In other words, it does not appear as if race/ethnicity explains why preexisting knowledge moderates the effects of our treatments, despite the fact that preexisting knowledge is associated with respondent race/ethnicity.
To further explore the relationships among preexisting knowledge, respondent race/ethnicity, and our neighborhood information treatments, Tables S4a to S4d in the online supplement estimate three-way global interactions. It is important to note that some of these models are underpowered. Nevertheless, they provide suggestive evidence that preexisting knowledge consistently moderates our treatments independent of differences by respondent race/ethnicity. We also estimate a model interacting our neighborhood name type and ad type treatments to test whether effects vary for specific treatment combinations. Ad type effects are generally larger when they are assigned to fake neighborhood names, consistent with our finding that ad type effects are stronger when preexisting knowledge is low. We also find a few positive interaction terms for other name type–ad type combinations, suggesting there is some heterogeneity in effect sizes based on specific treatment combinations. However, we do not observe any systematic patterns (see Table S9 in the online supplement).
Altogether, our results demonstrate how online rental market information—both advertisements and neighborhood names—sustain and reproduce racialized and hierarchicalized perceptions of place. White neighborhoods are broadly considered the most desirable, and Black and Latinx neighborhoods are considered the least, particularly when they are also poor neighborhoods. These findings reveal that the information available in online housing searches does indeed have an effect on residents’ perceptions, and is somewhat consistent across respondents by race/ethnicity. However, signals are most effective when they align with the existing racial-spatial hierarchy or when residents have less preexisting information. Neighborhood desirability is therefore a product of multiple factors—racial demographics are certainly key, but so are residents’ existing familiarity with different neighborhoods and novel signals they encounter during the search.
Discussion and Conclusions
As the search for housing has increasingly moved online, the information environment for homeseekers has changed dramatically. Websites like Zillow and Craigslist offer quick and easy access to ads for units across entire metros—allowing for much faster comparisons and potentially facilitating new patterns of mobility by opening up previously unknown neighborhoods to a wider set of homeseekers. However, recent research has described systematic differences in the amount and type of information in online housing advertisements by neighborhood demographics and speculated that these differences reproduce offline information inequalities in ways that might, in turn, reproduce existing stereotypes of different neighborhoods and reinforce segregated mobility patterns. Furthermore, examinations of residents’ preexisting information about potential destinations is unevenly distributed; race/ethnicity is highly predictive of the neighborhood names residents recognize and are willing to consider moving to. Using a factorial survey experiment that more accurately reflects how residents are exposed to information online, we test if both neighborhood names and variations in housing advertisement text affect the desirability of neighborhoods as potential destinations.
We find, broadly, that the systematic differences in information on available rental housing by neighborhood demographics do affect local residents’ assessments of neighborhoods as desirable places to live. Even small pieces of information seen online act as heuristics that shape residents’ mental maps of their metros. Our results suggest that if we could break the well-documented links between neighborhood ethnoracial composition and name/reputation and advertisement text, as we do in our experiment, we could indeed shift local residents’ perceptions of the neighborhood desirability hierarchy.
Put another way, race is indeed the prism through which residents see their cities (Krysan and Bader 2007; Krysan and Crowder 2017; Zubrinsky and Bobo 1996). Residents’ prior familiarity with neighborhoods in their metro and their race/ethnicity altered how they interpreted information in online housing advertisements, but the racial-spatial hierarchy remained largely intact, with non-poor White neighborhoods consistently rated as the most desirable. The effect sizes in these analyses are significant, but they also raise further questions, particularly about the relative importance of the information homeseekers view online. Future work should explore more precisely what pieces of information available in online housing ads are more or less important in mobility decision-making (e.g., text language, but also unit amenities versus geographic location), and how online information has more or less of an effect relative to advice homeseekers receive from offline sources like family members, social network connections, and housing market intermediaries.
