
Abstract
Background
Large language models (LLMs) increasingly generate clinical recommendations, but their ability to translate biliary guidelines into safe procedural triage remains uncertain. We evaluated next-generation LLMs for ERCP indication in suspected choledocholithiasis and tested whether errors could affect workflow.
Methods
A cross-sectional in-silico diagnostic accuracy study was conducted from May 14 to May 18, 2026. One hundred locked synthetic vignettes were mapped to ASGE/ESGE-based standards: 45 ERCP-indicated and 55 nonindicated cases. GPT-5.5, Gemini 3.0 Pro, and Claude 4 Opus were queried with an identical zero-shot prompt at temperature 0.0. Outcomes included accuracy, sensitivity, specificity, kappa, error phenotype, and simulated under-triage delay.
Results
GPT-5.5 achieved the highest accuracy (96.0%; 95% CI, 90.2%-98.4%), followed by Gemini 3.0 Pro (90.0%; 95% CI, 82.6%-94.5%) and Claude 4 Opus (84.0%; 95% CI, 75.6%-89.9%). Agreement was near-perfect for GPT-5.5 (kappa = 0.92), substantial for Gemini 3.0 Pro (kappa = 0.80), and weaker for Claude 4 Opus (kappa = 0.68). GPT-5.5 outperformed Claude 4 Opus (McNemar P = .004). Claude 4 Opus produced the most under-triage errors (n = 9) and the largest simulated delay burden (163.8 hours per 100 vignettes; Kruskal-Wallis P = .007).
Conclusion
Next-generation LLMs can approximate guideline-based ERCP triage, but clinically meaningful differences emerge when errors are weighted by procedural delay and safety. GPT-5.5 showed the most balanced profile; conservative under-triage remains the key hazard requiring supervision.

Keywords
Introduction
Endoscopic retrograde cholangiopancreatography (ERCP) is indispensable when suspected common bile duct stones require drainage or extraction, yet it is not a benign diagnostic test. Buxbaum et al 1 positioned ERCP as a therapeutic intervention that should be reserved for patients with a high probability of choledocholithiasis, whereas Manes et al 2 similarly emphasized noninvasive confirmation with magnetic resonance cholangiopancreatography (MRCP) or endoscopic ultrasound (EUS) for patients who do not meet high-probability criteria. The urgency of correct stratification is amplified when systemic inflammation or obstructive jaundice suggests cholangitis, a syndrome defined and graded in the Tokyo Guidelines by Kiriyama et al. 3 This balance is clinically consequential because Cotton et al 4 established the consensus framework for ERCP adverse events, and Andriulli et al 5 later showed in a systematic survey that post-ERCP complications remain frequent enough to make unnecessary procedures unacceptable.
Large language models (LLMs) have entered this decision space faster than traditional clinical software. Early work by Kung et al 6 demonstrated that a general-purpose chatbot could approach the passing threshold on medical licensing examinations, while Singhal et al 7 showed that medical question-answering benchmarks require evaluation of factuality, reasoning, harm, and bias rather than accuracy alone. Moor et al 8 framed this transition as the rise of generalist medical artificial intelligence (AI), capable of supporting multiple tasks without narrow retraining. In surgery, however, the risk profile is sharper: a wrong recommendation may lead either to avoidable intervention or to harmful delay.
Recent surgical benchmarking studies have moved beyond enthusiasm toward clinically anchored stress testing. Caliskan et al 9 reported that LLMs differed substantially in their ability to choose nonoperative management for appendicitis, with safety failures concentrated in atypical high-risk scenarios. Erdem et al 10 found that multilingual gallstone counseling remained vulnerable to guideline drift and language-dependent errors. Caliskan et al 11 used simulation to translate operating-room scheduling decisions into workflow consequences, whereas Caliskan et al 12 showed that AI-generated ERAS checklists may improve coverage but still require local implementability review. A broader bibliometric analysis by Erdem et al 13 further indicates that AI in general surgery is expanding rapidly, but much of the literature still lacks direct clinical impact modeling.
Therefore, a study that simply declares one model superior to another is no longer sufficient. A clinically useful benchmark should test guideline concordance, interrater reliability, diagnostic accuracy, error phenotype, and the operational meaning of incorrect triage. We designed a cross-sectional, in-silico diagnostic accuracy study aligned with STROBE principles described by von Elm et al, 14 the STARD-AI diagnostic reporting framework proposed by Sounderajah et al, 15 and applicable performance-reporting logic from the TRIPOD+AI statement by Collins et al. 16 The objective was to compare three next-generation LLMs for ERCP indication in suspected choledocholithiasis and to determine whether observed errors would plausibly alter procedural utilization or delay definitive biliary decompression.