Digital Data and Experimental Treatments
Survey experiments are often critiqued for presenting respondents with choices that do not reflect real-world situations (Barabas and Jerit 2010; Findley et al. 2021). In the case of residential preferences, for example, past work has asked respondents about the desirability of nonexistent neighborhoods with racial/ethnic demographic characteristics assigned by the researcher. By using representative samples of residents in different metros, assigning actual names of neighborhoods within those metros, and developing ad text treatments based on housing advertisements observed in those metros, our study design more accurately captures the experience of information exposure in the housing search process. In addition, our design exploits the fact that searchers typically view multiple listings within any given neighborhood. This study therefore better assesses the extent to which information gleaned during searches can shape neighborhood desirability. However, our survey treatments did not include pictures—information that searchers almost certainly use in deciding whether to pursue a particular housing unit. While our focus is on neighborhood as opposed to unit desirability, the two are often linked. Future research could use novel image scraping and classifying algorithms to develop representative images from online housing advertisements, which could then be used as treatments in experiments aimed at understanding the relative influence of pictures in determining homeseekers’ interest (see Hwang et al. 2023; Zhang and Leung 2026).
Our focus on advertisement text does answer recent calls to better integrate the ubiquity of the internet in most Americans’ daily activities (Hargittai and Micheli 2019), and in particular in modeling behavior in the housing market (Rosen et al. 2021). Our study design can also act as a template for scholars looking to increase the external validity of survey experiments (de la Cuesta, Egami, and Imai 2022). In an era of more easily obtained big data, a wider set of behaviors, opinions, objects, and other social artifacts can be analyzed for patterns that can then be used as experimental treatments (Edelmann et al. 2020; Salganik 2018). The most obvious pathway is the one used here, where a large corpus of text can be analyzed with structural topic models to find modal uses of language in a particular field of social action, which can then be used as experimental treatments (Fong and Grimmer 2023).
Yet text is only one form of aggregate digital data available. Other forms of digital data that have recently become prominent in social science research include aggregate measures of daily mobility flows derived from cell-phone tracking, data on individual stock and asset investments from day trading websites, and user-generated ratings of businesses and products from shopping and consumer platforms. Large-scale visual data are also more readily available and analyzable (Hwang and Naik 2023; Zhang and Leung 2026). Creative researchers should think about how these data can help structure experiments in ways that more accurately reflect the choices individuals face in their day-to-day lives; this would increase external validity and strengthen any causal claims (Schachter and Weisshaar 2025).
Neighborhood Reputations and Residential Mobility in the Digital Age
Our findings reveal that explicit racial language—which is banned by fair housing laws and (relatively) easy to flag and block in online postings using automated methods—is unnecessary to elicit racialized assumptions about neighborhoods. Race anchors neighborhood reputations, even in the absence of explicit racism. Indeed, we have shown that neighborhood reputations are easily communicated through small, simple signals like text in housing advertisements and even neighborhood names. Past work indicates that anti-Black racism and discrimination are likely at play as residents make a host of negative assumptions about neighborhoods that are majority Black (Chiricos, McEntire, and Gerz 2001; Quillian and Pager 2001). These effects are even stronger when neighborhoods are majority Black and have relatively higher shares of poor residents or residents who rent (Harris 1999; Sampson and Raudenbush 2004). This is true in our analyses as well: poor Black neighborhood names were rated as the least desirable neighborhoods. Segregated neighborhoods remain the norm across metropolitan America (Hwang and McDaniel 2022; Massey and Denton 1993; Mikulas, Beck, and Besbris 2024), but the five metros where we implemented our survey experiment skew high on Black-White segregation indexes, and it is possible Black neighborhood reputations—easily communicated via neighborhood names—are particularly entrenched as a result. Future research should certainly test for similar effects in other metropolitan settings where segregation is lower.