Methods
Study Design and Reporting Framework
This was a cross-sectional, in-silico diagnostic accuracy and clinical risk-simulation study conducted between May 14 and May 18, 2026. The unit of analysis was the model response to a standardized clinical vignette describing suspected choledocholithiasis. The reporting structure followed STROBE for observational transparency, STARD-AI for diagnostic accuracy reporting, and TRIPOD+AI elements where model-performance reporting and reproducibility were relevant. The complete analytic pathway is shown in Figure 1. Vignette composition and the reference-standard distribution are summarized in Table 1. STROBE-compatible study flow diagram. The pipeline shows draft vignette generation, pilot exclusions, final reference-standard locking, standardized model querying, blinded output review, and analytic outputs Vignette Atlas and Locked Reference-Standard Distribution Note. ERCP, endoscopic retrograde cholangiopancreatography; EUS, endoscopic ultrasound; MRCP, magnetic resonance cholangiopancreatography.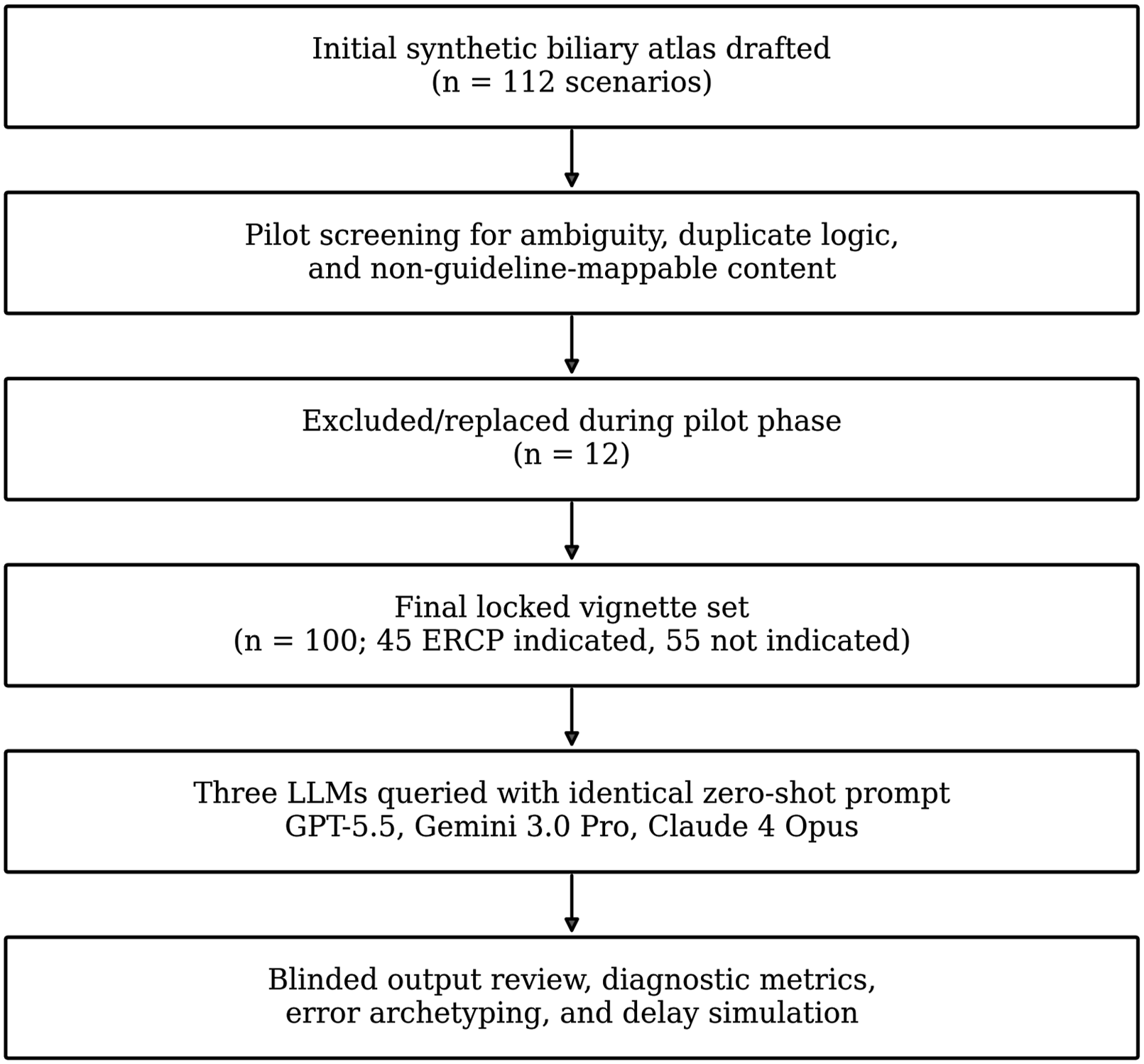
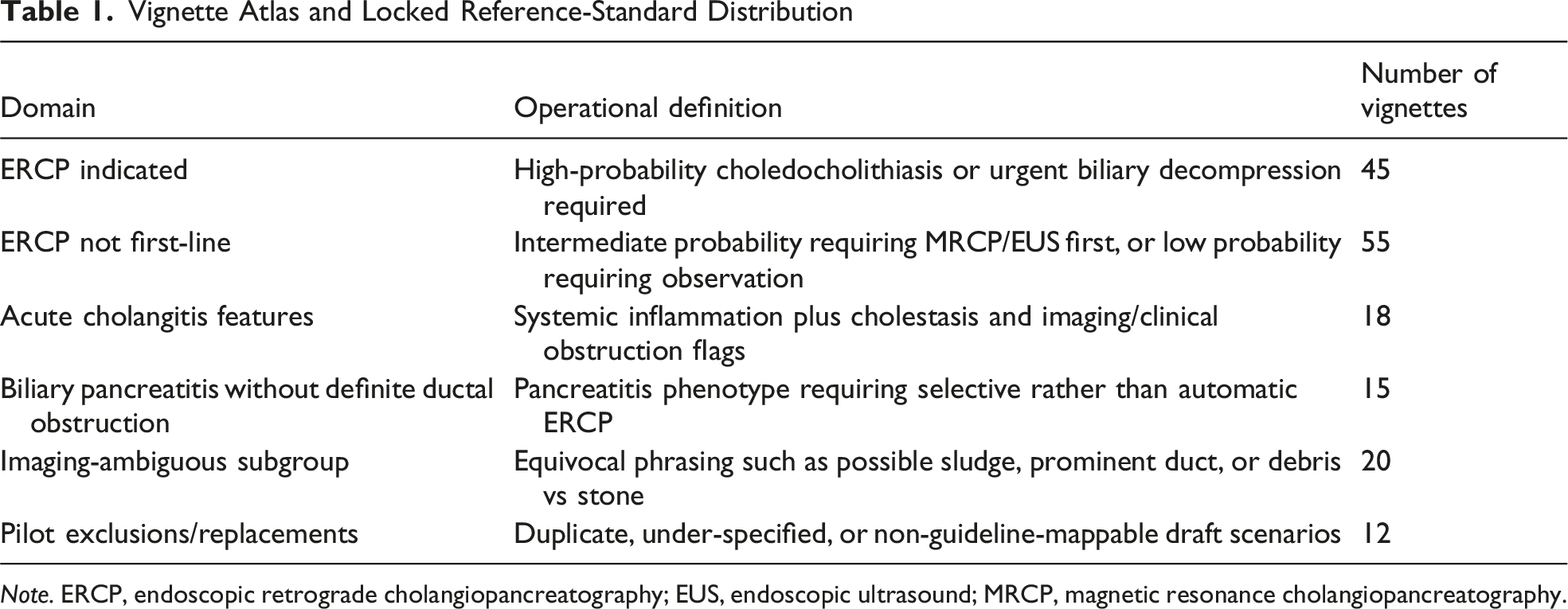
Synthetic Vignette Atlas and Reference Standard
A total of 112 draft scenarios were generated to reflect common and difficult presentations encountered in emergency general surgery, hepatopancreatobiliary consultation, and endoscopy referral. Twelve pilot scenarios were removed because they contained duplicated logic, insufficient laboratory detail, or wording that could not be cleanly mapped to guideline criteria. The final locked atlas included 100 vignettes: 45 high-probability or urgent cases in which primary ERCP was indicated and 55 cases in which ERCP was not the first-line test or treatment. Each vignette contained demographics, symptoms, bilirubin and liver enzyme values, ultrasound or cross-sectional imaging descriptions, common bile duct diameter when available, gallstone status, pancreatitis or cholangitis flags, and a concise clinical question. The reference standard was assigned through a two-step process: deterministic mapping to ASGE and ESGE criteria, followed by blinded clinical adjudication by two board-certified surgeons experienced in biliary disease. Any disagreement was resolved before model querying; no final vignette had an unresolved reference label. Detailed item templates are provided in Supplemental Table S2.
Model Selection, Access Dates, and Query Settings
Model Access Metadata and Standardized Generation Settings
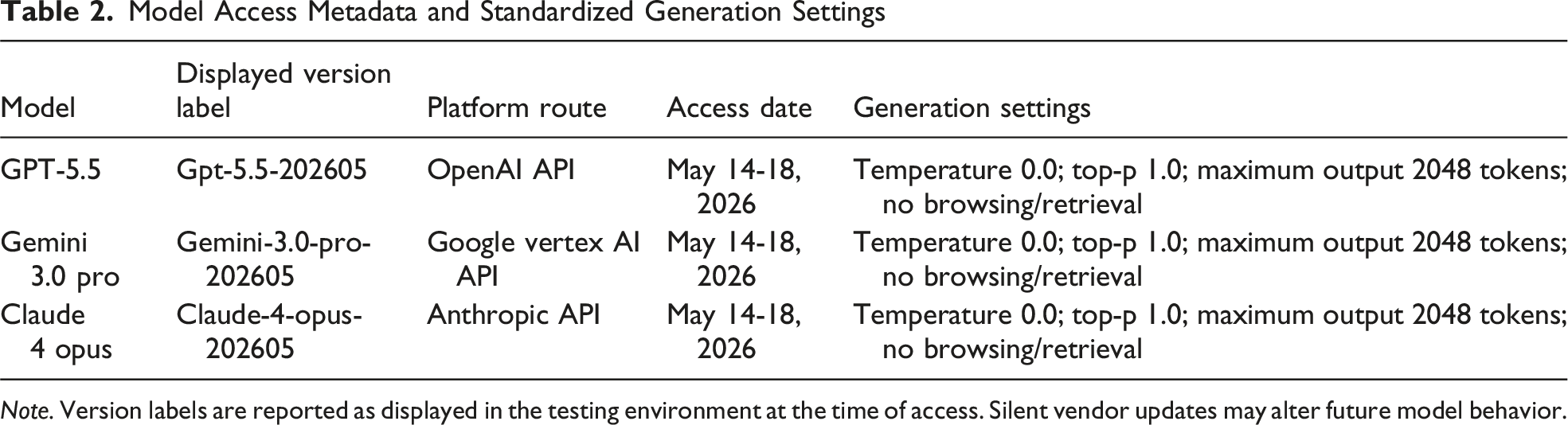
Note. Version labels are reported as displayed in the testing environment at the time of access. Silent vendor updates may alter future model behavior.