Our findings also show that poor Latinx neighborhoods are highly stigmatized, sometimes to a greater extent than poor Black neighborhoods. Spanish language text seems to evoke negative neighborhood assessments by residents—a topic that deserves further examination given the negative stereotypes associated with language, ethnicity, and immigration status (Davis and Moore 2014; Flores and Schachter 2018; Jiménez, Fields, and Schachter 2015). As the number of majority-Latinx neighborhoods continues to grow, future work should not only examine if and how these neighborhoods are deemed undesirable relative to others, but researchers should also attempt to uncover the mechanisms by which their Latinx-ness is communicated. Chinese in advertisements for rental housing also had a negative effect, such that respondents viewing ads containing Chinese from poor Asian neighborhoods rated these neighborhoods as relatively less desirable than did their same-race counterparts viewing ads from the same type of neighborhood with no Chinese text. Yet we do not observe the same overall stigma for poor Asian neighborhoods as we do for Latinx ones. Stereotypes about the quality of Asian and Latinx neighborhoods clearly matter for the desirability of neighborhoods and their potential inclusion in residential choice sets.
These findings also indicate that further work could be done to avoid or at least reduce the quick valorization or stigmatization of neighborhoods that occurs in the existing information environment, and to potentially foster the development of wider destination choice sets across residents—breaking what Krysan and Crowder (2017) call the “assumption of correlated characteristics.” Municipalities interested in expanding mobility may seek to more closely regulate or standardize housing advertisements. For example, requiring all ads to be multilingual should reduce the negative assumptions residents seem to make about neighborhoods advertised in Spanish or Chinese.
Prevailing theory argues that information is key to understanding residential mobility, as residents are familiar with only a very narrow set of potential destinations when they move (Hwang and Zhang 2025; Krysan and Crowder 2017). Online search tools may be changing searcher behavior by granting access to information on a wider set of neighborhoods than searchers have from their own social experience, but our findings suggest this expanded access is unlikely to lead to novel forms of mobility. Residents are indeed highly susceptible to new information online, but this information largely reflects existing assumptions, stereotypes, and assessments of racialized neighborhoods.
When residents utilize online search tools to explore neighborhoods they may be unfamiliar with—and where their own ethnoracial group is not the majority—they are encountering very different signals about the type of expected tenant, the neighborhood amenities, and even the physical qualities of the houses themselves (Adu and Delmelle 2022; Besbris et al. 2021; Kennedy et al. 2021). We show that these informational differences across neighborhoods matter for residents’ assessments of neighborhoods as more or less desirable potential destinations. Technological changes have indeed made more information on a wider set of places readily available, but these novel tools have not transformed how information is produced. The information searchers encounter online not only reflects existing patterns of segregation and inequality—as past work has shown—but it also reproduces these patterns social psychologically. Demographic differences in residential mobility are therefore not likely to be altered by online search tools in their current form.
Supplemental Material
sj-pdf-1-asr-10.1177_00031224261446899 – Supplemental material for Neighborhood Desirability and Decision-Making in Online, Multiracial, Metropolitan America
Supplemental material, sj-pdf-1-asr-10.1177_00031224261446899 for Neighborhood Desirability and Decision-Making in Online, Multiracial, Metropolitan America by Max Besbris, Ariela Schachter and John Kuk in American Sociological Review
Footnotes
Acknowledgements
We would like to thank Armin Sauermann for excellent research support and Elizabeth Korver-Glenn for providing helpful comments on an earlier draft. Thanks to participants of both Princeton’s Joint Degree Program in Social Science and Social Policy Advanced Empirical Seminar and the Population Studies & Training Center’s Colloquium at Brown. Their questions and comments improved the paper. We are grateful to various colleagues for their thoughtful insights along the way, including Felix Elwert, René Flores, Ann Owens, and especially Mike Bader and Maria Krysan whose own work sparked our ideas years ago.
Authors’ Note
All authors contributed equally to this article.
Funding
This research was made possible with support from the National Science Foundation (SES Grant #1947591/1947598/2041304), the University of Wisconsin-Madison Institute for Diversity Science, the Weidenbaum Center on the Economy, Government, and Policy at Washington University in St. Louis, and the Ministry of Education of the Republic of Korea and the National Research Foundation of Korea (NRF-2024S1A3A2A07046269).
Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Notes
Author Biographies
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.