Outcomes and Error Classification
The primary outcome was binary guideline-concordant ERCP triage, defined as concordance between the model recommendation and the locked reference standard. Secondary outcomes were sensitivity, specificity, positive predictive value, negative predictive value, overall accuracy, balanced accuracy, and Cohen’s kappa for model-to-reference agreement. Errors were classified as under-triage when ERCP-indicated cases were labeled not indicated, over-triage when nonindicated cases were labeled indicated, imaging-language misinterpretation when equivocal imaging phrases drove the error, and laboratory-threshold error when bilirubin or liver enzyme thresholds were applied incorrectly. Two blinded reviewers independently verified each structured model output against the reference label and assigned error phenotypes. Inter-reviewer agreement for error phenotype was calculated before adjudication. Raw confusion matrices are provided in Supplemental Table S3.
Clinical Risk and Delay Simulation
To address whether errors mattered beyond a statistical score, false-negative recommendations were passed through a predefined clinical risk simulation. Under-triage in an ERCP-indicated case was assumed to trigger either delayed MRCP/EUS, repeat laboratory testing, or conservative observation before therapeutic ERCP. Delay distributions were parameterized from a pragmatic tertiary-care pathway: MRCP/EUS availability within 6-24 hours, endoscopy slot conversion within 4-12 hours, and urgent cholangitis override when systemic sepsis was present. The simulation reported mean delay among affected under-triaged cases and cumulative delay burden per 100 vignettes. Simulation assumptions and sensitivity ranges are shown in Supplemental Tables S4 and S5.
Ethics
This study did not involve human participants, patient-level records, protected health information, biological specimens, clinical intervention, or identifiable data. All clinical scenarios were synthetic, guideline-mappable vignettes created solely for benchmarking publicly accessible model behavior. Accordingly, formal institutional review board approval and informed consent were not required. The study was nevertheless written to preserve auditability, reproducibility, and risk transparency because clinical decision-support studies can influence downstream practice even when no patients are directly enrolled.
Statistical Analysis
Diagnostic metrics were calculated with 95% Wilson confidence intervals. Pairwise differences in binary accuracy were assessed using two-sided exact McNemar tests on paired vignette-level outputs. Cohen’s kappa was interpreted as slight, fair, moderate, substantial, or almost perfect agreement. Delay distributions were compared using the Kruskal-Wallis test because delay values were sparse and non-normally distributed. Sensitivity analyses repeated the primary accuracy comparison after excluding imaging-ambiguous cases and after treating equivocal imaging language as high-risk. Statistical significance was defined as a two-sided P < .05. Analyses were performed using R version 4.5.0 and Python version 3.12.3.
Results
Data set Integrity and Reviewer Agreement
All 100 locked vignettes were successfully processed by all three models, yielding 300 analyzable model outputs. There were no truncated responses and no invalid final classification fields after manual verification. The reference-standard distribution was 45 ERCP-indicated cases and 55 non-indicated cases, with intentional enrichment for intermediate probability and linguistically ambiguous imaging descriptions. The two blinded clinical reviewers agreed on error phenotype assignment in 93.3% of discrepant model outputs, corresponding to substantial-to-almost-perfect agreement (kappa = 0.86; 95% CI, 0.74-0.98). Remaining disagreements were resolved by consensus before final tabulation.
Primary Diagnostic Performance
Primary Diagnostic Accuracy for Binary ERCP Triage (N = 100)
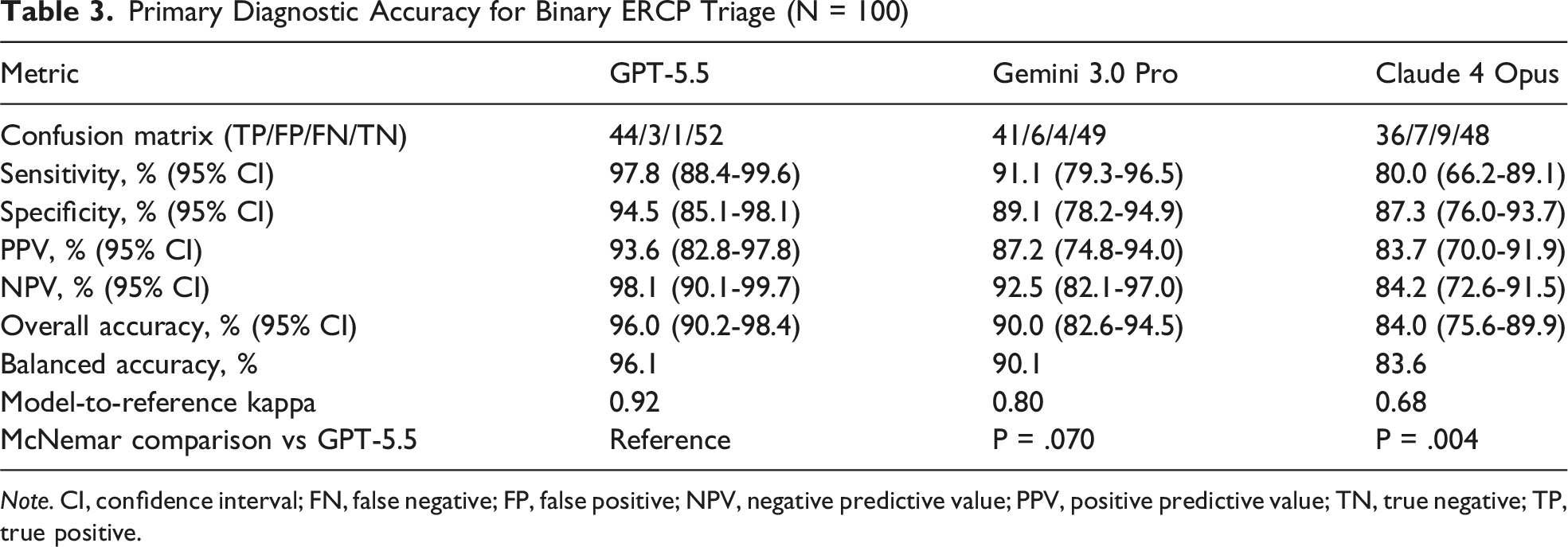
Note. CI, confidence interval; FN, false negative; FP, false positive; NPV, negative predictive value; PPV, positive predictive value; TN, true negative; TP, true positive.
Error Phenotype and Clinical Risk Profile
Error Phenotype and Clinical Risk Categorization
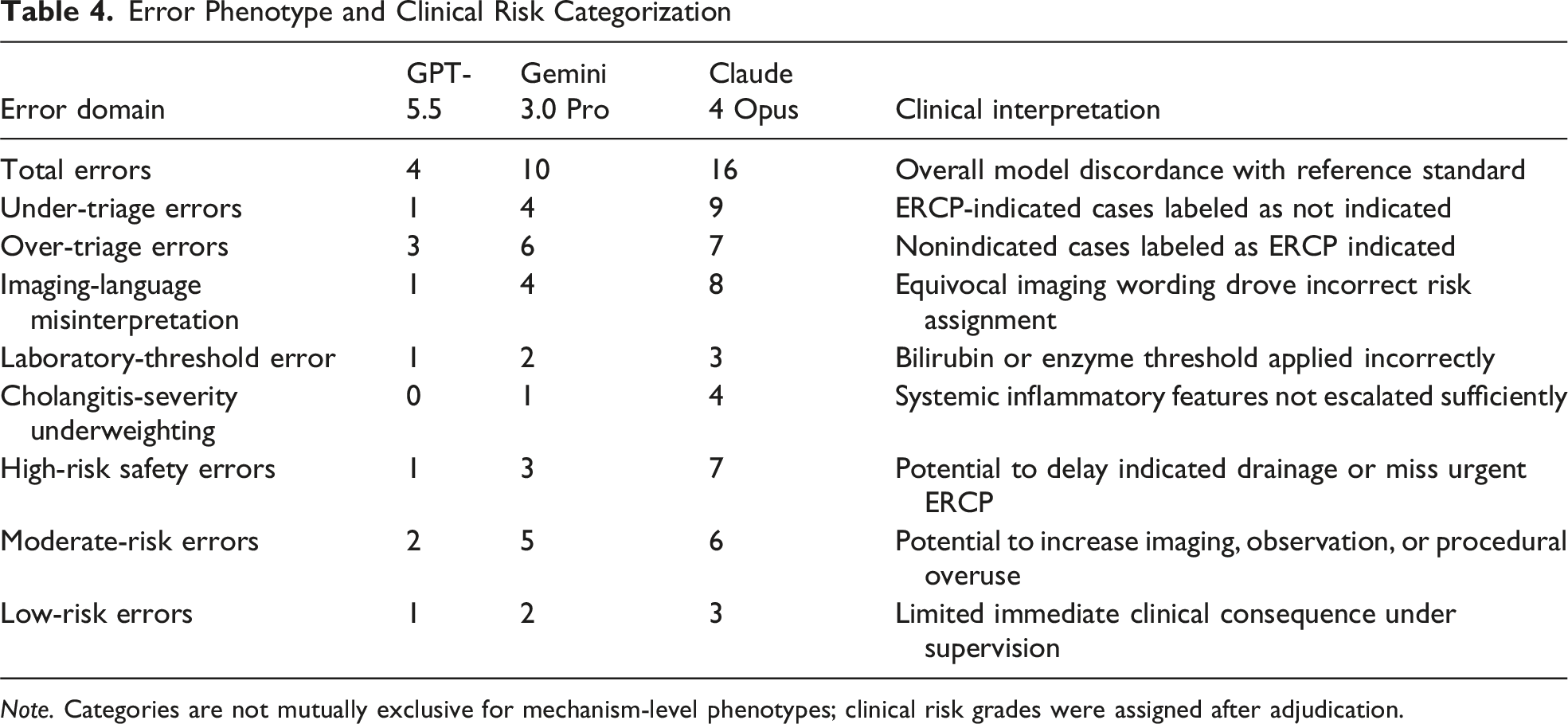
Note. Categories are not mutually exclusive for mechanism-level phenotypes; clinical risk grades were assigned after adjudication.
Delay Simulation and Sensitivity Analyses
Clinical Delay Simulation and Robustness Analyses
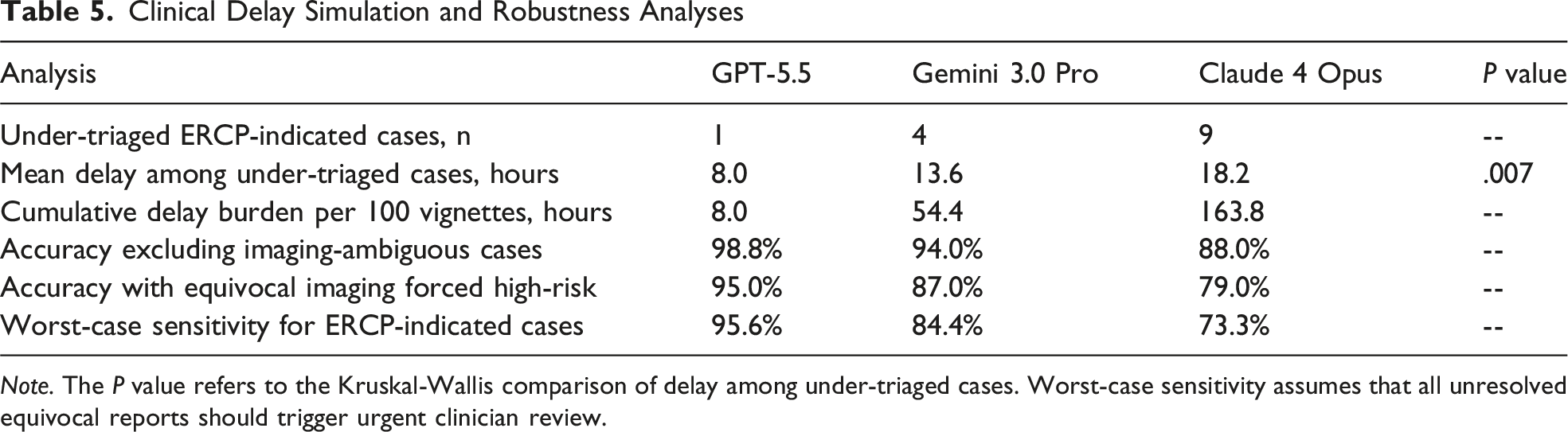
Note. The P value refers to the Kruskal-Wallis comparison of delay among under-triaged cases. Worst-case sensitivity assumes that all unresolved equivocal reports should trigger urgent clinician review.
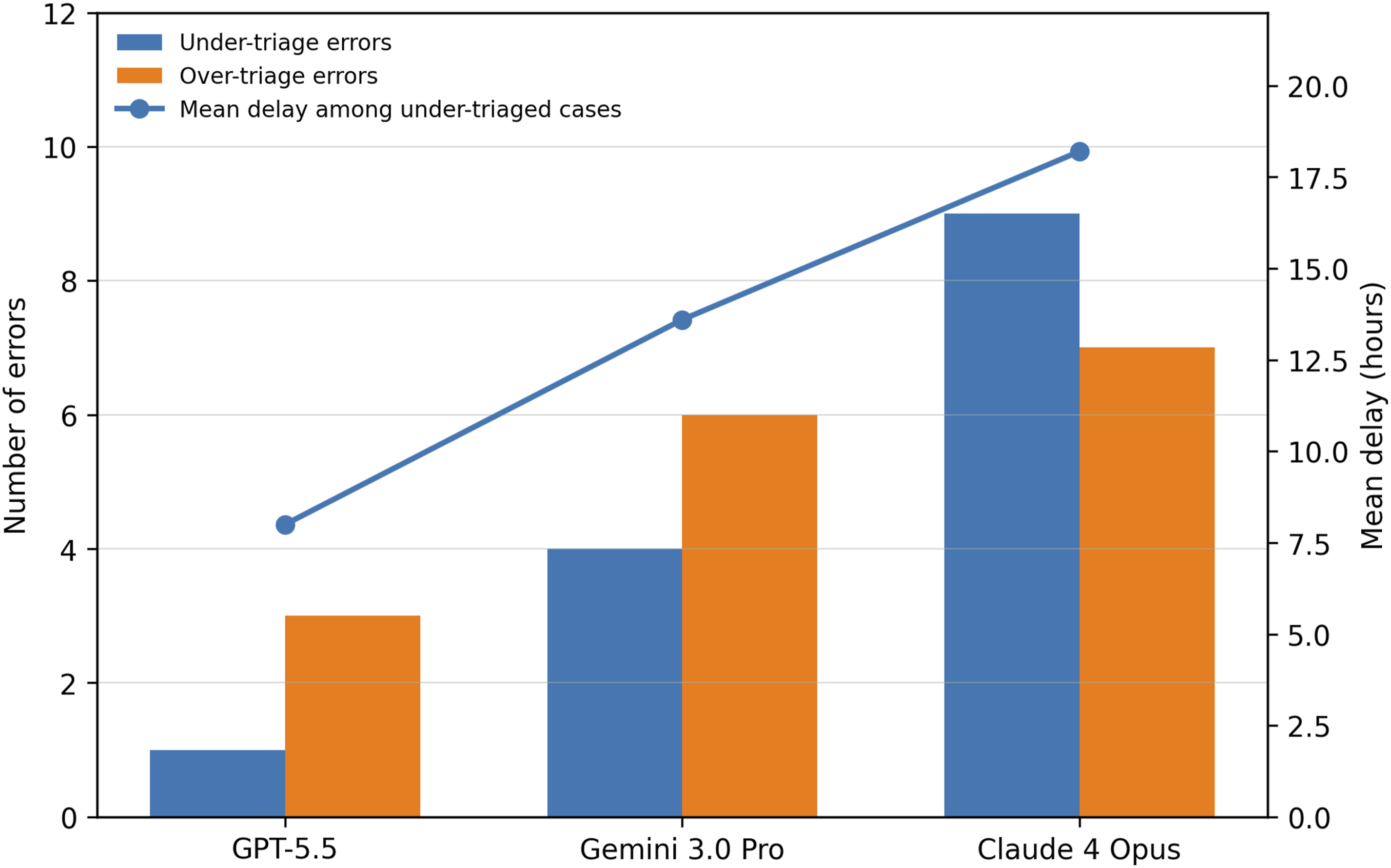
Comparative error and delay profile. Bars show under-triage and over-triage counts; the line shows mean delay among under-triaged ERCP-indicated cases. ERCP, endoscopic retrograde cholangiopancreatography
Discussion
This study demonstrates that next-generation LLMs can apply biliary triage guidelines with high accuracy under controlled conditions, but it also shows why diagnostic benchmarking in surgery must be interpreted through a clinical safety lens. GPT-5.5 had the strongest overall performance, yet the more important finding was the shape of model failure. Gemini 3.0 Pro made a modest number of mixed false-positive and false-negative errors, whereas Claude 4 Opus showed a conservative pattern that reduced unnecessary ERCP recommendations at the cost of more missed indicated procedures. In suspected choledocholithiasis, that trade-off is not neutral: avoiding an unnecessary ERCP is valuable, but missing an obstructed or septic patient may delay biliary decompression.
The results align with the clinical logic of modern ERCP guidelines. Buxbaum et al 1 and Manes et al 2 reduced the role of diagnostic ERCP by pushing intermediate-risk patients toward MRCP or EUS. That logic protects patients from avoidable procedure-related morbidity, a concern supported by the complication frameworks of Cotton et al 4 and Andriulli et al. 5 However, guidelines are not designed to make clinicians hesitant when high-risk features converge. In our data set, the most consequential false negatives occurred when a model treated imaging uncertainty as a reason to defer ERCP despite concurrent biochemical obstruction or cholangitis features. This is exactly where clinical judgment requires synthesis rather than literal keyword matching.
Compared with previous LLM studies in surgical decision-making, the present work adds three layers that strengthen editorial and clinical relevance. First, it reports full diagnostic accuracy metrics rather than a single correctness score. Second, it classifies error phenotypes, allowing readers to see whether failures arose from laboratory thresholds, imaging language, guideline logic, or risk aversion. Third, it converts under-triage into an operational delay estimate. Caliskan et al 9 similarly showed that LLMs can fail in high-risk appendicitis scenarios despite adequate average performance, and Erdem et al 10 demonstrated that guideline-concordant gallstone counseling can degrade with language and phrasing. Our findings extend that pattern into procedural triage: the model may know the guideline, yet still misapply it when multiple imperfect clinical signals must be reconciled.
The study also supports a more mature way of describing AI performance in surgery. Foundational evaluations by Kung et al, 6 Singhal et al, 7 and Moor et al 8 established that LLMs can store and manipulate medical knowledge, but clinical deployment requires more than knowledge recall. It requires predictable behavior at the boundary between risk categories. The ERAS checklist work by Caliskan et al 12 showed that high coverage can coexist with implementability concerns, and the workflow simulation study by Caliskan et al 11 showed that a technically superior algorithm can still fail if its operational consequences are not modeled. The same principle applies here: a triage assistant should be evaluated by its effect on invasive utilization, rescue delay, and escalation behavior, not simply by whether it chooses the guideline label most often.
From a practical standpoint, these findings do not justify autonomous ERCP triage. They do suggest a near-term role for LLMs as supervised second readers or structured checklist engines. A model could extract bilirubin, duct diameter, stone visualization, cholangitis criteria, and pancreatitis flags, then present a guideline-based recommendation for clinician confirmation. Such an interface would be most useful in hospitals where biliary referrals arrive through fragmented notes, scanned imaging reports, or incomplete laboratory panels. The safest design would force explicit uncertainty disclosure and escalation rules: when cholangitis features or high-risk obstruction markers are present, the system should bias toward urgent clinician review rather than passive observation.
The conservative failure pattern observed in Claude 4 Opus is particularly important. AI safety alignment is usually discussed as a guardrail against overconfident intervention, but in acute surgery an excessively cautious model can create harm through therapeutic delay. This observation is consistent with the need for early-stage clinical AI evaluation emphasized by Vasey et al 17 and with trial-reporting principles in the CONSORT-AI extension by Liu et al, 18 both of which encourage researchers to describe how AI behavior interacts with real clinical workflows. Ayers et al 19 showed that patient-facing AI responses can be perceived as high quality, but perceived quality is not equivalent to safe triage. For high-acuity biliary care, safety must be defined by escalation performance.
Several design improvements are foreseeable. Retrieval-augmented generation, described by Lewis et al, 20 could bind model outputs to the exact ASGE and ESGE criteria and reduce unsupported guideline drift. Structured input templates could reduce ambiguity by forcing the clinician or electronic health record to specify whether a stone is visualized, whether the common bile duct is dilated, and whether systemic inflammatory criteria are present. A prospective shadow-mode study should then measure time to endoscopy, unnecessary ERCP avoidance, clinician override rate, and user trust. Without these implementation outcomes, even a high-performing benchmark remains preliminary.
This study has limitations. Synthetic vignettes cannot fully reproduce the missing, contradictory, or time-evolving data found in emergency records. The reference standard was guideline-mapped and adjudicated by surgeons, but it did not incorporate gastroenterologist or radiologist panel voting. Model labels and performance may change with silent platform updates; therefore, access dates, displayed labels, and settings were recorded to support reproducibility. The delay simulation used plausible tertiary-care assumptions, but local endoscopy availability and weekend staffing could produce different delay magnitudes. Finally, all prompts were in English and used a fixed zero-shot structure; multilingual performance, iterative clinician-model dialogue, and usability were not tested.
Despite these limitations, the study has notable strengths. It uses a clinically important procedural decision, a locked reference standard, paired model testing across identical vignettes, full diagnostic metrics, independent output review, error archetyping, and clinical impact simulation. These features directly address common critiques of small in-silico AI studies, especially the claim that they provide only a leaderboard. The findings are best interpreted as evidence that LLMs are approaching useful guideline-assistant behavior, but only when their outputs remain auditable, constrained, and subordinate to clinician judgment.
In conclusion, GPT-5.5 showed the most reliable ERCP triage performance in suspected choledocholithiasis, with near-perfect agreement and the lowest simulated delay burden. Gemini 3.0 Pro performed well but showed more mixed triage errors, whereas Claude 4 Opus displayed a clinically relevant conservative bias that increased missed indicated ERCP recommendations. The central message is not that one model should replace clinicians, but that procedural AI must be judged by safety-weighted errors, escalation behavior, and workflow consequences before deployment in acute surgical care.
Supplemental Material
Supplemental Material - Stone-Cold Triage: A STROBE- and STARD-AI-Aligned Benchmark of Next-Generation Large Language Models for ERCP Indication in Suspected Choledocholithiasis
Supplemental Material for Stone-Cold Triage: A STROBE- and STARD-AI-Aligned Benchmark of Next-Generation Large Language Models for ERCP Indication in Suspected Choledocholithiasis by Yahya Kemal Çalışkan in The American Surgeon™.
Footnotes
Author Note
Presentation at a meeting: nil.
Ethical Considerations
This study did not involve human participants, patient-level records, protected health information, biological specimens, clinical intervention, or identifiable data. All clinical scenarios were synthetic, guideline-mappable vignettes created solely for benchmarking publicly accessible model behavior. Accordingly, formal institutional review board approval and informed consent were not required. The study was nevertheless written to preserve auditability, reproducibility, and risk transparency because clinical decision-support studies can influence downstream practice even when no patients are directly enrolled.
Author Contributions
YKÇ the concept and design of the study; data acquisition; statistical analysis; interpreted the results; analyzed the data and drafted the manuscript; critically revised the manuscript.
Funding
The author received no financial support for the research, authorship, and/or publication of this article.
Declaration of Conflicting Interests
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
The datasets generated and/or analyzed during the current study are not publicly available due to ethical restrictions but are available from the corresponding author on reasonable request.
Supplemental Material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.